Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleDetection
提交
993b955b
P
PaddleDetection
项目概览
PaddlePaddle
/
PaddleDetection
大约 2 年 前同步成功
通知
708
Star
11112
Fork
2696
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
184
列表
看板
标记
里程碑
合并请求
40
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
184
Issue
184
列表
看板
标记
里程碑
合并请求
40
合并请求
40
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
993b955b
编写于
12月 31, 2019
作者:
W
whs
提交者:
GitHub
12月 31, 2019
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add tutorial for sensitive (#129)
上级
6574f8b2
变更
3
显示空白变更内容
内联
并排
Showing
3 changed file
with
302 addition
and
0 deletion
+302
-0
slim/sensitive/README.md
slim/sensitive/README.md
+96
-0
slim/sensitive/images/mobilev1_yolov3_voc_sensitives.png
slim/sensitive/images/mobilev1_yolov3_voc_sensitives.png
+0
-0
slim/sensitive/sensitive.py
slim/sensitive/sensitive.py
+206
-0
未找到文件。
slim/sensitive/README.md
0 → 100644
浏览文件 @
993b955b
# 卷积层敏感度分析教程
请确保已正确
[
安装PaddleDetection
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.1/docs/INSTALL_cn.md
)
及其依赖。
该文档介绍如何使用
[
PaddleSlim
](
https://paddlepaddle.github.io/PaddleSlim
)
的敏感度分析接口对检测库中的模型的卷积层进行敏感度分析。
在检测库中,可以直接调用
`PaddleDetection/slim/sensitive/sensitive.py`
脚本实现敏感度分析,在该脚本中调用了PaddleSlim的
[
paddleslim.prune.sensitivity
](
https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#sensitivity
)
接口。
该教程中所示操作,如无特殊说明,均在
`PaddleDetection/slim/sensitive/`
路径下执行。
## 数据准备
请参考检测库
[
数据模块
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.1/docs/DATA_cn.md
)
文档准备数据。
## 模型选择
通过
`-c`
选项指定待分析模型的配置文件的相对路径,更多可选配置文件请参考:
[
检测库配置文件
](
https://github.com/PaddlePaddle/PaddleDetection/tree/release/0.1/configs
)
通过
`-o weights`
指定模型的权重,可以指定url或本地文件系统的路径。如下所示:
```
-o weights=https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar
```
或
```
-o weights=output/yolov3_mobilenet_v1_voc/model_final
```
官方已发布的模型请参考:
[
模型库
](
https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.1/docs/MODEL_ZOO_cn.md
)
## 确定待分析参数
在计算敏感度之前,需要查出待分析的卷积层的参数的名称。通过以下命令查看当前模型的所有参数:
```
python sensitive.py \
-c ../../configs/yolov3_mobilenet_v1_voc.yml \
--print_params
```
通过观察参数名称和参数的形状,筛选出所有卷积层参数,并确定要分析的卷积层参数。
## 执行分析
通过选项
`--pruned_params`
指定待分析的卷积层参数名,参数名间以英文字符逗号分割。
通过选项
`--sensitivities_file`
指定敏感度信息保存的文件,敏感度信息会追加到该文件中。重启敏感度计算任务,该文件中已计算的信息不会再被计算。
示例如下:
```
nohup python sensitive.py \
-c ../../configs/yolov3_mobilenet_v1_voc.yml \
--pruned_params "yolo_block.0.0.0.conv.weights,yolo_block.0.0.1.conv.weights,yolo_block.0.1.0.conv.weights,yolo_block.0.1.1.conv.weights,yolo_block.0.2.conv.weights,yolo_block.0.tip.conv.weights,yolo_block.1.0.0.conv.weights,yolo_block.1.0.1.conv.weights,yolo_block.1.1.0.conv.weights,yolo_block.1.1.1.conv.weights,yolo_block.1.2.conv.weights,yolo_block.1.tip.conv.weights,yolo_block.2.0.0.conv.weights,yolo_block.2.0.1.conv.weights,yolo_block.2.1.0.conv.weights,yolo_block.2.1.1.conv.weights,yolo_block.2.2.conv.weights,yolo_block.2.tip.conv.weights" \
--sensitivities_file "./demo.data"
```
执行
`python sensitive.py --help`
查看更多选项。
## 分析敏感度信息
可以通过
[
paddleslim.prune.load_sensitivities
](
https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#load_sensitivities
)
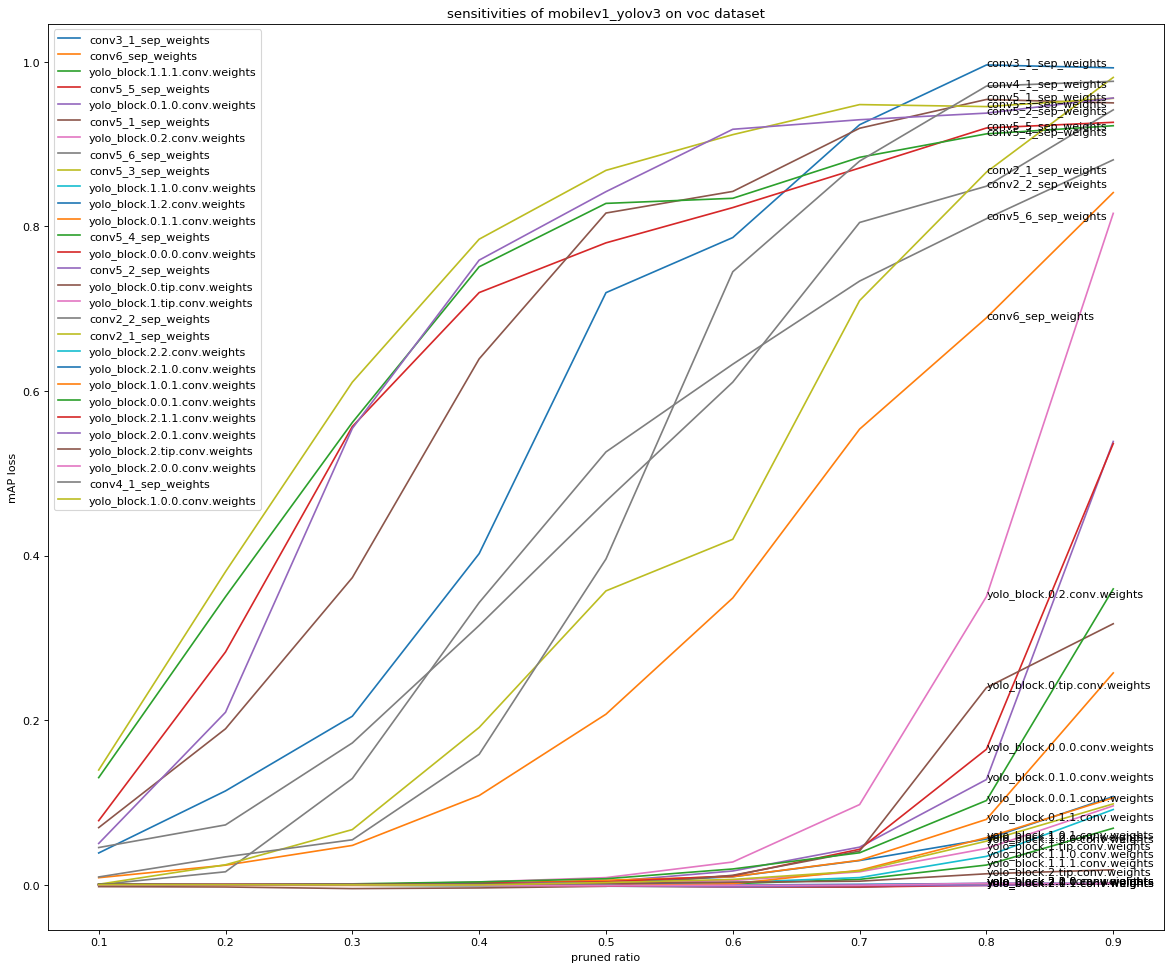
从文件中加载敏感度信息,并使用Python数据分析工具画图分析。下图展示了
`MobileNetv1-YOLOv3-VOC`
模型在VOC数据上的敏感度信息:
<div
align=
"center"
>
<img
src=
"./images/mobilev1_yolov3_voc_sensitives.png"
/>
</div>
通过画图分析,可以确定一组合适的剪裁率,或者通过
[
paddleslim.prune.get_ratios_by_loss
](
https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#get_ratios_by_losssensitivities-loss
)
获得合适的剪裁率。
## 分布式计算敏感度信息
如果模型评估速度比较慢,可以考虑使用多进程加速敏感度计算的过程。
通过
`--pruned_ratios`
指定当前进程计算敏感度时用的剪裁率,默认为"0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9"。可以将该组剪切率分配到不同的进程进行计算,如下所示:
```
# 进程1
nohup python sensitive.py \
-c ../../configs/yolov3_mobilenet_v1_voc.yml \
--pruned_params "yolo_block.0.0.0.conv.weights" \
--pruned_ratios "0.1 0.2 0.3 0.4 0.5"
--sensitivities_file "./demo.data.1"
```
```
# 进程2
nohup python sensitive.py \
-c ../../configs/yolov3_mobilenet_v1_voc.yml \
--pruned_params "yolo_block.0.0.0.conv.weights" \
--pruned_ratios "0.6 0.7 0.8 0.9"
--sensitivities_file "./demo.data.2"
```
待以上两个进程执行完毕,通过
[
paddleslim.prune.merge_sensitive
](
https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#merge_sensitive
)
将
`demo.data.1`
和
`demo.data.2`
两个文件合并分析。
slim/sensitive/images/mobilev1_yolov3_voc_sensitives.png
0 → 100644
浏览文件 @
993b955b
336.8 KB
slim/sensitive/sensitive.py
0 → 100644
浏览文件 @
993b955b
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
import
time
import
numpy
as
np
import
datetime
from
collections
import
deque
def
set_paddle_flags
(
**
kwargs
):
for
key
,
value
in
kwargs
.
items
():
if
os
.
environ
.
get
(
key
,
None
)
is
None
:
os
.
environ
[
key
]
=
str
(
value
)
# NOTE(paddle-dev): All of these flags should be set before
# `import paddle`. Otherwise, it would not take any effect.
set_paddle_flags
(
FLAGS_eager_delete_tensor_gb
=
0
,
# enable GC to save memory
)
from
paddle
import
fluid
from
ppdet.experimental
import
mixed_precision_context
from
ppdet.core.workspace
import
load_config
,
merge_config
,
create
#from ppdet.data.data_feed import create_reader
from
ppdet.data.reader
import
create_reader
from
ppdet.utils.cli
import
print_total_cfg
from
ppdet.utils
import
dist_utils
from
ppdet.utils.eval_utils
import
parse_fetches
,
eval_run
,
eval_results
from
ppdet.utils.stats
import
TrainingStats
from
ppdet.utils.cli
import
ArgsParser
from
ppdet.utils.check
import
check_gpu
,
check_version
import
ppdet.utils.checkpoint
as
checkpoint
from
ppdet.modeling.model_input
import
create_feed
from
paddleslim.prune
import
sensitivity
import
logging
FORMAT
=
'%(asctime)s-%(levelname)s: %(message)s'
logging
.
basicConfig
(
level
=
logging
.
INFO
,
format
=
FORMAT
)
logger
=
logging
.
getLogger
(
__name__
)
def
main
():
env
=
os
.
environ
print
(
"FLAGS.config: {}"
.
format
(
FLAGS
.
config
))
cfg
=
load_config
(
FLAGS
.
config
)
assert
'architecture'
in
cfg
main_arch
=
cfg
.
architecture
merge_config
(
FLAGS
.
opt
)
print_total_cfg
(
cfg
)
place
=
fluid
.
CUDAPlace
(
0
)
exe
=
fluid
.
Executor
(
place
)
# build program
startup_prog
=
fluid
.
Program
()
eval_prog
=
fluid
.
Program
()
with
fluid
.
program_guard
(
eval_prog
,
startup_prog
):
with
fluid
.
unique_name
.
guard
():
model
=
create
(
main_arch
)
inputs_def
=
cfg
[
'EvalReader'
][
'inputs_def'
]
feed_vars
,
eval_loader
=
model
.
build_inputs
(
**
inputs_def
)
fetches
=
model
.
eval
(
feed_vars
)
eval_prog
=
eval_prog
.
clone
(
True
)
if
FLAGS
.
print_params
:
print
(
"-------------------------All parameters in current graph----------------------"
)
for
block
in
eval_prog
.
blocks
:
for
param
in
block
.
all_parameters
():
print
(
"parameter name: {}
\t
shape: {}"
.
format
(
param
.
name
,
param
.
shape
))
print
(
"------------------------------------------------------------------------------"
)
return
eval_reader
=
create_reader
(
cfg
.
EvalReader
)
eval_loader
.
set_sample_list_generator
(
eval_reader
,
place
)
# parse eval fetches
extra_keys
=
[]
if
cfg
.
metric
==
'COCO'
:
extra_keys
=
[
'im_info'
,
'im_id'
,
'im_shape'
]
if
cfg
.
metric
==
'VOC'
:
extra_keys
=
[
'gt_box'
,
'gt_label'
,
'is_difficult'
]
if
cfg
.
metric
==
'WIDERFACE'
:
extra_keys
=
[
'im_id'
,
'im_shape'
,
'gt_box'
]
eval_keys
,
eval_values
,
eval_cls
=
parse_fetches
(
fetches
,
eval_prog
,
extra_keys
)
exe
.
run
(
startup_prog
)
fuse_bn
=
getattr
(
model
.
backbone
,
'norm_type'
,
None
)
==
'affine_channel'
ignore_params
=
cfg
.
finetune_exclude_pretrained_params
\
if
'finetune_exclude_pretrained_params'
in
cfg
else
[]
start_iter
=
0
if
cfg
.
weights
:
checkpoint
.
load_params
(
exe
,
eval_prog
,
cfg
.
weights
)
else
:
logger
.
warn
(
"Please set cfg.weights to load trained model."
)
# whether output bbox is normalized in model output layer
is_bbox_normalized
=
False
if
hasattr
(
model
,
'is_bbox_normalized'
)
and
\
callable
(
model
.
is_bbox_normalized
):
is_bbox_normalized
=
model
.
is_bbox_normalized
()
# if map_type not set, use default 11point, only use in VOC eval
map_type
=
cfg
.
map_type
if
'map_type'
in
cfg
else
'11point'
def
test
(
program
):
compiled_eval_prog
=
fluid
.
compiler
.
CompiledProgram
(
program
)
results
=
eval_run
(
exe
,
compiled_eval_prog
,
eval_loader
,
eval_keys
,
eval_values
,
eval_cls
)
resolution
=
None
if
'mask'
in
results
[
0
]:
resolution
=
model
.
mask_head
.
resolution
dataset
=
cfg
[
'EvalReader'
][
'dataset'
]
box_ap_stats
=
eval_results
(
results
,
cfg
.
metric
,
cfg
.
num_classes
,
resolution
,
is_bbox_normalized
,
FLAGS
.
output_eval
,
map_type
,
dataset
=
dataset
)
return
box_ap_stats
[
0
]
pruned_params
=
FLAGS
.
pruned_params
assert
(
FLAGS
.
pruned_params
is
not
None
),
"FLAGS.pruned_params is empty!!! Please set it by '--pruned_params' option."
pruned_params
=
FLAGS
.
pruned_params
.
strip
().
split
(
","
)
logger
.
info
(
"pruned params: {}"
.
format
(
pruned_params
))
pruned_ratios
=
[
float
(
n
)
for
n
in
FLAGS
.
pruned_ratios
.
strip
().
split
(
" "
)]
logger
.
info
(
"pruned ratios: {}"
.
format
(
pruned_ratios
))
sensitivity
(
eval_prog
,
place
,
pruned_params
,
test
,
sensitivities_file
=
FLAGS
.
sensitivities_file
,
pruned_ratios
=
pruned_ratios
)
if
__name__
==
'__main__'
:
parser
=
ArgsParser
()
parser
.
add_argument
(
"--output_eval"
,
default
=
None
,
type
=
str
,
help
=
"Evaluation directory, default is current directory."
)
parser
.
add_argument
(
"-d"
,
"--dataset_dir"
,
default
=
None
,
type
=
str
,
help
=
"Dataset path, same as DataFeed.dataset.dataset_dir"
)
parser
.
add_argument
(
"-s"
,
"--sensitivities_file"
,
default
=
"sensitivities.data"
,
type
=
str
,
help
=
"The file used to save sensitivities."
)
parser
.
add_argument
(
"-p"
,
"--pruned_params"
,
default
=
None
,
type
=
str
,
help
=
"The parameters to be pruned when calculating sensitivities."
)
parser
.
add_argument
(
"-r"
,
"--pruned_ratios"
,
default
=
"0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9"
,
type
=
str
,
help
=
"The ratios pruned iteratively for each parameter when calculating sensitivities."
)
parser
.
add_argument
(
"-P"
,
"--print_params"
,
default
=
False
,
action
=
'store_true'
,
help
=
"Whether to only print the parameters' names and shapes."
)
FLAGS
=
parser
.
parse_args
()
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}