Merge pull request #1057 from luotao1/doc
add translated chinese docs into catalog
Showing
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
{kind=link}
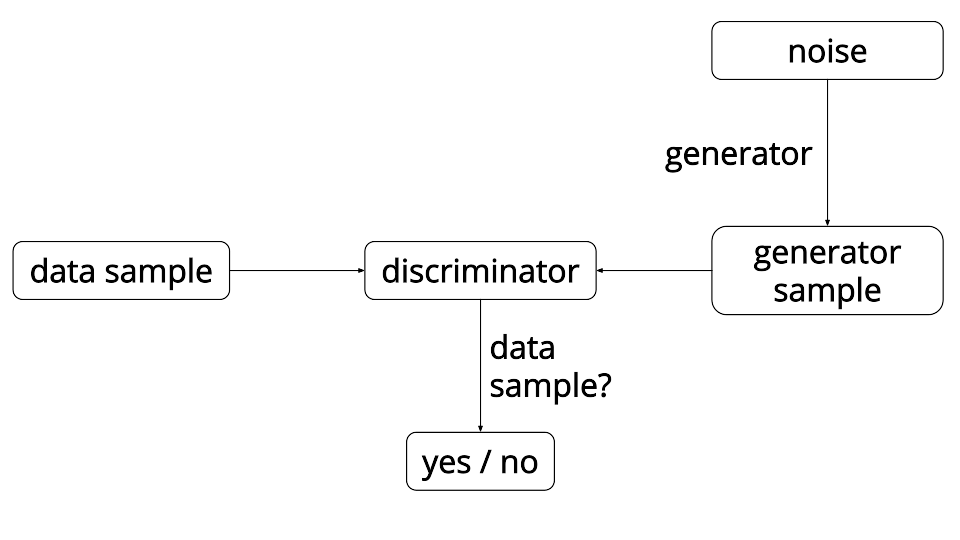
| W: | H:
| W: | H:
{kind=link}
{kind=link}
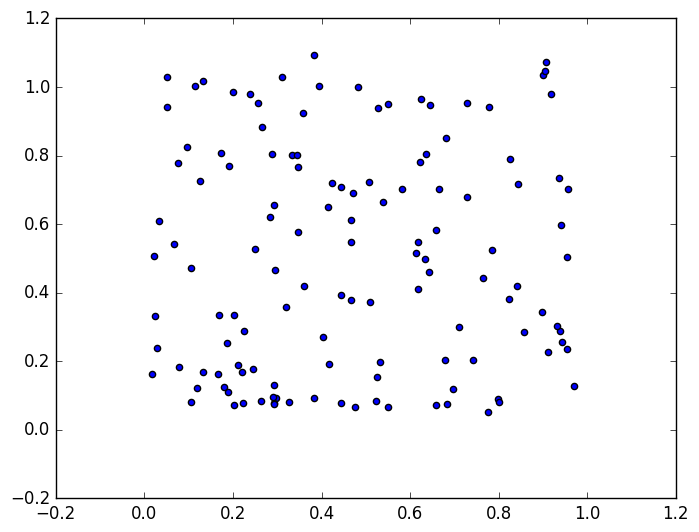
| W: | H:
| W: | H:
add translated chinese docs into catalog
| W: | H:
| W: | H:
| W: | H:
| W: | H: