Merge branch 'develop' of github.com:baidu/Paddle into feature/make_python_catch_enforce_not_met
Showing
文件已添加
{kind=link}
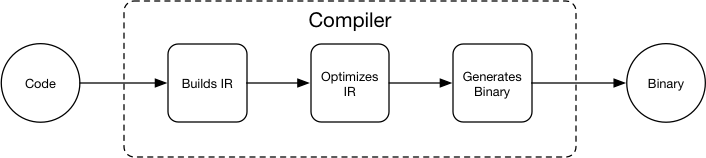
15.5 KB
文件已移动
{kind=link}
文件已添加
{kind=link}
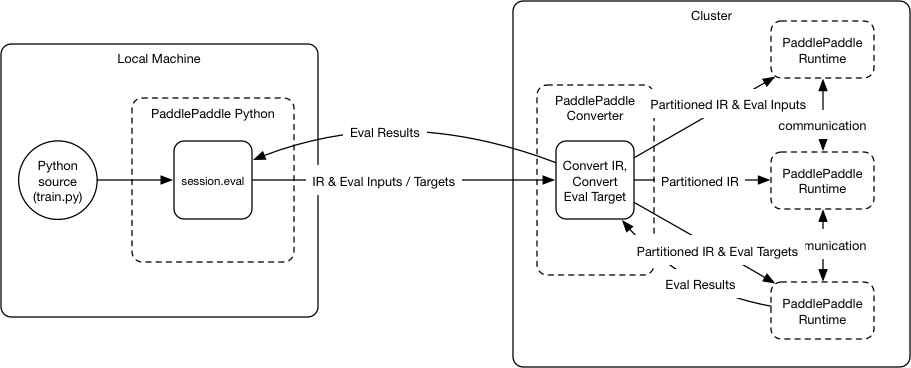
46.5 KB
文件已移动
{kind=link}
文件已添加
{kind=link}
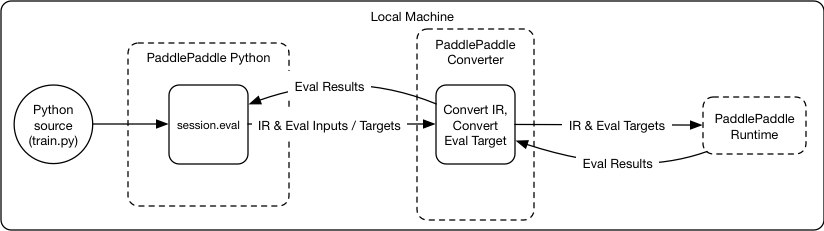
28.3 KB
文件已添加
{kind=link}
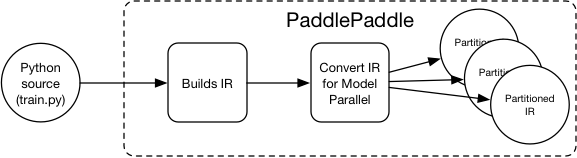
19.7 KB
15.5 KB
46.5 KB
28.3 KB
19.7 KB