# Design Doc: Lookup Remote Table while Distributed training
## Abstract
We propose an approach to pre-fetch the parameters from a Parameter Server while distributed training so that Fluid can train a model with the very large parameter that cannot be stored in one trainer's memory.
## Background
For an embedding layer, the trainable parameter may be very large, and it is likely that it may not be able to be stored in one trainer's memory. In Fluid distributed training,
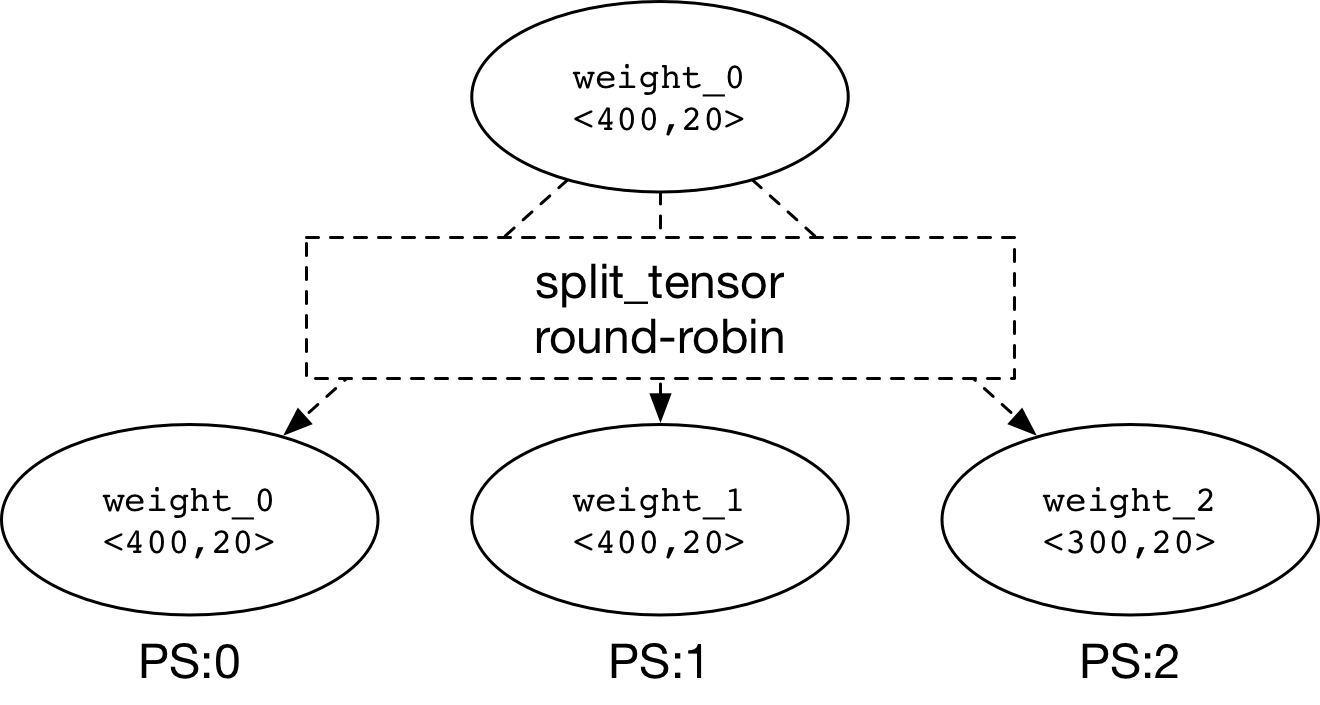
the [Distributed Transpiler](./parameter_server.md#distributed-transpiler) would split every parameter into some small parameters that stored on the Parameter Server. Hence, we can pre-fetch the parameter from the specified Parameter Server using the input `Ids`.
## Design
Prior to reading this design, it would be useful for the reader to make themselves familiar with Fluid [Distributed Training Architecture](./distributed_architecture.md) and
[Parameter Server](./parameter_server.md).
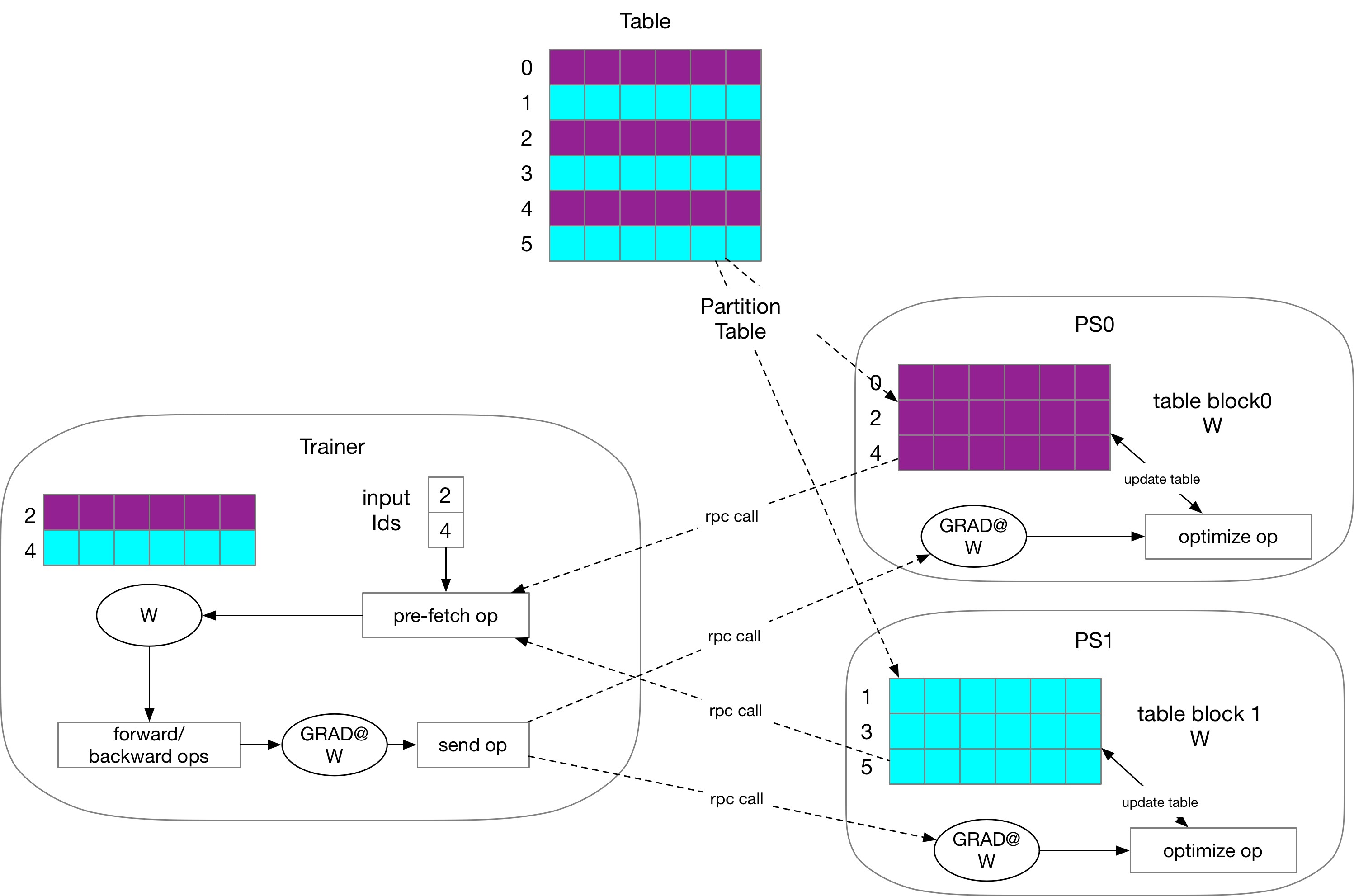
The execution of `lookup local table` is as follows:
<imgsrc="src/lookup_local_table.png"width="700"/>
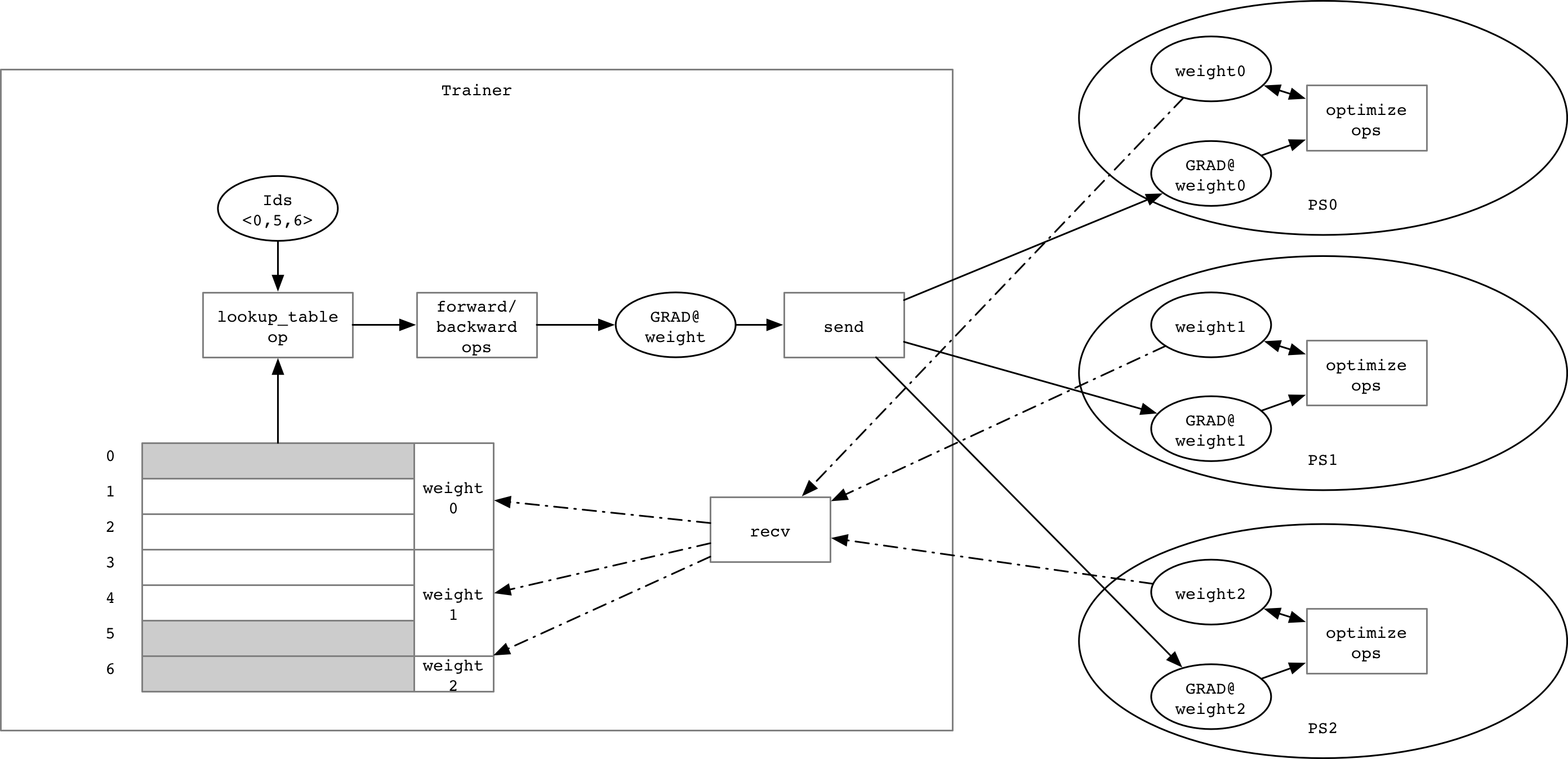
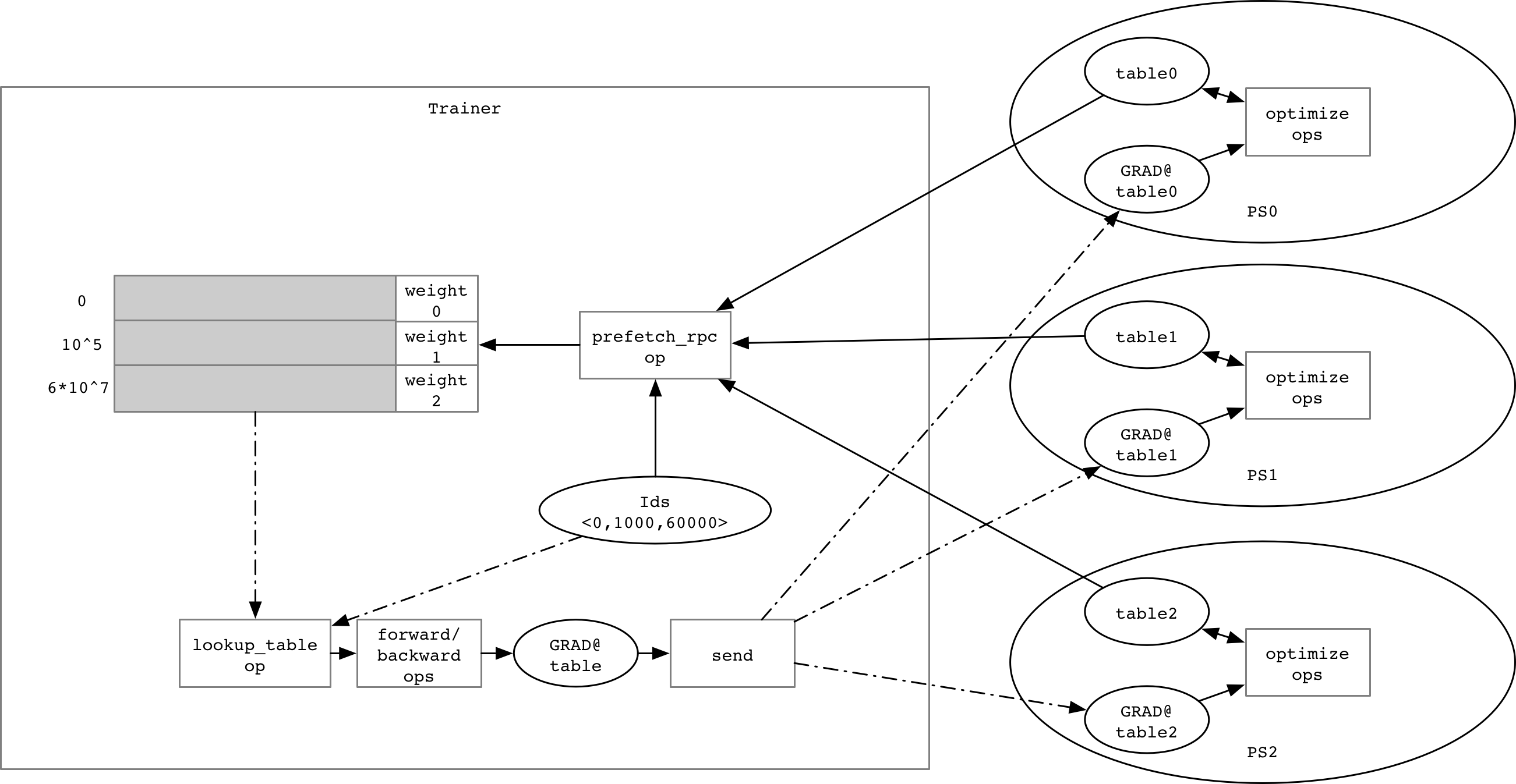
For some cases, the parameter(`weight`) may be very large, such as 10 billion features, the entire
data could not be stored in one trainer's memory, so we need to partition this parameter and
pre-fetch it at the beginning of each mini-batch, and we call it `lookup remote table`:
{kind=link}
{kind=link}
{kind=link}
{kind=link}