# PP-LCNet Series
---
## Catalogue
- [1. Abstract](#1)
- [2. Introduction](#2)
- [3. Method](#3)
- [3.1 Better Activation Function](#3.1)
- [3.2 SE Modules at Appropriate Positions](#3.2)
- [3.3 Larger Convolution Kernels](#3.3)
- [3.4 Larger Dimensional 1 × 1 Conv Layer after GAP](#3.4)
- [4. Experiments](#4)
- [4.1 Image Classification](#4.1)
- [4.2 Object Detection](#4.2)
- [4.3 Semantic Segmentation](#4.3)
- [5. Inference speed based on V100 GPU](#5)
- [6. Inference speed based on SD855](#6)
- [7. Conclusion](#7)
- [8. Reference](#8)
## 1. Abstract
In the field of computer vision, the quality of backbone network determines the outcome of the whole vision task. In previous studies, researchers generally focus on the optimization of FLOPs or Params, but inference speed actually serves as an importance indicator of model quality in real-world scenarios. Nevertheless, it is difficult to balance inference speed and accuracy. In view of various CPU-based applications in industry, we are now working to raise the adaptability of the backbone network to Intel CPU, so as to obtain a faster and more accurate lightweight backbone network. At the same time, the performance of downstream vision tasks such as object detection and semantic segmentation are also improved.
## 2. Introduction
Recent years witnessed the emergence of many lightweight backbone networks. In past two years, in particular, there were abundant networks searched by NAS that either enjoy advantages on FLOPs or Params, or have an edge in terms of inference speed on ARM devices. However, few of them dedicated to specified optimization of Intel CPU, resulting their imperfect inference speed on the intel CPU side. Based on this, we specially design the backbone network PP-LCNet for Intel CPU devices with its acceleration library MKLDNN. Compared with other lightweight SOTA models, this backbone network can further improve the performance of the model without increasing the inference time, significantly outperforming the existing SOTA models. A comparison chart with other models is shown below.
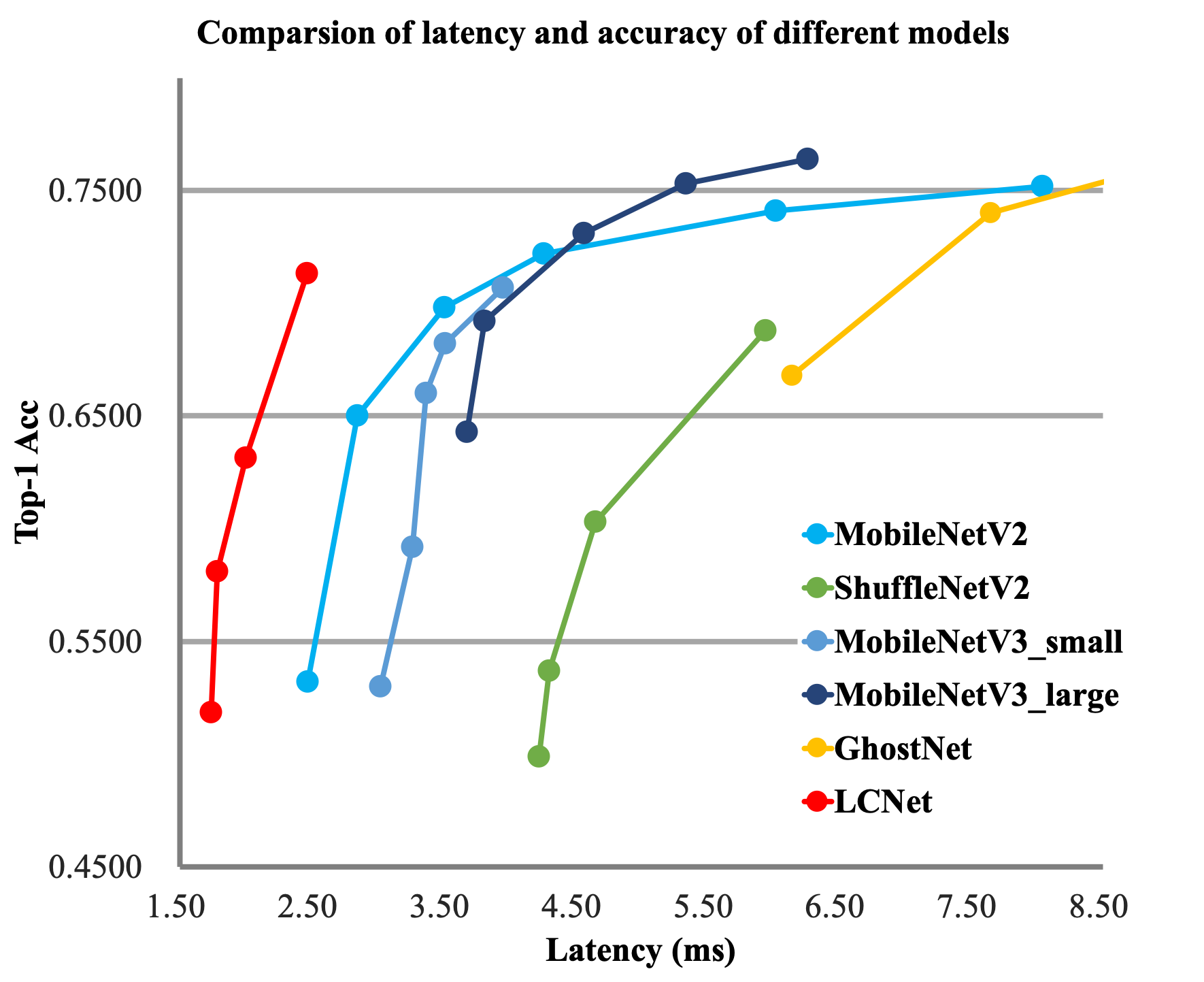
Batch Size=1
(ms) | FP32
Batch Size=1\4
(ms) | FP32
Batch Size=8
(ms) |
| ------------- | --------- | ----------------- | ---------------------------- | -------------------------------- | ------------------------------ |
| PPLCNet_x0_25 | 224 | 256 | 0.72 | 1.17 | 1.71 |
| PPLCNet_x0_35 | 224 | 256 | 0.69 | 1.21 | 1.82 |
| PPLCNet_x0_5 | 224 | 256 | 0.70 | 1.32 | 1.94 |
| PPLCNet_x0_75 | 224 | 256 | 0.71 | 1.49 | 2.19 |
| PPLCNet_x1_0 | 224 | 256 | 0.73 | 1.64 | 2.53 |
| PPLCNet_x1_5 | 224 | 256 | 0.82 | 2.06 | 3.12 |
| PPLCNet_x2_0 | 224 | 256 | 0.94 | 2.58 | 4.08 |
## 6. Inference speed based on SD855
| Models | SD855 time(ms)
bs=1, thread=1 | SD855 time(ms)
bs=1, thread=2 | SD855 time(ms)
bs=1, thread=4 |
| ------------- | -------------------------------- | --------------------------------- | --------------------------------- |
| PPLCNet_x0_25 | 2.30 | 1.62 | 1.32 |
| PPLCNet_x0_35 | 3.15 | 2.11 | 1.64 |
| PPLCNet_x0_5 | 4.27 | 2.73 | 1.92 |
| PPLCNet_x0_75 | 7.38 | 4.51 | 2.91 |
| PPLCNet_x1_0 | 10.78 | 6.49 | 3.98 |
| PPLCNet_x1_5 | 20.55 | 12.26 | 7.54 |
| PPLCNet_x2_0 | 33.79 | 20.17 | 12.10 |
| PPLCNet_x2_5 | 49.89 | 29.60 | 17.82 |
## 7. Conclusion
Rather than holding on to perfect FLOPs and Params as academics do, PP-LCNet focuses on analyzing how to add Intel CPU-friendly modules to improve the performance of the model, which can better balance accuracy and inference time. The experimental conclusions therein are available to other researchers in network structure design, while providing NAS search researchers with a smaller search space and general conclusions. The finished PP-LCNet can also be better accepted and applied in industry.
## 8. Reference
Reference to cite when you use PP-LCNet in a paper:
```
@misc{cui2021pplcnet,
title={PP-LCNet: A Lightweight CPU Convolutional Neural Network},
author={Cheng Cui and Tingquan Gao and Shengyu Wei and Yuning Du and Ruoyu Guo and Shuilong Dong and Bin Lu and Ying Zhou and Xueying Lv and Qiwen Liu and Xiaoguang Hu and Dianhai Yu and Yanjun Ma},
year={2021},
eprint={2109.15099},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```