# PP-LCNet Series
## Abstract
In the field of computer vision, the quality of backbone network determines the outcome of the whole vision task. In previous studies, researchers generally focus on the optimization of FLOPs or Params, but inference speed actually serves as an importance indicator of model quality in real-world scenarios. Nevertheless, it is difficult to balance inference speed and accuracy. In view of various CPU-based applications in industry, we are now working to raise the adaptability of the backbone network to Intel CPU, so as to obtain a faster and more accurate lightweight backbone network. At the same time, the performance of downstream vision tasks such as object detection and semantic segmentation are also improved.
## Introduction
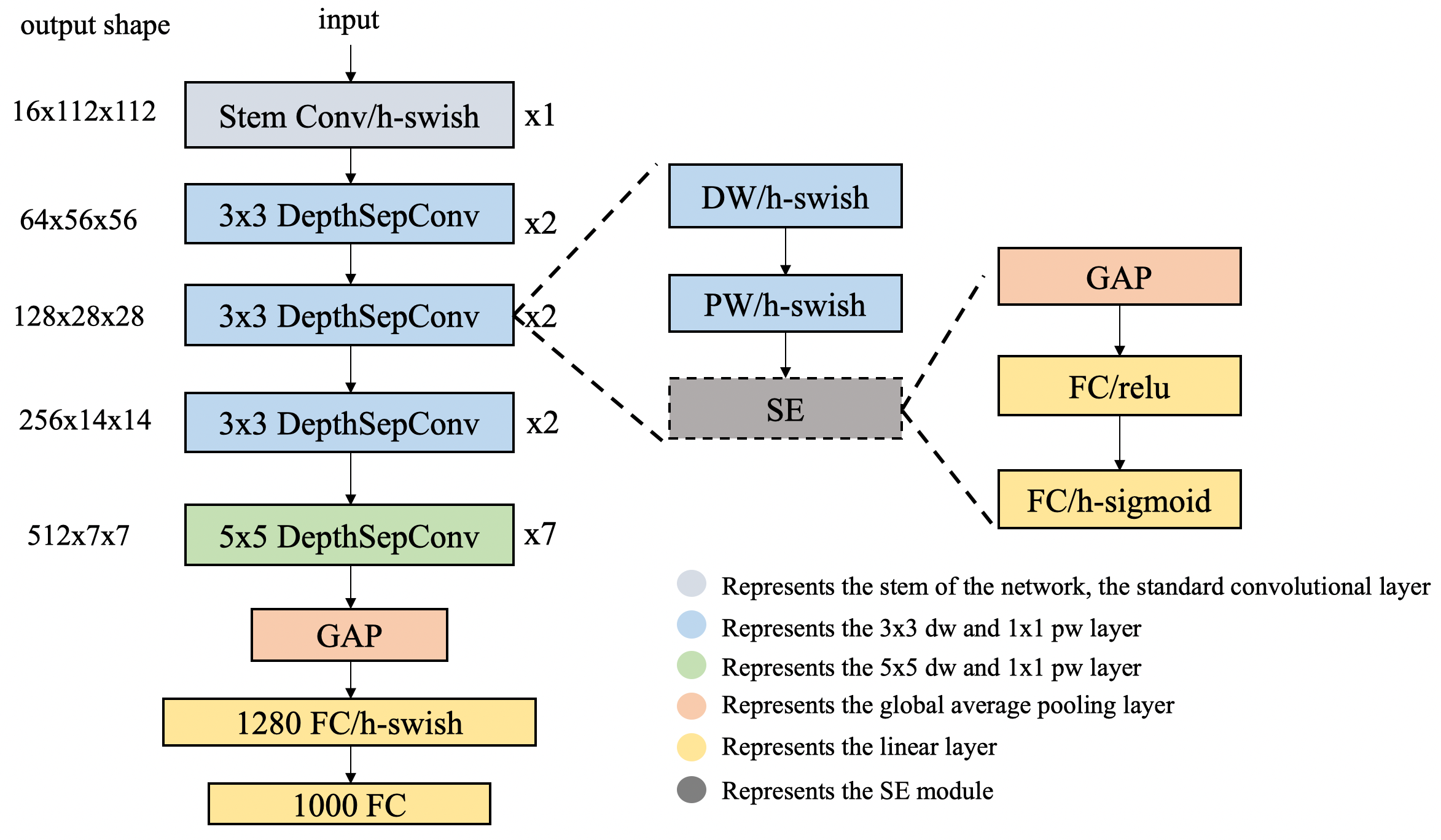
Recent years witnessed the emergence of many lightweight backbone networks. In past two years, in particular, there were abundant networks searched by NAS that either enjoy advantages on FLOPs or Params, or have an edge in terms of inference speed on ARM devices. However, few of them dedicated to specified optimization of Intel CPU, resulting their imperfect inference speed on the intel CPU side. Based on this, we specially design the backbone network PP-LCNet for Intel CPU devices with its acceleration library MKLDNN. Compared with other lightweight SOTA models, this backbone network can further improve the performance of the model without increasing the inference time, significantly outperforming the existing SOTA models. A comparison chart with other models is shown below.