## PP-ShiTu V2图像识别系统
## 目录
- [1. PP-ShiTu V2模型和应用场景介绍](#1-pp-shituv2模型和应用场景介绍)
- [2. 模型快速体验](#2-模型快速体验)
- [2.1 PP-ShiTu android demo 快速体验](#21-pp-shitu-android-demo-快速体验)
- [2.2 命令行代码快速体验](#22-命令行代码快速体验)
- [3 模块介绍与训练](#3-模块介绍与训练)
- [3.1 主体检测](#31-主体检测)
- [3.2 特征提取](#32-特征提取)
- [3.3 向量检索](#33-向量检索)
- [4. 推理部署](#4-推理部署)
- [4.1 推理模型准备](#41-推理模型准备)
- [4.1.1 基于训练得到的权重导出 inference 模型](#411-基于训练得到的权重导出-inference-模型)
- [4.1.2 直接下载 inference 模型](#412-直接下载-inference-模型)
- [4.2 测试数据准备](#42-测试数据准备)
- [4.3 基于 Python 预测引擎推理](#43-基于-python-预测引擎推理)
- [4.3.1 预测单张图像](#431-预测单张图像)
- [4.3.2 基于文件夹的批量预测](#432-基于文件夹的批量预测)
- [4.4 基于 C++ 预测引擎推理](#44-基于-c-预测引擎推理)
- [4.5 服务化部署](#45-服务化部署)
- [4.6 端侧部署](#46-端侧部署)
- [4.7 Paddle2ONNX 模型转换与预测](#47-paddle2onnx-模型转换与预测)
- [参考文献](#参考文献)
## 1. PP-ShiTuV2模型和应用场景介绍
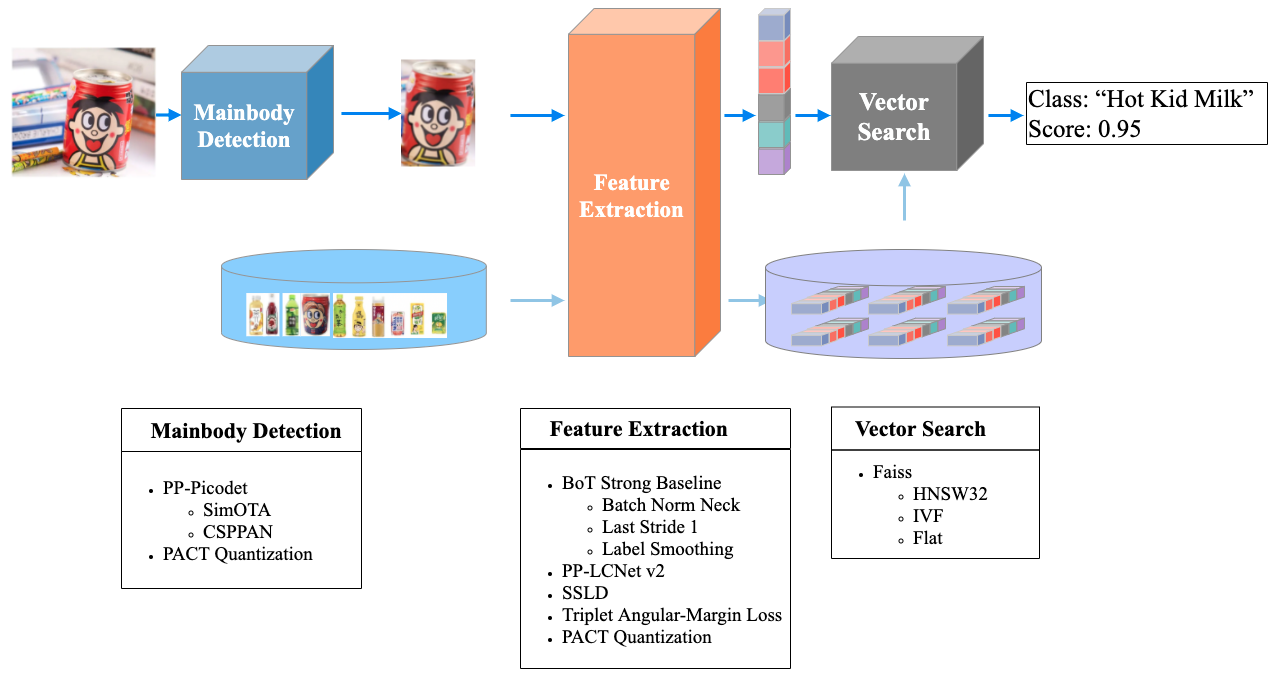
PP-ShiTuV2 是基于 PP-ShiTuV1 改进的一个实用轻量级通用图像识别系统,由主体检测、特征提取、向量检索三个模块构成,相比 PP-ShiTuV1 具有更高的识别精度、更强的泛化能力以及相近的推理速度*。主要针对训练数据集、特征提取两个部分进行优化,使用了更优的骨干网络、损失函数与训练策略,使得 PP-ShiTuV2 在多个实际应用场景上的检索性能有显著提升。
**本文档提供了用户使用 PaddleClas 的 PP-ShiTuV2 图像识别方案进行快速构建轻量级、高精度、可落地的图像识别pipeline。该pipeline可以广泛应用于商场商品识别场景、安防人脸或行人识别场景、海量图像检索过滤等场景中。**
下表列出了 PP-ShiTuV2 用不同的模型结构与训练策略所得到的相关指标,
| 模型 | 存储(主体检测+特征提取) | product |
| :--------- | :---------------------- | :------------------ |
| | | recall@1 |
| PP-ShiTuV1 | 64(30+34)MB | 66.8% |
| PP-ShiTuV2 | 49(30+19)MB | 73.8% |
**注:**
- recall及mAP指标的介绍可以参考 [常用指标](../../algorithm_introduction/ReID.md#22-常用指标)。
- 延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
## 2. 模型快速体验
### 2.1 PP-ShiTu android demo 快速体验
可以通过扫描二维码或者 [点击链接](https://paddle-imagenet-models-name.bj.bcebos.com/demos/PP-ShiTu.apk) 下载并安装APP
然后将以下体验图片保存到手机上:
打开安装好的APP,点击下方“**本地识别**”按钮,选择上面这张保存的图片,再点击确定,就能得到如下识别结果:
更详细的说明参考[PP-ShiTu android demo功能说明](https://github.com/weisy11/PaddleClas/blob/develop/docs/zh_CN/quick_start/quick_start_recognition.md)
### 2.2 命令行代码快速体验
- 首先按照以下命令,安装paddlepaddle和faiss
```shell
# 如果您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
python3.7 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 如果您的机器是CPU,请运行以下命令安装
python3.7 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
# 安装 faiss 库
python3.7 -m pip install faiss-cpu==1.7.1post2
```
- 然后按照以下命令,安装paddleclas whl包
```shell
# 进入到PaddleClas根目录下
cd PaddleClas
# 安装paddleclas
python3.7 setup.py install
```
- 然后执行以下命令下载并解压好demo数据,最后执行一行命令体验图像识别
```shell
# 下载并解压demo数据
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v2.0.tar && tar -xf drink_dataset_v2.0.tar
# 执行识别命令
paddleclas \
--model_name=PP-ShiTuV2 \
--infer_imgs=./drink_dataset_v2.0/test_images/100.jpeg \
--index_dir=./drink_dataset_v2.0/index/ \
--data_file=./drink_dataset_v2.0/gallery/drink_label.txt
```
## 3 模块介绍与训练
### 3.1 主体检测
主体检测是目前应用非常广泛的一种检测技术,它指的是检测出图片中一个或者多个主体的坐标位置,然后将图像中的对应区域裁剪下来进行识别。主体检测是识别任务的前序步骤,输入图像经过主体检测后再进行识别,可以过滤复杂背景,有效提升识别精度。
考虑到检测速度、模型大小、检测精度等因素,最终选择 PaddleDetection 自研的轻量级模型 `PicoDet-LCNet_x2_5` 作为 PP-ShiTuV2 的主体检测模型
主体检测模型的数据集、训练、评估、推理等详细信息可以参考文档:[picodet_lcnet_x2_5_640_mainbody](../../training/PP-ShiTu/mainbody_detection.md)。
### 3.2 特征提取
特征提取是图像识别中的关键一环,它的作用是将输入的图片转化为固定维度的特征向量,用于后续的 [向量检索](./vector_search.md) 。考虑到特征提取模型的速度、模型大小、特征提取性能等因素,最终选择 PaddleClas 自研的 [`PPLCNetV2_base`](../ImageNet1k/PP-LCNetV2.md) 作为特征提取网络。相比 PP-ShiTuV1 所使用的 `PPLCNet_x2_5`, `PPLCNetV2_base` 基本保持了较高的分类精度,并减少了40%的推理时间*。
**注:** *推理环境基于 Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。
在实验过程中我们也发现可以对 `PPLCNetV2_base` 进行适当的改进,在保持速度基本不变的情况下,让其在识别任务中得到更高的性能,包括:去掉 `PPLCNetV2_base` 末尾的 `ReLU` 和 `FC`、将最后一个 stage(RepDepthwiseSeparable) 的 stride 改为1。
特征提取模型的数据集、训练、评估、推理等详细信息可以参考文档:[PPLCNetV2_base_ShiTu](../../training/PP-ShiTu/feature_extraction.md)。
### 3.3 向量检索
向量检索技术在图像识别、图像检索中应用比较广泛。其主要目标是对于给定的查询向量,在已经建立好的向量库中进行特征向量的相似度或距离计算,返回候选向量的相似度排序结果。
在 PP-ShiTuV2 识别系统中,我们使用了 [Faiss](https://github.com/facebookresearch/faiss) 向量检索开源库对此部分进行支持,其具有适配性好、安装方便、算法丰富、同时支持CPU与GPU的优点。
PP-ShiTuV2 系统中关于 Faiss 向量检索库的安装及使用可以参考文档:[vector search](../../deployment/PP-ShiTu/vector_search.md)。
## 4. 推理部署
### 4.1 推理模型准备
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。相比于直接基于预训练模型进行预测,Paddle Inference可使用 MKLDNN、CUDNN、TensorRT 进行预测加速,从而实现更优的推理性能。更多关于 Paddle Inference 推理引擎的介绍,可以参考 [Paddle Inference官网教程](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/infer/inference/inference_cn.html)。
当使用 Paddle Inference 推理时,加载的模型类型为 inference 模型。本案例提供了两种获得 inference 模型的方法,如果希望得到和文档相同的结果,请选择 [直接下载 inference 模型](#412-直接下载-inference-模型) 的方式。
#### 4.1.1 基于训练得到的权重导出 inference 模型
- 主体检测模型权重导出请参考文档 [主体检测推理模型准备](../../training/PP-ShiTu/mainbody_detection.md#41-推理模型准备),或者参照 [4.1.2](#412-直接下载-inference-模型) 直接下载解压即可。
- 特征提取模型权重导出可以参考以下命令:
```shell
python3.7 tools/export_model.py \
-c ./ppcls/configs/GeneralRecognitionV2/GeneralRecognitionV2_PPLCNetV2_base.yaml \
-o Global.pretrained_model="https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/pretrain/PPShiTuV2/general_PPLCNetV2_base_pretrained_v1.0.pdparams" \
-o Global.save_inference_dir=deploy/models/GeneralRecognitionV2_PPLCNetV2_base`
```
执行完该脚本后会在 `deploy/models/` 下生成 `GeneralRecognitionV2_PPLCNetV2_base` 文件夹,具有如下文件结构:
```log
deploy/models/
├── GeneralRecognitionV2_PPLCNetV2_base
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
```
#### 4.1.2 直接下载 inference 模型
[4.1.1 小节](#411-基于训练得到的权重导出-inference-模型) 提供了导出 inference 模型的方法,此处提供我们导出好的 inference 模型,可以按以下命令,下载模型到指定位置解压进行体验。
```shell
cd deploy/models
# 下载主体检测inference模型并解压
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar && tar -xf picodet_PPLCNet_x2_5_mainbody_lite_v1.0_infer.tar
# 下载特征提取inference模型并解压
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/PP-ShiTuV2/general_PPLCNetV2_base_pretrained_v1.0_infer.tar && tar -xf general_PPLCNetV2_base_pretrained_v1.tar
```
### 4.2 测试数据准备
准备好主体检测、特征提取模型之后,还需要准备作为输入的测试数据,可以执行以下命令下载并解压测试数据。
```shell
# 返回deploy
cd ../
# 下载测试数据drink_dataset_v2.0,并解压
wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v2.0.tar && tar -xf drink_dataset_v2.0.tar
```
### 4.3 基于 Python 预测引擎推理
#### 4.3.1 预测单张图像
然后执行以下命令对单张图像 `./drink_dataset_v2.0/test_images/100.jpeg` 进行识别。
```shell
# 执行下面的命令使用 GPU 进行预测
python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v2.0/test_images/100.jpeg"
# 执行下面的命令使用 CPU 进行预测
python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v2.0/test_images/100.jpeg" -o Global.use_gpu=False
```
最终输出结果如下。
```log
[{'bbox': [437, 71, 660, 728], 'rec_docs': '元气森林', 'rec_scores': 0.7740249}, {'bbox': [221, 72, 449, 701], 'rec_docs': '元气森林', 'rec_scores': 0.6950992}, {'bbox': [794, 104, 979, 652], 'rec_docs': '元气森林', 'rec_scores': 0.6305153}]
```
#### 4.3.2 基于文件夹的批量预测
如果希望预测文件夹内的图像,可以直接修改配置文件中的 Global.infer_imgs 字段,也可以通过下面的 -o 参数修改对应的配置。
```shell
# 使用下面的命令使用 GPU 进行预测
python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v2.0/test_images"
# 使用下面的命令使用 CPU 进行预测
python3.7 python/predict_system.py -c configs/inference_general.yaml -o Global.infer_imgs="./drink_dataset_v2.0/test_images" -o Global.use_gpu=False
```
终端中会输出该文件夹内所有图像的分类结果,如下所示。
```log
...
[{'bbox': [0, 0, 600, 600], 'rec_docs': '红牛-强化型', 'rec_scores': 0.74081033}]
Inference: 120.39852142333984 ms per batch image
[{'bbox': [0, 0, 514, 436], 'rec_docs': '康师傅矿物质水', 'rec_scores': 0.6918598}]
Inference: 32.045602798461914 ms per batch image
[{'bbox': [138, 40, 573, 1198], 'rec_docs': '乐虎功能饮料', 'rec_scores': 0.68214047}]
Inference: 113.41428756713867 ms per batch image
[{'bbox': [328, 7, 467, 272], 'rec_docs': '脉动', 'rec_scores': 0.60406065}]
Inference: 122.04337120056152 ms per batch image
[{'bbox': [242, 82, 498, 726], 'rec_docs': '味全_每日C', 'rec_scores': 0.5428652}]
Inference: 37.95266151428223 ms per batch image
[{'bbox': [437, 71, 660, 728], 'rec_docs': '元气森林', 'rec_scores': 0.7740249}, {'bbox': [221, 72, 449, 701], 'rec_docs': '元气森林', 'rec_scores': 0.6950992}, {'bbox': [794, 104, 979, 652], 'rec_docs': '元气森林', 'rec_scores': 0.6305153}]
...
```
其中 `bbox` 表示检测出的主体所在位置,`rec_docs` 表示索引库中与检测框最为相似的类别,`rec_scores` 表示对应的相似度。
### 4.4 基于 C++ 预测引擎推理
PaddleClas 提供了基于 C++ 预测引擎推理的示例,您可以参考 [服务器端 C++ 预测](../../../../deploy/cpp_shitu/readme.md) 来完成相应的推理部署。如果您使用的是 Windows 平台,可以参考 [基于 Visual Studio 2019 Community CMake 编译指南](../../deployment/image_classification/cpp/windows.md) 完成相应的预测库编译和模型预测工作。
### 4.5 服务化部署
Paddle Serving 提供高性能、灵活易用的工业级在线推理服务。Paddle Serving 支持 RESTful、gRPC、bRPC 等多种协议,提供多种异构硬件和多种操作系统环境下推理解决方案。更多关于Paddle Serving 的介绍,可以参考 [Paddle Serving 代码仓库](https://github.com/PaddlePaddle/Serving)。
PaddleClas 提供了基于 Paddle Serving 来完成模型服务化部署的示例,您可以参考 [模型服务化部署](../../deployment/PP-ShiTu/paddle_serving.md) 来完成相应的部署工作。
### 4.6 端侧部署
Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及服务器端在内的多硬件平台。更多关于 Paddle Lite 的介绍,可以参考 [Paddle Lite 代码仓库](https://github.com/PaddlePaddle/Paddle-Lite)。
### 4.7 Paddle2ONNX 模型转换与预测
Paddle2ONNX 支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式。通过 ONNX 可以完成将 Paddle 模型到多种推理引擎的部署,包括TensorRT/OpenVINO/MNN/TNN/NCNN,以及其它对 ONNX 开源格式进行支持的推理引擎或硬件。更多关于 Paddle2ONNX 的介绍,可以参考 [Paddle2ONNX 代码仓库](https://github.com/PaddlePaddle/Paddle2ONNX)。
PaddleClas 提供了基于 Paddle2ONNX 来完成 inference 模型转换 ONNX 模型并作推理预测的示例,您可以参考 [Paddle2ONNX 模型转换与预测](../../deployment/image_classification/paddle2onnx.md) 来完成相应的部署工作。
## 参考文献
1. Schall, Konstantin, et al. "GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval." International Conference on Multimedia Modeling. Springer, Cham, 2022.
2. Luo, Hao, et al. "A strong baseline and batch normalization neck for deep person re-identification." IEEE Transactions on Multimedia 22.10 (2019): 2597-2609.