# PP-LCNet 系列
---
## 目录
- [1. 摘要](#1)
- [2. 介绍](#2)
- [3. 方法](#3)
- [3.1 更好的激活函数](#3.1)
- [3.2 合适的位置添加 SE 模块](#3.2)
- [3.3 合适的位置添加更大的卷积核](#3.3)
- [3.4 GAP 后使用更大的 1x1 卷积层](#3.4)
- [4. 实验部分](#4)
- [4.1 图像分类](#4.1)
- [4.2 目标检测](#4.2)
- [4.3 语义分割](#4.3)
- [5. 基于 V100 GPU 的预测速度](#5)
- [6. 总结](#6)
- [7. 引用](#7)
## 1. 摘要
在计算机视觉领域中,骨干网络的好坏直接影响到整个视觉任务的结果。在之前的一些工作中,相关的研究者普遍将 FLOPs 或者 Params 作为优化目的,但是在工业界真实落地的场景中,推理速度才是考量模型好坏的重要指标,然而,推理速度和准确性很难兼得。考虑到工业界有很多基于 Intel CPU 的应用,所以我们本次的工作旨在使骨干网络更好的适应 Intel CPU,从而得到一个速度更快、准确率更高的轻量级骨干网络,与此同时,目标检测、语义分割等下游视觉任务的性能也同样得到提升。
## 2. 介绍
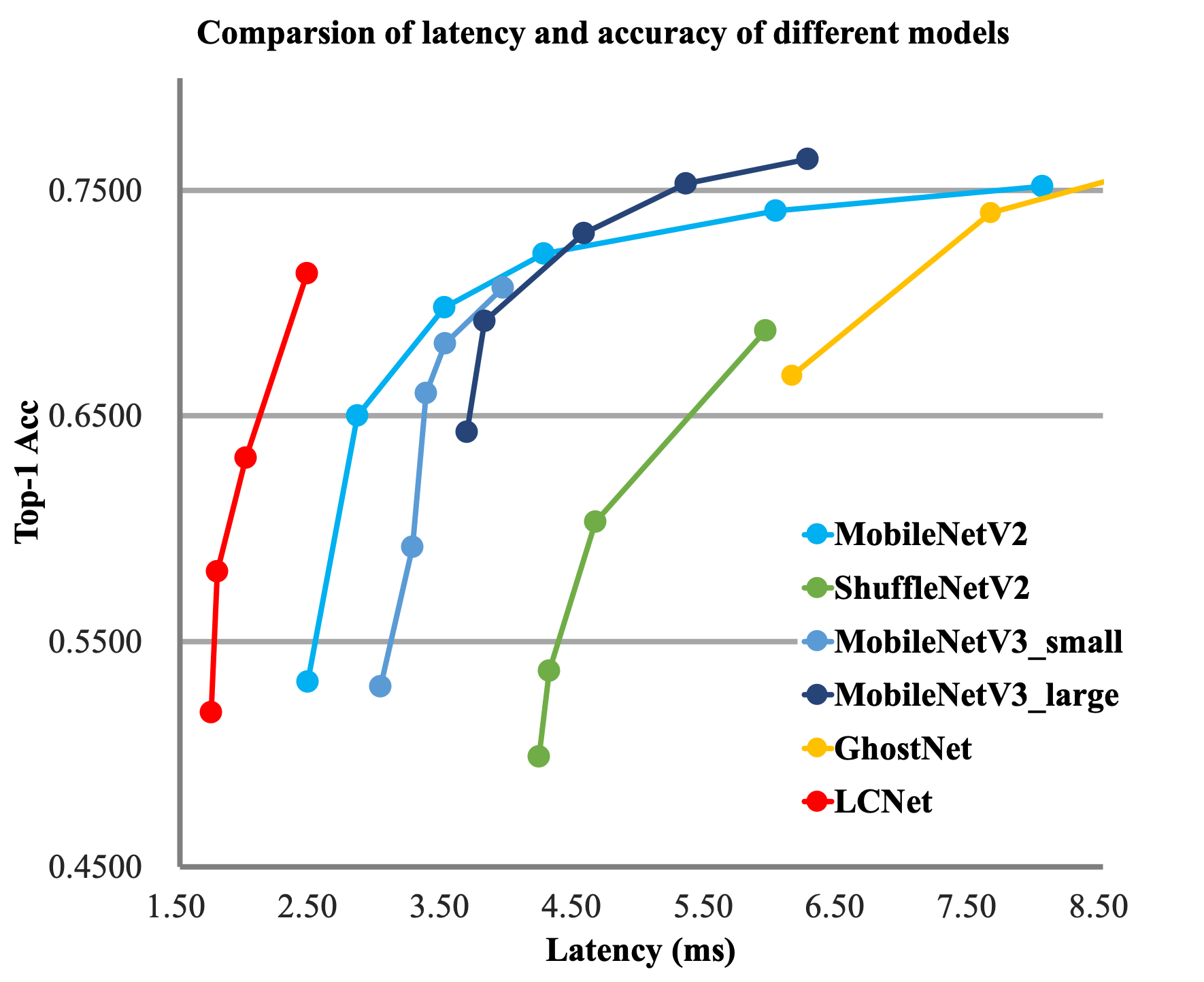
近年来,有很多轻量级的骨干网络问世,尤其最近两年,各种 NAS 搜索出的网络层出不穷,这些网络要么主打 FLOPs 或者 Params 上的优势,要么主打 ARM 设备上的推理速度的优势,很少有网络专门针对 Intel CPU 做特定的优化,导致这些网络在 Intel CPU 端的推理速度并不是很完美。基于此,我们针对 Intel CPU 设备以及其加速库 MKLDNN 设计了特定的骨干网络 PP-LCNet,比起其他的轻量级的 SOTA 模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的 SOTA 模型。与其他模型的对比图如下。

Batch Size=1
(ms) | FP32
Batch Size=1\4
(ms) | FP32
Batch Size=8
(ms) |
| ------------- | --------- | ----------------- | ---------------------------- | -------------------------------- | ------------------------------ |
| PPLCNet_x0_25 | 224 | 256 | 0.72 | 1.17 | 1.71 |
| PPLCNet_x0_35 | 224 | 256 | 0.69 | 1.21 | 1.82 |
| PPLCNet_x0_5 | 224 | 256 | 0.70 | 1.32 | 1.94 |
| PPLCNet_x0_75 | 224 | 256 | 0.71 | 1.49 | 2.19 |
| PPLCNet_x1_0 | 224 | 256 | 0.73 | 1.64 | 2.53 |
| PPLCNet_x1_5 | 224 | 256 | 0.82 | 2.06 | 3.12 |
| PPLCNet_x2_0 | 224 | 256 | 0.94 | 2.58 | 4.08 |
## 6. 总结
PP-LCNet 没有像学术界那样死扣极致的 FLOPs 与 Params,而是着眼于分析如何添加对 Intel CPU 友好的模块来提升模型的性能,这样可以更好的平衡准确率和推理时间,其中的实验结论也很适合其他网络结构设计的研究者,同时也为 NAS 搜索研究者提供了更小的搜索空间和一般结论。最终的 PP-LCNet 在产业界也可以更好的落地和应用。
## 7. 引用
如果你的论文用到了 PP-LCNet 的方法,请添加如下 cite:
```
@misc{cui2021pplcnet,
title={PP-LCNet: A Lightweight CPU Convolutional Neural Network},
author={Cheng Cui and Tingquan Gao and Shengyu Wei and Yuning Du and Ruoyu Guo and Shuilong Dong and Bin Lu and Ying Zhou and Xueying Lv and Qiwen Liu and Xiaoguang Hu and Dianhai Yu and Yanjun Ma},
year={2021},
eprint={2109.15099},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```