# MobileNetV2 系列
-----
## 目录
- [1. 模型介绍](#1)
- [1.1 模型简介](#1.1)
- [1.2 模型指标](#1.2)
- [1.3 Benchmark](#1.3)
- [1.3.1 基于 SD855 的预测速度](#1.3.1)
- [1.3.2 基于 V100 GPU 的预测速度](#1.3.2)
- [1.3.3 基于 T4 GPU 的预测速度](#1.3.3)
- [2. 模型快速体验](#2)
- [3. 模型训练、评估和预测](#3)
- [4. 模型推理部署](#4)
- [4.1 推理模型准备](#4.1)
- [4.2 基于 Python 预测引擎推理](#4.2)
- [4.3 基于 C++ 预测引擎推理](#4.3)
- [4.4 服务化部署](#4.4)
- [4.5 端侧部署](#4.5)
- [4.6 Paddle2ONNX 模型转换与预测](#4.6)
## 1. 模型介绍
### 1.1 模型简介
MobileNetV2 是 Google 继 MobileNetV1 提出的一种轻量级网络。相比 MobileNetV1,MobileNetV2 提出了 Linear bottlenecks 与 Inverted residual block 作为网络基本结构,通过大量地堆叠这些基本模块,构成了 MobileNetV2 的网络结构。最终,在 FLOPs 只有 MobileNetV1 的一半的情况下取得了更高的分类精度。


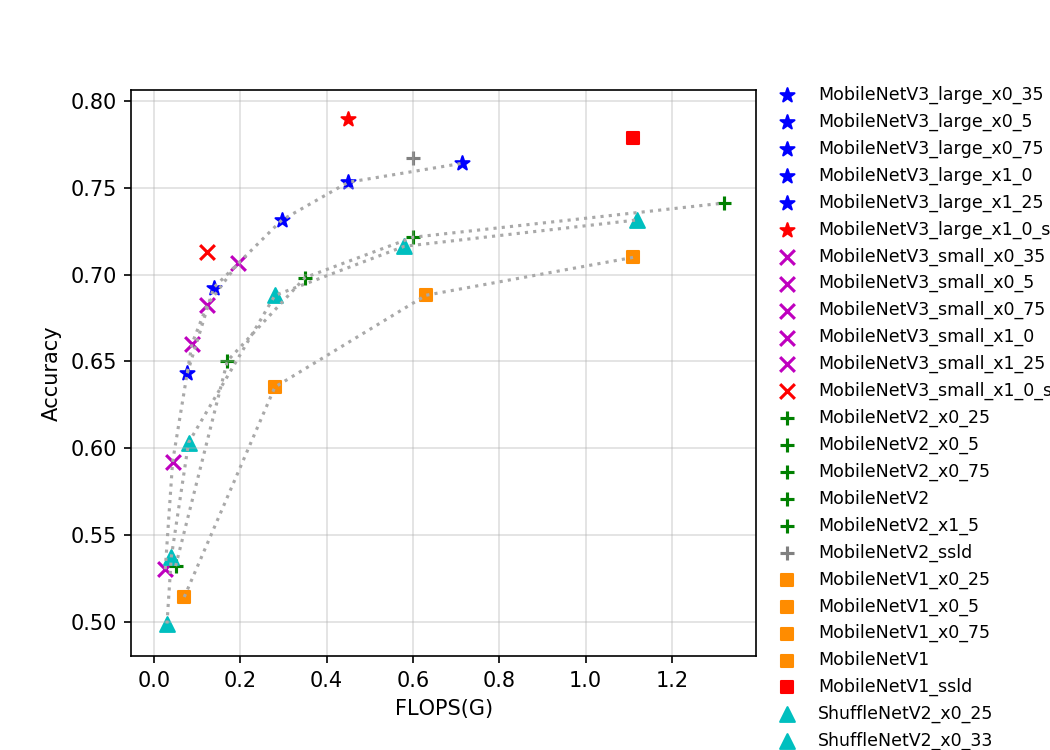

目前 PaddleClas 开源的的移动端系列的预训练模型一共有 35 个,其指标如图所示。从图片可以看出,越新的轻量级模型往往有更优的表现,MobileNetV3 代表了目前主流的轻量级神经网络结构。在 MobileNetV3 中,作者为了获得更高的精度,在 global-avg-pooling 后使用了 1x1 的卷积。该操作大幅提升了参数量但对计算量影响不大,所以如果从存储角度评价模型的优异程度,MobileNetV3 优势不是很大,但由于其更小的计算量,使得其有更快的推理速度。此外,我们模型库中的 ssld 蒸馏模型表现优异,从各个考量角度下,都刷新了当前轻量级模型的精度。由于 MobileNetV3 模型结构复杂,分支较多,对 GPU 并不友好,GPU 预测速度不如 MobileNetV1。GhostNet 于 2020 年提出,通过引入 ghost 的网络设计理念,大大降低了计算量和参数量,同时在精度上也超过前期最高的 MobileNetV3 网络结构。
### 1.2 模型指标
| Models | Top1 | Top5 | Reference
top1 | Reference
top5 | FLOPs
(G) | Params
(M) |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| MobileNetV2_x0_25 | 0.532 | 0.765 | | | 0.050 | 1.500 |
| MobileNetV2_x0_5 | 0.650 | 0.857 | 0.654 | 0.864 | 0.170 | 1.930 |
| MobileNetV2_x0_75 | 0.698 | 0.890 | 0.698 | 0.896 | 0.350 | 2.580 |
| MobileNetV2 | 0.722 | 0.907 | 0.718 | 0.910 | 0.600 | 3.440 |
| MobileNetV2_x1_5 | 0.741 | 0.917 | | | 1.320 | 6.760 |
| MobileNetV2_x2_0 | 0.752 | 0.926 | | | 2.320 | 11.130 |
| MobileNetV2_ssld | 0.7674 | 0.9339 | | | 0.600 | 3.440 |
### 1.3 Benchmark
#### 1.3.1 基于 SD855 的预测速度和存储大小
| Models | SD855 time(ms)
bs=1, thread=1 | SD855 time(ms)
bs=1, thread=2 | SD855 time(ms)
bs=1, thread=4 | Storage Size(M) |
|:--:|----|----|----|----|
| MobileNetV2_x0_25 | 3.46 | 2.51 | 2.03 | 6.100 |
| MobileNetV2_x0_5 | 7.69 | 4.92 | 3.57 | 7.800 |
| MobileNetV2_x0_75 | 13.69 | 8.60 | 5.82 | 10.000 |
| MobileNetV2 | 20.74 | 12.71 | 8.10 | 14.000 |
| MobileNetV2_x1_5 | 40.79 | 24.49 | 15.50 | 26.000 |
| MobileNetV2_x2_0 | 67.50 | 40.03 | 25.55 | 43.000 |
| MobileNetV2_ssld | 20.71 | 12.70 | 8.06 | 14.000 |
#### 1.3.2 基于 V100 GPU 的预测速度
| Models | Size | Latency(ms)
bs=1 | Latency(ms)
bs=4 | Latency(ms)
bs=8 |
| -------------------------------- | ----------------- | ------------------------------ | ------------------------------ | ------------------------------ |
| MobileNetV2_x0_25 | 224 | 0.83 | 1.17 | 1.78 |
| MobileNetV2_x0_5 | 224 | 0.84 | 1.45 | 2.04 |
| MobileNetV2_x0_75 | 224 | 0.96 | 1.62 | 2.53 |
| MobileNetV2 | 224 | 1.02 | 1.93 | 2.89 |
| MobileNetV2_x1_5 | 224 | 1.32 | 2.58 | 4.14 |
| MobileNetV2_x2_0 | 224 | 1.57 | 3.13 | 4.76 |
| MobileNetV2_ssld | 224 | 1.01 | 1.97 | 2.84 |
**备注:** 精度类型为 FP32,推理过程使用 TensorRT。
#### 1.3.3 基于 T4 GPU 的预测速度
| Models | Size | Latency(ms)
FP32
bs=1 | Latency(ms)
FP32
bs=4 | Latency(ms)
FP32
bs=8 |
|----------------------------|-----------------------|-----------------------|-----------------------|-----------------------|
| MobileNetV2_x0_25 | 224 | 0.83 | 1.17 | 1.78 |
| MobileNetV2_x0_5 | 224 | 0.84 | 1.45 | 2.04 |
| MobileNetV2_x0_75 | 224 | 0.96 | 1.62 | 2.53 |
| MobileNetV2 | 224 | 1.02 | 1.93 | 2.89 |
| MobileNetV2_x1_5 | 224 | 1.32 | 2.58 | 4.14 |
| MobileNetV2_x2_0 | 224 | 1.57 | 3.13 | 4.76 |
| MobileNetV2_ssld | 224 | 1.01 | 1.97 | 2.84 |
**备注:** 推理过程使用 TensorRT。
## 2. 模型快速体验
安装 paddlepaddle 和 paddleclas 即可快速对图片进行预测,体验方法可以参考[ResNet50 模型快速体验](./ResNet.md#2-模型快速体验)。
## 3. 模型训练、评估和预测
此部分内容包括训练环境配置、ImageNet数据的准备、该模型在 ImageNet 上的训练、评估、预测等内容。在 `ppcls/configs/ImageNet/MobileNetV2/` 中提供了该模型的训练配置,启动训练方法可以参考:[ResNet50 模型训练、评估和预测](./ResNet.md#3-模型训练评估和预测)。
## 4. 模型推理部署
### 4.1 推理模型准备
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。相比于直接基于预训练模型进行预测,Paddle Inference可使用 MKLDNN、CUDNN、TensorRT 进行预测加速,从而实现更优的推理性能。更多关于Paddle Inference推理引擎的介绍,可以参考[Paddle Inference官网教程](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/infer/inference/inference_cn.html)。
Inference 的获取可以参考 [ResNet50 推理模型准备](./ResNet.md#41-推理模型准备) 。
### 4.2 基于 Python 预测引擎推理
PaddleClas 提供了基于 python 预测引擎推理的示例。您可以参考[ResNet50 基于 Python 预测引擎推理](./ResNet.md#42-基于-python-预测引擎推理) 。
### 4.3 基于 C++ 预测引擎推理
PaddleClas 提供了基于 C++ 预测引擎推理的示例,您可以参考[服务器端 C++ 预测](../inference_deployment/cpp_deploy.md)来完成相应的推理部署。如果您使用的是 Windows 平台,可以参考[基于 Visual Studio 2019 Community CMake 编译指南](../inference_deployment/cpp_deploy_on_windows.md)完成相应的预测库编译和模型预测工作。
### 4.4 服务化部署
Paddle Serving 提供高性能、灵活易用的工业级在线推理服务。Paddle Serving 支持 RESTful、gRPC、bRPC 等多种协议,提供多种异构硬件和多种操作系统环境下推理解决方案。更多关于Paddle Serving 的介绍,可以参考[Paddle Serving 代码仓库](https://github.com/PaddlePaddle/Serving)。
PaddleClas 提供了基于 Paddle Serving 来完成模型服务化部署的示例,您可以参考[模型服务化部署](../inference_deployment/paddle_serving_deploy.md)来完成相应的部署工作。
### 4.5 端侧部署
Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及服务器端在内的多硬件平台。更多关于 Paddle Lite 的介绍,可以参考[Paddle Lite 代码仓库](https://github.com/PaddlePaddle/Paddle-Lite)。
PaddleClas 提供了基于 Paddle Lite 来完成模型端侧部署的示例,您可以参考[端侧部署](../inference_deployment/paddle_lite_deploy.md)来完成相应的部署工作。
### 4.6 Paddle2ONNX 模型转换与预测
Paddle2ONNX 支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式。通过 ONNX 可以完成将 Paddle 模型到多种推理引擎的部署,包括TensorRT/OpenVINO/MNN/TNN/NCNN,以及其它对 ONNX 开源格式进行支持的推理引擎或硬件。更多关于 Paddle2ONNX 的介绍,可以参考[Paddle2ONNX 代码仓库](https://github.com/PaddlePaddle/Paddle2ONNX)。
PaddleClas 提供了基于 Paddle2ONNX 来完成 inference 模型转换 ONNX 模型并作推理预测的示例,您可以参考[Paddle2ONNX 模型转换与预测](../../../deploy/paddle2onnx/readme.md)来完成相应的部署工作。