# 向量检索
向量检索技术在图像识别、图像检索中应用比较广泛。其主要目标是,对于给定的查询向量,在已经建立好的向量库中,与库中所有的待查询向量,进行特征向量的相似度或距离计算,得到相似度排序。在图像识别系统中,我们使用 [Faiss](https://github.com/facebookresearch/faiss) 对此部分进行支持,具体信息请详查 [Faiss 官网](https://github.com/facebookresearch/faiss)。`Faiss` 主要有以下优势
- 适配性好:支持 Windos、Linux、MacOS 系统
- 安装方便: 支持 `python` 接口,直接使用 `pip` 安装
- 算法丰富:支持多种检索算法,满足不同场景的需求
- 同时支持 CPU、GPU,能够加速检索过程
值得注意的是,为了更好是适配性,目前版本,`PaddleClas` 中暂时**只使用 CPU 进行向量检索**。
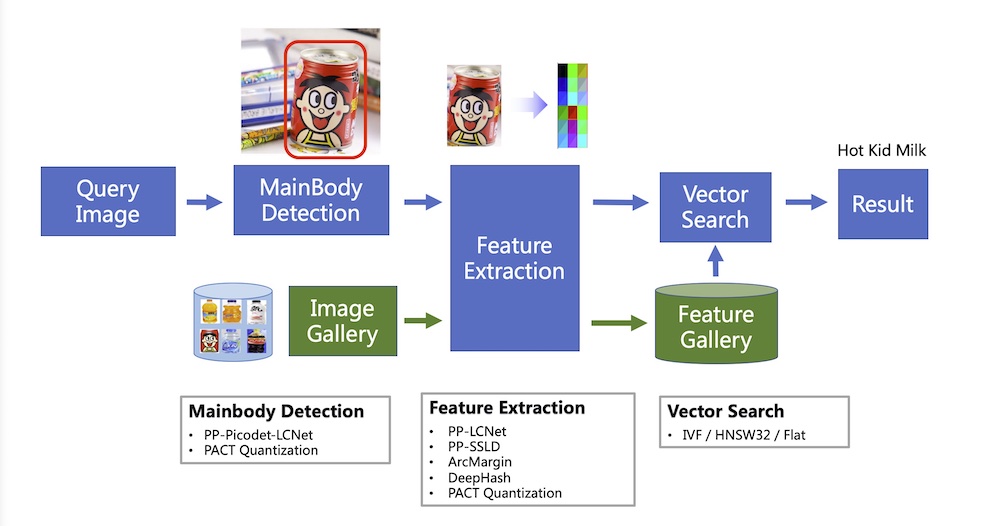
如上图中所示,向量检索部分,在整个 `PP-ShiTu` 系统中有两部分内容
- 图中绿色部分:建立检索库,供检索时查询使用,同时提供增、删等功能
- 图中蓝色部分:检索功能,即给定一张图的特征向量,返回库中相似图像的 label
本文档主要主要介绍 PaddleClas 中检索模块的安装、使用的检索算法、建库流程的及相关配置文件中参数介绍。
--------------------------
## 目录
- [1. 检索库安装](#1)
- [2. 使用的检索算法](#2)
- [3. 使用及配置文档介绍](#3)
- [3.1 建库及配置文件参数](#3.1)
- [3.2 检索配置文件参数](#3.2)
## 1. 检索库安装
`Faiss` 具体安装方法如下:
```python
pip install faiss-cpu==1.7.1post2
```
若使用时,不能正常引用,则 `uninstall` 之后,重新 `install`,尤其是 `windows` 下。
## 2. 使用的检索算法
目前 `PaddleClas` 中检索模块,支持如下三种检索算法
- **HNSW32**: 一种图索引方法。检索精度较高,速度较快。但是特征库只支持添加图像功能,不支持删除图像特征功能。(默认方法)
- **IVF**:倒排索引检索方法。速度较快,但是精度略低。特征库支持增加、删除图像特征功能。
- **FLAT**: 暴力检索算法。精度最高,但是数据量大时,检索速度较慢。特征库支持增加、删除图像特征功能。
每种检索算法,满足不同场景。其中 `HNSW32` 为默认方法,此方法的检索精度、检索速度可以取得一个较好的平衡,具体算法介绍可以查看[官方文档](https://github.com/facebookresearch/faiss/wiki)。
## 3. 使用及配置文档介绍
涉及检索模块配置文件位于:`deploy/configs/` 下,其中 `build_*.yaml` 是建立特征库的相关配置文件,`inference_*.yaml` 是检索或者分类的推理配置文件。
### 3.1 建库及配置文件参数
建库的具体操作如下:
```shell
# 进入 deploy 目录
cd deploy
# yaml 文件根据需要改成自己所需的具体 yaml 文件
python python/build_gallery.py -c configs/build_***.yaml
```
其中 `yaml` 文件的建库的配置如下,在运行时,请根据实际情况进行修改。建库操作会将根据 `data_file` 的图像列表,将 `image_root` 下的图像进行特征提取,并在 `index_dir` 下进行存储,以待后续检索使用。
其中 `data_file` 文件存储的是图像文件的路径和标签,每一行的格式为:`image_path label`。中间间隔以 `yaml` 文件中 `delimiter` 参数作为间隔。
关于特征提取的具体模型参数,可查看 `yaml` 文件。
```yaml
# indexing engine config
IndexProcess:
index_method: "HNSW32" # supported: HNSW32, IVF, Flat
index_dir: "./recognition_demo_data_v1.1/gallery_product/index"
image_root: "./recognition_demo_data_v1.1/gallery_product/"
data_file: "./recognition_demo_data_v1.1/gallery_product/data_file.txt"
index_operation: "new" # suported: "append", "remove", "new"
delimiter: "\t"
dist_type: "IP"
embedding_size: 512
```
- **index_method**:使用的检索算法。目前支持三种,HNSW32、IVF、Flat
- **index_dir**:构建的特征库所存放的文件夹
- **image_root**:构建特征库所需要的标注图像所存储的文件夹位置
- **data_file**:构建特征库所需要的标注图像的数据列表,每一行的格式:relative_path label
- **index_operation**: 此次运行建库的操作:`new` 新建,`append` 将 data_file 的图像特征添加到特征库中,`remove` 将 data_file 的图像从特征库中删除
- **delimiter**:**data_file** 中每一行的间隔符
- **dist_type**: 特征匹配过程中使用的相似度计算方式。例如 `IP` 内积相似度计算方式,`L2` 欧式距离计算方法
- **embedding_size**:特征维度
### 3.2 检索配置文件参数
将检索的过程融合到 `PP-ShiTu` 的整体流程中,请参考 [README](../../../README_ch.md) 中 `PP-ShiTu 图像识别系统介绍` 部分。检索具体使用操作请参考[识别快速开始文档](../quick_start/quick_start_recognition.md)。
其中,检索部分配置如下,整体检索配置文件,请参考 `deploy/configs/inference_*.yaml` 文件。
```yaml
IndexProcess:
index_dir: "./recognition_demo_data_v1.1/gallery_logo/index/"
return_k: 5
score_thres: 0.5
```
与建库配置文件不同,新参数主要如下:
- `return_k`: 检索结果返回 `k` 个结果
- `score_thres`: 检索匹配的阈值