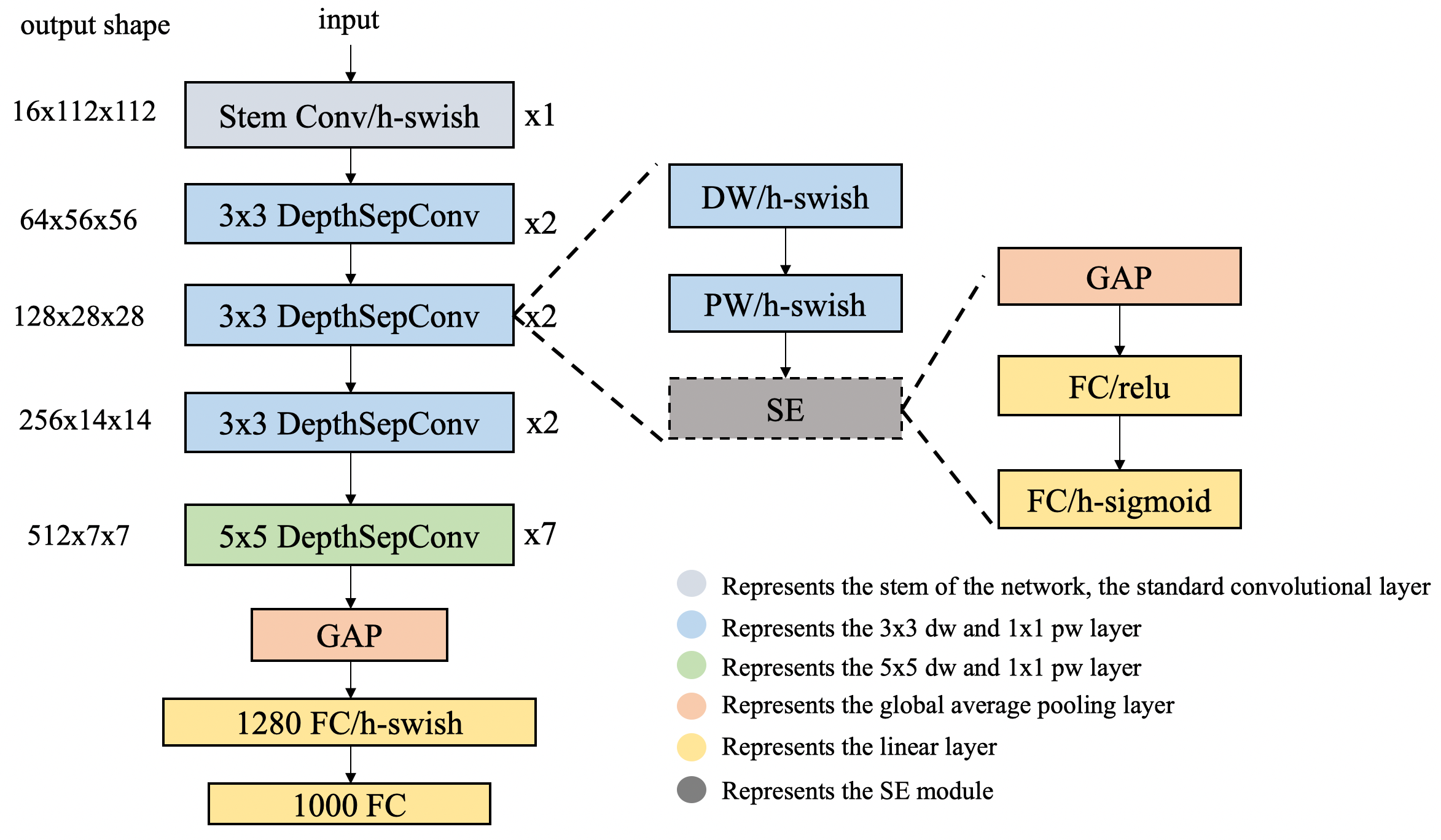
# PP-LCNet 系列
---
## 目录
- [1. 摘要](#1)
- [2. 介绍](#2)
- [3. 方法](#3)
- [3.1 更好的激活函数](#3.1)
- [3.2 合适的位置添加 SE 模块](#3.2)
- [3.3 合适的位置添加更大的卷积核](#3.3)
- [3.4 GAP 后使用更大的 1x1 卷积层](#3.4)
- [4. 实验部分](#4)
- [4.1 图像分类](#4.1)
- [4.2 目标检测](#4.2)
- [4.3 语义分割](#4.3)
- [5. 总结](#5)
- [6. 引用](#6)
## 1. 摘要
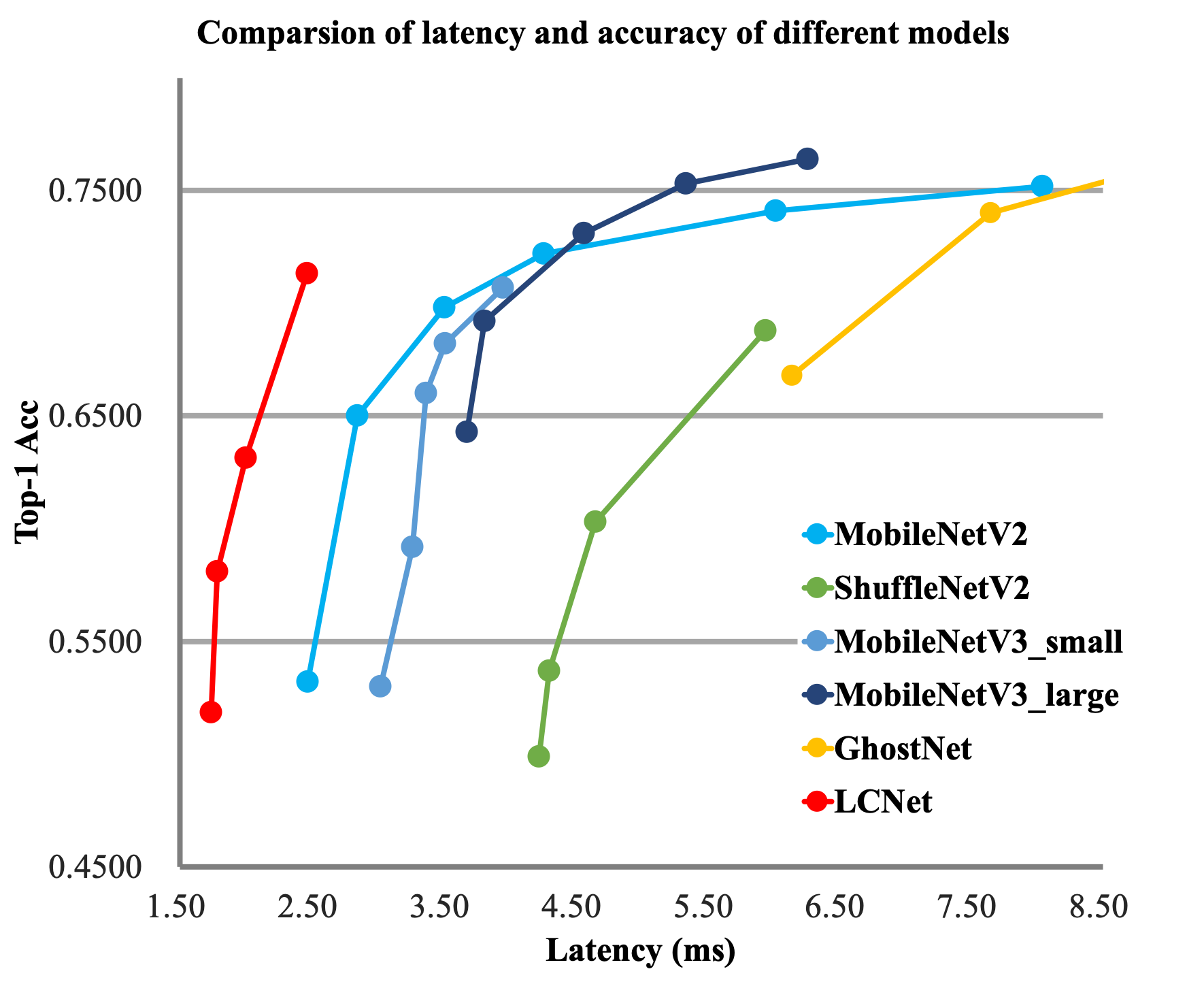
在计算机视觉领域中,骨干网络的好坏直接影响到整个视觉任务的结果。在之前的一些工作中,相关的研究者普遍将 FLOPs 或者 Params 作为优化目的,但是在工业界真实落地的场景中,推理速度才是考量模型好坏的重要指标,然而,推理速度和准确性很难兼得。考虑到工业界有很多基于 Intel CPU 的应用,所以我们本次的工作旨在使骨干网络更好的适应 Intel CPU,从而得到一个速度更快、准确率更高的轻量级骨干网络,与此同时,目标检测、语义分割等下游视觉任务的性能也同样得到提升。
## 2. 介绍
近年来,有很多轻量级的骨干网络问世,尤其最近两年,各种 NAS 搜索出的网络层出不穷,这些网络要么主打 FLOPs 或者 Params 上的优势,要么主打 ARM 设备上的推理速度的优势,很少有网络专门针对 Intel CPU 做特定的优化,导致这些网络在 Intel CPU 端的推理速度并不是很完美。基于此,我们针对 Intel CPU 设备以及其加速库 MKLDNN 设计了特定的骨干网络 PP-LCNet,比起其他的轻量级的 SOTA 模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的 SOTA 模型。与其他模型的对比图如下。