diff --git a/docs/zh_CN/quick_start/overview.md b/docs/zh_CN/quick_start/overview.md
index 0a2f0ba307aafb12634a13b588683af1981b5e7c..62136dcbd42f19021e5750039961384ca63050ce 100644
--- a/docs/zh_CN/quick_start/overview.md
+++ b/docs/zh_CN/quick_start/overview.md
@@ -1,259 +1,224 @@
-# PaddleClas 代码解析
+# PaddleClas项目结构文档
+
+该文档介绍了PaddleClas整体结构、代码组成以及运行逻辑,可以由本文档出发对PaddleClas项目进行学习。
+
+---
## 目录
+- [1. 项目整体介绍](#1-项目整体介绍)
+- [2. 代码解析](#2-代码解析)
+ - [2.1 代码总体结构](#21-代码总体结构)
+ - [2.2 代码运行逻辑](#22-代码运行逻辑)
+- [3. 应用项目介绍](#3-应用项目介绍)
+ - [3.1 PULC超轻量级图像分类方案](#31-PULC超轻量级图像分类方案)
+ - [3.2 PP-ShiTu图像识别系统](#32-PP-ShiTu图像识别系统)
-- [1. 整体代码和目录概览](#1)
-- [2. 训练模块定义](#2)
- - [2.1 数据](#2.1)
- - [2.2 模型结构](#2.2)
- - [2.3 损失函数](#2.3)
- - [2.4 优化器和学习率衰减、权重衰减策略](#2.4)
- - [2.5 训练时评估](#2.5)
- - [2.6 模型存储](#2.6)
- - [2.7 模型裁剪与量化](#2.7)
-- [3. 预测部署代码和方式](#3)
-
-## 1. 整体代码和目录概览
+
-PaddleClas 主要代码和目录结构如下
+## 1. 项目整体介绍
+PaddleClas是一个致力于为工业界和学术界提供运用PaddlePaddle快速实现图像分类和图像识别的套件库,能够帮助开发者训练和部署性能更强的视觉模型。同时,PaddleClas提供了数个特色方案:[PULC超轻量级图像分类方案](#31-PULC超轻量级图像分类方案)、[PP-ShiTU图像识别系统](#32-PP-ShiTu图像识别系统)、[PP系列骨干网络模型](../models/ImageNet1k/model_list.md)和[SSLD半监督知识蒸馏算法](../training/advanced/ssld.md)。
+
+

+
PaddleClas全景图
+
+

+
代码结构图
+
+

+
代码运行逻辑
+
+

+
+

+
+

+
+
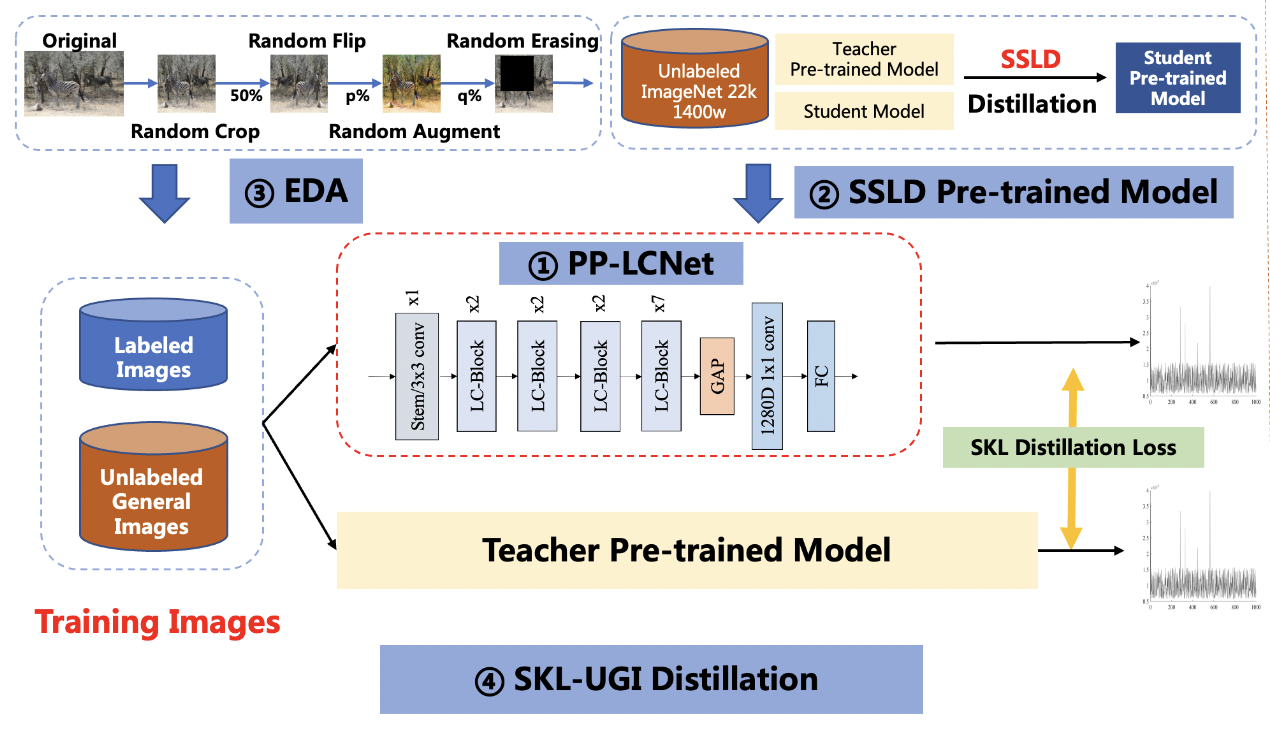
+
PULC超轻量级图像分类方案
+
+

+
PULC超轻量级图像分类方案
+