Merge pull request #1498 from RainFrost1/whole_chain_c++
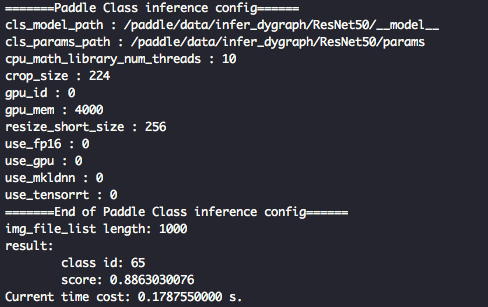
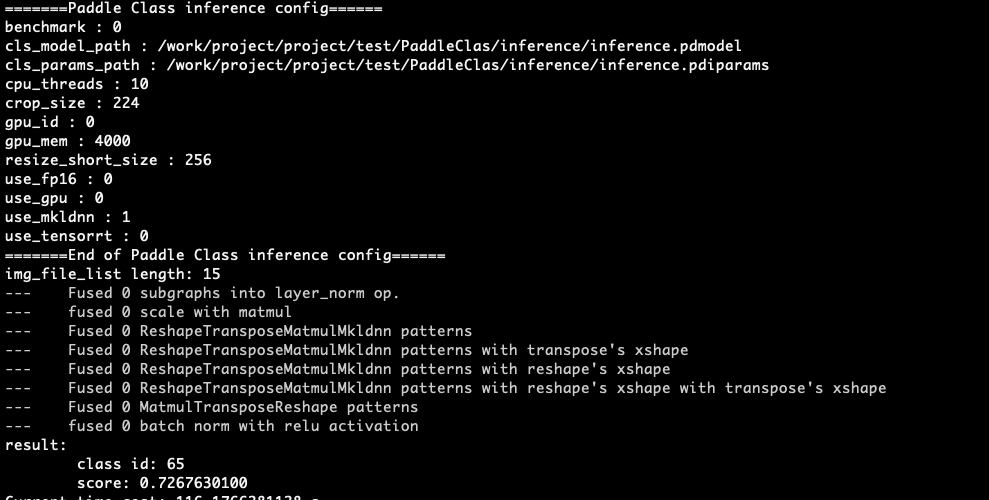
更新分类cpp infer输入为yaml文件
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H:
deploy/cpp/tools/config.txt
已删除
100755 → 0
deploy/cpp/tools/run.sh
已删除
100755 → 0
更新分类cpp infer输入为yaml文件
| W: | H:
| W: | H: