-[4. Model evaluation and inference deployment](#4-model-evaluation-and-inference-deployment)
-[4.1 Model Evaluation](#41-model-evaluation)
-[4.2 Model Inference](#42-model-inference)
-[4.2.1 Inference model preparation](#421-inference-model-preparation)
-[4.2.2 Inference based on Python prediction engine](#422-inference-based-on-python-prediction-engine)
-[4.2.3 Inference based on C++ prediction engine](#423-inference-based-on-c-prediction-engine)
-[4.3 Service deployment](#43-service-deployment)
-[4.4 Lite deployment](#44-lite-deployment)
-[4.5 Paddle2ONNX Model Conversion and Prediction](#45-paddle2onnx-model-conversion-and-prediction)
-[5. Summary](#5-summary)
-[5.1 Method summary and comparison](#51-method-summary-and-comparison)
-[5.2 Usage advice/FAQ](#52-usage-advicefaq)
-[6. References](#6-references)
### 1. Introduction to algorithms/application scenarios
Person re-identification (Re-ID), also known as person re-identification, has been widely studied as a cross-shot pedestrian retrieval problem. Given a pedestrian image captured by a certain camera, the goal is to determine whether the pedestrian has appeared in images captured by different cameras or in different time periods. The given pedestrian data can be a picture, a video frame, or even a text description. In recent years, the application demand of this technology in the field of public safety has been increasing, and the influence of pedestrian re-identification in intelligent monitoring technology is also increasing.
At present, pedestrian re-identification is still a challenging task, especially the problems of different viewpoints, resolutions, illumination changes, occlusions, multi-modalities, as well as complex camera environment and background, labeling data noise, etc. There is great uncertainty. In addition, when the actual landing, the shooting camera may change, the large-scale retrieval database, the distribution shift of the data set, the unknown scene, the incremental update of the model, and the change of the clothing of the retrieval person, which also increases a lot of difficulties.
Early work on person re-identification mainly focused on hand-designed feature extraction operators, including adding human pose features, or learning distance metric functions. With the development of deep learning technology, pedestrian recognition has also made great progress. In general, the whole process of pedestrian re-identification includes 5 steps: 1) data collection, 2) pedestrian location box annotation, 3) pedestrian category annotation, 4) model training, and 5) pedestrian retrieval (model testing).
Among them, $N$ is the number of query samples, and $result_i$ is the label set of the retrieval results of each query sample. According to the formula, the CMC curve can be understood as an array composed of Top1-Acc, Top2-Acc, ..., TopK-Acc , which is obviously a monotonic curve. Among them, the common Rank-1 and Top1-Acc metric refer to CMC(1)
2. mAP
Assuming that a query sample is used and a set of query results is returned, then according to the following formula, consider the first K query results one by one, and for each K, calculate the precision rate $Precision$ and recall rate $Recall$.
The obtained multiple groups (Precision, Recall) are converted into a curve graph, and the area enclosed by the curve and the coordinate axis is called Average Precision (AP),
For each sample, calculate its AP value, and then take the average to get the mAP.
### 3. ReID algorithm
#### 3.1 ReID strong-baseline
Paper source: [Bag of Tricks and A Strong Baseline for Deep Person Re-identification](https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdf)
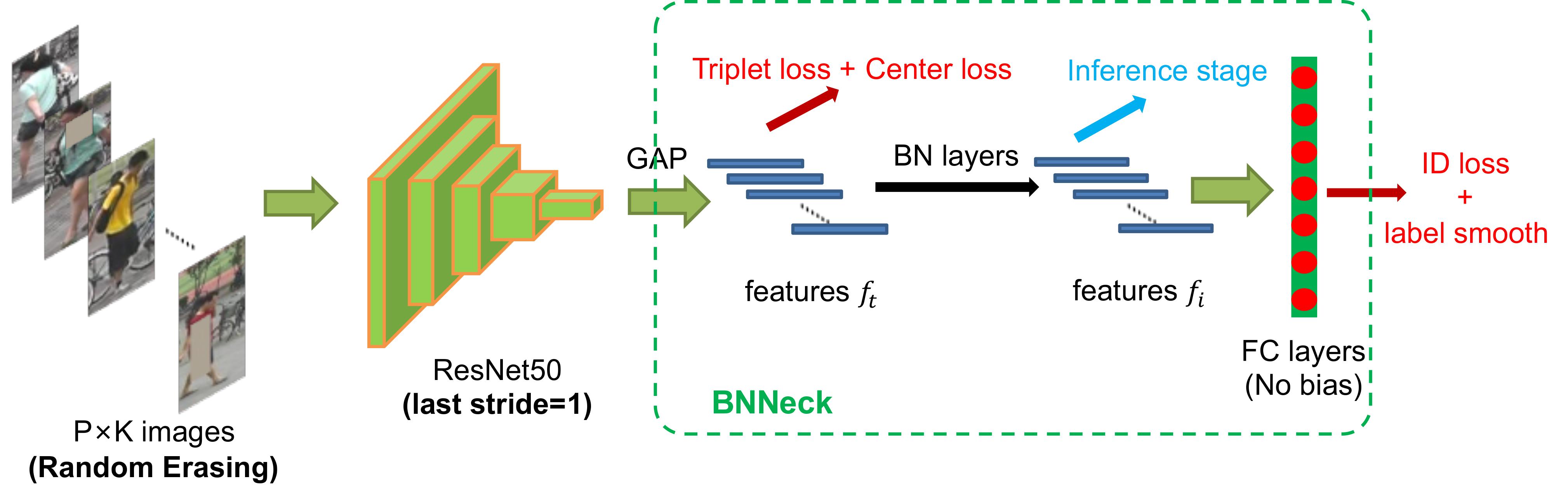
Based on the commonly used person re-identification model based on ResNet50, the author explores and summarizes the following effective and applicable optimization methods, which greatly improves the indicators on multiple person re-identification datasets.
1. Warmup: At the beginning of training, let the learning rate gradually increase from a small value and then start to decrease, which is conducive to the stability of gradient descent optimization, so as to find a better parameter model.
2. Random erasing augmentation: Random area erasing, which improves the generalization ability of the model through data augmentation.
3. Label smoothing: Label smoothing to improve the generalization ability of the model.
4. Last stride=1: Set the downsampling of the last stage of the feature extraction module to 1, increase the resolution of the output feature map to retain more details and improve the classification ability of the model.
5. BNNeck: Before the feature vector is input to the classification head, it goes through BNNeck, so that the feature obeys the normal distribution on the surface of the hypersphere, which reduces the difficulty of optimizing IDLoss and TripLetLoss at the same time.
6. Center loss: Give each category a learnable cluster center, and make the intra-class features close to the cluster center during training to reduce intra-class differences and increase inter-class differences.
7. Reranking: Consider the neighbor candidates of the query image during retrieval, optimize the distance matrix according to whether the neighbor images of the candidate object also contain the query image, and finally improve the retrieval accuracy.
##### 3.1.2 Accuracy metrics
The following table summarizes the accuracy metrics of the 3 configurations of the recurring ReID strong-baseline on the Market1501 dataset,
Note: The above reference indicators are obtained by using the author's open source code to train on our equipment for many times. Due to different system environment, torch version, CUDA version and other reasons, there may be slight differences with the indicators provided by the author.
Next, we mainly take the `softmax_triplet_with_center.yaml` configuration and trained model file as an example to show the process of training, testing, and inference on the Market1501 dataset.
##### 3.1.3 Data Preparation
Download the [Market-1501-v15.09.15.zip](https://pan.baidu.com/s/1ntIi2Op?_at_=1654142245770) dataset, extract it to `PaddleClas/dataset/`, and organize it into the following file structure :
```shell
PaddleClas/dataset/market1501
└── Market-1501-v15.09.15/
├── bounding_box_test/ # gallery set pictures
├── bounding_box_train/ # training set image
├── gt_bbox/
├── gt_query/
├── query/ # query set image
├── generate_anno.py
├── bounding_box_test.txt # gallery set path
├── bounding_box_train.txt # training set path
├── query.txt # query set path
└── readme.txt
```
##### 3.1.4 Model training
1. Execute the following command to start training
2. View training logs and saved model parameter files
During the training process, indicator information such as loss will be printed on the screen in real time, and the log file `train.log`, model parameter file `*.pdparams`, optimizer parameter file `*.pdopt` and other contents will be saved to `Global.output_dir` `Under the specified folder, the default is under the `PaddleClas/output/RecModel/` folder.
### 4. Model evaluation and inference deployment
#### 4.1 Model Evaluation
Prepare the `*.pdparams` model parameter file for evaluation. You can use the trained model or the model saved in [2.1.4 Model training] (#214-model training).
- Take the `latest.pdparams` saved during training as an example, execute the following command to evaluate.
- Take the trained model as an example, download [softmax_triplet_with_center_pretrained.pdparams](https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/reid/pretrain/softmax_triplet_with_center_pretrained.pdparams) to `PaddleClas/ In the pretrained_models` folder, execute the following command to evaluate.
Note: The address filled after `pretrained_model` does not need to be suffixed with `.pdparams`, it will be added automatically when the program is running.
- View output results
```log
...
...
ppcls INFO: unique_endpoints {''}
ppcls INFO: Found /root/.paddleclas/weights/resnet50-19c8e357_torch2paddle.pdparams
The default evaluation log is saved in `PaddleClas/output/RecModel/eval.log`. You can see that the evaluation indicators of the `softmax_triplet_with_center_pretrained.pdparams` model provided by us on the Market1501 dataset are recall@1=0.94507, recall@5=0.98248 , mAP=0.85827
- use the re-ranking option to improve the evaluation metrics
The main idea of re-ranking is to use the relationship between the retrieval libraries to further optimize the retrieval results, and the k-reciprocal algorithm is widely used. Turn on re-ranking during evaluation in PaddleClas to improve the final retrieval accuracy.
This can be enabled by adding `-o Global.re_ranking=True` to the evaluation command as shown below.
It can be seen that after re-ranking is enabled, the evaluation indicators are recall@1=0.95546, recall@5=0.97743, and mAP=0.94252. It can be found that the algorithm improves the mAP indicator significantly (0.85827->0.94252).
**Note**: The computational complexity of re-ranking is currently high, so it is not enabled by default.
#### 4.2 Model Inference
##### 4.2.1 Inference model preparation
You can convert the model file saved during training into an inference model and inference, or use the converted inference model we provide for direct inference
- Convert the model file saved during the training process to an inference model, also take `latest.pdparams` as an example, execute the following command to convert
##### 4.2.2 Inference based on Python prediction engine
1. Modify `PaddleClas/deploy/configs/inference_rec.yaml`- Change the path segment after `infer_imgs:` to any image path under the query folder in Market1501 (the configuration below uses the path of the `0294_c1s1_066631_00.jpg` image)
- Change the field after `rec_inference_model_dir:` to the decompressed softmax_triplet_with_center_infer folder path
- Change the preprocessing configuration under the `transform_ops:` field to the preprocessing configuration under `Eval.Query.dataset` in `softmax_triplet_with_center.yaml`
3. Check the output result, the actual result is a vector of length 2048, which represents the feature vector obtained after the input image is transformed by the model
The output vector for inference is stored in the `result_dict` variable in [predict_rec.py](../../../deploy/python/predict_rec.py#L134-L135).
4. For batch prediction, change the path after `infer_imgs:` in the configuration file to a folder, such as `../dataset/market1501/Market-1501-v15.09.15/query`, it will predict and output queries one by one The feature vectors of all the images below.
##### 4.2.3 Inference based on C++ prediction engine
PaddleClas provides an example of inference based on the C++ prediction engine, you can refer to [Server-side C++ prediction](../inference_deployment/cpp_deploy.md) to complete the corresponding inference deployment. If you are using the Windows platform, you can refer to the Visual Studio 2019 Community CMake Compilation Guide to complete the corresponding prediction library compilation and model prediction work.
#### 4.3 Service deployment
Paddle Serving provides high-performance, flexible and easy-to-use industrial-grade online inference services. Paddle Serving supports RESTful, gRPC, bRPC and other protocols, and provides inference solutions in a variety of heterogeneous hardware and operating system environments. For more introduction to Paddle Serving, please refer to the Paddle Serving code repository.
PaddleClas provides an example of model serving deployment based on Paddle Serving. You can refer to [Model serving deployment](../inference_deployment/paddle_serving_deploy.md) to complete the corresponding deployment.
#### 4.4 Lite deployment
Paddle Lite is a high-performance, lightweight, flexible and easily extensible deep learning inference framework, positioned to support multiple hardware platforms including mobile, embedded and server. For more introduction to Paddle Lite, please refer to the Paddle Lite code repository.
PaddleClas provides an example of deploying models based on Paddle Lite. You can refer to [Deployment](../inference_deployment/paddle_lite_deploy.md) to complete the corresponding deployment.
#### 4.5 Paddle2ONNX Model Conversion and Prediction
Paddle2ONNX supports converting PaddlePaddle model format to ONNX model format. The deployment of Paddle models to various inference engines can be completed through ONNX, including TensorRT/OpenVINO/MNN/TNN/NCNN, and other inference engines or hardware that support the ONNX open source format. For more information about Paddle2ONNX, please refer to the Paddle2ONNX code repository.
PaddleClas provides an example of converting an inference model to an ONNX model and making inference prediction based on Paddle2ONNX. You can refer to [Paddle2ONNX model conversion and prediction](../../../deploy/paddle2onnx/readme.md) to complete the corresponding deployment work.
### 5. Summary
#### 5.1 Method summary and comparison
The above algorithm can be quickly migrated to most ReID models, which can further improve the performance of ReID models.
#### 5.2 Usage advice/FAQ
The Market1501 dataset is relatively small, so you can try to train multiple times to get the highest accuracy.
### 6. References
1.[Bag of Tricks and A Strong Baseline for Deep Person Re-identification](https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdf)
论文出处:[Bag of Tricks and A Strong Baseline for Deep Person Re-identification](https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdf)
PaddleClas 提供了基于 C++ 预测引擎推理的示例,您可以参考[服务器端 C++ 预测](../inference_deployment/cpp_deploy.md)来完成相应的推理部署。如果您使用的是 Windows 平台,可以参考基于 Visual Studio 2019 Community CMake 编译指南完成相应的预测库编译和模型预测工作。
1.[Bag of Tricks and A Strong Baseline for Deep Person Re-identification](https://openaccess.thecvf.com/content_CVPRW_2019/papers/TRMTMCT/Luo_Bag_of_Tricks_and_a_Strong_Baseline_for_Deep_Person_CVPRW_2019_paper.pdf)
{kind=link}

{kind=link}