diff --git a/README_en.md b/README_en.md
index 64159d57980bb3d19981db0f8d5a2dc65a56c481..9404b11694d788e186f32ef49509595289ca2fe9 100644
--- a/README_en.md
+++ b/README_en.md
@@ -33,8 +33,8 @@ For the introduction of PP-LCNet, please refer to [paper](https://arxiv.org/pdf/
## Features
-PaddleClas release PP-HGNet、PP-LCNetv2、 PP-LCNet and **S**imple **S**emi-supervised **L**abel **D**istillation algorithms, and support plenty of
-image classification and image recognition algorithms.
+PaddleClas release PP-HGNet、PP-LCNetv2、 PP-LCNet and **S**imple **S**emi-supervised **L**abel **D**istillation algorithms, and support plenty of
+image classification and image recognition algorithms.
Based on th algorithms above, PaddleClas release PP-ShiTu image recognition system and [**P**ractical **U**ltra **L**ight-weight image **C**lassification solutions](docs/en/PULC/PULC_quickstart_en.md).
@@ -52,12 +52,15 @@ Based on th algorithms above, PaddleClas release PP-ShiTu image recognition syst
## Quick Start
Quick experience of PP-ShiTu image recognition system:[Link](./docs/en/tutorials/quick_start_recognition_en.md)
-Quick experience of **P**ractical **U**ltra **L**ight-weight image **C**lassification models:[Link](docs/en/PULC/PULC_quickstart.md)
+Quick experience of **P**ractical **U**ltra **L**ight-weight image **C**lassification models:[Link](docs/en/PULC/PULC_quickstart_en.md)
## Tutorials
- [Quick Installation](./docs/en/tutorials/install_en.md)
- [Practical Ultra Light-weight image Classification solutions](./docs/en/PULC/PULC_quickstart_en.md)
+ - [PULC Quick Start](docs/en/PULC/PULC_quickstart_en.md)
+ - [PULC Model Zoo](docs/en/PULC/PULC_model_list_en.md)
+ - [PULC Classification Model of Someone or Nobody](docs/en/PULC/PULC_person_exists_en.md)
- [Quick Start of Recognition](./docs/en/tutorials/quick_start_recognition_en.md)
- [Introduction to Image Recognition Systems](#Introduction_to_Image_Recognition_Systems)
- [Demo images](#Demo_images)
diff --git a/deploy/paddle2onnx/readme_en.md b/deploy/paddle2onnx/readme_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..6df13e5fe31805d642432dea8526661e82b6e95b
--- /dev/null
+++ b/deploy/paddle2onnx/readme_en.md
@@ -0,0 +1,59 @@
+# Paddle2ONNX: Converting To ONNX and Deployment
+
+This section introduce that how to convert the Paddle Inference Model ResNet50_vd to ONNX model and deployment based on ONNX engine.
+
+## 1. Installation
+
+First, you need to install Paddle2ONNX and onnxruntime. Paddle2ONNX is a toolkit to convert Paddle Inference Model to ONNX model. Please refer to [Paddle2ONNX](https://github.com/PaddlePaddle/Paddle2ONNX/blob/develop/README_en.md) for more information.
+
+- Paddle2ONNX Installation
+```
+python3.7 -m pip install paddle2onnx
+```
+
+- ONNX Installation
+```
+python3.7 -m pip install onnxruntime
+```
+
+## 2. Converting to ONNX
+
+Download the Paddle Inference Model ResNet50_vd:
+
+```
+cd deploy
+mkdir models && cd models
+wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/inference/ResNet50_vd_infer.tar && tar xf ResNet50_vd_infer.tar
+cd ..
+```
+
+Converting to ONNX model:
+
+```
+paddle2onnx --model_dir=./models/ResNet50_vd_infer/ \
+--model_filename=inference.pdmodel \
+--params_filename=inference.pdiparams \
+--save_file=./models/ResNet50_vd_infer/inference.onnx \
+--opset_version=10 \
+--enable_onnx_checker=True
+```
+
+After running the above command, the ONNX model file converted would be save in `./models/ResNet50_vd_infer/`.
+
+## 3. Deployment
+
+Deployment with ONNX model, command is as shown below.
+
+```
+python3.7 python/predict_cls.py \
+-c configs/inference_cls.yaml \
+-o Global.use_onnx=True \
+-o Global.use_gpu=False \
+-o Global.inference_model_dir=./models/ResNet50_vd_infer
+```
+
+The prediction results:
+
+```
+ILSVRC2012_val_00000010.jpeg: class id(s): [153, 204, 229, 332, 155], score(s): [0.69, 0.10, 0.02, 0.01, 0.01], label_name(s): ['Maltese dog, Maltese terrier, Maltese', 'Lhasa, Lhasa apso', 'Old English sheepdog, bobtail', 'Angora, Angora rabbit', 'Shih-Tzu']
+```
diff --git a/docs/en/PULC/PULC_person_exists_en.md b/docs/en/PULC/PULC_person_exists_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..1772e1ffd09c8ff12cb002a2646f16af1021f29c
--- /dev/null
+++ b/docs/en/PULC/PULC_person_exists_en.md
@@ -0,0 +1,459 @@
+# PULC Classification Model of Someone or Nobody
+
+------
+
+## Catalogue
+
+- [1. Introduction](#1)
+- [2. Quick Start](#2)
+ - [2.1 PaddlePaddle Installation](#2.1)
+ - [2.2 PaddleClas Installation](#2.2)
+ - [2.3 Prediction](#2.3)
+- [3. Training, Evaluation and Inference](#3)
+ - [3.1 Installation](#3.1)
+ - [3.2 Dataset](#3.2)
+ - [3.2.1 Dataset Introduction](#3.2.1)
+ - [3.2.2 Getting Dataset](#3.2.2)
+ - [3.3 Training](#3.3)
+ - [3.4 Evaluation](#3.4)
+ - [3.5 Inference](#3.5)
+- [4. Model Compression](#4)
+ - [4.1 SKL-UGI Knowledge Distillation](#4.1)
+ - [4.1.1 Teacher Model Training](#4.1.1)
+ - [4.1.2 Knowledge Distillation Training](#4.1.2)
+- [5. SHAS](#5)
+- [6. Inference Deployment](#6)
+ - [6.1 Getting Paddle Inference Model](#6.1)
+ - [6.1.1 Exporting Paddle Inference Model](#6.1.1)
+ - [6.1.2 Downloading Inference Model](#6.1.2)
+ - [6.2 Prediction with Python](#6.2)
+ - [6.2.1 Image Prediction](#6.2.1)
+ - [6.2.2 Images Prediction](#6.2.2)
+ - [6.3 Deployment with C++](#6.3)
+ - [6.4 Deployment as Service](#6.4)
+ - [6.5 Deployment on Mobile](#6.5)
+ - [6.6 Converting To ONNX and Deployment](#6.6)
+
+
+
+## 1. Introduction
+
+This case provides a way for users to quickly build a lightweight, high-precision and practical classification model of human exists using PaddleClas PULC (Practical Ultra Lightweight Classification). The model can be widely used in monitoring scenarios, personnel access control scenarios, massive data filtering scenarios, etc.
+
+The following table lists the relevant indicators of the model. The first two lines means that using SwinTransformer_tiny and MobileNetV3_small_x0_35 as the backbone to training. The third to sixth lines means that the backbone is replaced by PPLCNet, additional use of EDA strategy and additional use of EDA strategy and SKL-UGI knowledge distillation strategy.
+
+| Backbone | Tpr(%) | Latency(ms) | Size(M)| Training Strategy |
+|-------|-----------|----------|---------------|---------------|
+| SwinTranformer_tiny | 95.69 | 95.30 | 107 | using ImageNet pretrained |
+| MobileNetV3_small_x0_35 | 68.25 | 2.85 | 1.6 | using ImageNet pretrained |
+| PPLCNet_x1_0 | 89.57 | 2.12 | 6.5 | using ImageNet pretrained |
+| PPLCNet_x1_0 | 92.10 | 2.12 | 6.5 | using SSLD pretrained |
+| PPLCNet_x1_0 | 93.43 | 2.12 | 6.5 | using SSLD pretrained + EDA strategy |
+| PPLCNet_x1_0 | 95.60 | 2.12 | 6.5 | using SSLD pretrained + EDA strategy + SKL-UGI knowledge distillation strategy|
+
+It can be seen that high Tpr can be getted when backbone is SwinTranformer_tiny, but the speed is slow. Replacing backbone with the lightweight model MobileNetV3_small_x0_35, the speed can be greatly improved, but the Tpr will be greatly reduced. Replacing backbone with faster backbone PPLCNet_x1_0, the Tpr is higher more 20 percentage points higher than MobileNetv3_small_x0_35. At the same time, the speed can be more than 20% faster. After additional using the SSLD pretrained model, the Tpr can be improved by about 2.6 percentage points without affecting the inference speed. Further, additional using the EDA strategy, the Tpr can be increased by 1.3 percentage points. Finally, after additional using the SKL-UGI knowledge distillation, the Tpr can be further improved by 2.2 percentage points. At this point, the Tpr close to that of SwinTranformer_tiny is obtained, but the speed is more than 40 times faster. The training method and deployment instructions of PULC will be introduced in detail below.
+
+**Note**:
+
+* About `Tpr` metric, please refer to [3.2 section](#3.2) for more information .
+* The Latency is tested on Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz. The MKLDNN is enabled and the number of threads is 10.
+* About PP-LCNet, please refer to [PP-LCNet Introduction](../models/PP-LCNet_en.md) and [PP-LCNet Paper](https://arxiv.org/abs/2109.15099).
+
+
+
+## 2. Quick Start
+
+
+
+### 2.1 PaddlePaddle Installation
+
+- Run the following command to install if CUDA9 or CUDA10 is available.
+
+```bash
+python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
+```
+
+- Run the following command to install if GPU device is unavailable.
+
+```bash
+python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+```
+
+Please refer to [PaddlePaddle Installation](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/en/install/pip/linux-pip_en.html) for more information about installation, for examples other versions.
+
+
+
+### 2.2 PaddleClas wheel Installation
+
+The command of PaddleClas installation as bellow:
+
+```bash
+pip3 install paddleclas
+```
+
+
+
+### 2.3 Prediction
+
+First, please click [here](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip) to download and unzip to get the test demo images.
+
+
+* Prediction with CLI
+
+```bash
+paddleclas --model_name=person_exists --infer_imgs=pulc_demo_imgs/person_exists/objects365_01780782.jpg
+```
+
+Results:
+```
+>>> result
+class_ids: [0], scores: [0.9955421453341842], label_names: ['nobody'], filename: pulc_demo_imgs/person_exists/objects365_01780782.jpg
+Predict complete!
+```
+
+**Note**: If you want to test other images, only need to specify the `--infer_imgs` argument, and the directory containing images is also supported.
+
+* Prediction in Python
+
+```python
+import paddleclas
+model = paddleclas.PaddleClas(model_name="person_exists")
+result = model.predict(input_data="pulc_demo_imgs/person_exists/objects365_01780782.jpg")
+print(next(result))
+```
+
+**Note**: The `result` returned by `model.predict()` is a generator, so you need to use the `next()` function to call it or `for` loop to loop it. And it will predict with `batch_size` size batch and return the prediction results when called. The default `batch_size` is 1, and you also specify the `batch_size` when instantiating, such as `model = paddleclas.PaddleClas(model_name="person_exists", batch_size=2)`. The result of demo above:
+
+```
+>>> result
+[{'class_ids': [0], 'scores': [0.9955421453341842], 'label_names': ['nobody'], 'filename': 'pulc_demo_imgs/person_exists/objects365_01780782.jpg'}]
+```
+
+
+
+## 3. Training, Evaluation and Inference
+
+
+
+### 3.1 Installation
+
+Please refer to [Installation](../installation/install_paddleclas_en.md) to get the description about installation.
+
+
+
+### 3.2 Dataset
+
+
+
+#### 3.2.1 Dataset Introduction
+
+All datasets used in this case are open source data. Train data is the subset of [MS-COCO](https://cocodataset.org/#overview) training data. And the validation data is the subset of [Object365](https://www.objects365.org/overview.html) training data. ImageNet_val is [ImageNet-1k](https://www.image-net.org/) validation data.
+
+
+
+#### 3.2.2 Getting Dataset
+
+The data used in this case can be getted by processing the open source data. The detailed processes are as follows:
+
+- Training data. This case deals with the annotation file of MS-COCO data training data. If a certain image contains the label of "person" and the area of this box is greater than 10% in the whole image, it is considered that the image contains human. If there is no label of "person" in a certain image, It is considered that the image does not contain human. After processing, 92964 pieces of available data were obtained, including 39813 images containing human and 53151 images without containing human.
+- Validation data: randomly select a small part of data from object365 data, use the better model trained on MS-COCO to predict these data, take the intersection between the prediction results and the data annotation file, and filter the intersection results into the validation set according to the method of obtaining the training set. After processing, 27820 pieces of available data were obtained. There are 2255 pieces of data with human and 25565 pieces of data without human. The data visualization of the processed dataset is as follows:
+
+Some image of the processed dataset is as follows:
+
+
+
+And you can also download the data processed directly.
+
+```
+cd path_to_PaddleClas
+```
+
+Enter the `dataset/` directory, download and unzip the dataset.
+
+```shell
+cd dataset
+wget https://paddleclas.bj.bcebos.com/data/PULC/person_exists.tar
+tar -xf person_exists.tar
+cd ../
+```
+
+The datas under `person_exists` directory:
+
+```
+├── train
+│ ├── 000000000009.jpg
+│ ├── 000000000025.jpg
+...
+├── val
+│ ├── objects365_01780637.jpg
+│ ├── objects365_01780640.jpg
+...
+├── ImageNet_val
+│ ├── ILSVRC2012_val_00000001.JPEG
+│ ├── ILSVRC2012_val_00000002.JPEG
+...
+├── train_list.txt
+├── train_list.txt.debug
+├── train_list_for_distill.txt
+├── val_list.txt
+└── val_list.txt.debug
+```
+
+Where `train/` and `val/` are training set and validation set respectively. The `train_list.txt` and `val_list.txt` are label files of training data and validation data respectively. The file `train_list.txt.debug` and `val_list.txt.debug` are subset of `train_list.txt` and `val_list.txt` respectively. `ImageNet_val/` is the validation data of ImageNet-1k, which will be used for SKL-UGI knowledge distillation, and its label file is `train_list_for_distill.txt`.
+
+**Note**:
+
+* About the contents format of `train_list.txt` and `val_list.txt`, please refer to [Description about Classification Dataset in PaddleClas](../data_preparation/classification_dataset_en.md).
+* About the `train_list_for_distill.txt`, please refer to [Knowledge Distillation Label](../advanced_tutorials/distillation/distillation_en.md).
+
+
+
+### 3.3 Training
+
+The details of training config in `ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml`. The command about training as follows:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml
+```
+
+The best metric of validation data is between `0.94` and `0.95`. There would be fluctuations because the data size is small.
+
+**Note**:
+
+* The metric Tpr, that describe the True Positive Rate when False Positive Rate is less than a certain threshold(1/1000 used in this case), is one of the commonly used metric for binary classification. About the details of Fpr and Tpr, please refer [here](https://en.wikipedia.org/wiki/Receiver_operating_characteristic).
+* When evaluation, the best metric TprAtFpr will be printed that include `Fpr`, `Tpr` and the current `threshold`. The `Tpr` means the Recall rate under the current `Fpr`. The `Tpr` higher, the model better. The `threshold` would be used in deployment, which means the classification threshold under best `Fpr` metric.
+
+
+
+### 3.4 Evaluation
+
+After training, you can use the following commands to evaluate the model.
+
+```bash
+python3 tools/eval.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
+ -o Global.pretrained_model="output/PPLCNet_x1_0/best_model"
+```
+
+Among the above command, the argument `-o Global.pretrained_model="output/PPLCNet_x1_0/best_model"` specify the path of the best model weight file. You can specify other path if needed.
+
+
+
+### 3.5 Inference
+
+After training, you can use the model that trained to infer. Command is as follow:
+
+```python
+python3 tools/infer.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
+ -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
+```
+
+The results:
+
+```
+[{'class_ids': [1], 'scores': [0.9999976], 'label_names': ['someone'], 'file_name': 'deploy/images/PULC/person_exists/objects365_02035329.jpg'}]
+```
+
+**Note**:
+
+* Among the above command, argument `-o Global.pretrained_model="output/PPLCNet_x1_0/best_model"` specify the path of the best model weight file. You can specify other path if needed.
+* The default test image is `deploy/images/PULC/person_exists/objects365_02035329.jpg`. And you can test other image, only need to specify the argument `-o Infer.infer_imgs=path_to_test_image`.
+* The default threshold is `0.5`. If needed, you can specify the argument `Infer.PostProcess.threshold`, such as: `-o Infer.PostProcess.threshold=0.9794`. And the argument `threshold` is needed to be specified according by specific case. The `0.9794` is the best threshold when `Fpr` is less than `1/1000` in this valuation dataset.
+
+
+
+## 4. Model Compression
+
+
+
+### 4.1 SKL-UGI Knowledge Distillation
+
+SKL-UGI is a simple but effective knowledge distillation algrithem proposed by PaddleClas.
+
+
+
+
+
+
+#### 4.1.1 Teacher Model Training
+
+Training the teacher model with hyperparameters specified in `ppcls/configs/PULC/person_exists/PPLCNet/PPLCNet_x1_0.yaml`. The command is as follow:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
+ -o Arch.name=ResNet101_vd
+```
+
+The best metric of validation data is between `0.96` and `0.98`. The best teacher model weight would be saved in file `output/ResNet101_vd/best_model.pdparams`.
+
+
+
+#### 4.1.2 Knowledge Distillation Training
+
+The training strategy, specified in training config file `ppcls/configs/PULC/person_exists/PPLCNet_x1_0_distillation.yaml`, the teacher model is `ResNet101_vd`, the student model is `PPLCNet_x1_0` and the additional unlabeled training data is validation data of ImageNet1k. The command is as follow:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0_distillation.yaml \
+ -o Arch.models.0.Teacher.pretrained=output/ResNet101_vd/best_model
+```
+
+The best metric is between `0.95` and `0.97`. The best student model weight would be saved in file `output/DistillationModel/best_model_student.pdparams`.
+
+
+
+## 5. Hyperparameters Searching
+
+The hyperparameters used by [3.2 section](#3.2) and [4.1 section](#4.1) are according by `Hyperparameters Searching` in PaddleClas. If you want to get better results on your own dataset, you can refer to [Hyperparameters Searching](PULC_train_en.md#4) to get better hyperparameters.
+
+**Note**: This section is optional. Because the search process will take a long time, you can selectively run according to your specific. If not replace the dataset, you can ignore this section.
+
+
+
+## 6. Inference Deployment
+
+
+
+### 6.1 Getting Paddle Inference Model
+
+Paddle Inference is the original Inference Library of the PaddlePaddle, provides high-performance inference for server deployment. And compared with directly based on the pretrained model, Paddle Inference can use tools to accelerate prediction, so as to achieve better inference performance. Please refer to [Paddle Inference](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/infer/inference/inference_cn.html) for more information.
+
+Paddle Inference need Paddle Inference Model to predict. Two process provided to get Paddle Inference Model. If want to use the provided by PaddleClas, you can download directly, click [Downloading Inference Model](#6.1.2).
+
+
+
+### 6.1.1 Exporting Paddle Inference Model
+
+The command about exporting Paddle Inference Model is as follow:
+
+```bash
+python3 tools/export_model.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
+ -o Global.pretrained_model=output/DistillationModel/best_model_student \
+ -o Global.save_inference_dir=deploy/models/PPLCNet_x1_0_person_exists_infer
+```
+
+After running above command, the inference model files would be saved in `deploy/models/PPLCNet_x1_0_person_exists_infer`, as shown below:
+
+```
+├── PPLCNet_x1_0_person_exists_infer
+│ ├── inference.pdiparams
+│ ├── inference.pdiparams.info
+│ └── inference.pdmodel
+```
+
+**Note**: The best model is from knowledge distillation training. If knowledge distillation training is not used, the best model would be saved in `output/PPLCNet_x1_0/best_model.pdparams`.
+
+
+
+### 6.1.2 Downloading Inference Model
+
+You can also download directly.
+
+```
+cd deploy/models
+# download the inference model and decompression
+wget https://paddleclas.bj.bcebos.com/models/PULC/person_exists_infer.tar && tar -xf person_exists_infer.tar
+```
+
+After decompression, the directory `models` should be shown below.
+
+```
+├── person_exists_infer
+│ ├── inference.pdiparams
+│ ├── inference.pdiparams.info
+│ └── inference.pdmodel
+```
+
+
+
+### 6.2 Prediction with Python
+
+
+
+#### 6.2.1 Image Prediction
+
+Return the directory `deploy`:
+
+```
+cd ../
+```
+
+Run the following command to classify whether there are human in the image `./images/PULC/person_exists/objects365_02035329.jpg`.
+
+```shell
+# Use the following command to predict with GPU.
+python3.7 python/predict_cls.py -c configs/PULC/person_exists/inference_person_exists.yaml
+# Use the following command to predict with CPU.
+python3.7 python/predict_cls.py -c configs/PULC/person_exists/inference_person_exists.yaml -o Global.use_gpu=False
+```
+
+The prediction results:
+
+```
+objects365_02035329.jpg: class id(s): [1], score(s): [1.00], label_name(s): ['someone']
+```
+
+**Note**: The default threshold is `0.5`. If needed, you can specify the argument `Infer.PostProcess.threshold`, such as: `-o Infer.PostProcess.threshold=0.9794`. And the argument `threshold` is needed to be specified according by specific case. The `0.9794` is the best threshold when `Fpr` is less than `1/1000` in this valuation dataset. Please refer to [3.3 section](#3.3) for details.
+
+
+
+#### 6.2.2 Images Prediction
+
+If you want to predict images in directory, please specify the argument `Global.infer_imgs` as directory path by `-o Global.infer_imgs`. The command is as follow.
+
+```shell
+# Use the following command to predict with GPU. If want to replace with CPU, you can add argument -o Global.use_gpu=False
+python3.7 python/predict_cls.py -c configs/PULC/person_exists/inference_person_exists.yaml -o Global.infer_imgs="./images/PULC/person_exists/"
+```
+
+All prediction results will be printed, as shown below.
+
+```
+objects365_01780782.jpg: class id(s): [0], score(s): [1.00], label_name(s): ['nobody']
+objects365_02035329.jpg: class id(s): [1], score(s): [1.00], label_name(s): ['someone']
+```
+
+Among the prediction results above, `someone` means that there is a human in the image, `nobody` means that there is no human in the image.
+
+
+
+### 6.3 Deployment with C++
+
+PaddleClas provides an example about how to deploy with C++. Please refer to [Deployment with C++](../inference_deployment/cpp_deploy_en.md).
+
+
+
+### 6.4 Deployment as Service
+
+Paddle Serving is a flexible, high-performance carrier for machine learning models, and supports different protocol, such as RESTful, gRPC, bRPC and so on, which provides different deployment solutions for a variety of heterogeneous hardware and operating system environments. Please refer [Paddle Serving](https://github.com/PaddlePaddle/Serving) for more information.
+
+PaddleClas provides an example about how to deploy as service by Paddle Serving. Please refer to [Paddle Serving Deployment](../inference_deployment/paddle_serving_deploy_en.md).
+
+
+
+### 6.5 Deployment on Mobile
+
+Paddle-Lite is an open source deep learning framework that designed to make easy to perform inference on mobile, embeded, and IoT devices. Please refer to [Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite) for more information.
+
+PaddleClas provides an example of how to deploy on mobile by Paddle-Lite. Please refer to [Paddle-Lite deployment](../inference_deployment/paddle_lite_deploy_en.md).
+
+
+
+### 6.6 Converting To ONNX and Deployment
+
+Paddle2ONNX support convert Paddle Inference model to ONNX model. And you can deploy with ONNX model on different inference engine, such as TensorRT, OpenVINO, MNN/TNN, NCNN and so on. About Paddle2ONNX details, please refer to [Paddle2ONNX](https://github.com/PaddlePaddle/Paddle2ONNX).
+
+PaddleClas provides an example of how to convert Paddle Inference model to ONNX model by paddle2onnx toolkit and predict by ONNX model. You can refer to [paddle2onnx](../../../deploy/paddle2onnx/readme_en.md) for deployment details.
diff --git a/docs/en/PULC/PULC_train_en.md b/docs/en/PULC/PULC_train_en.md
index d7d0a1997c7f9473abb647bf9912f977f3c09362..9f94265e9ffb38f40633c671b0f6a60846f8cd08 100644
--- a/docs/en/PULC/PULC_train_en.md
+++ b/docs/en/PULC/PULC_train_en.md
@@ -14,7 +14,7 @@
- [3.3 EDA strategy](#3.3)
- [3.4 SKL-UGI knowledge distillation](#3.4)
- [3.5 Summary](#3.5)
-- [4. Hyperparameter Search](#4)
+- [4. Hyperparameters Searching](#4)
- [4.1 Search based on default configuration](#4.1)
- [4.2 Custom search configuration](#4.2)
@@ -31,7 +31,7 @@ The PULC solution has been verified to be effective in many scenarios, such as h
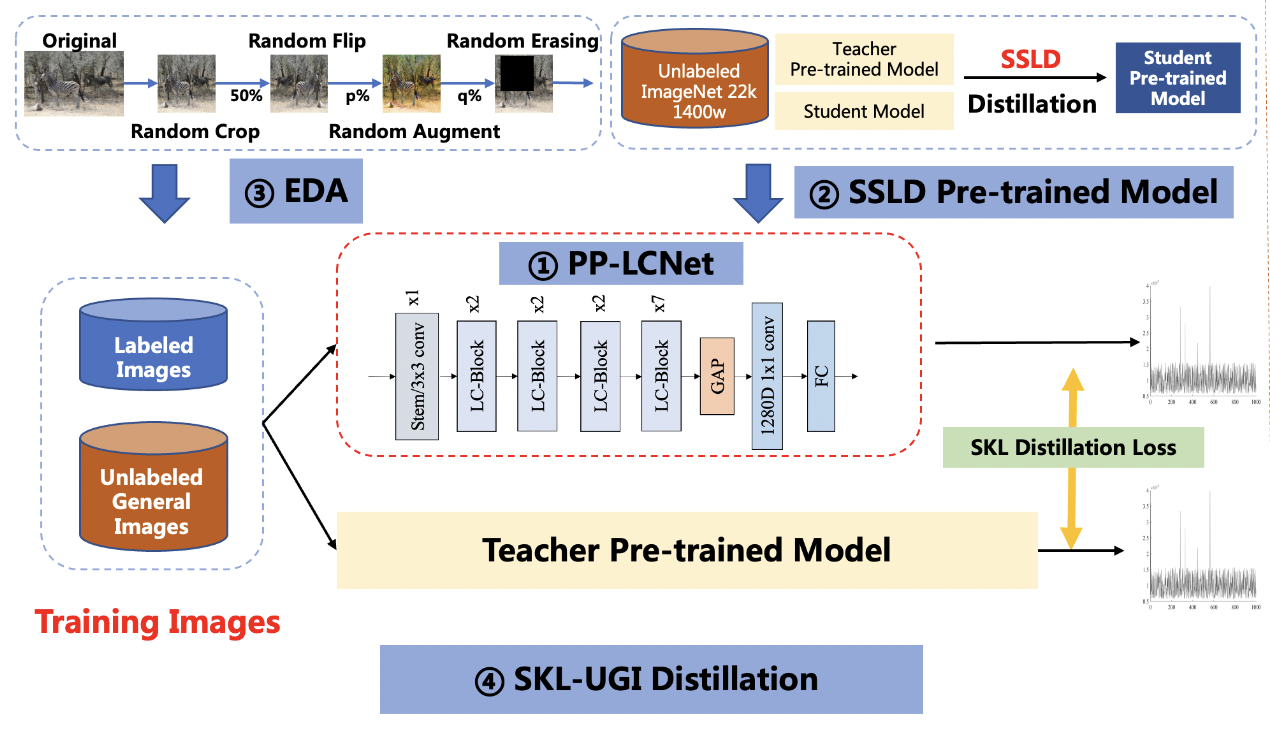 -The solution mainly includes 4 parts, namely: PP-LCNet lightweight backbone network, SSLD pre-trained model, Ensemble Data Augmentation (EDA) and SKL-UGI knowledge distillation algorithm. In addition, we also adopt the method of hyperparameter search to efficiently optimize the hyperparameters in training. Below, we take the person exists or not scene as an example to illustrate the solution.
+The solution mainly includes 4 parts, namely: PP-LCNet lightweight backbone network, SSLD pre-trained model, Ensemble Data Augmentation (EDA) and SKL-UGI knowledge distillation algorithm. In addition, we also adopt the method of hyperparameters searching to efficiently optimize the hyperparameters in training. Below, we take the person exists or not scene as an example to illustrate the solution.
**Note**:For some specific scenarios, we provide basic training documents for reference, such as [person exists or not classification model](PULC_person_exists_en.md), etc. You can find these documents [here](./PULC_model_list_en.md). If the methods in these documents do not meet your needs, or if you need a custom training task, you can refer to this document.
@@ -201,22 +201,22 @@ We also used the same optimization strategy in the other 8 scenarios and got the
| Text Image Orientation Classification | SwinTransformer_tiny |99.12 | PPLCNet_x1_0 | 99.06 |
| Text-line Orientation Classification | SwinTransformer_tiny | 93.61 | PPLCNet_x1_0 | 96.01 |
| Language Classification | SwinTransformer_tiny | 98.12 | PPLCNet_x1_0 | 99.26 |
-
+
It can be seen from the results that the PULC scheme can improve the model accuracy in multiple application scenarios. Using the PULC scheme can greatly reduce the workload of model optimization and quickly obtain models with higher accuracy.
-
+
-### 4. Hyperparameter Search
+### 4. Hyperparameters Searching
-In the above training process, we adjusted parameters such as learning rate, data augmentation probability, and stage learning rate mult list. The optimal values of these parameters may not be the same in different scenarios. We provide a quick hyperparameter search script to automate the process of hyperparameter tuning. This script traverses the parameters in the search value list to replace the parameters in the default configuration, then trains in sequence, and finally selects the parameters corresponding to the model with the highest accuracy as the search result.
+In the above training process, we adjusted parameters such as learning rate, data augmentation probability, and stage learning rate mult list. The optimal values of these parameters may not be the same in different scenarios. We provide a quick hyperparameters searching script to automate the process of hyperparameter tuning. This script traverses the parameters in the search value list to replace the parameters in the default configuration, then trains in sequence, and finally selects the parameters corresponding to the model with the highest accuracy as the search result.
#### 4.1 Search based on default configuration
-The configuration file [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) defines the configuration of hyperparameter search in person exists or not scenarios. Use the following commands to complete hyperparameter search.
+The configuration file [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) defines the configuration of hyperparameters searching in person exists or not scenarios. Use the following commands to complete hyperparameters searching.
```bash
python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
@@ -228,8 +228,8 @@ python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
#### 4.2 Custom search configuration
-
-You can also modify the configuration of hyperparameter search based on training results or your parameter tuning experience.
+
+You can also modify the configuration of hyperparameters searching based on training results or your parameter tuning experience.
Modify the `search_values` field in `lrs` to modify the list of learning rate search values;
diff --git a/docs/zh_CN/PULC/PULC_car_exists.md b/docs/zh_CN/PULC/PULC_car_exists.md
index 1dc9bb180719609ff6bd4dbf0b502a838c45bdda..0ccb0c2d45a94968f326146d8533b9c551bfd00f 100644
--- a/docs/zh_CN/PULC/PULC_car_exists.md
+++ b/docs/zh_CN/PULC/PULC_car_exists.md
@@ -54,22 +54,22 @@
| PPLCNet_x1_0 | 95.48 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0 | 95.92 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 13 个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.7 个百分点,进一步地,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.44 个百分点。此时,PPLCNet_x1_0 达到了接近 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 13 个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.7 个百分点,进一步地,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.44 个百分点。此时,PPLCNet_x1_0 达到了接近 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
* `Tpr`指标的介绍可以参考 [3.3节](#3.3)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
-
-
+
+
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,11 +81,11 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
@@ -93,11 +93,11 @@ python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
pip3 install paddleclas
```
-
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -130,7 +130,7 @@ print(next(result))
>>> result
[{'class_ids': [1], 'scores': [0.9871138], 'label_names': ['contains_car'], 'filename': 'pulc_demo_imgs/car_exists/objects365_00001507.jpeg'}]
```
-
+
@@ -326,7 +326,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_language_classification.md b/docs/zh_CN/PULC/PULC_language_classification.md
index 05b2c5eb449ae4ec8ca6af4d7b22e0dac13445fe..c11aafe6e9c017be60e55d8d03fefee4e5e5725e 100644
--- a/docs/zh_CN/PULC/PULC_language_classification.md
+++ b/docs/zh_CN/PULC/PULC_language_classification.md
@@ -49,7 +49,7 @@
| PPLCNet_x1_0 | 99.12 | 2.58 | 6.5 | 使用SSLD预训练模型+EDA策略 |
| **PPLCNet_x1_0** | **99.26** | **2.58** | **6.5** | 使用SSLD预训练模型+EDA策略+SKL-UGI知识蒸馏策略 |
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 且调整预处理输入尺寸和网络的下采样stride时,速度略为提升,同时精度较 MobileNetV3_large_x1_0 高2.43个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.35 个百分点,进一步地,当融合EDA策略后,精度可以再提升 0.42 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.14 个百分点。此时,PPLCNet_x1_0 超过了 SwinTranformer_tiny 模型的精度,并且速度有了明显提升。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 且调整预处理输入尺寸和网络的下采样stride时,速度略为提升,同时精度较 MobileNetV3_large_x1_0 高2.43个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.35 个百分点,进一步地,当融合EDA策略后,精度可以再提升 0.42 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.14 个百分点。此时,PPLCNet_x1_0 超过了 SwinTranformer_tiny 模型的精度,并且速度有了明显提升。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
@@ -60,9 +60,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -74,23 +74,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -309,7 +309,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_person_attribute.md b/docs/zh_CN/PULC/PULC_person_attribute.md
index e3f4d1369907f7b32b7397e650477e6a417a4fcd..96b0ba2f6ff2dd6b46e3de85fd68658aba04e7da 100644
--- a/docs/zh_CN/PULC/PULC_person_attribute.md
+++ b/docs/zh_CN/PULC/PULC_person_attribute.md
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -313,7 +313,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_person_exists.md b/docs/zh_CN/PULC/PULC_person_exists.md
index 6a091315545f34dc01bc2d28dbb8459e135c8886..037ac714f7f1fb52ba5c9d2feefca708f3f02390 100644
--- a/docs/zh_CN/PULC/PULC_person_exists.md
+++ b/docs/zh_CN/PULC/PULC_person_exists.md
@@ -54,7 +54,7 @@
| PPLCNet_x1_0 | 93.43 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0 | 95.60 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 20 多个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 2.6 个百分点,进一步地,当融合EDA策略后,精度可以再提升 1.3 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 2.2 个百分点。此时,PPLCNet_x1_0 达到了 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 20 多个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 2.6 个百分点,进一步地,当融合EDA策略后,精度可以再提升 1.3 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 2.2 个百分点。此时,PPLCNet_x1_0 达到了 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -328,7 +328,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_safety_helmet.md b/docs/zh_CN/PULC/PULC_safety_helmet.md
index dd8ae93896986924ae234da30ef90ce33fd9c95f..515d4b938290ad2f1d592ebfee14fac0bcddee04 100644
--- a/docs/zh_CN/PULC/PULC_safety_helmet.md
+++ b/docs/zh_CN/PULC/PULC_safety_helmet.md
@@ -53,12 +53,12 @@
| PPLCNet_x1_0 | 99.30 | 2.03 | 6.5 | 使用SSLD预训练模型+EDA策略|
| PPLCNet_x1_0 | 99.38 | 2.03 | 6.5 | 使用SSLD预训练模型+EDA策略+UDML知识蒸馏策略|
-从表中可以看出,在使用服务器端大模型作为 backbone 时,SwinTranformer_tiny 精度较低,Res2Net200_vd_26w_4s 精度较高,但服务器端大模型推理速度普遍较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度显著降低。在将 backbone 替换为 PPLCNet_x1_0 后,精度较 MobileNetV3_small_x0_35 提高约 8.5 个百分点,与此同时速度快 20% 以上。在此基础上,将 PPLCNet_x1_0 的预训练模型替换为 SSLD 预训练模型后,在对推理速度无影响的前提下,精度提升约 4.9 个百分点,进一步地使用 EDA 策略后,精度可以再提升 1.1 个百分点。此时,PPLCNet_x1_0 已经超过 Res2Net200_vd_26w_4s 模型的精度,但是速度快 70+ 倍。最后,在使用 UDML 知识蒸馏后,精度可以再提升 0.08 个百分点。下面详细介绍关于 PULC 安全帽模型的训练方法和推理部署方法。
+从表中可以看出,在使用服务器端大模型作为 backbone 时,SwinTranformer_tiny 精度较低,Res2Net200_vd_26w_4s 精度较高,但服务器端大模型推理速度普遍较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度显著降低。在将 backbone 替换为 PPLCNet_x1_0 后,精度较 MobileNetV3_small_x0_35 提高约 8.5 个百分点,与此同时速度快 20% 以上。在此基础上,将 PPLCNet_x1_0 的预训练模型替换为 SSLD 预训练模型后,在对推理速度无影响的前提下,精度提升约 4.9 个百分点,进一步地使用 EDA 策略后,精度可以再提升 1.1 个百分点。此时,PPLCNet_x1_0 已经超过 Res2Net200_vd_26w_4s 模型的精度,但是速度快 70+ 倍。最后,在使用 UDML 知识蒸馏后,精度可以再提升 0.08 个百分点。下面详细介绍关于 PULC 安全帽模型的训练方法和推理部署方法。
**备注:**
* `Tpr`指标的介绍可以参考 [3.3小节](#3.3)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启MKLDNN加速策略,线程数为10。
-
+
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -295,7 +295,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注**:此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_text_image_orientation.md b/docs/zh_CN/PULC/PULC_text_image_orientation.md
index 9b398b50da6b6e942d56802432cc99ff6023ac80..ca0a767d3cebb83c3894cdf9930c9c8168ae6c20 100644
--- a/docs/zh_CN/PULC/PULC_text_image_orientation.md
+++ b/docs/zh_CN/PULC/PULC_text_image_orientation.md
@@ -38,7 +38,7 @@
在诸如文档扫描、证照拍摄等过程中,有时为了拍摄更清晰,会将拍摄设备进行旋转,导致得到的图片也是不同方向的。此时,标准的OCR流程无法很好地应对这些数据。利用图像分类技术,可以预先判断含文字图像的方向,并将其进行方向调整,从而提高OCR处理的准确性。该案例提供了用户使用 PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight Classification)快速构建轻量级、高精度、可落地的含文字图像方向的分类模型。该模型可以广泛应用于金融、政务等行业的旋转图片的OCR处理场景中。
-下表列出了判断含文字图像方向分类模型的相关指标,前两行展现了使用 SwinTranformer_tiny 和 MobileNetV3_small_x0_35 作为 backbone 训练得到的模型的相关指标,第三行至第五行依次展现了替换 backbone 为 PPLCNet_x1_0、使用 SSLD 预训练模型、使用 SHAS 超参数搜索策略训练得到的模型的相关指标。
+下表列出了判断含文字图像方向分类模型的相关指标,前两行展现了使用 SwinTranformer_tiny 和 MobileNetV3_small_x0_35 作为 backbone 训练得到的模型的相关指标,第三行至第五行依次展现了替换 backbone 为 PPLCNet_x1_0、使用 SSLD 预训练模型、使用 超参数搜索策略训练得到的模型的相关指标。
| 模型 | 精度(%) | 延时(ms) | 存储(M) | 策略 |
| ----------------------- | --------- | ---------- | --------- | ------------------------------------- |
@@ -48,9 +48,9 @@
| PPLCNet_x1_0 | 98.02 | 2.16 | 6.5 | 使用SSLD预训练模型 |
| **PPLCNet_x1_0** | **99.06** | **2.16** | **6.5** | 使用SSLD预训练模型+SHAS超参数搜索策略 |
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 时,速度略为提升,同时精度较 MobileNetV3_small_x0_35 高了 14.24 个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.17 个百分点,进一步地,当使用SHAS超参数搜索策略搜索最优超参数后,精度可以再提升 1.04 个百分点。此时,PPLCNet_x1_0 与 SwinTranformer_tiny 的精度差别不大,但是速度明显变快。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 时,速度略为提升,同时精度较 MobileNetV3_small_x0_35 高了 14.24 个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.17 个百分点,进一步地,当使用SHAS超参数搜索策略搜索最优超参数后,精度可以再提升 1.04 个百分点。此时,PPLCNet_x1_0 与 SwinTranformer_tiny 的精度差别不大,但是速度明显变快。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
-**备注:**
+**备注:**
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -59,9 +59,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -73,23 +73,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -319,7 +319,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_textline_orientation.md b/docs/zh_CN/PULC/PULC_textline_orientation.md
index c2d84b8b4e9cc8c4ee152d6dbf95887884074383..b4de6351e2fc3bce51f7bfde14afaaa9f5cb2a8f 100644
--- a/docs/zh_CN/PULC/PULC_textline_orientation.md
+++ b/docs/zh_CN/PULC/PULC_textline_orientation.md
@@ -55,11 +55,11 @@
| PPLCNet_x1_0** | 96.01 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0** | 95.86 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5 个百分点(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05 个百分点 ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5 个百分点(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05 个百分点 ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
-* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h\*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h\*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)搜索得到的。
+* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h\*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h\*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[超参数搜索策略](PULC_train.md#4-超参搜索)搜索得到的。
* 延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -68,9 +68,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -82,23 +82,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -314,7 +314,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。
diff --git a/docs/zh_CN/PULC/PULC_traffic_sign.md b/docs/zh_CN/PULC/PULC_traffic_sign.md
index 5c04bc5c6616f58aa4893328ea751a9f71ed984c..b8eed290914edcc53ea51e831e29147a2d3c0113 100644
--- a/docs/zh_CN/PULC/PULC_traffic_sign.md
+++ b/docs/zh_CN/PULC/PULC_traffic_sign.md
@@ -66,9 +66,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -80,23 +80,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -344,7 +344,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_vehicle_attribute.md b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
index cd508934e66eb2a00e17d237cd24cb232d13e09b..cfc74245658dd0adc5c7c5311bd3cbce34471c38 100644
--- a/docs/zh_CN/PULC/PULC_vehicle_attribute.md
+++ b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
@@ -337,7 +337,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
-The solution mainly includes 4 parts, namely: PP-LCNet lightweight backbone network, SSLD pre-trained model, Ensemble Data Augmentation (EDA) and SKL-UGI knowledge distillation algorithm. In addition, we also adopt the method of hyperparameter search to efficiently optimize the hyperparameters in training. Below, we take the person exists or not scene as an example to illustrate the solution.
+The solution mainly includes 4 parts, namely: PP-LCNet lightweight backbone network, SSLD pre-trained model, Ensemble Data Augmentation (EDA) and SKL-UGI knowledge distillation algorithm. In addition, we also adopt the method of hyperparameters searching to efficiently optimize the hyperparameters in training. Below, we take the person exists or not scene as an example to illustrate the solution.
**Note**:For some specific scenarios, we provide basic training documents for reference, such as [person exists or not classification model](PULC_person_exists_en.md), etc. You can find these documents [here](./PULC_model_list_en.md). If the methods in these documents do not meet your needs, or if you need a custom training task, you can refer to this document.
@@ -201,22 +201,22 @@ We also used the same optimization strategy in the other 8 scenarios and got the
| Text Image Orientation Classification | SwinTransformer_tiny |99.12 | PPLCNet_x1_0 | 99.06 |
| Text-line Orientation Classification | SwinTransformer_tiny | 93.61 | PPLCNet_x1_0 | 96.01 |
| Language Classification | SwinTransformer_tiny | 98.12 | PPLCNet_x1_0 | 99.26 |
-
+
It can be seen from the results that the PULC scheme can improve the model accuracy in multiple application scenarios. Using the PULC scheme can greatly reduce the workload of model optimization and quickly obtain models with higher accuracy.
-
+
-### 4. Hyperparameter Search
+### 4. Hyperparameters Searching
-In the above training process, we adjusted parameters such as learning rate, data augmentation probability, and stage learning rate mult list. The optimal values of these parameters may not be the same in different scenarios. We provide a quick hyperparameter search script to automate the process of hyperparameter tuning. This script traverses the parameters in the search value list to replace the parameters in the default configuration, then trains in sequence, and finally selects the parameters corresponding to the model with the highest accuracy as the search result.
+In the above training process, we adjusted parameters such as learning rate, data augmentation probability, and stage learning rate mult list. The optimal values of these parameters may not be the same in different scenarios. We provide a quick hyperparameters searching script to automate the process of hyperparameter tuning. This script traverses the parameters in the search value list to replace the parameters in the default configuration, then trains in sequence, and finally selects the parameters corresponding to the model with the highest accuracy as the search result.
#### 4.1 Search based on default configuration
-The configuration file [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) defines the configuration of hyperparameter search in person exists or not scenarios. Use the following commands to complete hyperparameter search.
+The configuration file [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) defines the configuration of hyperparameters searching in person exists or not scenarios. Use the following commands to complete hyperparameters searching.
```bash
python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
@@ -228,8 +228,8 @@ python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
#### 4.2 Custom search configuration
-
-You can also modify the configuration of hyperparameter search based on training results or your parameter tuning experience.
+
+You can also modify the configuration of hyperparameters searching based on training results or your parameter tuning experience.
Modify the `search_values` field in `lrs` to modify the list of learning rate search values;
diff --git a/docs/zh_CN/PULC/PULC_car_exists.md b/docs/zh_CN/PULC/PULC_car_exists.md
index 1dc9bb180719609ff6bd4dbf0b502a838c45bdda..0ccb0c2d45a94968f326146d8533b9c551bfd00f 100644
--- a/docs/zh_CN/PULC/PULC_car_exists.md
+++ b/docs/zh_CN/PULC/PULC_car_exists.md
@@ -54,22 +54,22 @@
| PPLCNet_x1_0 | 95.48 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0 | 95.92 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 13 个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.7 个百分点,进一步地,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.44 个百分点。此时,PPLCNet_x1_0 达到了接近 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 13 个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.7 个百分点,进一步地,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.44 个百分点。此时,PPLCNet_x1_0 达到了接近 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
* `Tpr`指标的介绍可以参考 [3.3节](#3.3)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
-
-
+
+
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,11 +81,11 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
@@ -93,11 +93,11 @@ python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
pip3 install paddleclas
```
-
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -130,7 +130,7 @@ print(next(result))
>>> result
[{'class_ids': [1], 'scores': [0.9871138], 'label_names': ['contains_car'], 'filename': 'pulc_demo_imgs/car_exists/objects365_00001507.jpeg'}]
```
-
+
@@ -326,7 +326,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_language_classification.md b/docs/zh_CN/PULC/PULC_language_classification.md
index 05b2c5eb449ae4ec8ca6af4d7b22e0dac13445fe..c11aafe6e9c017be60e55d8d03fefee4e5e5725e 100644
--- a/docs/zh_CN/PULC/PULC_language_classification.md
+++ b/docs/zh_CN/PULC/PULC_language_classification.md
@@ -49,7 +49,7 @@
| PPLCNet_x1_0 | 99.12 | 2.58 | 6.5 | 使用SSLD预训练模型+EDA策略 |
| **PPLCNet_x1_0** | **99.26** | **2.58** | **6.5** | 使用SSLD预训练模型+EDA策略+SKL-UGI知识蒸馏策略 |
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 且调整预处理输入尺寸和网络的下采样stride时,速度略为提升,同时精度较 MobileNetV3_large_x1_0 高2.43个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.35 个百分点,进一步地,当融合EDA策略后,精度可以再提升 0.42 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.14 个百分点。此时,PPLCNet_x1_0 超过了 SwinTranformer_tiny 模型的精度,并且速度有了明显提升。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 且调整预处理输入尺寸和网络的下采样stride时,速度略为提升,同时精度较 MobileNetV3_large_x1_0 高2.43个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.35 个百分点,进一步地,当融合EDA策略后,精度可以再提升 0.42 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.14 个百分点。此时,PPLCNet_x1_0 超过了 SwinTranformer_tiny 模型的精度,并且速度有了明显提升。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
@@ -60,9 +60,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -74,23 +74,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -309,7 +309,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_person_attribute.md b/docs/zh_CN/PULC/PULC_person_attribute.md
index e3f4d1369907f7b32b7397e650477e6a417a4fcd..96b0ba2f6ff2dd6b46e3de85fd68658aba04e7da 100644
--- a/docs/zh_CN/PULC/PULC_person_attribute.md
+++ b/docs/zh_CN/PULC/PULC_person_attribute.md
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -313,7 +313,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_person_exists.md b/docs/zh_CN/PULC/PULC_person_exists.md
index 6a091315545f34dc01bc2d28dbb8459e135c8886..037ac714f7f1fb52ba5c9d2feefca708f3f02390 100644
--- a/docs/zh_CN/PULC/PULC_person_exists.md
+++ b/docs/zh_CN/PULC/PULC_person_exists.md
@@ -54,7 +54,7 @@
| PPLCNet_x1_0 | 93.43 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0 | 95.60 | 2.12 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 20 多个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 2.6 个百分点,进一步地,当融合EDA策略后,精度可以再提升 1.3 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 2.2 个百分点。此时,PPLCNet_x1_0 达到了 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是会导致精度大幅下降。将 backbone 替换为速度更快的 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 20 多个百分点,与此同时速度依旧可以快 20% 以上。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 2.6 个百分点,进一步地,当融合EDA策略后,精度可以再提升 1.3 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 2.2 个百分点。此时,PPLCNet_x1_0 达到了 SwinTranformer_tiny 模型的精度,但是速度快 40 多倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -328,7 +328,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_safety_helmet.md b/docs/zh_CN/PULC/PULC_safety_helmet.md
index dd8ae93896986924ae234da30ef90ce33fd9c95f..515d4b938290ad2f1d592ebfee14fac0bcddee04 100644
--- a/docs/zh_CN/PULC/PULC_safety_helmet.md
+++ b/docs/zh_CN/PULC/PULC_safety_helmet.md
@@ -53,12 +53,12 @@
| PPLCNet_x1_0 | 99.30 | 2.03 | 6.5 | 使用SSLD预训练模型+EDA策略|
| PPLCNet_x1_0 | 99.38 | 2.03 | 6.5 | 使用SSLD预训练模型+EDA策略+UDML知识蒸馏策略|
-从表中可以看出,在使用服务器端大模型作为 backbone 时,SwinTranformer_tiny 精度较低,Res2Net200_vd_26w_4s 精度较高,但服务器端大模型推理速度普遍较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度显著降低。在将 backbone 替换为 PPLCNet_x1_0 后,精度较 MobileNetV3_small_x0_35 提高约 8.5 个百分点,与此同时速度快 20% 以上。在此基础上,将 PPLCNet_x1_0 的预训练模型替换为 SSLD 预训练模型后,在对推理速度无影响的前提下,精度提升约 4.9 个百分点,进一步地使用 EDA 策略后,精度可以再提升 1.1 个百分点。此时,PPLCNet_x1_0 已经超过 Res2Net200_vd_26w_4s 模型的精度,但是速度快 70+ 倍。最后,在使用 UDML 知识蒸馏后,精度可以再提升 0.08 个百分点。下面详细介绍关于 PULC 安全帽模型的训练方法和推理部署方法。
+从表中可以看出,在使用服务器端大模型作为 backbone 时,SwinTranformer_tiny 精度较低,Res2Net200_vd_26w_4s 精度较高,但服务器端大模型推理速度普遍较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度显著降低。在将 backbone 替换为 PPLCNet_x1_0 后,精度较 MobileNetV3_small_x0_35 提高约 8.5 个百分点,与此同时速度快 20% 以上。在此基础上,将 PPLCNet_x1_0 的预训练模型替换为 SSLD 预训练模型后,在对推理速度无影响的前提下,精度提升约 4.9 个百分点,进一步地使用 EDA 策略后,精度可以再提升 1.1 个百分点。此时,PPLCNet_x1_0 已经超过 Res2Net200_vd_26w_4s 模型的精度,但是速度快 70+ 倍。最后,在使用 UDML 知识蒸馏后,精度可以再提升 0.08 个百分点。下面详细介绍关于 PULC 安全帽模型的训练方法和推理部署方法。
**备注:**
* `Tpr`指标的介绍可以参考 [3.3小节](#3.3)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启MKLDNN加速策略,线程数为10。
-
+
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -295,7 +295,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注**:此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_text_image_orientation.md b/docs/zh_CN/PULC/PULC_text_image_orientation.md
index 9b398b50da6b6e942d56802432cc99ff6023ac80..ca0a767d3cebb83c3894cdf9930c9c8168ae6c20 100644
--- a/docs/zh_CN/PULC/PULC_text_image_orientation.md
+++ b/docs/zh_CN/PULC/PULC_text_image_orientation.md
@@ -38,7 +38,7 @@
在诸如文档扫描、证照拍摄等过程中,有时为了拍摄更清晰,会将拍摄设备进行旋转,导致得到的图片也是不同方向的。此时,标准的OCR流程无法很好地应对这些数据。利用图像分类技术,可以预先判断含文字图像的方向,并将其进行方向调整,从而提高OCR处理的准确性。该案例提供了用户使用 PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight Classification)快速构建轻量级、高精度、可落地的含文字图像方向的分类模型。该模型可以广泛应用于金融、政务等行业的旋转图片的OCR处理场景中。
-下表列出了判断含文字图像方向分类模型的相关指标,前两行展现了使用 SwinTranformer_tiny 和 MobileNetV3_small_x0_35 作为 backbone 训练得到的模型的相关指标,第三行至第五行依次展现了替换 backbone 为 PPLCNet_x1_0、使用 SSLD 预训练模型、使用 SHAS 超参数搜索策略训练得到的模型的相关指标。
+下表列出了判断含文字图像方向分类模型的相关指标,前两行展现了使用 SwinTranformer_tiny 和 MobileNetV3_small_x0_35 作为 backbone 训练得到的模型的相关指标,第三行至第五行依次展现了替换 backbone 为 PPLCNet_x1_0、使用 SSLD 预训练模型、使用 超参数搜索策略训练得到的模型的相关指标。
| 模型 | 精度(%) | 延时(ms) | 存储(M) | 策略 |
| ----------------------- | --------- | ---------- | --------- | ------------------------------------- |
@@ -48,9 +48,9 @@
| PPLCNet_x1_0 | 98.02 | 2.16 | 6.5 | 使用SSLD预训练模型 |
| **PPLCNet_x1_0** | **99.06** | **2.16** | **6.5** | 使用SSLD预训练模型+SHAS超参数搜索策略 |
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 时,速度略为提升,同时精度较 MobileNetV3_small_x0_35 高了 14.24 个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.17 个百分点,进一步地,当使用SHAS超参数搜索策略搜索最优超参数后,精度可以再提升 1.04 个百分点。此时,PPLCNet_x1_0 与 SwinTranformer_tiny 的精度差别不大,但是速度明显变快。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度比较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度提升明显,但精度有了大幅下降。将 backbone 替换为 PPLCNet_x1_0 时,速度略为提升,同时精度较 MobileNetV3_small_x0_35 高了 14.24 个百分点。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升 0.17 个百分点,进一步地,当使用SHAS超参数搜索策略搜索最优超参数后,精度可以再提升 1.04 个百分点。此时,PPLCNet_x1_0 与 SwinTranformer_tiny 的精度差别不大,但是速度明显变快。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
-**备注:**
+**备注:**
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -59,9 +59,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -73,23 +73,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -319,7 +319,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_textline_orientation.md b/docs/zh_CN/PULC/PULC_textline_orientation.md
index c2d84b8b4e9cc8c4ee152d6dbf95887884074383..b4de6351e2fc3bce51f7bfde14afaaa9f5cb2a8f 100644
--- a/docs/zh_CN/PULC/PULC_textline_orientation.md
+++ b/docs/zh_CN/PULC/PULC_textline_orientation.md
@@ -55,11 +55,11 @@
| PPLCNet_x1_0** | 96.01 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0** | 95.86 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5 个百分点(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05 个百分点 ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5 个百分点(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05 个百分点 ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
-* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h\*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h\*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)搜索得到的。
+* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h\*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h\*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[超参数搜索策略](PULC_train.md#4-超参搜索)搜索得到的。
* 延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -68,9 +68,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -82,23 +82,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -314,7 +314,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。
diff --git a/docs/zh_CN/PULC/PULC_traffic_sign.md b/docs/zh_CN/PULC/PULC_traffic_sign.md
index 5c04bc5c6616f58aa4893328ea751a9f71ed984c..b8eed290914edcc53ea51e831e29147a2d3c0113 100644
--- a/docs/zh_CN/PULC/PULC_traffic_sign.md
+++ b/docs/zh_CN/PULC/PULC_traffic_sign.md
@@ -66,9 +66,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -80,23 +80,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -344,7 +344,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_vehicle_attribute.md b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
index cd508934e66eb2a00e17d237cd24cb232d13e09b..cfc74245658dd0adc5c7c5311bd3cbce34471c38 100644
--- a/docs/zh_CN/PULC/PULC_vehicle_attribute.md
+++ b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
@@ -337,7 +337,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。