
Merge branch 'release/2.3' into develop
208.9 KB
211.5 KB
898.6 KB
74.3 KB
763.0 KB
35.9 KB


7.4 KB
55.4 KB
70.7 KB

1.7 MB
124.1 KB
74.3 KB
697.7 KB
90.8 KB
132.8 KB
53.5 KB
132.6 KB
30.3 KB
144.6 KB
33.7 KB
56.6 KB
106.3 KB
161.9 KB
89.3 KB
131.6 KB
119.6 KB
96.4 KB
23.3 KB
200.1 KB

1.1 MB

24.3 KB

94.9 KB

463.0 KB

21.0 KB

288.9 KB

336.4 KB

313.3 KB

86.9 KB

1.3 MB
106.3 KB

48.8 KB

330.1 KB

274.3 KB

972.8 KB

234.7 KB

263.8 KB

196.7 KB

957.9 KB

288.0 KB

254.9 KB
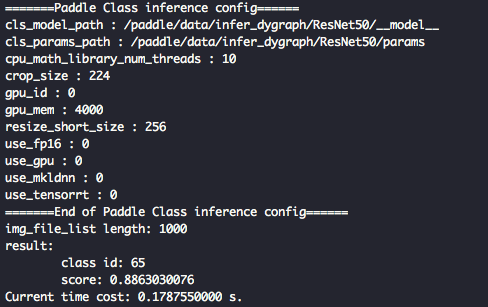
41.8 KB
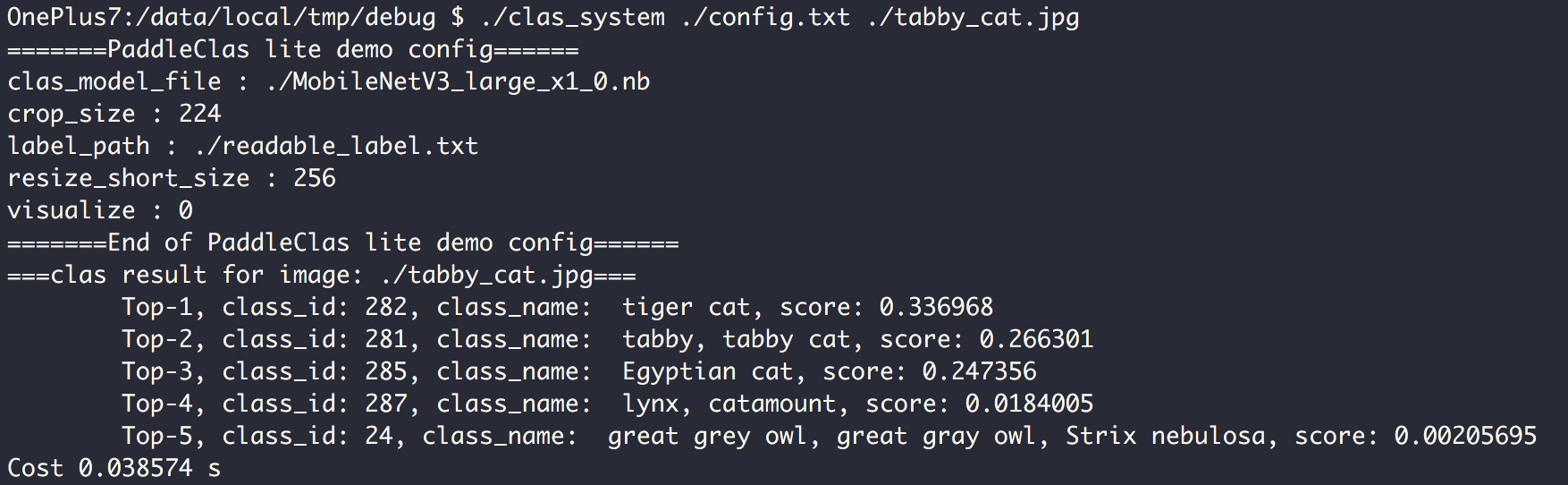
142.7 KB
75.3 KB
84.3 KB
56.9 KB
44.9 KB
62.4 KB
83.3 KB

37.4 KB

352.8 KB
4.9 KB
191.8 KB

178.5 KB

275.4 KB

200.0 KB

939.8 KB

902.9 KB
922.2 KB
982.6 KB

1.0 MB

1.1 MB
152.3 KB

1.1 MB
118.8 KB
68.7 KB
88.5 KB
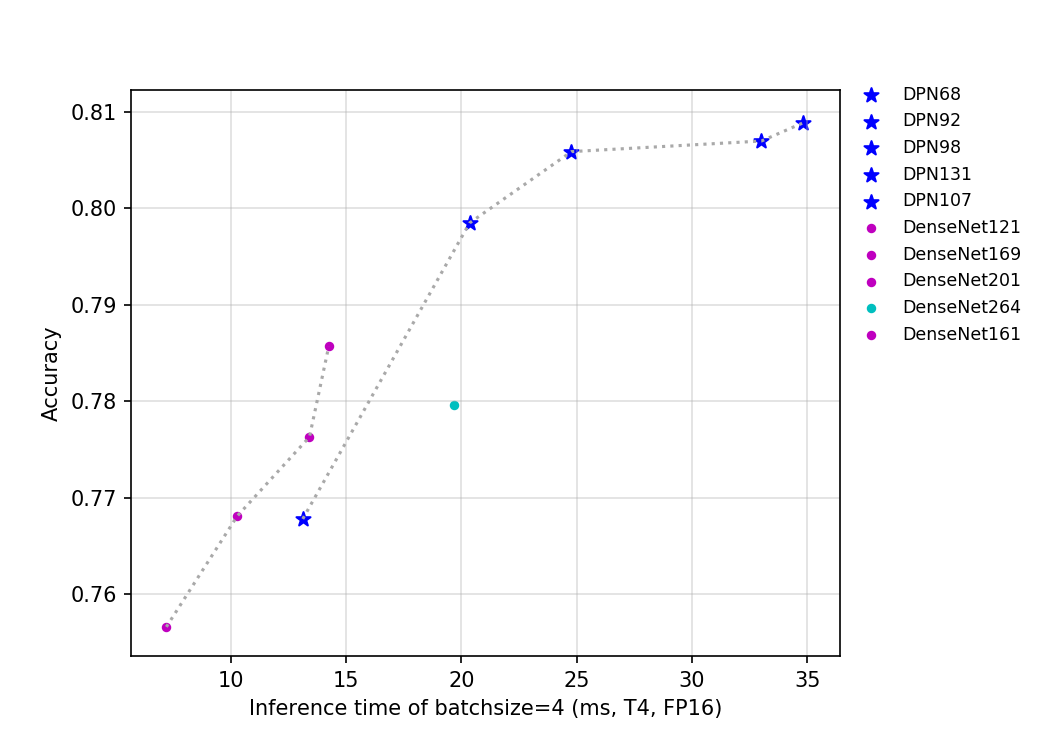
57.3 KB
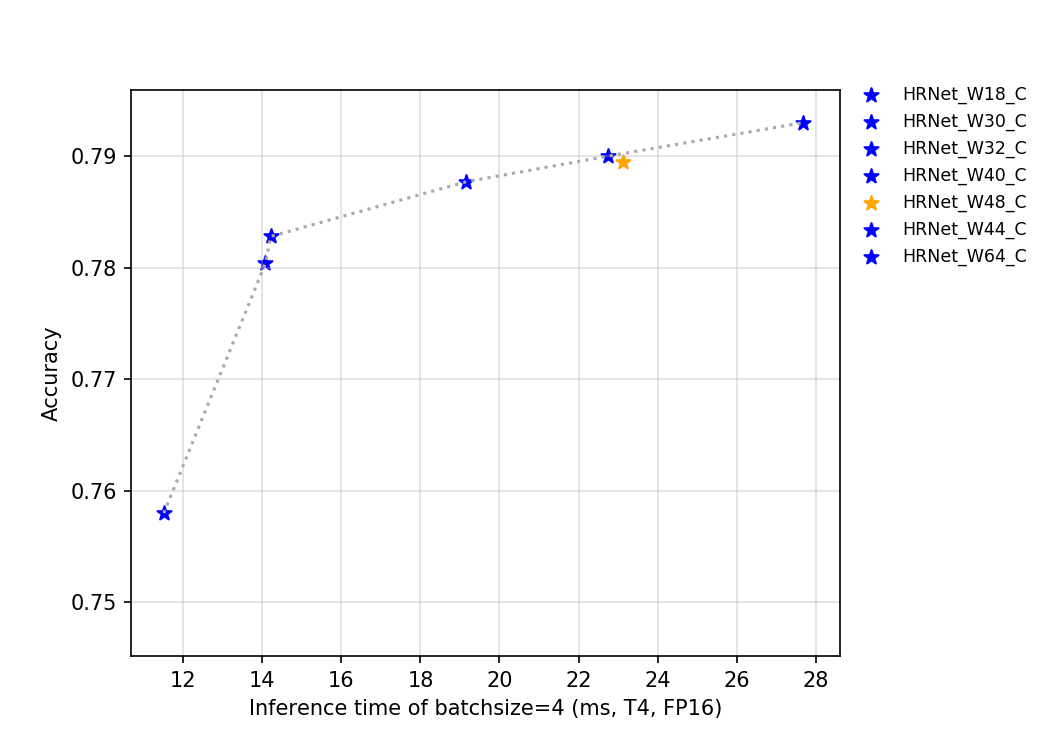
54.4 KB
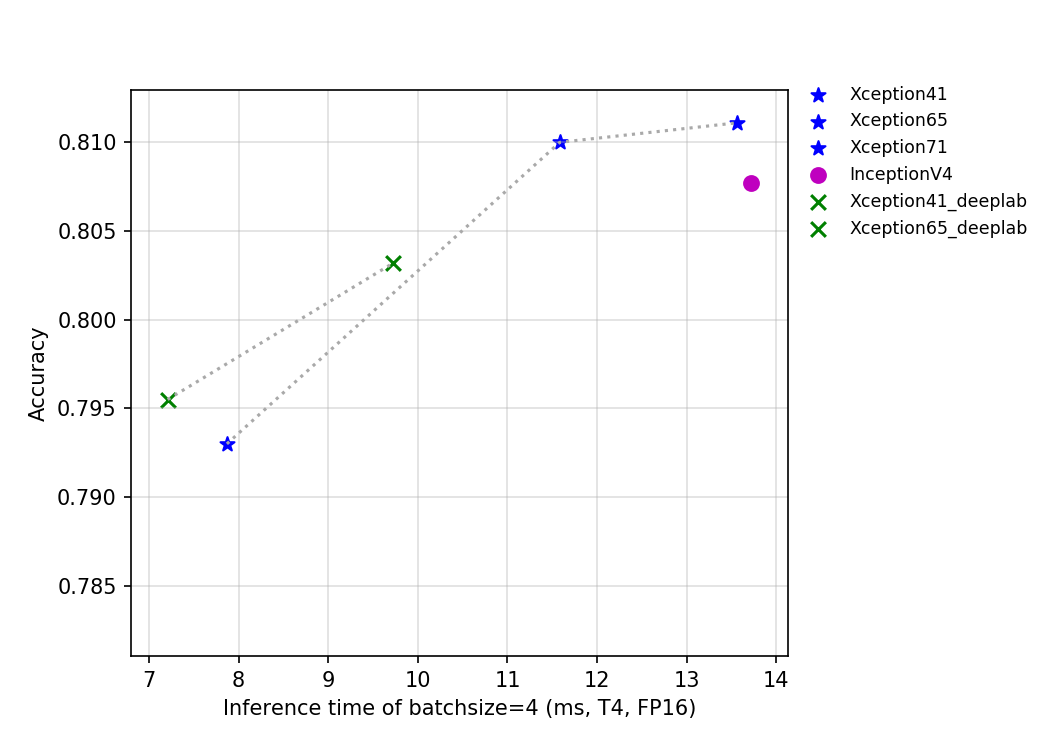
57.1 KB
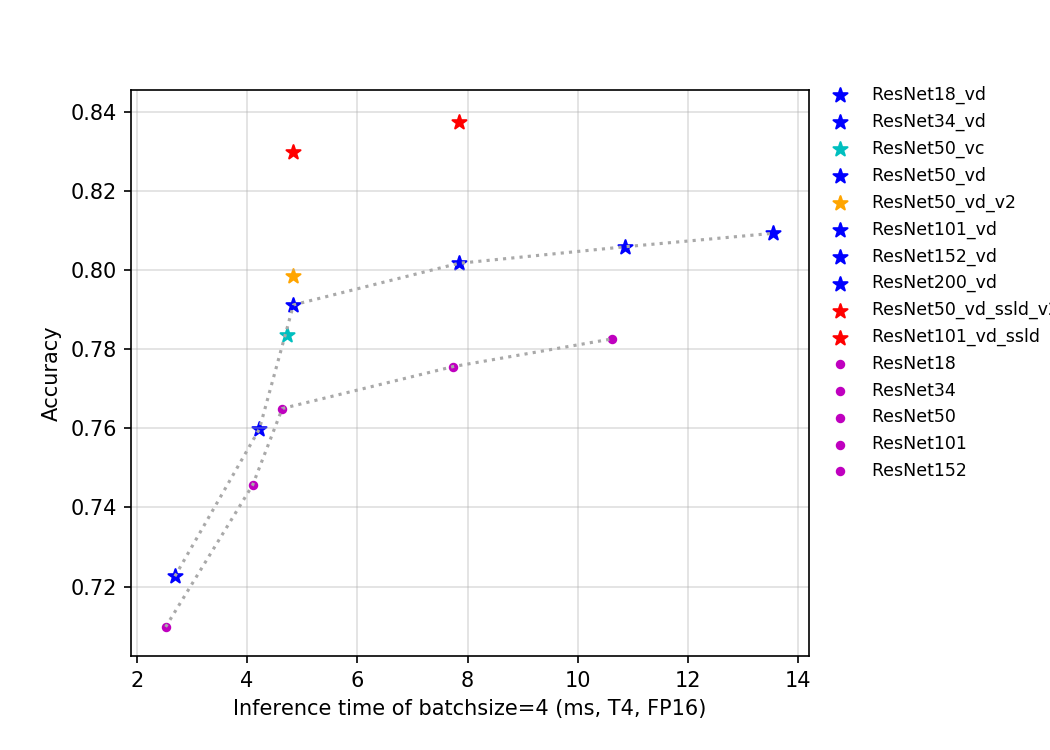
84.1 KB
109.8 KB
88.6 KB

165.5 KB
54.3 KB
56.2 KB
58.1 KB
81.6 KB
80.8 KB
49.3 KB
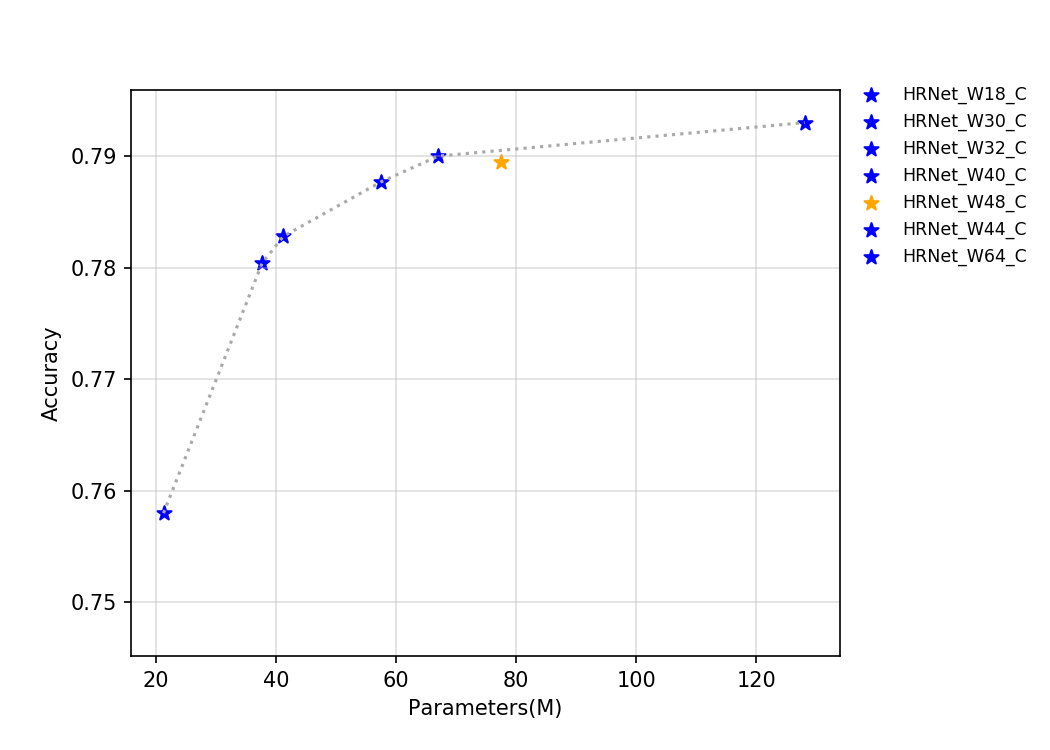
50.6 KB
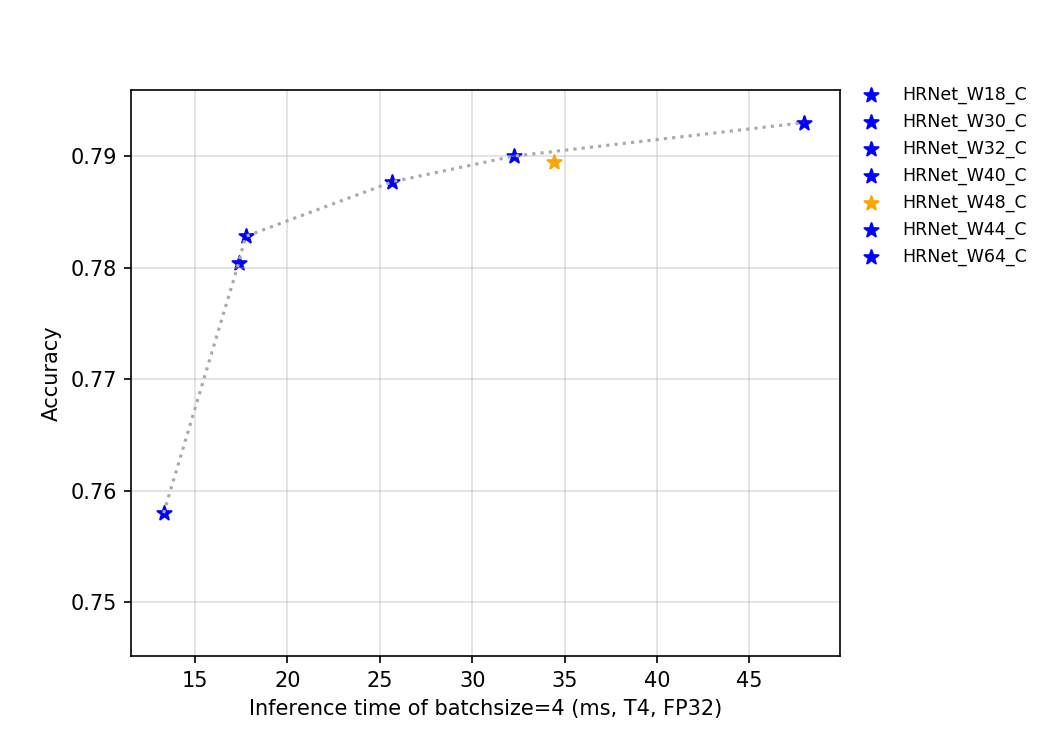
53.7 KB
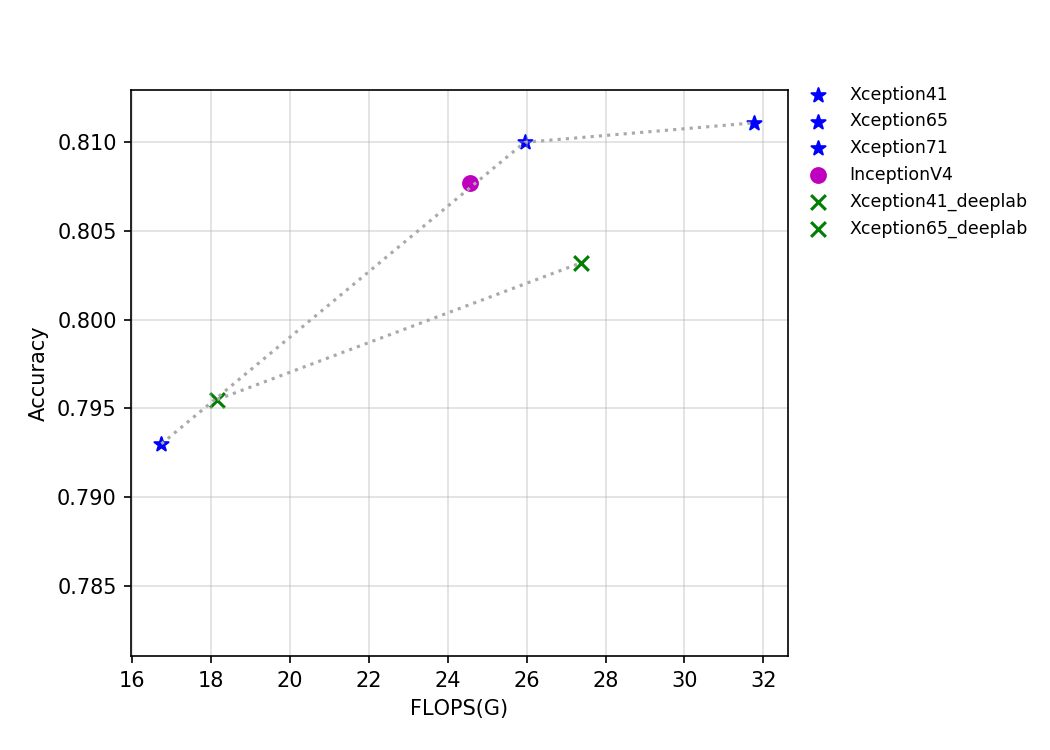
53.9 KB
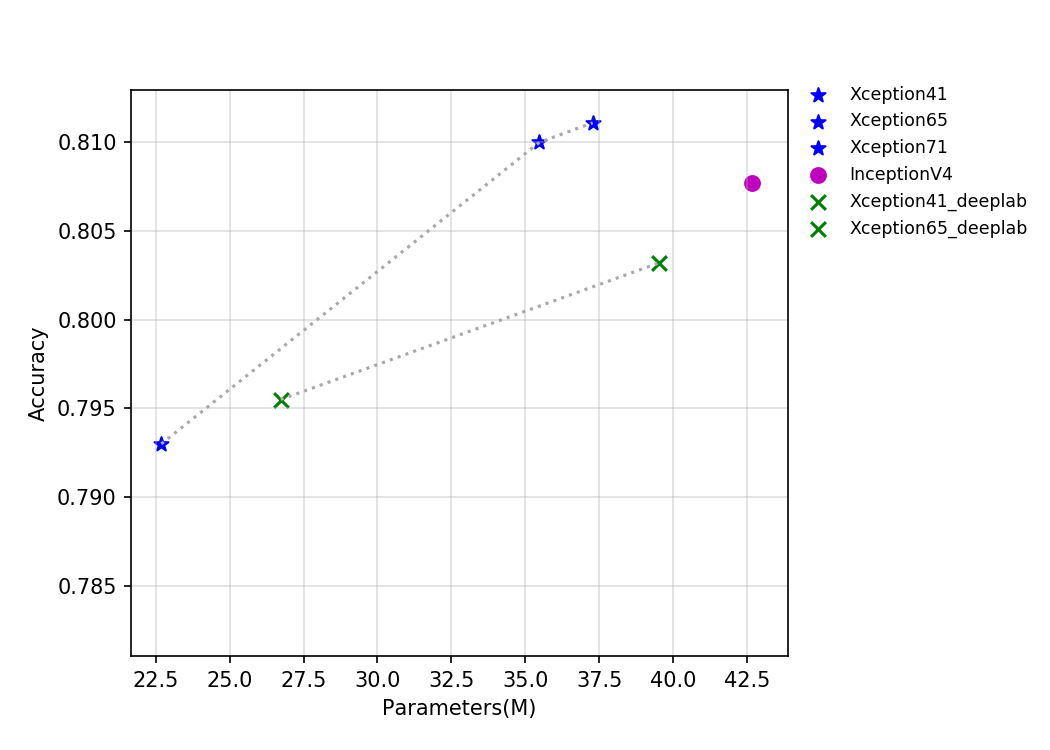
54.5 KB
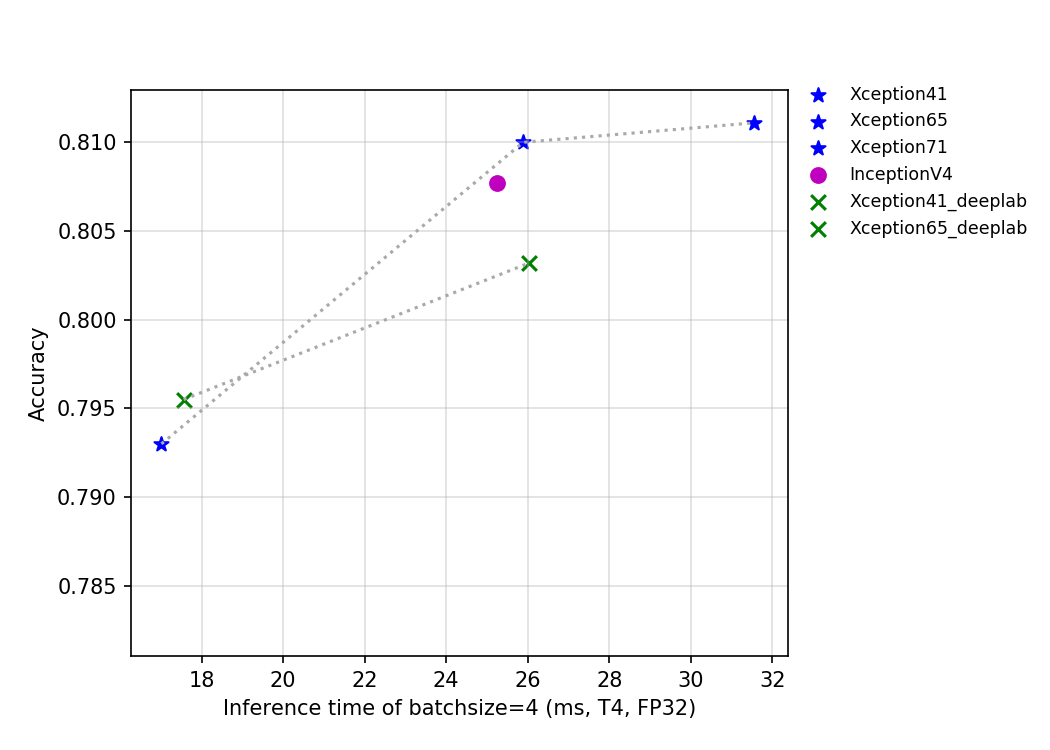
58.2 KB
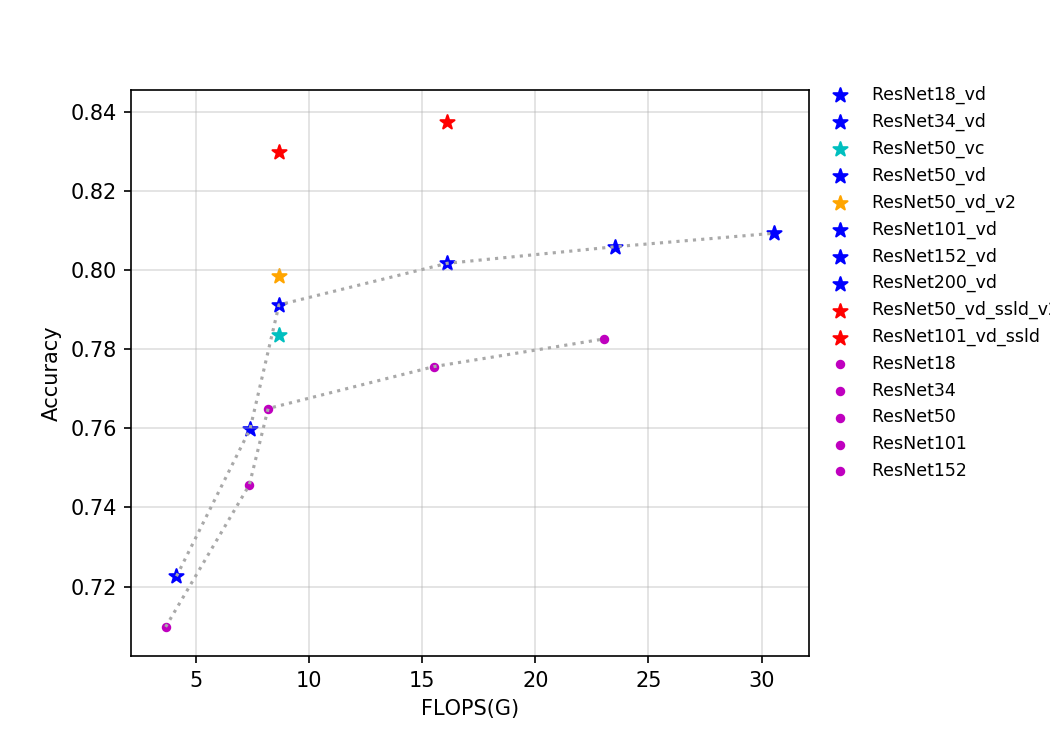
78.6 KB

80.7 KB

83.3 KB

109.3 KB

110.4 KB

112.2 KB

165.5 KB

140.5 KB

141.0 KB

57.8 KB

88.5 KB

55.8 KB

55.5 KB

85.5 KB

106.0 KB

161.6 KB

164.7 KB

145.6 KB

140.6 KB

3.4 KB

1.8 MB

3.0 MB

952.1 KB

149.5 KB

232.6 KB

53.4 KB

133.5 KB

109.5 KB

160.6 KB

217.8 KB

87.7 KB

34.8 KB

33.3 KB

52.4 KB

168.1 KB

148.8 KB

4.1 MB
344.8 KB
21.1 KB
3.5 MB

433.8 KB

43.9 KB

364.5 KB


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

11.1 KB
{kind=link}

54.0 KB
{kind=link}

44.0 KB
{kind=link}

109.2 KB
{kind=link}

111.2 KB
{kind=link}

88.3 KB
{kind=link}

92.0 KB
{kind=link}

3.2 MB
{kind=link}

421.8 KB
{kind=link}

83.3 KB
{kind=link}

258.5 KB
{kind=link}

186.7 KB
{kind=link}

1.7 MB
{kind=link}

286.9 KB
{kind=link}

37.4 KB
{kind=link}

55.4 KB