
diff --git a/deploy/configs/PULC/car_exists/inference_car_exists.yaml b/deploy/configs/PULC/car_exists/inference_car_exists.yaml
index 7204b27238226748932d6c27549195f52d3a8651..b6733069d99b5622c83321bc628f3d70274ce8d4 100644
--- a/deploy/configs/PULC/car_exists/inference_car_exists.yaml
+++ b/deploy/configs/PULC/car_exists/inference_car_exists.yaml
@@ -30,7 +30,7 @@ PostProcess:
main_indicator: ThreshOutput
ThreshOutput:
threshold: 0.5
- label_0: nocar
+ label_0: no_car
label_1: contains_car
SavePreLabel:
save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/car_exists/inference_person_exists.yaml b/deploy/configs/PULC/car_exists/inference_person_exists.yaml
deleted file mode 100644
index 7204b27238226748932d6c27549195f52d3a8651..0000000000000000000000000000000000000000
--- a/deploy/configs/PULC/car_exists/inference_person_exists.yaml
+++ /dev/null
@@ -1,36 +0,0 @@
-Global:
- infer_imgs: "./images/PULC/car_exists/objects365_00001507.jpeg"
- inference_model_dir: "./models/car_exists_infer"
- batch_size: 1
- use_gpu: True
- enable_mkldnn: False
- cpu_num_threads: 10
- enable_benchmark: True
- use_fp16: False
- ir_optim: True
- use_tensorrt: False
- gpu_mem: 8000
- enable_profile: False
-
-PreProcess:
- transform_ops:
- - ResizeImage:
- resize_short: 256
- - CropImage:
- size: 224
- - NormalizeImage:
- scale: 0.00392157
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: ''
- channel_num: 3
- - ToCHWImage:
-
-PostProcess:
- main_indicator: ThreshOutput
- ThreshOutput:
- threshold: 0.5
- label_0: nocar
- label_1: contains_car
- SavePreLabel:
- save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/vehicle_exists/inference_vehicle_exists.yaml b/deploy/configs/PULC/vehicle_exists/inference_vehicle_exists.yaml
deleted file mode 100644
index cdd289dda9960e03a6af956691b3bd73beb6b375..0000000000000000000000000000000000000000
--- a/deploy/configs/PULC/vehicle_exists/inference_vehicle_exists.yaml
+++ /dev/null
@@ -1,36 +0,0 @@
-Global:
- infer_imgs: "./images/PULC/vehicle_exists/objects365_00001507.jpeg"
- inference_model_dir: "./models/vehicle_exists_infer"
- batch_size: 1
- use_gpu: True
- enable_mkldnn: False
- cpu_num_threads: 10
- enable_benchmark: True
- use_fp16: False
- ir_optim: True
- use_tensorrt: False
- gpu_mem: 8000
- enable_profile: False
-
-PreProcess:
- transform_ops:
- - ResizeImage:
- resize_short: 256
- - CropImage:
- size: 224
- - NormalizeImage:
- scale: 0.00392157
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: ''
- channel_num: 3
- - ToCHWImage:
-
-PostProcess:
- main_indicator: ThreshOutput
- ThreshOutput:
- threshold: 0.5
- label_0: no_vehicle
- label_1: contains_vehicle
- SavePreLabel:
- save_dir: ./pre_label/
diff --git a/deploy/images/PULC/vehicle_exists/objects365_00001507.jpeg b/deploy/images/PULC/vehicle_exists/objects365_00001507.jpeg
deleted file mode 100644
index 9959954b6b8bf27589e1d2081f86c6078d16e2c1..0000000000000000000000000000000000000000
Binary files a/deploy/images/PULC/vehicle_exists/objects365_00001507.jpeg and /dev/null differ
diff --git a/deploy/images/PULC/vehicle_exists/objects365_00001521.jpeg b/deploy/images/PULC/vehicle_exists/objects365_00001521.jpeg
deleted file mode 100644
index ea65b3108ec0476ce952b3221c31ac54fcef161d..0000000000000000000000000000000000000000
Binary files a/deploy/images/PULC/vehicle_exists/objects365_00001521.jpeg and /dev/null differ
diff --git a/docs/en/PULC/PULC_model_list_en.md b/docs/en/PULC/PULC_model_list_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..6b287b523ba28dcd329e82e37556e7502733a584
--- /dev/null
+++ b/docs/en/PULC/PULC_model_list_en.md
@@ -0,0 +1,25 @@
+# PULC Model Zoo
+
+------
+
+The PULC model zoo is provided here, mainly providing indicators, model storage size, and download links of the model. The pre-trained model can be used for fine-tuning training, and the inference model can be directly used for prediction and deployment.
+
+
+|Model name| Model Description | Metrics |Storage Size| Latency| Download Address|
+| --- | --- | --- | --- | --- | --- |
+| person_exists |[Human Exists Classification](PULC_person_exists_en.md)| 95.60 |6.5M|2.58ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/person_exists_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/person_exists_pretrained.pdparams)|
+| person_attribute |[Pedestrian Attribute Classification](PULC_person_attribute_en.md)| 78.59 |6.6M|2.01ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/person_attribute_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/person_attribute_pretrained.pdparams)|
+| safety_helmet |[Classification of Wheather Wearing Safety Helmet](PULC_safety_helmet_en.md)| 99.38 |6.5M|2.03ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/safety_helmet_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/safety_helmet_pretrained.pdparams)|
+| traffic_sign |[Traffic Sign Classification](PULC_traffic_sign_en.md)| 98.35 |8.2M|2.10ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/traffic_sign_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/traffic_sign_pretrained.pdparams)|
+| vehicle_attribute |[Vehicle Attribute Classification](PULC_vehicle_attribute_en.md)| 90.81 |7.2M|2.36ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/vehicle_attribute_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/vehicle_attribute_pretrained.pdparams)|
+| car_exists |[Car Exists Classification](PULC_car_exists_en.md) | 95.92 | 6.6M | 2.38ms |[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/car_exists_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/car_exists_pretrained.pdparams)|
+| text_image_orientation |[Text Image Orientation Classification](PULC_text_image_orientation_en.md)| 99.06 | 6.5M | 2.16ms |[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/text_image_orientation_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/text_image_orientation_pretrained.pdparams)|
+| textline_orientation |[Text-line Orientation Classification](PULC_textline_orientation_en.md)| 96.01 |6.5M|2.72ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/textline_orientation_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/textline_orientation_pretrained.pdparams)|
+| language_classification |[Language Classification](PULC_language_classification_en.md)| 99.26 |6.5M|2.58ms|[inference model](https://paddleclas.bj.bcebos.com/models/PULC/inference/language_classification_infer.tar) / [pretrained model](https://paddleclas.bj.bcebos.com/models/PULC/pretrained/language_classification_pretrained.pdparams)|
+
+
+**Note:**
+
+* The backbone of all the above models is PPLCNet_x1_0. The different sizes of some models are caused by the different output sizes of the classification layer. The inference time is tested on the Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz. During the test process, the MKLDNN acceleration strategy is turned on, and the number of threads is 10. There will be slight fluctuations during the speed test process.
+
+* The evaluation indicators of person_exists, safety_helmet, and car_exists are TprAtFpr. The evaluation indicators of person_attribute and vehicle_attribute are ma. The evaluation indicators of traffic_sign, text_image_orientation, textline_orientation and language_classification are Top-1 Acc.
diff --git a/docs/en/PULC/PULC_quickstart_en.md b/docs/en/PULC/PULC_quickstart_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..087c359283c0e288db91bc80774163eda336853b
--- /dev/null
+++ b/docs/en/PULC/PULC_quickstart_en.md
@@ -0,0 +1,123 @@
+# PULC Quick Start
+
+------
+
+This document introduces the prediction using PULC series model based on PaddleClas wheel.
+
+## Catalogue
+
+- [1. Installation](#1)
+ - [1.1 PaddlePaddle Installation](#11)
+ - [1.2 PaddleClas wheel Installation](#12)
+- [2. Quick Start](#2)
+ - [2.1 Predicion with Command Line](#2.1)
+ - [2.2 Predicion with Python](#2.2)
+ - [2.3 Supported Model List](#2.3)
+- [3. Summary](#3)
+
+
+
+## 1. Installation
+
+
+
+### 1.1 PaddlePaddle Installation
+
+- Run the following command to install if CUDA9 or CUDA10 is available.
+
+```bash
+python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
+```
+
+- Run the following command to install if GPU device is unavailable.
+
+```bash
+python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
+```
+
+Please refer to [PaddlePaddle Installation](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/en/install/pip/linux-pip_en.html) for more information about installation, for examples other versions.
+
+
+
+### 1.2 PaddleClas wheel Installation
+
+```bash
+pip3 install paddleclas
+```
+
+
+
+## 2. Quick Start
+
+PaddleClas provides a series of test cases, which contain demos of different scenes about people, cars, OCR, etc. Click [here](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip) to download the data.
+
+
+
+### 2.1 Predicion with Command Line
+
+```
+cd /path/to/pulc_demo_imgs
+```
+
+The prediction command:
+
+```bash
+paddleclas --model_name=person_exists --infer_imgs=pulc_demo_imgs/person_exists/objects365_01780782.jpg
+```
+
+Result:
+
+```
+>>> result
+class_ids: [0], scores: [0.9955421453341842], label_names: ['nobody'], filename: pulc_demo_imgs/person_exists/objects365_01780782.jpg
+Predict complete!
+```
+`Nobody` means there is no one in the image, `someone` means there is someone in the image. Therefore, the prediction result indicates that there is no one in the figure.
+
+**Note**: The "--infer_imgs" argument specify the image(s) to be predict, and you can also specify a directoy contains images. If use other model, you can specify the `--model_name` argument. Please refer to [2.3 Supported Model List](#2.3) for the supported model list.
+
+
+
+### 2.2 Predicion with Python
+
+You can also use in Python:
+
+```python
+import paddleclas
+model = paddleclas.PaddleClas(model_name="person_exists")
+result = model.predict(input_data="pulc_demo_imgs/person_exists/objects365_01780782.jpg")
+print(next(result))
+```
+
+The printed result information:
+
+```
+>>> result
+[{'class_ids': [0], 'scores': [0.9955421453341842], 'label_names': ['nobody'], 'filename': 'pulc_demo_imgs/person_exists/objects365_01780782.jpg'}]
+```
+
+**Note**: `model.predict()` is a generator, so `next()` or `for` is needed to call it. This would to predict by batch that length is `batch_size`, default by 1. You can specify the argument `batch_size` and `model_name` when instantiating PaddleClas object, for example: `model = paddleclas.PaddleClas(model_name="person_exists", batch_size=2)`. Please refer to [2.3 Supported Model List](#2.3) for the supported model list.
+
+
+
+### 2.3 Supported Model List
+
+The name of PULC series models are as follows:
+
+| Name | Intro |
+| --- | --- |
+| person_exists | Human Exists Classification |
+| person_attribute | Pedestrian Attribute Classification |
+| safety_helmet | Classification of Wheather Wearing Safety Helmet |
+| traffic_sign | Traffic Sign Classification |
+| vehicle_attribute | Vehicle Attribute Classification |
+| car_exists | Car Exists Classification |
+| text_image_orientation | Text Image Orientation Classification |
+| textline_orientation | Text-line Orientation Classification |
+| language_classification | Language Classification |
+
+
+
+## 3. Summary
+
+The PULC series models have been verified to be effective in different scenarios about people, vehicles, OCR, etc. The ultra lightweight model can achieve the accuracy close to SwinTransformer model, and the speed is increased by 40+ times. And PULC also provides the whole process of dataset getting, model training, model compression and deployment. Please refer to [Human Exists Classification](PULC_person_exists_en.md)、[Pedestrian Attribute Classification](PULC_person_attribute_en.md)、[Classification of Wheather Wearing Safety Helmet](PULC_safety_helmet_en.md)、[Traffic Sign Classification](PULC_traffic_sign_en.md)、[Vehicle Attribute Classification](PULC_vehicle_attribute_en.md)、[Car Exists Classification](PULC_car_exists_en.md)、[Text Image Orientation Classification](PULC_text_image_orientation_en.md)、[Text-line Orientation Classification](PULC_textline_orientation_en.md)、[Language Classification](PULC_language_classification_en.md) for more information about different scenarios.
diff --git a/docs/en/PULC/PULC_train_en.md b/docs/en/PULC/PULC_train_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..d7d0a1997c7f9473abb647bf9912f977f3c09362
--- /dev/null
+++ b/docs/en/PULC/PULC_train_en.md
@@ -0,0 +1,246 @@
+## Practical Ultra Lightweight Classification scheme PULC
+------
+
+
+## Catalogue
+
+- [1. Introduction of PULC solution](#1)
+- [2. Data preparation](#2)
+ - [2.1 Dataset format description](#2.1)
+ - [2.2 Annotation file generation method](#2.2)
+- [3. Training with standard classification configuration](#3)
+ - [3.1 PP-LCNet as backbone](#3.1)
+ - [3.2 SSLD pretrained model](#3.2)
+ - [3.3 EDA strategy](#3.3)
+ - [3.4 SKL-UGI knowledge distillation](#3.4)
+ - [3.5 Summary](#3.5)
+- [4. Hyperparameter Search](#4)
+ - [4.1 Search based on default configuration](#4.1)
+ - [4.2 Custom search configuration](#4.2)
+
+
+
+### 1. Introduction of PULC solution
+
+Image classification is one of the basic algorithms of computer vision, and it is also the most common algorithm in enterprise applications, and further, it is also an important part of many CV applications. In recent years, the backbone network model has developed rapidly, and the accuracy record of ImageNet has been continuously refreshed. However, the performance of these models in practical scenarios is sometimes unsatisfactory. On the one hand, models with high precision tend to have large storage and slow inference speed, which are often difficult to meet actual deployment requirements; on the other hand, after selecting a suitable model, experienced engineers are often required to adjust parameters, which is time-consuming and labor-intensive. In order to solve the problems of enterprise application and make the training and parameter adjustment of classification models easier, PaddleClas summarized and launched a Practical Ultra Lightweight Classification (PULC) solution. PULC integrates various state-of-the-art algorithms such as backbone network, data augmentation and distillation, etc., and finally can automatically obtain a lightweight and high-precision image classification model.
+
+
+The PULC solution has been verified to be effective in many scenarios, such as human-related scenarios, car-related scenarios, and OCR-related scenarios. With an ultra-lightweight model, the accuracy close to SwinTransformer can be achieved, and the inference speed can be 40+ times faster.
+
+
+
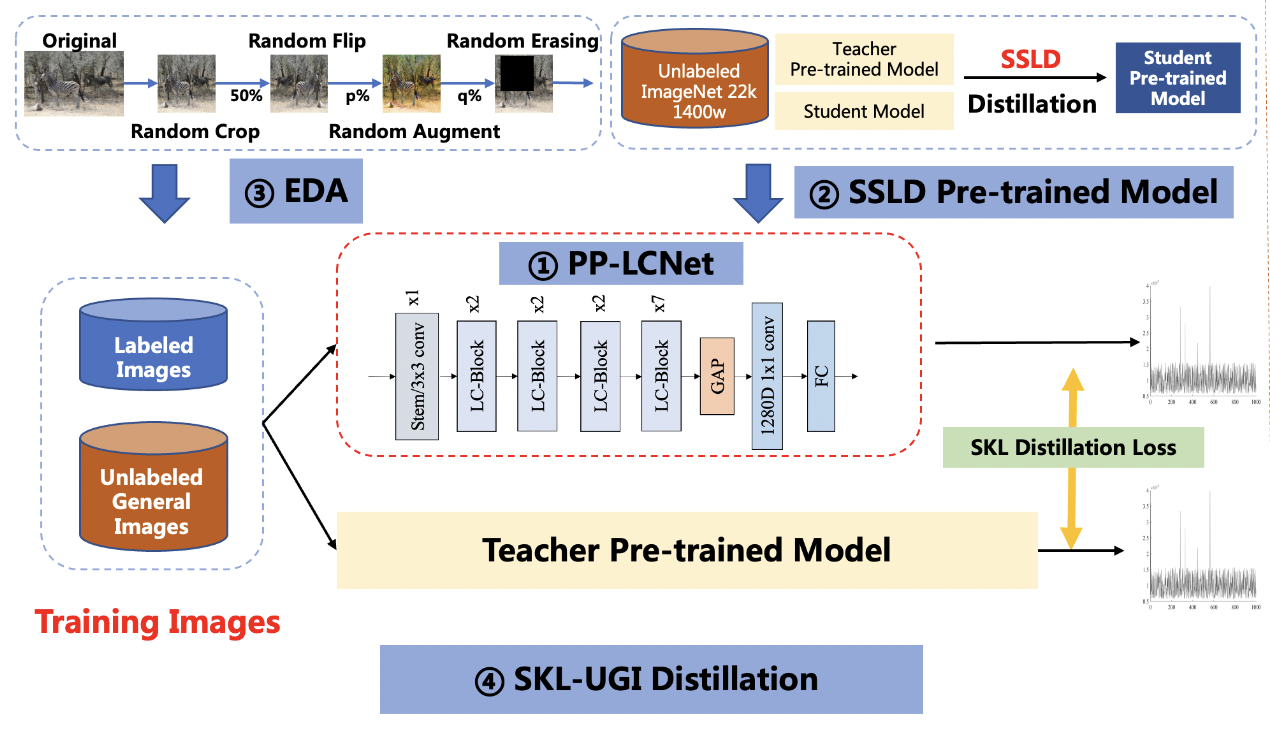
+
+
+The solution mainly includes 4 parts, namely: PP-LCNet lightweight backbone network, SSLD pre-trained model, Ensemble Data Augmentation (EDA) and SKL-UGI knowledge distillation algorithm. In addition, we also adopt the method of hyperparameter search to efficiently optimize the hyperparameters in training. Below, we take the person exists or not scene as an example to illustrate the solution.
+
+**Note**:For some specific scenarios, we provide basic training documents for reference, such as [person exists or not classification model](PULC_person_exists_en.md), etc. You can find these documents [here](./PULC_model_list_en.md). If the methods in these documents do not meet your needs, or if you need a custom training task, you can refer to this document.
+
+
+
+### 2. Data preparation
+
+
+
+#### 2.1 Dataset format description
+
+PaddleClas uses the `txt` format file to specify the training set and validation set. Take the person exists or not scene as an example, you need to specify `train_list.txt` and `val_list.txt` as the data labels of the training set and validation set. The format is in the form of as follows:
+
+```
+# Each line uses "space" to separate the image path and label
+train/1.jpg 0
+train/10.jpg 1
+...
+```
+
+If you want to get more information about common classification datasets, you can refer to the document [PaddleClas Classification Dataset Format Description](../data_preparation/classification_dataset_en.md).
+
+
+
+
+#### 2.2 Annotation file generation method
+
+If you already have the data in the actual scene, you can label it according to the format in the previous section. Here, we provide a script to quickly generate annotation files. You only need to put different categories of data in folders and run the script to generate annotation files.
+
+First, assume that the path where you store the data is `./train`, `train/` contains the data of each category, the category number starts from 0, and the folder of each category contains specific image data.
+
+```shell
+train
+├── 0
+│ ├── 0.jpg
+│ ├── 1.jpg
+│ └── ...
+└── 1
+ ├── 0.jpg
+ ├── 1.jpg
+ └── ...
+└── ...
+```
+
+```shell
+tree -r -i -f train | grep -E "jpg|JPG|jpeg|JPEG|png|PNG" | awk -F "/" '{print $0" "$2}' > train_list.txt
+```
+
+Among them, if more image name suffixes are involved, the content after `grep -E` can be added, and the `2` in `$2` is the level of the category number folder.
+
+**Note:** The above is an introduction to the method of dataset acquisition and generation. Here you can directly download the person exists or not scene data to quickly start the experience.
+
+
+Go to the PaddleClas directory.
+
+```
+cd path_to_PaddleClas
+```
+
+Go to the `dataset/` directory, download and unzip the data.
+
+```shell
+cd dataset
+wget https://paddleclas.bj.bcebos.com/data/PULC/person_exists.tar
+tar -xf person_exists.tar
+cd ../
+```
+
+
+
+### 3. Training with standard classification configuration
+
+
+
+#### 3.1 PP-LCNet as backbone
+
+PULC adopts the lightweight backbone network PP-LCNet, which is 50% faster than other networks with the same accuracy. You can view the detailed introduction of the backbone network in [PP-LCNet Introduction](../models/PP-LCNet_en.md).
+
+The command to train with PP-LCNet is:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0_search.yaml
+```
+
+For performance comparison, we also provide configuration files for the large model SwinTransformer_tiny and the lightweight model MobileNetV3_small_x0_35, which you can train with the command:
+
+SwinTransformer_tiny:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/SwinTransformer_tiny_patch4_window7_224.yaml
+```
+
+MobileNetV3_small_x0_35:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python3 -m paddle.distributed.launch \
+ --gpus="0,1,2,3" \
+ tools/train.py \
+ -c ./ppcls/configs/PULC/person_exists/MobileNetV3_small_x0_35.yaml
+```
+
+
+The accuracy of the trained models is compared in the following table.
+
+| Model | Tpr(%) | Latency(ms) | Storage Size(M) | Strategy |
+|-------|-----------|----------|---------------|---------------|
+| SwinTranformer_tiny | 95.69 | 95.30 | 107 | Use ImageNet pretrained model|
+| MobileNetV3_small_x0_35 | 68.25 | 2.85 | 1.6 | Use ImageNet pretrained model |
+| PPLCNet_x1_0 | 89.57 | 2.12 | 6.5 | Use ImageNet pretrained model |
+
+It can be seen that PP-LCNet is much faster than SwinTransformer, but the accuracy is also slightly lower. Below we improve the accuracy of the PP-LCNet model through a series of optimizations.
+
+
+
+#### 3.2 SSLD pretrained model
+
+SSLD is a semi-supervised distillation algorithm developed by Baidu. On the ImageNet dataset, the model accuracy can be improved by 3-7 points. You can find a detailed introduction in [SSLD introduction](../advanced_tutorials/distillation/distillation_en.md). We found that using SSLD pre-trained weights can effectively improve the accuracy of the applied classification model. In addition, using a smaller resolution in training can effectively improve model accuracy. At the same time, we also optimize the learning rate.
+Based on the above three improvements, the accuracy of our trained model is 92.1%, an increase of 2.6%.
+
+
+
+#### 3.3 EDA strategy
+
+Data augmentation is a commonly used optimization strategy in vision algorithms, which can significantly improve the accuracy of the model. In addition to the traditional RandomCrop, RandomFlip, etc. methods, we also apply RandomAugment and RandomErasing. You can find a detailed introduction at [Data Augmentation Introduction](../advanced_tutorials/DataAugmentation_en.md).
+Since these two kinds of data augmentation greatly modify the picture, making the classification task more difficult, it may lead to under-fitting of the model on some datasets. We will set the probability of enabling these two methods in advance.
+Based on the above improvements, we obtained a model accuracy of 93.43%, an increase of 1.3%.
+
+
+
+#### 3.4 SKL-UGI knowledge distillation
+
+Knowledge distillation is a method that can effectively improve the accuracy of small models. You can find a detailed introduction in [Introduction to Knowledge Distillation](../advanced_tutorials/distillation/distillation_en.md). We choose ResNet101_vd as the teacher model for distillation. In order to adapt to the distillation process, we also adjust the learning rate of different stages of the network here. Based on the above improvements, we trained the model to get a model accuracy of 95.6%, an increase of 1.4%.
+
+
+
+#### 3.5 Summary
+
+After the optimization of the above methods, the final accuracy of PP-LCNet reaches 95.6%, reaching the accuracy level of the large model. We summarize the experimental results in the following table:
+
+| Model | Tpr(%) | Latency(ms) | Storage Size(M) | Strategy |
+|-------|-----------|----------|---------------|---------------|
+| SwinTranformer_tiny | 95.69 | 95.30 | 107 | Use ImageNet pretrained model |
+| MobileNetV3_small_x0_35 | 68.25 | 2.85 | 1.6 | Use ImageNet pretrained model |
+| PPLCNet_x1_0 | 89.57 | 2.12 | 6.5 | Use ImageNet pretrained model |
+| PPLCNet_x1_0 | 92.10 | 2.12 | 6.5 | Use SSLD pretrained model |
+| PPLCNet_x1_0 | 93.43 | 2.12 | 6.5 | Use SSLD pretrained model + EDA Strategy|
+|
PPLCNet_x1_0 | 95.60 | 2.12 | 6.5 | Use SSLD pretrained model + EDA Strategy + SKL-UGI knowledge distillation |
+
+We also used the same optimization strategy in the other 8 scenarios and got the following results:
+
+| scenarios | large model | large model metrics(%) | small model | small model metrics(%) |
+|----------|----------|----------|----------|----------|
+| Pedestrian Attribute Classification | Res2Net200_vd | 81.25 | PPLCNet_x1_0 | 78.59 |
+| Classification of Wheather Wearing Safety Helmet | Res2Net200_vd| 98.92 | PPLCNet_x1_0 |99.38 |
+| Traffic Sign Classification | SwinTransformer_tiny | 98.11 | PPLCNet_x1_0 | 98.35 |
+| Vehicle Attribute Classification | Res2Net200_vd_26w_4s | 91.36 | PPLCNet_x1_0 | 90.81 |
+| Car Exists Classification | SwinTransformer_tiny | 97.71 | PPLCNet_x1_0 | 95.92 |
+| Text Image Orientation Classification | SwinTransformer_tiny |99.12 | PPLCNet_x1_0 | 99.06 |
+| Text-line Orientation Classification | SwinTransformer_tiny | 93.61 | PPLCNet_x1_0 | 96.01 |
+| Language Classification | SwinTransformer_tiny | 98.12 | PPLCNet_x1_0 | 99.26 |
+
+
+It can be seen from the results that the PULC scheme can improve the model accuracy in multiple application scenarios. Using the PULC scheme can greatly reduce the workload of model optimization and quickly obtain models with higher accuracy.
+
+
+
+
+### 4. Hyperparameter Search
+
+In the above training process, we adjusted parameters such as learning rate, data augmentation probability, and stage learning rate mult list. The optimal values of these parameters may not be the same in different scenarios. We provide a quick hyperparameter search script to automate the process of hyperparameter tuning. This script traverses the parameters in the search value list to replace the parameters in the default configuration, then trains in sequence, and finally selects the parameters corresponding to the model with the highest accuracy as the search result.
+
+
+
+#### 4.1 Search based on default configuration
+
+The configuration file [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) defines the configuration of hyperparameter search in person exists or not scenarios. Use the following commands to complete hyperparameter search.
+
+```bash
+python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
+```
+
+**Note**:Regarding the search part, we are also constantly improving, so stay tuned.
+
+
+
+#### 4.2 Custom search configuration
+
+
+You can also modify the configuration of hyperparameter search based on training results or your parameter tuning experience.
+
+Modify the `search_values` field in `lrs` to modify the list of learning rate search values;
+
+Modify the `search_values` field in `resolutions` to modify the search value list of resolutions;
+
+Modify the `search_values` field in `ra_probs` to modify the search value list of RandAugment activation probability;
+
+Modify the `search_values` field in `re_probs` to modify the search value list of RnadomErasing on probability;
+
+Modify the `search_values` field in `lr_mult_list` to modify the lr_mult search value list;
+
+Modify the `search_values` field in `teacher` to modify the search list of the teacher model.
+
+After the search is completed, the final results will be generated in `output/search_person_exists`, where, except for `search_res`, the directories in `output/search_person_exists` are the weights and training log files of the results of the corresponding hyperparameters of each search training, ` search_res` corresponds to the result of knowledge distillation, that is, the final model. The weights of the model are stored in `output/output_dir/search_person_exists/DistillationModel/best_model_student.pdparams`.
diff --git a/docs/en/inference_deployment/whl_deploy_en.md b/docs/en/inference_deployment/whl_deploy_en.md
index 9fd7223274b187ec187ecb4046948c5837c73b59..323a5723a1e0c57c23c6004f48bf294dc4837e6f 100644
--- a/docs/en/inference_deployment/whl_deploy_en.md
+++ b/docs/en/inference_deployment/whl_deploy_en.md
@@ -1,6 +1,6 @@
# PaddleClas wheel package
-Paddleclas supports Python WHL package for prediction. At present, WHL package only supports image classification, but does not support subject detection, feature extraction and vector retrieval.
+PaddleClas supports Python wheel package for prediction. At present, PaddleClas wheel supports image classification including ImagetNet1k models and PULC models, but does not support mainbody detection, feature extraction and vector retrieval.
---
@@ -9,7 +9,7 @@ Paddleclas supports Python WHL package for prediction. At present, WHL package o
- [1. Installation](#1)
- [2. Quick Start](#2)
- [3. Definition of Parameters](#3)
-- [4. Usage](#4)
+- [4. More usage](#4)
- [4.1 View help information](#4.1)
- [4.2 Prediction using inference model provide by PaddleClas](#4.2)
- [4.3 Prediction using local model files](#4.3)
@@ -20,6 +20,7 @@ Paddleclas supports Python WHL package for prediction. At present, WHL package o
- [4.8 Specify the mapping between class id and label name](#4.8)
+
## 1. Installation
* installing from pypi
@@ -36,8 +37,14 @@ pip3 install dist/*
```
+
## 2. Quick Start
-* Using the `ResNet50` model provided by PaddleClas, the following image(`'docs/images/inference_deployment/whl_demo.jpg'`) as an example.
+
+
+
+### 2.1 ImageNet1k models
+
+Using the `ResNet50` model provided by PaddleClas, the following image(`'docs/images/inference_deployment/whl_demo.jpg'`) as an example.

@@ -68,25 +75,89 @@ filename: docs/images/inference_deployment/whl_demo.jpg, top-5, class_ids: [8, 7
Predict complete!
```
+
+
+
+### 2.2 PULC models
+
+PULC integrates various state-of-the-art algorithms such as backbone network, data augmentation and distillation, etc., and finally can automatically obtain a lightweight and high-precision image classification model.
+
+PaddleClas provides a series of test cases, which contain demos of different scenes about people, cars, OCR, etc. Click [here](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip) to download the data.
+
+Prection using the PULC "Human Exists Classification" model provided by PaddleClas:
+
+* Python
+
+```python
+import paddleclas
+model = paddleclas.PaddleClas(model_name="person_exists")
+result = model.predict(input_data="pulc_demo_imgs/person_exists/objects365_01780782.jpg")
+print(next(result))
+```
+
+```
+>>> result
+[{'class_ids': [0], 'scores': [0.9955421453341842], 'label_names': ['nobody'], 'filename': 'pulc_demo_imgs/person_exists/objects365_01780782.jpg'}]
+```
+
+`Nobody` means there is no one in the image, `someone` means there is someone in the image. Therefore, the prediction result indicates that there is no one in the figure.
+
+**Note**: `model.predict()` is a generator, so `next()` or `for` is needed to call it. This would to predict by batch that length is `batch_size`, default by 1. You can specify the argument `batch_size` and `model_name` when instantiating PaddleClas object, for example: `model = paddleclas.PaddleClas(model_name="person_exists", batch_size=2)`. Please refer to [Supported Model List](#PULC_Models) for the supported model list.
+
+* CLI
+
+```bash
+paddleclas --model_name=person_exists --infer_imgs=pulc_demo_imgs/person_exists/objects365_01780782.jpg
+```
+
+```
+>>> result
+class_ids: [0], scores: [0.9955421453341842], label_names: ['nobody'], filename: pulc_demo_imgs/person_exists/objects365_01780782.jpg
+Predict complete!
+```
+
+**Note**: The "--infer_imgs" argument specify the image(s) to be predict, and you can also specify a directoy contains images. If use other model, you can specify the `--model_name` argument. Please refer to [Supported Model List](#PULC_Models) for the supported model list.
+
+
+
+**Supported Model List**
+
+The name of PULC series models are as follows:
+
+| Name | Intro |
+| --- | --- |
+| person_exists | Human Exists Classification |
+| person_attribute | Pedestrian Attribute Classification |
+| safety_helmet | Classification of Wheather Wearing Safety Helmet |
+| traffic_sign | Traffic Sign Classification |
+| vehicle_attribute | Vehicle Attribute Classification |
+| car_exists | Car Exists Classification |
+| text_image_orientation | Text Image Orientation Classification |
+| textline_orientation | Text-line Orientation Classification |
+| language_classification | Language Classification |
+
+Please refer to [Human Exists Classification](../PULC/PULC_person_exists_en.md)、[Pedestrian Attribute Classification](../PULC/PULC_person_attribute_en.md)、[Classification of Wheather Wearing Safety Helmet](../PULC/PULC_safety_helmet_en.md)、[Traffic Sign Classification](../PULC/PULC_traffic_sign_en.md)、[Vehicle Attribute Classification](../PULC/PULC_vehicle_attribute_en.md)、[Car Exists Classification](../PULC/PULC_car_exists_en.md)、[Text Image Orientation Classification](../PULC/PULC_text_image_orientation_en.md)、[Text-line Orientation Classification](../PULC/PULC_textline_orientation_en.md)、[Language Classification](../PULC/PULC_language_classification_en.md) for more information about different scenarios.
+
+
## 3. Definition of Parameters
The following parameters can be specified in Command Line or used as parameters of the constructor when instantiating the PaddleClas object in Python.
* model_name(str): If using inference model based on ImageNet1k provided by Paddle, please specify the model's name by the parameter.
* inference_model_dir(str): Local model files directory, which is valid when `model_name` is not specified. The directory should contain `inference.pdmodel` and `inference.pdiparams`.
* infer_imgs(str): The path of image to be predicted, or the directory containing the image files, or the URL of the image from Internet.
-* use_gpu(bool): Whether to use GPU or not, default by `True`.
-* gpu_mem(int): GPU memory usages,default by `8000`。
-* use_tensorrt(bool): Whether to open TensorRT or not. Using it can greatly promote predict preformance, default by `False`.
-* enable_mkldnn(bool): Whether enable MKLDNN or not, default `False`.
-* cpu_num_threads(int): Assign number of cpu threads, valid when `--use_gpu` is `False` and `--enable_mkldnn` is `True`, default by `10`.
-* batch_size(int): Batch size, default by `1`.
-* resize_short(int): Resize the minima between height and width into `resize_short`, default by `256`.
-* crop_size(int): Center crop image to `crop_size`, default by `224`.
-* topk(int): Print (return) the `topk` prediction results, default by `5`.
-* class_id_map_file(str): The mapping file between class ID and label, default by `ImageNet1K` dataset's mapping.
-* pre_label_image(bool): whether prelabel or not, default=False.
-* save_dir(str): The directory to save the prediction results that can be used as pre-label, default by `None`, that is, not to save.
+* use_gpu(bool): Whether to use GPU or not.
+* gpu_mem(int): GPU memory usages.
+* use_tensorrt(bool): Whether to open TensorRT or not. Using it can greatly promote predict preformance.
+* enable_mkldnn(bool): Whether enable MKLDNN or not.
+* cpu_num_threads(int): Assign number of cpu threads, valid when `--use_gpu` is `False` and `--enable_mkldnn` is `True`.
+* batch_size(int): Batch size.
+* resize_short(int): Resize the minima between height and width into `resize_short`.
+* crop_size(int): Center crop image to `crop_size`.
+* topk(int): Print (return) the `topk` prediction results when Topk postprocess is used.
+* threshold(float): The threshold of ThreshOutput when postprocess is used.
+* class_id_map_file(str): The mapping file between class ID and label.
+* save_dir(str): The directory to save the prediction results that can be used as pre-label.
**Note**: If you want to use `Transformer series models`, such as `DeiT_***_384`, `ViT_***_384`, etc., please pay attention to the input size of model, and need to set `resize_short=384`, `resize=384`. The following is a demo.
@@ -103,6 +174,7 @@ clas = PaddleClas(model_name='ViT_base_patch16_384', resize_short=384, crop_size
```
+
## 4. Usage
PaddleClas provides two ways to use:
@@ -110,6 +182,7 @@ PaddleClas provides two ways to use:
2. Bash command line programming.
+
### 4.1 View help information
* CLI
@@ -118,6 +191,7 @@ paddleclas -h
```
+
### 4.2 Prediction using inference model provide by PaddleClas
You can use the inference model provided by PaddleClas to predict, and only need to specify `model_name`. In this case, PaddleClas will automatically download files of specified model and save them in the directory `~/.paddleclas/`.
@@ -136,6 +210,7 @@ paddleclas --model_name='ResNet50' --infer_imgs='docs/images/inference_deploymen
```
+
### 4.3 Prediction using local model files
You can use the local model files trained by yourself to predict, and only need to specify `inference_model_dir`. Note that the directory must contain `inference.pdmodel` and `inference.pdiparams`.
@@ -154,6 +229,7 @@ paddleclas --inference_model_dir='./inference/' --infer_imgs='docs/images/infere
```
+
### 4.4 Prediction by batch
You can predict by batch, only need to specify `batch_size` when `infer_imgs` is direcotry contain image files.
@@ -173,6 +249,7 @@ paddleclas --model_name='ResNet50' --infer_imgs='docs/images/' --batch_size 2
```
+
### 4.5 Prediction of Internet image
You can predict the Internet image, only need to specify URL of Internet image by `infer_imgs`. In this case, the image file will be downloaded and saved in the directory `~/.paddleclas/images/`.
@@ -191,6 +268,7 @@ paddleclas --model_name='ResNet50' --infer_imgs='https://raw.githubusercontent.c
```
+
### 4.6 Prediction of NumPy.array format image
In Python code, you can predict the `NumPy.array` format image, only need to use the `infer_imgs` to transfer variable of image data. Note that the models in PaddleClas only support to predict 3 channels image data, and channels order is `RGB`.
@@ -205,6 +283,7 @@ print(next(result))
```
+
### 4.7 Save the prediction result(s)
You can save the prediction result(s) as pre-label, only need to use `pre_label_out_dir` to specify the directory to save.
@@ -223,6 +302,7 @@ paddleclas --model_name='ResNet50' --infer_imgs='docs/images/' --save_dir='./out
```
+
### 4.8 Specify the mapping between class id and label name
You can specify the mapping between class id and label name, only need to use `class_id_map_file` to specify the mapping file. PaddleClas uses ImageNet1K's mapping by default.
diff --git a/docs/images/PULC/docs/safety_helmet_data_demo.jpg b/docs/images/PULC/docs/safety_helmet_data_demo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..70bd2d952fd20e6f8fe39182914e400177d913c4
Binary files /dev/null and b/docs/images/PULC/docs/safety_helmet_data_demo.jpg differ
diff --git a/docs/images/PULC/docs/safety_helmet_data_demo.png b/docs/images/PULC/docs/safety_helmet_data_demo.png
deleted file mode 100644
index 8e2f1c4afe460bf2e0867c3bd35dc22fd3211293..0000000000000000000000000000000000000000
Binary files a/docs/images/PULC/docs/safety_helmet_data_demo.png and /dev/null differ
diff --git a/docs/zh_CN/PULC/PULC_car_exists.md b/docs/zh_CN/PULC/PULC_car_exists.md
index 7d76bc1c684e9cdd346dc608613b3945d158cf69..1dc9bb180719609ff6bd4dbf0b502a838c45bdda 100644
--- a/docs/zh_CN/PULC/PULC_car_exists.md
+++ b/docs/zh_CN/PULC/PULC_car_exists.md
@@ -1,4 +1,4 @@
-# PULC 有人/无人分类模型
+# PULC 有车/无车分类模型
------
@@ -40,7 +40,7 @@
## 1. 模型和应用场景介绍
-该案例提供了用户使用 PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight Classification)快速构建轻量级、高精度、可落地的有人/无人的分类模型。该模型可以广泛应用于如监控场景、人员进出管控场景、海量数据过滤场景等。
+该案例提供了用户使用 PaddleClas 的超轻量图像分类方案(PULC,Practical Ultra Lightweight Classification)快速构建轻量级、高精度、可落地的有车/无车的分类模型。该模型可以广泛应用于如监控场景、海量数据过滤场景等。
下表列出了判断图片中是否有车的二分类模型的相关指标,前两行展现了使用 SwinTranformer_tiny 和 MobileNetV3_small_x0_35 作为 backbone 训练得到的模型的相关指标,第三行至第六行依次展现了替换 backbone 为 PPLCNet_x1_0、使用 SSLD 预训练模型、使用 SSLD 预训练模型 + EDA 策略、使用 SSLD 预训练模型 + EDA 策略 + SKL-UGI 知识蒸馏策略训练得到的模型的相关指标。
@@ -58,7 +58,7 @@
**备注:**
-* `Tpr`指标的介绍可以参考 [3.2 小节](#3.2)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
+* `Tpr`指标的介绍可以参考 [3.3节](#3.3)的备注部分,延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -160,7 +160,7 @@ print(next(result))
- 训练集合,本案例处理了 Objects365 数据训练集的标注文件,如果某张图含有“car”的标签,且这个框的面积在整张图中的比例大于 10%,即认为该张图中含有车,如果某张图中没有任何与交通工具,例如car、bus等相关的的标签,则认为该张图中不含有车。经过处理后,得到 108629 条可用数据,其中有车的数据有 27422 条,无车的数据 81207 条。
-- 验证集合,处理方法与训练集相同,数据来源与 Objects365 数据集的验证集。为了测试结果准确,验证集经过人工校正,去除了一些可能存在标注错误的图像。
+- 验证集合,处理方法与训练集相同,数据来源于 Objects365 数据集的验证集。为了测试结果准确,验证集经过人工校正,去除了一些可能存在标注错误的图像。
* 注:由于objects365的标签并不是完全互斥的,例如F1赛车可能是 "F1 Formula",也可能被标称"car"。为了减轻干扰,我们仅保留"car"标签作为有车,而将不含任何交通工具的图作为无车。
@@ -265,7 +265,7 @@ python3 tools/infer.py \
输出结果如下:
```
-[{'class_ids': [1], 'scores': [0.9871138], 'label_names': ['contains_vehicle'], 'filename': 'deploy/images/PULC/car_exists/objects365_00001507.jpeg'}]
+[{'class_ids': [1], 'scores': [0.9871138], 'label_names': ['contains_car'], 'filename': 'deploy/images/PULC/car_exists/objects365_00001507.jpeg'}]
```
**备注:**
@@ -274,7 +274,7 @@ python3 tools/infer.py \
* 默认是对 `deploy/images/PULC/car_exists/objects365_00001507.jpeg` 进行预测,此处也可以通过增加字段 `-o Infer.infer_imgs=xxx` 对其他图片预测。
-* 二分类默认的阈值为0.5, 如果需要指定阈值,可以重写 `Infer.PostProcess.threshold` ,如`-o Infer.PostProcess.threshold=0.9794`,该值需要根据实际场景来确定,此处的 `0.9794` 是在该场景中的 `val` 数据集在千分之一 Fpr 下得到的最佳 Tpr 所得到的。
+* 二分类默认的阈值为0.5, 如果需要指定阈值,可以重写 `Infer.PostProcess.threshold` ,如`-o Infer.PostProcess.threshold=0.9794`,该值需要根据实际场景来确定,此处的 `0.9794` 是在该场景中的 `val` 数据集在百分之一 Fpr 下得到的最佳 Tpr 所得到的。
@@ -326,7 +326,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
@@ -417,7 +417,7 @@ objects365_00001507.jpeg: class id(s): [1], score(s): [0.99], label_name(s
```
-**备注:** 二分类默认的阈值为0.5, 如果需要指定阈值,可以重写 `Infer.PostProcess.threshold` ,如`-o Infer.PostProcess.threshold=0.9794`,该值需要根据实际场景来确定,此处的 `0.9794` 是在该场景中的 `val` 数据集在千分之一 Fpr 下得到的最佳 Tpr 所得到的。该阈值的确定方法可以参考[3.3节](#3.3)备注部分。
+**备注:** 二分类默认的阈值为0.5, 如果需要指定阈值,可以重写 `Infer.PostProcess.threshold` ,如`-o Infer.PostProcess.threshold=0.9794`,该值需要根据实际场景来确定,此处的 `0.9794` 是在该场景中的 `val` 数据集在百分之一 Fpr 下得到的最佳 Tpr 所得到的。该阈值的确定方法可以参考[3.3节](#3.3)备注部分。
diff --git a/docs/zh_CN/PULC/PULC_person_exists.md b/docs/zh_CN/PULC/PULC_person_exists.md
index fd6963b9d2b48cd04f4f3241f6b030f6cfded58b..6a091315545f34dc01bc2d28dbb8459e135c8886 100644
--- a/docs/zh_CN/PULC/PULC_person_exists.md
+++ b/docs/zh_CN/PULC/PULC_person_exists.md
@@ -261,7 +261,7 @@ python3 tools/eval.py \
```python
python3 tools/infer.py \
-c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
- -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
+ -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
```
输出结果如下:
@@ -328,7 +328,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
diff --git a/docs/zh_CN/PULC/PULC_quickstart.md b/docs/zh_CN/PULC/PULC_quickstart.md
index 07dcb030637961f931d98e181fe6e3eaf92b88aa..c7c6980625d6325bddbd5a6fed619147534c43b7 100644
--- a/docs/zh_CN/PULC/PULC_quickstart.md
+++ b/docs/zh_CN/PULC/PULC_quickstart.md
@@ -2,7 +2,7 @@
------
-本文主要介绍PaddleClas whl包对 PULC 系列模型的快速使用。
+本文主要介绍通过 PaddleClas whl 包,使用 PULC 系列模型进行预测。
## 目录
@@ -49,9 +49,7 @@ pip3 install paddleclas
## 2. 快速体验
-PaddleClas 提供了一系列测试图片,里边包含人、车、OCR等方向的多个场景大的demo数据。点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载并解压,然后在终端中切换到相应目录。
-
-
+PaddleClas 提供了一系列测试图片,里边包含人、车、OCR等方向的多个场景的demo数据。点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载并解压,然后在终端中切换到相应目录。
@@ -125,7 +123,3 @@ PULC 系列模型的名称和简介如下:
通过本节内容,相信您已经熟练掌握 PaddleClas whl 包的 PULC 模型使用方法并获得了初步效果。
PULC 方法产出的系列模型在人、车、OCR等方向的多个场景中均验证有效,用超轻量模型就可实现与 SwinTransformer 模型接近的精度,预测速度提高 40+ 倍。并且打通数据、模型训练、压缩和推理部署全流程,具体地,您可以参考[PULC有人/无人分类模型](PULC_person_exists.md)、[PULC人体属性识别模型](PULC_person_attribute.md)、[PULC佩戴安全帽分类模型](PULC_safety_helmet.md)、[PULC交通标志分类模型](PULC_traffic_sign.md)、[PULC车辆属性识别模型](PULC_vehicle_attribute.md)、[PULC有车/无车分类模型](PULC_car_exists.md)、[PULC含文字图像方向分类模型](PULC_text_image_orientation.md)、[PULC文本行方向分类模型](PULC_textline_orientation.md)、[PULC语种分类模型](PULC_language_classification.md)。
-
-
-
-
diff --git a/docs/zh_CN/PULC/PULC_safety_helmet.md b/docs/zh_CN/PULC/PULC_safety_helmet.md
index a7f348beb1e38aeada6d1235b270dbc1843d3753..dd8ae93896986924ae234da30ef90ce33fd9c95f 100644
--- a/docs/zh_CN/PULC/PULC_safety_helmet.md
+++ b/docs/zh_CN/PULC/PULC_safety_helmet.md
@@ -165,7 +165,7 @@ print(next(result))
处理后的数据集部分数据可视化如下:
-
+
此处提供了经过上述方法处理好的数据,可以直接下载得到。
@@ -217,7 +217,7 @@ python3 -m paddle.distributed.launch \
-c ./ppcls/configs/PULC/safety_helmet/PPLCNet_x1_0.yaml
```
-验证集的最佳指标在 `0.975-0.985` 之间(数据集较小,容易造成波动)。
+验证集的最佳指标在 `0.985-0.993` 之间(数据集较小,容易造成波动)。
**备注:**
diff --git a/docs/zh_CN/PULC/PULC_textline_orientation.md b/docs/zh_CN/PULC/PULC_textline_orientation.md
index f443b5f34a9729c4d9a8e97f7a7bbbca3159e1a1..c2d84b8b4e9cc8c4ee152d6dbf95887884074383 100644
--- a/docs/zh_CN/PULC/PULC_textline_orientation.md
+++ b/docs/zh_CN/PULC/PULC_textline_orientation.md
@@ -55,11 +55,11 @@
| PPLCNet_x1_0** | 96.01 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略|
| PPLCNet_x1_0** | 95.86 | 2.72 | 6.5 | 使用 SSLD 预训练模型+EDA 策略+SKL-UGI 知识蒸馏策略|
-从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5%(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05% ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 SwinTranformer_tiny 时精度较高,但是推理速度较慢。将 backboone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,精度下降也比较明显。将 backbone 替换为 PPLCNet_x1_0 时,精度较 MobileNetV3_small_x0_35 高 8.6 个百分点,速度快10%左右。在此基础上,更改分辨率和stride, 速度变慢 27%,但是精度可以提升 4.5 个百分点(采用[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)的方案),使用 SSLD 预训练模型后,精度可以继续提升约 0.05 个百分点 ,进一步地,当融合EDA策略后,精度可以再提升 1.9 个百分点。最后,融合SKL-UGI 知识蒸馏策略后,在该场景无效。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
-* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[SHAS 超参数搜索策略](#TODO)搜索得到的。
+* 其中不带\*的模型表示分辨率为224x224,带\*的模型表示分辨率为48x192(h\*w),数据增强从网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,该策略为 [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) 提供的文本行方向分类器方案。带\*\*的模型表示分辨率为80x160(h\*w), 网络中的 stride 改为 `[2, [2, 1], [2, 1], [2, 1], [2, 1]]`,其中,外层列表中的每一个元素代表网络结构下采样层的stride,此分辨率是经过[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)搜索得到的。
* 延时是基于 Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 测试得到,开启 MKLDNN 加速策略,线程数为10。
* 关于PP-LCNet的介绍可以参考[PP-LCNet介绍](../models/PP-LCNet.md),相关论文可以查阅[PP-LCNet paper](https://arxiv.org/abs/2109.15099)。
@@ -116,7 +116,6 @@ Predict complete!
**备注**: 更换其他预测的数据时,只需要改变 `--infer_imgs=xx` 中的字段即可,支持传入整个文件夹。
-
* 在 Python 代码中预测
```python
import paddleclas
@@ -140,7 +139,7 @@ print(next(result))
### 3.1 环境配置
-* 安装:请先参考 [Paddle 安装教程](../installation/install_paddle.md) 以及 [PaddleClas 安装教程](../installation/install_paddleclas.md) 配置 PaddleClas 运行环境。
+* 安装:请先参考文档 [环境准备](../installation/install_paddleclas.md) 配置 PaddleClas 运行环境。
@@ -168,17 +167,15 @@ print(next(result))

-
此处提供了经过上述方法处理好的数据,可以直接下载得到。
-
进入 PaddleClas 目录。
```
cd path_to_PaddleClas
```
-进入 `dataset/` 目录,下载并解压有人/无人场景的数据。
+进入 `dataset/` 目录,下载并解压文本行方向分类场景的数据。
```shell
cd dataset
@@ -190,7 +187,6 @@ cd ../
执行上述命令后,`dataset/` 下存在 `textline_orientation` 目录,该目录中具有以下数据:
```
-
├── 0
│ ├── img_0.jpg
│ ├── img_1.jpg
@@ -253,7 +249,7 @@ python3 tools/eval.py \
```python
python3 tools/infer.py \
-c ./ppcls/configs/PULC/textline_orientation/PPLCNet_x1_0.yaml \
- -o Global.pretrained_model=output/PPLCNet_x1_0/best_model \
+ -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
```
输出结果如下:
@@ -318,7 +314,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。
diff --git a/docs/zh_CN/PULC/PULC_train.md b/docs/zh_CN/PULC/PULC_train.md
index 66a03cb387776f8a30b6e5cc6f62813cbf1647d8..035535c7f9eb04af952c628fca85cedaaffc97b8 100644
--- a/docs/zh_CN/PULC/PULC_train.md
+++ b/docs/zh_CN/PULC/PULC_train.md
@@ -212,7 +212,7 @@ SSLD 是百度自研的半监督蒸馏算法,在 ImageNet 数据集上,模
#### 4.1 基于默认配置搜索
-配置文件 [search.yaml](../../ppcls/configs/PULC/person_exists/search.yaml) 定义了有人/无人场景超参搜索的配置,使用如下命令即可完成超参数的搜索。
+配置文件 [search.yaml](../../../ppcls/configs/PULC/person_exists/search.yaml) 定义了有人/无人场景超参搜索的配置,使用如下命令即可完成超参数的搜索。
```bash
python3 tools/search_strategy.py -c ppcls/configs/PULC/person_exists/search.yaml
diff --git a/docs/zh_CN/PULC/PULC_vehicle_attribute.md b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
index 2469aa440f856355128fb557aa8a21503dce9519..cd508934e66eb2a00e17d237cd24cb232d13e09b 100644
--- a/docs/zh_CN/PULC/PULC_vehicle_attribute.md
+++ b/docs/zh_CN/PULC/PULC_vehicle_attribute.md
@@ -55,7 +55,7 @@
| PPLCNet_x1_0 | 90.59 | 2.36 | 7.2 | 使用SSLD预训练模型+EDA策略|
| PPLCNet_x1_0 | 90.81 | 2.36 | 8.2 | 使用SSLD预训练模型+EDA策略+SKL-UGI知识蒸馏策略|
-从表中可以看出,backbone 为 Res2Net200_vd_26w_4s 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度下降明显。将 backbone 替换为 PPLCNet_x1_0 时,精度提升 2.16%,同时速度也提升 23% 左右。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.5%,进一步地,当融合EDA策略后,精度可以再提升 0.52%,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.23%。此时,PPLCNet_x1_0 的精度与 Res2Net200_vd_26w_4s 仅相差0.55%,但是速度快32倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
+从表中可以看出,backbone 为 Res2Net200_vd_26w_4s 时精度较高,但是推理速度较慢。将 backbone 替换为轻量级模型 MobileNetV3_small_x0_35 后,速度可以大幅提升,但是精度下降明显。将 backbone 替换为 PPLCNet_x1_0 时,精度提升 2 个百分点,同时速度也提升 23% 左右。在此基础上,使用 SSLD 预训练模型后,在不改变推理速度的前提下,精度可以提升约 0.5 个百分点,进一步地,当融合EDA策略后,精度可以再提升 0.52 个百分点,最后,在使用 SKL-UGI 知识蒸馏后,精度可以继续提升 0.23 个百分点。此时,PPLCNet_x1_0 的精度与 Res2Net200_vd_26w_4s 仅相差 0.55 个百分点,但是速度快 32 倍。关于 PULC 的训练方法和推理部署方法将在下面详细介绍。
**备注:**
@@ -67,9 +67,9 @@
## 2. 模型快速体验
-
+
### 2.1 安装 paddlepaddle
-
+
- 您的机器安装的是 CUDA9 或 CUDA10,请运行以下命令安装
```bash
@@ -81,23 +81,23 @@ python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
```bash
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
```
-
+
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
+
-
+
### 2.2 安装 paddleclas
使用如下命令快速安装 paddleclas
```
pip3 install paddleclas
-```
-
+```
+
### 2.3 预测
-
+
点击[这里](https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip)下载 demo 数据并解压,然后在终端中切换到相应目录。
* 使用命令行快速预测
@@ -337,7 +337,7 @@ python3 -m paddle.distributed.launch \
## 5. 超参搜索
-在 [3.2 节](#3.2)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
+在 [3.3 节](#3.3)和 [4.1 节](#4.1)所使用的超参数是根据 PaddleClas 提供的 `SHAS 超参数搜索策略` 搜索得到的,如果希望在自己的数据集上得到更好的结果,可以参考[SHAS 超参数搜索策略](PULC_train.md#4-超参搜索)来获得更好的训练超参数。
**备注:** 此部分内容是可选内容,搜索过程需要较长的时间,您可以根据自己的硬件情况来选择执行。如果没有更换数据集,可以忽略此节内容。
@@ -368,10 +368,10 @@ python3 tools/export_model.py \
执行完该脚本后会在 `deploy/models/` 下生成 `PPLCNet_x1_0_vehicle_attributeibute_infer` 文件夹,`models` 文件夹下应有如下文件结构:
```
-├── PPLCNet_x1_0_vehicle_attribute_infer
-│ ├── inference.pdiparams
-│ ├── inference.pdiparams.info
-│ └── inference.pdmodel
+└── PPLCNet_x1_0_vehicle_attribute_infer
+ ├── inference.pdiparams
+ ├── inference.pdiparams.info
+ └── inference.pdmodel
```
**备注:** 此处的最佳权重是经过知识蒸馏后的权重路径,如果没有执行知识蒸馏的步骤,最佳模型保存在`output/PPLCNet_x1_0/best_model.pdparams`中。
diff --git a/docs/zh_CN/advanced_tutorials/ssld.md b/docs/zh_CN/advanced_tutorials/ssld.md
index a2ab670cc013238f73f4375ded878d2c1548dadf..e19a98cbc866bc02f0ca9df6d8e939b3342663f5 100644
--- a/docs/zh_CN/advanced_tutorials/ssld.md
+++ b/docs/zh_CN/advanced_tutorials/ssld.md
@@ -6,7 +6,7 @@
- [1. 算法介绍](#1)
- [1.1 知识蒸馏简介](#1.1)
- [1.2 SSLD蒸馏策略](#1.2)
- - [1.2 SKL-UGI蒸馏策略](#1.3)
+ - [1.3 SKL-UGI蒸馏策略](#1.3)
- [2. SSLD预训练模型库](#2)
- [3. SSLD使用](#3)
- [3.1 加载SSLD模型进行微调](#3.1)
@@ -19,6 +19,8 @@
## 1. 算法介绍
+
+
### 1.1 简介
PaddleClas 融合已有的知识蒸馏方法 [2,3],提供了一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation),基于 ImageNet1k 分类数据集,在 ResNet_vd 以及 MobileNet 系列上的精度均有超过 3% 的绝对精度提升,具体指标如下图所示。
@@ -27,6 +29,8 @@ PaddleClas 融合已有的知识蒸馏方法 [2,3],提供了一种简单的半

+ -
-PULC实用图像分类模型效果展示
+
-
-PULC实用图像分类模型效果展示
+ -
-PP-ShiTu图像识别系统效果展示
+
-
-PP-ShiTu图像识别系统效果展示
+ +
+ -
- +
+