Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
770bde53
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
770bde53
编写于
1月 27, 2022
作者:
D
dongshuilong
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
fix bugs and update readme for ppshitu_lite
上级
1e2af322
变更
4
显示空白变更内容
内联
并排
Showing
4 changed file
with
31 addition
and
121 deletion
+31
-121
deploy/lite_shitu/README.md
deploy/lite_shitu/README.md
+24
-113
deploy/lite_shitu/images/demo.jpg
deploy/lite_shitu/images/demo.jpg
+0
-0
deploy/lite_shitu/src/main.cc
deploy/lite_shitu/src/main.cc
+7
-8
docs/images/ppshitu_lite_demo.png
docs/images/ppshitu_lite_demo.png
+0
-0
未找到文件。
deploy/lite_shitu/README.md
浏览文件 @
770bde53
...
@@ -75,113 +75,24 @@ inference_lite_lib.android.armv8/
...
@@ -75,113 +75,24 @@ inference_lite_lib.android.armv8/
## 2 开始运行
## 2 开始运行
### 2.1 模型
优化
### 2.1 模型
准备
Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括量化、子图融合、混合调度、Kernel优选等方法,使用Paddle-Lite的
`opt`
工具可以自动对inference模型进行优化,目前支持两种优化方式,优化后的模型更轻量,模型运行速度更快。
**注意**
:如果已经准备好了
`.nb`
结尾的模型文件,可以跳过此步骤。
#### 2.1.1 模型准备
#### 2.1.1 安装paddle_lite_opt工具
安装
`paddle_lite_opt`
工具有如下两种方法:
1.
[
**建议**
]pip安装paddlelite并进行转换
```
shell
pip
install
paddlelite
==
2.10rc
```
2.
源码编译Paddle-Lite生成
`paddle_lite_opt`
工具
模型优化需要Paddle-Lite的`opt`可执行文件,可以通过编译Paddle-Lite源码获得,编译步骤如下:
```shell
# 如果准备环境时已经clone了Paddle-Lite,则不用重新clone Paddle-Lite
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
git checkout develop
# 启动编译
./lite/tools/build.sh build_optimize_tool
```
编译完成后,`opt`文件位于`build.opt/lite/api/`下,可通过如下方式查看`opt`的运行选项和使用方式;
```shell
cd build.opt/lite/api/
./opt
```
`opt`的使用方式与参数与上面的`paddle_lite_opt`完全一致。
之后使用
`paddle_lite_opt`
工具可以进行inference模型的转换。
`paddle_lite_opt`
的部分参数如下:
|选项|说明|
|-|-|
|--model_file|待优化的PaddlePaddle模型(combined形式)的网络结构文件路径|
|--param_file|待优化的PaddlePaddle模型(combined形式)的权重文件路径|
|--optimize_out_type|输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现,默认为naive_buffer|
|--optimize_out|优化模型的输出路径|
|--valid_targets|指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm|
更详细的
`paddle_lite_opt`
工具使用说明请参考
[
使用opt转化模型文档
](
https://paddle-lite.readthedocs.io/zh/latest/user_guides/opt/opt_bin.html
)
`--model_file`
表示inference模型的model文件地址,
`--param_file`
表示inference模型的param文件地址;
`optimize_out`
用于指定输出文件的名称(不需要添加
`.nb`
的后缀)。直接在命令行中运行
`paddle_lite_opt`
,也可以查看所有参数及其说明。
#### 2.1.3 转换示例
下面介绍使用
`paddle_lite_opt`
完成主体检测模型和识别模型的预训练模型,转成inference模型,最终转换成Paddle-Lite的优化模型的过程。
##### 2.1.3.1 转换主体检测模型
```
shell
```
shell
# 当前目录为 $PaddleClas/deploy/lite_shitu
# 进入lite_ppshitu目录
# $code_path需替换成相应的运行目录,可以根据需要,将$code_path设置成需要的目录
export
$code_path
=
~
cd
$code_path
git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 进入PaddleDetection根目录
cd
PaddleDetection
# 将预训练模型导出为inference模型
python tools/export_model.py
-c
configs/picodet/application/mainbody_detection/picodet_lcnet_x2_5_640_mainbody.yml
-o
weights
=
https://paddledet.bj.bcebos.com/models/picodet_lcnet_x2_5_640_mainbody.pdparams
--output_dir
=
inference
# 将inference模型转化为Paddle-Lite优化模型
paddle_lite_opt
--model_file
=
inference/picodet_lcnet_x2_5_640_mainbody/model.pdmodel
--param_file
=
inference/picodet_lcnet_x2_5_640_mainbody/model.pdiparams
--optimize_out
=
inference/picodet_lcnet_x2_5_640_mainbody/mainbody_det
# 将转好的模型复制到lite_shitu目录下
cd
$PaddleClas
/deploy/lite_shitu
cd
$PaddleClas
/deploy/lite_shitu
mkdir
models
wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/lite/ppshitu_lite_models_v1.0.tar
cp
$code_path
/PaddleDetection/inference/picodet_lcnet_x2_5_640_mainbody/mainbody_det.nb
$PaddleClas
/deploy/lite_shitu/models
tar
-xf
ppshitu_lite_models_v1.0.tar
```
rm
-f
ppshitu_lite_models_v1.0.tar
##### 2.1.3.2 转换识别模型
```
shell
# 转换inference model
待补充,生成的inference model存储在PaddleClas/inference下,同时生成label.txt,也存在此文件夹下
# 转换为Paddle-Lite模型
paddle_lite_opt
--model_file
=
inference/inference.pdmodel
--param_file
=
inference/inference.pdiparams
--optimize_out
=
inference/rec
# 将模型、label文件拷贝到lite_shitu下
cp
inference/rec.nb deploy/lite_shitu/models/
cp
inference/label.txt deploy/lite_shitu/models/
cd
deploy/lite_shitu
```
```
**注意**
:
`--optimize_out`
参数为优化后模型的保存路径,无需加后缀
`.nb`
;
`--model_file`
参数为模型结构信息文件的路径,
`--param_file`
参数为模型权重信息文件的路径,请注意文件名。
#### 2.1.2将yaml文件转换成json文件
##### 2.1.3.3 准备测试图像
```
shell
mkdir
images
# 根据需要准备测试图像,可以在images文件夹中存放多张图像
cp
../images/wangzai.jpg images/
```
##### 2.1.3.4 将yaml文件转换成json文件
```
shell
```
shell
# 如果测试单张图像
# 如果测试单张图像
python generate_json_config.py
--det_model_path
models/mainbody_det.nb
--rec_model_path
models/rec.nb
--rec_label_path
models/label.txt
--img_path
images/wangzai
.jpg
python generate_json_config.py
--det_model_path
ppshitu_lite_models_v1.0/mainbody_PPLCNet_x2_5_640_v1.0_lite.nb
--rec_model_path
ppshitu_lite_models_v1.0/general_PPLCNet_x2_5_quant_v1.0_lite.nb
--rec_label_path
ppshitu_lite_models_v1.0/label.txt
--img_path
images/demo
.jpg
# or
# or
# 如果测试多张图像
# 如果测试多张图像
python generate_json_config.py
--det_model_path
models/mainbody_det.nb
--rec_model_path
models/rec.nb
--rec_label_path
models/label.txt
--img_dir
images
python generate_json_config.py
--det_model_path
models/mainbody_det.nb
--rec_model_path
models/rec.nb
--rec_label_path
models/label.txt
--img_dir
images
...
@@ -225,12 +136,11 @@ List of devices attached
...
@@ -225,12 +136,11 @@ List of devices attached
```
shell
```
shell
cd
$PaddleClas
/deploy/lite_shitu
cd
$PaddleClas
/deploy/lite_shitu
# ${lite prediction library path}下载的Paddle-Lite库路径
inference_lite_path
=
/
{
lite prediction library path
}
/inference_lite_lib.android.armv8.gcc.c++_static.with_extra.with_cv/
inference_lite_path
=
$
{
lite
prediction library path
}
/inference_lite_lib.android.armv8.gcc.c++_static.with_extra.with_cv/
mkdir
$inference_lite_path
/demo/cxx/ppshitu_lite
mkdir
$inference_lite_path
/demo/cxx/ppshitu_lite
cp
-r
Makefile src/ include/
*
.json models/ images/
$inference_lite_path
/demo/cxx/ppshitu_lite
cp
-r
*
$inference_lite_path
/demo/cxx/ppshitu_lite
cd
$inference_lite_path
/demo/cxx/ppshitu_lite
cd
$inference_lite_path
/demo/cxx/ppshitu_lite
# 执行编译,等待完成后得到可执行文件main
# 执行编译,等待完成后得到可执行文件main
...
@@ -242,24 +152,25 @@ make ARM_ABI=arm8
...
@@ -242,24 +152,25 @@ make ARM_ABI=arm8
```
shell
```
shell
mkdir
deploy
mkdir
deploy
mv
models
deploy/
mv
ppshitu_lite_models_v1.0
deploy/
mv
images deploy/
mv
images deploy/
mv
shitu_config.json deploy/
cp
pp_shitu deploy/
cp
pp_shitu deploy/
cd
deploy
# 将C++预测动态库so文件复制到deploy文件夹中
# 将C++预测动态库so文件复制到deploy文件夹中
cp
../../../cxx/lib/libpaddle_light_api_shared.so
.
/
cp
../../../cxx/lib/libpaddle_light_api_shared.so
deploy
/
```
```
执行完成后,deploy文件夹下将有如下文件格式:
执行完成后,deploy文件夹下将有如下文件格式:
```
```
shell
deploy/
deploy/
|--
models
/
|--
ppshitu_lite_models_v1.0
/
| |--mainbody_
det.nb
优化后的主体检测模型文件
| |--mainbody_
PPLCNet_x2_5_640_v1.0_lite.nb
优化后的主体检测模型文件
| |--
rec.nb
优化后的识别模型文件
| |--
general_PPLCNet_x2_5_quant_v1.0_lite.nb
优化后的识别模型文件
| |--label.txt 识别模型的label文件
| |--label.txt 识别模型的label文件
|-- images/
|-- images/
| |--demo.jpg 图片文件
| ... 图片文件
| ... 图片文件
|-- pp_shitu 生成的移动端执行文件
|-- pp_shitu 生成的移动端执行文件
|-- shitu_config.json 执行时参数配置文件
|-- shitu_config.json 执行时参数配置文件
...
...
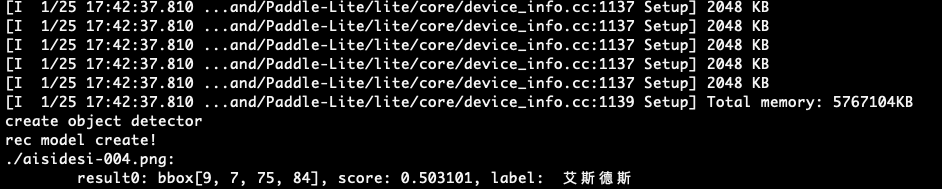
deploy/lite_shitu/images/demo.jpg
0 → 100644
浏览文件 @
770bde53
445.0 KB
deploy/lite_shitu/src/main.cc
浏览文件 @
770bde53
...
@@ -141,6 +141,11 @@ int main(int argc, char **argv) {
...
@@ -141,6 +141,11 @@ int main(int argc, char **argv) {
std
::
cout
<<
"Please set [det_model_path] in "
<<
config_path
<<
std
::
endl
;
std
::
cout
<<
"Please set [det_model_path] in "
<<
config_path
<<
std
::
endl
;
return
-
1
;
return
-
1
;
}
}
if
(
!
RT_Config
[
"Global"
][
"infer_imgs_dir"
].
as
<
std
::
string
>
().
empty
()
&&
img_dir
.
empty
())
{
img_dir
=
RT_Config
[
"Global"
][
"infer_imgs_dir"
].
as
<
std
::
string
>
();
}
if
(
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
()
&&
if
(
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
()
&&
img_dir
.
empty
())
{
img_dir
.
empty
())
{
std
::
cout
<<
"Please set [infer_imgs] in "
<<
config_path
std
::
cout
<<
"Please set [infer_imgs] in "
<<
config_path
...
@@ -148,12 +153,6 @@ int main(int argc, char **argv) {
...
@@ -148,12 +153,6 @@ int main(int argc, char **argv) {
<<
" [image_dir]>"
<<
std
::
endl
;
<<
" [image_dir]>"
<<
std
::
endl
;
return
-
1
;
return
-
1
;
}
}
if
(
!
img_dir
.
empty
())
{
std
::
cout
<<
"Use image_dir in command line overide the path in config file"
<<
std
::
endl
;
RT_Config
[
"Global"
][
"infer_imgs_dir"
]
=
img_dir
;
RT_Config
[
"Global"
][
"infer_imgs"
]
=
""
;
}
// Load model and create a object detector
// Load model and create a object detector
PPShiTu
::
ObjectDetector
det
(
PPShiTu
::
ObjectDetector
det
(
RT_Config
,
RT_Config
[
"Global"
][
"det_model_path"
].
as
<
std
::
string
>
(),
RT_Config
,
RT_Config
[
"Global"
][
"det_model_path"
].
as
<
std
::
string
>
(),
...
@@ -167,7 +166,7 @@ int main(int argc, char **argv) {
...
@@ -167,7 +166,7 @@ int main(int argc, char **argv) {
std
::
vector
<
cv
::
Mat
>
batch_imgs
;
std
::
vector
<
cv
::
Mat
>
batch_imgs
;
double
rec_time
;
double
rec_time
;
if
(
!
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
()
||
if
(
!
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
()
||
!
RT_Config
[
"Global"
][
"infer_imgs_dir"
].
as
<
std
::
string
>
()
.
empty
())
{
!
img_dir
.
empty
())
{
std
::
vector
<
std
::
string
>
all_img_paths
;
std
::
vector
<
std
::
string
>
all_img_paths
;
std
::
vector
<
cv
::
String
>
cv_all_img_paths
;
std
::
vector
<
cv
::
String
>
cv_all_img_paths
;
if
(
!
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
())
{
if
(
!
RT_Config
[
"Global"
][
"infer_imgs"
].
as
<
std
::
string
>
().
empty
())
{
...
@@ -179,7 +178,7 @@ int main(int argc, char **argv) {
...
@@ -179,7 +178,7 @@ int main(int argc, char **argv) {
return
-
1
;
return
-
1
;
}
}
}
else
{
}
else
{
cv
::
glob
(
RT_Config
[
"Global"
][
"infer_imgs_dir"
].
as
<
std
::
string
>
()
,
cv
::
glob
(
img_dir
,
cv_all_img_paths
);
cv_all_img_paths
);
for
(
const
auto
&
img_path
:
cv_all_img_paths
)
{
for
(
const
auto
&
img_path
:
cv_all_img_paths
)
{
all_img_paths
.
push_back
(
img_path
);
all_img_paths
.
push_back
(
img_path
);
...
...
docs/images/ppshitu_lite_demo.png
查看替换文件 @
1e2af322
浏览文件 @
770bde53
53.7 KB
|
W:
|
H:
82.0 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}
{kind=link}