Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
513e2fbf
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
513e2fbf
编写于
10月 23, 2021
作者:
D
dongshuilong
提交者:
Tingquan Gao
10月 25, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add model quantization and prune docs
上级
e15857e4
变更
6
显示空白变更内容
内联
并排
Showing
6 changed file
with
198 addition
and
0 deletion
+198
-0
docs/zh_CN_tmp/advanced_tutorials/model_prune_quantization.md
.../zh_CN_tmp/advanced_tutorials/model_prune_quantization.md
+145
-0
docs/zh_CN_tmp/algorithm_introduction/fpgm.png
docs/zh_CN_tmp/algorithm_introduction/fpgm.png
+0
-0
docs/zh_CN_tmp/algorithm_introduction/model_prune_quantization.md
...CN_tmp/algorithm_introduction/model_prune_quantization.md
+53
-0
docs/zh_CN_tmp/algorithm_introduction/quantization.jpg
docs/zh_CN_tmp/algorithm_introduction/quantization.jpg
+0
-0
docs/zh_CN_tmp/algorithm_introduction/quantization_formula.png
...zh_CN_tmp/algorithm_introduction/quantization_formula.png
+0
-0
docs/zh_CN_tmp/algorithm_introduction/quantization_formula_slim.png
..._tmp/algorithm_introduction/quantization_formula_slim.png
+0
-0
未找到文件。
docs/zh_CN_tmp/advanced_tutorials/model_prune_quantization.md
0 → 100644
浏览文件 @
513e2fbf
## 模型量化、裁剪使用介绍
复杂的模型有利于提高模型的性能,但也导致模型中存在一定冗余。此部分提供精简模型的功能,包括两部分:模型量化(量化训练、离线量化)、模型剪枝。
其中模型量化将全精度缩减到定点数减少这种冗余,达到减少模型计算复杂度,提高模型推理性能的目的。
模型量化可以在基本不损失模型的精度的情况下,将FP32精度的模型参数转换为Int8精度,减小模型参数大小并加速计算,使用量化后的模型在移动端等部署时更具备速度优势。
模型剪枝将CNN中不重要的卷积核裁剪掉,减少模型参数量,从而降低模型计算复杂度。
本教程将介绍如何使用飞桨模型压缩库PaddleSlim做PaddleClas模型的压缩,即裁剪、量化功能。
[
PaddleSlim
](
https://github.com/PaddlePaddle/PaddleSlim
)
集成了模型剪枝、量化(包括量化训练和离线量化)、蒸馏和神经网络搜索等多种业界常用且领先的模型压缩功能,如果您感兴趣,可以关注并了解。
在开始本教程之前,建议先了解
[
PaddleClas模型的训练方法
](
../../zh_CN/tutorials/getting_started.md
)
以及
[
PaddleSlim
](
https://paddleslim.readthedocs.io/zh_CN/latest/index.html
)
,相关裁剪、量化方法可以参考
[
模型裁剪量化算法介绍文档
](
../algorithm_introduction/model_prune_quantization.md
)
。
## 快速开始
当训练出一个模型后,如果希望进一步的压缩模型大小并加速预测,可使用量化或者剪枝的方法压缩模型。
模型压缩主要包括五个步骤:
1.
安装 PaddleSlim
2.
准备训练好的模型
3.
模型压缩
4.
导出量化推理模型
5.
量化模型预测部署
### 1. 安装PaddleSlim
*
可以通过pip install的方式进行安装。
```
bash
pip
install
paddleslim
-i
https://pypi.tuna.tsinghua.edu.cn/simple
```
*
如果获取PaddleSlim的最新特性,可以从源码安装。
```
bash
git clone https://github.com/PaddlePaddle/PaddleSlim.git
cd
Paddleslim
python3.7 setup.py
install
```
### 2. 准备训练好的模型
PaddleClas提供了一系列训练好的
[
模型
](
../../zh_CN/models/models_intro.md
)
,如果待量化的模型不在列表中,需要按照
[
常规训练
](
../../zh_CN/tutorials/getting_started.md
)
方法得到训练好的模型。
### 3. 模型裁剪、量化
进入PaddleClas根目录
```
bash
cd
PaddleClas
```
`slim`
训练相关代码已经集成到
`ppcls/engine/`
下,离线量化代码位于
`deploy/slim/quant_post_static.py`
。
#### 3.1 模型量化
量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。
##### 3.1.1 在线量化训练
训练指令如下:
*
CPU/单卡GPU
以CPU为例,若使用GPU,则将命令中改成
`cpu`
改成
`gpu`
```
bash
python3.7 tools/train.py
-c
ppcls/configs/slim/ResNet50_vd_quantization.yaml
-o
Global.device
=
cpu
```
其中
`yaml`
文件解析详见
[
参考文档
](
../../zh_CN/tutorials/config_description.md
)
。为了保证精度,
`yaml`
文件中已经使用
`pretrained model`
.
*
单机多卡/多机多卡启动
```
bash
export
CUDA_VISIBLE_DEVICES
=
0,1,2,3
python3.7
-m
paddle.distributed.launch
\
--gpus
=
"0,1,2,3"
\
tools/train.py
\
-c
ppcls/configs/slim/ResNet50_vd_quantization.yaml
```
##### 3.1.2 离线量化
**注意**
:目前离线量化,必须使用已经训练好的模型,导出的
`inference model`
进行量化。一般模型导出
`inference model`
可参考
[
教程
](
../../zh_CN/inference.md
)
.
一般来说,离线量化损失模型精度较多。
生成
`inference model`
后,离线量化运行方式如下
```
bash
python3.7 deploy/slim/quant_post_static.py
-c
ppcls/configs/ImageNet/ResNet/ResNet50_vd.yaml
-o
Global.save_inference_dir
=
./deploy/models/class_ResNet50_vd_ImageNet_infer
```
`Global.save_inference_dir`
是
`inference model`
存放的目录。
执行成功后,在
`Global.save_inference_dir`
的目录下,生成
`quant_post_static_model`
文件夹,其中存储生成的离线量化模型,其可以直接进行预测部署,无需再重新导出模型。
#### 3.2 模型剪枝
训练指令如下:
-
CPU/单卡GPU
以CPU为例,若使用GPU,则将命令中改成
`cpu`
改成
`gpu`
```
bash
python3.7 tools/train.py
-c
ppcls/configs/slim/ResNet50_vd_prune.yaml
-o
Global.device
=
cpu
```
-
单机单卡/单机多卡/多机多卡启动
```
bash
export
CUDA_VISIBLE_DEVICES
=
0,1,2,3
python3.7
-m
paddle.distributed.launch
\
--gpus
=
"0,1,2,3"
\
tools/train.py
\
-c
ppcls/configs/slim/ResNet50_vd_prune.yaml
```
### 4. 导出模型
在得到在线量化训练、模型剪枝保存的模型后,可以将其导出为inference model,用于预测部署,以模型剪枝为例:
```
bash
python3.7 tools/export.py
\
-c
ppcls/configs/slim/ResNet50_vd_prune.yaml
\
-o
Global.pretrained_model
=
./output/ResNet50_vd/best_model
\
-o
Global.save_inference_dir
=
./inference
```
### 5. 模型部署
上述步骤导出的模型可以通过PaddleLite的opt模型转换工具完成模型转换。
模型部署的可参考
[
移动端模型部署
](
../../../deploy/lite/readme.md
)
## 训练超参数建议
*
量化、裁剪训练时,建议加载常规训练得到的预训练模型,加速量化训练收敛。
*
量化训练时,建议初始学习率修改为常规训练的
`1/20~1/10`
,同时将训练epoch数修改为常规训练的
`1/5~1/2`
,学习率策略方面,加上Warmup,其他配置信息不建议修改。
*
裁剪训练时,建议超参数配置与普通训练一致。
docs/zh_CN_tmp/algorithm_introduction/fpgm.png
0 → 100644
浏览文件 @
513e2fbf
763.0 KB
docs/zh_CN_tmp/algorithm_introduction/model_prune_quantization.md
0 → 100644
浏览文件 @
513e2fbf
## 模型裁剪、量化算法介绍
深度学习因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署。其中模型量化、裁剪应用比较广泛。在PaddleClas中,主要应该应用以下两种算法。
-
量化方法:PACT量化
-
裁剪:FPGM裁剪
其中具体算法参数请参考
[
PaddeSlim
](
https://github.com/PaddlePaddle/PaddleSlim/
)
。
### PACT量化方法
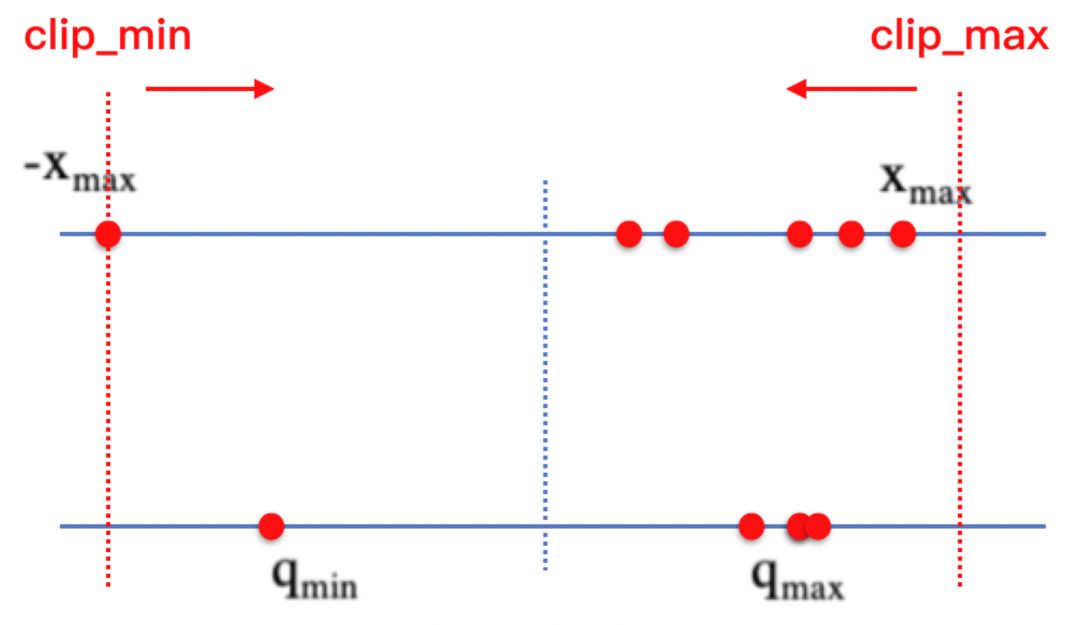
模型量化主要包括两个部分,一是对权重Weight量化,一是针对激活值Activation量化。同时对两部分进行量化,才能获得最大的计算效率收益。权重可以借助网络正则化等手段,让权重分布尽量紧凑,减少离群点、不均匀分布情况发生,而对于激活值还缺乏有效的手段。
**PACT量化(PArameterized Clipping acTivation)**
是一种新的量化方法,该方法通过在量化激活值之前去掉一些离群点,将模型量化带来的精度损失降到最低,甚至比原模型准确率更高。提出方法的背景是作者发现:“在运用权重量化方案来量化activation时,激活值的量化结果和全精度结果相差较大”。作者发现,activation的量化可能引起的误差很大(相较于weight基本在 0到1范围内,activation的值的范围是无限大的,这是RELU的结果),所以提出
**截断式RELU**
的激活函数。该截断的上界,即$α$ 是可学习的参数,这保证了每层能够通过训练学习到不一样的量化范围,最大程度降低量化带来的舍入误差。其中量化的示意图如下图所示,
**PACT**
解决问题的方法是,不断裁剪激活值范围,使得激活值分布收窄,从而降低量化映射损失。
**PACT**
通过对激活数值做裁剪,从而减少激活分布中的离群点,使量化模型能够得到一个更合理的量化scale,降低量化损失。
<div
align=
"center"
>
<img
src=
"./quantization.jpg"
width =
"600"
/>
</div>
**PACT**
量化公式如下:
<div
align=
"center"
>
<img
src=
"./quantization_formula.png"
width =
"800"
height=
"100"
/>
</div>
可以看出PACT思想是用上述量化代替
*ReLU*
函数,对大于零的部分进行一个截断操作,截断阈值为$a$。但是在
*PaddleSlim*
中对上述公式做了进一步的改进,其改进如下:
<div
align=
"center"
>
<img
src=
"./quantization_formula_slim.png"
width =
"550"
height=
"120"
/>
</div>
经过如上改进后,在激活值和待量化的OP(卷积,全连接等)之间插入
*PACT*
预处理,不只对大于0的分布进行截断,同时也对小于0的部分做同样的限制,从而更好地得到待量化的范围,降低量化损失。同时,截断阈值是一个可训练的参数,在量化训练过程中,模型会自动的找到一个合理的截断阈值,从而进一步降低量化精度损失。
算法具体参数请参考PaddleSlim中
[
参数介绍
](
https://github.com/PaddlePaddle/PaddleSlim/blob/release/2.0.0/docs/zh_cn/api_cn/dygraph/quanter/qat.rst#qat
)
。
### FPGM裁剪
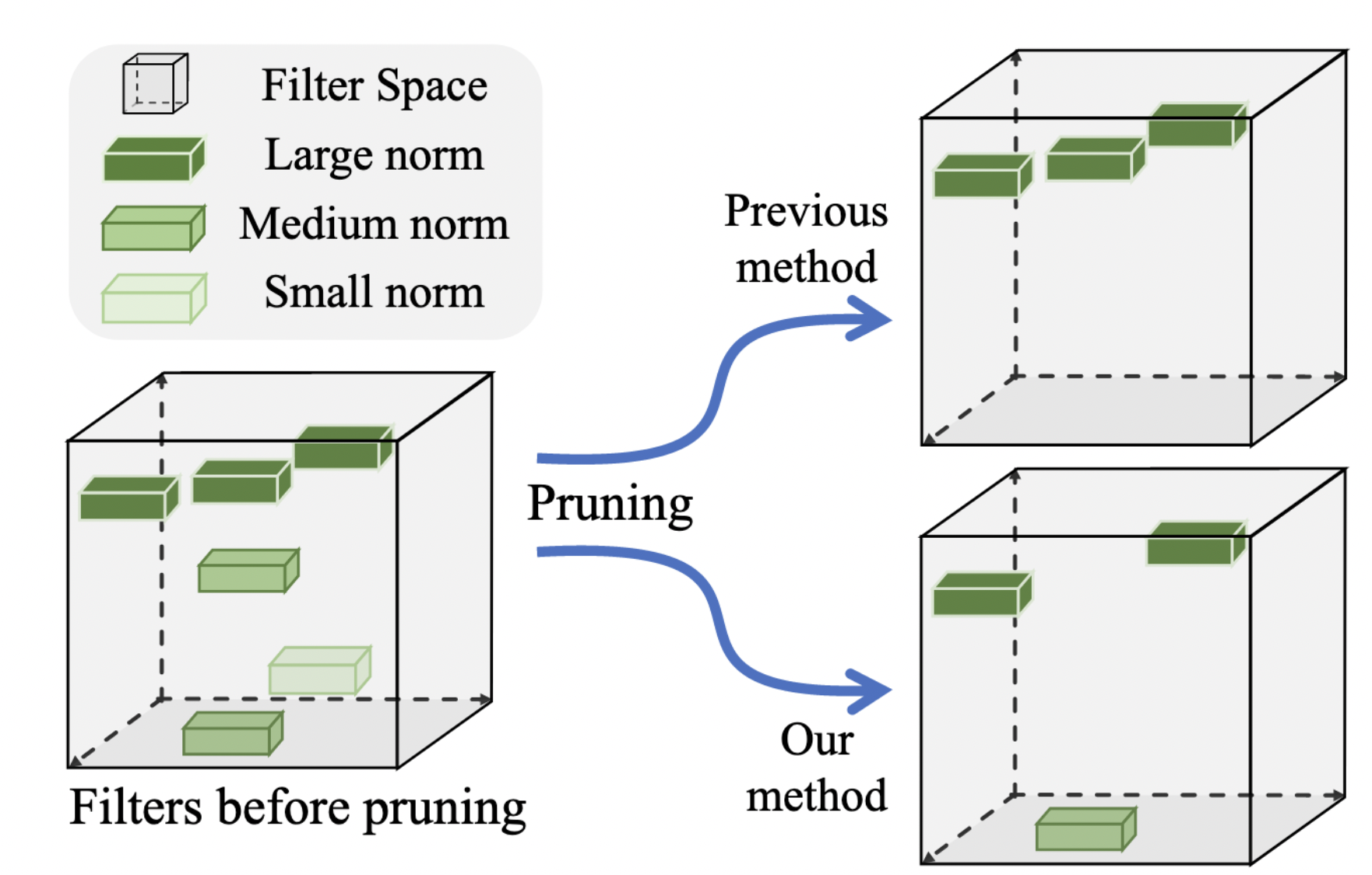
模型剪枝是减小模型大小,提升预测效率的一种非常重要的手段。在之前的网络剪枝文章中一般将网络filter的范数作为其重要性度量,
**范数值较小的代表的filter越不重要**
,将其从网络中裁剪掉,反之也就越重要。而
**FPGM**
认为之前的方法要依赖如下两点
-
filter的范数偏差应该比较大,这样重要和非重要的filter才可以很好区分开
-
不重要的filter的范数应该足够的小
基于此,
**FPGM**
利用层中filter的几何中心特性,由于那些靠近中心的filter可以被其它的表达,因而可以将其剔除,从而避免了上面提到的两点剪枝条件,从信息的冗余度出发,而不是选择范数少的进行剪枝。下图展示了
**FPGM**
方法与之前方法的不同,具体细节请详看
[
论文
](
https://openaccess.thecvf.com/content_CVPR_2019/papers/He_Filter_Pruning_via_Geometric_Median_for_Deep_Convolutional_Neural_Networks_CVPR_2019_paper.pdf
)
。
<div
align=
"center"
>
<img
src=
"./fpgm.png"
width =
"600"
/>
</div>
算法具体参数请参考PaddleSlim中
[
参数介绍
](
https://github.com/PaddlePaddle/PaddleSlim/blob/release/2.0.0/docs/zh_cn/api_cn/dygraph/pruners/fpgm_filter_pruner.rst#fpgmfilterpruner
)
。
docs/zh_CN_tmp/algorithm_introduction/quantization.jpg
0 → 100644
浏览文件 @
513e2fbf
35.9 KB
docs/zh_CN_tmp/algorithm_introduction/quantization_formula.png
0 → 100644
浏览文件 @
513e2fbf
5.5 KB
docs/zh_CN_tmp/algorithm_introduction/quantization_formula_slim.png
0 → 100644
浏览文件 @
513e2fbf
7.4 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录


{kind=link}
{kind=link}
{kind=link}
{kind=link}