Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
4c6e658a
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
大约 2 年 前同步成功
通知
118
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
4c6e658a
编写于
4月 21, 2020
作者:
D
dyning
提交者:
GitHub
4月 21, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #54 from littletomatodonkey/master
Add quick start doc
上级
bf86e09d
5aaaad57
变更
10
显示空白变更内容
内联
并排
Showing
10 changed file
with
246 addition
and
115 deletion
+246
-115
configs/flower.yaml
configs/flower.yaml
+0
-75
configs/quick_start/R50_vd_distill_MV3_large_x1_0.yaml
configs/quick_start/R50_vd_distill_MV3_large_x1_0.yaml
+2
-2
docs/images/quick_start/all_acc.png
docs/images/quick_start/all_acc.png
+0
-0
docs/images/quick_start/r50_vd_acc.png
docs/images/quick_start/r50_vd_acc.png
+0
-0
docs/images/quick_start/r50_vd_pretrained_acc.png
docs/images/quick_start/r50_vd_pretrained_acc.png
+0
-0
docs/zh_CN/application/transfer_learning.md
docs/zh_CN/application/transfer_learning.md
+2
-7
docs/zh_CN/tutorials/data.md
docs/zh_CN/tutorials/data.md
+17
-27
docs/zh_CN/tutorials/index.rst
docs/zh_CN/tutorials/index.rst
+3
-2
docs/zh_CN/tutorials/quick_start.md
docs/zh_CN/tutorials/quick_start.md
+221
-0
ppcls/modeling/loss.py
ppcls/modeling/loss.py
+1
-2
未找到文件。
configs/flower.yaml
已删除
100644 → 0
浏览文件 @
bf86e09d
mode
:
'
train'
ARCHITECTURE
:
name
:
'
ResNet50_vd'
pretrained_model
:
model_save_dir
:
"
./output/"
classes_num
:
102
total_images
:
1020
save_interval
:
10
validate
:
True
valid_interval
:
1
epochs
:
40
topk
:
5
image_shape
:
[
3
,
224
,
224
]
ls_epsilon
:
0.1
LEARNING_RATE
:
function
:
'
Cosine'
params
:
lr
:
0.00375
OPTIMIZER
:
function
:
'
Momentum'
params
:
momentum
:
0.9
regularizer
:
function
:
'
L2'
factor
:
0.000001
TRAIN
:
batch_size
:
32
num_workers
:
1
file_list
:
"
./dataset/flowers102/train_list.txt"
data_dir
:
"
./dataset/flowers102"
shuffle_seed
:
0
transforms
:
-
DecodeImage
:
to_rgb
:
True
to_np
:
False
channel_first
:
False
-
RandCropImage
:
size
:
224
-
RandFlipImage
:
flip_code
:
1
-
NormalizeImage
:
scale
:
1./255.
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
-
ToCHWImage
:
#mix:
# - MixupOperator:
# alpha: 0.2
VALID
:
batch_size
:
64
num_workers
:
1
file_list
:
"
./dataset/flowers102/val_list.txt"
data_dir
:
"
./dataset/flowers102/"
shuffle_seed
:
0
transforms
:
-
DecodeImage
:
to_rgb
:
True
to_np
:
False
channel_first
:
False
-
ResizeImage
:
resize_short
:
256
-
CropImage
:
size
:
224
-
NormalizeImage
:
scale
:
1.0/255.0
mean
:
[
0.485
,
0.456
,
0.406
]
std
:
[
0.229
,
0.224
,
0.225
]
order
:
'
'
-
ToCHWImage
:
configs/quick_start/R50_vd_distill_MV3_large_x1_0.yaml
浏览文件 @
4c6e658a
...
...
@@ -3,7 +3,7 @@ ARCHITECTURE:
name
:
'
ResNet50_vd_distill_MobileNetV3_large_x1_0'
pretrained_model
:
-
"
./pretrain/flowers102_R50_vd_final/ppcls"
-
"
./pretrain
ed
/flowers102_R50_vd_final/ppcls"
-
"
./pretrained/MobileNetV3_large_x1_0_pretrained/"
model_save_dir
:
"
./output/"
classes_num
:
102
...
...
@@ -33,7 +33,7 @@ OPTIMIZER:
TRAIN
:
batch_size
:
32
num_workers
:
4
file_list
:
"
./dataset/flowers102/train_
test
_list.txt"
file_list
:
"
./dataset/flowers102/train_
extra
_list.txt"
data_dir
:
"
./dataset/flowers102/"
shuffle_seed
:
0
transforms
:
...
...
docs/images/quick_start/all_acc.png
0 → 100644
浏览文件 @
4c6e658a
232.6 KB
docs/images/quick_start/r50_vd_acc.png
0 → 100644
浏览文件 @
4c6e658a
168.1 KB
docs/images/quick_start/r50_vd_pretrained_acc.png
0 → 100644
浏览文件 @
4c6e658a
148.8 KB
docs/zh_CN/application/transfer_learning.md
浏览文件 @
4c6e658a
...
...
@@ -79,11 +79,6 @@ Mixup: [False, True]
-
通过上述的实验验证了当使用一组固定参数时,相比于ImageNet预训练模型,使用大规模分类模型作为预训练模型在大多数情况下能够提升模型在新的数据集上得效果,通过参数搜索可以进一步提升精度。
## 三、图像分类迁移学习实战
*
该部分内容正在持续更新中。
## 参考文献
[1] Kornblith, Simon, Jonathon Shlens, and Quoc V. Le. "Do better imagenet models transfer better?."
*Proceedings of the IEEE conference on computer vision and pattern recognition*
. 2019.
...
...
docs/zh_CN/tutorials/data.md
浏览文件 @
4c6e658a
...
...
@@ -3,21 +3,20 @@
---
## 1.简介
本文档介绍ImageNet1k和Flower102数据准备过程。
以及PaddleClas提供了丰富的
[
预训练模型
](
../models/models_intro.md
)
本文档介绍ImageNet1k和flowers102数据准备过程。
## 2.数据集准备
数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注|
:------:|:---------------:|:---------------------:|:-----------:|:-----------:
[
Flower102
](
https://www.robots.ox.ac.uk/~vgg/data/flowers/102/
)
|1k | 6k | 102 |
[
flowers102
](
https://www.robots.ox.ac.uk/~vgg/data/flowers/102/
)
|1k | 6k | 102 |
[
ImageNet1k
](
http://www.image-net.org/challenges/LSVRC/2012/
)
|1.2M| 50k | 1000 |
数据格式
*
数据格式
按照如下结构组织数据,其中train_list.txt 和val_list.txt的格式形如
```
#每一行采用"空格"分隔图像路径与标注
```
shell
#
每一行采用"空格"分隔图像路径与标注
ILSVRC2012_val_00000001.JPEG 65
...
...
...
@@ -44,24 +43,28 @@ PaddleClas/dataset/imagenet/
|_ train_list.txt
|_ val_list.txt
```
### Flower
### Flower
s102
从
[
VGG官方网站
](
https://www.robots.ox.ac.uk/~vgg/data/flowers/102/
)
下载后的数据,解压后包括
```
shell
jpg/
setid.mat
imagelabels.mat
将以上文件放置在PaddleClas/dataset/flower102/下
```
通过运行generate_flower_list.py生成train_list.txt和val_list.txt
将以上文件放置在PaddleClas/dataset/flowers102/下
通过运行generate_flowers102_list.py生成train_list.txt和val_list.txt
```
bash
python generate_flower_list.py jpg train
>
train_list.txt
python generate_flower_list.py jpg valid
>
val_list.txt
python generate_flower
s102
_list.py jpg train
>
train_list.txt
python generate_flower
s102
_list.py jpg valid
>
val_list.txt
```
按照如下结构组织数据:
```
bash
PaddleClas/dataset/flower102/
PaddleClas/dataset/flower
s
102/
|_ jpg/
| |_ image_03601.jpg
| |_ ...
...
...
@@ -69,16 +72,3 @@ PaddleClas/dataset/flower102/
|_ train_list.txt
|_ val_list.txt
```
## 3.下载预训练模型
通过tools/download.py下载所需要的预训练模型。
```
bash
python tools/download.py
-a
ResNet50_vd
-p
./pretrained
-d
True
```
参数说明:
+
`architecture`
(简写 a):模型结构
+
`path`
(简写 p):下载路径
+
`decompress`
(简写 d):是否解压
docs/zh_CN/tutorials/index.rst
浏览文件 @
4c6e658a
...
...
@@ -5,6 +5,7 @@
:maxdepth: 1
install.md
quick_start.md
data.md
getting_started.md
config.md
\ No newline at end of file
data.md
docs/zh_CN/tutorials/quick_start.md
0 → 100644
浏览文件 @
4c6e658a
# 30min玩转PaddleClas
请事先参考
[
安装指南
](
install.md
)
配置运行环境和克隆PaddleClas代码。
## 一、数据和模型准备
*
进入PaddleClas目录。
```
cd path_to_PaddleClas
```
*
进入
`dataset/flowers102`
目录,下载并解压flowers102数据集.
```
shell
cd
dataset/flowers102
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/102flowers.tgz
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/imagelabels.mat
wget https://www.robots.ox.ac.uk/~vgg/data/flowers/102/setid.mat
tar
-xf
102flowers.tgz
```
*
制作train/val/test标签文件
```
shell
python generate_flowers102_list.py jpg train
>
train_list.txt
python generate_flowers102_list.py jpg valid
>
val_list.txt
python generate_flowers102_list.py jpg
test
>
extra_list.txt
cat
train_list.txt extra_list.txt
>
train_extra_list.txt
```
**注意**
:这里将train_list.txt和extra_list.txt合并成train_extra_list.txt,是为了之后在进行知识蒸馏时,使用更多的数据提升无标签知识蒸馏任务的效果。
*
返回
`PaddleClas`
根目录
```
cd ../../
```
## 二、环境准备
### 2.1 设置PYTHONPATH环境变量
```
bash
export
PYTHONPATH
=
./:
$PYTHONPATH
```
### 下载预训练模型
通过tools/download.py下载所需要的预训练模型。
```
bash
python tools/download.py
-a
ResNet50_vd
-p
./pretrained
-d
True
python tools/download.py
-a
ResNet50_vd_ssld
-p
./pretrained
-d
True
python tools/download.py
-a
MobileNetV3_large_x1_0
-p
./pretrained
-d
True
```
参数说明:
+
`architecture`
(简写 a):模型结构
+
`path`
(简写 p):下载路径
+
`decompress`
(简写 d):是否解压
### 2.2 环境说明
*
下面所有的训练过程均在
`单卡V100`
机器上运行。
## 三、模型训练
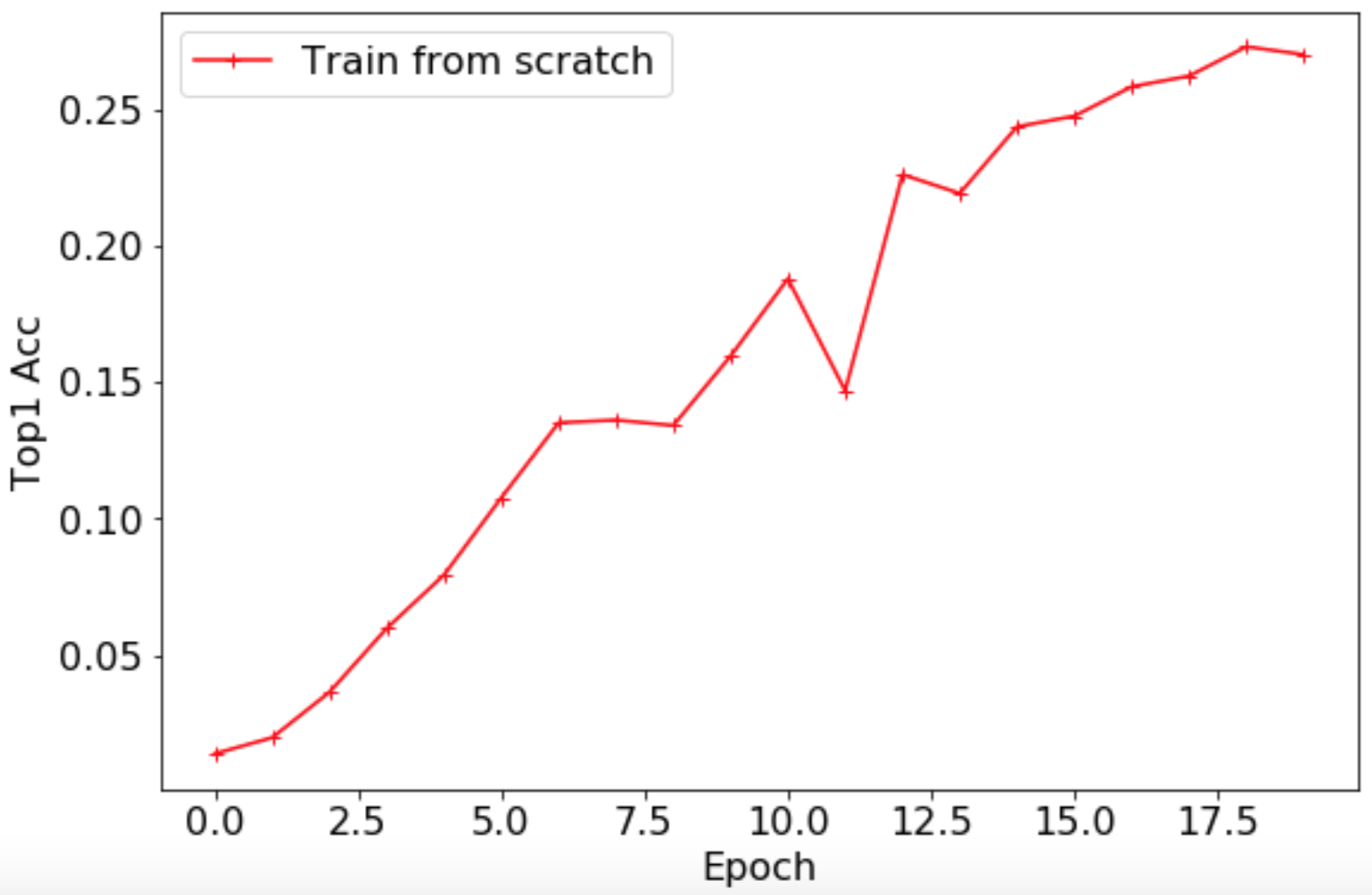
### 3.1 零基础训练:不加载预训练模型的训练
*
基于ResNet50_vd模型,训练脚本如下所示。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/ResNet50_vd.yaml
```
`Top1 Acc`
曲线如下所示,最高准确率为0.2735。

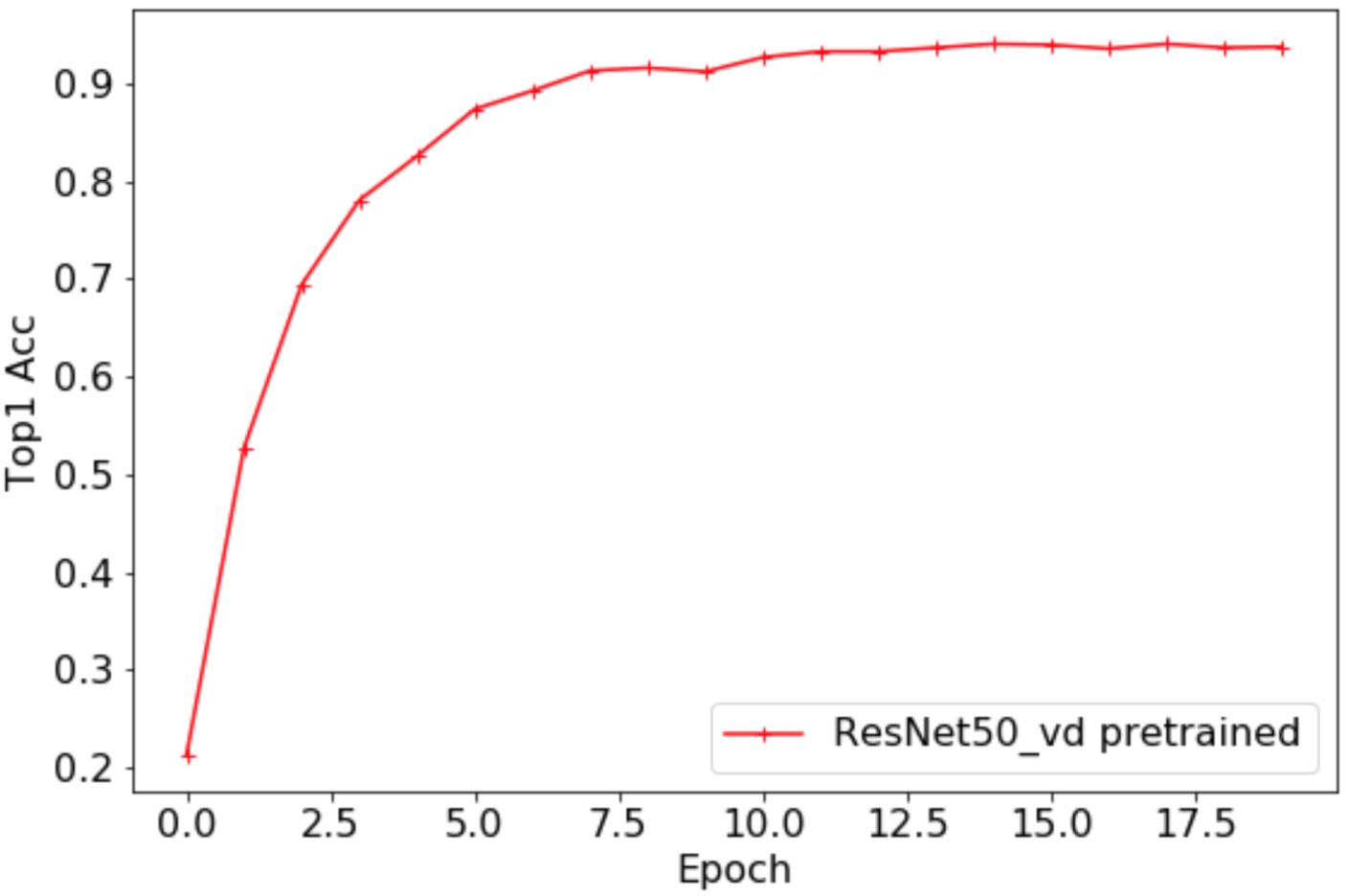
### 3.2 模型微调-基于ResNet50_vd预训练模型(准确率79.12\%)
*
基于ImageNet1k分类预训练模型进行微调,训练脚本如下所示。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/ResNet50_vd_finetune.yaml
```
`Top1 Acc`
曲线如下所示,最高准确率为0.9402,加载预训练模型之后,flowers102数据集精度大幅提升,绝对精度涨幅超过65
\%
。

### 3.3 SSLD模型微调-基于ResNet50_vd_ssld预训练模型(准确率82.39\%)
需要注意的是,在使用通过知识蒸馏得到的预训练模型进行微调时,我们推荐使用相对较小的网络中间层学习率。
```
yaml
ARCHITECTURE
:
name
:
'
ResNet50_vd'
params
:
lr_mult_list
:
[
0.1
,
0.1
,
0.2
,
0.2
,
0.3
]
pretrained_model
:
"
./pretrained/ResNet50_vd_ssld_pretrained"
```
训练脚本如下。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/ResNet50_vd_ssld_finetune.yaml
```
最终flowers102验证集上精度指标为0.95,相对于79.12
\%
预训练模型的微调结构,新数据集指标可以再次提升0.9
\%
。
### 3.4 尝试更多的模型结构-MobileNetV3
训练脚本如下所示。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml
```
最终flowers102验证集上的精度为0.90,比加载了预训练模型的ResNet50_vd的精度差了5
\%
。不同模型结构的网络在相同数据集上的性能表现不同,需要根据预测耗时以及存储的需求选择合适的模型。
### 3.5 数据增广的尝试-RandomErasing
训练数据量较小时,使用数据增广可以进一步提升模型精度,基于
`3.3节`
中的训练方法,结合RandomErasing的数据增广方式进行训练,具体的训练脚本如下所示。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/ResNet50_vd_ssld_random_erasing_finetune.yaml
```
最终flowers102验证集上的精度为0.9627,使用数据增广可以使得模型精度再次提升1.27
\%
。
*
如果希望体验
`3.6节`
的知识蒸馏部分,可以首先保存训练得到的ResNet50_vd预训练模型到合适的位置,作为蒸馏时教师模型的预训练模型。脚本如下所示。
```
shell
cp
-r
output/ResNet50_vd/19/ ./pretrained/flowers102_R50_vd_final/
```
### 3.6 知识蒸馏小试牛刀
*
使用flowers102数据集进行模型蒸馏,为了进一步提提升模型的精度,使用test_list.txt充当无标签数据,在这里有几点需要注意:
*
`test_list.txt`
与
`val_list.txt`
的样本没有重复。
*
即使引入了有标签的test_list.txt中的测试集图像,但是代码中没有使用标签信息,因此仍然可以视为无标签的模型蒸馏。
*
蒸馏过程中,教师模型使用的预训练模型为flowers102数据集上的训练结果,学生模型使用的是ImageNet1k数据集上精度为75.32
\%
的MobileNetV3_large_x1_0预训练模型。
配置文件中数据数量、模型结构、预训练地址以及训练的数据配置如下:
```
yaml
total_images
:
7169
ARCHITECTURE
:
name
:
'
ResNet50_vd_distill_MobileNetV3_large_x1_0'
pretrained_model
:
-
"
./pretrained/flowers102_R50_vd_final/ppcls"
-
"
./pretrained/MobileNetV3_large_x1_0_pretrained/”
TRAIN:
file_list:
"./dataset/flowers102/train_extra_list.txt"
```
最终的训练脚本如下所示。
```
shell
export
CUDA_VISIBLE_DEVICES
=
0
python -m paddle.distributed.launch
\
--selected_gpus
=
"0"
\
tools/train.py
\
-c ./configs/quick_start/R50_vd_distill_MV3_large_x1_0.yaml
```
最终flowers102验证集上的精度为0.9647,结合更多的无标签数据,使用教师模型进行知识蒸馏,MobileNetV3的精度涨幅高达6.47
\%
。
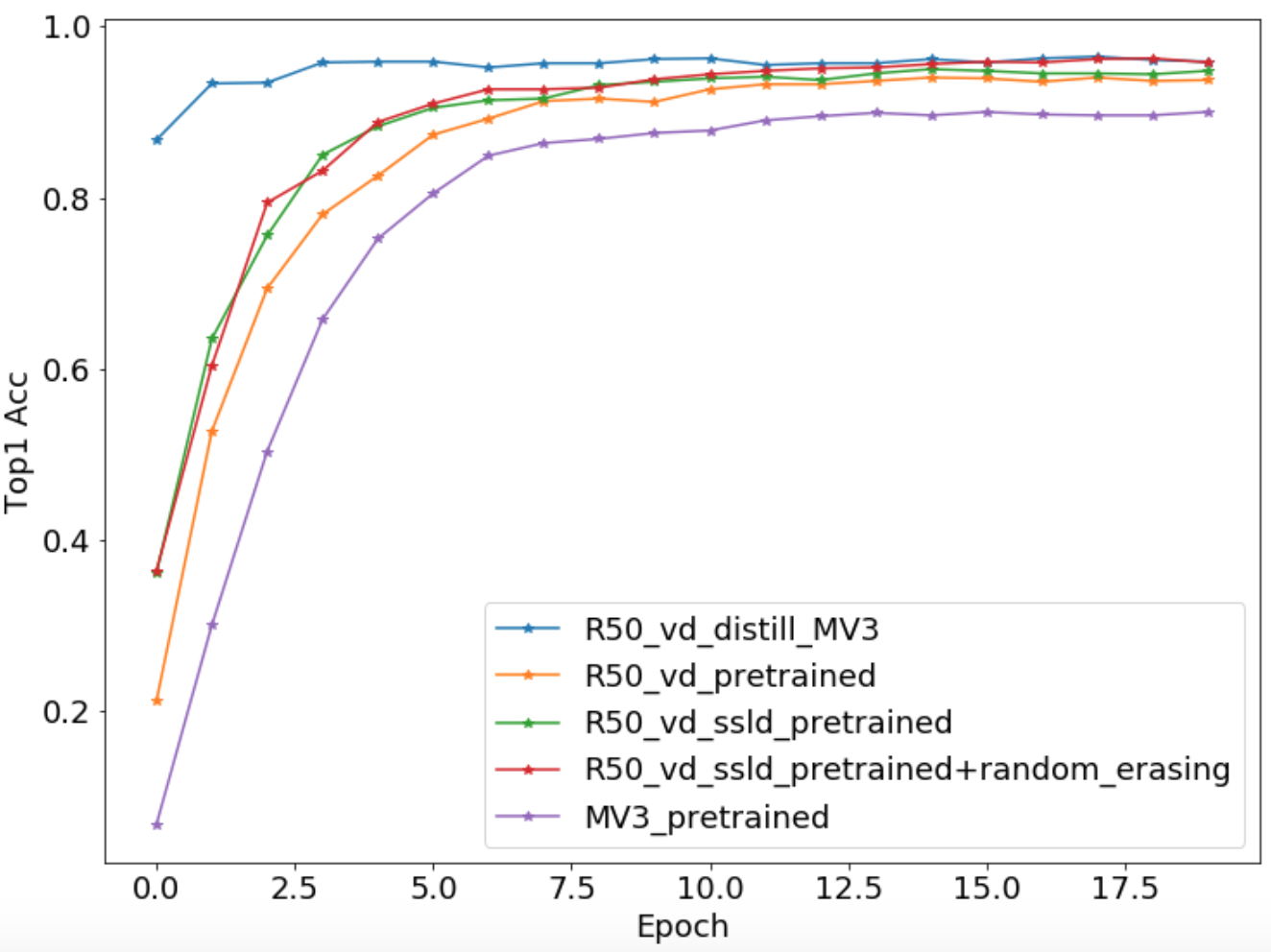
### 3.6 精度一览
*
下表给出了不同训练yaml文件对应的精度。
|配置文件 | Top1 Acc |
|- |:-: |
| ResNet50_vd.yaml | 0.2735 |
| MobileNetV3_large_x1_0_finetune.yaml | 0.9000 |
| ResNet50_vd_finetune.yaml | 0.9402 |
| ResNet50_vd_ssld_finetune.yaml | 0.9500 |
| ResNet50_vd_ssld_random_erasing_finetune.yaml | 0.9627 |
| R50_vd_distill_MV3_large_x1_0.yaml | 0.9647 |
下图给出了不同配置文件在迭代过程中的
`Top1 Acc`
的精度曲线变化图。

*
更多训练及评估流程,请参考
[
开始使用文档
](
./getting_started.md
)
ppcls/modeling/loss.py
浏览文件 @
4c6e658a
...
...
@@ -12,7 +12,6 @@
#See the License for the specific language governing permissions and
#limitations under the License.
import
paddle
import
paddle.fluid
as
fluid
__all__
=
[
'CELoss'
,
'MixCELoss'
,
'GoogLeNetLoss'
,
'JSDivLoss'
]
...
...
@@ -26,7 +25,7 @@ class Loss(object):
def
__init__
(
self
,
class_dim
=
1000
,
epsilon
=
None
):
assert
class_dim
>
1
,
"class_dim=%d is not larger than 1"
%
(
class_dim
)
self
.
_class_dim
=
class_dim
if
epsilon
and
epsilon
>=
0.0
and
epsilon
<=
1.0
:
if
epsilon
is
not
None
and
epsilon
>=
0.0
and
epsilon
<=
1.0
:
self
.
_epsilon
=
epsilon
self
.
_label_smoothing
=
True
else
:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}