
@@ -105,6 +135,11 @@ PP-ShiTu图像识别快速体验:[点击这里](./docs/zh_CN/quick_start/quick
PP-ShiTu是一个实用的轻量级通用图像识别系统,主要由主体检测、特征学习和向量检索三个模块组成。该系统从骨干网络选择和调整、损失函数的选择、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型裁剪量化8个方面,采用多种策略,对各个模块的模型进行优化,最终得到在CPU上仅0.2s即可完成10w+库的图像识别的系统。更多细节请参考[PP-ShiTu技术方案](https://arxiv.org/pdf/2111.00775.pdf)。
+
+## PULC实用图像分类模型效果展示
+
+

+
## PP-ShiTu图像识别系统效果展示
diff --git a/README_en.md b/README_en.md
index 9b0d7c85d76cf06eac8fb265abb85c3bb98a275f..4bf960e57f2e56972f889c4bcf6a6d715b903477 100644
--- a/README_en.md
+++ b/README_en.md
@@ -4,39 +4,41 @@
## Introduction
-PaddleClas is an image recognition toolset for industry and academia, helping users train better computer vision models and apply them in real scenarios.
+PaddleClas is an image classification and image recognition toolset for industry and academia, helping users train better computer vision models and apply them in real scenarios.
-**Recent updates**
-
-- 2022.4.21 Added the related [code](https://github.com/PaddlePaddle/PaddleClas/pull/1820/files) of the CVPR2022 oral paper [MixFormer](https://arxiv.org/pdf/2204.02557.pdf).
-
-- 2021.09.17 Add PP-LCNet series model developed by PaddleClas, these models show strong competitiveness on Intel CPUs.
-For the introduction of PP-LCNet, please refer to [paper](https://arxiv.org/pdf/2109.15099.pdf) or [PP-LCNet model introduction](docs/en/models/PP-LCNet_en.md). The metrics and pretrained model are available [here](docs/en/ImageNet_models_en.md).
-
-- 2021.06.29 Add Swin-transformer series model,Highest top1 acc on ImageNet1k dataset reaches 87.2%, training, evaluation and inference are all supported. Pretrained models can be downloaded [here](docs/en/models/models_intro_en.md).
-- 2021.06.16 PaddleClas release/2.2. Add metric learning and vector search modules. Add product recognition, animation character recognition, vehicle recognition and logo recognition. Added 30 pretrained models of LeViT, Twins, TNT, DLA, HarDNet, and RedNet, and the accuracy is roughly the same as that of the paper.
-- [more](./docs/en/update_history_en.md)
+
+

-## Features
+PULC demo images
+
+
-- A practical image recognition system consist of detection, feature learning and retrieval modules, widely applicable to all types of image recognition tasks.
-Four sample solutions are provided, including product recognition, vehicle recognition, logo recognition and animation character recognition.
-- Rich library of pre-trained models: Provide a total of 164 ImageNet pre-trained models in 35 series, among which 6 selected series of models support fast structural modification.
+
+

-- Comprehensive and easy-to-use feature learning components: 12 metric learning methods are integrated and can be combined and switched at will through configuration files.
+PP-ShiTu demo images
+
-- SSLD knowledge distillation: The 14 classification pre-training models generally improved their accuracy by more than 3%; among them, the ResNet50_vd model achieved a Top-1 accuracy of 84.0% on the Image-Net-1k dataset and the Res2Net200_vd pre-training model achieved a Top-1 accuracy of 85.1%.
+**Recent updates**
+- 2022.6.15 Release [**P**ractical **U**ltra **L**ight-weight image **C**lassification solutions](./docs/en/PULC/PULC_quickstart_en.md). PULC models inference within 3ms on CPU devices, with accuracy on par with SwinTransformer. We also release 9 practical classification models covering pedestrian, vehicle and OCR scenario.
+- 2022.4.21 Added the related [code](https://github.com/PaddlePaddle/PaddleClas/pull/1820/files) of the CVPR2022 oral paper [MixFormer](https://arxiv.org/pdf/2204.02557.pdf).
-- Data augmentation: Provide 8 data augmentation algorithms such as AutoAugment, Cutout, Cutmix, etc. with detailed introduction, code replication and evaluation of effectiveness in a unified experimental environment.
+- 2021.09.17 Add PP-LCNet series model developed by PaddleClas, these models show strong competitiveness on Intel CPUs.
+For the introduction of PP-LCNet, please refer to [paper](https://arxiv.org/pdf/2109.15099.pdf) or [PP-LCNet model introduction](docs/en/models/PP-LCNet_en.md). The metrics and pretrained model are available [here](docs/en/algorithm_introduction/ImageNet_models_en.md).
+- 2021.06.29 Add [Swin-transformer](docs/en/models/SwinTransformer_en.md)) series model,Highest top1 acc on ImageNet1k dataset reaches 87.2%, training, evaluation and inference are all supported. Pretrained models can be downloaded [here](docs/en/algorithm_introduction/ImageNet_models_en.md#16).
+- 2021.06.16 PaddleClas release/2.2. Add metric learning and vector search modules. Add product recognition, animation character recognition, vehicle recognition and logo recognition. Added 30 pretrained models of LeViT, Twins, TNT, DLA, HarDNet, and RedNet, and the accuracy is roughly the same as that of the paper.
+- [more](./docs/en/others/update_history_en.md)
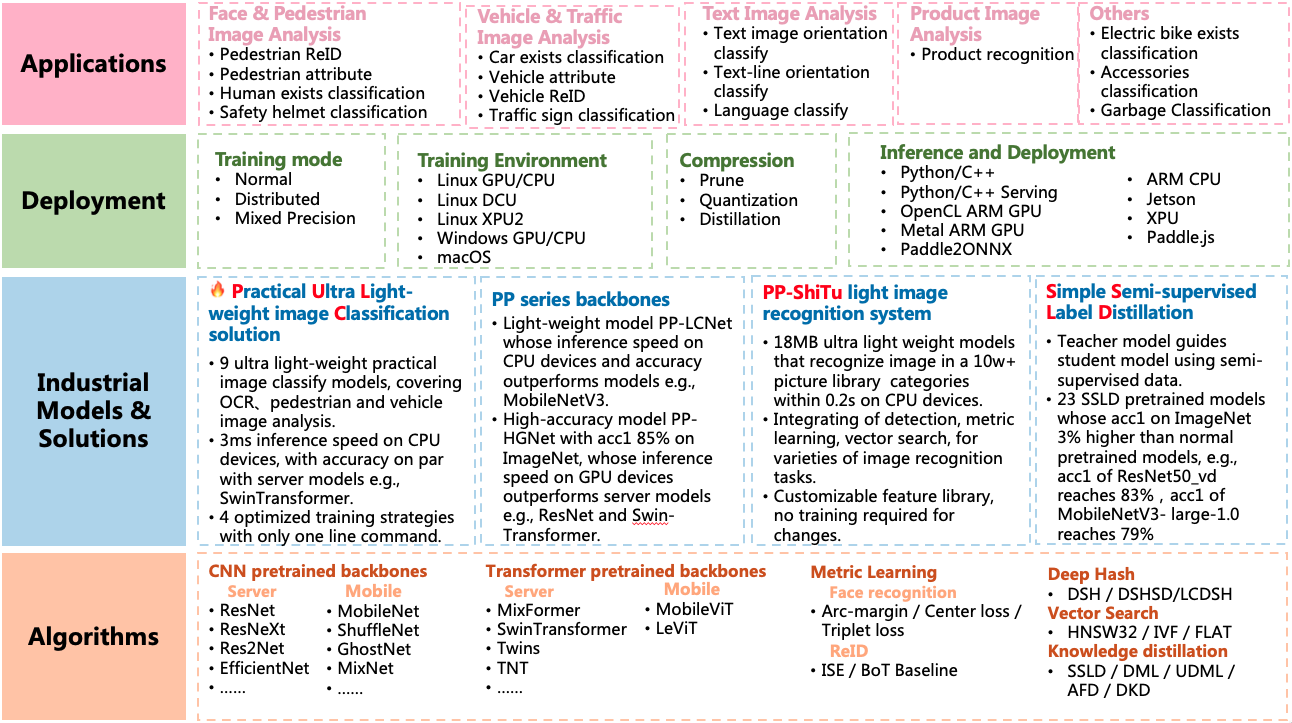
+## Features
+PaddleClas release PP-HGNet、PP-LCNetv2、 PP-LCNet and **S**imple **S**emi-supervised **L**abel **D**istillation algorithms, and support plenty of
+image classification and image recognition algorithms.
+Based on th algorithms above, PaddleClas release PP-ShiTu image recognition system and [**P**ractical **U**ltra **L**ight-weight image **C**lassification solutions](docs/en/PULC/PULC_quickstart_en.md).
-
-

-
+
## Welcome to Join the Technical Exchange Group
@@ -48,41 +50,57 @@ Four sample solutions are provided, including product recognition, vehicle recog
## Quick Start
-Quick experience of image recognition:[Link](./docs/en/tutorials/quick_start_recognition_en.md)
+Quick experience of PP-ShiTu image recognition system:[Link](./docs/en/quick_start/quick_start_recognition_en.md)
+
+Quick experience of **P**ractical **U**ltra **L**ight-weight image **C**lassification models:[Link](docs/en/PULC/PULC_quickstart_en.md)
## Tutorials
-- [Quick Installation](./docs/en/tutorials/install_en.md)
-- [Quick Start of Recognition](./docs/en/tutorials/quick_start_recognition_en.md)
+- [Install Paddle](./docs/en/installation/install_paddle_en.md)
+- [Install PaddleClas Environment](./docs/en/installation/install_paddleclas_en.md)
+- [Practical Ultra Light-weight image Classification solutions](./docs/en/PULC/PULC_train_en.md)
+ - [PULC Quick Start](docs/en/PULC/PULC_quickstart_en.md)
+ - [PULC Model Zoo](docs/en/PULC/PULC_model_list_en.md)
+ - [PULC Classification Model of Someone or Nobody](docs/en/PULC/PULC_person_exists_en.md)
+ - [PULC Recognition Model of Person Attribute](docs/en/PULC/PULC_person_attribute_en.md)
+ - [PULC Classification Model of Wearing or Unwearing Safety Helmet](docs/en/PULC/PULC_safety_helmet_en.md)
+ - [PULC Classification Model of Traffic Sign](docs/en/PULC/PULC_traffic_sign_en.md)
+ - [PULC Recognition Model of Vehicle Attribute](docs/en/PULC/PULC_vehicle_attribute_en.md)
+ - [PULC Classification Model of Containing or Uncontaining Car](docs/en/PULC/PULC_car_exists_en.md)
+ - [PULC Classification Model of Text Image Orientation](docs/en/PULC/PULC_text_image_orientation_en.md)
+ - [PULC Classification Model of Textline Orientation](docs/en/PULC/PULC_textline_orientation_en.md)
+ - [PULC Classification Model of Language](docs/en/PULC/PULC_language_classification_en.md)
+- [Quick Start of Recognition](./docs/en/quick_start/quick_start_recognition_en.md)
- [Introduction to Image Recognition Systems](#Introduction_to_Image_Recognition_Systems)
-- [Demo images](#Demo_images)
+- [Image Recognition Demo images](#Rec_Demo_images)
+- [PULC demo images](#Clas_Demo_images)
- Algorithms Introduction
- - [Backbone Network and Pre-trained Model Library](./docs/en/ImageNet_models_en.md)
- - [Mainbody Detection](./docs/en/application/mainbody_detection_en.md)
- - [Image Classification](./docs/en/tutorials/image_classification_en.md)
- - [Feature Learning](./docs/en/application/feature_learning_en.md)
- - [Product Recognition](./docs/en/application/product_recognition_en.md)
- - [Vehicle Recognition](./docs/en/application/vehicle_recognition_en.md)
- - [Logo Recognition](./docs/en/application/logo_recognition_en.md)
- - [Animation Character Recognition](./docs/en/application/cartoon_character_recognition_en.md)
+ - [Backbone Network and Pre-trained Model Library](./docs/en/algorithm_introduction/ImageNet_models_en.md)
+ - [Mainbody Detection](./docs/en/image_recognition_pipeline/mainbody_detection_en.md)
+ - [Feature Learning](./docs/en/image_recognition_pipeline/feature_extraction_en.md)
- [Vector Search](./deploy/vector_search/README.md)
-- Models Training/Evaluation
- - [Image Classification](./docs/en/tutorials/getting_started_en.md)
- - [Feature Learning](./docs/en/tutorials/getting_started_retrieval_en.md)
- Inference Model Prediction
- - [Python Inference](./docs/en/inference.md)
+ - [Python Inference](./docs/en/inference_deployment/python_deploy_en.md)
- [C++ Classfication Inference](./deploy/cpp/readme_en.md), [C++ PP-ShiTu Inference](deploy/cpp_shitu/readme_en.md)
- Model Deploy (only support classification for now, recognition coming soon)
- [Hub Serving Deployment](./deploy/hubserving/readme_en.md)
- [Mobile Deployment](./deploy/lite/readme_en.md)
- - [Inference Using whl](./docs/en/whl_en.md)
+ - [Inference Using whl](./docs/en/inference_deployment/whl_deploy_en.md)
- Advanced Tutorial
- [Knowledge Distillation](./docs/en/advanced_tutorials/distillation/distillation_en.md)
- - [Model Quantization](./docs/en/extension/paddle_quantization_en.md)
- - [Data Augmentation](./docs/en/advanced_tutorials/image_augmentation/ImageAugment_en.md)
+ - [Model Quantization](./docs/en/algorithm_introduction/model_prune_quantization_en.md)
+ - [Data Augmentation](./docs/en/advanced_tutorials/DataAugmentation_en.md)
- [License](#License)
- [Contribution](#Contribution)
+

diff --git a/deploy/configs/PULC/car_exists/inference_car_exists.yaml b/deploy/configs/PULC/car_exists/inference_car_exists.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..b6733069d99b5622c83321bc628f3d70274ce8d4
--- /dev/null
+++ b/deploy/configs/PULC/car_exists/inference_car_exists.yaml
@@ -0,0 +1,36 @@
+Global:
+ infer_imgs: "./images/PULC/car_exists/objects365_00001507.jpeg"
+ inference_model_dir: "./models/car_exists_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 256
+ - CropImage:
+ size: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: ThreshOutput
+ ThreshOutput:
+ threshold: 0.5
+ label_0: no_car
+ label_1: contains_car
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/language_classification/inference_language_classification.yaml b/deploy/configs/PULC/language_classification/inference_language_classification.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..fb9fb6b6631e774e7486bcdb31c25621e2b7d790
--- /dev/null
+++ b/deploy/configs/PULC/language_classification/inference_language_classification.yaml
@@ -0,0 +1,33 @@
+Global:
+ infer_imgs: "./images/PULC/language_classification/word_35404.png"
+ inference_model_dir: "./models/language_classification_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ size: [160, 80]
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: Topk
+ Topk:
+ topk: 2
+ class_id_map_file: "../ppcls/utils/PULC_label_list/language_classification_label_list.txt"
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/person_attribute/inference_person_attribute.yaml b/deploy/configs/PULC/person_attribute/inference_person_attribute.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d5be2a3568291d0a31a7026974fc22ecf54a8f4c
--- /dev/null
+++ b/deploy/configs/PULC/person_attribute/inference_person_attribute.yaml
@@ -0,0 +1,32 @@
+Global:
+ infer_imgs: "./images/PULC/person_attribute/090004.jpg"
+ inference_model_dir: "./models/person_attribute_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: True
+ cpu_num_threads: 10
+ benchmark: False
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ size: [192, 256]
+ - NormalizeImage:
+ scale: 1.0/255.0
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: PersonAttribute
+ PersonAttribute:
+ threshold: 0.5 #default threshold
+ glasses_threshold: 0.3 #threshold only for glasses
+ hold_threshold: 0.6 #threshold only for hold
diff --git a/deploy/configs/PULC/person_exists/inference_person_exists.yaml b/deploy/configs/PULC/person_exists/inference_person_exists.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3df94a80c7c75814e778e5320a31b20a8a7eb742
--- /dev/null
+++ b/deploy/configs/PULC/person_exists/inference_person_exists.yaml
@@ -0,0 +1,36 @@
+Global:
+ infer_imgs: "./images/PULC/person_exists/objects365_02035329.jpg"
+ inference_model_dir: "./models/person_exists_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 256
+ - CropImage:
+ size: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: ThreshOutput
+ ThreshOutput:
+ threshold: 0.5
+ label_0: nobody
+ label_1: someone
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/safety_helmet/inference_safety_helmet.yaml b/deploy/configs/PULC/safety_helmet/inference_safety_helmet.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..66a4cebb359a9b1f03a205ee6a031ca6464cffa8
--- /dev/null
+++ b/deploy/configs/PULC/safety_helmet/inference_safety_helmet.yaml
@@ -0,0 +1,36 @@
+Global:
+ infer_imgs: "./images/PULC/safety_helmet/safety_helmet_test_1.png"
+ inference_model_dir: "./models/safety_helmet_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 256
+ - CropImage:
+ size: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: ThreshOutput
+ ThreshOutput:
+ threshold: 0.5
+ label_0: wearing_helmet
+ label_1: unwearing_helmet
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/text_image_orientation/inference_text_image_orientation.yaml b/deploy/configs/PULC/text_image_orientation/inference_text_image_orientation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c6c3969ffa627288fe58fab28b3fe1cbffe9dd03
--- /dev/null
+++ b/deploy/configs/PULC/text_image_orientation/inference_text_image_orientation.yaml
@@ -0,0 +1,35 @@
+Global:
+ infer_imgs: "./images/PULC/text_image_orientation/img_rot0_demo.jpg"
+ inference_model_dir: "./models/text_image_orientation_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 256
+ - CropImage:
+ size: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: Topk
+ Topk:
+ topk: 2
+ class_id_map_file: "../ppcls/utils/PULC_label_list/text_image_orientation_label_list.txt"
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/textline_orientation/inference_textline_orientation.yaml b/deploy/configs/PULC/textline_orientation/inference_textline_orientation.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..108b3dd53a95c06345bdd7ccd34b2e5252d2df19
--- /dev/null
+++ b/deploy/configs/PULC/textline_orientation/inference_textline_orientation.yaml
@@ -0,0 +1,33 @@
+Global:
+ infer_imgs: "./images/PULC/textline_orientation/textline_orientation_test_0_0.png"
+ inference_model_dir: "./models/textline_orientation_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: True
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ size: [160, 80]
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: Topk
+ Topk:
+ topk: 1
+ class_id_map_file: "../ppcls/utils/PULC_label_list/textline_orientation_label_list.txt"
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/traffic_sign/inference_traffic_sign.yaml b/deploy/configs/PULC/traffic_sign/inference_traffic_sign.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..53699718b4fdd38da86eaee4cccc584dcc87d2b7
--- /dev/null
+++ b/deploy/configs/PULC/traffic_sign/inference_traffic_sign.yaml
@@ -0,0 +1,35 @@
+Global:
+ infer_imgs: "./images/PULC/traffic_sign/99603_17806.jpg"
+ inference_model_dir: "./models/traffic_sign_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: True
+ cpu_num_threads: 10
+ benchmark: False
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 256
+ - CropImage:
+ size: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: Topk
+ Topk:
+ topk: 5
+ class_id_map_file: "../ppcls/utils/PULC_label_list/traffic_sign_label_list.txt"
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/PULC/vehicle_attribute/inference_vehicle_attribute.yaml b/deploy/configs/PULC/vehicle_attribute/inference_vehicle_attribute.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..14ae348d09faca113d5863fbb57f066675b3f447
--- /dev/null
+++ b/deploy/configs/PULC/vehicle_attribute/inference_vehicle_attribute.yaml
@@ -0,0 +1,32 @@
+Global:
+ infer_imgs: "./images/PULC/vehicle_attribute/0002_c002_00030670_0.jpg"
+ inference_model_dir: "./models/vehicle_attribute_infer"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: True
+ cpu_num_threads: 10
+ benchmark: False
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ size: [256, 192]
+ - NormalizeImage:
+ scale: 1.0/255.0
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: VehicleAttribute
+ VehicleAttribute:
+ color_threshold: 0.5
+ type_threshold: 0.5
+
diff --git a/deploy/configs/inference_attr.yaml b/deploy/configs/inference_attr.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..88f73db5419414812450b768ac783982386f0a78
--- /dev/null
+++ b/deploy/configs/inference_attr.yaml
@@ -0,0 +1,33 @@
+Global:
+ infer_imgs: "./images/Pedestrain_Attr.jpg"
+ inference_model_dir: "../inference/"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: False
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ size: [192, 256]
+ - NormalizeImage:
+ scale: 1.0/255.0
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: PersonAttribute
+ PersonAttribute:
+ threshold: 0.5 #default threshold
+ glasses_threshold: 0.3 #threshold only for glasses
+ hold_threshold: 0.6 #threshold only for hold
+
diff --git a/deploy/configs/inference_cartoon.yaml b/deploy/configs/inference_cartoon.yaml
index 7d93d98cc0696d8e1508e02db2cc864d6f917d19..e79da55090130223466fd6b6a078b9909d6e26f2 100644
--- a/deploy/configs/inference_cartoon.yaml
+++ b/deploy/configs/inference_cartoon.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/configs/inference_cls.yaml b/deploy/configs/inference_cls.yaml
index fc0f0fe67aa628e504bb6fcb743f29fd020548cc..d9181278cc617822f98e4966abf0d12ceca498a4 100644
--- a/deploy/configs/inference_cls.yaml
+++ b/deploy/configs/inference_cls.yaml
@@ -1,5 +1,5 @@
Global:
- infer_imgs: "./images/ILSVRC2012_val_00000010.jpeg"
+ infer_imgs: "./images/ImageNet/ILSVRC2012_val_00000010.jpeg"
inference_model_dir: "./models"
batch_size: 1
use_gpu: True
@@ -32,4 +32,4 @@ PostProcess:
topk: 5
class_id_map_file: "../ppcls/utils/imagenet1k_label_list.txt"
SavePreLabel:
- save_dir: ./pre_label/
\ No newline at end of file
+ save_dir: ./pre_label/
diff --git a/deploy/configs/inference_cls_based_action.yaml b/deploy/configs/inference_cls_based_action.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..005301c2ab395277020ef34db644cb1ffc26c2c3
--- /dev/null
+++ b/deploy/configs/inference_cls_based_action.yaml
@@ -0,0 +1,33 @@
+Global:
+ infer_imgs: "./images/ImageNet/ILSVRC2012_val_00000010.jpeg"
+ inference_model_dir: "./models/PPHGNet_tiny_calling_halfbody/"
+ batch_size: 1
+ use_gpu: True
+ enable_mkldnn: True
+ cpu_num_threads: 10
+ enable_benchmark: True
+ use_fp16: False
+ ir_optim: True
+ use_tensorrt: False
+ gpu_mem: 8000
+ enable_profile: False
+
+PreProcess:
+ transform_ops:
+ - ResizeImage:
+ resize_short: 224
+ - NormalizeImage:
+ scale: 0.00392157
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: ''
+ channel_num: 3
+ - ToCHWImage:
+
+PostProcess:
+ main_indicator: Topk
+ Topk:
+ topk: 2
+ class_id_map_file: "../dataset/data/phone_label_list.txt"
+ SavePreLabel:
+ save_dir: ./pre_label/
diff --git a/deploy/configs/inference_cls_ch4.yaml b/deploy/configs/inference_cls_ch4.yaml
index 9b740ed8293c3d66a325682cafc42e2b1415df4d..85f9acb29a88772da63abe302354f5e17a9c3e59 100644
--- a/deploy/configs/inference_cls_ch4.yaml
+++ b/deploy/configs/inference_cls_ch4.yaml
@@ -1,5 +1,5 @@
Global:
- infer_imgs: "./images/ILSVRC2012_val_00000010.jpeg"
+ infer_imgs: "./images/ImageNet/ILSVRC2012_val_00000010.jpeg"
inference_model_dir: "./models"
batch_size: 1
use_gpu: True
@@ -32,4 +32,4 @@ PostProcess:
topk: 5
class_id_map_file: "../ppcls/utils/imagenet1k_label_list.txt"
SavePreLabel:
- save_dir: ./pre_label/
\ No newline at end of file
+ save_dir: ./pre_label/
diff --git a/deploy/configs/inference_det.yaml b/deploy/configs/inference_det.yaml
index c809a0257bc7c5b774f20fb3edb50a08e7d67bbb..dab7908ef7f59bfed077d9189811aedb650b0e92 100644
--- a/deploy/configs/inference_det.yaml
+++ b/deploy/configs/inference_det.yaml
@@ -5,7 +5,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 1
- labe_list:
+ label_list:
- foreground
# inference engine config
diff --git a/deploy/configs/inference_drink.yaml b/deploy/configs/inference_drink.yaml
index d044965f446634dcc151fd496a9d7b403b869d68..1c3e2c29aa8ddd5db46bbc8660c9f45942696a9c 100644
--- a/deploy/configs/inference_drink.yaml
+++ b/deploy/configs/inference_drink.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/configs/inference_general.yaml b/deploy/configs/inference_general.yaml
index 6b397b5047b427d02014060380112b096e0b2da2..8fb8ae3a56697b882be00da554f33750ead42f70 100644
--- a/deploy/configs/inference_general.yaml
+++ b/deploy/configs/inference_general.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/configs/inference_general_binary.yaml b/deploy/configs/inference_general_binary.yaml
index d76dae8f8f7c70f27996f6b20fd623bdc00bc441..72ec31fc438d1f884bada59507a90d172ab4a416 100644
--- a/deploy/configs/inference_general_binary.yaml
+++ b/deploy/configs/inference_general_binary.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/configs/inference_logo.yaml b/deploy/configs/inference_logo.yaml
index f78ca25a042b3224a973d81f7b0242ace7c25430..2b8228eab772f8b1488275163518a6e059a49c53 100644
--- a/deploy/configs/inference_logo.yaml
+++ b/deploy/configs/inference_logo.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/configs/inference_product.yaml b/deploy/configs/inference_product.yaml
index e7b494c383aa5f42b4515446805b1357ba43107c..78ba32068cb696e897c39d516e66b323bd12ad61 100644
--- a/deploy/configs/inference_product.yaml
+++ b/deploy/configs/inference_product.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
# inference engine config
diff --git a/deploy/configs/inference_vehicle.yaml b/deploy/configs/inference_vehicle.yaml
index d99f42ad684150f1efeaf65f031ee1ea707fee37..e289e9f523b061dd26b8d687e594499dd7cdec37 100644
--- a/deploy/configs/inference_vehicle.yaml
+++ b/deploy/configs/inference_vehicle.yaml
@@ -8,7 +8,7 @@ Global:
image_shape: [3, 640, 640]
threshold: 0.2
max_det_results: 5
- labe_list:
+ label_list:
- foreground
use_gpu: True
diff --git a/deploy/cpp_shitu/include/object_detector.h b/deploy/cpp_shitu/include/object_detector.h
index 5bfc56253b1845a50f3b6b093db314e97505cfef..6855a0dcc84c2711283fe8d23ba1d2afe376fb0e 100644
--- a/deploy/cpp_shitu/include/object_detector.h
+++ b/deploy/cpp_shitu/include/object_detector.h
@@ -33,106 +33,106 @@ using namespace paddle_infer;
namespace Detection {
// Object Detection Result
- struct ObjectResult {
- // Rectangle coordinates of detected object: left, right, top, down
- std::vector
rect;
- // Class id of detected object
- int class_id;
- // Confidence of detected object
- float confidence;
- };
+struct ObjectResult {
+ // Rectangle coordinates of detected object: left, right, top, down
+ std::vector rect;
+ // Class id of detected object
+ int class_id;
+ // Confidence of detected object
+ float confidence;
+};
// Generate visualization colormap for each class
- std::vector GenerateColorMap(int num_class);
+std::vector GenerateColorMap(int num_class);
// Visualiztion Detection Result
- cv::Mat VisualizeResult(const cv::Mat &img,
- const std::vector &results,
- const std::vector &lables,
- const std::vector &colormap, const bool is_rbox);
-
- class ObjectDetector {
- public:
- explicit ObjectDetector(const YAML::Node &config_file) {
- this->use_gpu_ = config_file["Global"]["use_gpu"].as();
- if (config_file["Global"]["gpu_id"].IsDefined())
- this->gpu_id_ = config_file["Global"]["gpu_id"].as();
- this->gpu_mem_ = config_file["Global"]["gpu_mem"].as();
- this->cpu_math_library_num_threads_ =
- config_file["Global"]["cpu_num_threads"].as();
- this->use_mkldnn_ = config_file["Global"]["enable_mkldnn"].as();
- this->use_tensorrt_ = config_file["Global"]["use_tensorrt"].as();
- this->use_fp16_ = config_file["Global"]["use_fp16"].as();
- this->model_dir_ =
- config_file["Global"]["det_inference_model_dir"].as();
- this->threshold_ = config_file["Global"]["threshold"].as();
- this->max_det_results_ = config_file["Global"]["max_det_results"].as();
- this->image_shape_ =
- config_file["Global"]["image_shape"].as < std::vector < int >> ();
- this->label_list_ =
- config_file["Global"]["labe_list"].as < std::vector < std::string >> ();
- this->ir_optim_ = config_file["Global"]["ir_optim"].as();
- this->batch_size_ = config_file["Global"]["batch_size"].as();
-
- preprocessor_.Init(config_file["DetPreProcess"]["transform_ops"]);
- LoadModel(model_dir_, batch_size_, run_mode);
- }
-
- // Load Paddle inference model
- void LoadModel(const std::string &model_dir, const int batch_size = 1,
- const std::string &run_mode = "fluid");
-
- // Run predictor
- void Predict(const std::vector imgs, const int warmup = 0,
- const int repeats = 1,
- std::vector *result = nullptr,
- std::vector *bbox_num = nullptr,
- std::vector *times = nullptr);
-
- const std::vector &GetLabelList() const {
- return this->label_list_;
- }
-
- const float &GetThreshold() const { return this->threshold_; }
-
- private:
- bool use_gpu_ = true;
- int gpu_id_ = 0;
- int gpu_mem_ = 800;
- int cpu_math_library_num_threads_ = 6;
- std::string run_mode = "fluid";
- bool use_mkldnn_ = false;
- bool use_tensorrt_ = false;
- bool batch_size_ = 1;
- bool use_fp16_ = false;
- std::string model_dir_;
- float threshold_ = 0.5;
- float max_det_results_ = 5;
- std::vector image_shape_ = {3, 640, 640};
- std::vector label_list_;
- bool ir_optim_ = true;
- bool det_permute_ = true;
- bool det_postprocess_ = true;
- int min_subgraph_size_ = 30;
- bool use_dynamic_shape_ = false;
- int trt_min_shape_ = 1;
- int trt_max_shape_ = 1280;
- int trt_opt_shape_ = 640;
- bool trt_calib_mode_ = false;
-
- // Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat &image_mat);
-
- // Postprocess result
- void Postprocess(const std::vector mats,
- std::vector *result, std::vector bbox_num,
- bool is_rbox);
-
- std::shared_ptr predictor_;
- Preprocessor preprocessor_;
- ImageBlob inputs_;
- std::vector output_data_;
- std::vector out_bbox_num_data_;
- };
+cv::Mat VisualizeResult(const cv::Mat &img,
+ const std::vector &results,
+ const std::vector &lables,
+ const std::vector &colormap, const bool is_rbox);
+
+class ObjectDetector {
+public:
+ explicit ObjectDetector(const YAML::Node &config_file) {
+ this->use_gpu_ = config_file["Global"]["use_gpu"].as();
+ if (config_file["Global"]["gpu_id"].IsDefined())
+ this->gpu_id_ = config_file["Global"]["gpu_id"].as();
+ this->gpu_mem_ = config_file["Global"]["gpu_mem"].as();
+ this->cpu_math_library_num_threads_ =
+ config_file["Global"]["cpu_num_threads"].as();
+ this->use_mkldnn_ = config_file["Global"]["enable_mkldnn"].as();
+ this->use_tensorrt_ = config_file["Global"]["use_tensorrt"].as();
+ this->use_fp16_ = config_file["Global"]["use_fp16"].as();
+ this->model_dir_ =
+ config_file["Global"]["det_inference_model_dir"].as();
+ this->threshold_ = config_file["Global"]["threshold"].as();
+ this->max_det_results_ = config_file["Global"]["max_det_results"].as();
+ this->image_shape_ =
+ config_file["Global"]["image_shape"].as>();
+ this->label_list_ =
+ config_file["Global"]["label_list"].as>();
+ this->ir_optim_ = config_file["Global"]["ir_optim"].as();
+ this->batch_size_ = config_file["Global"]["batch_size"].as();
+
+ preprocessor_.Init(config_file["DetPreProcess"]["transform_ops"]);
+ LoadModel(model_dir_, batch_size_, run_mode);
+ }
+
+ // Load Paddle inference model
+ void LoadModel(const std::string &model_dir, const int batch_size = 1,
+ const std::string &run_mode = "fluid");
+
+ // Run predictor
+ void Predict(const std::vector imgs, const int warmup = 0,
+ const int repeats = 1,
+ std::vector *result = nullptr,
+ std::vector *bbox_num = nullptr,
+ std::vector *times = nullptr);
+
+ const std::vector &GetLabelList() const {
+ return this->label_list_;
+ }
+
+ const float &GetThreshold() const { return this->threshold_; }
+
+private:
+ bool use_gpu_ = true;
+ int gpu_id_ = 0;
+ int gpu_mem_ = 800;
+ int cpu_math_library_num_threads_ = 6;
+ std::string run_mode = "fluid";
+ bool use_mkldnn_ = false;
+ bool use_tensorrt_ = false;
+ bool batch_size_ = 1;
+ bool use_fp16_ = false;
+ std::string model_dir_;
+ float threshold_ = 0.5;
+ float max_det_results_ = 5;
+ std::vector image_shape_ = {3, 640, 640};
+ std::vector label_list_;
+ bool ir_optim_ = true;
+ bool det_permute_ = true;
+ bool det_postprocess_ = true;
+ int min_subgraph_size_ = 30;
+ bool use_dynamic_shape_ = false;
+ int trt_min_shape_ = 1;
+ int trt_max_shape_ = 1280;
+ int trt_opt_shape_ = 640;
+ bool trt_calib_mode_ = false;
+
+ // Preprocess image and copy data to input buffer
+ void Preprocess(const cv::Mat &image_mat);
+
+ // Postprocess result
+ void Postprocess(const std::vector mats,
+ std::vector *result, std::vector bbox_num,
+ bool is_rbox);
+
+ std::shared_ptr predictor_;
+ Preprocessor preprocessor_;
+ ImageBlob inputs_;
+ std::vector output_data_;
+ std::vector out_bbox_num_data_;
+};
} // namespace Detection
diff --git a/deploy/hubserving/readme.md b/deploy/hubserving/readme.md
index 6b2b2dd4dd703965f52fa7d16cd6be41672186a9..8506c9e4144b4792a06ff36de6c0f6d4698b40cf 100644
--- a/deploy/hubserving/readme.md
+++ b/deploy/hubserving/readme.md
@@ -1,83 +1,117 @@
-[English](readme_en.md) | 简体中文
+简体中文 | [English](readme_en.md)
-# 基于PaddleHub Serving的服务部署
+# 基于 PaddleHub Serving 的服务部署
-hubserving服务部署配置服务包`clas`下包含3个必选文件,目录如下:
-```
-hubserving/clas/
- └─ __init__.py 空文件,必选
- └─ config.json 配置文件,可选,使用配置启动服务时作为参数传入
- └─ module.py 主模块,必选,包含服务的完整逻辑
- └─ params.py 参数文件,必选,包含模型路径、前后处理参数等参数
+PaddleClas 支持通过 PaddleHub 快速进行服务化部署。目前支持图像分类的部署,图像识别的部署敬请期待。
+
+
+## 目录
+- [1. 简介](#1-简介)
+- [2. 准备环境](#2-准备环境)
+- [3. 下载推理模型](#3-下载推理模型)
+- [4. 安装服务模块](#4-安装服务模块)
+- [5. 启动服务](#5-启动服务)
+ - [5.1 命令行启动](#51-命令行启动)
+ - [5.2 配置文件启动](#52-配置文件启动)
+- [6. 发送预测请求](#6-发送预测请求)
+- [7. 自定义修改服务模块](#7-自定义修改服务模块)
+
+
+
+## 1. 简介
+
+hubserving 服务部署配置服务包 `clas` 下包含 3 个必选文件,目录如下:
+
+```shell
+deploy/hubserving/clas/
+├── __init__.py # 空文件,必选
+├── config.json # 配置文件,可选,使用配置启动服务时作为参数传入
+├── module.py # 主模块,必选,包含服务的完整逻辑
+└── params.py # 参数文件,必选,包含模型路径、前后处理参数等参数
```
-## 快速启动服务
-### 1. 准备环境
+
+
+## 2. 准备环境
```shell
-# 安装paddlehub,请安装2.0版本
-pip3 install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
+# 安装 paddlehub,建议安装 2.1.0 版本
+python3.7 -m pip install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
```
-### 2. 下载推理模型
+
+
+## 3. 下载推理模型
+
安装服务模块前,需要准备推理模型并放到正确路径,默认模型路径为:
-```
-分类推理模型结构文件:PaddleClas/inference/inference.pdmodel
-分类推理模型权重文件:PaddleClas/inference/inference.pdiparams
-```
+
+* 分类推理模型结构文件:`PaddleClas/inference/inference.pdmodel`
+* 分类推理模型权重文件:`PaddleClas/inference/inference.pdiparams`
**注意**:
-* 模型文件路径可在`PaddleClas/deploy/hubserving/clas/params.py`中查看和修改:
+* 模型文件路径可在 `PaddleClas/deploy/hubserving/clas/params.py` 中查看和修改:
+
```python
"inference_model_dir": "../inference/"
```
- 需要注意,模型文件(包括.pdmodel与.pdiparams)名称必须为`inference`。
-* 我们也提供了大量基于ImageNet-1k数据集的预训练模型,模型列表及下载地址详见[模型库概览](../../docs/zh_CN/models/models_intro.md),也可以使用自己训练转换好的模型。
+* 模型文件(包括 `.pdmodel` 与 `.pdiparams`)的名称必须为 `inference`。
+* 我们提供了大量基于 ImageNet-1k 数据集的预训练模型,模型列表及下载地址详见[模型库概览](../../docs/zh_CN/algorithm_introduction/ImageNet_models.md),也可以使用自己训练转换好的模型。
-### 3. 安装服务模块
-针对Linux环境和Windows环境,安装命令如下。
-* 在Linux环境下,安装示例如下:
-```shell
-cd PaddleClas/deploy
-# 安装服务模块:
-hub install hubserving/clas/
-```
+
+## 4. 安装服务模块
+
+* 在 Linux 环境下,安装示例如下:
+ ```shell
+ cd PaddleClas/deploy
+ # 安装服务模块:
+ hub install hubserving/clas/
+ ```
+
+* 在 Windows 环境下(文件夹的分隔符为`\`),安装示例如下:
+
+ ```shell
+ cd PaddleClas\deploy
+ # 安装服务模块:
+ hub install hubserving\clas\
+ ```
+
-* 在Windows环境下(文件夹的分隔符为`\`),安装示例如下:
+
+## 5. 启动服务
+
+
+
+### 5.1 命令行启动
+
+该方式仅支持使用 CPU 预测。启动命令:
```shell
-cd PaddleClas\deploy
-# 安装服务模块:
-hub install hubserving\clas\
+hub serving start \
+--modules clas_system
+--port 8866
```
+这样就完成了一个服务化 API 的部署,使用默认端口号 8866。
-### 4. 启动服务
-#### 方式1. 命令行命令启动(仅支持CPU)
-**启动命令:**
-```shell
-$ hub serving start --modules Module1==Version1 \
- --port XXXX \
- --use_multiprocess \
- --workers \
-```
+**参数说明**:
+| 参数 | 用途 |
+| ------------------ | ----------------------------------------------------------------------------------------------------------------------------- |
+| --modules/-m | [**必选**] PaddleHub Serving 预安装模型,以多个 Module==Version 键值对的形式列出
*`当不指定 Version 时,默认选择最新版本`* |
+| --port/-p | [**可选**] 服务端口,默认为 8866 |
+| --use_multiprocess | [**可选**] 是否启用并发方式,默认为单进程方式,推荐多核 CPU 机器使用此方式
*`Windows 操作系统只支持单进程方式`* |
+| --workers | [**可选**] 在并发方式下指定的并发任务数,默认为 `2*cpu_count-1`,其中 `cpu_count` 为 CPU 核数 |
+更多部署细节详见 [PaddleHub Serving模型一键服务部署](https://paddlehub.readthedocs.io/zh_CN/release-v2.1/tutorial/serving.html)
-**参数:**
-|参数|用途|
-|-|-|
-|--modules/-m| [**必选**] PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出
*`当不指定Version时,默认选择最新版本`*|
-|--port/-p| [**可选**] 服务端口,默认为8866|
-|--use_multiprocess| [**可选**] 是否启用并发方式,默认为单进程方式,推荐多核CPU机器使用此方式
*`Windows操作系统只支持单进程方式`*|
-|--workers| [**可选**] 在并发方式下指定的并发任务数,默认为`2*cpu_count-1`,其中`cpu_count`为CPU核数|
+
+### 5.2 配置文件启动
-如按默认参数启动服务: ```hub serving start -m clas_system```
+该方式仅支持使用 CPU 或 GPU 预测。启动命令:
-这样就完成了一个服务化API的部署,使用默认端口号8866。
+```shell
+hub serving start -c config.json
+```
-#### 方式2. 配置文件启动(支持CPU、GPU)
-**启动命令:**
-```hub serving start -c config.json```
+其中,`config.json` 格式如下:
-其中,`config.json`格式如下:
```json
{
"modules_info": {
@@ -97,92 +131,109 @@ $ hub serving start --modules Module1==Version1 \
}
```
-- `init_args`中的可配参数与`module.py`中的`_initialize`函数接口一致。其中,
- - 当`use_gpu`为`true`时,表示使用GPU启动服务。
- - 当`enable_mkldnn`为`true`时,表示使用MKL-DNN加速。
-- `predict_args`中的可配参数与`module.py`中的`predict`函数接口一致。
+**参数说明**:
+* `init_args` 中的可配参数与 `module.py` 中的 `_initialize` 函数接口一致。其中,
+ - 当 `use_gpu` 为 `true` 时,表示使用 GPU 启动服务。
+ - 当 `enable_mkldnn` 为 `true` 时,表示使用 MKL-DNN 加速。
+* `predict_args` 中的可配参数与 `module.py` 中的 `predict` 函数接口一致。
-**注意:**
-- 使用配置文件启动服务时,其他参数会被忽略。
-- 如果使用GPU预测(即,`use_gpu`置为`true`),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:```export CUDA_VISIBLE_DEVICES=0```,否则不用设置。
-- **`use_gpu`不可与`use_multiprocess`同时为`true`**。
-- **`use_gpu`与`enable_mkldnn`同时为`true`时,将忽略`enable_mkldnn`,而使用GPU**。
+**注意**:
+* 使用配置文件启动服务时,将使用配置文件中的参数设置,其他命令行参数将被忽略;
+* 如果使用 GPU 预测(即,`use_gpu` 置为 `true`),则需要在启动服务之前,设置 `CUDA_VISIBLE_DEVICES` 环境变量来指定所使用的 GPU 卡号,如:`export CUDA_VISIBLE_DEVICES=0`;
+* **`use_gpu` 不可与 `use_multiprocess` 同时为 `true`**;
+* **`use_gpu` 与 `enable_mkldnn` 同时为 `true` 时,将忽略 `enable_mkldnn`,而使用 GPU**。
+
+如使用 GPU 3 号卡启动服务:
-如,使用GPU 3号卡启动串联服务:
```shell
cd PaddleClas/deploy
export CUDA_VISIBLE_DEVICES=3
hub serving start -c hubserving/clas/config.json
-```
+```
-## 发送预测请求
-配置好服务端,可使用以下命令发送预测请求,获取预测结果:
+
+## 6. 发送预测请求
+
+配置好服务端后,可使用以下命令发送预测请求,获取预测结果:
```shell
cd PaddleClas/deploy
-python hubserving/test_hubserving.py server_url image_path
-```
-
-需要给脚本传递2个必须参数:
-- **server_url**:服务地址,格式为
-`http://[ip_address]:[port]/predict/[module_name]`
-- **image_path**:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径。
-- **batch_size**:[**可选**] 以`batch_size`大小为单位进行预测,默认为`1`。
-- **resize_short**:[**可选**] 预处理时,按短边调整大小,默认为`256`。
-- **crop_size**:[**可选**] 预处理时,居中裁剪的大小,默认为`224`。
-- **normalize**:[**可选**] 预处理时,是否进行`normalize`,默认为`True`。
-- **to_chw**:[**可选**] 预处理时,是否调整为`CHW`顺序,默认为`True`。
+python3.7 hubserving/test_hubserving.py \
+--server_url http://127.0.0.1:8866/predict/clas_system \
+--image_file ./hubserving/ILSVRC2012_val_00006666.JPEG \
+--batch_size 8
+```
+**预测输出**
+```log
+The result(s): class_ids: [57, 67, 68, 58, 65], label_names: ['garter snake, grass snake', 'diamondback, diamondback rattlesnake, Crotalus adamanteus', 'sidewinder, horned rattlesnake, Crotalus cerastes', 'water snake', 'sea snake'], scores: [0.21915, 0.15631, 0.14794, 0.13177, 0.12285]
+The average time of prediction cost: 2.970 s/image
+The average time cost: 3.014 s/image
+The average top-1 score: 0.110
+```
-**注意**:如果使用`Transformer`系列模型,如`DeiT_***_384`, `ViT_***_384`等,请注意模型的输入数据尺寸,需要指定`--resize_short=384 --crop_size=384`。
+**脚本参数说明**:
+* **server_url**:服务地址,格式为`http://[ip_address]:[port]/predict/[module_name]`。
+* **image_path**:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径。
+* **batch_size**:[**可选**] 以 `batch_size` 大小为单位进行预测,默认为 `1`。
+* **resize_short**:[**可选**] 预处理时,按短边调整大小,默认为 `256`。
+* **crop_size**:[**可选**] 预处理时,居中裁剪的大小,默认为 `224`。
+* **normalize**:[**可选**] 预处理时,是否进行 `normalize`,默认为 `True`。
+* **to_chw**:[**可选**] 预处理时,是否调整为 `CHW` 顺序,默认为 `True`。
+**注意**:如果使用 `Transformer` 系列模型,如 `DeiT_***_384`, `ViT_***_384` 等,请注意模型的输入数据尺寸,需要指定`--resize_short=384 --crop_size=384`。
-访问示例:
+**返回结果格式说明**:
+返回结果为列表(list),包含 top-k 个分类结果,以及对应的得分,还有此图片预测耗时,具体如下:
```shell
-python hubserving/test_hubserving.py --server_url http://127.0.0.1:8866/predict/clas_system --image_file ./hubserving/ILSVRC2012_val_00006666.JPEG --batch_size 8
-```
-
-### 返回结果格式说明
-返回结果为列表(list),包含top-k个分类结果,以及对应的得分,还有此图片预测耗时,具体如下:
-```
list: 返回结果
-└─ list: 第一张图片结果
- └─ list: 前k个分类结果,依score递减排序
- └─ list: 前k个分类结果对应的score,依score递减排序
- └─ float: 该图分类耗时,单位秒
+└──list: 第一张图片结果
+ ├── list: 前 k 个分类结果,依 score 递减排序
+ ├── list: 前 k 个分类结果对应的 score,依 score 递减排序
+ └── float: 该图分类耗时,单位秒
```
-**说明:** 如果需要增加、删除、修改返回字段,可对相应模块进行修改,完整流程参考下一节自定义修改服务模块。
-## 自定义修改服务模块
-如果需要修改服务逻辑,你一般需要操作以下步骤:
-- 1、 停止服务
-```hub serving stop --port/-p XXXX```
+
+## 7. 自定义修改服务模块
-- 2、 到相应的`module.py`和`params.py`等文件中根据实际需求修改代码。`module.py`修改后需要重新安装(`hub install hubserving/clas/`)并部署。在进行部署前,可通过`python hubserving/clas/module.py`测试已安装服务模块。
+如果需要修改服务逻辑,需要进行以下操作:
-- 3、 卸载旧服务包
-```hub uninstall clas_system```
+1. 停止服务
+ ```shell
+ hub serving stop --port/-p XXXX
+ ```
-- 4、 安装修改后的新服务包
-```hub install hubserving/clas/```
+2. 到相应的 `module.py` 和 `params.py` 等文件中根据实际需求修改代码。`module.py` 修改后需要重新安装(`hub install hubserving/clas/`)并部署。在进行部署前,可先通过 `python3.7 hubserving/clas/module.py` 命令来快速测试准备部署的代码。
-- 5、重新启动服务
-```hub serving start -m clas_system```
+3. 卸载旧服务包
+ ```shell
+ hub uninstall clas_system
+ ```
+
+4. 安装修改后的新服务包
+ ```shell
+ hub install hubserving/clas/
+ ```
+
+5. 重新启动服务
+ ```shell
+ hub serving start -m clas_system
+ ```
**注意**:
-常用参数可在[params.py](./clas/params.py)中修改:
+常用参数可在 `PaddleClas/deploy/hubserving/clas/params.py` 中修改:
* 更换模型,需要修改模型文件路径参数:
```python
"inference_model_dir":
```
- * 更改后处理时返回的`top-k`结果数量:
+ * 更改后处理时返回的 `top-k` 结果数量:
```python
'topk':
```
- * 更改后处理时的lable与class id对应映射文件:
+ * 更改后处理时的 lable 与 class id 对应映射文件:
```python
'class_id_map_file':
```
-为了避免不必要的延时以及能够以batch_size进行预测,数据预处理逻辑(包括resize、crop等操作)在客户端完成,因此需要在[test_hubserving.py](./test_hubserving.py#L35-L52)中修改。
+为了避免不必要的延时以及能够以 batch_size 进行预测,数据预处理逻辑(包括 `resize`、`crop` 等操作)均在客户端完成,因此需要在 [PaddleClas/deploy/hubserving/test_hubserving.py#L41-L47](./test_hubserving.py#L41-L47) 以及 [PaddleClas/deploy/hubserving/test_hubserving.py#L51-L76](./test_hubserving.py#L51-L76) 中修改数据预处理逻辑相关代码。
diff --git a/deploy/hubserving/readme_en.md b/deploy/hubserving/readme_en.md
index bb0ddbd2c3a994b164d8781767b8de38d484b420..6dce5cc52cc32ef41b8f18d5eb772cc44a1661ad 100644
--- a/deploy/hubserving/readme_en.md
+++ b/deploy/hubserving/readme_en.md
@@ -1,83 +1,116 @@
English | [简体中文](readme.md)
-# Service deployment based on PaddleHub Serving
+# Service deployment based on PaddleHub Serving
+
+PaddleClas supports rapid service deployment through PaddleHub. Currently, the deployment of image classification is supported. Please look forward to the deployment of image recognition.
+
+## Catalogue
+- [1 Introduction](#1-introduction)
+- [2. Prepare the environment](#2-prepare-the-environment)
+- [3. Download the inference model](#3-download-the-inference-model)
+- [4. Install the service module](#4-install-the-service-module)
+- [5. Start service](#5-start-service)
+ - [5.1 Start with command line parameters](#51-start-with-command-line-parameters)
+ - [5.2 Start with configuration file](#52-start-with-configuration-file)
+- [6. Send prediction requests](#6-send-prediction-requests)
+- [7. User defined service module modification](#7-user-defined-service-module-modification)
-HubServing service pack contains 3 files, the directory is as follows:
-```
-hubserving/clas/
- └─ __init__.py Empty file, required
- └─ config.json Configuration file, optional, passed in as a parameter when using configuration to start the service
- └─ module.py Main module file, required, contains the complete logic of the service
- └─ params.py Parameter file, required, including parameters such as model path, pre- and post-processing parameters
-```
-## Quick start service
-### 1. Prepare the environment
+
+## 1 Introduction
+
+The hubserving service deployment configuration service package `clas` contains 3 required files, the directories are as follows:
+
```shell
-# Install version 2.0 of PaddleHub
-pip3 install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
+deploy/hubserving/clas/
+├── __init__.py # Empty file, required
+├── config.json # Configuration file, optional, passed in as a parameter when starting the service with configuration
+├── module.py # The main module, required, contains the complete logic of the service
+└── params.py # Parameter file, required, including model path, pre- and post-processing parameters and other parameters
```
-### 2. Download inference model
-Before installing the service module, you need to prepare the inference model and put it in the correct path. The default model path is:
-```
-Model structure file: PaddleClas/inference/inference.pdmodel
-Model parameters file: PaddleClas/inference/inference.pdiparams
+
+## 2. Prepare the environment
+```shell
+# Install paddlehub, version 2.1.0 is recommended
+python3.7 -m pip install paddlehub==2.1.0 --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
```
-* The model file path can be viewed and modified in `PaddleClas/deploy/hubserving/clas/params.py`.
- It should be noted that the prefix of model structure file and model parameters file must be `inference`.
+
+## 3. Download the inference model
-* More models provided by PaddleClas can be obtained from the [model library](../../docs/en/models/models_intro_en.md). You can also use models trained by yourself.
+Before installing the service module, you need to prepare the inference model and put it in the correct path. The default model path is:
-### 3. Install Service Module
+* Classification inference model structure file: `PaddleClas/inference/inference.pdmodel`
+* Classification inference model weight file: `PaddleClas/inference/inference.pdiparams`
-* On Linux platform, the examples are as follows.
-```shell
-cd PaddleClas/deploy
-hub install hubserving/clas/
-```
+**Notice**:
+* Model file paths can be viewed and modified in `PaddleClas/deploy/hubserving/clas/params.py`:
+
+ ```python
+ "inference_model_dir": "../inference/"
+ ```
+* Model files (including `.pdmodel` and `.pdiparams`) must be named `inference`.
+* We provide a large number of pre-trained models based on the ImageNet-1k dataset. For the model list and download address, see [Model Library Overview](../../docs/en/algorithm_introduction/ImageNet_models_en.md), or you can use your own trained and converted models.
+
+
+
+## 4. Install the service module
+
+* In the Linux environment, the installation example is as follows:
+ ```shell
+ cd PaddleClas/deploy
+ # Install the service module:
+ hub install hubserving/clas/
+ ```
+
+* In the Windows environment (the folder separator is `\`), the installation example is as follows:
+
+ ```shell
+ cd PaddleClas\deploy
+ # Install the service module:
+ hub install hubserving\clas\
+ ```
+
+
+
+## 5. Start service
+
+
+
+### 5.1 Start with command line parameters
+
+This method only supports prediction using CPU. Start command:
-* On Windows platform, the examples are as follows.
```shell
-cd PaddleClas\deploy
-hub install hubserving\clas\
+hub serving start \
+--modules clas_system
+--port 8866
```
+This completes the deployment of a serviced API, using the default port number 8866.
-### 4. Start service
-#### Way 1. Start with command line parameters (CPU only)
+**Parameter Description**:
+| parameters | uses |
+| ------------------ | ------------------- |
+| --modules/-m | [**required**] PaddleHub Serving pre-installed model, listed in the form of multiple Module==Version key-value pairs
*`When no Version is specified, the latest is selected by default version`* |
+| --port/-p | [**OPTIONAL**] Service port, default is 8866 |
+| --use_multiprocess | [**Optional**] Whether to enable the concurrent mode, the default is single-process mode, it is recommended to use this mode for multi-core CPU machines
*`Windows operating system only supports single-process mode`* |
+| --workers | [**Optional**] The number of concurrent tasks specified in concurrent mode, the default is `2*cpu_count-1`, where `cpu_count` is the number of CPU cores |
+For more deployment details, see [PaddleHub Serving Model One-Click Service Deployment](https://paddlehub.readthedocs.io/zh_CN/release-v2.1/tutorial/serving.html)
-**start command:**
-```shell
-$ hub serving start --modules Module1==Version1 \
- --port XXXX \
- --use_multiprocess \
- --workers \
-```
-**parameters:**
-
-|parameters|usage|
-|-|-|
-|--modules/-m|PaddleHub Serving pre-installed model, listed in the form of multiple Module==Version key-value pairs
*`When Version is not specified, the latest version is selected by default`*|
-|--port/-p|Service port, default is 8866|
-|--use_multiprocess|Enable concurrent mode, the default is single-process mode, this mode is recommended for multi-core CPU machines
*`Windows operating system only supports single-process mode`*|
-|--workers|The number of concurrent tasks specified in concurrent mode, the default is `2*cpu_count-1`, where `cpu_count` is the number of CPU cores|
-
-For example, start the 2-stage series service:
-```shell
-hub serving start -m clas_system
-```
+
+### 5.2 Start with configuration file
-This completes the deployment of a service API, using the default port number 8866.
+This method only supports prediction using CPU or GPU. Start command:
-#### Way 2. Start with configuration file(CPU、GPU)
-**start command:**
```shell
-hub serving start --config/-c config.json
-```
-Wherein, the format of `config.json` is as follows:
+hub serving start -c config.json
+```
+
+Among them, the format of `config.json` is as follows:
+
```json
{
"modules_info": {
@@ -96,104 +129,110 @@ Wherein, the format of `config.json` is as follows:
"workers": 2
}
```
-- The configurable parameters in `init_args` are consistent with the `_initialize` function interface in `module.py`. Among them,
- - when `use_gpu` is `true`, it means that the GPU is used to start the service.
- - when `enable_mkldnn` is `true`, it means that use MKL-DNN to accelerate.
-- The configurable parameters in `predict_args` are consistent with the `predict` function interface in `module.py`.
-
-**Note:**
-- When using the configuration file to start the service, other parameters will be ignored.
-- If you use GPU prediction (that is, `use_gpu` is set to `true`), you need to set the environment variable CUDA_VISIBLE_DEVICES before starting the service, such as: ```export CUDA_VISIBLE_DEVICES=0```, otherwise you do not need to set it.
-- **`use_gpu` and `use_multiprocess` cannot be `true` at the same time.**
-- **When both `use_gpu` and `enable_mkldnn` are set to `true` at the same time, GPU is used to run and `enable_mkldnn` will be ignored.**
-
-For example, use GPU card No. 3 to start the 2-stage series service:
+
+**Parameter Description**:
+* The configurable parameters in `init_args` are consistent with the `_initialize` function interface in `module.py`. in,
+ - When `use_gpu` is `true`, it means to use GPU to start the service.
+ - When `enable_mkldnn` is `true`, it means to use MKL-DNN acceleration.
+* The configurable parameters in `predict_args` are consistent with the `predict` function interface in `module.py`.
+
+**Notice**:
+* When using the configuration file to start the service, the parameter settings in the configuration file will be used, and other command line parameters will be ignored;
+* If you use GPU prediction (ie, `use_gpu` is set to `true`), you need to set the `CUDA_VISIBLE_DEVICES` environment variable to specify the GPU card number used before starting the service, such as: `export CUDA_VISIBLE_DEVICES=0`;
+* **`use_gpu` cannot be `true`** at the same time as `use_multiprocess`;
+* ** When both `use_gpu` and `enable_mkldnn` are `true`, `enable_mkldnn` will be ignored and GPU** will be used.
+
+If you use GPU No. 3 card to start the service:
+
```shell
cd PaddleClas/deploy
export CUDA_VISIBLE_DEVICES=3
hub serving start -c hubserving/clas/config.json
-```
-
-## Send prediction requests
-After the service starts, you can use the following command to send a prediction request to obtain the prediction result:
-```shell
-cd PaddleClas/deploy
-python hubserving/test_hubserving.py server_url image_path
```
-Two required parameters need to be passed to the script:
-- **server_url**: service address,format of which is
-`http://[ip_address]:[port]/predict/[module_name]`
-- **image_path**: Test image path, can be a single image path or an image directory path
-- **batch_size**: [**Optional**] batch_size. Default by `1`.
-- **resize_short**: [**Optional**] In preprocessing, resize according to short size. Default by `256`。
-- **crop_size**: [**Optional**] In preprocessing, centor crop size. Default by `224`。
-- **normalize**: [**Optional**] In preprocessing, whether to do `normalize`. Default by `True`。
-- **to_chw**: [**Optional**] In preprocessing, whether to transpose to `CHW`. Default by `True`。
+
+## 6. Send prediction requests
-**Notice**:
-If you want to use `Transformer series models`, such as `DeiT_***_384`, `ViT_***_384`, etc., please pay attention to the input size of model, and need to set `--resize_short=384`, `--crop_size=384`.
+After configuring the server, you can use the following command to send a prediction request to get the prediction result:
-**Eg.**
```shell
-python hubserving/test_hubserving.py --server_url http://127.0.0.1:8866/predict/clas_system --image_file ./hubserving/ILSVRC2012_val_00006666.JPEG --batch_size 8
-```
-
-### Returned result format
-The returned result is a list, including the `top_k`'s classification results, corresponding scores and the time cost of prediction, details as follows.
-
-```
-list: The returned results
-└─ list: The result of first picture
- └─ list: The top-k classification results, sorted in descending order of score
- └─ list: The scores corresponding to the top-k classification results, sorted in descending order of score
- └─ float: The time cost of predicting the picture, unit second
+cd PaddleClas/deploy
+python3.7 hubserving/test_hubserving.py \
+--server_url http://127.0.0.1:8866/predict/clas_system \
+--image_file ./hubserving/ILSVRC2012_val_00006666.JPEG \
+--batch_size 8
+```
+**Predicted output**
+```log
+The result(s): class_ids: [57, 67, 68, 58, 65], label_names: ['garter snake, grass snake', 'diamondback, diamondback rattlesnake, Crotalus adamanteus', 'sidewinder, horned rattlesnake, Crotalus cerastes' , 'water snake', 'sea snake'], scores: [0.21915, 0.15631, 0.14794, 0.13177, 0.12285]
+The average time of prediction cost: 2.970 s/image
+The average time cost: 3.014 s/image
+The average top-1 score: 0.110
+```
+
+**Script parameter description**:
+* **server_url**: Service address, the format is `http://[ip_address]:[port]/predict/[module_name]`.
+* **image_path**: The test image path, which can be a single image path or an image collection directory path.
+* **batch_size**: [**OPTIONAL**] Make predictions in `batch_size` size, default is `1`.
+* **resize_short**: [**optional**] When preprocessing, resize by short edge, default is `256`.
+* **crop_size**: [**Optional**] The size of the center crop during preprocessing, the default is `224`.
+* **normalize**: [**Optional**] Whether to perform `normalize` during preprocessing, the default is `True`.
+* **to_chw**: [**Optional**] Whether to adjust to `CHW` order when preprocessing, the default is `True`.
+
+**Note**: If you use `Transformer` series models, such as `DeiT_***_384`, `ViT_***_384`, etc., please pay attention to the input data size of the model, you need to specify `--resize_short=384 -- crop_size=384`.
+
+**Return result format description**:
+The returned result is a list (list), including the top-k classification results, the corresponding scores, and the time-consuming prediction of this image, as follows:
+```shell
+list: return result
+└──list: first image result
+ ├── list: the top k classification results, sorted in descending order of score
+ ├── list: the scores corresponding to the first k classification results, sorted in descending order of score
+ └── float: The image classification time, in seconds
```
-**Note:** If you need to add, delete or modify the returned fields, you can modify the corresponding module. For the details, refer to the user-defined modification service module in the next section.
-## User defined service module modification
-If you need to modify the service logic, the following steps are generally required:
-1. Stop service
-```shell
-hub serving stop --port/-p XXXX
-```
+
+## 7. User defined service module modification
-2. Modify the code in the corresponding files, like `module.py` and `params.py`, according to the actual needs. You need re-install(hub install hubserving/clas/) and re-deploy after modifing `module.py`.
-After modifying and installing and before deploying, you can use `python hubserving/clas/module.py` to test the installed service module.
+If you need to modify the service logic, you need to do the following:
-For example, if you need to replace the model used by the deployed service, you need to modify model path parameters `cfg.model_file` and `cfg.params_file` in `params.py`. Of course, other related parameters may need to be modified at the same time. Please modify and debug according to the actual situation.
-
-3. Uninstall old service module
-```shell
-hub uninstall clas_system
-```
+1. Stop the service
+ ```shell
+ hub serving stop --port/-p XXXX
+ ```
-4. Install modified service module
-```shell
-hub install hubserving/clas/
-```
+2. Go to the corresponding `module.py` and `params.py` and other files to modify the code according to actual needs. `module.py` needs to be reinstalled after modification (`hub install hubserving/clas/`) and deployed. Before deploying, you can use the `python3.7 hubserving/clas/module.py` command to quickly test the code ready for deployment.
-5. Restart service
-```shell
-hub serving start -m clas_system
-```
+3. Uninstall the old service pack
+ ```shell
+ hub uninstall clas_system
+ ```
-**Note**:
+4. Install the new modified service pack
+ ```shell
+ hub install hubserving/clas/
+ ```
-Common parameters can be modified in params.py:
-* Directory of model files(include model structure file and model parameters file):
- ```python
- "inference_model_dir":
- ```
-* The number of Top-k results returned during post-processing:
- ```python
- 'topk':
- ```
-* Mapping file corresponding to label and class ID during post-processing:
- ```python
- 'class_id_map_file':
- ```
+5. Restart the service
+ ```shell
+ hub serving start -m clas_system
+ ```
-In order to avoid unnecessary delay and be able to predict in batch, the preprocessing (include resize, crop and other) is completed in the client, so modify [test_hubserving.py](./test_hubserving.py#L35-L52) if necessary.
+**Notice**:
+Common parameters can be modified in `PaddleClas/deploy/hubserving/clas/params.py`:
+ * To replace the model, you need to modify the model file path parameters:
+ ```python
+ "inference_model_dir":
+ ```
+ * Change the number of `top-k` results returned when postprocessing:
+ ```python
+ 'topk':
+ ```
+ * The mapping file corresponding to the lable and class id when changing the post-processing:
+ ```python
+ 'class_id_map_file':
+ ```
+
+In order to avoid unnecessary delay and be able to predict with batch_size, data preprocessing logic (including `resize`, `crop` and other operations) is completed on the client side, so it needs to modify data preprocessing logic related code in [PaddleClas/deploy/hubserving/test_hubserving.py# L41-L47](./test_hubserving.py#L41-L47) and [PaddleClas/deploy/hubserving/test_hubserving.py#L51-L76](./test_hubserving.py#L51-L76).
diff --git a/deploy/images/ILSVRC2012_val_00000010.jpeg b/deploy/images/ImageNet/ILSVRC2012_val_00000010.jpeg
similarity index 100%
rename from deploy/images/ILSVRC2012_val_00000010.jpeg
rename to deploy/images/ImageNet/ILSVRC2012_val_00000010.jpeg
diff --git a/deploy/images/ILSVRC2012_val_00010010.jpeg b/deploy/images/ImageNet/ILSVRC2012_val_00010010.jpeg
similarity index 100%
rename from deploy/images/ILSVRC2012_val_00010010.jpeg
rename to deploy/images/ImageNet/ILSVRC2012_val_00010010.jpeg
diff --git a/deploy/images/ILSVRC2012_val_00020010.jpeg b/deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg
similarity index 100%
rename from deploy/images/ILSVRC2012_val_00020010.jpeg
rename to deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg
diff --git a/deploy/images/ILSVRC2012_val_00030010.jpeg b/deploy/images/ImageNet/ILSVRC2012_val_00030010.jpeg
similarity index 100%
rename from deploy/images/ILSVRC2012_val_00030010.jpeg
rename to deploy/images/ImageNet/ILSVRC2012_val_00030010.jpeg
diff --git a/deploy/images/PULC/car_exists/objects365_00001507.jpeg b/deploy/images/PULC/car_exists/objects365_00001507.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..9959954b6b8bf27589e1d2081f86c6078d16e2c1
Binary files /dev/null and b/deploy/images/PULC/car_exists/objects365_00001507.jpeg differ
diff --git a/deploy/images/PULC/car_exists/objects365_00001521.jpeg b/deploy/images/PULC/car_exists/objects365_00001521.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..ea65b3108ec0476ce952b3221c31ac54fcef161d
Binary files /dev/null and b/deploy/images/PULC/car_exists/objects365_00001521.jpeg differ
diff --git a/deploy/images/PULC/language_classification/word_17.png b/deploy/images/PULC/language_classification/word_17.png
new file mode 100644
index 0000000000000000000000000000000000000000..c0cd74632460e01676fbc5a43b220c0a7f7d0474
Binary files /dev/null and b/deploy/images/PULC/language_classification/word_17.png differ
diff --git a/deploy/images/PULC/language_classification/word_20.png b/deploy/images/PULC/language_classification/word_20.png
new file mode 100644
index 0000000000000000000000000000000000000000..f9149670e8a2aa086c91451442f63a727661fd7d
Binary files /dev/null and b/deploy/images/PULC/language_classification/word_20.png differ
diff --git a/deploy/images/PULC/language_classification/word_35404.png b/deploy/images/PULC/language_classification/word_35404.png
new file mode 100644
index 0000000000000000000000000000000000000000..9e1789ab47aefecac8eaf1121decfc6a8cfb1e8b
Binary files /dev/null and b/deploy/images/PULC/language_classification/word_35404.png differ
diff --git a/deploy/images/PULC/person_attribute/090004.jpg b/deploy/images/PULC/person_attribute/090004.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..140694eeec3d2925303e8c0d544ef5979cd78219
Binary files /dev/null and b/deploy/images/PULC/person_attribute/090004.jpg differ
diff --git a/deploy/images/PULC/person_attribute/090007.jpg b/deploy/images/PULC/person_attribute/090007.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9fea2e7c9e0047a8b59606877ad41fe24bf2e24c
Binary files /dev/null and b/deploy/images/PULC/person_attribute/090007.jpg differ
diff --git a/deploy/images/PULC/person_exists/objects365_01780782.jpg b/deploy/images/PULC/person_exists/objects365_01780782.jpg
new file mode 100755
index 0000000000000000000000000000000000000000..a0dd0df59ae5a6386a04a8e0cf9cdbc529139c16
Binary files /dev/null and b/deploy/images/PULC/person_exists/objects365_01780782.jpg differ
diff --git a/deploy/images/PULC/person_exists/objects365_02035329.jpg b/deploy/images/PULC/person_exists/objects365_02035329.jpg
new file mode 100755
index 0000000000000000000000000000000000000000..16d7f2d08cd87bda1b67d21655f00f94a0c6e4e4
Binary files /dev/null and b/deploy/images/PULC/person_exists/objects365_02035329.jpg differ
diff --git a/deploy/images/PULC/safety_helmet/safety_helmet_test_1.png b/deploy/images/PULC/safety_helmet/safety_helmet_test_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..c28f54f77d54df6e68e471538846b01db4387e08
Binary files /dev/null and b/deploy/images/PULC/safety_helmet/safety_helmet_test_1.png differ
diff --git a/deploy/images/PULC/safety_helmet/safety_helmet_test_2.png b/deploy/images/PULC/safety_helmet/safety_helmet_test_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..8e784af808afb58d67fdb3e277dfeebd134ee846
Binary files /dev/null and b/deploy/images/PULC/safety_helmet/safety_helmet_test_2.png differ
diff --git a/deploy/images/PULC/text_image_orientation/img_rot0_demo.jpg b/deploy/images/PULC/text_image_orientation/img_rot0_demo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..412d41956ba48c8e3243bdeff746d389be7e762b
Binary files /dev/null and b/deploy/images/PULC/text_image_orientation/img_rot0_demo.jpg differ
diff --git a/deploy/images/PULC/text_image_orientation/img_rot180_demo.jpg b/deploy/images/PULC/text_image_orientation/img_rot180_demo.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f4725b96698e2ac222ae9d4830d8f29a33322443
Binary files /dev/null and b/deploy/images/PULC/text_image_orientation/img_rot180_demo.jpg differ
diff --git a/deploy/images/PULC/textline_orientation/textline_orientation_test_0_0.png b/deploy/images/PULC/textline_orientation/textline_orientation_test_0_0.png
new file mode 100644
index 0000000000000000000000000000000000000000..4b8d24d29ff0f8b4befff6bf943d506c36061d4d
Binary files /dev/null and b/deploy/images/PULC/textline_orientation/textline_orientation_test_0_0.png differ
diff --git a/deploy/images/PULC/textline_orientation/textline_orientation_test_0_1.png b/deploy/images/PULC/textline_orientation/textline_orientation_test_0_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..42ad5234973679e65be6054f90c1cc7c0f989bd2
Binary files /dev/null and b/deploy/images/PULC/textline_orientation/textline_orientation_test_0_1.png differ
diff --git a/deploy/images/PULC/textline_orientation/textline_orientation_test_1_0.png b/deploy/images/PULC/textline_orientation/textline_orientation_test_1_0.png
new file mode 100644
index 0000000000000000000000000000000000000000..ac2447842dd0fac260c0d3c6e0d156dda9890923
Binary files /dev/null and b/deploy/images/PULC/textline_orientation/textline_orientation_test_1_0.png differ
diff --git a/deploy/images/PULC/textline_orientation/textline_orientation_test_1_1.png b/deploy/images/PULC/textline_orientation/textline_orientation_test_1_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..7d5b75f7e5bbeabded56eba1b4b566c4ca019590
Binary files /dev/null and b/deploy/images/PULC/textline_orientation/textline_orientation_test_1_1.png differ
diff --git a/deploy/images/PULC/traffic_sign/100999_83928.jpg b/deploy/images/PULC/traffic_sign/100999_83928.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6f32ed5ae2d8483d29986e3a45db1789da2a4d43
Binary files /dev/null and b/deploy/images/PULC/traffic_sign/100999_83928.jpg differ
diff --git a/deploy/images/PULC/traffic_sign/99603_17806.jpg b/deploy/images/PULC/traffic_sign/99603_17806.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..c792fdf6eb64395fffaf8289a1ec14d47279860e
Binary files /dev/null and b/deploy/images/PULC/traffic_sign/99603_17806.jpg differ
diff --git a/deploy/images/PULC/vehicle_attribute/0002_c002_00030670_0.jpg b/deploy/images/PULC/vehicle_attribute/0002_c002_00030670_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..bb5de9fc6ff99550bf9bff8d4a9f0d0e0fe18c06
Binary files /dev/null and b/deploy/images/PULC/vehicle_attribute/0002_c002_00030670_0.jpg differ
diff --git a/deploy/images/PULC/vehicle_attribute/0014_c012_00040750_0.jpg b/deploy/images/PULC/vehicle_attribute/0014_c012_00040750_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..76207d43ce597a1079c523dca0c32923bf15db19
Binary files /dev/null and b/deploy/images/PULC/vehicle_attribute/0014_c012_00040750_0.jpg differ
diff --git a/deploy/images/Pedestrain_Attr.jpg b/deploy/images/Pedestrain_Attr.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6a87e856af8c17a3b93617b93ea517b91c508619
Binary files /dev/null and b/deploy/images/Pedestrain_Attr.jpg differ
diff --git a/deploy/lite_shitu/README.md b/deploy/lite_shitu/README.md
index 52871c3c16dc9990f9cf23de24b24cb54067cac6..e2a03caedd0d4bf63af96d3541d1a8d021206e52 100644
--- a/deploy/lite_shitu/README.md
+++ b/deploy/lite_shitu/README.md
@@ -92,9 +92,9 @@ PaddleClas 提供了转换并优化后的推理模型,可以直接参考下方
```shell
# 进入lite_ppshitu目录
cd $PaddleClas/deploy/lite_shitu
-wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/lite/ppshitu_lite_models_v1.1.tar
-tar -xf ppshitu_lite_models_v1.1.tar
-rm -f ppshitu_lite_models_v1.1.tar
+wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/lite/ppshitu_lite_models_v1.2.tar
+tar -xf ppshitu_lite_models_v1.2.tar
+rm -f ppshitu_lite_models_v1.2.tar
```
#### 2.1.2 使用其他模型
@@ -162,7 +162,7 @@ git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 进入PaddleDetection根目录
cd PaddleDetection
# 将预训练模型导出为inference模型
-python tools/export_model.py -c configs/picodet/application/mainbody_detection/picodet_lcnet_x2_5_640_mainbody.yml -o weights=https://paddledet.bj.bcebos.com/models/picodet_lcnet_x2_5_640_mainbody.pdparams --output_dir=inference
+python tools/export_model.py -c configs/picodet/application/mainbody_detection/picodet_lcnet_x2_5_640_mainbody.yml -o weights=https://paddledet.bj.bcebos.com/models/picodet_lcnet_x2_5_640_mainbody.pdparams export_post_process=False --output_dir=inference
# 将inference模型转化为Paddle-Lite优化模型
paddle_lite_opt --model_file=inference/picodet_lcnet_x2_5_640_mainbody/model.pdmodel --param_file=inference/picodet_lcnet_x2_5_640_mainbody/model.pdiparams --optimize_out=inference/picodet_lcnet_x2_5_640_mainbody/mainbody_det
# 将转好的模型复制到lite_shitu目录下
@@ -183,24 +183,56 @@ cd deploy/lite_shitu
**注意**:`--optimize_out` 参数为优化后模型的保存路径,无需加后缀`.nb`;`--model_file` 参数为模型结构信息文件的路径,`--param_file` 参数为模型权重信息文件的路径,请注意文件名。
-### 2.2 将yaml文件转换成json文件
+### 2.2 生成新的检索库
+
+由于lite 版本的检索库用的是`faiss1.5.3`版本,与新版本不兼容,因此需要重新生成index库
+
+#### 2.2.1 数据及环境配置
+
+```shell
+# 进入上级目录
+cd ..
+# 下载瓶装饮料数据集
+wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v1.0.tar && tar -xf drink_dataset_v1.0.tar
+rm -rf drink_dataset_v1.0.tar
+rm -rf drink_dataset_v1.0/index
+
+# 安装1.5.3版本的faiss
+pip install faiss-cpu==1.5.3
+
+# 下载通用识别模型,可替换成自己的inference model
+wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/models/inference/general_PPLCNet_x2_5_lite_v1.0_infer.tar
+tar -xf general_PPLCNet_x2_5_lite_v1.0_infer.tar
+rm -rf general_PPLCNet_x2_5_lite_v1.0_infer.tar
+```
+
+#### 2.2.2 生成新的index文件
+
+```shell
+# 生成新的index库,注意指定好识别模型的路径,同时将index_mothod修改成Flat,HNSW32和IVF在此版本中可能存在bug,请慎重使用。
+# 如果使用自己的识别模型,对应的修改inference model的目录
+python python/build_gallery.py -c configs/inference_drink.yaml -o Global.rec_inference_model_dir=general_PPLCNet_x2_5_lite_v1.0_infer -o IndexProcess.index_method=Flat
+
+# 进入到lite_shitu目录
+cd lite_shitu
+mv ../drink_dataset_v1.0 .
+```
+
+### 2.3 将yaml文件转换成json文件
```shell
# 如果测试单张图像
-python generate_json_config.py --det_model_path ppshitu_lite_models_v1.1/mainbody_PPLCNet_x2_5_640_quant_v1.1_lite.nb --rec_model_path ppshitu_lite_models_v1.1/general_PPLCNet_x2_5_lite_v1.1_infer.nb --img_path images/demo.jpg
+python generate_json_config.py --det_model_path ppshitu_lite_models_v1.2/mainbody_PPLCNet_x2_5_640_v1.2_lite.nb --rec_model_path ppshitu_lite_models_v1.2/general_PPLCNet_x2_5_lite_v1.2_infer.nb --img_path images/demo.jpeg
# or
# 如果测试多张图像
-python generate_json_config.py --det_model_path ppshitu_lite_models_v1.1/mainbody_PPLCNet_x2_5_640_quant_v1.1_lite.nb --rec_model_path ppshitu_lite_models_v1.1/general_PPLCNet_x2_5_lite_v1.1_infer.nb --img_dir images
+python generate_json_config.py --det_model_path ppshitu_lite_models_v1.2/mainbody_PPLCNet_x2_5_640_v1.2_lite.nb --rec_model_path ppshitu_lite_models_v1.2/general_PPLCNet_x2_5_lite_v1.2_infer.nb --img_dir images
# 执行完成后,会在lit_shitu下生成shitu_config.json配置文件
```
-### 2.3 index字典转换
+### 2.4 index字典转换
由于python的检索库字典,使用`pickle`进行的序列化存储,导致C++不方便读取,因此需要进行转换
```shell
-# 下载瓶装饮料数据集
-wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v1.0.tar && tar -xf drink_dataset_v1.0.tar
-rm -rf drink_dataset_v1.0.tar
# 转化id_map.pkl为id_map.txt
python transform_id_map.py -c ../configs/inference_drink.yaml
@@ -208,7 +240,7 @@ python transform_id_map.py -c ../configs/inference_drink.yaml
转换成功后,会在`IndexProcess.index_dir`目录下生成`id_map.txt`。
-### 2.4 与手机联调
+### 2.5 与手机联调
首先需要进行一些准备工作。
1. 准备一台arm8的安卓手机,如果编译的预测库是armv7,则需要arm7的手机,并修改Makefile中`ARM_ABI=arm7`。
@@ -308,8 +340,9 @@ chmod 777 pp_shitu
运行效果如下:
```
-images/demo.jpg:
- result0: bbox[253, 275, 1146, 872], score: 0.974196, label: 伊藤园_果蔬汁
+images/demo.jpeg:
+ result0: bbox[344, 98, 527, 593], score: 0.811656, label: 红牛-强化型
+ result1: bbox[0, 0, 600, 600], score: 0.729664, label: 红牛-强化型
```
## FAQ
diff --git a/deploy/lite_shitu/generate_json_config.py b/deploy/lite_shitu/generate_json_config.py
index 37d06c47e686daf5335dbbf1a193658c4ac20ac3..642dfcd9d6a46e2894ec0f01f0914a5347bc8d72 100644
--- a/deploy/lite_shitu/generate_json_config.py
+++ b/deploy/lite_shitu/generate_json_config.py
@@ -95,7 +95,7 @@ def main():
config_json["Global"]["det_model_path"] = args.det_model_path
config_json["Global"]["rec_model_path"] = args.rec_model_path
config_json["Global"]["rec_label_path"] = args.rec_label_path
- config_json["Global"]["label_list"] = config_yaml["Global"]["labe_list"]
+ config_json["Global"]["label_list"] = config_yaml["Global"]["label_list"]
config_json["Global"]["rec_nms_thresold"] = config_yaml["Global"][
"rec_nms_thresold"]
config_json["Global"]["max_det_results"] = config_yaml["Global"][
diff --git a/deploy/lite_shitu/images/demo.jpeg b/deploy/lite_shitu/images/demo.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..2ef10aae5f7f5ce515cb51f857b66c6195f6664b
Binary files /dev/null and b/deploy/lite_shitu/images/demo.jpeg differ
diff --git a/deploy/lite_shitu/images/demo.jpg b/deploy/lite_shitu/images/demo.jpg
deleted file mode 100644
index 075dc31d4e6b407b792cc8abca82dcd541be8d11..0000000000000000000000000000000000000000
Binary files a/deploy/lite_shitu/images/demo.jpg and /dev/null differ
diff --git a/deploy/lite_shitu/include/config_parser.h b/deploy/lite_shitu/include/config_parser.h
index dca0e5a6898a219932ee978591d89c7624988f3f..2bed92059c41be344b863d5b8a81f9367dfa48fc 100644
--- a/deploy/lite_shitu/include/config_parser.h
+++ b/deploy/lite_shitu/include/config_parser.h
@@ -29,16 +29,16 @@
namespace PPShiTu {
-void load_jsonf(std::string jsonfile, Json::Value& jsondata);
+void load_jsonf(std::string jsonfile, Json::Value &jsondata);
// Inference model configuration parser
class ConfigPaser {
- public:
+public:
ConfigPaser() {}
~ConfigPaser() {}
- bool load_config(const Json::Value& config) {
+ bool load_config(const Json::Value &config) {
// Get model arch : YOLO, SSD, RetinaNet, RCNN, Face
if (config["Global"].isMember("det_arch")) {
@@ -89,4 +89,4 @@ class ConfigPaser {
std::vector fpn_stride_;
};
-} // namespace PPShiTu
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/feature_extractor.h b/deploy/lite_shitu/include/feature_extractor.h
index 1961459ecfab149695890df60cef550ed5177b52..6ef5cae13fe8b9a3724d88a30e562f5d091efc89 100644
--- a/deploy/lite_shitu/include/feature_extractor.h
+++ b/deploy/lite_shitu/include/feature_extractor.h
@@ -18,6 +18,7 @@
#include
#include
#include
+#include
#include
#include
#include
@@ -48,10 +49,6 @@ public:
config_file["Global"]["rec_model_path"].as());
this->predictor = CreatePaddlePredictor(config);
- if (config_file["Global"]["rec_label_path"].as().empty()) {
- std::cout << "Please set [rec_label_path] in config file" << std::endl;
- exit(-1);
- }
SetPreProcessParam(config_file["RecPreProcess"]["transform_ops"]);
printf("feature extract model create!\n");
}
@@ -68,24 +65,29 @@ public:
this->mean.emplace_back(tmp.as());
}
for (auto tmp : item["std"]) {
- this->std.emplace_back(1 / tmp.as());
+ this->std.emplace_back(tmp.as());
}
this->scale = item["scale"].as();
}
}
}
- void RunRecModel(const cv::Mat &img, double &cost_time, std::vector &feature);
- //void PostProcess(std::vector &feature);
- cv::Mat ResizeImage(const cv::Mat &img);
- void NeonMeanScale(const float *din, float *dout, int size);
+ void RunRecModel(const cv::Mat &img, double &cost_time,
+ std::vector &feature);
+ // void PostProcess(std::vector &feature);
+ void FeatureNorm(std::vector &featuer);
private:
std::shared_ptr predictor;
- //std::vector label_list;
+ // std::vector label_list;
std::vector mean = {0.485f, 0.456f, 0.406f};
- std::vector std = {1 / 0.229f, 1 / 0.224f, 1 / 0.225f};
+ std::vector std = {0.229f, 0.224f, 0.225f};
double scale = 0.00392157;
- float size = 224;
+ int size = 224;
+
+ // pre-process
+ Resize resize_op_;
+ NormalizeImage normalize_op_;
+ Permute permute_op_;
};
} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/object_detector.h b/deploy/lite_shitu/include/object_detector.h
index 779cc89d197ece9115788ac25b9fa5d4c862e2fe..83212d7ea3ec2a93cf410c5930951709ab6d031d 100644
--- a/deploy/lite_shitu/include/object_detector.h
+++ b/deploy/lite_shitu/include/object_detector.h
@@ -16,24 +16,24 @@
#include
#include
+#include
#include
#include
#include
-#include
+#include "json/json.h"
#include
#include
#include
-#include "json/json.h"
-#include "paddle_api.h" // NOLINT
+#include "paddle_api.h" // NOLINT
#include "include/config_parser.h"
+#include "include/picodet_postprocess.h"
#include "include/preprocess_op.h"
#include "include/utils.h"
-#include "include/picodet_postprocess.h"
-using namespace paddle::lite_api; // NOLINT
+using namespace paddle::lite_api; // NOLINT
namespace PPShiTu {
@@ -41,53 +41,51 @@ namespace PPShiTu {
std::vector GenerateColorMap(int num_class);
// Visualiztion Detection Result
-cv::Mat VisualizeResult(const cv::Mat& img,
- const std::vector& results,
- const std::vector& lables,
- const std::vector& colormap,
- const bool is_rbox);
+cv::Mat VisualizeResult(const cv::Mat &img,
+ const std::vector &results,
+ const std::vector &lables,
+ const std::vector &colormap, const bool is_rbox);
class ObjectDetector {
- public:
- explicit ObjectDetector(const Json::Value& config,
- const std::string& model_dir,
- int cpu_threads = 1,
+public:
+ explicit ObjectDetector(const Json::Value &config,
+ const std::string &model_dir, int cpu_threads = 1,
const int batch_size = 1) {
config_.load_config(config);
printf("config created\n");
preprocessor_.Init(config_.preprocess_info_);
printf("before object detector\n");
- if(config["Global"]["det_model_path"].as().empty()){
- std::cout << "Please set [det_model_path] in config file" << std::endl;
- exit(-1);
+ if (config["Global"]["det_model_path"].as().empty()) {
+ std::cout << "Please set [det_model_path] in config file" << std::endl;
+ exit(-1);
}
- LoadModel(config["Global"]["det_model_path"].as(), cpu_threads);
- printf("create object detector\n"); }
+ LoadModel(config["Global"]["det_model_path"].as(),
+ cpu_threads);
+ printf("create object detector\n");
+ }
// Load Paddle inference model
void LoadModel(std::string model_file, int num_theads);
// Run predictor
- void Predict(const std::vector& imgs,
- const int warmup = 0,
+ void Predict(const std::vector &imgs, const int warmup = 0,
const int repeats = 1,
- std::vector* result = nullptr,
- std::vector* bbox_num = nullptr,
- std::vector* times = nullptr);
+ std::vector *result = nullptr,
+ std::vector *bbox_num = nullptr,
+ std::vector *times = nullptr);
// Get Model Label list
- const std::vector& GetLabelList() const {
+ const std::vector &GetLabelList() const {
return config_.label_list_;
}
- private:
+private:
// Preprocess image and copy data to input buffer
- void Preprocess(const cv::Mat& image_mat);
+ void Preprocess(const cv::Mat &image_mat);
// Postprocess result
void Postprocess(const std::vector mats,
- std::vector* result,
- std::vector bbox_num,
- bool is_rbox);
+ std::vector *result,
+ std::vector bbox_num, bool is_rbox);
std::shared_ptr predictor_;
Preprocessor preprocessor_;
@@ -96,7 +94,6 @@ class ObjectDetector {
std::vector out_bbox_num_data_;
float threshold_;
ConfigPaser config_;
-
};
-} // namespace PPShiTu
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/picodet_postprocess.h b/deploy/lite_shitu/include/picodet_postprocess.h
index 758795b5fbfba459ce6b7ea2d24c04c40eddd543..72dfd1b88af8296d81b56cbbc220dac61e8fa2b9 100644
--- a/deploy/lite_shitu/include/picodet_postprocess.h
+++ b/deploy/lite_shitu/include/picodet_postprocess.h
@@ -14,25 +14,23 @@
#pragma once
-#include
-#include
-#include
-#include
#include
+#include
#include
+#include
+#include
+#include
#include "include/utils.h"
namespace PPShiTu {
-void PicoDetPostProcess(std::vector* results,
- std::vector outs,
- std::vector fpn_stride,
- std::vector im_shape,
- std::vector scale_factor,
- float score_threshold = 0.3,
- float nms_threshold = 0.5,
- int num_class = 80,
- int reg_max = 7);
+void PicoDetPostProcess(std::vector *results,
+ std::vector outs,
+ std::vector fpn_stride,
+ std::vector im_shape,
+ std::vector scale_factor,
+ float score_threshold = 0.3, float nms_threshold = 0.5,
+ int num_class = 80, int reg_max = 7);
-} // namespace PPShiTu
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/preprocess_op.h b/deploy/lite_shitu/include/preprocess_op.h
index f7050fa86951bfe80aa4030adabc11ff43f82371..b7ed5e878d77c6aae15e399e57f8384e7a6d19fb 100644
--- a/deploy/lite_shitu/include/preprocess_op.h
+++ b/deploy/lite_shitu/include/preprocess_op.h
@@ -21,16 +21,16 @@
#include
#include
+#include "json/json.h"
#include
#include
#include
-#include "json/json.h"
namespace PPShiTu {
// Object for storing all preprocessed data
class ImageBlob {
- public:
+public:
// image width and height
std::vector im_shape_;
// Buffer for image data after preprocessing
@@ -45,20 +45,20 @@ class ImageBlob {
// Abstraction of preprocessing opration class
class PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) = 0;
- virtual void Run(cv::Mat* im, ImageBlob* data) = 0;
+public:
+ virtual void Init(const Json::Value &item) = 0;
+ virtual void Run(cv::Mat *im, ImageBlob *data) = 0;
};
class InitInfo : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {}
- virtual void Run(cv::Mat* im, ImageBlob* data);
+public:
+ virtual void Init(const Json::Value &item) {}
+ virtual void Run(cv::Mat *im, ImageBlob *data);
};
class NormalizeImage : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {
+public:
+ virtual void Init(const Json::Value &item) {
mean_.clear();
scale_.clear();
for (auto tmp : item["mean"]) {
@@ -70,9 +70,11 @@ class NormalizeImage : public PreprocessOp {
is_scale_ = item["is_scale"].as();
}
- virtual void Run(cv::Mat* im, ImageBlob* data);
+ virtual void Run(cv::Mat *im, ImageBlob *data);
+ void Run_feature(cv::Mat *im, const std::vector &mean,
+ const std::vector &std, float scale);
- private:
+private:
// CHW or HWC
std::vector mean_;
std::vector scale_;
@@ -80,14 +82,15 @@ class NormalizeImage : public PreprocessOp {
};
class Permute : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {}
- virtual void Run(cv::Mat* im, ImageBlob* data);
+public:
+ virtual void Init(const Json::Value &item) {}
+ virtual void Run(cv::Mat *im, ImageBlob *data);
+ void Run_feature(const cv::Mat *im, float *data);
};
class Resize : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {
+public:
+ virtual void Init(const Json::Value &item) {
interp_ = item["interp"].as();
// max_size_ = item["target_size"].as();
keep_ratio_ = item["keep_ratio"].as();
@@ -98,11 +101,13 @@ class Resize : public PreprocessOp {
}
// Compute best resize scale for x-dimension, y-dimension
- std::pair GenerateScale(const cv::Mat& im);
+ std::pair GenerateScale(const cv::Mat &im);
- virtual void Run(cv::Mat* im, ImageBlob* data);
+ virtual void Run(cv::Mat *im, ImageBlob *data);
+ void Run_feature(const cv::Mat &img, cv::Mat &resize_img, int max_size_len,
+ int size = 0);
- private:
+private:
int interp_;
bool keep_ratio_;
std::vector target_size_;
@@ -111,46 +116,43 @@ class Resize : public PreprocessOp {
// Models with FPN need input shape % stride == 0
class PadStride : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {
+public:
+ virtual void Init(const Json::Value &item) {
stride_ = item["stride"].as();
}
- virtual void Run(cv::Mat* im, ImageBlob* data);
+ virtual void Run(cv::Mat *im, ImageBlob *data);
- private:
+private:
int stride_;
};
class TopDownEvalAffine : public PreprocessOp {
- public:
- virtual void Init(const Json::Value& item) {
+public:
+ virtual void Init(const Json::Value &item) {
trainsize_.clear();
for (auto tmp : item["trainsize"]) {
trainsize_.emplace_back(tmp.as());
}
}
- virtual void Run(cv::Mat* im, ImageBlob* data);
+ virtual void Run(cv::Mat *im, ImageBlob *data);
- private:
+private:
int interp_ = 1;
std::vector trainsize_;
};
-void CropImg(cv::Mat& img,
- cv::Mat& crop_img,
- std::vector& area,
- std::vector& center,
- std::vector& scale,
+void CropImg(cv::Mat &img, cv::Mat &crop_img, std::vector &area,
+ std::vector ¢er, std::vector &scale,
float expandratio = 0.15);
class Preprocessor {
- public:
- void Init(const Json::Value& config_node) {
+public:
+ void Init(const Json::Value &config_node) {
// initialize image info at first
ops_["InitInfo"] = std::make_shared();
- for (const auto& item : config_node) {
+ for (const auto &item : config_node) {
auto op_name = item["type"].as();
ops_[op_name] = CreateOp(op_name);
@@ -158,7 +160,7 @@ class Preprocessor {
}
}
- std::shared_ptr CreateOp(const std::string& name) {
+ std::shared_ptr CreateOp(const std::string &name) {
if (name == "DetResize") {
return std::make_shared();
} else if (name == "DetPermute") {
@@ -176,13 +178,13 @@ class Preprocessor {
return nullptr;
}
- void Run(cv::Mat* im, ImageBlob* data);
+ void Run(cv::Mat *im, ImageBlob *data);
- public:
+public:
static const std::vector RUN_ORDER;
- private:
+private:
std::unordered_map> ops_;
};
-} // namespace PPShiTu
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/utils.h b/deploy/lite_shitu/include/utils.h
index a3b57c882561577defff97e384fb775b78204f36..b23cae31898f92cb55cf240ecc0bb544dba6bb05 100644
--- a/deploy/lite_shitu/include/utils.h
+++ b/deploy/lite_shitu/include/utils.h
@@ -38,6 +38,23 @@ struct ObjectResult {
std::vector rec_result;
};
-void nms(std::vector &input_boxes, float nms_threshold, bool rec_nms=false);
+void nms(std::vector &input_boxes, float nms_threshold,
+ bool rec_nms = false);
+template
+static inline bool SortScorePairDescend(const std::pair &pair1,
+ const std::pair &pair2) {
+ return pair1.first > pair2.first;
+}
+
+float RectOverlap(const ObjectResult &a, const ObjectResult &b);
+
+inline void
+GetMaxScoreIndex(const std::vector &det_result,
+ const float threshold,
+ std::vector> &score_index_vec);
+
+void NMSBoxes(const std::vector det_result,
+ const float score_threshold, const float nms_threshold,
+ std::vector &indices);
} // namespace PPShiTu
diff --git a/deploy/lite_shitu/include/vector_search.h b/deploy/lite_shitu/include/vector_search.h
index 89ef7733ab86c534a5c507cb4f87c9d4597dba15..49c95cc35edf9248d56b7a3a660285698cd6df8b 100644
--- a/deploy/lite_shitu/include/vector_search.h
+++ b/deploy/lite_shitu/include/vector_search.h
@@ -70,4 +70,4 @@ private:
std::vector I;
SearchResult sr;
};
-}
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/src/config_parser.cc b/deploy/lite_shitu/src/config_parser.cc
index d98b2f90f0a860189b8b3b12e9ffd5646dae1d24..09f09f782c93cdfc6fd5d41b97a630cbbafa5917 100644
--- a/deploy/lite_shitu/src/config_parser.cc
+++ b/deploy/lite_shitu/src/config_parser.cc
@@ -29,4 +29,4 @@ void load_jsonf(std::string jsonfile, Json::Value &jsondata) {
}
}
-} // namespace PPShiTu
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/src/feature_extractor.cc b/deploy/lite_shitu/src/feature_extractor.cc
index aca5c1cbbe5c70cd214c922609831e9350be28a0..67940f011eb9399aadc0aa5f38ad8d8dde197aa0 100644
--- a/deploy/lite_shitu/src/feature_extractor.cc
+++ b/deploy/lite_shitu/src/feature_extractor.cc
@@ -13,24 +13,29 @@
// limitations under the License.
#include "include/feature_extractor.h"
+#include
+#include
namespace PPShiTu {
-void FeatureExtract::RunRecModel(const cv::Mat &img,
- double &cost_time,
+void FeatureExtract::RunRecModel(const cv::Mat &img, double &cost_time,
std::vector &feature) {
// Read img
- cv::Mat resize_image = ResizeImage(img);
-
cv::Mat img_fp;
- resize_image.convertTo(img_fp, CV_32FC3, scale);
+ this->resize_op_.Run_feature(img, img_fp, this->size, this->size);
+ this->normalize_op_.Run_feature(&img_fp, this->mean, this->std, this->scale);
+ std::vector input(1 * 3 * img_fp.rows * img_fp.cols, 0.0f);
+ this->permute_op_.Run_feature(&img_fp, input.data());
// Prepare input data from image
std::unique_ptr input_tensor(std::move(this->predictor->GetInput(0)));
- input_tensor->Resize({1, 3, img_fp.rows, img_fp.cols});
+ input_tensor->Resize({1, 3, this->size, this->size});
auto *data0 = input_tensor->mutable_data();
- const float *dimg = reinterpret_cast(img_fp.data);
- NeonMeanScale(dimg, data0, img_fp.rows * img_fp.cols);
+ // const float *dimg = reinterpret_cast(img_fp.data);
+ // NeonMeanScale(dimg, data0, img_fp.rows * img_fp.cols);
+ for (int i = 0; i < input.size(); ++i) {
+ data0[i] = input[i];
+ }
auto start = std::chrono::system_clock::now();
// Run predictor
@@ -38,7 +43,7 @@ void FeatureExtract::RunRecModel(const cv::Mat &img,
// Get output and post process
std::unique_ptr output_tensor(
- std::move(this->predictor->GetOutput(0))); //only one output
+ std::move(this->predictor->GetOutput(0))); // only one output
auto end = std::chrono::system_clock::now();
auto duration =
std::chrono::duration_cast(end - start);
@@ -46,7 +51,7 @@ void FeatureExtract::RunRecModel(const cv::Mat &img,
std::chrono::microseconds::period::num /
std::chrono::microseconds::period::den;
- //do postprocess
+ // do postprocess
int output_size = 1;
for (auto dim : output_tensor->shape()) {
output_size *= dim;
@@ -54,63 +59,15 @@ void FeatureExtract::RunRecModel(const cv::Mat &img,
feature.resize(output_size);
output_tensor->CopyToCpu(feature.data());
- //postprocess include sqrt or binarize.
- //PostProcess(feature);
+ // postprocess include sqrt or binarize.
+ FeatureNorm(feature);
return;
}
-// void FeatureExtract::PostProcess(std::vector &feature){
-// float feature_sqrt = std::sqrt(std::inner_product(
-// feature.begin(), feature.end(), feature.begin(), 0.0f));
-// for (int i = 0; i < feature.size(); ++i)
-// feature[i] /= feature_sqrt;
-// }
-
-void FeatureExtract::NeonMeanScale(const float *din, float *dout, int size) {
-
- if (this->mean.size() != 3 || this->std.size() != 3) {
- std::cerr << "[ERROR] mean or scale size must equal to 3\n";
- exit(1);
- }
- float32x4_t vmean0 = vdupq_n_f32(mean[0]);
- float32x4_t vmean1 = vdupq_n_f32(mean[1]);
- float32x4_t vmean2 = vdupq_n_f32(mean[2]);
- float32x4_t vscale0 = vdupq_n_f32(std[0]);
- float32x4_t vscale1 = vdupq_n_f32(std[1]);
- float32x4_t vscale2 = vdupq_n_f32(std[2]);
-
- float *dout_c0 = dout;
- float *dout_c1 = dout + size;
- float *dout_c2 = dout + size * 2;
-
- int i = 0;
- for (; i < size - 3; i += 4) {
- float32x4x3_t vin3 = vld3q_f32(din);
- float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0);
- float32x4_t vsub1 = vsubq_f32(vin3.val[1], vmean1);
- float32x4_t vsub2 = vsubq_f32(vin3.val[2], vmean2);
- float32x4_t vs0 = vmulq_f32(vsub0, vscale0);
- float32x4_t vs1 = vmulq_f32(vsub1, vscale1);
- float32x4_t vs2 = vmulq_f32(vsub2, vscale2);
- vst1q_f32(dout_c0, vs0);
- vst1q_f32(dout_c1, vs1);
- vst1q_f32(dout_c2, vs2);
-
- din += 12;
- dout_c0 += 4;
- dout_c1 += 4;
- dout_c2 += 4;
- }
- for (; i < size; i++) {
- *(dout_c0++) = (*(din++) - this->mean[0]) * this->std[0];
- *(dout_c1++) = (*(din++) - this->mean[1]) * this->std[1];
- *(dout_c2++) = (*(din++) - this->mean[2]) * this->std[2];
- }
-}
-
-cv::Mat FeatureExtract::ResizeImage(const cv::Mat &img) {
- cv::Mat resize_img;
- cv::resize(img, resize_img, cv::Size(this->size, this->size));
- return resize_img;
-}
+void FeatureExtract::FeatureNorm(std::vector &feature) {
+ float feature_sqrt = std::sqrt(std::inner_product(
+ feature.begin(), feature.end(), feature.begin(), 0.0f));
+ for (int i = 0; i < feature.size(); ++i)
+ feature[i] /= feature_sqrt;
}
+} // namespace PPShiTu
diff --git a/deploy/lite_shitu/src/main.cc b/deploy/lite_shitu/src/main.cc
index 3f278dc778701a7a7591e74336e0f86fe52105ea..fb516c297d83c438b1b5df88732ad386377c781f 100644
--- a/deploy/lite_shitu/src/main.cc
+++ b/deploy/lite_shitu/src/main.cc
@@ -27,6 +27,7 @@
#include "include/feature_extractor.h"
#include "include/object_detector.h"
#include "include/preprocess_op.h"
+#include "include/utils.h"
#include "include/vector_search.h"
#include "json/json.h"
@@ -158,6 +159,11 @@ int main(int argc, char **argv) {
<< " [image_dir]>" << std::endl;
return -1;
}
+
+ float rec_nms_threshold = 0.05;
+ if (RT_Config["Global"]["rec_nms_thresold"].isDouble())
+ rec_nms_threshold = RT_Config["Global"]["rec_nms_thresold"].as();
+
// Load model and create a object detector
PPShiTu::ObjectDetector det(
RT_Config, RT_Config["Global"]["det_model_path"].as(),
@@ -174,6 +180,7 @@ int main(int argc, char **argv) {
// for vector search
std::vector feature;
std::vector features;
+ std::vector indeices;
double rec_time;
if (!RT_Config["Global"]["infer_imgs"].as().empty() ||
!img_dir.empty()) {
@@ -208,9 +215,9 @@ int main(int argc, char **argv) {
RT_Config["Global"]["max_det_results"].as(), false, &det);
// add the whole image for recognition to improve recall
-// PPShiTu::ObjectResult result_whole_img = {
-// {0, 0, srcimg.cols, srcimg.rows}, 0, 1.0};
-// det_result.push_back(result_whole_img);
+ PPShiTu::ObjectResult result_whole_img = {
+ {0, 0, srcimg.cols, srcimg.rows}, 0, 1.0};
+ det_result.push_back(result_whole_img);
// get rec result
PPShiTu::SearchResult search_result;
@@ -225,10 +232,18 @@ int main(int argc, char **argv) {
// do vectore search
search_result = searcher.Search(features.data(), det_result.size());
+ for (int i = 0; i < det_result.size(); ++i) {
+ det_result[i].confidence = search_result.D[search_result.return_k * i];
+ }
+ NMSBoxes(det_result, searcher.GetThreshold(), rec_nms_threshold,
+ indeices);
PrintResult(img_path, det_result, searcher, search_result);
batch_imgs.clear();
det_result.clear();
+ features.clear();
+ feature.clear();
+ indeices.clear();
}
}
return 0;
diff --git a/deploy/lite_shitu/src/object_detector.cc b/deploy/lite_shitu/src/object_detector.cc
index ffea31bb9d76b1dd90eed2a90cd066b0edb20057..18388f7a5b0a4fd7b63c37269bd4eea81aad6db1 100644
--- a/deploy/lite_shitu/src/object_detector.cc
+++ b/deploy/lite_shitu/src/object_detector.cc
@@ -13,9 +13,9 @@
// limitations under the License.
#include
// for setprecision
+#include "include/object_detector.h"
#include
#include
-#include "include/object_detector.h"
namespace PPShiTu {
@@ -30,10 +30,10 @@ void ObjectDetector::LoadModel(std::string model_file, int num_theads) {
}
// Visualiztion MaskDetector results
-cv::Mat VisualizeResult(const cv::Mat& img,
- const std::vector& results,
- const std::vector& lables,
- const std::vector& colormap,
+cv::Mat VisualizeResult(const cv::Mat &img,
+ const std::vector &results,
+ const std::vector &lables,
+ const std::vector &colormap,
const bool is_rbox = false) {
cv::Mat vis_img = img.clone();
for (int i = 0; i < results.size(); ++i) {
@@ -75,24 +75,18 @@ cv::Mat VisualizeResult(const cv::Mat& img,
origin.y = results[i].rect[1];
// Configure text background
- cv::Rect text_back = cv::Rect(results[i].rect[0],
- results[i].rect[1] - text_size.height,
- text_size.width,
- text_size.height);
+ cv::Rect text_back =
+ cv::Rect(results[i].rect[0], results[i].rect[1] - text_size.height,
+ text_size.width, text_size.height);
// Draw text, and background
cv::rectangle(vis_img, text_back, roi_color, -1);
- cv::putText(vis_img,
- text,
- origin,
- font_face,
- font_scale,
- cv::Scalar(255, 255, 255),
- thickness);
+ cv::putText(vis_img, text, origin, font_face, font_scale,
+ cv::Scalar(255, 255, 255), thickness);
}
return vis_img;
}
-void ObjectDetector::Preprocess(const cv::Mat& ori_im) {
+void ObjectDetector::Preprocess(const cv::Mat &ori_im) {
// Clone the image : keep the original mat for postprocess
cv::Mat im = ori_im.clone();
// cv::cvtColor(im, im, cv::COLOR_BGR2RGB);
@@ -100,7 +94,7 @@ void ObjectDetector::Preprocess(const cv::Mat& ori_im) {
}
void ObjectDetector::Postprocess(const std::vector mats,
- std::vector* result,
+ std::vector *result,
std::vector bbox_num,
bool is_rbox = false) {
result->clear();
@@ -156,12 +150,11 @@ void ObjectDetector::Postprocess(const std::vector mats,
}
}
-void ObjectDetector::Predict(const std::vector& imgs,
- const int warmup,
+void ObjectDetector::Predict(const std::vector &imgs, const int warmup,
const int repeats,
- std::vector* result,
- std::vector* bbox_num,
- std::vector* times) {
+ std::vector *result,
+ std::vector *bbox_num,
+ std::vector *times) {
auto preprocess_start = std::chrono::steady_clock::now();
int batch_size = imgs.size();
@@ -180,29 +173,29 @@ void ObjectDetector::Predict(const std::vector& imgs,
scale_factor_all[bs_idx * 2 + 1] = inputs_.scale_factor_[1];
// TODO: reduce cost time
- in_data_all.insert(
- in_data_all.end(), inputs_.im_data_.begin(), inputs_.im_data_.end());
+ in_data_all.insert(in_data_all.end(), inputs_.im_data_.begin(),
+ inputs_.im_data_.end());
}
auto preprocess_end = std::chrono::steady_clock::now();
std::vector output_data_list_;
// Prepare input tensor
auto input_names = predictor_->GetInputNames();
- for (const auto& tensor_name : input_names) {
+ for (const auto &tensor_name : input_names) {
auto in_tensor = predictor_->GetInputByName(tensor_name);
if (tensor_name == "image") {
int rh = inputs_.in_net_shape_[0];
int rw = inputs_.in_net_shape_[1];
in_tensor->Resize({batch_size, 3, rh, rw});
- auto* inptr = in_tensor->mutable_data();
+ auto *inptr = in_tensor->mutable_data();
std::copy_n(in_data_all.data(), in_data_all.size(), inptr);
} else if (tensor_name == "im_shape") {
in_tensor->Resize({batch_size, 2});
- auto* inptr = in_tensor->mutable_data();
+ auto *inptr = in_tensor->mutable_data();
std::copy_n(im_shape_all.data(), im_shape_all.size(), inptr);
} else if (tensor_name == "scale_factor") {
in_tensor->Resize({batch_size, 2});
- auto* inptr = in_tensor->mutable_data();
+ auto *inptr = in_tensor->mutable_data();
std::copy_n(scale_factor_all.data(), scale_factor_all.size(), inptr);
}
}
@@ -216,7 +209,7 @@ void ObjectDetector::Predict(const std::vector& imgs,
if (config_.arch_ == "PicoDet") {
for (int j = 0; j < output_names.size(); j++) {
auto output_tensor = predictor_->GetTensor(output_names[j]);
- const float* outptr = output_tensor->data();
+ const float *outptr = output_tensor->data();
std::vector output_shape = output_tensor->shape();
output_data_list_.push_back(outptr);
}
@@ -242,7 +235,7 @@ void ObjectDetector::Predict(const std::vector& imgs,
if (config_.arch_ == "PicoDet") {
for (int i = 0; i < output_names.size(); i++) {
auto output_tensor = predictor_->GetTensor(output_names[i]);
- const float* outptr = output_tensor->data();
+ const float *outptr = output_tensor->data();
std::vector output_shape = output_tensor->shape();
if (i == 0) {
num_class = output_shape[2];
@@ -268,16 +261,15 @@ void ObjectDetector::Predict(const std::vector& imgs,
std::cerr << "[WARNING] No object detected." << std::endl;
}
output_data_.resize(output_size);
- std::copy_n(
- output_tensor->mutable_data(), output_size, output_data_.data());
+ std::copy_n(output_tensor->mutable_data(), output_size,
+ output_data_.data());
int out_bbox_num_size = 1;
for (int j = 0; j < out_bbox_num_shape.size(); ++j) {
out_bbox_num_size *= out_bbox_num_shape[j];
}
out_bbox_num_data_.resize(out_bbox_num_size);
- std::copy_n(out_bbox_num->mutable_data(),
- out_bbox_num_size,
+ std::copy_n(out_bbox_num->mutable_data(), out_bbox_num_size,
out_bbox_num_data_.data());
}
// Postprocessing result
@@ -285,9 +277,8 @@ void ObjectDetector::Predict(const std::vector  +
+

 +
+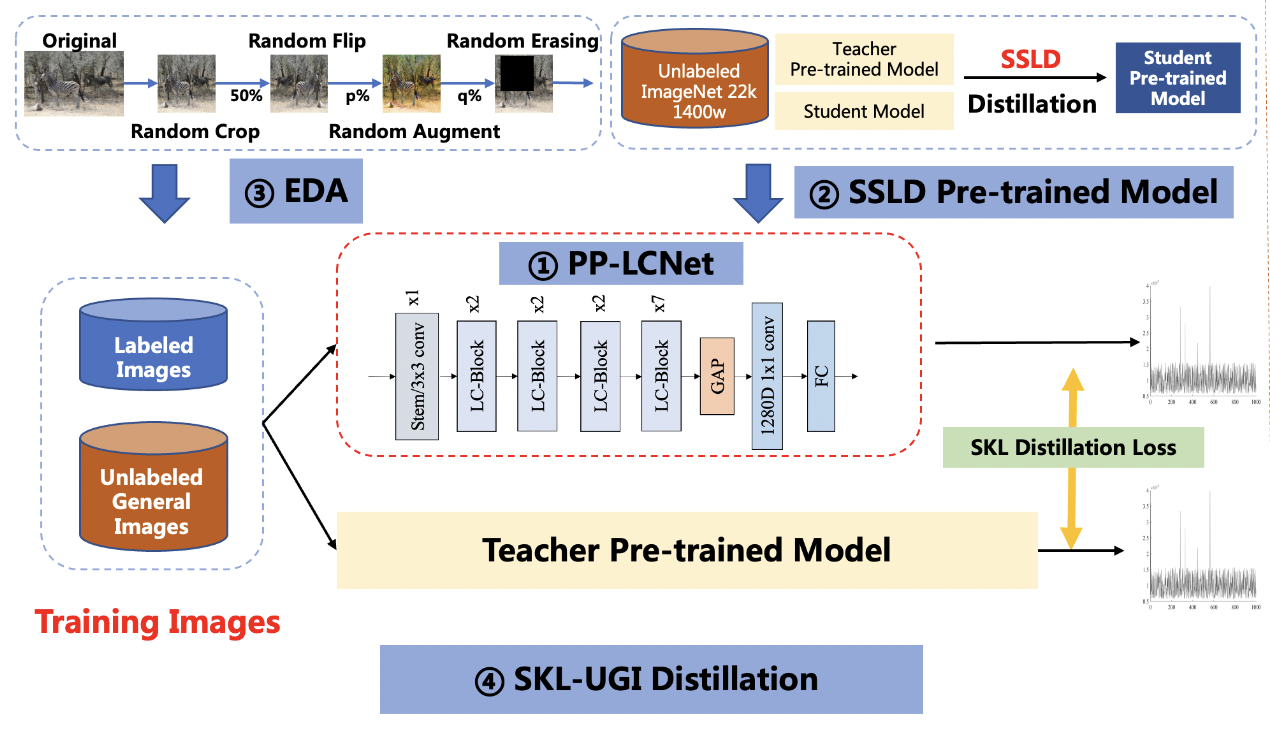 +
+ +
+