# Design for GAN
GAN (General Adversarial Net [https://arxiv.org/abs/1406.2661]) is an important model for unsupervised learning and widely used in many areas.
It applies several important concepts in machine learning system design, including building and running subgraphs, dependency tracing, different optimizers in one executor and so forth.
In our GAN design, we wrap it as a user-friendly easily customized python API to design different models. We take the conditional DC-GAN (Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks [https://arxiv.org/abs/1511.06434]) as an example due to its good performance on image generation.
| important building blocks | People in Charge | Required |
|---------------------------|-------------------|----------|
| convolution 2d (done) | Chengduo | Y |
| cudnn conv 2d (missing) | Chengduo | N |
| deconv 2d (missing) | Zhuoyuan, Zhihong | Y |
| cudnn deconv 2d (missing) | Zhuoyuan, Zhihong | N |
| batch norm (missing) | Zhuoyuan, Jiayi | Y |
| cudnn batch norm (missing)| Zhuoyuan, Jiayi | N |
| max-pooling (done) | ? | Y |
| cudnn-max-pool (missing) | Chengduo | Y |
| fc (done) | ? | Y |
| softmax loss (done) | ? | Y |
| reshape op (done) | ? | Y |
| Dependency Engine (done) | Jiayi | Y * |
| Python API (done) | Longfei, Jiayi | Y * |
| Executor (done) | Tony | Y * |
| Multi optimizer (woking) | Longfei | Y * |
| Optimizer with any para | ? | Y * |
| Concat op (done) | ? | N (Cond) |
| Repmat op (done) | ? | N (Cond) |
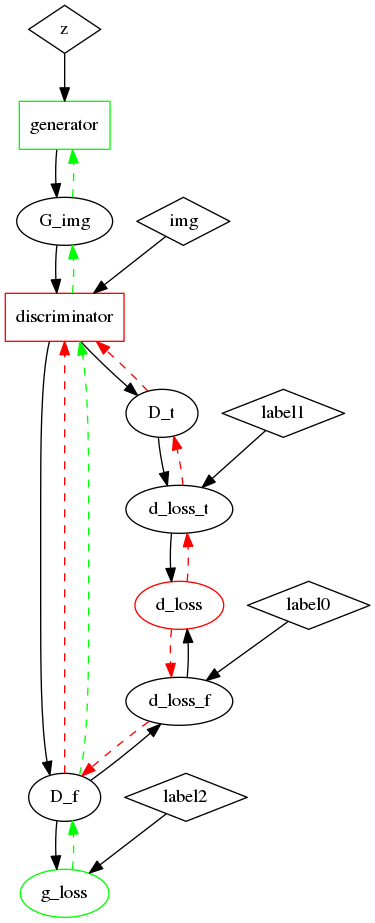
The overall running logic of GAN. The black solid arrows indicate the forward pass; the green dashed arrows indicate the backward pass of generator training; the red dashed arrows indicate the backward pass of the discriminator training. The BP pass of the green (red) arrow should only update the parameters in the green (red) boxes. The diamonds indicate the data providers. d\_loss and g\_loss mared in red and green are the two targets we would like to run.

Photo borrowed from the original DC-GAN paper.
## The Conditional-GAN might be a class.
This design we adopt the popular open source design in https://github.com/carpedm20/DCGAN-tensorflow and https://github.com/rajathkmp/DCGAN. It contains following data structure:
- DCGAN(object): which contains everything required to build a GAN model. It provides following member functions methods as API:
- __init__(...): Initialize hyper-parameters (like conv dimension and so forth), and declare model parameters of discriminator and generator as well.
- generator(z, y=None): Generate a fake image from input noise z. If the label y is provided, the conditional GAN model will be chosen.
Returns a generated image.
- discriminator(image):
Given an image, decide if it is from a real source or a fake one.
Returns a 0/1 binary label.
- build_model(self):
build the whole GAN model, define training loss for both generator and discrimator.
## Discussion on Engine Functions required to build GAN
- Trace the tensor and variable dependency in the engine executor. (Very critical, otherwise GAN can'be be trained correctly)
- Different optimizers responsible for optimizing different loss.
To be more detailed, we introduce our design of DCGAN as following:
### Class member Function: Initializer
- Set up hyper-parameters, including condtional dimension, noise dimension, batch size and so forth.
- Declare and define all the model variables. All the discriminator parameters are included in the list self.theta_D and all the generator parameters are included in the list self.theta_G.
```python
class DCGAN(object):
def __init__(self, y_dim=None):
# hyper parameters
self.y_dim = y_dim # conditional gan or not
self.batch_size = 100
self.z_dim = z_dim # input noise dimension
# define parameters of discriminators
self.D_W0 = pd.Variable(shape=[3,3, 1, 128], data=pd.gaussian_normal_randomizer())
self.D_b0 = pd.Variable(np.zeros(128)) # variable also support initialization using a numpy data
self.D_W1 = pd.Variable(shape=[784, 128], data=pd.gaussian_normal_randomizer())
self.D_b1 = pd.Variable(np.zeros(128)) # variable also support initialization using a numpy data
self.D_W2 = pd.Varialble(np.random.rand(128, 1))
self.D_b2 = pd.Variable(np.zeros(128))
self.theta_D = [self.D_W0, self.D_b0, self.D_W1, self.D_b1, self.D_W2, self.D_b2]
# define parameters of generators
self.G_W0 = pd.Variable(shape=[784, 128], data=pd.gaussian_normal_randomizer())
self.G_b0 = pd.Variable(np.zeros(128)) # variable also support initialization using a numpy data
self.G_W1 = pd.Variable(shape=[784, 128], data=pd.gaussian_normal_randomizer())
self.G_b1 = pd.Variable(np.zeros(128)) # variable also support initialization using a numpy data
self.G_W2 = pd.Varialble(np.random.rand(128, 1))
self.G_b2 = pd.Variable(np.zeros(128))
self.theta_G = [self.G_W0, self.G_b0, self.G_W1, self.G_b1, self.G_W2, self.G_b2]
```
### Class member Function: Generator
- Given a noisy input z, returns a fake image.
- Concatenation, batch-norm, FC operations required;
- Deconv layer required, which is missing now...
```python
class DCGAN(object):
def generator(self, z, y = None):
# input z: the random noise
# input y: input data label (optional)
# output G_im: generated fake images
if not self.y_dim:
z = pd.layer.concat(1, [z, y])
G_h0 = pd.layer.fc(z, self.G_w0, self.G_b0)
G_h0_bn = pd.layer.batch_norm(G_h0)
G_h0_relu = pd.layer.relu(G_h0_bn)
G_h1 = pd.layer.deconv(G_h0_relu, self.G_w1, self.G_b1)
G_h1_bn = pd.layer.batch_norm(G_h1)
G_h1_relu = pd.layer.relu(G_h1_bn)
G_h2 = pd.layer.deconv(G_h1_relu, self.G_W2, self.G_b2))
G_im = pd.layer.tanh(G_im)
return G_im
```
### Class member function: Discriminator
- Given a noisy input z, returns a fake image.
- Concatenation, Convolution, batch-norm, FC, Leaky-ReLU operations required;
```python
class DCGAN(object):
def discriminator(self, image):
# input image: either generated images or real ones
# output D_h2: binary logit of the label
D_h0 = pd.layer.conv2d(image, w=self.D_w0, b=self.D_b0)
D_h0_bn = pd.layer.batchnorm(h0)
D_h0_relu = pd.layer.lrelu(h0_bn)
D_h1 = pd.layer.conv2d(D_h0_relu, w=self.D_w1, b=self.D_b1)
D_h1_bn = pd.layer.batchnorm(D_h1)
D_h1_relu = pd.layer.lrelu(D_h1_bn)
D_h2 = pd.layer.fc(D_h1_relu, w=self.D_w2, b=self.D_b2)
return D_h2
```
### Class member function: Build the model
- Define data readers as placeholders to hold the data;
- Build generator and discriminators;
- Define two training losses for discriminator and generator, respectively.
If we have execution dependency engine to back-trace all tensors, the module building our GAN model will be like this:
```python
class DCGAN(object):
def build_model(self):
if self.y_dim:
self.y = pd.data(pd.float32, [self.batch_size, self.y_dim])
self.images = pd.data(pd.float32, [self.batch_size, self.im_size, self.im_size])
self.faked_images = pd.data(pd.float32, [self.batch_size, self.im_size, self.im_size])
self.z = pd.data(tf.float32, [None, self.z_size])
# step 1: generate images by generator, classify real/fake images with discriminator
if self.y_dim: # if conditional GAN, includes label
self.G = self.generator(self.z, self.y)
self.D_t = self.discriminator(self.images)
# generated fake images
self.sampled = self.sampler(self.z, self.y)
self.D_f = self.discriminator(self.G)
else: # original version of GAN
self.G = self.generator(self.z)
self.D_t = self.discriminator(self.images)
# generate fake images
self.sampled = self.sampler(self.z)
self.D_f = self.discriminator(self.images)
# step 2: define the two losses
self.d_loss_real = pd.reduce_mean(pd.cross_entropy(self.D_t, np.ones(self.batch_size))
self.d_loss_fake = pd.reduce_mean(pd.cross_entropy(self.D_f, np.zeros(self.batch_size))
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss = pd.reduce_mean(pd.cross_entropy(self.D_f, np.ones(self.batch_szie))
```
If we do not have dependency engine but blocks, the module building our GAN model will be like this:
```python
class DCGAN(object):
def build_model(self, default_block):
# input data in the default block
if self.y_dim:
self.y = pd.data(pd.float32, [self.batch_size, self.y_dim])
self.images = pd.data(pd.float32, [self.batch_size, self.im_size, self.im_size])
# self.faked_images = pd.data(pd.float32, [self.batch_size, self.im_size, self.im_size])
self.z = pd.data(tf.float32, [None, self.z_size])
# step 1: generate images by generator, classify real/fake images with discriminator
with pd.default_block().g_block():
if self.y_dim: # if conditional GAN, includes label
self.G = self.generator(self.z, self.y)
self.D_g = self.discriminator(self.G, self.y)
else: # original version of GAN
self.G = self.generator(self.z)
self.D_g = self.discriminator(self.G, self.y)
self.g_loss = pd.reduce_mean(pd.cross_entropy(self.D_g, np.ones(self.batch_szie))
with pd.default_block().d_block():
if self.y_dim: # if conditional GAN, includes label
self.D_t = self.discriminator(self.images, self.y)
self.D_f = self.discriminator(self.G, self.y)
else: # original version of GAN
self.D_t = self.discriminator(self.images)
self.D_f = self.discriminator(self.G)
# step 2: define the two losses
self.d_loss_real = pd.reduce_mean(pd.cross_entropy(self.D_t, np.ones(self.batch_size))
self.d_loss_fake = pd.reduce_mean(pd.cross_entropy(self.D_f, np.zeros(self.batch_size))
self.d_loss = self.d_loss_real + self.d_loss_fake
```
Some small confusion and problems with this design:
- D\_g and D\_f are actually the same thing, but has to be written twice; i.e., if we want to run two sub-graphs conceptually, the same codes have to be written twice if they are shared by the graph.
- Requires ability to create a block anytime, rather than in if-else or rnn only;
## Main function for the demo:
Generally, the user of GAN just need to the following things:
- Define an object as DCGAN class;
- Build the DCGAN model;
- Specify two optimizers for two different losses with respect to different parameters.
```python
# pd for short, should be more concise.
from paddle.v2 as pd
import numpy as np
import logging
if __name__ == "__main__":
# dcgan class in the default graph/block
# if we use dependency engine as tensorflow
# the codes, will be slightly different like:
# dcgan = DCGAN()
# dcgan.build_model()
with pd.block() as def_block:
dcgan = DCGAN()
dcgan.build_model(def_block)
# load mnist data
data_X, data_y = self.load_mnist()
# Two subgraphs required!!!
with pd.block().d_block():
d_optim = pd.train.Adam(lr = .001, beta= .1)
d_step = d_optim.minimize(dcgan.d_loss, dcgan.theta_D)
with pd.block.g_block():
g_optim = pd.train.Adam(lr = .001, beta= .1)
g_step = pd.minimize(dcgan.g_loss, dcgan.theta_G)
# executor
sess = pd.executor()
# training
for epoch in xrange(10000):
for batch_id in range(N / batch_size):
idx = ...
# sample a batch
batch_im, batch_label = data_X[idx:idx+batch_size], data_y[idx:idx+batch_size]
# sample z
batch_z = np.random.uniform(-1., 1., [batch_size, z_dim])
if batch_id % 2 == 0:
sess.run(d_step,
feed_dict = {dcgan.images: batch_im,
dcgan.y: batch_label,
dcgan.z: batch_z})
else:
sess.run(g_step,
feed_dict = {dcgan.z: batch_z})
```
# More thinking about dependency engine v.s. block design:
- What if we just want to run an intermediate result? Do we need to run the whole block/graph?
- Should we call eval() to get the fake images in the first stage? And then train the discriminator in the second stage?