
此教程会介绍如何使用Python的cProfile包,与Python库yep,google perftools来运行性能分析(Profiling)与调优。
运行性能分析可以让开发人员科学的,有条不紊的对程序进行性能优化。性能分析是性能调优的基础。因为在程序实际运行中,真正的瓶颈可能和程序员开发过程中想象的瓶颈相去甚远。
性能优化的步骤,通常是循环重复若干次『性能分析 –> 寻找瓶颈 —> 调优瓶颈 –> 性能分析确认调优效果』。其中性能分析是性能调优的至关重要的量化指标。
Paddle提供了Python语言绑定。用户使用Python进行神经网络编程,训练,测试。Python解释器通过pybind和swig调用Paddle的动态链接库,进而调用Paddle C++部分的代码。所以Paddle的性能分析与调优分为两个部分:
- Python代码的性能分析
- Python与C++混合代码的性能分析
Python代码的性能分析¶
生成性能分析文件¶
Python标准库中提供了性能分析的工具包,cProfile。生成Python性能分析的命令如下:
python -m cProfile -o profile.out main.py
其中-o标识了一个输出的文件名,用来存储本次性能分析的结果。如果不指定这个文件,cProfile会打印一些统计信息到stdout。这不方便我们进行后期处理(进行sort, split, cut等等)。
查看性能分析文件¶
当main.py运行完毕后,性能分析结果文件profile.out就生成出来了。我们可以使用cprofilev来查看性能分析结果。cprofilev是一个Python的第三方库。使用它会开启一个HTTP服务,将性能分析结果以网页的形式展示出来。
使用pip install cprofilev安装cprofilev工具。安装完成后,使用如下命令开启HTTP服务
cprofilev -a 0.0.0.0 -p 3214 -f profile.out main.py
其中-a标识HTTP服务绑定的IP。使用0.0.0.0允许外网访问这个HTTP服务。-p标识HTTP服务的端口。-f标识性能分析的结果文件。main.py标识被性能分析的源文件。
访问对应网址,即可显示性能分析的结果。性能分析结果格式如下:
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.284 0.284 29.514 29.514 main.py:1(<module>)
4696 0.128 0.000 15.748 0.003 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/executor.py:20(run)
4696 12.040 0.003 12.040 0.003 {built-in method run}
1 0.144 0.144 6.534 6.534 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/__init__.py:14(<module>)
每一列的含义是:
| 列名 | 含义 | | — | — | | ncalls | 函数的调用次数 | | tottime | 函数实际使用的总时间。该时间去除掉本函数调用其他函数的时间 | | percall | tottime的每次调用平均时间 | | cumtime | 函数总时间。包含这个函数调用其他函数的时间 | | percall | cumtime的每次调用平均时间 | | filename:lineno(function) | 文件名, 行号,函数名 |
寻找性能瓶颈¶
通常tottime和cumtime是寻找瓶颈的关键指标。这两个指标代表了某一个函数真实的运行时间。
将性能分析结果按照tottime排序,效果如下:
4696 12.040 0.003 12.040 0.003 {built-in method run}
300005 0.874 0.000 1.681 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/dataset/mnist.py:38(reader)
107991 0.676 0.000 1.519 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:219(__init__)
4697 0.626 0.000 2.291 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp)
1 0.618 0.618 0.618 0.618 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/__init__.py:1(<module>)
可以看到最耗时的函数是C++端的run函数。这需要联合我们第二节Python与C++混合代码的性能分析来进行调优。而sync_with_cpp函数的总共耗时很长,每次调用的耗时也很长。于是我们可以点击sync_with_cpp的详细信息,了解其调用关系。
Called By:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
Function was called by...
ncalls tottime cumtime
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp) <- 4697 0.626 2.291 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp)
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp) <- 4696 0.019 2.316 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:487(clone)
1 0.000 0.001 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:534(append_backward)
Called:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
通常观察热点函数间的调用关系,和对应行的代码,就可以了解到问题代码在哪里。当我们做出性能修正后,再次进行性能分析(profiling)即可检查我们调优后的修正是否能够改善程序的性能。
Python与C++混合代码的性能分析¶
生成性能分析文件¶
C++的性能分析工具非常多。常见的包括gprof, valgrind, google-perftools。但是调试Python中使用的动态链接库与直接调试原始二进制相比增加了很多复杂度。幸而Python的一个第三方库yep提供了方便的和google-perftools交互的方法。于是这里使用yep进行Python与C++混合代码的性能分析
使用yep前需要安装google-perftools与yep包。ubuntu下安装命令为
apt install libgoogle-perftools-dev
pip install yep
安装完毕后,我们可以通过
python -m yep -v main.py
生成性能分析文件。生成的性能分析文件为main.py.prof。
命令行中的-v指定在生成性能分析文件之后,在命令行显示分析结果。我们可以在命令行中简单的看一下生成效果。因为C++与Python不同,编译时可能会去掉调试信息,运行时也可能因为多线程产生混乱不可读的性能分析结果。为了生成更可读的性能分析结果,可以采取下面几点措施:
- 编译时指定
-g生成调试信息。使用cmake的话,可以将CMAKE_BUILD_TYPE指定为RelWithDebInfo。 - 编译时一定要开启优化。单纯的
Debug编译性能会和-O2或者-O3有非常大的差别。Debug模式下的性能测试是没有意义的。 - 运行性能分析的时候,先从单线程开始,再开启多线程,进而多机。毕竟如果单线程调试更容易。可以设置
OMP_NUM_THREADS=1这个环境变量关闭openmp优化。
查看性能分析文件¶
在运行完性能分析后,会生成性能分析结果文件。我们可以使用pprof来显示性能分析结果。注意,这里使用了用Go语言重构后的pprof,因为这个工具具有web服务界面,且展示效果更好。
安装pprof的命令和一般的Go程序是一样的,其命令如下:
go get github.com/google/pprof
进而我们可以使用如下命令开启一个HTTP服务:
pprof -http=0.0.0.0:3213 `which python` ./main.py.prof
这行命令中,-http指开启HTTP服务。which python会产生当前Python二进制的完整路径,进而指定了Python可执行文件的路径。./main.py.prof输入了性能分析结果。
访问对应的网址,我们可以查看性能分析的结果。结果如下图所示:
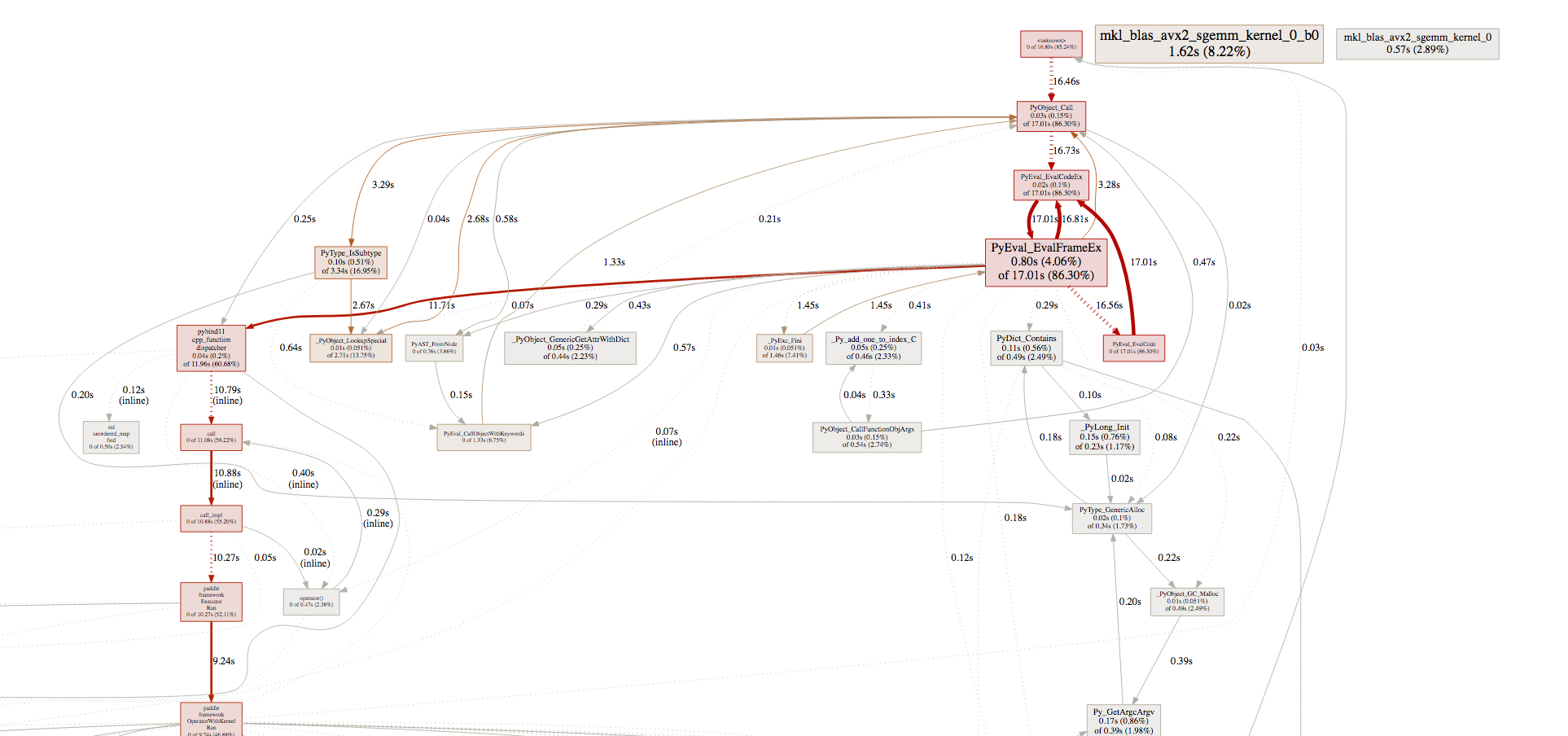
寻找性能瓶颈¶
与寻找Python代码的性能瓶颈类似,寻找Python与C++混合代码的性能瓶颈也是要看tottime和cumtime。而pprof展示的调用图也可以帮助我们发现性能中的问题。
例如下图中,

在一次训练中,乘法和乘法梯度的计算占用2%-4%左右的计算时间。而MomentumOp占用了17%左右的计算时间。显然,MomentumOp的性能有问题。
在pprof中,对于性能的关键路径都做出了红色标记。先检查关键路径的性能问题,再检查其他部分的性能问题,可以更有次序的完成性能的优化。
总结¶
至此,两种性能分析的方式都介绍完毕了。希望通过这两种性能分析的方式,Paddle的开发人员和使用人员可以有次序的,科学的发现和解决性能问题。