
语义角色标注教程¶
语义角色标注(Semantic role labeling, SRL)是浅层语义解析的一种形式,其目的是在给定的输入句子中发现每个谓词的谓词论元结构。 SRL作为很多自然语言处理任务中的中间步骤是很有用的,如信息提取、文档自动分类和问答。 实例如下 [1]:
[ A0 He ] [ AM-MOD would ][ AM-NEG n’t ] [ V accept] [ A1 anything of value ] from [A2 those he was writing about ].
- V: 动词
- A0: 接受者
- A1: 接受的东西
- A2: 从……接受
- A3: 属性
- AM-MOD: 情态动词
- AM-NEG: 否定
给定动词“accept”,句子中的组块将会扮演某些语义角色。这里,标签方案来自 Penn Proposition Bank。
到目前为止,大多数成功的SRL系统是建立在某种形式的句法分析结果之上的,使用了基于句法结构的预定义特征模板。 本教程将介绍使用深度双向长短期记忆(DB-LSTM)模型[2]的端到端系统来解决SRL任务,这在很大程度上优于先前的最先进的系统。 这个系统将SRL任务视为序列标注问题。
数据描述¶
相关论文[2]采用 CoNLL-2005&2012 共享任务中设置的数据进行训练和测试。由于数据许可的原因,演示采用 CoNLL-2005 的测试数据集,可以在网站上找到。
用户只需执行以下命令就可以下载并处理原始数据:
cd data
./get_data.sh
data目录会出现如下几个新的文件:
conll05st-release:the test data set of CoNll-2005 shared task
test.wsj.words:the Wall Street Journal data sentences
test.wsj.props: the propositional arguments
feature: the extracted features from data set
训练¶
DB-LSTM¶
请参阅情感分析的演示以了解有关长期短期记忆单元的更多信息。
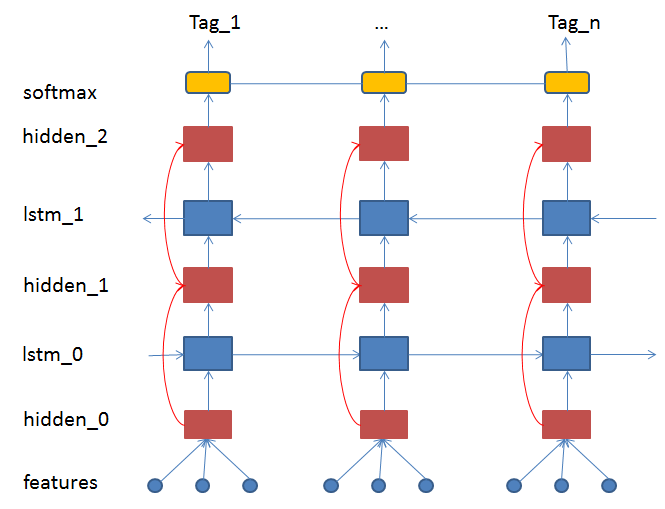
与在 Sentiment Analysis 演示中使用的 Bidirectional-LSTM 不同,DB-LSTM 采用另一种方法来堆叠LSTM层。首先,标准LSTM以正向处理该序列。该 LSTM 层的输入和输出作为下一个 LSTM 层的输入,并被反向处理。这两个标准 LSTM 层组成一对 LSTM。然后我们堆叠一对对的 LSTM 层后得到深度 LSTM 模型。
下图展示了时间扩展的2层 DB-LSTM 网络。
特征¶
两个输入特征在这个流程中起着至关重要的作用:predicate(pred)和argument(arguments)。 还采用了两个其他特征:谓词上下文(ctx-p)和区域标记(mr)。 因为单个谓词不能精确地描述谓词信息,特别是当相同的词在句子中出现多于一次时。 使用谓词上下文,可以在很大程度上消除歧义。类似地,如果它位于谓词上下文区域中,则使用区域标记 mr = 1 来表示参数位置,反之则 mr = 0。这四个简单的特征是我们的SRL系统所需要的。上下文大小设置为1的一个样本的特征如下[2]所示:
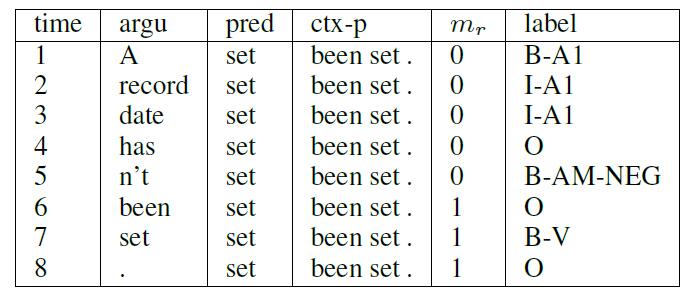
在这个示例中,相应的标记句子是:
[ A1 A record date ] has [ AM-NEG n’t ] been [ V set ] .
在演示中, 我们采用上面的特征模板, 包括: argument, predicate, ctx-p (p=-1,0,1), mark 并使用 B/I/O 方案来标记每个参数。这些特征和标签存储在 feature 文件中, 用\t分割。
数据提供¶
dataprovider.py 是一个包装数据的 Python 文件。 函数 hook() 定义了网络的数据槽。六个特征和标签都是索引槽。
def hook(settings, word_dict, label_dict, **kwargs):
settings.word_dict = word_dict
settings.label_dict = label_dict
#all inputs are integral and sequential type
settings.slots = [
integer_value_sequence(len(word_dict)),
integer_value_sequence(len(predicate_dict)),
integer_value_sequence(len(word_dict)),
integer_value_sequence(len(word_dict)),
integer_value_sequence(len(word_dict)),
integer_value_sequence(len(word_dict)),
integer_value_sequence(len(word_dict)),
integer_value_sequence(2),
integer_value_sequence(len(label_dict))]
相应的数据迭代器如下:
@provider(init_hook=hook, should_shuffle=True, calc_batch_size=get_batch_size,
can_over_batch_size=False, cache=CacheType.CACHE_PASS_IN_MEM)
def process(settings, file_name):
with open(file_name, 'r') as fdata:
for line in fdata:
sentence, predicate, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, mark, label = \
line.strip().split('\t')
words = sentence.split()
sen_len = len(words)
word_slot = [settings.word_dict.get(w, UNK_IDX) for w in words]
predicate_slot = [settings.predicate_dict.get(predicate)] * sen_len
ctx_n2_slot = [settings.word_dict.get(ctx_n2, UNK_IDX)] * sen_len
ctx_n1_slot = [settings.word_dict.get(ctx_n1, UNK_IDX)] * sen_len
ctx_0_slot = [settings.word_dict.get(ctx_0, UNK_IDX)] * sen_len
ctx_p1_slot = [settings.word_dict.get(ctx_p1, UNK_IDX)] * sen_len
ctx_p2_slot = [settings.word_dict.get(ctx_p2, UNK_IDX)] * sen_len
marks = mark.split()
mark_slot = [int(w) for w in marks]
label_list = label.split()
label_slot = [settings.label_dict.get(w) for w in label_list]
yield word_slot, predicate_slot, ctx_n2_slot, ctx_n1_slot, \
ctx_0_slot, ctx_p1_slot, ctx_p2_slot, mark_slot, label_slot
函数 process 返回8个特征list和1个标签list。
神经网络配置¶
db_lstm.py 是在训练过程中加载字典并定义数据提供程序模块和网络架构的神经网络配置文件。
九个 data_layer 从数据提供程序加载实例。八个特征分别转换为向量,并由mixed_layer混合。 深度双向LSTM层提取softmax层的特征。目标函数是标签的交叉熵。
训练¶
训练的脚本是 train.sh,用户只需执行:
./train.sh
train.sh 中的内容:
paddle train \
--config=./db_lstm.py \
--use_gpu=0 \
--log_period=5000 \
--trainer_count=1 \
--show_parameter_stats_period=5000 \
--save_dir=./output \
--num_passes=10000 \
--average_test_period=10000000 \
--init_model_path=./data \
--load_missing_parameter_strategy=rand \
--test_all_data_in_one_period=1 \
2>&1 | tee 'train.log'
- --config=./db_lstm.py : 网络配置文件
- --use_gpu=false: 使用 CPU 训练(如果已安装 PaddlePaddle GPU版本并想使用 GPU 训练可以设置为true,目前 crf_layer 不支持 GPU)
- --log_period=500: 每20个batch输出日志
- --trainer_count=1: 设置线程数(或 GPU 数)
- --show_parameter_stats_period=5000: 每100个batch显示参数统计
- --save_dir=./output: 模型输出路径
- --num_passes=10000: 设置数据遍历次数,一个pass意味着PaddlePaddle训练数据集中的所有样本被遍历一次
- --average_test_period=10000000: 每个 average_test_period 批次对平均参数进行测试
- --init_model_path=./data: 参数初始化路径
- --load_missing_parameter_strategy=rand: 随机初始不存在的参数
- --test_all_data_in_one_period=1: 在一个周期内测试所有数据
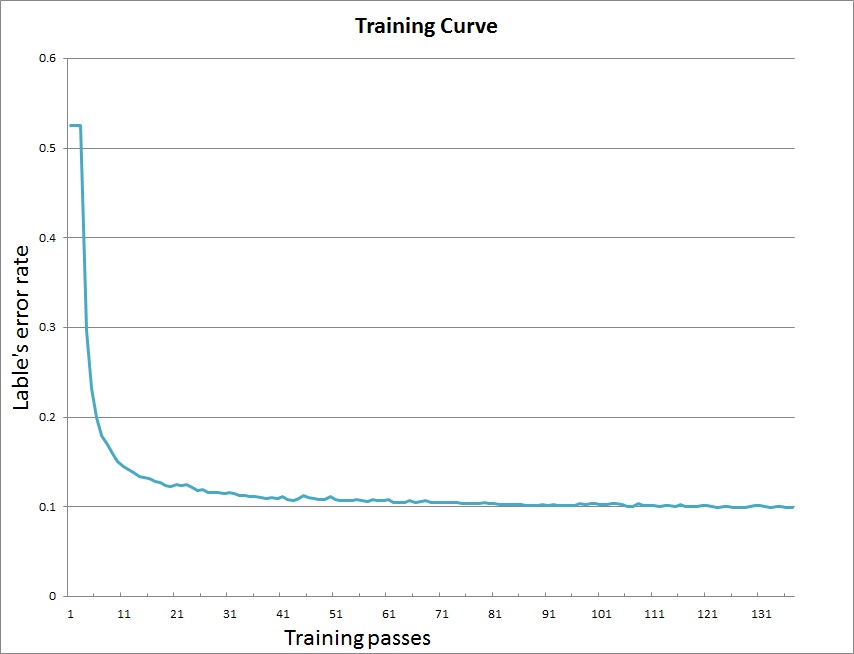
训练后,模型将保存在目录output中。 我们的训练曲线如下:
测试¶
测试脚本是 test.sh, 执行:
./test.sh
tesh.sh 的主要部分:
paddle train \
--config=./db_lstm.py \
--model_list=$model_list \
--job=test \
--config_args=is_test=1 \
- --config=./db_lstm.py: 网络配置文件
- --model_list=$model_list.list: 模型列表文件
- --job=test: 指示测试任务
- --config_args=is_test=1: 指示测试任务的标记
- --test_all_data_in_one_period=1: 在一个周期内测试所有数据
预测¶
预测脚本是 predict.sh,用户只需执行:
./predict.sh
在predict.sh中,用户应该提供网络配置文件,模型路径,标签文件,字典文件,特征文件。
python predict.py
-c $config_file \
-w $best_model_path \
-l $label_file \
-p $predicate_dict_file \
-d $dict_file \
-i $input_file \
-o $output_file
predict.py 是主要的可执行python脚本,其中包括函数:加载模型,加载数据,数据预测。网络模型将输出标签的概率分布。 在演示中,我们使用最大概率的标签作为结果。用户还可以根据概率分布矩阵实现柱搜索或维特比解码。
预测后,结果保存在 predict.res 中。
引用¶
[1] Martha Palmer, Dan Gildea, and Paul Kingsbury. The Proposition Bank: An Annotated Corpus of Semantic Roles , Computational Linguistics, 31(1), 2005.
[2] Zhou, Jie, and Wei Xu. “End-to-end learning of semantic role labeling using recurrent neural networks.” Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.