# Intel® MKL-DNN on PaddlePaddle: Design Doc
我们计划将英特尔深度神经网络数学库[Intel MKL-DNN](https://github.com/01org/mkl-dnn)
(Intel Math Kernel Library for Deep Neural Networks)集成到PaddlePaddle,
充分展现英特尔平台的优势,有效提升PaddlePaddle在英特尔架构上的性能。
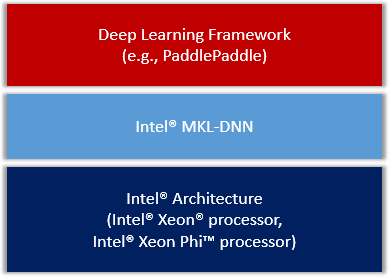
Figure 1. PaddlePaddle on IA
近期目标
- 完成常用Layer的MKL-DNN实现。
- 完成常见深度神经网络VGG,GoogLeNet 和 ResNet的MKL-DNN实现。
目前的优化,主要针对PaddlePaddle在重构之前的代码框架以及V1的API。
具体的完成状态可以参见[这里](https://github.com/PaddlePaddle/Paddle/projects/21)。
## Contents
- [Overview](#overview)
- [Actions](#actions)
- [CMake](#cmake)
- [Matrix](#matrix)
- [Layers](#layers)
- [Activations](#activations)
- [Parameters](#parameters)
- [Gradients](#gradients)
- [Unit Tests](#unit-tests)
- [Protobuf Messages](#protobuf-messages)
- [Python API](#python-api)
- [Demos](#demos)
- [Benchmarking](#benchmarking)
- [Others](#others)
- [Design Concerns](#design-concerns)
## Overview
我们会把MKL-DNN会作为第三方库集成进PaddlePaddle,与其他第三方库一样,会在编译PaddlePaddle的时候下载并编译MKL-DNN。
同时,为了进一步提升PaddlePaddle在基本数学运算的计算速度,我们也将MKLML即(MKL small library\[[1](#references)\])
作为另一个第三方库集成进PaddlePaddle,它只会包括生成好的动态库和头文件。
MKLML可以与MKL-DNN共同使用,以此达到最好的性能。
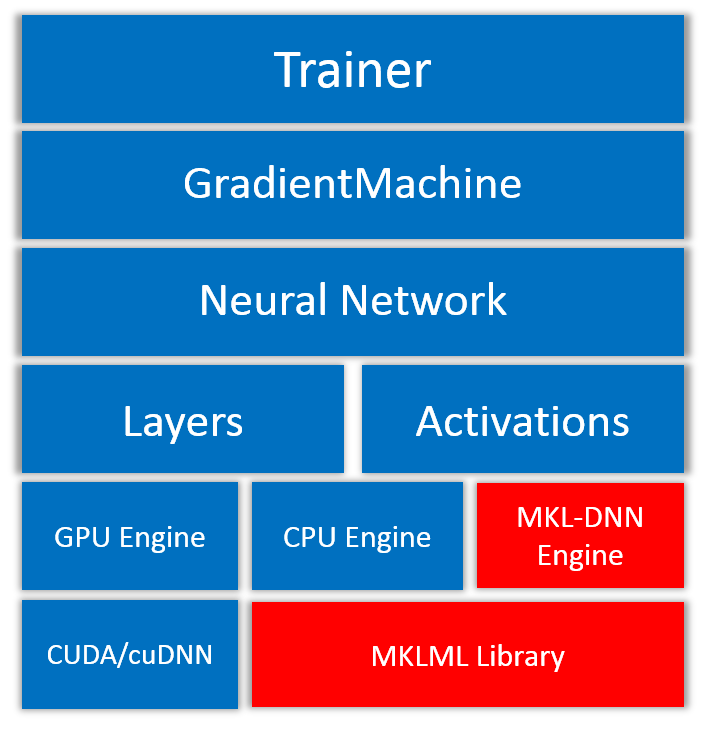
Figure 2. PaddlePaddle with MKL Engines
## Actions
添加的相关文件和目录结构如下:
```txt
PaddlePaddle/Paddle
├── ...
├── cmake/
│ ├── external/
│ │ ├── ...
│ │ ├── mkldnn.cmake
│ │ └── mklml.cmake
└── paddle/
├── ...
├── math/
│ ├── ...
│ └── MKLDNNMatrix.*
└── gserver/
├── ...
├── layers/
│ ├── ...
│ └── MKLDNN*Layer.*
├── activations/
│ ├── ...
│ └── MKLDNNActivations.*
└── tests/
├── ...
├── MKLDNNTester.*
└── test_MKLDNN.cpp
```
### CMake
在`CMakeLists.txt`中提供一个与MKL有关的总开关:`WITH_MKL`,它负责决定编译时是否使用MKLML和MKL-DNN
- `WITH_MKLML` 控制是否使用MKLML库。
当打开`WITH_MKL`时,会自动使用MKLML库作为PaddlePaddle的CBLAS和LAPACK库,同时会开启Intel OpenMP用于提高MKLML的性能。
- `WITH_MKLDNN` 控制是否使用MKL-DNN。
当开启`WITH_MKL`时,会自动根据硬件配置[[2](#references)]选择是否编译MKL-DNN。
### Matrix
目前在PaddlePaddle中数据都是以`nchw`的格式存储,但是在MKL-DNN中的排列方式不止这一种。
所以我们定义了一个`MKLDNNMatrix`用于管理MKL-DNN数据的不同格式以及相互之间的转换。
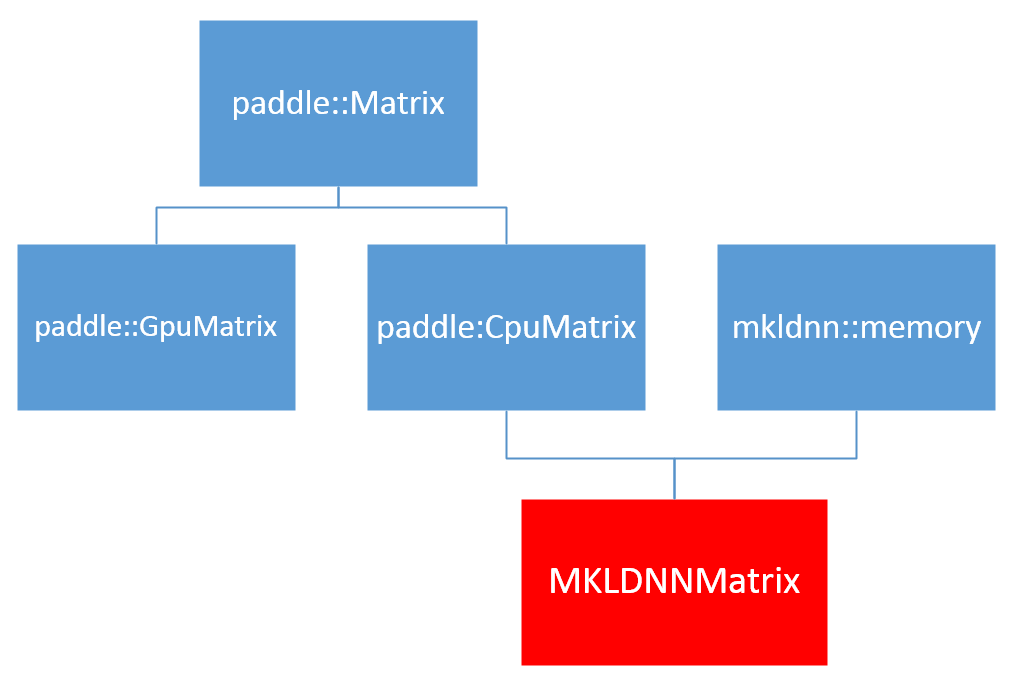
Figure 3. MKLDNNMatrix
### Layers
所有MKL-DNN的Layers都会继承于`MKLDNNLayer`,该类继承于PaddlePaddle的基类`Layer`。
在`MKLDNNLayer`中会提供一些必要的接口和函数,并且会写好`forward`和`backward`的基本逻辑,
子类只需要使用定义好的接口,实现具体的函数功能即可。
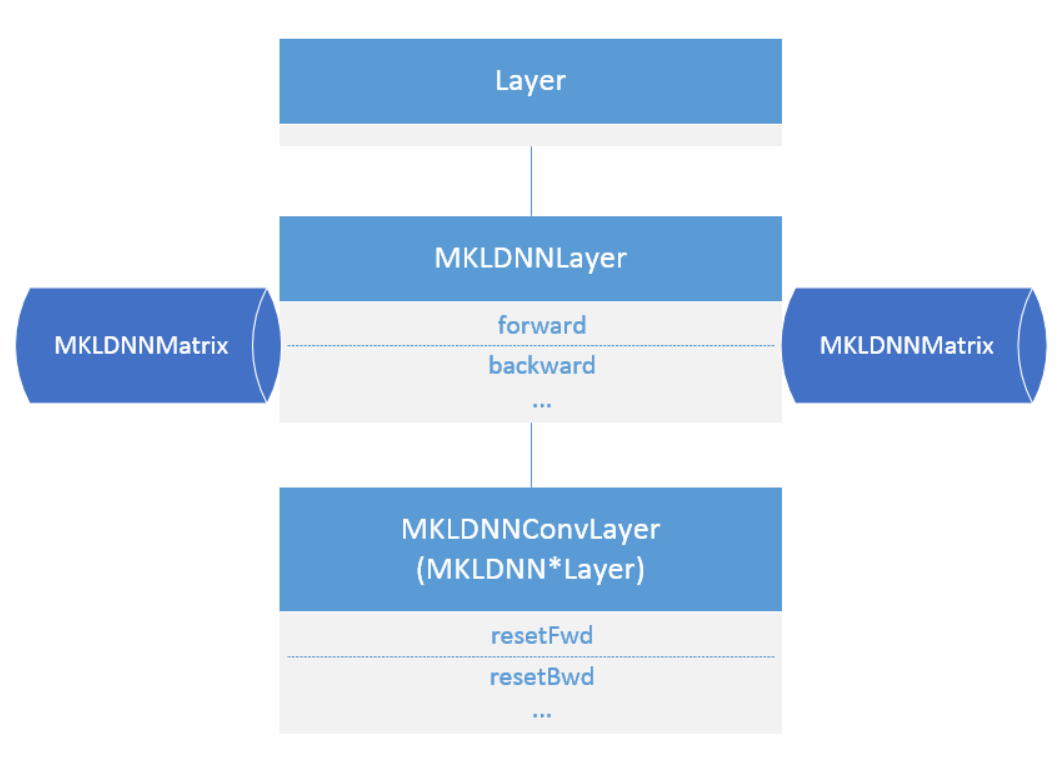
Figure 4. MKLDNNLayer
每个`MKLDNNlayer`都会有`inVal_`,`inGrad_`,`outVal_`和`outGrad_`的`MKLDNNMatrix`,
分别代表input value, input gradient,output value和output gradient。
它们会存放MKL-DNN用到的internal memory,同时还会定义以*ext*开头的`MKLDNNMatrix`(表示external的memory)。
他们主要是当数据格式与PaddlePaddle默认的`nchw`格式不匹配时,用于转换内存的工作。
必要的转换函数也会在`MKLDNNLayer`中提前定义好(具体包括reset input、output的value和grad),
这些函数会根据输入参数重新设置internal和external的memory(当然这两者也可以相等,即表示不需要转换),
每个`MKLDNNlayer`的子类只需要使用internal的memory就可以了,所有external的转换工作都会在reset函数中都准备好。
一般来说,每个`MKLDNNLayer`中的`extOutVal_`和`extOutGrad_`必须分别与`output_.value`和`output_.grad`共享内存,
因为PaddlePaddle的activation会直接使用`output_.value`和`output_.grad`,
如果不需要external的buffer用于转换,那么internal的buffer也会与它们共享内存。
### Activations
在重构前的PaddlePaddle中,激活函数是独立于`Layer`的概念,并且输入输出都是公用一块内存,
所以添加了对应的`MKLDNNActivation`来实现,方式类似于`MKLDNNLayer`。
### Parameters
对于有参数的层,我们会保证`MKLDNNLayer`使用的参数与PaddlePaddle申请的buffer公用一块内存。
如果存在数据排列格式不一样的情况时,我们会在网络训练之前把格式转换为MKL-DNN希望的格式,
在训练结束的时候再保存为PaddlePaddle的格式,但是整个训练过程中不需要任何转换。
这样既使得最终保存的参数格式与PaddlePaddle一致,又可以避免不必要的转换。
### Gradients
由于MKL-DNN的操作都是直接覆盖的形式,也就是说输出的结果不会在原来的数据上累加,
这样带来的好处就是不需要一直清空memory,节省了不必要的操作。
但是注意的是,当网络出现分支且在`backward`的时候,需要累加不同Layer传过来的梯度。
所以在`MKLDNNlayer`中实现了一个merge的方法,此时每个小分支的`Input Gradient`
会先临时保存在`MKLDNNMatrix`中,由分支处的Layer负责求和,并把结果放到当前层的`output_.grad`中。
所以整体上,在实现每个子类的时候就不需要关心分支的事情了。
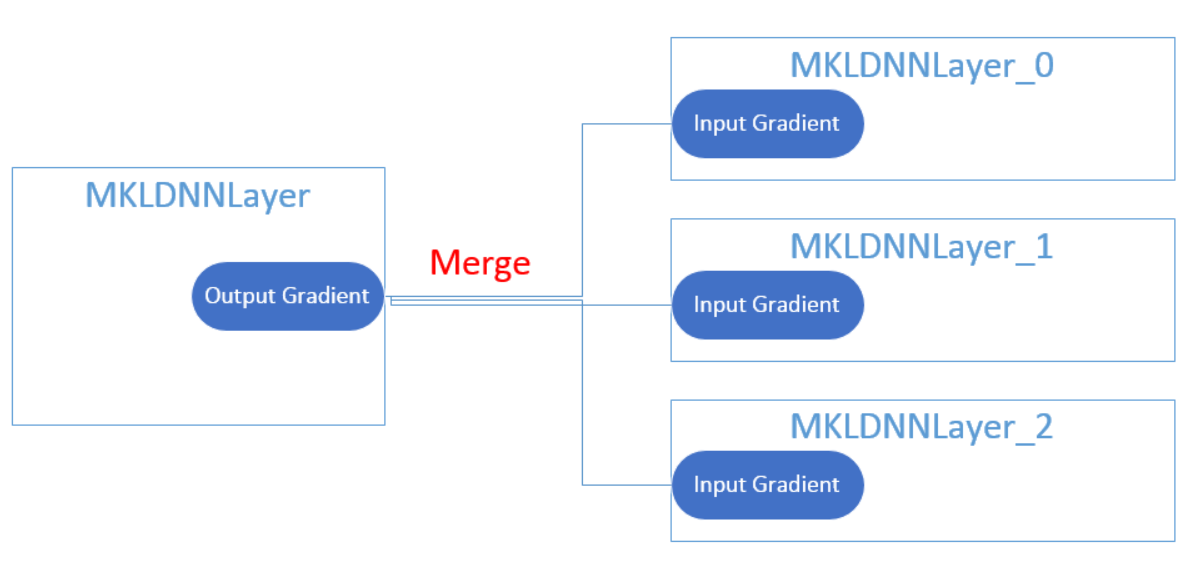
Figure 5. Merge Gradients
### Unit Tests
我们会添加`test_MKLDNN.cpp`和`MKLDNNTester.*`用于MKL-DNN的测试。
测试分为每个Layer(或Activation)的单元测试和简单网络的整体测试。
每个测试会对比PaddlePaddle中CPU算出的结果与MKL-DNN的结果,小于某个比较小的阈值认为通过。
### Protobuf Messages
根据具体layer的需求可能会在`proto/ModelConfig.proto`里面添加必要的选项。
### Python API
目前只考虑**v1 API**。
计划在`python/paddle/trainer/config_parser.py`里面添加`use_mkldnn`这个选择,方便用户选择使用MKL-DNN的layers。
具体实现方式比如:
```python
use_mkldnn = bool(int(g_command_config_args.get("use_mkldnn", 0)))
if use_mkldnn
self.layer_type = mkldnn_*
```
所有MKL-DNN的`layer_type`会以*mkldnn_*开头,这些会在`MKLDNN*Layer`注册layer的时候保证,以示区分。
同时,会在`paddle/utils.Flags`中添加一个`use_mkldnn`的flag,用于选择是否使用MKL-DNN的相关功能。
### Demos
可能会在`v1_api_demo`目录下添加一个`mkldnn`的文件夹,里面放入一些用于MKL-DNN测试的demo脚本。
### Benchmarking
会添加`benchmark/paddle/image/run_mkldnn.sh`,用于测试和对比,在使用MKL-DNN前后的性能。
### Others
1. 如果在使用MKL-DNN的情况下,会把CPU的Buffer对齐为4096,具体可以参考MKL-DNN中的[memory](https://github.com/01org/mkl-dnn/blob/master/include/mkldnn.hpp#L673)。
2. 深入PaddlePaddle,寻找有没有其他可以优化的可能,进一步优化。比如可能会用OpenMP改进SGD的更新性能。
## Design Concerns
为了更好的符合PaddlePaddle的代码风格\[[3](#references)\],同时又尽可能少的牺牲MKL-DNN的性能\[[4](#references)\]。
我们总结出一些特别需要注意的点:
1. 使用**deviceId_**。为了尽可能少的在父类Layer中添加变量或者函数,
我们决定使用已有的`deviceId_`变量来区分layer的属性,定义`-2`为`MKLDNNLayer`特有的设备ID。
2. 重写父类Layer的**init**函数,修改`deviceId_`为`-2`,代表这个layer是用于跑在MKL-DNN的环境下。
3. 创建`MKLDNNBase`,定义一些除了layer和memory相关的类和函数。
包括MKL-DNN会用到`MKLDNNStream`和`CPUEngine`,和未来可能还会用到`FPGAEngine`等。
4. 如果MKL-DNN layer的后面接有cpu device,那么就会使`output_.value`与`extOutVal_`共享内存,
同时数据格式就是`nchw`,这样下一个cpu device就能拿到正确的数据。
在有cpu device的时候,external的memory的格式始终是`nchw`或者`nc`。
## References
1. [MKL small library](https://github.com/01org/mkl-dnn#linking-your-application)是[Intel MKL](https://software.intel.com/en-us/mkl)的一个子集。
主要包括了深度学习相关的数学原语与操作,一般由MKL-DNN在发布[新版本](https://github.com/01org/mkl-dnn/releases)时一起更新。
2. [MKL-DNN System Requirements](https://github.com/01org/mkl-dnn#system-requirements)。
目前在PaddlePaddle中,仅会在支持AVX2指令集及以上的机器才使用MKL-DNN。
3. [原来的方案](https://github.com/PaddlePaddle/Paddle/pull/3096)会引入**nextLayer**的信息。
但是在PaddlePaddle中,无论是重构前的layer还是重构后的op,都不会想要知道next layer/op的信息。
4. MKL-DNN的高性能格式与PaddlePaddle原有的`NCHW`不同(PaddlePaddle中的cuDNN部分使用的也是`NCHW`,所以不存在这个问题)。
所以需要引入一个转换方法,并且只需要在必要的时候转换这种格式,才能更好的发挥MKL-DNN的性能。