
分布式训练¶
本节将介绍如何使用PaddlePaddle在不同的集群框架下完成分布式训练。分布式训练架构如下图所示:
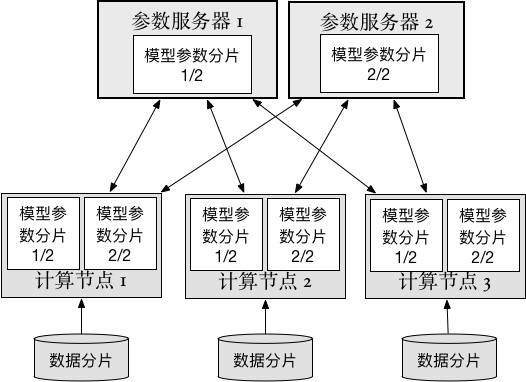
- 数据分片(Data shard): 用于训练神经网络的数据,被切分成多个部分,每个部分分别给每个trainer使用。
- 计算节点(Trainer): 每个trainer启动后读取切分好的一部分数据,开始神经网络的“前馈”和“后馈”计算,并和参数服务器通信。在完成一定量数据的训练后,上传计算得出的梯度(gradients),然后下载优化更新后的神经网络参数(parameters)。
- 参数服务器(Parameter server):每个参数服务器只保存整个神经网络所有参数的一部分。参数服务器接收从计算节点上传的梯度,并完成参数优化更新,再将更新后的参数下发到每个计算节点。
这样,通过计算节点和参数服务器的分布式协作,可以完成神经网络的SGD方法的训练。PaddlePaddle可以同时支持同步随机梯度下降(SGD)和异步随机梯度下降。
在使用同步SGD训练神经网络时,PaddlePaddle使用同步屏障(barrier),使梯度的提交和参数的更新按照顺序方式执行。在异步SGD中,则并不会等待所有trainer提交梯度才更新参数,这样极大地提高了计算的并行性:参数服务器之间不相互依赖,并行地接收梯度和更新参数,参数服务器也不会等待计算节点全部都提交梯度之后才开始下一步,计算节点之间也不会相互依赖,并行地执行模型的训练。可以看出,虽然异步SGD方式会提高参数更新并行度, 但是并不能保证参数同步更新,在任意时间某一台参数服务器上保存的参数可能比另一台要更新,与同步SGD相比,梯度会有噪声。