## 训练数据的存储和分发
### 概念解释
### 流程介绍
生产环境中的训练数据集通常体积很大,并被存储在诸如Hadoop HDFS,Ceph,AWS S3之类的分布式存储之上。这些分布式存储服务通常会把数据切割成多个分片分布式的存储在多个节点之上。这样就可以在云端执行多种数据类计算任务,包括:
* 数据预处理任务
* Paddle训练任务
* 在线模型预测服务
在上图中显示了在一个实际生产环境中的应用(人脸识别)的数据流图。生产环境的日志数据会通过实时流的方式(Kafka)和离线数据的方式(HDFS)存储,并在集群中运行多个分布式数据处理任务,比如流式数据处理(online data process),离线批处理(offline data process)完成数据的预处理,提供给paddle作为训练数据。用户也可以上传labeled data到分布式存储补充训练数据。在paddle之上运行的深度学习训练输出的模型会提供给在线人脸识别的应用使用。
### 训练数据存储
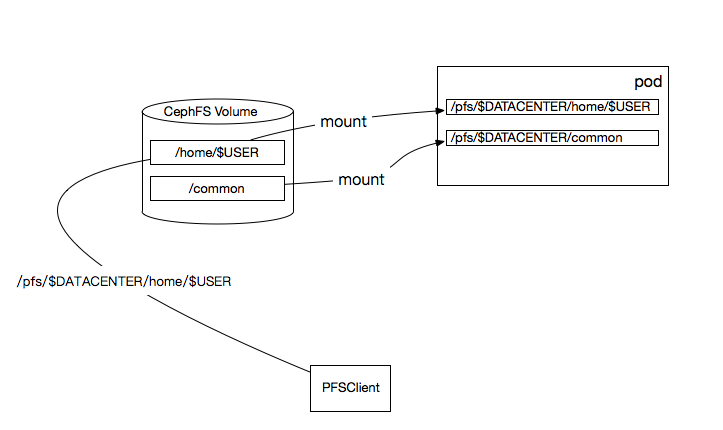
我们选择[CephFS](http://docs.ceph.com/docs/master/cephfs/)作为存储系统。
- 无论是从[PFSClient](../file_manager/README.md)的角度,还是从[Pod](https://kubernetes.io/docs/concepts/workloads/pods/pod/)中运行任务的角度,统一用`/pfs/$DATACENTER/home/$USER`来访问用户自己的数据。
- `/pfs/$DATACENTER/Common`下存放公共数据集合
### 文件预处理
在开始训练之前, 数据集需要预先被转换成PaddlePaddle分布式训练使用的存储格[RecordIO](https://github.com/PaddlePaddle/Paddle/issues/1947)。我们提供两个转换方式:
- 提供给用户本地转换的库,用户可以编写程序完成转换。
- 用户可以上传自己的数据集,在集群运行MapReduce job完成转换。
转换生成的文件名会是以下格式:
```text
name_prefix-aaaaa-of-bbbbb
```
"aaaaa"和"bbbbb"都是五位的数字,每一个文件是数据集的一个shard,"aaaaa"代表shard的index,"bbbbb"代表这个shard的最大index。
比如ImageNet这个数据集可能被分成1000个shard,它们的文件名是:
```text
imagenet-00000-of-00999
imagenet-00001-of-00999
...
imagenet-00999-of-00999
```
#### 转换库
无论是在本地或是云端转换,我们都提供Python的转换库,接口是:
```python
def convert(output_path, reader, num_shards, name_prefix)
```
- `output_path`: directory in which output files will be saved.
- `reader`: a [data reader](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/reader/README.md#data-reader-interface), from which the convert program will read data instances.
- `num_shards`: the number of shards that the dataset will be partitioned into.
- `name_prefix`: the name prefix of generated files.
`reader`每次输出一个data instance,这个instance可以是单个值,或者用tuple表示的多个值:
```python
yield 1 # 单个值
yield numpy.random.uniform(-1, 1, size=28*28) # 单个值
yield numpy.random.uniform(-1, 1, size=28*28), 0 # 多个值
```
每个值的类型可以是整形、浮点型数据、字符串,或者由它们组成的list,以及numpy.ndarray。如果是其它类型,会被Pickle序列化成字符串。
### 示例程序
#### 使用转换库
以下`reader_creator`生成的`reader`每次输出一个data instance,每个data instance包涵两个值:numpy.ndarray类型的值和整型的值:
```python
def reader_creator():
def reader():
for i in range(1000):
yield numpy.random.uniform(-1, 1, size=28*28), 0 # 多个值
return reader
```
把`reader_creator`生成的`reader`传入`convert`函数即可完成转换:
```python
convert("./", reader_creator(), 100, random_images)
```
以上命令会在当前目录下生成100个文件:
```text
random_images-00000-of-00099
random_images-00001-of-00099
...
random_images-00099-of-00099
```
#### 进行训练
PaddlePaddle提供专用的[data reader creator](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/reader/README.md#python-data-reader-design-doc),生成给定`RecordIO`文件对应的data reader。**无论在本地还是在云端,reader的使用方式都是一致的**:
```python
# ...
reader = paddle.reader.creator.RecordIO("/pfs/datacenter_name/home/user_name/random_images-*-of-*")
batch_reader = paddle.batch(paddle.dataset.mnist.train(), 128)
trainer.train(batch_reader, ...)
```
以上代码的reader输出的data instance与生成数据集时,reader输出的data instance是一模一样的。
### 上传训练文件
使用下面命令,可以把本地的数据上传到存储集群中。
```bash
paddle pfs cp filenames /pfs/$DATACENTER/home/$USER/folder/
```
比如,把之前示例中转换完毕的random_images数据集上传到云端的`/home/`可以用以下指令:
```bash
paddle pfs cp random_images-*-of-* /pfs/$DATACENTER/home/$USER/folder/
```
需要`$DATACENTER`的配置写到配置文件中,例如
```
# config file
[datacenter_1]
username=wuyi
usercert=wuyi.pem
userkey=wuyi-key.pem
endpoint=datacenter1.paddlepaddle.org
[datacenter_2]
username=wuyi
usercert=wuyi.pem
userkey=wuyi-key.pem
endpoint=datacenter2.paddlepaddle.org
```
## TODO
### 文件访问的权限
控制用户权限
- `Common`数据集合只读不能写
- 现在mount到本地以后读写权限
- 用户可以把自己的数据分享给别人
### 文件访问方式
不用mount的方式来访问数据,而是直接用API的接口远程访问
```
f = open('/pfs/datacenter_name/home/user_name/test1.dat')
```
### 支持用户自定义的数据预处理job