# Design Doc: Asynchronous Update With Distributed Training
## Background
For the typical synchronous distributed training, some significant steps are as follows:
1. A Trainer will compute the gradients and SEND them to the Parameter Server(PServer) nodes.
1. After the PServer node received gradients came from all the Trainers,
it would apply the gradient to the respective variables, and using an optimize algorithms(SGD,
Momentment...) to update the parameters.
1. The Trainer would wait for the PServers finished the optimize stage, and GET the parameters from PServer,
so all the Trainers would get the same parameters.
In the synchronously distributed training, there should be a `Barrier` to synchronise the
parameters after the optimizing stage. The performance of a distributed training job would
depend on the slowest node if there were hundreds or thousands of training nodes in a
Job, the performance of synchronously distributed training might be very poor because of
the slow node. So this design doc would introduce an approach to implement
*asynchronously* distributed training in PaddlePaddle Fluid.
## Design
 As the figure above, we describe a global view of asynchronously update process and use
the parameter `w1` as an example to introduce the steps:
1. For each gradient variables, they may distribute on different GPU card and aggregate
them while they are all calculated.
1. Split the gradient variable into multiple blocks according to the number of PServer
instances and then sent them.
1. PServer would run an `Optimize Block` using a specified optimize algorithm to update
the specified parameter.
1. The trainer will fetch the parameter before running forward Op depends on the specified
parameter.
1. Broadcast the received variable into multiple GPU cards and continue to run the next
mini-batch.
### Trainer
- For the multiple devices distributed training, we need to aggregate the gradient
variables which placed on different devices firstly, and then schedule a `SendVars` Operator to
send the gradient variables to the multiple PServer instances.
- Schedule `FetchVars` operator to fetch the latest parameter from PServer before running
the forward ops.
- There could be a large number of gradient variables to be sent, so we need to use another
thread pool(IO Threadpool) which a number of the schedulable threads is larger than the
computing thread pool to avoid competitive the thread resources with computing.
### Parameter Server
As the figure above, we describe a global view of asynchronously update process and use
the parameter `w1` as an example to introduce the steps:
1. For each gradient variables, they may distribute on different GPU card and aggregate
them while they are all calculated.
1. Split the gradient variable into multiple blocks according to the number of PServer
instances and then sent them.
1. PServer would run an `Optimize Block` using a specified optimize algorithm to update
the specified parameter.
1. The trainer will fetch the parameter before running forward Op depends on the specified
parameter.
1. Broadcast the received variable into multiple GPU cards and continue to run the next
mini-batch.
### Trainer
- For the multiple devices distributed training, we need to aggregate the gradient
variables which placed on different devices firstly, and then schedule a `SendVars` Operator to
send the gradient variables to the multiple PServer instances.
- Schedule `FetchVars` operator to fetch the latest parameter from PServer before running
the forward ops.
- There could be a large number of gradient variables to be sent, so we need to use another
thread pool(IO Threadpool) which a number of the schedulable threads is larger than the
computing thread pool to avoid competitive the thread resources with computing.
### Parameter Server
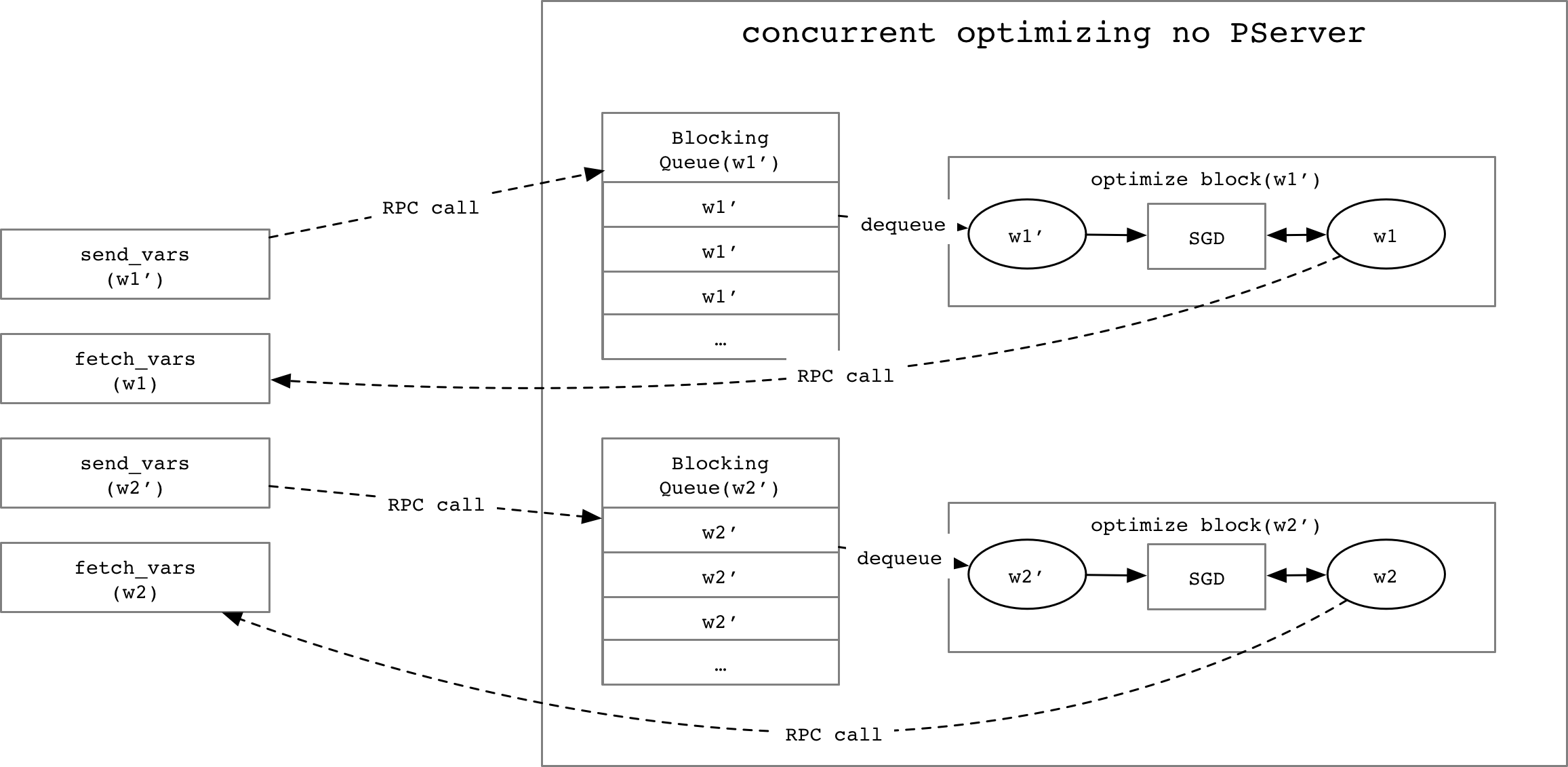 - There should be multiple trainer instances want to optimize the same parameter at
the same time, to avoid the pollution, we need one `BlockingQueue` for each gradient
variable to process them one by one.
- We need a `Map` structure to map a gradient variable name to the `OptimizeBlock` which
can optimize the respective parameter.
- There should be multiple trainer instances want to optimize the same parameter at
the same time, to avoid the pollution, we need one `BlockingQueue` for each gradient
variable to process them one by one.
- We need a `Map` structure to map a gradient variable name to the `OptimizeBlock` which
can optimize the respective parameter.