Created by: yihuaxu
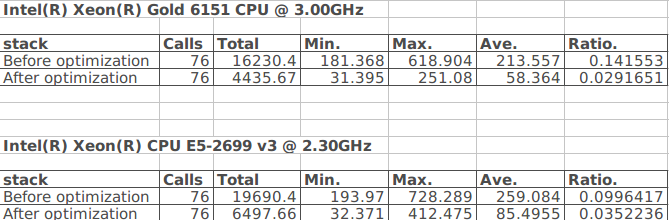
According to the performance status of stack operator, just implemented the optimization to accelerate the data processing.
Platform: Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz / Intel(R) Xeon(R) CPU E5-2699 v3 @ 2.30GHz Batch Size: 300 Command: build/paddle/fluid/inference/tests/api/test_analyzer_dam --infer_model=PaddlePaddle/pretrained_models/dam --infer_data=build/third_party/inference_demo/dam/data.txt --gtest_filter=Analyzer_dam.profile --batch_size=300 --repeat=1 --test_all_data=true --num_threads=1 --use_analysis=false
The following is the comparison with the different scenarios.