Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
f6e82bcf
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
f6e82bcf
编写于
11月 27, 2017
作者:
G
guosheng
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' of
https://github.com/PaddlePaddle/paddle
into fix-addtolayer-check
上级
5981918c
e6546baa
变更
30
显示空白变更内容
内联
并排
Showing
30 changed file
with
502 addition
and
218 deletion
+502
-218
doc/howto/optimization/cpu_profiling.md
doc/howto/optimization/cpu_profiling.md
+163
-0
doc/howto/optimization/pprof_1.png
doc/howto/optimization/pprof_1.png
+0
-0
doc/howto/optimization/pprof_2.png
doc/howto/optimization/pprof_2.png
+0
-0
paddle/gserver/layers/ROIPoolLayer.cpp
paddle/gserver/layers/ROIPoolLayer.cpp
+3
-4
paddle/operators/CMakeLists.txt
paddle/operators/CMakeLists.txt
+7
-0
paddle/operators/conv_cudnn_op.cc
paddle/operators/conv_cudnn_op.cc
+34
-7
paddle/operators/conv_cudnn_op.cu.cc
paddle/operators/conv_cudnn_op.cu.cc
+94
-35
paddle/platform/cudnn_helper.h
paddle/platform/cudnn_helper.h
+2
-3
python/paddle/v2/fluid/executor.py
python/paddle/v2/fluid/executor.py
+81
-3
python/paddle/v2/fluid/tests/.gitignore
python/paddle/v2/fluid/tests/.gitignore
+1
-0
python/paddle/v2/fluid/tests/op_test.py
python/paddle/v2/fluid/tests/op_test.py
+7
-3
python/paddle/v2/fluid/tests/test_array_read_write_op.py
python/paddle/v2/fluid/tests/test_array_read_write_op.py
+12
-15
python/paddle/v2/fluid/tests/test_conditional_block.py
python/paddle/v2/fluid/tests/test_conditional_block.py
+5
-8
python/paddle/v2/fluid/tests/test_conv2d_op.py
python/paddle/v2/fluid/tests/test_conv2d_op.py
+7
-7
python/paddle/v2/fluid/tests/test_conv3d_op.py
python/paddle/v2/fluid/tests/test_conv3d_op.py
+26
-0
python/paddle/v2/fluid/tests/test_executor_and_mul.py
python/paddle/v2/fluid/tests/test_executor_and_mul.py
+4
-8
python/paddle/v2/fluid/tests/test_inference_model_io.py
python/paddle/v2/fluid/tests/test_inference_model_io.py
+14
-19
python/paddle/v2/fluid/tests/test_lod_array_length_op.py
python/paddle/v2/fluid/tests/test_lod_array_length_op.py
+1
-1
python/paddle/v2/fluid/tests/test_lod_tensor_array_ops.py
python/paddle/v2/fluid/tests/test_lod_tensor_array_ops.py
+5
-4
python/paddle/v2/fluid/tests/test_mnist_if_else_op.py
python/paddle/v2/fluid/tests/test_mnist_if_else_op.py
+9
-23
python/paddle/v2/fluid/tests/test_parameter.py
python/paddle/v2/fluid/tests/test_parameter.py
+1
-1
python/paddle/v2/fluid/tests/test_recurrent_op.py
python/paddle/v2/fluid/tests/test_recurrent_op.py
+3
-2
python/paddle/v2/fluid/tests/test_rnn_memory_helper_op.py
python/paddle/v2/fluid/tests/test_rnn_memory_helper_op.py
+8
-17
python/paddle/v2/fluid/tests/test_shrink_rnn_memory.py
python/paddle/v2/fluid/tests/test_shrink_rnn_memory.py
+4
-7
python/paddle/v2/fluid/tests/test_split_and_merge_lod_tensor_op.py
...ddle/v2/fluid/tests/test_split_and_merge_lod_tensor_op.py
+7
-2
python/paddle/v2/fluid/tests/test_while_op.py
python/paddle/v2/fluid/tests/test_while_op.py
+4
-13
python/paddle/v2/fluid/tests/tmp/inference_model/__model__
python/paddle/v2/fluid/tests/tmp/inference_model/__model__
+0
-0
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.b_0
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.b_0
+0
-0
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.w_0
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.w_0
+0
-0
python/paddle/v2/framework/tests/test_elementwise_mod_op.py
python/paddle/v2/framework/tests/test_elementwise_mod_op.py
+0
-36
未找到文件。
doc/howto/optimization/cpu_profiling.md
0 → 100644
浏览文件 @
f6e82bcf
此教程会介绍如何使用Python的cProfile包,与Python库yep,google perftools来运行性能分析(Profiling)与调优。
运行性能分析可以让开发人员科学的,有条不紊的对程序进行性能优化。性能分析是性能调优的基础。因为在程序实际运行中,真正的瓶颈可能和程序员开发过程中想象的瓶颈相去甚远。
性能优化的步骤,通常是循环重复若干次『性能分析 --> 寻找瓶颈 ---> 调优瓶颈 --> 性能分析确认调优效果』。其中性能分析是性能调优的至关重要的量化指标。
Paddle提供了Python语言绑定。用户使用Python进行神经网络编程,训练,测试。Python解释器通过
`pybind`
和
`swig`
调用Paddle的动态链接库,进而调用Paddle C++部分的代码。所以Paddle的性能分析与调优分为两个部分:
*
Python代码的性能分析
*
Python与C++混合代码的性能分析
## Python代码的性能分析
### 生成性能分析文件
Python标准库中提供了性能分析的工具包,
[
cProfile
](
https://docs.python.org/2/library/profile.html
)
。生成Python性能分析的命令如下:
```
bash
python
-m
cProfile
-o
profile.out main.py
```
其中
`-o`
标识了一个输出的文件名,用来存储本次性能分析的结果。如果不指定这个文件,
`cProfile`
会打印一些统计信息到
`stdout`
。这不方便我们进行后期处理(进行
`sort`
,
`split`
,
`cut`
等等)。
### 查看性能分析文件
当main.py运行完毕后,性能分析结果文件
`profile.out`
就生成出来了。我们可以使用
[
cprofilev
](
https://github.com/ymichael/cprofilev
)
来查看性能分析结果。
`cprofilev`
是一个Python的第三方库。使用它会开启一个HTTP服务,将性能分析结果以网页的形式展示出来。
使用
`pip install cprofilev`
安装
`cprofilev`
工具。安装完成后,使用如下命令开启HTTP服务
```
bash
cprofilev
-a
0.0.0.0
-p
3214
-f
profile.out main.py
```
其中
`-a`
标识HTTP服务绑定的IP。使用
`0.0.0.0`
允许外网访问这个HTTP服务。
`-p`
标识HTTP服务的端口。
`-f`
标识性能分析的结果文件。
`main.py`
标识被性能分析的源文件。
访问对应网址,即可显示性能分析的结果。性能分析结果格式如下:
```
text
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.284 0.284 29.514 29.514 main.py:1(<module>)
4696 0.128 0.000 15.748 0.003 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/executor.py:20(run)
4696 12.040 0.003 12.040 0.003 {built-in method run}
1 0.144 0.144 6.534 6.534 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/__init__.py:14(<module>)
```
每一列的含义是:
| 列名 | 含义 |
| --- | --- |
| ncalls | 函数的调用次数 |
| tottime | 函数实际使用的总时间。该时间去除掉本函数调用其他函数的时间 |
| percall | tottime的每次调用平均时间 |
| cumtime | 函数总时间。包含这个函数调用其他函数的时间 |
| percall | cumtime的每次调用平均时间 |
| filename:lineno(function) | 文件名, 行号,函数名 |
### 寻找性能瓶颈
通常
`tottime`
和
`cumtime`
是寻找瓶颈的关键指标。这两个指标代表了某一个函数真实的运行时间。
将性能分析结果按照tottime排序,效果如下:
```
text
4696 12.040 0.003 12.040 0.003 {built-in method run}
300005 0.874 0.000 1.681 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/dataset/mnist.py:38(reader)
107991 0.676 0.000 1.519 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:219(__init__)
4697 0.626 0.000 2.291 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp)
1 0.618 0.618 0.618 0.618 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/__init__.py:1(<module>)
```
可以看到最耗时的函数是C++端的
`run`
函数。这需要联合我们第二节
`Python与C++混合代码的性能分析`
来进行调优。而
`sync_with_cpp`
函数的总共耗时很长,每次调用的耗时也很长。于是我们可以点击
`sync_with_cpp`
的详细信息,了解其调用关系。
```
text
Called By:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
Function was called by...
ncalls tottime cumtime
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp) <- 4697 0.626 2.291 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp)
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp) <- 4696 0.019 2.316 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:487(clone)
1 0.000 0.001 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:534(append_backward)
Called:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
```
通常观察热点函数间的调用关系,和对应行的代码,就可以了解到问题代码在哪里。当我们做出性能修正后,再次进行性能分析(profiling)即可检查我们调优后的修正是否能够改善程序的性能。
## Python与C++混合代码的性能分析
### 生成性能分析文件
C++的性能分析工具非常多。常见的包括
`gprof`
,
`valgrind`
,
`google-perftools`
。但是调试Python中使用的动态链接库与直接调试原始二进制相比增加了很多复杂度。幸而Python的一个第三方库
`yep`
提供了方便的和
`google-perftools`
交互的方法。于是这里使用
`yep`
进行Python与C++混合代码的性能分析
使用
`yep`
前需要安装
`google-perftools`
与
`yep`
包。ubuntu下安装命令为
```
bash
apt
install
libgoogle-perftools-dev
pip
install
yep
```
安装完毕后,我们可以通过
```
bash
python
-m
yep
-v
main.py
```
生成性能分析文件。生成的性能分析文件为
`main.py.prof`
。
命令行中的
`-v`
指定在生成性能分析文件之后,在命令行显示分析结果。我们可以在命令行中简单的看一下生成效果。因为C++与Python不同,编译时可能会去掉调试信息,运行时也可能因为多线程产生混乱不可读的性能分析结果。为了生成更可读的性能分析结果,可以采取下面几点措施:
1.
编译时指定
`-g`
生成调试信息。使用cmake的话,可以将CMAKE_BUILD_TYPE指定为
`RelWithDebInfo`
。
2.
编译时一定要开启优化。单纯的
`Debug`
编译性能会和
`-O2`
或者
`-O3`
有非常大的差别。
`Debug`
模式下的性能测试是没有意义的。
3.
运行性能分析的时候,先从单线程开始,再开启多线程,进而多机。毕竟如果单线程调试更容易。可以设置
`OMP_NUM_THREADS=1`
这个环境变量关闭openmp优化。
### 查看性能分析文件
在运行完性能分析后,会生成性能分析结果文件。我们可以使用
[
pprof
](
https://github.com/google/pprof
)
来显示性能分析结果。注意,这里使用了用
`Go`
语言重构后的
`pprof`
,因为这个工具具有web服务界面,且展示效果更好。
安装
`pprof`
的命令和一般的
`Go`
程序是一样的,其命令如下:
```
bash
go get github.com/google/pprof
```
进而我们可以使用如下命令开启一个HTTP服务:
```
bash
pprof
-http
=
0.0.0.0:3213
`
which python
`
./main.py.prof
```
这行命令中,
`-http`
指开启HTTP服务。
`which python`
会产生当前Python二进制的完整路径,进而指定了Python可执行文件的路径。
`./main.py.prof`
输入了性能分析结果。
访问对应的网址,我们可以查看性能分析的结果。结果如下图所示:

### 寻找性能瓶颈
与寻找Python代码的性能瓶颈类似,寻找Python与C++混合代码的性能瓶颈也是要看
`tottime`
和
`cumtime`
。而
`pprof`
展示的调用图也可以帮助我们发现性能中的问题。
例如下图中,

在一次训练中,乘法和乘法梯度的计算占用2%-4%左右的计算时间。而
`MomentumOp`
占用了17%左右的计算时间。显然,
`MomentumOp`
的性能有问题。
在
`pprof`
中,对于性能的关键路径都做出了红色标记。先检查关键路径的性能问题,再检查其他部分的性能问题,可以更有次序的完成性能的优化。
## 总结
至此,两种性能分析的方式都介绍完毕了。希望通过这两种性能分析的方式,Paddle的开发人员和使用人员可以有次序的,科学的发现和解决性能问题。
doc/howto/optimization/pprof_1.png
0 → 100644
浏览文件 @
f6e82bcf
344.4 KB
doc/howto/optimization/pprof_2.png
0 → 100644
浏览文件 @
f6e82bcf
189.5 KB
paddle/gserver/layers/ROIPoolLayer.cpp
浏览文件 @
f6e82bcf
...
...
@@ -13,6 +13,7 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include "ROIPoolLayer.h"
#include <cfloat>
namespace
paddle
{
...
...
@@ -126,10 +127,8 @@ void ROIPoolLayer::forward(PassType passType) {
bool
isEmpty
=
(
hend
<=
hstart
)
||
(
wend
<=
wstart
);
size_t
poolIndex
=
ph
*
pooledWidth_
+
pw
;
if
(
isEmpty
)
{
outputData
[
poolIndex
]
=
0
;
outputData
[
poolIndex
]
=
isEmpty
?
0
:
-
FLT_MAX
;
argmaxData
[
poolIndex
]
=
-
1
;
}
for
(
size_t
h
=
hstart
;
h
<
hend
;
++
h
)
{
for
(
size_t
w
=
wstart
;
w
<
wend
;
++
w
)
{
...
...
paddle/operators/CMakeLists.txt
浏览文件 @
f6e82bcf
...
...
@@ -73,6 +73,13 @@ function(op_library TARGET)
file
(
APPEND
${
pybind_file
}
"USE_OP(conv2d);
\n
"
)
endif
()
# conv_cudnn_op contains several operators
if
(
"
${
TARGET
}
"
STREQUAL
"conv_cudnn_op"
)
set
(
pybind_flag 1
)
# It's enough to just adding one operator to pybind
file
(
APPEND
${
pybind_file
}
"USE_OP(conv2d_cudnn);
\n
"
)
endif
()
# pool_op contains several operators
if
(
"
${
TARGET
}
"
STREQUAL
"pool_op"
)
set
(
pybind_flag 1
)
...
...
paddle/operators/conv_cudnn_op.cc
浏览文件 @
f6e82bcf
...
...
@@ -17,9 +17,9 @@
namespace
paddle
{
namespace
operators
{
class
CudnnConvOpMaker
:
public
Conv2DOpMaker
{
class
CudnnConv
2D
OpMaker
:
public
Conv2DOpMaker
{
public:
CudnnConvOpMaker
(
framework
::
OpProto
*
proto
,
CudnnConv
2D
OpMaker
(
framework
::
OpProto
*
proto
,
framework
::
OpAttrChecker
*
op_checker
)
:
Conv2DOpMaker
(
proto
,
op_checker
)
{
AddAttr
<
int
>
(
"workspace_size_MB"
,
...
...
@@ -32,16 +32,43 @@ class CudnnConvOpMaker : public Conv2DOpMaker {
}
};
class
CudnnConv3DOpMaker
:
public
Conv3DOpMaker
{
public:
CudnnConv3DOpMaker
(
framework
::
OpProto
*
proto
,
framework
::
OpAttrChecker
*
op_checker
)
:
Conv3DOpMaker
(
proto
,
op_checker
)
{
AddAttr
<
int
>
(
"workspace_size_MB"
,
"workspace size for cudnn, in MB, "
"workspace is a section of GPU memory which will be "
"allocated/freed each time the operator runs, larger "
"workspace size can increase performance but also requires "
"better hardware. This size should be chosen carefully."
)
.
SetDefault
(
4096
);
}
};
}
// namespace operators
}
// namespace paddle
namespace
ops
=
paddle
::
operators
;
REGISTER_OP
(
conv_cudnn
,
ops
::
ConvOp
,
ops
::
CudnnConvOpMaker
,
conv_cudnn_grad
,
ops
::
ConvOpGrad
);
REGISTER_OP
(
conv2d_cudnn
,
ops
::
ConvOp
,
ops
::
CudnnConv2DOpMaker
,
conv2d_cudnn_grad
,
ops
::
ConvOpGrad
);
REGISTER_OP
(
conv3d_cudnn
,
ops
::
ConvOp
,
ops
::
CudnnConv3DOpMaker
,
conv3d_cudnn_grad
,
ops
::
ConvOpGrad
);
REGISTER_OP_CPU_KERNEL
(
conv2d_cudnn
,
ops
::
GemmConvKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
ops
::
GemmConvKernel
<
paddle
::
platform
::
CPUPlace
,
double
>
);
REGISTER_OP_CPU_KERNEL
(
conv2d_cudnn_grad
,
ops
::
GemmConvGradKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
ops
::
GemmConvGradKernel
<
paddle
::
platform
::
CPUPlace
,
double
>
);
REGISTER_OP_CPU_KERNEL
(
conv_cudnn
,
REGISTER_OP_CPU_KERNEL
(
conv
3d
_cudnn
,
ops
::
GemmConvKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
ops
::
GemmConvKernel
<
paddle
::
platform
::
CPUPlace
,
double
>
);
REGISTER_OP_CPU_KERNEL
(
conv_cudnn_grad
,
ops
::
GemmConvGradKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
conv3d_cudnn_grad
,
ops
::
GemmConvGradKernel
<
paddle
::
platform
::
CPUPlace
,
float
>
,
ops
::
GemmConvGradKernel
<
paddle
::
platform
::
CPUPlace
,
double
>
);
paddle/operators/conv_cudnn_op.cu.cc
浏览文件 @
f6e82bcf
...
...
@@ -56,6 +56,21 @@ class CudnnConvOpKernel : public framework::OpKernel<T> {
ScopedFilterDescriptor
filter_desc
;
ScopedConvolutionDescriptor
conv_desc
;
DataLayout
layout
=
DataLayout
::
kNCHW
;
if
(
input
->
dims
().
size
()
==
5
)
{
layout
=
DataLayout
::
kNCDHW
;
}
cudnnConvolutionDescriptor_t
cudnn_conv_desc
=
conv_desc
.
descriptor
<
T
>
(
paddings
,
strides
,
dilations
);
#if CUDNN_VERSION_MIN(7, 0, 0)
// cudnn 7 can support groups, no need to do it mannually
// FIXME(typhoonzero): find a better way to disable groups
// rather than setting it to 1.
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnSetConvolutionGroupCount
(
cudnn_conv_desc
,
groups
));
groups
=
1
;
#endif
cudnnTensorDescriptor_t
cudnn_input_desc
=
input_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
input
->
dims
()),
groups
);
...
...
@@ -63,19 +78,34 @@ class CudnnConvOpKernel : public framework::OpKernel<T> {
layout
,
framework
::
vectorize2int
(
output
->
dims
()),
groups
);
cudnnFilterDescriptor_t
cudnn_filter_desc
=
filter_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
filter
->
dims
()),
groups
);
cudnnConvolutionDescriptor_t
cudnn_conv_desc
=
conv_desc
.
descriptor
<
T
>
(
paddings
,
strides
,
dilations
);
int
input_channels
=
input
->
dims
()[
1
];
int
input_height
=
input
->
dims
()[
2
];
int
input_width
=
input
->
dims
()[
3
];
int
output_channels
=
output
->
dims
()[
1
];
int
output_height
=
output
->
dims
()[
2
];
int
output_width
=
output
->
dims
()[
3
];
int
input_height
,
input_width
,
input_depth
;
if
(
input
->
dims
().
size
()
==
5
)
{
input_depth
=
input
->
dims
()[
2
];
input_height
=
input
->
dims
()[
3
];
input_width
=
input
->
dims
()[
4
];
}
else
{
// dim size is enforced in InferShape
input_depth
=
1
;
input_height
=
input
->
dims
()[
2
];
input_width
=
input
->
dims
()[
3
];
}
int
output_channels
=
filter
->
dims
()[
0
];
int
output_height
,
output_width
,
output_depth
;
if
(
output
->
dims
().
size
()
==
5
)
{
output_depth
=
output
->
dims
()[
2
];
output_height
=
output
->
dims
()[
3
];
output_width
=
output
->
dims
()[
4
];
}
else
{
output_depth
=
1
;
output_height
=
output
->
dims
()[
2
];
output_width
=
output
->
dims
()[
3
];
}
int
group_offset_in
=
input_channels
/
groups
*
input_height
*
input_width
;
int
group_offset_in
=
input_channels
/
groups
*
input_height
*
input_width
*
input_depth
;
int
group_offset_out
=
output_channels
/
groups
*
output_height
*
output_width
;
output_channels
/
groups
*
output_height
*
output_width
*
output_depth
;
int
group_offset_filter
=
filter
->
numel
()
/
groups
;
// ------------------- cudnn conv workspace ---------------------
void
*
cudnn_workspace
=
nullptr
;
...
...
@@ -138,12 +168,26 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
// ------------------- cudnn descriptors ---------------------
ScopedTensorDescriptor
input_desc
;
ScopedTensorDescriptor
output_grad_desc
;
ScopedTensorDescriptor
input_grad_desc
;
ScopedFilterDescriptor
filter_desc
;
ScopedFilterDescriptor
filter_grad_desc
;
ScopedConvolutionDescriptor
conv_desc
;
DataLayout
layout
=
DataLayout
::
kNCHW
;
if
(
input
->
dims
().
size
()
==
5
)
{
layout
=
DataLayout
::
kNCDHW
;
}
cudnnConvolutionDescriptor_t
cudnn_conv_desc
=
conv_desc
.
descriptor
<
T
>
(
paddings
,
strides
,
dilations
);
#if CUDNN_VERSION_MIN(7, 0, 0)
// cudnn 7 can support groups, no need to do it mannually
// FIXME(typhoonzero): find a better way to disable groups
// rather than setting it to 1.
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnSetConvolutionGroupCount
(
cudnn_conv_desc
,
groups
));
groups
=
1
;
#endif
cudnnTensorDescriptor_t
cudnn_input_desc
=
input_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
input
->
dims
()),
groups
);
...
...
@@ -152,22 +196,35 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
layout
,
framework
::
vectorize2int
(
output_grad
->
dims
()),
groups
);
cudnnFilterDescriptor_t
cudnn_filter_desc
=
filter_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
filter
->
dims
()),
groups
);
cudnnTensorDescriptor_t
cudnn_input_grad_desc
=
nullptr
;
cudnnFilterDescriptor_t
cudnn_filter_grad_desc
=
nullptr
;
cudnnConvolutionDescriptor_t
cudnn_conv_desc
=
conv_desc
.
descriptor
<
T
>
(
paddings
,
strides
,
dilations
);
int
input_channels
=
input
->
dims
()[
1
];
int
input_height
=
input
->
dims
()[
2
];
int
input_width
=
input
->
dims
()[
3
];
int
input_height
,
input_width
,
input_depth
;
if
(
input
->
dims
().
size
()
==
5
)
{
input_depth
=
input
->
dims
()[
2
];
input_height
=
input
->
dims
()[
3
];
input_width
=
input
->
dims
()[
4
];
}
else
{
// dim size is enforced in InferShape
input_depth
=
1
;
input_height
=
input
->
dims
()[
2
];
input_width
=
input
->
dims
()[
3
];
}
int
output_grad_channels
=
filter
->
dims
()[
0
];
int
output_grad_height
=
output_grad
->
dims
()[
2
];
int
output_grad_width
=
output_grad
->
dims
()[
3
];
int
output_grad_height
,
output_grad_width
,
output_grad_depth
;
if
(
input
->
dims
().
size
()
==
5
)
{
output_grad_depth
=
output_grad
->
dims
()[
2
];
output_grad_height
=
output_grad
->
dims
()[
3
];
output_grad_width
=
output_grad
->
dims
()[
4
];
}
else
{
output_grad_depth
=
1
;
output_grad_height
=
output_grad
->
dims
()[
2
];
output_grad_width
=
output_grad
->
dims
()[
3
];
}
int
group_offset_in
=
input_channels
/
groups
*
input_height
*
input_width
;
int
group_offset_out
=
output_grad_channels
/
groups
*
output_grad_height
*
output_grad_width
;
int
group_offset_in
=
input_channels
/
groups
*
input_height
*
input_width
*
input_depth
;
int
group_offset_out
=
output_grad_channels
/
groups
*
output_grad_height
*
output_grad_width
*
output_grad_depth
;
int
group_offset_filter
=
filter
->
numel
()
/
groups
;
// ------------------- cudnn backward algorithm ---------------------
cudnnConvolutionBwdDataAlgo_t
data_algo
;
...
...
@@ -180,8 +237,6 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
auto
handle
=
ctx
.
cuda_device_context
().
cudnn_handle
();
if
(
input_grad
)
{
cudnn_input_grad_desc
=
input_grad_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
input_grad
->
dims
()),
groups
);
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnGetConvolutionBackwardDataAlgorithm
(
handle
,
cudnn_filter_desc
,
...
...
@@ -190,19 +245,17 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
cudnn_output_grad_desc
,
cudnn_conv_desc
,
// dxDesc: Handle to the previously initialized output tensor
// descriptor.
cudnn_input_
grad_
desc
,
cudnn_input_desc
,
CUDNN_CONVOLUTION_BWD_DATA_SPECIFY_WORKSPACE_LIMIT
,
workspace_size_limit
,
&
data_algo
));
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnGetConvolutionBackwardDataWorkspaceSize
(
handle
,
cudnn_filter_desc
,
cudnn_output_grad_desc
,
cudnn_conv_desc
,
cudnn_input_
grad_
desc
,
data_algo
,
&
tmp_size
));
cudnn_conv_desc
,
cudnn_input_desc
,
data_algo
,
&
tmp_size
));
workspace_size_in_bytes
=
std
::
max
(
workspace_size_in_bytes
,
tmp_size
);
}
if
(
filter_grad
)
{
cudnn_filter_grad_desc
=
filter_grad_desc
.
descriptor
<
T
>
(
layout
,
framework
::
vectorize2int
(
filter_grad
->
dims
()),
groups
);
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnGetConvolutionBackwardFilterAlgorithm
(
handle
,
cudnn_input_desc
,
cudnn_output_grad_desc
,
cudnn_conv_desc
,
...
...
@@ -222,7 +275,6 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
platform
::
GPUPlace
gpu
=
boost
::
get
<
platform
::
GPUPlace
>
(
ctx
.
GetPlace
());
cudnn_workspace
=
paddle
::
memory
::
Alloc
(
gpu
,
workspace_size_in_bytes
);
// ------------------- cudnn conv backward data ---------------------
// FIXME(typhoonzero): template type T may not be the same as cudnn call.
T
alpha
=
1.0
f
,
beta
=
0.0
f
;
if
(
input_grad
)
{
T
*
input_grad_data
=
input_grad
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
...
...
@@ -233,21 +285,20 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
handle
,
&
alpha
,
cudnn_filter_desc
,
filter_data
+
i
*
group_offset_filter
,
cudnn_output_grad_desc
,
output_grad_data
+
i
*
group_offset_out
,
cudnn_conv_desc
,
data_algo
,
cudnn_workspace
,
workspace_size_in_bytes
,
&
beta
,
cudnn_input_grad_desc
,
input_grad_data
+
i
*
group_offset_in
));
cudnn_workspace
,
workspace_size_in_bytes
,
&
beta
,
cudnn_input_desc
,
input_grad_data
+
i
*
group_offset_in
));
}
}
// ------------------- cudnn conv backward filter ---------------------
if
(
filter_grad
)
{
T
*
filter_grad_data
=
filter_grad
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
// Because beta is zero, it is unnecessary to reset filter_grad.
for
(
int
i
=
0
;
i
<
groups
;
i
++
)
{
PADDLE_ENFORCE
(
platform
::
dynload
::
cudnnConvolutionBackwardFilter
(
handle
,
&
alpha
,
cudnn_input_desc
,
input_data
+
i
*
group_offset_in
,
cudnn_output_grad_desc
,
output_grad_data
+
i
*
group_offset_out
,
cudnn_conv_desc
,
filter_algo
,
cudnn_workspace
,
workspace_size_in_bytes
,
&
beta
,
cudnn_filter_
grad_
desc
,
workspace_size_in_bytes
,
&
beta
,
cudnn_filter_desc
,
filter_grad_data
+
i
*
group_offset_filter
));
}
}
...
...
@@ -259,8 +310,16 @@ class CudnnConvGradOpKernel : public framework::OpKernel<T> {
}
// namespace operators
}
// namespace paddle
REGISTER_OP_GPU_KERNEL
(
conv_cudnn
,
paddle
::
operators
::
CudnnConvOpKernel
<
float
>
,
REGISTER_OP_GPU_KERNEL
(
conv2d_cudnn
,
paddle
::
operators
::
CudnnConvOpKernel
<
float
>
,
paddle
::
operators
::
CudnnConvOpKernel
<
double
>
);
REGISTER_OP_GPU_KERNEL
(
conv2d_cudnn_grad
,
paddle
::
operators
::
CudnnConvGradOpKernel
<
float
>
,
paddle
::
operators
::
CudnnConvGradOpKernel
<
double
>
);
REGISTER_OP_GPU_KERNEL
(
conv3d_cudnn
,
paddle
::
operators
::
CudnnConvOpKernel
<
float
>
,
paddle
::
operators
::
CudnnConvOpKernel
<
double
>
);
REGISTER_OP_GPU_KERNEL
(
conv_cudnn_grad
,
REGISTER_OP_GPU_KERNEL
(
conv
3d
_cudnn_grad
,
paddle
::
operators
::
CudnnConvGradOpKernel
<
float
>
,
paddle
::
operators
::
CudnnConvGradOpKernel
<
double
>
);
paddle/platform/cudnn_helper.h
浏览文件 @
f6e82bcf
...
...
@@ -116,7 +116,7 @@ inline cudnnTensorFormat_t GetCudnnTensorFormat(
case
DataLayout
::
kNCHW
:
return
CUDNN_TENSOR_NCHW
;
case
DataLayout
::
kNCDHW
:
return
CUDNN_TENSOR_NCHW
;
//
TODO(chengduoZH) : add CUDNN_TENSOR_NCDHW
return
CUDNN_TENSOR_NCHW
;
//
NOTE: cudnn treat NdTensor as the same
default:
PADDLE_THROW
(
"Unknown cudnn equivalent for order"
);
}
...
...
@@ -143,7 +143,7 @@ class ScopedTensorDescriptor {
strides
[
i
]
=
dims
[
i
+
1
]
*
strides
[
i
+
1
];
}
// Update tensor descriptor dims setting if groups > 1
//
FIXME(typhoonzero)
: Assume using NCHW or NCDHW order
//
NOTE
: Assume using NCHW or NCDHW order
std
::
vector
<
int
>
dims_with_group
(
dims
.
begin
(),
dims
.
end
());
// copy
if
(
groups
>
1
)
{
dims_with_group
[
1
]
=
dims_with_group
[
1
]
/
groups
;
...
...
@@ -186,7 +186,6 @@ class ScopedFilterDescriptor {
// width of the filter.
std
::
vector
<
int
>
kernel_with_group
(
kernel
.
begin
(),
kernel
.
end
());
if
(
groups
>
1
)
{
// M /= groups
kernel_with_group
[
0
]
/=
groups
;
// NOTE: input filter(C) of the filter is already asserted to be C/groups.
}
...
...
python/paddle/v2/fluid/executor.py
浏览文件 @
f6e82bcf
import
numpy
as
np
import
paddle.v2.fluid.core
as
core
from
paddle.v2.fluid.framework
import
Block
,
Program
,
g_main_program
g_scope
=
core
.
Scope
()
def
as_numpy
(
tensor
):
if
isinstance
(
tensor
,
list
):
return
[
as_numpy
(
t
)
for
t
in
tensor
]
assert
isinstance
(
tensor
,
core
.
LoDTensor
)
lod
=
tensor
.
lod
()
tensor_data
=
np
.
array
(
tensor
)
if
len
(
lod
)
==
0
:
ans
=
tensor_data
else
:
raise
RuntimeError
(
"LoD Calculate lacks unit tests and buggy"
)
# elif len(lod) == 1:
# ans = []
# idx = 0
# while idx < len(lod) - 1:
# ans.append(tensor_data[lod[idx]:lod[idx + 1]])
# idx += 1
# else:
# for l in reversed(lod):
# ans = []
# idx = 0
# while idx < len(l) - 1:
# ans.append(tensor_data[l[idx]:l[idx + 1]])
# idx += 1
# tensor_data = ans
# ans = tensor_data
return
ans
class
Executor
(
object
):
def
__init__
(
self
,
places
):
if
not
isinstance
(
places
,
list
)
and
not
isinstance
(
places
,
tuple
):
...
...
@@ -16,6 +45,47 @@ class Executor(object):
act_places
.
append
(
p
)
self
.
executor
=
core
.
Executor
(
act_places
)
self
.
places
=
places
def
aslodtensor
(
self
,
data
):
def
accumulate
(
data
):
if
not
isinstance
(
data
,
list
):
return
1
return
sum
([
accumulate
(
sub
)
for
sub
in
data
])
def
parselod
(
data
):
seq_lens
=
[
accumulate
(
seq
)
for
seq
in
data
]
cur_len
=
0
lod
=
[
cur_len
]
for
l
in
seq_lens
:
cur_len
+=
l
lod
.
append
(
cur_len
)
return
lod
assert
len
(
self
.
places
)
!=
0
if
not
isinstance
(
data
,
list
):
# pure tensor case
tensor
=
core
.
LoDTensor
()
tensor
.
set
(
data
,
self
.
places
[
0
])
return
tensor
else
:
raise
RuntimeError
(
"Current implementation lacks unittests"
)
# lodtensor case
lod
=
[]
if
not
isinstance
(
data
[
0
],
list
):
lod
.
append
(
parselod
(
data
))
flattened_data
=
np
.
concatenate
(
data
,
axis
=
0
).
astype
(
"int64"
)
else
:
while
isinstance
(
data
[
0
],
list
):
lod
.
append
(
parselod
(
seq
))
flattened_data
=
[
item
for
seq
in
data
for
item
in
seq
]
data
=
flattened_data
flattened_data
=
np
.
concatenate
(
data
,
axis
=
0
).
astype
(
"int64"
)
flattened_data
=
flattened_data
.
reshape
([
len
(
flattened_data
),
1
])
tensor
=
core
.
LoDTensor
()
tensor
.
set
(
flattened_data
,
self
.
places
[
0
])
tensor
.
set_lod
(
lod
)
return
tensor
def
run
(
self
,
program
=
None
,
...
...
@@ -23,7 +93,8 @@ class Executor(object):
fetch_list
=
None
,
feed_var_name
=
'feed'
,
fetch_var_name
=
'fetch'
,
scope
=
None
):
scope
=
None
,
return_numpy
=
True
):
if
feed
is
None
:
feed
=
{}
if
fetch_list
is
None
:
...
...
@@ -52,7 +123,10 @@ class Executor(object):
inputs
=
{
'X'
:
[
feed_var
]},
outputs
=
{
'Out'
:
[
out
]},
attrs
=
{
'col'
:
i
})
core
.
set_feed_variable
(
scope
,
feed
[
name
],
feed_var
.
name
,
i
)
cur_feed
=
feed
[
name
]
if
not
isinstance
(
cur_feed
,
core
.
LoDTensor
):
cur_feed
=
self
.
aslodtensor
(
cur_feed
)
core
.
set_feed_variable
(
scope
,
cur_feed
,
feed_var
.
name
,
i
)
fetch_var
=
global_block
.
create_var
(
name
=
fetch_var_name
,
...
...
@@ -66,7 +140,11 @@ class Executor(object):
attrs
=
{
'col'
:
i
})
self
.
executor
.
run
(
program
.
desc
,
scope
,
0
,
True
)
return
[
outs
=
[
core
.
get_fetch_variable
(
scope
,
fetch_var_name
,
i
)
for
i
in
xrange
(
len
(
fetch_list
))
]
if
return_numpy
:
outs
=
as_numpy
(
outs
)
return
outs
python/paddle/v2/fluid/tests/.gitignore
浏览文件 @
f6e82bcf
image/
fit_a_line.model/
tmp
python/paddle/v2/fluid/tests/op_test.py
浏览文件 @
f6e82bcf
...
...
@@ -261,7 +261,10 @@ class OpTest(unittest.TestCase):
feed_map
=
self
.
feed_var
(
inputs
,
place
)
exe
=
Executor
(
place
)
outs
=
exe
.
run
(
program
,
feed
=
feed_map
,
fetch_list
=
fetch_list
)
outs
=
exe
.
run
(
program
,
feed
=
feed_map
,
fetch_list
=
fetch_list
,
return_numpy
=
False
)
for
out_name
,
out_dup
in
Operator
.
get_op_outputs
(
self
.
op_type
):
if
out_name
not
in
self
.
outputs
:
...
...
@@ -500,5 +503,6 @@ class OpTest(unittest.TestCase):
fetch_list
=
[
g
for
p
,
g
in
param_grad_list
]
executor
=
Executor
(
place
)
result
=
executor
.
run
(
prog
,
feed_dict
,
fetch_list
)
return
map
(
np
.
array
,
result
)
return
map
(
np
.
array
,
executor
.
run
(
prog
,
feed_dict
,
fetch_list
,
return_numpy
=
False
))
python/paddle/v2/fluid/tests/test_array_read_write_op.py
浏览文件 @
f6e82bcf
...
...
@@ -52,15 +52,13 @@ class TestArrayReadWrite(unittest.TestCase):
exe
=
Executor
(
cpu
)
tensor
=
core
.
LoDTensor
()
tensor
.
set
(
numpy
.
random
.
random
(
size
=
(
100
,
100
)).
astype
(
'float32'
),
cpu
)
tensor
=
numpy
.
random
.
random
(
size
=
(
100
,
100
)).
astype
(
'float32'
)
outs
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'x0'
:
tensor
,
outs
=
exe
.
run
(
feed
=
{
'x0'
:
tensor
,
'x1'
:
tensor
,
'x2'
:
tensor
},
fetch_list
=
[
a_sum
,
x_sum
],
scope
=
scope
)
)
scope
=
scope
)
self
.
assertEqual
(
outs
[
0
],
outs
[
1
])
total_sum
=
layers
.
sums
(
input
=
[
a_sum
,
x_sum
])
...
...
@@ -72,12 +70,11 @@ class TestArrayReadWrite(unittest.TestCase):
[
each_x
.
name
+
"@GRAD"
for
each_x
in
x
])
g_out
=
[
item
.
sum
()
for
item
in
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'x0'
:
tensor
,
for
item
in
exe
.
run
(
feed
=
{
'x0'
:
tensor
,
'x1'
:
tensor
,
'x2'
:
tensor
},
fetch_list
=
g_vars
)
)
fetch_list
=
g_vars
)
]
g_out_sum
=
numpy
.
array
(
g_out
).
sum
()
...
...
python/paddle/v2/fluid/tests/test_conditional_block.py
浏览文件 @
f6e82bcf
...
...
@@ -21,18 +21,15 @@ class ConditionalBlock(unittest.TestCase):
exe
=
Executor
(
cpu
)
exe
.
run
(
g_startup_program
)
x
=
core
.
LoDTensor
()
x
.
set
(
numpy
.
random
.
random
(
size
=
(
10
,
1
)).
astype
(
'float32'
),
cpu
)
x
=
numpy
.
random
.
random
(
size
=
(
10
,
1
)).
astype
(
'float32'
)
outs
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'X'
:
x
},
fetch_list
=
[
out
])
)[
0
]
outs
=
exe
.
run
(
feed
=
{
'X'
:
x
},
fetch_list
=
[
out
]
)[
0
]
print
outs
loss
=
layers
.
mean
(
x
=
out
)
append_backward_ops
(
loss
=
loss
)
outs
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'X'
:
x
},
fetch_list
=
[
g_main_program
.
block
(
0
).
var
(
data
.
name
+
"@GRAD"
)
]))[
0
]
outs
=
exe
.
run
(
feed
=
{
'X'
:
x
},
fetch_list
=
[
g_main_program
.
block
(
0
).
var
(
data
.
name
+
"@GRAD"
)])[
0
]
print
outs
...
...
python/paddle/v2/fluid/tests/test_conv2d_op.py
浏览文件 @
f6e82bcf
...
...
@@ -16,8 +16,8 @@ def conv2d_forward_naive(input, filter, group, conv_param):
out_w
=
1
+
(
in_w
+
2
*
pad
[
1
]
-
(
dilation
[
1
]
*
(
f_w
-
1
)
+
1
))
/
stride
[
1
]
out
=
np
.
zeros
((
in_n
,
out_c
,
out_h
,
out_w
))
d_bolck_
w
=
(
dilation
[
0
]
*
(
f_h
-
1
)
+
1
)
d_bolck_
h
=
(
dilation
[
1
]
*
(
f_w
-
1
)
+
1
)
d_bolck_
h
=
(
dilation
[
0
]
*
(
f_h
-
1
)
+
1
)
d_bolck_
w
=
(
dilation
[
1
]
*
(
f_w
-
1
)
+
1
)
input_pad
=
np
.
pad
(
input
,
((
0
,
),
(
0
,
),
(
pad
[
0
],
),
(
pad
[
1
],
)),
mode
=
'constant'
,
...
...
@@ -167,27 +167,27 @@ class TestWithDilation(TestConv2dOp):
#----------------Conv2dCudnn----------------
class
TestCudnn
(
TestConv2dOp
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv_cudnn"
self
.
op_type
=
"conv
2d
_cudnn"
class
TestCudnnWithPad
(
TestWithPad
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv_cudnn"
self
.
op_type
=
"conv
2d
_cudnn"
class
TestCudnnWithStride
(
TestWithStride
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv_cudnn"
self
.
op_type
=
"conv
2d
_cudnn"
class
TestCudnnWithGroup
(
TestWithGroup
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv_cudnn"
self
.
op_type
=
"conv
2d
_cudnn"
class
TestCudnnWith1x1
(
TestWith1x1
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv_cudnn"
self
.
op_type
=
"conv
2d
_cudnn"
# cudnn v5 does not support dilation conv.
...
...
python/paddle/v2/fluid/tests/test_conv3d_op.py
浏览文件 @
f6e82bcf
...
...
@@ -169,5 +169,31 @@ class TestWithDilation(TestConv3dOp):
self
.
groups
=
3
class
TestCudnn
(
TestConv3dOp
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv3d_cudnn"
class
TestWithGroup1Cudnn
(
TestWithGroup1
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv3d_cudnn"
class
TestWithGroup2Cudnn
(
TestWithGroup2
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv3d_cudnn"
class
TestWith1x1Cudnn
(
TestWith1x1
):
def
init_op_type
(
self
):
self
.
op_type
=
"conv3d_cudnn"
# FIXME(typhoonzero): find a way to determine if
# using cudnn > 6 in python
# class TestWithDilationCudnn(TestWithDilation):
# def init_op_type(self):
# self.op_type = "conv3d_cudnn"
if
__name__
==
'__main__'
:
unittest
.
main
()
python/paddle/v2/fluid/tests/test_executor_and_mul.py
浏览文件 @
f6e82bcf
import
unittest
from
paddle.v2.fluid.layers
import
mul
,
data
from
paddle.v2.fluid.layers
import
mul
,
data
,
sequence_pool
import
paddle.v2.fluid.core
as
core
from
paddle.v2.fluid.executor
import
Executor
from
paddle.v2.fluid.framework
import
g_main_program
...
...
@@ -17,17 +17,13 @@ class TestExecutor(unittest.TestCase):
out
=
mul
(
x
=
a
,
y
=
b
)
place
=
core
.
CPUPlace
()
a_np
=
numpy
.
random
.
random
((
100
,
784
)).
astype
(
'float32'
)
tensor_a
=
core
.
LoDTensor
()
tensor_a
.
set
(
a_np
,
place
)
b_np
=
numpy
.
random
.
random
((
784
,
100
)).
astype
(
'float32'
)
tensor_b
=
core
.
LoDTensor
()
tensor_b
.
set
(
b_np
,
place
)
exe
=
Executor
(
place
)
outs
=
exe
.
run
(
g_main_program
,
feed
=
{
'a'
:
tensor_a
,
'b'
:
tensor_b
},
feed
=
{
'a'
:
a_np
,
'b'
:
b_np
},
fetch_list
=
[
out
])
out
=
numpy
.
array
(
outs
[
0
])
out
=
outs
[
0
]
self
.
assertEqual
((
100
,
100
),
out
.
shape
)
self
.
assertTrue
(
numpy
.
allclose
(
out
,
numpy
.
dot
(
a_np
,
b_np
)))
...
...
python/paddle/v2/fluid/tests/test_inference_model_io.py
浏览文件 @
f6e82bcf
import
paddle.v2
as
paddle
import
paddle.v2.fluid.layers
as
layers
import
unittest
import
numpy
as
np
import
paddle.v2.fluid.core
as
core
import
paddle.v2.fluid.optimizer
as
optimizer
import
paddle.v2.fluid.executor
as
executor
import
paddle.v2.fluid.layers
as
layers
import
paddle.v2.fluid.optimizer
as
optimizer
from
paddle.v2.fluid.framework
import
Program
from
paddle.v2.fluid.io
import
save_inference_model
,
load_inference_model
import
paddle.v2.fluid.executor
as
executor
import
unittest
import
numpy
as
np
class
TestBook
(
unittest
.
TestCase
):
...
...
@@ -44,7 +44,7 @@ class TestBook(unittest.TestCase):
x
=
cost
,
main_program
=
program
,
startup_program
=
init_program
)
sgd_optimizer
=
optimizer
.
SGDOptimizer
(
learning_rate
=
0.001
)
opts
=
sgd_optimizer
.
minimize
(
avg_cost
,
init_program
)
sgd_optimizer
.
minimize
(
avg_cost
,
init_program
)
place
=
core
.
CPUPlace
()
exe
=
executor
.
Executor
(
place
)
...
...
@@ -52,25 +52,20 @@ class TestBook(unittest.TestCase):
exe
.
run
(
init_program
,
feed
=
{},
fetch_list
=
[])
for
i
in
xrange
(
100
):
x_data
=
np
.
array
(
tensor_x
=
np
.
array
(
[[
1
,
1
],
[
1
,
2
],
[
3
,
4
],
[
5
,
2
]]).
astype
(
"float32"
)
y_data
=
np
.
array
([[
-
2
],
[
-
3
],
[
-
7
],
[
-
7
]]).
astype
(
"float32"
)
tensor_y
=
np
.
array
([[
-
2
],
[
-
3
],
[
-
7
],
[
-
7
]]).
astype
(
"float32"
)
tensor_x
=
core
.
LoDTensor
()
tensor_x
.
set
(
x_data
,
place
)
tensor_y
=
core
.
LoDTensor
()
tensor_y
.
set
(
y_data
,
place
)
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor_x
,
'y'
:
tensor_y
},
fetch_list
=
[
avg_cost
])
save_inference_model
(
MODEL_DIR
,
[
"x"
,
"y"
],
[
avg_cost
],
exe
,
program
)
outs
=
exe
.
run
(
program
,
expected
=
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor_x
,
'y'
:
tensor_y
},
fetch_list
=
[
avg_cost
])
expected
=
np
.
array
(
outs
[
0
])
fetch_list
=
[
avg_cost
])[
0
]
reload
(
executor
)
# reload to build a new scope
exe
=
executor
.
Executor
(
place
)
...
...
@@ -83,7 +78,7 @@ class TestBook(unittest.TestCase):
feed
=
{
feed_var_names
[
0
]:
tensor_x
,
feed_var_names
[
1
]:
tensor_y
},
fetch_list
=
fetch_vars
)
actual
=
np
.
array
(
outs
[
0
])
actual
=
outs
[
0
]
self
.
assertEqual
(
feed_var_names
,
[
"x"
,
"y"
])
self
.
assertEqual
(
len
(
fetch_vars
),
1
)
...
...
python/paddle/v2/fluid/tests/test_lod_array_length_op.py
浏览文件 @
f6e82bcf
...
...
@@ -13,7 +13,7 @@ class TestLoDArrayLength(unittest.TestCase):
arr_len
=
layers
.
array_length
(
arr
)
cpu
=
core
.
CPUPlace
()
exe
=
Executor
(
cpu
)
result
=
numpy
.
array
(
exe
.
run
(
fetch_list
=
[
arr_len
])[
0
])
result
=
exe
.
run
(
fetch_list
=
[
arr_len
])[
0
]
self
.
assertEqual
(
11
,
result
[
0
])
...
...
python/paddle/v2/fluid/tests/test_lod_tensor_array_ops.py
浏览文件 @
f6e82bcf
...
...
@@ -151,10 +151,11 @@ class TestCPULoDTensorArrayOpGrad(unittest.TestCase):
exe
=
Executor
(
place
)
g_out
=
[
item
.
sum
()
for
item
in
map
(
numpy
.
array
,
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
g_vars
]))
numpy
.
array
(
item
).
sum
()
for
item
in
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
g_vars
],
return_numpy
=
False
)
]
g_out_sum
=
numpy
.
array
(
g_out
).
sum
()
...
...
python/paddle/v2/fluid/tests/test_mnist_if_else_op.py
浏览文件 @
f6e82bcf
...
...
@@ -65,17 +65,10 @@ class TestMNISTIfElseOp(unittest.TestCase):
y_data
=
np
.
array
(
map
(
lambda
x
:
x
[
1
],
data
)).
astype
(
"int64"
)
y_data
=
np
.
expand_dims
(
y_data
,
axis
=
1
)
tensor_x
=
core
.
LoDTensor
()
tensor_x
.
set
(
x_data
,
place
)
tensor_y
=
core
.
LoDTensor
()
tensor_y
.
set
(
y_data
,
place
)
outs
=
map
(
np
.
array
,
exe
.
run
(
kwargs
[
'main_program'
],
feed
=
{
'x'
:
tensor_x
,
'y'
:
tensor_y
},
fetch_list
=
[
avg_loss
]))
outs
=
exe
.
run
(
kwargs
[
'main_program'
],
feed
=
{
'x'
:
x_data
,
'y'
:
y_data
},
fetch_list
=
[
avg_loss
])
print
outs
[
0
]
if
outs
[
0
]
<
1.0
:
return
...
...
@@ -129,19 +122,12 @@ class TestMNISTIfElseOp(unittest.TestCase):
for
data
in
train_reader
():
x_data
=
np
.
array
(
map
(
lambda
x
:
x
[
0
],
data
)).
astype
(
"float32"
)
y_data
=
np
.
array
(
map
(
lambda
x
:
x
[
1
],
data
)).
astype
(
"int64"
)
y_data
=
np
.
expand_dims
(
y_data
,
axis
=
1
)
tensor_x
=
core
.
LoDTensor
()
tensor_x
.
set
(
x_data
,
place
)
tensor_y
=
core
.
LoDTensor
()
tensor_y
.
set
(
y_data
,
place
)
y_data
=
y_data
.
reshape
((
y_data
.
shape
[
0
],
1
))
outs
=
map
(
np
.
array
,
exe
.
run
(
kwargs
[
'main_program'
],
feed
=
{
'x'
:
tensor_x
,
'y'
:
tensor_y
},
fetch_list
=
[
avg_loss
]))
outs
=
exe
.
run
(
kwargs
[
'main_program'
],
feed
=
{
'x'
:
x_data
,
'y'
:
y_data
},
fetch_list
=
[
avg_loss
])
print
outs
[
0
]
if
outs
[
0
]
<
1.0
:
return
...
...
python/paddle/v2/fluid/tests/test_parameter.py
浏览文件 @
f6e82bcf
...
...
@@ -24,7 +24,7 @@ class TestParameter(unittest.TestCase):
self
.
assertEqual
(
0
,
param
.
block
.
idx
)
exe
=
Executor
(
core
.
CPUPlace
())
p
=
exe
.
run
(
g_main_program
,
fetch_list
=
[
param
])[
0
]
self
.
assertTrue
(
np
.
allclose
(
np
.
array
(
p
)
,
np
.
ones
(
shape
)
*
val
))
self
.
assertTrue
(
np
.
allclose
(
p
,
np
.
ones
(
shape
)
*
val
))
p
=
io
.
get_parameter_value_by_name
(
'fc.w'
,
exe
,
g_main_program
)
self
.
assertTrue
(
np
.
allclose
(
np
.
array
(
p
),
np
.
ones
(
shape
)
*
val
))
...
...
python/paddle/v2/fluid/tests/test_recurrent_op.py
浏览文件 @
f6e82bcf
...
...
@@ -156,7 +156,7 @@ class RecurrentOpTest1(unittest.TestCase):
feed
=
self
.
feed_map
,
fetch_list
=
[
self
.
output
])
return
np
.
array
(
out
[
0
])
return
out
[
0
]
def
backward
(
self
):
self
.
feed_map
=
{
...
...
@@ -171,7 +171,8 @@ class RecurrentOpTest1(unittest.TestCase):
exe
=
Executor
(
self
.
place
)
return
exe
.
run
(
self
.
main_program
,
feed
=
self
.
feed_map
,
fetch_list
=
fetch_list
)
fetch_list
=
fetch_list
,
return_numpy
=
False
)
def
test_backward
(
self
):
self
.
check_forward
()
...
...
python/paddle/v2/fluid/tests/test_rnn_memory_helper_op.py
浏览文件 @
f6e82bcf
...
...
@@ -7,12 +7,6 @@ import numpy as np
import
paddle.v2.fluid.core
as
core
def
create_tensor
(
np_data
,
place
):
tensor
=
core
.
LoDTensor
()
tensor
.
set
(
np_data
,
place
)
return
tensor
class
RNNMemoryHelperOpTest
(
unittest
.
TestCase
):
def
setUp
(
self
):
self
.
program
=
Program
()
...
...
@@ -30,13 +24,13 @@ class RNNMemoryHelperOpTest(unittest.TestCase):
def
test_forward
(
self
):
x_np
=
np
.
random
.
normal
(
size
=
(
2
,
3
)).
astype
(
"float32"
)
self
.
feed_map
=
{
'X'
:
create_tensor
(
x_np
,
self
.
place
)
}
self
.
feed_map
=
{
'X'
:
x_np
}
self
.
fetch_list
=
[
self
.
Out
]
exe
=
Executor
(
self
.
place
)
out
=
exe
.
run
(
self
.
program
,
feed
=
self
.
feed_map
,
fetch_list
=
self
.
fetch_list
)
np
.
isclose
(
np
.
array
(
out
[
0
]),
x_np
,
rtol
=
1e-5
)
self
.
assertTrue
(
np
.
allclose
(
out
[
0
],
x_np
,
rtol
=
1e-5
)
)
class
RNNMemoryHelperGradOpTest
(
unittest
.
TestCase
):
...
...
@@ -66,8 +60,7 @@ class RNNMemoryHelperGradOpTest(unittest.TestCase):
def
test_backward
(
self
):
self
.
feed_map
=
{
name
:
create_tensor
(
np
.
random
.
normal
(
size
=
(
2
,
3
)).
astype
(
"float32"
),
self
.
place
)
name
:
np
.
random
.
normal
(
size
=
(
2
,
3
)).
astype
(
"float32"
)
for
name
in
self
.
input_names
}
self
.
fetch_list
=
[
self
.
output_vars
[
'X@GRAD'
]]
...
...
@@ -76,7 +69,7 @@ class RNNMemoryHelperGradOpTest(unittest.TestCase):
out
=
exe
.
run
(
self
.
program
,
feed
=
self
.
feed_map
,
fetch_list
=
self
.
fetch_list
)
np
.
isclose
(
np
.
array
(
out
[
0
])
,
self
.
feed_map
[
'Out@GRAD'
],
rtol
=
1e-5
)
np
.
isclose
(
out
[
0
]
,
self
.
feed_map
[
'Out@GRAD'
],
rtol
=
1e-5
)
class
RNNMemoryHelperGradOpWithoutInputTest
(
unittest
.
TestCase
):
...
...
@@ -110,8 +103,7 @@ class RNNMemoryHelperGradOpWithoutInputTest(unittest.TestCase):
def
test_backward
(
self
):
self
.
feed_map
=
{
name
:
create_tensor
(
np
.
random
.
normal
(
size
=
(
2
,
3
)).
astype
(
"float32"
),
self
.
place
)
name
:
np
.
random
.
normal
(
size
=
(
2
,
3
)).
astype
(
"float32"
)
for
name
in
[
'X'
,
'Out'
]
}
self
.
fetch_list
=
[
self
.
output_vars
[
'X@GRAD'
]]
...
...
@@ -120,10 +112,9 @@ class RNNMemoryHelperGradOpWithoutInputTest(unittest.TestCase):
out
=
exe
.
run
(
self
.
program
,
feed
=
self
.
feed_map
,
fetch_list
=
self
.
fetch_list
)
np
.
isclose
(
np
.
array
(
out
[
0
]),
np
.
zeros
(
shape
=
(
2
,
3
)).
astype
(
"float32"
),
rtol
=
1e-5
)
self
.
assertTrue
(
np
.
allclose
(
out
[
0
],
np
.
zeros
(
shape
=
(
2
,
3
)).
astype
(
"float32"
),
rtol
=
1e-5
))
if
__name__
==
'__main__'
:
...
...
python/paddle/v2/fluid/tests/test_shrink_rnn_memory.py
浏览文件 @
f6e82bcf
...
...
@@ -27,19 +27,16 @@ class TestShrinkRNNMemory(unittest.TestCase):
tensor_np
=
numpy
.
random
.
random
(
size
=
(
3
,
100
)).
astype
(
'float32'
)
tensor
.
set
(
tensor_np
,
cpu
)
exe
=
Executor
(
cpu
)
outs
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
mem1
,
mem2
,
mem3
]))
outs
=
exe
.
run
(
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
mem1
,
mem2
,
mem3
])
self
.
assertTrue
(
numpy
.
allclose
(
tensor_np
[
0
:
3
],
outs
[
0
]))
self
.
assertTrue
(
numpy
.
allclose
(
tensor_np
[
0
:
2
],
outs
[
1
]))
self
.
assertTrue
(
numpy
.
allclose
(
tensor_np
[
0
:
1
],
outs
[
2
]))
mem3_mean
=
layers
.
mean
(
x
=
mem3
)
append_backward_ops
(
loss
=
mem3_mean
)
x_grad
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
g_main_program
.
global_block
().
var
(
'x@GRAD'
)
]))[
0
]
x_grad
=
exe
.
run
(
feed
=
{
'x'
:
tensor
},
fetch_list
=
[
g_main_program
.
global_block
().
var
(
'x@GRAD'
)])[
0
]
self
.
assertAlmostEqual
(
1.0
,
x_grad
.
sum
(),
delta
=
0.1
)
...
...
python/paddle/v2/fluid/tests/test_split_and_merge_lod_tensor_op.py
浏览文件 @
f6e82bcf
...
...
@@ -98,7 +98,11 @@ class TestCPULoDTensorArrayOps(unittest.TestCase):
exe
=
Executor
(
place
)
scope
=
core
.
Scope
()
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor
,
'y'
:
mask
},
scope
=
scope
)
exe
.
run
(
program
,
feed
=
{
'x'
:
tensor
,
'y'
:
mask
},
scope
=
scope
,
return_numpy
=
False
)
var_true
=
scope
.
find_var
(
out_true
.
name
).
get_tensor
()
...
...
@@ -169,7 +173,8 @@ class TestCPUSplitMergeLoDTensorGrad(unittest.TestCase):
feed
=
{
'x'
:
tensor
,
'y'
:
mask
},
fetch_list
=
[
g_vars
],
scope
=
scope
))
scope
=
scope
,
return_numpy
=
False
))
]
g_out_sum
=
np
.
array
(
g_out
).
sum
()
...
...
python/paddle/v2/fluid/tests/test_while_op.py
浏览文件 @
f6e82bcf
...
...
@@ -55,19 +55,10 @@ class TestWhileOp(unittest.TestCase):
for
i
in
xrange
(
3
):
d
.
append
(
numpy
.
random
.
random
(
size
=
[
10
]).
astype
(
'float32'
))
d_tensor
=
[]
for
item
in
d
:
t
=
core
.
LoDTensor
()
t
.
set
(
item
,
cpu
)
d_tensor
.
append
(
t
)
outs
=
map
(
numpy
.
array
,
exe
.
run
(
feed
=
{
'd0'
:
d_tensor
[
0
],
'd1'
:
d_tensor
[
1
],
'd2'
:
d_tensor
[
2
]
},
fetch_list
=
[
sum_result
]))
outs
=
exe
.
run
(
feed
=
{
'd0'
:
d
[
0
],
'd1'
:
d
[
1
],
'd2'
:
d
[
2
]},
fetch_list
=
[
sum_result
])
self
.
assertAlmostEqual
(
numpy
.
sum
(
d
),
numpy
.
sum
(
outs
[
0
]),
delta
=
0.01
)
...
...
python/paddle/v2/fluid/tests/tmp/inference_model/__model__
已删除
100644 → 0
浏览文件 @
5981918c
文件已删除
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.b_0
已删除
100644 → 0
浏览文件 @
5981918c
文件已删除
python/paddle/v2/fluid/tests/tmp/inference_model/fc_0.w_0
已删除
100644 → 0
浏览文件 @
5981918c
文件已删除
python/paddle/v2/framework/tests/test_elementwise_mod_op.py
已删除
100644 → 0
浏览文件 @
5981918c
import
unittest
import
numpy
as
np
from
op_test
import
OpTest
class
ElementwiseModOp
(
OpTest
):
def
setUp
(
self
):
self
.
op_type
=
"elementwise_mod"
""" Warning
CPU gradient check error!
'X': np.random.randint((32,84)).astype("int32"),
'Y': np.random.randint((32,84)).astype("int32")
"""
self
.
inputs
=
{
'X'
:
np
.
random
.
randint
(
1
,
10
,
[
13
,
17
]).
astype
(
"int32"
),
'Y'
:
np
.
random
.
randint
(
1
,
10
,
[
13
,
17
]).
astype
(
"int32"
)
}
self
.
outputs
=
{
'Out'
:
np
.
mod
(
self
.
inputs
[
'X'
],
self
.
inputs
[
'Y'
])}
def
test_check_output
(
self
):
self
.
check_output
()
def
test_check_grad_normal
(
self
):
self
.
check_grad
([
'X'
,
'Y'
],
'Out'
,
max_relative_error
=
0.05
)
def
test_check_grad_ingore_x
(
self
):
self
.
check_grad
(
[
'Y'
],
'Out'
,
max_relative_error
=
0.05
,
no_grad_set
=
set
(
"X"
))
def
test_check_grad_ingore_y
(
self
):
self
.
check_grad
(
[
'X'
],
'Out'
,
max_relative_error
=
0.05
,
no_grad_set
=
set
(
'Y'
))
if
__name__
==
'__main__'
:
unittest
.
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
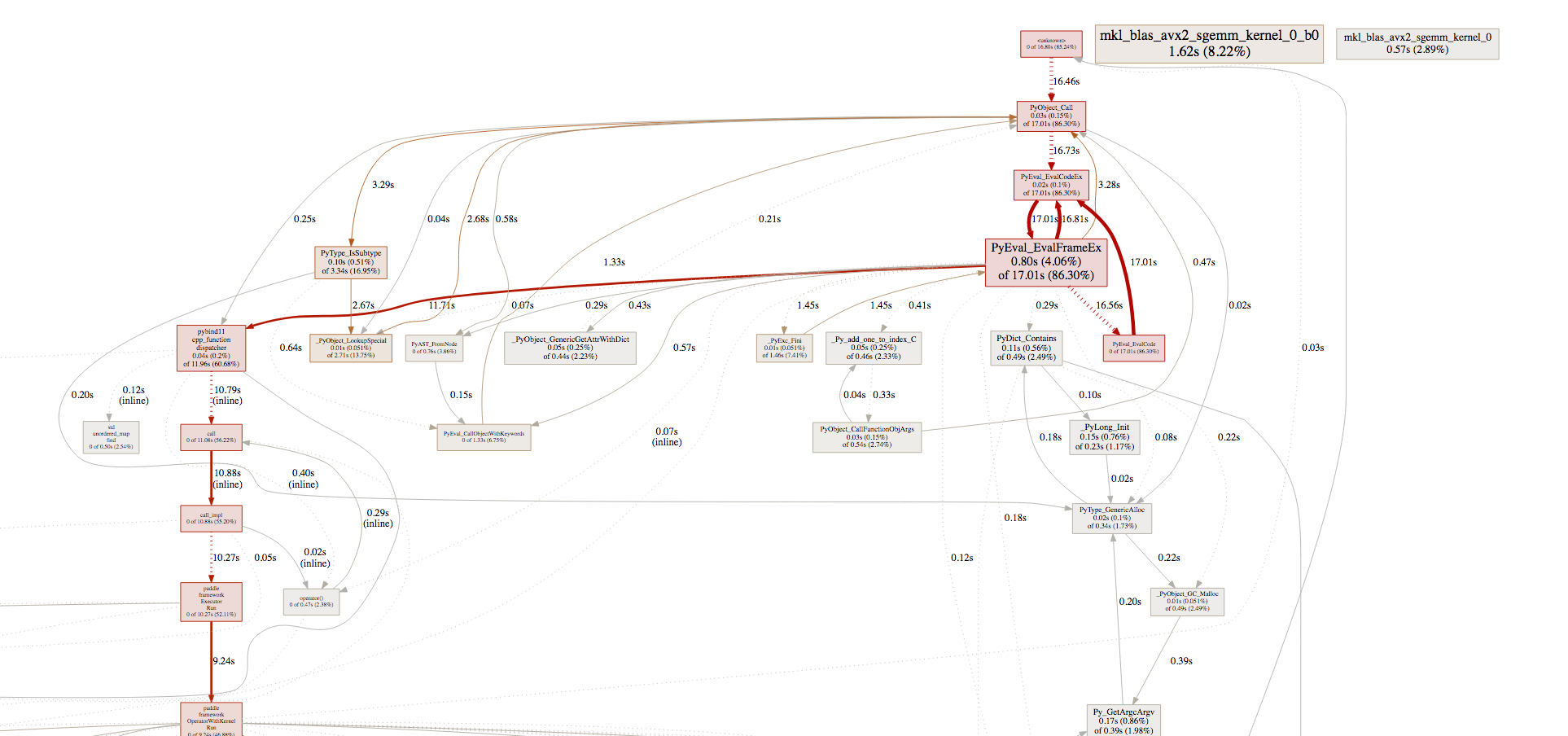
{kind=link}
