Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
eeca7be7
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
eeca7be7
编写于
11月 20, 2016
作者:
C
chenguoyan01
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
fix some md syntax error.
上级
212dcedc
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
105 addition
and
52 deletion
+105
-52
doc_cn/cluster/k8s/distributed_training_on_kubernetes.md
doc_cn/cluster/k8s/distributed_training_on_kubernetes.md
+105
-52
doc_cn/cluster/k8s/k8s-paddle-arch.png
doc_cn/cluster/k8s/k8s-paddle-arch.png
+0
-0
未找到文件。
doc_cn/cluster/k8s/distributed_training_on_kubernetes.md
浏览文件 @
eeca7be7
# Paddle on Kubernetes:分布式训练
前一篇文章介绍了如何在Kubernetes集群上启动一个单机Paddle
训练作业 (Job)。在这篇文章里,我们介绍如何在Kubernetes集群上进行分布式Paddle训练作业。关于Paddle的分布式训练,可以参考
[
Cluster Training
](
https://github.com/baidu/Paddle/blob/develop/doc/cluster/opensource/cluster_train.md
)
, 本文利用Kubernetes的调度功能与容器编排能力,快速构建
Paddle容器集群,进行分布式训练任务。
前一篇文章介绍了如何在Kubernetes集群上启动一个单机Paddle
Paddle训练作业 (Job)。在这篇文章里,我们介绍如何在Kubernetes集群上进行分布式PaddlePaddle训练作业。关于PaddlePaddle的分布式训练,可以参考
[
Cluster Training
](
https://github.com/baidu/Paddle/blob/develop/doc/cluster/opensource/cluster_train.md
)
,本文利用Kubernetes的调度功能与容器编排能力,快速构建Paddle
Paddle容器集群,进行分布式训练任务。
## Kubernetes 基本概念
在介绍分布式训练之前,需要对Kubernetes(k8s)有一个基本的认识,下面先简要介绍一下本文用到的几个k8
s概念。
[
*Kubernetes*
](
http://kubernetes.io/
)
是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用。在介绍分布式训练之前,需要对
[
Kubernetes
](
http://kubernetes.io/
)
有一个基本的认识,下面先简要介绍一下本文用到的几个Kubernete
s概念。
### Node
-
[
*Node*
](
http://kubernetes.io/docs/admin/node/
)
表示一个Kubernetes集群中的一个工作节点,这个节点可以是物理机或者虚拟机,Kubernetes集群就是由node节点与master节点组成的。
[
`Node`
](
http://kubernetes.io/docs/admin/node/
)
表示一个k8s集群中的一个工作节点,这个节点可以是物理机或者虚拟机,k8s集群就是由
`node`
节点与
`master`
节点组成的。每个node都安装有Docker,在本文的例子中,
`Paadle`
容器就在node上运行
。
-
[
*Pod*
](
http://kubernetes.io/docs/user-guide/pods/
)
是一组(一个或多个)容器,pod是Kubernetes的最小调度单元,一个pod中的所有容器会被调度到同一个node上。Pod中的容器共享NET,PID,IPC,UTS等Linux namespace。由于容器之间共享NET namespace,所以它们使用同一个IP地址,可以通过
*localhost*
互相通信。不同pod之间可以通过IP地址访问
。
### Pod
-
[
*Job*
](
http://kubernetes.io/docs/user-guide/jobs/
)
是Kubernetes上运行的作业,一次作业称为一个job,通常每个job包括一个或者多个pods。
一个
[
`Pod`
](
http://kubernetes.io/docs/user-guide/pods/
)
是一组(一个或多个)容器,pod是k8s的最小调度单元,一个 pod中的所有容器会被调度到同一个node上。Pod中的容器共享NET,PID,IPC,UTS等Linux namespace,它们使用同一个IP地址,可以通过
`localhost`
互相通信。不同pod之间可以通过IP地址访问
。
-
[
*Volume*
](
http://kubernetes.io/docs/user-guide/volumes/
)
存储卷,是pod内的容器都可以访问的共享目录,也是容器与node之间共享文件的方式,因为容器内的文件都是暂时存在的,当容器因为各种原因被销毁时,其内部的文件也会随之消失。通过volume,就可以将这些文件持久化存储。Kubernetes支持多种volume,例如hostPath(宿主机目录),gcePersistentDisk,awsElasticBlockStore等
。
### Job
[
`Job`
](
http://kubernetes.io/docs/user-guide/jobs/
)
可以翻译为作业,每个job可以设定pod成功完成的次数,一次作业会创建多个pod,当成功完成的pod个数达到预设值时,就表示job成功结束了。
### Volume
[
`Volume`
](
http://kubernetes.io/docs/user-guide/volumes/
)
存储卷,是pod内的容器都可以访问的共享目录,也是容器与node之间共享文件的方式,因为容器内的文件都是暂时存在的,当容器因为各种原因被销毁时,其内部的文件也会随之消失。通过volume,就可以将这些文件持久化存储。k8s支持多种volume,例如
`hostPath(宿主机目录)`
,
`gcePersistentDisk`
,
`awsElasticBlockStore`
等。
### Namespace
[
`Namespaces`
](
http://kubernetes.io/docs/user-guide/volumes/
)
命名空间,在k8s中创建的所有资源对象(例如上文的pod,job)等都属于一个命名空间,在同一个命名空间中,资源对象的名字是唯一的,不同空间的资源名可以重复,命名空间主要用来为不同的用户提供相对隔离的环境。本文只使用了
`default`
默认命名空间,读者可以不关心此概念。
-
[
*Namespaces*
](
http://kubernetes.io/docs/user-guide/volumes/
)
命名空间,在kubernetes中创建的所有资源对象(例如上文的pod,job)等都属于一个命名空间,在同一个命名空间中,资源对象的名字是唯一的,不同空间的资源名可以重复,命名空间主要为了对象进行逻辑上的分组便于管理。本文只使用了默认命名空间。
## 整体方案
### 前提条件
### 部署Kubernetes集群
首先,我们需要拥有一个Kubernetes集群,在这个集群中所有node与pod都可以互相通信。关于Kubernetes集群搭建,可以参考
[
官方文档
](
http://kubernetes.io/docs/getting-started-guides/kubeadm/
)
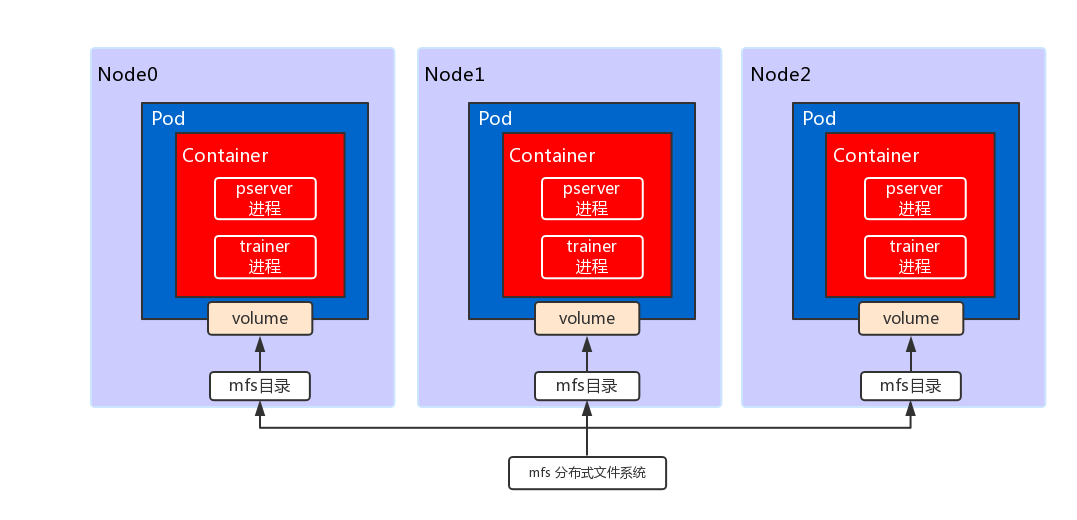
,在以后的文章中我们也会介绍AWS上搭建的方案。本文假设大家能找到几台物理机,并且可以按照官方文档在上面部署Kubernetes。在本文的环境中,Kubernetes集群中所有node都挂载了一个
*mfs*
(分布式文件系统)共享目录,我们通过这个目录来存放训练文件与最终输出的模型。在训练之前,用户将配置与训练数据切分好放在mfs目录中,训练时,程序从此目录拷贝文件到容器内进行训练,将结果保存到此目录里。整体的结果图如下:
首先,我们需要拥有一个k8s集群,在这个集群中所有node与pod都可以互相通信。关于k8s集群搭建,可以参考
[
官方文档
](
http://kubernetes.io/docs/getting-started-guides/kubeadm/
)
,在以后的文章中我们也会介绍AWS上搭建的方案。在本文的环境中,k8s集群中所有node都挂载了一个
`mfs`
(分布式文件系统)共享目录,我们通过这个目录来存放训练文件与最终输出的模型。在训练之前,用户将配置与训练数据切分好放在mfs目录中,训练时,程序从此目录拷贝文件到容器内进行训练,将结果保存到此目录里。

### 使用
`Job`
### 使用
Job
我们使用
k8s中的job这个概念来代表一次分布式训练。
`Job`
表示一次性作业,在作业完成后,k8
s会销毁job产生的容器并且释放相关资源。
我们使用
Kubernetes中的job这个概念来代表一次分布式训练。Job表示一次性作业,在作业完成后,Kubernete
s会销毁job产生的容器并且释放相关资源。
在
k8s中,可以通过编写一个
`yaml`
文件,来描述这个job,在这个文件中,主要包含了一些配置信息,例如Paddle节点的个数,
`paddle pserver`
开放的端口个数与端口号,
`paddle`
使用的网卡设备等,这些信息通过环境变量的形式传递给容器内的程序使用。
在
Kubernetes中,可以通过编写一个YAML文件,来描述这个job,在这个文件中,主要包含了一些配置信息,例如PaddlePaddle的节点个数,
`paddle pserver`
开放的端口个数与端口号,
使用的网卡设备等,这些信息通过环境变量的形式传递给容器内的程序使用。
在一次分布式训练中,用户确定好本次训练需要的Paddle
节点个数,将切分好的训练数据与配置文件上传到
`mfs`
共享目录中。然后编写这次训练的
`job yaml`
文件,提交给k8
s集群创建并开始作业。
在一次分布式训练中,用户确定好本次训练需要的Paddle
Paddle节点个数,将切分好的训练数据与配置文件上传到mfs共享目录中。然后编写这次训练的job YAML文件,提交给Kubernete
s集群创建并开始作业。
### 创建
`Paddle`
节点
### 创建
PaddlePaddle
节点
当
k8s master收到
`job yaml`
文件后,会解析相关字段,创建出多个pod(个数为Paddle节点数),k8s会把这些pod调度到集群的node上运行。一个
`pod`
就代表一个
`Paddle`
节点,当pod被成功分配到一台物理/虚拟机上后,k8s会启动pod内的容器,这个容器会根据
`job yaml`
文件中的环境变量,启动
`paddle pserver`
与
`paddle train`
进程。
当
Kubernetes master收到请求,解析完YAML文件后,会创建出多个pod(个数为PaddlePaddle节点数),Kubernetes会把这些pod调度到集群的node上运行。一个pod就代表一个PaddlePaddle节点,当pod被成功分配到一台物理/虚拟机上后,Kubernetes会启动pod内的容器,这个容器会根据YAML
文件中的环境变量,启动
`paddle pserver`
与
`paddle train`
进程。
### 启动训练
在容器启动后,会通过脚本来启动这次分布式训练,我们知道
`paddle train`
进程启动时需要知道其他节点的IP地址以及本节点的
`trainer_id`
,由于
`Paddle`
本身不提供类似服务发现的功能,所以在本文的启动脚本中,每个节点会根据
`job name`
向
`k8s apiserver`
查询这个
`job`
对应的所有
`pod`
信息(k8s默认会在每个容器的环境变量中写入
`apiserver`
的地址)。
在容器启动后,会通过脚本来启动这次分布式训练,我们知道
`paddle train`
进程启动时需要知道其他节点的IP地址以及本节点的
trainer_id,由于Paddle本身不提供类似服务发现的功能,所以在本文的启动脚本中,每个节点会根据job name向Kubernetes apiserver查询这个job对应的所有pod信息(Kubernetes默认会在每个容器的环境变量中写入apiserver
的地址)。
根据这些pod信息,就可以通过某种方式,为每个pod分配一个唯一的
`trainer_id`
。本文把所有pod的IP地址进行排序,将顺序作为每个
`Paddle`
节点的
`trainer_id`
。启动脚本的工作流程大致如下:
根据这些pod信息,就可以通过某种方式,为每个pod分配一个唯一的
trainer_id。本文把所有pod的IP地址进行排序,将顺序作为每个PaddlePaddle节点的trainer_id
。启动脚本的工作流程大致如下:
1.
查询
`k8s apiserver`
获取pod信息,根据IP分配
`trainer_id`
1.
从
`mfs`
共享目录中拷贝训练文件到容器内
1.
查询
Kubernetes apiserver获取pod信息,根据IP分配trainer_id
1.
从
mfs
共享目录中拷贝训练文件到容器内
1.
根据环境变量,解析出
`paddle pserver`
与
`paddle train`
的启动参数,启动进程
1.
训练时,
`Paddle`
会自动将结果保存在
`trainer_id`
为0的节点上,将输出路径设置为
`mfs`
目录,保存输出的文件
1.
训练时,
PaddlePaddle会自动将结果保存在trainer_id为0的节点上,将输出路径设置为mfs
目录,保存输出的文件
## 搭建过程
根据前文的描述,要在已有的
k8s集群上进行
`Paddle`
的分布式训练,主要分为以下几个步骤:
根据前文的描述,要在已有的
Kubernetes集群上进行PaddlePaddle
的分布式训练,主要分为以下几个步骤:
1.
制作
`Paddle`
镜像
1.
制作
PaddlePaddle
镜像
1.
将训练文件与切分好的数据上传到共享存储
1.
编写本次训练的
`job yaml`
文件,创建
`k8s job`
1.
编写本次训练的
YAML文件,创建一个Kubernetes job
1.
训练结束后查看输出结果
下面就根据这几个步骤分别介绍。
### 制作镜像
`Paddle`
镜像需要提供
`paddle pserver`
与
`paddle train`
进程的运行环境,用这个镜像创建的容器需要有以下两个功能:
PaddlePaddle
镜像需要提供
`paddle pserver`
与
`paddle train`
进程的运行环境,用这个镜像创建的容器需要有以下两个功能:
-
拷贝训练文件到容器内
-
生成
`paddle pserver`
与
`paddle train`
进程的启动参数,并且启动训练
因为官方镜像
`paddledev/paddle:cpu-latest`
内已经包含
`Paddle`
的执行程序但是还没上述功能,所以我们可以在这个基础上,添加启动脚本,制作新镜像来完成以上的工作。镜像的
`Dockerfile`
如下:
因为官方镜像
`paddledev/paddle:cpu-latest`
内已经包含
PaddlePaddle的执行程序但是还没上述功能,所以我们可以在这个基础上,添加启动脚本,制作新镜像来完成以上的工作。镜像的
*Dockerfile*
如下:
```
Dockerfile
FROM
paddledev/paddle:cpu-latest
...
...
@@ -92,25 +83,87 @@ CMD ["bash"," -c","/root/start.sh"]
[
`start.sh`
](
start.sh
)
文件拷贝训练文件到容器内,然后执行
[
`start_paddle.py`
](
start_paddle.py
)
脚本启动训练,前文提到的获取其他节点IP地址,分配
`trainer_id`
等都在
`start_paddle.py`
脚本中完成。
`start_paddle.py`
脚本开始时,会先进行参数的初始化与解析。
```
python
parser
=
argparse
.
ArgumentParser
(
prog
=
"start_paddle.py"
,
description
=
'simple tool for k8s'
)
args
,
train_args_list
=
parser
.
parse_known_args
()
train_args
=
refine_unknown_args
(
train_args_list
)
train_args_dict
=
dict
(
zip
(
train_args
[:
-
1
:
2
],
train_args
[
1
::
2
]))
podlist
=
getPodList
()
```
然后通过函数
`getPodList()`
访问Kubernetes的接口来查询此job对应的所有pod信息。当所有pod都处于running状态(容器运行都运行)时,再通过函数
`getIdMap(podlist)`
获取trainer_id。
```
python
podlist
=
getPodList
()
# need to wait until all pods are running
while
not
isPodAllRunning
(
podlist
):
time
.
sleep
(
10
)
podlist
=
getPodList
()
idMap
=
getIdMap
(
podlist
)
```
在函数
`getIdMap(podlist)`
内部,我们通过读取
`podlist`
中每个pod的IP地址,将IP排序生成的序号作为trainer_id。
```
python
def
getIdMap
(
podlist
):
'''
generate tainer_id by ip
'''
ips
=
[]
for
pod
in
podlist
[
"items"
]:
ips
.
append
(
pod
[
"status"
][
"podIP"
])
ips
.
sort
()
idMap
=
{}
for
i
in
range
(
len
(
ips
)):
idMap
[
ips
[
i
]]
=
i
return
idMap
```
在得到
`idMap`
后,通过函数
`startPaddle(idMap, train_args_dict)`
构造
`paddle pserver`
与
`paddle train`
的启动参数并执行进程。
在函数
`startPaddle`
中,最主要的工作就是解析出
`paddle pserver`
与
`paddle train`
的启动参数。例如
`paddle train`
参数的解析,解析环境变量得到
`PADDLE_NIC`
,
`PADDLE_PORT`
,
`PADDLE_PORTS_NUM`
等参数,然后通过自身的IP地址在
`idMap`
中获取
`trainerId`
。
```
python
program
=
'paddle train'
args
=
" --nics="
+
PADDLE_NIC
args
+=
" --port="
+
str
(
PADDLE_PORT
)
args
+=
" --ports_num="
+
str
(
PADDLE_PORTS_NUM
)
args
+=
" --comment="
+
"paddle_process_by_paddle"
ip_string
=
""
for
ip
in
idMap
.
keys
():
ip_string
+=
(
ip
+
","
)
ip_string
=
ip_string
.
rstrip
(
","
)
args
+=
" --pservers="
+
ip_string
args_ext
=
""
for
key
,
value
in
train_args_dict
.
items
():
args_ext
+=
(
' --'
+
key
+
'='
+
value
)
localIP
=
socket
.
gethostbyname
(
socket
.
gethostname
())
trainerId
=
idMap
[
localIP
]
args
+=
" "
+
args_ext
+
" --trainer_id="
+
\
str
(
trainerId
)
+
" --save_dir="
+
JOB_PATH_OUTPUT
```
使用
`docker build`
构建镜像:
```
bash
docker build
-t
registry.baidu.com/public
/paddle:mypaddle .
docker build
-t
your_repo
/paddle:mypaddle .
```
然后将构建成功的镜像上传到镜像仓库
,注意本文中使用的
`registry.baidu.com`
是一个私有仓库,读者可以根据自己的情况部署私有仓库或者使用
`Docker hub`
。
然后将构建成功的镜像上传到镜像仓库。
```
bash
docker push
registry.baidu.com/public
/paddle:mypaddle
docker push
your_repo
/paddle:mypaddle
```
### 上传训练文件
本文使用
`Paddle`
官方的
`recommendation demo`
作为这次训练的内容,我们将训练文件与数据放在一个
`job name`
命名的目录中,上传到
`mfs`
共享存储。完成后
`mfs`
上的文件内容大致如下:
本文使用
Paddle官方的
[
recommendation demo
](
http://www.paddlepaddle.org/doc/demo/index.html#recommendation
)
作为这次训练的内容,我们将训练文件与数据放在一个job name命名的目录中,上传到mfs共享存储。完成后mfs
上的文件内容大致如下:
```
bash
[
root@paddle-k
8
s-node0 mfs]# tree
-d
[
root@paddle-k
ubernete
s-node0 mfs]# tree
-d
.
└── paddle-cluster-job
├── data
...
...
@@ -123,13 +176,13 @@ docker push registry.baidu.com/public/paddle:mypaddle
└── recommendation
```
目录中
`paddle-cluster-job`
是本次训练对应的
`job name`
,本次训练要求有3个
`Paddle`
节点,在
`paddle-cluster-job/data`
目录中存放切分好的数据,文件夹
`0,1,2`
分别代表3个节点的
`trainer_id`
。
`recommendation`
文件夹内存放训练文件,
`output`
文件夹存放训练结果与日志。
目录中
paddle-cluster-job是本次训练对应的job name,本次训练要求有3个Paddle节点,在paddle-cluster-job/data目录中存放切分好的数据,文件夹0,1,2分别代表3个节点的trainer_id。recommendation文件夹内存放训练文件,output
文件夹存放训练结果与日志。
### 创建
`job`
### 创建
Job
`k8s`
可以通过
`yaml`
文件来创建相关对象,然后可以使用命令行工具创建
`job`
。
Kubernetes可以通过YAML文件来创建相关对象,然后可以使用命令行工具创建job
。
`job yaml`
文件描述了这次训练使用的Docker镜像,需要启动的节点个数以及
`paddle pserver`
与
`paddle train`
进程启动的必要参数,也描述了容器需要使用的存储卷挂载的情况。
`yaml`
文件中各个字段的具体含义,可以查看
[
`k8s官方文档`
](
http://kubernetes.io/docs/api-reference/batch/v1/definitions/#_v1_job
)
。例如,本次训练的
`yaml`
文件可以写成:
Job YAML文件描述了这次训练使用的Docker镜像,需要启动的节点个数以及
`paddle pserver`
与
`paddle train`
进程启动的必要参数,也描述了容器需要使用的存储卷挂载的情况。YAML文件中各个字段的具体含义,可以查看
[
Kubernetes Job API
](
http://kubernetes.io/docs/api-reference/batch/v1/definitions/#_v1_job
)
。例如,本次训练的YAML
文件可以写成:
```
yaml
apiVersion
:
batch/v1
...
...
@@ -149,7 +202,7 @@ spec:
path
:
/home/work/mfs
containers
:
-
name
:
trainer
image
:
registry.baidu.com/public
/paddle:mypaddle
image
:
your_repo
/paddle:mypaddle
command
:
[
"
bin/bash"
,
"
-c"
,
"
/root/start.sh"
]
env
:
-
name
:
JOB_NAME
...
...
@@ -176,7 +229,7 @@ spec:
restartPolicy
:
Never
```
文件中,
`metadata`
下的
`name`
表示这个
`job`
的名字。
`parallelism,completions`
字段表示这个
`job`
会同时开启3个
`Paddle`
节点,成功训练且退出的
`pod`
数目为3时,这个
`job`
才算成功结束。然后申明一个存储卷
`jobpath`
,代表宿主机目录
`/home/work/mfs`
,在对容器的描述
`containers`
字段中,将此目录挂载为容器的
`/home/jobpath`
目录,这样容器的
`/home/jobpath`
目录就成为了共享存储,放在这个目录里的文件其实是保存到了
`mfs`
上。
文件中,
`metadata`
下的
`name`
表示这个
job的名字。
`parallelism,completions`
字段表示这个job会同时开启3个Paddle节点,成功训练且退出的pod数目为3时,这个job才算成功结束。然后申明一个存储卷
`jobpath`
,代表宿主机目录
`/home/work/mfs`
,在对容器的描述
`containers`
字段中,将此目录挂载为容器的
`/home/jobpath`
目录,这样容器的
`/home/jobpath`
目录就成为了共享存储,放在这个目录里的文件其实是保存到了mfs
上。
`env`
字段表示容器的环境变量,我们将
`paddle`
运行的一些参数通过这种方式传递到容器内。
...
...
@@ -190,21 +243,21 @@ spec:
`CONF_PADDLE_GRADIENT_NUM`
表示训练节点数量,即
`--num_gradient_servers`
参数
编写完
`yaml`
文件后,可以使用k8s的命令行工具创建
`job`
.
编写完
YAML文件后,可以使用Kubernetes的命令行工具创建job。
```
bash
kubectl create
-f
job.yaml
```
创建成功后,
k8s就会创建3个
`pod`
作为
`Paddle`
节点然后拉取镜像,启动容器开始训练。
创建成功后,
Kubernetes就会创建3个pod作为PaddlePaddle
节点然后拉取镜像,启动容器开始训练。
### 查看输出
在训练过程中,可以在共享存储上查看输出的日志和模型,例如
`output`
目录下就存放了输出结果。注意
`node_0`
,
`node_1`
,
`node_2`
这几个目录表示
`Paddle`
节点与
`trainer_id`
,并不是k8s中的
`node`
概念。
在训练过程中,可以在共享存储上查看输出的日志和模型,例如
output目录下就存放了输出结果。注意node_0,node_1,node_2这几个目录表示Paddle节点与trainer_id,并不是Kubernetes中的node
概念。
```
bash
[
root@paddle-k
8
s-node0 output]# tree
-d
[
root@paddle-k
ubernete
s-node0 output]# tree
-d
.
├── node_0
│ ├── server.log
...
...
@@ -224,7 +277,7 @@ kubectl create -f job.yaml
我们可以通过日志查看容器训练的情况,例如:
```
bash
[
root@paddle-k
8
s-node0 node_0]#
cat
train.log
[
root@paddle-k
ubernete
s-node0 node_0]#
cat
train.log
I1116 09:10:17.123121 50 Util.cpp:155] commandline:
/usr/local/bin/../opt/paddle/bin/paddle_trainer
--nics
=
eth0
--port
=
7164
...
...
doc_cn/cluster/k8s/k8s-paddle-arch.png
0 → 100644
浏览文件 @
eeca7be7
21.6 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}