Merge branch 'develop' into transpiler_doc
Showing
paddle/contrib/tape/README.md
已删除
100644 → 0
{kind=link}
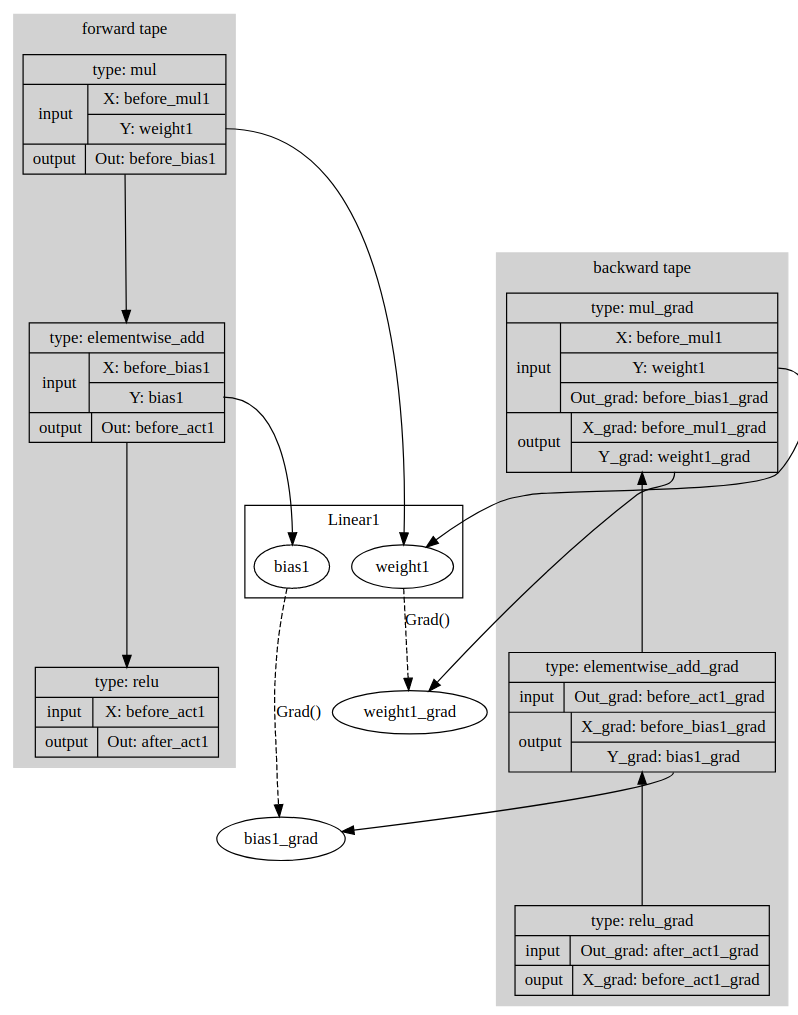
94.4 KB
paddle/contrib/tape/tape.cc
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/print_signatures.py
0 → 100644
此差异已折叠。