refine according to comments
Showing
{kind=link}
{kind=link}
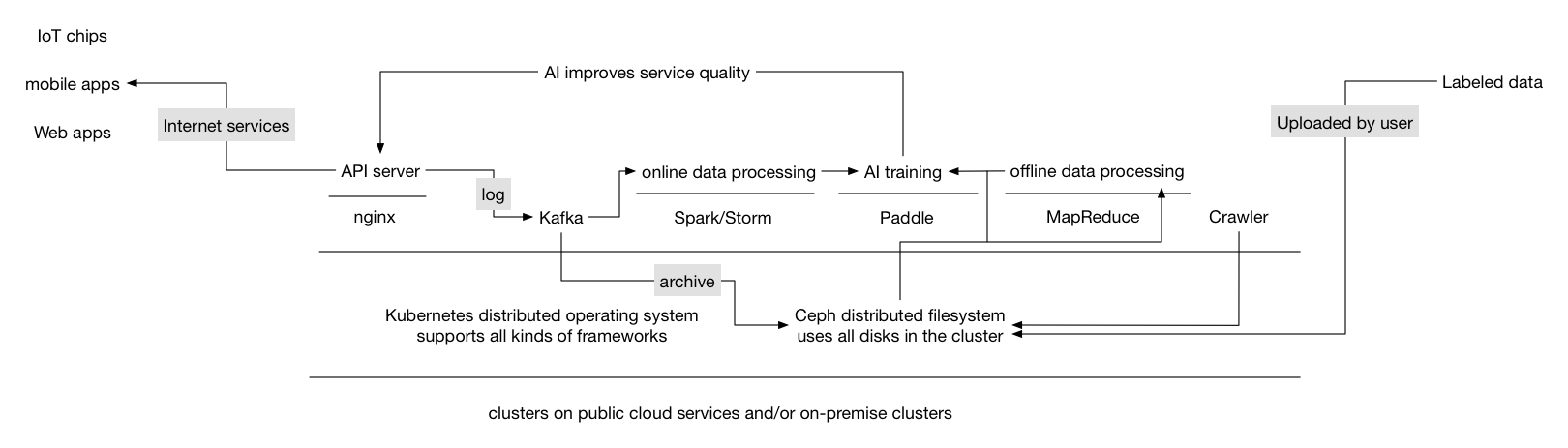
| W: | H:
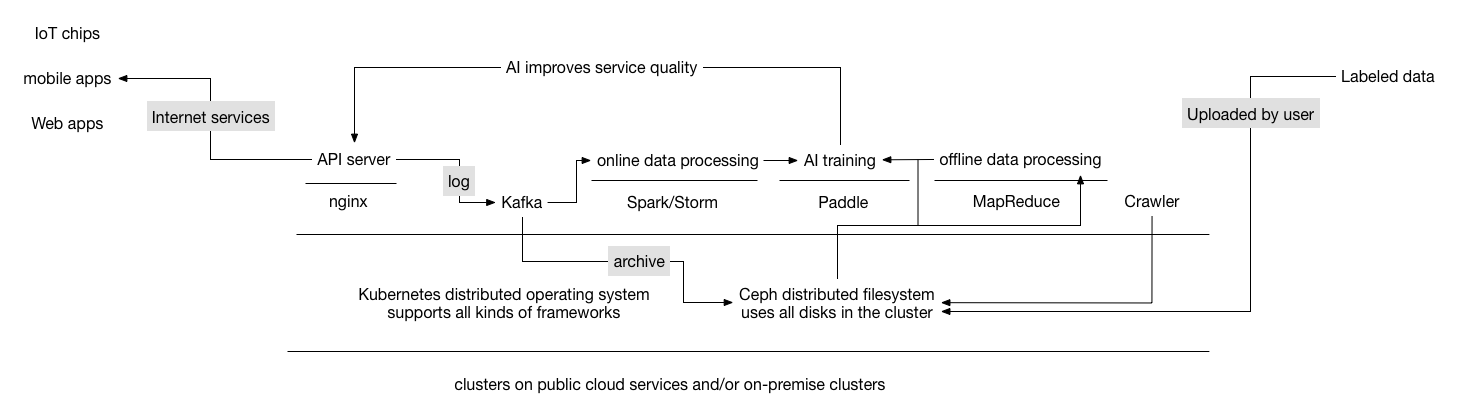
| W: | H:
{kind=link}
{kind=link}
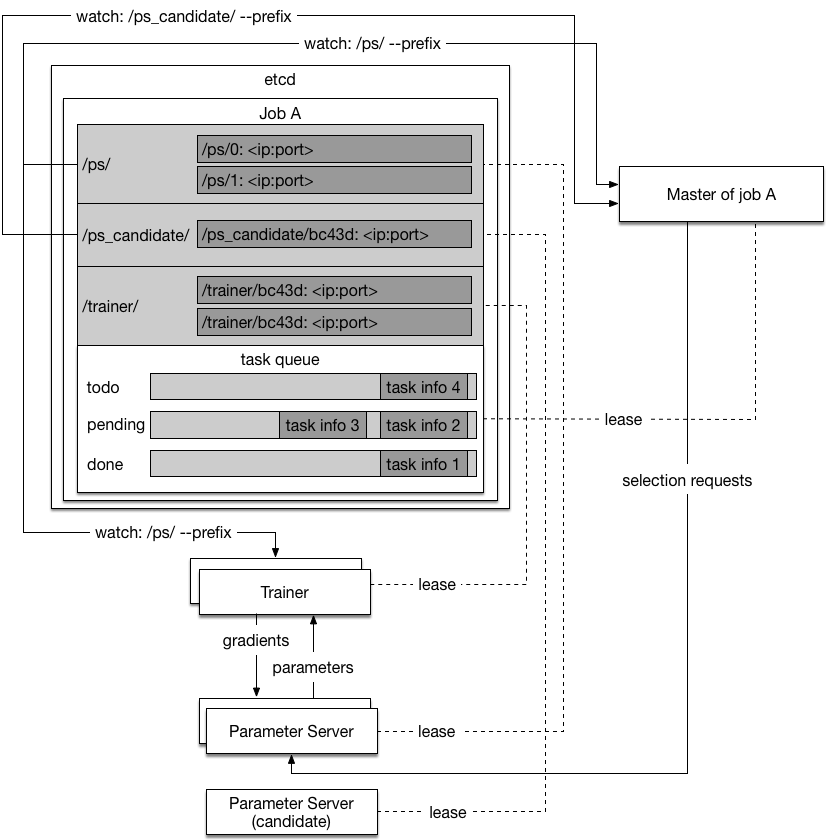
| W: | H:
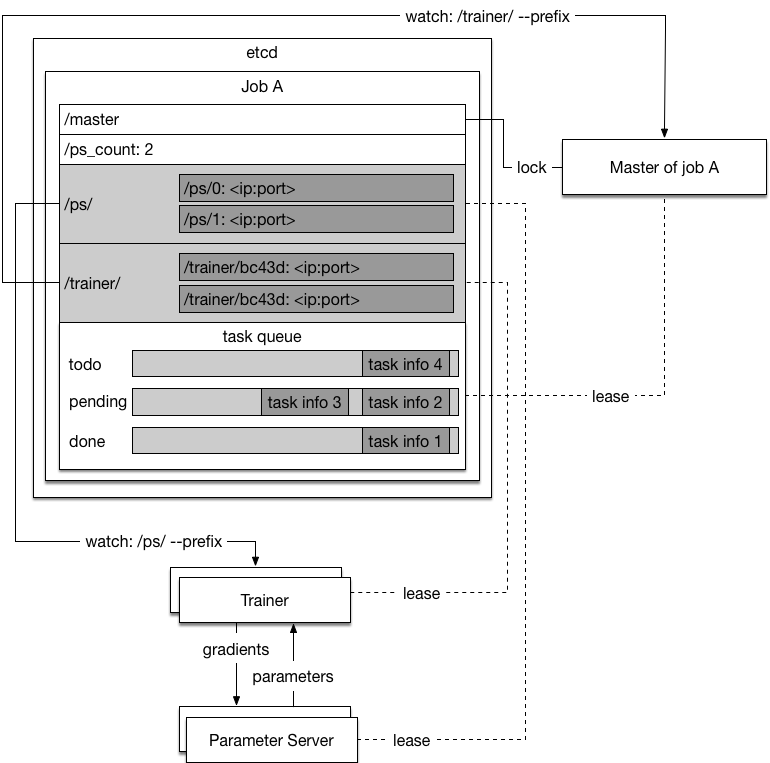
| W: | H:
{kind=link}
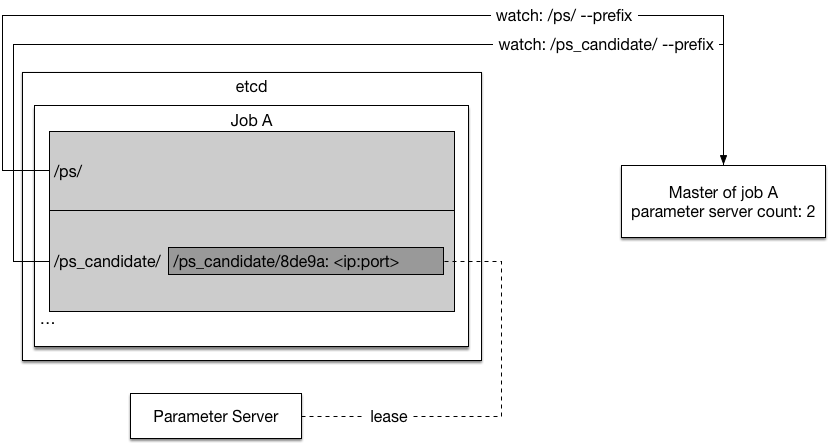
28.9 KB
{kind=link}
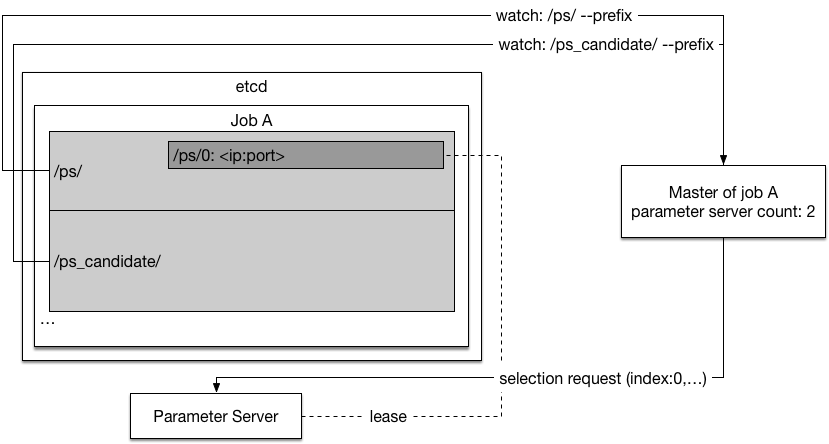
31.1 KB
{kind=link}
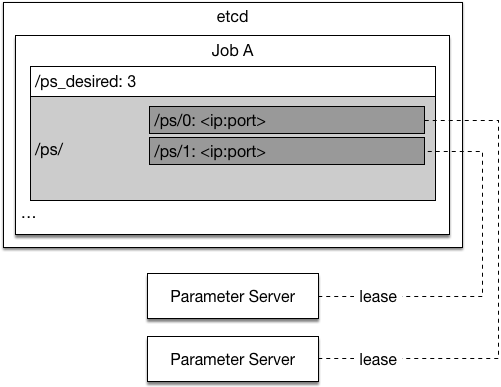
18.9 KB
{kind=link}
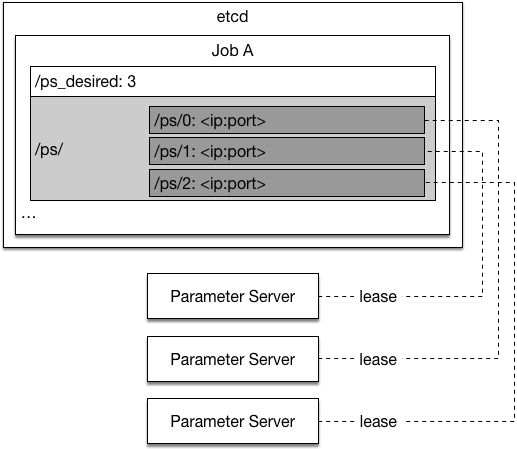
24.7 KB
文件已删除
{kind=link}
40.3 KB
{kind=link}
41.8 KB
文件已添加
{kind=link}
{kind=link}
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
28.9 KB
31.1 KB
18.9 KB
24.7 KB
40.3 KB
41.8 KB
| W: | H:
| W: | H: