Translated and added PaddlePaddle on Kubernetes part in English.
Showing
{kind=link}
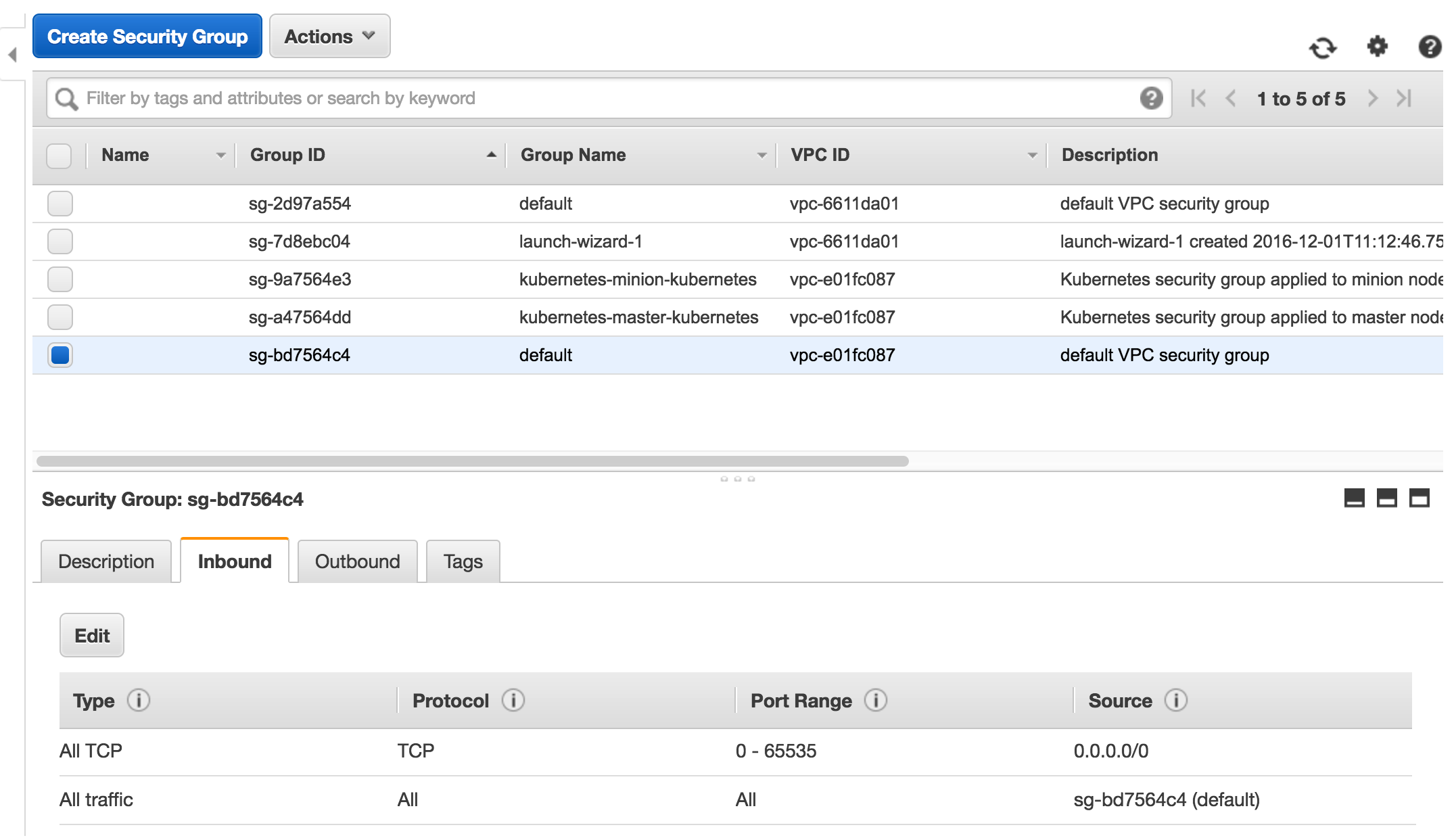
231.9 KB
doc/cluster/aws/create_efs.png
0 → 100644
{kind=link}
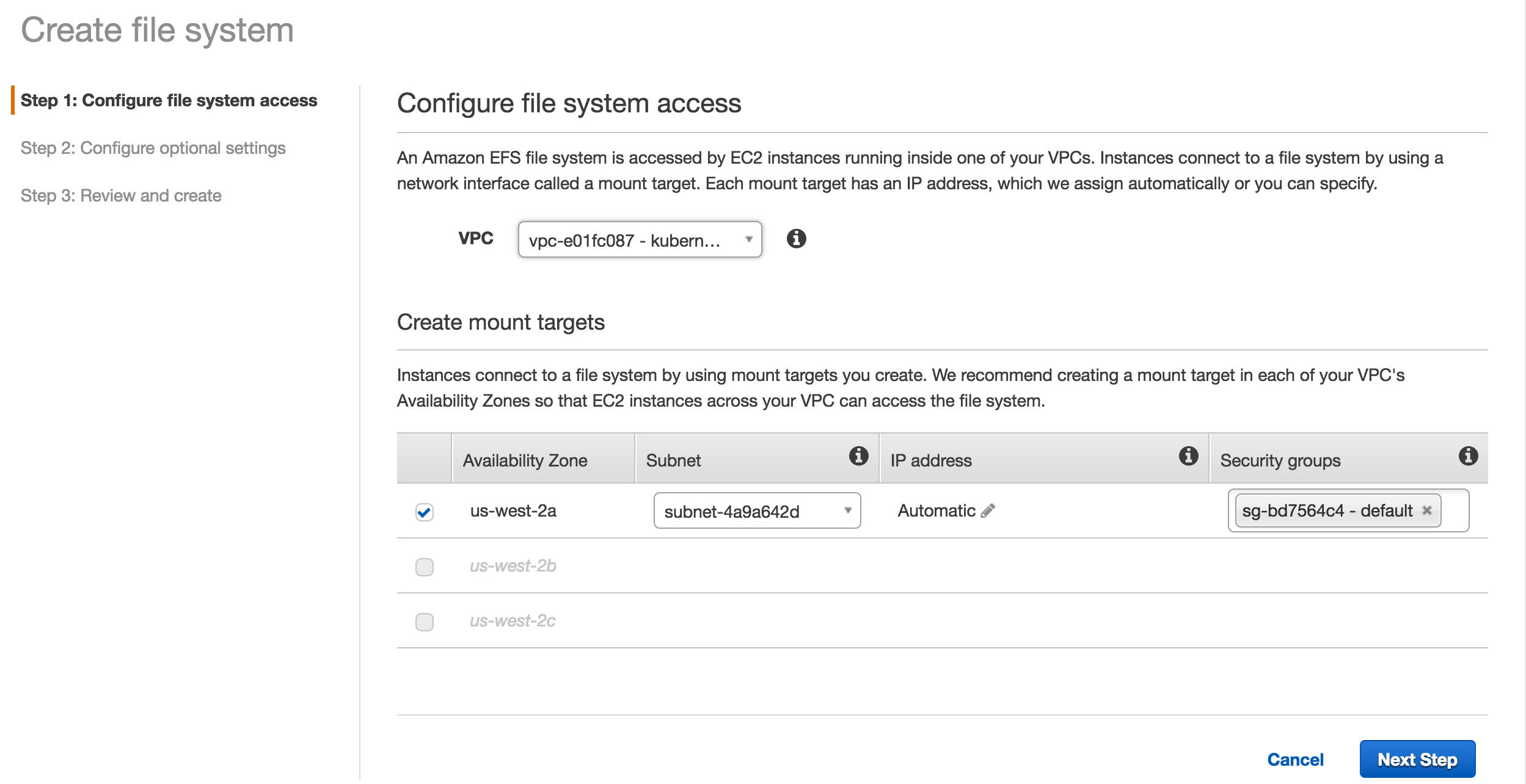
244.5 KB
doc/cluster/aws/efs_mount.png
0 → 100644
{kind=link}
225.2 KB
{kind=link}
241.5 KB
231.9 KB
244.5 KB
225.2 KB
241.5 KB