Merge branch 'develop' into feature/clean_parameter_functionalities
Showing
{kind=link}
{kind=link}
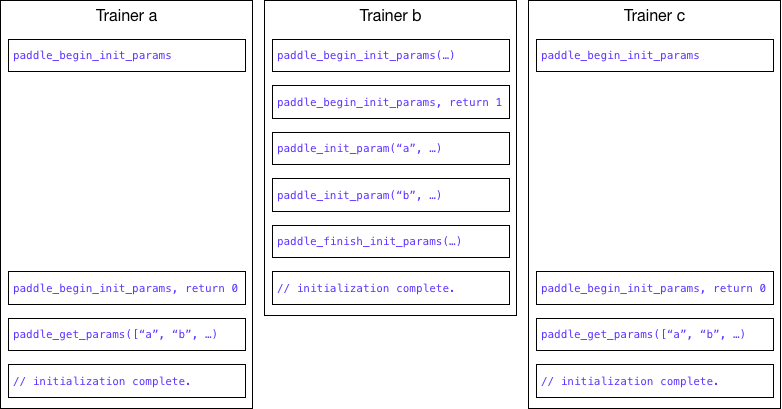
| W: | H:
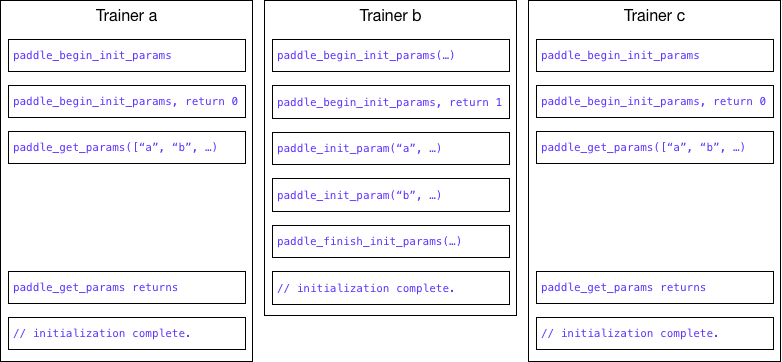
| W: | H:
doc/design/parameters_in_cpp.md
0 → 100644
doc/design/speech/README.MD
0 → 100644
{kind=link}
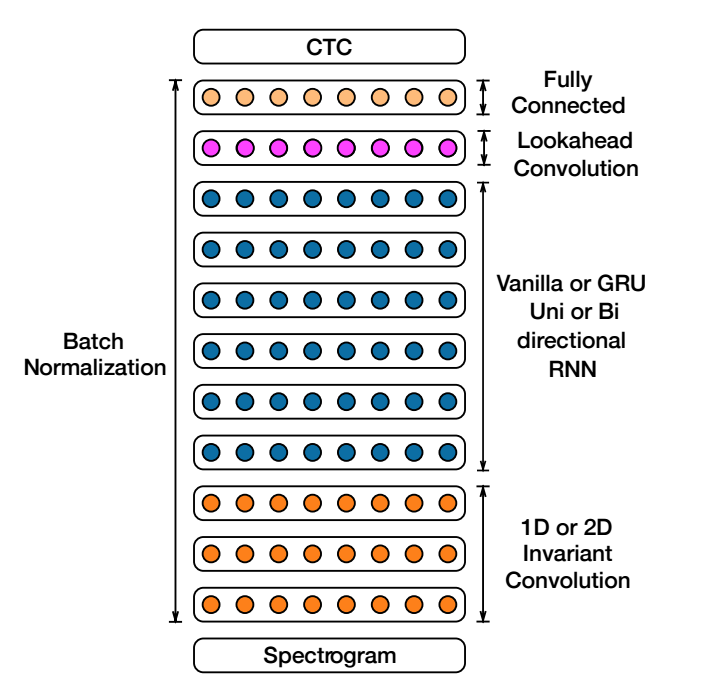
113.8 KB
paddle/go/cmd/master/master.go
0 → 100644
paddle/go/master/service.go
0 → 100644