Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into block_expand_py
Showing
CODE_OF_CONDUCT.md
0 → 100644
CODE_OF_CONDUCT_cn.md
0 → 100644
adversarial/README.md
已删除
100644 → 0
adversarial/fluid_mnist.py
已删除
100644 → 0
doc/design/fluid_compiler.md
0 → 100644
doc/howto/dev/new_op_kernel_en.md
0 → 100644
66.9 KB
17.4 KB
28.0 KB
24.3 KB
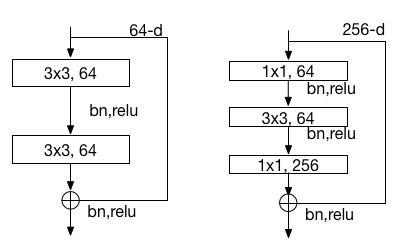
21.9 KB
此差异已折叠。

35.0 KB

53.0 KB

43.0 KB
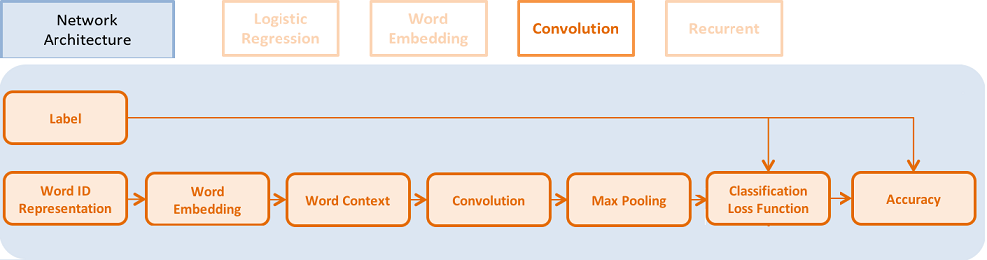
57.7 KB

29.6 KB
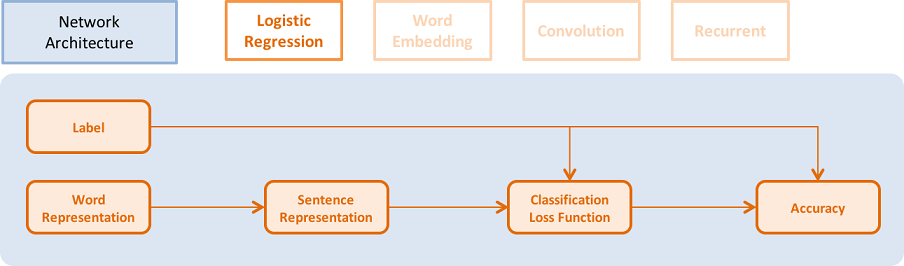
48.3 KB

45.3 KB

55.8 KB


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

9.2 KB
{kind=link}

8.5 KB
{kind=link}

9.0 KB
{kind=link}

8.6 KB
{kind=link}

13.9 KB
{kind=link}

11.4 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/ctc_align_op.cc
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.cu
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v1_api_demo/README.md
已删除
100644 → 0
此差异已折叠。
v1_api_demo/gan/.gitignore
已删除
100644 → 0
此差异已折叠。
v1_api_demo/gan/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
v1_api_demo/gan/gan_conf.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
v1_api_demo/mnist/.gitignore
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v1_api_demo/mnist/train.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
v1_api_demo/vae/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
v1_api_demo/vae/dataloader.py
已删除
100644 → 0
此差异已折叠。
v1_api_demo/vae/vae_conf.py
已删除
100644 → 0
此差异已折叠。
v1_api_demo/vae/vae_train.py
已删除
100644 → 0
此差异已折叠。