Deploy to GitHub Pages: 7c57f90d
Showing
develop/doc/_images/pprof_1.png
0 → 100644
{kind=link}
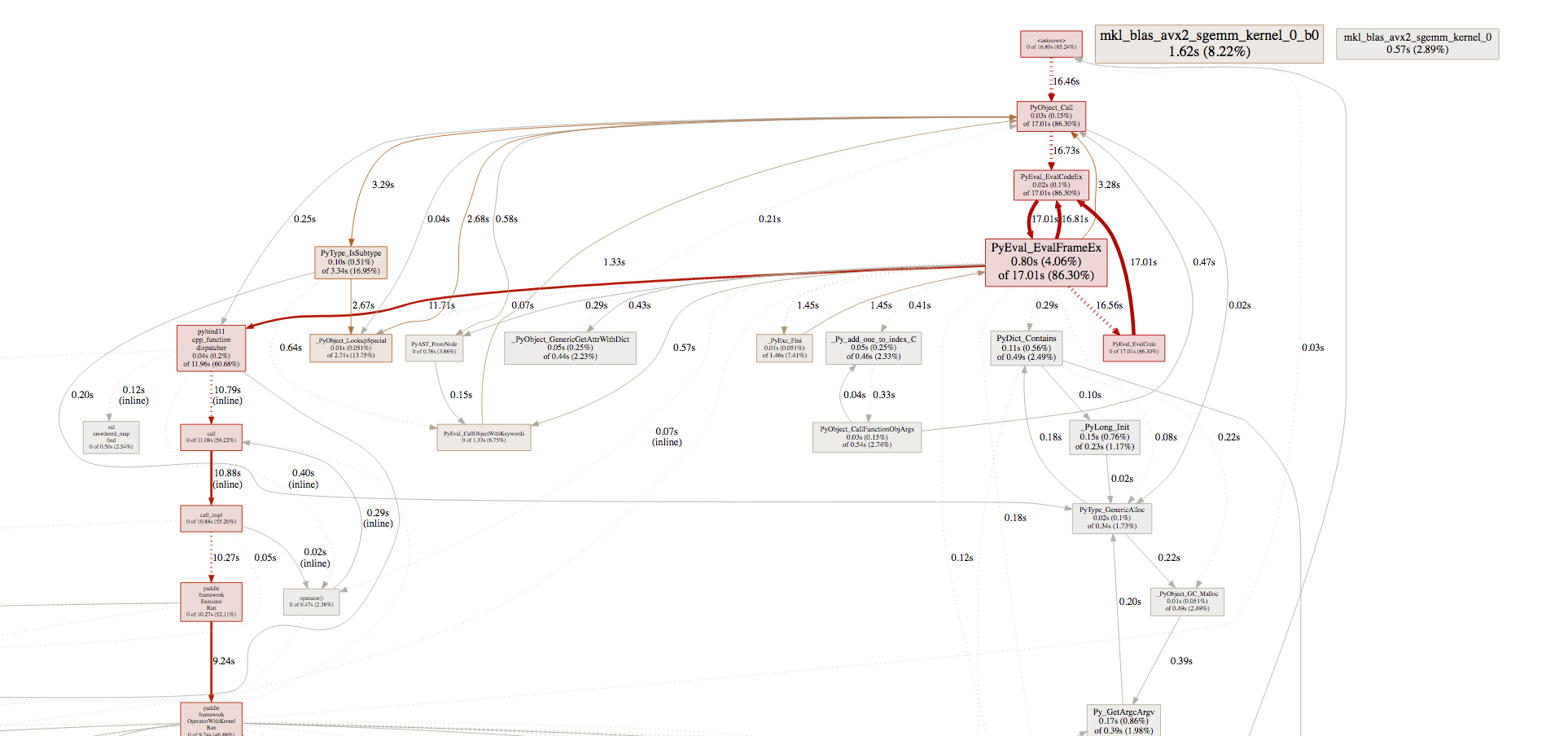
344.4 KB
develop/doc/_images/pprof_2.png
0 → 100644
{kind=link}

189.5 KB
无法预览此类型文件
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
{kind=link}
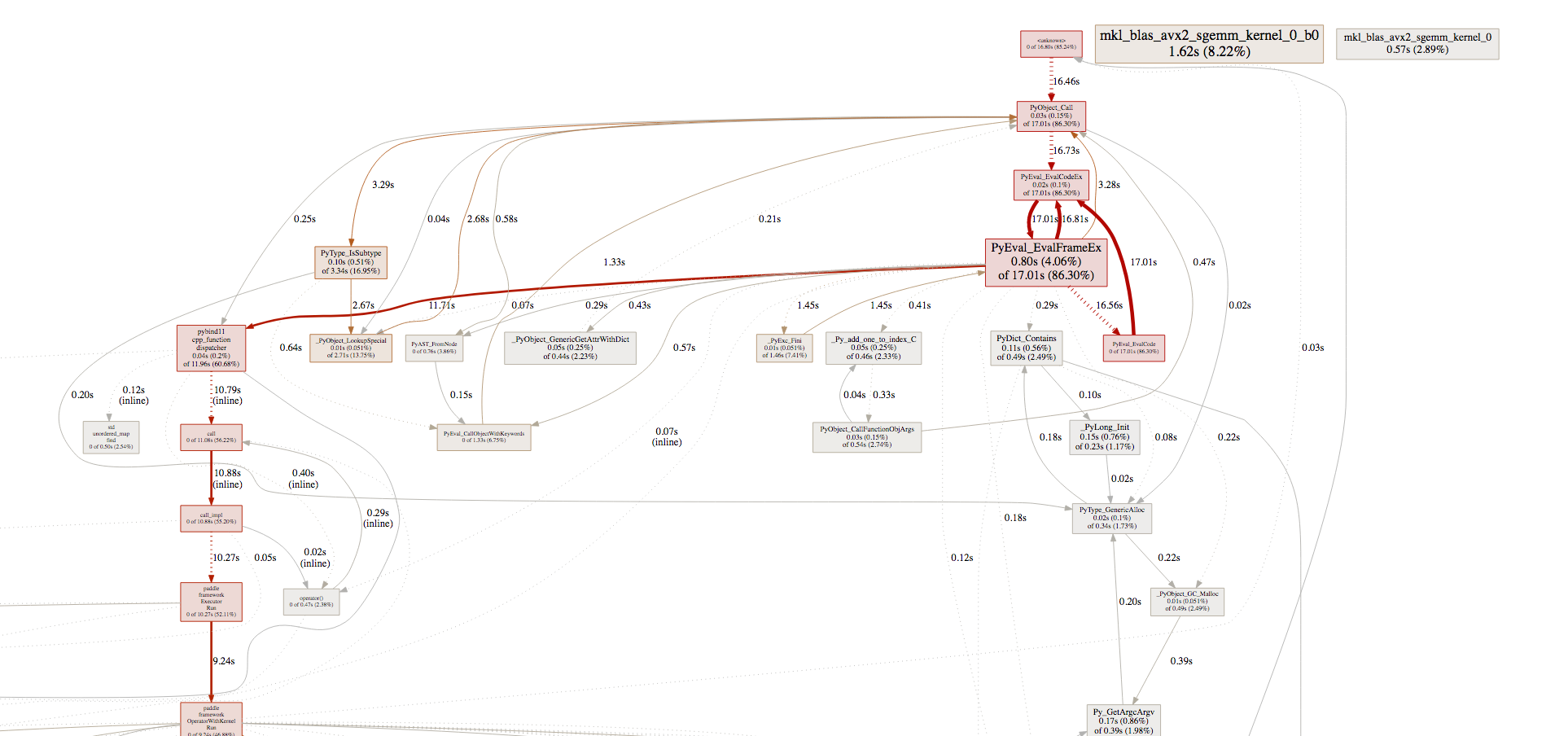
344.4 KB
{kind=link}

189.5 KB
无法预览此类型文件
因为 它太大了无法显示 source diff 。你可以改为 查看blob。