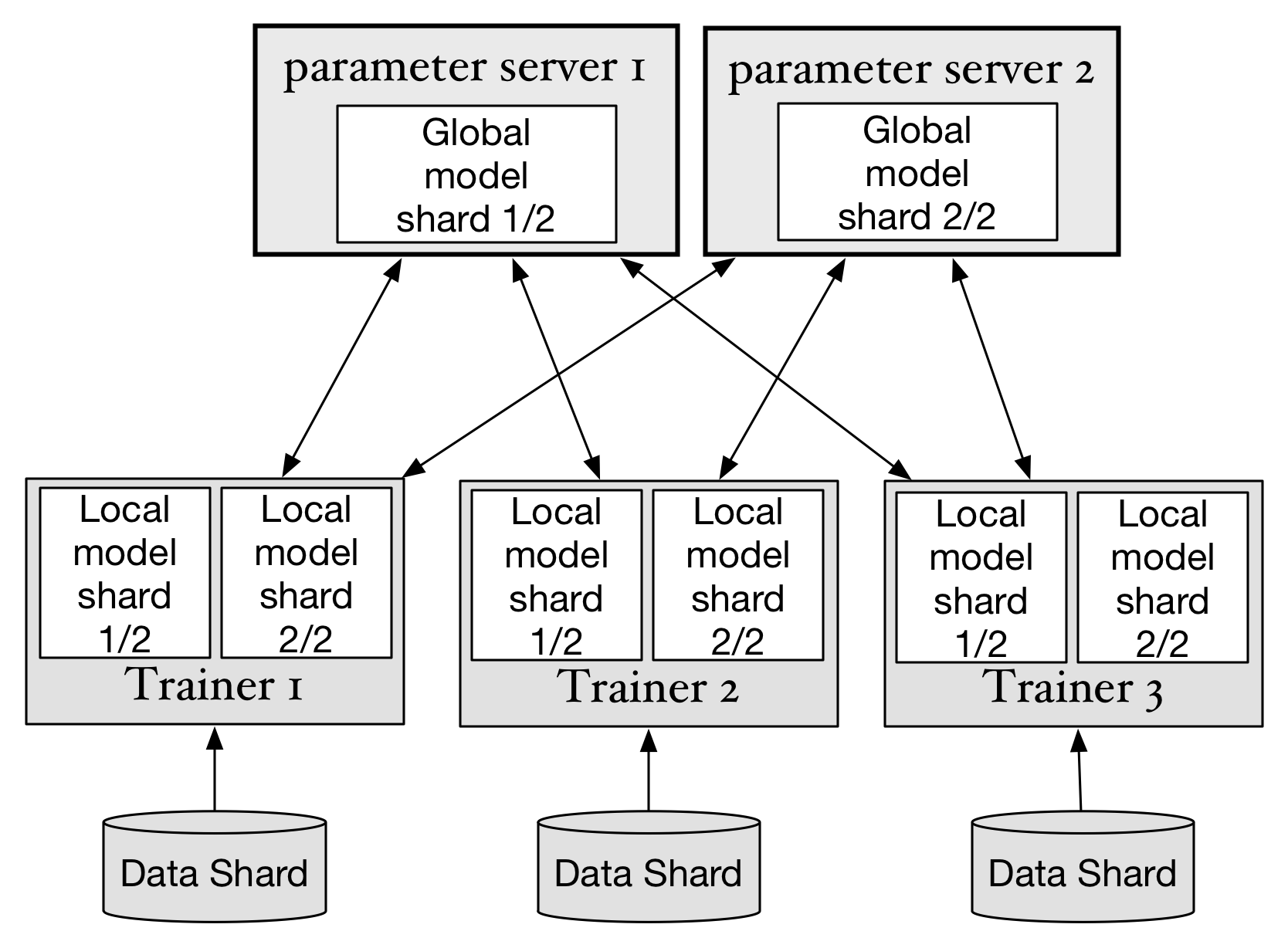
In this section, we'll explain how to run distributed training jobs with PaddlePaddle on different types of clusters. The diagram below shows the main architecture of a distributed trainning job:
.. image:: src/ps_en.png
:width: 500
- Data shard: training data will be split into multiple partitions, trainers use the partitions of the whole dataset to do the training job.
- Trainer: each trainer reads the data shard, and train the neural network. Then the trainer will upload calculated "gradients" to parameter servers, and wait for parameters to be optimized on the parameter server side. When that finishes, the trainer download optimized parameters and continues its training.
- Parameter server: every parameter server stores part of the whole neural network model data. They will do optimization calculations when gradients are uploaded from trainers, and then send updated parameters to trainers.
PaddlePaddle can support both synchronize stochastic gradient descent (SGD) and asynchronous SGD.
When training with synchronize SGD, PaddlePaddle uses an internal "synchronize barrier" which makes gradients update and parameter download in strict order. On the other hand, asynchronous SGD won't wait for all trainers to finish upload at a single step, this will increase the parallelism of distributed training: parameter servers do not depend on each other, they'll do parameter optimization concurrently. Parameter servers will not wait for trainers, so trainers will also do their work concurrently. But asynchronous SGD will introduce more randomness and noises in the gradient.
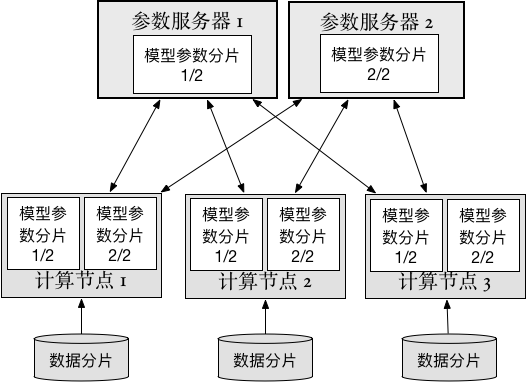
In this section, we'll explain how to run distributed training jobs with PaddlePaddle on different types of clusters. The diagram below shows the main architecture of a distributed trainning job:
- Data shard: training data will be split into multiple partitions, trainers use the partitions of the whole dataset to do the training job.
- Trainer: each trainer reads the data shard, and train the neural network. Then the trainer will upload calculated "gradients" to parameter servers, and wait for parameters to be optimized on the parameter server side. When that finishes, the trainer download optimized parameters and continues its training.
- Parameter server: every parameter server stores part of the whole neural network model data. They will do optimization calculations when gradients are uploaded from trainers, and then send updated parameters to trainers.
PaddlePaddle can support both synchronize stochastic gradient descent (SGD) and asynchronous SGD.
When training with synchronize SGD, PaddlePaddle uses an internal "synchronize barrier" which makes gradients update and parameter download in strict order. On the other hand, asynchronous SGD won't wait for all trainers to finish upload at a single step, this will increase the parallelism of distributed training: parameter servers do not depend on each other, they'll do parameter optimization concurrently. Parameter servers will not wait for trainers, so trainers will also do their work concurrently. But asynchronous SGD will introduce more randomness and noises in the gradient.
{kind=link}
{kind=link}