Fix faq adn docker doc conflicts
Showing
.dockerignore
0 → 120000
benchmark/.gitignore
0 → 100644
benchmark/README.md
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
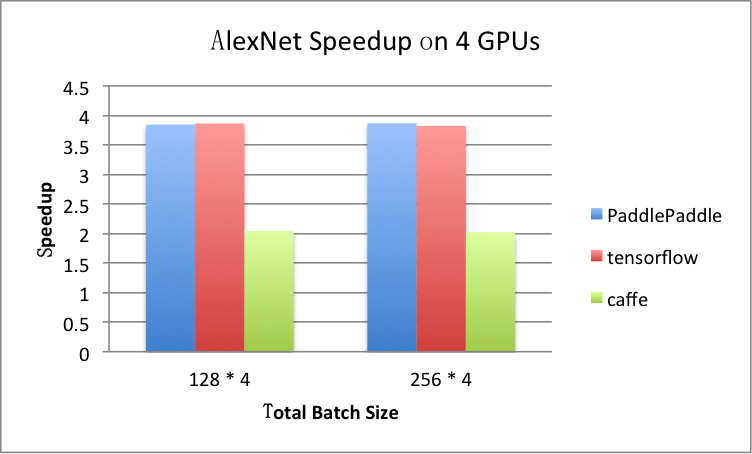
81.8 KB
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}
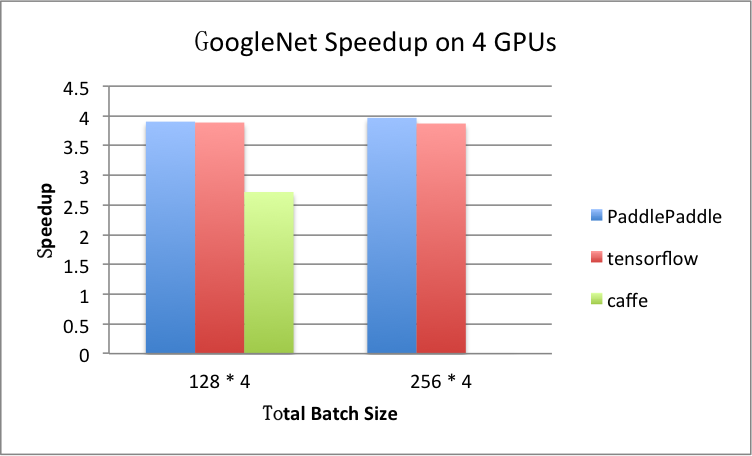
81.8 KB
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
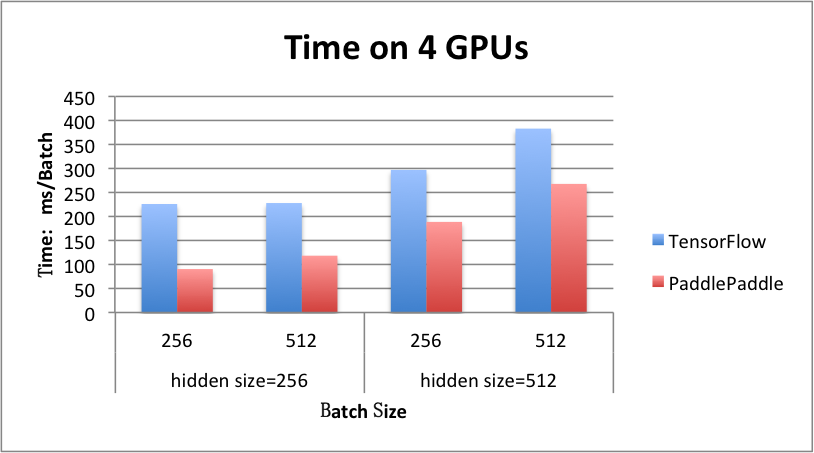
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}
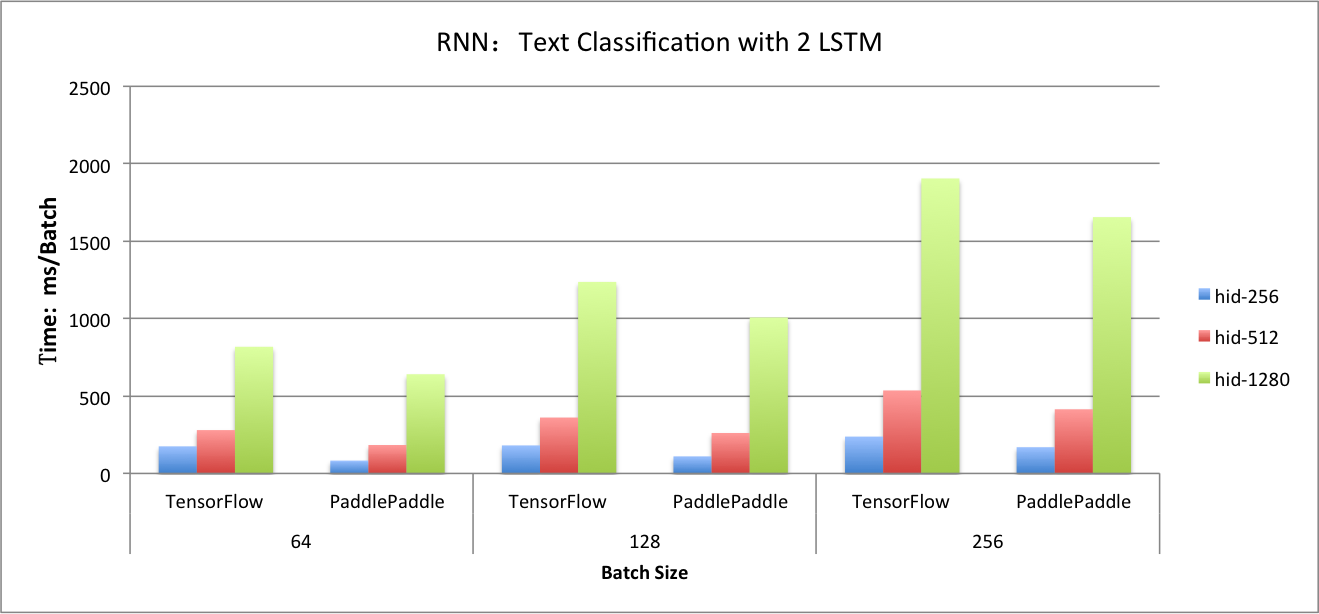
114.9 KB
benchmark/paddle/image/alexnet.py
0 → 100644
benchmark/paddle/image/run.sh
0 → 100755
benchmark/paddle/rnn/imdb.py
0 → 100755
benchmark/paddle/rnn/provider.py
0 → 100644
benchmark/paddle/rnn/rnn.py
0 → 100755
benchmark/paddle/rnn/run.sh
0 → 100755
此差异已折叠。
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
cmake/version.cmake
0 → 100644
此差异已折叠。
demo/gan/.gitignore
0 → 100644
此差异已折叠。
demo/gan/README.md
0 → 100644
此差异已折叠。
demo/gan/data/download_cifar.sh
0 → 100755
此差异已折叠。
demo/gan/data/get_mnist_data.sh
0 → 100644
此差异已折叠。
demo/gan/gan_conf.py
0 → 100644
此差异已折叠。
demo/gan/gan_conf_image.py
0 → 100644
此差异已折叠。
demo/gan/gan_trainer.py
0 → 100644
此差异已折叠。
demo/image_classification/predict.sh
100644 → 100755
文件模式从 100644 更改为 100755
demo/semantic_role_labeling/predict.sh
100644 → 100755
文件模式从 100644 更改为 100755
demo/semantic_role_labeling/test.sh
100644 → 100755
文件模式从 100644 更改为 100755
demo/semantic_role_labeling/train.sh
100644 → 100755
文件模式从 100644 更改为 100755
此差异已折叠。
doc/Doxyfile.in
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/tests/TensorCheck.h
0 → 100644
此差异已折叠。
paddle/math/tests/TestUtils.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/Dockerfile
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/build.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。