Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
7c57f90d
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
7c57f90d
编写于
11月 27, 2017
作者:
Y
Yu Yang
提交者:
GitHub
11月 27, 2017
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Feature/cpu profiling (#5895)
* Add documentation of cProfile tools * Complete doc * Refine code
上级
54b39949
变更
3
显示空白变更内容
内联
并排
Showing
3 changed file
with
163 addition
and
0 deletion
+163
-0
doc/howto/optimization/cpu_profiling.md
doc/howto/optimization/cpu_profiling.md
+163
-0
doc/howto/optimization/pprof_1.png
doc/howto/optimization/pprof_1.png
+0
-0
doc/howto/optimization/pprof_2.png
doc/howto/optimization/pprof_2.png
+0
-0
未找到文件。
doc/howto/optimization/cpu_profiling.md
0 → 100644
浏览文件 @
7c57f90d
此教程会介绍如何使用Python的cProfile包,与Python库yep,google perftools来运行性能分析(Profiling)与调优。
运行性能分析可以让开发人员科学的,有条不紊的对程序进行性能优化。性能分析是性能调优的基础。因为在程序实际运行中,真正的瓶颈可能和程序员开发过程中想象的瓶颈相去甚远。
性能优化的步骤,通常是循环重复若干次『性能分析 --> 寻找瓶颈 ---> 调优瓶颈 --> 性能分析确认调优效果』。其中性能分析是性能调优的至关重要的量化指标。
Paddle提供了Python语言绑定。用户使用Python进行神经网络编程,训练,测试。Python解释器通过
`pybind`
和
`swig`
调用Paddle的动态链接库,进而调用Paddle C++部分的代码。所以Paddle的性能分析与调优分为两个部分:
*
Python代码的性能分析
*
Python与C++混合代码的性能分析
## Python代码的性能分析
### 生成性能分析文件
Python标准库中提供了性能分析的工具包,
[
cProfile
](
https://docs.python.org/2/library/profile.html
)
。生成Python性能分析的命令如下:
```
bash
python
-m
cProfile
-o
profile.out main.py
```
其中
`-o`
标识了一个输出的文件名,用来存储本次性能分析的结果。如果不指定这个文件,
`cProfile`
会打印一些统计信息到
`stdout`
。这不方便我们进行后期处理(进行
`sort`
,
`split`
,
`cut`
等等)。
### 查看性能分析文件
当main.py运行完毕后,性能分析结果文件
`profile.out`
就生成出来了。我们可以使用
[
cprofilev
](
https://github.com/ymichael/cprofilev
)
来查看性能分析结果。
`cprofilev`
是一个Python的第三方库。使用它会开启一个HTTP服务,将性能分析结果以网页的形式展示出来。
使用
`pip install cprofilev`
安装
`cprofilev`
工具。安装完成后,使用如下命令开启HTTP服务
```
bash
cprofilev
-a
0.0.0.0
-p
3214
-f
profile.out main.py
```
其中
`-a`
标识HTTP服务绑定的IP。使用
`0.0.0.0`
允许外网访问这个HTTP服务。
`-p`
标识HTTP服务的端口。
`-f`
标识性能分析的结果文件。
`main.py`
标识被性能分析的源文件。
访问对应网址,即可显示性能分析的结果。性能分析结果格式如下:
```
text
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.284 0.284 29.514 29.514 main.py:1(<module>)
4696 0.128 0.000 15.748 0.003 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/executor.py:20(run)
4696 12.040 0.003 12.040 0.003 {built-in method run}
1 0.144 0.144 6.534 6.534 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/__init__.py:14(<module>)
```
每一列的含义是:
| 列名 | 含义 |
| --- | --- |
| ncalls | 函数的调用次数 |
| tottime | 函数实际使用的总时间。该时间去除掉本函数调用其他函数的时间 |
| percall | tottime的每次调用平均时间 |
| cumtime | 函数总时间。包含这个函数调用其他函数的时间 |
| percall | cumtime的每次调用平均时间 |
| filename:lineno(function) | 文件名, 行号,函数名 |
### 寻找性能瓶颈
通常
`tottime`
和
`cumtime`
是寻找瓶颈的关键指标。这两个指标代表了某一个函数真实的运行时间。
将性能分析结果按照tottime排序,效果如下:
```
text
4696 12.040 0.003 12.040 0.003 {built-in method run}
300005 0.874 0.000 1.681 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/dataset/mnist.py:38(reader)
107991 0.676 0.000 1.519 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:219(__init__)
4697 0.626 0.000 2.291 0.000 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp)
1 0.618 0.618 0.618 0.618 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/__init__.py:1(<module>)
```
可以看到最耗时的函数是C++端的
`run`
函数。这需要联合我们第二节
`Python与C++混合代码的性能分析`
来进行调优。而
`sync_with_cpp`
函数的总共耗时很长,每次调用的耗时也很长。于是我们可以点击
`sync_with_cpp`
的详细信息,了解其调用关系。
```
text
Called By:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
Function was called by...
ncalls tottime cumtime
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:428(sync_with_cpp) <- 4697 0.626 2.291 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp)
/home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:562(sync_with_cpp) <- 4696 0.019 2.316 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:487(clone)
1 0.000 0.001 /home/yuyang/perf_test/.env/lib/python2.7/site-packages/paddle/v2/fluid/framework.py:534(append_backward)
Called:
Ordered by: internal time
List reduced from 4497 to 2 due to restriction <'sync_with_cpp'>
```
通常观察热点函数间的调用关系,和对应行的代码,就可以了解到问题代码在哪里。当我们做出性能修正后,再次进行性能分析(profiling)即可检查我们调优后的修正是否能够改善程序的性能。
## Python与C++混合代码的性能分析
### 生成性能分析文件
C++的性能分析工具非常多。常见的包括
`gprof`
,
`valgrind`
,
`google-perftools`
。但是调试Python中使用的动态链接库与直接调试原始二进制相比增加了很多复杂度。幸而Python的一个第三方库
`yep`
提供了方便的和
`google-perftools`
交互的方法。于是这里使用
`yep`
进行Python与C++混合代码的性能分析
使用
`yep`
前需要安装
`google-perftools`
与
`yep`
包。ubuntu下安装命令为
```
bash
apt
install
libgoogle-perftools-dev
pip
install
yep
```
安装完毕后,我们可以通过
```
bash
python
-m
yep
-v
main.py
```
生成性能分析文件。生成的性能分析文件为
`main.py.prof`
。
命令行中的
`-v`
指定在生成性能分析文件之后,在命令行显示分析结果。我们可以在命令行中简单的看一下生成效果。因为C++与Python不同,编译时可能会去掉调试信息,运行时也可能因为多线程产生混乱不可读的性能分析结果。为了生成更可读的性能分析结果,可以采取下面几点措施:
1.
编译时指定
`-g`
生成调试信息。使用cmake的话,可以将CMAKE_BUILD_TYPE指定为
`RelWithDebInfo`
。
2.
编译时一定要开启优化。单纯的
`Debug`
编译性能会和
`-O2`
或者
`-O3`
有非常大的差别。
`Debug`
模式下的性能测试是没有意义的。
3.
运行性能分析的时候,先从单线程开始,再开启多线程,进而多机。毕竟如果单线程调试更容易。可以设置
`OMP_NUM_THREADS=1`
这个环境变量关闭openmp优化。
### 查看性能分析文件
在运行完性能分析后,会生成性能分析结果文件。我们可以使用
[
pprof
](
https://github.com/google/pprof
)
来显示性能分析结果。注意,这里使用了用
`Go`
语言重构后的
`pprof`
,因为这个工具具有web服务界面,且展示效果更好。
安装
`pprof`
的命令和一般的
`Go`
程序是一样的,其命令如下:
```
bash
go get github.com/google/pprof
```
进而我们可以使用如下命令开启一个HTTP服务:
```
bash
pprof
-http
=
0.0.0.0:3213
`
which python
`
./main.py.prof
```
这行命令中,
`-http`
指开启HTTP服务。
`which python`
会产生当前Python二进制的完整路径,进而指定了Python可执行文件的路径。
`./main.py.prof`
输入了性能分析结果。
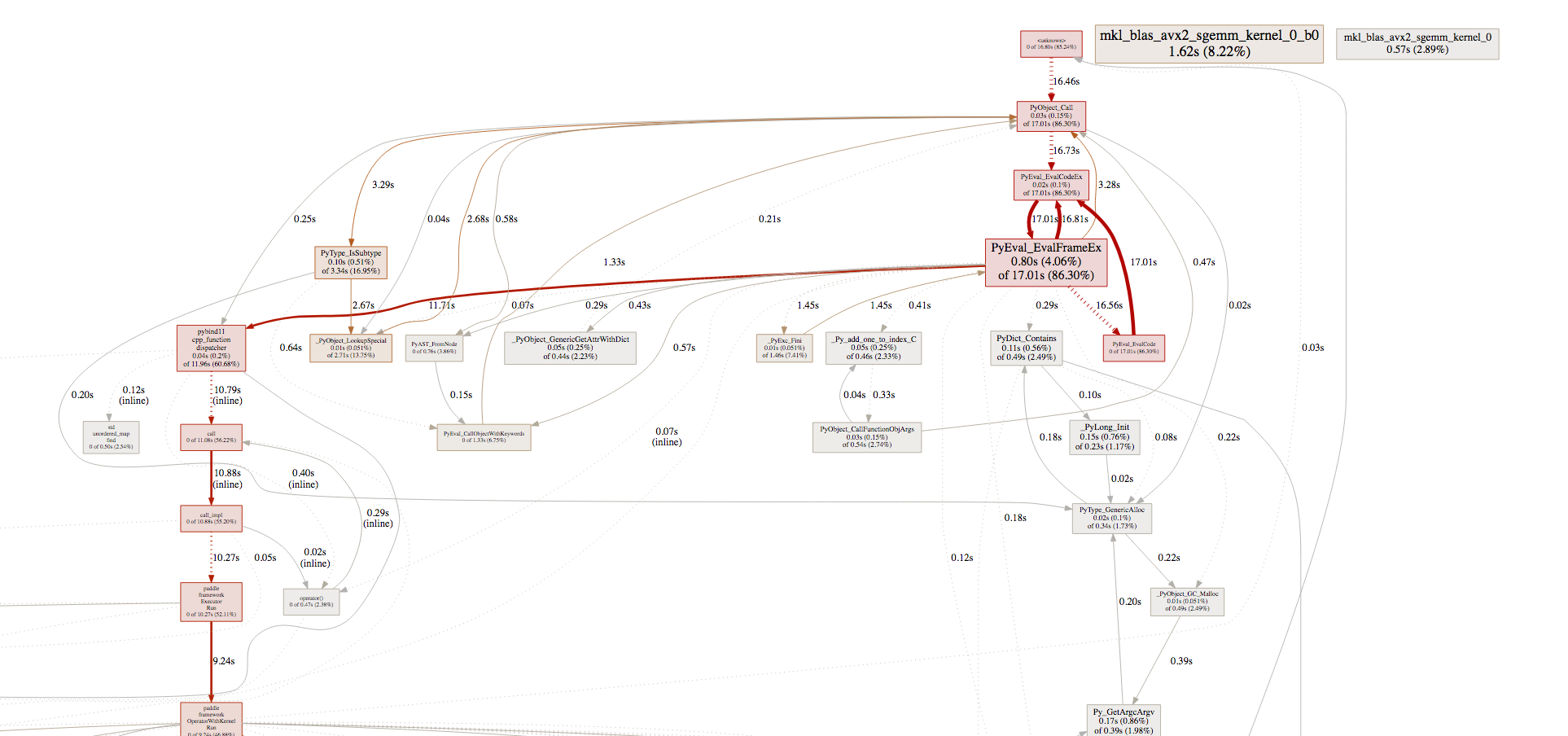
访问对应的网址,我们可以查看性能分析的结果。结果如下图所示:

### 寻找性能瓶颈
与寻找Python代码的性能瓶颈类似,寻找Python与C++混合代码的性能瓶颈也是要看
`tottime`
和
`cumtime`
。而
`pprof`
展示的调用图也可以帮助我们发现性能中的问题。
例如下图中,

在一次训练中,乘法和乘法梯度的计算占用2%-4%左右的计算时间。而
`MomentumOp`
占用了17%左右的计算时间。显然,
`MomentumOp`
的性能有问题。
在
`pprof`
中,对于性能的关键路径都做出了红色标记。先检查关键路径的性能问题,再检查其他部分的性能问题,可以更有次序的完成性能的优化。
## 总结
至此,两种性能分析的方式都介绍完毕了。希望通过这两种性能分析的方式,Paddle的开发人员和使用人员可以有次序的,科学的发现和解决性能问题。
doc/howto/optimization/pprof_1.png
0 → 100644
浏览文件 @
7c57f90d
344.4 KB
doc/howto/optimization/pprof_2.png
0 → 100644
浏览文件 @
7c57f90d
189.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
