Merge branch 'develop' into kmax_score_layer
Showing
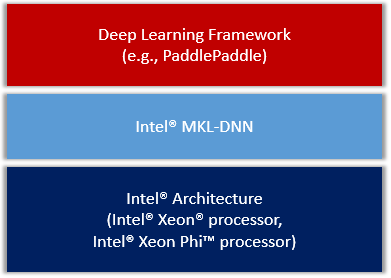
doc/design/mkldnn/README.MD
0 → 100644
{kind=link}
9.7 KB
paddle/operators/.clang-format
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已添加
文件已移动
此差异已折叠。
此差异已折叠。