Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
59a8ebc6
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
59a8ebc6
编写于
8月 07, 2017
作者:
C
caoying03
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'develop' into kmax_score_layer
上级
98a83cd2
50fe7abe
变更
126
隐藏空白更改
内联
并排
Showing
126 changed file
with
4841 addition
and
3682 deletion
+4841
-3682
.pre-commit-config.yaml
.pre-commit-config.yaml
+1
-1
CMakeLists.txt
CMakeLists.txt
+2
-2
Dockerfile
Dockerfile
+4
-1
cmake/configure.cmake
cmake/configure.cmake
+0
-2
cmake/cpplint.cmake
cmake/cpplint.cmake
+10
-18
cmake/external/any.cmake
cmake/external/any.cmake
+1
-1
cmake/external/gflags.cmake
cmake/external/gflags.cmake
+8
-1
cmake/external/openblas.cmake
cmake/external/openblas.cmake
+7
-2
cmake/external/python.cmake
cmake/external/python.cmake
+0
-1
cmake/flags.cmake
cmake/flags.cmake
+2
-1
cmake/generic.cmake
cmake/generic.cmake
+13
-0
cmake/util.cmake
cmake/util.cmake
+8
-5
doc/design/mkldnn/README.MD
doc/design/mkldnn/README.MD
+110
-0
doc/design/mkldnn/image/overview.png
doc/design/mkldnn/image/overview.png
+0
-0
paddle/.set_python_path.sh
paddle/.set_python_path.sh
+12
-19
paddle/api/test/CMakeLists.txt
paddle/api/test/CMakeLists.txt
+6
-2
paddle/cuda/src/hl_batch_transpose.cu
paddle/cuda/src/hl_batch_transpose.cu
+7
-9
paddle/cuda/src/hl_cuda_aggregate.cu
paddle/cuda/src/hl_cuda_aggregate.cu
+61
-101
paddle/cuda/src/hl_cuda_cnn.cu
paddle/cuda/src/hl_cuda_cnn.cu
+275
-134
paddle/cuda/src/hl_cuda_lstm.cu
paddle/cuda/src/hl_cuda_lstm.cu
+331
-159
paddle/cuda/src/hl_cuda_matrix.cu
paddle/cuda/src/hl_cuda_matrix.cu
+147
-196
paddle/cuda/src/hl_cuda_sequence.cu
paddle/cuda/src/hl_cuda_sequence.cu
+96
-88
paddle/cuda/src/hl_cuda_sparse.cu
paddle/cuda/src/hl_cuda_sparse.cu
+475
-509
paddle/cuda/src/hl_perturbation_util.cu
paddle/cuda/src/hl_perturbation_util.cu
+104
-45
paddle/cuda/src/hl_table_apply.cu
paddle/cuda/src/hl_table_apply.cu
+35
-33
paddle/cuda/src/hl_top_k.cu
paddle/cuda/src/hl_top_k.cu
+127
-114
paddle/framework/attribute.proto
paddle/framework/attribute.proto
+7
-7
paddle/framework/op_desc.proto
paddle/framework/op_desc.proto
+17
-17
paddle/framework/op_proto.proto
paddle/framework/op_proto.proto
+72
-70
paddle/framework/operator.cc
paddle/framework/operator.cc
+2
-2
paddle/framework/operator.h
paddle/framework/operator.h
+9
-5
paddle/framework/operator_test.cc
paddle/framework/operator_test.cc
+4
-4
paddle/function/BlockExpandOpTest.cpp
paddle/function/BlockExpandOpTest.cpp
+8
-8
paddle/function/BufferArgTest.cpp
paddle/function/BufferArgTest.cpp
+1
-1
paddle/function/ContextProjectionOpGpu.cu
paddle/function/ContextProjectionOpGpu.cu
+70
-56
paddle/function/CosSimOpGpu.cu
paddle/function/CosSimOpGpu.cu
+34
-26
paddle/function/CropOpGpu.cu
paddle/function/CropOpGpu.cu
+59
-25
paddle/function/CrossMapNormalOpGpu.cu
paddle/function/CrossMapNormalOpGpu.cu
+46
-25
paddle/function/CrossMapNormalOpTest.cpp
paddle/function/CrossMapNormalOpTest.cpp
+10
-10
paddle/function/DepthwiseConvOpGpu.cu
paddle/function/DepthwiseConvOpGpu.cu
+253
-218
paddle/function/FunctionTest.cpp
paddle/function/FunctionTest.cpp
+6
-6
paddle/function/Im2ColOpGpu.cu
paddle/function/Im2ColOpGpu.cu
+150
-106
paddle/function/MulOpGpu.cu
paddle/function/MulOpGpu.cu
+1
-1
paddle/function/PadOpGpu.cu
paddle/function/PadOpGpu.cu
+49
-15
paddle/function/RowConvOpGpu.cu
paddle/function/RowConvOpGpu.cu
+87
-68
paddle/function/TensorShapeTest.cpp
paddle/function/TensorShapeTest.cpp
+12
-12
paddle/function/TensorTypeTest.cpp
paddle/function/TensorTypeTest.cpp
+7
-7
paddle/function/nnpack/NNPACKConvOp.cpp
paddle/function/nnpack/NNPACKConvOp.cpp
+53
-47
paddle/gserver/activations/ActivationFunction.cpp
paddle/gserver/activations/ActivationFunction.cpp
+7
-3
paddle/gserver/layers/ExpandConvLayer.cpp
paddle/gserver/layers/ExpandConvLayer.cpp
+1
-2
paddle/gserver/layers/GruCompute.cu
paddle/gserver/layers/GruCompute.cu
+4
-3
paddle/gserver/layers/KmaxSeqScoreLayer.cpp
paddle/gserver/layers/KmaxSeqScoreLayer.cpp
+10
-4
paddle/gserver/layers/LstmCompute.cu
paddle/gserver/layers/LstmCompute.cu
+38
-17
paddle/gserver/layers/PrintLayer.cpp
paddle/gserver/layers/PrintLayer.cpp
+1
-1
paddle/gserver/tests/CMakeLists.txt
paddle/gserver/tests/CMakeLists.txt
+0
-5
paddle/gserver/tests/test_ActivationGrad.cpp
paddle/gserver/tests/test_ActivationGrad.cpp
+33
-0
paddle/math/BaseMatrix.cu
paddle/math/BaseMatrix.cu
+619
-366
paddle/math/TrainingAlgorithmOp.cu
paddle/math/TrainingAlgorithmOp.cu
+32
-33
paddle/math/tests/test_Tensor.cu
paddle/math/tests/test_Tensor.cu
+167
-170
paddle/math/tests/test_lazyAssign.cu
paddle/math/tests/test_lazyAssign.cu
+40
-34
paddle/math/tests/test_matrixCompare.cpp
paddle/math/tests/test_matrixCompare.cpp
+1
-1
paddle/operators/.clang-format
paddle/operators/.clang-format
+5
-0
paddle/operators/CMakeLists.txt
paddle/operators/CMakeLists.txt
+2
-1
paddle/operators/add_op.cc
paddle/operators/add_op.cc
+5
-5
paddle/operators/add_op.h
paddle/operators/add_op.h
+1
-1
paddle/operators/cross_entropy_op.cc
paddle/operators/cross_entropy_op.cc
+18
-4
paddle/operators/cross_entropy_op.h
paddle/operators/cross_entropy_op.h
+34
-9
paddle/operators/fc_op.cc
paddle/operators/fc_op.cc
+6
-8
paddle/operators/fill_zeros_like_op.cc
paddle/operators/fill_zeros_like_op.cc
+3
-4
paddle/operators/fill_zeros_like_op.h
paddle/operators/fill_zeros_like_op.h
+1
-1
paddle/operators/mean_op.cc
paddle/operators/mean_op.cc
+3
-3
paddle/operators/mean_op.h
paddle/operators/mean_op.h
+2
-2
paddle/operators/mul_op.cc
paddle/operators/mul_op.cc
+12
-8
paddle/operators/mul_op.h
paddle/operators/mul_op.h
+1
-1
paddle/operators/net_op.h
paddle/operators/net_op.h
+2
-2
paddle/operators/net_op_test.cc
paddle/operators/net_op_test.cc
+2
-2
paddle/operators/recurrent_op.cc
paddle/operators/recurrent_op.cc
+56
-208
paddle/operators/recurrent_op.h
paddle/operators/recurrent_op.h
+11
-82
paddle/operators/recurrent_op_test.cc
paddle/operators/recurrent_op_test.cc
+10
-13
paddle/operators/rnn/recurrent_op_utils.cc
paddle/operators/rnn/recurrent_op_utils.cc
+160
-0
paddle/operators/rnn/recurrent_op_utils.h
paddle/operators/rnn/recurrent_op_utils.h
+93
-0
paddle/operators/rowwise_add_op.cc
paddle/operators/rowwise_add_op.cc
+2
-2
paddle/operators/rowwise_add_op.h
paddle/operators/rowwise_add_op.h
+1
-1
paddle/operators/sgd_op.cc
paddle/operators/sgd_op.cc
+2
-2
paddle/operators/sgd_op.h
paddle/operators/sgd_op.h
+1
-1
paddle/operators/sigmoid_op.cc
paddle/operators/sigmoid_op.cc
+7
-7
paddle/operators/sigmoid_op.cu
paddle/operators/sigmoid_op.cu
+2
-0
paddle/operators/sigmoid_op.h
paddle/operators/sigmoid_op.h
+20
-1
paddle/operators/softmax_op.cc
paddle/operators/softmax_op.cc
+3
-3
paddle/operators/softmax_op.h
paddle/operators/softmax_op.h
+2
-2
paddle/operators/type_alias.h
paddle/operators/type_alias.h
+4
-9
paddle/scripts/docker/build.sh
paddle/scripts/docker/build.sh
+32
-15
paddle/scripts/run_python_tests.sh
paddle/scripts/run_python_tests.sh
+0
-55
paddle/setup.py.in
paddle/setup.py.in
+3
-1
paddle/trainer/tests/compare_sparse_data
paddle/trainer/tests/compare_sparse_data
+0
-0
paddle/trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.proto_data
...vider_wrapper_dir/test_pydata_provider_wrapper.proto_data
+0
-0
paddle/trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.protolist
...ovider_wrapper_dir/test_pydata_provider_wrapper.protolist
+1
-1
paddle/trainer/tests/sample_trainer_config_compare_sparse.conf
...e/trainer/tests/sample_trainer_config_compare_sparse.conf
+154
-0
paddle/trainer/tests/test_CompareSparse.cpp
paddle/trainer/tests/test_CompareSparse.cpp
+1
-1
paddle/trainer/tests/train_sparse.list
paddle/trainer/tests/train_sparse.list
+1
-0
proto/DataConfig.proto
proto/DataConfig.proto
+27
-26
proto/DataFormat.proto
proto/DataFormat.proto
+22
-16
proto/ModelConfig.proto
proto/ModelConfig.proto
+57
-57
proto/OptimizerConfig.proto
proto/OptimizerConfig.proto
+36
-36
proto/ParameterConfig.proto
proto/ParameterConfig.proto
+23
-22
proto/ParameterServerConfig.proto
proto/ParameterServerConfig.proto
+10
-13
proto/ParameterService.proto
proto/ParameterService.proto
+37
-64
proto/TrainerConfig.proto
proto/TrainerConfig.proto
+43
-39
python/paddle/v2/framework/create_op_creation_methods.py
python/paddle/v2/framework/create_op_creation_methods.py
+15
-15
python/paddle/v2/framework/tests/CMakeLists.txt
python/paddle/v2/framework/tests/CMakeLists.txt
+23
-17
python/paddle/v2/framework/tests/op_test_util.py
python/paddle/v2/framework/tests/op_test_util.py
+14
-12
python/paddle/v2/framework/tests/test_add_two_op.py
python/paddle/v2/framework/tests/test_add_two_op.py
+5
-3
python/paddle/v2/framework/tests/test_cross_entropy_op.py
python/paddle/v2/framework/tests/test_cross_entropy_op.py
+8
-4
python/paddle/v2/framework/tests/test_mean_op.py
python/paddle/v2/framework/tests/test_mean_op.py
+2
-2
python/paddle/v2/framework/tests/test_mul_op.py
python/paddle/v2/framework/tests/test_mul_op.py
+5
-3
python/paddle/v2/framework/tests/test_op_creation_methods.py
python/paddle/v2/framework/tests/test_op_creation_methods.py
+17
-17
python/paddle/v2/framework/tests/test_protobuf.py
python/paddle/v2/framework/tests/test_protobuf.py
+2
-4
python/paddle/v2/framework/tests/test_recurrent_op.py
python/paddle/v2/framework/tests/test_recurrent_op.py
+48
-42
python/paddle/v2/framework/tests/test_rowwise_add_op.py
python/paddle/v2/framework/tests/test_rowwise_add_op.py
+5
-3
python/paddle/v2/framework/tests/test_sgd_op.py
python/paddle/v2/framework/tests/test_sgd_op.py
+7
-4
python/paddle/v2/framework/tests/test_sigmoid_op.py
python/paddle/v2/framework/tests/test_sigmoid_op.py
+5
-2
python/paddle/v2/framework/tests/test_softmax_op.py
python/paddle/v2/framework/tests/test_softmax_op.py
+4
-2
python/paddle/v2/plot/tests/CMakeLists.txt
python/paddle/v2/plot/tests/CMakeLists.txt
+1
-1
python/paddle/v2/reader/tests/CMakeLists.txt
python/paddle/v2/reader/tests/CMakeLists.txt
+2
-1
python/paddle/v2/tests/CMakeLists.txt
python/paddle/v2/tests/CMakeLists.txt
+7
-2
python/setup.py.in
python/setup.py.in
+1
-1
未找到文件。
.pre-commit-config.yaml
浏览文件 @
59a8ebc6
...
...
@@ -24,7 +24,7 @@
description
:
Format files with ClangFormat.
entry
:
clang-format -i
language
:
system
files
:
\.(c|cc|cxx|cpp|
h|hpp|hxx
)$
files
:
\.(c|cc|cxx|cpp|
cu|h|hpp|hxx|proto
)$
-
repo
:
https://github.com/PaddlePaddle/pre-commit-golang
sha
:
8337620115c25ff8333f1b1a493bd031049bd7c0
hooks
:
...
...
CMakeLists.txt
浏览文件 @
59a8ebc6
...
...
@@ -36,8 +36,8 @@ include(simd)
################################ Configurations #######################################
option
(
WITH_GPU
"Compile PaddlePaddle with NVIDIA GPU"
${
CUDA_FOUND
}
)
option
(
WITH_AVX
"Compile PaddlePaddle with AVX intrinsics"
${
AVX_FOUND
}
)
option
(
WITH_MKLDNN
"Compile PaddlePaddle with mkl-dnn support."
OFF
)
option
(
WITH_MKLML
"Compile PaddlePaddle with mklml package."
OFF
)
option
(
WITH_MKLDNN
"Compile PaddlePaddle with mkl-dnn support."
${
AVX_FOUND
}
)
option
(
WITH_MKLML
"Compile PaddlePaddle with mklml package."
${
AVX_FOUND
}
)
option
(
WITH_DSO
"Compile PaddlePaddle with dynamic linked CUDA"
ON
)
option
(
WITH_TESTING
"Compile PaddlePaddle with unit testing"
ON
)
option
(
WITH_SWIG_PY
"Compile PaddlePaddle with inference api"
ON
)
...
...
Dockerfile
浏览文件 @
59a8ebc6
...
...
@@ -27,13 +27,16 @@ RUN apt-get update && \
git python-pip python-dev openssh-server bison
\
wget unzip unrar
tar
xz-utils bzip2
gzip
coreutils ntp
\
curl
sed grep
graphviz libjpeg-dev zlib1g-dev
\
python-
numpy python-
matplotlib gcc-4.8 g++-4.8
\
python-matplotlib gcc-4.8 g++-4.8
\
automake locales clang-format-3.8 swig doxygen cmake
\
liblapack-dev liblapacke-dev libboost-dev
\
clang-3.8 llvm-3.8 libclang-3.8-dev
\
net-tools
&&
\
apt-get clean
-y
# paddle is using numpy.flip, which is introduced since 1.12.0
RUN
pip
--no-cache-dir
install
'numpy>=1.12.0'
# Install Go and glide
RUN
wget
-O
go.tgz https://storage.googleapis.com/golang/go1.8.1.linux-amd64.tar.gz
&&
\
tar
-C
/usr/local
-xzf
go.tgz
&&
\
...
...
cmake/configure.cmake
浏览文件 @
59a8ebc6
...
...
@@ -74,8 +74,6 @@ if(WITH_MKLDNN)
set
(
OPENMP_FLAGS
"-fopenmp"
)
set
(
CMAKE_C_CREATE_SHARED_LIBRARY_FORBIDDEN_FLAGS
${
OPENMP_FLAGS
}
)
set
(
CMAKE_CXX_CREATE_SHARED_LIBRARY_FORBIDDEN_FLAGS
${
OPENMP_FLAGS
}
)
set
(
CMAKE_SHARED_LINKER_FLAGS
"
${
CMAKE_SHARED_LINKER_FLAGS
}
-L
${
MKLDNN_IOMP_DIR
}
-liomp5 -Wl,--as-needed"
)
set
(
CMAKE_EXE_LINKER_FLAGS
"
${
CMAKE_EXE_LINKER_FLAGS
}
-L
${
MKLDNN_IOMP_DIR
}
-liomp5 -Wl,--as-needed"
)
set
(
CMAKE_C_FLAGS
"
${
CMAKE_C_FLAGS
}
${
OPENMP_FLAGS
}
"
)
set
(
CMAKE_CXX_FLAGS
"
${
CMAKE_CXX_FLAGS
}
${
OPENMP_FLAGS
}
"
)
else
()
...
...
cmake/cpplint.cmake
浏览文件 @
59a8ebc6
...
...
@@ -42,29 +42,21 @@ macro(add_style_check_target TARGET_NAME)
if
(
WITH_STYLE_CHECK
)
set
(
SOURCES_LIST
${
ARGN
}
)
list
(
REMOVE_DUPLICATES SOURCES_LIST
)
list
(
SORT SOURCES_LIST
)
foreach
(
filename
${
SOURCES_LIST
}
)
set
(
LINT ON
)
foreach
(
pattern
${
IGNORE_PATTERN
}
)
if
(
filename MATCHES
${
pattern
}
)
message
(
STATUS
"DROP LINT
${
filename
}
"
)
set
(
LINT OFF
)
list
(
REMOVE_ITEM SOURCES_LIST
${
filename
}
)
endif
()
endforeach
()
if
(
LINT MATCHES ON
)
# cpplint code style
get_filename_component
(
base_filename
${
filename
}
NAME
)
set
(
CUR_GEN
${
CMAKE_CURRENT_BINARY_DIR
}
/
${
base_filename
}
.cpplint
)
add_custom_command
(
OUTPUT
${
CUR_GEN
}
PRE_BUILD
COMMAND
"
${
PYTHON_EXECUTABLE
}
"
"
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py"
"--filter=
${
STYLE_FILTER
}
"
"--write-success=
${
CUR_GEN
}
"
${
filename
}
DEPENDS
${
filename
}
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
add_custom_target
(
${
base_filename
}
.cpplint DEPENDS
${
CUR_GEN
}
)
add_dependencies
(
${
TARGET_NAME
}
${
base_filename
}
.cpplint
)
endif
()
endforeach
()
if
(
SOURCES_LIST
)
add_custom_command
(
TARGET
${
TARGET_NAME
}
POST_BUILD
COMMAND
"
${
PYTHON_EXECUTABLE
}
"
"
${
PROJ_ROOT
}
/paddle/scripts/cpplint.py"
"--filter=
${
STYLE_FILTER
}
"
${
SOURCES_LIST
}
COMMENT
"cpplint: Checking source code style"
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
endif
()
endif
()
endmacro
()
cmake/external/any.cmake
浏览文件 @
59a8ebc6
...
...
@@ -7,7 +7,7 @@ INCLUDE_DIRECTORIES(${ANY_SOURCE_DIR}/src/extern_lib_any)
ExternalProject_Add
(
extern_lib_any
${
EXTERNAL_PROJECT_LOG_ARGS
}
GIT_REPOSITORY
"https://github.com/
thelink2012
/any.git"
GIT_REPOSITORY
"https://github.com/
PaddlePaddle
/any.git"
GIT_TAG
"8fef1e93710a0edf8d7658999e284a1142c4c020"
PREFIX
${
ANY_SOURCE_DIR
}
UPDATE_COMMAND
""
...
...
cmake/external/gflags.cmake
浏览文件 @
59a8ebc6
...
...
@@ -28,7 +28,14 @@ INCLUDE_DIRECTORIES(${GFLAGS_INCLUDE_DIR})
ExternalProject_Add
(
extern_gflags
${
EXTERNAL_PROJECT_LOG_ARGS
}
GIT_REPOSITORY
"https://github.com/gflags/gflags.git"
# TODO(yiwang): The annoying warnings mentioned in
# https://github.com/PaddlePaddle/Paddle/issues/3277 are caused by
# gflags. I fired a PR https://github.com/gflags/gflags/pull/230
# to fix it. Before it gets accepted by the gflags team, we use
# my personal fork, which contains above fix, temporarily. Let's
# change this back to the official Github repo once my PR is
# merged.
GIT_REPOSITORY
"https://github.com/wangkuiyi/gflags.git"
PREFIX
${
GFLAGS_SOURCES_DIR
}
UPDATE_COMMAND
""
CMAKE_ARGS -DCMAKE_CXX_COMPILER=
${
CMAKE_CXX_COMPILER
}
...
...
cmake/external/openblas.cmake
浏览文件 @
59a8ebc6
...
...
@@ -69,8 +69,13 @@ ENDIF(NOT ${CBLAS_FOUND})
MESSAGE
(
STATUS
"BLAS library:
${
CBLAS_LIBRARIES
}
"
)
INCLUDE_DIRECTORIES
(
${
CBLAS_INC_DIR
}
)
ADD_LIBRARY
(
cblas STATIC IMPORTED
)
SET_PROPERTY
(
TARGET cblas PROPERTY IMPORTED_LOCATION
${
CBLAS_LIBRARIES
}
)
# FIXME(gangliao): generate cblas target to track all high performance
# linear algebra libraries for cc_library(xxx SRCS xxx.c DEPS cblas)
SET
(
dummyfile
${
CMAKE_CURRENT_BINARY_DIR
}
/cblas_dummy.c
)
FILE
(
WRITE
${
dummyfile
}
"const char * dummy =
\"
${
dummyfile
}
\"
;"
)
ADD_LIBRARY
(
cblas STATIC
${
dummyfile
}
)
TARGET_LINK_LIBRARIES
(
cblas
${
CBLAS_LIBRARIES
}
)
IF
(
NOT
${
CBLAS_FOUND
}
)
ADD_DEPENDENCIES
(
cblas extern_openblas
)
LIST
(
APPEND external_project_dependencies cblas
)
...
...
cmake/external/python.cmake
浏览文件 @
59a8ebc6
...
...
@@ -24,7 +24,6 @@ IF(WITH_PYTHON)
ENDIF
(
WITH_PYTHON
)
SET
(
py_env
""
)
SET
(
USE_VIRTUALENV_FOR_TEST 1
)
IF
(
PYTHONINTERP_FOUND
)
find_python_module
(
pip REQUIRED
)
find_python_module
(
numpy REQUIRED
)
...
...
cmake/flags.cmake
浏览文件 @
59a8ebc6
...
...
@@ -115,7 +115,7 @@ set(COMMON_FLAGS
-Wno-error=literal-suffix
-Wno-error=sign-compare
-Wno-error=unused-local-typedefs
-Wno-error=parentheses-equality
# Warnings in
P
ybind11
-Wno-error=parentheses-equality
# Warnings in
p
ybind11
)
set
(
GPU_COMMON_FLAGS
...
...
@@ -195,6 +195,7 @@ endif()
# Modern gpu architectures: Pascal
if
(
CUDA_VERSION VERSION_GREATER
"8.0"
OR CUDA_VERSION VERSION_EQUAL
"8.0"
)
list
(
APPEND __arch_flags
" -gencode arch=compute_60,code=sm_60"
)
list
(
APPEND CUDA_NVCC_FLAGS --expt-relaxed-constexpr
)
endif
()
# Custom gpu architecture
...
...
cmake/generic.cmake
浏览文件 @
59a8ebc6
...
...
@@ -403,3 +403,16 @@ function(py_proto_compile TARGET_NAME)
protobuf_generate_python
(
py_srcs
${
py_proto_compile_SRCS
}
)
add_custom_target
(
${
TARGET_NAME
}
ALL DEPENDS
${
py_srcs
}
)
endfunction
()
function
(
py_test TARGET_NAME
)
if
(
WITH_TESTING
)
set
(
options STATIC static SHARED shared
)
set
(
oneValueArgs
""
)
set
(
multiValueArgs SRCS DEPS
)
cmake_parse_arguments
(
py_test
"
${
options
}
"
"
${
oneValueArgs
}
"
"
${
multiValueArgs
}
"
${
ARGN
}
)
add_test
(
NAME
${
TARGET_NAME
}
COMMAND env PYTHONPATH=
${
PADDLE_PYTHON_PACKAGE_DIR
}
python2
${
py_test_SRCS
}
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
endif
()
endfunction
()
cmake/util.cmake
浏览文件 @
59a8ebc6
...
...
@@ -149,9 +149,12 @@ endfunction()
# Create a python unittest using run_python_tests.sh,
# which takes care of making correct running environment
function
(
add_python_test TEST_NAME
)
add_test
(
NAME
${
TEST_NAME
}
COMMAND env PADDLE_PACKAGE_DIR=
${
PADDLE_PYTHON_PACKAGE_DIR
}
bash
${
PROJ_ROOT
}
/paddle/scripts/run_python_tests.sh
${
USE_VIRTUALENV_FOR_TEST
}
${
PYTHON_EXECUTABLE
}
${
ARGN
}
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
foreach
(
arg
${
ARGN
}
)
get_filename_component
(
py_fn
${
arg
}
NAME_WE
)
set
(
TRG_NAME
${
TEST_NAME
}
_
${
py_fn
}
)
add_test
(
NAME
${
TRG_NAME
}
COMMAND env PYTHONPATH=
${
PADDLE_PYTHON_PACKAGE_DIR
}
python2
${
arg
}
WORKING_DIRECTORY
${
CMAKE_CURRENT_SOURCE_DIR
}
)
endforeach
()
endfunction
()
doc/design/mkldnn/README.MD
0 → 100644
浏览文件 @
59a8ebc6
# Intel® MKL-DNN on PaddlePaddle: Design Doc
我们计划将Intel深度神经网络数学库(
**MKL-DNN**
\[
[
1
](
#references
)
\]
)集成到PaddlePaddle,充分展现英特尔平台的优势,有效提升PaddlePaddle在英特尔架构上的性能。
我们短期内的基本目标是:
-
完成常用layer的MKL-DNN实现。
-
完成常见深度神经网络VGG,GoogLeNet 和 ResNet的MKL-DNN实现。
## Contents
-
[
Overview
](
#overview
)
-
[
Actions
](
#actions
)
-
[
CMake
](
#cmake
)
-
[
Layers
](
#layers
)
-
[
Activations
](
#activations
)
-
[
Unit Tests
](
#unit-tests
)
-
[
Protobuf Messages
](
#protobuf-messages
)
-
[
Python API
](
#python-api
)
-
[
Demos
](
#demos
)
-
[
Benchmarking
](
#benchmarking
)
-
[
Others
](
#others
)
-
[
Design Concerns
](
#design-concerns
)
## Overview
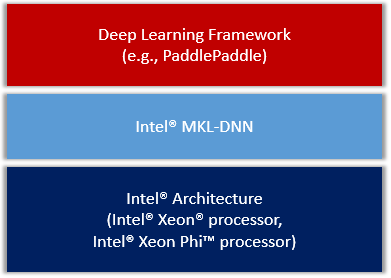
我们会把MKL-DNN作为第三方库集成进PaddlePaddle,整体框架图
<div
align=
"center"
>
<img
src=
"image/overview.png"
width=
350
><br/>
Figure 1. PaddlePaddle on IA.
</div>
## Actions
我们把集成方案大致分为了如下几个方面。
### CMake
我们会在
`CMakeLists.txt`
中会添加
`WITH_MKLDNN`
的选项,当设置这个值为
`ON`
的时候会启用编译MKL-DNN功能。同时会自动开启OpenMP用于提高MKL-DNN的性能。
同时,我们会引入
`WITH_MKLML`
选项,用于选择是否使用MKL-DNN自带的MKLML安装包。这个安装包可以独立于MKL-DNN使用,但是建议在开启MKL-DNN的同时也打开MKLML的开关,这样才能发挥最好的性能。
所以,我们会在
`cmake/external`
目录新建
`mkldnn.cmake`
和
`mklml.cmake`
文件,它们会在编译PaddlePaddle的时候下载对应的软件包,并放到PaddlePaddle的third party目录中。
**备注**
:当
`WITH_MKLML=ON`
的时候,会优先使用这个包作为PaddlePaddle的CBLAS和LAPACK库,所以会稍微改动
`cmake/cblas.cmake`
中的逻辑。
### Layers
所有MKL-DNN相关的C++ layers,都会按照PaddlePaddle的目录结构存放在
`paddle/gserver/layers`
中,并且文件名都会一以
*Mkldnn*
开头。
所有MKL-DNN的layers都会继承于一个叫做
`MkldnnLayer`
的父类,该父类继承于PaddlePaddle的基类
`Layer`
。
### Activations
由于在PaddlePaddle中,激活函数是独立于layer概念的,所以会在
`paddle/gserver/activations`
目录下添加一个
`MkldnnActivation.h`
文件定义一些用于MKL-DNN的接口,实现方法还是会在
`ActivationFunction.cpp`
文件。
### Unit Tests
会在
`paddle/gserver/test`
目录下添加
`test_Mkldnn.cpp`
和
`MkldnnTester.*`
用于MKL-DNN的测试。
Activation的测试,计划在PaddlePaddle原有的测试文件上直接添加新的测试type。
### Protobuf Messages
根据具体layer的需求可能会在
`proto/ModelConfig.proto`
里面添加必要的选项。
### Python API
目前只考虑
**v1 API**
。
计划在
`python/paddle/trainer/config_parser.py`
里面添加
`use_mkldnn`
这个选择,方便用户选择使用MKL-DNN的layers。
具体实现方式比如:
```
python
use_mkldnn
=
bool
(
int
(
g_command_config_args
.
get
(
"use_mkldnn"
,
0
)))
if
use_mkldnn
self
.
layer_type
=
mkldnn_
*
```
所有MKL-DNN的layer type会以
*mkldnn_*
开头,以示区分。
并且可能在
`python/paddle/trainer_config_helper`
目录下的
`activations.py `
和
`layers.py`
里面添加必要的MKL-DNN的接口。
### Demos
会在
`v1_api_demo`
目录下添加一个
`mkldnn`
的文件夹,里面放入一些用于MKL-DNN测试的demo脚本。
### Benchmarking
会考虑添加部分逻辑在
`benchmark/paddle/image/run.sh`
,添加使用MKL-DNN的测试。
### Others
1.
如果在使用MKL-DNN的情况下,会把CPU的Buffer对齐为64。
2.
深入PaddlePaddle,寻找有没有其他可以优化的可能,进一步优化。比如可能会用OpenMP改进SGD的更新性能。
## Design Concerns
为了更好的符合PaddlePaddle的代码风格
\[
[
2
](
#references
)
\]
,同时又尽可能少的牺牲MKL-DNN的性能
\[
[
3
](
#references
)
\]
。
我们总结出一些特别需要注意的点:
1.
使用
**deviceId_**
。为了尽可能少的在父类Layer中添加变量或者函数,我们决定使用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为
`MkldnnLayer`
特有的设备ID。
2.
重写父类Layer的
**init**
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKL-DNN的环境下。
3.
创建
`MkldnnMatrix`
,用于管理MKL-DNN会用到的相关memory函数、接口以及会用的到格式信息。
4.
创建
`MkldnnBase`
,定义一些除了layer和memory相关的类和函数。包括MKL-DNN会用到
`MkldnnStream`
和
`CpuEngine`
,和未来可能还会用到
`FPGAEngine`
等。
5.
在
**Argument**
里添加两个
`MkldnnMatrixPtr`
,取名为
`mkldnnValue`
和
`mkldnnGrad`
,用于存放
`MkldnnLayer`
会用到的memory buffer。 并且添加函数cvt(会修改为一个更加合适的函数名),用于处理"CPU device"和"MKL-DNN device"之间memory的相互转化。
6.
在父类
`Layer`
中的
`getOutput`
函数中添加一段逻辑,用于判断
`deviceId`
,并针对device在MKL-DNN和CPU之间不统一的情况,做一个前期转换。 也就是调用
`Argument`
的cvt函数把output统一到需要的device上。
7.
在原来的
`FLAGS`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKL-DNN的相关功能。
## References
1.
[
Intel Math Kernel Library for Deep Neural Networks (Intel MKL-DNN)
](
https://github.com/01org/mkl-dnn
"Intel MKL-DNN"
)
2.
[
原来的方案
](
https://github.com/PaddlePaddle/Paddle/pull/3096
)
会引入
**nextLayer**
的信息。但是在PaddlePaddle中,无论是重构前的layer还是重构后的op,都不会想要知道next layer/op的信息。
3.
MKL-DNN的高性能格式与PaddlePaddle原有的
`NCHW`
不同(PaddlePaddle中的CUDNN部分使用的也是
`NCHW`
,所以不存在这个问题),所以需要引入一个转换方法,并且只需要在必要的时候转换这种格式,才能更好的发挥MKL-DNN的性能。
doc/design/mkldnn/image/overview.png
0 → 100644
浏览文件 @
59a8ebc6
9.7 KB
paddle/.set_python_path.sh
浏览文件 @
59a8ebc6
...
...
@@ -21,22 +21,15 @@
#
# It same as PYTHONPATH=${YOUR_PYTHON_PATH}:$PYTHONPATH {exec...}
#
if
!
python
-c
"import paddle"
>
/dev/null 2>/dev/null
;
then
PYPATH
=
""
set
-x
while
getopts
"d:"
opt
;
do
case
$opt
in
d
)
PYPATH
=
$OPTARG
;;
esac
done
shift
$((
$OPTIND
-
1
))
export
PYTHONPATH
=
$PYPATH
:
$PYTHONPATH
$@
else
echo
"paddle package is already in your PYTHONPATH. But unittest need a clean environment."
echo
"Please uninstall paddle package before start unittest. Try to 'pip uninstall paddle'"
exit
1
fi
PYPATH
=
""
set
-x
while
getopts
"d:"
opt
;
do
case
$opt
in
d
)
PYPATH
=
$OPTARG
;;
esac
done
shift
$((
$OPTIND
-
1
))
export
PYTHONPATH
=
$PYPATH
:
$PYTHONPATH
$@
paddle/api/test/CMakeLists.txt
浏览文件 @
59a8ebc6
add_python_test
(
test_swig_api
testArguments.py testGradientMachine.py testMatrix.py testVector.py testTrain.py testTrainer.py
)
py_test
(
testTrain SRCS testTrain.py
)
py_test
(
testMatrix SRCS testMatrix.py
)
py_test
(
testVector SRCS testVector.py
)
py_test
(
testTrainer SRCS testTrainer.py
)
py_test
(
testArguments SRCS testArguments.py
)
py_test
(
testGradientMachine SRCS testGradientMachine.py
)
paddle/cuda/src/hl_batch_transpose.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,17 +12,15 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_batch_transpose.h"
#include "hl_base.h"
#include "hl_batch_transpose.h"
const
int
TILE_DIM
=
64
;
const
int
BLOCK_ROWS
=
16
;
// No bank-conflict transpose for a batch of data.
__global__
void
batchTransposeNoBankConflicts
(
real
*
odata
,
const
real
*
idata
,
int
numSamples
,
int
width
,
int
height
)
{
__global__
void
batchTransposeNoBankConflicts
(
real
*
odata
,
const
real
*
idata
,
int
numSamples
,
int
width
,
int
height
)
{
__shared__
float
tile
[
TILE_DIM
][
TILE_DIM
+
1
];
const
int
x
=
blockIdx
.
x
*
TILE_DIM
+
threadIdx
.
x
;
...
...
@@ -50,12 +48,12 @@ __global__ void batchTransposeNoBankConflicts(real* odata,
newX
]
=
tile
[
threadIdx
.
x
][
j
];
}
void
batchTranspose
(
const
real
*
input
,
real
*
output
,
int
width
,
int
height
,
int
batchSize
)
{
void
batchTranspose
(
const
real
*
input
,
real
*
output
,
int
width
,
int
height
,
int
batchSize
)
{
dim3
dimBlock
(
TILE_DIM
,
BLOCK_ROWS
,
1
);
dim3
dimGrid
(
DIVUP
(
width
,
TILE_DIM
),
DIVUP
(
height
,
TILE_DIM
),
batchSize
);
batchTransposeNoBankConflicts
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input
,
batchSize
,
width
,
height
);
batchTransposeNoBankConflicts
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input
,
batchSize
,
width
,
height
);
CHECK_SYNC
(
"batchTranspose failed!"
);
}
paddle/cuda/src/hl_cuda_aggregate.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,27 +12,23 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_aggregate.h"
#include "hl_base.h"
#include "hl_cuda.h"
#include "hl_cuda.ph"
#include "hl_aggregate.h"
#include "hl_thread.ph"
#include "hl_matrix_base.cuh"
#include "hl_thread.ph"
#include "paddle/utils/Logging.h"
/**
* @brief matrix row operator.
*/
template
<
class
Agg
,
int
blockSize
>
__global__
void
KeMatrixRowOp
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimN
)
{
template
<
class
Agg
,
int
blockSize
>
__global__
void
KeMatrixRowOp
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimN
)
{
__shared__
real
sum_s
[
blockSize
];
int
cnt
=
(
dimN
+
blockSize
-
1
)
/
blockSize
;
int
rowId
=
blockIdx
.
x
+
blockIdx
.
y
*
gridDim
.
x
;
int
index
=
rowId
*
dimN
;
int
cnt
=
(
dimN
+
blockSize
-
1
)
/
blockSize
;
int
rowId
=
blockIdx
.
x
+
blockIdx
.
y
*
gridDim
.
x
;
int
index
=
rowId
*
dimN
;
int
tid
=
threadIdx
.
x
;
int
lmt
=
tid
;
...
...
@@ -44,7 +40,7 @@ __global__ void KeMatrixRowOp(Agg agg,
sum_s
[
tid
]
=
tmp
;
__syncthreads
();
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
if
(
tid
<
stride
)
{
sum_s
[
tid
]
=
agg
(
sum_s
[
tid
],
sum_s
[
tid
+
stride
]);
}
...
...
@@ -58,29 +54,21 @@ __global__ void KeMatrixRowOp(Agg agg,
}
template
<
class
Agg
>
void
hl_matrix_row_op
(
Agg
agg
,
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_row_op
(
Agg
agg
,
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
int
blocksX
=
dimM
;
int
blocksY
=
1
;
dim3
threads
(
128
,
1
);
dim3
grid
(
blocksX
,
blocksY
);
KeMatrixRowOp
<
Agg
,
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimN
);
KeMatrixRowOp
<
Agg
,
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimN
);
}
void
hl_matrix_row_sum
(
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_row_op
(
aggregate
::
sum
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_row_op
(
aggregate
::
sum
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_row_sum failed"
);
}
...
...
@@ -88,11 +76,7 @@ void hl_matrix_row_max(real *A_d, real *C_d, int dimM, int dimN) {
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_row_op
(
aggregate
::
max
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_row_op
(
aggregate
::
max
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_row_max failed"
);
}
...
...
@@ -100,23 +84,16 @@ void hl_matrix_row_min(real *A_d, real *C_d, int dimM, int dimN) {
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_row_op
(
aggregate
::
min
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_row_op
(
aggregate
::
min
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_row_min failed"
);
}
/**
* @brief matrix column operator.
*/
template
<
class
Agg
>
__global__
void
KeMatrixColumnOp
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimM
,
int
dimN
)
{
template
<
class
Agg
>
__global__
void
KeMatrixColumnOp
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimM
,
int
dimN
)
{
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
real
tmp
=
agg
.
init
();
if
(
rowIdx
<
dimN
)
{
...
...
@@ -127,15 +104,12 @@ __global__ void KeMatrixColumnOp(Agg agg,
}
}
template
<
class
Agg
,
int
blockDimX
,
int
blockDimY
>
__global__
void
KeMatrixColumnOp_S
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimM
,
int
dimN
)
{
__shared__
real
_sum
[
blockDimX
*
blockDimY
];
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
index
=
threadIdx
.
y
;
template
<
class
Agg
,
int
blockDimX
,
int
blockDimY
>
__global__
void
KeMatrixColumnOp_S
(
Agg
agg
,
real
*
E
,
real
*
Sum
,
int
dimM
,
int
dimN
)
{
__shared__
real
_sum
[
blockDimX
*
blockDimY
];
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
index
=
threadIdx
.
y
;
real
tmp
=
agg
.
init
();
if
(
rowIdx
<
dimN
)
{
...
...
@@ -144,14 +118,14 @@ __global__ void KeMatrixColumnOp_S(Agg agg,
index
+=
blockDimY
;
}
}
_sum
[
threadIdx
.
x
+
threadIdx
.
y
*
blockDimX
]
=
tmp
;
_sum
[
threadIdx
.
x
+
threadIdx
.
y
*
blockDimX
]
=
tmp
;
__syncthreads
();
if
(
rowIdx
<
dimN
)
{
if
(
threadIdx
.
y
==
0
)
{
if
(
threadIdx
.
y
==
0
)
{
real
tmp
=
agg
.
init
();
for
(
int
i
=
0
;
i
<
blockDimY
;
i
++
)
{
tmp
=
agg
(
tmp
,
_sum
[
threadIdx
.
x
+
i
*
blockDimX
]);
for
(
int
i
=
0
;
i
<
blockDimY
;
i
++
)
{
tmp
=
agg
(
tmp
,
_sum
[
threadIdx
.
x
+
i
*
blockDimX
]);
}
Sum
[
rowIdx
]
=
tmp
;
}
...
...
@@ -159,25 +133,21 @@ __global__ void KeMatrixColumnOp_S(Agg agg,
}
template
<
class
Agg
>
void
hl_matrix_column_op
(
Agg
agg
,
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_column_op
(
Agg
agg
,
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
if
(
dimN
>=
8192
)
{
int
blocksX
=
(
dimN
+
128
-
1
)
/
128
;
int
blocksX
=
(
dimN
+
128
-
1
)
/
128
;
int
blocksY
=
1
;
dim3
threads
(
128
,
1
);
dim3
grid
(
blocksX
,
blocksY
);
KeMatrixColumnOp
<
Agg
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimM
,
dimN
);
KeMatrixColumnOp
<
Agg
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimM
,
dimN
);
}
else
{
int
blocksX
=
(
dimN
+
32
-
1
)
/
32
;
int
blocksX
=
(
dimN
+
32
-
1
)
/
32
;
int
blocksY
=
1
;
dim3
threads
(
32
,
32
);
dim3
grid
(
blocksX
,
blocksY
);
KeMatrixColumnOp_S
<
Agg
,
32
,
32
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimM
,
dimN
);
KeMatrixColumnOp_S
<
Agg
,
32
,
32
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
agg
,
A_d
,
C_d
,
dimM
,
dimN
);
}
return
;
...
...
@@ -187,11 +157,7 @@ void hl_matrix_column_sum(real *A_d, real *C_d, int dimM, int dimN) {
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_column_op
(
aggregate
::
sum
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_column_op
(
aggregate
::
sum
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_column_sum failed"
);
}
...
...
@@ -200,11 +166,7 @@ void hl_matrix_column_max(real *A_d, real *C_d, int dimM, int dimN) {
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_column_op
(
aggregate
::
max
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_column_op
(
aggregate
::
max
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_column_max failed"
);
}
...
...
@@ -213,11 +175,7 @@ void hl_matrix_column_min(real *A_d, real *C_d, int dimM, int dimN) {
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
hl_matrix_column_op
(
aggregate
::
min
(),
A_d
,
C_d
,
dimM
,
dimN
);
hl_matrix_column_op
(
aggregate
::
min
(),
A_d
,
C_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_column_min failed"
);
}
...
...
@@ -226,16 +184,16 @@ template <int blockSize>
__global__
void
KeVectorSum
(
real
*
E
,
real
*
Sum
,
int
dimM
)
{
__shared__
double
sum_s
[
blockSize
];
int
tid
=
threadIdx
.
x
;
int
index
=
blockIdx
.
y
*
blockDim
.
x
+
threadIdx
.
x
;
int
index
=
blockIdx
.
y
*
blockDim
.
x
+
threadIdx
.
x
;
sum_s
[
tid
]
=
0.0
f
;
while
(
index
<
dimM
)
{
sum_s
[
tid
]
+=
E
[
index
];
index
+=
blockDim
.
x
*
gridDim
.
y
;
index
+=
blockDim
.
x
*
gridDim
.
y
;
}
__syncthreads
();
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
if
(
tid
<
stride
)
{
sum_s
[
tid
]
+=
sum_s
[
tid
+
stride
];
}
...
...
@@ -259,38 +217,39 @@ void hl_vector_sum(real *A_d, real *C_h, int dimM) {
dim3
threads
(
blockSize
,
1
);
dim3
grid
(
blocksX
,
blocksY
);
struct
_hl_event_st
hl_event_st
=
{.
cu_event
=
t_resource
.
event
};
struct
_hl_event_st
hl_event_st
=
{.
cu_event
=
t_resource
.
event
};
hl_event_t
hl_event
=
&
hl_event_st
;
while
(
!
hl_cuda_event_is_ready
(
hl_event
))
{}
while
(
!
hl_cuda_event_is_ready
(
hl_event
))
{
}
KeVectorSum
<
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
t_resource
.
gpu_mem
,
dimM
);
KeVectorSum
<
128
><<<
1
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
t_resource
.
gpu_mem
,
t_resource
.
cpu_mem
,
128
);
KeVectorSum
<
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
t_resource
.
gpu_mem
,
dimM
);
KeVectorSum
<
128
><<<
1
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
t_resource
.
gpu_mem
,
t_resource
.
cpu_mem
,
128
);
hl_memcpy_async
(
C_h
,
t_resource
.
cpu_mem
,
sizeof
(
real
),
HPPL_STREAM_DEFAULT
);
hl_stream_record_event
(
HPPL_STREAM_DEFAULT
,
hl_event
);
hl_stream_synchronize
(
HPPL_STREAM_DEFAULT
);
cudaError_t
err
=
(
cudaError_t
)
hl_get_device_last_error
();
CHECK_EQ
(
cudaSuccess
,
err
)
<<
"CUDA error: "
<<
hl_get_device_error_string
((
size_t
)
err
);
CHECK_EQ
(
cudaSuccess
,
err
)
<<
"CUDA error: "
<<
hl_get_device_error_string
((
size_t
)
err
);
}
template
<
int
blockSize
>
__global__
void
KeVectorAbsSum
(
real
*
E
,
real
*
Sum
,
int
dimM
)
{
__shared__
double
sum_s
[
blockSize
];
int
tid
=
threadIdx
.
x
;
int
index
=
blockIdx
.
y
*
blockDim
.
x
+
threadIdx
.
x
;
int
index
=
blockIdx
.
y
*
blockDim
.
x
+
threadIdx
.
x
;
sum_s
[
tid
]
=
0.0
f
;
while
(
index
<
dimM
)
{
sum_s
[
tid
]
+=
abs
(
E
[
index
]);
index
+=
blockDim
.
x
*
gridDim
.
y
;
index
+=
blockDim
.
x
*
gridDim
.
y
;
}
__syncthreads
();
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
for
(
int
stride
=
blockSize
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
if
(
tid
<
stride
)
{
sum_s
[
tid
]
+=
sum_s
[
tid
+
stride
];
}
...
...
@@ -314,20 +273,21 @@ void hl_vector_abs_sum(real *A_d, real *C_h, int dimM) {
dim3
threads
(
blockSize
,
1
);
dim3
grid
(
blocksX
,
blocksY
);
struct
_hl_event_st
hl_event_st
=
{.
cu_event
=
t_resource
.
event
};
struct
_hl_event_st
hl_event_st
=
{.
cu_event
=
t_resource
.
event
};
hl_event_t
hl_event
=
&
hl_event_st
;
while
(
!
hl_cuda_event_is_ready
(
hl_event
))
{}
while
(
!
hl_cuda_event_is_ready
(
hl_event
))
{
}
KeVectorAbsSum
<
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
t_resource
.
gpu_mem
,
dimM
);
KeVectorAbsSum
<
128
><<<
1
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
t_resource
.
gpu_mem
,
t_resource
.
cpu_mem
,
128
);
KeVectorAbsSum
<
128
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
t_resource
.
gpu_mem
,
dimM
);
KeVectorAbsSum
<
128
><<<
1
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
t_resource
.
gpu_mem
,
t_resource
.
cpu_mem
,
128
);
hl_memcpy_async
(
C_h
,
t_resource
.
cpu_mem
,
sizeof
(
real
),
HPPL_STREAM_DEFAULT
);
hl_stream_record_event
(
HPPL_STREAM_DEFAULT
,
hl_event
);
hl_stream_synchronize
(
HPPL_STREAM_DEFAULT
);
cudaError_t
err
=
(
cudaError_t
)
hl_get_device_last_error
();
CHECK_EQ
(
cudaSuccess
,
err
)
<<
"CUDA error: "
<<
hl_get_device_error_string
((
size_t
)
err
);
CHECK_EQ
(
cudaSuccess
,
err
)
<<
"CUDA error: "
<<
hl_get_device_error_string
((
size_t
)
err
);
}
paddle/cuda/src/hl_cuda_cnn.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,21 +12,27 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <float.h>
#include "hl_base.h"
#include "hl_cnn.h"
#include "hl_device_functions.cuh"
__global__
void
KeMaxPoolForward
(
const
int
nthreads
,
const
real
*
inputData
,
const
int
channels
,
const
int
height
,
__global__
void
KeMaxPoolForward
(
const
int
nthreads
,
const
real
*
inputData
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
ksizeW
,
const
int
ksizeH
,
const
int
strideH
,
const
int
strideW
,
const
int
offsetH
,
const
int
offsetW
,
real
*
tgtData
,
const
int
tgtStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
const
int
pooledH
,
const
int
pooledW
,
const
int
ksizeW
,
const
int
ksizeH
,
const
int
strideH
,
const
int
strideW
,
const
int
offsetH
,
const
int
offsetW
,
real
*
tgtData
,
const
int
tgtStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
int
pw
=
index
%
pooledW
;
int
ph
=
(
index
/
pooledW
)
%
pooledH
;
...
...
@@ -46,44 +52,70 @@ __global__ void KeMaxPoolForward(const int nthreads, const real* inputData,
maxval
=
inputData
[
h
*
width
+
w
];
}
}
int
tgtIndex
=
index
%
(
pooledW
*
pooledH
*
channels
)
+
frameNum
*
tgtStride
;
int
tgtIndex
=
index
%
(
pooledW
*
pooledH
*
channels
)
+
frameNum
*
tgtStride
;
tgtData
[
tgtIndex
]
=
maxval
;
}
}
void
hl_maxpool_forward
(
const
int
frameCnt
,
const
real
*
inputData
,
void
hl_maxpool_forward
(
const
int
frameCnt
,
const
real
*
inputData
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
*
tgtData
,
const
int
tgtStride
)
{
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
*
tgtData
,
const
int
tgtStride
)
{
int
num_kernels
=
pooledH
*
pooledW
*
channels
*
frameCnt
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blocks
,
1
);
KeMaxPoolForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
tgtData
,
tgtStride
);
KeMaxPoolForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
tgtData
,
tgtStride
);
CHECK_SYNC
(
"hl_maxpool_forward failed"
);
}
__global__
void
KeMaxPoolBackward
(
const
int
nthreads
,
const
real
*
inputData
,
const
real
*
outData
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
__global__
void
KeMaxPoolBackward
(
const
int
nthreads
,
const
real
*
inputData
,
const
real
*
outData
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
scaleA
,
real
scaleB
,
real
*
targetGrad
,
const
int
outStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
scaleA
,
real
scaleB
,
real
*
targetGrad
,
const
int
outStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
// find out the local index
// find out the local offset
...
...
@@ -107,43 +139,69 @@ __global__ void KeMaxPoolBackward(const int nthreads, const real* inputData,
}
}
}
targetGrad
[
index
]
=
scaleB
*
targetGrad
[
index
]
+
scaleA
*
gradient
;
targetGrad
[
index
]
=
scaleB
*
targetGrad
[
index
]
+
scaleA
*
gradient
;
}
}
void
hl_maxpool_backward
(
const
int
frameCnt
,
const
real
*
inputData
,
const
real
*
outData
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
scaleA
,
real
scaleB
,
real
*
targetGrad
,
const
int
outStride
)
{
void
hl_maxpool_backward
(
const
int
frameCnt
,
const
real
*
inputData
,
const
real
*
outData
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
scaleA
,
real
scaleB
,
real
*
targetGrad
,
const
int
outStride
)
{
int
num_kernels
=
height
*
width
*
channels
*
frameCnt
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
KeMaxPoolBackward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
outData
,
outGrad
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
scaleA
,
scaleB
,
targetGrad
,
outStride
);
KeMaxPoolBackward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
outData
,
outGrad
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
scaleA
,
scaleB
,
targetGrad
,
outStride
);
CHECK_SYNC
(
"hl_maxpool_backward"
);
}
__global__
void
KeAvgPoolForward
(
const
int
nthreads
,
const
real
*
inputData
,
__global__
void
KeAvgPoolForward
(
const
int
nthreads
,
const
real
*
inputData
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
*
tgtData
,
const
int
tgtStride
)
{
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
*
tgtData
,
const
int
tgtStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
int
pw
=
index
%
pooledW
;
...
...
@@ -168,39 +226,64 @@ __global__ void KeAvgPoolForward(const int nthreads, const real* inputData,
aveval
+=
inputData
[
h
*
width
+
w
];
}
}
int
tgtIndex
=
index
%
(
pooledW
*
pooledH
*
channels
)
+
frameNum
*
tgtStride
;
int
tgtIndex
=
index
%
(
pooledW
*
pooledH
*
channels
)
+
frameNum
*
tgtStride
;
tgtData
[
tgtIndex
]
=
aveval
/
pool_size
;
}
}
void
hl_avgpool_forward
(
const
int
frameCnt
,
const
real
*
inputData
,
void
hl_avgpool_forward
(
const
int
frameCnt
,
const
real
*
inputData
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
*
tgtData
,
const
int
tgtStride
)
{
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
*
tgtData
,
const
int
tgtStride
)
{
int
num_kernels
=
pooledH
*
pooledW
*
channels
*
frameCnt
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
KeAvgPoolForward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
tgtData
,
tgtStride
);
KeAvgPoolForward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inputData
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
tgtData
,
tgtStride
);
CHECK_SYNC
(
"hl_avgpool_forward failed"
);
}
__global__
void
KeAvgPoolBackward
(
const
int
nthreads
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
__global__
void
KeAvgPoolBackward
(
const
int
nthreads
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
scaleA
,
real
scaleB
,
real
*
tgtGrad
,
const
int
outStride
)
{
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
padH
,
const
int
padW
,
real
scaleA
,
real
scaleB
,
real
*
tgtGrad
,
const
int
outStride
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
int
offsetW
=
index
%
width
+
padW
;
...
...
@@ -215,7 +298,6 @@ __global__ void KeAvgPoolBackward(const int nthreads, const real* outGrad,
real
gradient
=
0
;
outGrad
+=
(
frameNum
*
outStride
+
offsetC
*
pooledH
*
pooledW
);
for
(
int
ph
=
phstart
;
ph
<
phend
;
++
ph
)
{
for
(
int
pw
=
pwstart
;
pw
<
pwend
;
++
pw
)
{
// figure out the pooling size
...
...
@@ -224,32 +306,50 @@ __global__ void KeAvgPoolBackward(const int nthreads, const real* outGrad,
int
hend
=
min
(
hstart
+
sizeY
,
height
+
padH
);
int
wend
=
min
(
wstart
+
sizeX
,
width
+
padW
);
int
poolsize
=
(
hend
-
hstart
)
*
(
wend
-
wstart
);
gradient
+=
outGrad
[
ph
*
pooledW
+
pw
]
/
poolsize
;
gradient
+=
outGrad
[
ph
*
pooledW
+
pw
]
/
poolsize
;
}
}
tgtGrad
[
index
]
=
scaleB
*
tgtGrad
[
index
]
+
scaleA
*
gradient
;
}
}
void
hl_avgpool_backward
(
const
int
frameCnt
,
const
real
*
outGrad
,
void
hl_avgpool_backward
(
const
int
frameCnt
,
const
real
*
outGrad
,
const
int
channels
,
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
scaleA
,
real
scaleB
,
real
*
backGrad
,
const
int
outStride
)
{
const
int
height
,
const
int
width
,
const
int
pooledH
,
const
int
pooledW
,
const
int
sizeX
,
const
int
sizeY
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
real
scaleA
,
real
scaleB
,
real
*
backGrad
,
const
int
outStride
)
{
int
num_kernels
=
height
*
width
*
channels
*
frameCnt
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
KeAvgPoolBackward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
outGrad
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
scaleA
,
scaleB
,
backGrad
,
outStride
);
KeAvgPoolBackward
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
outGrad
,
channels
,
height
,
width
,
pooledH
,
pooledW
,
sizeX
,
sizeY
,
strideH
,
strideW
,
paddingH
,
paddingW
,
scaleA
,
scaleB
,
backGrad
,
outStride
);
CHECK_SYNC
(
"hl_avgpool_backward failed"
);
}
...
...
@@ -266,7 +366,7 @@ __global__ void KeBilinearInterpFw(const real* in,
const
size_t
numChannels
,
const
real
ratioH
,
const
real
ratioW
)
{
int
nthreads
=
outputH
*
outputW
;
int
nthreads
=
outputH
*
outputW
;
int
tid
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
tid
<
nthreads
)
{
int
outIdH
=
tid
/
outputW
;
...
...
@@ -287,13 +387,14 @@ __global__ void KeBilinearInterpFw(const real* in,
real
w1lambda
=
ratioW
*
outImgIdx
-
inImgIdx
;
real
w2lambda
=
1.
f
-
w1lambda
;
const
real
*
inPos
=
&
in
[
outIdH
*
inputW
+
channelId
*
inImgSize
+
inImgIdy
*
inImgW
+
inImgIdx
];
const
real
*
inPos
=
&
in
[
outIdH
*
inputW
+
channelId
*
inImgSize
+
inImgIdy
*
inImgW
+
inImgIdx
];
// bilinear interpolation
out
[
outIdH
*
outputW
+
outIdW
]
=
h2lambda
*
(
w2lambda
*
inPos
[
0
]
+
w1lambda
*
inPos
[
wId
])
+
h1lambda
*
(
w2lambda
*
inPos
[
hId
*
inImgW
]
+
w1lambda
*
inPos
[
hId
*
inImgW
+
wId
]);
h2lambda
*
(
w2lambda
*
inPos
[
0
]
+
w1lambda
*
inPos
[
wId
])
+
h1lambda
*
(
w2lambda
*
inPos
[
hId
*
inImgW
]
+
w1lambda
*
inPos
[
hId
*
inImgW
+
wId
]);
}
}
...
...
@@ -313,9 +414,19 @@ void hl_bilinear_forward(const real* inData,
int
threadNum
=
outputH
*
outputW
;
int
blocks
=
(
threadNum
+
1024
-
1
)
/
1024
;
KeBilinearInterpFw
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
inData
,
inImgH
,
inImgW
,
inputH
,
inputW
,
outData
,
outImgH
,
outImgW
,
outputH
,
outputW
,
numChannels
,
ratioH
,
ratioW
);
KeBilinearInterpFw
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
inData
,
inImgH
,
inImgW
,
inputH
,
inputW
,
outData
,
outImgH
,
outImgW
,
outputH
,
outputW
,
numChannels
,
ratioH
,
ratioW
);
CHECK_SYNC
(
"hl_bilinear_forward failed"
);
}
...
...
@@ -353,13 +464,15 @@ __global__ void KeBilinearInterpBw(real* in,
real
w1lambda
=
ratioW
*
outImgIdx
-
inImgIdx
;
real
w2lambda
=
1.
f
-
w1lambda
;
real
*
inPos
=
&
in
[
outIdH
*
inputW
+
channelId
*
inImgSize
+
inImgIdy
*
inImgW
+
inImgIdx
];
real
*
inPos
=
&
in
[
outIdH
*
inputW
+
channelId
*
inImgSize
+
inImgIdy
*
inImgW
+
inImgIdx
];
const
real
*
outPos
=
&
out
[
outIdH
*
outputW
+
outIdW
];
paddle
::
paddleAtomicAdd
(
&
inPos
[
0
],
h2lambda
*
w2lambda
*
outPos
[
0
]);
paddle
::
paddleAtomicAdd
(
&
inPos
[
wId
],
h2lambda
*
w1lambda
*
outPos
[
0
]);
paddle
::
paddleAtomicAdd
(
&
inPos
[
hId
*
inImgW
],
h1lambda
*
w2lambda
*
outPos
[
0
]);
paddle
::
paddleAtomicAdd
(
&
inPos
[
hId
*
inImgW
+
wId
],
h1lambda
*
w1lambda
*
outPos
[
0
]);
paddle
::
paddleAtomicAdd
(
&
inPos
[
hId
*
inImgW
],
h1lambda
*
w2lambda
*
outPos
[
0
]);
paddle
::
paddleAtomicAdd
(
&
inPos
[
hId
*
inImgW
+
wId
],
h1lambda
*
w1lambda
*
outPos
[
0
]);
}
}
...
...
@@ -379,22 +492,37 @@ void hl_bilinear_backward(real* inGrad,
int
threadNum
=
outputH
*
outputW
;
int
blocks
=
(
threadNum
+
1024
-
1
)
/
1024
;
KeBilinearInterpBw
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
inImgH
,
inImgW
,
inputH
,
inputW
,
outGrad
,
outImgH
,
outImgW
,
outputH
,
outputW
,
numChannels
,
ratioH
,
ratioW
);
KeBilinearInterpBw
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
inImgH
,
inImgW
,
inputH
,
inputW
,
outGrad
,
outImgH
,
outImgW
,
outputH
,
outputW
,
numChannels
,
ratioH
,
ratioW
);
CHECK_SYNC
(
"hl_bilinear_backward failed"
);
}
__global__
void
maxoutFpCompute
(
size_t
nthreads
,
const
real
*
inData
,
real
*
outData
,
int
*
idData
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
__global__
void
maxoutFpCompute
(
size_t
nthreads
,
const
real
*
inData
,
real
*
outData
,
int
*
idData
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
if
(
index
<
nthreads
)
{
size_t
batch_idx
=
index
/
size
;
size_t
i
=
index
%
size
;
size_t
channel_idx
=
i
/
featLen
;
size_t
feat_idx
=
i
%
featLen
;
size_t
data_idx
=
(
batch_idx
*
size
+
channel_idx
*
featLen
)
*
groups
+
feat_idx
;
size_t
data_idx
=
(
batch_idx
*
size
+
channel_idx
*
featLen
)
*
groups
+
feat_idx
;
real
max
=
inData
[
data_idx
];
int
maxId
=
0
;
for
(
size_t
g
=
1
;
g
<
groups
;
++
g
)
{
...
...
@@ -409,37 +537,50 @@ __global__ void maxoutFpCompute(size_t nthreads, const real * inData,
}
}
void
hl_maxout_forward
(
const
real
*
inData
,
real
*
outData
,
int
*
idData
,
size_t
batchSize
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
void
hl_maxout_forward
(
const
real
*
inData
,
real
*
outData
,
int
*
idData
,
size_t
batchSize
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
int
num_kernels
=
size
*
batchSize
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
maxoutFpCompute
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inData
,
outData
,
idData
,
size
,
featLen
,
groups
);
maxoutFpCompute
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inData
,
outData
,
idData
,
size
,
featLen
,
groups
);
CHECK_SYNC
(
"hl_maxout_forward failed"
);
}
__global__
void
maxoutBpCompute
(
size_t
nthreads
,
real
*
inGrad
,
const
real
*
outGrad
,
const
int
*
idData
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
__global__
void
maxoutBpCompute
(
size_t
nthreads
,
real
*
inGrad
,
const
real
*
outGrad
,
const
int
*
idData
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
if
(
index
<
nthreads
)
{
size_t
batch_idx
=
index
/
size
;
size_t
i
=
index
%
size
;
size_t
channel_idx
=
i
/
featLen
;
size_t
feat_idx
=
i
%
featLen
;
size_t
newIndex
=
batch_idx
*
size
;
size_t
gradIdx
=
(
channel_idx
*
groups
+
(
idData
+
newIndex
)[
i
])
*
featLen
+
feat_idx
;
size_t
gradIdx
=
(
channel_idx
*
groups
+
(
idData
+
newIndex
)[
i
])
*
featLen
+
feat_idx
;
(
inGrad
+
newIndex
*
groups
)[
gradIdx
]
+=
(
outGrad
+
newIndex
)[
i
];
}
}
void
hl_maxout_backward
(
real
*
inGrad
,
const
real
*
outGrad
,
const
int
*
idData
,
size_t
batchSize
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
void
hl_maxout_backward
(
real
*
inGrad
,
const
real
*
outGrad
,
const
int
*
idData
,
size_t
batchSize
,
size_t
size
,
size_t
featLen
,
size_t
groups
)
{
int
num_kernels
=
size
*
batchSize
;
int
blocks
=
(
num_kernels
+
1024
-
1
)
/
1024
;
maxoutBpCompute
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inGrad
,
outGrad
,
idData
,
size
,
featLen
,
groups
);
maxoutBpCompute
<<<
blocks
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
num_kernels
,
inGrad
,
outGrad
,
idData
,
size
,
featLen
,
groups
);
CHECK_SYNC
(
"hl_maxout_backward failed"
);
}
paddle/cuda/src/hl_cuda_lstm.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,14 +12,13 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_activation_functions.h"
#include "hl_base.h"
#include "hl_cuda_cublas.h"
#include "hl_device_functions.cuh"
#include "hl_activation_functions.h"
#include "paddle/utils/Logging.h"
typedef
hppl
::
Active
<
real
>::
forward
t_forward
;
typedef
hppl
::
Active
<
real
>::
forward
t_forward
;
typedef
hppl
::
Active
<
real
>::
backward
t_backward
;
bool
hl_lstm_sequence_parallel
(
int
frameSize
)
{
...
...
@@ -42,9 +41,9 @@ public:
value_
+=
(
start
+
length
-
1
)
*
frameSize
+
idx
;
}
}
__device__
inline
real
*
getPtr
()
const
{
return
value_
;
}
__device__
inline
real
getValue
()
{
return
*
value_
;
}
__device__
inline
void
setValue
(
real
value
)
{
*
value_
=
value
;
}
__device__
inline
real
*
getPtr
()
const
{
return
value_
;
}
__device__
inline
real
getValue
()
{
return
*
value_
;
}
__device__
inline
void
setValue
(
real
value
)
{
*
value_
=
value
;
}
template
<
int
reversed
,
int
frameSize
>
__device__
inline
void
nextFrame
()
{
if
(
reversed
==
0
)
{
...
...
@@ -55,28 +54,25 @@ public:
}
};
__device__
__forceinline__
void
ptx_sync
(
const
int
id
,
const
int
barriers
)
{
__device__
__forceinline__
void
ptx_sync
(
const
int
id
,
const
int
barriers
)
{
asm
volatile
(
"bar.sync %0, %1;"
:
:
"r"
(
id
),
"r"
(
barriers
)
:
"memory"
);
}
__device__
__forceinline__
void
ptx_arrive
(
const
int
id
,
const
int
barriers
)
{
__device__
__forceinline__
void
ptx_arrive
(
const
int
id
,
const
int
barriers
)
{
asm
volatile
(
"bar.arrive %0, %1;"
:
:
"r"
(
id
),
"r"
(
barriers
)
:
"memory"
);
}
template
<
int
valueSize
,
int
frameSize
>
__device__
__forceinline__
real
forward_sequence
(
real
value
,
real
*
shValue
,
real
*
state
,
real
*
preOutput
,
real
*
output
,
real
check
,
int
index
,
t_forward
activeNode
,
t_forward
activeGate
,
t_forward
activeState
)
{
template
<
int
valueSize
,
int
frameSize
>
__device__
__forceinline__
real
forward_sequence
(
real
value
,
real
*
shValue
,
real
*
state
,
real
*
preOutput
,
real
*
output
,
real
check
,
int
index
,
t_forward
activeNode
,
t_forward
activeGate
,
t_forward
activeState
)
{
real
out
;
real
prevOut
;
real
state_r
;
...
...
@@ -112,17 +108,20 @@ forward_sequence(real value,
if
(
idy
==
0
)
{
ptx_sync
(
2
,
frameSize
*
2
);
prevOut
=
state
[
idx
];
prevOut
=
activeState
(
prevOut
);
prevOut
=
activeState
(
prevOut
);
preOutput
[
idx
]
=
prevOut
;
ptx_arrive
(
3
,
frameSize
*
2
);
}
return
value
;
}
#define OUTPUT_BARRIER_ID 10
#define OUTPUT_BARRIER_ID2 11
template
<
int
valueSize
,
int
frameSize
,
int
reversed
,
int
computeThreads
,
int
blockSize
>
#define OUTPUT_BARRIER_ID 10
#define OUTPUT_BARRIER_ID2 11
template
<
int
valueSize
,
int
frameSize
,
int
reversed
,
int
computeThreads
,
int
blockSize
>
__global__
void
KeLstmForward
(
real
*
gateValue
,
real
*
state
,
real
*
output
,
...
...
@@ -184,10 +183,16 @@ __global__ void KeLstmForward(real *gateValue,
}
}
value
=
forward_sequence
<
valueSize
,
frameSize
>
(
value
,
shValue
,
shState
,
shPrevOutput
,
shOutput
,
check
,
index
,
hppl
::
gpu
::
forward
[
active_node
],
hppl
::
gpu
::
forward
[
active_gate
],
hppl
::
gpu
::
forward
[
active_state
]);
value
,
shValue
,
shState
,
shPrevOutput
,
shOutput
,
check
,
index
,
hppl
::
gpu
::
forward
[
active_node
],
hppl
::
gpu
::
forward
[
active_gate
],
hppl
::
gpu
::
forward
[
active_state
]);
const
int
idx
=
index
%
frameSize
;
const
int
idy
=
index
/
frameSize
;
if
(
valueSize
==
128
)
{
...
...
@@ -218,7 +223,7 @@ __global__ void KeLstmForward(real *gateValue,
real
B_r
[
frameSize
];
const
int
computeIdx
=
index
-
valueSize
;
if
(
i
==
0
)
{
#pragma unroll
#pragma unroll
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
B_r
[
n
]
=
weight
[
n
*
valueSize
+
computeIdx
];
}
...
...
@@ -230,7 +235,7 @@ __global__ void KeLstmForward(real *gateValue,
}
real
sum
=
0.0
f
;
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
sum
+=
A_r
[
n
]
*
B_r
[
n
];
sum
+=
A_r
[
n
]
*
B_r
[
n
];
}
shValue
[
computeIdx
]
=
sum
;
ptx_arrive
(
OUTPUT_BARRIER_ID2
,
blockSize
);
...
...
@@ -239,14 +244,14 @@ __global__ void KeLstmForward(real *gateValue,
if
(
valueSize
==
256
)
{
real
B_r
[
frameSize
];
if
(
i
==
0
)
{
#pragma unroll
#pragma unroll
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
B_r
[
n
]
=
weight
[
n
*
valueSize
+
index
];
}
}
real
sum
=
0.0
f
;
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
sum
+=
shOutput
[
n
]
*
B_r
[
n
];
sum
+=
shOutput
[
n
]
*
B_r
[
n
];
}
value
+=
sum
;
}
...
...
@@ -273,50 +278,81 @@ void hl_lstm_parallel_forward(real *gateValue,
dim3
grid
(
numSequences
,
1
);
if
(
!
reversed
)
{
if
(
frameSize
==
32
)
{
KeLstmForward
<
128
,
32
,
0
,
128
,
256
>
<<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmForward
<
128
,
32
,
0
,
128
,
256
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
64
)
{
KeLstmForward
<
256
,
64
,
0
,
256
,
256
>
<<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmForward
<
256
,
64
,
0
,
256
,
256
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
}
else
{
if
(
frameSize
==
32
)
{
KeLstmForward
<
128
,
32
,
1
,
128
,
256
>
<<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmForward
<
128
,
32
,
1
,
128
,
256
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
64
)
{
KeLstmForward
<
256
,
64
,
1
,
256
,
256
>
<<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmForward
<
256
,
64
,
1
,
256
,
256
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
stateValue
,
outputValue
,
preOutputValue
,
checkIg
,
checkFg
,
checkOg
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
}
CHECK_SYNC
(
"hl_lstm_parallel_forward failed"
);
}
__device__
__forceinline__
void
transpose_32x32
(
real
a
[],
const
int
idx
)
{
__device__
__forceinline__
void
transpose_32x32
(
real
a
[],
const
int
idx
)
{
int
addr
=
idx
%
32
;
#pragma unroll
#pragma unroll
for
(
int
k
=
1
;
k
<
32
;
k
++
)
{
// rSrc[k] = __shfl(rSrc[k], (threadIdx.x + k) % 32, 32);
addr
=
__shfl
(
addr
,
(
idx
+
1
)
%
32
,
32
);
a
[
k
]
=
__shfl
(
a
[
k
],
addr
,
32
);
}
#pragma unroll
#pragma unroll
for
(
int
tid
=
0
;
tid
<
31
;
tid
++
)
{
real
tmp
=
(
idx
>
tid
)
?
a
[
0
]
:
a
[
1
];
#pragma unroll
#pragma unroll
for
(
int
k
=
31
;
k
>
0
;
k
--
)
{
a
[(
k
+
1
)
%
32
]
=
(
idx
>
tid
)
?
a
[
k
]
:
a
[(
k
+
1
)
%
32
];
}
...
...
@@ -324,29 +360,28 @@ void transpose_32x32(real a[], const int idx) {
}
addr
=
(
32
-
idx
)
%
32
;
#pragma unroll
#pragma unroll
for
(
int
k
=
0
;
k
<
32
;
k
++
)
{
a
[
k
]
=
__shfl
(
a
[
k
],
addr
,
32
);
addr
=
__shfl
(
addr
,
(
idx
+
31
)
%
32
,
32
);
}
}
template
<
int
valueSize
,
int
frameSize
>
__device__
void
backward_sequence
(
real
rGateValue
,
real
rOutputGrad
,
real
rPreOutputValue
,
real
&
rGateGrad
,
real
&
rStateGrad
,
real
*
shStateGrad
,
real
*
shStateValue
,
real
*
shGateValue
,
real
rCheck
,
real
&
rGateValuePrev
,
int
index
,
t_backward
activeNode
,
t_backward
activeGate
,
t_backward
activeState
)
{
template
<
int
valueSize
,
int
frameSize
>
__device__
void
backward_sequence
(
real
rGateValue
,
real
rOutputGrad
,
real
rPreOutputValue
,
real
&
rGateGrad
,
real
&
rStateGrad
,
real
*
shStateGrad
,
real
*
shStateValue
,
real
*
shGateValue
,
real
rCheck
,
real
&
rGateValuePrev
,
int
index
,
t_backward
activeNode
,
t_backward
activeGate
,
t_backward
activeState
)
{
const
int
frameIdx
=
index
%
frameSize
;
const
int
frameIdy
=
index
/
frameSize
;
if
(
frameIdy
==
3
)
{
...
...
@@ -363,8 +398,8 @@ backward_sequence(real rGateValue,
rStateGrad
=
rGateGrad
*
rCheck
;
shStateGrad
[
index
]
=
rStateGrad
;
ptx_sync
(
3
,
valueSize
);
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
2
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
2
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rGateGrad
=
rStateGrad
*
shGateValue
[
frameIdx
];
rGateGrad
=
activeGate
(
rGateGrad
,
rGateValue
);
}
else
if
(
frameIdy
==
2
)
{
...
...
@@ -373,7 +408,7 @@ backward_sequence(real rGateValue,
shStateGrad
[
index
]
=
rStateGrad
;
ptx_sync
(
3
,
valueSize
);
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rGateValuePrev
=
rGateValue
;
rGateGrad
=
rStateGrad
*
shStateValue
[
frameIdx
];
rGateGrad
=
activeGate
(
rGateGrad
,
rGateValue
);
...
...
@@ -381,43 +416,43 @@ backward_sequence(real rGateValue,
shGateValue
[
frameIdx
]
=
rGateValue
;
ptx_sync
(
3
,
valueSize
);
rStateGrad
=
shStateGrad
[
frameIdx
+
frameSize
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
2
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
2
];
rStateGrad
+=
shStateGrad
[
frameIdx
+
frameSize
*
3
];
rGateGrad
=
rStateGrad
*
shGateValue
[
frameIdx
+
frameSize
];
rGateGrad
=
activeNode
(
rGateGrad
,
rGateValue
);
}
}
template
<
int
valueSize
,
int
frameSize
>
template
<
int
valueSize
,
int
frameSize
>
__device__
void
load_weight
(
real
rWeight
[],
real
*
weight
,
const
int
index
)
{
if
(
valueSize
==
128
)
{
weight
+=
index
;
#pragma unroll
#pragma unroll
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
rWeight
[
n
]
=
weight
[
n
*
valueSize
];
rWeight
[
n
]
=
weight
[
n
*
valueSize
];
}
transpose_32x32
(
rWeight
,
index
%
32
);
}
if
(
valueSize
==
256
)
{
int
id
=
(
index
/
32
)
%
2
;
weight
+=
index
-
id
*
32
+
id
*
32
*
valueSize
;
#pragma unroll
#pragma unroll
for
(
int
n
=
0
;
n
<
32
;
n
++
)
{
rWeight
[
n
]
=
weight
[
n
*
valueSize
];
rWeight
[
n
+
32
]
=
weight
[
n
*
valueSize
+
32
];
rWeight
[
n
]
=
weight
[
n
*
valueSize
];
rWeight
[
n
+
32
]
=
weight
[
n
*
valueSize
+
32
];
}
transpose_32x32
(
rWeight
,
index
%
32
);
transpose_32x32
(
&
rWeight
[
32
],
index
%
32
);
}
}
template
<
int
valueSize
,
int
frameSize
,
int
reversed
>
template
<
int
valueSize
,
int
frameSize
,
int
reversed
>
__global__
void
KeLstmBackward
(
real
*
gateValue
,
real
*
gateGrad
,
real
*
stateValue
,
real
*
stateGrad
,
/* do not need save */
real
*
stateGrad
,
/* do not need save */
real
*
preOutputValue
,
real
*
preOutputGrad
,
/* do not need save */
real
*
preOutputGrad
,
/* do not need save */
real
*
checkIg
,
real
*
checkIgGrad
,
real
*
checkFg
,
...
...
@@ -484,20 +519,27 @@ __global__ void KeLstmBackward(real *gateValue,
for
(
int
i
=
0
;
i
<
length
;
++
i
)
{
if
(
frameIdy
==
3
)
{
if
(
i
!=
length
-
1
)
{
if
(
i
!=
length
-
1
)
{
frameStateValue
.
nextFrame
<!
reversed
,
frameSize
>
();
shStateValue
[
frameIdx
]
=
frameStateValue
.
getValue
();
}
else
{
shStateValue
[
frameIdx
]
=
0.0
;
}
}
backward_sequence
<
valueSize
,
frameSize
>
(
rGateValue
,
rOutputGrad
,
rPreOutputValue
,
rGateGrad
,
rStateGrad
,
shStateGrad
,
shStateValue
,
shGateValue
,
rCheck
,
rGateValuePrev
,
index
,
hppl
::
gpu
::
backward
[
active_node
],
hppl
::
gpu
::
backward
[
active_gate
],
hppl
::
gpu
::
backward
[
active_state
]);
backward_sequence
<
valueSize
,
frameSize
>
(
rGateValue
,
rOutputGrad
,
rPreOutputValue
,
rGateGrad
,
rStateGrad
,
shStateGrad
,
shStateValue
,
shGateValue
,
rCheck
,
rGateValuePrev
,
index
,
hppl
::
gpu
::
backward
[
active_node
],
hppl
::
gpu
::
backward
[
active_gate
],
hppl
::
gpu
::
backward
[
active_state
]);
if
(
frameIdy
==
3
)
{
rCheckGrad
+=
rGateGrad
*
rStateValue
;
rStateValue
=
shStateValue
[
frameIdx
];
...
...
@@ -523,9 +565,9 @@ __global__ void KeLstmBackward(real *gateValue,
shGateGrad
[
frameIdy
][
frameIdx
]
=
rGateGrad
;
if
(
valueSize
==
128
)
{
real
sum
=
0.0
f
;
#pragma unroll
#pragma unroll
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
sum
+=
shGateGrad
[
frameIdy
][
n
]
*
B_r
[
n
];
sum
+=
shGateGrad
[
frameIdy
][
n
]
*
B_r
[
n
];
}
if
(
frameIdy
==
3
)
{
rOutputGrad
+=
sum
;
...
...
@@ -541,7 +583,7 @@ __global__ void KeLstmBackward(real *gateValue,
}
real
sum
=
0.0
f
;
for
(
int
n
=
0
;
n
<
frameSize
;
n
++
)
{
sum
+=
A_r
[
n
]
*
B_r
[
n
];
sum
+=
A_r
[
n
]
*
B_r
[
n
];
}
if
(
frameIdy
==
3
)
{
rOutputGrad
+=
sum
;
...
...
@@ -552,8 +594,8 @@ __global__ void KeLstmBackward(real *gateValue,
if
(
frameIdy
==
3
)
{
ptx_sync
(
6
,
valueSize
);
#pragma unroll
for
(
int
i
=
0
;
i
<
3
;
i
++
)
{
#pragma unroll
for
(
int
i
=
0
;
i
<
3
;
i
++
)
{
rOutputGrad
+=
shOutputGrad
[
i
][
frameIdx
];
}
}
else
{
...
...
@@ -564,11 +606,14 @@ __global__ void KeLstmBackward(real *gateValue,
/* TODO: Temporary save & merger in another kernel */
if
(
frameIdy
==
1
)
{
if
(
checkIgGrad
)
paddle
::
paddleAtomicAdd
(
checkIgGrad
+
frameIdx
,
rCheckGrad
);
if
(
checkIgGrad
)
paddle
::
paddleAtomicAdd
(
checkIgGrad
+
frameIdx
,
rCheckGrad
);
}
else
if
(
frameIdy
==
2
)
{
if
(
checkFgGrad
)
paddle
::
paddleAtomicAdd
(
checkFgGrad
+
frameIdx
,
rCheckGrad
);
if
(
checkFgGrad
)
paddle
::
paddleAtomicAdd
(
checkFgGrad
+
frameIdx
,
rCheckGrad
);
}
else
if
(
frameIdy
==
3
)
{
if
(
checkOgGrad
)
paddle
::
paddleAtomicAdd
(
checkOgGrad
+
frameIdx
,
rCheckGrad
);
if
(
checkOgGrad
)
paddle
::
paddleAtomicAdd
(
checkOgGrad
+
frameIdx
,
rCheckGrad
);
}
}
...
...
@@ -593,68 +638,183 @@ void hl_lstm_parallel_backward_data(real *gateValue,
hl_activation_mode_t
active_node
,
hl_activation_mode_t
active_gate
,
hl_activation_mode_t
active_state
)
{
CHECK
(
frameSize
==
32
||
frameSize
==
64
||
frameSize
==
128
||
frameSize
==
256
);
CHECK
(
frameSize
==
32
||
frameSize
==
64
||
frameSize
==
128
||
frameSize
==
256
);
dim3
grid
(
numSequences
,
1
);
if
(
!
reversed
)
{
if
(
frameSize
==
32
)
{
KeLstmBackward
<
128
,
32
,
0
><<<
grid
,
128
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
128
,
32
,
0
><<<
grid
,
128
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
64
)
{
KeLstmBackward
<
256
,
64
,
0
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
256
,
64
,
0
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
128
)
{
KeLstmBackward
<
512
,
128
,
0
><<<
grid
,
512
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
512
,
128
,
0
><<<
grid
,
512
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
256
)
{
KeLstmBackward
<
1024
,
256
,
0
><<<
grid
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
1024
,
256
,
0
><<<
grid
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
}
else
{
if
(
frameSize
==
32
)
{
KeLstmBackward
<
128
,
32
,
1
><<<
grid
,
128
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
128
,
32
,
1
><<<
grid
,
128
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
64
)
{
KeLstmBackward
<
256
,
64
,
1
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
256
,
64
,
1
><<<
grid
,
256
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
128
)
{
KeLstmBackward
<
512
,
128
,
1
><<<
grid
,
512
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
512
,
128
,
1
><<<
grid
,
512
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
else
if
(
frameSize
==
256
)
{
KeLstmBackward
<
1024
,
256
,
1
><<<
grid
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
KeLstmBackward
<
1024
,
256
,
1
><<<
grid
,
1024
,
0
,
STREAM_DEFAULT
>>>
(
gateValue
,
gateGrad
,
stateValue
,
stateGrad
,
preOutputValue
,
preOutputGrad
,
checkIg
,
checkIgGrad
,
checkFg
,
checkFgGrad
,
checkOg
,
checkOgGrad
,
outputGrad
,
weight
,
sequence
,
active_node
,
active_gate
,
active_state
);
}
}
CHECK_SYNC
(
"hl_lstm_parallel_backward_data"
);
}
template
<
int
B_X
,
int
B_Y
>
template
<
int
B_X
,
int
B_Y
>
__global__
void
KeSetGradZero
(
real
*
gateGrad
,
const
int
*
starts
,
int
valueSize
,
int
numSequences
,
bool
reversed
)
{
const
int
*
starts
,
int
valueSize
,
int
numSequences
,
bool
reversed
)
{
// const int tid = threadIdx.x;
const
int
frameIdx
=
blockIdx
.
x
*
B_X
+
threadIdx
.
x
;
...
...
@@ -682,19 +842,31 @@ void hl_lstm_parallel_backward_weight(real *weightGrad,
int
valueSize
=
4
*
frameSize
;
dim3
threads
(
32
,
32
);
dim3
grid
((
valueSize
+
32
-
1
)
/
32
,
(
numSequences
+
32
-
1
)
/
32
);
KeSetGradZero
<
32
,
32
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
gateGrad
,
sequence
,
valueSize
,
numSequences
,
reversed
);
KeSetGradZero
<
32
,
32
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
gateGrad
,
sequence
,
valueSize
,
numSequences
,
reversed
);
if
(
!
reversed
)
{
hl_matrix_mul
(
outputValue
,
HPPL_OP_T
,
gateGrad
+
valueSize
,
HPPL_OP_N
,
weightGrad
,
frameSize
,
valueSize
,
batchSize
-
1
,
1.0
,
1.0
);
HPPL_OP_T
,
gateGrad
+
valueSize
,
HPPL_OP_N
,
weightGrad
,
frameSize
,
valueSize
,
batchSize
-
1
,
1.0
,
1.0
);
}
else
{
hl_matrix_mul
(
outputValue
+
frameSize
,
HPPL_OP_T
,
gateGrad
,
HPPL_OP_N
,
weightGrad
,
frameSize
,
valueSize
,
batchSize
-
1
,
1.0
,
1.0
);
HPPL_OP_T
,
gateGrad
,
HPPL_OP_N
,
weightGrad
,
frameSize
,
valueSize
,
batchSize
-
1
,
1.0
,
1.0
);
}
CHECK_SYNC
(
"hl_lstm_parallel_backward_weight"
);
}
paddle/cuda/src/hl_cuda_matrix.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,22 +12,21 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "hl_device_functions.cuh"
#include "hl_gpu_matrix_kernel.cuh"
#include "hl_matrix.h"
#include "hl_matrix_ops.cuh"
#include "hl_matrix_apply.cuh"
#include "hl_matrix_ops.cuh"
#include "hl_sequence.h"
#include "hl_sparse.ph"
#include "paddle/utils/Logging.h"
#include "hl_device_functions.cuh"
#include "hl_gpu_matrix_kernel.cuh"
DEFINE_MATRIX_UNARY_OP
(
Zero
,
a
=
0
);
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
_add
,
TWO_PARAMETER
,
c
=
p1
*
a
+
p2
*
b
);
void
hl_matrix_add
(
real
*
A_d
,
real
*
B_d
,
real
*
C_d
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
_add
,
TWO_PARAMETER
,
c
=
p1
*
a
+
p2
*
b
);
void
hl_matrix_add
(
real
*
A_d
,
real
*
B_d
,
real
*
C_d
,
int
dimM
,
int
dimN
,
real
alpha
,
...
...
@@ -36,33 +35,32 @@ void hl_matrix_add(real *A_d,
CHECK_NOTNULL
(
B_d
);
CHECK_NOTNULL
(
C_d
);
hl_gpu_apply_ternary_op
<
real
,
ternary
::
_add
<
real
>
,
0
,
0
>
(
ternary
::
_add
<
real
>
(
alpha
,
beta
),
A_d
,
B_d
,
C_d
,
dimM
,
dimN
,
dimN
,
dimN
,
dimN
);
hl_gpu_apply_ternary_op
<
real
,
ternary
::
_add
<
real
>
,
0
,
0
>
(
ternary
::
_add
<
real
>
(
alpha
,
beta
),
A_d
,
B_d
,
C_d
,
dimM
,
dimN
,
dimN
,
dimN
,
dimN
);
CHECK_SYNC
(
"hl_matrix_add failed"
);
}
#ifdef PADDLE_TYPE_DOUBLE
#define THRESHOLD
128
#define THRESHOLD
128
#else
#define THRESHOLD
64
#define THRESHOLD
64
#endif
__device__
__forceinline__
void
findMax
(
real
*
I
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
,
real
*
max
)
{
__device__
__forceinline__
void
findMax
(
real
*
I
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
,
real
*
max
)
{
dfMax_s
[
base
]
=
-
1.0e20
;
while
(
curIdx
<
dimN
)
{
if
(
dfMax_s
[
base
]
<
I
[
nextIdx
])
{
...
...
@@ -78,25 +76,24 @@ void findMax(real* I,
if
(
base
<
stride
)
{
nextIdx
=
base
+
stride
;
if
(
dfMax_s
[
base
]
<
dfMax_s
[
nextIdx
])
{
dfMax_s
[
base
]
=
dfMax_s
[
nextIdx
];
dfMax_s
[
base
]
=
dfMax_s
[
nextIdx
];
}
}
}
if
(
0
==
base
)
{
if
(
0
==
base
)
{
max
[
0
]
=
dfMax_s
[
0
];
}
__syncthreads
();
}
__device__
__forceinline__
void
subMaxAndExp
(
real
*
I
,
real
*
O
,
int
curIdx
,
int
nextIdx
,
int
blockSize
,
int
dimN
,
real
max
)
{
__device__
__forceinline__
void
subMaxAndExp
(
real
*
I
,
real
*
O
,
int
curIdx
,
int
nextIdx
,
int
blockSize
,
int
dimN
,
real
max
)
{
real
val
;
while
(
curIdx
<
dimN
)
{
val
=
I
[
nextIdx
]
-
max
;
...
...
@@ -115,14 +112,13 @@ void subMaxAndExp(real* I,
__syncthreads
();
}
__device__
__forceinline__
void
valueSum
(
real
*
O
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
)
{
__device__
__forceinline__
void
valueSum
(
real
*
O
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
)
{
dfMax_s
[
base
]
=
0
;
while
(
curIdx
<
dimN
)
{
dfMax_s
[
base
]
+=
O
[
nextIdx
];
...
...
@@ -141,13 +137,8 @@ void valueSum(real* O,
__syncthreads
();
}
__device__
__forceinline__
void
divSum
(
real
*
O
,
real
sum
,
int
curIdx
,
int
nextIdx
,
int
blockSize
,
int
dimN
)
{
__device__
__forceinline__
void
divSum
(
real
*
O
,
real
sum
,
int
curIdx
,
int
nextIdx
,
int
blockSize
,
int
dimN
)
{
while
(
curIdx
<
dimN
)
{
O
[
nextIdx
]
/=
sum
;
nextIdx
+=
blockSize
;
...
...
@@ -155,20 +146,18 @@ void divSum(real* O,
}
}
__device__
__forceinline__
void
softmax
(
real
*
I
,
real
*
O
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
)
{
__device__
__forceinline__
void
softmax
(
real
*
I
,
real
*
O
,
real
*
dfMax_s
,
int
blockSize
,
int
base
,
int
curIdx
,
int
nextIdx
,
int
dimN
)
{
__shared__
real
max
;
// find the max number
findMax
(
I
,
dfMax_s
,
blockSize
,
base
,
curIdx
,
nextIdx
,
dimN
,
&
max
);
findMax
(
I
,
dfMax_s
,
blockSize
,
base
,
curIdx
,
nextIdx
,
dimN
,
&
max
);
// sub max Value and do Exp operation
subMaxAndExp
(
I
,
O
,
base
,
nextIdx
,
blockSize
,
dimN
,
max
);
...
...
@@ -181,8 +170,8 @@ void softmax(real* I,
divSum
(
O
,
dfMax_s
[
0
],
curIdx
,
nextIdx
,
blockSize
,
dimN
);
}
template
<
int
blockSize
>
__global__
void
KeMatrixSoftMax
(
real
*
O
,
real
*
I
,
int
dimN
)
{
template
<
int
blockSize
>
__global__
void
KeMatrixSoftMax
(
real
*
O
,
real
*
I
,
int
dimN
)
{
int
base
=
threadIdx
.
x
;
__shared__
real
dfMax_s
[
blockSize
];
int
nextIdx
=
blockIdx
.
x
*
dimN
+
base
;
...
...
@@ -191,19 +180,18 @@ __global__ void KeMatrixSoftMax(real *O, real *I, int dimN) {
softmax
(
I
,
O
,
dfMax_s
,
blockSize
,
base
,
curIdx
,
nextIdx
,
dimN
);
}
void
hl_matrix_softmax
(
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_softmax
(
real
*
A_d
,
real
*
C_d
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
dim3
block
(
512
,
1
);
dim3
grid
(
dimM
,
1
);
KeMatrixSoftMax
<
512
>
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
dimN
);
KeMatrixSoftMax
<
512
><<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
dimN
);
CHECK_SYNC
(
"hl_matrix_softmax failed"
);
}
template
<
int
blockSize
>
__global__
void
KeSequenceSoftMax
(
real
*
O
,
real
*
I
,
const
int
*
index
)
{
template
<
int
blockSize
>
__global__
void
KeSequenceSoftMax
(
real
*
O
,
real
*
I
,
const
int
*
index
)
{
int
base
=
threadIdx
.
x
;
int
bid
=
blockIdx
.
x
;
__shared__
real
dfMax_s
[
blockSize
];
...
...
@@ -217,8 +205,8 @@ __global__ void KeSequenceSoftMax(real *O, real *I, const int* index) {
softmax
(
I
,
O
,
dfMax_s
,
blockSize
,
base
,
curIdx
,
nextIdx
,
dimN
);
}
void
hl_sequence_softmax_forward
(
real
*
A_d
,
real
*
C_d
,
void
hl_sequence_softmax_forward
(
real
*
A_d
,
real
*
C_d
,
const
int
*
index
,
int
numSequence
)
{
CHECK_NOTNULL
(
A_d
);
...
...
@@ -226,59 +214,48 @@ void hl_sequence_softmax_forward(real *A_d,
dim3
block
(
512
,
1
);
dim3
grid
(
numSequence
,
1
);
KeSequenceSoftMax
<
512
>
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
index
);
KeSequenceSoftMax
<
512
><<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
index
);
CHECK_SYNC
(
"hl_sequence_softmax_forward failed"
);
}
__global__
void
KeMatrixDerivative
(
real
*
grad_d
,
real
*
output_d
,
real
*
sftmaxSum_d
,
int
dimM
,
int
dimN
)
{
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
colIdx
=
blockIdx
.
y
*
blockDim
.
y
+
threadIdx
.
y
;
__global__
void
KeMatrixDerivative
(
real
*
grad_d
,
real
*
output_d
,
real
*
sftmaxSum_d
,
int
dimM
,
int
dimN
)
{
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
colIdx
=
blockIdx
.
y
*
blockDim
.
y
+
threadIdx
.
y
;
int
index
;
if
(
rowIdx
<
dimM
&&
colIdx
<
dimN
)
{
index
=
rowIdx
*
dimN
+
colIdx
;
index
=
rowIdx
*
dimN
+
colIdx
;
grad_d
[
index
]
=
output_d
[
index
]
*
(
grad_d
[
index
]
-
sftmaxSum_d
[
rowIdx
]);
}
}
void
hl_matrix_softmax_derivative
(
real
*
grad_d
,
real
*
output_d
,
real
*
sftmaxSum_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_softmax_derivative
(
real
*
grad_d
,
real
*
output_d
,
real
*
sftmaxSum_d
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
grad_d
);
CHECK_NOTNULL
(
output_d
);
CHECK_NOTNULL
(
sftmaxSum_d
);
int
blocksX
=
(
dimM
+
0
)
/
1
;
int
blocksY
=
(
dimN
+
1024
-
1
)
/
1024
;
int
blocksY
=
(
dimN
+
1024
-
1
)
/
1024
;
dim3
threads
(
1
,
1024
);
dim3
grid
(
blocksX
,
blocksY
);
KeMatrixDerivative
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_d
,
output_d
,
sftmaxSum_d
,
dimM
,
dimN
);
KeMatrixDerivative
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_d
,
output_d
,
sftmaxSum_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_softmax_derivative failed"
);
}
__global__
void
KeMatrixMultiBinaryCrossEntropy
(
real
*
output
,
real
*
entropy
,
int
*
row
,
int
*
col
,
int
dimM
,
int
dimN
)
{
__global__
void
KeMatrixMultiBinaryCrossEntropy
(
real
*
output
,
real
*
entropy
,
int
*
row
,
int
*
col
,
int
dimM
,
int
dimN
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
dimM
)
{
for
(
int
i
=
0
;
i
<
dimN
;
i
++
)
{
for
(
int
i
=
0
;
i
<
dimN
;
i
++
)
{
entropy
[
index
]
-=
log
(
1
-
output
[
index
*
dimN
+
i
]);
}
int
*
row_col
=
col
+
row
[
index
];
int
*
row_col
=
col
+
row
[
index
];
int
col_num
=
row
[
index
+
1
]
-
row
[
index
];
for
(
int
i
=
0
;
i
<
col_num
;
i
++
)
{
for
(
int
i
=
0
;
i
<
col_num
;
i
++
)
{
real
o
=
output
[
index
*
dimN
+
row_col
[
i
]];
entropy
[
index
]
-=
log
(
o
/
(
1
-
o
));
}
...
...
@@ -299,37 +276,30 @@ void hl_matrix_multi_binary_cross_entropy(real* output,
dim3
threads
(
n_threads
);
dim3
grid
(
blocks
);
hl_csr_matrix
mat
=
(
hl_csr_matrix
)(
csr_mat
->
matrix
);
KeMatrixMultiBinaryCrossEntropy
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
entropy
,
mat
->
csr_row
,
mat
->
csr_col
,
dimM
,
dimN
);
KeMatrixMultiBinaryCrossEntropy
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
entropy
,
mat
->
csr_row
,
mat
->
csr_col
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_multi_binary_cross_entropy failed"
);
}
__global__
void
KeMatrixMultiBinaryCrossEntropyBp
(
real
*
output
,
real
*
grad
,
int
*
row
,
int
*
col
,
int
dimM
,
int
dimN
)
{
__global__
void
KeMatrixMultiBinaryCrossEntropyBp
(
real
*
output
,
real
*
grad
,
int
*
row
,
int
*
col
,
int
dimM
,
int
dimN
)
{
int
row_idx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
row_idx
<
dimM
)
{
for
(
int
i
=
0
;
i
<
dimN
;
i
++
)
{
for
(
int
i
=
0
;
i
<
dimN
;
i
++
)
{
int
index
=
row_idx
*
dimN
+
i
;
grad
[
index
]
+=
1.0
/
(
1
-
output
[
index
]);
}
int
col_num
=
row
[
row_idx
+
1
]
-
row
[
row_idx
];
int
*
row_col
=
col
+
row
[
row_idx
];
for
(
int
i
=
0
;
i
<
col_num
;
i
++
)
{
int
*
row_col
=
col
+
row
[
row_idx
];
for
(
int
i
=
0
;
i
<
col_num
;
i
++
)
{
int
index
=
row_idx
*
dimN
+
row_col
[
i
];
grad
[
index
]
-=
1.0
/
(
output
[
index
]
*
(
1
-
output
[
index
]));
}
}
}
void
hl_matrix_multi_binary_cross_entropy_bp
(
real
*
output
,
real
*
grad
,
hl_sparse_matrix_s
csr_mat
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_multi_binary_cross_entropy_bp
(
real
*
output
,
real
*
grad
,
hl_sparse_matrix_s
csr_mat
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
output
);
CHECK_NOTNULL
(
grad
);
CHECK_NOTNULL
(
csr_mat
);
...
...
@@ -339,16 +309,13 @@ void hl_matrix_multi_binary_cross_entropy_bp(real* output,
dim3
threads
(
n_threads
);
dim3
grid
(
blocks
);
hl_csr_matrix
mat
=
(
hl_csr_matrix
)(
csr_mat
->
matrix
);
KeMatrixMultiBinaryCrossEntropyBp
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
grad
,
mat
->
csr_row
,
mat
->
csr_col
,
dimM
,
dimN
);
KeMatrixMultiBinaryCrossEntropyBp
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
grad
,
mat
->
csr_row
,
mat
->
csr_col
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_multi_binary_cross_entropy_bp failed"
);
}
__global__
void
KeMatrixCrossEntropy
(
real
*
O
,
real
*
E
,
int
*
label
,
int
dimM
,
int
dimN
)
{
__global__
void
KeMatrixCrossEntropy
(
real
*
O
,
real
*
E
,
int
*
label
,
int
dimM
,
int
dimN
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
newBase
;
if
(
index
<
dimM
)
{
...
...
@@ -358,59 +325,49 @@ __global__ void KeMatrixCrossEntropy(real* O,
}
}
void
hl_matrix_cross_entropy
(
real
*
A_d
,
real
*
C_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_cross_entropy
(
real
*
A_d
,
real
*
C_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
C_d
);
int
blocks
=
(
dimM
+
1024
-
1
)
/
1024
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blocks
,
1
);
KeMatrixCrossEntropy
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
C_d
,
label_d
,
dimM
,
dimN
);
KeMatrixCrossEntropy
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
C_d
,
label_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_cross_entropy failed"
);
}
__global__
void
KeMatrixCrossEntropyBp
(
real
*
grad_d
,
real
*
output_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
colIdx
=
blockIdx
.
y
*
blockDim
.
y
+
threadIdx
.
y
;
__global__
void
KeMatrixCrossEntropyBp
(
real
*
grad_d
,
real
*
output_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
int
rowIdx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
colIdx
=
blockIdx
.
y
*
blockDim
.
y
+
threadIdx
.
y
;
int
index
;
if
(
rowIdx
<
dimM
&&
colIdx
<
dimN
)
{
index
=
rowIdx
*
dimN
+
colIdx
;
index
=
rowIdx
*
dimN
+
colIdx
;
if
(
label_d
[
rowIdx
]
==
colIdx
)
{
grad_d
[
index
]
-=
1.0
f
/
output_d
[
index
];
}
}
}
void
hl_matrix_cross_entropy_bp
(
real
*
grad_d
,
real
*
output_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
void
hl_matrix_cross_entropy_bp
(
real
*
grad_d
,
real
*
output_d
,
int
*
label_d
,
int
dimM
,
int
dimN
)
{
CHECK_NOTNULL
(
grad_d
);
CHECK_NOTNULL
(
output_d
);
CHECK_NOTNULL
(
label_d
);
int
blocksX
=
(
dimM
+
0
)
/
1
;
int
blocksY
=
(
dimN
+
1024
-
1
)
/
1024
;
int
blocksX
=
(
dimM
+
0
)
/
1
;
int
blocksY
=
(
dimN
+
1024
-
1
)
/
1024
;
dim3
threads
(
1
,
1024
);
dim3
grid
(
blocksX
,
blocksY
);
KeMatrixCrossEntropyBp
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_d
,
output_d
,
label_d
,
dimM
,
dimN
);
KeMatrixCrossEntropyBp
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_d
,
output_d
,
label_d
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_matrix_cross_entropy_bp failed"
);
}
void
hl_matrix_zero_mem
(
real
*
data
,
int
num
)
{
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
data
,
1
,
num
,
num
);
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
data
,
1
,
num
,
num
);
}
__global__
void
KeParamReluForward
(
real
*
output
,
...
...
@@ -423,8 +380,8 @@ __global__ void KeParamReluForward(real* output,
int
ty
=
blockIdx
.
y
*
blockDim
.
y
+
threadIdx
.
y
;
if
(
tx
<
width
&&
ty
<
height
)
{
int
index
=
ty
*
width
+
tx
;
output
[
index
]
=
input
[
index
]
>
0
?
input
[
index
]
:
input
[
index
]
*
w
[
tx
/
partial_sum
];
output
[
index
]
=
input
[
index
]
>
0
?
input
[
index
]
:
input
[
index
]
*
w
[
tx
/
partial_sum
];
}
}
...
...
@@ -439,14 +396,14 @@ void hl_param_relu_forward(real* output,
CHECK_NOTNULL
(
w
);
dim3
threads
(
16
,
16
);
int
blockX
=
(
width
+
16
-
1
)
/
16
;
int
blockY
=
(
height
+
16
-
1
)
/
16
;
int
blockY
=
(
height
+
16
-
1
)
/
16
;
dim3
grid
(
blockX
,
blockY
);
KeParamReluForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input
,
w
,
width
,
height
,
partial_sum
);
KeParamReluForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input
,
w
,
width
,
height
,
partial_sum
);
CHECK_SYNC
(
"hl_param_relu_forward failed"
);
}
template
<
int
blockSize
>
template
<
int
blockSize
>
__global__
void
KeParamReluBackWardW
(
real
*
grad_w
,
real
*
grad_o
,
real
*
input
,
...
...
@@ -491,8 +448,8 @@ void hl_param_relu_backward_w(real* grad_w,
int
grid_num
=
width
/
partial_sum
;
dim3
threads
(
blockSize
,
1
);
dim3
grid
(
grid_num
,
1
);
KeParamReluBackWardW
<
blockSize
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_w
,
grad_o
,
input
,
width
,
height
,
partial_sum
);
KeParamReluBackWardW
<
blockSize
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_w
,
grad_o
,
input
,
width
,
height
,
partial_sum
);
CHECK_SYNC
(
"hl_param_relu_backward_w failed"
);
}
...
...
@@ -524,19 +481,15 @@ void hl_param_relu_backward_diff(real* grad_o,
CHECK_NOTNULL
(
diff
);
dim3
threads
(
16
,
16
);
int
blockX
=
(
width
+
16
-
1
)
/
16
;
int
blockY
=
(
height
+
16
-
1
)
/
16
;
int
blockY
=
(
height
+
16
-
1
)
/
16
;
dim3
grid
(
blockX
,
blockY
);
KeParamReluBackwardDiff
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_o
,
data
,
w
,
diff
,
width
,
height
,
partial_sum
);
KeParamReluBackwardDiff
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad_o
,
data
,
w
,
diff
,
width
,
height
,
partial_sum
);
CHECK_SYNC
(
"hl_param_relu_backward_diff failed"
);
}
__global__
void
KeMatrixAddSharedBias
(
real
*
A
,
real
*
B
,
const
int
channel
,
const
int
M
,
const
int
N
,
real
scale
)
{
__global__
void
KeMatrixAddSharedBias
(
real
*
A
,
real
*
B
,
const
int
channel
,
const
int
M
,
const
int
N
,
real
scale
)
{
int
index
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
dim
=
N
/
channel
;
if
(
index
<
M
*
N
)
{
...
...
@@ -554,15 +507,14 @@ void hl_matrix_add_shared_bias(real* A_d,
real
scale
)
{
const
int
blocks
=
512
;
const
int
grids
=
DIVUP
(
dimM
*
dimN
,
blocks
);
KeMatrixAddSharedBias
<<<
grids
,
blocks
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
B_d
,
channel
,
dimM
,
dimN
,
scale
);
KeMatrixAddSharedBias
<<<
grids
,
blocks
,
0
,
STREAM_DEFAULT
>>>
(
A_d
,
B_d
,
channel
,
dimM
,
dimN
,
scale
);
CHECK_SYNC
(
"hl_matrix_add_shared_bias failed"
);
}
template
<
int
blockSize
>
__global__
void
KeMatrixCollectSharedBias
(
real
*
B
,
real
*
A
,
__global__
void
KeMatrixCollectSharedBias
(
real
*
B
,
real
*
A
,
const
int
channel
,
const
int
M
,
const
int
N
,
...
...
@@ -589,7 +541,7 @@ __global__ void KeMatrixCollectSharedBias(real *B,
int
n
=
j
*
blockSize
+
tid
;
int
m
=
n
/
dim
;
int
w
=
n
%
dim
;
smem
[
tid
]
=
(
m
<
M
&&
w
<
dim
)
?
A
[
m
*
N
+
bid
*
dim
+
w
]
:
0.0
;
smem
[
tid
]
=
(
m
<
M
&&
w
<
dim
)
?
A
[
m
*
N
+
bid
*
dim
+
w
]
:
0.0
;
__syncthreads
();
simpleReduce
(
smem
,
tid
,
blockSize
);
sum
+=
smem
[
0
];
...
...
@@ -611,33 +563,32 @@ void hl_matrix_collect_shared_bias(real* B_d,
const
int
limit
=
64
;
int
grids
=
(
dimM
*
dim
)
<
limit
?
DIVUP
(
channel
,
blocks
)
:
channel
;
KeMatrixCollectSharedBias
<
blocks
>
<<<
grids
,
blocks
,
0
,
STREAM_DEFAULT
>>>
(
B_d
,
A_d
,
channel
,
dimM
,
dimN
,
dim
,
limit
,
scale
);
KeMatrixCollectSharedBias
<
blocks
><<<
grids
,
blocks
,
0
,
STREAM_DEFAULT
>>>
(
B_d
,
A_d
,
channel
,
dimM
,
dimN
,
dim
,
limit
,
scale
);
CHECK_SYNC
(
"hl_matrix_collect_shared_bias failed"
);
}
__global__
void
keMatrixRotate
(
real
*
mat
,
real
*
matRot
,
int
dimM
,
int
dimN
,
bool
clockWise
)
{
int
idx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
idx
<
dimM
*
dimN
)
{
int
i
=
idx
/
dimN
;
int
j
=
idx
%
dimN
;
if
(
clockWise
)
{
matRot
[
j
*
dimM
+
i
]
=
mat
[(
dimM
-
i
-
1
)
*
dimN
+
j
];
}
else
{
matRot
[
j
*
dimM
+
i
]
=
mat
[
i
*
dimN
+
(
dimN
-
j
-
1
)];
}
__global__
void
keMatrixRotate
(
real
*
mat
,
real
*
matRot
,
int
dimM
,
int
dimN
,
bool
clockWise
)
{
int
idx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
idx
<
dimM
*
dimN
)
{
int
i
=
idx
/
dimN
;
int
j
=
idx
%
dimN
;
if
(
clockWise
)
{
matRot
[
j
*
dimM
+
i
]
=
mat
[(
dimM
-
i
-
1
)
*
dimN
+
j
];
}
else
{
matRot
[
j
*
dimM
+
i
]
=
mat
[
i
*
dimN
+
(
dimN
-
j
-
1
)];
}
}
}
void
hl_matrix_rotate
(
real
*
mat
,
real
*
matRot
,
int
dimM
,
int
dimN
,
bool
clockWise
)
{
CHECK_NOTNULL
(
mat
);
CHECK_NOTNULL
(
matRot
);
const
int
threads
=
512
;
const
int
blocks
=
DIVUP
(
dimM
*
dimN
,
threads
);
keMatrixRotate
<<<
blocks
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
mat
,
matRot
,
dimM
,
dimN
,
clockWise
);
CHECK_SYNC
(
"hl_matrix_rotate failed"
);
void
hl_matrix_rotate
(
real
*
mat
,
real
*
matRot
,
int
dimM
,
int
dimN
,
bool
clockWise
)
{
CHECK_NOTNULL
(
mat
);
CHECK_NOTNULL
(
matRot
);
const
int
threads
=
512
;
const
int
blocks
=
DIVUP
(
dimM
*
dimN
,
threads
);
keMatrixRotate
<<<
blocks
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
mat
,
matRot
,
dimM
,
dimN
,
clockWise
);
CHECK_SYNC
(
"hl_matrix_rotate failed"
);
}
paddle/cuda/src/hl_cuda_sequence.cu
浏览文件 @
59a8ebc6
...
...
@@ -16,36 +16,36 @@ limitations under the License. */
#include "hl_device_functions.cuh"
#include "paddle/utils/Logging.h"
__global__
void
KeMaxSequenceForward
(
real
*
input
,
const
int
*
sequence
,
__global__
void
KeMaxSequenceForward
(
real
*
input
,
const
int
*
sequence
,
real
*
output
,
int
*
index
,
int
*
index
,
int
numSequences
,
int
dim
)
{
int
dimIdx
=
threadIdx
.
x
;
int
sequenceId
=
blockIdx
.
x
;
if
(
sequenceId
>=
numSequences
)
return
;
int
start
=
sequence
[
sequenceId
];
int
end
=
sequence
[
sequenceId
+
1
];
int
end
=
sequence
[
sequenceId
+
1
];
for
(
int
i
=
dimIdx
;
i
<
dim
;
i
+=
blockDim
.
x
)
{
real
tmp
=
-
HL_FLOAT_MAX
;
int
tmpId
=
-
1
;
for
(
int
insId
=
start
;
insId
<
end
;
insId
++
)
{
if
(
tmp
<
input
[
insId
*
dim
+
i
])
{
tmp
=
input
[
insId
*
dim
+
i
];
if
(
tmp
<
input
[
insId
*
dim
+
i
])
{
tmp
=
input
[
insId
*
dim
+
i
];
tmpId
=
insId
;
}
}
output
[
sequenceId
*
dim
+
i
]
=
tmp
;
index
[
sequenceId
*
dim
+
i
]
=
tmpId
;
output
[
sequenceId
*
dim
+
i
]
=
tmp
;
index
[
sequenceId
*
dim
+
i
]
=
tmpId
;
}
}
void
hl_max_sequence_forward
(
real
*
input
,
const
int
*
sequence
,
real
*
output
,
int
*
index
,
int
*
index
,
int
numSequences
,
int
dim
)
{
CHECK_NOTNULL
(
input
);
...
...
@@ -55,29 +55,23 @@ void hl_max_sequence_forward(real* input,
dim3
threads
(
256
,
1
);
dim3
grid
(
numSequences
,
1
);
KeMaxSequenceForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
output
,
index
,
numSequences
,
dim
);
KeMaxSequenceForward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
output
,
index
,
numSequences
,
dim
);
CHECK_SYNC
(
"hl_max_sequence_forward failed"
);
}
__global__
void
KeMaxSequenceBackward
(
real
*
outputGrad
,
int
*
index
,
real
*
inputGrad
,
int
numSequences
,
int
dim
)
{
__global__
void
KeMaxSequenceBackward
(
real
*
outputGrad
,
int
*
index
,
real
*
inputGrad
,
int
numSequences
,
int
dim
)
{
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
int
colIdx
=
idx
%
dim
;
if
(
idx
<
numSequences
*
dim
)
{
if
(
idx
<
numSequences
*
dim
)
{
int
insId
=
index
[
idx
];
inputGrad
[
insId
*
dim
+
colIdx
]
+=
outputGrad
[
idx
];
}
}
void
hl_max_sequence_backward
(
real
*
outputGrad
,
int
*
index
,
real
*
inputGrad
,
int
numSequences
,
int
dim
)
{
void
hl_max_sequence_backward
(
real
*
outputGrad
,
int
*
index
,
real
*
inputGrad
,
int
numSequences
,
int
dim
)
{
CHECK_NOTNULL
(
outputGrad
);
CHECK_NOTNULL
(
index
);
CHECK_NOTNULL
(
inputGrad
);
...
...
@@ -85,12 +79,12 @@ void hl_max_sequence_backward(real* outputGrad,
unsigned
int
blocks
=
(
numSequences
*
dim
+
128
-
1
)
/
128
;
dim3
threads
(
128
,
1
);
dim3
grid
(
blocks
,
1
);
KeMaxSequenceBackward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
outputGrad
,
index
,
inputGrad
,
numSequences
,
dim
);
KeMaxSequenceBackward
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
outputGrad
,
index
,
inputGrad
,
numSequences
,
dim
);
CHECK_SYNC
(
"hl_max_sequence_backward failed"
);
}
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
AddRow
>
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
AddRow
>
__global__
void
KeMatrixAddRows
(
real
*
output
,
real
*
table
,
int
*
ids
,
...
...
@@ -104,8 +98,8 @@ __global__ void KeMatrixAddRows(real* output,
while
(
sampleId
<
numSamples
)
{
int
tableId
=
ids
[
sampleId
];
if
((
0
<=
tableId
)
&&
(
tableId
<
tableSize
))
{
real
*
outputData
=
output
+
sampleId
*
dim
;
real
*
tableData
=
table
+
tableId
*
dim
;
real
*
outputData
=
output
+
sampleId
*
dim
;
real
*
tableData
=
table
+
tableId
*
dim
;
for
(
int
i
=
idx
;
i
<
dim
;
i
+=
blockDimX
)
{
if
(
AddRow
==
0
)
{
outputData
[
i
]
+=
tableData
[
i
];
...
...
@@ -114,24 +108,27 @@ __global__ void KeMatrixAddRows(real* output,
}
}
}
sampleId
+=
blockDimY
*
gridDimX
;
sampleId
+=
blockDimY
*
gridDimX
;
}
}
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
seq2batch
,
bool
isAdd
>
__global__
void
KeSequence2Batch
(
real
*
batch
,
real
*
sequence
,
const
int
*
batchIndex
,
int
seqWidth
,
int
batchCount
)
{
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
seq2batch
,
bool
isAdd
>
__global__
void
KeSequence2Batch
(
real
*
batch
,
real
*
sequence
,
const
int
*
batchIndex
,
int
seqWidth
,
int
batchCount
)
{
int
idx
=
threadIdx
.
x
;
int
idy
=
threadIdx
.
y
;
int
id
=
blockIdx
.
x
+
idy
*
gridDimX
;
while
(
id
<
batchCount
)
{
int
seqId
=
batchIndex
[
id
];
real
*
batchData
=
batch
+
id
*
seqWidth
;
real
*
seqData
=
sequence
+
seqId
*
seqWidth
;
real
*
batchData
=
batch
+
id
*
seqWidth
;
real
*
seqData
=
sequence
+
seqId
*
seqWidth
;
for
(
int
i
=
idx
;
i
<
seqWidth
;
i
+=
blockDimX
)
{
if
(
seq2batch
)
{
if
(
isAdd
)
{
...
...
@@ -147,13 +144,13 @@ void KeSequence2Batch(real *batch,
}
}
}
id
+=
blockDimY
*
gridDimX
;
id
+=
blockDimY
*
gridDimX
;
}
}
void
hl_sequence2batch_copy
(
real
*
batch
,
real
*
sequence
,
const
int
*
batchIndex
,
void
hl_sequence2batch_copy
(
real
*
batch
,
real
*
sequence
,
const
int
*
batchIndex
,
int
seqWidth
,
int
batchCount
,
bool
seq2batch
)
{
...
...
@@ -164,18 +161,18 @@ void hl_sequence2batch_copy(real *batch,
dim3
threads
(
128
,
8
);
dim3
grid
(
8
,
1
);
if
(
seq2batch
)
{
KeSequence2Batch
<
128
,
8
,
8
,
1
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
KeSequence2Batch
<
128
,
8
,
8
,
1
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
}
else
{
KeSequence2Batch
<
128
,
8
,
8
,
0
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
KeSequence2Batch
<
128
,
8
,
8
,
0
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
}
CHECK_SYNC
(
"hl_sequence2batch_copy failed"
);
}
void
hl_sequence2batch_add
(
real
*
batch
,
real
*
sequence
,
int
*
batchIndex
,
void
hl_sequence2batch_add
(
real
*
batch
,
real
*
sequence
,
int
*
batchIndex
,
int
seqWidth
,
int
batchCount
,
bool
seq2batch
)
{
...
...
@@ -186,23 +183,22 @@ void hl_sequence2batch_add(real *batch,
dim3
threads
(
128
,
8
);
dim3
grid
(
8
,
1
);
if
(
seq2batch
)
{
KeSequence2Batch
<
128
,
8
,
8
,
1
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
KeSequence2Batch
<
128
,
8
,
8
,
1
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
}
else
{
KeSequence2Batch
<
128
,
8
,
8
,
0
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
KeSequence2Batch
<
128
,
8
,
8
,
0
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
batchIndex
,
seqWidth
,
batchCount
);
}
CHECK_SYNC
(
"hl_sequence2batch_add failed"
);
}
template
<
bool
normByTimes
,
bool
seq2batch
>
__global__
void
KeSequence2BatchPadding
(
real
*
batch
,
real
*
sequence
,
const
int
*
sequenceStartPositions
,
const
size_t
sequenceWidth
,
const
size_t
maxSequenceLength
,
const
size_t
numSequences
)
{
template
<
bool
normByTimes
,
bool
seq2batch
>
__global__
void
KeSequence2BatchPadding
(
real
*
batch
,
real
*
sequence
,
const
int
*
sequenceStartPositions
,
const
size_t
sequenceWidth
,
const
size_t
maxSequenceLength
,
const
size_t
numSequences
)
{
int
batchIdx
=
blockIdx
.
y
;
int
sequenceStart
=
sequenceStartPositions
[
batchIdx
];
int
sequenceLength
=
sequenceStartPositions
[
batchIdx
+
1
]
-
sequenceStart
;
...
...
@@ -276,37 +272,49 @@ void hl_sequence2batch_copy_padding(real* batch,
if
(
seq2batch
)
{
/* sequence -> batch */
if
(
normByTimes
)
{
KeSequence2BatchPadding
<
1
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
KeSequence2BatchPadding
<
1
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
}
else
{
KeSequence2BatchPadding
<
0
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
KeSequence2BatchPadding
<
0
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
}
}
else
{
/* batch -> sequence */
if
(
normByTimes
)
{
KeSequence2BatchPadding
<
1
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
KeSequence2BatchPadding
<
1
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
}
else
{
KeSequence2BatchPadding
<
0
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
KeSequence2BatchPadding
<
0
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
batch
,
sequence
,
sequenceStartPositions
,
sequenceWidth
,
maxSequenceLength
,
numSequences
);
}
}
CHECK_SYNC
(
"hl_sequence2batch_copy_padding failed"
);
}
__device__
inline
float
my_rsqrt
(
float
x
)
{
return
rsqrtf
(
x
);
}
__device__
inline
float
my_rsqrt
(
float
x
)
{
return
rsqrtf
(
x
);
}
__device__
inline
double
my_rsqrt
(
double
x
)
{
return
rsqrt
(
x
);
}
__device__
inline
double
my_rsqrt
(
double
x
)
{
return
rsqrt
(
x
);
}
__global__
void
KeSequenceAvgForward
(
real
*
dst
,
real
*
src
,
...
...
@@ -327,8 +335,8 @@ __global__ void KeSequenceAvgForward(real* dst,
for
(
int
i
=
start
;
i
<
end
;
i
++
)
{
sum
+=
src
[
i
*
width
+
col
];
}
sum
=
mode
==
1
?
sum
:
(
mode
==
0
?
sum
/
seqLength
:
sum
*
my_rsqrt
((
real
)
seqLength
));
sum
=
mode
==
1
?
sum
:
(
mode
==
0
?
sum
/
seqLength
:
sum
*
my_rsqrt
((
real
)
seqLength
));
dst
[
gid
]
+=
sum
;
}
}
...
...
@@ -347,10 +355,10 @@ void hl_sequence_avg_forward(real* dst,
int
grid
=
DIVUP
(
width
*
height
,
512
);
CHECK
(
mode
==
0
||
mode
==
1
||
mode
==
2
)
<<
"mode error in hl_sequence_avg_forward!"
;
<<
"mode error in hl_sequence_avg_forward!"
;
KeSequenceAvgForward
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
src
,
starts
,
height
,
width
,
mode
);
KeSequenceAvgForward
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
src
,
starts
,
height
,
width
,
mode
);
CHECK_SYNC
(
"hl_sequence_avg_forward failed"
);
}
...
...
@@ -370,8 +378,8 @@ __global__ void KeSequenceAvgBackward(real* dst,
int
seqLength
=
end
-
start
;
if
(
seqLength
==
0
)
return
;
real
grad
=
src
[
gid
];
grad
=
mode
==
1
?
grad
:
(
mode
==
0
?
grad
/
seqLength
:
grad
*
my_rsqrt
((
real
)
seqLength
));
grad
=
mode
==
1
?
grad
:
(
mode
==
0
?
grad
/
seqLength
:
grad
*
my_rsqrt
((
real
)
seqLength
));
for
(
int
i
=
start
;
i
<
end
;
i
++
)
{
dst
[
i
*
width
+
col
]
+=
grad
;
}
...
...
@@ -392,9 +400,9 @@ void hl_sequence_avg_backward(real* dst,
int
grid
=
DIVUP
(
width
*
height
,
512
);
CHECK
(
mode
==
0
||
mode
==
1
||
mode
==
2
)
<<
"mode error in hl_sequence_avg_backward!"
;
<<
"mode error in hl_sequence_avg_backward!"
;
KeSequenceAvgBackward
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
src
,
starts
,
height
,
width
,
mode
);
KeSequenceAvgBackward
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
src
,
starts
,
height
,
width
,
mode
);
CHECK_SYNC
(
"hl_sequence_avg_backward failed"
);
}
paddle/cuda/src/hl_cuda_sparse.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,13 +12,12 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_cuda.h"
#include "hl_cuda_sparse.cuh"
#include "hl_matrix_apply.cuh"
#include "hl_matrix_ops.cuh"
#include "hl_sparse.h"
#include "hl_sparse.ph"
#include "hl_matrix_ops.cuh"
#include "hl_matrix_apply.cuh"
#include "hl_cuda_sparse.cuh"
#include "paddle/utils/Logging.h"
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
mul_scalar
,
ONE_PARAMETER
,
a
=
a
*
p
);
...
...
@@ -34,15 +33,15 @@ void hl_matrix_csr2dense(hl_sparse_matrix_s A_d,
CHECK
(
A_d
->
format
==
HL_SPARSE_CSR
)
<<
"matrix format error!"
;
if
(
A_d
->
nnz
==
0
)
{
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
C_d
,
dimM
,
dimN
,
dimN
);
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
C_d
,
dimM
,
dimN
,
dimN
);
return
;
}
/* nnz != 0 */
hl_csr_matrix
A_d2
=
(
hl_csr_matrix
)(
A_d
->
matrix
);
CHECK
((
A_d2
->
csr_val
||
A_d
->
type
==
HL_NO_VALUE
)
&&
A_d2
->
csr_row
&&
A_d2
->
csr_col
)
<<
"parameter transa error!"
;
CHECK
((
A_d2
->
csr_val
||
A_d
->
type
==
HL_NO_VALUE
)
&&
A_d2
->
csr_row
&&
A_d2
->
csr_col
)
<<
"parameter transa error!"
;
int
blocksX
=
(
dimN
+
CU_CSR2DENSE_THREAD_X
-
1
)
/
CU_CSR2DENSE_THREAD_X
;
int
blocksY
=
(
dimM
+
CU_CSR2DENSE_THREAD_X
-
1
)
/
CU_CSR2DENSE_THREAD_X
;
...
...
@@ -50,21 +49,11 @@ void hl_matrix_csr2dense(hl_sparse_matrix_s A_d,
dim3
grid
(
blocksX
,
blocksY
);
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCsr2Dense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
C_d
,
dimM
,
dimN
);
KeSMatrixCsr2Dense
<
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
C_d
,
dimM
,
dimN
);
}
else
if
(
A_d
->
type
==
HL_FLOAT_VALUE
)
{
KeSMatrixCsr2Dense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
C_d
,
dimM
,
dimN
);
KeSMatrixCsr2Dense
<
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
C_d
,
dimM
,
dimN
);
}
else
{
}
CHECK_SYNC
(
"hl_matrix_csr2dense failed"
);
...
...
@@ -80,15 +69,15 @@ void hl_matrix_csc2dense(hl_sparse_matrix_s A_d,
CHECK
(
A_d
->
format
==
HL_SPARSE_CSC
)
<<
"matrix format error!"
;
if
(
A_d
->
nnz
==
0
)
{
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
C_d
,
dimM
,
dimN
,
dimN
);
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
C_d
,
dimM
,
dimN
,
dimN
);
return
;
}
/* nnz != 0 */
hl_csc_matrix
A_d2
=
(
hl_csc_matrix
)(
A_d
->
matrix
);
CHECK
((
A_d2
->
csc_val
||
A_d
->
type
==
HL_NO_VALUE
)
&&
A_d2
->
csc_row
&&
A_d2
->
csc_col
)
<<
"parameter transa error!"
;
CHECK
((
A_d2
->
csc_val
||
A_d
->
type
==
HL_NO_VALUE
)
&&
A_d2
->
csc_row
&&
A_d2
->
csc_col
)
<<
"parameter transa error!"
;
int
blocksX
=
(
dimN
+
CU_CSR2DENSE_THREAD_X
-
1
)
/
CU_CSR2DENSE_THREAD_X
;
int
blocksY
=
(
dimM
+
CU_CSR2DENSE_THREAD_X
-
1
)
/
CU_CSR2DENSE_THREAD_X
;
...
...
@@ -96,21 +85,11 @@ void hl_matrix_csc2dense(hl_sparse_matrix_s A_d,
dim3
grid
(
blocksX
,
blocksY
);
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCsc2Dense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
C_d
,
dimM
,
dimN
);
KeSMatrixCsc2Dense
<
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
C_d
,
dimM
,
dimN
);
}
else
if
(
A_d
->
type
==
HL_FLOAT_VALUE
)
{
KeSMatrixCsc2Dense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
C_d
,
dimM
,
dimN
);
KeSMatrixCsc2Dense
<
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
C_d
,
dimM
,
dimN
);
}
else
{
}
CHECK_SYNC
(
"hl_matrix_csc2dense failed"
);
...
...
@@ -118,43 +97,43 @@ void hl_matrix_csc2dense(hl_sparse_matrix_s A_d,
void
hl_malloc_sparse_matrix
(
hl_sparse_matrix_s
*
A_d
,
hl_matrix_format_t
format
,
hl_matrix_value_t
value_type
,
hl_matrix_value_t
value_type
,
int
dimM
,
int
dimN
,
int
nnz
)
{
CHECK_NOTNULL
(
A_d
);
CHECK
(
format
==
HL_SPARSE_CSR
||
format
==
HL_SPARSE_CSC
)
<<
"sparse matrix format error!"
;
<<
"sparse matrix format error!"
;
CHECK
(
value_type
==
HL_FLOAT_VALUE
||
value_type
==
HL_NO_VALUE
)
<<
"sparse matrix value type error!"
;
<<
"sparse matrix value type error!"
;
/* avoid malloc 0 bytes */
int
nnz_s
=
(
nnz
==
0
?
1
:
nnz
);
if
(
format
==
HL_SPARSE_CSR
)
{
CHECK
(
dimM
>
0
&&
nnz
>=
0
)
<<
"sparse matrix size error!"
;
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
csr
->
sparsity
=
-
1.0
;
if
(
value_type
==
HL_NO_VALUE
)
{
csr
->
csr_val
=
NULL
;
csr
->
nnz_s
=
nnz_s
;
csr
->
row_s
=
dimM
+
1
;
csr
->
csr_row
=
(
int
*
)
hl_malloc_device
((
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_col
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csr
->
row_s
=
dimM
+
1
;
csr
->
csr_row
=
(
int
*
)
hl_malloc_device
((
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_col
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csr
;
}
else
if
(
value_type
==
HL_FLOAT_VALUE
)
{
csr
->
nnz_s
=
nnz_s
;
csr
->
row_s
=
dimM
+
1
;
csr
->
csr_val
=
(
real
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
real
));
csr
->
csr_row
=
(
int
*
)
hl_malloc_device
((
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_col
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csr
->
row_s
=
dimM
+
1
;
csr
->
csr_val
=
(
real
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
real
));
csr
->
csr_row
=
(
int
*
)
hl_malloc_device
((
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_col
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csr
;
...
...
@@ -162,28 +141,28 @@ void hl_malloc_sparse_matrix(hl_sparse_matrix_s *A_d,
}
else
if
(
format
==
HL_SPARSE_CSC
)
{
CHECK
(
dimM
>
0
&&
nnz
>=
0
)
<<
"sparse matrix size error!"
;
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
csc
->
sparsity
=
-
1.0
f
;
if
(
value_type
==
HL_NO_VALUE
)
{
csc
->
csc_val
=
NULL
;
csc
->
nnz_s
=
nnz_s
;
csc
->
col_s
=
dimN
+
1
;
csc
->
csc_row
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csc
->
csc_col
=
(
int
*
)
hl_malloc_device
((
dimN
+
1
)
*
sizeof
(
int
));
csc
->
col_s
=
dimN
+
1
;
csc
->
csc_row
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csc
->
csc_col
=
(
int
*
)
hl_malloc_device
((
dimN
+
1
)
*
sizeof
(
int
));
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csc
;
}
else
if
(
value_type
==
HL_FLOAT_VALUE
)
{
csc
->
nnz_s
=
nnz_s
;
csc
->
col_s
=
dimN
+
1
;
csc
->
csc_val
=
(
real
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
real
));
csc
->
csc_row
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csc
->
csc_col
=
(
int
*
)
hl_malloc_device
((
dimN
+
1
)
*
sizeof
(
int
));
csc
->
col_s
=
dimN
+
1
;
csc
->
csc_val
=
(
real
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
real
));
csc
->
csc_row
=
(
int
*
)
hl_malloc_device
((
nnz_s
)
*
sizeof
(
int
));
csc
->
csc_col
=
(
int
*
)
hl_malloc_device
((
dimN
+
1
)
*
sizeof
(
int
));
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csc
;
...
...
@@ -200,7 +179,7 @@ void hl_malloc_sparse_matrix(hl_sparse_matrix_s *A_d,
void
hl_free_sparse_matrix
(
hl_sparse_matrix_s
A_d
)
{
CHECK_NOTNULL
(
A_d
);
CHECK
(
A_d
->
format
==
HL_SPARSE_CSR
||
A_d
->
format
==
HL_SPARSE_CSC
)
<<
"sparse matrix format error!"
;
<<
"sparse matrix format error!"
;
if
(
A_d
->
matrix
==
NULL
)
{
free
(
A_d
);
...
...
@@ -249,77 +228,77 @@ void hl_free_sparse_matrix(hl_sparse_matrix_s A_d) {
}
void
hl_construct_sparse_matrix
(
hl_sparse_matrix_s
*
A_d
,
void
*
dest_d
,
void
*
dest_d
,
size_t
size
,
hl_matrix_format_t
format
,
hl_matrix_value_t
value_type
,
hl_matrix_value_t
value_type
,
int
dimM
,
int
dimN
,
int
nnz
)
{
CHECK_NOTNULL
(
A_d
);
CHECK
(
format
==
HL_SPARSE_CSR
||
format
==
HL_SPARSE_CSC
)
<<
"sparse matrix format error!"
;
<<
"sparse matrix format error!"
;
if
(
format
==
HL_SPARSE_CSR
)
{
CHECK
(
dimM
>
0
&&
nnz
>=
0
)
<<
"sparse matrix size error!"
;
size_t
size_
=
(
dimM
+
1
)
*
sizeof
(
int
)
+
nnz
*
sizeof
(
int
);
size_t
size_
=
(
dimM
+
1
)
*
sizeof
(
int
)
+
nnz
*
sizeof
(
int
);
if
(
value_type
!=
HL_NO_VALUE
)
{
size_
+=
nnz
*
sizeof
(
real
);
size_
+=
nnz
*
sizeof
(
real
);
}
CHECK_LE
(
size_
,
size
)
<<
"dest_d size("
<<
size
<<
") too small, should bigger than("
<<
size_
<<
")!"
;
<<
") too small, should bigger than("
<<
size_
<<
")!"
;
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
if
(
value_type
==
HL_NO_VALUE
)
{
csr
->
csr_val
=
NULL
;
csr
->
csr_row
=
(
int
*
)
dest_d
;
csr
->
csr_col
=
(
int
*
)((
char
*
)
dest_d
+
(
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_row
=
(
int
*
)
dest_d
;
csr
->
csr_col
=
(
int
*
)((
char
*
)
dest_d
+
(
dimM
+
1
)
*
sizeof
(
int
));
}
else
{
csr
->
csr_val
=
(
real
*
)
dest_d
;
csr
->
csr_row
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
));
csr
->
csr_col
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
)
+
(
dimM
+
1
)
*
sizeof
(
int
));
csr
->
csr_val
=
(
real
*
)
dest_d
;
csr
->
csr_row
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
));
csr
->
csr_col
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
)
+
(
dimM
+
1
)
*
sizeof
(
int
));
}
csr
->
nnz_s
=
nnz
;
csr
->
row_s
=
dimM
+
1
;
csr
->
row_s
=
dimM
+
1
;
csr
->
sparsity
=
-
1.0
;
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csr
;
}
else
if
(
format
==
HL_SPARSE_CSC
)
{
CHECK
(
dimM
>
0
&&
nnz
>=
0
)
<<
"sparse matrix size error!"
;
size_t
size_
=
(
dimN
+
1
)
*
sizeof
(
int
)
+
nnz
*
sizeof
(
int
);
size_t
size_
=
(
dimN
+
1
)
*
sizeof
(
int
)
+
nnz
*
sizeof
(
int
);
if
(
value_type
!=
HL_NO_VALUE
)
{
size_
+=
nnz
*
sizeof
(
real
);
size_
+=
nnz
*
sizeof
(
real
);
}
CHECK_LE
(
size_
,
size
)
<<
"dest_d size("
<<
size
<<
") too small, should bigger than("
<<
size_
<<
")!"
;
<<
") too small, should bigger than("
<<
size_
<<
")!"
;
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
if
(
value_type
==
HL_NO_VALUE
)
{
csc
->
csc_val
=
NULL
;
csc
->
csc_col
=
(
int
*
)
dest_d
;
csc
->
csc_row
=
(
int
*
)((
char
*
)
dest_d
+
(
dimN
+
1
)
*
sizeof
(
int
));
csc
->
csc_col
=
(
int
*
)
dest_d
;
csc
->
csc_row
=
(
int
*
)((
char
*
)
dest_d
+
(
dimN
+
1
)
*
sizeof
(
int
));
}
else
{
csc
->
csc_val
=
(
real
*
)
dest_d
;
csc
->
csc_col
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
));
csc
->
csc_row
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
)
+
(
dimN
+
1
)
*
sizeof
(
int
));
csc
->
csc_val
=
(
real
*
)
dest_d
;
csc
->
csc_col
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
));
csc
->
csc_row
=
(
int
*
)((
char
*
)
dest_d
+
nnz
*
sizeof
(
real
)
+
(
dimN
+
1
)
*
sizeof
(
int
));
}
csc
->
nnz_s
=
nnz
;
csc
->
col_s
=
dimN
+
1
;
csc
->
col_s
=
dimN
+
1
;
csc
->
sparsity
=
-
1.0
f
;
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csc
;
...
...
@@ -333,11 +312,11 @@ void hl_construct_sparse_matrix(hl_sparse_matrix_s *A_d,
}
void
hl_construct_sparse_matrix
(
hl_sparse_matrix_s
*
A_d
,
real
*
value_d
,
int
*
rows_d
,
int
*
cols_d
,
real
*
value_d
,
int
*
rows_d
,
int
*
cols_d
,
hl_matrix_format_t
format
,
hl_matrix_value_t
value_type
,
hl_matrix_value_t
value_type
,
int
dimM
,
int
dimN
,
int
nnz
)
{
...
...
@@ -345,11 +324,11 @@ void hl_construct_sparse_matrix(hl_sparse_matrix_s *A_d,
CHECK
(
dimM
>
0
&&
nnz
>=
0
)
<<
"sparse matrix size error!"
;
CHECK
(
format
==
HL_SPARSE_CSR
||
format
==
HL_SPARSE_CSC
)
<<
"sparse matrix format error!"
;
<<
"sparse matrix format error!"
;
if
(
format
==
HL_SPARSE_CSR
)
{
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csr_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
...
...
@@ -362,8 +341,8 @@ void hl_construct_sparse_matrix(hl_sparse_matrix_s *A_d,
*
A_d
=
(
hl_sparse_matrix_s
)
tmp
;
(
*
A_d
)
->
matrix
=
(
hl_matrix_s
)
csr
;
}
else
if
(
format
==
HL_SPARSE_CSC
)
{
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
char
*
tmp
=
(
char
*
)
malloc
(
sizeof
(
_hl_sparse_matrix_s
)
+
sizeof
(
_hl_csc_matrix
));
CHECK_NOTNULL
(
tmp
);
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
tmp
+
sizeof
(
_hl_sparse_matrix_s
));
...
...
@@ -396,35 +375,30 @@ void hl_memcpy_csr_matrix(hl_sparse_matrix_s csr_matrix,
hl_stream_t
stream
)
{
CHECK_NOTNULL
(
csr_matrix
);
CHECK_EQ
(
csr_matrix
->
format
,
HL_SPARSE_CSR
)
<<
"csr_matrix is not csr format!"
;
<<
"csr_matrix is not csr format!"
;
CHECK_NOTNULL
(
csr_matrix
->
matrix
);
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
csr_matrix
->
matrix
);
CHECK_LE
(
csr_matrix
->
nnz
,
csr
->
nnz_s
)
<<
"copy size "
<<
csr_matrix
->
nnz
<<
" is big than alloc size "
<<
csr
->
nnz_s
;
CHECK_LE
(
csr_matrix
->
nnz
,
csr
->
nnz_s
)
<<
"copy size "
<<
csr_matrix
->
nnz
<<
" is big than alloc size "
<<
csr
->
nnz_s
;
CHECK_LE
((
csr_matrix
->
rows
+
1
),
csr
->
row_s
)
<<
"copy size "
<<
(
csr_matrix
->
rows
+
1
)
<<
" is big than alloc size "
<<
csr
->
row_s
;
CHECK_LE
((
csr_matrix
->
rows
+
1
),
csr
->
row_s
)
<<
"copy size "
<<
(
csr_matrix
->
rows
+
1
)
<<
" is big than alloc size "
<<
csr
->
row_s
;
CHECK
(
csr_matrix
->
type
==
HL_FLOAT_VALUE
||
csr_matrix
->
type
==
HL_NO_VALUE
)
<<
"sparse matrix value type error!"
;
CHECK
(
csr_matrix
->
type
==
HL_FLOAT_VALUE
||
csr_matrix
->
type
==
HL_NO_VALUE
)
<<
"sparse matrix value type error!"
;
if
(
csr_matrix
->
type
==
HL_NO_VALUE
)
{
if
(
csr_row
==
NULL
&&
csr_col
==
NULL
)
{
return
;
}
else
if
(
csr_row
!=
NULL
&&
csr_col
!=
NULL
)
{
hl_memcpy_async
(
csr
->
csr_row
,
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_row
,
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_col
,
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_col
,
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csr_row or csr_col is null pointer!"
;
}
...
...
@@ -432,30 +406,21 @@ void hl_memcpy_csr_matrix(hl_sparse_matrix_s csr_matrix,
if
(
csr_val
==
NULL
&&
csr_row
==
NULL
&&
csr_col
==
NULL
)
{
return
;
}
else
if
(
csr_val
!=
NULL
&&
csr_row
==
NULL
&&
csr_col
==
NULL
)
{
hl_memcpy_async
(
csr
->
csr_val
,
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csr
->
csr_val
,
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
}
else
if
(
csr_val
!=
NULL
&&
csr_row
!=
NULL
&&
csr_col
!=
NULL
)
{
hl_memcpy_async
(
csr
->
csr_val
,
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csr
->
csr_row
,
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_col
,
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_val
,
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csr
->
csr_row
,
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csr
->
csr_col
,
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csr_row or csr_col is null pointer!"
;
}
}
csr
->
sparsity
=
((
float
)
csr_matrix
->
nnz
)
/
((
float
)
csr_matrix
->
rows
)
/
csr
->
sparsity
=
((
float
)
csr_matrix
->
nnz
)
/
((
float
)
csr_matrix
->
rows
)
/
((
float
)
csr_matrix
->
cols
);
}
...
...
@@ -466,33 +431,28 @@ void hl_memcpy_csc_matrix(hl_sparse_matrix_s csc_matrix,
hl_stream_t
stream
)
{
CHECK_NOTNULL
(
csc_matrix
);
CHECK_EQ
(
csc_matrix
->
format
,
HL_SPARSE_CSC
)
<<
"csc_matrix is not csc format error!"
;
<<
"csc_matrix is not csc format error!"
;
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
csc_matrix
->
matrix
);
CHECK_LE
(
csc_matrix
->
nnz
,
csc
->
nnz_s
)
<<
"copy size "
<<
csc_matrix
->
nnz
<<
" is big than alloc size "
<<
csc
->
nnz_s
;
CHECK_LE
(
csc_matrix
->
nnz
,
csc
->
nnz_s
)
<<
"copy size "
<<
csc_matrix
->
nnz
<<
" is big than alloc size "
<<
csc
->
nnz_s
;
CHECK_LE
((
csc_matrix
->
cols
+
1
),
csc
->
col_s
)
<<
"copy size "
<<
(
csc_matrix
->
cols
+
1
)
<<
" is big than alloc size "
<<
csc
->
col_s
;
CHECK_LE
((
csc_matrix
->
cols
+
1
),
csc
->
col_s
)
<<
"copy size "
<<
(
csc_matrix
->
cols
+
1
)
<<
" is big than alloc size "
<<
csc
->
col_s
;
CHECK
(
csc_matrix
->
type
==
HL_FLOAT_VALUE
||
csc_matrix
->
type
==
HL_NO_VALUE
)
<<
"sparse matrix value type error!"
;
CHECK
(
csc_matrix
->
type
==
HL_FLOAT_VALUE
||
csc_matrix
->
type
==
HL_NO_VALUE
)
<<
"sparse matrix value type error!"
;
if
(
csc_matrix
->
type
==
HL_NO_VALUE
)
{
if
(
csc_row
==
NULL
&&
csc_col
==
NULL
)
{
return
;
}
else
if
(
csc_row
!=
NULL
&&
csc_col
!=
NULL
)
{
hl_memcpy_async
(
csc
->
csc_row
,
csc_row
,
(
csc_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_col
,
csc_col
,
(
csc_matrix
->
cols
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_row
,
csc_row
,
(
csc_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_col
,
csc_col
,
(
csc_matrix
->
cols
+
1
)
*
sizeof
(
int
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csc_row or csc_col is null pointer!"
;
}
...
...
@@ -500,30 +460,21 @@ void hl_memcpy_csc_matrix(hl_sparse_matrix_s csc_matrix,
if
(
csc_val
==
NULL
&&
csc_row
==
NULL
&&
csc_col
==
NULL
)
{
return
;
}
else
if
(
csc_val
!=
NULL
&&
csc_row
==
NULL
&&
csc_col
==
NULL
)
{
hl_memcpy_async
(
csc
->
csc_val
,
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csc
->
csc_val
,
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
}
else
if
(
csc_val
!=
NULL
&&
csc_row
!=
NULL
&&
csc_col
!=
NULL
)
{
hl_memcpy_async
(
csc
->
csc_val
,
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csc
->
csc_row
,
csc_row
,
(
csc_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_col
,
csc_col
,
(
csc_matrix
->
cols
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_val
,
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
hl_memcpy_async
(
csc
->
csc_row
,
csc_row
,
(
csc_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
(
csc
->
csc_col
,
csc_col
,
(
csc_matrix
->
cols
+
1
)
*
sizeof
(
int
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csc_row or csc_col is null pointer!"
;
}
}
csc
->
sparsity
=
((
float
)
csc_matrix
->
nnz
)
/
((
float
)
csc_matrix
->
rows
)
/
csc
->
sparsity
=
((
float
)
csc_matrix
->
nnz
)
/
((
float
)
csc_matrix
->
rows
)
/
((
float
)
csc_matrix
->
cols
);
}
...
...
@@ -531,32 +482,23 @@ void hl_memcpy_sparse_matrix(hl_sparse_matrix_s dst,
hl_sparse_matrix_s
src
,
hl_stream_t
stream
)
{
CHECK
(
dst
&&
src
&&
dst
->
matrix
&&
src
->
matrix
)
<<
"parameter dst or src is null pointer!"
;
CHECK_EQ
(
dst
->
format
,
src
->
format
)
<<
"sparse matrix format does not match!"
;
<<
"parameter dst or src is null pointer!"
;
CHECK_EQ
(
dst
->
format
,
src
->
format
)
<<
"sparse matrix format does not match!"
;
CHECK
(
dst
->
type
!=
HL_FLOAT_VALUE
||
src
->
type
!=
HL_NO_VALUE
)
<<
"src sparse matrix is no value, dst sparse matrix has value!"
;
<<
"src sparse matrix is no value, dst sparse matrix has value!"
;
if
(
dst
->
format
==
HL_SPARSE_CSR
)
{
dst
->
rows
=
src
->
rows
;
dst
->
cols
=
src
->
cols
;
dst
->
nnz
=
src
->
nnz
;
dst
->
nnz
=
src
->
nnz
;
hl_csr_matrix
csr
=
(
hl_csr_matrix
)
src
->
matrix
;
hl_memcpy_csr_matrix
(
dst
,
csr
->
csr_val
,
csr
->
csr_row
,
csr
->
csr_col
,
stream
);
hl_memcpy_csr_matrix
(
dst
,
csr
->
csr_val
,
csr
->
csr_row
,
csr
->
csr_col
,
stream
);
}
else
if
(
dst
->
format
==
HL_SPARSE_CSC
)
{
dst
->
rows
=
src
->
rows
;
dst
->
cols
=
src
->
cols
;
dst
->
nnz
=
src
->
nnz
;
dst
->
nnz
=
src
->
nnz
;
hl_csc_matrix
csc
=
(
hl_csc_matrix
)
src
->
matrix
;
hl_memcpy_csc_matrix
(
dst
,
csc
->
csc_val
,
csc
->
csc_row
,
csc
->
csc_col
,
stream
);
hl_memcpy_csc_matrix
(
dst
,
csc
->
csc_val
,
csc
->
csc_row
,
csc
->
csc_col
,
stream
);
}
else
{
LOG
(
FATAL
)
<<
"sparse matrix format error!"
;
}
...
...
@@ -569,20 +511,24 @@ static void _beta_mul_c(real *c, int dimM, int dimN, real beta) {
if
(
beta
==
0.0
)
{
hl_gpu_apply_unary_op
(
unary
::
Zero
<
real
>
(),
c
,
dimM
,
dimN
,
dimN
);
}
else
{
if
(
beta
!=
1.0
){
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
c
,
dimM
,
dimN
,
dimN
);
if
(
beta
!=
1.0
)
{
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
c
,
dimM
,
dimN
,
dimN
);
}
}
return
;
}
void
hl_matrix_csr_mul_dense
(
hl_sparse_matrix_s
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
void
hl_matrix_csr_mul_dense
(
hl_sparse_matrix_s
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
real
*
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
CHECK_EQ
(
transb
,
HPPL_OP_N
);
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -592,7 +538,7 @@ void hl_matrix_csr_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
if
((
HPPL_OP_N
==
transa
&&
(
A_d
->
rows
!=
dimM
||
A_d
->
cols
!=
dimK
))
||
(
HPPL_OP_T
==
transa
&&
(
A_d
->
rows
!=
dimK
||
A_d
->
cols
!=
dimM
)))
{
LOG
(
FATAL
)
<<
"parameter error!"
;
LOG
(
FATAL
)
<<
"parameter error!"
;
}
if
(
A_d
->
nnz
==
0
)
{
...
...
@@ -603,8 +549,7 @@ void hl_matrix_csr_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
/* nnz != 0 */
hl_csr_matrix
A_d2
=
(
hl_csr_matrix
)(
A_d
->
matrix
);
if
((
A_d2
->
csr_val
==
NULL
&&
A_d
->
type
!=
HL_NO_VALUE
)
||
A_d2
->
csr_row
==
NULL
||
A_d2
->
csr_col
==
NULL
)
{
A_d2
->
csr_row
==
NULL
||
A_d2
->
csr_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter error!"
;
}
...
...
@@ -617,63 +562,63 @@ void hl_matrix_csr_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
/* sparsity pattern */
// A_d->sparsity;
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCsrMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCsrMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixCsrMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCsrMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
if
(
HPPL_OP_T
==
transa
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
int
blocksX
=
(
dimN
+
CU_CSC_MUL_DENSE_BLOCK_N
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_N
;
int
blocksY
=
(
dimK
+
CU_CSC_MUL_DENSE_BLOCK_K
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_K
;
int
blocksX
=
(
dimN
+
CU_CSC_MUL_DENSE_BLOCK_N
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_N
;
int
blocksY
=
(
dimK
+
CU_CSC_MUL_DENSE_BLOCK_K
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_K
;
dim3
threads
(
CU_CSC_MUL_DENSE_THREAD_X
,
CU_CSC_MUL_DENSE_THREAD_Y
);
dim3
grid
(
blocksX
,
blocksY
);
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCscMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCscMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixCscMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCscMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csr_val
,
A_d2
->
csr_col
,
A_d2
->
csr_row
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
{
LOG
(
FATAL
)
<<
"parameter transa error!"
;
...
...
@@ -682,11 +627,16 @@ void hl_matrix_csr_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
CHECK_SYNC
(
"hl_matrix_csr_mul_dense failed"
);
}
void
hl_matrix_dense_mul_csc
(
real
*
A_d
,
hl_trans_op_t
transa
,
hl_sparse_matrix_s
B_d
,
hl_trans_op_t
transb
,
void
hl_matrix_dense_mul_csc
(
real
*
A_d
,
hl_trans_op_t
transa
,
hl_sparse_matrix_s
B_d
,
hl_trans_op_t
transb
,
real
*
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
CHECK_EQ
(
transa
,
HPPL_OP_N
);
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -698,8 +648,7 @@ void hl_matrix_dense_mul_csc(real *A_d, hl_trans_op_t transa,
LOG
(
FATAL
)
<<
"parameter dims error!"
;
}
CHECK_EQ
(
B_d
->
format
,
HL_SPARSE_CSC
)
<<
"matrix format error!"
;
CHECK_EQ
(
B_d
->
format
,
HL_SPARSE_CSC
)
<<
"matrix format error!"
;
if
(
B_d
->
nnz
==
0
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
...
...
@@ -709,8 +658,7 @@ void hl_matrix_dense_mul_csc(real *A_d, hl_trans_op_t transa,
/* nnz != 0 */
hl_csc_matrix
B_d2
=
(
hl_csc_matrix
)(
B_d
->
matrix
);
if
((
B_d2
->
csc_val
==
NULL
&&
B_d
->
type
!=
HL_NO_VALUE
)
||
B_d2
->
csc_row
==
NULL
||
B_d2
->
csc_col
==
NULL
)
{
B_d2
->
csc_row
==
NULL
||
B_d2
->
csc_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter B is null!"
;
}
...
...
@@ -721,60 +669,60 @@ void hl_matrix_dense_mul_csc(real *A_d, hl_trans_op_t transa,
dim3
grid
(
blocksX
,
blocksY
);
if
(
B_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixDenseMulCsc
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_row
,
B_d2
->
csc_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsc
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_row
,
B_d2
->
csc_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixDenseMulCsc
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_row
,
B_d2
->
csc_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsc
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_row
,
B_d2
->
csc_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
if
(
transb
==
HPPL_OP_T
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
int
blocksX
=
1
+
(
dimK
-
1
)
/
CU_DM_CSR_THREAD_X
;
int
blocksY
=
1
+
(
dimM
-
1
)
/
CU_DM_CSR_BLOCK_M
;
int
blocksX
=
1
+
(
dimK
-
1
)
/
CU_DM_CSR_THREAD_X
;
int
blocksY
=
1
+
(
dimM
-
1
)
/
CU_DM_CSR_BLOCK_M
;
dim3
threads
(
CU_DM_CSR_THREAD_X
,
CU_DM_CSR_THREAD_Y
);
dim3
grid
(
blocksX
,
blocksY
);
if
(
B_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixDenseMulCsr
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_col
,
B_d2
->
csc_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsr
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_col
,
B_d2
->
csc_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixDenseMulCsr
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_col
,
B_d2
->
csc_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsr
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csc_val
,
B_d2
->
csc_col
,
B_d2
->
csc_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
{
LOG
(
FATAL
)
<<
"parameter transb error!"
;
...
...
@@ -783,24 +731,28 @@ void hl_matrix_dense_mul_csc(real *A_d, hl_trans_op_t transa,
CHECK_SYNC
(
"hl_matrix_dense_mul_csc failed"
);
}
void
hl_matrix_dense_mul_csr
(
real
*
A_d
,
hl_trans_op_t
transa
,
hl_sparse_matrix_s
B_d
,
hl_trans_op_t
transb
,
void
hl_matrix_dense_mul_csr
(
real
*
A_d
,
hl_trans_op_t
transa
,
hl_sparse_matrix_s
B_d
,
hl_trans_op_t
transb
,
real
*
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
CHECK_EQ
(
transa
,
HPPL_OP_N
);
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
CHECK_NOTNULL
(
C_d
);
if
(
dimM
<=
0
||
dimN
<=
0
||
dimK
<=
0
||
(
transb
==
HPPL_OP_N
&&
(
B_d
->
rows
!=
dimK
||
B_d
->
cols
!=
dimN
))
||
(
transb
==
HPPL_OP_T
&&
(
B_d
->
rows
!=
dimN
||
B_d
->
cols
!=
dimK
)))
{
if
(
dimM
<=
0
||
dimN
<=
0
||
dimK
<=
0
||
(
transb
==
HPPL_OP_N
&&
(
B_d
->
rows
!=
dimK
||
B_d
->
cols
!=
dimN
))
||
(
transb
==
HPPL_OP_T
&&
(
B_d
->
rows
!=
dimN
||
B_d
->
cols
!=
dimK
)))
{
LOG
(
FATAL
)
<<
"parameter dims error!"
;
}
CHECK_EQ
(
B_d
->
format
,
HL_SPARSE_CSR
)
<<
"matrix format error!"
;
CHECK_EQ
(
B_d
->
format
,
HL_SPARSE_CSR
)
<<
"matrix format error!"
;
if
(
B_d
->
nnz
==
0
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
...
...
@@ -810,41 +762,40 @@ void hl_matrix_dense_mul_csr(real *A_d, hl_trans_op_t transa,
/* nnz != 0 */
hl_csr_matrix
B_d2
=
(
hl_csr_matrix
)(
B_d
->
matrix
);
if
((
B_d2
->
csr_val
==
NULL
&&
B_d
->
type
!=
HL_NO_VALUE
)
||
B_d2
->
csr_row
==
NULL
||
B_d2
->
csr_col
==
NULL
)
{
B_d2
->
csr_row
==
NULL
||
B_d2
->
csr_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter transa error!"
;
}
if
(
transb
==
HPPL_OP_N
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
int
blocksX
=
1
+
(
dimK
-
1
)
/
CU_DM_CSR_THREAD_X
;
int
blocksY
=
1
+
(
dimM
-
1
)
/
CU_DM_CSR_BLOCK_M
;
int
blocksX
=
1
+
(
dimK
-
1
)
/
CU_DM_CSR_THREAD_X
;
int
blocksY
=
1
+
(
dimM
-
1
)
/
CU_DM_CSR_BLOCK_M
;
dim3
threads
(
CU_DM_CSR_THREAD_X
,
CU_DM_CSR_THREAD_Y
);
dim3
grid
(
blocksX
,
blocksY
);
if
(
B_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixDenseMulCsr
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_row
,
B_d2
->
csr_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsr
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_row
,
B_d2
->
csr_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixDenseMulCsr
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_row
,
B_d2
->
csr_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsr
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_row
,
B_d2
->
csr_col
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
if
(
transb
==
HPPL_OP_T
)
{
int
blocksX
=
(
dimM
+
CU_CSCMM_BLOCK_M_BEST
-
1
)
/
CU_CSCMM_BLOCK_M_BEST
;
...
...
@@ -852,29 +803,29 @@ void hl_matrix_dense_mul_csr(real *A_d, hl_trans_op_t transa,
dim3
threads
(
CU_CSCMM_THREAD_X_BEST
,
CU_CSCMM_THREAD_Y_BEST
);
dim3
grid
(
blocksX
,
blocksY
);
if
(
B_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixDenseMulCsc
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_col
,
B_d2
->
csr_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsc
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_col
,
B_d2
->
csr_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixDenseMulCsc
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_col
,
B_d2
->
csr_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulCsc
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d
,
B_d2
->
csr_val
,
B_d2
->
csr_col
,
B_d2
->
csr_row
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
{
LOG
(
FATAL
)
<<
"parameter transb error!"
;
...
...
@@ -883,11 +834,16 @@ void hl_matrix_dense_mul_csr(real *A_d, hl_trans_op_t transa,
CHECK_SYNC
(
"hl_matrix_dense_mul_csr failed"
);
}
void
hl_matrix_csc_mul_dense
(
hl_sparse_matrix_s
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
void
hl_matrix_csc_mul_dense
(
hl_sparse_matrix_s
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
real
*
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
CHECK_EQ
(
transb
,
HPPL_OP_N
);
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -908,42 +864,43 @@ void hl_matrix_csc_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
/* nnz != 0 */
hl_csc_matrix
A_d2
=
(
hl_csc_matrix
)(
A_d
->
matrix
);
if
((
A_d2
->
csc_val
==
NULL
&&
A_d
->
type
!=
HL_NO_VALUE
)
||
A_d2
->
csc_row
==
NULL
||
A_d2
->
csc_col
==
NULL
)
{
A_d2
->
csc_row
==
NULL
||
A_d2
->
csc_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter error!"
;
}
if
(
HPPL_OP_N
==
transa
)
{
_beta_mul_c
(
C_d
,
dimM
,
dimN
,
beta
);
int
blocksX
=
(
dimN
+
CU_CSC_MUL_DENSE_BLOCK_N
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_N
;
int
blocksY
=
(
dimK
+
CU_CSC_MUL_DENSE_BLOCK_K
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_K
;
int
blocksX
=
(
dimN
+
CU_CSC_MUL_DENSE_BLOCK_N
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_N
;
int
blocksY
=
(
dimK
+
CU_CSC_MUL_DENSE_BLOCK_K
-
1
)
/
CU_CSC_MUL_DENSE_BLOCK_K
;
dim3
threads
(
CU_CSC_MUL_DENSE_THREAD_X
,
CU_CSC_MUL_DENSE_THREAD_Y
);
dim3
grid
(
blocksX
,
blocksY
);
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCscMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCscMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixCscMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCscMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
if
(
HPPL_OP_T
==
transa
)
{
int
blocksX
=
(
dimN
+
CU_CSRMM_BLOCK_N
-
1
)
/
CU_CSRMM_BLOCK_N
;
...
...
@@ -954,29 +911,29 @@ void hl_matrix_csc_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
/* sparsity pattern */
// A_d->sparsity;
if
(
A_d
->
type
==
HL_NO_VALUE
)
{
KeSMatrixCsrMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCsrMulDense
<
0
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
else
{
KeSMatrixCsrMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixCsrMulDense
<
1
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d
,
A_d2
->
csc_val
,
A_d2
->
csc_row
,
A_d2
->
csc_col
,
B_d
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
}
}
else
{
LOG
(
FATAL
)
<<
"parameter transa error!"
;
...
...
@@ -985,11 +942,16 @@ void hl_matrix_csc_mul_dense(hl_sparse_matrix_s A_d, hl_trans_op_t transa,
CHECK_SYNC
(
"hl_matrix_csc_mul_dense failed"
);
}
void
hl_sparse_matrix_mul
(
real
*
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
hl_sparse_matrix_s
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
void
hl_sparse_matrix_mul
(
real
*
A_d
,
hl_trans_op_t
transa
,
real
*
B_d
,
hl_trans_op_t
transb
,
hl_sparse_matrix_s
C_d
,
int
dimM
,
int
dimN
,
int
dimK
,
real
alpha
,
real
beta
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
CHECK_NOTNULL
(
C_d
);
...
...
@@ -1000,18 +962,14 @@ void hl_sparse_matrix_mul(real *A_d, hl_trans_op_t transa,
if
(
C_d
->
format
==
HL_SPARSE_CSC
)
{
hl_csc_matrix
C_d2
=
(
hl_csc_matrix
)(
C_d
->
matrix
);
if
(
C_d2
->
csc_val
==
NULL
||
C_d2
->
csc_row
==
NULL
||
if
(
C_d2
->
csc_val
==
NULL
||
C_d2
->
csc_row
==
NULL
||
C_d2
->
csc_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter error!"
;
}
if
(
beta
!=
1.0
)
{
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
C_d2
->
csc_val
,
1
,
C_d
->
nnz
,
C_d
->
nnz
);
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
C_d2
->
csc_val
,
1
,
C_d
->
nnz
,
C_d
->
nnz
);
}
int
blocksX
=
dimN
;
...
...
@@ -1020,34 +978,30 @@ void hl_sparse_matrix_mul(real *A_d, hl_trans_op_t transa,
dim3
grid
(
blocksX
,
blocksY
);
bool
transA
=
transa
==
HPPL_OP_T
?
1
:
0
;
bool
transB
=
transb
==
HPPL_OP_T
?
1
:
0
;
KeSMatrixDenseMulDense2CSC
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csc_val
,
C_d2
->
csc_row
,
C_d2
->
csc_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
KeSMatrixDenseMulDense2CSC
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csc_val
,
C_d2
->
csc_row
,
C_d2
->
csc_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
CHECK_SYNC
(
"hl_sparse_matrix_mul failed"
);
}
else
{
hl_csr_matrix
C_d2
=
(
hl_csr_matrix
)(
C_d
->
matrix
);
if
((
C_d2
->
csr_val
==
NULL
&&
C_d
->
type
!=
HL_NO_VALUE
)
||
C_d2
->
csr_row
==
NULL
||
C_d2
->
csr_col
==
NULL
)
{
C_d2
->
csr_row
==
NULL
||
C_d2
->
csr_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter error!"
;
}
if
(
beta
!=
1.0
)
{
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
C_d2
->
csr_val
,
1
,
C_d
->
nnz
,
C_d
->
nnz
);
hl_gpu_apply_unary_op
(
unary
::
mul_scalar
<
real
>
(
beta
),
C_d2
->
csr_val
,
1
,
C_d
->
nnz
,
C_d
->
nnz
);
}
bool
transA
=
transa
==
HPPL_OP_T
?
1
:
0
;
...
...
@@ -1058,20 +1012,20 @@ void hl_sparse_matrix_mul(real *A_d, hl_trans_op_t transa,
dim3
threads
(
CU_CSCMM_DMD2CSR_THREAD_X
,
1
);
dim3
grid
(
blocksX
,
blocksY
);
KeSMatrixDenseMulDense2CSR
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csr_val
,
C_d2
->
csr_row
,
C_d2
->
csr_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
CHECK_SYNC
(
"hl_sparse_matrix_mul failed"
);
KeSMatrixDenseMulDense2CSR
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csr_val
,
C_d2
->
csr_row
,
C_d2
->
csr_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
CHECK_SYNC
(
"hl_sparse_matrix_mul failed"
);
}
else
{
CHECK
(
!
transA
)
<<
"Not supported A is trans and B is not trans!"
;
...
...
@@ -1080,21 +1034,21 @@ void hl_sparse_matrix_mul(real *A_d, hl_trans_op_t transa,
avgNnzPerRow
=
avgNnzPerRow
>
0
?
avgNnzPerRow
:
1
;
int
gridx
=
DIVUP
(
avgNnzPerRow
,
CU_BLOCK_SIZE
);
dim3
grid
(
gridx
,
dimM
);
KeSMatrixDenseMulDenseTrans2CSR
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csr_val
,
C_d2
->
csr_row
,
C_d2
->
csr_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
CHECK_SYNC
(
"hl_sparse_matrix_mul failed"
);
}
KeSMatrixDenseMulDenseTrans2CSR
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
C_d2
->
csr_val
,
C_d2
->
csr_row
,
C_d2
->
csr_col
,
A_d
,
B_d
,
transA
,
transB
,
dimM
,
dimN
,
dimK
,
alpha
,
beta
);
CHECK_SYNC
(
"hl_sparse_matrix_mul failed"
);
}
}
}
...
...
@@ -1111,7 +1065,7 @@ void hl_memcpy_from_csc_matrix(real *csc_val,
CHECK_NOTNULL
(
csc_col
);
CHECK_EQ
(
csc_matrix
->
format
,
HL_SPARSE_CSC
)
<<
"csc_matrix is not csc format error!"
;
<<
"csc_matrix is not csc format error!"
;
if
(
csc_matrix
->
nnz
>
row_size
||
csc_matrix
->
cols
+
1
>
static_cast
<
int
>
(
col_size
))
{
...
...
@@ -1119,20 +1073,20 @@ void hl_memcpy_from_csc_matrix(real *csc_val,
}
hl_csc_matrix
csc
=
(
hl_csc_matrix
)(
csc_matrix
->
matrix
);
hl_memcpy_async
((
void
*
)
csc_row
,
(
void
*
)
csc
->
csc_row
,
hl_memcpy_async
((
void
*
)
csc_row
,
(
void
*
)
csc
->
csc_row
,
(
csc_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
((
void
*
)
csc_col
,
(
void
*
)
csc
->
csc_col
,
hl_memcpy_async
((
void
*
)
csc_col
,
(
void
*
)
csc
->
csc_col
,
(
csc_matrix
->
cols
+
1
)
*
sizeof
(
int
),
stream
);
if
(
csc_matrix
->
type
==
HL_FLOAT_VALUE
)
{
if
(
csc_val
!=
NULL
)
{
CHECK_LE
(
csc_matrix
->
nnz
,
val_size
)
<<
"size not match!"
;
hl_memcpy_async
((
void
*
)
csc_val
,
(
void
*
)
csc
->
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
hl_memcpy_async
((
void
*
)
csc_val
,
(
void
*
)
csc
->
csc_val
,
(
csc_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csr_val is null pointer!"
;
...
...
@@ -1152,7 +1106,7 @@ void hl_memcpy_from_csr_matrix(real *csr_val,
CHECK_NOTNULL
(
csr_row
);
CHECK_NOTNULL
(
csr_col
);
CHECK_EQ
(
csr_matrix
->
format
,
HL_SPARSE_CSR
)
<<
"csr_matrix is not csr format error!"
;
<<
"csr_matrix is not csr format error!"
;
if
(
csr_matrix
->
nnz
>
col_size
||
csr_matrix
->
rows
+
1
>
static_cast
<
int
>
(
row_size
))
{
...
...
@@ -1160,20 +1114,20 @@ void hl_memcpy_from_csr_matrix(real *csr_val,
}
hl_csr_matrix
csr
=
(
hl_csr_matrix
)(
csr_matrix
->
matrix
);
hl_memcpy_async
((
void
*
)
csr_row
,
(
void
*
)
csr
->
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
hl_memcpy_async
((
void
*
)
csr_row
,
(
void
*
)
csr
->
csr_row
,
(
csr_matrix
->
rows
+
1
)
*
sizeof
(
int
),
stream
);
hl_memcpy_async
((
void
*
)
csr_col
,
(
void
*
)
csr
->
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
hl_memcpy_async
((
void
*
)
csr_col
,
(
void
*
)
csr
->
csr_col
,
(
csr_matrix
->
nnz
)
*
sizeof
(
int
),
stream
);
if
(
csr_matrix
->
type
==
HL_FLOAT_VALUE
)
{
if
(
csr_val
!=
NULL
)
{
CHECK_LE
(
csr_matrix
->
nnz
,
val_size
)
<<
"size not match!"
;
hl_memcpy_async
((
void
*
)
csr_val
,
(
void
*
)
csr
->
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
hl_memcpy_async
((
void
*
)
csr_val
,
(
void
*
)
csr
->
csr_val
,
(
csr_matrix
->
nnz
)
*
sizeof
(
real
),
stream
);
}
else
{
LOG
(
FATAL
)
<<
"parameter csr_val is null pointer!"
;
...
...
@@ -1181,8 +1135,8 @@ void hl_memcpy_from_csr_matrix(real *csr_val,
}
}
void
hl_sparse_matrix_column_sum
(
real
*
A_d
,
hl_sparse_matrix_s
B_d
,
int
dimM
,
int
dimN
,
real
scale
)
{
void
hl_sparse_matrix_column_sum
(
real
*
A_d
,
hl_sparse_matrix_s
B_d
,
int
dimM
,
int
dimN
,
real
scale
)
{
if
(
B_d
->
format
==
HL_SPARSE_CSR
)
{
hl_matrix_csr_column_sum
(
A_d
,
B_d
,
dimM
,
dimN
,
scale
);
}
else
{
...
...
@@ -1190,8 +1144,8 @@ void hl_sparse_matrix_column_sum(real* A_d, hl_sparse_matrix_s B_d, int dimM,
}
}
void
hl_matrix_csr_column_sum
(
real
*
A_d
,
hl_sparse_matrix_s
B_d
,
int
dimM
,
int
dimN
,
real
scale
)
{
void
hl_matrix_csr_column_sum
(
real
*
A_d
,
hl_sparse_matrix_s
B_d
,
int
dimM
,
int
dimN
,
real
scale
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -1216,8 +1170,7 @@ void hl_matrix_csr_column_sum(real* A_d, hl_sparse_matrix_s B_d,
CHECK_SYNC
(
"hl_matrix_csr_column_sum failed"
);
}
void
hl_sparse_matrix_add_bias
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
real
scale
)
{
void
hl_sparse_matrix_add_bias
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
real
scale
)
{
if
(
A_d
->
format
==
HL_SPARSE_CSR
)
{
hl_matrix_csr_add_bias
(
A_d
,
B_d
,
scale
);
}
else
{
...
...
@@ -1225,8 +1178,7 @@ void hl_sparse_matrix_add_bias(hl_sparse_matrix_s A_d,
}
}
void
hl_matrix_csr_add_bias
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
real
scale
)
{
void
hl_matrix_csr_add_bias
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
real
scale
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -1247,8 +1199,12 @@ void hl_matrix_csr_add_bias(hl_sparse_matrix_s A_d, real* B_d,
CHECK_SYNC
(
"hl_sparse_matrix_add_bias failed"
);
}
void
hl_sparse_matrix_add_dense
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
int
dimM
,
int
dimN
,
real
alpha
,
real
beta
)
{
void
hl_sparse_matrix_add_dense
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
int
dimM
,
int
dimN
,
real
alpha
,
real
beta
)
{
if
(
A_d
->
format
==
HL_SPARSE_CSR
)
{
hl_matrix_csr_add_dense
(
A_d
,
B_d
,
dimM
,
dimN
,
alpha
,
beta
);
}
else
{
...
...
@@ -1256,8 +1212,12 @@ void hl_sparse_matrix_add_dense(hl_sparse_matrix_s A_d, real *B_d, int dimM,
}
}
void
hl_matrix_csr_add_dense
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
int
dimM
,
int
dimN
,
real
alpha
,
real
beta
)
{
void
hl_matrix_csr_add_dense
(
hl_sparse_matrix_s
A_d
,
real
*
B_d
,
int
dimM
,
int
dimN
,
real
alpha
,
real
beta
)
{
CHECK_NOTNULL
(
A_d
);
CHECK_NOTNULL
(
B_d
);
...
...
@@ -1277,20 +1237,26 @@ void hl_matrix_csr_add_dense(hl_sparse_matrix_s A_d, real* B_d, int dimM,
gridX
=
gridX
>
0
?
gridX
:
1
;
dim3
block
(
512
,
1
);
dim3
grid
(
gridX
,
dimM
);
KeSMatrixCsrAddDense
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
B_d
,
alpha
,
beta
,
dimM
,
dimN
);
KeSMatrixCsrAddDense
<<<
grid
,
block
,
0
,
STREAM_DEFAULT
>>>
(
A_d2
->
csr_val
,
A_d2
->
csr_row
,
A_d2
->
csr_col
,
B_d
,
alpha
,
beta
,
dimM
,
dimN
);
CHECK_SYNC
(
"hl_sparse_matrix_add_dense failed"
);
}
int
*
hl_sparse_matrix_get_rows
(
hl_sparse_matrix_s
sMat
)
{
int
*
hl_sparse_matrix_get_rows
(
hl_sparse_matrix_s
sMat
)
{
__sparse_get_return__
(
sMat
,
row
);
}
int
*
hl_sparse_matrix_get_cols
(
hl_sparse_matrix_s
sMat
)
{
int
*
hl_sparse_matrix_get_cols
(
hl_sparse_matrix_s
sMat
)
{
__sparse_get_return__
(
sMat
,
col
);
}
real
*
hl_sparse_matrix_get_value
(
hl_sparse_matrix_s
sMat
)
{
real
*
hl_sparse_matrix_get_value
(
hl_sparse_matrix_s
sMat
)
{
__sparse_get_return__
(
sMat
,
val
);
}
paddle/cuda/src/hl_perturbation_util.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,13 +12,12 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <cmath>
#include <stdlib.h>
#include "hl_cuda.h"
#include "hl_time.h"
#include <cmath>
#include "hl_base.h"
#include "hl_cuda.h"
#include "hl_perturbation_util.cuh"
#include "hl_time.h"
#define _USE_MATH_DEFINES
...
...
@@ -30,10 +29,16 @@ limitations under the License. */
* centerX, centerY: translation.
* sourceX, sourceY: output coordinates in the original image.
*/
__device__
void
getTranformCoord
(
int
x
,
int
y
,
real
theta
,
real
scale
,
real
tgtCenter
,
real
imgCenter
,
real
centerR
,
real
centerC
,
int
*
sourceX
,
int
*
sourceY
)
{
__device__
void
getTranformCoord
(
int
x
,
int
y
,
real
theta
,
real
scale
,
real
tgtCenter
,
real
imgCenter
,
real
centerR
,
real
centerC
,
int
*
sourceX
,
int
*
sourceY
)
{
real
H
[
4
]
=
{
cosf
(
-
theta
),
-
sinf
(
-
theta
),
sinf
(
-
theta
),
cosf
(
-
theta
)};
// compute coornidates in the rotated and scaled image
...
...
@@ -57,11 +62,17 @@ __device__ void getTranformCoord(int x, int y, real theta, real scale,
* created by Wei Xu (genome), converted by Jiang Wang
*/
__global__
void
kSamplingPatches
(
const
real
*
imgs
,
real
*
targets
,
int
imgSize
,
int
tgtSize
,
const
int
channels
,
int
samplingRate
,
const
real
*
thetas
,
const
real
*
scales
,
const
int
*
centerRs
,
const
int
*
centerCs
,
const
real
padValue
,
__global__
void
kSamplingPatches
(
const
real
*
imgs
,
real
*
targets
,
int
imgSize
,
int
tgtSize
,
const
int
channels
,
int
samplingRate
,
const
real
*
thetas
,
const
real
*
scales
,
const
int
*
centerRs
,
const
int
*
centerCs
,
const
real
padValue
,
const
int
numImages
)
{
const
int
caseIdx
=
blockIdx
.
x
*
4
+
threadIdx
.
x
;
const
int
pxIdx
=
blockIdx
.
y
*
128
+
threadIdx
.
y
;
...
...
@@ -80,8 +91,15 @@ __global__ void kSamplingPatches(const real* imgs, real* targets,
const
int
pxY
=
pxIdx
/
tgtSize
;
int
srcPxX
,
srcPxY
;
getTranformCoord
(
pxX
,
pxY
,
thetas
[
imgIdx
],
scales
[
imgIdx
],
tgtCenter
,
imgCenter
,
centerCs
[
caseIdx
],
centerRs
[
caseIdx
],
&
srcPxX
,
getTranformCoord
(
pxX
,
pxY
,
thetas
[
imgIdx
],
scales
[
imgIdx
],
tgtCenter
,
imgCenter
,
centerCs
[
caseIdx
],
centerRs
[
caseIdx
],
&
srcPxX
,
&
srcPxY
);
imgs
+=
(
imgIdx
*
imgPixels
+
srcPxY
*
imgSize
+
srcPxX
)
*
channels
;
...
...
@@ -100,10 +118,15 @@ __global__ void kSamplingPatches(const real* imgs, real* targets,
*
* created by Wei Xu
*/
void
hl_generate_disturb_params
(
real
*&
gpuAngle
,
real
*&
gpuScaleRatio
,
int
*&
gpuCenterR
,
int
*&
gpuCenterC
,
int
numImages
,
int
imgSize
,
real
rotateAngle
,
real
scaleRatio
,
int
samplingRate
,
void
hl_generate_disturb_params
(
real
*&
gpuAngle
,
real
*&
gpuScaleRatio
,
int
*&
gpuCenterR
,
int
*&
gpuCenterC
,
int
numImages
,
int
imgSize
,
real
rotateAngle
,
real
scaleRatio
,
int
samplingRate
,
bool
isTrain
)
{
// The number of output samples.
int
numPatches
=
numImages
*
samplingRate
;
...
...
@@ -123,7 +146,8 @@ void hl_generate_disturb_params(real*& gpuAngle, real*& gpuScaleRatio,
for
(
int
i
=
0
;
i
<
numImages
;
i
++
)
{
r_angle
[
i
]
=
(
rotateAngle
*
M_PI
/
180.0
)
*
(
rand
()
/
(
RAND_MAX
+
1.0
)
// NOLINT
-
0.5
);
-
0.5
);
s_ratio
[
i
]
=
1
+
(
rand
()
/
(
RAND_MAX
+
1.0
)
-
0.5
)
*
scaleRatio
;
// NOLINT
}
...
...
@@ -140,8 +164,10 @@ void hl_generate_disturb_params(real*& gpuAngle, real*& gpuScaleRatio,
int
pxY
=
(
int
)(
real
(
imgSize
-
1
)
*
rand
()
/
(
RAND_MAX
+
1.0
));
// NOLINT
const
real
H
[
4
]
=
{
cos
(
-
r_angle
[
i
]),
-
sin
(
-
r_angle
[
i
]),
sin
(
-
r_angle
[
i
]),
cos
(
-
r_angle
[
i
])};
const
real
H
[
4
]
=
{
cos
(
-
r_angle
[
i
]),
-
sin
(
-
r_angle
[
i
]),
sin
(
-
r_angle
[
i
]),
cos
(
-
r_angle
[
i
])};
real
x
=
pxX
-
imgCenter
;
real
y
=
pxY
-
imgCenter
;
real
xx
=
H
[
0
]
*
x
+
H
[
1
]
*
y
;
...
...
@@ -185,9 +211,12 @@ void hl_generate_disturb_params(real*& gpuAngle, real*& gpuScaleRatio,
delete
[]
center_c
;
}
void
hl_conv_random_disturb_with_params
(
const
real
*
images
,
int
imgSize
,
int
tgtSize
,
int
channels
,
int
numImages
,
int
samplingRate
,
void
hl_conv_random_disturb_with_params
(
const
real
*
images
,
int
imgSize
,
int
tgtSize
,
int
channels
,
int
numImages
,
int
samplingRate
,
const
real
*
gpuRotationAngle
,
const
real
*
gpuScaleRatio
,
const
int
*
gpuCenterR
,
...
...
@@ -202,29 +231,59 @@ void hl_conv_random_disturb_with_params(const real* images, int imgSize,
dim3
threadsPerBlock
(
4
,
128
);
dim3
numBlocks
(
DIVUP
(
numPatches
,
4
),
DIVUP
(
targetSize
,
128
));
kSamplingPatches
<<<
numBlocks
,
threadsPerBlock
>>>
(
images
,
target
,
imgSize
,
tgtSize
,
channels
,
samplingRate
,
gpuRotationAngle
,
gpuScaleRatio
,
gpuCenterR
,
gpuCenterC
,
paddingValue
,
numImages
);
kSamplingPatches
<<<
numBlocks
,
threadsPerBlock
>>>
(
images
,
target
,
imgSize
,
tgtSize
,
channels
,
samplingRate
,
gpuRotationAngle
,
gpuScaleRatio
,
gpuCenterR
,
gpuCenterC
,
paddingValue
,
numImages
);
hl_device_synchronize
();
}
void
hl_conv_random_disturb
(
const
real
*
images
,
int
imgSize
,
int
tgtSize
,
int
channels
,
int
numImages
,
real
scaleRatio
,
real
rotateAngle
,
int
samplingRate
,
real
*
gpu_r_angle
,
real
*
gpu_s_ratio
,
int
*
gpu_center_r
,
int
*
gpu_center_c
,
int
paddingValue
,
bool
isTrain
,
real
*
targets
)
{
void
hl_conv_random_disturb
(
const
real
*
images
,
int
imgSize
,
int
tgtSize
,
int
channels
,
int
numImages
,
real
scaleRatio
,
real
rotateAngle
,
int
samplingRate
,
real
*
gpu_r_angle
,
real
*
gpu_s_ratio
,
int
*
gpu_center_r
,
int
*
gpu_center_c
,
int
paddingValue
,
bool
isTrain
,
real
*
targets
)
{
// generate the random disturbance sequence and the sampling locations
hl_generate_disturb_params
(
gpu_r_angle
,
gpu_s_ratio
,
gpu_center_r
,
gpu_center_c
,
numImages
,
imgSize
,
rotateAngle
,
scaleRatio
,
samplingRate
,
isTrain
);
hl_conv_random_disturb_with_params
(
images
,
imgSize
,
tgtSize
,
channels
,
numImages
,
samplingRate
,
gpu_r_angle
,
gpu_s_ratio
,
gpu_center_r
,
gpu_center_r
,
paddingValue
,
targets
);
hl_generate_disturb_params
(
gpu_r_angle
,
gpu_s_ratio
,
gpu_center_r
,
gpu_center_c
,
numImages
,
imgSize
,
rotateAngle
,
scaleRatio
,
samplingRate
,
isTrain
);
hl_conv_random_disturb_with_params
(
images
,
imgSize
,
tgtSize
,
channels
,
numImages
,
samplingRate
,
gpu_r_angle
,
gpu_s_ratio
,
gpu_center_r
,
gpu_center_r
,
paddingValue
,
targets
);
}
paddle/cuda/src/hl_table_apply.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,15 +12,16 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "hl_device_functions.cuh"
#include "hl_cuda.h"
#include "hl_device_functions.cuh"
#include "paddle/utils/Logging.h"
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
AddRow
>
__global__
void
KeMatrixAddRows
(
real
*
output
,
int
ldo
,
real
*
table
,
int
ldt
,
template
<
int
blockDimX
,
int
blockDimY
,
int
gridDimX
,
bool
AddRow
>
__global__
void
KeMatrixAddRows
(
real
*
output
,
int
ldo
,
real
*
table
,
int
ldt
,
int
*
ids
,
int
numSamples
,
int
tableSize
,
...
...
@@ -31,8 +32,8 @@ __global__ void KeMatrixAddRows(real* output, int ldo,
while
(
idy
<
numSamples
)
{
int
tableId
=
ids
[
idy
];
if
((
0
<=
tableId
)
&&
(
tableId
<
tableSize
))
{
real
*
out
=
output
+
idy
*
ldo
;
real
*
tab
=
table
+
tableId
*
ldt
;
real
*
out
=
output
+
idy
*
ldo
;
real
*
tab
=
table
+
tableId
*
ldt
;
for
(
int
i
=
idx
;
i
<
dim
;
i
+=
blockDimX
)
{
if
(
AddRow
)
{
paddle
::
paddleAtomicAdd
(
&
tab
[
i
],
out
[
i
]);
...
...
@@ -45,8 +46,10 @@ __global__ void KeMatrixAddRows(real* output, int ldo,
}
}
void
hl_matrix_select_rows
(
real
*
output
,
int
ldo
,
real
*
table
,
int
ldt
,
void
hl_matrix_select_rows
(
real
*
output
,
int
ldo
,
real
*
table
,
int
ldt
,
int
*
ids
,
int
numSamples
,
int
tableSize
,
...
...
@@ -57,14 +60,16 @@ void hl_matrix_select_rows(real* output, int ldo,
dim3
threads
(
128
,
8
);
dim3
grid
(
8
,
1
);
KeMatrixAddRows
<
128
,
8
,
8
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
ldo
,
table
,
ldt
,
ids
,
numSamples
,
tableSize
,
dim
);
KeMatrixAddRows
<
128
,
8
,
8
,
0
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
ldo
,
table
,
ldt
,
ids
,
numSamples
,
tableSize
,
dim
);
CHECK_SYNC
(
"hl_matrix_select_rows failed"
);
}
void
hl_matrix_add_to_rows
(
real
*
table
,
int
ldt
,
real
*
input
,
int
ldi
,
void
hl_matrix_add_to_rows
(
real
*
table
,
int
ldt
,
real
*
input
,
int
ldi
,
int
*
ids
,
int
numSamples
,
int
tableSize
,
...
...
@@ -75,16 +80,15 @@ void hl_matrix_add_to_rows(real* table, int ldt,
dim3
threads
(
128
,
8
);
dim3
grid
(
8
,
1
);
KeMatrixAddRows
<
128
,
8
,
8
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
ldi
,
table
,
ldt
,
ids
,
numSamples
,
tableSize
,
dim
);
KeMatrixAddRows
<
128
,
8
,
8
,
1
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
ldi
,
table
,
ldt
,
ids
,
numSamples
,
tableSize
,
dim
);
CHECK_SYNC
(
"hl_matrix_add_to_rows failed"
);
}
template
<
class
T
,
int
blockDimX
,
int
gridDimX
>
__global__
void
KeVectorSelect
(
T
*
dst
,
int
sized
,
const
T
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
)
{
template
<
class
T
,
int
blockDimX
,
int
gridDimX
>
__global__
void
KeVectorSelect
(
T
*
dst
,
int
sized
,
const
T
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
)
{
int
idx
=
threadIdx
.
x
+
blockDimX
*
blockIdx
.
x
;
while
(
idx
<
sizei
)
{
int
index
=
ids
[
idx
];
...
...
@@ -95,9 +99,8 @@ __global__ void KeVectorSelect(T* dst, int sized,
}
template
<
class
T
>
void
hl_vector_select_from
(
T
*
dst
,
int
sized
,
const
T
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
)
{
void
hl_vector_select_from
(
T
*
dst
,
int
sized
,
const
T
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
)
{
CHECK_NOTNULL
(
dst
);
CHECK_NOTNULL
(
src
);
CHECK_NOTNULL
(
ids
);
...
...
@@ -105,18 +108,17 @@ void hl_vector_select_from(T* dst, int sized,
dim3
threads
(
512
,
1
);
dim3
grid
(
8
,
1
);
KeVectorSelect
<
T
,
512
,
8
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
sized
,
src
,
sizes
,
ids
,
sizei
);
KeVectorSelect
<
T
,
512
,
8
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
dst
,
sized
,
src
,
sizes
,
ids
,
sizei
);
CHECK_SYNC
(
"hl_vector_select_from failed"
);
}
template
void
hl_vector_select_from
(
real
*
dst
,
int
sized
,
const
real
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
);
template
void
hl_vector_select_from
(
int
*
dst
,
int
sized
,
const
int
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
);
template
void
hl_vector_select_from
(
real
*
dst
,
int
sized
,
const
real
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
);
template
void
hl_vector_select_from
(
int
*
dst
,
int
sized
,
const
int
*
src
,
int
sizes
,
const
int
*
ids
,
int
sizei
);
paddle/cuda/src/hl_top_k.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,45 +12,37 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "hl_top_k.h"
#include "hl_sparse.ph"
#include "hl_top_k.h"
#include "paddle/utils/Logging.h"
// using namespace hppl;
struct
Pair
{
__device__
__forceinline__
Pair
()
{}
__device__
__forceinline__
Pair
()
{}
__device__
__forceinline__
Pair
(
real
value
,
int
id
)
:
v_
(
value
),
id_
(
id
)
{}
__device__
__forceinline__
Pair
(
real
value
,
int
id
)
:
v_
(
value
),
id_
(
id
)
{}
__device__
__forceinline__
void
set
(
real
value
,
int
id
)
{
__device__
__forceinline__
void
set
(
real
value
,
int
id
)
{
v_
=
value
;
id_
=
id
;
}
__device__
__forceinline__
void
operator
=
(
const
Pair
&
in
)
{
__device__
__forceinline__
void
operator
=
(
const
Pair
&
in
)
{
v_
=
in
.
v_
;
id_
=
in
.
id_
;
}
__device__
__forceinline__
bool
operator
<
(
const
real
value
)
const
{
__device__
__forceinline__
bool
operator
<
(
const
real
value
)
const
{
return
(
v_
<
value
);
}
__device__
__forceinline__
bool
operator
<
(
const
Pair
&
in
)
const
{
__device__
__forceinline__
bool
operator
<
(
const
Pair
&
in
)
const
{
return
(
v_
<
in
.
v_
)
||
((
v_
==
in
.
v_
)
&&
(
id_
>
in
.
id_
));
}
__device__
__forceinline__
bool
operator
>
(
const
Pair
&
in
)
const
{
__device__
__forceinline__
bool
operator
>
(
const
Pair
&
in
)
const
{
return
(
v_
>
in
.
v_
)
||
((
v_
==
in
.
v_
)
&&
(
id_
<
in
.
id_
));
}
...
...
@@ -58,8 +50,9 @@ struct Pair {
int
id_
;
};
__device__
__forceinline__
void
addTo
(
Pair
topK
[],
const
Pair
&
p
,
int
beamSize
)
{
__device__
__forceinline__
void
addTo
(
Pair
topK
[],
const
Pair
&
p
,
int
beamSize
)
{
for
(
int
k
=
beamSize
-
2
;
k
>=
0
;
k
--
)
{
if
(
topK
[
k
]
<
p
)
{
topK
[
k
+
1
]
=
topK
[
k
];
...
...
@@ -71,9 +64,8 @@ void addTo(Pair topK[], const Pair &p, int beamSize) {
topK
[
0
]
=
p
;
}
template
<
int
beamSize
>
__device__
__forceinline__
void
addTo
(
Pair
topK
[],
const
Pair
&
p
)
{
template
<
int
beamSize
>
__device__
__forceinline__
void
addTo
(
Pair
topK
[],
const
Pair
&
p
)
{
for
(
int
k
=
beamSize
-
2
;
k
>=
0
;
k
--
)
{
if
(
topK
[
k
]
<
p
)
{
topK
[
k
+
1
]
=
topK
[
k
];
...
...
@@ -85,9 +77,9 @@ void addTo(Pair topK[], const Pair &p) {
topK
[
0
]
=
p
;
}
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
src
,
int
idx
,
int
dim
,
int
beamSize
)
{
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
src
,
int
idx
,
int
dim
,
int
beamSize
)
{
while
(
idx
<
dim
)
{
if
(
topK
[
beamSize
-
1
]
<
src
[
idx
])
{
Pair
tmp
(
src
[
idx
],
idx
);
...
...
@@ -97,10 +89,9 @@ void getTopK(Pair topK[], real *src, int idx, int dim, int beamSize) {
}
}
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
src
,
int
idx
,
int
dim
,
const
Pair
&
max
,
int
beamSize
)
{
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
src
,
int
idx
,
int
dim
,
const
Pair
&
max
,
int
beamSize
)
{
while
(
idx
<
dim
)
{
if
(
topK
[
beamSize
-
1
]
<
src
[
idx
])
{
Pair
tmp
(
src
[
idx
],
idx
);
...
...
@@ -112,10 +103,9 @@ void getTopK(Pair topK[], real *src, int idx, int dim,
}
}
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
val
,
int
*
col
,
int
idx
,
int
dim
,
int
beamSize
)
{
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
val
,
int
*
col
,
int
idx
,
int
dim
,
int
beamSize
)
{
while
(
idx
<
dim
)
{
if
(
topK
[
beamSize
-
1
]
<
val
[
idx
])
{
Pair
tmp
(
val
[
idx
],
col
[
idx
]);
...
...
@@ -125,10 +115,14 @@ void getTopK(Pair topK[], real *val, int *col,
}
}
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
val
,
int
*
col
,
int
idx
,
int
dim
,
const
Pair
&
max
,
int
beamSize
)
{
template
<
int
blockSize
>
__device__
__forceinline__
void
getTopK
(
Pair
topK
[],
real
*
val
,
int
*
col
,
int
idx
,
int
dim
,
const
Pair
&
max
,
int
beamSize
)
{
while
(
idx
<
dim
)
{
if
(
topK
[
beamSize
-
1
]
<
val
[
idx
])
{
Pair
tmp
(
val
[
idx
],
col
[
idx
]);
...
...
@@ -140,12 +134,16 @@ void getTopK(Pair topK[], real *val, int *col, int idx, int dim,
}
}
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
threadGetTopK
(
Pair
topK
[],
int
&
beam
,
int
beamSize
,
real
*
src
,
bool
&
firstStep
,
bool
&
isEmpty
,
Pair
&
max
,
int
dim
,
const
int
tid
)
{
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
threadGetTopK
(
Pair
topK
[],
int
&
beam
,
int
beamSize
,
real
*
src
,
bool
&
firstStep
,
bool
&
isEmpty
,
Pair
&
max
,
int
dim
,
const
int
tid
)
{
if
(
beam
>
0
)
{
int
length
=
beam
<
beamSize
?
beam
:
beamSize
;
if
(
firstStep
)
{
...
...
@@ -160,8 +158,7 @@ void threadGetTopK(Pair topK[], int& beam, int beamSize,
}
}
if
(
!
isEmpty
)
{
getTopK
<
blockSize
>
(
topK
+
maxLength
-
beam
,
src
,
tid
,
dim
,
max
,
length
);
getTopK
<
blockSize
>
(
topK
+
maxLength
-
beam
,
src
,
tid
,
dim
,
max
,
length
);
}
}
...
...
@@ -171,12 +168,17 @@ void threadGetTopK(Pair topK[], int& beam, int beamSize,
}
}
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
threadGetTopK
(
Pair
topK
[],
int
&
beam
,
int
beamSize
,
real
*
val
,
int
*
col
,
bool
&
firstStep
,
bool
&
isEmpty
,
Pair
&
max
,
int
dim
,
const
int
tid
)
{
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
threadGetTopK
(
Pair
topK
[],
int
&
beam
,
int
beamSize
,
real
*
val
,
int
*
col
,
bool
&
firstStep
,
bool
&
isEmpty
,
Pair
&
max
,
int
dim
,
const
int
tid
)
{
if
(
beam
>
0
)
{
int
length
=
beam
<
beamSize
?
beam
:
beamSize
;
if
(
firstStep
)
{
...
...
@@ -191,8 +193,8 @@ void threadGetTopK(Pair topK[], int& beam, int beamSize,
}
}
if
(
!
isEmpty
)
{
getTopK
<
blockSize
>
(
topK
+
maxLength
-
beam
,
val
,
col
,
tid
,
dim
,
max
,
length
);
getTopK
<
blockSize
>
(
topK
+
maxLength
-
beam
,
val
,
col
,
tid
,
dim
,
max
,
length
);
}
}
...
...
@@ -202,12 +204,16 @@ void threadGetTopK(Pair topK[], int& beam, int beamSize,
}
}
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
blockReduce
(
Pair
*
shTopK
,
int
*
maxId
,
Pair
topK
[],
real
**
topVal
,
int
**
topIds
,
int
&
beam
,
int
&
beamSize
,
const
int
tid
,
const
int
warp
)
{
template
<
int
maxLength
,
int
blockSize
>
__device__
__forceinline__
void
blockReduce
(
Pair
*
shTopK
,
int
*
maxId
,
Pair
topK
[],
real
**
topVal
,
int
**
topIds
,
int
&
beam
,
int
&
beamSize
,
const
int
tid
,
const
int
warp
)
{
while
(
true
)
{
__syncthreads
();
if
(
tid
<
blockSize
/
2
)
{
...
...
@@ -218,7 +224,7 @@ void blockReduce(Pair* shTopK, int* maxId, Pair topK[],
}
}
__syncthreads
();
for
(
int
stride
=
blockSize
/
4
;
stride
>
0
;
stride
=
stride
/
2
)
{
for
(
int
stride
=
blockSize
/
4
;
stride
>
0
;
stride
=
stride
/
2
)
{
if
(
tid
<
stride
)
{
if
(
shTopK
[
maxId
[
tid
]]
<
shTopK
[
maxId
[
tid
+
stride
]])
{
maxId
[
tid
]
=
maxId
[
tid
+
stride
];
...
...
@@ -257,10 +263,12 @@ void blockReduce(Pair* shTopK, int* maxId, Pair topK[],
* 3. go to the second setp, until one thread's topK value is null;
* 4. go to the first setp, until get the topK value.
*/
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeMatrixTopK
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeMatrixTopK
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
int
dim
,
int
beamSize
)
{
__shared__
Pair
shTopK
[
blockSize
];
...
...
@@ -271,7 +279,7 @@ __global__ void KeMatrixTopK(real* topVal, int ldv,
topVal
+=
blockIdx
.
x
*
ldv
;
topIds
+=
blockIdx
.
x
*
beamSize
;
Pair
topK
[
maxLength
];
// NOLINT
Pair
topK
[
maxLength
];
// NOLINT
int
beam
=
maxLength
;
Pair
max
;
bool
isEmpty
=
false
;
...
...
@@ -281,18 +289,19 @@ __global__ void KeMatrixTopK(real* topVal, int ldv,
topK
[
k
].
set
(
-
HL_FLOAT_MAX
,
-
1
);
}
while
(
beamSize
)
{
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
src
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
src
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
shTopK
[
tid
]
=
topK
[
0
];
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
}
}
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeSMatrixTopK
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeSMatrixTopK
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
val
,
int
*
row
,
int
*
col
,
...
...
@@ -304,7 +313,7 @@ __global__ void KeSMatrixTopK(real* topVal, int ldv,
topVal
+=
blockIdx
.
x
*
ldv
;
topIds
+=
blockIdx
.
x
*
beamSize
;
Pair
topK
[
maxLength
];
// NOLINT
Pair
topK
[
maxLength
];
// NOLINT
int
beam
=
maxLength
;
Pair
max
;
bool
isEmpty
=
false
;
...
...
@@ -330,18 +339,20 @@ __global__ void KeSMatrixTopK(real* topVal, int ldv,
topK
[
k
].
set
(
-
HL_FLOAT_MAX
,
-
1
);
}
while
(
beamSize
)
{
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
val
,
col
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
val
,
col
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
shTopK
[
tid
]
=
topK
[
0
];
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
}
}
void
hl_matrix_top_k
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
void
hl_matrix_top_k
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
int
dim
,
int
beamSize
,
int
numSamples
)
{
...
...
@@ -353,33 +364,32 @@ void hl_matrix_top_k(real* topVal, int ldv,
dim3
threads
(
256
,
1
);
dim3
grid
(
numSamples
,
1
);
KeMatrixTopK
<
5
,
256
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
src
,
lds
,
dim
,
beamSize
);
KeMatrixTopK
<
5
,
256
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
src
,
lds
,
dim
,
beamSize
);
CHECK_SYNC
(
"hl_matrix_top_k failed"
);
}
void
hl_sparse_matrix_top_k
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
void
hl_sparse_matrix_top_k
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
hl_sparse_matrix_s
src
,
int
beamSize
,
int
numSamples
)
{
CHECK_NOTNULL
(
topVal
);
CHECK_NOTNULL
(
topIds
);
CHECK_NOTNULL
(
src
);
CHECK_EQ
(
src
->
format
,
HL_SPARSE_CSR
)
<<
"sparse matrix format error!"
;
CHECK_EQ
(
src
->
format
,
HL_SPARSE_CSR
)
<<
"sparse matrix format error!"
;
hl_csr_matrix
csr
=
(
hl_csr_matrix
)
src
->
matrix
;
if
(
csr
->
csr_val
==
NULL
||
csr
->
csr_row
==
NULL
||
csr
->
csr_col
==
NULL
)
{
if
(
csr
->
csr_val
==
NULL
||
csr
->
csr_row
==
NULL
||
csr
->
csr_col
==
NULL
)
{
LOG
(
FATAL
)
<<
"parameter src is null!"
;
}
dim3
threads
(
256
,
1
);
dim3
grid
(
numSamples
,
1
);
KeSMatrixTopK
<
5
,
256
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
csr
->
csr_val
,
csr
->
csr_row
,
csr
->
csr_col
,
beamSize
);
KeSMatrixTopK
<
5
,
256
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
csr
->
csr_val
,
csr
->
csr_row
,
csr
->
csr_col
,
beamSize
);
CHECK_SYNC
(
"hl_sparse_matrix_top_k failed"
);
}
...
...
@@ -392,10 +402,12 @@ void hl_sparse_matrix_top_k(real* topVal, int ldv,
* 3. go to the second setp, until one thread's topK value is null;
* 4. go to the first setp, until get the topK value.
*/
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeMatrixTopKClassificationError
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
template
<
int
maxLength
,
int
blockSize
>
__global__
void
KeMatrixTopKClassificationError
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
int
dim
,
int
beamSize
,
int
*
label
,
...
...
@@ -408,7 +420,7 @@ __global__ void KeMatrixTopKClassificationError(real* topVal, int ldv,
topVal
+=
blockIdx
.
x
*
ldv
;
topIds
+=
blockIdx
.
x
*
beamSize
;
Pair
topK
[
maxLength
];
// NOLINT
Pair
topK
[
maxLength
];
// NOLINT
int
beam
=
maxLength
;
Pair
max
;
bool
isEmpty
=
false
;
...
...
@@ -420,34 +432,36 @@ __global__ void KeMatrixTopKClassificationError(real* topVal, int ldv,
}
while
(
beamSize
)
{
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
src
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
threadGetTopK
<
maxLength
,
blockSize
>
(
topK
,
beam
,
beamSize
,
src
,
firstStep
,
isEmpty
,
max
,
dim
,
tid
);
shTopK
[
tid
]
=
topK
[
0
];
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
blockReduce
<
maxLength
,
blockSize
>
(
shTopK
,
maxId
,
topK
,
&
topVal
,
&
topIds
,
beam
,
beamSize
,
tid
,
warp
);
}
__syncthreads
();
if
(
tid
==
0
)
{
for
(
int
i
=
0
;
i
<
topkSize
;
i
++
)
{
if
(
*--
topIds
==
label
[
blockIdx
.
x
])
{
recResult
[
blockIdx
.
x
]
=
0
;
break
;
}
recResult
[
blockIdx
.
x
]
=
1.0
f
;
if
(
*--
topIds
==
label
[
blockIdx
.
x
])
{
recResult
[
blockIdx
.
x
]
=
0
;
break
;
}
recResult
[
blockIdx
.
x
]
=
1.0
f
;
}
}
}
void
hl_matrix_classification_error
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
int
dim
,
int
topkSize
,
int
numSamples
,
int
*
label
,
real
*
recResult
)
{
void
hl_matrix_classification_error
(
real
*
topVal
,
int
ldv
,
int
*
topIds
,
real
*
src
,
int
lds
,
int
dim
,
int
topkSize
,
int
numSamples
,
int
*
label
,
real
*
recResult
)
{
CHECK_NOTNULL
(
topVal
);
CHECK_NOTNULL
(
topIds
);
CHECK_NOTNULL
(
src
);
...
...
@@ -456,9 +470,8 @@ void hl_matrix_classification_error(real* topVal, int ldv,
dim3
threads
(
256
,
1
);
dim3
grid
(
numSamples
,
1
);
KeMatrixTopKClassificationError
<
5
,
256
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
src
,
lds
,
dim
,
topkSize
,
label
,
recResult
);
KeMatrixTopKClassificationError
<
5
,
256
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
topVal
,
ldv
,
topIds
,
src
,
lds
,
dim
,
topkSize
,
label
,
recResult
);
CHECK_SYNC
(
"hl_matrix_top_k classification error failed"
);
}
paddle/framework/attribute.proto
浏览文件 @
59a8ebc6
...
...
@@ -12,17 +12,17 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
syntax
=
"proto2"
;
syntax
=
"proto2"
;
package
paddle
.
framework
;
// Attribute Type for paddle's Op.
// Op contains many attributes. Each type of attributes could be different.
// The AttrType will be shared between AttrDesc and AttrProto.
enum
AttrType
{
INT
=
0
;
FLOAT
=
1
;
STRING
=
2
;
INTS
=
3
;
FLOATS
=
4
;
STRINGS
=
5
;
INT
=
0
;
FLOAT
=
1
;
STRING
=
2
;
INTS
=
3
;
FLOATS
=
4
;
STRINGS
=
5
;
}
\ No newline at end of file
paddle/framework/op_desc.proto
浏览文件 @
59a8ebc6
...
...
@@ -12,7 +12,7 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
syntax
=
"proto2"
;
syntax
=
"proto2"
;
package
paddle
.
framework
;
import
"attribute.proto"
;
...
...
@@ -22,14 +22,14 @@ import "attribute.proto";
//
// e.g, for scale=3.0: name=scala, type=AttrType.FLOAT, value=3.0
message
AttrDesc
{
required
string
name
=
1
;
required
AttrType
type
=
2
;
optional
int32
i
=
3
;
optional
float
f
=
4
;
optional
string
s
=
5
;
repeated
int32
ints
=
6
;
repeated
float
floats
=
7
;
repeated
string
strings
=
8
;
required
string
name
=
1
;
required
AttrType
type
=
2
;
optional
int32
i
=
3
;
optional
float
f
=
4
;
optional
string
s
=
5
;
repeated
int32
ints
=
6
;
repeated
float
floats
=
7
;
repeated
string
strings
=
8
;
};
// Protocol Message to describe an Operator.
...
...
@@ -42,15 +42,15 @@ message AttrDesc {
// 3rd-party language can build this proto message and call
// AddOp(const OpDesc& op_desc) of Paddle core to create an Operator.
message
OpDesc
{
// input names of this Operator.
repeated
string
inputs
=
1
;
// input names of this Operator.
repeated
string
inputs
=
1
;
// output names of this Operator.
repeated
string
outputs
=
2
;
// output names of this Operator.
repeated
string
outputs
=
2
;
// type of this Operator, such as "add", "sub", "fc".
required
string
type
=
3
;
// type of this Operator, such as "add", "sub", "fc".
required
string
type
=
3
;
// Attributes of this Operator. e.g., scale=3.0 in cosine op.
repeated
AttrDesc
attrs
=
4
;
// Attributes of this Operator. e.g., scale=3.0 in cosine op.
repeated
AttrDesc
attrs
=
4
;
};
\ No newline at end of file
paddle/framework/op_proto.proto
浏览文件 @
59a8ebc6
...
...
@@ -15,10 +15,11 @@ limitations under the License. */
// Protocol Message for 3rd-party language binding.
//
// Paddle Python package will use `OpProto` to generate op creation methods.
// The op creation methods take user's input and generate `OpDesc` proto message,
// The op creation methods take user's input and generate `OpDesc` proto
// message,
// then pass `OpDesc` to C++ side and create Op pointer.
//
syntax
=
"proto2"
;
syntax
=
"proto2"
;
package
paddle
.
framework
;
import
"attribute.proto"
;
...
...
@@ -26,89 +27,90 @@ import "attribute.proto";
// Attribute protocol message for 3rd-party language binding.
// It will store the Op support what attribute and what type.
message
AttrProto
{
// Supported attribute name. e.g. `scale` for cosine op.
required
string
name
=
1
;
// Supported attribute name. e.g. `scale` for cosine op.
required
string
name
=
1
;
// Supported attribute type.
required
AttrType
type
=
2
;
// Supported attribute type.
required
AttrType
type
=
2
;
// Supported attribute comments. It helps 3rd-party language generate doc-string.
required
string
comment
=
3
;
// Supported attribute comments. It helps 3rd-party language generate
// doc-string.
required
string
comment
=
3
;
// If that attribute is generated, it means the Paddle third language
// binding has responsibility to fill that attribute. End-User should
// not set that attribute.
optional
bool
generated
=
4
[
default
=
false
];
// If that attribute is generated, it means the Paddle third language
// binding has responsibility to fill that attribute. End-User should
// not set that attribute.
optional
bool
generated
=
4
[
default
=
false
];
}
// Input or output message for 3rd-party language binding.
// It contains parameter name and its comments.
message
VarProto
{
// Input or output name in that op creation function.
// e.g. `cos(a, b, output, ...)`, "a", "b", "output" are names.
required
string
name
=
1
;
// The comment for that input. It helps 3rd-party language generate doc-string.
required
string
comment
=
2
;
// Is that input/output could be a list or not.
// If so, that Op should write a attributed named `input_format` or
// `output_format`.
//
// e.g.
// If the op is a fc op, the inputs are `X`, `W`, `b`. The `X` and `W`
// could be multiple, so the multiple of `X` and `W` is True, and OpDesc
// will hold a attribute of them.
//
// The Op desc of same fc could be
// {
// "type": "fc",
// "input": ["X1", "X2", "W1", "W2", "b"],
// "output": "fc.out",
// "attrs" : {
// "input_format": [0, 2, 4, 5]
// }
// }
//
optional
bool
multiple
=
3
[
default
=
false
];
// It marks that output is a temporary output. That output is not used by
// user, but used by other op internally as input. If other op is not use
// that output, it could be optimized early.
//
// Attribute temporary_index will be set in OpDesc if there is some
// outputs are temporary.
//
// output = [ "xxx.out1", "xxx.tmp", "xxx.out2"],
// attrs = {
// "temporary_index": [1]
// }
optional
bool
temporary
=
4
[
default
=
false
];
// The gradient of operator can be ignored immediately
// e.g. operator AddOp, y = x1 + x2, the gradient of dy/dx1, dy/dx2
// can be ignored for the future optimized on graph.
optional
bool
ignore_gradient
=
6
;
// Input or output name in that op creation function.
// e.g. `cos(a, b, output, ...)`, "a", "b", "output" are names.
required
string
name
=
1
;
// The comment for that input. It helps 3rd-party language generate
// doc-string.
required
string
comment
=
2
;
// Is that input/output could be a list or not.
// If so, that Op should write a attributed named `input_format` or
// `output_format`.
//
// e.g.
// If the op is a fc op, the inputs are `X`, `W`, `b`. The `X` and `W`
// could be multiple, so the multiple of `X` and `W` is True, and OpDesc
// will hold a attribute of them.
//
// The Op desc of same fc could be
// {
// "type": "fc",
// "input": ["X1", "X2", "W1", "W2", "b"],
// "output": "fc.out",
// "attrs" : {
// "input_format": [0, 2, 4, 5]
// }
// }
//
optional
bool
multiple
=
3
[
default
=
false
];
// It marks that output is a temporary output. That output is not used by
// user, but used by other op internally as input. If other op is not use
// that output, it could be optimized early.
//
// Attribute temporary_index will be set in OpDesc if there is some
// outputs are temporary.
//
// output = [ "xxx.out1", "xxx.tmp", "xxx.out2"],
// attrs = {
// "temporary_index": [1]
// }
optional
bool
temporary
=
4
[
default
=
false
];
// The gradient of operator can be ignored immediately
// e.g. operator AddOp, y = x1 + x2, the gradient of dy/dx1, dy/dx2
// can be ignored for the future optimized on graph.
optional
bool
ignore_gradient
=
6
;
}
// Op protocol message for 3rd-party language binding.
// It contains all information for generating op creation method.
message
OpProto
{
// The input information to generate op creation method.
repeated
VarProto
inputs
=
1
;
// The input information to generate op creation method.
repeated
VarProto
inputs
=
1
;
// The output information to generate op creation method.
repeated
VarProto
outputs
=
2
;
// The output information to generate op creation method.
repeated
VarProto
outputs
=
2
;
// The attribute information to generate op creation method.
repeated
AttrProto
attrs
=
3
;
// The attribute information to generate op creation method.
repeated
AttrProto
attrs
=
3
;
// The comments for that Op. It helps 3rd-party language generate
// doc-string. The whole documentation of that Op is generated by comment,
// inputs, outputs, attrs together.
required
string
comment
=
4
;
// The type of that Op.
required
string
type
=
5
;
// The comments for that Op. It helps 3rd-party language generate
// doc-string. The whole documentation of that Op is generated by comment,
// inputs, outputs, attrs together.
required
string
comment
=
4
;
// The type of that Op.
required
string
type
=
5
;
}
paddle/framework/operator.cc
浏览文件 @
59a8ebc6
...
...
@@ -22,14 +22,14 @@ namespace framework {
template
<
>
Eigen
::
DefaultDevice
&
ExecutionContext
::
GetEigenDevice
<
platform
::
CPUPlace
,
Eigen
::
DefaultDevice
>
()
const
{
return
*
device_context_
.
get_eigen_device
<
Eigen
::
DefaultDevice
>
();
return
*
device_context_
->
get_eigen_device
<
Eigen
::
DefaultDevice
>
();
}
#ifndef PADDLE_ONLY_CPU
template
<
>
Eigen
::
GpuDevice
&
ExecutionContext
::
GetEigenDevice
<
platform
::
GPUPlace
,
Eigen
::
GpuDevice
>
()
const
{
return
*
device_context_
.
get_eigen_device
<
Eigen
::
GpuDevice
>
();
return
*
device_context_
->
get_eigen_device
<
Eigen
::
GpuDevice
>
();
}
#endif
...
...
paddle/framework/operator.h
浏览文件 @
59a8ebc6
...
...
@@ -174,7 +174,11 @@ class OperatorContext {
template
<
typename
T
>
T
*
Output
(
const
size_t
index
)
const
{
auto
var
=
OutputVar
(
index
);
PADDLE_ENFORCE
(
var
!=
nullptr
,
"Output(%d) should not be nullptr"
,
index
);
PADDLE_ENFORCE
(
var
!=
nullptr
,
"Output(%d) not be nullptr, which means variable [%s] does not "
"exist in scope"
,
index
,
op_
.
outputs_
[
index
]);
return
var
->
GetMutable
<
T
>
();
}
...
...
@@ -252,7 +256,7 @@ struct EigenDeviceConverter<platform::GPUPlace> {
class
ExecutionContext
:
public
OperatorContext
{
public:
ExecutionContext
(
const
OperatorBase
*
op
,
const
Scope
&
scope
,
const
platform
::
DeviceContext
&
device_context
)
const
platform
::
DeviceContext
*
device_context
)
:
OperatorContext
(
op
,
scope
),
device_context_
(
device_context
)
{}
template
<
typename
PlaceType
,
...
...
@@ -260,9 +264,9 @@ class ExecutionContext : public OperatorContext {
typename
EigenDeviceConverter
<
PlaceType
>::
EigenDeviceType
>
DeviceType
&
GetEigenDevice
()
const
;
platform
::
Place
GetPlace
()
const
{
return
device_context_
.
GetPlace
();
}
platform
::
Place
GetPlace
()
const
{
return
device_context_
->
GetPlace
();
}
const
platform
::
DeviceContext
&
device_context_
;
const
platform
::
DeviceContext
*
device_context_
;
};
class
OpKernel
{
...
...
@@ -311,7 +315,7 @@ class OperatorWithKernel : public OperatorBase {
void
Run
(
const
Scope
&
scope
,
const
platform
::
DeviceContext
&
dev_ctx
)
const
final
{
auto
&
opKernel
=
AllOpKernels
().
at
(
type_
).
at
(
OpKernelKey
(
dev_ctx
));
opKernel
->
Compute
(
ExecutionContext
(
this
,
scope
,
dev_ctx
));
opKernel
->
Compute
(
ExecutionContext
(
this
,
scope
,
&
dev_ctx
));
}
static
std
::
unordered_map
<
std
::
string
/* op_type */
,
OpKernelMap
>&
...
...
paddle/framework/operator_test.cc
浏览文件 @
59a8ebc6
...
...
@@ -157,22 +157,22 @@ class CPUKernalMultiInputsTest : public OpKernel {
ASSERT_EQ
(
xs
[
2
],
"x2"
);
auto
inVar0
=
ctx
.
MultiInputVar
(
"xs"
);
ASSERT_EQ
(
inVar0
.
size
(),
3
);
ASSERT_EQ
(
inVar0
.
size
(),
3
U
);
auto
intVar1
=
ctx
.
InputVar
(
"k"
);
ASSERT_NE
(
intVar1
,
nullptr
);
auto
outVar0
=
ctx
.
MultiOutputVar
(
"ys"
);
ASSERT_EQ
(
outVar0
.
size
(),
2
);
ASSERT_EQ
(
outVar0
.
size
(),
2
U
);
auto
inTensor0
=
ctx
.
MultiInput
<
Tensor
>
(
"xs"
);
ASSERT_EQ
(
inTensor0
.
size
(),
3
);
ASSERT_EQ
(
inTensor0
.
size
(),
3
U
);
auto
intTensor1
=
ctx
.
Input
<
Tensor
>
(
"k"
);
ASSERT_NE
(
intTensor1
,
nullptr
);
auto
outTensor0
=
ctx
.
MultiOutput
<
Tensor
>
(
"ys"
);
ASSERT_EQ
(
outTensor0
.
size
(),
2
);
ASSERT_EQ
(
outTensor0
.
size
(),
2
U
);
auto
k
=
ctx
.
op_
.
Input
(
"k"
);
ASSERT_EQ
(
k
,
"k0"
);
...
...
paddle/function/BlockExpandOpTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -18,10 +18,10 @@ limitations under the License. */
namespace
paddle
{
TEST
(
BlockExpandForward
,
real
)
{
for
(
size_t
batchSize
:
{
5
,
32
})
{
for
(
size_t
channels
:
{
1
,
5
,
32
})
{
for
(
size_t
inputHeight
:
{
5
,
33
,
100
})
{
for
(
size_t
inputWidth
:
{
5
,
32
,
96
})
{
for
(
size_t
batchSize
:
{
5
})
{
for
(
size_t
channels
:
{
1
,
5
})
{
for
(
size_t
inputHeight
:
{
5
,
33
})
{
for
(
size_t
inputWidth
:
{
5
,
32
})
{
for
(
size_t
block
:
{
1
,
3
,
5
})
{
for
(
size_t
stride
:
{
1
,
2
})
{
for
(
size_t
padding
:
{
0
,
1
})
{
...
...
@@ -61,10 +61,10 @@ TEST(BlockExpandForward, real) {
}
TEST
(
BlockExpandBackward
,
real
)
{
for
(
size_t
batchSize
:
{
5
,
32
})
{
for
(
size_t
channels
:
{
1
,
5
,
32
})
{
for
(
size_t
inputHeight
:
{
5
,
33
,
100
})
{
for
(
size_t
inputWidth
:
{
5
,
32
,
96
})
{
for
(
size_t
batchSize
:
{
5
})
{
for
(
size_t
channels
:
{
1
,
5
})
{
for
(
size_t
inputHeight
:
{
5
,
33
})
{
for
(
size_t
inputWidth
:
{
5
,
32
})
{
for
(
size_t
block
:
{
1
,
3
,
5
})
{
for
(
size_t
stride
:
{
1
,
2
})
{
for
(
size_t
padding
:
{
0
,
1
})
{
...
...
paddle/function/BufferArgTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -32,7 +32,7 @@ TEST(BufferTest, SequenceIdArg) {
sizeOfValuType
(
VALUE_TYPE_INT32
));
SequenceIdArg
buffer
(
memory
.
getBuf
(),
shape
);
EXPECT_EQ
(
buffer
.
data
(),
memory
.
getBuf
());
EXPECT_EQ
(
buffer
.
numSeqs
(),
9
);
EXPECT_EQ
(
buffer
.
numSeqs
(),
9
U
);
}
}
// namespace paddle
paddle/function/ContextProjectionOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "ContextProjectionOp.h"
#include "hl_base.h"
namespace
paddle
{
...
...
@@ -30,7 +30,7 @@ __global__ void KeContextProjectionForward(const real* input,
int
block_size
=
blockDim
.
x
;
int
sequenceId
=
blockIdx
.
x
;
int
seq_start
=
sequence
[
sequenceId
];
int
seq_end
=
sequence
[
sequenceId
+
1
];
int
seq_end
=
sequence
[
sequenceId
+
1
];
real
value
=
0
;
int
instances
=
seq_end
-
seq_start
+
context_length
-
1
;
...
...
@@ -49,8 +49,9 @@ __global__ void KeContextProjectionForward(const real* input,
}
else
if
((
i
+
context_start
)
>=
(
seq_end
-
seq_start
))
{
if
(
padding
)
{
value
=
weight
[(
begin_pad
+
i
+
context_start
-
(
seq_end
-
seq_start
))
*
input_dim
+
idx
];
weight
[(
begin_pad
+
i
+
context_start
-
(
seq_end
-
seq_start
))
*
input_dim
+
idx
];
}
else
{
continue
;
}
...
...
@@ -61,7 +62,7 @@ __global__ void KeContextProjectionForward(const real* input,
int
outx
=
(
i
-
context_length
)
<
0
?
i
:
(
context_length
-
1
);
int
outy
=
(
i
-
context_length
)
<
0
?
0
:
(
i
-
(
context_length
-
1
));
real
*
output_r
=
output
+
outy
*
input_dim
*
context_length
+
outx
*
input_dim
;
output
+
outy
*
input_dim
*
context_length
+
outx
*
input_dim
;
for
(
int
j
=
outy
;
j
<
seq_end
-
seq_start
;
j
++
)
{
output_r
[
idx
]
+=
value
;
if
(
j
-
outy
==
outx
)
break
;
...
...
@@ -108,13 +109,25 @@ void hl_context_projection_forward(const real* input,
dim3
grid
(
blocks_x
,
blocks_y
);
if
(
weight
)
{
KeContextProjectionForward
<
true
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
weight
,
output
,
input_dim
,
context_length
,
context_start
,
begin_pad
);
}
else
{
KeContextProjectionForward
<
false
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
weight
,
output
,
input_dim
,
context_length
,
context_start
,
begin_pad
);
KeContextProjectionForward
<
true
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
weight
,
output
,
input_dim
,
context_length
,
context_start
,
begin_pad
);
}
else
{
KeContextProjectionForward
<
false
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
input
,
sequence
,
weight
,
output
,
input_dim
,
context_length
,
context_start
,
begin_pad
);
}
CHECK_SYNC
(
"hl_context_projection_forward failed"
);
}
...
...
@@ -148,7 +161,7 @@ __global__ void KeContextProjectionBackwardData(const real* out_grad,
int
block_size
=
blockDim
.
x
;
int
sequenceId
=
blockIdx
.
x
;
int
seq_start
=
sequence
[
sequenceId
];
int
seq_end
=
sequence
[
sequenceId
+
1
];
int
seq_end
=
sequence
[
sequenceId
+
1
];
real
value
=
0
;
int
instances
=
seq_end
-
seq_start
+
context_length
-
1
;
...
...
@@ -170,7 +183,7 @@ __global__ void KeContextProjectionBackwardData(const real* out_grad,
int
outx
=
(
i
-
context_length
)
<
0
?
i
:
(
context_length
-
1
);
int
outy
=
(
i
-
context_length
)
<
0
?
0
:
(
i
-
(
context_length
-
1
));
real
*
output_r
=
out
+
outy
*
input_dim
*
context_length
+
outx
*
input_dim
;
out
+
outy
*
input_dim
*
context_length
+
outx
*
input_dim
;
for
(
int
j
=
outy
;
j
<
seq_end
-
seq_start
;
j
++
)
{
value
+=
output_r
[
idx
];
if
(
j
-
outy
==
outx
)
break
;
...
...
@@ -211,8 +224,8 @@ void hl_context_projection_backward_data(const real* out_grad,
int
blocks_y
=
1
;
dim3
threads
(
block_size
,
1
);
dim3
grid
(
blocks_x
,
blocks_y
);
KeContextProjectionBackwardData
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
out_grad
,
sequence
,
input_grad
,
input_dim
,
context_length
,
context_start
);
KeContextProjectionBackwardData
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
out_grad
,
sequence
,
input_grad
,
input_dim
,
context_length
,
context_start
);
CHECK_SYNC
(
"hl_context_projection_backward_data failed"
);
}
...
...
@@ -231,7 +244,7 @@ void ContextProjectionBackwardData<DEVICE_TYPE_GPU>(const GpuMatrix& out_grad,
context_start
);
}
template
<
int
THREADS_X
,
int
THREADS_Y
>
template
<
int
THREADS_X
,
int
THREADS_Y
>
__global__
void
KeContextProjectionBackwardWeight
(
const
real
*
out_grad
,
const
int
*
sequence
,
real
*
w_grad
,
...
...
@@ -254,17 +267,17 @@ __global__ void KeContextProjectionBackwardWeight(const real* out_grad,
if
(
weight_idx
<
w_dim
)
{
for
(
int
seqId
=
idy
;
seqId
<
num_sequences
;
seqId
+=
THREADS_Y
)
{
int
seq_start
=
sequence
[
seqId
];
int
seq_end
=
sequence
[
seqId
+
1
];
output_r
=
const_cast
<
real
*>
(
out_grad
)
+
seq_start
*
w_dim
*
context_length
;
int
seq_end
=
sequence
[
seqId
+
1
];
output_r
=
const_cast
<
real
*>
(
out_grad
)
+
seq_start
*
w_dim
*
context_length
;
if
(
context_start
<
0
)
{
if
(
padId
+
context_start
<
0
)
{
instanceId
=
padId
;
}
else
{
// begin_pad > 0;
instanceId
=
(
padId
-
begin_pad
)
+
(
seq_end
-
seq_start
)
-
context_start
;
instanceId
=
(
padId
-
begin_pad
)
+
(
seq_end
-
seq_start
)
-
context_start
;
}
}
else
{
if
(
padId
+
(
seq_end
-
seq_start
)
<
context_start
)
{
...
...
@@ -275,10 +288,11 @@ __global__ void KeContextProjectionBackwardWeight(const real* out_grad,
}
}
int
outx
=
(
instanceId
-
context_length
)
<
0
?
instanceId
:
(
context_length
-
1
);
int
outy
=
(
instanceId
-
context_length
)
<
0
?
0
:
(
instanceId
-
(
context_length
-
1
));
int
outx
=
(
instanceId
-
context_length
)
<
0
?
instanceId
:
(
context_length
-
1
);
int
outy
=
(
instanceId
-
context_length
)
<
0
?
0
:
(
instanceId
-
(
context_length
-
1
));
output_r
+=
outy
*
w_dim
*
context_length
+
outx
*
w_dim
;
for
(
int
j
=
outy
;
j
<
seq_end
-
seq_start
;
j
++
)
{
value
+=
output_r
[
weight_idx
];
...
...
@@ -290,7 +304,7 @@ __global__ void KeContextProjectionBackwardWeight(const real* out_grad,
}
__syncthreads
();
for
(
int
stride
=
THREADS_Y
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
for
(
int
stride
=
THREADS_Y
/
2
;
stride
>
0
;
stride
=
stride
/
2
)
{
if
(
idy
<
stride
)
{
sum_s
[
idy
][
idx
]
+=
sum_s
[
idy
+
stride
][
idx
];
}
...
...
@@ -339,22 +353,27 @@ void hl_context_projection_backward_weight(const real* out_grad,
dim3
threads
(
threads_x
,
threads_y
);
dim3
grid
(
blocks_x
,
1
);
KeContextProjectionBackwardWeight
<
32
,
32
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
out_grad
,
sequence
,
w_grad
,
num_sequences
,
w_dim
,
context_length
,
context_start
,
begin_pad
);
KeContextProjectionBackwardWeight
<
32
,
32
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
out_grad
,
sequence
,
w_grad
,
num_sequences
,
w_dim
,
context_length
,
context_start
,
begin_pad
);
CHECK_SYNC
(
"hl_context_projection_backward_weight failed"
);
}
template
<
>
void
ContextProjectionBackwardWeight
<
DEVICE_TYPE_GPU
>
(
const
GpuMatrix
&
out_grad
,
GpuMatrix
&
w_grad
,
const
GpuIVector
&
seq_vec
,
size_t
context_length
,
int
context_start
,
size_t
total_pad
,
size_t
begin_pad
)
{
void
ContextProjectionBackwardWeight
<
DEVICE_TYPE_GPU
>
(
const
GpuMatrix
&
out_grad
,
GpuMatrix
&
w_grad
,
const
GpuIVector
&
seq_vec
,
size_t
context_length
,
int
context_start
,
size_t
total_pad
,
size_t
begin_pad
)
{
hl_context_projection_backward_weight
(
out_grad
.
getData
(),
seq_vec
.
getData
(),
w_grad
.
getData
(),
...
...
@@ -376,23 +395,18 @@ void ContextProjectionBackward<DEVICE_TYPE_GPU>(const GpuMatrix& out_grad,
size_t
begin_pad
,
bool
is_padding
,
size_t
total_pad
)
{
if
(
in_grad
)
{
ContextProjectionBackwardData
<
DEVICE_TYPE_GPU
>
(
out_grad
,
in_grad
,
sequence
,
context_length
,
context_start
);
}
if
(
is_padding
&&
w_grad
)
{
ContextProjectionBackwardWeight
<
DEVICE_TYPE_GPU
>
(
out_grad
,
w_grad
,
sequence
,
context_length
,
context_start
,
total_pad
,
begin_pad
);
if
(
in_grad
)
{
ContextProjectionBackwardData
<
DEVICE_TYPE_GPU
>
(
out_grad
,
in_grad
,
sequence
,
context_length
,
context_start
);
}
if
(
is_padding
&&
w_grad
)
{
ContextProjectionBackwardWeight
<
DEVICE_TYPE_GPU
>
(
out_grad
,
w_grad
,
sequence
,
context_length
,
context_start
,
total_pad
,
begin_pad
);
}
}
...
...
paddle/function/CosSimOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,13 +12,13 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "CosSimOp.h"
#include "hl_base.h"
#include "hl_device_functions.cuh"
#include "CosSimOp.h"
namespace
paddle
{
template
<
int
block_size
>
template
<
int
block_size
>
__global__
void
KeCosSim
(
real
*
output
,
const
real
*
input1
,
const
real
*
input2
,
...
...
@@ -78,8 +78,8 @@ void hlCossim(real* output,
dim3
threads
(
block_size
,
1
);
dim3
grid
(
1
,
input1_height
);
KeCosSim
<
block_size
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input1
,
input2
,
width
,
input1_height
,
input2_height
,
scale
);
KeCosSim
<
block_size
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
output
,
input1
,
input2
,
width
,
input1_height
,
input2_height
,
scale
);
CHECK_SYNC
(
"hlCossim failed"
);
}
...
...
@@ -99,7 +99,7 @@ void CosSimForward<DEVICE_TYPE_GPU>(GpuMatrix& out_mat,
hlCossim
(
out
,
x
,
y
,
dim
,
in1_mat
.
getHeight
(),
in2_mat
.
getHeight
(),
scale
);
}
template
<
int
block_size
>
template
<
int
block_size
>
__global__
void
KeCosSimDerivative
(
const
real
*
grad
,
const
real
*
output
,
const
real
*
prev_out_x
,
...
...
@@ -148,14 +148,13 @@ __global__ void KeCosSimDerivative(const real* grad,
if
(
xy
[
0
]
==
0
)
{
real
reciprocal
=
1.0
/
(
sqrt
(
xx
[
0
])
*
sqrt
(
yy
[
0
]));
for
(
int
index
=
tid
;
index
<
width
;
index
+=
block_size
)
{
prev_grad_x
[
index
]
+=
scale
*
grad
[
ty
]
*
prev_out_y
[
index
]
*
reciprocal
;
prev_grad_x
[
index
]
+=
scale
*
grad
[
ty
]
*
prev_out_y
[
index
]
*
reciprocal
;
if
(
input2_height
>
1
)
{
prev_grad_y
[
index
]
+=
scale
*
grad
[
ty
]
*
prev_out_x
[
index
]
*
reciprocal
;
prev_grad_y
[
index
]
+=
scale
*
grad
[
ty
]
*
prev_out_x
[
index
]
*
reciprocal
;
}
else
{
paddle
::
paddleAtomicAdd
(
prev_grad_y
+
index
,
scale
*
grad
[
ty
]
*
prev_out_x
[
index
]
*
reciprocal
);
paddle
::
paddleAtomicAdd
(
prev_grad_y
+
index
,
scale
*
grad
[
ty
]
*
prev_out_x
[
index
]
*
reciprocal
);
}
}
}
else
{
...
...
@@ -163,17 +162,18 @@ __global__ void KeCosSimDerivative(const real* grad,
real
reciprocalSquareSumX
=
1.0
/
xx
[
0
];
real
reciprocalSquareSumY
=
1.0
/
yy
[
0
];
for
(
int
index
=
tid
;
index
<
width
;
index
+=
block_size
)
{
prev_grad_x
[
index
]
+=
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_y
[
index
]
*
reciprocalXY
-
prev_out_x
[
index
]
*
reciprocalSquareSumX
);
prev_grad_x
[
index
]
+=
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_y
[
index
]
*
reciprocalXY
-
prev_out_x
[
index
]
*
reciprocalSquareSumX
);
if
(
input2_height
>
1
)
{
prev_grad_y
[
index
]
+=
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_x
[
index
]
*
reciprocalXY
-
prev_out_y
[
index
]
*
reciprocalSquareSumY
);
prev_grad_y
[
index
]
+=
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_x
[
index
]
*
reciprocalXY
-
prev_out_y
[
index
]
*
reciprocalSquareSumY
);
}
else
{
paddle
::
paddleAtomicAdd
(
prev_grad_y
+
index
,
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_x
[
index
]
*
reciprocalXY
-
prev_out_y
[
index
]
*
reciprocalSquareSumY
));
paddle
::
paddleAtomicAdd
(
prev_grad_y
+
index
,
output
[
ty
]
*
grad
[
ty
]
*
(
prev_out_x
[
index
]
*
reciprocalXY
-
prev_out_y
[
index
]
*
reciprocalSquareSumY
));
}
}
}
...
...
@@ -198,9 +198,17 @@ void hlCossimDerivative(const real* grad,
const
int
block_size
=
256
;
dim3
threads
(
block_size
,
1
);
dim3
grid
(
1
,
input1_height
);
KeCosSimDerivative
<
block_size
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad
,
output
,
prev_out_x
,
prev_out_y
,
prev_grad_x
,
prev_grad_y
,
width
,
input1_height
,
input2_height
,
scale
);
KeCosSimDerivative
<
block_size
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
grad
,
output
,
prev_out_x
,
prev_out_y
,
prev_grad_x
,
prev_grad_y
,
width
,
input1_height
,
input2_height
,
scale
);
CHECK_SYNC
(
"hlCossimDerivate failed"
);
}
...
...
@@ -214,9 +222,9 @@ void CosSimBackward<DEVICE_TYPE_GPU>(const GpuMatrix& out_grad,
real
scale
)
{
CHECK
(
out_grad
.
getData
()
&&
out_val
.
getData
()
&&
in1_val
.
getData
()
&&
in2_val
.
getData
()
&&
in1_grad
.
getData
()
&&
in2_grad
.
getData
());
CHECK
(
out_grad
.
useGpu_
&&
out_val
.
useGpu_
&&
in1_val
.
useGpu_
&&
in2_val
.
useGpu_
&&
in1_grad
.
useGpu_
&&
in2_grad
.
useGpu_
)
<<
"Matrix types are not equally GPU"
;
CHECK
(
out_grad
.
useGpu_
&&
out_val
.
useGpu_
&&
in1_val
.
useGpu_
&&
in2_val
.
useGpu_
&&
in1_grad
.
useGpu_
&&
in2_grad
.
useGpu_
)
<<
"Matrix types are not equally GPU"
;
size_t
dim
=
in1_val
.
getWidth
();
const
real
*
grad
=
out_grad
.
getData
();
...
...
paddle/function/CropOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,15 +12,23 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "CropOp.h"
#include "hl_base.h"
namespace
paddle
{
__global__
void
KeCrop
(
real
*
outputs
,
const
real
*
inputs
,
int
inC
,
int
inH
,
int
inW
,
int
cropC
,
int
cropH
,
int
cropW
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
__global__
void
KeCrop
(
real
*
outputs
,
const
real
*
inputs
,
int
inC
,
int
inH
,
int
inW
,
int
cropC
,
int
cropH
,
int
cropW
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
nthreads
)
{
const
int
w
=
idx
%
outW
;
...
...
@@ -35,12 +43,12 @@ __global__ void KeCrop(real* outputs, const real* inputs,
template
<
>
void
Crop
<
DEVICE_TYPE_GPU
>
(
real
*
outputs
,
const
real
*
inputs
,
const
TensorShape
inShape
,
const
TensorShape
outShape
,
const
FuncConfig
&
conf
)
{
const
real
*
inputs
,
const
TensorShape
inShape
,
const
TensorShape
outShape
,
const
FuncConfig
&
conf
)
{
std
::
vector
<
uint32_t
>
crop_corner
=
conf
.
get
<
std
::
vector
<
uint32_t
>>
(
"crop_corner"
);
conf
.
get
<
std
::
vector
<
uint32_t
>>
(
"crop_corner"
);
int
cropC
=
crop_corner
[
1
];
int
cropH
=
crop_corner
[
2
];
int
cropW
=
crop_corner
[
3
];
...
...
@@ -58,16 +66,33 @@ void Crop<DEVICE_TYPE_GPU>(real* outputs,
int
blockSize
=
1024
;
int
gridSize
=
(
nth
+
blockSize
-
1
)
/
blockSize
;
KeCrop
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
outputs
,
inputs
,
inC
,
inH
,
inW
,
cropC
,
cropH
,
cropW
,
outC
,
outH
,
outW
,
nth
);
KeCrop
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
outputs
,
inputs
,
inC
,
inH
,
inW
,
cropC
,
cropH
,
cropW
,
outC
,
outH
,
outW
,
nth
);
CHECK_SYNC
(
"Crop"
);
}
__global__
void
KeCropDiff
(
const
real
*
inGrad
,
real
*
outGrad
,
int
inC
,
int
inH
,
int
inW
,
int
cropC
,
int
cropH
,
int
cropW
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
__global__
void
KeCropDiff
(
const
real
*
inGrad
,
real
*
outGrad
,
int
inC
,
int
inH
,
int
inW
,
int
cropC
,
int
cropH
,
int
cropW
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
nthreads
)
{
const
int
w
=
idx
%
inW
;
...
...
@@ -84,12 +109,12 @@ __global__ void KeCropDiff(const real* inGrad, real* outGrad,
template
<
>
void
CropGrad
<
DEVICE_TYPE_GPU
>
(
const
real
*
inGrad
,
real
*
outGrad
,
const
TensorShape
inShape
,
const
TensorShape
outShape
,
const
FuncConfig
&
conf
)
{
real
*
outGrad
,
const
TensorShape
inShape
,
const
TensorShape
outShape
,
const
FuncConfig
&
conf
)
{
std
::
vector
<
uint32_t
>
crop_corner
=
conf
.
get
<
std
::
vector
<
uint32_t
>>
(
"crop_corner"
);
conf
.
get
<
std
::
vector
<
uint32_t
>>
(
"crop_corner"
);
int
cropC
=
crop_corner
[
1
];
int
cropH
=
crop_corner
[
2
];
int
cropW
=
crop_corner
[
3
];
...
...
@@ -107,9 +132,18 @@ void CropGrad<DEVICE_TYPE_GPU>(const real* inGrad,
int
blockSize
=
1024
;
int
gridSize
=
(
nth
+
blockSize
-
1
)
/
blockSize
;
KeCropDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
outGrad
,
inC
,
inH
,
inW
,
cropC
,
cropH
,
cropW
,
outC
,
outH
,
outW
,
nth
);
KeCropDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
outGrad
,
inC
,
inH
,
inW
,
cropC
,
cropH
,
cropW
,
outC
,
outH
,
outW
,
nth
);
CHECK_SYNC
(
"CropGrad"
);
}
...
...
paddle/function/CrossMapNormalOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,14 +12,18 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "CrossMapNormalOp.h"
#include "hl_base.h"
namespace
paddle
{
__global__
void
KeCMRNormFillScale
(
size_t
imageSize
,
const
real
*
in
,
real
*
scale
,
size_t
channels
,
size_t
height
,
size_t
width
,
size_t
size
,
__global__
void
KeCMRNormFillScale
(
size_t
imageSize
,
const
real
*
in
,
real
*
scale
,
size_t
channels
,
size_t
height
,
size_t
width
,
size_t
size
,
real
alpha
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
imageSize
)
{
...
...
@@ -51,8 +55,10 @@ __global__ void KeCMRNormFillScale(size_t imageSize, const real* in,
}
}
__global__
void
KeCMRNormOutput
(
size_t
inputSize
,
const
real
*
in
,
const
real
*
scale
,
real
negative_beta
,
__global__
void
KeCMRNormOutput
(
size_t
inputSize
,
const
real
*
in
,
const
real
*
scale
,
real
negative_beta
,
real
*
out
)
{
const
int
index
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
index
<
inputSize
)
{
...
...
@@ -74,24 +80,30 @@ void CrossMapNormal<DEVICE_TYPE_GPU>(real* outputs,
size_t
imageSize
=
numSamples
*
height
*
width
;
int
blockSize
=
1024
;
int
gridSize
=
(
imageSize
+
1024
-
1
)
/
1024
;
KeCMRNormFillScale
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
imageSize
,
inputs
,
denoms
,
channels
,
height
,
width
,
size
,
scale
);
KeCMRNormFillScale
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
imageSize
,
inputs
,
denoms
,
channels
,
height
,
width
,
size
,
scale
);
size_t
inputSize
=
numSamples
*
height
*
width
*
channels
;
size_t
inputSize
=
numSamples
*
height
*
width
*
channels
;
blockSize
=
1024
;
gridSize
=
(
inputSize
+
1024
-
1
)
/
1024
;
KeCMRNormOutput
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inputSize
,
inputs
,
denoms
,
-
pow
,
outputs
);
KeCMRNormOutput
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inputSize
,
inputs
,
denoms
,
-
pow
,
outputs
);
CHECK_SYNC
(
"CrossMapNormal"
);
}
__global__
void
KeCMRNormDiff
(
size_t
imageSize
,
const
real
*
bottom_data
,
const
real
*
top_data
,
const
real
*
scale
,
const
real
*
top_diff
,
size_t
channels
,
size_t
height
,
size_t
width
,
size_t
size
,
real
negative_beta
,
real
cache_ratio
,
real
*
bottom_diff
)
{
__global__
void
KeCMRNormDiff
(
size_t
imageSize
,
const
real
*
bottom_data
,
const
real
*
top_data
,
const
real
*
scale
,
const
real
*
top_diff
,
size_t
channels
,
size_t
height
,
size_t
width
,
size_t
size
,
real
negative_beta
,
real
cache_ratio
,
real
*
bottom_diff
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
imageSize
)
{
const
int
w
=
idx
%
width
;
...
...
@@ -113,17 +125,17 @@ __global__ void KeCMRNormDiff(size_t imageSize, const real* bottom_data,
while
(
index
<
channels
+
post_pad
)
{
if
(
index
<
channels
)
{
accum
+=
top_diff
[
index
*
step
]
*
top_data
[
index
*
step
]
/
scale
[
index
*
step
];
scale
[
index
*
step
];
}
if
(
index
>=
size
)
{
accum
-=
top_diff
[(
index
-
size
)
*
step
]
*
top_data
[(
index
-
size
)
*
step
]
/
scale
[(
index
-
size
)
*
step
];
top_data
[(
index
-
size
)
*
step
]
/
scale
[(
index
-
size
)
*
step
];
}
if
(
index
>=
post_pad
)
{
bottom_diff
[(
index
-
post_pad
)
*
step
]
+=
top_diff
[(
index
-
post_pad
)
*
step
]
*
pow
(
scale
[(
index
-
post_pad
)
*
step
],
negative_beta
)
-
cache_ratio
*
bottom_data
[(
index
-
post_pad
)
*
step
]
*
accum
;
top_diff
[(
index
-
post_pad
)
*
step
]
*
pow
(
scale
[(
index
-
post_pad
)
*
step
],
negative_beta
)
-
cache_ratio
*
bottom_data
[(
index
-
post_pad
)
*
step
]
*
accum
;
}
++
index
;
}
...
...
@@ -147,9 +159,18 @@ void CrossMapNormalGrad<DEVICE_TYPE_GPU>(real* inputsGrad,
int
blockSize
=
1024
;
int
gridSize
=
(
imageSize
+
1024
-
1
)
/
1024
;
KeCMRNormDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
imageSize
,
inputsValue
,
outputsValue
,
denoms
,
outputsGrad
,
channels
,
height
,
width
,
size
,
-
pow
,
2.0
f
*
pow
*
scale
,
inputsGrad
);
KeCMRNormDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
imageSize
,
inputsValue
,
outputsValue
,
denoms
,
outputsGrad
,
channels
,
height
,
width
,
size
,
-
pow
,
2.0
f
*
pow
*
scale
,
inputsGrad
);
CHECK_SYNC
(
"CrossMapNormalGrad"
);
}
...
...
paddle/function/CrossMapNormalOpTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -18,11 +18,11 @@ limitations under the License. */
namespace
paddle
{
TEST
(
CrossMapNormal
,
real
)
{
for
(
size_t
numSamples
:
{
5
,
32
})
{
for
(
size_t
channels
:
{
1
,
5
,
32
})
{
for
(
size_t
imgSizeH
:
{
5
,
33
,
100
})
{
for
(
size_t
imgSizeW
:
{
5
,
32
,
96
})
{
for
(
size_t
size
:
{
1
,
2
,
3
,
5
,
7
})
{
for
(
size_t
numSamples
:
{
5
})
{
for
(
size_t
channels
:
{
1
,
5
})
{
for
(
size_t
imgSizeH
:
{
5
,
33
})
{
for
(
size_t
imgSizeW
:
{
5
,
32
})
{
for
(
size_t
size
:
{
1
,
3
})
{
VLOG
(
3
)
<<
" numSamples="
<<
numSamples
<<
" channels="
<<
channels
<<
" imgSizeH="
<<
imgSizeH
<<
" imgSizeW="
<<
imgSizeW
<<
" size="
<<
size
;
...
...
@@ -48,11 +48,11 @@ TEST(CrossMapNormal, real) {
}
TEST
(
CrossMapNormalGrad
,
real
)
{
for
(
size_t
numSamples
:
{
5
,
32
})
{
for
(
size_t
channels
:
{
1
,
5
,
32
})
{
for
(
size_t
imgSizeH
:
{
5
,
33
,
100
})
{
for
(
size_t
imgSizeW
:
{
5
,
32
,
96
})
{
for
(
size_t
size
:
{
1
,
2
,
3
,
5
,
7
})
{
for
(
size_t
numSamples
:
{
5
})
{
for
(
size_t
channels
:
{
1
,
5
})
{
for
(
size_t
imgSizeH
:
{
5
,
33
})
{
for
(
size_t
imgSizeW
:
{
5
,
32
})
{
for
(
size_t
size
:
{
1
,
3
})
{
VLOG
(
3
)
<<
" numSamples="
<<
numSamples
<<
" channels="
<<
channels
<<
" imgSizeH="
<<
imgSizeH
<<
" imgSizeW="
<<
imgSizeW
<<
" size="
<<
size
;
...
...
paddle/function/DepthwiseConvOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -20,17 +20,25 @@ namespace paddle {
// CUDA kernel to compute the depthwise convolution forward pass
template
<
class
T
>
__global__
void
ConvolutionDepthwiseForward
(
const
int
nthreads
,
const
T
*
const
inputData
,
const
T
*
const
filterData
,
const
int
batchSize
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
outputData
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
__global__
void
ConvolutionDepthwiseForward
(
const
int
nthreads
,
const
T
*
const
inputData
,
const
T
*
const
filterData
,
const
int
batchSize
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
outputData
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
const
int
batch
=
index
/
outputChannels
/
outputHeight
/
outputWidth
;
...
...
@@ -45,32 +53,36 @@ void ConvolutionDepthwiseForward(const int nthreads,
const
int
w_in_start
=
-
paddingW
+
w_out
*
strideW
;
const
int
h_in_end
=
-
paddingH
+
h_out
*
strideH
+
filterHeight
-
1
;
const
int
w_in_end
=
-
paddingW
+
w_out
*
strideW
+
filterWidth
-
1
;
if
((
h_in_start
>=
0
)
&&
(
h_in_end
<
inputHeight
)
&&
(
w_in_start
>=
0
)
&&
(
w_in_end
<
inputWidth
))
{
for
(
int
kh
=
0
;
kh
<
filterHeight
;
++
kh
)
{
for
(
int
kw
=
0
;
kw
<
filterWidth
;
++
kw
)
{
const
int
h_in
=
-
paddingH
+
h_out
*
strideH
+
kh
;
const
int
w_in
=
-
paddingW
+
w_out
*
strideW
+
kw
;
const
int
offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
value
+=
(
*
weight
)
*
inputData
[
offset
];
++
weight
;
}
if
((
h_in_start
>=
0
)
&&
(
h_in_end
<
inputHeight
)
&&
(
w_in_start
>=
0
)
&&
(
w_in_end
<
inputWidth
))
{
for
(
int
kh
=
0
;
kh
<
filterHeight
;
++
kh
)
{
for
(
int
kw
=
0
;
kw
<
filterWidth
;
++
kw
)
{
const
int
h_in
=
-
paddingH
+
h_out
*
strideH
+
kh
;
const
int
w_in
=
-
paddingW
+
w_out
*
strideW
+
kw
;
const
int
offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
value
+=
(
*
weight
)
*
inputData
[
offset
];
++
weight
;
}
}
}
else
{
for
(
int
kh
=
0
;
kh
<
filterHeight
;
++
kh
)
{
for
(
int
kw
=
0
;
kw
<
filterWidth
;
++
kw
)
{
const
int
h_in
=
-
paddingH
+
h_out
*
strideH
+
kh
;
const
int
w_in
=
-
paddingW
+
w_out
*
strideW
+
kw
;
if
((
h_in
>=
0
)
&&
(
h_in
<
inputHeight
)
&&
(
w_in
>=
0
)
&&
(
w_in
<
inputWidth
))
{
const
int
offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
value
+=
(
*
weight
)
*
inputData
[
offset
];
}
++
weight
;
}
}
for
(
int
kh
=
0
;
kh
<
filterHeight
;
++
kh
)
{
for
(
int
kw
=
0
;
kw
<
filterWidth
;
++
kw
)
{
const
int
h_in
=
-
paddingH
+
h_out
*
strideH
+
kh
;
const
int
w_in
=
-
paddingW
+
w_out
*
strideW
+
kw
;
if
((
h_in
>=
0
)
&&
(
h_in
<
inputHeight
)
&&
(
w_in
>=
0
)
&&
(
w_in
<
inputWidth
))
{
const
int
offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
value
+=
(
*
weight
)
*
inputData
[
offset
];
}
++
weight
;
}
}
}
outputData
[
index
]
=
value
;
}
...
...
@@ -78,16 +90,25 @@ void ConvolutionDepthwiseForward(const int nthreads,
// CUDA kernel to compute the depthwise convolution backprop w.r.t input.
template
<
class
T
>
__global__
void
ConvolutionDepthwiseInputBackward
(
const
int
nthreads
,
const
T
*
const
top_diff
,
const
T
*
const
weight_data
,
const
int
num
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
bottom_diff
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
__global__
void
ConvolutionDepthwiseInputBackward
(
const
int
nthreads
,
const
T
*
const
top_diff
,
const
T
*
const
weight_data
,
const
int
num
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
bottom_diff
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
const
int
batch
=
index
/
inputChannels
/
inputHeight
/
inputWidth
;
const
int
c_in
=
(
index
/
inputHeight
/
inputWidth
)
%
inputChannels
;
...
...
@@ -96,65 +117,80 @@ void ConvolutionDepthwiseInputBackward(const int nthreads,
const
int
c_out_start
=
c_in
*
filterMultiplier
;
int
h_out_start
=
(
h_in
-
filterHeight
+
paddingH
+
strideH
)
/
strideH
;
int
h_out_start
=
(
h_in
-
filterHeight
+
paddingH
+
strideH
)
/
strideH
;
h_out_start
=
0
>
h_out_start
?
0
:
h_out_start
;
int
h_out_end
=
(
h_in
+
paddingH
)
/
strideH
;
h_out_end
=
outputHeight
-
1
<
h_out_end
?
outputHeight
-
1
:
h_out_end
;
int
w_out_start
=
(
w_in
-
filterWidth
+
paddingW
+
strideW
)
/
strideW
;
int
h_out_end
=
(
h_in
+
paddingH
)
/
strideH
;
h_out_end
=
outputHeight
-
1
<
h_out_end
?
outputHeight
-
1
:
h_out_end
;
int
w_out_start
=
(
w_in
-
filterWidth
+
paddingW
+
strideW
)
/
strideW
;
w_out_start
=
0
>
w_out_start
?
0
:
w_out_start
;
int
w_out_end
=
(
w_in
+
paddingW
)
/
strideW
;
w_out_end
=
outputWidth
-
1
<
w_out_end
?
outputWidth
-
1
:
w_out_end
;
int
w_out_end
=
(
w_in
+
paddingW
)
/
strideW
;
w_out_end
=
outputWidth
-
1
<
w_out_end
?
outputWidth
-
1
:
w_out_end
;
T
value
=
0
;
for
(
int
c_out
=
c_out_start
;
c_out
<
c_out_start
+
filterMultiplier
;
c_out
++
)
{
for
(
int
h_out
=
h_out_start
;
h_out
<=
h_out_end
;
++
h_out
)
{
const
int
filter_h
=
h_in
+
paddingH
-
h_out
*
strideH
;
for
(
int
w_out
=
w_out_start
;
w_out
<=
w_out_end
;
++
w_out
)
{
const
int
filter_w
=
w_in
+
paddingW
-
w_out
*
strideW
;
const
int
filter_offset
=
c_out
*
filterHeight
*
filterWidth
+
filter_h
*
filterWidth
+
filter_w
;
const
int
top_diff_offset
=
((
batch
*
outputChannels
+
c_out
)
*
outputHeight
+
h_out
)
*
outputWidth
+
w_out
;
value
+=
top_diff
[
top_diff_offset
]
*
weight_data
[
filter_offset
];
}
for
(
int
c_out
=
c_out_start
;
c_out
<
c_out_start
+
filterMultiplier
;
c_out
++
)
{
for
(
int
h_out
=
h_out_start
;
h_out
<=
h_out_end
;
++
h_out
)
{
const
int
filter_h
=
h_in
+
paddingH
-
h_out
*
strideH
;
for
(
int
w_out
=
w_out_start
;
w_out
<=
w_out_end
;
++
w_out
)
{
const
int
filter_w
=
w_in
+
paddingW
-
w_out
*
strideW
;
const
int
filter_offset
=
c_out
*
filterHeight
*
filterWidth
+
filter_h
*
filterWidth
+
filter_w
;
const
int
top_diff_offset
=
((
batch
*
outputChannels
+
c_out
)
*
outputHeight
+
h_out
)
*
outputWidth
+
w_out
;
value
+=
top_diff
[
top_diff_offset
]
*
weight_data
[
filter_offset
];
}
}
}
bottom_diff
[
index
]
+=
value
;
}
}
}
// CUDA kernel to compute the depthwise convolution backprop w.r.t filter.
template
<
class
T
>
__global__
void
ConvolutionDepthwiseFilterBackward
(
const
int
num_i
,
const
int
nthreads
,
const
T
*
const
top_diff
,
const
T
*
const
inputData
,
const
int
num
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
buffer_data
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
__global__
void
ConvolutionDepthwiseFilterBackward
(
const
int
num_i
,
const
int
nthreads
,
const
T
*
const
top_diff
,
const
T
*
const
inputData
,
const
int
num
,
const
int
outputChannels
,
const
int
outputHeight
,
const
int
outputWidth
,
const
int
inputChannels
,
const
int
inputHeight
,
const
int
inputWidth
,
const
int
filterMultiplier
,
const
int
filterHeight
,
const
int
filterWidth
,
const
int
strideH
,
const
int
strideW
,
const
int
paddingH
,
const
int
paddingW
,
T
*
const
buffer_data
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
nthreads
)
{
const
int
h_out
=
(
index
/
outputWidth
)
%
outputHeight
;
const
int
w_out
=
index
%
outputWidth
;
const
int
kh
=
(
index
/
filterWidth
/
outputHeight
/
outputWidth
)
%
filterHeight
;
const
int
kh
=
(
index
/
filterWidth
/
outputHeight
/
outputWidth
)
%
filterHeight
;
const
int
kw
=
(
index
/
outputHeight
/
outputWidth
)
%
filterWidth
;
const
int
h_in
=
-
paddingH
+
h_out
*
strideH
+
kh
;
const
int
w_in
=
-
paddingW
+
w_out
*
strideW
+
kw
;
if
((
h_in
>=
0
)
&&
(
h_in
<
inputHeight
)
&&
(
w_in
>=
0
)
&&
(
w_in
<
inputWidth
))
{
const
int
c_out
=
index
/
(
filterHeight
*
filterWidth
*
outputHeight
*
outputWidth
);
if
((
h_in
>=
0
)
&&
(
h_in
<
inputHeight
)
&&
(
w_in
>=
0
)
&&
(
w_in
<
inputWidth
))
{
const
int
c_out
=
index
/
(
filterHeight
*
filterWidth
*
outputHeight
*
outputWidth
);
const
int
c_in
=
c_out
/
filterMultiplier
;
const
int
batch
=
num_i
;
const
int
top_offset
=
((
batch
*
outputChannels
+
c_out
)
*
outputHeight
+
h_out
)
*
outputWidth
+
w_out
;
const
int
bottom_offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
const
int
top_offset
=
((
batch
*
outputChannels
+
c_out
)
*
outputHeight
+
h_out
)
*
outputWidth
+
w_out
;
const
int
bottom_offset
=
((
batch
*
inputChannels
+
c_in
)
*
inputHeight
+
h_in
)
*
inputWidth
+
w_in
;
buffer_data
[
index
]
=
top_diff
[
top_offset
]
*
inputData
[
bottom_offset
];
}
else
{
buffer_data
[
index
]
=
0
;
...
...
@@ -163,170 +199,169 @@ void ConvolutionDepthwiseFilterBackward(const int num_i, const int nthreads,
}
template
<
class
T
>
class
DepthwiseConvFunctor
<
DEVICE_TYPE_GPU
,
T
>
{
class
DepthwiseConvFunctor
<
DEVICE_TYPE_GPU
,
T
>
{
public:
void
operator
()(
const
T
*
inputData
,
const
T
*
filterData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
outputData
)
{
const
T
*
filterData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
outputData
)
{
int
outputSize
=
batchSize
*
outputChannels
*
outputHeight
*
outputWidth
;
size_t
blocks
=
(
outputSize
+
1024
-
1
)
/
1024
;
size_t
blocks
=
(
outputSize
+
1024
-
1
)
/
1024
;
size_t
blockX
=
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
ConvolutionDepthwiseForward
<
T
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
outputSize
,
inputData
,
filterData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
outputData
);
}
ConvolutionDepthwiseForward
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
outputSize
,
inputData
,
filterData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
outputData
);
}
};
template
<
class
T
>
class
DepthwiseConvGradInputFunctor
<
DEVICE_TYPE_GPU
,
T
>
{
class
DepthwiseConvGradInputFunctor
<
DEVICE_TYPE_GPU
,
T
>
{
public:
void
operator
()(
const
T
*
outputGrad
,
const
T
*
filterData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
inputGrad
)
{
const
T
*
filterData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
inputGrad
)
{
int
inputSize
=
batchSize
*
inputChannels
*
inputHeight
*
inputWidth
;
size_t
blocks
=
(
inputSize
+
1024
-
1
)
/
1024
;
size_t
blocks
=
(
inputSize
+
1024
-
1
)
/
1024
;
size_t
blockX
=
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
ConvolutionDepthwiseInputBackward
<
T
>
// NOLINT_NEXT_LINE(whitespace/operators)
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
inputSize
,
outputGrad
,
filterData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
inputGrad
);
}
// NOLINT_NEXT_LINE(whitespace/operators)
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
inputSize
,
outputGrad
,
filterData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
inputGrad
);
}
};
template
<
class
T
>
class
DepthwiseConvGradFilterFunctor
<
DEVICE_TYPE_GPU
,
T
>
{
public:
void
operator
()(
const
T
*
outputGrad
,
const
T
*
inputData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
colData
,
T
*
filterGrad
)
{
int
colDataSize
=
outputChannels
*
filterHeight
*
filterWidth
*
outputHeight
*
outputWidth
;
const
T
*
inputData
,
int
batchSize
,
int
outputChannels
,
int
outputHeight
,
int
outputWidth
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterMultiplier
,
int
filterHeight
,
int
filterWidth
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
T
*
colData
,
T
*
filterGrad
)
{
int
colDataSize
=
outputChannels
*
filterHeight
*
filterWidth
*
outputHeight
*
outputWidth
;
size_t
blocks
=
(
colDataSize
+
1024
-
1
)
/
1024
;
size_t
blockX
=
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
BaseMatrix
filterGradMatrix
(
outputChannels
*
filterHeight
*
filterWidth
,
1
,
filterGrad
,
false
,
true
);
size_t
blocks
=
(
colDataSize
+
1024
-
1
)
/
1024
;
size_t
blockX
=
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
BaseMatrix
filterGradMatrix
(
outputChannels
*
filterHeight
*
filterWidth
,
1
,
filterGrad
,
false
,
true
);
for
(
int
i
=
0
;
i
<
batchSize
;
i
++
)
{
ConvolutionDepthwiseFilterBackward
<
T
>
<<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
i
,
colDataSize
,
outputGrad
,
inputData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
colData
);
int
K
=
outputHeight
*
outputWidth
;
int
M
=
colDataSize
/
K
;
for
(
int
i
=
0
;
i
<
batchSize
;
i
++
)
{
ConvolutionDepthwiseFilterBackward
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
i
,
colDataSize
,
outputGrad
,
inputData
,
batchSize
,
outputChannels
,
outputHeight
,
outputWidth
,
inputChannels
,
inputHeight
,
inputWidth
,
filterMultiplier
,
filterHeight
,
filterWidth
,
strideH
,
strideW
,
paddingH
,
paddingW
,
colData
);
int
K
=
outputHeight
*
outputWidth
;
int
M
=
colDataSize
/
K
;
BaseMatrix
colMatrix
(
M
,
K
,
colData
,
false
,
true
);
filterGradMatrix
.
sumRows
(
colMatrix
,
(
T
)
1.0
,
(
T
)
1.0
);
}
BaseMatrix
colMatrix
(
M
,
K
,
colData
,
false
,
true
);
filterGradMatrix
.
sumRows
(
colMatrix
,
(
T
)
1.0
,
(
T
)
1.0
);
}
}
};
#ifdef PADDLE_TYPE_DOUBLE
...
...
paddle/function/FunctionTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -24,14 +24,14 @@ void FunctionApi(typename Tensor<real, DType>::Matrix& output,
template
<
>
void
FunctionApi
<
DEVICE_TYPE_CPU
>
(
CpuMatrix
&
output
,
const
CpuMatrix
&
input
)
{
EXPECT_EQ
(
output
.
getHeight
(),
100
);
EXPECT_EQ
(
output
.
getWidth
(),
200
);
EXPECT_EQ
(
output
.
getHeight
(),
100
U
);
EXPECT_EQ
(
output
.
getWidth
(),
200
U
);
}
template
<
>
void
FunctionApi
<
DEVICE_TYPE_GPU
>
(
GpuMatrix
&
output
,
const
GpuMatrix
&
input
)
{
EXPECT_EQ
(
output
.
getHeight
(),
10
);
EXPECT_EQ
(
output
.
getWidth
(),
20
);
EXPECT_EQ
(
output
.
getHeight
(),
10
U
);
EXPECT_EQ
(
output
.
getWidth
(),
20
U
);
}
template
<
DeviceType
DType
>
...
...
@@ -85,14 +85,14 @@ void testBufferArgs(const BufferArgs& inputs,
}
void
testBufferArgs
(
const
BufferArgs
&
inputs
,
const
CheckBufferArg
&
check
)
{
EXPECT_EQ
(
inputs
.
size
(),
1
);
EXPECT_EQ
(
inputs
.
size
(),
1
U
);
check
(
inputs
[
0
]);
}
TEST
(
Arguments
,
Matrix
)
{
MatrixPtr
matrix
=
Matrix
::
create
(
100
,
200
);
CheckBufferArg
check
=
[
=
](
const
BufferArg
&
arg
)
{
EXPECT_EQ
(
arg
.
shape
().
ndims
(),
2
);
EXPECT_EQ
(
arg
.
shape
().
ndims
(),
2
U
);
EXPECT_EQ
(
arg
.
shape
()[
0
],
100
);
EXPECT_EQ
(
arg
.
shape
()[
1
],
200
);
EXPECT_EQ
(
arg
.
data
(),
matrix
->
getData
());
...
...
paddle/function/Im2ColOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -17,16 +17,21 @@ limitations under the License. */
namespace
paddle
{
template
<
class
T
>
__global__
void
im2col
(
const
T
*
data_im
,
int
numOuts
,
int
height
,
int
width
,
int
blockH
,
int
blockW
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
int
height_col
,
int
width_col
,
T
*
data_col
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
template
<
class
T
>
__global__
void
im2col
(
const
T
*
data_im
,
int
numOuts
,
int
height
,
int
width
,
int
blockH
,
int
blockW
,
int
strideH
,
int
strideW
,
int
paddingH
,
int
paddingW
,
int
height_col
,
int
width_col
,
T
*
data_col
)
{
int
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
numOuts
)
{
int
w_out
=
index
%
width_col
;
index
/=
width_col
;
...
...
@@ -39,17 +44,17 @@ void im2col(const T* data_im, int numOuts, int height, int width,
data_col
+=
(
channel_out
*
height_col
+
h_out
)
*
width_col
+
w_out
;
for
(
int
i
=
0
;
i
<
blockH
;
++
i
)
{
for
(
int
j
=
0
;
j
<
blockW
;
++
j
)
{
int
rIdx
=
int
(
h_in
+
i
);
int
cIdx
=
int
(
w_in
+
j
);
if
((
rIdx
-
(
int
)
paddingH
)
>=
(
int
)
height
||
(
rIdx
-
(
int
)
paddingH
)
<
0
||
(
cIdx
-
(
int
)
paddingW
)
>=
(
int
)
width
||
(
cIdx
-
(
int
)
paddingW
)
<
0
)
{
int
rIdx
=
int
(
h_in
+
i
);
int
cIdx
=
int
(
w_in
+
j
);
if
((
rIdx
-
(
int
)
paddingH
)
>=
(
int
)
height
||
(
rIdx
-
(
int
)
paddingH
)
<
0
||
(
cIdx
-
(
int
)
paddingW
)
>=
(
int
)
width
||
(
cIdx
-
(
int
)
paddingW
)
<
0
)
{
*
data_col
=
0
;
}
else
{
rIdx
=
rIdx
+
channel_in
*
height
-
paddingH
;
rIdx
=
rIdx
+
channel_in
*
height
-
paddingH
;
cIdx
=
cIdx
-
paddingW
;
*
data_col
=
data_im
[
rIdx
*
width
+
cIdx
];
*
data_col
=
data_im
[
rIdx
*
width
+
cIdx
];
}
data_col
+=
height_col
*
width_col
;
}
...
...
@@ -82,60 +87,73 @@ public:
int
outputWidth
=
colShape
[
4
];
int
numKernels
=
inputChannels
*
outputHeight
*
outputWidth
;
int
blocks
=
(
numKernels
+
1024
-
1
)
/
1024
;
int
blocks
=
(
numKernels
+
1024
-
1
)
/
1024
;
int
blockX
=
512
;
int
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
im2col
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
numKernels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
,
colData
);
im2col
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
numKernels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
,
colData
);
CHECK_SYNC
(
"Im2ColFunctor GPU failed"
);
}
};
template
<
class
T
>
__global__
void
col2im
(
size_t
n
,
const
T
*
data_col
,
size_t
height
,
size_t
width
,
size_t
channels
,
size_t
blockH
,
size_t
blockW
,
size_t
strideH
,
size_t
strideW
,
size_t
paddingH
,
size_t
paddingW
,
size_t
height_col
,
size_t
width_col
,
T
*
data_im
)
{
template
<
class
T
>
__global__
void
col2im
(
size_t
n
,
const
T
*
data_col
,
size_t
height
,
size_t
width
,
size_t
channels
,
size_t
blockH
,
size_t
blockW
,
size_t
strideH
,
size_t
strideW
,
size_t
paddingH
,
size_t
paddingW
,
size_t
height_col
,
size_t
width_col
,
T
*
data_im
)
{
size_t
index
=
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
(
blockIdx
.
x
*
gridDim
.
y
+
blockIdx
.
y
)
*
blockDim
.
x
+
threadIdx
.
x
;
if
(
index
<
n
)
{
T
val
=
0
;
int
w
=
int
(
index
%
width
);
int
h
=
int
((
index
/
width
)
%
height
);
int
c
=
int
(
index
/
(
width
*
height
));
if
((
w
-
(
int
)
paddingW
)
>=
0
&&
(
w
-
(
int
)
paddingW
)
<
(
width
-
2
*
paddingW
)
&&
(
h
-
(
int
)
paddingH
)
>=
0
&&
(
h
-
paddingH
)
<
(
height
-
2
*
paddingH
))
{
(
w
-
(
int
)
paddingW
)
<
(
width
-
2
*
paddingW
)
&&
(
h
-
(
int
)
paddingH
)
>=
0
&&
(
h
-
paddingH
)
<
(
height
-
2
*
paddingH
))
{
// compute the start and end of the output
int
w_col_start
=
(
w
<
(
int
)
blockW
)
?
0
:
(
w
-
int
(
blockW
))
/
(
int
)
strideW
+
1
;
int
w_col_end
=
min
((
int
)(
w
/
(
int
)
strideW
+
1
),
(
int
)(
width_col
));
(
w
<
(
int
)
blockW
)
?
0
:
(
w
-
int
(
blockW
))
/
(
int
)
strideW
+
1
;
int
w_col_end
=
min
((
int
)(
w
/
(
int
)
strideW
+
1
),
(
int
)(
width_col
));
int
h_col_start
=
(
h
<
(
int
)
blockH
)
?
0
:
(
h
-
(
int
)
blockH
)
/
(
int
)
strideH
+
1
;
(
h
<
(
int
)
blockH
)
?
0
:
(
h
-
(
int
)
blockH
)
/
(
int
)
strideH
+
1
;
int
h_col_end
=
min
(
int
(
h
/
strideH
+
1
),
int
(
height_col
));
for
(
int
h_col
=
h_col_start
;
h_col
<
h_col_end
;
++
h_col
)
{
for
(
int
w_col
=
w_col_start
;
w_col
<
w_col_end
;
++
w_col
)
{
// the col location: [c * width * height + h_out, w_out]
int
c_col
=
int
(
c
*
blockH
*
blockW
)
+
\
(
h
-
h_col
*
(
int
)
strideH
)
*
(
int
)
blockW
+
(
w
-
w_col
*
(
int
)
strideW
);
int
c_col
=
int
(
c
*
blockH
*
blockW
)
+
(
h
-
h_col
*
(
int
)
strideH
)
*
(
int
)
blockW
+
(
w
-
w_col
*
(
int
)
strideW
);
val
+=
data_col
[(
c_col
*
height_col
+
h_col
)
*
width_col
+
w_col
];
}
}
h
-=
paddingH
;
w
-=
paddingW
;
data_im
[
c
*
((
width
-
2
*
paddingW
)
*
(
height
-
2
*
paddingH
))
+
h
*
(
width
-
2
*
paddingW
)
+
w
]
+=
val
;
data_im
[
c
*
((
width
-
2
*
paddingW
)
*
(
height
-
2
*
paddingH
))
+
h
*
(
width
-
2
*
paddingW
)
+
w
]
+=
val
;
}
}
}
...
...
@@ -164,32 +182,32 @@ public:
int
outputHeight
=
colShape
[
3
];
int
outputWidth
=
colShape
[
4
];
size_t
numKernels
=
inputChannels
*
(
inputHeight
+
2
*
paddingHeight
)
*
(
inputWidth
+
2
*
paddingWidth
);
size_t
numKernels
=
inputChannels
*
(
inputHeight
+
2
*
paddingHeight
)
*
(
inputWidth
+
2
*
paddingWidth
);
size_t
blocks
=
(
numKernels
+
1024
-
1
)
/
1024
;
size_t
blocks
=
(
numKernels
+
1024
-
1
)
/
1024
;
size_t
blockX
=
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
size_t
blockY
=
(
blocks
+
512
-
1
)
/
512
;
dim3
threads
(
1024
,
1
);
dim3
grid
(
blockX
,
blockY
);
// To avoid involving atomic operations, we will launch one kernel per
// bottom dimension, and then in the kernel add up the top dimensions.
col2im
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
numKernels
,
colData
,
inputHeight
+
2
*
paddingHeight
,
inputWidth
+
2
*
paddingWidth
,
inputChannels
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
,
imData
);
col2im
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
numKernels
,
colData
,
inputHeight
+
2
*
paddingHeight
,
inputWidth
+
2
*
paddingWidth
,
inputChannels
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
,
imData
);
CHECK_SYNC
(
"Col2ImFunctor GPU failed"
);
}
};
...
...
@@ -199,31 +217,35 @@ template class Im2ColFunctor<kCFO, DEVICE_TYPE_GPU, double>;
template
class
Col2ImFunctor
<
kCFO
,
DEVICE_TYPE_GPU
,
float
>;
template
class
Col2ImFunctor
<
kCFO
,
DEVICE_TYPE_GPU
,
double
>;
template
<
class
T
>
__global__
void
im2colOCF
(
const
T
*
imData
,
T
*
colData
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterHeight
,
int
filterWidth
,
int
strideHeight
,
int
strideWidth
,
int
paddingHeight
,
int
paddingWidth
,
int
outputHeight
,
int
outputWidth
)
{
template
<
class
T
>
__global__
void
im2colOCF
(
const
T
*
imData
,
T
*
colData
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterHeight
,
int
filterWidth
,
int
strideHeight
,
int
strideWidth
,
int
paddingHeight
,
int
paddingWidth
,
int
outputHeight
,
int
outputWidth
)
{
int
swId
=
blockIdx
.
x
;
int
shId
=
blockIdx
.
y
;
for
(
int
channelId
=
threadIdx
.
z
;
channelId
<
inputChannels
;
for
(
int
channelId
=
threadIdx
.
z
;
channelId
<
inputChannels
;
channelId
+=
blockDim
.
z
)
{
for
(
int
idy
=
threadIdx
.
y
;
idy
<
filterHeight
;
idy
+=
blockDim
.
y
)
{
for
(
int
idx
=
threadIdx
.
x
;
idx
<
filterWidth
;
idx
+=
blockDim
.
x
)
{
int
widthOffset
=
idx
+
swId
*
strideWidth
-
paddingWidth
;
int
heightOffset
=
idy
+
shId
*
strideHeight
-
paddingHeight
;
int
imOffset
=
widthOffset
+
heightOffset
*
inputWidth
+
channelId
*
inputHeight
*
inputWidth
;
int
imOffset
=
widthOffset
+
heightOffset
*
inputWidth
+
channelId
*
inputHeight
*
inputWidth
;
int
colOffset
=
idx
+
idy
*
filterWidth
+
channelId
*
filterHeight
*
filterWidth
+
(
shId
*
outputWidth
+
swId
)
*
(
inputChannels
*
filterHeight
*
filterWidth
);
int
colOffset
=
idx
+
idy
*
filterWidth
+
channelId
*
filterHeight
*
filterWidth
+
(
shId
*
outputWidth
+
swId
)
*
(
inputChannels
*
filterHeight
*
filterWidth
);
if
(
heightOffset
>=
inputHeight
||
heightOffset
<
0
||
widthOffset
>=
inputWidth
||
widthOffset
<
0
)
{
...
...
@@ -279,39 +301,52 @@ public:
int
blockDimZ
=
1024
/
blockDimX
/
blockDimY
;
dim3
threads
(
blockDimX
,
blockDimY
,
std
::
min
(
blockDimZ
,
inputChannels
));
dim3
grid
(
outputWidth
,
outputHeight
);
im2colOCF
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
colData
,
inputChannels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
);
im2colOCF
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
colData
,
inputChannels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
);
CHECK_SYNC
(
"Im2ColFunctor GPU failed"
);
}
};
template
<
class
T
>
__global__
void
col2imOCF
(
T
*
imData
,
const
T
*
colData
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterHeight
,
int
filterWidth
,
int
strideHeight
,
int
strideWidth
,
int
paddingHeight
,
int
paddingWidth
,
int
outputHeight
,
int
outputWidth
)
{
template
<
class
T
>
__global__
void
col2imOCF
(
T
*
imData
,
const
T
*
colData
,
int
inputChannels
,
int
inputHeight
,
int
inputWidth
,
int
filterHeight
,
int
filterWidth
,
int
strideHeight
,
int
strideWidth
,
int
paddingHeight
,
int
paddingWidth
,
int
outputHeight
,
int
outputWidth
)
{
int
swId
=
blockIdx
.
x
;
int
shId
=
blockIdx
.
y
;
for
(
int
channelId
=
threadIdx
.
z
;
channelId
<
inputChannels
;
for
(
int
channelId
=
threadIdx
.
z
;
channelId
<
inputChannels
;
channelId
+=
blockDim
.
z
)
{
for
(
int
idy
=
threadIdx
.
y
;
idy
<
filterHeight
;
idy
+=
blockDim
.
y
)
{
for
(
int
idx
=
threadIdx
.
x
;
idx
<
filterWidth
;
idx
+=
blockDim
.
x
)
{
int
widthOffset
=
idx
+
swId
*
strideWidth
-
paddingWidth
;
int
heightOffset
=
idy
+
shId
*
strideHeight
-
paddingHeight
;
int
imOffset
=
widthOffset
+
heightOffset
*
inputWidth
+
channelId
*
inputHeight
*
inputWidth
;
int
imOffset
=
widthOffset
+
heightOffset
*
inputWidth
+
channelId
*
inputHeight
*
inputWidth
;
int
colOffset
=
idx
+
idy
*
filterWidth
+
channelId
*
filterHeight
*
filterWidth
+
(
shId
*
outputWidth
+
swId
)
*
(
inputChannels
*
filterHeight
*
filterWidth
);
int
colOffset
=
idx
+
idy
*
filterWidth
+
channelId
*
filterHeight
*
filterWidth
+
(
shId
*
outputWidth
+
swId
)
*
(
inputChannels
*
filterHeight
*
filterWidth
);
if
(
heightOffset
>=
0
&&
heightOffset
<
inputHeight
&&
widthOffset
>=
0
&&
widthOffset
<
inputWidth
)
{
...
...
@@ -365,10 +400,19 @@ public:
int
blockDimZ
=
1024
/
blockDimX
/
blockDimY
;
dim3
threads
(
blockDimX
,
blockDimY
,
std
::
min
(
blockDimZ
,
inputChannels
));
dim3
grid
(
outputWidth
,
outputHeight
);
col2imOCF
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
colData
,
inputChannels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
);
col2imOCF
<
T
><<<
grid
,
threads
,
0
,
STREAM_DEFAULT
>>>
(
imData
,
colData
,
inputChannels
,
inputHeight
,
inputWidth
,
filterHeight
,
filterWidth
,
strideHeight
,
strideWidth
,
paddingHeight
,
paddingWidth
,
outputHeight
,
outputWidth
);
CHECK_SYNC
(
"Col2ImFunctor GPU failed"
);
}
};
...
...
paddle/function/MulOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,8 +12,8 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "MulOp.h"
#include "hl_base.h"
#include "paddle/math/Matrix.h"
#include "paddle/math/SparseMatrix.h"
...
...
paddle/function/PadOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,15 +12,23 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "PadOp.h"
#include "hl_base.h"
namespace
paddle
{
__global__
void
KePad
(
real
*
outputs
,
const
real
*
inputs
,
int
inC
,
int
inH
,
int
inW
,
int
padc
,
int
padh
,
int
padw
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
__global__
void
KePad
(
real
*
outputs
,
const
real
*
inputs
,
int
inC
,
int
inH
,
int
inW
,
int
padc
,
int
padh
,
int
padw
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
nthreads
)
{
const
int
w
=
idx
%
inW
;
...
...
@@ -50,16 +58,33 @@ void Pad<DEVICE_TYPE_GPU>(real* outputs,
int
outC
=
inC
+
cstart
+
cend
;
int
outH
=
inH
+
hstart
+
hend
;
int
outW
=
inW
+
wstart
+
wend
;
KePad
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
outputs
,
inputs
,
inC
,
inH
,
inW
,
cstart
,
hstart
,
wstart
,
outC
,
outH
,
outW
,
nth
);
KePad
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
outputs
,
inputs
,
inC
,
inH
,
inW
,
cstart
,
hstart
,
wstart
,
outC
,
outH
,
outW
,
nth
);
CHECK_SYNC
(
"Pad"
);
}
__global__
void
KePadDiff
(
real
*
inGrad
,
const
real
*
outGrad
,
int
inC
,
int
inH
,
int
inW
,
int
padc
,
int
padh
,
int
padw
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
__global__
void
KePadDiff
(
real
*
inGrad
,
const
real
*
outGrad
,
int
inC
,
int
inH
,
int
inW
,
int
padc
,
int
padh
,
int
padw
,
int
outC
,
int
outH
,
int
outW
,
int
nthreads
)
{
const
int
idx
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
if
(
idx
<
nthreads
)
{
const
int
w
=
idx
%
inW
;
...
...
@@ -89,9 +114,18 @@ void PadGrad<DEVICE_TYPE_GPU>(real* inGrad,
int
outC
=
inC
+
cstart
+
cend
;
int
outH
=
inH
+
hstart
+
hend
;
int
outW
=
inW
+
wstart
+
wend
;
KePadDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
outGrad
,
inC
,
inH
,
inW
,
cstart
,
hstart
,
wstart
,
outC
,
outH
,
outW
,
nth
);
KePadDiff
<<<
gridSize
,
blockSize
,
0
,
STREAM_DEFAULT
>>>
(
inGrad
,
outGrad
,
inC
,
inH
,
inW
,
cstart
,
hstart
,
wstart
,
outC
,
outH
,
outW
,
nth
);
CHECK_SYNC
(
"PadGrad"
);
}
...
...
paddle/function/RowConvOpGpu.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,16 +12,20 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "hl_base.h"
#include "RowConvOp.h"
#include "hl_base.h"
namespace
paddle
{
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConv
(
real
*
y
,
const
real
*
x
,
const
real
*
w
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConv
(
real
*
y
,
const
real
*
x
,
const
real
*
w
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
blky
=
blockDim
.
y
;
...
...
@@ -30,7 +34,7 @@ __global__ void KeRowConv(real* y, const real* x, const real* w,
__shared__
real
sw
[
BLOCK_H
][
BLOCK_W
];
for
(
int
i
=
tidy
;
i
<
context
;
i
+=
blky
)
{
sw
[
i
][
tidx
]
=
gidx
+
tidx
<
width
?
w
[
i
*
width
+
gidx
+
tidx
]
:
0.0
;
sw
[
i
][
tidx
]
=
gidx
+
tidx
<
width
?
w
[
i
*
width
+
gidx
+
tidx
]
:
0.0
;
}
__syncthreads
();
...
...
@@ -56,9 +60,14 @@ __global__ void KeRowConv(real* y, const real* x, const real* w,
}
}
__global__
void
KeRowConv2
(
real
*
y
,
const
real
*
x
,
const
real
*
w
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
__global__
void
KeRowConv2
(
real
*
y
,
const
real
*
x
,
const
real
*
w
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
blky
=
blockDim
.
y
;
...
...
@@ -84,8 +93,6 @@ __global__ void KeRowConv2(real* y, const real* x, const real* w,
}
}
template
<
>
void
RowConv
<
DEVICE_TYPE_GPU
>
(
GpuMatrix
&
out
,
const
GpuMatrix
&
in
,
...
...
@@ -105,21 +112,24 @@ void RowConv<DEVICE_TYPE_GPU>(GpuMatrix& out,
dim3
dimGrid
(
DIVUP
(
width
,
dimBlock
.
x
),
1
);
if
(
contextLength
<=
32
)
{
KeRowConv
<
32
,
32
><<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
y
,
x
,
w
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConv
<
32
,
32
><<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
y
,
x
,
w
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
else
{
KeRowConv2
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
y
,
x
,
w
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConv2
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
y
,
x
,
w
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
CHECK_SYNC
(
"RowConv"
);
}
template
<
int
BLOCK_H
,
int
BLOCK_W
,
int
CONTEXT
>
__global__
void
KeRowConvBwWeight
(
real
*
dw
,
const
real
*
x
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
template
<
int
BLOCK_H
,
int
BLOCK_W
,
int
CONTEXT
>
__global__
void
KeRowConvBwWeight
(
real
*
dw
,
const
real
*
x
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
blky
=
blockDim
.
y
;
...
...
@@ -138,21 +148,21 @@ __global__ void KeRowConvBwWeight(real* dw, const real* x, const real* dy,
const
int
start
=
starts
[
i
];
const
int
end
=
starts
[
i
+
1
];
const
int
steps
=
end
-
start
;
const
int
size
=
((
steps
+
BLOCK_H
-
1
)
/
BLOCK_H
)
*
BLOCK_H
;
const
int
size
=
((
steps
+
BLOCK_H
-
1
)
/
BLOCK_H
)
*
BLOCK_H
;
for
(
int
j
=
tidy
;
j
<
size
;
j
+=
BLOCK_H
)
{
int
xoff
=
gidx
+
tidx
;
int
yoff
=
start
+
j
;
// transpose
sh_x
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
x
[
yoff
*
width
+
xoff
]
:
0.0
;
sh_dy
[
tidx
][
tidy
+
context
-
1
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
dy
[
yoff
*
width
+
xoff
]
:
0.0
;
sh_x
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
x
[
yoff
*
width
+
xoff
]
:
0.0
;
sh_dy
[
tidx
][
tidy
+
context
-
1
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
dy
[
yoff
*
width
+
xoff
]
:
0.0
;
__syncthreads
();
if
(
tidy
<
(
context
-
1
))
{
yoff
=
yoff
-
context
+
1
;
sh_dy
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
>=
start
)
?
dy
[
yoff
*
width
+
xoff
]
:
0.0
;
sh_dy
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
>=
start
)
?
dy
[
yoff
*
width
+
xoff
]
:
0.0
;
}
__syncthreads
();
...
...
@@ -179,11 +189,15 @@ __global__ void KeRowConvBwWeight(real* dw, const real* x, const real* dy,
}
}
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConvBwWeight2
(
real
*
dw
,
const
real
*
x
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConvBwWeight2
(
real
*
dw
,
const
real
*
x
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
gidx
=
blockIdx
.
x
*
blockDim
.
x
;
...
...
@@ -196,19 +210,21 @@ __global__ void KeRowConvBwWeight2(real* dw, const real* x, const real* dy,
const
int
end
=
starts
[
i
+
1
];
const
int
steps
=
end
-
start
;
const
int
size
=
((
steps
+
BLOCK_H
-
1
)
/
BLOCK_H
)
*
BLOCK_H
;
const
int
size
=
((
steps
+
BLOCK_H
-
1
)
/
BLOCK_H
)
*
BLOCK_H
;
for
(
int
j
=
tidy
;
j
<
size
;
j
+=
BLOCK_H
)
{
int
xoff
=
gidx
+
tidx
;
int
yoff
=
start
+
j
;
// transpose
sh_x
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
x
[
yoff
*
width
+
xoff
]
:
0.0
;
sh_x
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
yoff
<
end
)
?
x
[
yoff
*
width
+
xoff
]
:
0.0
;
__syncthreads
();
for
(
int
t
=
0
;
t
<
context
;
t
++
)
{
sh_dy
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
(
yoff
-
t
)
>=
start
&&
yoff
-
t
<
end
)
?
dy
[(
yoff
-
t
)
*
width
+
xoff
]
:
0.0
;
sh_dy
[
tidx
][
tidy
]
=
(
xoff
<
width
&&
(
yoff
-
t
)
>=
start
&&
yoff
-
t
<
end
)
?
dy
[(
yoff
-
t
)
*
width
+
xoff
]
:
0.0
;
__syncthreads
();
real
val
=
sh_x
[
tidy
][
tidx
]
*
sh_dy
[
tidy
][
tidx
];
...
...
@@ -222,18 +238,22 @@ __global__ void KeRowConvBwWeight2(real* dw, const real* x, const real* dy,
__syncthreads
();
if
(
tidx
==
0
&&
(
gidx
+
tidy
)
<
width
)
{
dw
[
t
*
width
+
gidx
+
tidy
]
+=
val
;
dw
[
t
*
width
+
gidx
+
tidy
]
+=
val
;
}
}
}
}
}
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConvBwData
(
real
*
dx
,
const
real
*
w
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
template
<
int
BLOCK_H
,
int
BLOCK_W
>
__global__
void
KeRowConvBwData
(
real
*
dx
,
const
real
*
w
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
blky
=
blockDim
.
y
;
...
...
@@ -242,7 +262,7 @@ __global__ void KeRowConvBwData(real* dx, const real* w, const real* dy,
__shared__
real
sw
[
BLOCK_H
][
BLOCK_W
];
for
(
int
i
=
tidy
;
i
<
context
;
i
+=
blky
)
{
sw
[
i
][
tidx
]
=
gidx
+
tidx
<
width
?
w
[
i
*
width
+
gidx
+
tidx
]
:
0.0
;
sw
[
i
][
tidx
]
=
gidx
+
tidx
<
width
?
w
[
i
*
width
+
gidx
+
tidx
]
:
0.0
;
}
__syncthreads
();
...
...
@@ -266,10 +286,14 @@ __global__ void KeRowConvBwData(real* dx, const real* w, const real* dy,
}
}
__global__
void
KeRowConvBwData2
(
real
*
dx
,
const
real
*
w
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
__global__
void
KeRowConvBwData2
(
real
*
dx
,
const
real
*
w
,
const
real
*
dy
,
const
int
*
starts
,
const
int
height
,
const
int
width
,
const
int
numSeq
,
const
int
context
)
{
const
int
tidx
=
threadIdx
.
x
;
const
int
tidy
=
threadIdx
.
y
;
const
int
blky
=
blockDim
.
y
;
...
...
@@ -295,14 +319,13 @@ __global__ void KeRowConvBwData2(real* dx, const real* w, const real* dy,
}
}
template
<
>
void
RowConvGrad
<
DEVICE_TYPE_GPU
>
(
const
GpuMatrix
&
outG
,
const
GpuMatrix
&
in
,
const
GpuMatrix
&
filter
,
GpuMatrix
&
inG
,
GpuMatrix
&
filterG
,
const
GpuIVector
&
seq
)
{
const
GpuMatrix
&
in
,
const
GpuMatrix
&
filter
,
GpuMatrix
&
inG
,
GpuMatrix
&
filterG
,
const
GpuIVector
&
seq
)
{
const
size_t
numSeq
=
seq
.
getSize
()
-
1
;
const
size_t
contextLength
=
filter
.
getHeight
();
const
size_t
height
=
in
.
getHeight
();
...
...
@@ -318,13 +341,11 @@ void RowConvGrad<DEVICE_TYPE_GPU>(const GpuMatrix& outG,
dim3
dimGrid
(
DIVUP
(
width
,
dimBlock
.
x
),
1
);
real
*
dw
=
filterG
.
getData
();
if
(
contextLength
<=
32
)
{
KeRowConvBwWeight
<
32
,
32
,
32
>
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
dw
,
x
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConvBwWeight
<
32
,
32
,
32
><<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
dw
,
x
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
else
{
KeRowConvBwWeight2
<
32
,
32
>
<<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
dw
,
x
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConvBwWeight2
<
32
,
32
><<<
dimGrid
,
dimBlock
,
0
,
STREAM_DEFAULT
>>>
(
dw
,
x
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
}
...
...
@@ -333,13 +354,11 @@ void RowConvGrad<DEVICE_TYPE_GPU>(const GpuMatrix& outG,
dim3
dimBlock2
(
32
,
32
);
dim3
dimGrid2
(
DIVUP
(
width
,
dimBlock2
.
x
),
1
);
if
(
contextLength
<=
64
)
{
KeRowConvBwData
<
32
,
64
>
<<<
dimGrid2
,
dimBlock2
,
0
,
STREAM_DEFAULT
>>>
(
dx
,
w
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConvBwData
<
32
,
64
><<<
dimGrid2
,
dimBlock2
,
0
,
STREAM_DEFAULT
>>>
(
dx
,
w
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
else
{
KeRowConvBwData2
<<<
dimGrid2
,
dimBlock2
,
0
,
STREAM_DEFAULT
>>>
(
dx
,
w
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
KeRowConvBwData2
<<<
dimGrid2
,
dimBlock2
,
0
,
STREAM_DEFAULT
>>>
(
dx
,
w
,
dy
,
starts
,
height
,
width
,
numSeq
,
contextLength
);
}
}
...
...
paddle/function/TensorShapeTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -19,35 +19,35 @@ namespace paddle {
TEST
(
TensorShape
,
Constructor
)
{
TensorShape
t1
;
EXPECT_EQ
(
t1
.
ndims
(),
0
);
EXPECT_EQ
(
t1
.
getElements
(),
0
);
EXPECT_EQ
(
t1
.
ndims
(),
0
U
);
EXPECT_EQ
(
t1
.
getElements
(),
0
U
);
TensorShape
t2
(
3
);
EXPECT_EQ
(
t2
.
ndims
(),
3
);
EXPECT_EQ
(
t2
.
getElements
(),
1
);
EXPECT_EQ
(
t2
.
ndims
(),
3
U
);
EXPECT_EQ
(
t2
.
getElements
(),
1
U
);
TensorShape
t3
({
8
,
10
});
EXPECT_EQ
(
t3
.
ndims
(),
2
);
EXPECT_EQ
(
t3
.
getElements
(),
80
);
EXPECT_EQ
(
t3
.
ndims
(),
2
U
);
EXPECT_EQ
(
t3
.
getElements
(),
80
U
);
TensorShape
t4
(
t3
);
EXPECT_EQ
(
t4
.
ndims
(),
t3
.
ndims
());
EXPECT_EQ
(
t4
.
getElements
(),
t3
.
getElements
());
TensorShape
t5
({
1
,
2
,
3
,
4
,
5
});
EXPECT_EQ
(
t5
.
ndims
(),
5
);
EXPECT_EQ
(
t5
.
getElements
(),
120
);
EXPECT_EQ
(
t5
.
ndims
(),
5
U
);
EXPECT_EQ
(
t5
.
getElements
(),
120
U
);
}
TEST
(
TensorShape
,
GetAndSet
)
{
TensorShape
t
({
1
,
2
,
3
});
EXPECT_EQ
(
t
.
ndims
(),
3
);
EXPECT_EQ
(
t
.
getElements
(),
6
);
EXPECT_EQ
(
t
.
ndims
(),
3
U
);
EXPECT_EQ
(
t
.
getElements
(),
6
U
);
EXPECT_EQ
(
t
[
1
],
2
);
t
.
setDim
(
1
,
100
);
EXPECT_EQ
(
t
.
getElements
(),
300
);
EXPECT_EQ
(
t
[
1
],
100
);
EXPECT_EQ
(
t
.
getElements
(),
300
U
);
EXPECT_EQ
(
t
[
1
],
100
U
);
}
}
// namespace paddle
paddle/function/TensorTypeTest.cpp
浏览文件 @
59a8ebc6
...
...
@@ -19,9 +19,9 @@ namespace paddle {
TEST
(
TensorType
,
Matrix
)
{
Tensor
<
real
,
DEVICE_TYPE_CPU
>::
Matrix
matrix
(
100
,
200
);
EXPECT_EQ
(
matrix
.
getHeight
(),
100
);
EXPECT_EQ
(
matrix
.
getWidth
(),
200
);
EXPECT_EQ
(
matrix
.
getElementCnt
(),
100
*
200
);
EXPECT_EQ
(
matrix
.
getHeight
(),
100
U
);
EXPECT_EQ
(
matrix
.
getWidth
(),
200
U
);
EXPECT_EQ
(
matrix
.
getElementCnt
(),
100
U
*
200U
);
EXPECT_EQ
(
matrix
.
useGpu
(),
false
);
Tensor
<
real
,
DEVICE_TYPE_GPU
>::
Matrix
testGpu
(
100
,
200
);
...
...
@@ -33,15 +33,15 @@ TEST(TensorType, Vector) {
Tensor
<
real
,
DEVICE_TYPE_GPU
>::
Vector
gpuVector
(
100
);
EXPECT_EQ
(
cpuVector
.
useGpu
(),
false
);
EXPECT_EQ
(
gpuVector
.
useGpu
(),
true
);
EXPECT_EQ
(
cpuVector
.
getSize
(),
100
);
EXPECT_EQ
(
gpuVector
.
getSize
(),
100
);
EXPECT_EQ
(
cpuVector
.
getSize
(),
100
U
);
EXPECT_EQ
(
gpuVector
.
getSize
(),
100
U
);
Tensor
<
int
,
DEVICE_TYPE_CPU
>::
Vector
cpuIVector
(
100
);
Tensor
<
int
,
DEVICE_TYPE_GPU
>::
Vector
gpuIVector
(
100
);
EXPECT_EQ
(
cpuIVector
.
useGpu
(),
false
);
EXPECT_EQ
(
gpuIVector
.
useGpu
(),
true
);
EXPECT_EQ
(
cpuIVector
.
getSize
(),
100
);
EXPECT_EQ
(
gpuIVector
.
getSize
(),
100
);
EXPECT_EQ
(
cpuIVector
.
getSize
(),
100
U
);
EXPECT_EQ
(
gpuIVector
.
getSize
(),
100
U
);
}
TEST
(
TensorType
,
EmptyMatrix
)
{
...
...
paddle/function/nnpack/NNPACKConvOp.cpp
浏览文件 @
59a8ebc6
...
...
@@ -49,9 +49,7 @@ class NNPACKConvFunction : public ConvFunctionBase {
public:
void
init
(
const
FuncConfig
&
config
)
override
{
ConvFunctionBase
::
init
(
config
);
CHECK_EQ
(
groups_
,
(
size_t
)
1
);
algorithm_
=
get_nnp_convolution_algorithm
(
config
.
get
<
std
::
string
>
(
"algo"
));
// algorithm_ = nnp_convolution_algorithm_auto;
transform_strategy_
=
nnp_convolution_transform_strategy_compute
;
nnp_status
status
=
nnp_initialize
();
CHECK_EQ
(
status
,
nnp_status_success
);
...
...
@@ -67,8 +65,7 @@ public:
}
}
virtual
void
check
(
const
BufferArgs
&
inputs
,
const
BufferArgs
&
outputs
)
override
{
void
check
(
const
BufferArgs
&
inputs
,
const
BufferArgs
&
outputs
)
override
{
const
TensorShape
&
input
=
inputs
[
0
].
shape
();
const
TensorShape
&
filter
=
inputs
[
1
].
shape
();
const
TensorShape
&
output
=
outputs
[
0
].
shape
();
...
...
@@ -91,8 +88,8 @@ public:
size_t
filterHeight
=
getFilterHeight
(
filter
);
size_t
filterWidth
=
getFilterWidth
(
filter
);
size_t
outputChannels
=
output
[
1
];
//
size_t outputHeight = output[2];
//
size_t outputWidth = output[3];
size_t
outputHeight
=
output
[
2
];
size_t
outputWidth
=
output
[
3
];
nnp_size
inputSize
=
{.
width
=
inputWidth
,
.
height
=
inputHeight
};
nnp_padding
padding
=
{.
top
=
(
size_t
)
paddingH
(),
...
...
@@ -171,49 +168,58 @@ public:
}
}
size_t
inputOffset
=
inputChannels
/
groups_
*
inputHeight
*
inputWidth
;
size_t
outputOffset
=
outputChannels
/
groups_
*
outputHeight
*
outputWidth
;
size_t
filterOffset
=
filter
.
getElements
()
/
groups_
;
if
(
batchSize
==
1
)
{
nnp_status
status
=
nnp_convolution_inference
(
algorithm_
,
transform_strategy_
,
inputChannels
,
outputChannels
,
inputSize
,
padding
,
kernelSize
,
outputSubsampling
,
inputData
,
filterData
,
nullptr
,
/* bias */
outputData
,
bufferPtr
,
sizePtr
,
nnp_activation_identity
,
nullptr
,
threadpool_
,
/* threadpool */
nullptr
);
CHECK_EQ
(
status
,
nnp_status_success
);
for
(
size_t
g
=
0
;
g
<
groups_
;
g
++
)
{
nnp_status
status
=
nnp_convolution_inference
(
algorithm_
,
transform_strategy_
,
inputChannels
/
groups_
,
outputChannels
/
groups_
,
inputSize
,
padding
,
kernelSize
,
outputSubsampling
,
inputData
+
inputOffset
*
g
,
filterData
+
filterOffset
*
g
,
nullptr
,
/* bias */
outputData
+
outputOffset
*
g
,
bufferPtr
,
sizePtr
,
nnp_activation_identity
,
nullptr
,
threadpool_
,
/* threadpool */
nullptr
);
CHECK_EQ
(
status
,
nnp_status_success
);
}
}
else
{
// only supports stride = 1
CHECK_EQ
(
strideH
(),
1
);
CHECK_EQ
(
strideW
(),
1
);
nnp_status
status
=
nnp_convolution_output
(
algorithm_
,
batchSize
,
inputChannels
,
outputChannels
,
inputSize
,
padding
,
kernelSize
,
inputData
,
filterData
,
nullptr
,
/* bias */
outputData
,
bufferPtr
,
sizePtr
,
nnp_activation_identity
,
nullptr
,
threadpool_
,
/* threadpool */
nullptr
);
CHECK_EQ
(
status
,
nnp_status_success
);
for
(
size_t
g
=
0
;
g
<
groups_
;
g
++
)
{
// only supports stride = 1
CHECK_EQ
(
strideH
(),
1
);
CHECK_EQ
(
strideW
(),
1
);
nnp_status
status
=
nnp_convolution_output
(
algorithm_
,
batchSize
,
inputChannels
/
groups_
,
outputChannels
/
groups_
,
inputSize
,
padding
,
kernelSize
,
inputData
+
inputOffset
*
g
,
filterData
+
filterOffset
*
g
,
nullptr
,
/* bias */
outputData
+
outputOffset
*
g
,
bufferPtr
,
sizePtr
,
nnp_activation_identity
,
nullptr
,
threadpool_
,
/* threadpool */
nullptr
);
CHECK_EQ
(
status
,
nnp_status_success
);
}
}
}
...
...
paddle/gserver/activations/ActivationFunction.cpp
浏览文件 @
59a8ebc6
...
...
@@ -186,7 +186,10 @@ Error __must_check forward(Argument& act) {
useGpu
(
act
.
deviceId
));
}
auto
starts
=
act
.
sequenceStartPositions
->
getVector
(
useGpu
(
act
.
deviceId
));
auto
starts
=
act
.
hasSubseq
()
?
act
.
subSequenceStartPositions
->
getVector
(
useGpu
(
act
.
deviceId
))
:
act
.
sequenceStartPositions
->
getVector
(
useGpu
(
act
.
deviceId
));
act
.
value
->
sequenceSoftmax
(
*
act
.
value
,
*
starts
);
return
Error
();
}
...
...
@@ -197,8 +200,9 @@ Error __must_check backward(Argument& act) {
"Input width for each timestep of sequence softmax should be 1"
);
}
size_t
numSequences
=
act
.
getNumSequences
();
const
int
*
starts
=
act
.
sequenceStartPositions
->
getData
(
false
);
size_t
numSequences
=
act
.
hasSubseq
()
?
act
.
getNumSubSequences
()
:
act
.
getNumSequences
();
const
int
*
starts
=
act
.
getCpuStartPositions
();
for
(
size_t
i
=
0
;
i
<
numSequences
;
++
i
)
{
// TODO(Dangqingqing) optimization for GPU
...
...
paddle/gserver/layers/ExpandConvLayer.cpp
浏览文件 @
59a8ebc6
...
...
@@ -57,8 +57,7 @@ bool ExpandConvLayer::init(const LayerMap &layerMap,
convGradFilterType
=
"GemmConvGradFilter"
;
}
if
(
FLAGS_use_nnpack
)
{
CHECK_EQ
(
isDeconv_
,
false
);
if
(
FLAGS_use_nnpack
&&
!
isDeconv_
)
{
createFunction
(
forward_
,
"NNPACKConv"
,
FuncConfig
()
...
...
paddle/gserver/layers/GruCompute.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,7 +12,6 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "GruCompute.h"
#include "hl_recurrent_apply.cuh"
...
...
@@ -31,8 +30,10 @@ void GruCompute::forward<1>(hl_gru_value value, int frameSize, int batchSize) {
}
template
<
>
void
GruCompute
::
backward
<
1
>
(
hl_gru_value
value
,
hl_gru_grad
grad
,
int
frameSize
,
int
batchSize
)
{
void
GruCompute
::
backward
<
1
>
(
hl_gru_value
value
,
hl_gru_grad
grad
,
int
frameSize
,
int
batchSize
)
{
hl_gpu_gru_backward
(
hppl
::
backward
::
gru_stateGrad
(),
hppl
::
backward
::
gru_resetGrad
(),
value
,
...
...
paddle/gserver/layers/KmaxSeqScoreLayer.cpp
浏览文件 @
59a8ebc6
...
...
@@ -97,13 +97,19 @@ void KmaxSeqScoreLayer::forward(PassType passType) {
scores_
=
inputScore
;
}
int
seqNum
=
input
.
hasSubseq
()
?
input
.
getNumSubSequences
()
:
input
.
getNumSequences
();
Matrix
::
resizeOrCreate
(
output_
.
value
,
seqNum
,
beamSize_
,
false
,
false
);
Matrix
::
resizeOrCreate
(
output_
.
value
,
input
.
hasSubseq
()
?
input
.
getNumSubSequences
()
:
input
.
getNumSequences
(),
beamSize_
,
false
,
false
);
output_
.
value
->
one
();
output_
.
value
->
mulScalar
(
-
1.
);
kmaxScorePerSeq
(
scores_
->
getData
(),
output_
.
value
->
getData
(),
seqNum
);
kmaxScorePerSeq
(
scores_
->
getData
(),
output_
.
value
->
getData
(),
input
.
hasSubseq
()
?
input
.
subSequenceStartPositions
:
input
.
sequenceStartPositions
);
}
void
KmaxSeqScoreLayer
::
backward
(
const
UpdateCallback
&
callback
)
{}
...
...
paddle/gserver/layers/LstmCompute.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,41 +12,62 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "LstmCompute.h"
#include "hl_recurrent_apply.cuh"
namespace
paddle
{
template
<
>
void
LstmCompute
::
forwardBatch
<
1
>
(
hl_lstm_value
value
,
int
frameSize
,
int
batchSize
)
{
hl_gpu_lstm_forward
(
hppl
::
forward
::
lstm
(),
value
,
frameSize
,
batchSize
,
activeNode_
,
activeGate_
,
void
LstmCompute
::
forwardBatch
<
1
>
(
hl_lstm_value
value
,
int
frameSize
,
int
batchSize
)
{
hl_gpu_lstm_forward
(
hppl
::
forward
::
lstm
(),
value
,
frameSize
,
batchSize
,
activeNode_
,
activeGate_
,
activeState_
);
}
template
<
>
void
LstmCompute
::
backwardBatch
<
1
>
(
hl_lstm_value
value
,
hl_lstm_grad
grad
,
int
frameSize
,
int
batchSize
)
{
hl_gpu_lstm_backward
(
hppl
::
backward
::
lstm
(),
value
,
grad
,
frameSize
,
batchSize
,
activeNode_
,
activeGate_
,
activeState_
);
void
LstmCompute
::
backwardBatch
<
1
>
(
hl_lstm_value
value
,
hl_lstm_grad
grad
,
int
frameSize
,
int
batchSize
)
{
hl_gpu_lstm_backward
(
hppl
::
backward
::
lstm
(),
value
,
grad
,
frameSize
,
batchSize
,
activeNode_
,
activeGate_
,
activeState_
);
}
template
<
>
void
LstmCompute
::
forwardOneSequence
<
1
>
(
hl_lstm_value
value
,
int
frameSize
)
{
hl_gpu_lstm_forward
(
hppl
::
forward
::
lstm
(),
value
,
frameSize
,
/* batchSize */
1
,
activeNode_
,
activeGate_
,
activeState_
);
hl_gpu_lstm_forward
(
hppl
::
forward
::
lstm
(),
value
,
frameSize
,
/* batchSize */
1
,
activeNode_
,
activeGate_
,
activeState_
);
}
template
<
>
void
LstmCompute
::
backwardOneSequence
<
1
>
(
hl_lstm_value
value
,
hl_lstm_grad
grad
,
void
LstmCompute
::
backwardOneSequence
<
1
>
(
hl_lstm_value
value
,
hl_lstm_grad
grad
,
int
frameSize
)
{
hl_gpu_lstm_backward
(
hppl
::
backward
::
lstm
(),
value
,
grad
,
frameSize
,
/* batchSize */
1
,
activeNode_
,
activeGate_
,
activeState_
);
hl_gpu_lstm_backward
(
hppl
::
backward
::
lstm
(),
value
,
grad
,
frameSize
,
/* batchSize */
1
,
activeNode_
,
activeGate_
,
activeState_
);
}
}
// namespace paddle
paddle/gserver/layers/PrintLayer.cpp
浏览文件 @
59a8ebc6
...
...
@@ -29,7 +29,7 @@ public:
vals
.
push_back
(
s
.
str
());
}
size_t
pos
=
0
;
in
t
i
=
0
;
size_
t
i
=
0
;
std
::
ostringstream
s
;
const
std
::
string
&
format
=
config_
.
user_arg
();
while
(
true
)
{
...
...
paddle/gserver/tests/CMakeLists.txt
浏览文件 @
59a8ebc6
# gserver pacakge unittests
file
(
GLOB_RECURSE GSERVER_HEADER RELATIVE
"
${
CMAKE_CURRENT_SOURCE_DIR
}
"
"*.h"
)
file
(
GLOB_RECURSE GSERVER_SOURCES RELATIVE
"
${
CMAKE_CURRENT_SOURCE_DIR
}
"
"*.cpp"
)
add_style_check_target
(
paddle_gserver
${
GSERVER_SOURCES
}
)
add_style_check_target
(
paddle_gserver
${
GSERVER_HEADER
}
)
################### test_ProtoDataProvider ############
add_unittest_without_exec
(
test_ProtoDataProvider
test_ProtoDataProvider.cpp
)
...
...
paddle/gserver/tests/test_ActivationGrad.cpp
浏览文件 @
59a8ebc6
...
...
@@ -57,6 +57,39 @@ TEST(Activation, activation) {
}
}
void
testSequenceSoftmaxAct
(
bool
hasSubseq
)
{
LOG
(
INFO
)
<<
"test activation: sequence softmax"
;
const
size_t
size
=
1
;
TestConfig
config
;
config
.
biasSize
=
0
;
config
.
layerConfig
.
set_type
(
"addto"
);
config
.
layerConfig
.
set_size
(
size
);
config
.
layerConfig
.
set_active_type
(
"sequence_softmax"
);
config
.
inputDefs
.
push_back
(
{
hasSubseq
?
INPUT_HASSUB_SEQUENCE_DATA
:
INPUT_SEQUENCE_DATA
,
"layer_0"
,
1
,
0
});
config
.
layerConfig
.
add_inputs
();
for
(
auto
useGpu
:
{
false
,
true
})
{
testLayerGrad
(
config
,
"sequence_softmax"
,
100
,
/* trans= */
false
,
useGpu
,
/* useWeight */
true
);
}
}
TEST
(
SequenceSoftmaxActivation
,
activation
)
{
for
(
auto
hasSubseq
:
{
false
,
true
})
{
LOG
(
INFO
)
<<
"hasSubseq = "
<<
hasSubseq
;
testSequenceSoftmaxAct
(
hasSubseq
);
}
}
int
main
(
int
argc
,
char
**
argv
)
{
testing
::
InitGoogleTest
(
&
argc
,
argv
);
initMain
(
argc
,
argv
);
...
...
paddle/math/BaseMatrix.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,21 +12,21 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include <cmath>
#include <string.h>
#include <paddle/utils/Logging.h>
#include <string.h>
#include <cmath>
#include "BaseMatrix.h"
#include "hl_matrix_ops.cuh"
#include "hl_matrix_base.cuh"
#include "hl_matrix_apply.cuh"
#include "SIMDFunctions.h"
#include "MathFunctions.h"
#include "SIMDFunctions.h"
#include "hl_matrix_apply.cuh"
#include "hl_matrix_base.cuh"
#include "hl_matrix_ops.cuh"
namespace
paddle
{
const
char
*
SPARSE_SUPPORT_ERROR
=
"Sparse Matrix/Vector is not supported."
;
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyUnary
(
Op
op
)
{
MatrixOffset
offset
(
0
,
0
);
...
...
@@ -34,9 +34,11 @@ int BaseMatrixT<T>::applyUnary(Op op) {
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyUnary
(
Op
op
,
int
numRows
,
int
numCols
,
int
BaseMatrixT
<
T
>::
applyUnary
(
Op
op
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
)
{
CHECK
(
!
this
->
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
int
dimM
=
numRows
;
...
...
@@ -56,7 +58,7 @@ int BaseMatrixT<T>::applyUnary(Op op, int numRows, int numCols,
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyBinary
(
Op
op
,
BaseMatrixT
&
b
)
{
CHECK
(
height_
==
b
.
height_
&&
width_
==
b
.
width_
)
...
...
@@ -67,18 +69,23 @@ int BaseMatrixT<T>::applyBinary(Op op, BaseMatrixT& b) {
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyBinary
(
Op
op
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
)
{
int
BaseMatrixT
<
T
>::
applyBinary
(
Op
op
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
)
{
applyBinary
(
op
,
b
,
numRows
,
numCols
,
offset
,
false_type
(),
false_type
());
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
,
class
bAsRowVector
,
class
bAsColVector
>
int
BaseMatrixT
<
T
>::
applyBinary
(
Op
op
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
bAsRowVector
,
bAsColVector
)
{
int
BaseMatrixT
<
T
>::
applyBinary
(
Op
op
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
bAsRowVector
,
bAsColVector
)
{
CHECK
(
!
this
->
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
CHECK
(
!
b
.
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
CHECK
(
useGpu_
==
b
.
useGpu_
)
<<
"Matrix type mismatch"
;
...
...
@@ -91,8 +98,8 @@ int BaseMatrixT<T>::applyBinary(Op op, BaseMatrixT& b, int numRows, int numCols,
T
*
A
=
data_
;
T
*
B
=
b
.
data_
;
CAL_MATRIX_START_ADDRESS
(
A
,
height_
,
width_
,
lda
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CHECK_LE
(
dimM
+
offset
.
aRow_
,
this
->
height_
);
CHECK_LE
(
dimN
+
offset
.
aCol_
,
this
->
width_
);
if
(
!
bAsRowVector
::
value
&&
!
bAsColVector
::
value
)
{
...
...
@@ -115,7 +122,7 @@ int BaseMatrixT<T>::applyBinary(Op op, BaseMatrixT& b, int numRows, int numCols,
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyTernary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
CHECK_EQ
(
height_
,
b
.
height_
);
...
...
@@ -129,21 +136,29 @@ int BaseMatrixT<T>::applyTernary(Op op, BaseMatrixT& b, BaseMatrixT& c) {
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyTernary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
int
BaseMatrixT
<
T
>::
applyTernary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
)
{
applyTernary
(
op
,
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
false_type
());
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
,
class
cAsRowVector
,
class
cAsColVector
>
int
BaseMatrixT
<
T
>::
applyTernary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
cAsRowVector
,
cAsColVector
)
{
int
BaseMatrixT
<
T
>::
applyTernary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
cAsRowVector
,
cAsColVector
)
{
CHECK
(
!
this
->
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
CHECK
(
!
b
.
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
CHECK
(
!
c
.
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
...
...
@@ -160,10 +175,10 @@ int BaseMatrixT<T>::applyTernary(Op op, BaseMatrixT& b, BaseMatrixT& c,
T
*
B
=
b
.
data_
;
T
*
C
=
c
.
data_
;
CAL_MATRIX_START_ADDRESS
(
A
,
height_
,
width_
,
lda
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
CHECK_LE
(
dimM
+
offset
.
aRow_
,
this
->
height_
);
CHECK_LE
(
dimN
+
offset
.
aCol_
,
this
->
width_
);
...
...
@@ -180,21 +195,21 @@ int BaseMatrixT<T>::applyTernary(Op op, BaseMatrixT& b, BaseMatrixT& c,
}
if
(
true
==
useGpu_
)
{
hl_gpu_apply_ternary_op
<
T
,
Op
,
cAsRowVector
::
value
,
cAsColVector
::
value
>
(
hl_gpu_apply_ternary_op
<
T
,
Op
,
cAsRowVector
::
value
,
cAsColVector
::
value
>
(
op
,
A
,
B
,
C
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
);
}
else
{
hl_cpu_apply_ternary_op
<
T
,
Op
,
cAsRowVector
::
value
,
cAsColVector
::
value
>
(
hl_cpu_apply_ternary_op
<
T
,
Op
,
cAsRowVector
::
value
,
cAsColVector
::
value
>
(
op
,
A
,
B
,
C
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
);
}
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyQuaternary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
BaseMatrixT
<
T
>::
applyQuaternary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
)
{
CHECK_EQ
(
height_
,
b
.
height_
);
CHECK_EQ
(
width_
,
b
.
width_
);
...
...
@@ -209,10 +224,14 @@ int BaseMatrixT<T>::applyQuaternary(Op op, BaseMatrixT& b, BaseMatrixT& c,
return
0
;
}
template
<
class
T
>
template
<
class
T
>
template
<
class
Op
>
int
BaseMatrixT
<
T
>::
applyQuaternary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
,
int
numRows
,
int
numCols
,
int
BaseMatrixT
<
T
>::
applyQuaternary
(
Op
op
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
)
{
CHECK
(
!
this
->
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
CHECK
(
!
b
.
isSparse
())
<<
SPARSE_SUPPORT_ERROR
;
...
...
@@ -234,12 +253,12 @@ int BaseMatrixT<T>::applyQuaternary(Op op, BaseMatrixT& b, BaseMatrixT& c,
T
*
C
=
c
.
data_
;
T
*
D
=
d
.
data_
;
CAL_MATRIX_START_ADDRESS
(
A
,
height_
,
width_
,
lda
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
CAL_MATRIX_START_ADDRESS
(
D
,
d
.
height_
,
d
.
width_
,
ldd
,
offset
.
dCol_
,
offset
.
dRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
CAL_MATRIX_START_ADDRESS
(
D
,
d
.
height_
,
d
.
width_
,
ldd
,
offset
.
dCol_
,
offset
.
dRow_
);
CHECK_LE
(
dimM
+
offset
.
aRow_
,
this
->
height_
);
CHECK_LE
(
dimN
+
offset
.
aCol_
,
this
->
width_
);
...
...
@@ -250,22 +269,29 @@ int BaseMatrixT<T>::applyQuaternary(Op op, BaseMatrixT& b, BaseMatrixT& c,
CHECK_LE
(
dimM
+
offset
.
dRow_
,
d
.
height_
);
CHECK_LE
(
dimN
+
offset
.
dCol_
,
d
.
width_
);
if
(
true
==
useGpu_
)
{
hl_gpu_apply_quaternary_op
(
op
,
A
,
B
,
C
,
D
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
,
ldd
);
hl_gpu_apply_quaternary_op
(
op
,
A
,
B
,
C
,
D
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
,
ldd
);
}
else
{
hl_cpu_apply_quaternary_op
(
op
,
A
,
B
,
C
,
D
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
,
ldd
);
hl_cpu_apply_quaternary_op
(
op
,
A
,
B
,
C
,
D
,
dimM
,
dimN
,
lda
,
ldb
,
ldc
,
ldd
);
}
return
0
;
}
template
<
class
T
>
template
<
class
Agg
,
class
Op
,
class
Saver
,
class
aAsRowVector
,
template
<
class
T
>
template
<
class
Agg
,
class
Op
,
class
Saver
,
class
aAsRowVector
,
class
aAsColVector
>
int
BaseMatrixT
<
T
>::
aggregate
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
aAsRowVector
,
aAsColVector
)
{
int
BaseMatrixT
<
T
>::
aggregate
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
aAsRowVector
,
aAsColVector
)
{
CHECK_EQ
(
useGpu_
,
b
.
useGpu_
);
int
ld
=
stride_
;
...
...
@@ -273,10 +299,10 @@ int BaseMatrixT<T>::aggregate(Agg agg, Op op, Saver sv, BaseMatrixT& b,
T
*
dst
=
data_
;
T
*
B
=
b
.
data_
;
CAL_MATRIX_START_ADDRESS
(
dst
,
height_
,
width_
,
ld
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
dst
,
height_
,
width_
,
ld
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
if
(
aAsRowVector
::
value
&&
!
aAsColVector
::
value
)
{
if
(
useGpu_
)
{
...
...
@@ -297,12 +323,21 @@ int BaseMatrixT<T>::aggregate(Agg agg, Op op, Saver sv, BaseMatrixT& b,
return
0
;
}
template
<
class
T
>
template
<
class
Agg
,
class
Op
,
class
Saver
,
class
aAsRowVector
,
template
<
class
T
>
template
<
class
Agg
,
class
Op
,
class
Saver
,
class
aAsRowVector
,
class
aAsColVector
>
int
BaseMatrixT
<
T
>::
aggregate
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
aAsRowVector
,
int
BaseMatrixT
<
T
>::
aggregate
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
int
numRows
,
int
numCols
,
MatrixOffset
&
offset
,
aAsRowVector
,
aAsColVector
)
{
CHECK_EQ
(
useGpu_
,
b
.
useGpu_
);
CHECK_EQ
(
useGpu_
,
c
.
useGpu_
);
...
...
@@ -314,28 +349,28 @@ int BaseMatrixT<T>::aggregate(Agg agg, Op op, Saver sv, BaseMatrixT& b,
T
*
dst
=
data_
;
T
*
B
=
b
.
data_
;
T
*
C
=
c
.
data_
;
CAL_MATRIX_START_ADDRESS
(
dst
,
height_
,
width_
,
ld
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
CAL_MATRIX_START_ADDRESS
(
dst
,
height_
,
width_
,
ld
,
offset
.
aCol_
,
offset
.
aRow_
);
CAL_MATRIX_START_ADDRESS
(
B
,
b
.
height_
,
b
.
width_
,
ldb
,
offset
.
bCol_
,
offset
.
bRow_
);
CAL_MATRIX_START_ADDRESS
(
C
,
c
.
height_
,
c
.
width_
,
ldc
,
offset
.
cCol_
,
offset
.
cRow_
);
if
(
aAsRowVector
::
value
&&
!
aAsColVector
::
value
)
{
if
(
useGpu_
)
{
hl_gpu_matrix_column_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
B
,
ldb
,
C
,
ldc
);
hl_gpu_matrix_column_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
B
,
ldb
,
C
,
ldc
);
}
else
{
hl_cpu_matrix_column_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
B
,
ldb
,
C
,
ldc
);
hl_cpu_matrix_column_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
B
,
ldb
,
C
,
ldc
);
}
}
else
if
(
!
aAsRowVector
::
value
&&
aAsColVector
::
value
)
{
if
(
useGpu_
)
{
hl_gpu_matrix_row_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
ld
,
B
,
ldb
,
C
,
ldc
);
hl_gpu_matrix_row_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
ld
,
B
,
ldb
,
C
,
ldc
);
}
else
{
hl_cpu_matrix_row_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
ld
,
B
,
ldb
,
C
,
ldc
);
hl_cpu_matrix_row_op
(
agg
,
op
,
sv
,
numRows
,
numCols
,
dst
,
ld
,
B
,
ldb
,
C
,
ldc
);
}
}
else
{
LOG
(
FATAL
)
<<
"not supported"
;
...
...
@@ -350,15 +385,19 @@ int BaseMatrixT<T>::aggregate(Agg agg, Op op, Saver sv, BaseMatrixT& b,
*/
DEFINE_MATRIX_UNARY_OP
(
Neg
,
a
=
-
a
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
neg
()
{
applyUnary
(
unary
::
Neg
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
neg
()
{
applyUnary
(
unary
::
Neg
<
T
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Exp
,
a
=
exp
(
a
));
template
<
>
void
BaseMatrixT
<
real
>::
exp2
()
{
applyUnary
(
unary
::
Exp
<
real
>
());
}
template
<
>
void
BaseMatrixT
<
real
>::
exp2
()
{
applyUnary
(
unary
::
Exp
<
real
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Log
,
a
=
log
(
a
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
log2
()
{
if
(
useGpu_
)
{
applyUnary
(
unary
::
Log
<
real
>
());
...
...
@@ -368,30 +407,42 @@ void BaseMatrixT<real>::log2() {
}
DEFINE_MATRIX_UNARY_OP
(
Sqrt
,
a
=
sqrt
(
a
));
template
<
>
void
BaseMatrixT
<
real
>::
sqrt2
()
{
applyUnary
(
unary
::
Sqrt
<
real
>
());
}
template
<
>
void
BaseMatrixT
<
real
>::
sqrt2
()
{
applyUnary
(
unary
::
Sqrt
<
real
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Square
,
a
=
a
*
a
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
square2
()
{
applyUnary
(
unary
::
Square
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
square2
()
{
applyUnary
(
unary
::
Square
<
T
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Reciprocal
,
a
=
1.0
f
/
a
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocal2
()
{
applyUnary
(
unary
::
Reciprocal
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocal2
()
{
applyUnary
(
unary
::
Reciprocal
<
T
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Abs
,
a
=
a
>
0
?
a
:
-
a
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
abs2
()
{
applyUnary
(
unary
::
Abs
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
abs2
()
{
applyUnary
(
unary
::
Abs
<
T
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Sign
,
a
=
(
a
>
0
)
-
(
a
<
0
));
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sign2
()
{
applyUnary
(
unary
::
Sign
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sign2
()
{
applyUnary
(
unary
::
Sign
<
T
>
());
}
DEFINE_MATRIX_UNARY_OP
(
Zero
,
a
=
0
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
zero
()
{
applyUnary
(
unary
::
Zero
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
zero
()
{
applyUnary
(
unary
::
Zero
<
T
>
());
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
zeroAtOffset
(
int64_t
columnOffset
,
int64_t
numColumns
)
{
int
numRows
=
height_
;
int
numCols
=
numColumns
;
...
...
@@ -400,11 +451,13 @@ void BaseMatrixT<T>::zeroAtOffset(int64_t columnOffset, int64_t numColumns) {
}
DEFINE_MATRIX_UNARY_OP
(
One
,
a
=
1
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
one
()
{
applyUnary
(
unary
::
One
<
T
>
());
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
one
()
{
applyUnary
(
unary
::
One
<
T
>
());
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Pow
,
ONE_PARAMETER
,
a
=
pow
(
a
,
p
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
pow2
(
real
p
)
{
if
(
useGpu_
)
{
applyUnary
(
unary
::
Pow
<
real
>
(
p
));
...
...
@@ -414,51 +467,67 @@ void BaseMatrixT<real>::pow2(real p) {
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
SubScalar
,
ONE_PARAMETER
,
a
-=
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
subScalar
(
T
p
)
{
applyUnary
(
unary
::
SubScalar
<
T
>
(
p
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
subScalar
(
T
p
)
{
applyUnary
(
unary
::
SubScalar
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
MulScalar
,
ONE_PARAMETER
,
a
*=
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
mulScalar
(
T
p
)
{
applyUnary
(
unary
::
MulScalar
<
T
>
(
p
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
mulScalar
(
T
p
)
{
applyUnary
(
unary
::
MulScalar
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
DivScalar
,
ONE_PARAMETER
,
a
/=
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
divScalar
(
T
p
)
{
applyUnary
(
unary
::
DivScalar
<
T
>
(
p
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
divScalar
(
T
p
)
{
applyUnary
(
unary
::
DivScalar
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Assign
,
ONE_PARAMETER
,
a
=
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
assign
(
T
p
)
{
applyUnary
(
unary
::
Assign
<
T
>
(
p
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
assign
(
T
p
)
{
applyUnary
(
unary
::
Assign
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Add
,
ONE_PARAMETER
,
a
+=
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
T
p
)
{
applyUnary
(
unary
::
Add
<
T
>
(
p
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
T
p
)
{
applyUnary
(
unary
::
Add
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Add2
,
TWO_PARAMETER
,
a
=
a
*
p1
+
p2
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
T
p1
,
T
p2
)
{
applyUnary
(
unary
::
Add2
<
T
>
(
p1
,
p2
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
T
p1
,
T
p2
)
{
applyUnary
(
unary
::
Add2
<
T
>
(
p1
,
p2
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Clip
,
TWO_PARAMETER
,
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
Clip
,
TWO_PARAMETER
,
a
=
a
<
p1
?
p1
:
(
a
>
p2
?
p2
:
a
));
template
<
class
T
>
void
BaseMatrixT
<
T
>::
clip
(
T
p1
,
T
p2
)
{
applyUnary
(
unary
::
Clip
<
T
>
(
p1
,
p2
));
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
clip
(
T
p1
,
T
p2
)
{
applyUnary
(
unary
::
Clip
<
T
>
(
p1
,
p2
));
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ClipDerivative
,
TWO_PARAMETER
,
a
=
b
<
p1
?
0
:
(
b
>
p2
?
0
:
1
));
template
<
class
T
>
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ClipDerivative
,
TWO_PARAMETER
,
a
=
b
<
p1
?
0
:
(
b
>
p2
?
0
:
1
));
template
<
class
T
>
void
BaseMatrixT
<
T
>::
clipDerivative
(
BaseMatrixT
&
b
,
T
p1
,
T
p2
)
{
applyBinary
(
binary
::
ClipDerivative
<
T
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
BiggerThanScalar
,
ONE_PARAMETER
,
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
BiggerThanScalar
,
ONE_PARAMETER
,
a
=
a
>
p
?
1.0
f
:
0.0
f
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
biggerThanScalar
(
T
p
)
{
applyUnary
(
unary
::
BiggerThanScalar
<
T
>
(
p
));
}
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
DownClip
,
ONE_PARAMETER
,
a
=
a
>
p
?
a
:
p
);
template
<
class
T
>
DEFINE_MATRIX_UNARY_PARAMETER_OP
(
DownClip
,
ONE_PARAMETER
,
a
=
a
>
p
?
a
:
p
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
downClip
(
T
p
)
{
applyUnary
(
unary
::
DownClip
<
T
>
(
p
));
}
...
...
@@ -469,12 +538,12 @@ void BaseMatrixT<T>::downClip(T p) {
*/
DEFINE_MATRIX_BINARY_OP
(
Add
,
a
+=
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Add
<
T
>
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
add
(
BaseMatrixT
&
b
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
Add
<
real
>
(),
b
);
...
...
@@ -485,7 +554,7 @@ void BaseMatrixT<real>::add(BaseMatrixT& b) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addAtOffset
(
BaseMatrixT
&
b
,
int64_t
columnOffset
)
{
if
(
columnOffset
+
b
.
width_
<=
width_
)
{
int
numRows
=
height_
;
...
...
@@ -504,43 +573,53 @@ void BaseMatrixT<T>::addAtOffset(BaseMatrixT& b, int64_t columnOffset) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addP2P
(
BaseMatrixT
&
b
)
{
T
*
A
=
data_
;
T
*
B
=
b
.
data_
;
int
dimM
=
height_
;
int
dimN
=
width_
;
hl_gpu_apply_binary_op
<
T
,
binary
::
Add
<
T
>
,
0
,
0
>
(
binary
::
Add
<
T
>
(),
A
,
B
,
dimM
,
dimN
,
dimN
,
dimN
);
hl_gpu_apply_binary_op
<
T
,
binary
::
Add
<
T
>
,
0
,
0
>
(
binary
::
Add
<
T
>
(),
A
,
B
,
dimM
,
dimN
,
dimN
,
dimN
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addColVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
Add
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
applyBinary
(
binary
::
Add
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/* bAsColVector */
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addRowVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
Add
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
applyBinary
(
binary
::
Add
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Add1
,
ONE_PARAMETER
,
a
+=
b
*
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
Add1
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Pow
,
ONE_PARAMETER
,
a
=
pow
(
b
,
p
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
pow2
(
BaseMatrixT
&
b
,
real
p
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
Pow
<
real
>
(
p
),
b
);
...
...
@@ -550,36 +629,45 @@ void BaseMatrixT<real>::pow2(BaseMatrixT& b, real p) {
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Add2
,
TWO_PARAMETER
,
a
=
p1
*
a
+
p2
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
BaseMatrixT
&
b
,
T
p1
,
T
p2
)
{
applyBinary
(
binary
::
Add2
<
T
>
(
p1
,
p2
),
b
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addBias
(
BaseMatrixT
&
b
,
T
scale
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
Add1
<
T
>
(
scale
),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
applyBinary
(
binary
::
Add1
<
T
>
(
scale
),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
}
DEFINE_MATRIX_BINARY_OP
(
Sub
,
a
-=
b
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sub
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Sub
<
T
>
(),
b
);
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sub
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Sub
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Sub1
,
ONE_PARAMETER
,
a
-=
b
*
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sub
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
Sub1
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Relu
,
b
=
a
>
0.0
f
?
a
:
0.0
f
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
relu
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Relu
<
T
>
(),
b
);
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
relu
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Relu
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
ReluDerivative
,
a
*=
(
b
>
0.0
f
?
1.0
f
:
0.0
f
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reluDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
ReluDerivative
<
T
>
(),
b
);
}
...
...
@@ -589,7 +677,7 @@ DEFINE_MATRIX_BINARY_OP(Softrelu, const T THRESHOLD = 40.0;
?
THRESHOLD
:
((
a
<
-
THRESHOLD
)
?
(
-
THRESHOLD
)
:
a
))));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
softrelu
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Softrelu
<
real
>
(),
b
);
}
...
...
@@ -599,97 +687,100 @@ DEFINE_MATRIX_BINARY_OP(
a
*=
(
1.0
-
exp
(
-
1.0
*
((
b
>
THRESHOLD
)
?
THRESHOLD
:
((
b
<
-
THRESHOLD
)
?
(
-
THRESHOLD
)
:
b
)))));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
softreluDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
SoftreluDerivative
<
real
>
(),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Brelu
,
TWO_PARAMETER
,
b
=
a
>
p1
?
a
:
p1
;
b
=
b
<
p2
?
b
:
p2
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
brelu
(
BaseMatrixT
&
b
)
{
int
p1
=
0
,
p2
=
24
;
//! TODO(yuyang18): Make p1,p2 configuable.
int
p1
=
0
,
p2
=
24
;
//! TODO(yuyang18): Make p1,p2 configuable.
applyBinary
(
binary
::
Brelu
<
T
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
BreluDerivative
,
TWO_PARAMETER
,
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
BreluDerivative
,
TWO_PARAMETER
,
a
*=
(
b
>
p1
&&
b
<
p2
)
?
1.0
:
0.0
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
breluDerivative
(
BaseMatrixT
&
b
)
{
int
p1
=
0
,
p2
=
24
;
applyBinary
(
binary
::
BreluDerivative
<
T
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Square
,
b
=
a
*
a
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
square2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Square
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
SquareDerivative
,
a
*=
2.0
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
squareDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
SquareDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Tanh
,
T
tmp
=
-
2.0
*
a
;
tmp
=
(
tmp
>
EXP_MAX_INPUT
)
?
EXP_MAX_INPUT
:
tmp
;
b
=
2.0
/
(
1.0
+
std
::
exp
(
tmp
))
-
1.0
);
template
<
>
DEFINE_MATRIX_BINARY_OP
(
Tanh
,
T
tmp
=
-
2.0
*
a
;
tmp
=
(
tmp
>
EXP_MAX_INPUT
)
?
EXP_MAX_INPUT
:
tmp
;
b
=
2.0
/
(
1.0
+
std
::
exp
(
tmp
))
-
1.0
);
template
<
>
void
BaseMatrixT
<
real
>::
tanh
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Tanh
<
real
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
TanhDerivative
,
a
*=
1
-
b
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
tanhDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
TanhDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ScaledTanh
,
TWO_PARAMETER
,
b
=
p1
*
(
2.0
/
(
1.0
+
exp
(
-
2
*
p2
*
a
))
-
1.0
));
template
<
>
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ScaledTanh
,
TWO_PARAMETER
,
b
=
p1
*
(
2.0
/
(
1.0
+
exp
(
-
2
*
p2
*
a
))
-
1.0
));
template
<
>
void
BaseMatrixT
<
real
>::
scaledTanh
(
BaseMatrixT
&
b
,
real
p1
,
real
p2
)
{
applyBinary
(
binary
::
ScaledTanh
<
real
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ScaledTanhDerivative
,
TWO_PARAMETER
,
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ScaledTanhDerivative
,
TWO_PARAMETER
,
a
*=
p2
*
(
p1
-
b
*
b
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
scaledTanhDerivative
(
BaseMatrixT
&
b
,
T
p1
,
T
p2
)
{
applyBinary
(
binary
::
ScaledTanhDerivative
<
T
>
(
p1
*
p1
,
p2
/
p1
),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Reciprocal
,
b
=
1.0
f
/
a
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocal2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Reciprocal
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
ReciprocalDerivative
,
a
*=
-
b
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocalDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
ReciprocalDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Abs
,
b
=
a
>
0.0
f
?
a
:
-
a
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
abs2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Abs
<
T
>
(),
b
);
}
template
<
class
T
>
void
BaseMatrixT
<
T
>::
abs2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Abs
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
AbsDerivative
,
a
=
(
b
>
0
)
?
a
:
(
b
<
0
)
?
-
a
:
0
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
absDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
AbsDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Sigmoid
,
const
T
THRESHOLD_MIN
=
-
40.0
;
const
T
THRESHOLD_MAX
=
13.0
;
T
tmp
=
(
a
<
THRESHOLD_MIN
)
?
THRESHOLD_MIN
:
((
a
>
THRESHOLD_MAX
)
?
THRESHOLD_MAX
:
a
);
b
=
1.0
f
/
(
1.0
f
+
exp
(
-
tmp
)));
template
<
>
DEFINE_MATRIX_BINARY_OP
(
Sigmoid
,
const
T
THRESHOLD_MIN
=
-
40.0
;
const
T
THRESHOLD_MAX
=
13.0
;
T
tmp
=
(
a
<
THRESHOLD_MIN
)
?
THRESHOLD_MIN
:
((
a
>
THRESHOLD_MAX
)
?
THRESHOLD_MAX
:
a
);
b
=
1.0
f
/
(
1.0
f
+
exp
(
-
tmp
)));
template
<
>
void
BaseMatrixT
<
real
>::
sigmoid
(
BaseMatrixT
&
b
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
Sigmoid
<
real
>
(),
b
);
...
...
@@ -723,31 +814,31 @@ void BaseMatrixT<real>::sigmoid(BaseMatrixT& b) {
}
DEFINE_MATRIX_BINARY_OP
(
SigmoidDerivative
,
a
*=
b
*
(
1
-
b
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sigmoidDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
SigmoidDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
ExpDerivative
,
a
*=
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
expDerivative
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
ExpDerivative
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Sign
,
b
=
a
>
0.0
f
?
1.0
f
:
-
1.0
f
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sign2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Sign
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Exp
,
a
=
exp
(
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
exp2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Exp
<
real
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
Log
,
a
=
log
(
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
log2
(
BaseMatrixT
&
b
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
Log
<
real
>
(),
b
);
...
...
@@ -757,13 +848,13 @@ void BaseMatrixT<real>::log2(BaseMatrixT& b) {
}
DEFINE_MATRIX_BINARY_OP
(
Sqrt
,
a
=
sqrt
(
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
sqrt2
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
Sqrt
<
real
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
InvSqrt
,
a
=
1.0
f
/
sqrt
(
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
invSqrt
(
BaseMatrixT
&
b
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
InvSqrt
<
real
>
(),
b
);
...
...
@@ -775,37 +866,37 @@ void BaseMatrixT<real>::invSqrt(BaseMatrixT& b) {
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
IsEqual
,
ONE_PARAMETER
,
a
=
(
b
==
p
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
isEqualTo
(
BaseMatrixT
&
b
,
T
value
)
{
applyBinary
(
binary
::
IsEqual
<
T
>
(
value
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
AddScalar
,
ONE_PARAMETER
,
a
=
b
+
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addScalar
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
AddScalar
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
SubScalar
,
ONE_PARAMETER
,
a
=
b
-
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
subScalar
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
SubScalar
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
MulScalar
,
ONE_PARAMETER
,
a
=
b
*
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
mulScalar
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
MulScalar
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
DivScalar
,
ONE_PARAMETER
,
a
=
b
/
p
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
divScalar
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
DivScalar
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ScalarDiv
,
ONE_PARAMETER
,
a
=
p
/
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
scalarDiv
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
ScalarDiv
<
T
>
(
p
),
b
);
}
...
...
@@ -817,20 +908,20 @@ void BaseMatrixT<T>::scalarDiv(BaseMatrixT& b, T p) {
DEFINE_MATRIX_TERNARY_OP
(
SoftCrossEntropy
,
a
=
-
c
*
log
(
b
)
-
(
1
-
c
)
*
log
(
1
-
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
softCrossEntropy
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
SoftCrossEntropy
<
real
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
SoftCrossEntropyBp
,
a
+=
(
b
-
c
)
/
(
b
*
(
1
-
b
)));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
softCrossEntropyBp
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
SoftCrossEntropyBp
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
BinaryCrossEntropy
,
a
=
c
>
0.5
?
-
log
(
b
)
:
-
log
(
1.0
-
b
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
binaryLabelCrossEntropy
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
if
(
useGpu_
)
{
...
...
@@ -858,70 +949,73 @@ void BaseMatrixT<real>::binaryLabelCrossEntropy(BaseMatrixT& b,
DEFINE_MATRIX_TERNARY_OP
(
BinaryCrossEntropyBp
,
a
+=
c
>
0.5
?
-
1.0
/
b
:
1.0
/
(
1.0
-
b
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
binaryLabelCrossEntropyBp
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
BinaryCrossEntropyBp
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
Add
,
a
=
b
+
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
Add
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
Add1
,
TWO_PARAMETER
,
a
=
p1
*
b
+
p2
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add
(
BaseMatrixT
&
b
,
T
p1
,
BaseMatrixT
&
c
,
T
p2
)
{
applyTernary
(
ternary
::
Add1
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
Sub
,
a
=
b
-
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sub
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
Sub
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
Sub1
,
TWO_PARAMETER
,
a
=
p1
*
b
-
p2
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sub
(
BaseMatrixT
&
b
,
T
p1
,
BaseMatrixT
&
c
,
T
p2
)
{
applyTernary
(
ternary
::
Sub1
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
Add2
,
a
=
a
+
b
+
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add2
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
Add2
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
Add3
,
THREE_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
Add3
,
THREE_PARAMETER
,
a
=
p1
*
a
+
p2
*
b
+
p3
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add2
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
,
T
p3
)
{
applyTernary
(
ternary
::
Add3
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
SgdUpdate
,
THREE_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
SgdUpdate
,
THREE_PARAMETER
,
c
=
p2
*
c
-
p1
*
(
b
+
p3
*
a
);
a
=
a
+
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sgdUpdate
(
BaseMatrixT
&
b
,
// grad
BaseMatrixT
&
c
,
// mom
T
p1
,
// learningRate,
T
p2
,
// momentum,
T
p3
)
{
// decayRate
T
p1
,
// learningRate,
T
p2
,
// momentum,
T
p3
)
{
// decayRate
applyTernary
(
ternary
::
SgdUpdate
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
);
}
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
SgdUpdate
,
THREE_PARAMETER
,
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
SgdUpdate
,
THREE_PARAMETER
,
c
=
p2
*
c
-
p1
*
d
*
(
b
+
p3
*
a
);
a
+=
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
sgdUpdate
(
BaseMatrixT
&
b
,
// grad,
BaseMatrixT
&
c
,
// mom,
BaseMatrixT
&
d
,
// lr,
T
p1
,
// learningRate,
T
p2
,
// momentum,
T
p3
)
{
// decayRate
T
p1
,
// learningRate,
T
p2
,
// momentum,
T
p3
)
{
// decayRate
applyQuaternary
(
quaternary
::
SgdUpdate
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
,
d
);
}
...
...
@@ -929,19 +1023,22 @@ DEFINE_MATRIX_BINARY_PARAMETER_OP(ApplyL1, ONE_PARAMETER, T lambda = p * b;
a
=
(
a
>
lambda
)
?
(
a
-
lambda
)
:
(
a
<
-
lambda
)
?
(
a
+
lambda
)
:
0
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
applyL1
(
BaseMatrixT
&
lr
,
T
learningRate
,
T
decayRate
)
{
applyBinary
(
binary
::
ApplyL1
<
T
>
(
learningRate
*
decayRate
),
lr
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
applyL1
(
BaseMatrixT
&
lr
,
real
learningRate
,
real
decayRate
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
ApplyL1
<
real
>
(
learningRate
*
decayRate
),
lr
);
}
else
{
simd
::
decayL1
(
this
->
data_
,
this
->
data_
,
lr
.
data_
,
learningRate
*
decayRate
,
simd
::
decayL1
(
this
->
data_
,
this
->
data_
,
lr
.
data_
,
learningRate
*
decayRate
,
height_
*
width_
);
}
}
...
...
@@ -950,24 +1047,25 @@ DEFINE_MATRIX_UNARY_PARAMETER_OP(ApplyL1, ONE_PARAMETER, T lambda = p;
a
=
(
a
>
lambda
)
?
(
a
-
lambda
)
:
(
a
<
-
lambda
)
?
(
a
+
lambda
)
:
0
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
applyL1
(
T
learningRate
,
T
decayRate
)
{
applyUnary
(
unary
::
ApplyL1
<
T
>
(
learningRate
*
decayRate
));
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
applyL1
(
real
learningRate
,
real
decayRate
)
{
if
(
useGpu_
)
{
applyUnary
(
unary
::
ApplyL1
<
real
>
(
learningRate
*
decayRate
));
}
else
{
simd
::
decayL1
(
this
->
data_
,
this
->
data_
,
learningRate
*
decayRate
,
height_
*
width_
);
simd
::
decayL1
(
this
->
data_
,
this
->
data_
,
learningRate
*
decayRate
,
height_
*
width_
);
}
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ApplyL2
,
ONE_PARAMETER
,
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
ApplyL2
,
ONE_PARAMETER
,
a
*=
(
1.0
f
/
(
1.0
f
+
p
*
b
)));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
applyL2
(
BaseMatrixT
&
lr
,
T
learningRate
,
T
decayRate
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
ApplyL2
<
T
>
(
learningRate
*
decayRate
),
lr
);
...
...
@@ -980,32 +1078,33 @@ void BaseMatrixT<T>::applyL2(BaseMatrixT& lr, T learningRate, T decayRate) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
applyL2
(
T
learningRate
,
T
decayRate
)
{
BaseMatrixT
<
T
>::
mulScalar
(
1.0
f
/
(
1.0
f
+
learningRate
*
decayRate
));
}
DEFINE_MATRIX_BINARY_OP
(
DotMul
,
a
*=
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMul
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
DotMul
<
T
>
(),
b
);
}
DEFINE_MATRIX_TERNARY_OP
(
DotMul
,
a
=
b
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMul
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
DotMul
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
DotDiv
,
a
=
(
b
==
0.0
)
?
0.0
:
b
/
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotDiv
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
DotDiv
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotDiv2P
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotDiv2P
,
TWO_PARAMETER
,
a
=
(
b
+
p1
)
/
(
c
+
p2
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotDiv
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
DotDiv2P
<
T
>
(
p1
,
p2
),
b
,
c
);
}
...
...
@@ -1015,7 +1114,7 @@ DEFINE_MATRIX_QUATERNARY_OP(RankLoss, const T THRESHOLD = 40.0; a = b - c;
?
THRESHOLD
:
((
a
<
-
THRESHOLD
)
?
(
-
THRESHOLD
)
:
a
);
a
=
log
(
1
+
exp
(
a
))
-
a
*
d
);
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
rankLoss
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
)
{
...
...
@@ -1026,8 +1125,9 @@ DEFINE_MATRIX_QUATERNARY_OP(RankLossBp, const T THRESHOLD = 40.0; a = b - c;
a
=
(
a
>
THRESHOLD
)
?
THRESHOLD
:
((
a
<
-
THRESHOLD
)
?
(
-
THRESHOLD
)
:
a
);
a
=
exp
(
a
);
a
=
(
a
/
(
1
+
a
)
-
d
));
template
<
>
a
=
exp
(
a
);
a
=
(
a
/
(
1
+
a
)
-
d
));
template
<
>
void
BaseMatrixT
<
real
>::
rankLossBp
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
)
{
...
...
@@ -1040,7 +1140,7 @@ DEFINE_MATRIX_TERNARY_OP(LogisticRegressionLoss, const T THRESHOLD = 40.0;
?
-
THRESHOLD
:
b
;
a
=
log
(
1
+
exp
(
x
))
-
c
*
x
);
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
logisticRegressionLoss
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
LogisticRegressionLoss
<
real
>
(),
b
,
c
);
}
...
...
@@ -1050,22 +1150,23 @@ DEFINE_MATRIX_TERNARY_OP(LogisticRegressionLossBp, const T THRESHOLD = 40.0;
T
x
=
(
b
>
THRESHOLD
)
?
THRESHOLD
:
(
b
<
-
THRESHOLD
)
?
-
THRESHOLD
:
b
;
x
=
exp
(
x
);
a
=
x
/
(
1
+
x
)
-
c
);
template
<
>
x
=
exp
(
x
);
a
=
x
/
(
1
+
x
)
-
c
);
template
<
>
void
BaseMatrixT
<
real
>::
logisticRegressionLossBp
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
LogisticRegressionLossBp
<
real
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
BiggerThan
,
a
=
(
b
>
c
)
?
1.0
f
:
0.0
f
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
biggerThan
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
BiggerThan
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_QUATERNARY_OP
(
BiggerThan
,
a
=
((
b
>
c
&&
d
>
0.5
f
)
||
(
b
<
c
&&
d
<
0.5
f
))
?
1.0
f
:
0.0
f
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
biggerThan
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
)
{
...
...
@@ -1073,25 +1174,34 @@ void BaseMatrixT<T>::biggerThan(BaseMatrixT& b,
}
DEFINE_MATRIX_TERNARY_OP
(
Max
,
a
=
(
b
>
c
)
?
b
:
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
max2
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
Max
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
BinaryClassificationError
,
ONE_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
BinaryClassificationError
,
ONE_PARAMETER
,
c
+=
((
a
>
p
)
==
(
b
>
p
))
?
0.0
f
:
1.0
f
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
binaryClassificationError2
(
size_t
destCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p
)
{
template
<
class
T
>
void
BaseMatrixT
<
T
>::
binaryClassificationError2
(
size_t
destCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p
)
{
CHECK
(
!
useGpu_
)
<<
"do not support gpu"
;
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
destCol
,
0
);
int
numRows
=
b
.
height_
;
int
numCols
=
b
.
width_
;
b
.
applyTernary
(
ternary
::
BinaryClassificationError
<
T
>
(
p
),
c
,
*
this
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
b
.
applyTernary
(
ternary
::
BinaryClassificationError
<
T
>
(
p
),
c
,
*
this
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
binaryClassificationError
(
size_t
destCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
...
...
@@ -1099,127 +1209,148 @@ void BaseMatrixT<real>::binaryClassificationError(size_t destCol,
MatrixOffset
offset
(
destCol
,
0
,
0
,
0
,
0
,
0
);
int
numRows
=
b
.
height_
;
int
numCols
=
b
.
width_
;
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
classificationError
(
p
),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
classificationError
(
p
),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
}
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
Add3
,
THREE_PARAMETER
,
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
Add3
,
THREE_PARAMETER
,
a
=
p1
*
b
+
p2
*
c
+
p3
*
d
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add3
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
,
T
p1
,
T
p2
,
T
p3
)
{
template
<
class
T
>
void
BaseMatrixT
<
T
>::
add3
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
&
d
,
T
p1
,
T
p2
,
T
p3
)
{
applyQuaternary
(
quaternary
::
Add3
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
,
d
);
}
DEFINE_MATRIX_TERNARY_OP
(
DotMulSquare
,
a
=
b
*
c
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMulSquare
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
DotMulSquare
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_OP
(
DotSquareSquare
,
a
=
b
*
b
*
c
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotSquareSquare
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
applyTernary
(
ternary
::
DotSquareSquare
<
T
>
(),
b
,
c
);
}
DEFINE_MATRIX_BINARY_OP
(
DotMulSquare
,
a
*=
b
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMulSquare
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
DotMulSquare
<
T
>
(),
b
);
}
DEFINE_MATRIX_BINARY_OP
(
DotSquareMul
,
a
=
a
*
a
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotSquareMul
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
DotSquareMul
<
T
>
(),
b
);
}
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
AddSquareSum
,
THREE_PARAMETER
,
DEFINE_MATRIX_QUATERNARY_PARAMETER_OP
(
AddSquareSum
,
THREE_PARAMETER
,
T
tmp
=
p1
*
b
+
p2
*
c
+
p3
*
d
;
a
+=
tmp
*
tmp
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addSquareSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
d
,
T
p1
,
T
p2
,
T
p3
)
{
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addSquareSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
BaseMatrixT
d
,
T
p1
,
T
p2
,
T
p3
)
{
applyQuaternary
(
quaternary
::
AddSquareSum
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
,
d
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
AddSquare
,
ONE_PARAMETER
,
a
+=
p
*
b
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addSquare
(
BaseMatrixT
&
b
,
T
p
)
{
applyBinary
(
binary
::
AddSquare
<
T
>
(
p
),
b
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
DecayAddSquare
,
TWO_PARAMETER
,
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
DecayAddSquare
,
TWO_PARAMETER
,
a
=
p1
*
a
+
p2
*
b
*
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
decayAddSquare
(
BaseMatrixT
&
b
,
T
p1
,
T
p2
)
{
applyBinary
(
binary
::
DecayAddSquare
<
T
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DecayAddSquareMul
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DecayAddSquareMul
,
TWO_PARAMETER
,
a
=
p1
*
a
+
p2
*
b
*
b
*
c
*
c
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
decayAddSquareMul
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
template
<
class
T
>
void
BaseMatrixT
<
T
>::
decayAddSquareMul
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
DecayAddSquareMul
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
ReciprocalSum
,
THREE_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
ReciprocalSum
,
THREE_PARAMETER
,
a
=
1
/
(
p1
*
b
+
p2
*
c
+
p3
));
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocalSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
,
T
p3
)
{
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocalSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
,
T
p3
)
{
applyTernary
(
ternary
::
ReciprocalSum
<
T
>
(
p1
,
p2
,
p3
),
b
,
c
);
}
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Reciprocal2
,
TWO_PARAMETER
,
DEFINE_MATRIX_BINARY_PARAMETER_OP
(
Reciprocal2
,
TWO_PARAMETER
,
a
=
1
/
(
p1
*
b
+
p2
));
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
reciprocal2
(
BaseMatrixT
&
b
,
T
p1
,
T
p2
)
{
applyBinary
(
binary
::
Reciprocal2
<
T
>
(
p1
,
p2
),
b
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotMulSquareSum
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotMulSquareSum
,
TWO_PARAMETER
,
T
tmp
=
p1
*
b
+
p2
*
c
;
a
*=
tmp
*
tmp
);
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMulSquareSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMulSquareSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
DotMulSquareSum
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotSquareSum
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotSquareSum
,
TWO_PARAMETER
,
T
tmp
=
p1
*
b
+
p2
*
c
;
a
=
tmp
*
tmp
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotSquareSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
DotSquareSum
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotMulSum
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
DotMulSum
,
TWO_PARAMETER
,
a
*=
p1
*
b
+
p2
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
dotMulSum
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
DotMulSum
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_BINARY_OP
(
CopyAndClear
,
b
=
a
;
a
=
0
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
copyAndClear
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
CopyAndClear
<
T
>
(),
b
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
AddDotMul
,
TWO_PARAMETER
,
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
AddDotMul
,
TWO_PARAMETER
,
a
=
p1
*
a
+
p2
*
b
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addDotMul
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p1
,
T
p2
)
{
applyTernary
(
ternary
::
AddDotMul
<
T
>
(
p1
,
p2
),
b
,
c
);
}
DEFINE_MATRIX_BINARY_OP
(
Assign
,
a
=
b
;);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
assign
(
BaseMatrixT
&
b
)
{
if
(
useGpu_
)
{
applyBinary
(
binary
::
Assign
<
T
>
(),
b
);
...
...
@@ -1230,7 +1361,7 @@ void BaseMatrixT<T>::assign(BaseMatrixT& b) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
assignAtOffset
(
BaseMatrixT
&
b
,
int64_t
columnOffset
)
{
if
(
columnOffset
+
b
.
width_
<=
width_
)
{
int
numRows
=
height_
;
...
...
@@ -1250,24 +1381,31 @@ void BaseMatrixT<T>::assignAtOffset(BaseMatrixT& b, int64_t columnOffset) {
}
DEFINE_MATRIX_BINARY_OP
(
DeepSwap
,
T
tmp
=
a
;
a
=
b
;
b
=
tmp
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
deepSwap
(
BaseMatrixT
&
b
)
{
applyBinary
(
binary
::
DeepSwap
<
T
>
(),
b
);
applyBinary
(
binary
::
DeepSwap
<
T
>
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
rowDotMul
(
size_t
destCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
int
numRows
=
b
.
height_
;
int
numCols
=
b
.
width_
;
MatrixOffset
offset
(
destCol
,
0
,
0
,
0
,
0
,
0
);
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
rowDotMul2
(
size_t
destCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
...
...
@@ -1290,17 +1428,24 @@ void BaseMatrixT<T>::rowDotMul2(size_t destCol,
}
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
addDotMulVMM
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
int
numRows
=
b
.
height_
;
int
numCols
=
b
.
width_
;
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
aggregate
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
base
::
binary
::
add
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
false_type
());
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addDotMulVMM2
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
CHECK
(
!
useGpu_
)
<<
"do not support gpu"
;
...
...
@@ -1321,16 +1466,22 @@ void BaseMatrixT<T>::addDotMulVMM2(BaseMatrixT& b, BaseMatrixT& c) {
}
DEFINE_MATRIX_TERNARY_OP
(
addDotMulMMV
,
a
+=
b
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addDotMulMMV
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/*cAsRowVector*/
,
false_type
());
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/*cAsRowVector*/
,
false_type
());
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addDotMulMMV2
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
CHECK
(
!
useGpu_
)
<<
"do not support gpu"
;
...
...
@@ -1350,16 +1501,22 @@ void BaseMatrixT<T>::addDotMulMMV2(BaseMatrixT& b, BaseMatrixT& c) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
rowScale
(
size_t
cCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
cCol
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
DotMul
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
applyTernary
(
ternary
::
DotMul
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
rowScale2
(
size_t
cCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
CHECK
(
!
useGpu_
)
<<
"do not support gpu"
;
...
...
@@ -1379,52 +1536,82 @@ void BaseMatrixT<T>::rowScale2(size_t cCol, BaseMatrixT& b, BaseMatrixT& c) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
colScale
(
size_t
cRow
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
cRow
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
DotMul
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/* cAsRowVector */
,
false_type
()
/* cAsColVector */
);
applyTernary
(
ternary
::
DotMul
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/* cAsRowVector */
,
false_type
()
/* cAsColVector */
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addColScale
(
size_t
cRow
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
cRow
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/* cAsRowVector */
,
false_type
()
/* cAsColVector */
);
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
true_type
()
/* cAsRowVector */
,
false_type
()
/* cAsColVector */
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
addRowScale
(
size_t
cCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
cCol
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
applyTernary
(
ternary
::
addDotMulMMV
<
T
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
}
DEFINE_MATRIX_TERNARY_PARAMETER_OP
(
RowAdd
,
ONE_PARAMETER
,
a
=
b
+
p
*
c
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
rowAdd
(
size_t
cCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
T
p
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
cCol
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
RowAdd
<
T
>
(
p
),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
applyTernary
(
ternary
::
RowAdd
<
T
>
(
p
),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
}
DEFINE_MATRIX_TERNARY_OP
(
RowPow
,
a
=
pow
(
b
,
c
));
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
rowPow
(
size_t
cCol
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
if
(
useGpu_
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
cCol
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyTernary
(
ternary
::
RowPow
<
real
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
applyTernary
(
ternary
::
RowPow
<
real
>
(),
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*cAsColVector*/
);
}
else
{
size_t
height
=
this
->
height_
;
size_t
width
=
this
->
width_
;
...
...
@@ -1441,44 +1628,64 @@ void BaseMatrixT<real>::rowPow(size_t cCol, BaseMatrixT& b, BaseMatrixT& c) {
}
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
mulRowVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
DotMul
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
applyBinary
(
binary
::
DotMul
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
}
DEFINE_MATRIX_BINARY_OP
(
DotDiv
,
a
/=
b
);
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
divRowVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
DotDiv
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
applyBinary
(
binary
::
DotDiv
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/* bAsRowVector */
,
false_type
());
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
mulColVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
DotMul
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/* bAsColVector */
);
applyBinary
(
binary
::
DotMul
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/* bAsColVector */
);
}
template
<
class
T
>
template
<
class
T
>
void
BaseMatrixT
<
T
>::
divColVector
(
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
);
int
numRows
=
height_
;
int
numCols
=
width_
;
applyBinary
(
binary
::
DotDiv
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/* bAsColVector */
);
applyBinary
(
binary
::
DotDiv
<
T
>
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/* bAsColVector */
);
}
template
<
>
template
<
>
template
<
class
Agg
>
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
...
...
@@ -1486,13 +1693,20 @@ int BaseMatrixT<real>::applyRow(Agg agg, BaseMatrixT& b) {
size_t
numCols
=
b
.
width_
;
CHECK_EQ
(
height_
,
numRows
);
CHECK_EQ
(
width_
,
1UL
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
base
::
binary
::
second
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
base
::
binary
::
second
(),
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
,
class
Saver
>
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
Saver
sv
,
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
...
...
@@ -1500,16 +1714,25 @@ int BaseMatrixT<real>::applyRow(Agg agg, Saver sv, BaseMatrixT& b) {
size_t
numCols
=
b
.
width_
;
CHECK_EQ
(
height_
,
numRows
);
CHECK_EQ
(
width_
,
1UL
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
sv
,
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
sv
,
b
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
>
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
)
{
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
)
{
if
(
scaleDest
!=
0
)
{
applyRow
(
agg
,
base
::
binary
::
add2
(
scaleDest
,
scaleAgg
),
b
);
}
else
{
...
...
@@ -1521,10 +1744,10 @@ int BaseMatrixT<real>::applyRow(
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
,
class
Op
,
class
Saver
>
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
Op
op
,
Saver
sv
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
size_t
numRows
=
b
.
height_
;
size_t
numCols
=
b
.
width_
;
...
...
@@ -1532,16 +1755,27 @@ int BaseMatrixT<real>::applyRow(Agg agg, Op op, Saver sv,
CHECK_EQ
(
width_
,
1UL
);
CHECK_EQ
(
c
.
height_
,
numRows
);
CHECK_EQ
(
c
.
width_
,
numCols
);
aggregate
(
agg
,
op
,
sv
,
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
aggregate
(
agg
,
op
,
sv
,
b
,
c
,
numRows
,
numCols
,
offset
,
false_type
(),
true_type
()
/*aAsColVector*/
);
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
,
class
Op
>
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
Op
op
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
int
BaseMatrixT
<
real
>::
applyRow
(
Agg
agg
,
Op
op
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
,
BaseMatrixT
&
c
)
{
if
(
scaleDest
!=
0
)
{
applyRow
(
agg
,
op
,
base
::
binary
::
add2
(
scaleDest
,
scaleAgg
),
b
,
c
);
}
else
{
...
...
@@ -1553,7 +1787,7 @@ int BaseMatrixT<real>::applyRow(Agg agg, Op op, real scaleDest, real scaleAgg,
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
>
int
BaseMatrixT
<
real
>::
applyCol
(
Agg
agg
,
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
...
...
@@ -1561,13 +1795,20 @@ int BaseMatrixT<real>::applyCol(Agg agg, BaseMatrixT& b) {
size_t
numCols
=
b
.
width_
;
CHECK_EQ
(
width_
,
numCols
);
CHECK_EQ
(
height_
,
1UL
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
base
::
binary
::
second
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
false_type
());
aggregate
(
agg
,
base
::
unary
::
identity
(),
base
::
binary
::
second
(),
b
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
false_type
());
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
,
class
Saver
>
int
BaseMatrixT
<
real
>::
applyCol
(
Agg
agg
,
Saver
sv
,
BaseMatrixT
&
b
)
{
MatrixOffset
offset
(
0
,
0
,
0
,
0
,
0
,
0
);
...
...
@@ -1575,16 +1816,25 @@ int BaseMatrixT<real>::applyCol(Agg agg, Saver sv, BaseMatrixT& b) {
size_t
numCols
=
b
.
width_
;
CHECK_EQ
(
width_
,
numCols
);
CHECK_EQ
(
height_
,
1UL
);
aggregate
(
agg
,
base
::
unary
::
identity
(),
sv
,
b
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
false_type
());
aggregate
(
agg
,
base
::
unary
::
identity
(),
sv
,
b
,
numRows
,
numCols
,
offset
,
true_type
()
/*aAsRowVector*/
,
false_type
());
return
0
;
}
template
<
>
template
<
>
template
<
class
Agg
>
int
BaseMatrixT
<
real
>::
applyCol
(
Agg
agg
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
)
{
int
BaseMatrixT
<
real
>::
applyCol
(
Agg
agg
,
real
scaleDest
,
real
scaleAgg
,
BaseMatrixT
&
b
)
{
if
(
scaleDest
!=
0
)
{
applyCol
(
agg
,
base
::
binary
::
add2
(
scaleDest
,
scaleAgg
),
b
);
}
else
{
...
...
@@ -1596,48 +1846,51 @@ int BaseMatrixT<real>::applyCol(
return
0
;
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
sumRows
(
BaseMatrixT
&
b
,
real
scaleSum
,
real
scaleDest
)
{
applyRow
(
aggregate
::
sum
(),
scaleDest
,
scaleSum
,
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
maxRows
(
BaseMatrixT
&
b
)
{
applyRow
(
aggregate
::
max
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
minRows
(
BaseMatrixT
&
b
)
{
applyRow
(
aggregate
::
min
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
maxCols
(
BaseMatrixT
&
b
)
{
applyCol
(
aggregate
::
max
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
minCols
(
BaseMatrixT
&
b
)
{
applyCol
(
aggregate
::
min
(),
b
);
}
template
<
>
template
<
>
void
BaseMatrixT
<
real
>::
sumCols
(
BaseMatrixT
&
b
,
real
scaleSum
,
real
scaleDest
)
{
applyCol
(
aggregate
::
sum
(),
scaleDest
,
scaleSum
,
b
);
}
template
<
>
void
BaseMatrixT
<
real
>::
sumOfSquaredDiffs
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
real
scaleSum
,
real
scaleDest
)
{
applyRow
(
aggregate
::
sum
(),
base
::
binary
::
squaredDiff
(),
scaleDest
,
scaleSum
,
b
,
c
);
template
<
>
void
BaseMatrixT
<
real
>::
sumOfSquaredDiffs
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
real
scaleSum
,
real
scaleDest
)
{
applyRow
(
aggregate
::
sum
(),
base
::
binary
::
squaredDiff
(),
scaleDest
,
scaleSum
,
b
,
c
);
}
template
<
>
void
BaseMatrixT
<
real
>::
sumOfProducts
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
real
scaleSum
,
real
scaleDest
)
{
applyRow
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
scaleDest
,
scaleSum
,
b
,
c
);
template
<
>
void
BaseMatrixT
<
real
>::
sumOfProducts
(
BaseMatrixT
&
b
,
BaseMatrixT
&
c
,
real
scaleSum
,
real
scaleDest
)
{
applyRow
(
aggregate
::
sum
(),
base
::
binary
::
mul
(),
scaleDest
,
scaleSum
,
b
,
c
);
}
template
class
BaseMatrixT
<
real
>;
...
...
paddle/math/TrainingAlgorithmOp.cu
浏览文件 @
59a8ebc6
...
...
@@ -12,9 +12,9 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/utils/Logging.h"
#include "BaseMatrix.h"
#include "TrainingAlgorithmOp.h"
#include "paddle/utils/Logging.h"
#if __cplusplus > 199711L
...
...
@@ -32,10 +32,10 @@ void sparseMomentumApply(BaseMatrix& value,
real
tau
,
real
learningRate
)
{
auto
expr1
=
momU
.
lazyAssign
(
momU
-
(
alpha
*
gamma
*
learningRate
)
*
grad
);
auto
expr2
=
momV
.
lazyAssign
(
momV
+
(
tau
*
alpha
*
gamma
*
learningRate
)
*
grad
);
auto
expr3
=
value
.
lazyAssign
(
(
tau
/
beta
+
(
real
)
1
/
alpha
)
*
momU
+
((
real
)
1
/
beta
)
*
momV
);
auto
expr2
=
momV
.
lazyAssign
(
momV
+
(
tau
*
alpha
*
gamma
*
learningRate
)
*
grad
);
auto
expr3
=
value
.
lazyAssign
(
(
tau
/
beta
+
(
real
)
1
/
alpha
)
*
momU
+
((
real
)
1
/
beta
)
*
momV
);
AssignEvaluate
(
expr1
,
expr2
,
expr3
);
}
...
...
@@ -52,12 +52,12 @@ void adadeltaApply(BaseMatrix& value,
real
momentum
,
real
decayRate
)
{
auto
expr1
=
accum
.
lazyAssign
(
rou
*
accum
+
((
real
)
1
-
rou
)
*
grad
.
square
());
auto
expr2
=
lr
.
lazyAssign
(
((
accum_update
+
epsilon
)
/
(
accum
+
epsilon
)).
sqrt
());
auto
expr3
=
accum_update
.
lazyAssign
(
rou
*
accum_update
+
((
real
)
1
-
rou
)
*
(
grad
*
lr
).
square
());
auto
expr4
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr2
=
lr
.
lazyAssign
(
((
accum_update
+
epsilon
)
/
(
accum
+
epsilon
)).
sqrt
());
auto
expr3
=
accum_update
.
lazyAssign
(
rou
*
accum_update
+
((
real
)
1
-
rou
)
*
(
grad
*
lr
).
square
());
auto
expr4
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr5
=
value
.
lazyAssign
(
value
+
mom
);
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
,
expr5
);
...
...
@@ -74,10 +74,10 @@ void adagradApply(BaseMatrix& value,
real
momentum
,
real
decayRate
)
{
auto
expr1
=
accum
.
lazyAssign
(
accum
+
grad
.
square
());
auto
expr2
=
lr
.
lazyAssign
(
(
accum_buffer
+
accum
+
epsilon
).
sqrt
().
reciprocal
());
auto
expr3
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr2
=
lr
.
lazyAssign
(
(
accum_buffer
+
accum
+
epsilon
).
sqrt
().
reciprocal
());
auto
expr3
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr4
=
value
.
lazyAssign
(
value
+
mom
);
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
);
...
...
@@ -98,8 +98,8 @@ void rmspropApply(BaseMatrix& value,
bool
firstTime
)
{
auto
expr2
=
f
.
lazyAssign
(
accumulatedRou
*
f
+
((
real
)
1
-
rou
)
*
grad
);
auto
expr3
=
lr
.
lazyAssign
((
g
-
f
.
square
()
+
epsilon
).
sqrt
().
reciprocal
());
auto
expr4
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr4
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr5
=
value
.
lazyAssign
(
value
+
mom
);
if
(
firstTime
)
{
...
...
@@ -107,8 +107,8 @@ void rmspropApply(BaseMatrix& value,
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
,
expr5
);
}
else
{
auto
expr1
=
g
.
lazyAssign
(
accumulatedRou
*
g
+
((
real
)
1
-
rou
)
*
grad
.
square
());
auto
expr1
=
g
.
lazyAssign
(
accumulatedRou
*
g
+
((
real
)
1
-
rou
)
*
grad
.
square
());
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
,
expr5
);
}
...
...
@@ -127,8 +127,8 @@ void decayedAdagradApply(BaseMatrix& value,
real
decayRate
,
bool
firstTime
)
{
auto
expr2
=
lr
.
lazyAssign
((
accum
+
epsilon
).
sqrt
().
reciprocal
());
auto
expr3
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr3
=
mom
.
lazyAssign
(
mom
*
momentum
-
learningRate
*
lr
*
(
grad
+
value
*
decayRate
));
auto
expr4
=
value
.
lazyAssign
(
value
+
mom
);
if
(
firstTime
)
{
...
...
@@ -136,8 +136,8 @@ void decayedAdagradApply(BaseMatrix& value,
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
);
}
else
{
auto
expr1
=
accum
.
lazyAssign
(
accumulatedRou
*
accum
+
((
real
)
1
-
rou
)
*
grad
.
square
());
auto
expr1
=
accum
.
lazyAssign
(
accumulatedRou
*
accum
+
((
real
)
1
-
rou
)
*
grad
.
square
());
AssignEvaluate
(
expr1
,
expr2
,
expr3
,
expr4
);
}
...
...
@@ -153,13 +153,12 @@ void adamApply(BaseMatrix& value,
real
beta2_power
,
real
epsilon
,
real
learningRate
)
{
real
alpha
=
learningRate
*
std
::
sqrt
((
real
)
1
-
beta2_power
)
/
((
real
)
1
-
beta1_power
);
real
alpha
=
learningRate
*
std
::
sqrt
((
real
)
1
-
beta2_power
)
/
((
real
)
1
-
beta1_power
);
auto
expr1
=
mom
.
lazyAssign
(
beta1
*
mom
+
((
real
)
1
-
beta1
)
*
grad
);
auto
expr2
=
v
.
lazyAssign
(
beta2
*
v
+
((
real
)
1
-
beta2
)
*
grad
.
square
());
auto
expr3
=
value
.
lazyAssign
(
value
-
(
mom
*
alpha
)
/
(
v
.
sqrt
()
+
epsilon
));
auto
expr3
=
value
.
lazyAssign
(
value
-
(
mom
*
alpha
)
/
(
v
.
sqrt
()
+
epsilon
));
AssignEvaluate
(
expr1
,
expr2
,
expr3
);
}
...
...
@@ -173,10 +172,10 @@ void adamaxApply(BaseMatrix& value,
int64_t
step
,
real
alpha
)
{
auto
expr1
=
mom
.
lazyAssign
(
beta1
*
mom
+
((
real
)
1
-
beta1
)
*
grad
);
auto
expr2
=
u
.
lazyAssign
(
(
beta2
*
u
>
grad
.
abs
()).
condition
(
beta2
*
u
,
grad
.
abs
()));
auto
expr2
=
u
.
lazyAssign
(
(
beta2
*
u
>
grad
.
abs
()).
condition
(
beta2
*
u
,
grad
.
abs
()));
auto
expr3
=
value
.
lazyAssign
(
value
-
(
alpha
/
((
real
)
1
-
(
real
)
std
::
pow
(
beta1
,
step
)))
*
(
mom
/
u
));
value
-
(
alpha
/
((
real
)
1
-
(
real
)
std
::
pow
(
beta1
,
step
)))
*
(
mom
/
u
));
AssignEvaluate
(
expr1
,
expr2
,
expr3
);
}
...
...
@@ -322,8 +321,8 @@ void adamApply(BaseMatrix& value,
real
beta2_power
,
real
epsilon
,
real
learningRate
)
{
real
alpha
=
learningRate
*
std
::
sqrt
((
real
)
1
-
beta2_power
)
/
((
real
)
1
-
beta1_power
);
real
alpha
=
learningRate
*
std
::
sqrt
((
real
)
1
-
beta2_power
)
/
((
real
)
1
-
beta1_power
);
// m_t = \beta_1 * m_{t-1} + (1-\beta_1)* g_t;
mom
=
beta1
*
mom
+
((
real
)
1
-
beta1
)
*
grad
;
...
...
@@ -331,7 +330,7 @@ void adamApply(BaseMatrix& value,
// v_t = \beta_2 * v_{t-1} + (1-\beta_2)* g_{t-1}^2
v
=
beta2
*
v
+
((
real
)
1
-
beta2
)
*
grad
.
square
();
value
-=
(
mom
*
alpha
)
/
(
v
.
sqrt
()
+
epsilon
);
value
-=
(
mom
*
alpha
)
/
(
v
.
sqrt
()
+
epsilon
);
}
void
adamaxApply
(
BaseMatrix
&
value
,
...
...
paddle/math/tests/test_Tensor.cu
浏览文件 @
59a8ebc6
...
...
@@ -13,8 +13,8 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "paddle/math/Matrix.h"
#include "TensorCheck.h"
#include "paddle/math/Matrix.h"
using
paddle
::
Matrix
;
using
paddle
::
CpuMatrix
;
...
...
@@ -26,25 +26,25 @@ using paddle::GpuIVector;
using
autotest
::
TensorCheckEqual
;
using
autotest
::
TensorCheckErr
;
#define INIT_UNARY(A1, A2)
\
Tensor A1(height, width);
\
Tensor A2(height, width);
\
A1.randomizeUniform();
\
A2.copyFrom(A1)
#define INIT_BINARY(A1, A2, B)
\
INIT_UNARY(A1, A2);
\
Tensor B(height, width);
\
B.randomizeUniform()
#define INIT_TERNARY(A1, A2, B, C)
\
INIT_BINARY(A1, A2, B);
\
Tensor C(height, width);
\
C.randomizeUniform()
#define INIT_QUATERNARY(A1, A2, B, C, D)
\
INIT_TERNARY(A1, A2, B, C);
\
Tensor D(height, width);
\
D.randomizeUniform()
template
<
typename
Tensor
>
#define INIT_UNARY(A1, A2) \
Tensor A1(height, width);
\
Tensor A2(height, width);
\
A1.randomizeUniform();
\
A2.copyFrom(A1)
#define INIT_BINARY(A1, A2, B) \
INIT_UNARY(A1, A2);
\
Tensor B(height, width);
\
B.randomizeUniform()
#define INIT_TERNARY(A1, A2, B, C) \
INIT_BINARY(A1, A2, B);
\
Tensor C(height, width);
\
C.randomizeUniform()
#define INIT_QUATERNARY(A1, A2, B, C, D) \
INIT_TERNARY(A1, A2, B, C);
\
Tensor D(height, width);
\
D.randomizeUniform()
template
<
typename
Tensor
>
struct
TestUnaryMatrix
{
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
)
>
UnaryFunc
;
...
...
@@ -59,7 +59,7 @@ struct TestUnaryMatrix {
}
};
template
<
typename
Tensor
>
template
<
typename
Tensor
>
struct
TestBinaryMatrix
{
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
>
BinaryFunc
;
...
...
@@ -74,10 +74,10 @@ struct TestBinaryMatrix {
}
};
template
<
typename
Tensor
>
template
<
typename
Tensor
>
struct
TestTernaryMatrix
{
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
>
TernaryFunc
;
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
>
TernaryFunc
;
explicit
TestTernaryMatrix
(
TernaryFunc
testTernaryFunc
)
{
for
(
auto
height
:
{
1
,
11
,
73
,
128
,
200
,
330
})
{
...
...
@@ -90,10 +90,11 @@ struct TestTernaryMatrix {
}
};
template
<
typename
Tensor
>
template
<
typename
Tensor
>
struct
TestQuaternaryMatrix
{
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
>
QuaternaryFunc
;
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
>
QuaternaryFunc
;
explicit
TestQuaternaryMatrix
(
QuaternaryFunc
testQuaternaryFunc
)
{
for
(
auto
height
:
{
1
,
11
,
73
,
128
,
200
,
330
})
{
...
...
@@ -106,7 +107,7 @@ struct TestQuaternaryMatrix {
}
};
template
<
typename
Tensor
,
class
T
>
template
<
typename
Tensor
,
class
T
>
struct
TestUnaryVectorT
{
typedef
std
::
function
<
void
(
Tensor
&
A1
,
Tensor
&
A2
)
>
UnaryFunc
;
...
...
@@ -142,11 +143,11 @@ void SetTensorValue(Matrix& matrix, real value) {
}
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAddScalar
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p1
=
2.5
;
real
p2
=
3.0
;
A1
.
add
(
p1
);
// a += p
A1
.
add
(
p1
);
// a += p
A2
+=
p1
;
TensorCheckEqual
(
A1
,
A2
);
...
...
@@ -155,7 +156,7 @@ void testTensorAddScalar(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSubScalar
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p
=
2.5
;
A1
.
subScalar
(
p
);
// a -= p
...
...
@@ -163,7 +164,7 @@ void testTensorSubScalar(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorMulScalar
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p
=
2.5
;
A1
.
mulScalar
(
p
);
// a *= p
...
...
@@ -177,7 +178,7 @@ void testTensorMulScalar(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorDivScalar
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p
=
2.5
;
A1
.
divScalar
(
p
);
// a /= p
...
...
@@ -185,44 +186,44 @@ void testTensorDivScalar(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorNeg
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
neg
();
// a = -a
A2
=
-
A2
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAbs
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
abs2
();
// a = a > 0 ? a : -a
A2
=
A2
.
abs
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSquare
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
square2
();
// a = a * a
A2
=
A2
.
square
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorReciprocal
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
reciprocal2
();
// a = 1.0f / a
A2
=
A2
.
reciprocal
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSign
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
sign2
();
// a = (a > 0) - (a < 0)
A2
=
A2
.
sign
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAssign
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
assign
(
1.5
);
// a = p
A1
.
assign
(
1.5
);
// a = p
A2
=
A2
.
constant
(
1.5
);
TensorCheckEqual
(
A1
,
A2
);
...
...
@@ -235,7 +236,7 @@ void testTensorAssign(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testUnaryBaseOp
(
Tensor
&
A1
,
Tensor
&
A2
)
{
testTensorAddScalar
(
A1
,
A2
);
testTensorSubScalar
(
A1
,
A2
);
...
...
@@ -249,9 +250,9 @@ void testUnaryBaseOp(Tensor& A1, Tensor& A2) {
testTensorAssign
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testUnaryBaseOpInt
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
add
(
2
);
// a += p
A1
.
add
(
2
);
// a += p
A2
+=
2
;
TensorCheckEqual
(
A1
,
A2
);
...
...
@@ -266,46 +267,46 @@ void testUnaryBaseOpInt(Tensor& A1, Tensor& A2) {
TEST
(
Unary
,
BaseOp
)
{
TestUnaryMatrix
<
CpuMatrix
>
testCpuMatrix
(
testUnaryBaseOp
<
CpuMatrix
>
);
TestUnaryVectorT
<
CpuVector
,
real
>
testCpuVector
(
testUnaryBaseOp
<
CpuVector
>
);
TestUnaryVectorT
<
CpuIVector
,
int
>
testCpuIVector
(
testUnaryBaseOpInt
<
CpuIVector
>
);
TestUnaryVectorT
<
CpuIVector
,
int
>
testCpuIVector
(
testUnaryBaseOpInt
<
CpuIVector
>
);
#ifndef PADDLE_ONLY_CPU
TestUnaryMatrix
<
GpuMatrix
>
testGpuMatrix
(
testUnaryBaseOp
<
GpuMatrix
>
);
TestUnaryVectorT
<
GpuVector
,
real
>
testGpuVector
(
testUnaryBaseOp
<
GpuVector
>
);
TestUnaryVectorT
<
GpuIVector
,
int
>
testGpuIVector
(
testUnaryBaseOpInt
<
GpuIVector
>
);
TestUnaryVectorT
<
GpuIVector
,
int
>
testGpuIVector
(
testUnaryBaseOpInt
<
GpuIVector
>
);
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorExp
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
exp2
();
// a = exp(a)
A2
=
A2
.
exp
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorLog
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
log2
();
// a = log(a)
A2
=
A2
.
log
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSqrt
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
sqrt2
();
// a = sqrt(a)
A2
=
A2
.
sqrt
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorPow
(
Tensor
&
A1
,
Tensor
&
A2
)
{
A1
.
pow2
(
3.2
);
// a = pow(a, p)
A2
=
A2
.
pow
(
3.2
);
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testUnayrMathOp
(
Tensor
&
A1
,
Tensor
&
A2
)
{
testTensorExp
(
A1
,
A2
);
testTensorLog
(
A1
,
A2
);
...
...
@@ -321,7 +322,7 @@ TEST(Unary, MathOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorClip
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p1
=
0.003
f
;
real
p2
=
0.877
f
;
...
...
@@ -331,7 +332,7 @@ void testTensorClip(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBiggerThanScalar
(
Tensor
&
A1
,
Tensor
&
A2
)
{
real
p
=
0.5
f
;
A1
.
biggerThanScalar
(
p
);
// a = a > p ? 1.0f : 0.0f
...
...
@@ -339,7 +340,7 @@ void testTensorBiggerThanScalar(Tensor& A1, Tensor& A2) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorapplyL1
(
Tensor
&
A1
,
Tensor
&
A2
)
{
/**
* T lambda = p;
...
...
@@ -351,14 +352,15 @@ void testTensorapplyL1(Tensor& A1, Tensor& A2) {
real
learningRate
=
0.7
f
;
real
decayRate
=
0.6
f
;
A1
.
applyL1
(
learningRate
,
decayRate
);
A2
=
(
A2
>
(
learningRate
*
decayRate
)).
condition
(
(
A2
-
(
learningRate
*
decayRate
)),
(
A2
<
-
(
learningRate
*
decayRate
)).
condition
(
(
A2
+
(
learningRate
*
decayRate
)),
(
real
)
0.0
));
A2
=
(
A2
>
(
learningRate
*
decayRate
))
.
condition
(
(
A2
-
(
learningRate
*
decayRate
)),
(
A2
<
-
(
learningRate
*
decayRate
))
.
condition
((
A2
+
(
learningRate
*
decayRate
)),
(
real
)
0.0
));
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testUnayrCompareOp
(
Tensor
&
A1
,
Tensor
&
A2
)
{
testTensorClip
(
A1
,
A2
);
testTensorBiggerThanScalar
(
A1
,
A2
);
...
...
@@ -377,7 +379,7 @@ TEST(Unary, CompareOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAdd
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p1
=
2.5
;
real
p2
=
3.2
;
...
...
@@ -406,7 +408,7 @@ void testTensorAdd(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSub
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p
=
2.5
;
A1
.
sub
(
B
);
// a -= b
...
...
@@ -422,7 +424,7 @@ void testTensorSub(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorMul
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p
=
2.5
;
A1
.
mulScalar
(
B
,
p
);
// a = b * p
...
...
@@ -442,7 +444,7 @@ void testTensorMul(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorDiv
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p
=
2.5
;
A1
.
divScalar
(
B
,
p
);
// a = b / p
...
...
@@ -454,28 +456,28 @@ void testTensorDiv(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAssign
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
assign
(
B
);
// a = b
A2
=
B
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSquare
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
square2
(
A1
);
// b = a * a
B
.
square2
(
A1
);
// b = a * a
A2
=
B
.
square
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSquareDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
squareDerivative
(
B
);
// a *= 2.0 * b
A2
=
A2
*
(
real
)
2.0
*
B
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorReciprocal
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
reciprocal2
(
A1
);
// b = 1.0f / a
A2
=
B
.
reciprocal
();
...
...
@@ -490,33 +492,33 @@ void testTensorReciprocal(Tensor& A1, Tensor& A2, Tensor& B) {
real
learningRate
=
0.7
f
;
real
decayRate
=
1.2
f
;
A1
.
applyL2
(
B
,
learningRate
,
decayRate
);
// a *= (1.0f / (1.0f + p * b))
A2
*=
(
B
.
constant
(
1.0
f
)
+
B
.
constant
(
learningRate
*
decayRate
)
*
B
)
.
reciprocal
();
A2
*=
(
B
.
constant
(
1.0
f
)
+
B
.
constant
(
learningRate
*
decayRate
)
*
B
)
.
reciprocal
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorReciprocalDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
reciprocalDerivative
(
B
);
// a *= -b * b
A2
*=
(
-
B
)
*
B
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSign
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
sign2
(
A1
);
// b = a > 0.0f ? 1.0f : -1.0f
A2
=
B
.
sign
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAbs
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
abs2
(
A1
);
// b = a > 0.0f ? a : -a
A2
=
B
.
abs
();
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testBinaryBaseOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
testTensorAdd
(
A1
,
A2
,
B
);
testTensorSub
(
A1
,
A2
,
B
);
...
...
@@ -539,7 +541,7 @@ TEST(Binary, BaseOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorExp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
// a = exp(b)
A1
.
exp2
(
B
);
...
...
@@ -547,14 +549,14 @@ void testTensorExp(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorExpDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
expDerivative
(
B
);
// a *= b
A2
*=
B
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorLog
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
// a = log(b)
A1
.
log2
(
B
);
...
...
@@ -562,7 +564,7 @@ void testTensorLog(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSqrt
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
// a = sqrt(b)
A1
.
sqrt2
(
B
);
...
...
@@ -570,7 +572,7 @@ void testTensorSqrt(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorInvSqrt
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
// a = 1.0f / sqrt(b)
A1
.
invSqrt
(
B
);
...
...
@@ -578,14 +580,14 @@ void testTensorInvSqrt(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorPow
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
pow2
(
B
,
2.5
f
);
// a = pow(b, p)
A2
=
B
.
pow
(
2.5
f
);
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSoftrelu
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
/*
* const T THRESHOLD = 40.0;
...
...
@@ -597,12 +599,14 @@ void testTensorSoftrelu(Tensor& A1, Tensor& A2, Tensor& B) {
real
THRESHOLD
=
40.0
;
A2
=
(
B
.
constant
(
1.0
f
)
+
(
B
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
)).
exp
()).
log
();
(
B
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
))
.
exp
())
.
log
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSoftreluDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
/*
* const T THRESHOLD = 40.0;
...
...
@@ -612,14 +616,16 @@ void testTensorSoftreluDerivative(Tensor& A1, Tensor& A2, Tensor& B) {
*/
A1
.
softreluDerivative
(
B
);
real
THRESHOLD
=
40.0
;
A2
=
A2
*
(
B
.
constant
(
1.0
f
)
-
(
B
.
constant
(
-
1.0
f
)
*
(
B
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
))).
exp
());
A2
=
A2
*
(
B
.
constant
(
1.0
f
)
-
(
B
.
constant
(
-
1.0
f
)
*
(
B
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
)))
.
exp
());
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSigmoid
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
/*
const T THRESHOLD_MIN = -40.0;
...
...
@@ -632,46 +638,47 @@ void testTensorSigmoid(Tensor& A1, Tensor& A2, Tensor& B) {
const
real
THRESHOLD_MIN
=
-
40.0
;
const
real
THRESHOLD_MAX
=
13.0
;
auto
tmp
=
(
B
<
THRESHOLD_MIN
).
condition
(
THRESHOLD_MIN
,
(
B
>
THRESHOLD_MAX
).
condition
(
THRESHOLD_MAX
,
B
));
auto
tmp
=
(
B
<
THRESHOLD_MIN
)
.
condition
(
THRESHOLD_MIN
,
(
B
>
THRESHOLD_MAX
).
condition
(
THRESHOLD_MAX
,
B
));
A2
=
(
B
.
constant
(
1.0
f
)
+
(
-
tmp
).
exp
()).
reciprocal
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSigmoidDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
sigmoidDerivative
(
B
);
// a *= b * (1 - b)
A2
*=
B
*
(
B
.
constant
(
1.0
f
)
-
B
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorTanh
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
tanh
(
A1
);
// b = 2.0 / (1.0 + exp(-2 * a)) - 1.0
A2
=
B
.
constant
(
2.0
f
)
/
((
B
*
((
real
)
-
2.0
f
)).
exp
()
+
(
real
)
1.0
f
)
-
(
real
)
1.0
f
;
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorTanhDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
tanhDerivative
(
B
);
// a *= 1 - b * b
A2
*=
B
.
constant
(
1.0
f
)
-
B
*
B
;
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorScaledTanh
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p1
=
2.5
;
real
p2
=
3.1
;
// b = p1 * (2.0 / (1.0 + exp(-2 * p2 * a)) - 1.0)
B
.
scaledTanh
(
A1
,
p1
,
p2
);
A2
=
B
.
constant
(
p1
)
*
(
B
.
constant
(
2.0
f
)
/
((
B
.
constant
(
-
2.0
f
)
*
p2
*
B
).
exp
()
+
(
real
)
1.0
)
-
(
real
)
1.0
);
(
B
.
constant
(
2.0
f
)
/
((
B
.
constant
(
-
2.0
f
)
*
p2
*
B
).
exp
()
+
(
real
)
1.0
)
-
(
real
)
1.0
);
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorScaledTanhDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p1
=
2.5
;
real
p2
=
3.1
;
...
...
@@ -681,7 +688,7 @@ void testTensorScaledTanhDerivative(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testBinaryMathOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
testTensorTanhDerivative
(
A1
,
A2
,
B
);
testTensorScaledTanhDerivative
(
A1
,
A2
,
B
);
...
...
@@ -708,21 +715,21 @@ TEST(Binary, MathOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorRelu
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
relu
(
A1
);
// b = a > 0.0f ? a : 0.0f
A2
=
(
B
>
(
real
)
0.0
f
).
condition
(
B
,
(
real
)
0.0
f
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorReluDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
reluDerivative
(
B
);
// a *= (b > 0.0f ? 1.0f : 0.0f)
A2
*=
(
B
>
(
real
)
0.0
).
condition
((
real
)
1.0
,
(
real
)
0.0
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBrelu
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
/*
* b = a > p1 ? a : p1
...
...
@@ -736,7 +743,7 @@ void testTensorBrelu(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBreluDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
SetTensorValue
(
B
,
32.0
f
);
/*
...
...
@@ -748,15 +755,15 @@ void testTensorBreluDerivative(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAbsDerivative
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
A1
.
absDerivative
(
B
);
// a = (b > 0) ? a : (b < 0) ? -a : 0
A2
=
(
B
>
(
real
)
0.0
f
)
.
condition
(
A2
,
(
B
<
(
real
)
0.0
f
).
condition
(
-
A2
,
(
real
)
0.0
f
));
A2
=
(
B
>
(
real
)
0.0
f
)
.
condition
(
A2
,
(
B
<
(
real
)
0.0
f
).
condition
(
-
A2
,
(
real
)
0.0
f
));
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorIsEqualTo
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
real
p
=
0.613
;
SetTensorValue
(
B
,
p
);
...
...
@@ -765,7 +772,7 @@ void testTensorIsEqualTo(Tensor& A1, Tensor& A2, Tensor& B) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorapplyL1
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
/**
* T lambda = p * b;
...
...
@@ -778,12 +785,13 @@ void testTensorapplyL1(Tensor& A1, Tensor& A2, Tensor& B) {
real
decayRate
=
0.6
f
;
A1
.
applyL1
(
B
,
learningRate
,
decayRate
);
auto
lambda
=
B
.
constant
(
learningRate
*
decayRate
)
*
B
;
A2
=
(
A2
>
lambda
).
condition
(
(
A2
-
lambda
),
(
A2
<
-
lambda
).
condition
((
A2
+
lambda
),
(
real
)
0.0
f
));
A2
=
(
A2
>
lambda
)
.
condition
((
A2
-
lambda
),
(
A2
<
-
lambda
).
condition
((
A2
+
lambda
),
(
real
)
0.0
f
));
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testBinaryCompareOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
)
{
B
.
subScalar
(
0.5
f
);
SetTensorValue
(
B
,
0.0
f
);
...
...
@@ -807,7 +815,7 @@ TEST(Binary, CompareOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorAdd
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
add
(
B
,
C
);
// a = b + c
A2
=
B
+
C
;
...
...
@@ -833,7 +841,7 @@ void testTensorAdd(Tensor& A1, Tensor& A2, Tensor& B, Tensor& C) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSub
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
sub
(
B
,
C
);
// a = b - c
A2
=
B
-
C
;
...
...
@@ -846,7 +854,7 @@ void testTensorSub(Tensor& A1, Tensor& A2, Tensor& B, Tensor& C) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorMul
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
dotMul
(
B
,
C
);
// a = b * c
A2
=
B
*
C
;
...
...
@@ -892,7 +900,7 @@ void testTensorMul(Tensor& A1, Tensor& A2, Tensor& B, Tensor& C) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorDiv
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
dotDiv
(
B
,
C
);
// a = (b == 0.0) ? 0.0 : b / c
A2
=
(
B
==
(
real
)
0.0
).
condition
((
real
)
0.0
,
B
/
C
);
...
...
@@ -905,7 +913,7 @@ void testTensorDiv(Tensor& A1, Tensor& A2, Tensor& B, Tensor& C) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorReciprocal
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
real
p1
=
1.5
;
real
p2
=
2.5
;
...
...
@@ -915,14 +923,14 @@ void testTensorReciprocal(Tensor& A1, Tensor& A2, Tensor& B, Tensor& C) {
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSoftCrossEntropy
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
softCrossEntropy
(
B
,
C
);
// a = -c * log(b) - (1 - c) * log(1 - b)
A2
=
-
C
*
B
.
log
()
-
(
C
.
constant
(
1.0
f
)
-
C
)
*
(
B
.
constant
(
1.0
f
)
-
B
).
log
();
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorSoftCrossEntropyBp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
...
...
@@ -932,7 +940,7 @@ void testTensorSoftCrossEntropyBp(Tensor& A1,
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTernaryBaseOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
testTensorAdd
(
A1
,
A2
,
B
,
C
);
testTensorSub
(
A1
,
A2
,
B
,
C
);
...
...
@@ -952,30 +960,30 @@ TEST(Ternary, BaseOp) {
#endif
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBinaryLabelCrossEntropy
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
binaryLabelCrossEntropy
(
B
,
C
);
// a = c > 0.5 ? -log(b) : -log(1.0 - b)
A2
=
(
C
>
(
real
)
0.5
).
condition
(
-
(
B
.
log
()),
-
((
B
.
constant
(
1.0
f
)
-
B
).
log
()));
A2
=
(
C
>
(
real
)
0.5
).
condition
(
-
(
B
.
log
()),
-
((
B
.
constant
(
1.0
f
)
-
B
).
log
()));
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBinaryLabelCrossEntropyBp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
// a += c > 0.5 ? -1.0 / b : 1.0 / (1.0 - b)
A1
.
binaryLabelCrossEntropyBp
(
B
,
C
);
A2
+=
(
C
>
(
real
)
0.5
).
condition
(
(
B
.
constant
(
-
1.0
f
)
/
B
),
(
B
.
constant
(
1.0
f
)
-
B
).
reciprocal
());
A2
+=
(
C
>
(
real
)
0.5
)
.
condition
((
B
.
constant
(
-
1.0
f
)
/
B
),
(
B
.
constant
(
1.0
f
)
-
B
).
reciprocal
());
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorLogisticRegressionLoss
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
...
...
@@ -991,13 +999,14 @@ void testTensorLogisticRegressionLoss(Tensor& A1,
*/
A1
.
logisticRegressionLoss
(
B
,
C
);
real
THRESHOLD
=
40.0
;
auto
tmp
=
(
B
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
));
auto
tmp
=
(
B
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
));
A2
=
(
C
.
constant
(
1.0
f
)
+
tmp
.
exp
()).
log
()
-
C
*
tmp
;
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorLogisticRegressionLossBp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
...
...
@@ -1013,28 +1022,29 @@ void testTensorLogisticRegressionLossBp(Tensor& A1,
*/
A1
.
logisticRegressionLossBp
(
B
,
C
);
real
THRESHOLD
=
40.0
;
auto
tmp
=
(
B
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
));
auto
tmp
=
(
B
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
B
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
B
));
auto
tmp2
=
tmp
.
exp
();
A2
=
tmp2
/
(
C
.
constant
(
1.0
)
+
tmp2
)
-
C
;
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorBiggerThan
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
biggerThan
(
B
,
C
);
// a = (b > c) ? 1.0f : 0.0f
A2
=
(
B
>
C
).
condition
((
real
)
1.0
f
,
(
real
)
0.0
f
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTensorMax
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
A1
.
max2
(
B
,
C
);
// a = (b > c) ? b : c
A2
=
(
B
>
C
).
condition
(
B
,
C
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testTernaryCompareOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
)
{
testTensorBinaryLabelCrossEntropyBp
(
A1
,
A2
,
B
,
C
);
testTensorBinaryLabelCrossEntropy
(
A1
,
A2
,
B
,
C
);
...
...
@@ -1053,12 +1063,9 @@ TEST(Ternary, CompareOp) {
#endif
}
template
<
typename
Tensor
>
void
testQuaternaryAdd
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
template
<
typename
Tensor
>
void
testQuaternaryAdd
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
// A1.add3(B, C, D, 1.5f, 2.5f, 3.5f); // a = p1 * b + p2 * c + p3 * d
// A2 = B * 1.5f + C * 2.5f + D * 3.5f;
// TensorCheckEqual(A1, A2);
...
...
@@ -1084,25 +1091,19 @@ TEST(Quaternary, BaseOp) {
#endif
}
template
<
typename
Tensor
>
void
testTensorBiggerThan
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
template
<
typename
Tensor
>
void
testTensorBiggerThan
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
// a = ((b > c && d > 0.5f) || (b < c && d < 0.5f)) ? 1.0f : 0.0f);
A1
.
biggerThan
(
B
,
C
,
D
);
A2
=
((
B
>
C
&&
D
>
(
real
)
0.5
)
||
(
B
<
C
&&
D
<
(
real
)
0.5
))
.
condition
((
real
)
1.0
,
(
real
)
0.0
);
A2
=
((
B
>
C
&&
D
>
(
real
)
0.5
)
||
(
B
<
C
&&
D
<
(
real
)
0.5
))
.
condition
((
real
)
1.0
,
(
real
)
0.0
);
TensorCheckEqual
(
A1
,
A2
);
}
template
<
typename
Tensor
>
void
testTensorRankLoss
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
template
<
typename
Tensor
>
void
testTensorRankLoss
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
/**
* const T THRESHOLD = 40.0; a = b - c;
* a = (a > THRESHOLD)
...
...
@@ -1114,19 +1115,17 @@ void testTensorRankLoss(Tensor& A1,
real
THRESHOLD
=
40.0
;
auto
tmp
=
B
-
C
;
auto
tmp2
=
(
tmp
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
tmp
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
tmp
));
auto
tmp2
=
(
tmp
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
tmp
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
tmp
));
A2
=
(
D
.
constant
(
1.0
f
)
+
tmp2
.
exp
()).
log
()
-
tmp2
*
D
;
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
void
testTensorRankLossBp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
template
<
typename
Tensor
>
void
testTensorRankLossBp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
/**
* const T THRESHOLD = 40.0; a = b - c;
* a = (a > THRESHOLD)
...
...
@@ -1137,20 +1136,18 @@ void testTensorRankLossBp(Tensor& A1,
A1
.
rankLossBp
(
B
,
C
,
D
);
real
THRESHOLD
=
40.0
;
auto
tmp
=
B
-
C
;
auto
tmp2
=
(
tmp
>
THRESHOLD
).
condition
(
THRESHOLD
,
(
tmp
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
tmp
));
auto
tmp2
=
(
tmp
>
THRESHOLD
)
.
condition
(
THRESHOLD
,
(
tmp
<
-
THRESHOLD
).
condition
(
-
THRESHOLD
,
tmp
));
auto
tmp3
=
tmp2
.
exp
();
A2
=
tmp3
/
(
D
.
constant
(
1.0
f
)
+
tmp3
)
-
D
;
TensorCheckErr
(
A1
,
A2
);
}
template
<
typename
Tensor
>
void
testQuaternaryCompareOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
template
<
typename
Tensor
>
void
testQuaternaryCompareOp
(
Tensor
&
A1
,
Tensor
&
A2
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
)
{
testTensorBiggerThan
(
A1
,
A2
,
B
,
C
,
D
);
testTensorRankLoss
(
A1
,
A2
,
B
,
C
,
D
);
testTensorRankLossBp
(
A1
,
A2
,
B
,
C
,
D
);
...
...
paddle/math/tests/test_lazyAssign.cu
浏览文件 @
59a8ebc6
...
...
@@ -13,10 +13,10 @@ See the License for the specific language governing permissions and
limitations under the License. */
#include <gtest/gtest.h>
#include "PerfUtils.h"
#include "TensorCheck.h"
#include "paddle/math/Matrix.h"
#include "paddle/math/TensorAssign.h"
#include "TensorCheck.h"
#include "PerfUtils.h"
using
paddle
::
BaseMatrix
;
using
paddle
::
CpuMatrix
;
...
...
@@ -27,14 +27,28 @@ using autotest::TensorCheckErr;
typedef
std
::
function
<
void
(
int
height
,
int
width
)
>
testMatrixFunc
;
void
testMatrixCase
(
testMatrixFunc
matrixFunc
)
{
for
(
auto
height
:
{
1
})
{
for
(
auto
width
:
{
1
,
32
,
64
,
128
,
512
,
1024
,
4096
,
32768
,
65536
,
131072
,
262144
,
524288
,
1048576
,
2097152
,
4194304
,
8388608
})
{
for
(
auto
width
:
{
1
,
32
,
64
,
128
,
512
,
1024
,
4096
,
32768
,
65536
,
131072
,
262144
,
524288
,
1048576
,
2097152
,
4194304
,
8388608
})
{
matrixFunc
(
height
,
width
);
}
}
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testLazyAssign
(
int
height
,
int
width
)
{
Tensor
A1
(
height
,
width
);
Tensor
A2
(
height
,
width
);
...
...
@@ -49,40 +63,39 @@ void testLazyAssign(int height, int width) {
EXPRESSION_PERFORMANCE
(
A1
=
B
+
C
;
A1
=
A1
*
D
;);
EXPRESSION_PERFORMANCE
(
auto
expr1
=
A2
.
lazyAssign
(
B
+
C
);
auto
expr2
=
A2
.
lazyAssign
(
A2
*
D
);
AssignEvaluate
(
expr1
,
expr2
););
EXPRESSION_PERFORMANCE
(
auto
expr1
=
A2
.
lazyAssign
(
B
+
C
);
auto
expr2
=
A2
.
lazyAssign
(
A2
*
D
);
AssignEvaluate
(
expr1
,
expr2
););
TensorCheckErr
(
A1
,
A2
);
}
TEST
(
lazyAssign
,
CPU
)
{
testMatrixCase
(
testLazyAssign
<
CpuMatrix
>
);
}
TEST
(
lazyAssign
,
CPU
)
{
testMatrixCase
(
testLazyAssign
<
CpuMatrix
>
);
}
#ifndef PADDLE_ONLY_CPU
TEST
(
lazyAssign
,
GPU
)
{
testMatrixCase
(
testLazyAssign
<
GpuMatrix
>
);
}
TEST
(
lazyAssign
,
GPU
)
{
testMatrixCase
(
testLazyAssign
<
GpuMatrix
>
);
}
#endif
template
<
typename
Tensor
>
void
sgdUpdateTensor
(
Tensor
&
A
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
,
real
p1
,
real
p2
,
real
p3
)
{
template
<
typename
Tensor
>
void
sgdUpdateTensor
(
Tensor
&
A
,
Tensor
&
B
,
Tensor
&
C
,
Tensor
&
D
,
real
p1
,
real
p2
,
real
p3
)
{
C
=
C
*
p2
-
D
*
(
B
+
A
*
p3
)
*
p1
;
A
+=
C
;
}
void
sgdUpdateLazyAssign
(
BaseMatrix
&
A
,
BaseMatrix
&
B
,
BaseMatrix
&
C
,
BaseMatrix
&
D
,
real
p1
,
real
p2
,
real
p3
)
{
void
sgdUpdateLazyAssign
(
BaseMatrix
&
A
,
BaseMatrix
&
B
,
BaseMatrix
&
C
,
BaseMatrix
&
D
,
real
p1
,
real
p2
,
real
p3
)
{
auto
expr1
=
C
.
lazyAssign
(
C
*
p2
-
D
*
(
B
+
A
*
p3
)
*
p1
);
auto
expr2
=
A
.
lazyAssign
(
A
+
C
);
AssignEvaluate
(
expr1
,
expr2
);
}
template
<
typename
Tensor
>
template
<
typename
Tensor
>
void
testSgdUpdate
(
int
height
,
int
width
)
{
Tensor
A1
(
height
,
width
);
Tensor
A2
(
height
,
width
);
...
...
@@ -113,16 +126,13 @@ void testSgdUpdate(int height, int width) {
* a = a + c;
*/
// BaseMatrix API
EXPRESSION_PERFORMANCE
(
A1
.
sgdUpdate
(
B
,
C1
,
D
,
p1
,
p2
,
p3
););
EXPRESSION_PERFORMANCE
(
A1
.
sgdUpdate
(
B
,
C1
,
D
,
p1
,
p2
,
p3
););
// Tensor expression
EXPRESSION_PERFORMANCE
(
sgdUpdateTensor
(
A2
,
B
,
C2
,
D
,
p1
,
p2
,
p3
));
EXPRESSION_PERFORMANCE
(
sgdUpdateTensor
(
A2
,
B
,
C2
,
D
,
p1
,
p2
,
p3
));
// lazyAssign
EXPRESSION_PERFORMANCE
(
sgdUpdateLazyAssign
(
A3
,
B
,
C3
,
D
,
p1
,
p2
,
p3
));
EXPRESSION_PERFORMANCE
(
sgdUpdateLazyAssign
(
A3
,
B
,
C3
,
D
,
p1
,
p2
,
p3
));
TensorCheckErr
(
A1
,
A2
);
TensorCheckErr
(
A1
,
A3
);
...
...
@@ -130,12 +140,8 @@ void testSgdUpdate(int height, int width) {
TensorCheckErr
(
C1
,
C3
);
}
TEST
(
sgdUpdate
,
CPU
)
{
testMatrixCase
(
testSgdUpdate
<
CpuMatrix
>
);
}
TEST
(
sgdUpdate
,
CPU
)
{
testMatrixCase
(
testSgdUpdate
<
CpuMatrix
>
);
}
#ifndef PADDLE_ONLY_CPU
TEST
(
sgdUpdate
,
GPU
)
{
testMatrixCase
(
testSgdUpdate
<
GpuMatrix
>
);
}
TEST
(
sgdUpdate
,
GPU
)
{
testMatrixCase
(
testSgdUpdate
<
GpuMatrix
>
);
}
#endif
paddle/math/tests/test_matrixCompare.cpp
浏览文件 @
59a8ebc6
...
...
@@ -1146,7 +1146,7 @@ void testBatch2seqPadding(int batchSize, int inputDim) {
IVectorPtr
cpuSequence
;
generateSequenceStartPositions
(
batchSize
,
cpuSequence
);
for
(
int
i
=
0
;
i
<
cpuSequence
->
getSize
(
);
++
i
)
{
for
(
int
i
=
0
;
i
<
int
(
cpuSequence
->
getSize
()
);
++
i
)
{
(
cpuSequence
->
getData
())[
i
]
+=
1
;
// so no way that maxSeqLen is 0;
}
...
...
paddle/operators/.clang-format
0 → 100644
浏览文件 @
59a8ebc6
---
Language: Cpp
BasedOnStyle: Google
Standard: Cpp11
...
paddle/operators/CMakeLists.txt
浏览文件 @
59a8ebc6
...
...
@@ -63,5 +63,6 @@ op_library(sgd_op SRCS sgd_op.cc sgd_op.cu)
op_library
(
fc_op
SRCS fc_op.cc
DEPS mul_op rowwise_add_op sigmoid_op softmax_op net_op
)
op_library
(
recurrent_op SRCS recurrent_op.cc DEPS op_desc tensor op_registry operator net_op
)
op_library
(
recurrent_op SRCS recurrent_op.cc rnn/recurrent_op_utils.cc
DEPS op_desc tensor op_registry operator net_op
)
cc_test
(
recurrent_op_test SRCS recurrent_op_test.cc DEPS recurrent_op gtest mul_op add_op
)
paddle/operators/add_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,10 +18,10 @@ namespace paddle {
namespace
operators
{
class
AddOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"Input size of AddOp must be two"
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"Output size of AddOp must be one"
);
PADDLE_ENFORCE
_EQ
(
ctx
.
InputSize
(),
2
);
PADDLE_ENFORCE
_EQ
(
ctx
.
OutputSize
(),
1
);
PADDLE_ENFORCE
(
ctx
.
InputVar
(
0
)
!=
nullptr
&&
ctx
.
InputVar
(
1
)
!=
nullptr
,
"Inputs of AddOp must all be set"
);
PADDLE_ENFORCE
(
ctx
.
OutputVar
(
0
)
!=
nullptr
,
...
...
@@ -33,7 +33,7 @@ protected:
};
class
AddOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
AddOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"The first input of add op"
);
...
...
@@ -48,7 +48,7 @@ The equation is: Out = X + Y
};
class
AddOpGrad
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{}
};
...
...
paddle/operators/add_op.h
浏览文件 @
59a8ebc6
...
...
@@ -20,7 +20,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
AddKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
input0
=
context
.
Input
<
Tensor
>
(
0
);
auto
input1
=
context
.
Input
<
Tensor
>
(
1
);
...
...
paddle/operators/cross_entropy_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,7 +18,7 @@ namespace paddle {
namespace
operators
{
class
OnehotCrossEntropyOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"Input size of OnehotCrossEntropyOp must be two"
);
...
...
@@ -36,8 +36,19 @@ protected:
}
};
class
OnehotCrossEntropyGradientOp
:
public
OperatorWithKernel
{
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
auto
X_grad
=
ctx
.
Output
<
Tensor
>
(
framework
::
GradVarName
(
"X"
));
auto
X
=
ctx
.
Input
<
Tensor
>
(
"X"
);
// TODO(superjom) add enforce here after helper functions ready
X_grad
->
Resize
(
X
->
dims
());
}
};
class
OnehotCrossEntropyOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
OnehotCrossEntropyOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"The first input of OnehotCrossEntropyOp"
);
...
...
@@ -54,8 +65,11 @@ OnehotCrossEntropy Operator.
}
// namespace operators
}
// namespace paddle
REGISTER_OP
(
onehot_cross_entropy
,
ops
::
OnehotCrossEntropyOp
,
REGISTER_OP
(
onehot_cross_entropy
,
ops
::
OnehotCrossEntropyOp
,
ops
::
OnehotCrossEntropyOpMaker
);
REGISTER_OP_CPU_KERNEL
(
onehot_cross_entropy
,
ops
::
OnehotCrossEntropyOpKernel
<
ops
::
CPUPlace
,
float
>
);
REGISTER_OP_CPU_KERNEL
(
onehot_cross_entropy_grad
,
ops
::
OnehotCrossEntropyGradientOpKernel
<
ops
::
CPUPlace
,
float
>
);
paddle/operators/cross_entropy_op.h
浏览文件 @
59a8ebc6
...
...
@@ -18,28 +18,53 @@ limitations under the License. */
namespace
paddle
{
namespace
operators
{
static
const
float
kCrossEntropyLogThreshold
{
1e-20
};
template
<
typename
Place
,
typename
T
>
class
OnehotCrossEntropyOpKernel
:
public
OpKernel
{
public:
constexpr
T
LOG_THRESHOLD
()
const
{
return
static_cast
<
T
>
(
1e-20
);
}
public:
void
Compute
(
const
ExecutionContext
&
ctx
)
const
override
{
auto
X
=
ctx
.
Input
<
Tensor
>
(
0
);
const
T
*
X
_
data
=
X
->
data
<
T
>
();
auto
X
=
ctx
.
Input
<
Tensor
>
(
"X"
);
const
T
*
Xdata
=
X
->
data
<
T
>
();
const
int
*
label_data
=
ctx
.
Input
<
Tensor
>
(
1
)
->
data
<
int
>
();
auto
Y
=
ctx
.
Output
<
Tensor
>
(
0
);
auto
Y
=
ctx
.
Output
<
Tensor
>
(
"Y"
);
Y
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
T
*
Y
_
data
=
Y
->
data
<
T
>
();
T
*
Ydata
=
Y
->
data
<
T
>
();
int
batch_size
=
X
->
dims
()[
0
];
int
class_num
=
X
->
dims
()[
1
];
// Y[i] = -log(X[i][j])
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
Y_data
[
i
]
=
-
std
::
log
(
std
::
max
(
X_data
[
i
*
class_num
+
label_data
[
i
]],
LOG_THRESHOLD
()));
Ydata
[
i
]
=
-
std
::
log
(
std
::
max
(
Xdata
[
i
*
class_num
+
label_data
[
i
]],
kCrossEntropyLogThreshold
));
}
}
};
template
<
typename
Place
,
typename
T
>
class
OnehotCrossEntropyGradientOpKernel
:
public
OpKernel
{
public:
void
Compute
(
const
ExecutionContext
&
ctx
)
const
override
{
auto
X
=
ctx
.
Input
<
Tensor
>
(
"X"
);
auto
dX
=
ctx
.
Output
<
Tensor
>
(
framework
::
GradVarName
(
"X"
));
auto
dY
=
ctx
.
Input
<
Tensor
>
(
framework
::
GradVarName
(
"Y"
));
auto
label
=
ctx
.
Input
<
Tensor
>
(
"label"
);
auto
*
dXdata
=
dX
->
template
mutable_data
<
T
>(
ctx
.
GetPlace
());
auto
*
dYdata
=
dY
->
template
data
<
T
>();
auto
*
Xdata
=
X
->
template
data
<
T
>();
auto
*
label_data
=
label
->
data
<
int
>
();
const
int
batch_size
=
X
->
dims
()[
0
];
const
int
class_num
=
X
->
dims
()[
1
];
for
(
int
i
=
0
;
i
<
batch_size
;
++
i
)
{
dXdata
[
i
*
class_num
+
label_data
[
i
]]
=
-
dYdata
[
i
]
/
std
::
max
(
Xdata
[
i
*
class_num
+
label_data
[
i
]],
kCrossEntropyLogThreshold
);
}
}
};
...
...
paddle/operators/fc_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,31 +18,29 @@ namespace paddle {
namespace
operators
{
class
FullyConnectedOp
:
public
NetOp
{
public:
public:
void
Init
()
override
{
AddOp
(
OpRegistry
::
CreateOp
(
"mul"
,
{
Input
(
"X"
),
Input
(
"W"
),
},
{
Output
(
"before_act"
)},
{}));
{
Output
(
"before_act"
)},
{}));
auto
b
=
Input
(
"b"
);
if
(
b
!=
framework
::
kEmptyVarName
)
{
AddOp
(
OpRegistry
::
CreateOp
(
"rowwise_add"
,
{
Output
(
"before_act"
),
Input
(
"b"
)},
{
Output
(
"before_act"
)},
{}));
{
Output
(
"before_act"
)},
{}));
}
auto
activation
=
GetAttr
<
std
::
string
>
(
"activation"
);
AddOp
(
OpRegistry
::
CreateOp
(
activation
,
{
Output
(
"before_act"
)},
{
Output
(
"Y"
)},
{}));
AddOp
(
OpRegistry
::
CreateOp
(
activation
,
{
Output
(
"before_act"
)},
{
Output
(
"Y"
)},
{}));
CompleteAddOp
(
false
);
}
};
class
FullyConnectedOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
FullyConnectedOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"the input of fc operator"
);
...
...
paddle/operators/fill_zeros_like_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -20,7 +20,7 @@ namespace paddle {
namespace
operators
{
class
FillZerosLikeOp
:
public
framework
::
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
framework
::
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
1UL
,
"Input size of FillZerosLikeOp must be one."
);
...
...
@@ -36,7 +36,7 @@ protected:
};
class
FillZerosLikeOpMaker
:
public
framework
::
OpProtoAndCheckerMaker
{
public:
public:
FillZerosLikeOpMaker
(
framework
::
OpProto
*
proto
,
framework
::
OpAttrChecker
*
op_checker
)
:
framework
::
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
...
...
@@ -52,8 +52,7 @@ The output will have the same size with input.
}
// namespace operators
}
// namespace paddle
REGISTER_OP
(
fill_zeros_like
,
paddle
::
operators
::
FillZerosLikeOp
,
REGISTER_OP
(
fill_zeros_like
,
paddle
::
operators
::
FillZerosLikeOp
,
paddle
::
operators
::
FillZerosLikeOpMaker
);
REGISTER_OP_CPU_KERNEL
(
fill_zeros_like
,
...
...
paddle/operators/fill_zeros_like_op.h
浏览文件 @
59a8ebc6
...
...
@@ -22,7 +22,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
FillZerosLikeKernel
:
public
framework
::
OpKernel
{
public:
public:
void
Compute
(
const
framework
::
ExecutionContext
&
context
)
const
override
{
auto
*
output
=
context
.
Output
<
framework
::
Tensor
>
(
0
);
output
->
mutable_data
<
T
>
(
context
.
GetPlace
());
...
...
paddle/operators/mean_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,7 +18,7 @@ namespace paddle {
namespace
operators
{
class
MeanOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
1
,
"Input size of AddOp must be one"
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"Output size of AddOp must be one"
);
...
...
@@ -29,7 +29,7 @@ protected:
};
class
MeanOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
MeanOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"The input of mean op"
);
...
...
@@ -39,7 +39,7 @@ public:
};
class
MeanGradOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
ctx
.
Output
<
Tensor
>
(
"X"
+
framework
::
kGradVarSuffix
)
->
Resize
(
ctx
.
Input
<
Tensor
>
(
"X"
)
->
dims
());
...
...
paddle/operators/mean_op.h
浏览文件 @
59a8ebc6
...
...
@@ -20,7 +20,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
MeanKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
input
=
context
.
Input
<
Tensor
>
(
0
);
auto
output
=
context
.
Output
<
Tensor
>
(
0
);
...
...
@@ -37,7 +37,7 @@ public:
template
<
typename
Place
,
typename
T
>
class
MeanGradKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
OG
=
context
.
Input
<
Tensor
>
(
"Out"
+
framework
::
kGradVarSuffix
);
PADDLE_ENFORCE
(
framework
::
product
(
OG
->
dims
())
==
1
,
...
...
paddle/operators/mul_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,23 +18,27 @@ namespace paddle {
namespace
operators
{
class
MulOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"The mul op must take two inputs"
);
auto
dim0
=
ctx
.
Input
<
Tensor
>
(
0
)
->
dims
();
auto
dim1
=
ctx
.
Input
<
Tensor
>
(
1
)
->
dims
();
PADDLE_ENFORCE
(
dim0
.
size
()
==
2
&&
dim1
.
size
()
==
2
,
"The input of mul op must be matrix"
);
PADDLE_ENFORCE
(
dim0
[
1
]
==
dim1
[
0
],
PADDLE_ENFORCE_EQ
(
dim0
.
size
(),
2
,
"input X(%s) should be a tensor with 2 dims, a matrix"
,
ctx
.
op_
.
Input
(
"X"
));
PADDLE_ENFORCE_EQ
(
dim1
.
size
(),
2
,
"input Y(%s) should be a tensor with 2 dims, a matrix"
,
ctx
.
op_
.
Input
(
"Y"
));
PADDLE_ENFORCE_EQ
(
dim0
[
1
],
dim1
[
0
],
"First matrix's width must be equal with second matrix's height."
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"The mul op must take
one output"
);
PADDLE_ENFORCE
_EQ
(
ctx
.
OutputSize
(),
1
,
"The mul op takes only
one output"
);
ctx
.
Output
<
Tensor
>
(
0
)
->
Resize
({
dim0
[
0
],
dim1
[
1
]});
}
};
class
MulOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
MulOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"The first input of mul op"
);
...
...
@@ -49,7 +53,7 @@ The equation is: Out = X * Y
};
class
MulOpGrad
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{}
std
::
string
DebugString
()
const
override
{
LOG
(
INFO
)
<<
"MulGrad"
;
...
...
paddle/operators/mul_op.h
浏览文件 @
59a8ebc6
...
...
@@ -21,7 +21,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
MulKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
Eigen
::
array
<
Eigen
::
IndexPair
<
Eigen
::
DenseIndex
>
,
1
>
dim_pair
=
{
{
Eigen
::
IndexPair
<
Eigen
::
DenseIndex
>
(
1
,
0
)}};
...
...
paddle/operators/net_op.h
浏览文件 @
59a8ebc6
...
...
@@ -40,7 +40,7 @@ namespace operators {
* it defines.
*/
class
NetOp
:
public
framework
::
OperatorBase
{
public:
public:
/**
* Infer all the operators' input and output variables' shapes, will be called
* before every mini-batch
...
...
@@ -90,7 +90,7 @@ public:
std
::
vector
<
std
::
shared_ptr
<
OperatorBase
>>
ops_
;
private:
private:
bool
add_op_done_
{
false
};
template
<
typename
T
,
typename
KeyType
>
...
...
paddle/operators/net_op_test.cc
浏览文件 @
59a8ebc6
...
...
@@ -12,7 +12,7 @@ static int infer_shape_cnt = 0;
static
int
run_cnt
=
0
;
class
TestOp
:
public
OperatorBase
{
public:
public:
void
InferShape
(
const
framework
::
Scope
&
scope
)
const
override
{
++
infer_shape_cnt
;
}
...
...
@@ -23,7 +23,7 @@ public:
};
class
EmptyOp
:
public
OperatorBase
{
public:
public:
void
InferShape
(
const
Scope
&
scope
)
const
override
{}
void
Run
(
const
Scope
&
scope
,
const
platform
::
DeviceContext
&
dev_ctx
)
const
override
{}
...
...
paddle/operators/recurrent_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -25,214 +25,75 @@
namespace
paddle
{
namespace
operators
{
namespace
rnn
{
void
SegmentInputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
inlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
)
{
PADDLE_ENFORCE
(
!
inlinks
.
empty
(),
"no in links are provided."
);
for
(
size_t
i
=
0
;
i
<
inlinks
.
size
();
++
i
)
{
auto
input_var
=
step_scopes
[
0
]
->
FindVar
(
inlinks
[
i
].
external
);
PADDLE_ENFORCE
(
input_var
!=
nullptr
,
"input link [%s] is not in scope."
,
inlinks
[
i
].
external
);
Tensor
*
input
=
input_var
->
GetMutable
<
Tensor
>
();
framework
::
DDim
dims
=
input
->
dims
();
PADDLE_ENFORCE
(
static_cast
<
size_t
>
(
dims
[
0
])
==
seq_len
,
"all the inlinks must have same length"
);
framework
::
DDim
step_dims
=
slice_ddim
(
dims
,
1
,
dims
.
size
());
for
(
size_t
j
=
0
;
j
<
seq_len
;
j
++
)
{
Tensor
*
step_input
=
step_scopes
[
j
]
->
NewVar
(
inlinks
[
i
].
internal
)
->
GetMutable
<
Tensor
>
();
if
(
!
infer_shape_mode
)
{
*
step_input
=
input
->
Slice
<
float
>
(
j
,
j
+
1
);
}
step_input
->
Resize
(
step_dims
);
}
}
}
void
ConcatOutputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
outlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
)
{
for
(
size_t
i
=
0
;
i
<
outlinks
.
size
();
i
++
)
{
auto
output_var
=
step_scopes
[
0
]
->
FindVar
(
outlinks
[
i
].
external
);
PADDLE_ENFORCE
(
output_var
!=
nullptr
,
"output link [%s] is not in scope."
,
outlinks
[
i
].
external
);
Tensor
*
output
=
output_var
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
framework
::
DDim
step_dims
=
step_scopes
[
0
]
->
FindVar
(
outlinks
[
i
].
internal
)
->
GetMutable
<
Tensor
>
()
->
dims
();
std
::
vector
<
int
>
dims_vec
=
vectorize
(
step_dims
);
dims_vec
.
insert
(
dims_vec
.
begin
(),
seq_len
);
output
->
Resize
(
framework
::
make_ddim
(
dims_vec
));
}
else
{
output
->
mutable_data
<
float
>
(
platform
::
CPUPlace
());
for
(
size_t
j
=
0
;
j
<
seq_len
;
j
++
)
{
Tensor
*
step_output
=
step_scopes
[
j
]
->
FindVar
(
outlinks
[
i
].
internal
)
->
GetMutable
<
Tensor
>
();
// TODO(luotao02) data type and platform::DeviceContext() should set
// correctly
(
output
->
Slice
<
float
>
(
j
,
j
+
1
))
.
CopyFrom
<
float
>
(
*
step_output
,
platform
::
CPUPlace
());
}
}
}
}
void
LinkMemories
(
const
std
::
vector
<
Scope
*>&
scopes
,
const
std
::
vector
<
rnn
::
MemoryAttr
>&
memories
,
const
size_t
step_id
,
const
int
offset
,
bool
infer_shape_mode
)
{
PADDLE_ENFORCE
(
step_id
<
scopes
.
size
(),
"step [%d] is out of range of step scopes' size [%d]"
,
step_id
,
scopes
.
size
());
PADDLE_ENFORCE
(
static_cast
<
int
>
(
step_id
)
+
offset
>=
0
,
"offset [%d] must be large than -[%d]"
,
offset
,
step_id
);
PADDLE_ENFORCE
(
step_id
+
offset
<
scopes
.
size
(),
"offset [%d] is out of range, it must be less than (%d - %d)"
,
offset
,
scopes
.
size
(),
step_id
);
auto
scope
=
scopes
[
step_id
];
auto
linked_scope
=
scopes
[
step_id
+
offset
];
for
(
auto
&
attr
:
memories
)
{
auto
mem
=
scope
->
FindVar
(
attr
.
pre_var
)
->
GetMutable
<
Tensor
>
();
auto
linked_mem
=
linked_scope
->
FindVar
(
attr
.
var
)
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
mem
->
Resize
(
linked_mem
->
dims
());
}
else
{
mem
->
ShareDataWith
<
float
>
(
*
linked_mem
);
}
}
}
void
InitArgument
(
const
ArgumentName
&
name
,
Argument
*
arg
,
const
OperatorBase
&
op
)
{
arg
->
step_net
=
op
.
Input
(
name
.
step_net
);
arg
->
step_scopes
=
op
.
Output
(
name
.
step_scopes
);
auto
inlinks
=
op
.
Inputs
(
name
.
inlinks
);
auto
inlink_alias
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
inlink_alias
);
PADDLE_ENFORCE
(
inlinks
.
size
()
==
inlink_alias
.
size
(),
"the size of inlinks and inlink_alias don't match:%d,%d"
,
inlinks
.
size
(),
inlink_alias
.
size
());
for
(
size_t
i
=
0
;
i
<
inlinks
.
size
();
++
i
)
{
rnn
::
Link
link
;
link
.
external
=
inlinks
[
i
];
link
.
internal
=
inlink_alias
[
i
];
(
arg
->
inlinks
).
push_back
(
link
);
}
auto
outlinks
=
op
.
Outputs
(
name
.
outlinks
);
auto
outlink_alias
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
outlink_alias
);
PADDLE_ENFORCE
(
outlinks
.
size
()
==
outlink_alias
.
size
(),
"the size of outlinks and outlink_alias don't match:%d,%d"
,
outlinks
.
size
(),
outlink_alias
.
size
());
for
(
size_t
i
=
0
;
i
<
outlinks
.
size
();
++
i
)
{
rnn
::
Link
link
;
link
.
external
=
outlinks
[
i
];
link
.
internal
=
outlink_alias
[
i
];
(
arg
->
outlinks
).
push_back
(
link
);
}
auto
boot_memories
=
op
.
Inputs
(
name
.
boot_memories
);
// attributes
auto
memories
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
memories
);
auto
pre_memories
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
pre_memories
);
PADDLE_ENFORCE
(
memories
.
size
()
==
boot_memories
.
size
(),
"the size of memories, boot_memories don't match:%d,%d"
,
memories
.
size
(),
boot_memories
.
size
());
PADDLE_ENFORCE
(
pre_memories
.
size
()
==
boot_memories
.
size
(),
"the size of pre_memories, boot_memories don't match:%d,%d"
,
pre_memories
.
size
(),
boot_memories
.
size
());
PADDLE_ENFORCE
(
memories
.
size
()
>
0
,
"more than 1 memories should be set"
);
for
(
size_t
i
=
0
;
i
<
memories
.
size
();
++
i
)
{
rnn
::
MemoryAttr
mem_attr
;
mem_attr
.
var
=
memories
[
i
];
mem_attr
.
pre_var
=
pre_memories
[
i
];
mem_attr
.
boot_var
=
boot_memories
[
i
];
(
arg
->
memories
).
push_back
(
mem_attr
);
}
}
}
// namespace rnn
void
RecurrentAlgorithm
::
InferShape
(
const
Scope
&
scope
)
const
{
seq_len_
=
scope
.
FindVar
((
arg_
->
inlinks
[
0
]).
external
)
->
GetMutable
<
Tensor
>
()
->
dims
()[
0
];
CreateScopes
(
scope
);
auto
step_scopes
=
GetStepScopes
(
scope
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
InitMemories
(
step_scopes
[
0
],
true
/*infer_shape_mode*/
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net
!=
nullptr
,
"failed to get step net"
);
for
(
size_t
i
=
0
;
i
<
seq_len_
;
i
++
)
{
if
(
i
>
0
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
i
,
-
1
,
true
/*infer_shape_mode*/
);
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
i
,
-
1
,
true
/*infer_shape_mode*/
);
}
net
->
GetMutable
<
NetOp
>
()
->
InferShape
(
*
step_scopes
[
i
]);
}
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
}
void
RecurrentAlgorithm
::
Run
(
const
Scope
&
scope
,
const
platform
::
DeviceContext
&
dev_ctx
)
const
{
auto
step_scopes
=
GetStepScopes
(
scope
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
InitMemories
(
step_scopes
[
0
],
false
/*infer_shape_mode*/
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
for
(
size_t
step_id
=
0
;
step_id
<
seq_len_
;
step_id
++
)
{
// create output alias variables
if
(
step_id
>
0
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
-
1
,
false
/*infer_shape_mode*/
);
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
-
1
,
false
/*infer_shape_mode*/
);
}
net
->
GetMutable
<
NetOp
>
()
->
Run
(
*
step_scopes
[
step_id
],
dev_ctx
);
}
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
}
void
RecurrentAlgorithm
::
CreateScopes
(
const
Scope
&
scope
)
const
{
// TODO(
xxx
) Only two scopes are needed for inference, this case will be
// TODO(
superjom
) Only two scopes are needed for inference, this case will be
// supported later.
auto
step_scopes
=
scope
.
FindVar
(
arg_
->
step_scopes
)
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
auto
step_scopes_var
=
scope
.
FindVar
(
arg_
->
step_scopes
);
PADDLE_ENFORCE
(
step_scopes_var
!=
nullptr
,
""
);
auto
step_scopes
=
step_scopes_var
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
// Now all variables in scope must be created outside of op.
auto
net_var
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net_var
!=
nullptr
,
"no stepnet called %s in scope"
,
arg_
->
step_net
);
auto
net_op
=
net_var
->
GetMutable
<
NetOp
>
();
PADDLE_ENFORCE
(
!
net_op
->
outputs_
.
empty
(),
"net_op has no outputs"
);
if
(
seq_len_
>
step_scopes
->
size
())
{
for
(
size_t
i
=
step_scopes
->
size
();
i
<
seq_len_
;
++
i
)
{
auto
&
step_scope
=
scope
.
NewScope
();
// Now all variables in scope must be created outside of op.
auto
net_op
=
scope
.
FindVar
(
arg_
->
step_net
)
->
GetMutable
<
NetOp
>
();
// create step net's temp inputs
for
(
auto
&
input
:
net_op
->
inputs_
)
{
// the weight are located in parent scope
if
(
!
step_scope
.
FindVar
(
input
))
step_scope
.
NewVar
(
input
);
if
(
!
step_scope
.
FindVar
(
input
))
step_scope
.
NewVar
(
input
)
->
GetMutable
<
Tensor
>
();
}
for
(
auto
&
output
:
net_op
->
outputs_
)
{
// create stepnet's outputs
for
(
const
auto
&
output
:
net_op
->
outputs_
)
{
step_scope
.
NewVar
(
output
);
}
step_scopes
->
emplace_back
(
&
step_scope
);
...
...
@@ -245,37 +106,27 @@ void RecurrentAlgorithm::InitMemories(Scope* step_scope,
for
(
auto
&
attr
:
arg_
->
memories
)
{
Tensor
*
pre_mem
=
step_scope
->
NewVar
(
attr
.
pre_var
)
->
GetMutable
<
Tensor
>
();
PADDLE_ENFORCE
(
step_scope
->
FindVar
(
attr
.
boot_var
)
!=
nullptr
,
"memory [%s]'s boot variable [%s] not exists"
,
attr
.
var
,
"memory [%s]'s boot variable [%s] not exists"
,
attr
.
var
,
attr
.
boot_var
);
Tensor
*
boot_mem
=
step_scope
->
FindVar
(
attr
.
boot_var
)
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
pre_mem
->
Resize
(
boot_mem
->
dims
());
PADDLE_ENFORCE_EQ
(
pre_mem
->
dims
().
size
(),
2
);
}
else
{
pre_mem
->
ShareDataWith
<
float
>
(
*
boot_mem
);
}
}
}
const
rnn
::
ArgumentName
RecurrentOp
::
kArgName
{
"step_net"
,
"step_scopes"
,
"inlinks"
,
"outlinks"
,
"inlink_alias"
,
"outlink_alias"
,
"memories"
,
"pre_memories"
,
"boot_memories"
};
const
rnn
::
ArgumentName
RecurrentOp
::
kArgName
{
"step_net"
,
"step_scopes"
,
"inlinks"
,
"outlinks"
,
"inlink_alias"
,
"outlink_alias"
,
"memories"
,
"pre_memories"
,
"boot_memories"
};
const
rnn
::
ArgumentName
RecurrentGradientOp
::
kArgName
{
"step_net"
,
"step_scopes"
,
"outlink@grad"
,
"inlink@grad"
,
"inlink_alias"
,
"outlink_alias"
,
"memories"
,
"pre_memories"
,
"boot_memories@grad"
};
const
rnn
::
ArgumentName
RecurrentGradientOp
::
kArgName
{
"step_net"
,
"step_scopes"
,
"outlink@grad"
,
"inlink@grad"
,
"inlink_alias"
,
"outlink_alias"
,
"memories"
,
"pre_memories"
,
"boot_memories@grad"
};
void
RecurrentOp
::
Init
()
{
OperatorBase
::
Init
();
...
...
@@ -285,7 +136,7 @@ void RecurrentOp::Init() {
}
class
RecurrentAlgorithmProtoAndCheckerMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
RecurrentAlgorithmProtoAndCheckerMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
...
...
@@ -316,31 +167,29 @@ public:
void
RecurrentGradientAlgorithm
::
Run
(
const
Scope
&
scope
,
const
platform
::
DeviceContext
&
dev_ctx
)
const
{
auto
step_scopes
=
GetStepScopes
(
scope
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net
!=
nullptr
,
"failed to get step net"
);
for
(
int
step_id
=
seq_len_
-
1
;
step_id
>=
0
;
--
step_id
)
{
if
(
static_cast
<
size_t
>
(
step_id
)
!=
seq_len_
-
1
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
1
,
false
/*infer_shape_mode*/
);
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
1
,
false
/*infer_shape_mode*/
);
}
net
->
GetMutable
<
NetOp
>
()
->
Run
(
*
step_scopes
[
step_id
],
dev_ctx
);
}
LinkBootMemoryGradients
(
step_scopes
[
0
],
false
);
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
false
/*infer_shape_mode*/
);
}
void
RecurrentGradientAlgorithm
::
LinkBootMemoryGradients
(
Scope
*
step_scope
,
bool
infer_shape_mode
)
const
{
for
(
auto
&
attr
:
arg_
->
memories
)
{
PADDLE_ENFORCE
(
step_scope
->
FindVar
(
attr
.
var
)
!=
nullptr
,
"memory variable [%s] does not exists"
,
attr
.
var
);
"memory variable [%s] does not exists"
,
attr
.
var
);
PADDLE_ENFORCE
(
step_scope
->
FindVar
(
attr
.
boot_var
)
!=
nullptr
,
"boot variable [%s] does not exists"
,
attr
.
boot_var
);
"boot variable [%s] does not exists"
,
attr
.
boot_var
);
Tensor
*
mem_grad
=
step_scope
->
NewVar
(
attr
.
var
)
->
GetMutable
<
Tensor
>
();
Tensor
*
boot_mem_grad
=
step_scope
->
NewVar
(
attr
.
boot_var
)
->
GetMutable
<
Tensor
>
();
...
...
@@ -357,19 +206,19 @@ void RecurrentGradientAlgorithm::InferShape(const Scope& scope) const {
->
GetMutable
<
Tensor
>
()
->
dims
()[
0
];
auto
step_scopes
=
GetStepScopes
(
scope
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
rnn
::
SegmentInputs
(
step_scopes
,
arg_
->
inlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
Variable
*
net
=
scope
.
FindVar
(
arg_
->
step_net
);
PADDLE_ENFORCE
(
net
!=
nullptr
,
"failed to get step net"
);
for
(
int
step_id
=
seq_len_
-
1
;
step_id
>=
0
;
--
step_id
)
{
if
(
static_cast
<
size_t
>
(
step_id
)
!=
seq_len_
-
1
)
{
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
1
,
true
/*infer_shape_mode*/
);
rnn
::
LinkMemories
(
step_scopes
,
arg_
->
memories
,
step_id
,
1
,
true
/*infer_shape_mode*/
);
}
net
->
GetMutable
<
NetOp
>
()
->
InferShape
(
*
step_scopes
[
step_id
]);
}
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
rnn
::
ConcatOutputs
(
step_scopes
,
arg_
->
outlinks
,
seq_len_
,
true
/*infer_shape_mode*/
);
LinkBootMemoryGradients
(
step_scopes
[
0
],
true
/*infer_shape_mode*/
);
}
...
...
@@ -383,6 +232,5 @@ void RecurrentGradientOp::Init() {
}
// namespace operators
}
// namespace paddle
REGISTER_OP
(
recurrent_op
,
paddle
::
operators
::
RecurrentOp
,
REGISTER_OP
(
recurrent_op
,
paddle
::
operators
::
RecurrentOp
,
paddle
::
operators
::
RecurrentAlgorithmProtoAndCheckerMaker
);
paddle/operators/recurrent_op.h
浏览文件 @
59a8ebc6
...
...
@@ -15,82 +15,11 @@
#pragma once
#include "paddle/framework/operator.h"
#include "paddle/operators/rnn/recurrent_op_utils.h"
namespace
paddle
{
namespace
operators
{
namespace
rnn
{
/**
* Memory of a RNN (same as the role of `Momory` in PaddlePaddle).
*
* Memory attributes cached by this op, dims will be infered from
* boot memories in father scope. Other attributes are copied from Op's proto
* attributes.
*/
struct
MemoryAttr
{
// name of current state variable
std
::
string
var
;
// name of previous step's state variable
std
::
string
pre_var
;
// name of the variables to init this memory (same role of `boot_layer` in
// PaddlePaddle), which is store in father's scope.
std
::
string
boot_var
;
};
struct
Link
{
// input or output links name.
std
::
string
internal
;
// alias to avoid duplicate keys in scopes.
std
::
string
external
;
};
struct
Argument
{
std
::
string
step_net
;
std
::
string
step_scopes
;
std
::
vector
<
Link
>
inlinks
;
std
::
vector
<
Link
>
outlinks
;
std
::
vector
<
rnn
::
MemoryAttr
>
memories
;
};
struct
ArgumentName
{
std
::
string
step_net
;
std
::
string
step_scopes
;
std
::
string
inlinks
;
std
::
string
outlinks
;
std
::
string
inlink_alias
;
// the alias of inlinks in step net.
std
::
string
outlink_alias
;
// the alias of outlinks in step net.
std
::
string
memories
;
// the memory name
std
::
string
pre_memories
;
// the previous memory name
std
::
string
boot_memories
;
// the boot memory name
};
/**
* Prepare inputs for each step net.
*/
void
SegmentInputs
(
const
std
::
vector
<
framework
::
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
inlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
);
/**
* Process outputs of step nets and merge to variables.
*/
void
ConcatOutputs
(
const
std
::
vector
<
framework
::
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
outlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
);
void
LinkMemories
(
const
std
::
vector
<
framework
::
Scope
*>&
step_scopes
,
const
std
::
vector
<
MemoryAttr
>&
memories
,
const
size_t
step_id
,
const
int
offset
,
bool
infer_shape_mode
);
void
InitArgument
(
const
ArgumentName
&
name
,
Argument
*
arg
);
};
// namespace rnn
// The sequence format in RecurrentOp is Tensor<seq_len, batch_size, dim> now.
// TODO(Yan Chunwei):
// 1. No-padding computing for sequences with indifinite length in one batch.
...
...
@@ -100,7 +29,7 @@ void InitArgument(const ArgumentName& name, Argument* arg);
// Refer to: https://arxiv.org/pdf/1502.02367.pdf
class
RecurrentAlgorithm
{
public:
public:
void
Run
(
const
framework
::
Scope
&
scope
,
const
platform
::
DeviceContext
&
dev_ctx
)
const
;
...
...
@@ -111,7 +40,7 @@ public:
*/
void
InferShape
(
const
framework
::
Scope
&
scope
)
const
;
protected:
protected:
/*
* The step scopes will be stored in the father scope as a variable.
*
...
...
@@ -128,7 +57,7 @@ protected:
void
InitMemories
(
framework
::
Scope
*
step_scopes
,
bool
infer_shape_mode
)
const
;
private:
private:
std
::
unique_ptr
<
rnn
::
Argument
>
arg_
;
mutable
size_t
seq_len_
;
};
...
...
@@ -144,7 +73,7 @@ class RecurrentGradientAlgorithm {
* lot, and the latter is a wrapper acts like an dapter for it to make RNN an
* operator.
*/
public:
public:
void
Init
(
std
::
unique_ptr
<
rnn
::
Argument
>
arg
)
{
arg_
=
std
::
move
(
arg
);
}
void
Run
(
const
framework
::
Scope
&
scope
,
...
...
@@ -158,20 +87,20 @@ public:
*/
void
InferShape
(
const
framework
::
Scope
&
scope
)
const
;
protected:
protected:
inline
const
std
::
vector
<
framework
::
Scope
*>&
GetStepScopes
(
const
framework
::
Scope
&
scope
)
const
{
return
*
scope
.
FindVar
(
arg_
->
step_scopes
)
->
GetMutable
<
std
::
vector
<
framework
::
Scope
*>>
();
}
private:
private:
std
::
unique_ptr
<
rnn
::
Argument
>
arg_
;
mutable
size_t
seq_len_
;
};
class
RecurrentOp
final
:
public
framework
::
OperatorBase
{
public:
public:
void
Init
()
override
;
/**
...
...
@@ -188,12 +117,12 @@ public:
static
const
rnn
::
ArgumentName
kArgName
;
private:
private:
RecurrentAlgorithm
alg_
;
};
class
RecurrentGradientOp
final
:
public
framework
::
OperatorBase
{
public:
public:
void
Init
()
override
;
/**
...
...
@@ -210,7 +139,7 @@ public:
static
const
rnn
::
ArgumentName
kArgName
;
private:
private:
RecurrentGradientAlgorithm
alg_
;
};
...
...
paddle/operators/recurrent_op_test.cc
浏览文件 @
59a8ebc6
...
...
@@ -29,7 +29,7 @@ using framework::make_ddim;
using
framework
::
DDim
;
class
RecurrentOpTest
:
public
::
testing
::
Test
{
protected:
protected:
virtual
void
SetUp
()
override
{
CreateGlobalVariables
();
CreateStepNet
();
...
...
@@ -174,7 +174,7 @@ TEST_F(RecurrentOpTest, Run) {
}
class
RecurrentGradientAlgorithmTest
:
public
::
testing
::
Test
{
protected:
protected:
virtual
void
SetUp
()
override
{
CreateGlobalVariables
();
CreateStepScopes
();
...
...
@@ -277,13 +277,11 @@ protected:
LOG
(
INFO
)
<<
"create variable step_net"
;
Variable
*
var
=
scope_
.
NewVar
(
"step_net"
);
auto
net
=
var
->
GetMutable
<
NetOp
>
();
net
->
AddOp
(
OpRegistry
::
CreateOp
(
"mul"
,
{
"rnn/h_pre"
,
"rnn/w"
,
"rnn/s_grad"
},
{
"rnn/h_pre_grad"
,
"rnn/w_grad"
},
{}));
net
->
AddOp
(
OpRegistry
::
CreateOp
(
"mul"
,
{
"rnn/h_pre"
,
"rnn/w"
,
"rnn/s_grad"
},
{
"rnn/h_pre_grad"
,
"rnn/w_grad"
},
{}));
net
->
AddOp
(
OpRegistry
::
CreateOp
(
"add_two"
,
{
"rnn/h_grad"
},
{
"rnn/x_grad"
,
"rnn/s_grad"
},
{}));
net
->
AddOp
(
OpRegistry
::
CreateOp
(
"add_two"
,
{
"rnn/h_grad"
},
{
"rnn/x_grad"
,
"rnn/s_grad"
},
{}));
net
->
CompleteAddOp
();
}
...
...
@@ -297,9 +295,7 @@ protected:
inlink
.
internal
=
"rnn/x"
;
auto
step_scopes
=
scope_
.
FindVar
(
"step_scopes"
)
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
rnn
::
SegmentInputs
(
*
step_scopes
,
std
::
vector
<
rnn
::
Link
>
{
inlink
},
10
,
rnn
::
SegmentInputs
(
*
step_scopes
,
std
::
vector
<
rnn
::
Link
>
{
inlink
},
10
,
true
/*infer_shape_mode*/
);
}
...
...
@@ -314,8 +310,8 @@ protected:
auto
step_scopes
=
scope_
.
FindVar
(
"step_scopes"
)
->
GetMutable
<
std
::
vector
<
Scope
*>>
();
for
(
int
i
=
1
;
i
<
10
;
++
i
)
{
rnn
::
LinkMemories
(
*
step_scopes
,
memories
,
i
,
-
1
,
true
/*infer_shape_mode*/
);
rnn
::
LinkMemories
(
*
step_scopes
,
memories
,
i
,
-
1
,
true
/*infer_shape_mode*/
);
}
}
...
...
@@ -395,3 +391,4 @@ TEST(RecurrentOp, LinkMemories) {
USE_OP
(
add_two
);
USE_OP
(
mul
);
USE_OP_WITHOUT_KERNEL
(
recurrent_op
);
paddle/operators/rnn/recurrent_op_utils.cc
0 → 100644
浏览文件 @
59a8ebc6
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserve.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/operators/rnn/recurrent_op_utils.h"
namespace
paddle
{
namespace
operators
{
namespace
rnn
{
namespace
fmw
=
paddle
::
framework
;
void
SegmentInputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
inlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
)
{
PADDLE_ENFORCE
(
!
inlinks
.
empty
(),
"no in links are provided."
);
for
(
size_t
i
=
0
;
i
<
inlinks
.
size
();
++
i
)
{
auto
input_var
=
step_scopes
[
0
]
->
FindVar
(
inlinks
[
i
].
external
);
PADDLE_ENFORCE
(
input_var
!=
nullptr
,
"input link [%s] is not in scope."
,
inlinks
[
i
].
external
);
Tensor
*
input
=
input_var
->
GetMutable
<
Tensor
>
();
fmw
::
DDim
dims
=
input
->
dims
();
PADDLE_ENFORCE
(
static_cast
<
size_t
>
(
dims
[
0
])
==
seq_len
,
"all the inlinks must have same length"
);
fmw
::
DDim
step_dims
=
slice_ddim
(
dims
,
1
,
dims
.
size
());
for
(
size_t
j
=
0
;
j
<
seq_len
;
j
++
)
{
Tensor
*
step_input
=
step_scopes
[
j
]
->
NewVar
(
inlinks
[
i
].
internal
)
->
GetMutable
<
Tensor
>
();
if
(
!
infer_shape_mode
)
{
*
step_input
=
input
->
Slice
<
float
>
(
j
,
j
+
1
);
}
step_input
->
Resize
(
step_dims
);
}
}
}
void
ConcatOutputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
outlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
)
{
for
(
size_t
i
=
0
;
i
<
outlinks
.
size
();
i
++
)
{
auto
output_var
=
step_scopes
[
0
]
->
FindVar
(
outlinks
[
i
].
external
);
PADDLE_ENFORCE
(
output_var
!=
nullptr
,
"output link [%s] is not in scope."
,
outlinks
[
i
].
external
);
Tensor
*
output
=
output_var
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
auto
step_scope_var
=
step_scopes
[
0
]
->
FindVar
(
outlinks
[
i
].
internal
);
PADDLE_ENFORCE
(
step_scope_var
!=
nullptr
,
"%s not in scope"
,
outlinks
[
i
].
internal
);
fmw
::
DDim
step_dims
=
step_scope_var
->
template
GetMutable
<
Tensor
>()
->
dims
();
std
::
vector
<
int
>
dims_vec
=
vectorize
(
step_dims
);
dims_vec
.
insert
(
dims_vec
.
begin
(),
seq_len
);
output
->
Resize
(
fmw
::
make_ddim
(
dims_vec
));
}
else
{
output
->
mutable_data
<
float
>
(
platform
::
CPUPlace
());
for
(
size_t
j
=
0
;
j
<
seq_len
;
j
++
)
{
Tensor
*
step_output
=
step_scopes
[
j
]
->
FindVar
(
outlinks
[
i
].
internal
)
->
GetMutable
<
Tensor
>
();
// TODO(luotao02) data type and platform::DeviceContext() should set
// correctly
(
output
->
Slice
<
float
>
(
j
,
j
+
1
))
.
CopyFrom
<
float
>
(
*
step_output
,
platform
::
CPUPlace
());
}
}
}
}
void
LinkMemories
(
const
std
::
vector
<
Scope
*>&
scopes
,
const
std
::
vector
<
rnn
::
MemoryAttr
>&
memories
,
const
size_t
step_id
,
const
int
offset
,
bool
infer_shape_mode
)
{
PADDLE_ENFORCE_LT
(
step_id
,
scopes
.
size
(),
"step [%d] is out of range of step scopes' size [%d]"
,
step_id
,
scopes
.
size
());
PADDLE_ENFORCE_GE
(
static_cast
<
int
>
(
step_id
)
+
offset
,
0
,
"offset [%d] must be large than -[%d]"
,
offset
,
step_id
);
PADDLE_ENFORCE_LT
(
step_id
+
offset
,
scopes
.
size
(),
"offset [%d] is out of range, it must be less than (%d - %d)"
,
offset
,
scopes
.
size
(),
step_id
);
auto
scope
=
scopes
[
step_id
];
auto
linked_scope
=
scopes
[
step_id
+
offset
];
for
(
auto
&
attr
:
memories
)
{
auto
mem
=
scope
->
FindVar
(
attr
.
pre_var
)
->
GetMutable
<
Tensor
>
();
auto
linked_mem
=
linked_scope
->
FindVar
(
attr
.
var
)
->
GetMutable
<
Tensor
>
();
if
(
infer_shape_mode
)
{
mem
->
Resize
(
linked_mem
->
dims
());
}
else
{
mem
->
ShareDataWith
<
float
>
(
*
linked_mem
);
}
}
}
void
InitArgument
(
const
ArgumentName
&
name
,
Argument
*
arg
,
const
OperatorBase
&
op
)
{
arg
->
step_net
=
op
.
Input
(
name
.
step_net
);
arg
->
step_scopes
=
op
.
Output
(
name
.
step_scopes
);
auto
inlinks
=
op
.
Inputs
(
name
.
inlinks
);
auto
inlink_alias
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
inlink_alias
);
PADDLE_ENFORCE
(
inlinks
.
size
()
==
inlink_alias
.
size
(),
"the size of inlinks and inlink_alias don't match:%d,%d"
,
inlinks
.
size
(),
inlink_alias
.
size
());
for
(
size_t
i
=
0
;
i
<
inlinks
.
size
();
++
i
)
{
rnn
::
Link
link
;
link
.
external
=
inlinks
[
i
];
link
.
internal
=
inlink_alias
[
i
];
(
arg
->
inlinks
).
push_back
(
link
);
}
auto
outlinks
=
op
.
Outputs
(
name
.
outlinks
);
auto
outlink_alias
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
outlink_alias
);
PADDLE_ENFORCE
(
outlinks
.
size
()
==
outlink_alias
.
size
(),
"the size of outlinks and outlink_alias don't match:%d,%d"
,
outlinks
.
size
(),
outlink_alias
.
size
());
for
(
size_t
i
=
0
;
i
<
outlinks
.
size
();
++
i
)
{
rnn
::
Link
link
;
link
.
external
=
outlinks
[
i
];
link
.
internal
=
outlink_alias
[
i
];
(
arg
->
outlinks
).
push_back
(
link
);
}
auto
boot_memories
=
op
.
Inputs
(
name
.
boot_memories
);
// attributes
auto
memories
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
memories
);
auto
pre_memories
=
op
.
GetAttr
<
std
::
vector
<
std
::
string
>>
(
name
.
pre_memories
);
PADDLE_ENFORCE
(
memories
.
size
()
==
boot_memories
.
size
(),
"the size of memories, boot_memories don't match:%d,%d"
,
memories
.
size
(),
boot_memories
.
size
());
PADDLE_ENFORCE
(
pre_memories
.
size
()
==
boot_memories
.
size
(),
"the size of pre_memories, boot_memories don't match:%d,%d"
,
pre_memories
.
size
(),
boot_memories
.
size
());
PADDLE_ENFORCE
(
memories
.
size
()
>
0
,
"more than 1 memories should be set"
);
for
(
size_t
i
=
0
;
i
<
memories
.
size
();
++
i
)
{
rnn
::
MemoryAttr
mem_attr
;
mem_attr
.
var
=
memories
[
i
];
mem_attr
.
pre_var
=
pre_memories
[
i
];
mem_attr
.
boot_var
=
boot_memories
[
i
];
(
arg
->
memories
).
push_back
(
mem_attr
);
}
}
}
// namespace rnn
}
// namespace operators
}
// namespace paddle
paddle/operators/rnn/recurrent_op_utils.h
0 → 100644
浏览文件 @
59a8ebc6
/* Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserve.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include <string>
#include "paddle/framework/operator.h"
#include "paddle/operators/type_alias.h"
namespace
paddle
{
namespace
operators
{
namespace
rnn
{
/**
* Memory of a RNN (same as the role of `Momory` in PaddlePaddle).
*
* Memory attributes cached by this op, dims will be infered from
* boot memories in father scope. Other attributes are copied from Op's proto
* attributes.
*/
struct
MemoryAttr
{
// name of current state variable
std
::
string
var
;
// name of previous step's state variable
std
::
string
pre_var
;
// name of the variables to init this memory (same role of `boot_layer` in
// PaddlePaddle), which is store in father's scope.
std
::
string
boot_var
;
};
struct
Link
{
// input or output links name.
std
::
string
internal
;
// alias to avoid duplicate keys in scopes.
std
::
string
external
;
};
struct
Argument
{
std
::
string
step_net
;
std
::
string
step_scopes
;
std
::
vector
<
Link
>
inlinks
;
std
::
vector
<
Link
>
outlinks
;
std
::
vector
<
rnn
::
MemoryAttr
>
memories
;
};
struct
ArgumentName
{
std
::
string
step_net
;
std
::
string
step_scopes
;
std
::
string
inlinks
;
std
::
string
outlinks
;
std
::
string
inlink_alias
;
// the alias of inlinks in step net.
std
::
string
outlink_alias
;
// the alias of outlinks in step net.
std
::
string
memories
;
// the memory name
std
::
string
pre_memories
;
// the previous memory name
std
::
string
boot_memories
;
// the boot memory name
};
/**
* Prepare inputs for each step net.
*/
void
SegmentInputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
inlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
);
/**
* Process outputs of step nets and merge to variables.
*/
void
ConcatOutputs
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
Link
>&
outlinks
,
const
size_t
seq_len
,
bool
infer_shape_mode
);
void
LinkMemories
(
const
std
::
vector
<
Scope
*>&
step_scopes
,
const
std
::
vector
<
MemoryAttr
>&
memories
,
const
size_t
step_id
,
const
int
offset
,
bool
infer_shape_mode
);
void
InitArgument
(
const
ArgumentName
&
name
,
Argument
*
arg
,
const
OperatorBase
&
op
);
}
// namespace rnn
}
// namespace operators
}
// namespace paddle
paddle/operators/rowwise_add_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -17,7 +17,7 @@ namespace paddle {
namespace
operators
{
class
RowWiseAddOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2UL
,
"Two inputs is needed by rowwise add"
);
...
...
@@ -33,7 +33,7 @@ protected:
};
class
RowWiseAddOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
RowWiseAddOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"The left input of row-wise add op, must be matrix"
);
...
...
paddle/operators/rowwise_add_op.h
浏览文件 @
59a8ebc6
...
...
@@ -20,7 +20,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
RowWiseAddKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
out
=
context
.
Output
<
Tensor
>
(
0
);
out
->
mutable_data
<
T
>
(
context
.
GetPlace
());
...
...
paddle/operators/sgd_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,7 +18,7 @@ namespace paddle {
namespace
operators
{
class
SGDOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
2
,
"Input size of SGDOp must be two"
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"Output size of SGDOp must be one"
);
...
...
@@ -32,7 +32,7 @@ protected:
};
class
SGDOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
SGDOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"param"
,
"input parameter"
);
...
...
paddle/operators/sgd_op.h
浏览文件 @
59a8ebc6
...
...
@@ -20,7 +20,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
SGDOpKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
ctx
)
const
override
{
auto
param
=
ctx
.
Input
<
Tensor
>
(
"param"
);
auto
grad
=
ctx
.
Input
<
Tensor
>
(
"grad"
);
...
...
paddle/operators/sigmoid_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -17,7 +17,7 @@ namespace paddle {
namespace
operators
{
class
SigmoidOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
1
,
"Sigmoid Op only have one input"
);
PADDLE_ENFORCE
(
ctx
.
OutputSize
()
==
1
,
"Sigmoid Op only have one output"
);
...
...
@@ -26,7 +26,7 @@ protected:
};
class
SigmoidOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
SigmoidOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"sigmoid input"
);
...
...
@@ -36,11 +36,9 @@ public:
};
class
SigmoidOpGrad
:
public
OperatorWithKernel
{
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{}
std
::
string
DebugString
()
const
override
{
LOG
(
INFO
)
<<
"SigmoidGrad"
;
return
""
;
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
ctx
.
Output
<
Tensor
>
(
0
)
->
Resize
(
ctx
.
Input
<
Tensor
>
(
0
)
->
dims
());
}
};
...
...
@@ -51,3 +49,5 @@ REGISTER_OP(sigmoid, ops::SigmoidOp, ops::SigmoidOpMaker);
REGISTER_GRADIENT_OP
(
sigmoid
,
sigmoid_grad
,
ops
::
SigmoidOpGrad
);
REGISTER_OP_CPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
CPUPlace
,
float
>
);
REGISTER_OP_CPU_KERNEL
(
sigmoid_grad
,
ops
::
SigmoidGradKernel
<
ops
::
CPUPlace
,
float
>
);
paddle/operators/sigmoid_op.cu
浏览文件 @
59a8ebc6
...
...
@@ -16,3 +16,5 @@
#include "paddle/operators/sigmoid_op.h"
REGISTER_OP_GPU_KERNEL
(
sigmoid
,
ops
::
SigmoidKernel
<
ops
::
GPUPlace
,
float
>
);
REGISTER_OP_GPU_KERNEL
(
sigmoid_grad
,
ops
::
SigmoidGradKernel
<
ops
::
GPUPlace
,
float
>
);
paddle/operators/sigmoid_op.h
浏览文件 @
59a8ebc6
...
...
@@ -21,12 +21,13 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
SigmoidKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
input
=
context
.
Input
<
Tensor
>
(
0
);
auto
output
=
context
.
Output
<
Tensor
>
(
0
);
output
->
mutable_data
<
T
>
(
context
.
GetPlace
());
// The clipping is used in Paddle's raw implenmention
auto
X
=
EigenVector
<
T
>::
Flatten
(
*
input
);
auto
Y
=
EigenVector
<
T
>::
Flatten
(
*
output
);
auto
place
=
context
.
GetEigenDevice
<
Place
>
();
...
...
@@ -34,5 +35,23 @@ public:
Y
.
device
(
place
)
=
1.0
/
(
1.0
+
(
-
1.0
*
X
).
exp
());
}
};
template
<
typename
Place
,
typename
T
>
class
SigmoidGradKernel
:
public
OpKernel
{
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
Y_t
=
context
.
Input
<
Tensor
>
(
"Y"
);
auto
dY_t
=
context
.
Input
<
Tensor
>
(
framework
::
GradVarName
(
"Y"
));
auto
dX_t
=
context
.
Output
<
Tensor
>
(
framework
::
GradVarName
(
"X"
));
dX_t
->
mutable_data
<
T
>
(
context
.
GetPlace
());
auto
dX
=
EigenVector
<
T
>::
Flatten
(
*
dX_t
);
auto
Y
=
EigenVector
<
T
>::
Flatten
(
*
Y_t
);
auto
dY
=
EigenVector
<
T
>::
Flatten
(
*
dY_t
);
dX
.
device
(
context
.
GetEigenDevice
<
Place
>
())
=
dY
*
Y
*
(
1.
-
Y
);
}
};
}
// namespace operators
}
// namespace paddle
paddle/operators/softmax_op.cc
浏览文件 @
59a8ebc6
...
...
@@ -18,7 +18,7 @@ namespace paddle {
namespace
operators
{
class
SoftmaxOp
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
1UL
,
"Only one input is need for softmax"
);
...
...
@@ -31,7 +31,7 @@ protected:
};
class
SoftmaxOpMaker
:
public
OpProtoAndCheckerMaker
{
public:
public:
SoftmaxOpMaker
(
OpProto
*
proto
,
OpAttrChecker
*
op_checker
)
:
OpProtoAndCheckerMaker
(
proto
,
op_checker
)
{
AddInput
(
"X"
,
"input of softmax"
);
...
...
@@ -41,7 +41,7 @@ public:
};
class
SoftmaxOpGrad
:
public
OperatorWithKernel
{
protected:
protected:
void
InferShape
(
const
InferShapeContext
&
ctx
)
const
override
{
PADDLE_ENFORCE
(
ctx
.
InputSize
()
==
3UL
,
"Input of SoftmaxOpGrad should be 3, X, Y, YG"
);
...
...
paddle/operators/softmax_op.h
浏览文件 @
59a8ebc6
...
...
@@ -24,7 +24,7 @@ namespace operators {
template
<
typename
Place
,
typename
T
>
class
SoftmaxKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
auto
input
=
context
.
Input
<
Tensor
>
(
"X"
);
auto
output
=
context
.
Output
<
Tensor
>
(
"Y"
);
...
...
@@ -63,7 +63,7 @@ public:
template
<
typename
Place
,
typename
T
>
class
SoftmaxGradKernel
:
public
OpKernel
{
public:
public:
void
Compute
(
const
ExecutionContext
&
context
)
const
override
{
std
::
shared_ptr
<
Tensor
>
scale_
=
std
::
make_shared
<
Tensor
>
();
...
...
paddle/operators/type_alias.h
浏览文件 @
59a8ebc6
...
...
@@ -26,21 +26,16 @@ using OperatorBase = framework::OperatorBase;
using
InferShapeContext
=
framework
::
InferShapeContext
;
using
ExecutionContext
=
framework
::
ExecutionContext
;
using
Variable
=
framework
::
Variable
;
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
typename
IndexType
=
Eigen
::
DenseIndex
>
using
EigenScalar
=
framework
::
EigenScalar
<
T
,
MajorType
,
IndexType
>
;
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
typename
IndexType
=
Eigen
::
DenseIndex
>
using
EigenVector
=
framework
::
EigenVector
<
T
,
MajorType
,
IndexType
>
;
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
template
<
typename
T
,
int
MajorType
=
Eigen
::
RowMajor
,
typename
IndexType
=
Eigen
::
DenseIndex
>
using
EigenMatrix
=
framework
::
EigenMatrix
<
T
,
MajorType
,
IndexType
>
;
template
<
typename
T
,
size_t
D
,
int
MajorType
=
Eigen
::
RowMajor
,
template
<
typename
T
,
size_t
D
,
int
MajorType
=
Eigen
::
RowMajor
,
typename
IndexType
=
Eigen
::
DenseIndex
>
using
EigenTensor
=
framework
::
EigenTensor
<
T
,
D
,
MajorType
,
IndexType
>
;
using
Tensor
=
framework
::
Tensor
;
...
...
paddle/scripts/docker/build.sh
浏览文件 @
59a8ebc6
...
...
@@ -39,6 +39,10 @@ Configuring cmake in /paddle/build ...
-DCMAKE_EXPORT_COMPILE_COMMANDS=ON
========================================
EOF
# Disable UNITTEST_USE_VIRTUALENV in docker because
# docker environment is fully controlled by this script.
# See /Paddle/CMakeLists.txt, UNITTEST_USE_VIRTUALENV option.
cmake ..
\
-DCMAKE_BUILD_TYPE
=
Release
\
-DWITH_DOC
=
OFF
\
...
...
@@ -52,39 +56,43 @@ cmake .. \
-DCMAKE_EXPORT_COMPILE_COMMANDS
=
ON
cat
<<
EOF
========================================
========================================
====
Building in /paddle/build ...
Build unit tests:
${
WITH_TESTING
:-
OFF
}
========================================
========================================
====
EOF
make
-j
`
nproc
`
if
[
${
WITH_TESTING
:-
OFF
}
==
"ON"
]
&&
[
${
RUN_TEST
:-
OFF
}
==
"ON"
]
;
then
pip uninstall
-y
py-paddle paddle
||
true
ctest
--output-on-failure
fi
if
[
${
WITH_TESTING
:-
OFF
}
==
"ON"
]
&&
[
${
RUN_TEST
:-
OFF
}
==
"ON"
]
;
then
cat
<<
EOF
========================================
Installing
...
Running unit tests
...
========================================
EOF
make
install
-j
`
nproc
`
pip
install
/usr/local/opt/paddle/share/wheels/
*
.whl
paddle version
# make install should also be test when unittest
make
install
-j
`
nproc
`
pip
install
/usr/local/opt/paddle/share/wheels/
*
.whl
paddle version
ctest
--output-on-failure
fi
# To build documentation, we need to run cmake again after installing
# PaddlePaddle. This awkwardness is due to
# https://github.com/PaddlePaddle/Paddle/issues/1854. It also
# describes a solution.
if
[[
${
WITH_DOC
}
==
"ON"
]]
;
then
if
[[
${
WITH_DOC
:-
OFF
}
==
"ON"
]]
;
then
cat
<<
EOF
========================================
Building documentation ...
In /paddle/build_doc
========================================
EOF
# build documentation need install Paddle before
make
install
-j
`
nproc
`
pip
install
/usr/local/opt/paddle/share/wheels/
*
.whl
paddle version
mkdir
-p
/paddle/build_doc
pushd
/paddle/build_doc
cmake ..
\
...
...
@@ -117,13 +125,22 @@ fi
# generate deb package for current build
# FIXME(typhoonzero): should we remove paddle/scripts/deb ?
cat
<<
EOF
if
[[
${
WITH_DEB
:-
OFF
}
==
"ON"
]]
;
then
cat
<<
EOF
========================================
Generating .deb package ...
========================================
EOF
cpack
-D
CPACK_GENERATOR
=
'DEB'
-j
`
nproc
`
..
set
+e
cpack
-D
CPACK_GENERATOR
=
'DEB'
-j
`
nproc
`
..
err_code
=
$?
if
[
${
err_code
}
-ne
0
]
;
then
# cat error logs if cpack failed.
cat
/paddle/build/_CPack_Packages/Linux/DEB/PreinstallOutput.log
exit
${
err_code
}
fi
set
-e
fi
cat
<<
EOF
========================================
...
...
paddle/scripts/run_python_tests.sh
已删除
100755 → 0
浏览文件 @
98a83cd2
#!/bin/bash
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
pushd
`
dirname
$0
`
>
/dev/null
SCRIPTPATH
=
$PWD
popd
>
/dev/null
USE_VIRTUALENV_FOR_TEST
=
$1
;
shift
PYTHON
=
$1
;
shift
if
[
$USE_VIRTUALENV_FOR_TEST
-ne
0
]
;
then
rm
-rf
.test_env
virtualenv .test_env
unset
PYTHONHOME
unset
PYTHONPATH
source
.test_env/bin/activate
PYTHON
=
python
fi
$PYTHON
-m
pip
install
$SCRIPTPATH
/../dist/
*
.whl
if
[
"X
${
PADDLE_PACKAGE_DIR
}
"
!=
"X"
]
;
then
$PYTHON
-m
pip
install
${
PADDLE_PACKAGE_DIR
}
/
*
.whl
else
export
PYTHONPATH
=
$SCRIPTPATH
/../../python/
fi
$PYTHON
-m
pip
install
ipython
==
5.3
for
fn
in
"
$@
"
do
echo
"test
$fn
"
$PYTHON
$fn
if
[
$?
-ne
0
]
;
then
exit
1
fi
done
if
[
$USE_VIRTUALENV_FOR_TEST
-ne
0
]
;
then
deactivate
rm
-rf
.test_env
fi
paddle/setup.py.in
浏览文件 @
59a8ebc6
...
...
@@ -22,7 +22,9 @@ setup(name="py_paddle",
package_data={'py_paddle':['*.py','_swig_paddle.so']},
install_requires = [
'nltk>=3.2.2',
'numpy>=1.8.0', # The numpy is required.
# We use `numpy.flip` in `test_image.py`.
# `numpy.flip` is introduced in `1.12.0`
'numpy>=1.12.0', # The numpy is required.
'protobuf==${PROTOBUF_VERSION}' # The paddle protobuf version
],
url='http://www.paddlepaddle.org/',
...
...
paddle/trainer/tests/compare_sparse_data
0 → 100644
浏览文件 @
59a8ebc6
文件已添加
paddle/trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.proto
→
paddle/trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.proto
_data
浏览文件 @
59a8ebc6
文件已移动
paddle/trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.protolist
浏览文件 @
59a8ebc6
./trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.proto
./trainer/tests/pydata_provider_wrapper_dir/test_pydata_provider_wrapper.proto
_data
paddle/trainer/tests/sample_trainer_config_compare_sparse.conf
0 → 100644
浏览文件 @
59a8ebc6
#edit-mode: -*- python -*-
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#Todo(luotao02) This config is only used for unitest. It is out of date now, and will be updated later.
# Note: when making change to this file, please make sure
# sample_trainer_config_rnn.conf is changed accordingly so that the uniitest
# for comparing these two nets can pass (test_CompareTwoNets)
default_initial_std
(
0
.
1
)
default_device
(
0
)
word_dim
=
999
l1
=
0
l2
=
0
model_type
(
"nn"
)
sparse_update
=
get_config_arg
(
"sparse_update"
,
bool
,
False
)
TrainData
(
ProtoData
(
type
=
"proto_sequence"
,
files
= (
'trainer/tests/train_sparse.list'
),
))
Settings
(
algorithm
=
'sgd'
,
batch_size
=
100
,
learning_rate
=
0
.
0001
,
learning_rate_decay_a
=
4
e
-
08
,
learning_rate_decay_b
=
0
.
0
,
learning_rate_schedule
=
'poly'
,
)
wordvec_dim
=
32
layer2_dim
=
16
layer3_dim
=
16
hidden_dim
=
32
slot_names
= [
"qb"
,
"qw"
,
"tb"
,
"tw"
]
def
ltr_network
(
network_name
,
word_dim
=
word_dim
,
wordvec_dim
=
wordvec_dim
,
layer2_dim
=
layer2_dim
,
layer3_dim
=
layer3_dim
,
hidden_dim
=
hidden_dim
,
slot_names
=
slot_names
,
l1
=
l1
,
l2
=
l2
):
slotnum
=
len
(
slot_names
)
for
i
in
xrange
(
slotnum
):
Inputs
(
slot_names
[
i
] +
network_name
)
for
i
in
xrange
(
slotnum
):
Layer
(
name
=
slot_names
[
i
] +
network_name
,
type
=
"data"
,
size
=
word_dim
,
device
= -
1
,
)
Layer
(
name
=
slot_names
[
i
] +
"_embedding_"
+
network_name
,
type
=
"mixed"
,
size
=
wordvec_dim
,
bias
=
False
,
device
= -
1
,
inputs
=
TableProjection
(
slot_names
[
i
] +
network_name
,
parameter_name
=
"embedding.w0"
,
decay_rate_l1
=
l1
,
sparse_remote_update
=
True
,
sparse_update
=
sparse_update
,
),
)
Layer
(
name
=
slot_names
[
i
] +
"_rnn1_"
+
network_name
,
type
=
"recurrent"
,
active_type
=
"tanh"
,
bias
=
Bias
(
initial_std
=
0
,
parameter_name
=
"rnn1.bias"
),
inputs
=
Input
(
slot_names
[
i
] +
"_embedding_"
+
network_name
,
parameter_name
=
"rnn1.w0"
)
)
Layer
(
name
=
slot_names
[
i
] +
"_rnnlast_"
+
network_name
,
type
=
"seqlastins"
,
inputs
= [
slot_names
[
i
] +
"_rnn1_"
+
network_name
,
],
)
Layer
(
name
=
"layer2_"
+
network_name
,
type
=
"fc"
,
active_type
=
"tanh"
,
size
=
layer2_dim
,
bias
=
Bias
(
parameter_name
=
"layer2.bias"
),
inputs
= [
Input
(
slot_name
+
"_rnnlast_"
+
network_name
,
parameter_name
=
"_layer2_"
+
slot_name
+
".w"
,
decay_rate
=
l2
,
initial_smart
=
True
)
for
slot_name
in
slot_names
]
)
Layer
(
name
=
"layer3_"
+
network_name
,
type
=
"fc"
,
active_type
=
"tanh"
,
size
=
layer3_dim
,
bias
=
Bias
(
parameter_name
=
"layer3.bias"
),
inputs
= [
Input
(
"layer2_"
+
network_name
,
parameter_name
=
"_layer3.w"
,
decay_rate
=
l2
,
initial_smart
=
True
),
]
)
Layer
(
name
=
"output_"
+
network_name
,
type
=
"fc"
,
size
=
1
,
bias
=
False
,
inputs
= [
Input
(
"layer3_"
+
network_name
,
parameter_name
=
"_layerO.w"
),
],
)
ltr_network
(
"left"
)
ltr_network
(
"right"
)
Inputs
(
"label"
)
Layer
(
name
=
"label"
,
type
=
"data"
,
size
=
1
,
)
Outputs
(
"cost"
,
"qb_rnnlast_left"
)
Layer
(
name
=
"cost"
,
type
=
"rank-cost"
,
inputs
= [
"output_left"
,
"output_right"
,
"label"
],
)
paddle/trainer/tests/test_CompareSparse.cpp
浏览文件 @
59a8ebc6
...
...
@@ -23,7 +23,7 @@ using namespace paddle; // NOLINT
using
namespace
std
;
// NOLINT
static
const
string
&
configFile1
=
"trainer/tests/sample_trainer_config_
qb_rnn
.conf"
;
"trainer/tests/sample_trainer_config_
compare_sparse
.conf"
;
DECLARE_bool
(
use_gpu
);
DECLARE_string
(
config
);
...
...
paddle/trainer/tests/train_sparse.list
0 → 100644
浏览文件 @
59a8ebc6
trainer/tests/compare_sparse_data
proto/DataConfig.proto
浏览文件 @
59a8ebc6
...
...
@@ -15,14 +15,13 @@ syntax = "proto2";
package
paddle
;
message
FileGroupConf
{
optional
uint32
queue_capacity
=
1
[
default
=
1
];
optional
uint32
queue_capacity
=
1
[
default
=
1
];
// how many files to load for a load file thread
optional
int32
load_file_count
=
2
[
default
=
1
];
optional
int32
load_file_count
=
2
[
default
=
1
];
// how many threads to load files
// Setting to be 5~10 is appropriate when loading files by hadoop vfs
optional
int32
load_thread_num
=
3
[
default
=
1
];
optional
int32
load_thread_num
=
3
[
default
=
1
];
};
message
DataConfig
{
...
...
@@ -32,26 +31,28 @@ message DataConfig {
// name of a text file which contains a list of file names at each line
optional
string
files
=
3
;
optional
int32
feat_dim
=
4
;
//
feature dimension of one frame
repeated
int32
slot_dims
=
5
;
//
feature slot dims
optional
int32
context_len
=
6
;
//
max neibour frame numbers
optional
uint64
buffer_capacity
=
7
;
//
the number of samples
optional
int32
feat_dim
=
4
;
//
feature dimension of one frame
repeated
int32
slot_dims
=
5
;
//
feature slot dims
optional
int32
context_len
=
6
;
//
max neibour frame numbers
optional
uint64
buffer_capacity
=
7
;
//
the number of samples
//part of data used in training
//if not -1, part of train data is used in training
optional
int64
train_sample_num
=
8
[
default
=
-
1
];
//
part of data used in training
//
if not -1, part of train data is used in training
optional
int64
train_sample_num
=
8
[
default
=
-
1
];
//The number of documents processed once
optional
int32
file_load_num
=
9
[
default
=
-
1
];
optional
bool
async_load_data
=
12
[
default
=
false
];
//
The number of documents processed once
optional
int32
file_load_num
=
9
[
default
=
-
1
];
optional
bool
async_load_data
=
12
[
default
=
false
];
/// Note the field number 10, 11 and 13 have been deprecated.
optional
bool
for_test
=
14
[
default
=
false
];
// whether this data is for test
optional
bool
for_test
=
14
[
default
=
false
];
// whether this data is for test
optional
FileGroupConf
file_group_conf
=
15
;
repeated
int32
float_slot_dims
=
16
;
/// Note the field number 17, 18 and 19 have been deprecated.
// a list of values which will be used to create additional one dimensional float
// a list of values which will be used to create additional one dimensional
// float
// values slots. These one dimensional slots can be used as the weight input
// for cost layers.
// Currently this is only supported by ProtoDataProvider.
...
...
@@ -65,21 +66,21 @@ message DataConfig {
// for MultiDataProvider
repeated
DataConfig
sub_data_configs
=
24
;
// sub dataproviders
/*
* the ratio of each sub dataproviders:
* e.g. sub dataprovider A's ratio is 1, B's ratio is 9, batch_size is 100,
* then each mini-batch is combined by 10 instance from A and 90 instances
* from B.
*/
/*
* the ratio of each sub dataproviders:
* e.g. sub dataprovider A's ratio is 1, B's ratio is 9, batch_size is 100,
* then each mini-batch is combined by 10 instance from A and 90 instances
* from B.
*/
optional
int32
data_ratio
=
25
;
/*
* if one of the sub dataproviders is running out of data, then
* (1) it is "main data", then finish current pass.
* (2) it is not "main data", then reset it, and try getNextBatch again.
*/
optional
bool
is_main_data
=
26
[
default
=
true
];
optional
bool
is_main_data
=
26
[
default
=
true
];
// the usage ratio of instances. Setting to 1.0 means the use of all instances.
optional
double
usage_ratio
=
27
[
default
=
1.0
];
// the usage ratio of instances. Setting to 1.0 means the use of all
// instances.
optional
double
usage_ratio
=
27
[
default
=
1.0
];
};
proto/DataFormat.proto
浏览文件 @
59a8ebc6
...
...
@@ -17,27 +17,32 @@ package paddle;
/*
If values is not empty and ids is empty, this is a dense vector.
If values is not empty and ids is not empty, this is a sparse vector. The position of each value
If values is not empty and ids is not empty, this is a sparse vector. The
position of each value
is specified by ids.
If values is empty and ids is not empty, this is a sparse vector whose non-zero values are 1.
If values is empty and ids is not empty, this is a sparse vector whose non-zero
values are 1.
The position of each 1 is specified by ids.
*/
message
VectorSlot
{
repeated
float
values
=
1
[
packed
=
true
];
repeated
uint32
ids
=
2
[
packed
=
true
];
repeated
float
values
=
1
[
packed
=
true
];
repeated
uint32
ids
=
2
[
packed
=
true
];
/* For multidimensional data, for example "image width height depth" */
repeated
uint32
dims
=
3
[
packed
=
true
];
repeated
string
strs
=
4
;
repeated
uint32
dims
=
3
[
packed
=
true
];
repeated
string
strs
=
4
;
};
/*
SubseqSlot use to record whether VectorSlot or any other slot in future has subseq.
If not all VectorSlot have subseq, we only store the one who has subseq, and use *slot_id* to record it.
One vector_slots has one sequence, and it may have N subseq, thus the number of *lens* will be N too.
SubseqSlot use to record whether VectorSlot or any other slot in future has
subseq.
If not all VectorSlot have subseq, we only store the one who has subseq, and
use *slot_id* to record it.
One vector_slots has one sequence, and it may have N subseq, thus the number of
*lens* will be N too.
*/
message
SubseqSlot
{
required
uint32
slot_id
=
1
;
//the id of slot who has subseq
repeated
uint32
lens
=
2
;
// lengths of sub-sequence in the slot
required
uint32
slot_id
=
1
;
//
the id of slot who has subseq
repeated
uint32
lens
=
2
;
// lengths of sub-sequence in the slot
};
message
SlotDef
{
...
...
@@ -45,13 +50,14 @@ message SlotDef {
VECTOR_DENSE
=
0
;
VECTOR_SPARSE_NON_VALUE
=
1
;
VECTOR_SPARSE_VALUE
=
2
;
INDEX
=
3
;
// This can be used as label, or word id, etc.
INDEX
=
3
;
// This can be used as label, or word id, etc.
VAR_MDIM_DENSE
=
4
;
VAR_MDIM_INDEX
=
5
;
STRING
=
6
;
}
required
SlotType
type
=
1
;
required
uint32
dim
=
2
;
// For INDEX slots, this means the maximal index plus 1.
required
uint32
dim
=
2
;
// For INDEX slots, this means the maximal index plus 1.
};
message
DataHeader
{
...
...
@@ -60,11 +66,11 @@ message DataHeader {
};
message
DataSample
{
optional
bool
is_beginning
=
1
[
default
=
true
];
// is the beginning of a sequence
optional
bool
is_beginning
=
1
[
default
=
true
];
// is the beginning of a sequence
repeated
VectorSlot
vector_slots
=
2
;
repeated
uint32
id_slots
=
3
[
packed
=
true
];
repeated
uint32
id_slots
=
3
[
packed
=
true
];
/* use ids of VectorSlot */
repeated
VectorSlot
var_id_slots
=
4
;
repeated
SubseqSlot
subseq_slots
=
5
;
};
proto/ModelConfig.proto
浏览文件 @
59a8ebc6
...
...
@@ -21,7 +21,6 @@ package paddle;
* Various structs for the configuration of a neural network
*/
message
ExternalConfig
{
repeated
string
layer_names
=
1
;
repeated
string
input_layer_names
=
2
;
...
...
@@ -68,7 +67,7 @@ message ConvConfig {
required
uint32
img_size
=
8
;
// caffe mode for output size coherence
required
bool
caffe_mode
=
9
[
default
=
true
];
required
bool
caffe_mode
=
9
[
default
=
true
];
// if filter_size_y is set , this convolutional layer will use
// filters of size filter_size * filter_size_y pixels.
...
...
@@ -99,7 +98,7 @@ message PoolConfig {
optional
uint32
start
=
4
;
// Defines the stride size between successive pooling squares.
required
uint32
stride
=
5
[
default
=
1
];
required
uint32
stride
=
5
[
default
=
1
];
// The size of output feature map.
required
uint32
output_x
=
6
;
...
...
@@ -109,7 +108,7 @@ message PoolConfig {
// padding = 4, instructs the net to implicitly
// pad the images with a 4-pixel border of zeros.
optional
uint32
padding
=
8
[
default
=
0
];
optional
uint32
padding
=
8
[
default
=
0
];
// if not set, use size_x
optional
uint32
size_y
=
9
;
...
...
@@ -194,9 +193,7 @@ message MaxOutConfig {
required
uint32
groups
=
2
;
}
message
RowConvConfig
{
required
uint32
context_length
=
1
;
}
message
RowConvConfig
{
required
uint32
context_length
=
1
;
}
message
SliceConfig
{
required
uint32
start
=
1
;
...
...
@@ -212,14 +209,14 @@ message ProjectionConfig {
// For ShiftProjection
optional
int32
context_start
=
5
;
optional
int32
context_length
=
6
;
optional
bool
trainable_padding
=
7
[
default
=
false
];
optional
bool
trainable_padding
=
7
[
default
=
false
];
// For convolution
optional
ConvConfig
conv_conf
=
8
;
optional
int32
num_filters
=
9
;
// For IdentityOffsetProjection
optional
uint64
offset
=
11
[
default
=
0
];
optional
uint64
offset
=
11
[
default
=
0
];
// For pool
optional
PoolConfig
pool_conf
=
12
;
...
...
@@ -236,7 +233,7 @@ message OperatorConfig {
required
uint64
output_size
=
4
;
// For DotMulOperator
optional
double
dotmul_scale
=
5
[
default
=
1.0
];
optional
double
dotmul_scale
=
5
[
default
=
1.0
];
// For ConvOperator
optional
ConvConfig
conv_conf
=
6
;
...
...
@@ -282,8 +279,8 @@ message MultiBoxLossConfig {
required
float
neg_overlap
=
4
;
required
uint32
background_id
=
5
;
required
uint32
input_num
=
6
;
optional
uint32
height
=
7
[
default
=
1
];
optional
uint32
width
=
8
[
default
=
1
];
optional
uint32
height
=
7
[
default
=
1
];
optional
uint32
width
=
8
[
default
=
1
];
}
message
DetectionOutputConfig
{
...
...
@@ -294,8 +291,8 @@ message DetectionOutputConfig {
required
uint32
input_num
=
5
;
required
uint32
keep_top_k
=
6
;
required
float
confidence_threshold
=
7
;
optional
uint32
height
=
8
[
default
=
1
];
optional
uint32
width
=
9
[
default
=
1
];
optional
uint32
height
=
8
[
default
=
1
];
optional
uint32
width
=
9
[
default
=
1
];
}
message
ClipConfig
{
...
...
@@ -331,7 +328,7 @@ message LayerConfig {
required
string
name
=
1
;
required
string
type
=
2
;
optional
uint64
size
=
3
;
//optional ActivationConfig activation = 4;
//
optional ActivationConfig activation = 4;
optional
string
active_type
=
4
;
repeated
LayerInputConfig
inputs
=
5
;
optional
string
bias_parameter_name
=
6
;
...
...
@@ -344,7 +341,7 @@ message LayerConfig {
// (which is how convnets are usually trained). Setting this to
// false will untie the biases, yielding a separate bias for
// every location at which the filter is applied.
optional
bool
shared_biases
=
8
[
default
=
false
];
optional
bool
shared_biases
=
8
[
default
=
false
];
// Valid values are ones that divide the area of the output
// grid in this convolutional layer. For example if this layer
...
...
@@ -362,33 +359,35 @@ message LayerConfig {
// the gpu device which the Layer's data in.
// Only used by ParallelNeuralNetork. Ignored otherwise.
optional
int32
device
=
12
[
default
=
-
1
];
optional
int32
device
=
12
[
default
=
-
1
];
// for recurrent layer. If true, the recurrence runs from the end to the beginning.
optional
bool
reversed
=
13
[
default
=
false
];
// for recurrent layer. If true, the recurrence runs from the end to the
// beginning.
optional
bool
reversed
=
13
[
default
=
false
];
// for lstmemory layer. Different types of nodes have different activation type.
optional
string
active_gate_type
=
14
;
// for lstmemory layer. Different types of nodes have different activation
// type.
optional
string
active_gate_type
=
14
;
optional
string
active_state_type
=
15
;
// For NCELayer
// The number of random negative labels for each sample
optional
int32
num_neg_samples
=
16
[
default
=
10
];
optional
int32
num_neg_samples
=
16
[
default
=
10
];
// For NCELayer
// The distribution for generating the random negative labels.
// A uniform distribution will be used if not provided
repeated
double
neg_sampling_dist
=
17
[
packed
=
true
];
repeated
double
neg_sampling_dist
=
17
[
packed
=
true
];
// For MaxLayer
// default: output VALUE of MaxLayer. set this flag to true for output INDEX
// INDEX will be put in Argument::value as double values.
optional
bool
output_max_index
=
19
[
default
=
false
];
optional
bool
output_max_index
=
19
[
default
=
false
];
/// The filed number 20 have been deprecated.
// For self-normalized estimation
optional
double
softmax_selfnorm_alpha
=
21
[
default
=
0.1
];
optional
double
softmax_selfnorm_alpha
=
21
[
default
=
0.1
];
/// The filed numbers 22 and 23 have been deprecated.
...
...
@@ -399,14 +398,14 @@ message LayerConfig {
optional
bool
norm_by_times
=
25
;
// for CostLayers
optional
double
coeff
=
26
[
default
=
1.0
];
optional
double
coeff
=
26
[
default
=
1.0
];
// for AverageLayer
// can be set to: 'average', 'sum' or 'squarerootn'
optional
string
average_strategy
=
27
;
// for error clipping
optional
double
error_clipping_threshold
=
28
[
default
=
0.0
];
optional
double
error_clipping_threshold
=
28
[
default
=
0.0
];
// for operators used by mixed layer
repeated
OperatorConfig
operator_confs
=
29
;
...
...
@@ -434,43 +433,44 @@ message LayerConfig {
optional
uint32
beam_size
=
39
;
// for seqlastins layer, whether select first instead last
optional
bool
select_first
=
40
[
default
=
false
];
optional
bool
select_first
=
40
[
default
=
false
];
// for seqlastins layer, AverageLayer, MaxLayer and ExpandLayer
// can be set to: 'non-seq','seq'
optional
string
trans_type
=
41
[
default
=
'non-seq'
];
optional
string
trans_type
=
41
[
default
=
'non-seq'
];
// to indicate whether selective_fc layer
// is used in sequence generation or not
optional
bool
selective_fc_pass_generation
=
42
[
default
=
false
];
optional
bool
selective_fc_pass_generation
=
42
[
default
=
false
];
// to indicate whether selective_fc layer take its last input to
// selected several columns and only compute the multiplications
// between the input matrices and the selected columns of
// the parameter matrices of this layer.
// if set false, selective_fc degrades into fc.
optional
bool
has_selected_colums
=
43
[
default
=
true
];
optional
bool
has_selected_colums
=
43
[
default
=
true
];
// this parameter is for speed consideration.
// if number of the selected columns is less than
// sample number * selective_fc output size * selective_fc_mull_mull_ratio
// sparse multiplication is used, otherwise, using full multiplication.
optional
double
selective_fc_full_mul_ratio
=
44
[
default
=
0.02
];
optional
double
selective_fc_full_mul_ratio
=
44
[
default
=
0.02
];
// to indicate how many threads selective_fc use to to accelate
// the plain_mul period
// leave empty or set to 0 to disable multi-thread accleleration
optional
uint32
selective_fc_parallel_plain_mul_thread_num
=
45
[
default
=
0
];
optional
uint32
selective_fc_parallel_plain_mul_thread_num
=
45
[
default
=
0
];
// for batch normalization layer
// if set use_global_stats true, will use the loaded mean and variance.
optional
bool
use_global_stats
=
46
;
// use to compute moving mean and variance.
optional
double
moving_average_fraction
=
47
[
default
=
0.9
];
optional
double
moving_average_fraction
=
47
[
default
=
0.9
];
// bias size
optional
uint32
bias_size
=
48
[
default
=
0
];
optional
uint32
bias_size
=
48
[
default
=
0
];
// this parameter can be used as a user-defined parameter when necessary,
// without changing the proto file.
...
...
@@ -485,18 +485,17 @@ message LayerConfig {
optional
uint64
width
=
51
;
// blank label used in ctc loss
optional
uint32
blank
=
52
[
default
=
0
];
optional
uint32
blank
=
52
[
default
=
0
];
// stride parameter for seqlastins layer, AverageLayer, MaxLayer, which
// controls the scope of pooling operation. can be set > 0.
// leave empty or set to -1 to disable this stride pooling.
optional
int32
seq_pool_stride
=
53
[
default
=
-
1
];
optional
int32
seq_pool_stride
=
53
[
default
=
-
1
];
// for crop layer
optional
int32
axis
=
54
[
default
=
2
];
optional
int32
axis
=
54
[
default
=
2
];
repeated
uint32
offset
=
55
;
repeated
uint32
shape
=
56
;
}
message
EvaluatorConfig
{
...
...
@@ -512,9 +511,9 @@ message EvaluatorConfig {
// Used by PrecisionRecallEvaluator and ClassificationErrorEvaluator
// For multi binary labels: true if output > classification_threshold
optional
double
classification_threshold
=
6
[
default
=
0.5
];
optional
double
classification_threshold
=
6
[
default
=
0.5
];
// The positive label. -1 means average precision and recall
optional
int32
positive_label
=
7
[
default
=
-
1
];
optional
int32
positive_label
=
7
[
default
=
-
1
];
// load dict from this file
optional
string
dict_file
=
8
;
...
...
@@ -523,10 +522,10 @@ message EvaluatorConfig {
optional
string
result_file
=
9
;
// top # results for max id printer
optional
int32
num_results
=
10
[
default
=
1
];
optional
int32
num_results
=
10
[
default
=
1
];
// whether to delimit the sequence in the seq_text_printer
optional
bool
delimited
=
11
[
default
=
true
];
optional
bool
delimited
=
11
[
default
=
true
];
// Used by ChunkEvaluator
// chunk of these types are not counted
...
...
@@ -534,23 +533,23 @@ message EvaluatorConfig {
// Used by ClassificationErrorEvaluator
// top # classification error
optional
int32
top_k
=
13
[
default
=
1
];
optional
int32
top_k
=
13
[
default
=
1
];
// Used by DetectionMAPEvaluator
optional
double
overlap_threshold
=
14
[
default
=
0.5
];
optional
double
overlap_threshold
=
14
[
default
=
0.5
];
optional
int32
background_id
=
15
[
default
=
0
];
optional
int32
background_id
=
15
[
default
=
0
];
optional
bool
evaluate_difficult
=
16
[
default
=
false
];
optional
bool
evaluate_difficult
=
16
[
default
=
false
];
optional
string
ap_type
=
17
[
default
=
"11point"
];
optional
string
ap_type
=
17
[
default
=
"11point"
];
}
message
LinkConfig
{
required
string
layer_name
=
1
;
required
string
link_name
=
2
;
// If true, this link has sub-sequence
optional
bool
has_subseq
=
3
[
default
=
false
];
optional
bool
has_subseq
=
3
[
default
=
false
];
}
message
MemoryConfig
{
...
...
@@ -563,18 +562,18 @@ message MemoryConfig {
optional
uint32
boot_with_const_id
=
7
;
// memory is a sequence, initailized by a sequence boot layer
optional
bool
is_sequence
=
6
[
default
=
false
];
optional
bool
is_sequence
=
6
[
default
=
false
];
}
message
GeneratorConfig
{
required
uint32
max_num_frames
=
1
;
required
string
eos_layer_name
=
2
;
optional
int32
num_results_per_sample
=
3
[
default
=
1
];
optional
int32
num_results_per_sample
=
3
[
default
=
1
];
// for beam search
optional
int32
beam_size
=
4
[
default
=
1
];
optional
int32
beam_size
=
4
[
default
=
1
];
optional
bool
log_prob
=
5
[
default
=
true
];
optional
bool
log_prob
=
5
[
default
=
true
];
}
message
SubModelConfig
{
...
...
@@ -584,10 +583,10 @@ message SubModelConfig {
repeated
string
output_layer_names
=
4
;
repeated
string
evaluator_names
=
5
;
optional
bool
is_recurrent_layer_group
=
6
[
default
=
false
];
optional
bool
is_recurrent_layer_group
=
6
[
default
=
false
];
// If true, the recurrence runs from the end to the beginning.
optional
bool
reversed
=
7
[
default
=
false
];
optional
bool
reversed
=
7
[
default
=
false
];
// name and link name of memory
repeated
MemoryConfig
memories
=
8
;
...
...
@@ -601,14 +600,15 @@ message SubModelConfig {
optional
GeneratorConfig
generator
=
11
;
// the id of inlink which share info with outlinks, used in recurrent layer group
// the id of inlink which share info with outlinks, used in recurrent layer
// group
optional
int32
target_inlinkid
=
12
;
}
message
ModelConfig
{
// type of the model.
// Currently, "nn", "recurrent_nn" and "recursive_nn" are supported
required
string
type
=
1
[
default
=
"nn"
];
required
string
type
=
1
[
default
=
"nn"
];
// layers should be ordered in such a way that the forward propagation
// can be correctly executed by going from the first layer to the last layer
...
...
proto/OptimizerConfig.proto
浏览文件 @
59a8ebc6
syntax
=
"proto2"
;
option
optimize_for
=
LITE_RUNTIME
;
package
paddle
;
...
...
@@ -9,13 +9,11 @@ message SGDConfig {
// momentum: float >= 0. Parameter updates momentum.
// decay: float >= 0. Learning rate decay over each update.
// nesterov: boolean. Whether to apply Nesterov momentum.
optional
double
momentum
=
21
[
default
=
0.0
];
optional
double
decay
=
23
[
default
=
0.0
];
optional
bool
nesterov
=
24
[
default
=
false
];
optional
double
momentum
=
21
[
default
=
0.0
];
optional
double
decay
=
23
[
default
=
0.0
];
optional
bool
nesterov
=
24
[
default
=
false
];
}
message
AdadeltaConfig
{
// Adadelta
// It is recommended to leave it at the default value.
...
...
@@ -23,21 +21,23 @@ message AdadeltaConfig {
// epsilon: float >= 0. Fuzz factor.
// decay: float >= 0. Learning rate decay over each update.
// reference : [Adadelta - an adaptive learning rate
method](http://arxiv.org/abs/1212.5701)
optional
double
rho
=
33
[
default
=
0.90
];
optional
double
epsilon
=
31
[
default
=
1e-5
];
optional
double
decay
=
32
[
default
=
0.0
];
// reference : [Adadelta - an adaptive learning rate
// method](http://arxiv.org/abs/1212.5701)
optional
double
rho
=
33
[
default
=
0.90
];
optional
double
epsilon
=
31
[
default
=
1e-5
];
optional
double
decay
=
32
[
default
=
0.0
];
}
message
AdagradConfig
{
// Adagrad
// epsilon: float >= 0.
// decay: float >= 0. Learning rate decay over each update.
// Adagrad
// epsilon: float >= 0.
// decay: float >= 0. Learning rate decay over each update.
// reference : [Adaptive Subgradient Methods for Online Learning and Stochastic Optimization](http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf)
optional
double
epsilon
=
41
[
default
=
1e-5
];
optional
double
decay
=
42
[
default
=
0.0
];
// reference : [Adaptive Subgradient Methods for Online Learning and
// Stochastic
// Optimization](http://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf)
optional
double
epsilon
=
41
[
default
=
1e-5
];
optional
double
decay
=
42
[
default
=
0.0
];
}
message
AdamConfig
{
...
...
@@ -46,7 +46,8 @@ message AdamConfig {
// beta_2: float, 0 < beta < 1. Generally close to 1.
// epsilon: float >= 0. Fuzz factor.
// decay: float >= 0. Learning rate decay over each update.
// reference : [Adam - A Method for Stochastic Optimization](http://arxiv.org/abs/1412.6980v8)
// reference : [Adam - A Method for Stochastic
// Optimization](http://arxiv.org/abs/1412.6980v8)
optional
double
beta_1
=
41
;
optional
double
beta_2
=
42
;
optional
double
epsilon
=
43
;
...
...
@@ -55,32 +56,32 @@ message AdamConfig {
message
ConstLrConfig
{
// learninRate Policy
optional
double
learning_rate
=
1
[
default
=
1.0
];
optional
double
learning_rate
=
1
[
default
=
1.0
];
}
message
LinearLrConfig
{
// learninRate Policy
optional
double
learning_rate
=
1
[
default
=
1.0
];
optional
double
learning_rate
=
1
[
default
=
1.0
];
optional
double
lr_decay_a
=
2
;
optional
double
lr_decay_b
=
3
;
}
message
TensorProto
{
enum
DataType
{
PADDLE_ELEMENT_TYPE_INT32
=
0
;
PADDLE_ELEMENT_TYPE_UINT32
=
1
;
PADDLE_ELEMENT_TYPE_INT64
=
2
;
PADDLE_ELEMENT_TYPE_UINT64
=
3
;
PADDLE_ELEMENT_TYPE_FLOAT32
=
4
;
PADDLE_ELEMENT_TYPE_FLOAT64
=
5
;
}
enum
DataType
{
PADDLE_ELEMENT_TYPE_INT32
=
0
;
PADDLE_ELEMENT_TYPE_UINT32
=
1
;
PADDLE_ELEMENT_TYPE_INT64
=
2
;
PADDLE_ELEMENT_TYPE_UINT64
=
3
;
PADDLE_ELEMENT_TYPE_FLOAT32
=
4
;
PADDLE_ELEMENT_TYPE_FLOAT64
=
5
;
}
optional
DataType
data_type
=
1
;
repeated
bytes
content
=
2
;
}
message
LrPolicyState
{
// learninRate Policy
optional
double
learning_rate
=
1
[
default
=
1.0
];
optional
double
learning_rate
=
1
[
default
=
1.0
];
optional
double
lr_decay_a
=
2
;
optional
double
lr_decay_b
=
3
;
}
...
...
@@ -104,7 +105,6 @@ message AdadeltaOptimizerState {
optional
TensorProto
update_delta
=
4
;
}
message
AdagradOptimizerState
{
optional
LrPolicyState
lr_state
=
101
;
optional
double
num_sample_passed
=
104
;
...
...
@@ -124,10 +124,10 @@ message AdamOptimizerState {
message
OptimizerConfig
{
enum
Optimizer
{
SGD
=
1
;
Adadelta
=
2
;
Adagrad
=
3
;
Adam
=
4
;
SGD
=
1
;
Adadelta
=
2
;
Adagrad
=
3
;
Adam
=
4
;
}
optional
Optimizer
optimizer
=
1
;
optional
SGDConfig
sgd
=
3
;
...
...
@@ -136,8 +136,8 @@ message OptimizerConfig {
optional
AdamConfig
adam
=
6
;
enum
LrPolicy
{
Const
=
0
;
Linear
=
1
;
Const
=
0
;
Linear
=
1
;
}
optional
LrPolicy
lr_policy
=
11
;
optional
ConstLrConfig
const_lr
=
12
;
...
...
proto/ParameterConfig.proto
浏览文件 @
59a8ebc6
...
...
@@ -27,56 +27,57 @@ enum ParameterInitStrategy {
message
ParameterUpdaterHookConfig
{
// hook type such as 'pruning'
required
string
type
=
1
;
// this represents the ratio of zero element to be set by the Parameter
optional
double
sparsity_ratio
=
2
[
default
=
0.6
];
// this represents the ratio of zero element to be set by the Parameter
optional
double
sparsity_ratio
=
2
[
default
=
0.6
];
}
message
ParameterConfig
{
required
string
name
=
1
;
required
uint64
size
=
2
;
optional
double
learning_rate
=
3
[
default
=
1.0
];
optional
double
momentum
=
4
[
default
=
0.0
];
optional
double
initial_mean
=
5
[
default
=
0.0
];
optional
double
initial_std
=
6
[
default
=
0.01
];
optional
double
learning_rate
=
3
[
default
=
1.0
];
optional
double
momentum
=
4
[
default
=
0.0
];
optional
double
initial_mean
=
5
[
default
=
0.0
];
optional
double
initial_std
=
6
[
default
=
0.01
];
// use L2-regularization if decay_rate set and decay_rate_l1 not set
optional
double
decay_rate
=
7
[
default
=
0.0
];
optional
double
decay_rate
=
7
[
default
=
0.0
];
// use L1-regularization if decay_rate_l1 set
optional
double
decay_rate_l1
=
8
[
default
=
0.0
];
optional
double
decay_rate_l1
=
8
[
default
=
0.0
];
// dims of Parameter, e.g. dims[0] as height, dims[1] as width..
repeated
uint64
dims
=
9
;
// the gpu device which the parameter in.
// Only used by ParallelNeuralNetork. Ignored otherwise.
optional
int32
device
=
10
[
default
=
-
1
];
optional
int32
device
=
10
[
default
=
-
1
];
// how to init the parameter: 0 -> normal, 1 -> uniform
// 0: treat initial_mean as mean, intial_std as standard deviation
// 1: range is (initial_mean - initial_std) to (initial_mean + initial_std)
optional
int32
initial_strategy
=
11
[
default
=
0
];
optional
int32
initial_strategy
=
11
[
default
=
0
];
// define the variance when init the parameter, by height of the Matrix
optional
bool
initial_smart
=
12
[
default
=
false
];
optional
bool
initial_smart
=
12
[
default
=
false
];
// apply regularization every # batches
optional
int32
num_batches_regularization
=
13
[
default
=
1
];
optional
int32
num_batches_regularization
=
13
[
default
=
1
];
// if is_sparse is true, para is sparse, else para is dense
optional
bool
is_sparse
=
14
[
default
=
false
];
// if para is sparse, format should be "csc" or "csr", empty means is not sparse
optional
string
format
=
15
[
default
=
""
];
optional
bool
is_sparse
=
14
[
default
=
false
];
// if para is sparse, format should be "csc" or "csr", empty means is not
// sparse
optional
string
format
=
15
[
default
=
""
];
// sparse remote update or not
optional
bool
sparse_remote_update
=
16
[
default
=
false
];
optional
bool
sparse_remote_update
=
16
[
default
=
false
];
// gradient clipping threshold, no clipping by default
optional
double
gradient_clipping_threshold
=
17
[
default
=
0.0
];
optional
double
gradient_clipping_threshold
=
17
[
default
=
0.0
];
// static parameters are fixed when training
optional
bool
is_static
=
18
[
default
=
false
];
optional
bool
is_static
=
18
[
default
=
false
];
// para_id should NOT be set by config_parser. It is for
// internal use.
optional
uint64
para_id
=
19
;
repeated
ParameterUpdaterHookConfig
update_hooks
=
20
;
// setup load mat -> csr
optional
bool
need_compact
=
21
[
default
=
false
];
optional
bool
need_compact
=
21
[
default
=
false
];
// whether to do sparse update for this parameter
optional
bool
sparse_update
=
22
[
default
=
false
];
optional
bool
sparse_update
=
22
[
default
=
false
];
// whether this parameter is shared or not.
optional
bool
is_shared
=
23
[
default
=
false
];
optional
bool
is_shared
=
23
[
default
=
false
];
// parameter block size
optional
uint64
parameter_block_size
=
24
[
default
=
0
];
optional
uint64
parameter_block_size
=
24
[
default
=
0
];
}
proto/ParameterServerConfig.proto
浏览文件 @
59a8ebc6
...
...
@@ -15,13 +15,10 @@ syntax = "proto2";
package
paddle
;
/**
* Configuration structure for ParameterClient2.
*/
message
ParameterClientConfig
{
required
int32
trainer_id
=
1
;
}
message
ParameterClientConfig
{
required
int32
trainer_id
=
1
;
}
/**
* Configuration structure for ParameterServer2.
...
...
@@ -30,24 +27,24 @@ message ParameterServerConfig {
// Number of ports for sending dense parameter,
// following ports on parameter server will be visited
// for sending dense parameter: [port, port+ports_num-1]
required
int32
ports_num
=
1
[
default
=
1
];
required
int32
ports_num
=
1
[
default
=
1
];
// Number of ports for sending sparse parameter,
// following ports on parameter server will be visited
// for sending sparse parameter:
// [port+ports_num, port+ports_num+ports_num_for_sparse-1]
required
int32
ports_num_for_sparse
=
2
[
default
=
0
];
required
int32
ports_num_for_sparse
=
2
[
default
=
0
];
// network device name for pservers
required
string
nics
=
3
[
default
=
"xgbe0,xgbe1"
];
required
string
rdma_tcp
=
4
[
default
=
"tcp"
];
required
string
nics
=
3
[
default
=
"xgbe0,xgbe1"
];
required
string
rdma_tcp
=
4
[
default
=
"tcp"
];
// Listening port for pserver
required
int32
port
=
5
[
default
=
20134
];
required
int32
port
=
5
[
default
=
20134
];
// number of gradient servers
required
int32
num_gradient_servers
=
6
[
default
=
1
];
required
int32
num_gradient_servers
=
6
[
default
=
1
];
// number of threads for sync op exec
required
int32
pserver_num_threads
=
7
[
default
=
1
];
required
int32
pserver_num_threads
=
7
[
default
=
1
];
// control config_.async_lagged_grad_discard_ratio() min value
required
double
async_lagged_ratio_min
=
8
[
default
=
1.0
];
required
double
async_lagged_ratio_min
=
8
[
default
=
1.0
];
// if async_lagged_grad_discard_ratio is not set in trainer_config.conf
// use it as defalut value
required
double
async_lagged_ratio_default
=
9
[
default
=
1.5
];
required
double
async_lagged_ratio_default
=
9
[
default
=
1.5
];
}
\ No newline at end of file
proto/ParameterService.proto
浏览文件 @
59a8ebc6
...
...
@@ -23,8 +23,8 @@ package paddle;
*/
enum
ParameterUpdateMode
{
// Set parameter
PSERVER_UPDATE_MODE_SET_PARAM
=
0
;
//
use local param
PSERVER_UPDATE_MODE_SET_PARAM_ZERO
=
1
;
//
set zero param
PSERVER_UPDATE_MODE_SET_PARAM
=
0
;
//
use local param
PSERVER_UPDATE_MODE_SET_PARAM_ZERO
=
1
;
//
set zero param
// Update parameter once a gradient is received
PSERVER_UPDATE_MODE_ASYNC_SGD
=
2
;
...
...
@@ -37,7 +37,7 @@ enum ParameterUpdateMode {
// No update. Only get parameters back.
PSERVER_UPDATE_MODE_GET_PARAM
=
5
;
PSERVER_UPDATE_MODE_GET_PARAM_SPARSE
=
6
;
//
only get sparse rows
PSERVER_UPDATE_MODE_GET_PARAM_SPARSE
=
6
;
//
only get sparse rows
};
message
ParameterBlock
{
...
...
@@ -80,42 +80,34 @@ message SendParameterRequest {
optional
int32
trainer_id
=
7
;
// send back parameter type on pserver, PARAMETER_VALUE by default
optional
int32
send_back_parameter_type
=
8
[
default
=
0
];
optional
int32
send_back_parameter_type
=
8
[
default
=
0
];
// forwardbackward time in usec
optional
uint64
forwardbackward_time
=
9
;
}
message
WaitPassStartRequest
{
}
message
WaitPassStartRequest
{}
message
WaitPassStartResponse
{
}
message
WaitPassStartResponse
{}
message
WaitPassFinishRequest
{
}
message
WaitPassFinishRequest
{}
message
WaitPassFinishResponse
{
}
message
WaitPassFinishResponse
{}
enum
SyncObject
{
SYNC_DEFAULT
=
0
;
// wait for the synchronizeBarrier_
SYNC_DATA
=
1
;
// wait for the synchronizeDataBarrier_
SYNC_DATA
=
1
;
// wait for the synchronizeDataBarrier_
}
message
SynchronizeRequest
{
required
SyncObject
sync_object_id
=
1
[
default
=
SYNC_DEFAULT
];
required
SyncObject
sync_object_id
=
1
[
default
=
SYNC_DEFAULT
];
optional
int32
trainer_id
=
2
;
}
message
SynchronizeResponse
{
}
message
SynchronizeResponse
{}
message
SendParameterResponse
{
repeated
ParameterBlock
blocks
=
1
;
}
message
SendParameterResponse
{
repeated
ParameterBlock
blocks
=
1
;
}
message
SetConfigRequest
{
repeated
ParameterConfig
param_configs
=
1
;
...
...
@@ -125,26 +117,18 @@ message SetConfigRequest {
required
bool
is_sparse_server
=
6
;
}
message
SetConfigResponse
{
}
message
SetConfigResponse
{}
message
GetStatusRequest
{
}
message
GetStatusRequest
{}
message
GetStatusResponse
{
required
PServerStatus
status
=
1
;
}
message
GetStatusResponse
{
required
PServerStatus
status
=
1
;
}
message
SetStatusRequest
{
required
PServerStatus
status
=
1
;
}
message
SetStatusRequest
{
required
PServerStatus
status
=
1
;
}
message
SetStatusResponse
{
}
message
SetStatusResponse
{}
// create a column vector. The size is the dimension of parameter
message
CreateVectorRequest
{
}
message
CreateVectorRequest
{}
message
CreateVectorResponse
{
// error message. Empty if success
...
...
@@ -153,9 +137,7 @@ message CreateVectorResponse {
required
int64
handle
=
2
;
}
message
ReleaseVectorRequest
{
required
int64
handle
=
1
;
}
message
ReleaseVectorRequest
{
required
int64
handle
=
1
;
}
message
ReleaseVectorResponse
{
// error message. Empty if success
...
...
@@ -164,9 +146,7 @@ message ReleaseVectorResponse {
// Create a column major matrix. The number of rows is the dimension
// of parameter. The number of columns is specifed by num_cols
message
CreateMatrixRequest
{
required
int32
num_cols
=
1
;
}
message
CreateMatrixRequest
{
required
int32
num_cols
=
1
;
}
message
CreateMatrixResponse
{
// error message. Empty if success
...
...
@@ -175,16 +155,13 @@ message CreateMatrixResponse {
required
int64
handle
=
2
;
}
message
ReleaseMatrixRequest
{
required
int64
handle
=
1
;
}
message
ReleaseMatrixRequest
{
required
int64
handle
=
1
;
}
message
ReleaseMatrixResponse
{
// error message. Empty if success
optional
string
return_message
=
1
;
}
/**
* The operations are defined using the variables commented at Operation
* and OperationResult
...
...
@@ -245,36 +222,36 @@ enum MatrixVectorOperation {
message
ProtoVector
{
required
int64
dim
=
1
;
repeated
double
values
=
2
[
packed
=
true
];
repeated
double
values
=
2
[
packed
=
true
];
}
message
ProtoMatrix
{
required
int64
num_rows
=
1
;
required
int64
num_cols
=
2
;
repeated
double
values
=
3
[
packed
=
true
];
repeated
double
values
=
3
[
packed
=
true
];
}
message
Operation
{
required
MatrixVectorOperation
operation
=
1
;
// vector handles created on the pserver
repeated
int64
pvectors
=
2
;
// u, v, w
repeated
int64
pvectors
=
2
;
// u, v, w
// matrix handles created on the pserver
repeated
int64
pmatrices
=
3
;
// A, B, C
repeated
int64
pmatrices
=
3
;
// A, B, C
repeated
double
scalars
=
4
;
// a, b, c
repeated
ProtoVector
vectors
=
5
;
// x, y, z
repeated
ProtoMatrix
matrices
=
6
;
// X, Y, Z
repeated
double
scalars
=
4
;
// a, b, c
repeated
ProtoVector
vectors
=
5
;
// x, y, z
repeated
ProtoMatrix
matrices
=
6
;
// X, Y, Z
}
message
OperationResult
{
// error message. Empty if success
optional
string
return_message
=
1
;
//
repeated
double
scalars
=
2
;
// d, e, f
//
repeated
double
scalars
=
2
;
// d, e, f
repeated
ProtoVector
vectors
=
3
;
// p, q, r
repeated
ProtoMatrix
matrices
=
4
;
// P, Q, R
repeated
ProtoMatrix
matrices
=
4
;
// P, Q, R
}
message
DoOperationRequest
{
...
...
@@ -301,18 +278,14 @@ message DoOperationResponse {
required
bool
pass_finish
=
3
;
}
message
LoadValueRequest
{
required
string
dir_name
=
1
;
}
message
LoadValueRequest
{
required
string
dir_name
=
1
;
}
message
LoadValueResponse
{
// error message. Empty if success
optional
string
return_message
=
1
;
}
message
SaveValueRequest
{
required
string
dir_name
=
1
;
}
message
SaveValueRequest
{
required
string
dir_name
=
1
;
}
message
SaveValueResponse
{
// error message. Empty if success
...
...
@@ -331,11 +304,11 @@ enum DataUpdateMode {
// Client send it's own ref label to pserver
DATA_UPDATE_MODE_SET_REF_LABEL
=
4
;
// Client get all ref labels from all pservers
DATA_UPDATE_MODE_GET_REF_LABEL
=
5
;
DATA_UPDATE_MODE_GET_REF_LABEL
=
5
;
// Client send it's own ref grad to pserver
DATA_UPDATE_MODE_SET_REF_GRAD
=
6
;
DATA_UPDATE_MODE_SET_REF_GRAD
=
6
;
// Client get all ref grad from all pservers
DATA_UPDATE_MODE_GET_REF_GRAD
=
7
;
DATA_UPDATE_MODE_GET_REF_GRAD
=
7
;
}
enum
SendDataType
{
...
...
@@ -360,7 +333,7 @@ message DataBlock {
// byte size of one data type
required
int32
data_size
=
2
;
// data_type
optional
TransDataType
data_type
=
3
[
default
=
TRANS_DOUBLE
];
optional
TransDataType
data_type
=
3
[
default
=
TRANS_DOUBLE
];
}
message
SendDataRequest
{
...
...
proto/TrainerConfig.proto
浏览文件 @
59a8ebc6
...
...
@@ -20,14 +20,14 @@ package paddle;
message
OptimizationConfig
{
required
int32
batch_size
=
3
;
required
string
algorithm
=
4
[
default
=
"async_sgd"
];
optional
int32
num_batches_per_send_parameter
=
5
[
default
=
1
];
optional
int32
num_batches_per_get_parameter
=
6
[
default
=
1
];
required
string
algorithm
=
4
[
default
=
"async_sgd"
];
optional
int32
num_batches_per_send_parameter
=
5
[
default
=
1
];
optional
int32
num_batches_per_get_parameter
=
6
[
default
=
1
];
required
double
learning_rate
=
7
;
optional
double
learning_rate_decay_a
=
8
[
default
=
0
];
optional
double
learning_rate_decay_b
=
9
[
default
=
0
];
optional
string
learning_rate_schedule
=
27
[
default
=
"constant"
];
optional
double
learning_rate_decay_a
=
8
[
default
=
0
];
optional
double
learning_rate_decay_b
=
9
[
default
=
0
];
optional
string
learning_rate_schedule
=
27
[
default
=
"constant"
];
// learning rate will be scaled according to learning_rate_schedule
// 1), constant:
// lr = learning_rate
...
...
@@ -49,88 +49,92 @@ message OptimizationConfig {
// owlqn related
// L1-regularization
optional
double
l1weight
=
10
[
default
=
0.1
];
optional
double
l1weight
=
10
[
default
=
0.1
];
// L2-regularization
optional
double
l2weight
=
11
[
default
=
0
];
optional
double
l2weight
=
11
[
default
=
0
];
// "c1" in wolfe condition: if (newobj <= oldobj + c1 * origDirDeriv * step)
// then accept the step
optional
double
c1
=
12
[
default
=
0.0001
];
optional
double
c1
=
12
[
default
=
0.0001
];
// multiply the step with "backoff", when wolfe condition doesn't satisfy
optional
double
backoff
=
13
[
default
=
0.5
];
optional
double
backoff
=
13
[
default
=
0.5
];
// how many "s"s and "y"s are kept in owlqn
optional
int32
owlqn_steps
=
14
[
default
=
10
];
optional
int32
owlqn_steps
=
14
[
default
=
10
];
// accept the step if encountered "max_backoff" times of "reduce the step"
optional
int32
max_backoff
=
15
[
default
=
5
];
optional
int32
max_backoff
=
15
[
default
=
5
];
// L2-regularization coefficient is reduced linearly from iteration 0 to
// "l2weight_zero_iter", and set to 0 after "l2weight_zero_iter"
// iterations. set "l2weight_zero_iter" to 0 to disable this strategy.
optional
int32
l2weight_zero_iter
=
17
[
default
=
0
];
optional
int32
l2weight_zero_iter
=
17
[
default
=
0
];
// averaged sgd
// About average_window * numBatchProcessed parameter are used
// for average. To be accurate, between average_window * numBatchProcessed
// and 2 * average_window * numBatchProcessed parameters are used for
// average.
optional
double
average_window
=
18
[
default
=
0
];
optional
int64
max_average_window
=
19
[
default
=
0x7fffffffffffffff
];
optional
double
average_window
=
18
[
default
=
0
];
optional
int64
max_average_window
=
19
[
default
=
0x7fffffffffffffff
];
//////////////////////////
// Options Adaptive SGD //
//////////////////////////
// learning method for sgd/asgd, such as "momentum", "adagrad", "adadelta", "rmsprop"
// default learning method("momentum") use global decayed learning rate with momentum.
// learning method for sgd/asgd, such as "momentum", "adagrad", "adadelta",
// "rmsprop"
// default learning method("momentum") use global decayed learning rate with
// momentum.
// "adagrad", "adadelta" and "rmsprop" can set momentum too.
optional
string
learning_method
=
23
[
default
=
"momentum"
];
optional
double
ada_epsilon
=
24
[
default
=
1e-6
];
optional
double
ada_rou
=
26
[
default
=
0.95
];
optional
string
learning_method
=
23
[
default
=
"momentum"
];
optional
double
ada_epsilon
=
24
[
default
=
1e-6
];
optional
double
ada_rou
=
26
[
default
=
0.95
];
// Force to do average in cpu in order to save gpu memory usage
optional
bool
do_average_in_cpu
=
25
[
default
=
false
];
optional
bool
do_average_in_cpu
=
25
[
default
=
false
];
// delta add rate in pserver, used while num_batches_per_send_parameter>1
// will be divided by #machines automatically.
optional
double
delta_add_rate
=
28
[
default
=
1.0
];
optional
double
delta_add_rate
=
28
[
default
=
1.0
];
// We split a large size into smaller mini-batches, whose sizes are
// determined by mini_batch_size. It only takes effect when there is
// an ExternalMachine.
optional
int32
mini_batch_size
=
29
[
default
=
128
];
optional
int32
mini_batch_size
=
29
[
default
=
128
];
// automatically set if any one of parameters set sparse remote update flag
optional
bool
use_sparse_remote_updater
=
30
[
default
=
false
];
optional
bool
use_sparse_remote_updater
=
30
[
default
=
false
];
// how to update center parameter and feedback to local parameter,
// how to update center parameter and feedback to local parameter,
// when use local sgd update in cluster training.
// A option is elastic_average, proposed by the paper: Deep learning with elastic averaging SGD.
// If use elastic_average method, every trainer node should sample from whole data sets.
optional
string
center_parameter_update_method
=
31
[
default
=
"average"
];
// A option is elastic_average, proposed by the paper: Deep learning with
// elastic averaging SGD.
// If use elastic_average method, every trainer node should sample from whole
// data sets.
optional
string
center_parameter_update_method
=
31
[
default
=
"average"
];
// shrink sparse parameter value
// only works if parameter is remote sparse update and has L1 decay rate
optional
double
shrink_parameter_value
=
32
[
default
=
0
];
optional
double
shrink_parameter_value
=
32
[
default
=
0
];
////////////////////////////
// Options Adam Optimizer //
////////////////////////////
optional
double
adam_beta1
=
33
[
default
=
0.9
];
optional
double
adam_beta2
=
34
[
default
=
0.999
];
optional
double
adam_epsilon
=
35
[
default
=
1e-8
];
optional
double
adam_beta1
=
33
[
default
=
0.9
];
optional
double
adam_beta2
=
34
[
default
=
0.999
];
optional
double
adam_epsilon
=
35
[
default
=
1e-8
];
// arguments for learning rate scheduler
// Format: num1:rate1,num2:rate2,...,numK:rateK
// For learning_rate_schedule="manual", num is the number of samples,
// For learning_rate_schedule="pass_manual",
// num is the number of passes (starting from 0)
optional
string
learning_rate_args
=
36
[
default
=
""
];
optional
string
learning_rate_args
=
36
[
default
=
""
];
// for async sgd gradient commit control.
// when async_lagged_grad_discard_ratio * num_gradient_servers commit passed,
// current async gradient will be discard silently.
optional
double
async_lagged_grad_discard_ratio
=
37
[
default
=
1.5
];
optional
double
async_lagged_grad_discard_ratio
=
37
[
default
=
1.5
];
// global threshold for gradient clipping
optional
double
gradient_clipping_threshold
=
38
[
default
=
0.0
];
// global threshold for gradient clipping
optional
double
gradient_clipping_threshold
=
38
[
default
=
0.0
];
};
message
TrainerConfig
{
...
...
@@ -141,7 +145,7 @@ message TrainerConfig {
repeated
string
config_files
=
5
;
// the directory to save/load model files for each training path
optional
string
save_dir
=
6
[
default
=
"./output/model"
];
optional
string
save_dir
=
6
[
default
=
"./output/model"
];
// Path of the initial model parameters.
// If it was set, start_pass will be ignored.
...
...
@@ -149,7 +153,7 @@ message TrainerConfig {
// Start training from this pass.
// Will load parameter from the previous pass.
optional
int32
start_pass
=
8
[
default
=
0
];
optional
int32
start_pass
=
8
[
default
=
0
];
// file path to the trainer config file
optional
string
config_file
=
9
;
...
...
python/paddle/v2/framework/create_op_creation_methods.py
浏览文件 @
59a8ebc6
import
paddle.v2.framework.core
as
core
import
paddle.v2.framework.proto.op_proto_pb2
as
op_proto_pb2
import
paddle.v2.framework.proto.op_desc_pb2
as
op_desc_pb2
import
paddle.v2.framework.proto.attr
_type_pb2
as
attr_typ
e_pb2
import
paddle.v2.framework.proto.attr
ibute_pb2
as
attribut
e_pb2
import
cStringIO
...
...
@@ -57,7 +57,7 @@ class OpDescCreationMethod(object):
op_desc
.
attrs
.
extend
([
out_format
])
if
len
(
tmp_index
)
!=
0
:
tmp_index_attr
=
op_desc
.
attrs
.
add
()
tmp_index_attr
.
type
=
attr
_typ
e_pb2
.
INTS
tmp_index_attr
.
type
=
attr
ibut
e_pb2
.
INTS
tmp_index_attr
.
name
=
"temporary_index"
tmp_index_attr
.
ints
.
extend
(
tmp_index
)
...
...
@@ -73,17 +73,17 @@ class OpDescCreationMethod(object):
new_attr
=
op_desc
.
attrs
.
add
()
new_attr
.
name
=
attr
.
name
new_attr
.
type
=
attr
.
type
if
attr
.
type
==
attr
_typ
e_pb2
.
INT
:
if
attr
.
type
==
attr
ibut
e_pb2
.
INT
:
new_attr
.
i
=
user_defined_attr
elif
attr
.
type
==
attr
_typ
e_pb2
.
FLOAT
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
FLOAT
:
new_attr
.
f
=
user_defined_attr
elif
attr
.
type
==
attr
_typ
e_pb2
.
STRING
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
STRING
:
new_attr
.
s
=
user_defined_attr
elif
attr
.
type
==
attr
_typ
e_pb2
.
INTS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
INTS
:
new_attr
.
ints
.
extend
(
user_defined_attr
)
elif
attr
.
type
==
attr
_typ
e_pb2
.
FLOATS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
FLOATS
:
new_attr
.
floats
.
extend
(
user_defined_attr
)
elif
attr
.
type
==
attr
_typ
e_pb2
.
STRINGS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
STRINGS
:
new_attr
.
strings
.
extend
(
user_defined_attr
)
else
:
raise
NotImplementedError
(
"Not support attribute type "
+
...
...
@@ -109,7 +109,7 @@ class OpDescCreationMethod(object):
retv
=
[]
if
multiple
:
var_format
=
op_desc_pb2
.
AttrDesc
()
var_format
.
type
=
attr
_typ
e_pb2
.
INTS
var_format
.
type
=
attr
ibut
e_pb2
.
INTS
var_format
.
name
=
"%s_format"
%
in_out
var_format
.
ints
.
append
(
0
)
...
...
@@ -185,17 +185,17 @@ def get_docstring_from_op_proto(op_proto):
for
attr
in
op_proto
.
attrs
:
attr_type
=
None
if
attr
.
type
==
attr
_typ
e_pb2
.
INT
:
if
attr
.
type
==
attr
ibut
e_pb2
.
INT
:
attr_type
=
"int"
elif
attr
.
type
==
attr
_typ
e_pb2
.
FLOAT
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
FLOAT
:
attr_type
=
"float"
elif
attr
.
type
==
attr
_typ
e_pb2
.
STRING
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
STRING
:
attr_type
=
"basestr"
elif
attr
.
type
==
attr
_typ
e_pb2
.
INTS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
INTS
:
attr_type
=
"list of int"
elif
attr
.
type
==
attr
_typ
e_pb2
.
FLOATS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
FLOATS
:
attr_type
=
"list of float"
elif
attr
.
type
==
attr
_typ
e_pb2
.
STRINGS
:
elif
attr
.
type
==
attr
ibut
e_pb2
.
STRINGS
:
attr_type
=
"list of basestr"
if
attr_type
is
None
:
...
...
python/paddle/v2/framework/tests/CMakeLists.txt
浏览文件 @
59a8ebc6
add_python_test
(
test_framework
test_protobuf.py
test_scope.py
test_default_scope_funcs.py
test_op_creation_methods.py
test_net.py
test_tensor.py
test_fc_op.py
test_add_two_op.py
test_sgd_op.py
test_mul_op.py
test_mean_op.py
test_sigmoid_op.py
test_softmax_op.py
test_rowwise_add_op.py
test_network.py
gradient_checker.py
)
py_test
(
test_net SRCS test_net.py
)
py_test
(
test_fc_op SRCS test_fc_op.py
)
py_test
(
test_scope SRCS test_scope.py
)
py_test
(
test_tensor SRCS test_tensor.py
)
py_test
(
test_mul_op SRCS test_mul_op.py
)
py_test
(
test_network SRCS test_network.py
)
py_test
(
test_mean_op SRCS test_mean_op.py
)
py_test
(
test_protobuf SRCS test_protobuf.py
)
py_test
(
test_add_two_op SRCS test_add_two_op.py
)
py_test
(
test_sigmoid_op SRCS test_sigmoid_op.py
)
py_test
(
test_softmax_op SRCS test_softmax_op.py
)
py_test
(
gradient_checker SRCS gradient_checker.py
)
py_test
(
test_rowwise_add_op SRCS test_rowwise_add_op.py
)
py_test
(
test_default_scope_funcs SRCS test_default_scope_funcs.py
)
py_test
(
test_op_creation_methods SRCS test_op_creation_methods.py
)
python/paddle/v2/framework/tests/op_test_util.py
浏览文件 @
59a8ebc6
...
...
@@ -33,23 +33,28 @@ class OpTestMeta(type):
for
place
in
places
:
for
in_name
in
func
.
all_input_args
:
if
hasattr
(
self
,
in_name
)
:
if
hasattr
(
self
,
"inputs"
)
and
in_name
in
self
.
inputs
:
kwargs
[
in_name
]
=
in_name
var
=
scope
.
new_var
(
in_name
).
get_tensor
()
arr
=
getattr
(
self
,
in_name
)
arr
=
self
.
inputs
[
in_name
]
var
.
set_dims
(
arr
.
shape
)
var
.
set
(
arr
,
place
)
else
:
kwargs
[
in_name
]
=
"@EMPTY@"
for
out_name
in
func
.
all_output_args
:
if
hasattr
(
self
,
out_name
):
kwargs
[
out_name
]
=
out_name
scope
.
new_var
(
out_name
).
get_tensor
()
if
not
hasattr
(
self
,
"outputs"
):
raise
ValueError
(
"The test op must set self.outputs dict."
)
if
out_name
not
in
self
.
outputs
:
raise
ValueError
(
"The %s is not in self.outputs dict."
%
(
out_name
))
kwargs
[
out_name
]
=
out_name
scope
.
new_var
(
out_name
).
get_tensor
()
for
attr_name
in
func
.
all_attr_args
:
if
hasattr
(
self
,
attr_name
)
:
kwargs
[
attr_name
]
=
getattr
(
self
,
attr_name
)
if
hasattr
(
self
,
"attrs"
)
and
attr_name
in
self
.
attrs
:
kwargs
[
attr_name
]
=
self
.
attrs
[
attr_name
]
op
=
func
(
**
kwargs
)
...
...
@@ -60,11 +65,8 @@ class OpTestMeta(type):
for
out_name
in
func
.
all_output_args
:
actual
=
numpy
.
array
(
scope
.
find_var
(
out_name
).
get_tensor
())
expect
=
getattr
(
self
,
out_name
)
# TODO(qijun) The default decimal is 7, but numpy.dot and eigen.mul
# has some diff, and could not pass unittest. So I set decimal 3 here.
# And I will check this in future.
numpy
.
testing
.
assert_almost_equal
(
actual
,
expect
,
decimal
=
3
)
expect
=
self
.
outputs
[
out_name
]
numpy
.
isclose
(
actual
,
expect
)
obj
.
test_all
=
test_all
return
obj
python/paddle/v2/framework/tests/test_add_two_op.py
浏览文件 @
59a8ebc6
...
...
@@ -12,9 +12,11 @@ class TestAddOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"add_two"
self
.
X
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
self
.
Y
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
self
.
Out
=
self
.
X
+
self
.
Y
self
.
inputs
=
{
'X'
:
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
),
'Y'
:
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
}
self
.
outputs
=
{
'Out'
:
self
.
inputs
[
'X'
]
+
self
.
inputs
[
'Y'
]}
class
TestAddGradOp
(
unittest
.
TestCase
):
...
...
python/paddle/v2/framework/tests/test_cross_entropy_op.py
浏览文件 @
59a8ebc6
...
...
@@ -7,16 +7,20 @@ class TestSGD(unittest.TestCase):
__metaclass__
=
OpTestMeta
def
setUp
(
self
):
# TODO this unit test is not passed
self
.
type
=
"onehot_cross_entropy"
batch_size
=
100
class_num
=
10
self
.
X
=
numpy
.
random
.
random
((
batch_size
,
class_num
)).
astype
(
"float32"
)
self
.
label
=
5
*
numpy
.
ones
(
batch_size
).
astype
(
"int32"
)
X
=
numpy
.
random
.
random
((
batch_size
,
class_num
)).
astype
(
"float32"
)
label
=
5
*
numpy
.
ones
(
batch_size
).
astype
(
"int32"
)
self
.
inputs
=
{
'X'
:
X
,
'label'
:
label
}
Y
=
[]
for
i
in
range
(
0
,
batch_size
):
Y
.
append
(
-
numpy
.
log
(
self
.
X
[
i
][
self
.
label
[
i
]]))
self
.
Y
=
numpy
.
array
(
Y
).
astype
(
"float32"
)
Y
.
append
(
-
numpy
.
log
(
X
[
i
][
label
[
i
]]))
self
.
outputs
=
{
'Y'
:
numpy
.
array
(
Y
).
astype
(
"float32"
)}
# TODO(superjom) add gradient check
if
__name__
==
"__main__"
:
unittest
.
main
()
python/paddle/v2/framework/tests/test_mean_op.py
浏览文件 @
59a8ebc6
...
...
@@ -8,8 +8,8 @@ class TestMeanOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"mean"
self
.
X
=
np
.
random
.
random
((
32
,
784
)).
astype
(
"float32"
)
self
.
Out
=
np
.
mean
(
self
.
X
)
self
.
inputs
=
{
'X'
:
np
.
random
.
random
((
32
,
784
)).
astype
(
"float32"
)}
self
.
outputs
=
{
'Out'
:
np
.
mean
(
self
.
inputs
[
'X'
])}
if
__name__
==
'__main__'
:
...
...
python/paddle/v2/framework/tests/test_mul_op.py
浏览文件 @
59a8ebc6
...
...
@@ -8,9 +8,11 @@ class TestMulOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"mul"
self
.
X
=
np
.
random
.
random
((
32
,
84
)).
astype
(
"float32"
)
self
.
Y
=
np
.
random
.
random
((
84
,
100
)).
astype
(
"float32"
)
self
.
Out
=
np
.
dot
(
self
.
X
,
self
.
Y
)
self
.
inputs
=
{
'X'
:
np
.
random
.
random
((
32
,
84
)).
astype
(
"float32"
),
'Y'
:
np
.
random
.
random
((
84
,
100
)).
astype
(
"float32"
)
}
self
.
outputs
=
{
'Out'
:
np
.
dot
(
self
.
inputs
[
'X'
],
self
.
inputs
[
'Y'
])}
if
__name__
==
'__main__'
:
...
...
python/paddle/v2/framework/tests/test_op_creation_methods.py
浏览文件 @
59a8ebc6
...
...
@@ -3,7 +3,7 @@ import paddle.v2.framework.create_op_creation_methods as creation
import
paddle.v2.framework.core
as
core
import
paddle.v2.framework.proto.op_proto_pb2
as
op_proto_pb2
import
paddle.v2.framework.proto.op_desc_pb2
as
op_desc_pb2
import
paddle.v2.framework.proto.attr
_type_pb2
as
attr_typ
e_pb2
import
paddle.v2.framework.proto.attr
ibute_pb2
as
attribut
e_pb2
class
TestGetAllProtos
(
unittest
.
TestCase
):
...
...
@@ -76,7 +76,7 @@ class TestOpDescCreationMethod(unittest.TestCase):
expected1
.
type
=
'fc'
attr
=
expected1
.
attrs
.
add
()
attr
.
name
=
'input_format'
attr
.
type
=
attr
_typ
e_pb2
.
INTS
attr
.
type
=
attr
ibut
e_pb2
.
INTS
attr
.
ints
.
extend
([
0
,
1
,
2
,
3
])
self
.
assertEqual
(
expected1
,
generated1
)
...
...
@@ -88,7 +88,7 @@ class TestOpDescCreationMethod(unittest.TestCase):
expected2
.
type
=
'fc'
attr
=
expected2
.
attrs
.
add
()
attr
.
name
=
'input_format'
attr
.
type
=
attr
_typ
e_pb2
.
INTS
attr
.
type
=
attr
ibut
e_pb2
.
INTS
attr
.
ints
.
extend
([
0
,
3
,
6
,
7
])
self
.
assertEqual
(
expected2
,
generated2
)
...
...
@@ -105,12 +105,12 @@ class TestOpDescCreationMethod(unittest.TestCase):
attr
.
comment
=
""
attr
.
type
=
type
__add_attr__
(
"int_attr"
,
attr
_typ
e_pb2
.
INT
)
__add_attr__
(
"float_attr"
,
attr
_typ
e_pb2
.
FLOAT
)
__add_attr__
(
"string_attr"
,
attr
_typ
e_pb2
.
STRING
)
__add_attr__
(
"ints_attr"
,
attr
_typ
e_pb2
.
INTS
)
__add_attr__
(
"floats_attr"
,
attr
_typ
e_pb2
.
FLOATS
)
__add_attr__
(
"strings_attr"
,
attr
_typ
e_pb2
.
STRINGS
)
__add_attr__
(
"int_attr"
,
attr
ibut
e_pb2
.
INT
)
__add_attr__
(
"float_attr"
,
attr
ibut
e_pb2
.
FLOAT
)
__add_attr__
(
"string_attr"
,
attr
ibut
e_pb2
.
STRING
)
__add_attr__
(
"ints_attr"
,
attr
ibut
e_pb2
.
INTS
)
__add_attr__
(
"floats_attr"
,
attr
ibut
e_pb2
.
FLOATS
)
__add_attr__
(
"strings_attr"
,
attr
ibut
e_pb2
.
STRINGS
)
op
.
comment
=
""
self
.
assertTrue
(
op
.
IsInitialized
())
...
...
@@ -131,32 +131,32 @@ class TestOpDescCreationMethod(unittest.TestCase):
expected
.
inputs
.
extend
([
'a'
])
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
"int_attr"
attr
.
type
=
attr
_typ
e_pb2
.
INT
attr
.
type
=
attr
ibut
e_pb2
.
INT
attr
.
i
=
10
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
"float_attr"
attr
.
type
=
attr
_typ
e_pb2
.
FLOAT
attr
.
type
=
attr
ibut
e_pb2
.
FLOAT
attr
.
f
=
3.2
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
"string_attr"
attr
.
type
=
attr
_typ
e_pb2
.
STRING
attr
.
type
=
attr
ibut
e_pb2
.
STRING
attr
.
s
=
"test_str"
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
"ints_attr"
attr
.
type
=
attr
_typ
e_pb2
.
INTS
attr
.
type
=
attr
ibut
e_pb2
.
INTS
attr
.
ints
.
extend
([
0
,
1
,
2
,
3
,
4
])
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
'floats_attr'
attr
.
type
=
attr
_typ
e_pb2
.
FLOATS
attr
.
type
=
attr
ibut
e_pb2
.
FLOATS
attr
.
floats
.
extend
([
0.2
,
3.2
,
4.5
])
attr
=
expected
.
attrs
.
add
()
attr
.
name
=
'strings_attr'
attr
.
type
=
attr
_typ
e_pb2
.
STRINGS
attr
.
type
=
attr
ibut
e_pb2
.
STRINGS
attr
.
strings
.
extend
([
'a'
,
'b'
,
'c'
])
self
.
assertEqual
(
expected
,
generated
)
...
...
@@ -185,7 +185,7 @@ class TestOpDescCreationMethod(unittest.TestCase):
desc
.
type
=
"test"
attr
=
desc
.
attrs
.
add
()
attr
.
name
=
"temporary_index"
attr
.
type
=
attr
_typ
e_pb2
.
INTS
attr
.
type
=
attr
ibut
e_pb2
.
INTS
attr
.
ints
.
append
(
2
)
self
.
assertEqual
(
generated
,
desc
)
...
...
@@ -219,7 +219,7 @@ This op is used for unit test, not a real op.
test_str
=
op
.
attrs
.
add
()
test_str
.
name
=
"str_attr"
test_str
.
type
=
attr
_typ
e_pb2
.
STRING
test_str
.
type
=
attr
ibut
e_pb2
.
STRING
test_str
.
comment
=
"A string attribute for test op"
actual
=
creation
.
get_docstring_from_op_proto
(
op
)
...
...
python/paddle/v2/framework/tests/test_protobuf.py
浏览文件 @
59a8ebc6
import
paddle.v2.framework.proto.op_proto_pb2
import
paddle.v2.framework.proto.attr
_type_pb2
import
paddle.v2.framework.proto.op_proto_pb2
as
op_proto_lib
import
paddle.v2.framework.proto.attr
ibute_pb2
as
attr_type_lib
import
unittest
class
TestFrameworkProto
(
unittest
.
TestCase
):
def
test_all
(
self
):
op_proto_lib
=
paddle
.
v2
.
framework
.
proto
.
op_proto_pb2
attr_type_lib
=
paddle
.
v2
.
framework
.
proto
.
attr_type_pb2
op_proto
=
op_proto_lib
.
OpProto
()
ipt0
=
op_proto
.
inputs
.
add
()
ipt0
.
name
=
"a"
...
...
python/paddle/v2/framework/tests/test_recurrent_op.py
浏览文件 @
59a8ebc6
import
logging
import
paddle.v2.framework.core
as
core
import
unittest
import
numpy
as
np
...
...
@@ -7,10 +8,9 @@ ops = creation.op_creations
def
create_tensor
(
scope
,
name
,
shape
):
tensor
=
scope
.
create
_var
(
name
).
get_tensor
()
tensor
=
scope
.
new
_var
(
name
).
get_tensor
()
tensor
.
set_dims
(
shape
)
tensor
.
alloc_float
()
tensor
.
set
(
np
.
random
.
random
(
shape
))
tensor
.
set
(
np
.
random
.
random
(
shape
),
core
.
CPUPlace
())
return
tensor
...
...
@@ -31,40 +31,36 @@ class TestRNN(unittest.TestCase):
- h
'''
input_dim
=
30
batch_size
=
50
weight_dim
=
15
sent_len
=
11
def
init
(
self
):
input_dim
=
30
batch_size
=
50
weight_dim
=
15
self
.
scope
=
core
.
Scope
(
None
)
# create vars
create_tensor
(
self
.
scope
,
"x"
,
[
batch_size
,
input_dim
])
create_tensor
(
self
.
scope
,
"W"
,
[
input_dim
,
weight_dim
])
create_tensor
(
self
.
scope
,
"U"
,
[
weight_dim
,
weight_dim
])
create_tensor
(
self
.
scope
,
"h_boot"
,
[
batch_size
,
weight_dim
])
x_alias
=
"x@alias"
y_alias
=
"y@alias"
memory
=
"h@alias"
prememory
=
"h@pre"
output
=
"rnn_out"
output_alias
=
"rnn_out@alias"
# create step net
stepnet_var
=
self
.
scope
.
create_var
(
"stepnet"
)
stepnet
=
stepnet_var
.
get_net
()
# stepnet = core.Net.create()
x_fc_op
=
ops
.
fc
(
X
=
x_alias
,
W
=
"W"
,
Y
=
"Wx"
)
h_fc_op
=
ops
.
fc
(
X
=
prememory
,
W
=
"U"
,
Y
=
"Uh"
)
sum_op
=
ops
.
add_two
(
X
=
"Wx"
,
Y
=
"Uh"
,
Out
=
"sum"
)
sig_op
=
ops
.
sigmoid
(
X
=
"sum"
,
Y
=
memory
)
stepnet
.
add_op
(
x_fc_op
)
stepnet
.
add_op
(
h_fc_op
)
stepnet
.
add_op
(
sum_op
)
stepnet
.
add_op
(
sig_op
)
stepnet
.
complete_add_op
(
True
)
self
.
scope
=
core
.
Scope
()
self
.
create_global_variables
()
self
.
create_step_net
()
rnn_op
=
self
.
create_rnn_op
()
ctx
=
core
.
DeviceContext
.
create
(
core
.
CPUPlace
())
print
'infer_shape'
rnn_op
.
infer_shape
(
self
.
scope
)
rnn_op
.
run
(
self
.
scope
,
ctx
)
def
create_global_variables
(
self
):
# create inlink
create_tensor
(
self
.
scope
,
"x"
,
[
self
.
sent_len
,
self
.
batch_size
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"W"
,
[
self
.
input_dim
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"U"
,
[
self
.
input_dim
,
self
.
input_dim
])
create_tensor
(
self
.
scope
,
"h_boot"
,
[
self
.
batch_size
,
self
.
input_dim
])
self
.
scope
.
new_var
(
"step_scopes"
)
self
.
scope
.
new_var
(
"h@alias"
)
self
.
scope
.
new_var
(
"h"
)
def
create_rnn_op
(
self
):
# create RNNOp
rnnop
=
ops
.
recurrent_op
(
# inputs
...
...
@@ -72,17 +68,27 @@ class TestRNN(unittest.TestCase):
boot_memories
=
[
"h_boot"
],
step_net
=
"stepnet"
,
# outputs
outlinks
=
[
output
],
outlinks
=
[
"h"
],
step_scopes
=
"step_scopes"
,
# attributes
inlink_alias
=
[
"x@alias"
],
outlink_alias
=
[
output_alias
],
pre_memories
=
[
prememory
],
memories
=
[
memory
])
outlink_alias
=
[
"h@alias"
],
pre_memories
=
[
"h@pre"
],
memories
=
[
"h@alias"
])
return
rnnop
def
create_step_net
(
self
):
var
=
self
.
scope
.
new_var
(
"stepnet"
)
stepnet
=
var
.
get_net
()
ctx
=
core
.
DeviceContext
.
cpu_context
()
rnnop
.
infer_shape
(
self
.
scope
)
rnnop
.
run
(
self
.
scope
,
ctx
)
x_fc_op
=
ops
.
fc
(
X
=
"x@alias"
,
W
=
"W"
,
Y
=
"Wx"
)
h_fc_op
=
ops
.
fc
(
X
=
"h@pre"
,
W
=
"U"
,
Y
=
"Uh"
)
sum_op
=
ops
.
add_two
(
X
=
"Wx"
,
Y
=
"Uh"
,
Out
=
"sum"
)
sig_op
=
ops
.
sigmoid
(
X
=
"sum"
,
Y
=
"h@alias"
)
for
op
in
[
x_fc_op
,
h_fc_op
,
sum_op
,
sig_op
]:
stepnet
.
add_op
(
op
)
stepnet
.
complete_add_op
(
True
)
def
test_recurrent
(
self
):
self
.
init
()
...
...
python/paddle/v2/framework/tests/test_rowwise_add_op.py
浏览文件 @
59a8ebc6
...
...
@@ -8,9 +8,11 @@ class TestRowwiseAddOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"rowwise_add"
self
.
X
=
np
.
random
.
random
((
32
,
84
)).
astype
(
"float32"
)
self
.
b
=
np
.
random
.
random
(
84
).
astype
(
"float32"
)
self
.
Out
=
np
.
add
(
self
.
X
,
self
.
b
)
self
.
inputs
=
{
'X'
:
np
.
random
.
random
((
32
,
84
)).
astype
(
"float32"
),
'b'
:
np
.
random
.
random
(
84
).
astype
(
"float32"
)
}
self
.
outputs
=
{
'Out'
:
np
.
add
(
self
.
inputs
[
'X'
],
self
.
inputs
[
'b'
])}
if
__name__
==
'__main__'
:
...
...
python/paddle/v2/framework/tests/test_sgd_op.py
浏览文件 @
59a8ebc6
...
...
@@ -8,10 +8,13 @@ class TestSGD(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"sgd"
self
.
param
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
self
.
grad
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
self
.
learning_rate
=
0.1
self
.
param_out
=
self
.
param
-
self
.
learning_rate
*
self
.
grad
w
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
g
=
numpy
.
random
.
random
((
102
,
105
)).
astype
(
"float32"
)
lr
=
0.1
self
.
inputs
=
{
'param'
:
w
,
'grad'
:
g
}
self
.
attrs
=
{
'learning_rate'
:
lr
}
self
.
outputs
=
{
'param_out'
:
w
-
lr
*
g
}
if
__name__
==
"__main__"
:
...
...
python/paddle/v2/framework/tests/test_sigmoid_op.py
浏览文件 @
59a8ebc6
...
...
@@ -8,9 +8,12 @@ class TestSigmoidOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"sigmoid"
self
.
X
=
np
.
random
.
random
((
32
,
100
)).
astype
(
"float32"
)
self
.
Y
=
1
/
(
1
+
np
.
exp
(
-
self
.
X
))
self
.
inputs
=
{
'X'
:
np
.
random
.
random
((
32
,
100
)).
astype
(
"float32"
)}
self
.
outputs
=
{
'Y'
:
1
/
(
1
+
np
.
exp
(
-
self
.
inputs
[
'X'
]))}
#class TestSigmoidGradOp(unittest.TestCase):
#TODO(qingqing) add unit test
if
__name__
==
'__main__'
:
unittest
.
main
()
python/paddle/v2/framework/tests/test_softmax_op.py
浏览文件 @
59a8ebc6
...
...
@@ -19,8 +19,10 @@ class TestSoftmaxOp(unittest.TestCase):
def
setUp
(
self
):
self
.
type
=
"softmax"
self
.
X
=
np
.
random
.
random
((
32
,
100
)).
astype
(
"float32"
)
self
.
Y
=
np
.
apply_along_axis
(
stable_softmax
,
1
,
self
.
X
)
self
.
inputs
=
{
'X'
:
np
.
random
.
random
((
32
,
100
)).
astype
(
"float32"
)}
self
.
outputs
=
{
'Y'
:
np
.
apply_along_axis
(
stable_softmax
,
1
,
self
.
inputs
[
'X'
])
}
class
TestSoftmaxGradOp
(
unittest
.
TestCase
):
...
...
python/paddle/v2/plot/tests/CMakeLists.txt
浏览文件 @
59a8ebc6
if
(
NOT APPLE
)
# The Mac OS X backend will not be able to function correctly if Python is
# not installed as a framework.
add_python_test
(
test_ploter
test_ploter.py
)
py_test
(
test_ploter SRCS
test_ploter.py
)
endif
()
python/paddle/v2/reader/tests/CMakeLists.txt
浏览文件 @
59a8ebc6
add_python_test
(
reader_tests creator_test.py decorator_test.py
)
py_test
(
creator_test SRCS creator_test.py
)
py_test
(
decorator_test SRCS decorator_test.py
)
python/paddle/v2/tests/CMakeLists.txt
浏览文件 @
59a8ebc6
add_python_test
(
test_v2_api test_data_feeder.py test_op.py test_parameters.py
test_layer.py test_rnn_layer.py test_topology.py test_image.py
)
py_test
(
test_op SRCS test_op.py
)
py_test
(
test_image SRCS test_image.py
)
py_test
(
test_layer SRCS test_layer.py
)
py_test
(
test_topology SRCS test_topology.py
)
py_test
(
test_rnn_layer SRCS test_rnn_layer.py
)
py_test
(
test_parameters SRCS test_parameters.py
)
py_test
(
test_data_feeder SRCS test_data_feeder.py
)
python/setup.py.in
浏览文件 @
59a8ebc6
...
...
@@ -14,7 +14,7 @@ packages=['paddle',
'paddle.v2.framework.proto']
setup_requires=["requests",
"numpy",
"numpy
>=1.12
",
"protobuf==3.1",
"recordio",
"matplotlib",
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}