Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
4d4df084
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
4d4df084
编写于
1月 08, 2018
作者:
Y
ying
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
follow comments.
上级
52c22786
变更
3
显示空白变更内容
内联
并排
Showing
3 changed file
with
121 addition
and
1 deletion
+121
-1
doc/howto/usage/capi/images/workflow_of_CAPI.png
doc/howto/usage/capi/images/workflow_of_CAPI.png
+0
-0
doc/howto/usage/capi/index_cn.rst
doc/howto/usage/capi/index_cn.rst
+1
-1
doc/howto/usage/capi/workflow_of_capi.md
doc/howto/usage/capi/workflow_of_capi.md
+120
-0
未找到文件。
doc/howto/usage/capi/images/workflow_of_CAPI.png
0 → 100644
浏览文件 @
4d4df084
447.8 KB
doc/howto/usage/capi/index_cn.rst
浏览文件 @
4d4df084
...
...
@@ -6,4 +6,4 @@ PaddlePaddle C-API
compile_paddle_lib_cn.md
organization_of_the_inputs_cn.md
a_simple_example_cn
.md
workflow_of_capi
.md
doc/howto/usage/capi/
a_simple_example_cn
.md
→
doc/howto/usage/capi/
workflow_of_capi
.md
浏览文件 @
4d4df084
## C-API
CPU 单线程预测示例
## C-API
使用流程
这篇文档
通过一个最简单的例子:手写数字识别,来介绍 CPU 下单线程使用 PaddlePaddle C-API 开发预测服务,完整代码见
[
此目录
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/examples/model_inference/dense/
)
。
这篇文档
介绍 PaddlePaddle C-API 开发预测服务的整体使用流程
。
### 使用流程
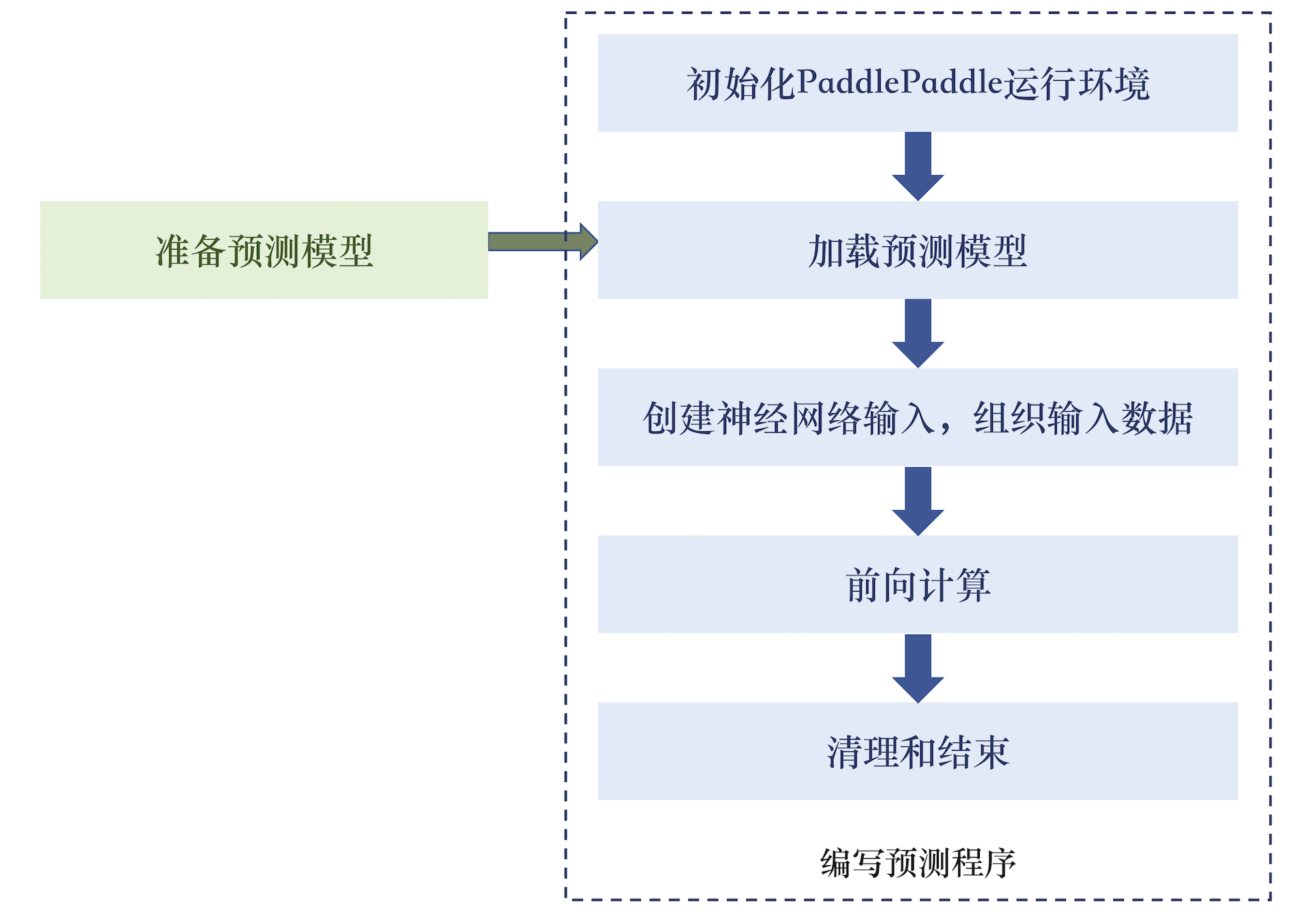
使用 C-API 分为:准备预测模型和预测程序开发两部分。
使用 C-API 的整体工作流程分为准备预测模型和预测程序开发两部分, 如图1所示。
<p
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/5842774/34658453-365f73ea-f46a-11e7-9b3f-0fd112b27bae.png"
width=
500
><br>
图1. C-API使用流程示意图
</p>
-
准备预测模型
1.
将神经网络模型结构进行序列化。
-
调用C-API预测时,需要提供序列化之后的网络结构和训练好的模型参数文件。
...
...
@@ -19,12 +24,14 @@
1.
进行前向计算,获得计算结果。
1.
清理。
本文档以手写数字识别任务为例,介绍如何使用 C-API 进行预测,完整代码请查看
[
此目录
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference/dense
)
。
### 准备预测模型
通过在终端执行
`python mnist_v2.py`
运行
[
目录
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference/dense
)
下的
`mnist_v2.py`
s可以使用 PaddlePaddle 内置的
[
MNIST 数据集
](
http://yann.lecun.com/exdb/mnist/
)
进行训练。脚本中的模型定义了一个简单的含有
[
两个隐层的全连接网络
](
https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md#softmax回归softmax-regression
)
,网络接受一幅图片作为输入,将图片分类到 0 ~ 9 类别标签之一。训练好的模型默认保存在当前运行目录下的
`models`
目录中。下面,我们将调用 C-API 加载训练好的模型进行预测。
在准备预测模型部分,我们以手写数字识别任务为例,这个任务定义了一个含有
[
两个隐层的简单全连接网络
](
https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md#softmax回归softmax-regression
)
,网络接受一幅图片作为输入,将图片分类到 0 ~ 9 类别标签之一。完整代码可以查看
[
此目录
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference/dense
)
中的相关脚本。
调用C-API开发预测程序需要一个训练好的模型,在终端执行
`python mnist_v2.py`
运行
[
目录
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference/dense
)
会使用 PaddlePaddle 内置的
[
MNIST 数据集
](
http://yann.lecun.com/exdb/mnist/
)
进行训练。训练好的模型默认保存在当前运行目录下的
`models`
目录中。
下面,我们将训练好的模型转换成预测模型。
1.
序列化神经网络模型配置
...
...
@@ -42,11 +49,11 @@
对本例,或运行 `python mnist_v2.py --task dump_config`,会对示例中的网络结构进行序列化,并将结果写入当前目录下的`trainer_config.bin`文件中。
当选择使用这种方式调用 C-API 时,如果神经网络有多个可学习参数,请将它们全部放在同一文件夹内,C-API会从指定的目录寻找并
加载训练好的模型。
使用这种方式,需要**在运行时将神经网络的多个可学习参数放在同一个目录中**,C-API可以通过分别指定序列化后的网络结构文件和参数目录来
加载训练好的模型。
2.
合并模型文件(可选)
一些情况下为了便于发布,希望能够将序列化后的神经网络结构和训练好的模型参数打包进一个文件,这时可以使用`paddle.utils.merge_model`中的`merge_v2_model`接口对神经网络结构和训练好的参数进行序列化,将序列化结果写入一个文件内
,调用C-API时直接只需加载这一个文件
。
一些情况下为了便于发布,希望能够将序列化后的神经网络结构和训练好的模型参数打包进一个文件,这时可以使用`paddle.utils.merge_model`中的`merge_v2_model`接口对神经网络结构和训练好的参数进行序列化,将序列化结果写入一个文件内。
代码示例如下:
...
...
@@ -59,32 +66,19 @@
output_file = "output.paddle.model"
merge_v2_model(net, param_file, output_file)
```
对本例,或者直接运行 `python merge_v2_model.py`,序列化结果将会写入当前目录下的`output.paddle.model`文件中
,该文件在调用C-API时,可被直接加载
。
对本例,或者直接运行 `python merge_v2_model.py`,序列化结果将会写入当前目录下的`output.paddle.model`文件中
。使用这种方式,运行时C-API可以通过指定output.paddle.model文件来加载模型
。
#### 注意事项
1.
C-API 需要序列化之后神经网络结构,
在调用
`dump_v2_config`
时,参数
`binary`
必须指定为
`True`
。
1.
将训练模型转换成预测模型,需要序列化神经网络结构。
在调用
`dump_v2_config`
时,参数
`binary`
必须指定为
`True`
。
1.
**预测使用的网络结构往往不同于训练**
,通常需要去掉网络中的:(1)类别标签层;(2)损失函数层;(3)
`evaluator`
等,只留下核心计算层,请注意是否需要修改网络结构。
1.
预测时,可以获取网络中定义的任意多个(大于等于一个)层前向计算的结果,需要哪些层的计算结果作为输出,就将这些层加入一个Python list中,作为调用
`dump_v2_config`
的第一个参数。
### 编写预测代码
#### step 1. 初始化PaddlePaddle运行环境
使用C-API第一步需首先调用
[
`paddle_init`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/main.h#L27
)
初始化PaddlePaddle运行环境。接口接受两个参数:参数的个数和参数。
下面的代码片段在初始化PaddlePaddle运行环境时指定不使用GPU:
```
c
// Initalize the PaddlePaddle runtime environment.
char
*
argv
[]
=
{
"--use_gpu=False"
};
CHECK
(
paddle_init
(
1
,
(
char
**
)
argv
));
```
预测代码更多详细示例代码请参考
[
C-API使用示例
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference
)
目录下的代码示例。这一节对图1中预测代码编写的5个步骤进行介绍和说明。
下面的代码片段在初始化PaddlePaddle运行环境时指定了两个参数:不使用GPU和
[
使用MKLDNN
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/mkl/mkldnn.md
)
:
```
c
char
*
argv
[]
=
{
"--use_gpu=False"
,
"--use_mkldnn=True"
};
CHECK
(
paddle_init
(
2
,
(
char
**
)
argv
));
```
#### step 1. 初始化PaddlePaddle运行环境
第一步需调用
[
`paddle_init`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/main.h#L27
)
初始化PaddlePaddle运行环境。该接口接受两个参数:参数的个数和参数列表。
#### step2. 加载模型
...
...
@@ -95,29 +89,12 @@ CHECK(paddle_init(2, (char**)argv));
1.
从磁盘加载:这时
`gradient machine`
会独立拥有一份训练好的模型;
1.
共享自其它
`gradient machine`
的模型:这种情况多出现在使用多线程预测时,通过多个线程共享同一个模型来减少内存开销。可参考
[
此示例
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/examples/model_inference/multi_thread/main.c
)
。
下面的代码片段创建
`gradient machine`
,并从指定路径加载训练好的模型。
```
c
// Read the binary configuration file generated by `convert_protobin.sh`
long
size
;
void
*
buf
=
read_config
(
CONFIG_BIN
,
&
size
);
// Create the gradient machine for inference.
paddle_gradient_machine
machine
;
CHECK
(
paddle_gradient_machine_create_for_inference
(
&
machine
,
buf
,
(
int
)
size
));
-
注意事项
1.
使用PaddlePaddle V2 API训练,模型中所有可学习参数会被存为一个压缩文件,需要手动进行解压,将它们放在同一目录中,C-API不会直接加载 V2 API 存储的压缩文件。
1.
如果使用
`merge model`
方式将神经网络结构和训练好的参数序列化到一个文件,请参考此
[
示例
](
https://github.com/PaddlePaddle/Mobile/blob/develop/Demo/linux/paddle_image_recognizer.cpp#L59
)
。
1.
加载模型有多种方式,也可以在程序运行过程中再加载另外一个模型。
// Load the trained model. Modify the parameter MODEL_PATH to set the correct
// path of the trained model.
CHECK
(
paddle_gradient_machine_load_parameter_from_disk
(
machine
,
MODEL_PATH
));
```
##### 注意事项
1.
以上代码片段使用“仅序列化神经网络结构”的方式加载模型,需要同时指定模型参数存储的路径。
-
使用PaddlePaddle V2 API训练,模型中所有可学习参数会被存为一个压缩文件,需要手动进行解压,将它们放在同一目录中,C-API不会直接加载 V2 API 存储的压缩文件。
1.
如果使用
`merge model`
方式将神经网络结构和训练好的参数序列化到一个文件,请参考此
[
示例
](
https://github.com/PaddlePaddle/Mobile/blob/develop/Demo/linux/paddle_image_recognizer.cpp#L59
)
。
1.
加载模型有多种方式,也可以在程序运行过程中再加载另外一个模型。
#### step 2. 创建神经网络输入,组织输入数据
#### step 3. 创建神经网络输入,组织输入数据
基本使用概念:
-
在PaddlePaddle内部,神经网络中一个计算层的输入输出被组织为一个
`Argument`
结构体,如果神经网络有多个输入或者多个输出,每一个输入/输出都会对应有自己的
`Argument`
。
...
...
@@ -134,87 +111,10 @@ CHECK(paddle_gradient_machine_load_parameter_from_disk(machine, MODEL_PATH));
与输入不同的是,输出
`argument`
的
`paddle_matrix`
变量并不需在使用C-API时为之分配存储空间。PaddlePaddle内部,神经网络进行前向计算时会自己分配/管理每个计算层的存储空间;这些细节C-API会代为处理,只需在概念上理解,并按照约定调用相关的 C-API 接口即可。
下面是示例代码片段。在这段代码中,生成了一条随机输入数据作为测试样本。
```
c
// Inputs and outputs of the network are organized as paddle_arguments object
// in C-API. In the comments below, "argument" specifically means one input of
// the neural network in PaddlePaddle C-API.
paddle_arguments
in_args
=
paddle_arguments_create_none
();
// There is only one data layer in this demo MNIST network, invoke this
// function to create one argument.
CHECK
(
paddle_arguments_resize
(
in_args
,
1
));
// Each argument needs one matrix or one ivector (integer vector, for sparse
// index input, usually used in NLP task) to holds the real input data.
// In the comments below, "matrix" specifically means the object needed by
// argument to hold the data. Here we create the matrix for the above created
// agument to store the testing samples.
paddle_matrix
mat
=
paddle_matrix_create
(
/* height = batch size */
1
,
/* width = dimensionality of the data layer */
784
,
/* whether to use GPU */
false
);
paddle_real
*
array
;
// Get the pointer pointing to the start address of the first row of the
// created matrix.
CHECK
(
paddle_matrix_get_row
(
mat
,
0
,
&
array
));
// Fill the matrix with a randomly generated test sample.
srand
(
time
(
0
));
for
(
int
i
=
0
;
i
<
784
;
++
i
)
{
array
[
i
]
=
rand
()
/
((
float
)
RAND_MAX
);
}
// Assign the matrix to the argument.
CHECK
(
paddle_arguments_set_value
(
in_args
,
0
,
mat
));
```
#### step 3. 前向计算
#### step 4. 前向计算
完成上述准备之后,通过调用
`paddle_gradient_machine_forward`
接口完成神经网络的前向计算。
示例代码片段如下:
```
c
// Create the output argument.
paddle_arguments
out_args
=
paddle_arguments_create_none
();
// Invoke the forward computation.
CHECK
(
paddle_gradient_machine_forward
(
machine
,
in_args
,
out_args
,
s
/* is train taks or not */
false
));
// Create the matrix to hold the forward result of the neural network.
paddle_matrix
prob
=
paddle_matrix_create_none
();
// Access the matrix of the output argument, the predicted result is stored in
// which.
CHECK
(
paddle_arguments_get_value
(
out_args
,
0
,
prob
));
uint64_t
height
;
uint64_t
width
;
CHECK
(
paddle_matrix_get_shape
(
prob
,
&
height
,
&
width
));
CHECK
(
paddle_matrix_get_row
(
prob
,
0
,
&
array
));
printf
(
"Prob:
\n
"
);
for
(
int
i
=
0
;
i
<
height
*
width
;
++
i
)
{
printf
(
"%.4f "
,
array
[
i
]);
if
((
i
+
1
)
%
width
==
0
)
{
printf
(
"
\n
"
);
}
}
printf
(
"
\n
"
);
```
#### step 4. 清理
结束预测之后,对使用的中间变量和资源进行清理和释放:
```
c
// The cleaning up.
CHECK
(
paddle_matrix_destroy
(
prob
));
CHECK
(
paddle_arguments_destroy
(
out_args
));
CHECK
(
paddle_matrix_destroy
(
mat
));
CHECK
(
paddle_arguments_destroy
(
in_args
));
CHECK
(
paddle_gradient_machine_destroy
(
machine
));
```
#### step 5. 清理
结束预测之后,对使用的中间变量和资源进行清理和释放。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}