Merge pull request #3860 from wangkuiyi/graph_construction_design_doc
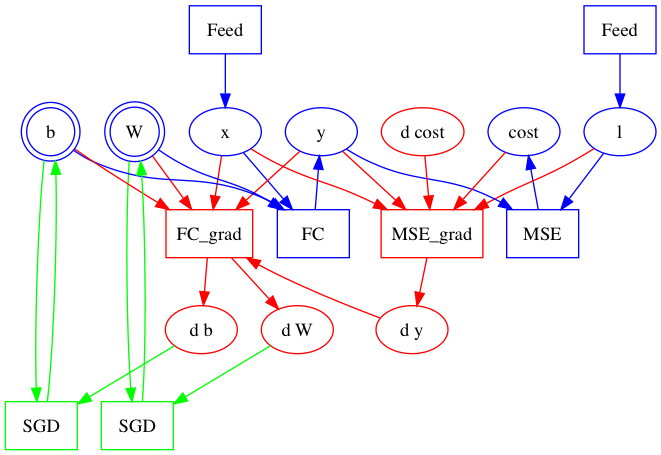
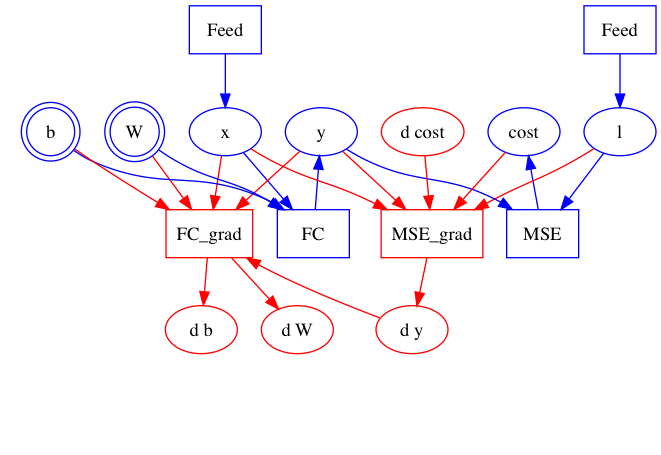
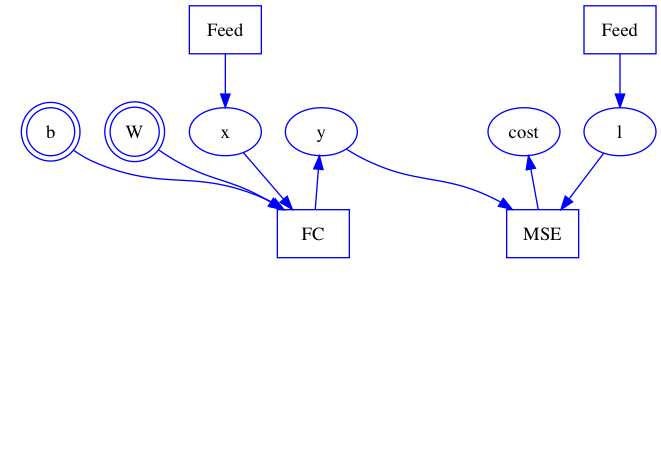
Add a graph building example
Showing
doc/design/graph.md
0 → 100644
{kind=link}
54.1 KB
{kind=link}
46.1 KB
{kind=link}
28.5 KB
Add a graph building example
54.1 KB
46.1 KB
28.5 KB