PaddlePaddle is a deep learning platform open-sourced by Baidu. With PaddlePaddle, you can easily train a classic neural network within a couple lines of configuration, or you can build sophisticated models that provide state-of-the-art performance on difficult learning tasks like sentiment analysis, machine translation, image caption and so on.
Problem Background
------------------
Now, to give you a hint of what using PaddlePaddle looks like, let's start with a fundamental learning problem - `simple linear regression <https://en.wikipedia.org/wiki/Simple_linear_regression>`_: you have observed a set of two-dimensional data points of ``X`` and ``Y``, where ``X`` is an explanatory variable and ``Y`` is corresponding dependent variable, and you want to recover the underlying correlation between ``X`` and ``Y``. Linear regression can be used in many practical scenarios. For example, ``X`` can be a variable about house size, and ``Y`` a variable about house price. You can build a model that captures relationship between them by observing real estate markets.
Prepare the Data
-----------------
Suppose the true relationship can be characterized as ``Y = 2X + 0.3``, let's see how to recover this pattern only from observed data. Here is a piece of python code that feeds synthetic data to PaddlePaddle. The code is pretty self-explanatory, the only extra thing you need to add for PaddlePaddle is a definition of input data types.
To recover this relationship between ``X`` and ``Y``, we use a neural network with one layer of linear activation units and a square error cost layer. Don't worry if you are not familiar with these terminologies, it's just saying that we are starting from a random line ``Y' = wX + b`` , then we gradually adapt ``w`` and ``b`` to minimize the difference between ``Y'`` and ``Y``. Here is what it looks like in PaddlePaddle:
.. code-block:: python
# trainer_config.py
from paddle.trainer_config_helpers import *
# 1. read data. Suppose you saved above python code as dataprovider.py
Some of the most fundamental usages of PaddlePaddle are demonstrated:
- The first part shows how to feed data into PaddlePaddle. In general cases, PaddlePaddle reads raw data from a list of files, and then do some user-defined process to get real input. In this case, we only need to create a placeholder file since we are generating synthetic data on the fly.
- The second part describes learning algorithm. It defines in what ways adjustments are made to model parameters. PaddlePaddle provides a rich set of optimizers, but a simple momentum based optimizer will suffice here, and it processes 12 data points each time.
- Finally, the network configuration. It usually is as simple as "stacking" layers. Three kinds of layers are used in this configuration:
- **Data Layer**: a network always starts with one or more data layers. They provide input data to the rest of the network. In this problem, two data layers are used respectively for ``X`` and ``Y``.
- **FC Layer**: FC layer is short for Fully Connected Layer, which connects all the input units to current layer and does the actual computation specified as activation function. Computation layers like this are the fundamental building blocks of a deeper model.
- **Cost Layer**: in training phase, cost layers are usually the last layers of the network. They measure the performance of current model, and provide guidence to adjust parameters.
Now that everything is ready, you can train the network with a simple command line call:
This means that PaddlePaddle will train this network on the synthectic dataset for 30 passes, and save all the models under path ``./output``. You will see from the messages printed out during training phase that the model cost is decreasing as time goes by, which indicates we are getting a closer guess.
Evaluate the Model
-------------------
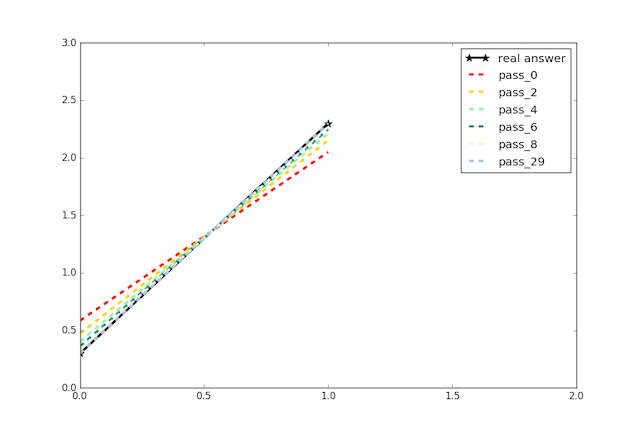
Usually, a different dataset that left out during training phase should be used to evalute the models. However, we are lucky enough to know the real answer: ``w=2, b=0.3``, thus a better option is to check out model parameters directly.
In PaddlePaddle, training is just to get a collection of model parameters, which are ``w`` and ``b`` in this case. Each parameter is saved in an individual file in the popular ``numpy`` array format. Here is the code that reads parameters from last pass.
Although starts from a random guess, you can see that value of ``w`` changes quickly towards 2 and ``b`` changes quickly towards 0.3. In the end, the predicted line is almost identical with real answer.
There, you have recovered the underlying pattern between ``X`` and ``Y`` only from observed data.
**NOTE: These options only take effect when running cmake for the first time, you need to clean the cmake cache or clean the build directory if you want to change it.**
**NOTE: These options only take effect when running cmake for the first time, you need to clean the cmake cache or clean the build directory if you want to change it.**
{kind=link}