# 模型可视化方法
Paddle Lite框架中主要使用到的模型结构有2种:(1) 为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式; (2) 使用[Lite模型优化工具opt](model_optimize_tool)优化后的模型格式。因此本章节包含内容如下:
1. [Paddle推理模型可视化](model_visualization.html#paddle)
2. [Lite优化模型可视化](model_visualization.html#lite)
3. [Lite子图方式下模型可视化](model_visualization.html#id2)
## Paddle推理模式可视化
Paddle用于推理的模型是通过[save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/save_inference_model_cn.html#save-inference-model)这个API保存下来的,存储格式有两种,由save_inference_model接口中的 `model_filename` 和 `params_filename` 变量控制:
- **non-combined形式**:参数保存到独立的文件,如设置 `model_filename` 为 `None` , `params_filename` 为 `None`
```bash
$ ls -l recognize_digits_model_non-combined/
total 192K
-rw-r--r-- 1 root root 28K Sep 24 09:39 __model__ # 模型文件
-rw-r--r-- 1 root root 104 Sep 24 09:39 conv2d_0.b_0 # 独立权重文件
-rw-r--r-- 1 root root 2.0K Sep 24 09:39 conv2d_0.w_0 # 独立权重文件
-rw-r--r-- 1 root root 224 Sep 24 09:39 conv2d_1.b_0 # ...
-rw-r--r-- 1 root root 98K Sep 24 09:39 conv2d_1.w_0
-rw-r--r-- 1 root root 64 Sep 24 09:39 fc_0.b_0
-rw-r--r-- 1 root root 32K Sep 24 09:39 fc_0.w_0
```
- **combined形式**:参数保存到同一个文件,如设置 `model_filename` 为 `model` , `params_filename` 为 `params`
```bash
$ ls -l recognize_digits_model_combined/
total 160K
-rw-r--r-- 1 root root 28K Sep 24 09:42 model # 模型文件
-rw-r--r-- 1 root root 132K Sep 24 09:42 params # 权重文件
```
通过以上方式保存下来的模型文件都可以通过[Netron](https://lutzroeder.github.io/netron/)工具来打开查看模型的网络结构。
**注意:**[Netron](https://github.com/lutzroeder/netron)当前要求PaddlePaddle的保存模型文件名必须为`__model__`,否则无法识别。如果是通过第二种方式保存下来的combined形式的模型文件,需要将文件重命名为`__model__`。
## Lite优化模型可视化
Paddle Lite在执行模型推理之前需要使用[模型优化工具opt](model_optimize_tool)来对模型进行优化,优化后的模型结构同样可以使用[Netron](https://lutzroeder.github.io/netron/)工具进行查看,但是必须保存为`protobuf`格式,而不是`naive_buffer`格式。
**注意**: 为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型(该模型格式是以`.nb`为后缀的单个文件)。但是Naive Buffer格式的模型为序列化模型,不支持可视化。
这里以[paddle_lite_opt](opt/opt_python)工具为例:
- 当模型输入为`non-combined`格式的Paddle模型时,需要通过`--model_dir`来指定模型文件夹
```bash
$ paddle_lite_opt \
--model_dir=./recognize_digits_model_non-combined/ \
--valid_targets=arm \
--optimize_out_type=protobuf \ # 注意:这里必须输出为protobuf格式
--optimize_out=model_opt_dir_non-combined
```
优化后的模型文件会存储在由`--optimize_out`指定的输出文件夹下,格式如下
```bash
$ ls -l model_opt_dir_non-combined/
total 152K
-rw-r--r-- 1 root root 17K Sep 24 09:51 model # 优化后的模型文件
-rw-r--r-- 1 root root 132K Sep 24 09:51 params # 优化后的权重文件
```
- 当模式输入为`combined`格式的Paddle模型时,需要同时输入`--model_file`和`--param_file`来分别指定Paddle模型的模型文件和权重文件
```bash
$ paddle_lite_opt \
--model_file=./recognize_digits_model_combined/model \
--param_file=./recognize_digits_model_combined/params \
--valid_targets=arm \
--optimize_out_type=protobuf \ # 注意:这里必须输出为protobuf格式
--optimize_out=model_opt_dir_combined
```
优化后的模型文件同样存储在由`--optimize_out`指定的输出文件夹下,格式相同
```bash
ls -l model_opt_dir_combined/
total 152K
-rw-r--r-- 1 root root 17K Sep 24 09:56 model # 优化后的模型文件
-rw-r--r-- 1 root root 132K Sep 24 09:56 params # 优化后的权重文件
```
将通过以上步骤输出的优化后的模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开即可查看优化后的模型结构。将优化前后的模型进行对比,即可发现优化后的模型比优化前的模型更轻量级,在推理任务中耗费资源更少且执行速度也更快。

## Lite子图方式下模型可视化
当模型优化的目标硬件平台为 [华为NPU](../demo_guides/huawei_kirin_npu), [百度XPU](../demo_guides/baidu_xpu), [瑞芯微NPU](../demo_guides/rockchip_npu), [联发科APU](../demo_guides/mediatek_apu) 等通过子图方式接入的硬件平台时,得到的优化后的`protobuf`格式模型中运行在这些硬件平台上的算子都由`subgraph`算子包含,无法查看具体的网络结构。
以[华为NPU](../demo_guides/huawei_kirin_npu)为例,运行以下命令进行模型优化,得到输出文件夹下的`model, params`两个文件。
```bash
$ paddle_lite_opt \
--model_dir=./recognize_digits_model_non-combined/ \
--valid_targets=npu,arm \ # 注意:这里的目标硬件平台为NPU,ARM
--optimize_out_type=protobuf \
--optimize_out=model_opt_dir_npu
```
将优化后的模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开,只看到单个的subgraph算子,如下图所示:
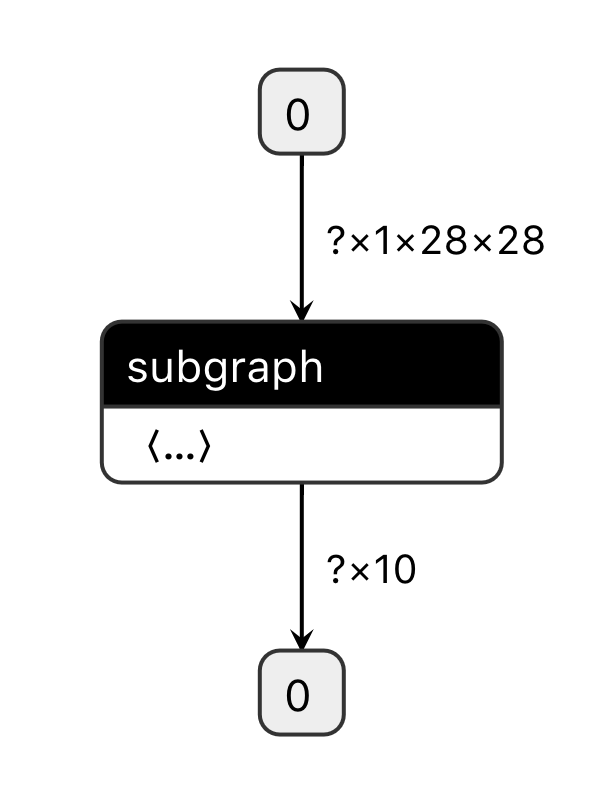
如果想要查看subgraph中的具体模型结构和算子信息需要打开Lite Debug Log,Lite在优化过程中会以.dot文本形式输出模型的拓扑结构,将.dot的文本内容复制到[webgraphviz](http://www.webgraphviz.com/)即可查看模型结构。
```bash
$ export GLOG_v=5 # 注意:这里打开Lite中Level为5及以下的的Debug Log信息
$ paddle_lite_opt \
--model_dir=./recognize_digits_model_non-combined/ \
--valid_targets=npu,arm \
--optimize_out_type=protobuf \
--optimize_out=model_opt_dir_npu > debug_log.txt 2>&1
# 以上命令会将所有的debug log存储在debug_log.txt文件中
```
打开debug_log.txt文件,将会看到多个由以下格式构成的拓扑图定义,由于recognize_digits模型在优化后仅存在一个subgraph,所以在文本搜索`subgraphs`的关键词,即可得到子图拓扑如下:
```shell
I0924 10:50:12.715279 122828 optimizer.h:202] == Running pass: npu_subgraph_pass
I0924 10:50:12.715335 122828 ssa_graph.cc:27] node count 33
I0924 10:50:12.715412 122828 ssa_graph.cc:27] node count 33
I0924 10:50:12.715438 122828 ssa_graph.cc:27] node count 33
subgraphs: 1 # 注意:搜索subgraphs:这个关键词,
digraph G {
node_30[label="fetch"]
node_29[label="fetch0" shape="box" style="filled" color="black" fillcolor="white"]
node_28[label="save_infer_model/scale_0.tmp_0"]
node_26[label="fc_0.tmp_1"]
node_24[label="fc_0.w_0"]
node_23[label="fc0_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
...
node_15[label="batch_norm_0.tmp_1"]
node_17[label="conv2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
node_19[label="conv2d_1.b_0"]
node_1->node_0
node_0->node_2
node_2->node_3
...
node_28->node_29
node_29->node_30
} // end G
I0924 10:50:12.715745 122828 op_lite.h:62] valid places 0
I0924 10:50:12.715764 122828 op_registry.cc:32] creating subgraph kernel for host/float/NCHW
I0924 10:50:12.715770 122828 op_lite.cc:89] pick kernel for subgraph host/float/NCHW get 0 kernels
```
将以上文本中以`digraph G {`开头和以`} // end G`结尾的这段文本复制粘贴到[webgraphviz](http://www.webgraphviz.com/),即可看到子图中的具体模型结构,如下图。其中高亮的方形节点为算子,椭圆形节点为变量或张量。

若模型中存在多个子图,以上方法同样可以得到所有子图的具体模型结构。
同样以[华为NPU](../demo_guides/huawei_kirin_npu)和ARM平台混合调度为例,子图的产生往往是由于模型中存在部分算子无法运行在NPU平台上(比如NPU不支持的算子),这会�导致整个模型被切分为多个子图,子图中包含的算子会运行在NPU平台上,而子图与子图之间的一个或多个算子则只能运行在ARM平台上。这里可以通过[华为NPU](../demo_guides/huawei_kirin_npu)的[自定义子图分割](../demo_guides/huawei_kirin_npu.html#npuarm-cpu)功能,将recognize_digits模型中的`batch_norm`设置为禁用NPU的算子,从而将模型分割为具有两个子图的模型:
```bash
# 此txt配置文件文件中的内容为 batch_norm
$ export SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE=./subgraph_custom_partition_config_file.txt
$ export GLOG_v=5 # 继续打开Lite的Debug Log信息
$ paddle_lite_opt \
--model_dir=./recognize_digits_model_non-combined/ \
--valid_targets=npu,arm \
--optimize_out_type=protobuf \
--optimize_out=model_opt_dir_npu > debug_log.txt 2>&1 #
```
将执行以上命令之后,得到的优化后模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开,就可以看到优化后的模型中存在2个subgraph算子,如左图所示,两个子图中间即为通过环境变量和配置文件指定的禁用NPU的`batch_norm`算子。
打开新保存的debug_log.txt文件,搜索`final program`关键字,拷贝在这之后的以`digraph G {`开头和以`} // end G`结尾的文本用[webgraphviz](http://www.webgraphviz.com/)查看,也是同样的模型拓扑结构,存在`subgraph1`和`subgraph3`两个子图,两个子图中间同样是被禁用NPU的`batch_norm`算子,如右图所示。
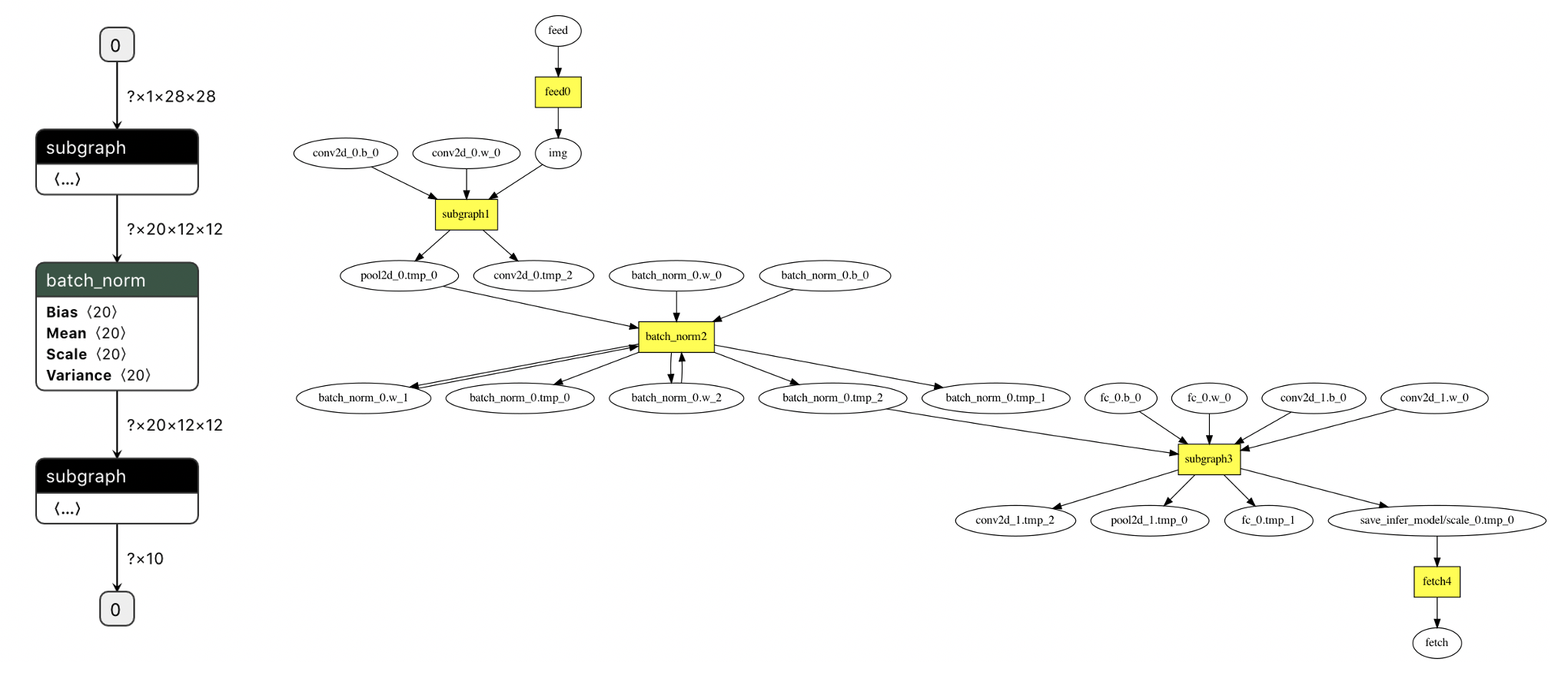
之后继续在debug_log.txt文件中,搜索`subgraphs`关键字,可以得到所有子图的.dot格式内容如下:
```bash
digraph G {
node_30[label="fetch"]
node_29[label="fetch0" shape="box" style="filled" color="black" fillcolor="white"]
node_28[label="save_infer_model/scale_0.tmp_0"]
node_26[label="fc_0.tmp_1"]
node_24[label="fc_0.w_0"]
...
node_17[label="conv2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
node_19[label="conv2d_1.b_0"]
node_0[label="feed0" shape="box" style="filled" color="black" fillcolor="white"]
node_5[label="conv2d_0.b_0"]
node_1[label="feed"]
node_23[label="fc0_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
node_7[label="pool2d0_subgraph_1" shape="box" style="filled" color="black" fillcolor="green"]
node_21[label="pool2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
...
node_18[label="conv2d_1.w_0"]
node_1->node_0
node_0->node_2
...
node_28->node_29
node_29->node_30
} // end G
```
将以上文本复制到[webgraphviz](http://www.webgraphviz.com/)查看,即可显示两个子图分别在整个模型中的结构,如下图所示。可以看到图中绿色高亮的方形节点的为`subgraph1`中的算子,红色高亮的方形节点为`subgraph2`中的算子,两个子图中间白色不高亮的方形节点即为被禁用NPU的`batch_norm`算子。

**注意:** 本章节用到的recognize_digits模型代码位于[PaddlePaddle/book](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits)