diff --git a/CMakeLists.txt b/CMakeLists.txt
index a28613647b32c44c472917b10cdcab7acab843d1..7a8f5e0a69aac3852cb2752c90d54d8f50b69483 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -16,12 +16,6 @@ cmake_minimum_required(VERSION 3.0)
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "${CMAKE_CURRENT_SOURCE_DIR}/cmake")
include(lite_utils)
-lite_option(WITH_PADDLE_MOBILE "Use the paddle-mobile legacy build" OFF)
-if (WITH_PADDLE_MOBILE)
- add_subdirectory(mobile)
- return()
-endif(WITH_PADDLE_MOBILE)
-
set(PADDLE_SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR})
set(PADDLE_BINARY_DIR ${CMAKE_CURRENT_BINARY_DIR})
set(CMAKE_CXX_STANDARD 11)
diff --git a/README.md b/README.md
index 70c53a5775148c6608008d0a86a6966aca29c644..d995bcc327705228098c1b26753213928ad4a79d 100644
--- a/README.md
+++ b/README.md
@@ -43,7 +43,6 @@ Paddle Lite提供了C++、Java、Python三种API,并且提供了相应API的
- [iOS示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/ios_app_demo.html)
- [ARMLinux示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/linux_arm_demo.html)
- [X86示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html)
-- [CUDA示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/cuda.html)
- [OpenCL示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/opencl.html)
- [FPGA示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/fpga.html)
- [华为NPU示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/huawei_kirin_npu.html)
@@ -77,7 +76,6 @@ Paddle Lite提供了C++、Java、Python三种API,并且提供了相应API的
| CPU(32bit) |  |  |  |  |
| CPU(64bit) |  |  |  |  |
| OpenCL | - | - |  | - |
-| CUDA |  |  | - | - |
| FPGA | - |  | - | - |
| 华为NPU | - | - |  | - |
| 百度 XPU |  |  | - | - |
diff --git a/cmake/configure.cmake b/cmake/configure.cmake
index 69fba7968d75f0308acdc787313b48c2804d6caf..e980922d5b4869ede65e57e750b5b85676ed0dde 100644
--- a/cmake/configure.cmake
+++ b/cmake/configure.cmake
@@ -199,13 +199,10 @@ if (LITE_WITH_EXCEPTION)
add_definitions("-DLITE_WITH_EXCEPTION")
endif()
-if (LITE_ON_FLATBUFFERS_DESC_VIEW)
- add_definitions("-DLITE_ON_FLATBUFFERS_DESC_VIEW")
- message(STATUS "Flatbuffers will be used as cpp default program description.")
-endif()
-
if (LITE_ON_TINY_PUBLISH)
add_definitions("-DLITE_ON_TINY_PUBLISH")
+ add_definitions("-DLITE_ON_FLATBUFFERS_DESC_VIEW")
+ message(STATUS "Flatbuffers will be used as cpp default program description.")
else()
add_definitions("-DLITE_WITH_FLATBUFFERS_DESC")
endif()
diff --git a/cmake/device/huawei_ascend_npu.cmake b/cmake/device/huawei_ascend_npu.cmake
index 0bd9591eee702f4db914a8b547c4c99b21d0473b..a2b664abd13591214b9955993854ebccea9a4bf4 100644
--- a/cmake/device/huawei_ascend_npu.cmake
+++ b/cmake/device/huawei_ascend_npu.cmake
@@ -16,6 +16,11 @@ if(NOT LITE_WITH_HUAWEI_ASCEND_NPU)
return()
endif()
+# require -D_GLIBCXX_USE_CXX11_ABI=0 if GCC 7.3.0
+if(CMAKE_CXX_COMPILER_VERSION VERSION_GREATER 5.0)
+ set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -D_GLIBCXX_USE_CXX11_ABI=0")
+endif()
+
# 1. path to Huawei Ascend Install Path
if(NOT DEFINED HUAWEI_ASCEND_NPU_DDK_ROOT)
set(HUAWEI_ASCEND_NPU_DDK_ROOT $ENV{HUAWEI_ASCEND_NPU_DDK_ROOT})
diff --git a/cmake/external/flatbuffers.cmake b/cmake/external/flatbuffers.cmake
index 4c2413c620d3531399ceede234eed16e9f4f0b6b..47b3042234cfa482ca7187baf8e51275ea8d3ac8 100644
--- a/cmake/external/flatbuffers.cmake
+++ b/cmake/external/flatbuffers.cmake
@@ -27,7 +27,7 @@ SET(FLATBUFFERS_SOURCES_DIR ${CMAKE_SOURCE_DIR}/third-party/flatbuffers)
SET(FLATBUFFERS_INSTALL_DIR ${THIRD_PARTY_PATH}/install/flatbuffers)
SET(FLATBUFFERS_INCLUDE_DIR "${FLATBUFFERS_SOURCES_DIR}/include" CACHE PATH "flatbuffers include directory." FORCE)
IF(WIN32)
- set(FLATBUFFERS_LIBRARIES "${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/libflatbuffers.lib" CACHE FILEPATH "FLATBUFFERS_LIBRARIES" FORCE)
+ set(FLATBUFFERS_LIBRARIES "${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/flatbuffers.lib" CACHE FILEPATH "FLATBUFFERS_LIBRARIES" FORCE)
ELSE(WIN32)
set(FLATBUFFERS_LIBRARIES "${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/libflatbuffers.a" CACHE FILEPATH "FLATBUFFERS_LIBRARIES" FORCE)
ENDIF(WIN32)
@@ -64,13 +64,6 @@ ExternalProject_Add(
-DCMAKE_POSITION_INDEPENDENT_CODE:BOOL=ON
-DCMAKE_BUILD_TYPE:STRING=${THIRD_PARTY_BUILD_TYPE}
)
-IF(WIN32)
- IF(NOT EXISTS "${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/libflatbuffers.lib")
- add_custom_command(TARGET extern_flatbuffers POST_BUILD
- COMMAND cmake -E copy ${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/flatbuffers_static.lib ${FLATBUFFERS_INSTALL_DIR}/${LIBDIR}/libflatbuffers.lib
- )
- ENDIF()
-ENDIF(WIN32)
ADD_LIBRARY(flatbuffers STATIC IMPORTED GLOBAL)
SET_PROPERTY(TARGET flatbuffers PROPERTY IMPORTED_LOCATION ${FLATBUFFERS_LIBRARIES})
ADD_DEPENDENCIES(flatbuffers extern_flatbuffers)
diff --git a/cmake/external/protobuf.cmake b/cmake/external/protobuf.cmake
index 76cc7b21deab41a40869a68df3a4dce359177c21..eb6c26e38dcd86aa4e0a536ea0f4541651bed6fa 100644
--- a/cmake/external/protobuf.cmake
+++ b/cmake/external/protobuf.cmake
@@ -217,6 +217,10 @@ FUNCTION(build_protobuf TARGET_NAME BUILD_FOR_HOST)
SET(OPTIONAL_ARGS ${OPTIONAL_ARGS} "-DCMAKE_GENERATOR_PLATFORM=x64")
ENDIF()
+ IF(LITE_WITH_HUAWEI_ASCEND_NPU)
+ SET(OPTIONAL_ARGS ${OPTIONAL_ARGS} "-DCMAKE_CXX_FLAGS=${CMAKE_CXX_FLAGS}")
+ ENDIF()
+
if(LITE_WITH_LIGHT_WEIGHT_FRAMEWORK)
ExternalProject_Add(
${TARGET_NAME}
diff --git a/cmake/generic.cmake b/cmake/generic.cmake
index d859404d559282970d96a735c400f745481e8efa..af05db559123e6d7305c35f95e3dacd58eeb7e19 100644
--- a/cmake/generic.cmake
+++ b/cmake/generic.cmake
@@ -267,6 +267,10 @@ function(cc_library TARGET_NAME)
list(REMOVE_ITEM cc_library_DEPS warpctc)
add_dependencies(${TARGET_NAME} warpctc)
endif()
+ if("${cc_library_DEPS};" MATCHES "fbs_headers;")
+ list(REMOVE_ITEM cc_library_DEPS fbs_headers)
+ add_dependencies(${TARGET_NAME} fbs_headers)
+ endif()
# Only deps libmklml.so, not link
if("${cc_library_DEPS};" MATCHES "mklml;")
list(REMOVE_ITEM cc_library_DEPS mklml)
diff --git a/docs/api_reference/cv.md b/docs/api_reference/cv.md
index d660bd7e382d80ac7151acacef3fd30caeb902bc..2192f4c7bbd1c020e65f5485c9292716ae12df84 100644
--- a/docs/api_reference/cv.md
+++ b/docs/api_reference/cv.md
@@ -91,14 +91,24 @@ ImagePreprocess::ImagePreprocess(ImageFormat srcFormat, ImageFormat dstFormat, T
// 方法二
void ImagePreprocess::imageCovert(const uint8_t* src,
uint8_t* dst, ImageFormat srcFormat, ImageFormat dstFormat);
+ // 方法三
+ void ImagePreprocess::imageCovert(const uint8_t* src,
+ uint8_t* dst, ImageFormat srcFormat, ImageFormat dstFormat,
+ int srcw, int srch);
```
+ 第一个 `imageCovert` 接口,缺省参数来源于 `ImagePreprocess` 类的成员变量。故在初始化 `ImagePreprocess` 类的对象时,必须要给以下成员变量赋值:
- param srcFormat:`ImagePreprocess` 类的成员变量`srcFormat_`
- param dstFormat:`ImagePreprocess` 类的成员变量`dstFormat_`
+ - param srcw: `ImagePreprocess` 类的成员变量`transParam_`结构体中的`iw`变量
+ - param srch: `ImagePreprocess` 类的成员变量`transParam_`结构体中的`ih`变量
- - 第二个`imageCovert` 接口,可以直接使用
+ - 第二个`imageCovert` 接口,缺省参数来源于 `ImagePreprocess` 类的成员变量。故在初始化 `ImagePreprocess` 类的对象时,必须要给以下成员变量赋值:
+ - param srcw: `ImagePreprocess` 类的成员变量`transParam_`结构体中的`iw`变量
+ - param srch: `ImagePreprocess` 类的成员变量`transParam_`结构体中的`ih`变量
+ - 第二个`imageCovert` 接口, 可以直接使用
+
### 缩放 Resize
`Resize` 功能支持颜色空间:GRAY、NV12(NV21)、RGB(BGR)和RGBA(BGRA)
diff --git a/docs/demo_guides/baidu_xpu.md b/docs/demo_guides/baidu_xpu.md
index 242188e0fd1397494db545757e0679c0fd957da1..ae60f9038707218fd204369f4b3ebbbda82f7aca 100644
--- a/docs/demo_guides/baidu_xpu.md
+++ b/docs/demo_guides/baidu_xpu.md
@@ -16,69 +16,12 @@ Paddle Lite已支持百度XPU在x86和arm服务器(例如飞腾 FT-2000+/64)
### 已支持的Paddle模型
-- [ResNet50](https://paddlelite-demo.bj.bcebos.com/models/resnet50_fp32_224_fluid.tar.gz)
-- [BERT](https://paddlelite-demo.bj.bcebos.com/models/bert_fp32_fluid.tar.gz)
-- [ERNIE](https://paddlelite-demo.bj.bcebos.com/models/ernie_fp32_fluid.tar.gz)
-- YOLOv3
-- Mask R-CNN
-- Faster R-CNN
-- UNet
-- SENet
-- SSD
+- [开源模型支持列表](../introduction/support_model_list)
- 百度内部业务模型(由于涉密,不方便透露具体细节)
### 已支持(或部分支持)的Paddle算子(Kernel接入方式)
-- scale
-- relu
-- tanh
-- sigmoid
-- stack
-- matmul
-- pool2d
-- slice
-- lookup_table
-- elementwise_add
-- elementwise_sub
-- cast
-- batch_norm
-- mul
-- layer_norm
-- softmax
-- conv2d
-- io_copy
-- io_copy_once
-- __xpu__fc
-- __xpu__multi_encoder
-- __xpu__resnet50
-- __xpu__embedding_with_eltwise_add
-
-### 已支持(或部分支持)的Paddle算子(子图/XTCL接入方式)
-
-- relu
-- tanh
-- conv2d
-- depthwise_conv2d
-- elementwise_add
-- pool2d
-- softmax
-- mul
-- batch_norm
-- stack
-- gather
-- scale
-- lookup_table
-- slice
-- transpose
-- transpose2
-- reshape
-- reshape2
-- layer_norm
-- gelu
-- dropout
-- matmul
-- cast
-- yolo_box
+- [算子支持列表](../introduction/support_operation_list)
## 参考示例演示
@@ -233,7 +176,7 @@ $ ./lite/tools/build.sh --arm_os=armlinux --arm_abi=armv8 --arm_lang=gcc --build
```
- 将编译生成的build.lite.x86/inference_lite_lib/cxx/include替换PaddleLite-linux-demo/libs/PaddleLite/amd64/include目录;
-- 将编译生成的build.lite.x86/inference_lite_lib/cxx/include/lib/libpaddle_full_api_shared.so替换PaddleLite-linux-demo/libs/PaddleLite/amd64/lib/libpaddle_full_api_shared.so文件;
+- 将编译生成的build.lite.x86/inference_lite_lib/cxx/lib/libpaddle_full_api_shared.so替换PaddleLite-linux-demo/libs/PaddleLite/amd64/lib/libpaddle_full_api_shared.so文件;
- 将编译生成的build.lite.armlinux.armv8.gcc/inference_lite_lib.armlinux.armv8.xpu/cxx/include替换PaddleLite-linux-demo/libs/PaddleLite/arm64/include目录;
- 将编译生成的build.lite.armlinux.armv8.gcc/inference_lite_lib.armlinux.armv8.xpu/cxx/lib/libpaddle_full_api_shared.so替换PaddleLite-linux-demo/libs/PaddleLite/arm64/lib/libpaddle_full_api_shared.so文件。
diff --git a/docs/demo_guides/cuda.md b/docs/demo_guides/cuda.md
index f863fd86864194c6d022e4cf1fc75eb46725cc2c..6460d327a4f30753a2d6942d4a931f709641e3ab 100644
--- a/docs/demo_guides/cuda.md
+++ b/docs/demo_guides/cuda.md
@@ -1,5 +1,7 @@
# PaddleLite使用CUDA预测部署
+**注意**: Lite CUDA仅作为Nvidia GPU加速库,支持模型有限,如有需要请使用[PaddleInference](https://paddle-inference.readthedocs.io/en/latest)。
+
Lite支持在x86_64,arm64架构上(如:TX2)进行CUDA的编译运行。
## 编译
diff --git a/docs/images/architecture.png b/docs/images/architecture.png
index 1af783d77dbd52923aa5facc90e00633c908f575..9397ed49a8a0071cf25b4551438d24a86de96bbb 100644
Binary files a/docs/images/architecture.png and b/docs/images/architecture.png differ
diff --git a/docs/images/workflow.png b/docs/images/workflow.png
new file mode 100644
index 0000000000000000000000000000000000000000..98201e78e1a35c830231881d19fb2c0acbdbaeba
Binary files /dev/null and b/docs/images/workflow.png differ
diff --git a/docs/index.rst b/docs/index.rst
index 24dac7f3692649f99bbeabafab53896c2221c29c..88170c3f6ee177b55631b008c888cb88eda866d3 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -57,7 +57,6 @@ Welcome to Paddle-Lite's documentation!
demo_guides/ios_app_demo
demo_guides/linux_arm_demo
demo_guides/x86
- demo_guides/cuda
demo_guides/opencl
demo_guides/fpga
demo_guides/huawei_kirin_npu
diff --git a/docs/introduction/architecture.md b/docs/introduction/architecture.md
index 1a94494af0b44a03988266d341be5788c46f96c2..8af678a5bf2bb1355e21df91752b777c466faee9 100644
--- a/docs/introduction/architecture.md
+++ b/docs/introduction/architecture.md
@@ -5,23 +5,25 @@ Mobile 在这次升级为 Lite 架构, 侧重多硬件、高性能的支持,
- 引入 Type system,强化多硬件、量化方法、data layout 的混合调度能力
- 硬件细节隔离,通过不同编译开关,对支持的任何硬件可以自由插拔
- 引入 MIR(Machine IR) 的概念,强化带执行环境下的优化支持
-- 优化期和执行期严格隔离,保证预测时轻量和高效率
+- 图优化模块和执行引擎实现了良好的解耦拆分,保证预测执行阶段的轻量和高效率
架构图如下
-
+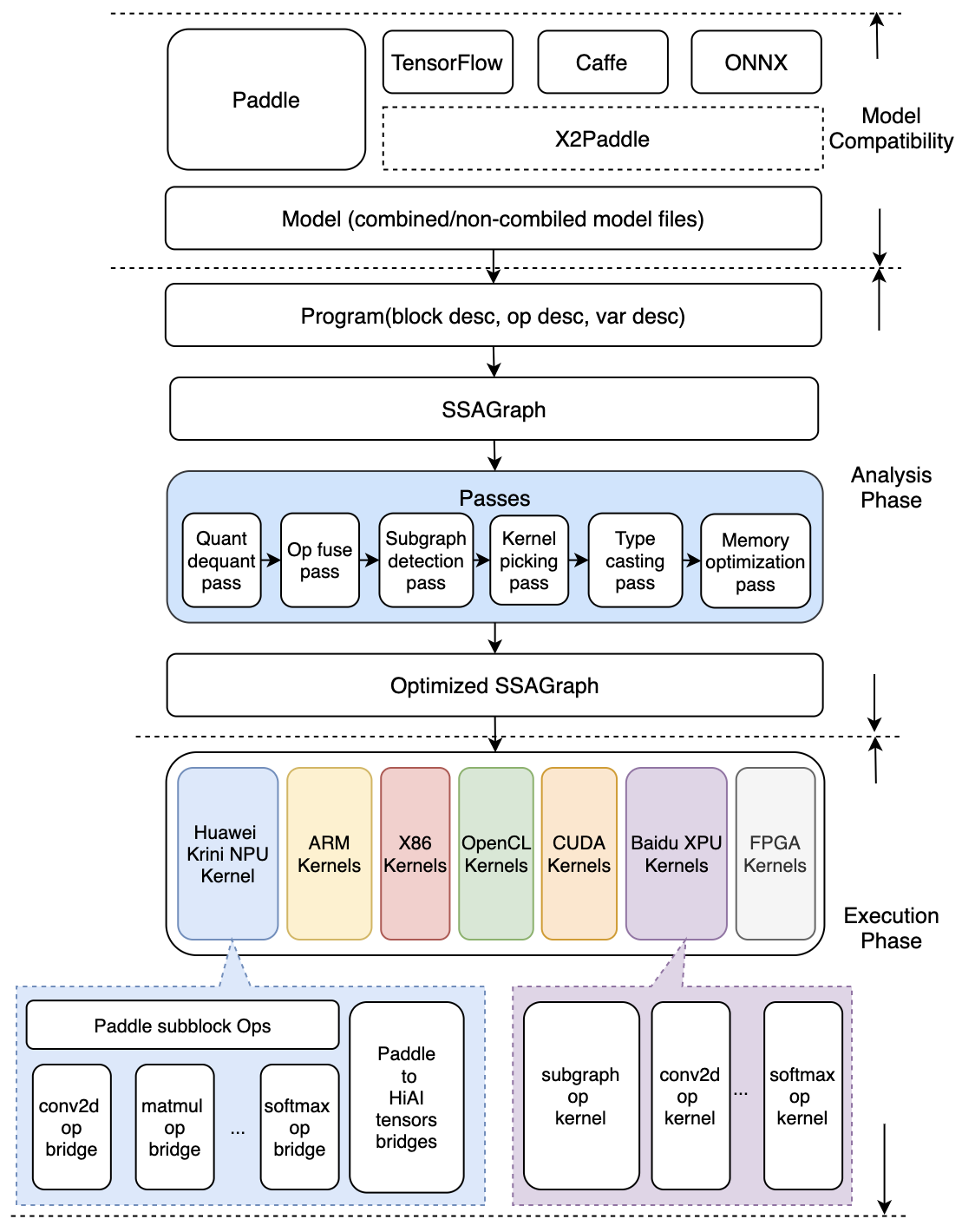
-## 编译期和执行期严格隔离设计
+## 模型优化阶段和预测执行阶段的隔离设计
-- compile time 优化完毕可以将优化信息存储到模型中;execution time 载入并执行
-- 两套 API 及对应的预测lib,满足不同场景
- - `CxxPredictor` 打包了 `Compile Time` 和 `Execution Time`,可以 runtime 在具体硬件上做分析和优化,得到最优效果
- - `MobilePredictor` 只打包 `Execution Time`,保持部署和执行的轻量
+- Analysis Phase为模型优化阶段,输入为Paddle的推理模型,通过Lite的模型加速和优化策略对计算图进行相关的优化分析,包含算子融合,计算裁剪,存储优化,量化精度转换、存储优化、Kernel优选等多类图优化手段。优化后的模型更轻量级,在相应的硬件上运行时耗费资源更少,并且执行速度也更快。
+- Execution Phase为预测执行阶段,输入为优化后的Lite模型,仅做模型加载和预测执行两步操作,支持极致的轻量级部署,无任何第三方依赖。
-## `Execution Time` 轻量级设计和实现
+Lite设计了两套 API 及对应的预测库,满足不同场景需求:
+ - `CxxPredictor` 同时包含 `Analysis Phase` 和 `Execution Phase`,支持一站式的预测任务,同时支持模型进行分析优化与预测执行任务,适用于对预测库大小不敏感的硬件场景。
+ - `MobilePredictor` 只包含 `Execution Phase`,保持预测部署和执行的轻量级和高性能,支持从内存或者文件中加载优化后的模型,并进行预测执行。
-- 每个 batch 实际执行只包含两个步骤执行
- - `Op.InferShape`
+## Execution Phase轻量级设计和实现
+
+- 在预测执行阶段,每个 batch 实际执行只包含两个步骤执行
+ - `OpLite.InferShape` 基于输入推断得到输出的维度
- `Kernel.Run`,Kernel 相关参数均使用指针提前确定,后续无查找或传参消耗
- 设计目标,执行时,只有 kernel 计算本身消耗
- 轻量级 `Op` 及 `Kernel` 设计,避免框架额外消耗
diff --git a/docs/introduction/support_hardware.md b/docs/introduction/support_hardware.md
index b1a6823d26d4fe8838afee00732707608b836599..3fa1b358aba0b2dd01328fad0e81efc95d75450d 100644
--- a/docs/introduction/support_hardware.md
+++ b/docs/introduction/support_hardware.md
@@ -29,7 +29,8 @@ Paddle Lite支持[ARM Cortex-A系列处理器](https://en.wikipedia.org/wiki/ARM
Paddle Lite支持移动端GPU和Nvidia端上GPU设备,支持列表如下:
- ARM Mali G 系列
- Qualcomm Adreno 系列
-- Nvida tegra系列: tx1, tx2, nano, xavier
+
+ Nvida tegra系列: tx1, tx2, nano, xavier
## NPU
Paddle Lite支持NPU,支持列表如下:
diff --git a/docs/introduction/support_model_list.md b/docs/introduction/support_model_list.md
index b30bcd729929de06848285bb27a4d38cec723e67..11f39134b5457703cc00b2dde93d5ab286e48636 100644
--- a/docs/introduction/support_model_list.md
+++ b/docs/introduction/support_model_list.md
@@ -1,32 +1,38 @@
# 支持模型
-目前已严格验证24个模型的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持,并在不断丰富中。
+目前已严格验证28个模型的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持,并在不断丰富中。
-| 类别 | 类别细分 | 模型 | 支持Int8 | 支持平台 |
-|-|-|:-:|:-:|-:|
-| CV | 分类 | mobilenetv1 | Y | ARM,X86,NPU,RKNPU,APU |
-| CV | 分类 | mobilenetv2 | Y | ARM,X86,NPU |
-| CV | 分类 | resnet18 | Y | ARM,NPU |
-| CV | 分类 | resnet50 | Y | ARM,X86,NPU,XPU |
-| CV | 分类 | mnasnet | | ARM,NPU |
-| CV | 分类 | efficientnet | | ARM |
-| CV | 分类 | squeezenetv1.1 | | ARM,NPU |
-| CV | 分类 | ShufflenetV2 | Y | ARM |
-| CV | 分类 | shufflenet | Y | ARM |
-| CV | 分类 | inceptionv4 | Y | ARM,X86,NPU |
-| CV | 分类 | vgg16 | Y | ARM |
-| CV | 分类 | googlenet | Y | ARM,X86 |
-| CV | 检测 | mobilenet_ssd | Y | ARM,NPU* |
-| CV | 检测 | mobilenet_yolov3 | Y | ARM,NPU* |
-| CV | 检测 | Faster RCNN | | ARM |
-| CV | 检测 | Mask RCNN | | ARM |
-| CV | 分割 | Deeplabv3 | Y | ARM |
-| CV | 分割 | unet | | ARM |
-| CV | 人脸 | facedetection | | ARM |
-| CV | 人脸 | facebox | | ARM |
-| CV | 人脸 | blazeface | Y | ARM |
-| CV | 人脸 | mtcnn | | ARM |
-| CV | OCR | ocr_attention | | ARM |
-| NLP | 机器翻译 | transformer | | ARM,NPU* |
+| 类别 | 类别细分 | 模型 | 支持平台 |
+|-|-|:-|:-|
+| CV | 分类 | [MobileNetV1](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v1_fp32_224_fluid.tar.gz) | ARM,X86,NPU,RKNPU,APU |
+| CV | 分类 | [MobileNetV2](https://paddlelite-demo.bj.bcebos.com/models/mobilenet_v2_fp32_224_fluid.tar.gz) | ARM,X86,NPU |
+| CV | 分类 | [ResNet18](https://paddlelite-demo.bj.bcebos.com/models/resnet18_fp32_224_fluid.tar.gz) | ARM,NPU |
+| CV | 分类 | [ResNet50](https://paddlelite-demo.bj.bcebos.com/models/resnet50_fp32_224_fluid.tar.gz) | ARM,X86,NPU,XPU |
+| CV | 分类 | [MnasNet](https://paddlelite-demo.bj.bcebos.com/models/mnasnet_fp32_224_fluid.tar.gz) | ARM,NPU |
+| CV | 分类 | [EfficientNet*](https://github.com/PaddlePaddle/PaddleClas) | ARM |
+| CV | 分类 | [SqueezeNet](https://paddlelite-demo.bj.bcebos.com/models/squeezenet_fp32_224_fluid.tar.gz) | ARM,NPU |
+| CV | 分类 | [ShufflenetV2*](https://github.com/PaddlePaddle/PaddleClas) | ARM |
+| CV | 分类 | [ShuffleNet](https://paddlepaddle-inference-banchmark.bj.bcebos.com/shufflenet_inference.tar.gz) | ARM |
+| CV | 分类 | [InceptionV4](https://paddle-inference-dist.bj.bcebos.com/inception_v4_simple.tar.gz) | ARM,X86,NPU |
+| CV | 分类 | [VGG16](https://paddlepaddle-inference-banchmark.bj.bcebos.com/VGG16_inference.tar) | ARM |
+| CV | 分类 | [VGG19](https://paddlepaddle-inference-banchmark.bj.bcebos.com/VGG19_inference.tar) | XPU|
+| CV | 分类 | [GoogleNet](https://paddlepaddle-inference-banchmark.bj.bcebos.com/GoogleNet_inference.tar) | ARM,X86,XPU |
+| CV | 检测 | [MobileNet-SSD](https://paddlelite-demo.bj.bcebos.com/models/ssd_mobilenet_v1_pascalvoc_fp32_300_fluid.tar.gz) | ARM,NPU* |
+| CV | 检测 | [YOLOv3-MobileNetV3](https://paddlelite-demo.bj.bcebos.com/models/yolov3_mobilenet_v3_prune86_FPGM_320_fp32_fluid.tar.gz) | ARM,NPU* |
+| CV | 检测 | [Faster RCNN](https://paddlepaddle-inference-banchmark.bj.bcebos.com/faster_rcnn.tar) | ARM |
+| CV | 检测 | [Mask RCNN*](https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/MODEL_ZOO_cn.md) | ARM |
+| CV | 分割 | [Deeplabv3](https://paddlelite-demo.bj.bcebos.com/models/deeplab_mobilenet_fp32_fluid.tar.gz) | ARM |
+| CV | 分割 | [UNet](https://paddlelite-demo.bj.bcebos.com/models/Unet.zip) | ARM |
+| CV | 人脸 | [FaceDetection](https://paddlelite-demo.bj.bcebos.com/models/facedetection_fp32_240_430_fluid.tar.gz) | ARM |
+| CV | 人脸 | [FaceBoxes*](https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/featured_model/FACE_DETECTION.md#FaceBoxes) | ARM |
+| CV | 人脸 | [BlazeFace*](https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.4/docs/featured_model/FACE_DETECTION.md#BlazeFace) | ARM |
+| CV | 人脸 | [MTCNN](https://paddlelite-demo.bj.bcebos.com/models/mtcnn.zip) | ARM |
+| CV | OCR | [OCR-Attention](https://paddle-inference-dist.bj.bcebos.com/ocr_attention.tar.gz) | ARM |
+| CV | GAN | [CycleGAN*](https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/gan/cycle_gan) | NPU |
+| NLP | 机器翻译 | [Transformer*](https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleNLP/machine_translation/transformer) | ARM,NPU* |
+| NLP | 机器翻译 | [BERT](https://paddle-inference-dist.bj.bcebos.com/PaddleLite/models_and_data_for_unittests/bert.tar.gz) | XPU |
+| NLP | 语义表示 | [ERNIE](https://paddle-inference-dist.bj.bcebos.com/PaddleLite/models_and_data_for_unittests/ernie.tar.gz) | XPU |
-> **注意:** NPU* 代表ARM+NPU异构计算
+**注意:**
+1. 模型列表中 * 代表该模型链接来自[PaddlePaddle/models](https://github.com/PaddlePaddle/models),否则为推理模型的下载链接
+2. 支持平台列表中 NPU* 代表ARM+NPU异构计算,否则为NPU计算
diff --git a/docs/quick_start/release_lib.md b/docs/quick_start/release_lib.md
index c2c441bbfa7dea0ae2ebd54f5545ae61590604ec..9c722df1537d49a2c7b8a009b5273b93ff68ffbe 100644
--- a/docs/quick_start/release_lib.md
+++ b/docs/quick_start/release_lib.md
@@ -76,7 +76,6 @@ pip install paddlelite
- [ArmLinux源码编译](../source_compile/compile_linux)
- [x86源码编译](../demo_guides/x86)
- [opencl源码编译](../demo_guides/opencl)
-- [CUDA源码编译](../demo_guides/cuda)
- [FPGA源码编译](../demo_guides/fpga)
- [华为NPU源码编译](../demo_guides/huawei_kirin_npu)
- [百度XPU源码编译](../demo_guides/baidu_xpu)
diff --git a/docs/quick_start/tutorial.md b/docs/quick_start/tutorial.md
index a7eb1327f812917e3f1609d097acaeec2a96997d..e5a63be350fe3111d480ba66e907b7f7613b1425 100644
--- a/docs/quick_start/tutorial.md
+++ b/docs/quick_start/tutorial.md
@@ -2,51 +2,63 @@
Lite是一种轻量级、灵活性强、易于扩展的高性能的深度学习预测框架,它可以支持诸如ARM、OpenCL、NPU等等多种终端,同时拥有强大的图优化及预测加速能力。如果您希望将Lite框架集成到自己的项目中,那么只需要如下几步简单操作即可。
-## 一. 准备模型
-Lite框架目前支持的模型结构为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式。因此,在您开始使用 Lite 框架前您需要准备一个由PaddlePaddle框架保存的模型。
-如果您手中的模型是由诸如Caffe2、Tensorflow等框架产出的,那么我们推荐您使用 [X2Paddle](https://github.com/PaddlePaddle/X2Paddle) 工具进行模型格式转换。
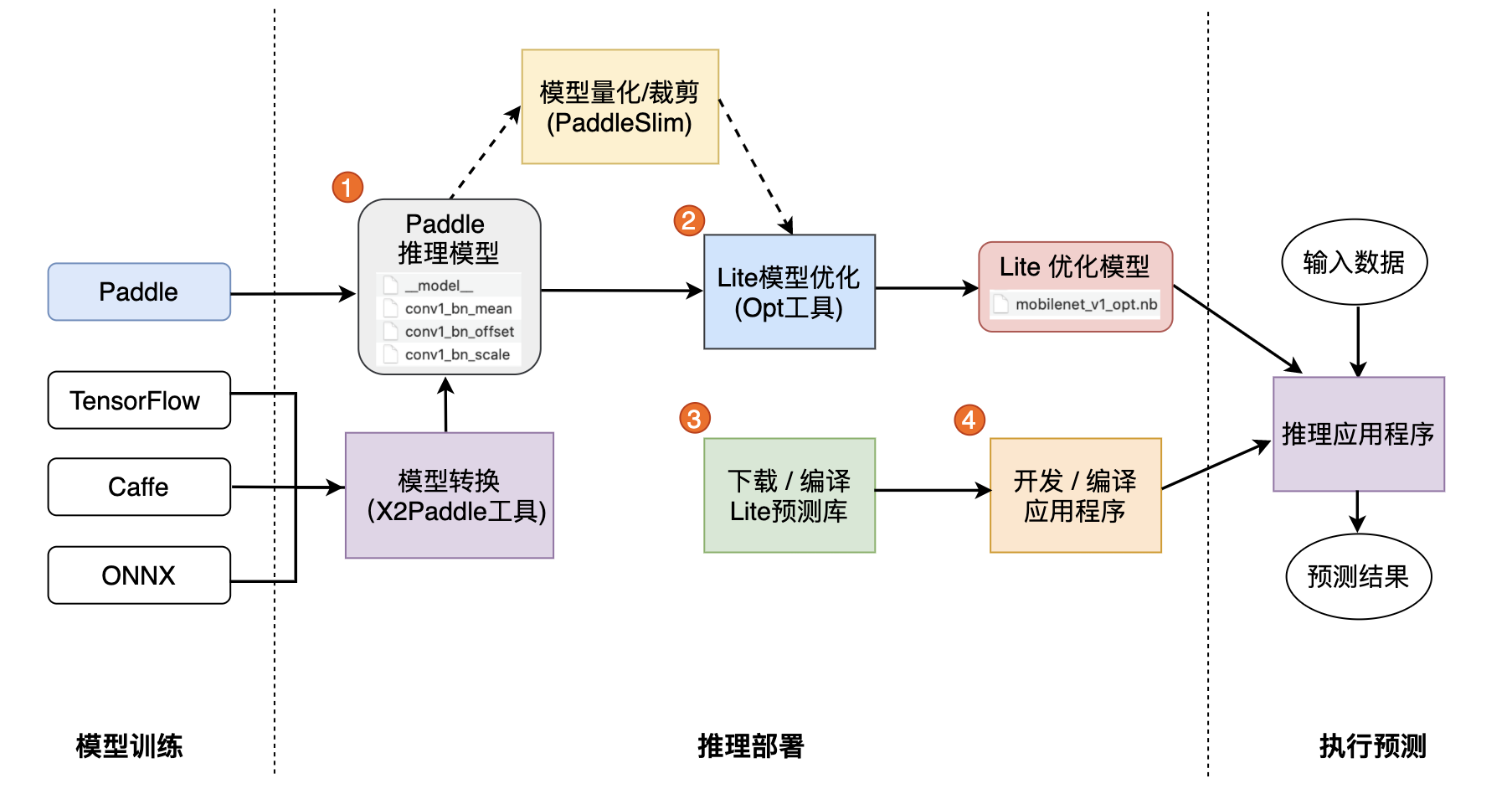
+
-## 二. 模型优化
+**一. 准备模型**
-Lite框架拥有强大的加速、优化策略及实现,其中包含诸如量化、子图融合、Kernel优选等等优化手段,为了方便您使用这些优化策略,我们提供了[opt](../user_guides/model_optimize_tool)帮助您轻松进行模型优化。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。
+Paddle Lite框架直接支持模型结构为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式。目前PaddlePaddle用于推理的模型是通过[save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/save_inference_model_cn.html#save-inference-model)这个API保存下来的。
+如果您手中的模型是由诸如Caffe、Tensorflow、PyTorch等框架产出的,那么您可以使用 [X2Paddle](https://github.com/PaddlePaddle/X2Paddle) 工具将模型转换为PadddlePaddle格式。
-opt的详细介绍,请您参考 [模型优化方法](../user_guides/model_optimize_tool)。
+**二. 模型优化**
-下载opt工具后执行以下代码:
+Paddle Lite框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。
+这些优化通过Paddle Lite提供的opt工具实现。opt工具还可以统计并打印出模型中的算子信息,并判断不同硬件平台下Paddle Lite的支持情况。您获取PaddlePaddle格式的模型之后,一般需要通该opt工具做模型优化。opt工具的下载和使用,请参考 [模型优化方法](https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html)。
-``` shell
-$ ./opt \
- --model_dir= \
- --model_file= \
- --param_file= \
- --optimize_out_type=(protobuf|naive_buffer) \
- --optimize_out= \
- --valid_targets=(arm|opencl|x86)
-```
+**注意**: 为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型。
-其中,optimize_out为您希望的优化模型的输出路径。optimize_out_type则可以指定输出模型的序列化方式,其目前支持Protobuf与Naive Buffer两种方式,其中Naive Buffer是一种更轻量级的序列化/反序列化实现。如果你需要使用Lite在mobile端进行预测,那么您需要设置optimize_out_type=naive_buffer。
+**三. 下载或编译**
-## 三. 使用Lite框架执行预测
+Paddle Lite提供了Android/iOS/X86平台的官方Release预测库下载,我们优先推荐您直接下载 [Paddle Lite预编译库](https://paddle-lite.readthedocs.io/zh/latest/quick_start/release_lib.html)。
+您也可以根据目标平台选择对应的[源码编译方法](https://paddle-lite.readthedocs.io/zh/latest/quick_start/release_lib.html#id2)。Paddle Lite 提供了源码编译脚本,位于 `lite/tools/`文件夹下,只需要 [准备环境](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html) 和 [调用编译脚本](https://paddle-lite.readthedocs.io/zh/latest/quick_start/release_lib.html#id2) 两个步骤即可一键编译得到目标平台的Paddle Lite预测库。
-在上一节中,我们已经通过`opt`获取到了优化后的模型,使用优化模型进行预测也十分的简单。为了方便您的使用,Lite进行了良好的API设计,隐藏了大量您不需要投入时间研究的细节。您只需要简单的五步即可使用Lite在移动端完成预测(以C++ API进行说明):
+**四. 开发应用程序**
+Paddle Lite提供了C++、Java、Python三种API,只需简单五步即可完成预测(以C++ API为例):
-1. 声明MobileConfig。在config中可以设置**从文件加载模型**也可以设置**从memory加载模型**。从文件加载模型需要声明模型文件路径,如 `config.set_model_from_file(FLAGS_model_file)` ;从memory加载模型方法现只支持加载优化后模型的naive buffer,实现方法为:
-`void set_model_from_buffer(model_buffer) `
+1. 声明`MobileConfig`,设置第二步优化后的模型文件路径,或选择从内存中加载模型
+2. 创建`Predictor`,调用`CreatePaddlePredictor`接口,一行代码即可完成引擎初始化
+3. 准备输入,通过`predictor->GetInput(i)`获取输入变量,并为其指定输入大小和输入值
+4. 执行预测,只需要运行`predictor->Run()`一行代码,即可使用Lite框架完成预测执行
+5. 获得输出,使用`predictor->GetOutput(i)`获取输出变量,并通过`data`取得输出值
-2. 创建Predictor。Predictor即为Lite框架的预测引擎,为了方便您的使用我们提供了 `CreatePaddlePredictor` 接口,你只需要简单的执行一行代码即可完成预测引擎的初始化,`std::shared_ptr predictor = CreatePaddlePredictor(config)` 。
-3. 准备输入。执行predictor->GetInput(0)您将会获得输入的第0个field,同样的,如果您的模型有多个输入,那您可以执行 `predictor->GetInput(i)` 来获取相应的输入变量。得到输入变量后您可以使用Resize方法指定其具体大小,并填入输入值。
-4. 执行预测。您只需要执行 `predictor->Run()` 即可使用Lite框架完成预测。
-5. 获取输出。与输入类似,您可以使用 `predictor->GetOutput(i)` 来获得输出的第i个变量。您可以通过其shape()方法获取输出变量的维度,通过 `data()` 模板方法获取其输出值。
+Paddle Lite提供了C++、Java、Python三种API的完整使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
+- [C++完整示例](cpp_demo.html)
+- [Java完整示例](java_demo.html)
+- [Python完整示例](python_demo.html)
+针对不同的硬件平台,Paddle Lite提供了各个平台的完整示例:
+- [Android示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/android_app_demo.html)
+- [iOS示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/ios_app_demo.html)
+- [ARMLinux示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/linux_arm_demo.html)
+- [X86示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html)
+- [OpenCL示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/opencl.html)
+- [FPGA示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/fpga.html)
+- [华为NPU示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/huawei_kirin_npu.html)
+- [百度XPU示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/baidu_xpu.html)
+- [瑞芯微NPU示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/rockchip_npu.html)
+- [联发科APU示例](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/mediatek_apu.html)
-## 四. Lite API
+您也可以下载以下基于Paddle-Lite开发的预测APK程序,安装到Andriod平台上,先睹为快:
-为了方便您的使用,我们提供了C++、Java、Python三种API,并且提供了相应的api的完整使用示例:[C++完整示例](cpp_demo)、[Java完整示例](java_demo)、[Python完整示例](python_demo),您可以参考示例中的说明快速了解C++/Java/Python的API使用方法,并集成到您自己的项目中去。需要说明的是,为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型,具体方法可参考第2节`模型优化`。
+- [图像分类](https://paddlelite-demo.bj.bcebos.com/apps/android/mobilenet_classification_demo.apk)
+- [目标检测](https://paddlelite-demo.bj.bcebos.com/apps/android/yolo_detection_demo.apk)
+- [口罩检测](https://paddlelite-demo.bj.bcebos.com/apps/android/mask_detection_demo.apk)
+- [人脸关键点](https://paddlelite-demo.bj.bcebos.com/apps/android/face_keypoints_detection_demo.apk)
+- [人像分割](https://paddlelite-demo.bj.bcebos.com/apps/android/human_segmentation_demo.apk)
-## 五. 测试工具
+## 更多测试工具
为了使您更好的了解并使用Lite框架,我们向有进一步使用需求的用户开放了 [Debug工具](../user_guides/debug) 和 [Profile工具](../user_guides/debug)。Lite Model Debug Tool可以用来查找Lite框架与PaddlePaddle框架在执行预测时模型中的对应变量值是否有差异,进一步快速定位问题Op,方便复现与排查问题。Profile Monitor Tool可以帮助您了解每个Op的执行时间消耗,其会自动统计Op执行的次数,最长、最短、平均执行时间等等信息,为性能调优做一个基础参考。您可以通过 [相关专题](../user_guides/debug) 了解更多内容。
diff --git a/docs/source_compile/compile_env.md b/docs/source_compile/compile_env.md
index 5322558afbf2c3ad09f04e0596ddc18f967ffabb..7c32311cda212091796a2cff7d60bbefbb751e7c 100644
--- a/docs/source_compile/compile_env.md
+++ b/docs/source_compile/compile_env.md
@@ -19,7 +19,6 @@ Paddle Lite提供了Android/iOS/X86平台的官方Release预测库下载,如
- [ArmLinux源码编译](../source_compile/compile_linux)
- [X86源码编译](../demo_guides/x86)
- [OpenCL源码编译](../demo_guides/opencl)
-- [CUDA源码编译](../demo_guides/cuda)
- [FPGA源码编译](../demo_guides/fpga)
- [华为NPU源码编译](../demo_guides/huawei_kirin_npu)
- [百度XPU源码编译](../demo_guides/baidu_xpu)
diff --git a/lite/CMakeLists.txt b/lite/CMakeLists.txt
index 228b09bcff8a30869d7828a2a5a71fa0cb802292..d69f6d6d9e77668c5789baff3f2f1051afe5df46 100755
--- a/lite/CMakeLists.txt
+++ b/lite/CMakeLists.txt
@@ -40,7 +40,8 @@ endif()
if (WITH_TESTING)
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "lite_naive_model.tar.gz")
if(LITE_WITH_LIGHT_WEIGHT_FRAMEWORK)
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1_int16.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v2_relu.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "resnet50.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "inception_v4_simple.tar.gz")
@@ -51,11 +52,19 @@ if (WITH_TESTING)
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "GoogleNet_inference.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v2_relu.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "resnet50.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "inception_v4_simple.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "step_rnn.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "bert.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "ernie.tar.gz")
+
+ set(LITE_URL_FOR_UNITTESTS "http://paddle-inference-dist.bj.bcebos.com/PaddleLite/models_and_data_for_unittests")
+ # models
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "resnet50.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "bert.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "ernie.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "GoogLeNet.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "VGG19.tar.gz")
+ # data
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "ILSVRC2012_small.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "bert_data.tar.gz")
endif()
endif()
diff --git a/lite/api/CMakeLists.txt b/lite/api/CMakeLists.txt
index 5be30b1ea5ec649e81d4e28dca2f412816cef361..3e8fd5fd637c02842e068801278fab94ac7d5d4f 100644
--- a/lite/api/CMakeLists.txt
+++ b/lite/api/CMakeLists.txt
@@ -15,7 +15,6 @@ if ((NOT LITE_ON_TINY_PUBLISH) AND (LITE_WITH_CUDA OR LITE_WITH_X86 OR LITE_WITH
#full api dynamic library
lite_cc_library(paddle_full_api_shared SHARED SRCS paddle_api.cc light_api.cc cxx_api.cc cxx_api_impl.cc light_api_impl.cc
DEPS paddle_api paddle_api_light paddle_api_full)
- target_sources(paddle_full_api_shared PUBLIC ${__lite_cc_files})
add_dependencies(paddle_full_api_shared op_list_h kernel_list_h framework_proto op_registry fbs_headers)
target_link_libraries(paddle_full_api_shared framework_proto op_registry)
if(LITE_WITH_X86)
@@ -70,6 +69,10 @@ else()
set(TARGET_COMIPILE_FLAGS "-fdata-sections")
if (NOT (ARM_TARGET_LANG STREQUAL "clang")) #gcc
set(TARGET_COMIPILE_FLAGS "${TARGET_COMIPILE_FLAGS} -flto")
+ # TODO (hong19860320): Disable lto temporarily since it causes fail to catch the exceptions in android when toolchain is gcc.
+ if (ARM_TARGET_OS STREQUAL "android" AND LITE_WITH_EXCEPTION)
+ set(TARGET_COMIPILE_FLAGS "")
+ endif()
endif()
set_target_properties(paddle_light_api_shared PROPERTIES COMPILE_FLAGS "${TARGET_COMIPILE_FLAGS}")
add_dependencies(paddle_light_api_shared op_list_h kernel_list_h fbs_headers)
@@ -288,6 +291,14 @@ if(LITE_WITH_LIGHT_WEIGHT_FRAMEWORK AND WITH_TESTING)
set(LINK_FLAGS "-Wl,--version-script ${PADDLE_SOURCE_DIR}/lite/core/lite.map")
set_target_properties(test_mobilenetv1 PROPERTIES LINK_FLAGS "${LINK_FLAGS}")
endif()
+
+ lite_cc_test(test_mobilenetv1_int16 SRCS mobilenetv1_int16_test.cc
+ DEPS ${lite_model_test_DEPS} ${light_lib_DEPS}
+ CL_DEPS ${opencl_kernels}
+ NPU_DEPS ${npu_kernels} ${npu_bridges}
+ ARGS --cl_path=${CMAKE_SOURCE_DIR}/lite/backends/opencl
+ --model_dir=${LITE_MODEL_DIR}/mobilenet_v1_int16 SERIAL)
+ add_dependencies(test_mobilenetv1 extern_lite_download_mobilenet_v1_int16_tar_gz)
lite_cc_test(test_mobilenetv2 SRCS mobilenetv2_test.cc
DEPS ${lite_model_test_DEPS}
diff --git a/lite/api/android/jni/native/CMakeLists.txt b/lite/api/android/jni/native/CMakeLists.txt
index 4638ed5fdfb360c1475ad6e2d1a8eb2051673eb1..1aa9aeeeff6f2737aa3a2a31beaedb0dbf4184f8 100644
--- a/lite/api/android/jni/native/CMakeLists.txt
+++ b/lite/api/android/jni/native/CMakeLists.txt
@@ -17,7 +17,6 @@ if (NOT LITE_ON_TINY_PUBLISH)
# Unlike static library, module library has to link target to be able to work
# as a single .so lib.
target_link_libraries(paddle_lite_jni ${lib_DEPS} ${arm_kernels} ${npu_kernels})
- add_dependencies(paddle_lite_jni fbs_headers)
if (LITE_WITH_NPU)
# Strips the symbols of our protobuf functions to fix the conflicts during
# loading HIAI builder libs (libhiai_ir.so and libhiai_ir_build.so)
diff --git a/lite/api/benchmark.cc b/lite/api/benchmark.cc
index 1dccbb49a4b15a397ae37b1373b5df3cf95e7e9f..b72a6e6bdb2dd170460d0cbb2f3257e337625671 100644
--- a/lite/api/benchmark.cc
+++ b/lite/api/benchmark.cc
@@ -30,8 +30,6 @@
#include
#include
#include "lite/api/paddle_api.h"
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
#include "lite/core/device_info.h"
#include "lite/utils/cp_logging.h"
#include "lite/utils/string.h"
diff --git a/lite/api/cxx_api_impl.cc b/lite/api/cxx_api_impl.cc
index 3b3337139b3c5e3d475503ac682194a0ed348e4f..0b5b9ad94c47a3d97492cd5b91618b184c9ef122 100644
--- a/lite/api/cxx_api_impl.cc
+++ b/lite/api/cxx_api_impl.cc
@@ -58,6 +58,16 @@ void CxxPaddleApiImpl::Init(const lite_api::CxxConfig &config) {
config.mlu_input_layout(),
config.mlu_firstconv_param());
#endif // LITE_WITH_MLU
+
+#ifdef LITE_WITH_BM
+ Env::Init();
+ int device_id = 0;
+ if (const char *c_id = getenv("BM_VISIBLE_DEVICES")) {
+ device_id = static_cast(*c_id) - 48;
+ }
+ TargetWrapper::SetDevice(device_id);
+#endif // LITE_WITH_BM
+
auto use_layout_preprocess_pass =
config.model_dir().find("OPENCL_PRE_PRECESS");
VLOG(1) << "use_layout_preprocess_pass:" << use_layout_preprocess_pass;
@@ -86,7 +96,7 @@ void CxxPaddleApiImpl::Init(const lite_api::CxxConfig &config) {
config.subgraph_model_cache_dir());
#endif
#if (defined LITE_WITH_X86) && (defined PADDLE_WITH_MKLML) && \
- !(defined LITE_ON_MODEL_OPTIMIZE_TOOL)
+ !(defined LITE_ON_MODEL_OPTIMIZE_TOOL) && !defined(__APPLE__)
int num_threads = config.x86_math_library_num_threads();
int real_num_threads = num_threads > 1 ? num_threads : 1;
paddle::lite::x86::MKL_Set_Num_Threads(real_num_threads);
diff --git a/lite/api/cxx_api_test.cc b/lite/api/cxx_api_test.cc
index 768480b1475c3609137f255cbac9ae9d4785a96b..8a28722799c4a2bb7f3512402b2f364fa84831ad 100644
--- a/lite/api/cxx_api_test.cc
+++ b/lite/api/cxx_api_test.cc
@@ -131,7 +131,8 @@ TEST(CXXApi, save_model) {
predictor.Build(FLAGS_model_dir, "", "", valid_places);
LOG(INFO) << "Save optimized model to " << FLAGS_optimized_model;
- predictor.SaveModel(FLAGS_optimized_model);
+ predictor.SaveModel(FLAGS_optimized_model,
+ lite_api::LiteModelType::kProtobuf);
predictor.SaveModel(FLAGS_optimized_model + ".naive",
lite_api::LiteModelType::kNaiveBuffer);
}
diff --git a/lite/api/light_api.cc b/lite/api/light_api.cc
index fbcf171726d741ef0073f423bc4a600c9f9389d0..56461fded536f87ee59ecc8efbe2d3463c7c3822 100644
--- a/lite/api/light_api.cc
+++ b/lite/api/light_api.cc
@@ -46,7 +46,6 @@ void LightPredictor::Build(const std::string& model_dir,
case lite_api::LiteModelType::kProtobuf:
LoadModelPb(model_dir, "", "", scope_.get(), program_desc_.get());
break;
-#endif
case lite_api::LiteModelType::kNaiveBuffer: {
if (model_from_memory) {
LoadModelNaiveFromMemory(
@@ -56,6 +55,7 @@ void LightPredictor::Build(const std::string& model_dir,
}
break;
}
+#endif
default:
LOG(FATAL) << "Unknown model type";
}
diff --git a/lite/api/light_api_impl.cc b/lite/api/light_api_impl.cc
index c9c34377e2a82b72d26e3148a694fe0662e985ce..3c5be7b9cdd340fe0fe82c589706c77875de0030 100644
--- a/lite/api/light_api_impl.cc
+++ b/lite/api/light_api_impl.cc
@@ -17,6 +17,10 @@
#include "lite/api/paddle_api.h"
#include "lite/core/version.h"
#include "lite/model_parser/model_parser.h"
+#ifndef LITE_ON_TINY_PUBLISH
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#endif
namespace paddle {
namespace lite {
diff --git a/lite/api/mobilenetv1_int16_test.cc b/lite/api/mobilenetv1_int16_test.cc
new file mode 100644
index 0000000000000000000000000000000000000000..266052044ef6543a0f00ad50bc9b89b70656bbe6
--- /dev/null
+++ b/lite/api/mobilenetv1_int16_test.cc
@@ -0,0 +1,83 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/cxx_api.h"
+#include "lite/api/light_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/core/op_registry.h"
+
+DEFINE_string(optimized_model,
+ "/data/local/tmp/int16_model",
+ "optimized_model");
+DEFINE_int32(N, 1, "input_batch");
+DEFINE_int32(C, 3, "input_channel");
+DEFINE_int32(H, 224, "input_height");
+DEFINE_int32(W, 224, "input_width");
+
+namespace paddle {
+namespace lite {
+
+void TestModel(const std::vector& valid_places,
+ const std::string& model_dir) {
+ DeviceInfo::Init();
+ DeviceInfo::Global().SetRunMode(lite_api::LITE_POWER_NO_BIND, FLAGS_threads);
+
+ LOG(INFO) << "Optimize model.";
+ lite::Predictor cxx_predictor;
+ cxx_predictor.Build(model_dir, "", "", valid_places);
+ cxx_predictor.SaveModel(FLAGS_optimized_model,
+ paddle::lite_api::LiteModelType::kNaiveBuffer);
+
+ LOG(INFO) << "Load optimized model.";
+ lite::LightPredictor predictor(FLAGS_optimized_model + ".nb", false);
+
+ auto* input_tensor = predictor.GetInput(0);
+ input_tensor->Resize(DDim(
+ std::vector({FLAGS_N, FLAGS_C, FLAGS_H, FLAGS_W})));
+ auto* data = input_tensor->mutable_data();
+ auto item_size = FLAGS_N * FLAGS_C * FLAGS_H * FLAGS_W;
+ for (int i = 0; i < item_size; i++) {
+ data[i] = 1.;
+ }
+
+ LOG(INFO) << "Predictor run.";
+ predictor.Run();
+
+ auto* out = predictor.GetOutput(0);
+ const auto* pdata = out->data();
+
+ std::vector ref = {
+ 0.000191383, 0.000592063, 0.000112282, 6.27426e-05, 0.000127522};
+ double eps = 1e-5;
+ for (int i = 0; i < ref.size(); ++i) {
+ EXPECT_NEAR(pdata[i], ref[i], eps);
+ }
+}
+
+TEST(MobileNetV1_Int16, test_arm) {
+ std::vector valid_places({
+ Place{TARGET(kARM), PRECISION(kFloat)},
+ });
+ std::string model_dir = FLAGS_model_dir;
+ TestModel(valid_places, model_dir);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/api/model_test.cc b/lite/api/model_test.cc
index 90575280873c8cda9310cfc951645f4614c2ce30..3cce247750341b37bf9aff07fce8ec54ee1428fe 100644
--- a/lite/api/model_test.cc
+++ b/lite/api/model_test.cc
@@ -25,8 +25,6 @@
#include "lite/core/profile/basic_profiler.h"
#endif // LITE_WITH_PROFILE
#include
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
using paddle::lite::profile::Timer;
diff --git a/lite/api/paddle_api.cc b/lite/api/paddle_api.cc
index a3d29dff93155b4a1eaefd91d35080831601eedf..d37657206d093f666ab486dff5aa1c151efce0eb 100644
--- a/lite/api/paddle_api.cc
+++ b/lite/api/paddle_api.cc
@@ -356,5 +356,13 @@ void MobileConfig::set_model_buffer(const char *model_buffer,
model_from_memory_ = true;
}
+// This is the method for allocating workspace_size according to L3Cache size
+void MobileConfig::SetArmL3CacheSize(L3CacheSetMethod method,
+ int absolute_val) {
+#ifdef LITE_WITH_ARM
+ lite::DeviceInfo::Global().SetArmL3CacheSize(method, absolute_val);
+#endif
+}
+
} // namespace lite_api
} // namespace paddle
diff --git a/lite/api/paddle_api.h b/lite/api/paddle_api.h
index 42a4b2228b5dc007bc0d6053f15e843bd6343c8f..7df7f7889af5b059a60aa191540a02e9f2ec755f 100644
--- a/lite/api/paddle_api.h
+++ b/lite/api/paddle_api.h
@@ -32,6 +32,14 @@ using shape_t = std::vector;
using lod_t = std::vector>;
enum class LiteModelType { kProtobuf = 0, kNaiveBuffer, UNK };
+// Methods for allocating L3Cache on Arm platform
+enum class L3CacheSetMethod {
+ kDeviceL3Cache = 0, // Use the system L3 Cache size, best performance.
+ kDeviceL2Cache = 1, // Use the system L2 Cache size, trade off performance
+ // with less memory consumption.
+ kAbsolute = 2, // Use the external setting.
+ // kAutoGrow = 3, // Not supported yet, least memory consumption.
+};
// return true if current device supports OpenCL model
LITE_API bool IsOpenCLBackendValid();
@@ -294,6 +302,11 @@ class LITE_API MobileConfig : public ConfigBase {
// NOTE: This is a deprecated API and will be removed in latter release.
const std::string& param_buffer() const { return param_buffer_; }
+
+ // This is the method for allocating workspace_size according to L3Cache size
+ void SetArmL3CacheSize(
+ L3CacheSetMethod method = L3CacheSetMethod::kDeviceL3Cache,
+ int absolute_val = -1);
};
template
diff --git a/lite/api/paddle_api_test.cc b/lite/api/paddle_api_test.cc
index c381546dfba9326d48b27e094a39dd4cd082c462..41799bdc2c6582e6d987d7d896db1f499eb4cdf4 100644
--- a/lite/api/paddle_api_test.cc
+++ b/lite/api/paddle_api_test.cc
@@ -15,8 +15,6 @@
#include "lite/api/paddle_api.h"
#include
#include
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
#include "lite/utils/cp_logging.h"
#include "lite/utils/io.h"
@@ -109,7 +107,8 @@ TEST(CxxApi, share_external_data) {
TEST(LightApi, run) {
lite_api::MobileConfig config;
config.set_model_from_file(FLAGS_model_dir + ".opt2.naive.nb");
-
+ // disable L3 cache on workspace_ allocating
+ config.SetArmL3CacheSize(L3CacheSetMethod::kDeviceL2Cache);
auto predictor = lite_api::CreatePaddlePredictor(config);
auto inputs = predictor->GetInputNames();
@@ -150,6 +149,8 @@ TEST(MobileConfig, LoadfromMemory) {
// set model buffer and run model
lite_api::MobileConfig config;
config.set_model_from_buffer(model_buffer);
+ // allocate 1M initial space for workspace_
+ config.SetArmL3CacheSize(L3CacheSetMethod::kAbsolute, 1024 * 1024);
auto predictor = lite_api::CreatePaddlePredictor(config);
auto input_tensor = predictor->GetInput(0);
diff --git a/lite/api/paddle_use_passes.h b/lite/api/paddle_use_passes.h
index cea2a45c5db15891a4de679265a9c2cd2779d0fb..a4ea030cbf3ae7ead5836f02638ff440335f89fe 100644
--- a/lite/api/paddle_use_passes.h
+++ b/lite/api/paddle_use_passes.h
@@ -62,6 +62,7 @@ USE_MIR_PASS(quantized_op_attributes_inference_pass);
USE_MIR_PASS(control_flow_op_unused_inputs_and_outputs_eliminate_pass)
USE_MIR_PASS(lite_scale_activation_fuse_pass);
USE_MIR_PASS(__xpu__resnet_fuse_pass);
+USE_MIR_PASS(__xpu__resnet_d_fuse_pass);
USE_MIR_PASS(__xpu__resnet_cbam_fuse_pass);
USE_MIR_PASS(__xpu__multi_encoder_fuse_pass);
USE_MIR_PASS(__xpu__embedding_with_eltwise_add_fuse_pass);
diff --git a/lite/api/python/pybind/CMakeLists.txt b/lite/api/python/pybind/CMakeLists.txt
index 1f8ee66a0dbce37480672cc213a60d87d28c4142..b0b897b5d47089eb4331bf4909b4e778092a6a7b 100644
--- a/lite/api/python/pybind/CMakeLists.txt
+++ b/lite/api/python/pybind/CMakeLists.txt
@@ -9,7 +9,7 @@ if(WIN32)
target_link_libraries(lite_pybind ${os_dependency_modules})
else()
lite_cc_library(lite_pybind SHARED SRCS pybind.cc DEPS ${PYBIND_DEPS})
- target_sources(lite_pybind PUBLIC ${__lite_cc_files})
+ target_sources(lite_pybind PUBLIC ${__lite_cc_files} fbs_headers)
endif(WIN32)
if (LITE_ON_TINY_PUBLISH)
diff --git a/lite/backends/apu/neuron_adapter.cc b/lite/backends/apu/neuron_adapter.cc
index 953c92d1828848bd030a65cb2a8af0eac0674ca1..ff08507504b8bd7e5342c5705afb17550f37469e 100644
--- a/lite/backends/apu/neuron_adapter.cc
+++ b/lite/backends/apu/neuron_adapter.cc
@@ -82,16 +82,20 @@ void NeuronAdapter::InitFunctions() {
PADDLE_DLSYM(NeuronModel_setOperandValue);
PADDLE_DLSYM(NeuronModel_setOperandSymmPerChannelQuantParams);
PADDLE_DLSYM(NeuronModel_addOperation);
+ PADDLE_DLSYM(NeuronModel_addOperationExtension);
PADDLE_DLSYM(NeuronModel_identifyInputsAndOutputs);
PADDLE_DLSYM(NeuronCompilation_create);
PADDLE_DLSYM(NeuronCompilation_free);
PADDLE_DLSYM(NeuronCompilation_finish);
+ PADDLE_DLSYM(NeuronCompilation_createForDevices);
PADDLE_DLSYM(NeuronExecution_create);
PADDLE_DLSYM(NeuronExecution_free);
PADDLE_DLSYM(NeuronExecution_setInput);
PADDLE_DLSYM(NeuronExecution_setOutput);
PADDLE_DLSYM(NeuronExecution_compute);
-
+ PADDLE_DLSYM(Neuron_getDeviceCount);
+ PADDLE_DLSYM(Neuron_getDevice);
+ PADDLE_DLSYM(NeuronDevice_getName);
#undef PADDLE_DLSYM
}
@@ -146,6 +150,25 @@ int NeuronModel_addOperation(NeuronModel* model,
model, type, inputCount, inputs, outputCount, outputs);
}
+int NeuronModel_addOperationExtension(NeuronModel* model,
+ const char* name,
+ const char* vendor,
+ const NeuronDevice* device,
+ uint32_t inputCount,
+ const uint32_t* inputs,
+ uint32_t outputCount,
+ const uint32_t* outputs) {
+ return paddle::lite::NeuronAdapter::Global()
+ ->NeuronModel_addOperationExtension()(model,
+ name,
+ vendor,
+ device,
+ inputCount,
+ inputs,
+ outputCount,
+ outputs);
+}
+
int NeuronModel_identifyInputsAndOutputs(NeuronModel* model,
uint32_t inputCount,
const uint32_t* inputs,
@@ -172,6 +195,15 @@ int NeuronCompilation_finish(NeuronCompilation* compilation) {
compilation);
}
+int NeuronCompilation_createForDevices(NeuronModel* model,
+ const NeuronDevice* const* devices,
+ uint32_t numDevices,
+ NeuronCompilation** compilation) {
+ return paddle::lite::NeuronAdapter::Global()
+ ->NeuronCompilation_createForDevices()(
+ model, devices, numDevices, compilation);
+}
+
int NeuronExecution_create(NeuronCompilation* compilation,
NeuronExecution** execution) {
return paddle::lite::NeuronAdapter::Global()->NeuronExecution_create()(
@@ -205,3 +237,18 @@ int NeuronExecution_compute(NeuronExecution* execution) {
return paddle::lite::NeuronAdapter::Global()->NeuronExecution_compute()(
execution);
}
+
+int Neuron_getDeviceCount(uint32_t* numDevices) {
+ return paddle::lite::NeuronAdapter::Global()->Neuron_getDeviceCount()(
+ numDevices);
+}
+
+int Neuron_getDevice(uint32_t devIndex, NeuronDevice** device) {
+ return paddle::lite::NeuronAdapter::Global()->Neuron_getDevice()(devIndex,
+ device);
+}
+
+int NeuronDevice_getName(const NeuronDevice* device, const char** name) {
+ return paddle::lite::NeuronAdapter::Global()->NeuronDevice_getName()(device,
+ name);
+}
diff --git a/lite/backends/apu/neuron_adapter.h b/lite/backends/apu/neuron_adapter.h
index c08db73279ea3969300c8f298016a976e30a7ac4..c1b9669a98626699b126913dcc840906de4de8e0 100644
--- a/lite/backends/apu/neuron_adapter.h
+++ b/lite/backends/apu/neuron_adapter.h
@@ -42,12 +42,25 @@ class NeuronAdapter final {
const uint32_t *,
uint32_t,
const uint32_t *);
+ using NeuronModel_addOperationExtension_Type = int (*)(NeuronModel *,
+ const char *,
+ const char *,
+ const NeuronDevice *,
+ uint32_t,
+ const uint32_t *,
+ uint32_t,
+ const uint32_t *);
using NeuronModel_identifyInputsAndOutputs_Type = int (*)(
NeuronModel *, uint32_t, const uint32_t *, uint32_t, const uint32_t *);
using NeuronCompilation_create_Type = int (*)(NeuronModel *,
NeuronCompilation **);
using NeuronCompilation_free_Type = void (*)(NeuronCompilation *);
using NeuronCompilation_finish_Type = int (*)(NeuronCompilation *);
+ using NeuronCompilation_createForDevices_Type =
+ int (*)(NeuronModel *,
+ const NeuronDevice *const *,
+ uint32_t,
+ NeuronCompilation **);
using NeuronExecution_create_Type = int (*)(NeuronCompilation *,
NeuronExecution **);
using NeuronExecution_free_Type = void (*)(NeuronExecution *);
@@ -59,6 +72,10 @@ class NeuronAdapter final {
using NeuronExecution_setOutput_Type = int (*)(
NeuronExecution *, int32_t, const NeuronOperandType *, void *, size_t);
using NeuronExecution_compute_Type = int (*)(NeuronExecution *);
+ using Neuron_getDeviceCount_Type = int (*)(uint32_t *);
+ using Neuron_getDevice_Type = int (*)(uint32_t, NeuronDevice **);
+ using NeuronDevice_getName_Type = int (*)(const NeuronDevice *,
+ const char **);
Neuron_getVersion_Type Neuron_getVersion() {
CHECK(Neuron_getVersion_ != nullptr) << "Cannot load Neuron_getVersion!";
@@ -105,6 +122,12 @@ class NeuronAdapter final {
return NeuronModel_addOperation_;
}
+ NeuronModel_addOperationExtension_Type NeuronModel_addOperationExtension() {
+ CHECK(NeuronModel_addOperationExtension_ != nullptr)
+ << "Cannot load NeuronModel_addOperationExtension!";
+ return NeuronModel_addOperationExtension_;
+ }
+
NeuronModel_identifyInputsAndOutputs_Type
NeuronModel_identifyInputsAndOutputs() {
CHECK(NeuronModel_identifyInputsAndOutputs_ != nullptr)
@@ -130,6 +153,12 @@ class NeuronAdapter final {
return NeuronCompilation_finish_;
}
+ NeuronCompilation_createForDevices_Type NeuronCompilation_createForDevices() {
+ CHECK(NeuronCompilation_createForDevices_ != nullptr)
+ << "Cannot load NeuronCompilation_createForDevices!";
+ return NeuronCompilation_createForDevices_;
+ }
+
NeuronExecution_create_Type NeuronExecution_create() {
CHECK(NeuronExecution_create_ != nullptr)
<< "Cannot load NeuronExecution_create!";
@@ -160,6 +189,23 @@ class NeuronAdapter final {
return NeuronExecution_compute_;
}
+ Neuron_getDeviceCount_Type Neuron_getDeviceCount() {
+ CHECK(Neuron_getDeviceCount_ != nullptr)
+ << "Cannot load Neuron_getDeviceCount!";
+ return Neuron_getDeviceCount_;
+ }
+
+ Neuron_getDevice_Type Neuron_getDevice() {
+ CHECK(Neuron_getDevice_ != nullptr) << "Cannot load Neuron_getDevice!";
+ return Neuron_getDevice_;
+ }
+
+ NeuronDevice_getName_Type NeuronDevice_getName() {
+ CHECK(NeuronDevice_getName_ != nullptr)
+ << "Cannot load NeuronDevice_getName!";
+ return NeuronDevice_getName_;
+ }
+
private:
NeuronAdapter();
NeuronAdapter(const NeuronAdapter &) = delete;
@@ -176,16 +222,23 @@ class NeuronAdapter final {
NeuronModel_setOperandSymmPerChannelQuantParams_Type
NeuronModel_setOperandSymmPerChannelQuantParams_{nullptr};
NeuronModel_addOperation_Type NeuronModel_addOperation_{nullptr};
+ NeuronModel_addOperationExtension_Type NeuronModel_addOperationExtension_{
+ nullptr};
NeuronModel_identifyInputsAndOutputs_Type
NeuronModel_identifyInputsAndOutputs_{nullptr};
NeuronCompilation_create_Type NeuronCompilation_create_{nullptr};
NeuronCompilation_free_Type NeuronCompilation_free_{nullptr};
NeuronCompilation_finish_Type NeuronCompilation_finish_{nullptr};
+ NeuronCompilation_createForDevices_Type NeuronCompilation_createForDevices_{
+ nullptr};
NeuronExecution_create_Type NeuronExecution_create_{nullptr};
NeuronExecution_free_Type NeuronExecution_free_{nullptr};
NeuronExecution_setInput_Type NeuronExecution_setInput_{nullptr};
NeuronExecution_setOutput_Type NeuronExecution_setOutput_{nullptr};
NeuronExecution_compute_Type NeuronExecution_compute_{nullptr};
+ Neuron_getDeviceCount_Type Neuron_getDeviceCount_{nullptr};
+ Neuron_getDevice_Type Neuron_getDevice_{nullptr};
+ NeuronDevice_getName_Type NeuronDevice_getName_{nullptr};
};
} // namespace lite
} // namespace paddle
diff --git a/lite/backends/arm/math/CMakeLists.txt b/lite/backends/arm/math/CMakeLists.txt
index 244467d62492bc3017ebdb6144b49ccb9fcd30c1..88c449e6a9d8b8078802e90dded5db1162459d3f 100644
--- a/lite/backends/arm/math/CMakeLists.txt
+++ b/lite/backends/arm/math/CMakeLists.txt
@@ -127,8 +127,10 @@ if (NOT HAS_ARM_MATH_LIB_DIR)
anchor_generator.cc
split_merge_lod_tenosr.cc
reduce_prod.cc
+ reduce_sum.cc
lstm.cc
clip.cc
pixel_shuffle.cc
+ scatter.cc
DEPS ${lite_kernel_deps} context tensor)
endif()
diff --git a/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc b/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
index c998ddc3a34c2f6194a5156b7d04b7a9db3fbcef..b4539db98c3ffb1a143c38dd3c4dd9e9924bd63e 100644
--- a/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
+++ b/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
@@ -25,6 +25,73 @@ namespace paddle {
namespace lite {
namespace arm {
namespace math {
+void conv_3x3s1_depthwise_fp32_bias(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx);
+
+void conv_3x3s1_depthwise_fp32_relu(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx);
+
+void conv_3x3s1_depthwise_fp32_relu6(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx);
+
+void conv_3x3s1_depthwise_fp32_leakyRelu(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx);
// clang-format off
#ifdef __aarch64__
#define COMPUTE \
@@ -335,7 +402,6 @@ namespace math {
"ldr r0, [%[outl]] @ load outc00 to r0\n" \
"vmla.f32 q12, q5, q0 @ w8 * inr32\n" \
"vmla.f32 q13, q5, q1 @ w8 * inr33\n" \
- "ldr r5, [%[outl], #36] @ load flag_relu to r5\n" \
"vmla.f32 q14, q5, q2 @ w8 * inr34\n" \
"vmla.f32 q15, q5, q3 @ w8 * inr35\n" \
"ldr r1, [%[outl], #4] @ load outc10 to r1\n" \
@@ -406,7 +472,6 @@ namespace math {
"vtrn.32 q10, q11 @ r0: q10: a2a3c2c3, q11: b2b3d2d3\n" \
"vtrn.32 q12, q13 @ r1: q12: a0a1c0c1, q13: b0b1d0d1\n" \
"vtrn.32 q14, q15 @ r1: q14: a2a3c2c3, q15: b2b3d2d3\n" \
- "ldr r5, [%[outl], #20] @ load outc11 to r5\n" \
"vswp d17, d20 @ r0: q8 : a0a1a2a3, q10: c0c1c2c3 \n" \
"vswp d19, d22 @ r0: q9 : b0b1b2b3, q11: d0d1d2d3 \n" \
"vswp d25, d28 @ r1: q12: a0a1a2a3, q14: c0c1c2c3 \n" \
@@ -417,12 +482,13 @@ namespace math {
"vst1.32 {d18-d19}, [r1] @ save outc10\n" \
"vst1.32 {d20-d21}, [r2] @ save outc20\n" \
"vst1.32 {d22-d23}, [r3] @ save outc30\n" \
+ "ldr r0, [%[outl], #20] @ load outc11 to r5\n" \
+ "ldr r1, [%[outl], #24] @ load outc21 to r0\n" \
+ "ldr r2, [%[outl], #28] @ load outc31 to r1\n" \
"vst1.32 {d24-d25}, [r4] @ save outc01\n" \
- "vst1.32 {d26-d27}, [r5] @ save outc11\n" \
- "ldr r0, [%[outl], #24] @ load outc21 to r0\n" \
- "ldr r1, [%[outl], #28] @ load outc31 to r1\n" \
- "vst1.32 {d28-d29}, [r0] @ save outc21\n" \
- "vst1.32 {d30-d31}, [r1] @ save outc31\n" \
+ "vst1.32 {d26-d27}, [r0] @ save outc11\n" \
+ "vst1.32 {d28-d29}, [r1] @ save outc21\n" \
+ "vst1.32 {d30-d31}, [r2] @ save outc31\n" \
"b 3f @ branch end\n" \
"2: \n" \
"vst1.32 {d16-d17}, [%[out0]]! @ save remain to pre_out\n" \
@@ -436,291 +502,86 @@ namespace math {
"3: \n"
#endif
// clang-format on
-void act_switch_3x3s1(const float* inr0,
- const float* inr1,
- const float* inr2,
- const float* inr3,
- float* out0,
- const float* weight_c,
- float flag_mask,
- void* outl_ptr,
- float32x4_t w0,
- float32x4_t w1,
- float32x4_t w2,
- float32x4_t w3,
- float32x4_t w4,
- float32x4_t w5,
- float32x4_t w6,
- float32x4_t w7,
- float32x4_t w8,
- float32x4_t vbias,
- const operators::ActivationParam act_param) {
- bool has_active = act_param.has_active;
- if (has_active) {
+void conv_3x3s1_depthwise_fp32(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ const operators::ConvParam& param,
+ const operators::ActivationParam act_param,
+ ARMContext* ctx) {
+ float six_ptr[4] = {0.f, 0.f, 0.f, 0.f};
+ float scale_ptr[4] = {1.f, 1.f, 1.f, 1.f};
+ float relu_ptr[4] = {0.f, 0.f, 0.f, 0.f};
+ if (act_param.has_active) {
switch (act_param.active_type) {
case lite_api::ActivationType::kRelu:
-#ifdef __aarch64__
- asm volatile(COMPUTE RELU STORE
- : [inr0] "+r"(inr0),
- [inr1] "+r"(inr1),
- [inr2] "+r"(inr2),
- [inr3] "+r"(inr3),
- [out] "+r"(out0)
- : [w0] "w"(w0),
- [w1] "w"(w1),
- [w2] "w"(w2),
- [w3] "w"(w3),
- [w4] "w"(w4),
- [w5] "w"(w5),
- [w6] "w"(w6),
- [w7] "w"(w7),
- [w8] "w"(w8),
- [vbias] "w"(vbias),
- [outl] "r"(outl_ptr),
- [flag_mask] "r"(flag_mask)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "x0",
- "x1",
- "x2",
- "x3",
- "x4",
- "x5",
- "x6",
- "x7");
-#else
-#if 1 // def LITE_WITH_ARM_CLANG
-#else
- asm volatile(COMPUTE RELU STORE
- : [r0] "+r"(inr0),
- [r1] "+r"(inr1),
- [r2] "+r"(inr2),
- [r3] "+r"(inr3),
- [out0] "+r"(out0),
- [wc0] "+r"(weight_c)
- : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
- : "cc",
- "memory",
- "q0",
- "q1",
- "q2",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15",
- "r0",
- "r1",
- "r2",
- "r3",
- "r4",
- "r5");
-#endif
-#endif
+ conv_3x3s1_depthwise_fp32_relu(i_data,
+ o_data,
+ bs,
+ oc,
+ oh,
+ ow,
+ ic,
+ ih,
+ win,
+ weights,
+ bias,
+ relu_ptr,
+ six_ptr,
+ scale_ptr,
+ param,
+ ctx);
break;
case lite_api::ActivationType::kRelu6:
-#ifdef __aarch64__
- asm volatile(COMPUTE RELU RELU6 STORE
- : [inr0] "+r"(inr0),
- [inr1] "+r"(inr1),
- [inr2] "+r"(inr2),
- [inr3] "+r"(inr3),
- [out] "+r"(out0)
- : [w0] "w"(w0),
- [w1] "w"(w1),
- [w2] "w"(w2),
- [w3] "w"(w3),
- [w4] "w"(w4),
- [w5] "w"(w5),
- [w6] "w"(w6),
- [w7] "w"(w7),
- [w8] "w"(w8),
- [vbias] "w"(vbias),
- [outl] "r"(outl_ptr),
- [flag_mask] "r"(flag_mask)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "x0",
- "x1",
- "x2",
- "x3",
- "x4",
- "x5",
- "x6",
- "x7");
-#else
-#if 1 // def LITE_WITH_ARM_CLANG
-#else
- asm volatile(COMPUTE RELU RELU6 STORE
- : [r0] "+r"(inr0),
- [r1] "+r"(inr1),
- [r2] "+r"(inr2),
- [r3] "+r"(inr3),
- [out0] "+r"(out0),
- [wc0] "+r"(weight_c)
- : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
- : "cc",
- "memory",
- "q0",
- "q1",
- "q2",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15",
- "r0",
- "r1",
- "r2",
- "r3",
- "r4",
- "r5");
-#endif
-#endif
+ six_ptr[0] = act_param.Relu_clipped_coef;
+ six_ptr[1] = act_param.Relu_clipped_coef;
+ six_ptr[2] = act_param.Relu_clipped_coef;
+ six_ptr[3] = act_param.Relu_clipped_coef;
+ conv_3x3s1_depthwise_fp32_relu6(i_data,
+ o_data,
+ bs,
+ oc,
+ oh,
+ ow,
+ ic,
+ ih,
+ win,
+ weights,
+ bias,
+ relu_ptr,
+ six_ptr,
+ scale_ptr,
+ param,
+ ctx);
break;
case lite_api::ActivationType::kLeakyRelu:
-#ifdef __aarch64__
- asm volatile(COMPUTE LEAKY_RELU STORE
- : [inr0] "+r"(inr0),
- [inr1] "+r"(inr1),
- [inr2] "+r"(inr2),
- [inr3] "+r"(inr3),
- [out] "+r"(out0)
- : [w0] "w"(w0),
- [w1] "w"(w1),
- [w2] "w"(w2),
- [w3] "w"(w3),
- [w4] "w"(w4),
- [w5] "w"(w5),
- [w6] "w"(w6),
- [w7] "w"(w7),
- [w8] "w"(w8),
- [vbias] "w"(vbias),
- [outl] "r"(outl_ptr),
- [flag_mask] "r"(flag_mask)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "x0",
- "x1",
- "x2",
- "x3",
- "x4",
- "x5",
- "x6",
- "x7");
-#else
-#if 1 // def LITE_WITH_ARM_CLANG
-#else
- asm volatile(COMPUTE LEAKY_RELU STORE
- : [r0] "+r"(inr0),
- [r1] "+r"(inr1),
- [r2] "+r"(inr2),
- [r3] "+r"(inr3),
- [out0] "+r"(out0),
- [wc0] "+r"(weight_c)
- : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
- : "cc",
- "memory",
- "q0",
- "q1",
- "q2",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15",
- "r0",
- "r1",
- "r2",
- "r3",
- "r4",
- "r5");
-#endif
-#endif
+ scale_ptr[0] = act_param.Leaky_relu_alpha;
+ scale_ptr[1] = act_param.Leaky_relu_alpha;
+ scale_ptr[2] = act_param.Leaky_relu_alpha;
+ scale_ptr[3] = act_param.Leaky_relu_alpha;
+ conv_3x3s1_depthwise_fp32_leakyRelu(i_data,
+ o_data,
+ bs,
+ oc,
+ oh,
+ ow,
+ ic,
+ ih,
+ win,
+ weights,
+ bias,
+ relu_ptr,
+ six_ptr,
+ scale_ptr,
+ param,
+ ctx);
break;
default:
LOG(FATAL) << "this act_type: "
@@ -728,108 +589,289 @@ void act_switch_3x3s1(const float* inr0,
<< " fuse not support";
}
} else {
-#ifdef __aarch64__
- asm volatile(COMPUTE STORE
- : [inr0] "+r"(inr0),
- [inr1] "+r"(inr1),
- [inr2] "+r"(inr2),
- [inr3] "+r"(inr3),
- [out] "+r"(out0)
- : [w0] "w"(w0),
- [w1] "w"(w1),
- [w2] "w"(w2),
- [w3] "w"(w3),
- [w4] "w"(w4),
- [w5] "w"(w5),
- [w6] "w"(w6),
- [w7] "w"(w7),
- [w8] "w"(w8),
- [vbias] "w"(vbias),
- [outl] "r"(outl_ptr),
- [flag_mask] "r"(flag_mask)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "x0",
- "x1",
- "x2",
- "x3",
- "x4",
- "x5",
- "x6",
- "x7");
-#else
-#if 1 // def LITE_WITH_ARM_CLANG
+ conv_3x3s1_depthwise_fp32_bias(i_data,
+ o_data,
+ bs,
+ oc,
+ oh,
+ ow,
+ ic,
+ ih,
+ win,
+ weights,
+ bias,
+ relu_ptr,
+ six_ptr,
+ scale_ptr,
+ param,
+ ctx);
+ }
+}
+
+void conv_3x3s1_depthwise_fp32_bias(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx) {
+ int threads = ctx->threads();
+
+ auto paddings = *param.paddings;
+ const int pad_h = paddings[0];
+ const int pad_w = paddings[2];
+
+ const int out_c_block = 4;
+ const int out_h_kernel = 2;
+ const int out_w_kernel = 4;
+ const int win_ext = ow + 2;
+ const int ow_round = ROUNDUP(ow, 4);
+ const int win_round = ROUNDUP(win_ext, 4);
+ const int hin_round = oh + 2;
+ const int prein_size = win_round * hin_round * out_c_block;
+ auto workspace_size =
+ threads * prein_size + win_round /*tmp zero*/ + ow_round /*tmp writer*/;
+ ctx->ExtendWorkspace(sizeof(float) * workspace_size);
+
+ bool flag_bias = param.bias != nullptr;
+
+ /// get workspace
+ LOG(INFO) << "conv_3x3s1_depthwise_fp32_bias: ";
+ float* ptr_zero = ctx->workspace_data();
+ memset(ptr_zero, 0, sizeof(float) * win_round);
+ float* ptr_write = ptr_zero + win_round;
+
+ int size_in_channel = win * ih;
+ int size_out_channel = ow * oh;
+
+ int ws = -pad_w;
+ int we = ws + win_round;
+ int hs = -pad_h;
+ int he = hs + hin_round;
+ int w_loop = ow_round / 4;
+ auto remain = w_loop * 4 - ow;
+ bool flag_remain = remain > 0;
+ remain = 4 - remain;
+ remain = remain > 0 ? remain : 0;
+ int row_len = win_round * out_c_block;
+
+ for (int n = 0; n < bs; ++n) {
+ const float* din_batch = i_data + n * ic * size_in_channel;
+ float* dout_batch = o_data + n * oc * size_out_channel;
+#pragma omp parallel for num_threads(threads)
+ for (int c = 0; c < oc; c += out_c_block) {
+#ifdef ARM_WITH_OMP
+ float* pre_din = ptr_write + ow_round + omp_get_thread_num() * prein_size;
#else
- asm volatile(COMPUTE STORE
- : [r0] "+r"(inr0),
- [r1] "+r"(inr1),
- [r2] "+r"(inr2),
- [r3] "+r"(inr3),
- [out0] "+r"(out0),
- [wc0] "+r"(weight_c)
- : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
- : "cc",
- "memory",
- "q0",
- "q1",
- "q2",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15",
- "r0",
- "r1",
- "r2",
- "r3",
- "r4",
- "r5");
+ float* pre_din = ptr_write + ow_round;
#endif
+ /// const array size
+ float pre_out[out_c_block * out_w_kernel * out_h_kernel]; // NOLINT
+ prepack_input_nxwc4_dw(
+ din_batch, pre_din, c, hs, he, ws, we, ic, win, ih, ptr_zero);
+ const float* weight_c = weights + c * 9; // kernel_w * kernel_h
+ float* dout_c00 = dout_batch + c * size_out_channel;
+ float bias_local[4] = {0, 0, 0, 0};
+ if (flag_bias) {
+ bias_local[0] = bias[c];
+ bias_local[1] = bias[c + 1];
+ bias_local[2] = bias[c + 2];
+ bias_local[3] = bias[c + 3];
+ }
+ float32x4_t vbias = vld1q_f32(bias_local);
+#ifdef __aarch64__
+ float32x4_t w0 = vld1q_f32(weight_c); // w0, v23
+ float32x4_t w1 = vld1q_f32(weight_c + 4); // w1, v24
+ float32x4_t w2 = vld1q_f32(weight_c + 8); // w2, v25
+ float32x4_t w3 = vld1q_f32(weight_c + 12); // w3, v26
+ float32x4_t w4 = vld1q_f32(weight_c + 16); // w4, v27
+ float32x4_t w5 = vld1q_f32(weight_c + 20); // w5, v28
+ float32x4_t w6 = vld1q_f32(weight_c + 24); // w6, v29
+ float32x4_t w7 = vld1q_f32(weight_c + 28); // w7, v30
+ float32x4_t w8 = vld1q_f32(weight_c + 32); // w8, v31
+#endif
+ for (int h = 0; h < oh; h += out_h_kernel) {
+ float* outc00 = dout_c00 + h * ow;
+ float* outc01 = outc00 + ow;
+ float* outc10 = outc00 + size_out_channel;
+ float* outc11 = outc10 + ow;
+ float* outc20 = outc10 + size_out_channel;
+ float* outc21 = outc20 + ow;
+ float* outc30 = outc20 + size_out_channel;
+ float* outc31 = outc30 + ow;
+ const float* inr0 = pre_din + h * row_len;
+ const float* inr1 = inr0 + row_len;
+ const float* inr2 = inr1 + row_len;
+ const float* inr3 = inr2 + row_len;
+ if (c + out_c_block > oc) {
+ switch (c + out_c_block - oc) {
+ case 3: // outc10-outc30 is ptr_write and extra
+ outc10 = ptr_write;
+ outc11 = ptr_write;
+ case 2: // outc20-outc30 is ptr_write and extra
+ outc20 = ptr_write;
+ outc21 = ptr_write;
+ case 1: // outc30 is ptr_write and extra
+ outc30 = ptr_write;
+ outc31 = ptr_write;
+ default:
+ break;
+ }
+ }
+ if (h + out_h_kernel > oh) {
+ outc01 = ptr_write;
+ outc11 = ptr_write;
+ outc21 = ptr_write;
+ outc31 = ptr_write;
+ }
+
+ float* outl[] = {outc00,
+ outc10,
+ outc20,
+ outc30,
+ outc01,
+ outc11,
+ outc21,
+ outc31,
+ reinterpret_cast(bias_local),
+ reinterpret_cast(relu_ptr),
+ reinterpret_cast(six_ptr),
+ reinterpret_cast(scale_ptr)};
+ void* outl_ptr = reinterpret_cast(outl);
+ for (int w = 0; w < w_loop; ++w) {
+ bool flag_mask = (w == w_loop - 1) && flag_remain;
+ float* out0 = pre_out;
+#ifdef __aarch64__
+ asm volatile(COMPUTE STORE
+ : [inr0] "+r"(inr0),
+ [inr1] "+r"(inr1),
+ [inr2] "+r"(inr2),
+ [inr3] "+r"(inr3),
+ [out] "+r"(out0)
+ : [w0] "w"(w0),
+ [w1] "w"(w1),
+ [w2] "w"(w2),
+ [w3] "w"(w3),
+ [w4] "w"(w4),
+ [w5] "w"(w5),
+ [w6] "w"(w6),
+ [w7] "w"(w7),
+ [w8] "w"(w8),
+ [vbias] "w"(vbias),
+ [outl] "r"(outl_ptr),
+ [flag_mask] "r"(flag_mask)
+ : "cc",
+ "memory",
+ "v0",
+ "v1",
+ "v2",
+ "v3",
+ "v4",
+ "v5",
+ "v6",
+ "v7",
+ "v8",
+ "v9",
+ "v10",
+ "v11",
+ "v15",
+ "v16",
+ "v17",
+ "v18",
+ "v19",
+ "v20",
+ "v21",
+ "v22",
+ "x0",
+ "x1",
+ "x2",
+ "x3",
+ "x4",
+ "x5",
+ "x6",
+ "x7");
+#else
+ asm volatile(COMPUTE STORE
+ : [r0] "+r"(inr0),
+ [r1] "+r"(inr1),
+ [r2] "+r"(inr2),
+ [r3] "+r"(inr3),
+ [out0] "+r"(out0),
+ [wc0] "+r"(weight_c)
+ : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
+ : "cc",
+ "memory",
+ "q0",
+ "q1",
+ "q2",
+ "q3",
+ "q4",
+ "q5",
+ "q6",
+ "q7",
+ "q8",
+ "q9",
+ "q10",
+ "q11",
+ "q12",
+ "q13",
+ "q14",
+ "q15",
+ "r0",
+ "r1",
+ "r2",
+ "r3",
+ "r4");
#endif
+ outl[0] += 4;
+ outl[1] += 4;
+ outl[2] += 4;
+ outl[3] += 4;
+ outl[4] += 4;
+ outl[5] += 4;
+ outl[6] += 4;
+ outl[7] += 4;
+ if (flag_mask) {
+ memcpy(outl[0] - 4, pre_out, remain * sizeof(float));
+ memcpy(outl[1] - 4, pre_out + 4, remain * sizeof(float));
+ memcpy(outl[2] - 4, pre_out + 8, remain * sizeof(float));
+ memcpy(outl[3] - 4, pre_out + 12, remain * sizeof(float));
+ memcpy(outl[4] - 4, pre_out + 16, remain * sizeof(float));
+ memcpy(outl[5] - 4, pre_out + 20, remain * sizeof(float));
+ memcpy(outl[6] - 4, pre_out + 24, remain * sizeof(float));
+ memcpy(outl[7] - 4, pre_out + 28, remain * sizeof(float));
+ }
+ }
+ }
+ }
}
}
-void conv_3x3s1_depthwise_fp32(const float* i_data,
- float* o_data,
- int bs,
- int oc,
- int oh,
- int ow,
- int ic,
- int ih,
- int win,
- const float* weights,
- const float* bias,
- const operators::ConvParam& param,
- const operators::ActivationParam act_param,
- ARMContext* ctx) {
+
+void conv_3x3s1_depthwise_fp32_relu(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx) {
int threads = ctx->threads();
auto paddings = *param.paddings;
@@ -869,31 +911,6 @@ void conv_3x3s1_depthwise_fp32(const float* i_data,
remain = remain > 0 ? remain : 0;
int row_len = win_round * out_c_block;
- float six_ptr[4] = {0.f, 0.f, 0.f, 0.f};
- float scale_ptr[4] = {1.f, 1.f, 1.f, 1.f};
- float relu_ptr[4] = {0.f, 0.f, 0.f, 0.f};
- if (act_param.has_active) {
- switch (act_param.active_type) {
- case lite_api::ActivationType::kRelu:
- break;
- case lite_api::ActivationType::kRelu6:
- six_ptr[0] = act_param.Relu_clipped_coef;
- six_ptr[1] = act_param.Relu_clipped_coef;
- six_ptr[2] = act_param.Relu_clipped_coef;
- six_ptr[3] = act_param.Relu_clipped_coef;
- break;
- case lite_api::ActivationType::kLeakyRelu:
- scale_ptr[0] = act_param.Leaky_relu_alpha;
- scale_ptr[1] = act_param.Leaky_relu_alpha;
- scale_ptr[2] = act_param.Leaky_relu_alpha;
- scale_ptr[3] = act_param.Leaky_relu_alpha;
- break;
- default:
- LOG(FATAL) << "this act_type: "
- << static_cast(act_param.active_type)
- << " fuse not support";
- }
- }
for (int n = 0; n < bs; ++n) {
const float* din_batch = i_data + n * ic * size_in_channel;
float* dout_batch = o_data + n * oc * size_out_channel;
@@ -944,13 +961,13 @@ void conv_3x3s1_depthwise_fp32(const float* i_data,
const float* inr3 = inr2 + row_len;
if (c + out_c_block > oc) {
switch (c + out_c_block - oc) {
- case 3:
+ case 3: // outc10-outc30 is ptr_write and extra
outc10 = ptr_write;
outc11 = ptr_write;
- case 2:
+ case 2: // outc20-outc30 is ptr_write and extra
outc20 = ptr_write;
outc21 = ptr_write;
- case 1:
+ case 1: // outc30 is ptr_write and extra
outc30 = ptr_write;
outc31 = ptr_write;
default:
@@ -981,48 +998,86 @@ void conv_3x3s1_depthwise_fp32(const float* i_data,
bool flag_mask = (w == w_loop - 1) && flag_remain;
float* out0 = pre_out;
#ifdef __aarch64__
- act_switch_3x3s1(inr0,
- inr1,
- inr2,
- inr3,
- out0,
- weight_c,
- flag_mask,
- outl_ptr,
- w0,
- w1,
- w2,
- w3,
- w4,
- w5,
- w6,
- w7,
- w8,
- vbias,
- act_param);
+ asm volatile(COMPUTE RELU STORE
+ : [inr0] "+r"(inr0),
+ [inr1] "+r"(inr1),
+ [inr2] "+r"(inr2),
+ [inr3] "+r"(inr3),
+ [out] "+r"(out0)
+ : [w0] "w"(w0),
+ [w1] "w"(w1),
+ [w2] "w"(w2),
+ [w3] "w"(w3),
+ [w4] "w"(w4),
+ [w5] "w"(w5),
+ [w6] "w"(w6),
+ [w7] "w"(w7),
+ [w8] "w"(w8),
+ [vbias] "w"(vbias),
+ [outl] "r"(outl_ptr),
+ [flag_mask] "r"(flag_mask)
+ : "cc",
+ "memory",
+ "v0",
+ "v1",
+ "v2",
+ "v3",
+ "v4",
+ "v5",
+ "v6",
+ "v7",
+ "v8",
+ "v9",
+ "v10",
+ "v11",
+ "v15",
+ "v16",
+ "v17",
+ "v18",
+ "v19",
+ "v20",
+ "v21",
+ "v22",
+ "x0",
+ "x1",
+ "x2",
+ "x3",
+ "x4",
+ "x5",
+ "x6",
+ "x7");
#else
-#if 1 // def LITE_WITH_ARM_CLANG
-#else
- act_switch_3x3s1(inr0,
- inr1,
- inr2,
- inr3,
- out0,
- weight_c,
- flag_mask,
- outl_ptr,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- vbias,
- act_param);
-#endif
+ asm volatile(COMPUTE RELU STORE
+ : [r0] "+r"(inr0),
+ [r1] "+r"(inr1),
+ [r2] "+r"(inr2),
+ [r3] "+r"(inr3),
+ [out0] "+r"(out0),
+ [wc0] "+r"(weight_c)
+ : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
+ : "cc",
+ "memory",
+ "q0",
+ "q1",
+ "q2",
+ "q3",
+ "q4",
+ "q5",
+ "q6",
+ "q7",
+ "q8",
+ "q9",
+ "q10",
+ "q11",
+ "q12",
+ "q13",
+ "q14",
+ "q15",
+ "r0",
+ "r1",
+ "r2",
+ "r3",
+ "r4");
#endif
outl[0] += 4;
outl[1] += 4;
@@ -1032,10 +1087,6 @@ void conv_3x3s1_depthwise_fp32(const float* i_data,
outl[5] += 4;
outl[6] += 4;
outl[7] += 4;
- inr0 += 16;
- inr1 += 16;
- inr2 += 16;
- inr3 += 16;
if (flag_mask) {
memcpy(outl[0] - 4, pre_out, remain * sizeof(float));
memcpy(outl[1] - 4, pre_out + 4, remain * sizeof(float));
@@ -1052,6 +1103,499 @@ void conv_3x3s1_depthwise_fp32(const float* i_data,
}
}
+void conv_3x3s1_depthwise_fp32_relu6(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx) {
+ int threads = ctx->threads();
+
+ auto paddings = *param.paddings;
+ const int pad_h = paddings[0];
+ const int pad_w = paddings[2];
+
+ const int out_c_block = 4;
+ const int out_h_kernel = 2;
+ const int out_w_kernel = 4;
+ const int win_ext = ow + 2;
+ const int ow_round = ROUNDUP(ow, 4);
+ const int win_round = ROUNDUP(win_ext, 4);
+ const int hin_round = oh + 2;
+ const int prein_size = win_round * hin_round * out_c_block;
+ auto workspace_size =
+ threads * prein_size + win_round /*tmp zero*/ + ow_round /*tmp writer*/;
+ ctx->ExtendWorkspace(sizeof(float) * workspace_size);
+
+ bool flag_bias = param.bias != nullptr;
+
+ /// get workspace
+ float* ptr_zero = ctx->workspace_data();
+ memset(ptr_zero, 0, sizeof(float) * win_round);
+ float* ptr_write = ptr_zero + win_round;
+
+ int size_in_channel = win * ih;
+ int size_out_channel = ow * oh;
+
+ int ws = -pad_w;
+ int we = ws + win_round;
+ int hs = -pad_h;
+ int he = hs + hin_round;
+ int w_loop = ow_round / 4;
+ auto remain = w_loop * 4 - ow;
+ bool flag_remain = remain > 0;
+ remain = 4 - remain;
+ remain = remain > 0 ? remain : 0;
+ int row_len = win_round * out_c_block;
+
+ for (int n = 0; n < bs; ++n) {
+ const float* din_batch = i_data + n * ic * size_in_channel;
+ float* dout_batch = o_data + n * oc * size_out_channel;
+#pragma omp parallel for num_threads(threads)
+ for (int c = 0; c < oc; c += out_c_block) {
+#ifdef ARM_WITH_OMP
+ float* pre_din = ptr_write + ow_round + omp_get_thread_num() * prein_size;
+#else
+ float* pre_din = ptr_write + ow_round;
+#endif
+ /// const array size
+ float pre_out[out_c_block * out_w_kernel * out_h_kernel]; // NOLINT
+ prepack_input_nxwc4_dw(
+ din_batch, pre_din, c, hs, he, ws, we, ic, win, ih, ptr_zero);
+ const float* weight_c = weights + c * 9; // kernel_w * kernel_h
+ float* dout_c00 = dout_batch + c * size_out_channel;
+ float bias_local[4] = {0, 0, 0, 0};
+ if (flag_bias) {
+ bias_local[0] = bias[c];
+ bias_local[1] = bias[c + 1];
+ bias_local[2] = bias[c + 2];
+ bias_local[3] = bias[c + 3];
+ }
+ float32x4_t vbias = vld1q_f32(bias_local);
+#ifdef __aarch64__
+ float32x4_t w0 = vld1q_f32(weight_c); // w0, v23
+ float32x4_t w1 = vld1q_f32(weight_c + 4); // w1, v24
+ float32x4_t w2 = vld1q_f32(weight_c + 8); // w2, v25
+ float32x4_t w3 = vld1q_f32(weight_c + 12); // w3, v26
+ float32x4_t w4 = vld1q_f32(weight_c + 16); // w4, v27
+ float32x4_t w5 = vld1q_f32(weight_c + 20); // w5, v28
+ float32x4_t w6 = vld1q_f32(weight_c + 24); // w6, v29
+ float32x4_t w7 = vld1q_f32(weight_c + 28); // w7, v30
+ float32x4_t w8 = vld1q_f32(weight_c + 32); // w8, v31
+#endif
+ for (int h = 0; h < oh; h += out_h_kernel) {
+ float* outc00 = dout_c00 + h * ow;
+ float* outc01 = outc00 + ow;
+ float* outc10 = outc00 + size_out_channel;
+ float* outc11 = outc10 + ow;
+ float* outc20 = outc10 + size_out_channel;
+ float* outc21 = outc20 + ow;
+ float* outc30 = outc20 + size_out_channel;
+ float* outc31 = outc30 + ow;
+ const float* inr0 = pre_din + h * row_len;
+ const float* inr1 = inr0 + row_len;
+ const float* inr2 = inr1 + row_len;
+ const float* inr3 = inr2 + row_len;
+ if (c + out_c_block > oc) {
+ switch (c + out_c_block - oc) {
+ case 3: // outc10-outc30 is ptr_write and extra
+ outc10 = ptr_write;
+ outc11 = ptr_write;
+ case 2: // outc20-outc30 is ptr_write and extra
+ outc20 = ptr_write;
+ outc21 = ptr_write;
+ case 1: // outc30 is ptr_write and extra
+ outc30 = ptr_write;
+ outc31 = ptr_write;
+ default:
+ break;
+ }
+ }
+ if (h + out_h_kernel > oh) {
+ outc01 = ptr_write;
+ outc11 = ptr_write;
+ outc21 = ptr_write;
+ outc31 = ptr_write;
+ }
+
+ float* outl[] = {outc00,
+ outc10,
+ outc20,
+ outc30,
+ outc01,
+ outc11,
+ outc21,
+ outc31,
+ reinterpret_cast(bias_local),
+ reinterpret_cast(relu_ptr),
+ reinterpret_cast(six_ptr),
+ reinterpret_cast(scale_ptr)};
+ void* outl_ptr = reinterpret_cast(outl);
+ for (int w = 0; w < w_loop; ++w) {
+ bool flag_mask = (w == w_loop - 1) && flag_remain;
+ float* out0 = pre_out;
+#ifdef __aarch64__
+ asm volatile(COMPUTE RELU RELU6 STORE
+ : [inr0] "+r"(inr0),
+ [inr1] "+r"(inr1),
+ [inr2] "+r"(inr2),
+ [inr3] "+r"(inr3),
+ [out] "+r"(out0)
+ : [w0] "w"(w0),
+ [w1] "w"(w1),
+ [w2] "w"(w2),
+ [w3] "w"(w3),
+ [w4] "w"(w4),
+ [w5] "w"(w5),
+ [w6] "w"(w6),
+ [w7] "w"(w7),
+ [w8] "w"(w8),
+ [vbias] "w"(vbias),
+ [outl] "r"(outl_ptr),
+ [flag_mask] "r"(flag_mask)
+ : "cc",
+ "memory",
+ "v0",
+ "v1",
+ "v2",
+ "v3",
+ "v4",
+ "v5",
+ "v6",
+ "v7",
+ "v8",
+ "v9",
+ "v10",
+ "v11",
+ "v15",
+ "v16",
+ "v17",
+ "v18",
+ "v19",
+ "v20",
+ "v21",
+ "v22",
+ "x0",
+ "x1",
+ "x2",
+ "x3",
+ "x4",
+ "x5",
+ "x6",
+ "x7");
+#else
+ asm volatile(COMPUTE RELU RELU6 STORE
+ : [r0] "+r"(inr0),
+ [r1] "+r"(inr1),
+ [r2] "+r"(inr2),
+ [r3] "+r"(inr3),
+ [out0] "+r"(out0),
+ [wc0] "+r"(weight_c)
+ : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
+ : "cc",
+ "memory",
+ "q0",
+ "q1",
+ "q2",
+ "q3",
+ "q4",
+ "q5",
+ "q6",
+ "q7",
+ "q8",
+ "q9",
+ "q10",
+ "q11",
+ "q12",
+ "q13",
+ "q14",
+ "q15",
+ "r0",
+ "r1",
+ "r2",
+ "r3",
+ "r4");
+#endif
+ outl[0] += 4;
+ outl[1] += 4;
+ outl[2] += 4;
+ outl[3] += 4;
+ outl[4] += 4;
+ outl[5] += 4;
+ outl[6] += 4;
+ outl[7] += 4;
+ if (flag_mask) {
+ memcpy(outl[0] - 4, pre_out, remain * sizeof(float));
+ memcpy(outl[1] - 4, pre_out + 4, remain * sizeof(float));
+ memcpy(outl[2] - 4, pre_out + 8, remain * sizeof(float));
+ memcpy(outl[3] - 4, pre_out + 12, remain * sizeof(float));
+ memcpy(outl[4] - 4, pre_out + 16, remain * sizeof(float));
+ memcpy(outl[5] - 4, pre_out + 20, remain * sizeof(float));
+ memcpy(outl[6] - 4, pre_out + 24, remain * sizeof(float));
+ memcpy(outl[7] - 4, pre_out + 28, remain * sizeof(float));
+ }
+ }
+ }
+ }
+ }
+}
+
+void conv_3x3s1_depthwise_fp32_leakyRelu(const float* i_data,
+ float* o_data,
+ int bs,
+ int oc,
+ int oh,
+ int ow,
+ int ic,
+ int ih,
+ int win,
+ const float* weights,
+ const float* bias,
+ float* relu_ptr,
+ float* six_ptr,
+ float* scale_ptr,
+ const operators::ConvParam& param,
+ ARMContext* ctx) {
+ int threads = ctx->threads();
+
+ auto paddings = *param.paddings;
+ const int pad_h = paddings[0];
+ const int pad_w = paddings[2];
+
+ const int out_c_block = 4;
+ const int out_h_kernel = 2;
+ const int out_w_kernel = 4;
+ const int win_ext = ow + 2;
+ const int ow_round = ROUNDUP(ow, 4);
+ const int win_round = ROUNDUP(win_ext, 4);
+ const int hin_round = oh + 2;
+ const int prein_size = win_round * hin_round * out_c_block;
+ auto workspace_size =
+ threads * prein_size + win_round /*tmp zero*/ + ow_round /*tmp writer*/;
+ ctx->ExtendWorkspace(sizeof(float) * workspace_size);
+
+ bool flag_bias = param.bias != nullptr;
+
+ /// get workspace
+ float* ptr_zero = ctx->workspace_data();
+ memset(ptr_zero, 0, sizeof(float) * win_round);
+ float* ptr_write = ptr_zero + win_round;
+
+ int size_in_channel = win * ih;
+ int size_out_channel = ow * oh;
+
+ int ws = -pad_w;
+ int we = ws + win_round;
+ int hs = -pad_h;
+ int he = hs + hin_round;
+ int w_loop = ow_round / 4;
+ auto remain = w_loop * 4 - ow;
+ bool flag_remain = remain > 0;
+ remain = 4 - remain;
+ remain = remain > 0 ? remain : 0;
+ int row_len = win_round * out_c_block;
+
+ for (int n = 0; n < bs; ++n) {
+ const float* din_batch = i_data + n * ic * size_in_channel;
+ float* dout_batch = o_data + n * oc * size_out_channel;
+#pragma omp parallel for num_threads(threads)
+ for (int c = 0; c < oc; c += out_c_block) {
+#ifdef ARM_WITH_OMP
+ float* pre_din = ptr_write + ow_round + omp_get_thread_num() * prein_size;
+#else
+ float* pre_din = ptr_write + ow_round;
+#endif
+ /// const array size
+ float pre_out[out_c_block * out_w_kernel * out_h_kernel]; // NOLINT
+ prepack_input_nxwc4_dw(
+ din_batch, pre_din, c, hs, he, ws, we, ic, win, ih, ptr_zero);
+ const float* weight_c = weights + c * 9; // kernel_w * kernel_h
+ float* dout_c00 = dout_batch + c * size_out_channel;
+ float bias_local[4] = {0, 0, 0, 0};
+ if (flag_bias) {
+ bias_local[0] = bias[c];
+ bias_local[1] = bias[c + 1];
+ bias_local[2] = bias[c + 2];
+ bias_local[3] = bias[c + 3];
+ }
+ float32x4_t vbias = vld1q_f32(bias_local);
+#ifdef __aarch64__
+ float32x4_t w0 = vld1q_f32(weight_c); // w0, v23
+ float32x4_t w1 = vld1q_f32(weight_c + 4); // w1, v24
+ float32x4_t w2 = vld1q_f32(weight_c + 8); // w2, v25
+ float32x4_t w3 = vld1q_f32(weight_c + 12); // w3, v26
+ float32x4_t w4 = vld1q_f32(weight_c + 16); // w4, v27
+ float32x4_t w5 = vld1q_f32(weight_c + 20); // w5, v28
+ float32x4_t w6 = vld1q_f32(weight_c + 24); // w6, v29
+ float32x4_t w7 = vld1q_f32(weight_c + 28); // w7, v30
+ float32x4_t w8 = vld1q_f32(weight_c + 32); // w8, v31
+#endif
+ for (int h = 0; h < oh; h += out_h_kernel) {
+ float* outc00 = dout_c00 + h * ow;
+ float* outc01 = outc00 + ow;
+ float* outc10 = outc00 + size_out_channel;
+ float* outc11 = outc10 + ow;
+ float* outc20 = outc10 + size_out_channel;
+ float* outc21 = outc20 + ow;
+ float* outc30 = outc20 + size_out_channel;
+ float* outc31 = outc30 + ow;
+ const float* inr0 = pre_din + h * row_len;
+ const float* inr1 = inr0 + row_len;
+ const float* inr2 = inr1 + row_len;
+ const float* inr3 = inr2 + row_len;
+ if (c + out_c_block > oc) {
+ switch (c + out_c_block - oc) {
+ case 3: // outc10-outc30 is ptr_write and extra
+ outc10 = ptr_write;
+ outc11 = ptr_write;
+ case 2: // outc20-outc30 is ptr_write and extra
+ outc20 = ptr_write;
+ outc21 = ptr_write;
+ case 1: // outc30 is ptr_write and extra
+ outc30 = ptr_write;
+ outc31 = ptr_write;
+ default:
+ break;
+ }
+ }
+ if (h + out_h_kernel > oh) {
+ outc01 = ptr_write;
+ outc11 = ptr_write;
+ outc21 = ptr_write;
+ outc31 = ptr_write;
+ }
+
+ float* outl[] = {outc00,
+ outc10,
+ outc20,
+ outc30,
+ outc01,
+ outc11,
+ outc21,
+ outc31,
+ reinterpret_cast(bias_local),
+ reinterpret_cast(relu_ptr),
+ reinterpret_cast(six_ptr),
+ reinterpret_cast(scale_ptr)};
+ void* outl_ptr = reinterpret_cast(outl);
+ for (int w = 0; w < w_loop; ++w) {
+ bool flag_mask = (w == w_loop - 1) && flag_remain;
+ float* out0 = pre_out;
+#ifdef __aarch64__
+ asm volatile(COMPUTE LEAKY_RELU STORE
+ : [inr0] "+r"(inr0),
+ [inr1] "+r"(inr1),
+ [inr2] "+r"(inr2),
+ [inr3] "+r"(inr3),
+ [out] "+r"(out0)
+ : [w0] "w"(w0),
+ [w1] "w"(w1),
+ [w2] "w"(w2),
+ [w3] "w"(w3),
+ [w4] "w"(w4),
+ [w5] "w"(w5),
+ [w6] "w"(w6),
+ [w7] "w"(w7),
+ [w8] "w"(w8),
+ [vbias] "w"(vbias),
+ [outl] "r"(outl_ptr),
+ [flag_mask] "r"(flag_mask)
+ : "cc",
+ "memory",
+ "v0",
+ "v1",
+ "v2",
+ "v3",
+ "v4",
+ "v5",
+ "v6",
+ "v7",
+ "v8",
+ "v9",
+ "v10",
+ "v11",
+ "v15",
+ "v16",
+ "v17",
+ "v18",
+ "v19",
+ "v20",
+ "v21",
+ "v22",
+ "x0",
+ "x1",
+ "x2",
+ "x3",
+ "x4",
+ "x5",
+ "x6",
+ "x7");
+#else
+ asm volatile(COMPUTE LEAKY_RELU STORE
+ : [r0] "+r"(inr0),
+ [r1] "+r"(inr1),
+ [r2] "+r"(inr2),
+ [r3] "+r"(inr3),
+ [out0] "+r"(out0),
+ [wc0] "+r"(weight_c)
+ : [flag_mask] "r"(flag_mask), [outl] "r"(outl_ptr)
+ : "cc",
+ "memory",
+ "q0",
+ "q1",
+ "q2",
+ "q3",
+ "q4",
+ "q5",
+ "q6",
+ "q7",
+ "q8",
+ "q9",
+ "q10",
+ "q11",
+ "q12",
+ "q13",
+ "q14",
+ "q15",
+ "r0",
+ "r1",
+ "r2",
+ "r3",
+ "r4");
+#endif
+ outl[0] += 4;
+ outl[1] += 4;
+ outl[2] += 4;
+ outl[3] += 4;
+ outl[4] += 4;
+ outl[5] += 4;
+ outl[6] += 4;
+ outl[7] += 4;
+ if (flag_mask) {
+ memcpy(outl[0] - 4, pre_out, remain * sizeof(float));
+ memcpy(outl[1] - 4, pre_out + 4, remain * sizeof(float));
+ memcpy(outl[2] - 4, pre_out + 8, remain * sizeof(float));
+ memcpy(outl[3] - 4, pre_out + 12, remain * sizeof(float));
+ memcpy(outl[4] - 4, pre_out + 16, remain * sizeof(float));
+ memcpy(outl[5] - 4, pre_out + 20, remain * sizeof(float));
+ memcpy(outl[6] - 4, pre_out + 24, remain * sizeof(float));
+ memcpy(outl[7] - 4, pre_out + 28, remain * sizeof(float));
+ }
+ }
+ }
+ }
+ }
+}
} // namespace math
} // namespace arm
} // namespace lite
diff --git a/lite/backends/arm/math/conv_impl.cc b/lite/backends/arm/math/conv_impl.cc
index 2bad1f997f457429c013c11a1dce35eb43dc26da..fa2f85311b3ff4247d52505d750566ec80e47256 100644
--- a/lite/backends/arm/math/conv_impl.cc
+++ b/lite/backends/arm/math/conv_impl.cc
@@ -620,8 +620,10 @@ void conv_depthwise_3x3_fp32(const void* din,
int pad = pad_w;
bool flag_bias = param.bias != nullptr;
bool pads_less = ((paddings[1] < 2) && (paddings[3] < 2));
+ bool ch_four = ch_in <= 4 * w_in;
if (stride == 1) {
- if (pads_less && (pad_h == pad_w) && (pad < 2)) { // support pad = [0, 1]
+ if (ch_four && pads_less && (pad_h == pad_w) &&
+ (pad < 2)) { // support pad = [0, 1]
conv_depthwise_3x3s1_fp32(reinterpret_cast(din),
reinterpret_cast(dout),
num,
@@ -638,7 +640,6 @@ void conv_depthwise_3x3_fp32(const void* din,
act_param,
ctx);
} else {
-#ifdef __aarch64__
conv_3x3s1_depthwise_fp32(reinterpret_cast(din),
reinterpret_cast(dout),
num,
@@ -653,30 +654,10 @@ void conv_depthwise_3x3_fp32(const void* din,
param,
act_param,
ctx);
-#else
-#ifdef LITE_WITH_ARM_CLANG
- LOG(FATAL) << "fp32 depthwise conv3x3s1px doesnot support in v7-clang, "
- "this can run in basic";
-#else
- conv_3x3s1_depthwise_fp32(reinterpret_cast(din),
- reinterpret_cast(dout),
- num,
- ch_out,
- h_out,
- w_out,
- ch_in,
- h_in,
- w_in,
- reinterpret_cast(weights),
- bias,
- param,
- act_param,
- ctx);
-#endif
-#endif
}
} else if (stride == 2) {
- if (pads_less && pad_h == pad_w && (pad < 2)) { // support pad = [0, 1]
+ if (ch_four && pads_less && pad_h == pad_w &&
+ (pad < 2)) { // support pad = [0, 1]
conv_depthwise_3x3s2_fp32(reinterpret_cast(din),
reinterpret_cast(dout),
num,
diff --git a/lite/backends/arm/math/funcs.h b/lite/backends/arm/math/funcs.h
index 2e52bd1e285b7493148a5a779bffcfcfd1336722..f1ac1d63a1b40e2ead5e976e0bffe6c435a2545b 100644
--- a/lite/backends/arm/math/funcs.h
+++ b/lite/backends/arm/math/funcs.h
@@ -53,7 +53,9 @@
#include "lite/backends/arm/math/reduce_max.h"
#include "lite/backends/arm/math/reduce_mean.h"
#include "lite/backends/arm/math/reduce_prod.h"
+#include "lite/backends/arm/math/reduce_sum.h"
#include "lite/backends/arm/math/scale.h"
+#include "lite/backends/arm/math/scatter.h"
#include "lite/backends/arm/math/sequence_expand.h"
#include "lite/backends/arm/math/sequence_pool.h"
#include "lite/backends/arm/math/sequence_pool_grad.h"
@@ -357,6 +359,15 @@ inline float32x4_t pow_ps(float32x4_t a, float32x4_t b) {
return exp_ps(vmulq_f32(b, log_ps(a)));
}
+inline float32x4_t vpaddq_f32(float32x4_t a, float32x4_t b) {
+ float32x4_t vrst;
+ vrst[0] = a[0] + a[1];
+ vrst[1] = a[2] + a[3];
+ vrst[2] = b[0] + b[1];
+ vrst[3] = b[2] + b[3];
+ return vrst;
+}
+
template
void fill_bias_fc(
T* tensor, const T* bias, int num, int channel, bool flag_relu);
diff --git a/lite/backends/arm/math/interpolate.cc b/lite/backends/arm/math/interpolate.cc
index 1c53142fc53bc785efcbf28fa007d403ad99ab70..4345c2e8137dbe0d0d1031cb4b41a2163d49ed57 100644
--- a/lite/backends/arm/math/interpolate.cc
+++ b/lite/backends/arm/math/interpolate.cc
@@ -70,7 +70,8 @@ void bilinear_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool with_align) {
+ bool align_corners,
+ bool align_mode) {
int* buf = new int[w_out + h_out + w_out * 2 + h_out * 2];
int* xofs = buf;
@@ -78,14 +79,13 @@ void bilinear_interp(const float* src,
float* alpha = reinterpret_cast(buf + w_out + h_out);
float* beta = reinterpret_cast(buf + w_out + h_out + w_out * 2);
+ bool with_align = (align_mode == 0 && !align_corners);
float fx = 0.0f;
float fy = 0.0f;
int sx = 0;
int sy = 0;
- if (with_align) {
- scale_x = static_cast(w_in - 1) / (w_out - 1);
- scale_y = static_cast(h_in - 1) / (h_out - 1);
+ if (!with_align) {
// calculate x axis coordinate
for (int dx = 0; dx < w_out; dx++) {
fx = dx * scale_x;
@@ -105,8 +105,6 @@ void bilinear_interp(const float* src,
beta[dy * 2 + 1] = fy;
}
} else {
- scale_x = static_cast(w_in) / w_out;
- scale_y = static_cast(h_in) / h_out;
// calculate x axis coordinate
for (int dx = 0; dx < w_out; dx++) {
fx = scale_x * (dx + 0.5f) - 0.5f;
@@ -468,15 +466,9 @@ void nearest_interp(const float* src,
float* dst,
int w_out,
int h_out,
- float scale_x,
- float scale_y,
+ float scale_w_new,
+ float scale_h_new,
bool with_align) {
- float scale_w_new = (with_align)
- ? (static_cast(w_in - 1) / (w_out - 1))
- : (static_cast(w_in) / (w_out));
- float scale_h_new = (with_align)
- ? (static_cast(h_in - 1) / (h_out - 1))
- : (static_cast(h_in) / (h_out));
if (with_align) {
for (int h = 0; h < h_out; ++h) {
float* dst_p = dst + h * w_out;
@@ -506,7 +498,8 @@ void interpolate(lite::Tensor* X,
int out_height,
int out_width,
float scale,
- bool with_align,
+ bool align_corners,
+ bool align_mode,
std::string interpolate_type) {
int in_h = X->dims()[2];
int in_w = X->dims()[3];
@@ -531,12 +524,12 @@ void interpolate(lite::Tensor* X,
out_width = out_size_data[1];
}
}
- float height_scale = scale;
- float width_scale = scale;
- if (out_width > 0 && out_height > 0) {
- height_scale = static_cast(out_height / X->dims()[2]);
- width_scale = static_cast(out_width / X->dims()[3]);
- }
+ // float height_scale = scale;
+ // float width_scale = scale;
+ // if (out_width > 0 && out_height > 0) {
+ // height_scale = static_cast(out_height / X->dims()[2]);
+ // width_scale = static_cast(out_width / X->dims()[3]);
+ // }
int num_cout = X->dims()[0];
int c_cout = X->dims()[1];
Out->Resize({num_cout, c_cout, out_height, out_width});
@@ -551,6 +544,10 @@ void interpolate(lite::Tensor* X,
int spatial_in = in_h * in_w;
int spatial_out = out_h * out_w;
+ float scale_x = (align_corners) ? (static_cast(in_w - 1) / (out_w - 1))
+ : (static_cast(in_w) / (out_w));
+ float scale_y = (align_corners) ? (static_cast(in_h - 1) / (out_h - 1))
+ : (static_cast(in_h) / (out_h));
if ("Bilinear" == interpolate_type) {
#pragma omp parallel for
for (int i = 0; i < count; ++i) {
@@ -560,9 +557,10 @@ void interpolate(lite::Tensor* X,
dout + spatial_out * i,
out_w,
out_h,
- 1.f / width_scale,
- 1.f / height_scale,
- with_align);
+ scale_x,
+ scale_y,
+ align_corners,
+ align_mode);
}
} else if ("Nearest" == interpolate_type) {
#pragma omp parallel for
@@ -573,9 +571,9 @@ void interpolate(lite::Tensor* X,
dout + spatial_out * i,
out_w,
out_h,
- 1.f / width_scale,
- 1.f / height_scale,
- with_align);
+ scale_x,
+ scale_y,
+ align_corners);
}
}
}
diff --git a/lite/backends/arm/math/interpolate.h b/lite/backends/arm/math/interpolate.h
index e9c41c5bc86c8f00d57e096e3cd2b5f37df3a474..82c4c068b69567c01d37cfa901f9b58626574865 100644
--- a/lite/backends/arm/math/interpolate.h
+++ b/lite/backends/arm/math/interpolate.h
@@ -30,7 +30,8 @@ void bilinear_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool with_align);
+ bool align_corners,
+ bool align_mode);
void nearest_interp(const float* src,
int w_in,
@@ -40,7 +41,7 @@ void nearest_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool with_align);
+ bool align_corners);
void interpolate(lite::Tensor* X,
lite::Tensor* OutSize,
@@ -50,7 +51,8 @@ void interpolate(lite::Tensor* X,
int out_height,
int out_width,
float scale,
- bool with_align,
+ bool align_corners,
+ bool align_mode,
std::string interpolate_type);
} /* namespace math */
diff --git a/lite/backends/arm/math/packed_sgemm.cc b/lite/backends/arm/math/packed_sgemm.cc
old mode 100644
new mode 100755
diff --git a/lite/backends/arm/math/pooling.cc b/lite/backends/arm/math/pooling.cc
index c3652217ededa10b57e211ba7f5d3dc76e235978..1817e934cc460fdff6f18ec7491838ff1a5ce640 100644
--- a/lite/backends/arm/math/pooling.cc
+++ b/lite/backends/arm/math/pooling.cc
@@ -2224,7 +2224,13 @@ void pooling3x3s2p1_max(const float* din,
w_unroll_size -= 1;
w_unroll_remian = wout - w_unroll_size * 4;
}
- float32x4_t vmin = vdupq_n_f32(std::numeric_limits::lowest());
+ int w_needed = wout * 2 + 1;
+ int need_right = w_needed - win - pad_right;
+ int w_2 = need_right > 0 ? w_unroll_remian : w_unroll_remian + 1;
+ w_2 = w_unroll_size <= 0 ? w_2 - 1 : w_2;
+ need_right = wout > 1 ? need_right : 0;
+ float minval = std::numeric_limits::lowest();
+ float32x4_t vmin = vdupq_n_f32(minval);
for (int n = 0; n < num; ++n) {
float* data_out_batch = data_out + n * chout * size_channel_out;
@@ -2263,6 +2269,11 @@ void pooling3x3s2p1_max(const float* din,
break;
}
}
+
+ auto pr0 = dr0;
+ auto pr1 = dr1;
+ auto pr2 = dr2;
+
int cnt_num = w_unroll_size;
if (w_unroll_size > 0) {
#ifdef __aarch64__
@@ -2316,27 +2327,60 @@ void pooling3x3s2p1_max(const float* din,
"q11",
"q15");
#endif
+
dr0 -= 8;
dr1 -= 8;
dr2 -= 8;
- }
- // deal with right pad
- int wstart = w_unroll_size * 4 * S - P;
- for (int j = 0; j < w_unroll_remian; ++j) {
- int wend = std::min(wstart + K, win);
- int st = wstart > 0 ? wstart : 0;
- float tmp = dr0[0];
- for (int i = 0; i < wend - st; i++) {
+ } else {
+ float tmp = minval;
+ int left_ = std::min(2, win);
+ for (int i = 0; i < left_; i++) {
tmp = std::max(tmp, dr0[i]);
tmp = std::max(tmp, dr1[i]);
tmp = std::max(tmp, dr2[i]);
}
- *(dr_out++) = tmp;
- dr0 += S - (st - wstart);
- dr1 += S - (st - wstart);
- dr2 += S - (st - wstart);
- wstart += S;
+
+ dr_out[0] = tmp;
+ dr0++;
+ dr1++;
+ dr2++;
+ dr_out++;
}
+
+ for (int w = 0; w < w_2 - 1; w += 1) {
+ float32x4_t vr0 = vld1q_f32(dr0);
+ float32x4_t vr1 = vld1q_f32(dr1);
+ float32x4_t vr2 = vld1q_f32(dr2);
+ vr0 = vsetq_lane_f32(minval, vr0, 3);
+ vr1 = vsetq_lane_f32(minval, vr1, 3);
+ vr2 = vsetq_lane_f32(minval, vr2, 3);
+ float32x4_t vmax1 = vmaxq_f32(vr0, vr1);
+ vmax1 = vmaxq_f32(vmax1, vr2);
+ float32x2_t vmax2 =
+ vpmax_f32(vget_low_f32(vmax1), vget_high_f32(vmax1));
+ float32x2_t vmax = vpmax_f32(vmax2, vmax2);
+ dr_out[0] = vget_lane_f32(vmax, 0);
+ dr_out++;
+
+ dr0 += 2;
+ dr1 += 2;
+ dr2 += 2;
+ }
+
+ if (need_right) {
+ float tmp = minval;
+ int idx = win - 1;
+ tmp = std::max(tmp, std::max(pr0[idx], pr1[idx]));
+ tmp = std::max(tmp, pr2[idx]);
+ dr_out[0] = tmp;
+ if (win % 2) {
+ idx = win - 2;
+ tmp = std::max(tmp, std::max(pr0[idx], pr1[idx]));
+ tmp = std::max(tmp, pr2[idx]);
+ dr_out[0] = tmp;
+ }
+ }
+
data_out_channel += wout;
}
}
@@ -2573,6 +2617,7 @@ void pooling3x3s2p0_max(const float* din,
int wend = std::min(tmp_val + K, win) - tmp_val;
float minval = std::numeric_limits::lowest();
remain = right > 0 ? remain : remain + 1;
+
for (int n = 0; n < num; ++n) {
float* data_out_batch = data_out + n * chout * size_channel_out;
const float* data_in_batch = data_in + n * chin * size_channel_in;
@@ -2663,13 +2708,14 @@ void pooling3x3s2p0_max(const float* din,
vpmax_f32(vget_low_f32(vmax1), vget_high_f32(vmax1));
float32x2_t vmax = vpmax_f32(vmax2, vmax2);
dr_out[0] = vget_lane_f32(vmax, 0);
+
dr_out++;
dr0 += 2;
dr1 += 2;
dr2 += 2;
}
- if (right) {
- float tmp = dr0[0]; // std::numeric_limits::min();
+ if (right > 0) {
+ float tmp = dr0[0];
for (int i = 0; i < wend; i++) {
tmp = std::max(tmp, std::max(dr0[i], dr1[i]));
tmp = std::max(tmp, dr2[i]);
diff --git a/lite/backends/arm/math/reduce_sum.cc b/lite/backends/arm/math/reduce_sum.cc
new file mode 100644
index 0000000000000000000000000000000000000000..b563887e8619e29e40d85699b6979713aae8c0a2
--- /dev/null
+++ b/lite/backends/arm/math/reduce_sum.cc
@@ -0,0 +1,385 @@
+/* Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License. */
+
+#include "lite/backends/arm/math/reduce_sum.h"
+#include "lite/backends/arm/math/funcs.h"
+#include "lite/core/tensor.h"
+
+namespace paddle {
+namespace lite {
+namespace arm {
+namespace math {
+
+template <>
+void reduce_sum_n(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int chw_size = channel_in * height_in * width_in;
+ if (num_in == 1) {
+ memcpy(dst, src, sizeof(float) * chw_size);
+ } else {
+ int cnt_n = num_in >> 2;
+ int remain_n = num_in & 3;
+ int cnt_chw = chw_size >> 3;
+ int cnt_rem = chw_size & 7;
+ int stride = chw_size << 2;
+ int stride_c = 0;
+ for (int c = 0; c < cnt_chw; c++) {
+ float32x4_t vsum0 = vdupq_n_f32(0.f);
+ float32x4_t vsum1 = vdupq_n_f32(0.f);
+ const float* din_ptr0 = src + stride_c;
+ const float* din_ptr1 = din_ptr0 + chw_size;
+ const float* din_ptr2 = din_ptr1 + chw_size;
+ const float* din_ptr3 = din_ptr2 + chw_size;
+ for (int n = 0; n < cnt_n; n++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ float32x4_t va1 = vld1q_f32(din_ptr0 + 4);
+ float32x4_t vb1 = vld1q_f32(din_ptr1 + 4);
+ float32x4_t vc0 = vld1q_f32(din_ptr2);
+ float32x4_t vd0 = vld1q_f32(din_ptr3);
+ float32x4_t vs00 = vaddq_f32(va0, vb0);
+ float32x4_t vc1 = vld1q_f32(din_ptr2 + 4);
+ float32x4_t vs10 = vaddq_f32(va1, vb1);
+ float32x4_t vd1 = vld1q_f32(din_ptr3 + 4);
+ float32x4_t vs01 = vaddq_f32(vc0, vd0);
+ vsum0 = vaddq_f32(vsum0, vs00);
+ float32x4_t vs11 = vaddq_f32(vc1, vd1);
+ vsum1 = vaddq_f32(vsum1, vs10);
+ din_ptr0 += stride;
+ din_ptr1 += stride;
+ vsum0 = vaddq_f32(vsum0, vs01);
+ din_ptr2 += stride;
+ din_ptr3 += stride;
+ vsum1 = vaddq_f32(vsum1, vs11);
+ }
+ for (int n = 0; n < remain_n; n++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t va1 = vld1q_f32(din_ptr0 + 4);
+ vsum0 = vaddq_f32(vsum0, va0);
+ din_ptr0 += chw_size;
+ vsum1 = vaddq_f32(vsum1, va1);
+ }
+ vst1q_f32(dst, vsum0);
+ dst += 4;
+ stride_c += 8;
+ vst1q_f32(dst, vsum1);
+ dst += 4;
+ }
+ if (cnt_rem > 3) {
+ float32x4_t vsum0 = vdupq_n_f32(0.f);
+ const float* din_ptr0 = src + stride_c;
+ const float* din_ptr1 = din_ptr0 + chw_size;
+ const float* din_ptr2 = din_ptr1 + chw_size;
+ const float* din_ptr3 = din_ptr2 + chw_size;
+ for (int n = 0; n < cnt_n; n++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ float32x4_t vc0 = vld1q_f32(din_ptr2);
+ float32x4_t vd0 = vld1q_f32(din_ptr3);
+ float32x4_t vs00 = vaddq_f32(va0, vb0);
+ float32x4_t vs01 = vaddq_f32(vc0, vd0);
+ vsum0 = vaddq_f32(vsum0, vs00);
+ din_ptr0 += stride;
+ din_ptr1 += stride;
+ vsum0 = vaddq_f32(vsum0, vs01);
+ din_ptr2 += stride;
+ din_ptr3 += stride;
+ }
+ for (int n = 0; n < remain_n; n++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ din_ptr0 += chw_size;
+ vsum0 = vaddq_f32(vsum0, va0);
+ }
+ stride_c += 4;
+ vst1q_f32(dst, vsum0);
+ dst += 4;
+ cnt_rem -= 4;
+ }
+ for (int c = 0; c < cnt_rem; c++) {
+ const float* din_ptr0 = src + stride_c;
+ const float* din_ptr1 = din_ptr0 + chw_size;
+ const float* din_ptr2 = din_ptr1 + chw_size;
+ const float* din_ptr3 = din_ptr2 + chw_size;
+ float sum = 0.0;
+ for (int n = 0; n < cnt_n; n++) {
+ float tmp0 = din_ptr0[0] + din_ptr1[0];
+ float tmp1 = din_ptr2[0] + din_ptr3[0];
+ din_ptr0 += stride;
+ din_ptr1 += stride;
+ sum += tmp0;
+ din_ptr2 += stride;
+ din_ptr3 += stride;
+ sum += tmp1;
+ }
+ for (int n = 0; n < remain_n; n++) {
+ sum += din_ptr0[0];
+ din_ptr0 += chw_size;
+ }
+ stride_c++;
+ dst[0] = sum;
+ dst++;
+ }
+ }
+}
+
+template <>
+void reduce_sum_c(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int hw_size = height_in * width_in;
+ int chw_size = hw_size * channel_in;
+ for (int n = 0; n < num_in; ++n) {
+ reduce_sum_n(src, dst, channel_in, 1, height_in, width_in);
+ src += chw_size;
+ dst += hw_size;
+ }
+}
+
+template <>
+void reduce_sum_h(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int nc_size = num_in * channel_in;
+ int hw_size = height_in * width_in;
+ for (int n = 0; n < nc_size; ++n) {
+ reduce_sum_n(src, dst, height_in, 1, 1, width_in);
+ src += hw_size;
+ dst += width_in;
+ }
+}
+
+template <>
+void reduce_sum_w(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int nch_size = num_in * channel_in * height_in;
+ int cnt_w = width_in >> 3;
+ int cnt_n = nch_size >> 2;
+ int rem_w = width_in & 7;
+ int rem_n = nch_size & 3;
+ int stride = 0;
+ int stride_n = width_in << 2;
+ for (int n = 0; n < cnt_n; n++) {
+ const float* din_ptr0 = src + stride;
+ const float* din_ptr1 = din_ptr0 + width_in;
+ const float* din_ptr2 = din_ptr1 + width_in;
+ const float* din_ptr3 = din_ptr2 + width_in;
+ float32x4_t vsum = vdupq_n_f32(0.f);
+ int tmp = rem_w;
+ for (int w = 0; w < cnt_w; w++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t va1 = vld1q_f32(din_ptr0 + 4);
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ float32x4_t vb1 = vld1q_f32(din_ptr1 + 4);
+ float32x4_t vc0 = vld1q_f32(din_ptr2);
+ float32x4_t vc1 = vld1q_f32(din_ptr2 + 4);
+ float32x4_t vs0 = vaddq_f32(va0, va1);
+ float32x4_t vd0 = vld1q_f32(din_ptr3);
+ float32x4_t vs1 = vaddq_f32(vb0, vb1);
+ float32x4_t vd1 = vld1q_f32(din_ptr3 + 4);
+ float32x4_t vs2 = vaddq_f32(vc0, vc1);
+ din_ptr0 += 8;
+ float32x4_t vs3 = vaddq_f32(vd0, vd1);
+ din_ptr1 += 8;
+ float32x4_t vs00 = vpaddq_f32(vs0, vs1);
+ din_ptr2 += 8;
+ float32x4_t vs01 = vpaddq_f32(vs2, vs3);
+ din_ptr3 += 8;
+ float32x4_t vs = vpaddq_f32(vs00, vs01);
+ vsum = vaddq_f32(vs, vsum);
+ }
+ if (tmp > 3) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ float32x4_t vc0 = vld1q_f32(din_ptr2);
+ float32x4_t vd0 = vld1q_f32(din_ptr3);
+ din_ptr0 += 4;
+ din_ptr1 += 4;
+ float32x4_t vs00 = vpaddq_f32(va0, vb0);
+ float32x4_t vs01 = vpaddq_f32(vc0, vd0);
+ din_ptr2 += 4;
+ din_ptr3 += 4;
+ float32x4_t vs = vpaddq_f32(vs00, vs01);
+ vsum = vaddq_f32(vs, vsum);
+ tmp -= 4;
+ }
+ for (int w = 0; w < tmp; w++) {
+ vsum[0] += *din_ptr0++;
+ vsum[1] += *din_ptr1++;
+ vsum[2] += *din_ptr2++;
+ vsum[3] += *din_ptr3++;
+ }
+ stride += stride_n;
+ vst1q_f32(dst, vsum);
+ dst += 4;
+ }
+ if (rem_n > 1) {
+ const float* din_ptr0 = src + stride;
+ const float* din_ptr1 = din_ptr0 + width_in;
+ float32x4_t vsum = vdupq_n_f32(0.f);
+ for (int w = 0; w < cnt_w; w++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ din_ptr0 += 4;
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ din_ptr1 += 4;
+ float32x4_t va1 = vld1q_f32(din_ptr0);
+ float32x4_t vb1 = vld1q_f32(din_ptr1);
+ float32x4_t vs0 = vpaddq_f32(va0, vb0);
+ din_ptr0 += 4;
+ float32x4_t vs1 = vpaddq_f32(va1, vb1);
+ din_ptr1 += 4;
+ float32x4_t vs00 = vpaddq_f32(vs0, vs1);
+ vsum = vaddq_f32(vs00, vsum);
+ }
+ int tmp = rem_w;
+ if (tmp > 3) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t vb0 = vld1q_f32(din_ptr1);
+ din_ptr0 += 4;
+ din_ptr1 += 4;
+ float32x4_t vs00 = vpaddq_f32(va0, vb0);
+ tmp -= 4;
+ vsum[0] += vs00[0];
+ vsum[2] += vs00[1];
+ vsum[1] += vs00[2];
+ vsum[3] += vs00[3];
+ }
+ vsum[0] += vsum[2];
+ vsum[1] += vsum[3];
+ for (int w = 0; w < tmp; w++) {
+ vsum[0] += *din_ptr0++;
+ vsum[1] += *din_ptr1++;
+ }
+ stride += width_in;
+ *dst++ = vsum[0];
+ stride += width_in;
+ *dst++ = vsum[1];
+ rem_n -= 2;
+ }
+ for (int n = 0; n < rem_n; n++) {
+ const float* din_ptr0 = src + stride;
+ float32x4_t vsum = vdupq_n_f32(0.f);
+ for (int w = 0; w < cnt_w; w++) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ float32x4_t va1 = vld1q_f32(din_ptr0 + 4);
+ float32x4_t vs0 = vaddq_f32(va0, va1);
+ din_ptr0 += 8;
+ vsum = vaddq_f32(vs0, vsum);
+ }
+ if (rem_w > 3) {
+ float32x4_t va0 = vld1q_f32(din_ptr0);
+ din_ptr0 += 4;
+ vsum = vaddq_f32(vsum, va0);
+ rem_w -= 4;
+ }
+ vsum[1] += vsum[2];
+ for (int w = 0; w < rem_w; w++) {
+ vsum[0] += *din_ptr0++;
+ }
+ vsum[1] += vsum[3];
+ vsum[0] += vsum[1];
+ *dst++ = vsum[0];
+ }
+}
+
+template <>
+void reduce_sum_all(const float* src, float* dst, int all_size) {
+ int cnt_n = all_size >> 4;
+ int rem_n = all_size & 15;
+ int cnt_rem = rem_n >> 2;
+ int rem_rem = rem_n & 3;
+ float32x4_t vsum = vdupq_n_f32(0.f);
+ for (int n = 0; n < cnt_n; n++) {
+ float32x4_t va0 = vld1q_f32(src);
+ float32x4_t va1 = vld1q_f32(src + 4);
+ float32x4_t va2 = vld1q_f32(src + 8);
+ float32x4_t va3 = vld1q_f32(src + 12);
+ src += 16;
+ float32x4_t vs0 = vaddq_f32(va0, va1);
+ float32x4_t vs1 = vaddq_f32(va2, va3);
+ float32x4_t vs = vpaddq_f32(vs0, vs1);
+ vsum = vaddq_f32(vsum, vs);
+ }
+ for (int n = 0; n < cnt_rem; n++) {
+ float32x4_t va0 = vld1q_f32(src);
+ src += 4;
+ vsum = vaddq_f32(vsum, va0);
+ }
+ vsum[1] += vsum[2];
+ for (int n = 0; n < rem_rem; n++) {
+ vsum[0] += *src++;
+ }
+ vsum[1] += vsum[3];
+ vsum[0] += vsum[1];
+ dst[0] = vsum[0];
+}
+
+template <>
+void reduce_sum_nc(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ // reduce nc.
+ int num = num_in * channel_in;
+ int size = height_in * width_in;
+ reduce_sum_n(src, dst, num, size, 1, 1);
+}
+
+template <>
+void reduce_sum_ch(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int ch_size = channel_in * height_in;
+ int chw_size = ch_size * width_in;
+ for (int n = 0; n < num_in; n++) {
+ reduce_sum_n(src, dst, ch_size, 1, 1, width_in);
+ src += chw_size;
+ dst += width_in;
+ }
+}
+
+template <>
+void reduce_sum_hw(const float* src,
+ float* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in) {
+ int hw_size = height_in * width_in;
+ int nc_size = num_in * channel_in;
+ reduce_sum_w(src, dst, nc_size, 1, 1, hw_size);
+}
+
+} // namespace math
+} // namespace arm
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/arm/math/reduce_sum.h b/lite/backends/arm/math/reduce_sum.h
new file mode 100644
index 0000000000000000000000000000000000000000..74e0b6dc75d17ca5a79c4b46c8535c7f30ec1c08
--- /dev/null
+++ b/lite/backends/arm/math/reduce_sum.h
@@ -0,0 +1,84 @@
+/* Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License. */
+
+#pragma once
+
+namespace paddle {
+namespace lite {
+namespace arm {
+namespace math {
+
+template
+void reduce_sum_n(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_c(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_h(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_w(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_nc(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_ch(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_hw(const T* src,
+ T* dst,
+ int num_in,
+ int channel_in,
+ int height_in,
+ int width_in);
+
+template
+void reduce_sum_all(const T* src, T* dst, int all_size);
+
+} // namespace math
+} // namespace arm
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/arm/math/scatter.cc b/lite/backends/arm/math/scatter.cc
new file mode 100644
index 0000000000000000000000000000000000000000..c9250a9bfa3fcfbdac2a8942aeff3bd28b4bc381
--- /dev/null
+++ b/lite/backends/arm/math/scatter.cc
@@ -0,0 +1,72 @@
+/* Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License. */
+
+#include "lite/backends/arm/math/scatter.h"
+#include "lite/backends/arm/math/funcs.h"
+#include "lite/core/tensor.h"
+
+namespace paddle {
+namespace lite {
+namespace arm {
+namespace math {
+
+template <>
+void scatter(const int64_t* indexs,
+ const float* src,
+ float* dst,
+ int index_size,
+ int num,
+ int size,
+ bool overwrite) {
+ for (int i = 0; i < num; i++) {
+ const float* din = src + indexs[i] * size;
+ memcpy(dst, din, sizeof(float) * size);
+ dst += size;
+ }
+ if (overwrite) {
+ for (int i = num; i < index_size; i++) {
+ const float* din = src + indexs[i] * size;
+ float* dout = dst + indexs[i] * size;
+ memcpy(dout, din, sizeof(float) * size);
+ }
+ } else {
+ int cnt = size >> 3;
+ int rem = size & 7;
+ for (int i = num; i < index_size; i++) {
+ const float* din = src + indexs[i] * size;
+ float* dout = dst + indexs[i] * size;
+ for (int j = 0; j < cnt; j++) {
+ float32x4_t va0 = vld1q_f32(din);
+ float32x4_t vb0 = vld1q_f32(dout);
+ float32x4_t va1 = vld1q_f32(din + 4);
+ float32x4_t vb1 = vld1q_f32(dout + 4);
+ vb0 = vaddq_f32(va0, vb0);
+ vb1 = vaddq_f32(va1, vb1);
+ din += 8;
+ vst1q_f32(dout, vb0);
+ vst1q_f32(dout + 4, vb0);
+ dout += 8;
+ }
+ for (int j = 0; j < rem; j++) {
+ dout[0] += *din++;
+ dout++;
+ }
+ }
+ }
+}
+
+} // namespace math
+} // namespace arm
+} // namespace lite
+} // namespace paddle
diff --git a/mobile/src/fpga/KD/dl_engine.hpp b/lite/backends/arm/math/scatter.h
similarity index 61%
rename from mobile/src/fpga/KD/dl_engine.hpp
rename to lite/backends/arm/math/scatter.h
index 861d7231dc745c90b415eba5757bdc6957290273..3d145367189eb61e7fdfbd5b20a55f5397ae702b 100644
--- a/mobile/src/fpga/KD/dl_engine.hpp
+++ b/lite/backends/arm/math/scatter.h
@@ -13,21 +13,22 @@ See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
-
-#include
-
-namespace paddle_mobile {
-namespace zynqmp {
-
-class DLEngine {
- public:
- static DLEngine& get_instance() {
- static DLEngine s_instance;
- return s_instance;
- }
-
- private:
- DLEngine();
-};
-} // namespace zynqmp
-} // namespace paddle_mobile
+#include
+
+namespace paddle {
+namespace lite {
+namespace arm {
+namespace math {
+
+template
+void scatter(const int64_t* indexs,
+ const T* updates,
+ T* dst,
+ int index_size,
+ int num,
+ int size,
+ bool overwrite);
+} // namespace math
+} // namespace arm
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/bm/target_wrapper.cc b/lite/backends/bm/target_wrapper.cc
index 6dab2a574d9c270573c00688768ad45a767abeae..83aa4dc8c1a6462bfd38a1c59f438e4836a3da00 100644
--- a/lite/backends/bm/target_wrapper.cc
+++ b/lite/backends/bm/target_wrapper.cc
@@ -23,7 +23,7 @@ int TargetWrapperBM::device_id_ = 0;
std::map TargetWrapperBM::bm_hds_;
size_t TargetWrapperBM::num_devices() {
- int count = 0;
+ int count = 1;
bm_status_t ret = bm_dev_getcount(&count);
CHECK_EQ(ret, BM_SUCCESS) << "Failed with error code: "
<< static_cast(ret);
diff --git a/lite/backends/opencl/cl_kernel/image/depthwise_conv2d_kernel.cl b/lite/backends/opencl/cl_kernel/image/depthwise_conv2d_kernel.cl
index 6fbdc21f934f21dd26c3eb66885f7087e3d340c0..7d86730b93e9e71c32d9f25c2ab0406715f6cdec 100755
--- a/lite/backends/opencl/cl_kernel/image/depthwise_conv2d_kernel.cl
+++ b/lite/backends/opencl/cl_kernel/image/depthwise_conv2d_kernel.cl
@@ -48,7 +48,7 @@ __kernel void depth_conv2d_3x3(
int2 ouput_pos_in_one_block = (int2)(out_w, out_nh_in_one_batch);
int2 in_pos_in_one_block =
- ouput_pos_in_one_block * stride_xy + (int2)(offset, offset);
+ ouput_pos_in_one_block * stride_xy + (int2)(offset + dilation - 1, offset + dilation - 1);
#ifdef BIASE_CH
CL_DTYPE4 output =
@@ -77,13 +77,13 @@ __kernel void depth_conv2d_3x3(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x - 1,
- pos_in_input_block.y + in_pos_in_one_block.y - 1)),
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x - dilation,
+ pos_in_input_block.y + in_pos_in_one_block.y - dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x - 1 < 0 ||
- in_pos_in_one_block.y - 1 < 0 ||
- in_pos_in_one_block.x - 1 >= input_width ||
- in_pos_in_one_block.y - 1 >= input_height)
+ (ushort4)((in_pos_in_one_block.x - dilation < 0 ||
+ in_pos_in_one_block.y - dilation < 0 ||
+ in_pos_in_one_block.x - dilation >= input_width ||
+ in_pos_in_one_block.y - dilation >= input_height)
<< 15));
inputs[1] = select(
@@ -91,45 +91,37 @@ __kernel void depth_conv2d_3x3(
input,
sampler,
(int2)(pos_in_input_block.x + in_pos_in_one_block.x,
- pos_in_input_block.y + in_pos_in_one_block.y - 1)),
+ pos_in_input_block.y + in_pos_in_one_block.y - dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x < 0 || in_pos_in_one_block.y - 1 < 0 ||
+ (ushort4)((in_pos_in_one_block.x < 0 || in_pos_in_one_block.y - dilation < 0 ||
in_pos_in_one_block.x >= input_width ||
- in_pos_in_one_block.y - 1 >= input_height)
+ in_pos_in_one_block.y - dilation >= input_height)
<< 15));
inputs[2] = select(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x + 1,
- pos_in_input_block.y + in_pos_in_one_block.y - 1)),
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x + dilation,
+ pos_in_input_block.y + in_pos_in_one_block.y - dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x + 1 < 0 ||
- in_pos_in_one_block.y - 1 < 0 ||
- in_pos_in_one_block.x + 1 >= input_width ||
- in_pos_in_one_block.y - 1 >= input_height)
+ (ushort4)((in_pos_in_one_block.x + dilation < 0 ||
+ in_pos_in_one_block.y - dilation < 0 ||
+ in_pos_in_one_block.x + dilation >= input_width ||
+ in_pos_in_one_block.y - dilation >= input_height)
<< 15));
inputs[3] = select(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x - 1,
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x - dilation,
pos_in_input_block.y + in_pos_in_one_block.y)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x - 1 < 0 || in_pos_in_one_block.y < 0 ||
- in_pos_in_one_block.x - 1 >= input_width ||
+ (ushort4)((in_pos_in_one_block.x - dilation < 0 || in_pos_in_one_block.y < 0 ||
+ in_pos_in_one_block.x - dilation >= input_width ||
in_pos_in_one_block.y >= input_height)
<< 15));
- /*
- if (output_pos.x == 112 && output_pos.y == 0) {
- CL_DTYPE4 input1 = inputs[3];
- float4 in = (float4)(input1.x, input1.y, input1.z, input1.w);
- printf(" input4 3 - %v4hlf \n", in);
- printf(" --- %d ---\n", in_pos_in_one_block.x - 1);
- }
- */
inputs[4] = select(
READ_IMG_TYPE(CL_DTYPE_CHAR,
@@ -147,11 +139,11 @@ __kernel void depth_conv2d_3x3(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x + 1,
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x + dilation,
pos_in_input_block.y + in_pos_in_one_block.y)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x + 1 < 0 || in_pos_in_one_block.y < 0 ||
- in_pos_in_one_block.x + 1 >= input_width ||
+ (ushort4)((in_pos_in_one_block.x + dilation < 0 || in_pos_in_one_block.y < 0 ||
+ in_pos_in_one_block.x + dilation >= input_width ||
in_pos_in_one_block.y >= input_height)
<< 15));
@@ -159,13 +151,13 @@ __kernel void depth_conv2d_3x3(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x - 1,
- pos_in_input_block.y + in_pos_in_one_block.y + 1)),
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x - dilation,
+ pos_in_input_block.y + in_pos_in_one_block.y + dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x - 1 < 0 ||
- in_pos_in_one_block.y + 1 < 0 ||
- in_pos_in_one_block.x - 1 >= input_width ||
- in_pos_in_one_block.y + 1 >= input_height)
+ (ushort4)((in_pos_in_one_block.x - dilation < 0 ||
+ in_pos_in_one_block.y + dilation < 0 ||
+ in_pos_in_one_block.x - dilation >= input_width ||
+ in_pos_in_one_block.y + dilation >= input_height)
<< 15));
inputs[7] = select(
@@ -173,24 +165,24 @@ __kernel void depth_conv2d_3x3(
input,
sampler,
(int2)(pos_in_input_block.x + in_pos_in_one_block.x,
- pos_in_input_block.y + in_pos_in_one_block.y + 1)),
+ pos_in_input_block.y + in_pos_in_one_block.y + dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x < 0 || in_pos_in_one_block.y + 1 < 0 ||
+ (ushort4)((in_pos_in_one_block.x < 0 || in_pos_in_one_block.y + dilation < 0 ||
in_pos_in_one_block.x >= input_width ||
- in_pos_in_one_block.y + 1 >= input_height)
+ in_pos_in_one_block.y + dilation >= input_height)
<< 15));
inputs[8] = select(
READ_IMG_TYPE(CL_DTYPE_CHAR,
input,
sampler,
- (int2)(pos_in_input_block.x + in_pos_in_one_block.x + 1,
- pos_in_input_block.y + in_pos_in_one_block.y + 1)),
+ (int2)(pos_in_input_block.x + in_pos_in_one_block.x + dilation,
+ pos_in_input_block.y + in_pos_in_one_block.y + dilation)),
(CL_DTYPE4)(0.0f),
- (ushort4)((in_pos_in_one_block.x + 1 < 0 ||
- in_pos_in_one_block.y + 1 < 0 ||
- in_pos_in_one_block.x + 1 >= input_width ||
- in_pos_in_one_block.y + 1 >= input_height)
+ (ushort4)((in_pos_in_one_block.x + dilation < 0 ||
+ in_pos_in_one_block.y + dilation < 0 ||
+ in_pos_in_one_block.x + dilation >= input_width ||
+ in_pos_in_one_block.y + dilation >= input_height)
<< 15));
CL_DTYPE4 filters[9];
@@ -221,14 +213,18 @@ __kernel void depth_conv2d_3x3(
/*
- if (output_pos.x == 112 && output_pos.y == 0) {
+ if (output_pos.x == 0 && output_pos.y == 0) {
for (int i = 0; i < 9; ++i) {
CL_DTYPE4 input1 = inputs[i];
float4 in = (float4)(input1.x, input1.y, input1.z, input1.w);
- printf(" input4 %d - %v4hlf \n", i, in);
+ printf(" input4[%d]: %v4hlf \n", i, in);
+ }
+ for (int i = 0; i < 9; ++i) {
+ CL_DTYPE4 filters1 = filters[i];
+ float4 f = (float4)(filters1.x, filters1.y, filters1.z, filters1.w);
+ printf(" weights4[%d]: %v4hlf \n", i, f);
}
-
float4 out = (float4)(output.x, output.y, output.z, output.w);
printf(" depth wise output output4 = %v4hlf \n", out);
printf(" pos_in_input_block -x %d \n ", pos_in_input_block.x);
diff --git a/lite/backends/x86/cpu_info.cc b/lite/backends/x86/cpu_info.cc
index 276b62654f3c8b25d23e629c706e4877dabc3889..3ba8dc50783b2118564fc24f802053e4d414aace 100644
--- a/lite/backends/x86/cpu_info.cc
+++ b/lite/backends/x86/cpu_info.cc
@@ -24,6 +24,7 @@
#include
#elif defined(_WIN32)
#define NOMINMAX // msvc max/min macro conflict with std::min/max
+#define GLOG_NO_ABBREVIATED_SEVERITIES
#include
#else
#include
diff --git a/lite/backends/x86/math/CMakeLists.txt b/lite/backends/x86/math/CMakeLists.txt
index a89107632341cf063ac3166aa9890ff383e3383f..b5262efa4e8ca3fbfa3076fb9a5eb6fe1993ccb2 100644
--- a/lite/backends/x86/math/CMakeLists.txt
+++ b/lite/backends/x86/math/CMakeLists.txt
@@ -61,3 +61,5 @@ math_library(search_fc DEPS blas dynload_mklml)
# cc_test(beam_search_test SRCS beam_search_test.cc DEPS beam_search)
# cc_test(concat_test SRCS concat_test.cc DEPS concat_and_split)
# cc_test(cpu_vec_test SRCS cpu_vec_test.cc DEPS blas cpu_info)
+math_library(box_coder DEPS math_function)
+math_library(prior_box DEPS math_function)
diff --git a/lite/backends/x86/math/box_coder.cc b/lite/backends/x86/math/box_coder.cc
new file mode 100644
index 0000000000000000000000000000000000000000..efe3c14fdad1ab529262731316c048e4238cd223
--- /dev/null
+++ b/lite/backends/x86/math/box_coder.cc
@@ -0,0 +1,166 @@
+/* Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License. */
+
+#include "lite/backends/x86/math/box_coder.h"
+#include
+
+namespace paddle {
+namespace lite {
+namespace x86 {
+namespace math {
+
+void encode_center_size(const int64_t row, // N
+ const int64_t col, // M
+ const int64_t len, // 4
+ const float* target_box_data,
+ const float* prior_box_data,
+ const float* prior_box_var_data,
+ const bool normalized,
+ const std::vector variance,
+ float* output) {
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(2)
+#endif
+ for (int64_t i = 0; i < row; ++i) {
+ for (int64_t j = 0; j < col; ++j) {
+ size_t offset = i * col * len + j * len;
+ float prior_box_width = prior_box_data[j * len + 2] -
+ prior_box_data[j * len] + (normalized == false);
+ float prior_box_height = prior_box_data[j * len + 3] -
+ prior_box_data[j * len + 1] +
+ (normalized == false);
+ float prior_box_center_x = prior_box_data[j * len] + prior_box_width / 2;
+ float prior_box_center_y =
+ prior_box_data[j * len + 1] + prior_box_height / 2;
+
+ float target_box_center_x =
+ (target_box_data[i * len + 2] + target_box_data[i * len]) / 2;
+ float target_box_center_y =
+ (target_box_data[i * len + 3] + target_box_data[i * len + 1]) / 2;
+ float target_box_width = target_box_data[i * len + 2] -
+ target_box_data[i * len] + (normalized == false);
+ float target_box_height = target_box_data[i * len + 3] -
+ target_box_data[i * len + 1] +
+ (normalized == false);
+
+ output[offset] =
+ (target_box_center_x - prior_box_center_x) / prior_box_width;
+ output[offset + 1] =
+ (target_box_center_y - prior_box_center_y) / prior_box_height;
+ output[offset + 2] =
+ std::log(std::fabs(target_box_width / prior_box_width));
+ output[offset + 3] =
+ std::log(std::fabs(target_box_height / prior_box_height));
+ }
+ }
+
+ if (prior_box_var_data) {
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(3)
+#endif
+ for (int64_t i = 0; i < row; ++i) {
+ for (int64_t j = 0; j < col; ++j) {
+ for (int64_t k = 0; k < len; ++k) {
+ size_t offset = i * col * len + j * len;
+ int prior_var_offset = j * len;
+ output[offset + k] /= prior_box_var_data[prior_var_offset + k];
+ }
+ }
+ }
+ } else if (!(variance.empty())) {
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(3)
+#endif
+ for (int64_t i = 0; i < row; ++i) {
+ for (int64_t j = 0; j < col; ++j) {
+ for (int64_t k = 0; k < len; ++k) {
+ size_t offset = i * col * len + j * len;
+ output[offset + k] /= variance[k];
+ }
+ }
+ }
+ }
+}
+
+void decode_center_size(const int axis,
+ const int var_size,
+ const int64_t row,
+ const int64_t col,
+ const int64_t len,
+ const float* target_box_data,
+ const float* prior_box_data,
+ const float* prior_box_var_data,
+ const bool normalized,
+ const std::vector variance,
+ float* output) {
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(2)
+#endif
+ for (int64_t i = 0; i < row; ++i) {
+ for (int64_t j = 0; j < col; ++j) {
+ float var_data[4] = {1., 1., 1., 1.};
+ float* var_ptr = var_data;
+ size_t offset = i * col * len + j * len;
+ int prior_box_offset = axis == 0 ? j * len : i * len;
+
+ float prior_box_width = prior_box_data[prior_box_offset + 2] -
+ prior_box_data[prior_box_offset] +
+ (normalized == false);
+ float prior_box_height = prior_box_data[prior_box_offset + 3] -
+ prior_box_data[prior_box_offset + 1] +
+ (normalized == false);
+ float prior_box_center_x =
+ prior_box_data[prior_box_offset] + prior_box_width / 2;
+ float prior_box_center_y =
+ prior_box_data[prior_box_offset + 1] + prior_box_height / 2;
+
+ float target_box_center_x = 0, target_box_center_y = 0;
+ float target_box_width = 0, target_box_height = 0;
+ int prior_var_offset = axis == 0 ? j * len : i * len;
+ if (var_size == 2) {
+ std::memcpy(
+ var_ptr, prior_box_var_data + prior_var_offset, 4 * sizeof(float));
+ } else if (var_size == 1) {
+ var_ptr = const_cast(variance.data());
+ }
+ float box_var_x = *var_ptr;
+ float box_var_y = *(var_ptr + 1);
+ float box_var_w = *(var_ptr + 2);
+ float box_var_h = *(var_ptr + 3);
+
+ target_box_center_x =
+ box_var_x * target_box_data[offset] * prior_box_width +
+ prior_box_center_x;
+ target_box_center_y =
+ box_var_y * target_box_data[offset + 1] * prior_box_height +
+ prior_box_center_y;
+ target_box_width =
+ std::exp(box_var_w * target_box_data[offset + 2]) * prior_box_width;
+ target_box_height =
+ std::exp(box_var_h * target_box_data[offset + 3]) * prior_box_height;
+
+ output[offset] = target_box_center_x - target_box_width / 2;
+ output[offset + 1] = target_box_center_y - target_box_height / 2;
+ output[offset + 2] =
+ target_box_center_x + target_box_width / 2 - (normalized == false);
+ output[offset + 3] =
+ target_box_center_y + target_box_height / 2 - (normalized == false);
+ }
+ }
+}
+
+} // namespace math
+} // namespace x86
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/x86/math/box_coder.h b/lite/backends/x86/math/box_coder.h
new file mode 100644
index 0000000000000000000000000000000000000000..fc31f888ab7ed281533e187ca8b51344f150662a
--- /dev/null
+++ b/lite/backends/x86/math/box_coder.h
@@ -0,0 +1,50 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include
+#include "lite/backends/x86/math/math_function.h"
+
+namespace paddle {
+namespace lite {
+namespace x86 {
+namespace math {
+
+void encode_center_size(const int64_t row,
+ const int64_t col,
+ const int64_t len,
+ const float* target_box_data,
+ const float* prior_box_data,
+ const float* prior_box_var_data,
+ const bool normalized,
+ const std::vector variance,
+ float* output);
+
+void decode_center_size(const int axis,
+ const int var_size,
+ const int64_t row,
+ const int64_t col,
+ const int64_t len,
+ const float* target_box_data,
+ const float* prior_box_data,
+ const float* prior_box_var_data,
+ const bool normalized,
+ const std::vector variance,
+ float* output);
+
+} // namespace math
+} // namespace x86
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/x86/math/context_project.h b/lite/backends/x86/math/context_project.h
index 72a2f4ce12cbd72b26cd87e97d0178275a4b4abd..6363488c4ccbe0a22245e96d62feab53f6a55185 100644
--- a/lite/backends/x86/math/context_project.h
+++ b/lite/backends/x86/math/context_project.h
@@ -161,7 +161,7 @@ class ContextProjectFunctor {
sequence_width});
if (up_pad > 0) { // add up pad
- int padding_rows = std::min(
+ int padding_rows = (std::min)(
up_pad, static_cast(lod_level_0[i + 1] - lod_level_0[i]));
for (int k = 0; k < padding_rows; ++k) {
@@ -180,10 +180,10 @@ class ContextProjectFunctor {
}
if (down_pad > 0) { // add down pad
int down_pad_begin_row =
- std::max(0,
- (sequence_height - context_start - context_length) + 1) +
+ (std::max)(
+ 0, (sequence_height - context_start - context_length) + 1) +
1;
- int padding_begin = std::max(0, context_start - sequence_height);
+ int padding_begin = (std::max)(0, context_start - sequence_height);
int padding_size =
sequence_height - context_start >= context_length
? 1
diff --git a/lite/backends/x86/math/pooling.cc b/lite/backends/x86/math/pooling.cc
index 4393c42157bb7667ec2218e8b76f05a2c60bcc86..ae2a0cd3319dad56589b631b961f0e3a1098a45f 100644
--- a/lite/backends/x86/math/pooling.cc
+++ b/lite/backends/x86/math/pooling.cc
@@ -67,8 +67,8 @@ class Pool2dFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -76,8 +76,8 @@ class Pool2dFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
T ele = pool_process.initial();
@@ -150,8 +150,8 @@ class Pool2dGradFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -159,8 +159,8 @@ class Pool2dGradFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
int pool_size = (exclusive || adaptive)
? (hend - hstart) * (wend - wstart)
@@ -228,12 +228,12 @@ class MaxPool2dGradFunctor {
for (int c = 0; c < output_channels; ++c) {
for (int ph = 0; ph < output_height; ++ph) {
int hstart = ph * stride_height - padding_height;
- int hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ int hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
for (int pw = 0; pw < output_width; ++pw) {
int wstart = pw * stride_width - padding_width;
- int wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ int wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
bool stop = false;
for (int h = hstart; h < hend && !stop; ++h) {
@@ -337,8 +337,8 @@ class Pool3dFunctor {
dend = AdaptEndIndex(pd, input_depth, output_depth);
} else {
dstart = pd * stride_depth - padding_depth;
- dend = std::min(dstart + ksize_depth, input_depth);
- dstart = std::max(dstart, 0);
+ dend = (std::min)(dstart + ksize_depth, input_depth);
+ dstart = (std::max)(dstart, 0);
}
for (int ph = 0; ph < output_height; ++ph) {
if (adaptive) {
@@ -346,8 +346,8 @@ class Pool3dFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -355,8 +355,8 @@ class Pool3dFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
int output_idx = (pd * output_height + ph) * output_width + pw;
T ele = pool_process.initial();
@@ -441,8 +441,8 @@ class Pool3dGradFunctor {
dend = AdaptEndIndex(pd, input_depth, output_depth);
} else {
dstart = pd * stride_depth - padding_depth;
- dend = std::min(dstart + ksize_depth, input_depth);
- dstart = std::max(dstart, 0);
+ dend = (std::min)(dstart + ksize_depth, input_depth);
+ dstart = (std::max)(dstart, 0);
}
for (int ph = 0; ph < output_height; ++ph) {
if (adaptive) {
@@ -450,8 +450,8 @@ class Pool3dGradFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -459,8 +459,8 @@ class Pool3dGradFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
int pool_size =
@@ -540,16 +540,16 @@ class MaxPool3dGradFunctor {
for (int c = 0; c < output_channels; ++c) {
for (int pd = 0; pd < output_depth; ++pd) {
int dstart = pd * stride_depth - padding_depth;
- int dend = std::min(dstart + ksize_depth, input_depth);
- dstart = std::max(dstart, 0);
+ int dend = (std::min)(dstart + ksize_depth, input_depth);
+ dstart = (std::max)(dstart, 0);
for (int ph = 0; ph < output_height; ++ph) {
int hstart = ph * stride_height - padding_height;
- int hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ int hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
for (int pw = 0; pw < output_width; ++pw) {
int wstart = pw * stride_width - padding_width;
- int wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ int wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
bool stop = false;
for (int d = dstart; d < dend && !stop; ++d) {
for (int h = hstart; h < hend && !stop; ++h) {
@@ -651,8 +651,8 @@ class MaxPool2dWithIndexFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -660,8 +660,8 @@ class MaxPool2dWithIndexFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
T1 ele = static_cast(-FLT_MAX);
@@ -794,8 +794,8 @@ class MaxPool3dWithIndexFunctor {
dend = AdaptEndIndex(pd, input_depth, output_depth);
} else {
dstart = pd * stride_depth - padding_depth;
- dend = std::min(dstart + ksize_depth, input_depth);
- dstart = std::max(dstart, 0);
+ dend = (std::min)(dstart + ksize_depth, input_depth);
+ dstart = (std::max)(dstart, 0);
}
for (int ph = 0; ph < output_height; ++ph) {
if (adaptive) {
@@ -803,8 +803,8 @@ class MaxPool3dWithIndexFunctor {
hend = AdaptEndIndex(ph, input_height, output_height);
} else {
hstart = ph * stride_height - padding_height;
- hend = std::min(hstart + ksize_height, input_height);
- hstart = std::max(hstart, 0);
+ hend = (std::min)(hstart + ksize_height, input_height);
+ hstart = (std::max)(hstart, 0);
}
for (int pw = 0; pw < output_width; ++pw) {
if (adaptive) {
@@ -812,8 +812,8 @@ class MaxPool3dWithIndexFunctor {
wend = AdaptEndIndex(pw, input_width, output_width);
} else {
wstart = pw * stride_width - padding_width;
- wend = std::min(wstart + ksize_width, input_width);
- wstart = std::max(wstart, 0);
+ wend = (std::min)(wstart + ksize_width, input_width);
+ wstart = (std::max)(wstart, 0);
}
int output_idx = (pd * output_height + ph) * output_width + pw;
diff --git a/lite/backends/x86/math/prior_box.cc b/lite/backends/x86/math/prior_box.cc
new file mode 100644
index 0000000000000000000000000000000000000000..159838895ad8145e4db81f5f3701ec8ddb2611a4
--- /dev/null
+++ b/lite/backends/x86/math/prior_box.cc
@@ -0,0 +1,118 @@
+/* Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License. */
+
+#include "lite/backends/x86/math/prior_box.h"
+#include
+#include
+
+namespace paddle {
+namespace lite {
+namespace x86 {
+namespace math {
+
+void density_prior_box(const int64_t img_width,
+ const int64_t img_height,
+ const int64_t feature_width,
+ const int64_t feature_height,
+ const float* input_data,
+ const float* image_data,
+ const bool clip,
+ const std::vector variances,
+ const std::vector fixed_sizes,
+ const std::vector fixed_ratios,
+ const std::vector densities,
+ const float step_width,
+ const float step_height,
+ const float offset,
+ const int num_priors,
+ float* boxes_data,
+ float* vars_data) {
+ int step_average = static_cast((step_width + step_height) * 0.5);
+
+ std::vector sqrt_fixed_ratios;
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for
+#endif
+ for (size_t i = 0; i < fixed_ratios.size(); i++) {
+ sqrt_fixed_ratios.push_back(sqrt(fixed_ratios[i]));
+ }
+
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(2)
+#endif
+ for (int64_t h = 0; h < feature_height; ++h) {
+ for (int64_t w = 0; w < feature_width; ++w) {
+ float center_x = (w + offset) * step_width;
+ float center_y = (h + offset) * step_height;
+ int64_t offset = (h * feature_width + w) * num_priors * 4;
+ // Generate density prior boxes with fixed sizes.
+ for (size_t s = 0; s < fixed_sizes.size(); ++s) {
+ auto fixed_size = fixed_sizes[s];
+ int density = densities[s];
+ int shift = step_average / density;
+ // Generate density prior boxes with fixed ratios.
+ for (size_t r = 0; r < fixed_ratios.size(); ++r) {
+ float box_width_ratio = fixed_size * sqrt_fixed_ratios[r];
+ float box_height_ratio = fixed_size / sqrt_fixed_ratios[r];
+ float density_center_x = center_x - step_average / 2. + shift / 2.;
+ float density_center_y = center_y - step_average / 2. + shift / 2.;
+ for (int di = 0; di < density; ++di) {
+ for (int dj = 0; dj < density; ++dj) {
+ float center_x_temp = density_center_x + dj * shift;
+ float center_y_temp = density_center_y + di * shift;
+ boxes_data[offset++] = std::max(
+ (center_x_temp - box_width_ratio / 2.) / img_width, 0.);
+ boxes_data[offset++] = std::max(
+ (center_y_temp - box_height_ratio / 2.) / img_height, 0.);
+ boxes_data[offset++] = std::min(
+ (center_x_temp + box_width_ratio / 2.) / img_width, 1.);
+ boxes_data[offset++] = std::min(
+ (center_y_temp + box_height_ratio / 2.) / img_height, 1.);
+ }
+ }
+ }
+ }
+ }
+ }
+ //! clip the prior's coordinate such that it is within [0, 1]
+ if (clip) {
+ int channel_size = feature_height * feature_width * num_priors * 4;
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for
+#endif
+ for (int d = 0; d < channel_size; ++d) {
+ boxes_data[d] = std::min(std::max(boxes_data[d], 0.f), 1.f);
+ }
+ }
+//! set the variance.
+#ifdef PADDLE_WITH_MKLML
+#pragma omp parallel for collapse(3)
+#endif
+ for (int h = 0; h < feature_height; ++h) {
+ for (int w = 0; w < feature_width; ++w) {
+ for (int i = 0; i < num_priors; ++i) {
+ int idx = ((h * feature_width + w) * num_priors + i) * 4;
+ vars_data[idx++] = variances[0];
+ vars_data[idx++] = variances[1];
+ vars_data[idx++] = variances[2];
+ vars_data[idx++] = variances[3];
+ }
+ }
+ }
+}
+
+} // namespace math
+} // namespace x86
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/x86/math/prior_box.h b/lite/backends/x86/math/prior_box.h
new file mode 100644
index 0000000000000000000000000000000000000000..6b090551a014a8019e38f5fdcede38b86bfab720
--- /dev/null
+++ b/lite/backends/x86/math/prior_box.h
@@ -0,0 +1,46 @@
+// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include
+#include "lite/backends/x86/math/math_function.h"
+
+namespace paddle {
+namespace lite {
+namespace x86 {
+namespace math {
+
+void density_prior_box(const int64_t img_width,
+ const int64_t img_height,
+ const int64_t feature_width,
+ const int64_t feature_height,
+ const float* input_data,
+ const float* image_data,
+ const bool clip,
+ const std::vector variances,
+ const std::vector fixed_sizes,
+ const std::vector fixed_ratios,
+ const std::vector densities,
+ const float step_width,
+ const float step_height,
+ const float offset,
+ const int num_priors,
+ float* boxes_data,
+ float* vars_data);
+
+} // namespace math
+} // namespace x86
+} // namespace lite
+} // namespace paddle
diff --git a/lite/backends/x86/math/sequence_padding.h b/lite/backends/x86/math/sequence_padding.h
index 5512c4aa11fb5dc05283d01b1d6d3da7fb83c064..f254242714d92852498b3cc72fed0a911510e829 100644
--- a/lite/backends/x86/math/sequence_padding.h
+++ b/lite/backends/x86/math/sequence_padding.h
@@ -35,7 +35,7 @@ inline static uint64_t MaximumSequenceLength(
uint64_t seq_num = seq_offset.size() - 1;
uint64_t max_seq_len = 0;
for (size_t i = 0; i < seq_num; ++i) {
- max_seq_len = std::max(max_seq_len, seq_offset[i + 1] - seq_offset[i]);
+ max_seq_len = (std::max)(max_seq_len, seq_offset[i + 1] - seq_offset[i]);
}
return max_seq_len;
}
diff --git a/lite/backends/x86/parallel.h b/lite/backends/x86/parallel.h
index 49794b8e15a8f90a6512798baa842534df879f6b..33ba672778fa53f4af77c8cbb663b163c2b9c5a3 100644
--- a/lite/backends/x86/parallel.h
+++ b/lite/backends/x86/parallel.h
@@ -26,7 +26,7 @@ namespace x86 {
static void SetNumThreads(int num_threads) {
#ifdef PADDLE_WITH_MKLML
- int real_num_threads = std::max(num_threads, 1);
+ int real_num_threads = (std::max)(num_threads, 1);
x86::MKL_Set_Num_Threads(real_num_threads);
omp_set_num_threads(real_num_threads);
#endif
@@ -52,14 +52,14 @@ static inline void RunParallelFor(const int64_t begin,
}
#ifdef PADDLE_WITH_MKLML
- int64_t num_threads = std::min(GetMaxThreads(), end - begin);
+ int64_t num_threads = (std::min)(GetMaxThreads(), end - begin);
if (num_threads > 1) {
#pragma omp parallel num_threads(num_threads)
{
int64_t tid = omp_get_thread_num();
int64_t chunk_size = (end - begin + num_threads - 1) / num_threads;
int64_t begin_tid = begin + tid * chunk_size;
- f(begin_tid, std::min(end, chunk_size + begin_tid));
+ f(begin_tid, (std::min)(end, chunk_size + begin_tid));
}
return;
}
diff --git a/lite/backends/xpu/target_wrapper.cc b/lite/backends/xpu/target_wrapper.cc
index a3d8729410299170964e3ce3b59feb4b970a121b..5f5eae4703a0a0c5db3f026dabaea76d3371b03a 100644
--- a/lite/backends/xpu/target_wrapper.cc
+++ b/lite/backends/xpu/target_wrapper.cc
@@ -18,6 +18,27 @@
namespace paddle {
namespace lite {
+void XPUScratchPad::Reserve(size_t new_size) {
+ if (new_size <= size_) {
+ return;
+ }
+
+ if (!is_l3_) {
+ TargetWrapperXPU::Free(addr_);
+ addr_ = TargetWrapperXPU::Malloc(new_size);
+ size_ = new_size;
+ } else {
+ CHECK(false) << "Not supported if is_l3_ == true";
+ }
+}
+
+void XPUScratchPadDeleter::operator()(XPUScratchPad* sp) const {
+ if (!sp->is_l3_) {
+ TargetWrapperXPU::Free(sp->addr_);
+ }
+ delete sp;
+}
+
void* TargetWrapperXPU::Malloc(size_t size) {
void* ptr{nullptr};
XPU_CALL(xpu_malloc(&ptr, size));
@@ -51,7 +72,7 @@ XPUScratchPadGuard TargetWrapperXPU::MallocScratchPad(size_t size,
ptr = TargetWrapperXPU::Malloc(size);
}
CHECK(ptr != nullptr) << "size = " << size << ", use_l3 = " << use_l3;
- return XPUScratchPadGuard(new XPUScratchPad(ptr, use_l3));
+ return XPUScratchPadGuard(new XPUScratchPad(ptr, size, use_l3));
}
std::string TargetWrapperXPU::multi_encoder_precision; // NOLINT
diff --git a/lite/backends/xpu/target_wrapper.h b/lite/backends/xpu/target_wrapper.h
index 1a888b126a43783ddae5654de38f5b2e201eaa5e..8151d733ba4b506d3d24fd7e7c150c5f12f1e691 100644
--- a/lite/backends/xpu/target_wrapper.h
+++ b/lite/backends/xpu/target_wrapper.h
@@ -37,19 +37,19 @@ const int XPU_MAX_LOD_SEQ_LEN = 512;
using TargetWrapperXPU = TargetWrapper;
struct XPUScratchPad {
- XPUScratchPad(void* addr, bool is_l3) : addr_(addr), is_l3_(is_l3) {}
+ XPUScratchPad(void* addr, size_t size, bool is_l3)
+ : addr_(addr), size_(size), is_l3_(is_l3) {}
+
+ // XXX(miaotianxiang): |size_| increases monotonically
+ void Reserve(size_t new_size);
void* addr_{nullptr};
+ size_t size_{0};
bool is_l3_{false};
};
struct XPUScratchPadDeleter {
- void operator()(XPUScratchPad* sp) const {
- if (!sp->is_l3_) {
- XPU_CALL(xpu_free(sp->addr_));
- }
- delete sp;
- }
+ void operator()(XPUScratchPad* sp) const;
};
using XPUScratchPadGuard = std::unique_ptr;
diff --git a/lite/core/CMakeLists.txt b/lite/core/CMakeLists.txt
index f6f8b231fe5448ca65f86e1234208c97d6860622..2a7751cd2a635ca83a602f7a53a1487e263b8c78 100644
--- a/lite/core/CMakeLists.txt
+++ b/lite/core/CMakeLists.txt
@@ -2,7 +2,7 @@ if (WITH_TESTING)
lite_cc_library(lite_gtest_main SRCS lite_gtest_main.cc DEPS gtest gflags)
endif()
lite_cc_library(target_wrapper SRCS target_wrapper.cc
- DEPS target_wrapper_host place
+ DEPS target_wrapper_host place fbs_headers
X86_DEPS target_wrapper_x86
CUDA_DEPS target_wrapper_cuda
XPU_DEPS target_wrapper_xpu
diff --git a/lite/core/device_info.cc b/lite/core/device_info.cc
index cd135f85b3b55641ae1996b2d3b933e1da7870dc..0cf13ab6996df09f76d32e9482455a87d53a5e15 100644
--- a/lite/core/device_info.cc
+++ b/lite/core/device_info.cc
@@ -176,6 +176,9 @@ void get_cpu_arch(std::vector* archs, const int cpu_num) {
case 0xd0a:
arch_type = kA75;
break;
+ case 0xd0d:
+ arch_type = kA77;
+ break;
case 0xd40:
arch_type = kA76;
break;
@@ -637,6 +640,20 @@ void DeviceInfo::SetArchInfo(int argc, ...) {
bool DeviceInfo::SetCPUInfoByName() {
/* Snapdragon */
+ if (dev_name_.find("KONA") != std::string::npos) { // 865
+ core_num_ = 8;
+ core_ids_ = {0, 1, 2, 3, 4, 5, 6, 7};
+ big_core_ids_ = {4, 5, 6, 7};
+ little_core_ids_ = {0, 1, 2, 3};
+ cluster_ids_ = {1, 1, 1, 1, 0, 0, 0, 0};
+ SetArchInfo(2, kA77, kA55);
+ SetCacheInfo(0, 2, 192 * 1024, 256 * 1024);
+ SetCacheInfo(1, 2, 768 * 1024, 512 * 1024);
+ SetCacheInfo(2, 1, 4 * 1024 * 1024);
+ SetFP16Info(1, 1);
+ SetDotInfo(2, 1, 1);
+ return true;
+ }
if (dev_name_.find("SM8150") != std::string::npos) { // 855
core_num_ = 8;
core_ids_ = {0, 1, 2, 3, 4, 5, 6, 7};
diff --git a/lite/core/device_info.h b/lite/core/device_info.h
index c95f285e1433e9ca55595d4a5f0cb814c488fe7b..bc82245c8d47379901f6454aecedea5842ce1973 100644
--- a/lite/core/device_info.h
+++ b/lite/core/device_info.h
@@ -17,6 +17,7 @@
#include
#include
#include
+#include "lite/api/paddle_api.h"
#include "lite/core/tensor.h"
#include "lite/utils/cp_logging.h"
#ifdef LITE_WITH_MLU
@@ -27,6 +28,7 @@
namespace paddle {
namespace lite {
+using L3CacheSetMethod = lite_api::L3CacheSetMethod;
#if ((defined LITE_WITH_ARM) || (defined LITE_WITH_MLU))
typedef enum {
@@ -38,6 +40,8 @@ typedef enum {
kA73 = 73,
kA75 = 75,
kA76 = 76,
+ kA77 = 77,
+ kA78 = 78,
kARMArch_UNKOWN = -1
} ARMArch;
@@ -65,11 +69,41 @@ class DeviceInfo {
int l1_cache_size() const { return L1_cache_[active_ids_[0]]; }
int l2_cache_size() const { return L2_cache_[active_ids_[0]]; }
int l3_cache_size() const { return L3_cache_[active_ids_[0]]; }
+ // Methods for allocating L3Cache on Arm platform
+ // Enum class L3CacheSetMethod is declared in `lite/api/paddle_api.h`
+ void SetArmL3CacheSize(
+ L3CacheSetMethod method = L3CacheSetMethod::kDeviceL3Cache,
+ int absolute_val = -1) {
+ l3_cache_method_ = method;
+ absolute_l3cache_size_ = absolute_val;
+ // Realloc memory for sgemm in this context.
+ workspace_.clear();
+ workspace_.Resize({llc_size()});
+ workspace_.mutable_data();
+ }
+
int llc_size() const {
- auto size = L3_cache_[active_ids_[0]] > 0 ? L3_cache_[active_ids_[0]]
- : L2_cache_[active_ids_[0]];
+ auto size = absolute_l3cache_size_;
+ switch (l3_cache_method_) {
+ // kDeviceL3Cache = 0, use the system L3 Cache size, best performance.
+ case L3CacheSetMethod::kDeviceL3Cache:
+ size = L3_cache_[active_ids_[0]] > 0 ? L3_cache_[active_ids_[0]]
+ : L2_cache_[active_ids_[0]];
+ break;
+ // kDeviceL2Cache = 1, use the system L2 Cache size, trade off performance
+ // with less memory consumption.
+ case L3CacheSetMethod::kDeviceL2Cache:
+ size = L2_cache_[active_ids_[0]];
+ break;
+ // kAbsolute = 2, use the external setting.
+ case L3CacheSetMethod::kAbsolute:
+ break;
+ default:
+ LOG(FATAL) << "Error: unknown l3_cache_method_ !";
+ }
return size > 0 ? size : 512 * 1024;
}
+
bool has_dot() const { return dot_[active_ids_[0]]; }
bool has_fp16() const { return fp16_[active_ids_[0]]; }
@@ -121,6 +155,10 @@ class DeviceInfo {
void RequestPowerRandHighMode(int shift_num, int thread_num);
void RequestPowerRandLowMode(int shift_num, int thread_num);
+ // Methods for allocating L3Cache on Arm platform
+ // Enum class L3CacheSetMethod is declared in `lite/api/paddle_api.h`
+ L3CacheSetMethod l3_cache_method_{L3CacheSetMethod::kDeviceL3Cache};
+ int absolute_l3cache_size_{-1};
DeviceInfo() = default;
};
#endif // LITE_WITH_ARM
diff --git a/lite/core/memory.h b/lite/core/memory.h
index c80c8fb6b6e1356ebfa52920a8ee39f61ed20692..872cfd120ca0db889ec6cacebcba1431dafc931b 100644
--- a/lite/core/memory.h
+++ b/lite/core/memory.h
@@ -13,6 +13,7 @@
// limitations under the License.
#pragma once
+#include
#include
#include "lite/api/paddle_place.h"
#include "lite/core/target_wrapper.h"
@@ -140,20 +141,21 @@ class Buffer {
#ifdef LITE_WITH_OPENCL
template
void ResetLazyImage2D(TargetType target,
- const size_t img_w,
- const size_t img_h,
+ const size_t img_w_req,
+ const size_t img_h_req,
void* host_ptr = nullptr) {
- if (target != target_ || cl_image2d_width_ < img_w ||
- cl_image2d_height_ < img_h || host_ptr != nullptr) {
+ if (target != target_ || cl_image2d_width_ < img_w_req ||
+ cl_image2d_height_ < img_h_req || host_ptr != nullptr) {
CHECK_EQ(own_data_, true) << "Can not reset unowned buffer.";
+ cl_image2d_width_ = std::max(cl_image2d_width_, img_w_req);
+ cl_image2d_height_ = std::max(cl_image2d_height_, img_h_req);
Free();
- data_ = TargetWrapperCL::MallocImage(img_w, img_h, host_ptr);
+ data_ = TargetWrapperCL::MallocImage(
+ cl_image2d_width_, cl_image2d_height_, host_ptr);
target_ = target;
- space_ = sizeof(T) * img_w * img_h *
+ space_ = sizeof(T) * cl_image2d_width_ * cl_image2d_height_ *
4; // un-used for opencl Image2D, 4 for RGBA,
cl_use_image2d_ = true;
- cl_image2d_width_ = img_w;
- cl_image2d_height_ = img_h;
}
}
#endif
diff --git a/lite/core/memory_test.cc b/lite/core/memory_test.cc
index cd9062afca7fbf05ef639fed34c50bdf8ee3cb7a..6343854db2b75f7db1fff852056f3c4d86a48c85 100644
--- a/lite/core/memory_test.cc
+++ b/lite/core/memory_test.cc
@@ -28,6 +28,12 @@ TEST(memory, test) {
ASSERT_TRUE(buf_cuda);
TargetFree(TARGET(kCUDA), buf_cuda);
#endif
+
+#ifdef LITE_WITH_OPENCL
+ auto* buf_cl = TargetMalloc(TARGET(kOpenCL), 10);
+ ASSERT_TRUE(buf_cl);
+ TargetFree(TARGET(kOpenCL), buf_cl);
+#endif
}
} // namespace lite
diff --git a/lite/core/mir/fusion/__xpu__conv2d_fuse_pass.cc b/lite/core/mir/fusion/__xpu__conv2d_fuse_pass.cc
index d8e9d9db4664cd717dbc949134e5ef52f52c9b61..adafa0f5b546b3dd4beb3352e8087a7099c4931e 100644
--- a/lite/core/mir/fusion/__xpu__conv2d_fuse_pass.cc
+++ b/lite/core/mir/fusion/__xpu__conv2d_fuse_pass.cc
@@ -244,6 +244,7 @@ class XPUConv2dBlock0Fuser : public FuseBase {
std::string output_name = "";
if (_with_relu) {
+ op_desc.SetAttr("act_type", std::string{"relu"});
output_name = matched.at("relu_out")->arg()->name;
} else {
output_name = matched.at("bn_out")->arg()->name;
@@ -433,6 +434,7 @@ class XPUConv2dBlock1Fuser : public FuseBase {
TARGET(kXPU), PRECISION(kFloat), DATALAYOUT(kNCHW));
scope->NewTensor(max_output_name);
op_desc.SetOutput("OutputMax", {max_output_name});
+ op_desc.SetAttr("act_type", std::string{"relu"});
auto conv_op = LiteOpRegistry::Global().Create("__xpu__conv2d");
auto& valid_places = conv_old->valid_places();
diff --git a/lite/core/mir/fusion/__xpu__resnet_fuse_pass.cc b/lite/core/mir/fusion/__xpu__resnet_fuse_pass.cc
index 39773e272a3345454c00c4da4b7e7c69617afd69..0692928dd212dd6bfc61f7a53e6321ac93439993 100644
--- a/lite/core/mir/fusion/__xpu__resnet_fuse_pass.cc
+++ b/lite/core/mir/fusion/__xpu__resnet_fuse_pass.cc
@@ -307,7 +307,7 @@ class XPUResNetBlock0Fuser : public FuseBase {
matched.at("right_bn1_variance")->arg()->name,
});
op_desc.SetOutput("Outputs", {matched.at("relu_out")->arg()->name});
- // XXX: keep these to fool SubgraphOp::AttachImpl()
+ // keep these to fool SubgraphOp::AttachImpl()
op_desc.SetAttr("sub_block", 0);
op_desc.SetAttr>("input_data_names", {});
op_desc.SetAttr>("output_data_names", {});
@@ -570,7 +570,7 @@ class XPUResNetBlock1Fuser : public FuseBase {
matched.at("right_bn3_variance")->arg()->name,
});
op_desc.SetOutput("Outputs", {matched.at("relu_out")->arg()->name});
- // XXX: keep these to fool SubgraphOp::AttachImpl()
+ // keep these to fool SubgraphOp::AttachImpl()
op_desc.SetAttr("sub_block", 0);
op_desc.SetAttr>("input_data_names", {});
op_desc.SetAttr>("output_data_names", {});
@@ -599,9 +599,658 @@ class XPUResNetBlock1Fuser : public FuseBase {
}
};
+class XPUResNetDtypeBlock0Fuser : public FuseBase {
+ public:
+ XPUResNetDtypeBlock0Fuser() {}
+
+ void BuildPattern() override {
+ auto* input = VarNode("input")
+ ->assert_is_op_input("conv2d", "Input")
+ ->assert_is_op_input("pool2d", "X")
+ ->AsInput();
+
+ auto* left_conv1_weight = VarNode("left_conv1_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* left_conv1 = OpNode("left_conv1", "conv2d");
+ auto* left_conv1_out = VarNode("left_conv1_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* left_bn1_scale = VarNode("left_bn1_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* left_bn1_bias = VarNode("left_bn1_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* left_bn1_mean = VarNode("left_bn1_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* left_bn1_var = VarNode("left_bn1_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* left_bn1 = OpNode("left_bn1", "batch_norm")->AsIntermediate();
+ auto* left_bn1_out = VarNode("left_bn1_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("relu", "X")
+ ->AsIntermediate();
+ auto* left_bn1_mean_out = VarNode("left_bn1_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* left_bn1_var_out =
+ VarNode("left_bn1_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* left_bn1_saved_mean =
+ VarNode("left_bn1_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* left_bn1_saved_var =
+ VarNode("left_bn1_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+ auto* left_relu1 = OpNode("left_relu1", "relu")->AsIntermediate();
+ auto* left_relu1_out = VarNode("left_relu1_out")
+ ->assert_is_op_output("relu", "Out")
+ ->assert_is_op_input("conv2d", "Input")
+ ->AsIntermediate();
+
+ auto* left_conv2_weight = VarNode("left_conv2_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* left_conv2 = OpNode("left_conv2", "conv2d")->AsIntermediate();
+ auto* left_conv2_out = VarNode("left_conv2_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* left_bn2_scale = VarNode("left_bn2_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* left_bn2_bias = VarNode("left_bn2_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* left_bn2_mean = VarNode("left_bn2_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* left_bn2_var = VarNode("left_bn2_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* left_bn2 = OpNode("left_bn2", "batch_norm")->AsIntermediate();
+ auto* left_bn2_out = VarNode("left_bn2_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("relu", "X")
+ ->AsIntermediate();
+ auto* left_bn2_mean_out = VarNode("left_bn2_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* left_bn2_var_out =
+ VarNode("left_bn2_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* left_bn2_saved_mean =
+ VarNode("left_bn2_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* left_bn2_saved_var =
+ VarNode("left_bn2_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+ auto* left_relu2 = OpNode("left_relu2", "relu")->AsIntermediate();
+ auto* left_relu2_out = VarNode("left_relu2_out")
+ ->assert_is_op_output("relu", "Out")
+ ->assert_is_op_input("conv2d", "Input")
+ ->AsIntermediate();
+
+ auto* left_conv3_weight = VarNode("left_conv3_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* left_conv3 = OpNode("left_conv3", "conv2d")->AsIntermediate();
+ auto* left_conv3_out = VarNode("left_conv3_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* left_bn3_scale = VarNode("left_bn3_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* left_bn3_bias = VarNode("left_bn3_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* left_bn3_mean = VarNode("left_bn3_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* left_bn3_var = VarNode("left_bn3_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* left_bn3 = OpNode("left_bn3", "batch_norm")->AsIntermediate();
+ auto* left_bn3_out = VarNode("left_bn3_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("elementwise_add", "Y")
+ ->AsIntermediate();
+ auto* left_bn3_mean_out = VarNode("left_bn3_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* left_bn3_var_out =
+ VarNode("left_bn3_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* left_bn3_saved_mean =
+ VarNode("left_bn3_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* left_bn3_saved_var =
+ VarNode("left_bn3_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+
+ auto* right_pool = OpNode("right_pool", "pool2d")->AsIntermediate();
+ auto* right_pool_out = VarNode("right_pool_out")
+ ->assert_is_op_output("pool2d", "Out")
+ ->assert_is_op_input("conv2d", "Input")
+ ->AsIntermediate();
+ auto* right_conv1_weight = VarNode("right_conv1_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* right_conv1 = OpNode("right_conv1", "conv2d")->AsIntermediate();
+ auto* right_conv1_out = VarNode("right_conv1_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* right_bn1_scale = VarNode("right_bn1_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* right_bn1_bias = VarNode("right_bn1_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* right_bn1_mean = VarNode("right_bn1_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* right_bn1_var = VarNode("right_bn1_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* right_bn1 = OpNode("right_bn1", "batch_norm")->AsIntermediate();
+ auto* right_bn1_out = VarNode("right_bn1_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("elementwise_add", "X")
+ ->AsIntermediate();
+ auto* right_bn1_mean_out =
+ VarNode("right_bn1_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* right_bn1_var_out =
+ VarNode("right_bn1_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* right_bn1_saved_mean =
+ VarNode("right_bn1_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* right_bn1_saved_var =
+ VarNode("right_bn1_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+
+ auto* add = OpNode("add", "elementwise_add")->AsIntermediate();
+ auto* add_out = VarNode("add_out")
+ ->assert_is_op_output("elementwise_add", "Out")
+ ->assert_is_op_input("relu", "X")
+ ->AsIntermediate();
+ auto* relu = OpNode("relu", "relu")->AsIntermediate();
+ auto* relu_out =
+ VarNode("relu_out")->assert_is_op_output("relu", "Out")->AsOutput();
+
+ *input >> *left_conv1 >> *left_conv1_out >> *left_bn1 >> *left_bn1_out >>
+ *left_relu1 >> *left_relu1_out >> *left_conv2 >> *left_conv2_out >>
+ *left_bn2 >> *left_bn2_out >> *left_relu2 >> *left_relu2_out >>
+ *left_conv3 >> *left_conv3_out >> *left_bn3 >> *left_bn3_out >> *add;
+
+ *left_conv1_weight >> *left_conv1;
+ *left_bn1_scale >> *left_bn1;
+ *left_bn1_bias >> *left_bn1;
+ *left_bn1_mean >> *left_bn1;
+ *left_bn1_var >> *left_bn1;
+ *left_bn1 >> *left_bn1_mean_out;
+ *left_bn1 >> *left_bn1_var_out;
+ *left_bn1 >> *left_bn1_saved_mean;
+ *left_bn1 >> *left_bn1_saved_var;
+
+ *left_conv2_weight >> *left_conv2;
+ *left_bn2_scale >> *left_bn2;
+ *left_bn2_bias >> *left_bn2;
+ *left_bn2_mean >> *left_bn2;
+ *left_bn2_var >> *left_bn2;
+ *left_bn2 >> *left_bn2_mean_out;
+ *left_bn2 >> *left_bn2_var_out;
+ *left_bn2 >> *left_bn2_saved_mean;
+ *left_bn2 >> *left_bn2_saved_var;
+
+ *left_conv3_weight >> *left_conv3;
+ *left_bn3_scale >> *left_bn3;
+ *left_bn3_bias >> *left_bn3;
+ *left_bn3_mean >> *left_bn3;
+ *left_bn3_var >> *left_bn3;
+ *left_bn3 >> *left_bn3_mean_out;
+ *left_bn3 >> *left_bn3_var_out;
+ *left_bn3 >> *left_bn3_saved_mean;
+ *left_bn3 >> *left_bn3_saved_var;
+
+ *input >> *right_pool >> *right_pool_out >> *right_conv1 >>
+ *right_conv1_out >> *right_bn1 >> *right_bn1_out >> *add;
+
+ *right_conv1_weight >> *right_conv1;
+ *right_bn1_scale >> *right_bn1;
+ *right_bn1_bias >> *right_bn1;
+ *right_bn1_mean >> *right_bn1;
+ *right_bn1_var >> *right_bn1;
+ *right_bn1 >> *right_bn1_mean_out;
+ *right_bn1 >> *right_bn1_var_out;
+ *right_bn1 >> *right_bn1_saved_mean;
+ *right_bn1 >> *right_bn1_saved_var;
+
+ *add >> *add_out >> *relu >> *relu_out;
+ }
+
+ void InsertNewNode(SSAGraph* graph, const key2nodes_t& matched) override {
+ cpp::OpDesc op_desc;
+ op_desc.SetType("resnet_block0_d");
+ op_desc.SetInput("Inputs", {matched.at("input")->arg()->name});
+ op_desc.SetInput("Filter",
+ {
+ matched.at("left_conv1_weight")->arg()->name,
+ matched.at("left_conv2_weight")->arg()->name,
+ matched.at("left_conv3_weight")->arg()->name,
+ matched.at("right_conv1_weight")->arg()->name,
+ });
+ op_desc.SetInput("Scale",
+ {
+ matched.at("left_bn1_scale")->arg()->name,
+ matched.at("left_bn2_scale")->arg()->name,
+ matched.at("left_bn3_scale")->arg()->name,
+ matched.at("right_bn1_scale")->arg()->name,
+ });
+ op_desc.SetInput("Bias",
+ {
+ matched.at("left_bn1_bias")->arg()->name,
+ matched.at("left_bn2_bias")->arg()->name,
+ matched.at("left_bn3_bias")->arg()->name,
+ matched.at("right_bn1_bias")->arg()->name,
+ });
+ op_desc.SetInput("Mean",
+ {
+ matched.at("left_bn1_mean")->arg()->name,
+ matched.at("left_bn2_mean")->arg()->name,
+ matched.at("left_bn3_mean")->arg()->name,
+ matched.at("right_bn1_mean")->arg()->name,
+ });
+ op_desc.SetInput("Var",
+ {
+ matched.at("left_bn1_variance")->arg()->name,
+ matched.at("left_bn2_variance")->arg()->name,
+ matched.at("left_bn3_variance")->arg()->name,
+ matched.at("right_bn1_variance")->arg()->name,
+ });
+ op_desc.SetOutput("Outputs", {matched.at("relu_out")->arg()->name});
+ // keep these to fool SubgraphOp::AttachImpl()
+ op_desc.SetAttr("sub_block", 0);
+ op_desc.SetAttr>("input_data_names", {});
+ op_desc.SetAttr>("output_data_names", {});
+
+ auto block0_stmt = matched.at("left_conv1")->stmt();
+ // block0_stmt->ResetOp(op_desc, graph->valid_places());
+ auto fake_subgraph_op = LiteOpRegistry::Global().Create("subgraph");
+ auto sub_program_desc = std::make_shared();
+ sub_program_desc->AddBlock();
+ static_cast(fake_subgraph_op.get())
+ ->SetProgramDesc(sub_program_desc);
+ fake_subgraph_op->Attach(op_desc, block0_stmt->op()->scope());
+ fake_subgraph_op->SetValidPlaces(block0_stmt->op()->valid_places());
+ block0_stmt->SetOp(fake_subgraph_op);
+
+ std::vector froms = {
+ "left_conv2_weight",
+ "left_conv3_weight",
+ "right_conv1_weight",
+ "left_bn1_bias",
+ "left_bn2_bias",
+ "left_bn3_bias",
+ "right_bn1_bias",
+ };
+ for (auto& from : froms) {
+ IR_NODE_LINK_TO(matched.at(from), matched.at("left_conv1"));
+ }
+ IR_OP_VAR_LINK(matched.at("left_conv1"), matched.at("relu_out"));
+ }
+};
+
class XPUResNet50Fuser : public xpu::XPUFuseBase {
public:
- XPUResNet50Fuser() {}
+ XPUResNet50Fuser() {}
+
+ void BuildPattern() override {
+ auto* input =
+ VarNode("input")->assert_is_op_input("conv2d", "Input")->AsInput();
+
+ auto* top_conv_weight = VarNode("top_conv_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* top_conv = OpNode("top_conv", "conv2d");
+ auto* top_conv_out = VarNode("top_conv_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* top_bn_scale = VarNode("top_bn_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* top_bn_bias = VarNode("top_bn_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* top_bn_mean = VarNode("top_bn_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* top_bn_var = VarNode("top_bn_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* top_bn = OpNode("top_bn", "batch_norm")->AsIntermediate();
+ auto* top_bn_out = VarNode("top_bn_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("relu", "X")
+ ->AsIntermediate();
+ auto* top_bn_mean_out = VarNode("top_bn_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* top_bn_var_out =
+ VarNode("top_bn_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* top_bn_saved_mean =
+ VarNode("top_bn_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* top_bn_saved_var =
+ VarNode("top_bn_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+ auto* top_relu = OpNode("top_relu", "relu")->AsIntermediate();
+ auto* top_relu_out = VarNode("top_relu_out")
+ ->assert_is_op_output("relu", "Out")
+ ->assert_is_op_input("pool2d", "X")
+ ->AsIntermediate();
+ auto* top_pool = OpNode("top_pool", "pool2d")->AsIntermediate();
+ auto* top_pool_out = VarNode("top_pool_out")
+ ->assert_is_op_output("pool2d", "Out")
+ ->assert_is_op_input("resnet_block0", "Inputs")
+ ->AsIntermediate();
+
+ // args are left out
+ auto* resnet_block0_1 =
+ OpNode("resnet_block0_1", "resnet_block0")->AsIntermediate();
+ auto* resnet_block0_1_out =
+ VarNode("resnet_block0_1_out")
+ ->assert_is_op_output("resnet_block0", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_1_1 =
+ OpNode("resnet_block1_1_1", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_1_1_out =
+ VarNode("resnet_block1_1_1_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_1_2 =
+ OpNode("resnet_block1_1_2", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_1_2_out =
+ VarNode("resnet_block1_1_2_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+
+ auto* resnet_block0_2 =
+ OpNode("resnet_block0_2", "resnet_block0")->AsIntermediate();
+ auto* resnet_block0_2_out =
+ VarNode("resnet_block0_2_out")
+ ->assert_is_op_output("resnet_block0", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_2_1 =
+ OpNode("resnet_block1_2_1", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_2_1_out =
+ VarNode("resnet_block1_2_1_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_2_2 =
+ OpNode("resnet_block1_2_2", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_2_2_out =
+ VarNode("resnet_block1_2_2_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_2_3 =
+ OpNode("resnet_block1_2_3", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_2_3_out =
+ VarNode("resnet_block1_2_3_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+
+ auto* resnet_block0_3 =
+ OpNode("resnet_block0_3", "resnet_block0")->AsIntermediate();
+ auto* resnet_block0_3_out =
+ VarNode("resnet_block0_3_out")
+ ->assert_is_op_output("resnet_block0", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_3_1 =
+ OpNode("resnet_block1_3_1", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_3_1_out =
+ VarNode("resnet_block1_3_1_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_3_2 =
+ OpNode("resnet_block1_3_2", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_3_2_out =
+ VarNode("resnet_block1_3_2_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_3_3 =
+ OpNode("resnet_block1_3_3", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_3_3_out =
+ VarNode("resnet_block1_3_3_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_3_4 =
+ OpNode("resnet_block1_3_4", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_3_4_out =
+ VarNode("resnet_block1_3_4_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_3_5 =
+ OpNode("resnet_block1_3_5", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_3_5_out =
+ VarNode("resnet_block1_3_5_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+
+ auto* resnet_block0_4 =
+ OpNode("resnet_block0_4", "resnet_block0")->AsIntermediate();
+ auto* resnet_block0_4_out =
+ VarNode("resnet_block0_4_out")
+ ->assert_is_op_output("resnet_block0", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_4_1 =
+ OpNode("resnet_block1_4_1", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_4_1_out =
+ VarNode("resnet_block1_4_1_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+ auto* resnet_block1_4_2 =
+ OpNode("resnet_block1_4_2", "resnet_block1")->AsIntermediate();
+ auto* resnet_block1_4_2_out =
+ VarNode("resnet_block1_4_2_out")
+ ->assert_is_op_output("resnet_block1", "Outputs")
+ ->AsIntermediate();
+
+ auto* bottom_pool = OpNode("bottom_pool", "pool2d")->AsIntermediate();
+ auto* bottom_pool_out = VarNode("bottom_pool_out")
+ ->assert_is_op_output("pool2d", "Out")
+ ->AsOutput();
+
+ *input >> *top_conv >> *top_conv_out >> *top_bn >> *top_bn_out >>
+ *top_relu >> *top_relu_out >> *top_pool >> *top_pool_out >>
+ *resnet_block0_1 >> *resnet_block0_1_out >> *resnet_block1_1_1 >>
+ *resnet_block1_1_1_out >> *resnet_block1_1_2 >>
+ *resnet_block1_1_2_out >> *resnet_block0_2 >> *resnet_block0_2_out >>
+ *resnet_block1_2_1 >> *resnet_block1_2_1_out >> *resnet_block1_2_2 >>
+ *resnet_block1_2_2_out >> *resnet_block1_2_3 >>
+ *resnet_block1_2_3_out >> *resnet_block0_3 >> *resnet_block0_3_out >>
+ *resnet_block1_3_1 >> *resnet_block1_3_1_out >> *resnet_block1_3_2 >>
+ *resnet_block1_3_2_out >> *resnet_block1_3_3 >>
+ *resnet_block1_3_3_out >> *resnet_block1_3_4 >>
+ *resnet_block1_3_4_out >> *resnet_block1_3_5 >>
+ *resnet_block1_3_5_out >> *resnet_block0_4 >> *resnet_block0_4_out >>
+ *resnet_block1_4_1 >> *resnet_block1_4_1_out >> *resnet_block1_4_2 >>
+ *resnet_block1_4_2_out >> *bottom_pool >> *bottom_pool_out;
+
+ *top_conv_weight >> *top_conv;
+ *top_bn_scale >> *top_bn;
+ *top_bn_bias >> *top_bn;
+ *top_bn_mean >> *top_bn;
+ *top_bn_var >> *top_bn;
+ *top_bn >> *top_bn_mean_out;
+ *top_bn >> *top_bn_var_out;
+ *top_bn >> *top_bn_saved_mean;
+ *top_bn >> *top_bn_saved_var;
+ }
+
+ void InsertNewNode(SSAGraph* graph,
+ const key2nodes_t& matched,
+ const std::vector& extra_input_vars) override {
+ cpp::OpDesc op_desc;
+ op_desc.SetType("__xpu__resnet50");
+ op_desc.SetInput("Input", {matched.at("input")->arg()->name});
+ std::vector filter_name = {
+ matched.at("top_conv_weight")->arg()->name};
+ std::vector scale_name = {
+ matched.at("top_bn_scale")->arg()->name};
+ std::vector bias_name = {
+ matched.at("top_bn_bias")->arg()->name};
+ std::vector mean_name = {
+ matched.at("top_bn_mean")->arg()->name};
+ std::vector var_name = {
+ matched.at("top_bn_variance")->arg()->name};
+ std::vector max_filter_name;
+ std::vector resnet_block_vec = {
+ "resnet_block0_1",
+ "resnet_block1_1_1",
+ "resnet_block1_1_2",
+ "resnet_block0_2",
+ "resnet_block1_2_1",
+ "resnet_block1_2_2",
+ "resnet_block1_2_3",
+ "resnet_block0_3",
+ "resnet_block1_3_1",
+ "resnet_block1_3_2",
+ "resnet_block1_3_3",
+ "resnet_block1_3_4",
+ "resnet_block1_3_5",
+ "resnet_block0_4",
+ "resnet_block1_4_1",
+ "resnet_block1_4_2",
+ };
+ for (auto& block : resnet_block_vec) {
+ auto* block_op_info = matched.at(block)->stmt()->op_info();
+ auto block_filter_name = block_op_info->Input("Filter");
+ std::copy(block_filter_name.begin(),
+ block_filter_name.end(),
+ std::back_inserter(filter_name));
+ auto block_scale_name = block_op_info->Input("Scale");
+ std::copy(block_scale_name.begin(),
+ block_scale_name.end(),
+ std::back_inserter(scale_name));
+ auto block_bias_name = block_op_info->Input("Bias");
+ std::copy(block_bias_name.begin(),
+ block_bias_name.end(),
+ std::back_inserter(bias_name));
+ auto block_mean_name = block_op_info->Input("Mean");
+ std::copy(block_mean_name.begin(),
+ block_mean_name.end(),
+ std::back_inserter(mean_name));
+ auto block_var_name = block_op_info->Input("Var");
+ std::copy(block_var_name.begin(),
+ block_var_name.end(),
+ std::back_inserter(var_name));
+ }
+ op_desc.SetInput("Filter", filter_name);
+ op_desc.SetInput("Bias", bias_name);
+ op_desc.SetOutput("Output", {matched.at("bottom_pool_out")->arg()->name});
+ op_desc.SetAttr("xpu", 1);
+
+ auto* resnet50_stmt = matched.at("top_conv")->stmt();
+ auto* scope = resnet50_stmt->op()->scope();
+ for (size_t i = 0; i < filter_name.size(); ++i) {
+ auto* filter_t = scope->FindMutableTensor(filter_name[i]);
+ auto* scale_t = scope->FindMutableTensor(scale_name[i]);
+ auto* bias_t = scope->FindMutableTensor(bias_name[i]);
+ auto* mean_t = scope->FindMutableTensor(mean_name[i]);
+ auto* var_t = scope->FindMutableTensor(var_name[i]);
+
+ int mean_len = mean_t->numel();
+ int filter_len = filter_t->numel();
+ int filter_stride = filter_len / mean_len;
+
+ float* filter_on_host = filter_t->mutable_data();
+ float* scale_on_host = scale_t->mutable_data();
+ float* bias_on_host = bias_t->mutable_data();
+ float* mean_on_host = mean_t->mutable_data();
+ float* var_on_host = var_t->mutable_data();
+
+ // Perform preprocess
+ for (int i = 0; i < mean_len; ++i) {
+ scale_on_host[i] = scale_on_host[i] / sqrtf(var_on_host[i] + 0.00001f);
+ }
+ for (int i = 0; i < mean_len; ++i) {
+ for (int j = 0; j < filter_stride; ++j) {
+ filter_on_host[i * filter_stride + j] *= scale_on_host[i];
+ }
+ }
+ for (int i = 0; i < mean_len; ++i) {
+ bias_on_host[i] += -mean_on_host[i] * scale_on_host[i];
+ }
+
+ float max_f =
+ paddle::lite::xpu::math::FindMaxAbs(filter_on_host, filter_len);
+ std::unique_ptr filter_int16(new int16_t[filter_len]);
+ paddle::lite::xpu::math::ConvertFP32ToInt16(
+ filter_on_host, filter_int16.get(), max_f, filter_len);
+ memcpy(filter_on_host, filter_int16.get(), filter_len * sizeof(int16_t));
+
+ // create new arg in graph and scope
+ std::string max_name = filter_name[i] + "_max";
+ max_filter_name.push_back(max_name);
+ auto* max_filter_node = graph->NewArgumentNode(max_name);
+ max_filter_node->arg()->is_weight = true;
+ max_filter_node->arg()->type = LiteType::GetTensorTy(
+ TARGET(kHost), PRECISION(kFloat), DATALAYOUT(kNCHW));
+ DirectedLink(max_filter_node, matched.at("top_conv"));
+ auto* max_filter_t = scope->NewTensor(max_name);
+ max_filter_t->Resize({4});
+ float* max_ptr = max_filter_t->mutable_data();
+ max_ptr[0] = max_f;
+ max_ptr[1] = max_f;
+ max_ptr[2] = max_f;
+ max_ptr[3] = max_f;
+ }
+ op_desc.SetInput("MaxFilter", max_filter_name);
+
+ auto resnet50_op = LiteOpRegistry::Global().Create(op_desc.Type());
+ resnet50_op->Attach(op_desc, scope);
+ resnet50_op->SetValidPlaces(resnet50_stmt->op()->valid_places());
+ auto kernels = resnet50_op->CreateKernels(resnet50_op->valid_places());
+ resnet50_stmt->SetOp(resnet50_op);
+ resnet50_stmt->SetKernels(std::move(kernels));
+
+ IR_NODE_LINK_TO(matched.at("top_bn_bias"), matched.at("top_conv"));
+ for (auto* node : extra_input_vars) {
+ IR_NODE_LINK_TO(node, matched.at("top_conv"));
+ }
+ IR_OP_VAR_LINK(matched.at("top_conv"), matched.at("bottom_pool_out"));
+ }
+};
+
+class XPUResNet50DtypeFuser : public xpu::XPUFuseBase {
+ public:
+ XPUResNet50DtypeFuser() {}
void BuildPattern() override {
auto* input =
@@ -650,8 +1299,102 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
auto* top_relu = OpNode("top_relu", "relu")->AsIntermediate();
auto* top_relu_out = VarNode("top_relu_out")
->assert_is_op_output("relu", "Out")
- ->assert_is_op_input("pool2d", "X")
+ ->assert_is_op_input("conv2d", "Input")
+ ->AsIntermediate();
+
+ auto* second_conv_weight = VarNode("second_conv_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* second_conv = OpNode("second_conv", "conv2d")->AsIntermediate();
+ auto* second_conv_out = VarNode("second_conv_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* second_bn_scale = VarNode("second_bn_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* second_bn_bias = VarNode("second_bn_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* second_bn_mean = VarNode("second_bn_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* second_bn_var = VarNode("second_bn_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* second_bn = OpNode("second_bn", "batch_norm")->AsIntermediate();
+ auto* second_bn_out = VarNode("second_bn_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("relu", "X")
+ ->AsIntermediate();
+ auto* second_bn_mean_out =
+ VarNode("second_bn_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* second_bn_var_out =
+ VarNode("second_bn_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* second_bn_saved_mean =
+ VarNode("second_bn_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* second_bn_saved_var =
+ VarNode("second_bn_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+ auto* second_relu = OpNode("second_relu", "relu")->AsIntermediate();
+ auto* second_relu_out = VarNode("second_relu_out")
+ ->assert_is_op_output("relu", "Out")
+ ->assert_is_op_input("conv2d", "Input")
+ ->AsIntermediate();
+
+ auto* third_conv_weight = VarNode("third_conv_weight")
+ ->assert_is_op_input("conv2d", "Filter")
+ ->AsInput();
+ auto* third_conv = OpNode("third_conv", "conv2d")->AsIntermediate();
+ auto* third_conv_out = VarNode("third_conv_out")
+ ->assert_is_op_output("conv2d", "Output")
+ ->assert_is_op_input("batch_norm", "X")
+ ->AsIntermediate();
+ auto* third_bn_scale = VarNode("third_bn_scale")
+ ->assert_is_op_input("batch_norm", "Scale")
+ ->AsIntermediate();
+ auto* third_bn_bias = VarNode("third_bn_bias")
+ ->assert_is_op_input("batch_norm", "Bias")
+ ->AsInput();
+ auto* third_bn_mean = VarNode("third_bn_mean")
+ ->assert_is_op_input("batch_norm", "Mean")
+ ->AsIntermediate();
+ auto* third_bn_var = VarNode("third_bn_variance")
+ ->assert_is_op_input("batch_norm", "Variance")
+ ->AsIntermediate();
+ auto* third_bn = OpNode("third_bn", "batch_norm")->AsIntermediate();
+ auto* third_bn_out = VarNode("third_bn_out")
+ ->assert_is_op_output("batch_norm", "Y")
+ ->assert_is_op_input("relu", "X")
->AsIntermediate();
+ auto* third_bn_mean_out = VarNode("third_bn_mean_out")
+ ->assert_is_op_output("batch_norm", "MeanOut")
+ ->AsIntermediate();
+ auto* third_bn_var_out =
+ VarNode("third_bn_var_out")
+ ->assert_is_op_output("batch_norm", "VarianceOut")
+ ->AsIntermediate();
+ auto* third_bn_saved_mean =
+ VarNode("third_bn_saved_mean")
+ ->assert_is_op_output("batch_norm", "SavedMean")
+ ->AsIntermediate();
+ auto* third_bn_saved_var =
+ VarNode("third_bn_saved_var")
+ ->assert_is_op_output("batch_norm", "SavedVariance")
+ ->AsIntermediate();
+ auto* third_relu = OpNode("third_relu", "relu")->AsIntermediate();
+ auto* third_relu_out = VarNode("third_relu_out")
+ ->assert_is_op_output("relu", "Out")
+ ->assert_is_op_input("pool2d", "X")
+ ->AsIntermediate();
+
auto* top_pool = OpNode("top_pool", "pool2d")->AsIntermediate();
auto* top_pool_out = VarNode("top_pool_out")
->assert_is_op_output("pool2d", "Out")
@@ -679,10 +1422,10 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
->AsIntermediate();
auto* resnet_block0_2 =
- OpNode("resnet_block0_2", "resnet_block0")->AsIntermediate();
+ OpNode("resnet_block0_2", "resnet_block0_d")->AsIntermediate();
auto* resnet_block0_2_out =
VarNode("resnet_block0_2_out")
- ->assert_is_op_output("resnet_block0", "Outputs")
+ ->assert_is_op_output("resnet_block0_d", "Outputs")
->AsIntermediate();
auto* resnet_block1_2_1 =
OpNode("resnet_block1_2_1", "resnet_block1")->AsIntermediate();
@@ -704,10 +1447,10 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
->AsIntermediate();
auto* resnet_block0_3 =
- OpNode("resnet_block0_3", "resnet_block0")->AsIntermediate();
+ OpNode("resnet_block0_3", "resnet_block0_d")->AsIntermediate();
auto* resnet_block0_3_out =
VarNode("resnet_block0_3_out")
- ->assert_is_op_output("resnet_block0", "Outputs")
+ ->assert_is_op_output("resnet_block0_d", "Outputs")
->AsIntermediate();
auto* resnet_block1_3_1 =
OpNode("resnet_block1_3_1", "resnet_block1")->AsIntermediate();
@@ -741,10 +1484,10 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
->AsIntermediate();
auto* resnet_block0_4 =
- OpNode("resnet_block0_4", "resnet_block0")->AsIntermediate();
+ OpNode("resnet_block0_4", "resnet_block0_d")->AsIntermediate();
auto* resnet_block0_4_out =
VarNode("resnet_block0_4_out")
- ->assert_is_op_output("resnet_block0", "Outputs")
+ ->assert_is_op_output("resnet_block0_d", "Outputs")
->AsIntermediate();
auto* resnet_block1_4_1 =
OpNode("resnet_block1_4_1", "resnet_block1")->AsIntermediate();
@@ -765,7 +1508,10 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
->AsOutput();
*input >> *top_conv >> *top_conv_out >> *top_bn >> *top_bn_out >>
- *top_relu >> *top_relu_out >> *top_pool >> *top_pool_out >>
+ *top_relu >> *top_relu_out >> *second_conv >> *second_conv_out >>
+ *second_bn >> *second_bn_out >> *second_relu >> *second_relu_out >>
+ *third_conv >> *third_conv_out >> *third_bn >> *third_bn_out >>
+ *third_relu >> *third_relu_out >> *top_pool >> *top_pool_out >>
*resnet_block0_1 >> *resnet_block0_1_out >> *resnet_block1_1_1 >>
*resnet_block1_1_1_out >> *resnet_block1_1_2 >>
*resnet_block1_1_2_out >> *resnet_block0_2 >> *resnet_block0_2_out >>
@@ -789,24 +1535,59 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
*top_bn >> *top_bn_var_out;
*top_bn >> *top_bn_saved_mean;
*top_bn >> *top_bn_saved_var;
+
+ *second_conv_weight >> *second_conv;
+ *second_bn_scale >> *second_bn;
+ *second_bn_bias >> *second_bn;
+ *second_bn_mean >> *second_bn;
+ *second_bn_var >> *second_bn;
+ *second_bn >> *second_bn_mean_out;
+ *second_bn >> *second_bn_var_out;
+ *second_bn >> *second_bn_saved_mean;
+ *second_bn >> *second_bn_saved_var;
+
+ *third_conv_weight >> *third_conv;
+ *third_bn_scale >> *third_bn;
+ *third_bn_bias >> *third_bn;
+ *third_bn_mean >> *third_bn;
+ *third_bn_var >> *third_bn;
+ *third_bn >> *third_bn_mean_out;
+ *third_bn >> *third_bn_var_out;
+ *third_bn >> *third_bn_saved_mean;
+ *third_bn >> *third_bn_saved_var;
}
void InsertNewNode(SSAGraph* graph,
const key2nodes_t& matched,
const std::vector& extra_input_vars) override {
cpp::OpDesc op_desc;
- op_desc.SetType("__xpu__resnet50");
+ op_desc.SetType("__xpu__resnet50_d");
op_desc.SetInput("Input", {matched.at("input")->arg()->name});
std::vector filter_name = {
- matched.at("top_conv_weight")->arg()->name};
+ matched.at("top_conv_weight")->arg()->name,
+ matched.at("second_conv_weight")->arg()->name,
+ matched.at("third_conv_weight")->arg()->name};
+
std::vector scale_name = {
- matched.at("top_bn_scale")->arg()->name};
+ matched.at("top_bn_scale")->arg()->name,
+ matched.at("second_bn_scale")->arg()->name,
+ matched.at("third_bn_scale")->arg()->name};
+
std::vector bias_name = {
- matched.at("top_bn_bias")->arg()->name};
+ matched.at("top_bn_bias")->arg()->name,
+ matched.at("second_bn_bias")->arg()->name,
+ matched.at("third_bn_bias")->arg()->name};
+
std::vector mean_name = {
- matched.at("top_bn_mean")->arg()->name};
+ matched.at("top_bn_mean")->arg()->name,
+ matched.at("second_bn_mean")->arg()->name,
+ matched.at("third_bn_mean")->arg()->name};
+
std::vector var_name = {
- matched.at("top_bn_variance")->arg()->name};
+ matched.at("top_bn_variance")->arg()->name,
+ matched.at("second_bn_variance")->arg()->name,
+ matched.at("third_bn_variance")->arg()->name};
+
std::vector max_filter_name;
std::vector resnet_block_vec = {
"resnet_block0_1",
@@ -900,7 +1681,9 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
max_filter_node->arg()->is_weight = true;
max_filter_node->arg()->type = LiteType::GetTensorTy(
TARGET(kHost), PRECISION(kFloat), DATALAYOUT(kNCHW));
+
DirectedLink(max_filter_node, matched.at("top_conv"));
+
auto* max_filter_t = scope->NewTensor(max_name);
max_filter_t->Resize({4});
float* max_ptr = max_filter_t->mutable_data();
@@ -919,6 +1702,11 @@ class XPUResNet50Fuser : public xpu::XPUFuseBase {
resnet50_stmt->SetKernels(std::move(kernels));
IR_NODE_LINK_TO(matched.at("top_bn_bias"), matched.at("top_conv"));
+ IR_NODE_LINK_TO(matched.at("second_conv_weight"), matched.at("top_conv"));
+ IR_NODE_LINK_TO(matched.at("second_bn_bias"), matched.at("top_conv"));
+ IR_NODE_LINK_TO(matched.at("third_conv_weight"), matched.at("top_conv"));
+ IR_NODE_LINK_TO(matched.at("third_bn_bias"), matched.at("top_conv"));
+
for (auto* node : extra_input_vars) {
IR_NODE_LINK_TO(node, matched.at("top_conv"));
}
@@ -951,6 +1739,31 @@ class XPUResNet50FusePass : public ProgramPass {
}
};
+class XPUResNet50DtypeFusePass : public ProgramPass {
+ public:
+ void Apply(const std::unique_ptr& graph) override {
+ if (GetBoolFromEnv("XPU_ENABLE_XTCL")) return;
+
+ bool changed = false;
+ SSAGraph backup;
+ backup.CloneFrom(*graph);
+
+ fusion::XPUResNetBlock0Fuser block0_fuser;
+ changed |= block0_fuser(graph.get());
+ fusion::XPUResNetDtypeBlock0Fuser d_type_block0_fuser;
+ changed |= d_type_block0_fuser(graph.get());
+ fusion::XPUResNetBlock1Fuser block1_fuser;
+ changed |= block1_fuser(graph.get());
+ fusion::XPUResNet50DtypeFuser resnet50_d_fuser;
+ size_t n_matches = resnet50_d_fuser(graph.get());
+
+ if (changed && !n_matches) {
+ // Restore graph from backuped one if no whole ResNet50 graph was found
+ graph->CloneFrom(backup);
+ }
+ }
+};
+
} // namespace mir
} // namespace lite
} // namespace paddle
@@ -959,3 +1772,8 @@ REGISTER_MIR_PASS(__xpu__resnet_fuse_pass,
paddle::lite::mir::XPUResNet50FusePass)
.BindTargets({TARGET(kXPU)})
.BindKernel("__xpu__resnet50");
+
+REGISTER_MIR_PASS(__xpu__resnet_d_fuse_pass,
+ paddle::lite::mir::XPUResNet50DtypeFusePass)
+ .BindTargets({TARGET(kXPU)})
+ .BindKernel("__xpu__resnet50_d");
diff --git a/lite/core/mir/fusion/conv_conv_fuse_pass.cc b/lite/core/mir/fusion/conv_conv_fuse_pass.cc
index d277da87689d7aa1f21ef260013b6e81f2146a09..b2c5d8d15ab95fbcc43adc01c4189ae83b1316ed 100644
--- a/lite/core/mir/fusion/conv_conv_fuse_pass.cc
+++ b/lite/core/mir/fusion/conv_conv_fuse_pass.cc
@@ -13,6 +13,7 @@
// limitations under the License.
#include "lite/core/mir/fusion/conv_conv_fuse_pass.h"
+#include
#include
#include
#include "lite/core/mir/fusion/conv_conv_fuser.h"
@@ -27,13 +28,10 @@ void ConvConvFusePass::Apply(const std::unique_ptr& graph) {
// initialze fuser params
std::vector conv_has_bias_cases{true, false};
std::vector conv_type_cases{"conv2d", "depthwise_conv2d"};
- bool has_fp32 = false;
bool has_int8 = false;
+ bool has_weight_quant = false;
for (auto& place : graph->valid_places()) {
if (place.target == TARGET(kARM) || place.target == TARGET(kHost)) {
- if (place.precision == PRECISION(kFloat)) {
- has_fp32 = true;
- }
if (place.precision == PRECISION(kInt8)) {
has_int8 = true;
}
@@ -42,8 +40,18 @@ void ConvConvFusePass::Apply(const std::unique_ptr& graph) {
return;
}
}
+ const std::list& nodes = graph->nodes();
+ for (auto& node : nodes) {
+ if (node.IsStmt()) {
+ auto* op_info = (node.stmt())->op_info();
+ if (op_info->HasAttr("quantization_type")) {
+ has_weight_quant = true;
+ break;
+ }
+ }
+ }
// only support arm-fp32
- if (has_int8 || (has_fp32 && has_int8)) {
+ if (has_int8 || has_weight_quant) {
return;
}
// only support fp32 fusion
diff --git a/lite/core/mir/fusion/quant_dequant_fuse_pass.cc b/lite/core/mir/fusion/quant_dequant_fuse_pass.cc
index da42d6d0c79a2a7975eacca7095fedababac6d89..4840a625c7551e96fa5f3ae03585bedf9a85c303 100644
--- a/lite/core/mir/fusion/quant_dequant_fuse_pass.cc
+++ b/lite/core/mir/fusion/quant_dequant_fuse_pass.cc
@@ -61,5 +61,4 @@ void QuantDequantFusePass::Apply(const std::unique_ptr& graph) {
REGISTER_MIR_PASS(lite_quant_dequant_fuse_pass,
paddle::lite::mir::QuantDequantFusePass)
- .BindTargets({TARGET(kAny)})
- .BindKernel("calib");
+ .BindTargets({TARGET(kAny)});
diff --git a/lite/core/mir/memory_optimize_pass.cc b/lite/core/mir/memory_optimize_pass.cc
index 3817d0049c9e302b5b39aae6bca96dff2180bd73..bf1867ac3be2c8c9f8c1c39db156eee31b31c127 100644
--- a/lite/core/mir/memory_optimize_pass.cc
+++ b/lite/core/mir/memory_optimize_pass.cc
@@ -148,7 +148,7 @@ void MemoryOptimizePass::CollectLifeCycleByDevice(
int cur_life =
(*lifecycles)[TargetToStr(target_type)][var_name].second;
(*lifecycles)[TargetToStr(target_type)][var_name].second =
- std::max(max_lifecycle_, cur_life);
+ (std::max)(max_lifecycle_, cur_life);
}
}
++max_lifecycle_;
diff --git a/lite/core/mir/static_kernel_pick_pass.h b/lite/core/mir/static_kernel_pick_pass.h
index 1b6c55e5e2b533c48a4a34feab9e0c5d5a157d73..3ecd92049d0f4838e80d743b82276cb7b6dfa79f 100644
--- a/lite/core/mir/static_kernel_pick_pass.h
+++ b/lite/core/mir/static_kernel_pick_pass.h
@@ -61,7 +61,7 @@ class StaticKernelPickPass : public mir::StmtPass {
float final_score{-1.};
Place winner_place{places[0]};
const int kMax =
- std::numeric_limits::max();
+ (std::numeric_limits::max)();
size_t place_size = places.size();
// NOTE: We compare kernel's place with place in valid_places to select the
diff --git a/lite/core/mir/subgraph/subgraph_pass_test.cc b/lite/core/mir/subgraph/subgraph_pass_test.cc
index 5a57623b0c984be24e2d0b97ee575b22d369fdad..1a615838e33b6688d7213787a7aa6ec35ed7f0b4 100644
--- a/lite/core/mir/subgraph/subgraph_pass_test.cc
+++ b/lite/core/mir/subgraph/subgraph_pass_test.cc
@@ -17,8 +17,6 @@
#include
#include "lite/api/paddle_api.h"
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
#include "lite/api/test_helper.h"
#include "lite/utils/cp_logging.h"
#include "lite/utils/string.h"
diff --git a/lite/core/mir/type_layout_cast_pass.cc b/lite/core/mir/type_layout_cast_pass.cc
index 44b6eaf1eb0c5c96630dd66d129919b40f3ea8c6..c1529aacf85c713c6c381974c408b536c608fa61 100644
--- a/lite/core/mir/type_layout_cast_pass.cc
+++ b/lite/core/mir/type_layout_cast_pass.cc
@@ -82,8 +82,11 @@ void TypeLayoutTransformPass::ComplementInputs(SSAGraph* graph,
// not a good judge, but don't find the source of this issue from
// static_pick_kernel_pass
// to this pass.
+ auto is_host = [](TargetType x) -> bool {
+ return x == TARGET(kHost) || x == TARGET(kX86) || x == TARGET(kARM);
+ };
auto* in_arg_type = const_cast(in->AsArg().type);
- if (in_arg_type->target() == TARGET(kARM) &&
+ if (is_host(in_arg_type->target()) &&
in_arg_type->layout() == DATALAYOUT(kImageDefault)) {
return;
}
diff --git a/lite/core/op_lite.cc b/lite/core/op_lite.cc
index 585aaf3b703bca0a0a34030106dbf793e2a31d52..dcab292be8f24a6294cb560506f6d03209552d4a 100644
--- a/lite/core/op_lite.cc
+++ b/lite/core/op_lite.cc
@@ -233,67 +233,98 @@ bool OpInfo::GetOutputIndex(const std::string &output_name, int *out) const {
return false;
}
-bool OpInfo::HasInputScale(const std::string &input_name) const {
- std::string argname;
- int index;
- if (GetInputArgname(input_name, &argname) &&
- GetInputIndex(input_name, &index)) {
- return HasAttr(argname + to_string(index) + "_scale");
+bool OpInfo::HasInputScale(const std::string &name, bool is_scale_name) const {
+ bool res = false;
+ if (is_scale_name) {
+ res = HasAttr(name);
} else {
- return false;
+ std::string argname;
+ int index;
+ if (GetInputArgname(name, &argname) && GetInputIndex(name, &index)) {
+ res = HasAttr(argname + to_string(index) + "_scale");
+ }
}
+ return res;
}
-bool OpInfo::HasOutputScale(const std::string &output_name) const {
- std::string argname;
- int index;
- if (GetOutputArgname(output_name, &argname) &&
- GetOutputIndex(output_name, &index)) {
- return HasAttr(argname + to_string(index) + "_scale");
+bool OpInfo::HasOutputScale(const std::string &name, bool is_scale_name) const {
+ bool res = false;
+ if (is_scale_name) {
+ res = HasAttr(name);
} else {
- return false;
+ std::string argname;
+ int index;
+ if (GetOutputArgname(name, &argname) && GetOutputIndex(name, &index)) {
+ res = HasAttr(argname + to_string(index) + "_scale");
+ }
}
+ return res;
}
-void OpInfo::SetInputScale(const std::string &input_name,
- const std::vector &scale_value) {
- std::string argname;
- int index;
- CHECK(GetInputArgname(input_name, &argname));
- CHECK(GetInputIndex(input_name, &index));
- CHECK(scale_value.size() > 0)
- << "Error in SetInputScale: the scales should not be empty";
- SetAttr>(argname + to_string(index) + "_scale",
- scale_value);
+void OpInfo::SetInputScale(const std::string &name,
+ const std::vector &scale_value,
+ bool is_scale_name) {
+ std::string scale_name;
+ if (is_scale_name) {
+ scale_name = name;
+ } else {
+ std::string argname;
+ int index;
+ CHECK(GetInputArgname(name, &argname));
+ CHECK(GetInputIndex(name, &index));
+ CHECK(scale_value.size() > 0)
+ << "Error in SetInputScale: the scales should not be empty";
+ scale_name = argname + to_string(index) + "_scale";
+ }
+ SetAttr>(scale_name, scale_value);
}
-void OpInfo::SetOutputScale(const std::string &output_name,
- const std::vector &scale_value) {
- std::string argname;
- int index;
- CHECK(GetOutputArgname(output_name, &argname));
- CHECK(GetOutputIndex(output_name, &index));
- CHECK(scale_value.size() > 0)
- << "Error in SetOutputScale: the scales should not be empty";
- SetAttr>(argname + to_string(index) + "_scale",
- scale_value);
+void OpInfo::SetOutputScale(const std::string &name,
+ const std::vector &scale_value,
+ bool is_scale_name) {
+ std::string scale_name;
+ if (is_scale_name) {
+ scale_name = name;
+ } else {
+ std::string argname;
+ int index;
+ CHECK(GetOutputArgname(name, &argname));
+ CHECK(GetOutputIndex(name, &index));
+ CHECK(scale_value.size() > 0)
+ << "Error in SetOutputScale: the scales should not be empty";
+ scale_name = argname + to_string(index) + "_scale";
+ }
+ SetAttr>(scale_name, scale_value);
}
-std::vector OpInfo::GetInputScale(const std::string &input_name) const {
- std::string argname;
- int index;
- CHECK(GetInputArgname(input_name, &argname));
- CHECK(GetInputIndex(input_name, &index));
- return GetAttr>(argname + to_string(index) + "_scale");
+std::vector OpInfo::GetInputScale(const std::string &name,
+ bool is_scale_name) const {
+ std::string scale_name;
+ if (is_scale_name) {
+ scale_name = name;
+ } else {
+ std::string argname;
+ int index;
+ CHECK(GetInputArgname(name, &argname));
+ CHECK(GetInputIndex(name, &index));
+ scale_name = argname + to_string(index) + "_scale";
+ }
+ return GetAttr>(scale_name);
}
-std::vector OpInfo::GetOutputScale(
- const std::string &output_name) const {
- std::string argname;
- int index;
- CHECK(GetOutputArgname(output_name, &argname));
- CHECK(GetOutputIndex(output_name, &index));
- return GetAttr>(argname + to_string(index) + "_scale");
+std::vector OpInfo::GetOutputScale(const std::string &name,
+ bool is_scale_name) const {
+ std::string scale_name;
+ if (is_scale_name) {
+ scale_name = name;
+ } else {
+ std::string argname;
+ int index;
+ CHECK(GetOutputArgname(name, &argname));
+ CHECK(GetOutputIndex(name, &index));
+ scale_name = argname + to_string(index) + "_scale";
+ }
+ return GetAttr>(scale_name);
}
} // namespace lite
diff --git a/lite/core/op_lite.h b/lite/core/op_lite.h
index d94753220a1b5d963092c62c43d7e49b03243c63..1e664152a39110bdfc28cbb037920b6174315aa5 100644
--- a/lite/core/op_lite.h
+++ b/lite/core/op_lite.h
@@ -251,19 +251,31 @@ class OpInfo : public cpp::OpDesc {
bool GetInputIndex(const std::string &input_name, int *out) const;
bool GetOutputIndex(const std::string &output_name, int *out) const;
- bool HasInputScale(const std::string &input_name) const;
- bool HasOutputScale(const std::string &output_name) const;
+ // If a quantized op has two input argname (X, Y) and one output
+ // argname (Out). The scales of input argname X are saved in op desc as
+ // (X0_scale, scale_value_0), (X1_scale, scale_value_1)...
+ // The following APIs get or set the quantized scale in op_desc.
+ // If use the input or output name, the is_scale_name should be false.
+ // If use the scale_name such as (X0_scale, scale_value_0),
+ // the is_scale_name should be true.
+ bool HasInputScale(const std::string &name, bool is_scale_name = false) const;
+ bool HasOutputScale(const std::string &name,
+ bool is_scale_name = false) const;
void SetInputScale(const std::string &input_name,
- const std::vector &scale_value);
+ const std::vector &scale_value,
+ bool is_scale_name = false);
void SetOutputScale(const std::string &output_name,
- const std::vector &scale_value);
+ const std::vector &scale_value,
+ bool is_scale_name = false);
// For conv2d, depthwise_conv2d and mul, the scale of weight are a vector.
// Otherwise, all input and output scales are scalar, but we save these
// as vecotr.
- std::vector GetInputScale(const std::string &input_name) const;
- std::vector GetOutputScale(const std::string &output_name) const;
+ std::vector GetInputScale(const std::string &name,
+ bool is_scale_name = false) const;
+ std::vector GetOutputScale(const std::string &name,
+ bool is_scale_name = false) const;
};
} // namespace lite
diff --git a/lite/core/optimizer.h b/lite/core/optimizer.h
index 2dfc444a26ffe013ad05c81a003dd073cc133177..7709090c038cf81bee5a735b682ea0721ee30ec1 100644
--- a/lite/core/optimizer.h
+++ b/lite/core/optimizer.h
@@ -80,97 +80,99 @@ class Optimizer {
InitControlFlowOpUnusedInputsAndOutputsEliminatePass();
if (passes.empty() || passes.size() == 1) {
- std::vector passes_local{
- {"lite_quant_dequant_fuse_pass", //
- "weight_quantization_preprocess_pass", //
- "lite_conv_elementwise_fuse_pass", // conv-elemwise-bn
- "lite_conv_bn_fuse_pass", //
- "lite_conv_elementwise_fuse_pass", // conv-bn-elemwise
- "lite_conv_conv_fuse_pass", //
- // TODO(Superjomn) Refine the fusion related design to select fusion
- // kernels for devices automatically.
- "lite_conv_activation_fuse_pass", //
- "lite_var_conv_2d_activation_fuse_pass", //
- "lite_match_matrix_activation_fuse_pass", //
- "lite_fc_fuse_pass", //
- "lite_shuffle_channel_fuse_pass", //
- "lite_transpose_softmax_transpose_fuse_pass", //
- "lite_interpolate_fuse_pass", //
- "identity_scale_eliminate_pass", //
- "lite_scales_fuse_pass", //
- "lite_sequence_reverse_embedding_fuse_pass", //
- "elementwise_mul_constant_eliminate_pass", //
- "lite_sequence_pool_concat_fuse_pass", //
- "lite_scale_activation_fuse_pass", //
+ std::vector passes_local{{
+ "lite_quant_dequant_fuse_pass", //
+ "weight_quantization_preprocess_pass", //
+ "lite_conv_elementwise_fuse_pass", // conv-elemwise-bn
+ "lite_conv_bn_fuse_pass", //
+ "lite_conv_elementwise_fuse_pass", // conv-bn-elemwise
+ "lite_conv_conv_fuse_pass", //
+ // TODO(Superjomn) Refine the fusion related design to select fusion
+ // kernels for devices automatically.
+ "lite_conv_activation_fuse_pass", //
+ "lite_var_conv_2d_activation_fuse_pass", //
+ "lite_match_matrix_activation_fuse_pass", //
+ "lite_fc_fuse_pass", //
+ "lite_shuffle_channel_fuse_pass", //
+ "lite_transpose_softmax_transpose_fuse_pass", //
+ "lite_interpolate_fuse_pass", //
+ "identity_scale_eliminate_pass", //
+ "lite_scales_fuse_pass", //
+ "lite_sequence_reverse_embedding_fuse_pass", //
+ "elementwise_mul_constant_eliminate_pass", //
+ "lite_sequence_pool_concat_fuse_pass", //
+ "lite_scale_activation_fuse_pass", //
#if (defined LITE_WITH_LIGHT_WEIGHT_FRAMEWORK) || (defined LITE_WITH_CUDA) || \
(defined LITE_WITH_ARM)
- "lite_elementwise_activation_fuse_pass", //
+ "lite_elementwise_activation_fuse_pass", //
#endif
- "identity_dropout_eliminate_pass",
- "__xpu__resnet_fuse_pass",
- "__xpu__resnet_cbam_fuse_pass",
- "__xpu__conv2d_fuse_pass",
- "__xpu__conv2d_link_previous_out_max_pass",
- "__xpu__sfa_head_meanstd_fuse_pass",
- "__xpu__sfa_head_moment_fuse_pass",
- "__xpu__mmdnn_fuse_pass",
- "__xpu__multi_encoder_fuse_pass",
- "__xpu__embedding_with_eltwise_add_fuse_pass",
- "__xpu__fc_fuse_pass",
- "quantized_op_attributes_inference_pass", // Only for fully
- // quantized model, infer
- // the output scale and
- // fix the attribute
- // 'enable_int8' for all
- // of the quantized ops.
- "npu_subgraph_pass",
- "huawei_ascend_npu_subgraph_pass",
- "xpu_subgraph_pass",
- "bm_subgraph_pass",
- "apu_subgraph_pass",
- "rknpu_subgraph_pass",
- "mlu_subgraph_pass",
- "control_flow_op_unused_inputs_and_outputs_eliminate_pass",
- "static_kernel_pick_pass", // pick original kernel from graph
-
- "remove_tf_redundant_ops_pass",
- "variable_place_inference_pass", // inference arg/var's
-
- "mlu_postprocess_pass",
- // info(target/precision/layout/device)
- // using kernel info
- "argument_type_display_pass", // debug pass: show arg-type-node's
- // info
- // (target/precision/layout/device)
-
- "type_target_cast_pass", // add io_copy/io_copy_once if meet
- // different targets when last and next
- // node
- "variable_place_inference_pass", //
- "argument_type_display_pass", //
-
- "io_copy_kernel_pick_pass", //
- "argument_type_display_pass", //
-
- "variable_place_inference_pass", //
- "argument_type_display_pass", //
-
- "type_precision_cast_pass", //
- "variable_place_inference_pass", //
- "argument_type_display_pass", //
-
- "type_layout_cast_pass", // add layout/layout_once op if meet
- // different layout when last and next node
- "argument_type_display_pass", //
-
- "variable_place_inference_pass", //
- "argument_type_display_pass",
-
- "runtime_context_assign_pass",
- "argument_type_display_pass",
- "lite_reshape_fuse_pass",
-
- "memory_optimize_pass"}};
+ "identity_dropout_eliminate_pass",
+ "__xpu__resnet_fuse_pass",
+ "__xpu__resnet_d_fuse_pass",
+ "__xpu__resnet_cbam_fuse_pass",
+ "__xpu__conv2d_fuse_pass",
+ "__xpu__conv2d_link_previous_out_max_pass",
+ "__xpu__sfa_head_meanstd_fuse_pass",
+ "__xpu__sfa_head_moment_fuse_pass",
+ "__xpu__mmdnn_fuse_pass",
+ "__xpu__multi_encoder_fuse_pass",
+ "__xpu__embedding_with_eltwise_add_fuse_pass",
+ "__xpu__fc_fuse_pass",
+ "quantized_op_attributes_inference_pass", // Only for fully
+ // quantized model, infer
+ // the output scale and
+ // fix the attribute
+ // 'enable_int8' for all
+ // of the quantized ops.
+ "npu_subgraph_pass",
+ "huawei_ascend_npu_subgraph_pass",
+ "xpu_subgraph_pass",
+ "bm_subgraph_pass",
+ "apu_subgraph_pass",
+ "rknpu_subgraph_pass",
+ "mlu_subgraph_pass",
+ "control_flow_op_unused_inputs_and_outputs_eliminate_pass",
+ "static_kernel_pick_pass", // pick original kernel from graph
+
+ "remove_tf_redundant_ops_pass",
+ "variable_place_inference_pass", // inference arg/var's
+
+ "mlu_postprocess_pass",
+ // info(target/precision/layout/device)
+ // using kernel info
+ "argument_type_display_pass", // debug pass: show arg-type-node's
+ // info
+ // (target/precision/layout/device)
+
+ "type_target_cast_pass", // add io_copy/io_copy_once if meet
+ // different targets when last and next
+ // node
+ "variable_place_inference_pass", //
+ "argument_type_display_pass", //
+
+ "io_copy_kernel_pick_pass", //
+ "argument_type_display_pass", //
+
+ "variable_place_inference_pass", //
+ "argument_type_display_pass", //
+
+ "type_precision_cast_pass", //
+ "variable_place_inference_pass", //
+ "argument_type_display_pass", //
+
+ "type_layout_cast_pass", // add layout/layout_once op if meet
+ // different layout when last and next node
+ "argument_type_display_pass", //
+
+ "variable_place_inference_pass", //
+ "argument_type_display_pass",
+
+ "runtime_context_assign_pass",
+ "argument_type_display_pass",
+ "lite_reshape_fuse_pass",
+ "memory_optimize_pass" // you can comment this line when enable
+ // PRECISION_PROFILE
+ }};
if (passes.size() == 1) {
// multi_stream_analysis_pass must be in the front of
diff --git a/lite/core/profile/precision_profiler.h b/lite/core/profile/precision_profiler.h
index fda2b74f8f37f4705382f768b353150fa0bda3d7..5ad541ad7c1464299bfde62d7340f4d80c20831d 100644
--- a/lite/core/profile/precision_profiler.h
+++ b/lite/core/profile/precision_profiler.h
@@ -18,10 +18,18 @@
* of each kernel.
*/
#pragma once
+
+#include
+#include
+
#include
+#include
+#include