diff --git a/docs/demo_guides/cuda.md b/docs/demo_guides/cuda.md
index f863fd86864194c6d022e4cf1fc75eb46725cc2c..6460d327a4f30753a2d6942d4a931f709641e3ab 100644
--- a/docs/demo_guides/cuda.md
+++ b/docs/demo_guides/cuda.md
@@ -1,5 +1,7 @@
# PaddleLite使用CUDA预测部署
+**注意**: Lite CUDA仅作为Nvidia GPU加速库,支持模型有限,如有需要请使用[PaddleInference](https://paddle-inference.readthedocs.io/en/latest)。
+
Lite支持在x86_64,arm64架构上(如:TX2)进行CUDA的编译运行。
## 编译
diff --git a/docs/images/architecture.png b/docs/images/architecture.png
index 1af783d77dbd52923aa5facc90e00633c908f575..9397ed49a8a0071cf25b4551438d24a86de96bbb 100644
Binary files a/docs/images/architecture.png and b/docs/images/architecture.png differ
diff --git a/docs/images/workflow.png b/docs/images/workflow.png
new file mode 100644
index 0000000000000000000000000000000000000000..98201e78e1a35c830231881d19fb2c0acbdbaeba
Binary files /dev/null and b/docs/images/workflow.png differ
diff --git a/docs/introduction/architecture.md b/docs/introduction/architecture.md
index 1a94494af0b44a03988266d341be5788c46f96c2..cd538fe6b005ed2a65d1238374ee5d742ce801d3 100644
--- a/docs/introduction/architecture.md
+++ b/docs/introduction/architecture.md
@@ -5,23 +5,25 @@ Mobile 在这次升级为 Lite 架构, 侧重多硬件、高性能的支持,
- 引入 Type system,强化多硬件、量化方法、data layout 的混合调度能力
- 硬件细节隔离,通过不同编译开关,对支持的任何硬件可以自由插拔
- 引入 MIR(Machine IR) 的概念,强化带执行环境下的优化支持
-- 优化期和执行期严格隔离,保证预测时轻量和高效率
+- 图优化模块和执行引擎实现了良好的解耦拆分,保证预测执行阶段的轻量和高效率
架构图如下
-
+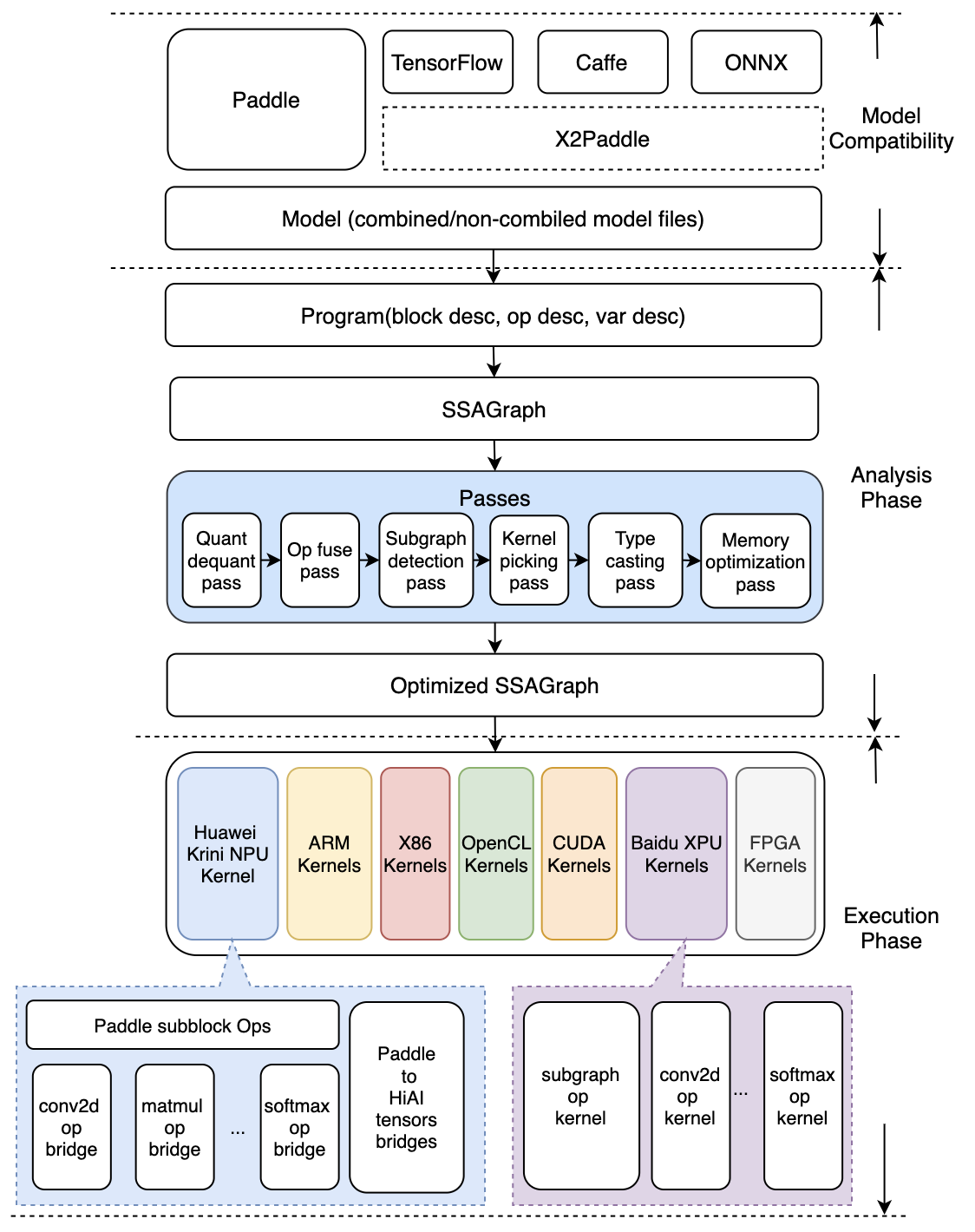
-## 编译期和执行期严格隔离设计
+## 模型优化阶段和预测执行阶段的隔离设计
-- compile time 优化完毕可以将优化信息存储到模型中;execution time 载入并执行
-- 两套 API 及对应的预测lib,满足不同场景
- - `CxxPredictor` 打包了 `Compile Time` 和 `Execution Time`,可以 runtime 在具体硬件上做分析和优化,得到最优效果
- - `MobilePredictor` 只打包 `Execution Time`,保持部署和执行的轻量
+- Analysis Phase为模型优化阶段,输入为Paddle的推理模型,通过Lite的模型加速和优化策略对计算图进行相关的优化分析,包含算子融合,计算裁剪,存储优化,量化精度转换、存储优化、Kernel优选等多类图优化手段。优化后的模型更轻量级,在相应的硬件上运行时耗费资源更少,并且执行速度也更快。
+- Execution Phase为预测执行阶段,输入为优化后的Lite模型,仅做模型加载和预测执行两步操作,支持极致的轻量级部署,无任何第三方依赖。
-## `Execution Time` 轻量级设计和实现
+Lite设计了两套 API 及对应的预测库,满足不同场景需求:
+ - `CxxPredictor` 同时包含 `Analysis Phase` 和 `Execution Phase`,支持一站式的预测任务,同时支持模型进行分析优化与预测执行任务,适用于对预测库大小不敏感的硬件场景。
+ - `MobilePredictor` 只包含 `Execution Phase`,保持预测部署和执行的轻量级和高性能,支持从内存或者文件中加载优化后的模型,并进行预测执行。
-- 每个 batch 实际执行只包含两个步骤执行
- - `Op.InferShape`
+## Execution Phase轻量级设计和实现
+
+- 在预测执行阶段,每个 batch 实际执行只包含两个步骤执行
+ - `OpLite.InferShape` 基于输入推断得到输出的维度
- `Kernel.Run`,Kernel 相关参数均使用指针提前确定,后续无查找或传参消耗
- 设计目标,执行时,只有 kernel 计算本身消耗
- 轻量级 `Op` 及 `Kernel` 设计,避免框架额外消耗
diff --git a/docs/introduction/support_model_list.md b/docs/introduction/support_model_list.md
index b30bcd729929de06848285bb27a4d38cec723e67..e9cc0215616a474ad7546eae45756b1398867def 100644
--- a/docs/introduction/support_model_list.md
+++ b/docs/introduction/support_model_list.md
@@ -1,32 +1,36 @@
# 支持模型
-目前已严格验证24个模型的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持,并在不断丰富中。
+目前已严格验证28个模型的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持,并在不断丰富中。
-| 类别 | 类别细分 | 模型 | 支持Int8 | 支持平台 |
-|-|-|:-:|:-:|-:|
-| CV | 分类 | mobilenetv1 | Y | ARM,X86,NPU,RKNPU,APU |
-| CV | 分类 | mobilenetv2 | Y | ARM,X86,NPU |
-| CV | 分类 | resnet18 | Y | ARM,NPU |
-| CV | 分类 | resnet50 | Y | ARM,X86,NPU,XPU |
-| CV | 分类 | mnasnet | | ARM,NPU |
-| CV | 分类 | efficientnet | | ARM |
-| CV | 分类 | squeezenetv1.1 | | ARM,NPU |
-| CV | 分类 | ShufflenetV2 | Y | ARM |
-| CV | 分类 | shufflenet | Y | ARM |
-| CV | 分类 | inceptionv4 | Y | ARM,X86,NPU |
-| CV | 分类 | vgg16 | Y | ARM |
-| CV | 分类 | googlenet | Y | ARM,X86 |
-| CV | 检测 | mobilenet_ssd | Y | ARM,NPU* |
-| CV | 检测 | mobilenet_yolov3 | Y | ARM,NPU* |
-| CV | 检测 | Faster RCNN | | ARM |
-| CV | 检测 | Mask RCNN | | ARM |
-| CV | 分割 | Deeplabv3 | Y | ARM |
-| CV | 分割 | unet | | ARM |
-| CV | 人脸 | facedetection | | ARM |
-| CV | 人脸 | facebox | | ARM |
-| CV | 人脸 | blazeface | Y | ARM |
-| CV | 人脸 | mtcnn | | ARM |
-| CV | OCR | ocr_attention | | ARM |
-| NLP | 机器翻译 | transformer | | ARM,NPU* |
+| 类别 | 类别细分 | 模型 | 支持平台 |
+|-|-|:-|:-|
+| CV | 分类 | mobilenetv1 | ARM,X86,NPU,RKNPU,APU |
+| CV | 分类 | mobilenetv2 | ARM,X86,NPU |
+| CV | 分类 | resnet18 | ARM,NPU |
+| CV | 分类 | resnet50 | ARM,X86,NPU,XPU |
+| CV | 分类 | mnasnet | ARM,NPU |
+| CV | 分类 | efficientnet | ARM |
+| CV | 分类 | squeezenetv1.1 | ARM,NPU |
+| CV | 分类 | ShufflenetV2 | ARM |
+| CV | 分类 | shufflenet | ARM |
+| CV | 分类 | inceptionv4 | ARM,X86,NPU |
+| CV | 分类 | vgg16 | ARM |
+| CV | 分类 | googlenet | ARM,X86 |
+| CV | 分类 | SENet | XPU |
+| CV | 检测 | mobilenet_ssd | ARM,NPU*,XPU |
+| CV | 检测 | mobilenet_yolov3 | ARM,NPU*,XPU |
+| CV | 检测 | Faster RCNN | ARM,XPU |
+| CV | 检测 | Mask RCNN | ARM,XPU |
+| CV | 分割 | Deeplabv3 | ARM |
+| CV | 分割 | unet | ARM,XPU |
+| CV | 人脸 | facedetection | ARM |
+| CV | 人脸 | facebox | ARM |
+| CV | 人脸 | blazeface | ARM |
+| CV | 人脸 | mtcnn | ARM |
+| CV | OCR | ocr_attention | ARM |
+| CV | GAN | CycleGAN | NPU |
+| NLP | 机器翻译 | transformer | ARM,NPU* |
+| NLP | 机器翻译 | BERT | XPU |
+| NLP | 语义表示 | ERNIE | XPU |
-> **注意:** NPU* 代表ARM+NPU异构计算
+**注意:** NPU* 代表ARM+NPU异构计算
diff --git a/docs/quick_start/tutorial.md b/docs/quick_start/tutorial.md
index a7eb1327f812917e3f1609d097acaeec2a96997d..5affbf6de0c8550db60ebbb8f3fd559ed32c7ba2 100644
--- a/docs/quick_start/tutorial.md
+++ b/docs/quick_start/tutorial.md
@@ -2,51 +2,64 @@
Lite是一种轻量级、灵活性强、易于扩展的高性能的深度学习预测框架,它可以支持诸如ARM、OpenCL、NPU等等多种终端,同时拥有强大的图优化及预测加速能力。如果您希望将Lite框架集成到自己的项目中,那么只需要如下几步简单操作即可。
-## 一. 准备模型
-Lite框架目前支持的模型结构为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式。因此,在您开始使用 Lite 框架前您需要准备一个由PaddlePaddle框架保存的模型。
-如果您手中的模型是由诸如Caffe2、Tensorflow等框架产出的,那么我们推荐您使用 [X2Paddle](https://github.com/PaddlePaddle/X2Paddle) 工具进行模型格式转换。
+
-## 二. 模型优化
+**一. 准备模型**
-Lite框架拥有强大的加速、优化策略及实现,其中包含诸如量化、子图融合、Kernel优选等等优化手段,为了方便您使用这些优化策略,我们提供了[opt](../user_guides/model_optimize_tool)帮助您轻松进行模型优化。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。
+Paddle Lite框架直接支持模型结构为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式。目前PaddlePaddle用于推理的模型是通过[save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/save_inference_model_cn.html#save-inference-model)这个API保存下来的。
+如果您手中的模型是由诸如Caffe、Tensorflow、PyTorch等框架产出的,那么您可以使用 [X2Paddle](https://github.com/PaddlePaddle/X2Paddle) 工具将模型转换为PadddlePaddle格式。
-opt的详细介绍,请您参考 [模型优化方法](../user_guides/model_optimize_tool)。
+**二. 模型优化**
-下载opt工具后执行以下代码:
+Paddle Lite框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。
+这些优化通过Paddle Lite提供的opt工具实现。opt工具还可以统计并打印出模型中的算子信息,并判断不同硬件平台下Paddle Lite的支持情况。您获取PaddlePaddle格式的模型之后,一般需要通该opt工具做模型优化。opt工具的下载和使用,请参考 [模型优化方法](../user_guides/model_optimize_tool.html)。
-``` shell
-$ ./opt \
- --model_dir= \
- --model_file= \
- --param_file= \
- --optimize_out_type=(protobuf|naive_buffer) \
- --optimize_out= \
- --valid_targets=(arm|opencl|x86)
-```
+**注意**: 为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型。
-其中,optimize_out为您希望的优化模型的输出路径。optimize_out_type则可以指定输出模型的序列化方式,其目前支持Protobuf与Naive Buffer两种方式,其中Naive Buffer是一种更轻量级的序列化/反序列化实现。如果你需要使用Lite在mobile端进行预测,那么您需要设置optimize_out_type=naive_buffer。
+**三. 下载或编译**
-## 三. 使用Lite框架执行预测
+Paddle Lite提供了Android/iOS/X86平台的官方Release预测库下载,我们优先推荐您直接下载 [Paddle Lite预编译库](../quick_start/release_lib.html)。
+您也可以根据目标平台选择对应的[源码编译方法](../source_compile/compile_env)。Paddle Lite 提供了源码编译脚本,位于 `lite/tools/`文件夹下,只需要 [准备环境](../source_compile/compile_env) 和 [调用编译脚本](../source_compile/compile_env) 两个步骤即可一键编译得到目标平台的Paddle Lite预测库。
-在上一节中,我们已经通过`opt`获取到了优化后的模型,使用优化模型进行预测也十分的简单。为了方便您的使用,Lite进行了良好的API设计,隐藏了大量您不需要投入时间研究的细节。您只需要简单的五步即可使用Lite在移动端完成预测(以C++ API进行说明):
+**四. 开发应用程序**
+Paddle Lite提供了C++、Java、Python三种API,只需简单五步即可完成预测(以C++ API为例):
-1. 声明MobileConfig。在config中可以设置**从文件加载模型**也可以设置**从memory加载模型**。从文件加载模型需要声明模型文件路径,如 `config.set_model_from_file(FLAGS_model_file)` ;从memory加载模型方法现只支持加载优化后模型的naive buffer,实现方法为:
-`void set_model_from_buffer(model_buffer) `
+1. 声明`MobileConfig`,设置第二步优化后的模型文件路径,或选择从内存中加载模型
+2. 创建`Predictor`,调用`CreatePaddlePredictor`接口,一行代码即可完成引擎初始化
+3. 准备输入,通过`predictor->GetInput(i)`获取输入变量,并为其指定输入大小和输入值
+4. 执行预测,只需要运行`predictor->Run()`一行代码,即可使用Lite框架完成预测执行
+5. 获得输出,使用`predictor->GetOutput(i)`获取输出变量,并通过`data`取得输出值
-2. 创建Predictor。Predictor即为Lite框架的预测引擎,为了方便您的使用我们提供了 `CreatePaddlePredictor` 接口,你只需要简单的执行一行代码即可完成预测引擎的初始化,`std::shared_ptr predictor = CreatePaddlePredictor(config)` 。
-3. 准备输入。执行predictor->GetInput(0)您将会获得输入的第0个field,同样的,如果您的模型有多个输入,那您可以执行 `predictor->GetInput(i)` 来获取相应的输入变量。得到输入变量后您可以使用Resize方法指定其具体大小,并填入输入值。
-4. 执行预测。您只需要执行 `predictor->Run()` 即可使用Lite框架完成预测。
-5. 获取输出。与输入类似,您可以使用 `predictor->GetOutput(i)` 来获得输出的第i个变量。您可以通过其shape()方法获取输出变量的维度,通过 `data()` 模板方法获取其输出值。
+Paddle Lite提供了C++、Java、Python三种API的完整使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
+- [C++完整示例](cpp_demo.html)
+- [Java完整示例](java_demo.html)
+- [Python完整示例](python_demo.html)
+针对不同的硬件平台,Paddle Lite提供了各个平台的完整示例:
+- [Android示例](../demo_guides/android_app_demo.html)
+- [iOS示例](../demo_guides/ios_app_demo.html)
+- [ARMLinux示例](../demo_guides/linux_arm_demo.html)
+- [X86示例](../demo_guides/x86.html)
+- [CUDA示例](../demo_guides/cuda.html)
+- [OpenCL示例](../demo_guides/opencl.html)
+- [FPGA示例](../demo_guides/fpga.html)
+- [华为NPU示例](../demo_guides/huawei_kirin_npu.html)
+- [百度XPU示例](../demo_guides/baidu_xpu.html)
+- [瑞芯微NPU示例](../demo_guides/rockchip_npu.html)
+- [联发科APU示例](../demo_guides/mediatek_apu.html)
-## 四. Lite API
+您也可以下载以下基于Paddle-Lite开发的预测APK程序,安装到Andriod平台上,先睹为快:
-为了方便您的使用,我们提供了C++、Java、Python三种API,并且提供了相应的api的完整使用示例:[C++完整示例](cpp_demo)、[Java完整示例](java_demo)、[Python完整示例](python_demo),您可以参考示例中的说明快速了解C++/Java/Python的API使用方法,并集成到您自己的项目中去。需要说明的是,为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型,具体方法可参考第2节`模型优化`。
+- [图像分类](https://paddlelite-demo.bj.bcebos.com/apps/android/mobilenet_classification_demo.apk)
+- [目标检测](https://paddlelite-demo.bj.bcebos.com/apps/android/yolo_detection_demo.apk)
+- [口罩检测](https://paddlelite-demo.bj.bcebos.com/apps/android/mask_detection_demo.apk)
+- [人脸关键点](https://paddlelite-demo.bj.bcebos.com/apps/android/face_keypoints_detection_demo.apk)
+- [人像分割](https://paddlelite-demo.bj.bcebos.com/apps/android/human_segmentation_demo.apk)
-## 五. 测试工具
+## 更多测试工具
为了使您更好的了解并使用Lite框架,我们向有进一步使用需求的用户开放了 [Debug工具](../user_guides/debug) 和 [Profile工具](../user_guides/debug)。Lite Model Debug Tool可以用来查找Lite框架与PaddlePaddle框架在执行预测时模型中的对应变量值是否有差异,进一步快速定位问题Op,方便复现与排查问题。Profile Monitor Tool可以帮助您了解每个Op的执行时间消耗,其会自动统计Op执行的次数,最长、最短、平均执行时间等等信息,为性能调优做一个基础参考。您可以通过 [相关专题](../user_guides/debug) 了解更多内容。