diff --git a/README.md b/README.md
index 83d0a986da1d73151b8915ec60e5aa2f711837b5..22b84888294b5ef60c3d91d7a7909aef8f601d81 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,74 @@
-编译方法: ./lite/tools/build_bm.sh --target_name=bm --bm_sdk_root=/Paddle-Lite/third-party/bmnnsdk2-bm1684_v2.0.1 bm
+[中文版](./README_cn.md)
+
+# Paddle Lite
+
+
+[](https://paddlepaddle.github.io/Paddle-Lite/)
+[](LICENSE)
+
+
+
+Paddle Lite is an updated version of Paddle-Mobile, an open-open source deep learning framework designed to make it easy to perform inference on mobile, embeded, and IoT devices. It is compatible with PaddlePaddle and pre-trained models from other sources.
+
+For tutorials, please see [PaddleLite Document](https://paddlepaddle.github.io/Paddle-Lite/).
+
+## Key Features
+
+### Light Weight
+
+On mobile devices, execution module can be deployed without third-party libraries, because our excecution module and analysis module are decoupled.
+
+On ARM V7, only 800KB are taken up, while on ARM V8, 1.3MB are taken up with the 80 operators and 85 kernels in the dynamic libraries provided by Paddle Lite.
+
+Paddle Lite enables immediate inference without extra optimization.
+
+### High Performance
+
+Paddle Lite enables device-optimized kernels, maximizing ARM CPU performance.
+
+It also supports INT8 quantizations with [PaddleSlim model compression tools](https://github.com/PaddlePaddle/models/tree/v1.5/PaddleSlim), reducing the size of models and increasing the performance of models.
+
+On Huawei NPU and FPGA, the performance is also boosted.
+
+The latest benchmark is located at [benchmark](https://paddlepaddle.github.io/Paddle-Lite/develop/benchmark/)
+
+### High Compatibility
+
+Hardware compatibility: Paddle Lite supports a diversity of hardwares — ARM CPU, Mali GPU, Adreno GPU, Huawei NPU and FPGA. In the near future, we will also support AI microchips from Cambricon and Bitmain.
+
+Model compatibility: The Op of Paddle Lite is fully compatible to that of PaddlePaddle. The accuracy and performance of 18 models (mostly CV models and OCR models) and 85 operators have been validated. In the future, we will also support other models.
+
+Framework compatibility: In addition to models trained on PaddlePaddle, those trained on Caffe and TensorFlow can also be converted to be used on Paddle Lite, via [X2Paddle](https://github.com/PaddlePaddle/X2Paddle). In the future to come, we will also support models of ONNX format.
+
+## Architecture
+
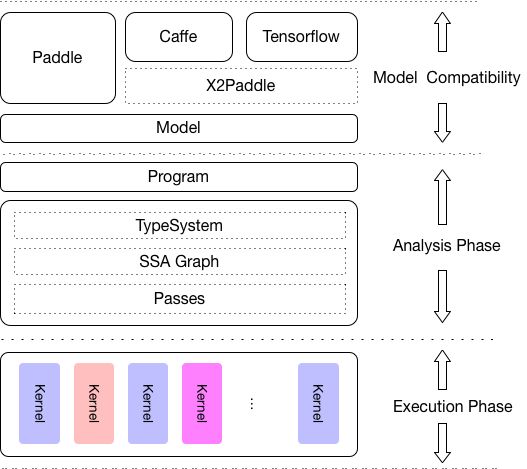
+Paddle Lite is designed to support a wide range of hardwares and devices, and it enables mixed execution of a single model on multiple devices, optimization on various phases, and leight-weighted applications on devices.
+
+
+
+As is shown in the figure above, analysis phase includes Machine IR module, and it enables optimizations like Op fusion and redundant computation pruning. Besides, excecution phase only involves Kernal exevution, so it can be deployed on its own to ensure maximized light-weighted deployment.
+
+## Key Info about the Update
+
+The earlier Paddle-Mobile was designed to be compatible with PaddlePaddle and multiple hardwares, including ARM CPU, Mali GPU, Adreno GPU, FPGA, ARM-Linux and Apple's GPU Metal. Within Baidu, inc, many product lines have been using Paddle-Mobile. For more details, please see: [mobile/README](https://github.com/PaddlePaddle/Paddle-Lite/blob/develop/mobile/README.md).
+
+As an update of Paddle-Mobile, Paddle Lite has incorporated many older capabilities into the [new architecture](https://github.com/PaddlePaddle/Paddle-Lite/tree/develop/lite). For the time being, the code of Paddle-mobile will be kept under the directory `mobile/`, before complete transfer to Paddle Lite.
+
+For demands of Apple's GPU Metal and web front end inference, please see `./metal` and `./web` . These two modules will be further developed and maintained.
+
+## Special Thanks
+
+Paddle Lite has referenced the following open-source projects:
+
+- [ARM compute library](http://agroup.baidu.com/paddle-infer/md/article/%28https://github.com/ARM-software/ComputeLibrary%29)
+- [Anakin](https://github.com/PaddlePaddle/Anakin). The optimizations under Anakin has been incorporated into Paddle Lite, and so there will not be any future updates of Anakin. As another high-performance inference project under PaddlePaddle, Anakin has been forward-looking and helpful to the making of Paddle Lite.
+
+
+## Feedback and Community Support
+
+- Questions, reports, and suggestions are welcome through Github Issues!
+- Forum: Opinions and questions are welcome at our [PaddlePaddle Forum](https://ai.baidu.com/forum/topic/list/168)!
+- WeChat Official Account: PaddlePaddle
+- QQ Group Chat: 696965088
+
+ WeChat Official Account QQ Group Chat
diff --git a/cmake/cross_compiling/ios.cmake b/cmake/cross_compiling/ios.cmake
index 76f62765aff791594123d689341b0876b3d0184d..0597ef0cc4ba4c0bcec172c767d66d0f362e1459 100644
--- a/cmake/cross_compiling/ios.cmake
+++ b/cmake/cross_compiling/ios.cmake
@@ -120,6 +120,7 @@
#
## Lite settings
+set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -flto")
if (ARM_TARGET_OS STREQUAL "ios")
set(PLATFORM "OS")
elseif(ARM_TARGET_OS STREQUAL "ios64")
diff --git a/cmake/cross_compiling/npu.cmake b/cmake/cross_compiling/npu.cmake
index 25aa4d2bc8c1c145e7a103c9164e1c9e231a8f9e..c22bb1db4fbf8a7370ff3e7c9aca40cc94d550a2 100644
--- a/cmake/cross_compiling/npu.cmake
+++ b/cmake/cross_compiling/npu.cmake
@@ -30,7 +30,7 @@ if(NOT NPU_DDK_INC)
message(FATAL_ERROR "Can not find HiAiModelManagerService.h in ${NPU_DDK_ROOT}/include")
endif()
-include_directories("${NPU_DDK_ROOT}")
+include_directories("${NPU_DDK_ROOT}/include")
set(NPU_SUB_LIB_PATH "lib64")
if(ARM_TARGET_ARCH_ABI STREQUAL "armv8")
diff --git a/lite/CMakeLists.txt b/lite/CMakeLists.txt
index c053d4ec2bd72258438694143fd08957cd0d35c0..cb6a872e061a51f142bd2301171f0559a1ccb129 100644
--- a/lite/CMakeLists.txt
+++ b/lite/CMakeLists.txt
@@ -224,10 +224,14 @@ if (LITE_WITH_LIGHT_WEIGHT_FRAMEWORK AND LITE_WITH_ARM)
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_full/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_full/Makefile"
COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_light" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_light/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_light/Makefile"
- COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
- COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_detection/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/ssd_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/ssd_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/ssd_detection/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/yolov3_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/yolov3_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/yolov3_detection/Makefile"
COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_classify" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_classify/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_classify/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/test_cv" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/test_cv/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/test_cv/Makefile"
)
add_dependencies(publish_inference_android_cxx_demos logging gflags)
add_dependencies(publish_inference_cxx_lib publish_inference_android_cxx_demos)
@@ -239,10 +243,14 @@ if (LITE_WITH_LIGHT_WEIGHT_FRAMEWORK AND LITE_WITH_ARM)
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/README.md" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_light" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_light/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_light/Makefile"
- COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
- COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_detection/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/ssd_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/ssd_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/ssd_detection/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/yolov3_detection" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/yolov3_detection/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/yolov3_detection/Makefile"
COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/mobile_classify" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/mobile_classify/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/mobile_classify/Makefile"
+ COMMAND cp -r "${CMAKE_SOURCE_DIR}/lite/demo/cxx/test_cv" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx"
+ COMMAND cp "${CMAKE_SOURCE_DIR}/lite/demo/cxx/makefiles/test_cv/Makefile.${ARM_TARGET_OS}.${ARM_TARGET_ARCH_ABI}" "${INFER_LITE_PUBLISH_ROOT}/demo/cxx/test_cv/Makefile"
)
add_dependencies(tiny_publish_cxx_lib publish_inference_android_cxx_demos)
endif()
diff --git a/lite/api/CMakeLists.txt b/lite/api/CMakeLists.txt
index d57496487a2bb2756f6755916b2761c04aa626d5..a1fde4c152c003e3b1adcea77aa78446ba7a1df5 100644
--- a/lite/api/CMakeLists.txt
+++ b/lite/api/CMakeLists.txt
@@ -35,6 +35,7 @@ if ((NOT LITE_ON_TINY_PUBLISH) AND (LITE_WITH_CUDA OR LITE_WITH_X86 OR ARM_TARGE
NPU_DEPS ${npu_kernels})
target_link_libraries(paddle_light_api_shared ${light_lib_DEPS} ${arm_kernels} ${npu_kernels})
+
if (LITE_WITH_NPU)
# Strips the symbols of our protobuf functions to fix the conflicts during
# loading HIAI builder libs (libhiai_ir.so and libhiai_ir_build.so)
@@ -45,8 +46,8 @@ else()
if ((ARM_TARGET_OS STREQUAL "android") OR (ARM_TARGET_OS STREQUAL "armlinux"))
add_library(paddle_light_api_shared SHARED "")
target_sources(paddle_light_api_shared PUBLIC ${__lite_cc_files} paddle_api.cc light_api.cc light_api_impl.cc)
- set_target_properties(paddle_light_api_shared PROPERTIES COMPILE_FLAGS "-flto -fdata-sections")
- add_dependencies(paddle_light_api_shared op_list_h kernel_list_h)
+ set_target_properties(paddle_light_api_shared PROPERTIES COMPILE_FLAGS "-flto -fdata-sections")
+ add_dependencies(paddle_light_api_shared op_list_h kernel_list_h)
if (LITE_WITH_NPU)
# Need to add HIAI runtime libs (libhiai.so) dependency
target_link_libraries(paddle_light_api_shared ${npu_builder_libs} ${npu_runtime_libs})
@@ -91,6 +92,7 @@ if (NOT LITE_ON_TINY_PUBLISH)
SRCS cxx_api.cc
DEPS ${cxx_api_deps} ${ops} ${host_kernels} program
X86_DEPS ${x86_kernels}
+ CUDA_DEPS ${cuda_kernels}
ARM_DEPS ${arm_kernels}
CV_DEPS paddle_cv_arm
NPU_DEPS ${npu_kernels}
@@ -129,7 +131,9 @@ if(WITH_TESTING)
DEPS cxx_api mir_passes lite_api_test_helper
${ops} ${host_kernels}
X86_DEPS ${x86_kernels}
+ CUDA_DEPS ${cuda_kernels}
ARM_DEPS ${arm_kernels}
+ CV_DEPS paddle_cv_arm
NPU_DEPS ${npu_kernels}
XPU_DEPS ${xpu_kernels}
CL_DEPS ${opencl_kernels}
@@ -293,12 +297,13 @@ if (LITE_ON_MODEL_OPTIMIZE_TOOL)
message(STATUS "Compiling model_optimize_tool")
lite_cc_binary(model_optimize_tool SRCS model_optimize_tool.cc cxx_api_impl.cc paddle_api.cc cxx_api.cc
DEPS gflags kernel op optimizer mir_passes utils)
- add_dependencies(model_optimize_tool op_list_h kernel_list_h all_kernel_faked_cc)
+ add_dependencies(model_optimize_tool op_list_h kernel_list_h all_kernel_faked_cc supported_kernel_op_info_h)
endif(LITE_ON_MODEL_OPTIMIZE_TOOL)
lite_cc_test(test_paddle_api SRCS paddle_api_test.cc DEPS paddle_api_full paddle_api_light
${ops}
ARM_DEPS ${arm_kernels}
+ CV_DEPS paddle_cv_arm
NPU_DEPS ${npu_kernels}
XPU_DEPS ${xpu_kernels}
CL_DEPS ${opencl_kernels}
@@ -327,13 +332,14 @@ if(NOT IOS)
lite_cc_binary(benchmark_bin SRCS benchmark.cc DEPS paddle_api_full paddle_api_light gflags utils
${ops} ${host_kernels}
ARM_DEPS ${arm_kernels}
+ CV_DEPS paddle_cv_arm
NPU_DEPS ${npu_kernels}
XPU_DEPS ${xpu_kernels}
CL_DEPS ${opencl_kernels}
FPGA_DEPS ${fpga_kernels}
X86_DEPS ${x86_kernels}
CUDA_DEPS ${cuda_kernels})
- lite_cc_binary(multithread_test SRCS lite_multithread_test.cc DEPS paddle_api_full paddle_api_light gflags utils
+ lite_cc_binary(multithread_test SRCS lite_multithread_test.cc DEPS paddle_api_full paddle_api_light gflags utils
${ops} ${host_kernels}
ARM_DEPS ${arm_kernels}
CV_DEPS paddle_cv_arm
diff --git a/lite/api/cxx_api.cc b/lite/api/cxx_api.cc
index 990d08f18f541088d797510e9dbd4881d42b164f..c1e9fc422450adf96d62c68d622907bd7e15b405 100644
--- a/lite/api/cxx_api.cc
+++ b/lite/api/cxx_api.cc
@@ -201,7 +201,11 @@ void Predictor::Build(const lite_api::CxxConfig &config,
const std::string &model_file = config.model_file();
const std::string ¶m_file = config.param_file();
const bool model_from_memory = config.model_from_memory();
- LOG(INFO) << "load from memory " << model_from_memory;
+ if (model_from_memory) {
+ LOG(INFO) << "Load model from memory.";
+ } else {
+ LOG(INFO) << "Load model from file.";
+ }
Build(model_path,
model_file,
diff --git a/lite/api/cxx_api_impl.cc b/lite/api/cxx_api_impl.cc
index 3e6e10103e9f3af51923459a5921f9781431f352..81ea60eac66849f8ce42fb8cb210226d18bbfa9b 100644
--- a/lite/api/cxx_api_impl.cc
+++ b/lite/api/cxx_api_impl.cc
@@ -42,11 +42,11 @@ void CxxPaddleApiImpl::Init(const lite_api::CxxConfig &config) {
#if (defined LITE_WITH_X86) && (defined PADDLE_WITH_MKLML) && \
!(defined LITE_ON_MODEL_OPTIMIZE_TOOL)
- int num_threads = config.cpu_math_library_num_threads();
+ int num_threads = config.x86_math_library_num_threads();
int real_num_threads = num_threads > 1 ? num_threads : 1;
paddle::lite::x86::MKL_Set_Num_Threads(real_num_threads);
omp_set_num_threads(real_num_threads);
- VLOG(3) << "set_cpu_math_library_math_threads() is set successfully and the "
+ VLOG(3) << "set_x86_math_library_math_threads() is set successfully and the "
"number of threads is:"
<< num_threads;
#endif
diff --git a/lite/api/lite_multithread_test.cc b/lite/api/lite_multithread_test.cc
old mode 100755
new mode 100644
diff --git a/lite/api/model_optimize_tool.cc b/lite/api/model_optimize_tool.cc
index b678c7ecd24c5ffbf3e9e3531264ac195c6a7325..fc23e0b54be41bff5b7b65b4e58908546b186bb4 100644
--- a/lite/api/model_optimize_tool.cc
+++ b/lite/api/model_optimize_tool.cc
@@ -16,8 +16,9 @@
#ifdef PADDLE_WITH_TESTING
#include
#endif
-// "all_kernel_faked.cc" and "kernel_src_map.h" are created automatically during
-// model_optimize_tool's compiling period
+// "supported_kernel_op_info.h", "all_kernel_faked.cc" and "kernel_src_map.h"
+// are created automatically during model_optimize_tool's compiling period
+#include
#include "all_kernel_faked.cc" // NOLINT
#include "kernel_src_map.h" // NOLINT
#include "lite/api/cxx_api.h"
@@ -25,8 +26,11 @@
#include "lite/api/paddle_use_ops.h"
#include "lite/api/paddle_use_passes.h"
#include "lite/core/op_registry.h"
+#include "lite/model_parser/compatible_pb.h"
+#include "lite/model_parser/pb/program_desc.h"
#include "lite/utils/cp_logging.h"
#include "lite/utils/string.h"
+#include "supported_kernel_op_info.h" // NOLINT
DEFINE_string(model_dir,
"",
@@ -62,10 +66,16 @@ DEFINE_string(valid_targets,
"The targets this model optimized for, should be one of (arm, "
"opencl, x86), splitted by space");
DEFINE_bool(prefer_int8_kernel, false, "Prefer to run model with int8 kernels");
+DEFINE_bool(print_supported_ops,
+ false,
+ "Print supported operators on the inputed target");
+DEFINE_bool(print_all_ops,
+ false,
+ "Print all the valid operators of Paddle-Lite");
+DEFINE_bool(print_model_ops, false, "Print operators in the input model");
namespace paddle {
namespace lite_api {
-
//! Display the kernel information.
void DisplayKernels() {
LOG(INFO) << ::paddle::lite::KernelRegistry::Global().DebugString();
@@ -130,9 +140,7 @@ void RunOptimize(const std::string& model_dir,
config.set_model_dir(model_dir);
config.set_model_file(model_file);
config.set_param_file(param_file);
-
config.set_valid_places(valid_places);
-
auto predictor = lite_api::CreatePaddlePredictor(config);
LiteModelType model_type;
@@ -168,6 +176,202 @@ void CollectModelMetaInfo(const std::string& output_dir,
lite::WriteLines(std::vector(total.begin(), total.end()),
output_path);
}
+void PrintOpsInfo(std::set valid_ops = {}) {
+ std::vector targets = {"kHost",
+ "kX86",
+ "kCUDA",
+ "kARM",
+ "kOpenCL",
+ "kFPGA",
+ "kNPU",
+ "kXPU",
+ "kAny",
+ "kUnk"};
+ int maximum_optype_length = 0;
+ for (auto it = supported_ops.begin(); it != supported_ops.end(); it++) {
+ maximum_optype_length = it->first.size() > maximum_optype_length
+ ? it->first.size()
+ : maximum_optype_length;
+ }
+ std::cout << std::setiosflags(std::ios::internal);
+ std::cout << std::setw(maximum_optype_length) << "OP_name";
+ for (int i = 0; i < targets.size(); i++) {
+ std::cout << std::setw(10) << targets[i].substr(1);
+ }
+ std::cout << std::endl;
+ if (valid_ops.empty()) {
+ for (auto it = supported_ops.begin(); it != supported_ops.end(); it++) {
+ std::cout << std::setw(maximum_optype_length) << it->first;
+ auto ops_valid_places = it->second;
+ for (int i = 0; i < targets.size(); i++) {
+ if (std::find(ops_valid_places.begin(),
+ ops_valid_places.end(),
+ targets[i]) != ops_valid_places.end()) {
+ std::cout << std::setw(10) << "Y";
+ } else {
+ std::cout << std::setw(10) << " ";
+ }
+ }
+ std::cout << std::endl;
+ }
+ } else {
+ for (auto op = valid_ops.begin(); op != valid_ops.end(); op++) {
+ std::cout << std::setw(maximum_optype_length) << *op;
+ // Check: If this kernel doesn't match any operator, we will skip it.
+ if (supported_ops.find(*op) == supported_ops.end()) {
+ continue;
+ }
+ // Print OP info.
+ auto ops_valid_places = supported_ops.at(*op);
+ for (int i = 0; i < targets.size(); i++) {
+ if (std::find(ops_valid_places.begin(),
+ ops_valid_places.end(),
+ targets[i]) != ops_valid_places.end()) {
+ std::cout << std::setw(10) << "Y";
+ } else {
+ std::cout << std::setw(10) << " ";
+ }
+ }
+ std::cout << std::endl;
+ }
+ }
+}
+/// Print help information
+void PrintHelpInfo() {
+ // at least one argument should be inputed
+ const char help_info[] =
+ "At least one argument should be inputed. Valid arguments are listed "
+ "below:\n"
+ " Arguments of model optimization:\n"
+ " `--model_dir=`\n"
+ " `--model_file=`\n"
+ " `--param_file=`\n"
+ " `--optimize_out_type=(protobuf|naive_buffer)`\n"
+ " `--optimize_out=`\n"
+ " `--valid_targets=(arm|opencl|x86|npu|xpu)`\n"
+ " `--prefer_int8_kernel=(true|false)`\n"
+ " `--record_tailoring_info=(true|false)`\n"
+ " Arguments of model checking and ops information:\n"
+ " `--print_all_ops=true` Display all the valid operators of "
+ "Paddle-Lite\n"
+ " `--print_supported_ops=true "
+ "--valid_targets=(arm|opencl|x86|npu|xpu)`"
+ " Display valid operators of input targets\n"
+ " `--print_model_ops=true --model_dir= "
+ "--valid_targets=(arm|opencl|x86|npu|xpu)`"
+ " Display operators in the input model\n";
+ std::cout << help_info << std::endl;
+ exit(1);
+}
+
+// Parse Input command
+void ParseInputCommand() {
+ if (FLAGS_print_all_ops) {
+ std::cout << "All OPs supported by Paddle-Lite: " << supported_ops.size()
+ << " ops in total." << std::endl;
+ PrintOpsInfo();
+ exit(1);
+ } else if (FLAGS_print_supported_ops) {
+ auto valid_places = paddle::lite_api::ParserValidPlaces();
+ // get valid_targets string
+ std::vector target_types = {};
+ for (int i = 0; i < valid_places.size(); i++) {
+ target_types.push_back(valid_places[i].target);
+ }
+ std::string targets_str = TargetToStr(target_types[0]);
+ for (int i = 1; i < target_types.size(); i++) {
+ targets_str = targets_str + TargetToStr(target_types[i]);
+ }
+
+ std::cout << "Supported OPs on '" << targets_str << "': " << std::endl;
+ target_types.push_back(TARGET(kHost));
+ target_types.push_back(TARGET(kUnk));
+
+ std::set valid_ops;
+ for (int i = 0; i < target_types.size(); i++) {
+ auto ops = supported_ops_target[static_cast(target_types[i])];
+ valid_ops.insert(ops.begin(), ops.end());
+ }
+ PrintOpsInfo(valid_ops);
+ exit(1);
+ }
+}
+// test whether this model is supported
+void CheckIfModelSupported() {
+ // 1. parse valid places and valid targets
+ auto valid_places = paddle::lite_api::ParserValidPlaces();
+ // set valid_ops
+ auto valid_ops = supported_ops_target[static_cast(TARGET(kHost))];
+ auto valid_unktype_ops = supported_ops_target[static_cast(TARGET(kUnk))];
+ valid_ops.insert(
+ valid_ops.end(), valid_unktype_ops.begin(), valid_unktype_ops.end());
+ for (int i = 0; i < valid_places.size(); i++) {
+ auto target = valid_places[i].target;
+ auto ops = supported_ops_target[static_cast(target)];
+ valid_ops.insert(valid_ops.end(), ops.begin(), ops.end());
+ }
+ // get valid ops
+ std::set valid_ops_set(valid_ops.begin(), valid_ops.end());
+
+ // 2.Load model into program to get ops in model
+ std::string prog_path = FLAGS_model_dir + "/__model__";
+ if (!FLAGS_model_file.empty() && !FLAGS_param_file.empty()) {
+ prog_path = FLAGS_model_file;
+ }
+ lite::cpp::ProgramDesc cpp_prog;
+ framework::proto::ProgramDesc pb_proto_prog =
+ *lite::LoadProgram(prog_path, false);
+ lite::pb::ProgramDesc pb_prog(&pb_proto_prog);
+ // Transform to cpp::ProgramDesc
+ lite::TransformProgramDescAnyToCpp(pb_prog, &cpp_prog);
+
+ std::set unsupported_ops;
+ std::set input_model_ops;
+ for (int index = 0; index < cpp_prog.BlocksSize(); index++) {
+ auto current_block = cpp_prog.GetBlock(index);
+ for (size_t i = 0; i < current_block->OpsSize(); ++i) {
+ auto& op_desc = *current_block->GetOp(i);
+ auto op_type = op_desc.Type();
+ input_model_ops.insert(op_type);
+ if (valid_ops_set.count(op_type) == 0) {
+ unsupported_ops.insert(op_type);
+ }
+ }
+ }
+ // 3. Print ops_info of input model and check if this model is supported
+ if (FLAGS_print_model_ops) {
+ std::cout << "OPs in the input model include:\n";
+ PrintOpsInfo(input_model_ops);
+ }
+ if (!unsupported_ops.empty()) {
+ std::string unsupported_ops_str = *unsupported_ops.begin();
+ for (auto op_str = ++unsupported_ops.begin();
+ op_str != unsupported_ops.end();
+ op_str++) {
+ unsupported_ops_str = unsupported_ops_str + ", " + *op_str;
+ }
+ std::vector targets = {};
+ for (int i = 0; i < valid_places.size(); i++) {
+ targets.push_back(valid_places[i].target);
+ }
+ std::sort(targets.begin(), targets.end());
+ targets.erase(unique(targets.begin(), targets.end()), targets.end());
+ std::string targets_str = TargetToStr(targets[0]);
+ for (int i = 1; i < targets.size(); i++) {
+ targets_str = targets_str + "," + TargetToStr(targets[i]);
+ }
+
+ LOG(ERROR) << "Error: This model is not supported, because "
+ << unsupported_ops.size() << " ops are not supported on '"
+ << targets_str << "'. These unsupported ops are: '"
+ << unsupported_ops_str << "'.";
+ exit(1);
+ }
+ if (FLAGS_print_model_ops) {
+ std::cout << "Paddle-Lite supports this model!" << std::endl;
+ exit(1);
+ }
+}
void Main() {
if (FLAGS_display_kernels) {
@@ -241,7 +445,13 @@ void Main() {
} // namespace paddle
int main(int argc, char** argv) {
+ // If there is none input argument, print help info.
+ if (argc < 2) {
+ paddle::lite_api::PrintHelpInfo();
+ }
google::ParseCommandLineFlags(&argc, &argv, false);
+ paddle::lite_api::ParseInputCommand();
+ paddle::lite_api::CheckIfModelSupported();
paddle::lite_api::Main();
return 0;
}
diff --git a/lite/api/model_test.cc b/lite/api/model_test.cc
index dc9fac96ee848d73ca14c8dc4555c0f44951400a..5b063a8ef19c85d3818d2ca57659170d7d86357d 100644
--- a/lite/api/model_test.cc
+++ b/lite/api/model_test.cc
@@ -86,6 +86,7 @@ void Run(const std::vector>& input_shapes,
for (int i = 0; i < input_shapes[j].size(); ++i) {
input_num *= input_shapes[j][i];
}
+
for (int i = 0; i < input_num; ++i) {
input_data[i] = 1.f;
}
diff --git a/lite/api/paddle_api.h b/lite/api/paddle_api.h
index a014719c5783bcec3988bba65c53cc8cf52f0b4c..6308699ac91900d161a55ee121e4d9777947fede 100644
--- a/lite/api/paddle_api.h
+++ b/lite/api/paddle_api.h
@@ -133,7 +133,9 @@ class LITE_API CxxConfig : public ConfigBase {
std::string model_file_;
std::string param_file_;
bool model_from_memory_{false};
- int cpu_math_library_math_threads_ = 1;
+#ifdef LITE_WITH_X86
+ int x86_math_library_math_threads_ = 1;
+#endif
public:
void set_valid_places(const std::vector& x) { valid_places_ = x; }
@@ -153,12 +155,14 @@ class LITE_API CxxConfig : public ConfigBase {
std::string param_file() const { return param_file_; }
bool model_from_memory() const { return model_from_memory_; }
- void set_cpu_math_library_num_threads(int threads) {
- cpu_math_library_math_threads_ = threads;
+#ifdef LITE_WITH_X86
+ void set_x86_math_library_num_threads(int threads) {
+ x86_math_library_math_threads_ = threads;
}
- int cpu_math_library_num_threads() const {
- return cpu_math_library_math_threads_;
+ int x86_math_library_num_threads() const {
+ return x86_math_library_math_threads_;
}
+#endif
};
/// MobileConfig is the config for the light weight predictor, it will skip
diff --git a/lite/api/test_step_rnn_lite_x86.cc b/lite/api/test_step_rnn_lite_x86.cc
index 075d314df6f46ab9dc8531b26c23d05d24e63bb4..013fd82b19bc22ace22184389249a7b2d9bf237e 100644
--- a/lite/api/test_step_rnn_lite_x86.cc
+++ b/lite/api/test_step_rnn_lite_x86.cc
@@ -30,7 +30,9 @@ TEST(Step_rnn, test_step_rnn_lite_x86) {
std::string model_dir = FLAGS_model_dir;
lite_api::CxxConfig config;
config.set_model_dir(model_dir);
- config.set_cpu_math_library_num_threads(1);
+#ifdef LITE_WITH_X86
+ config.set_x86_math_library_num_threads(1);
+#endif
config.set_valid_places({lite_api::Place{TARGET(kX86), PRECISION(kInt64)},
lite_api::Place{TARGET(kX86), PRECISION(kFloat)},
lite_api::Place{TARGET(kHost), PRECISION(kFloat)}});
diff --git a/lite/backends/arm/math/conv3x3s1_depthwise_fp32.cc b/lite/backends/arm/math/conv3x3s1_depthwise_fp32.cc
deleted file mode 100644
index 99aeea8bdea2a50795dcdca18464a196ee877291..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv3x3s1_depthwise_fp32.cc
+++ /dev/null
@@ -1,538 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include "lite/backends/arm/math/conv_block_utils.h"
-#include "lite/backends/arm/math/conv_impl.h"
-#include "lite/core/context.h"
-#include "lite/operators/op_params.h"
-#ifdef ARM_WITH_OMP
-#include
-#endif
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-void conv_3x3s1_depthwise_fp32(const float* i_data,
- float* o_data,
- int bs,
- int oc,
- int oh,
- int ow,
- int ic,
- int ih,
- int win,
- const float* weights,
- const float* bias,
- const operators::ConvParam& param,
- ARMContext* ctx) {
- int threads = ctx->threads();
- const int pad_h = param.paddings[0];
- const int pad_w = param.paddings[1];
- const int out_c_block = 4;
- const int out_h_kernel = 2;
- const int out_w_kernel = 4;
- const int win_ext = ow + 2;
- const int ow_round = ROUNDUP(ow, 4);
- const int win_round = ROUNDUP(win_ext, 4);
- const int hin_round = oh + 2;
- const int prein_size = win_round * hin_round * out_c_block;
- auto workspace_size =
- threads * prein_size + win_round /*tmp zero*/ + ow_round /*tmp writer*/;
- ctx->ExtendWorkspace(sizeof(float) * workspace_size);
-
- bool flag_relu = param.fuse_relu;
- bool flag_bias = param.bias != nullptr;
-
- /// get workspace
- float* ptr_zero = ctx->workspace_data();
- memset(ptr_zero, 0, sizeof(float) * win_round);
- float* ptr_write = ptr_zero + win_round;
-
- int size_in_channel = win * ih;
- int size_out_channel = ow * oh;
-
- int ws = -pad_w;
- int we = ws + win_round;
- int hs = -pad_h;
- int he = hs + hin_round;
- int w_loop = ow_round / 4;
- auto remain = w_loop * 4 - ow;
- bool flag_remain = remain > 0;
- remain = 4 - remain;
- remain = remain > 0 ? remain : 0;
- int row_len = win_round * out_c_block;
-
- for (int n = 0; n < bs; ++n) {
- const float* din_batch = i_data + n * ic * size_in_channel;
- float* dout_batch = o_data + n * oc * size_out_channel;
-#pragma omp parallel for num_threads(threads)
- for (int c = 0; c < oc; c += out_c_block) {
-#ifdef ARM_WITH_OMP
- float* pre_din = ptr_write + ow_round + omp_get_thread_num() * prein_size;
-#else
- float* pre_din = ptr_write + ow_round;
-#endif
- /// const array size
- float pre_out[out_c_block * out_w_kernel * out_h_kernel]; // NOLINT
- prepack_input_nxwc4_dw(
- din_batch, pre_din, c, hs, he, ws, we, ic, win, ih, ptr_zero);
- const float* weight_c = weights + c * 9; // kernel_w * kernel_h
- float* dout_c00 = dout_batch + c * size_out_channel;
- float bias_local[4] = {0, 0, 0, 0};
- if (flag_bias) {
- bias_local[0] = bias[c];
- bias_local[1] = bias[c + 1];
- bias_local[2] = bias[c + 2];
- bias_local[3] = bias[c + 3];
- }
- float32x4_t vbias = vld1q_f32(bias_local);
-#ifdef __aarch64__
- float32x4_t w0 = vld1q_f32(weight_c); // w0, v23
- float32x4_t w1 = vld1q_f32(weight_c + 4); // w1, v24
- float32x4_t w2 = vld1q_f32(weight_c + 8); // w2, v25
- float32x4_t w3 = vld1q_f32(weight_c + 12); // w3, v26
- float32x4_t w4 = vld1q_f32(weight_c + 16); // w4, v27
- float32x4_t w5 = vld1q_f32(weight_c + 20); // w5, v28
- float32x4_t w6 = vld1q_f32(weight_c + 24); // w6, v29
- float32x4_t w7 = vld1q_f32(weight_c + 28); // w7, v30
- float32x4_t w8 = vld1q_f32(weight_c + 32); // w8, v31
-#endif
- for (int h = 0; h < oh; h += out_h_kernel) {
- float* outc00 = dout_c00 + h * ow;
- float* outc01 = outc00 + ow;
- float* outc10 = outc00 + size_out_channel;
- float* outc11 = outc10 + ow;
- float* outc20 = outc10 + size_out_channel;
- float* outc21 = outc20 + ow;
- float* outc30 = outc20 + size_out_channel;
- float* outc31 = outc30 + ow;
- const float* inr0 = pre_din + h * row_len;
- const float* inr1 = inr0 + row_len;
- const float* inr2 = inr1 + row_len;
- const float* inr3 = inr2 + row_len;
- if (c + out_c_block > oc) {
- switch (c + out_c_block - oc) {
- case 3:
- outc10 = ptr_write;
- outc11 = ptr_write;
- case 2:
- outc20 = ptr_write;
- outc21 = ptr_write;
- case 1:
- outc30 = ptr_write;
- outc31 = ptr_write;
- default:
- break;
- }
- }
- if (h + out_h_kernel > oh) {
- outc01 = ptr_write;
- outc11 = ptr_write;
- outc21 = ptr_write;
- outc31 = ptr_write;
- }
- float* outl[] = {outc00,
- outc10,
- outc20,
- outc30,
- outc01,
- outc11,
- outc21,
- outc31,
- reinterpret_cast(bias_local),
- reinterpret_cast(flag_relu)};
- void* outl_ptr = reinterpret_cast(outl);
- for (int w = 0; w < w_loop; ++w) {
- bool flag_mask = (w == w_loop - 1) && flag_remain;
- float* out0 = pre_out;
-// clang-format off
-#ifdef __aarch64__
- asm volatile(
- "ldp q0, q1, [%[inr0]], #32\n" /* load input r0*/
- "ldp q6, q7, [%[inr1]], #32\n" /* load input r1*/
- "ldp q2, q3, [%[inr0]], #32\n" /* load input r0*/
- "ldp q8, q9, [%[inr1]], #32\n" /* load input r1*/
- "ldp q4, q5, [%[inr0]]\n" /* load input r0*/
- "ldp q10, q11, [%[inr1]]\n" /* load input r1*/
- /* r0, r1, mul w0, get out r0, r1 */
- "fmul v15.4s , %[w0].4s, v0.4s\n" /* outr00 = w0 * r0, 0*/
- "fmul v16.4s , %[w0].4s, v1.4s\n" /* outr01 = w0 * r0, 1*/
- "fmul v17.4s , %[w0].4s, v2.4s\n" /* outr02 = w0 * r0, 2*/
- "fmul v18.4s , %[w0].4s, v3.4s\n" /* outr03 = w0 * r0, 3*/
- "fmul v19.4s , %[w0].4s, v6.4s\n" /* outr10 = w0 * r1, 0*/
- "fmul v20.4s , %[w0].4s, v7.4s\n" /* outr11 = w0 * r1, 1*/
- "fmul v21.4s , %[w0].4s, v8.4s\n" /* outr12 = w0 * r1, 2*/
- "fmul v22.4s , %[w0].4s, v9.4s\n" /* outr13 = w0 * r1, 3*/
- /* r0, r1, mul w1, get out r0, r1 */
- "fmla v15.4s , %[w1].4s, v1.4s\n" /* outr00 = w1 * r0[1]*/
- "ldp q0, q1, [%[inr2]], #32\n" /* load input r2*/
- "fmla v16.4s , %[w1].4s, v2.4s\n" /* outr01 = w1 * r0[2]*/
- "fmla v17.4s , %[w1].4s, v3.4s\n" /* outr02 = w1 * r0[3]*/
- "fmla v18.4s , %[w1].4s, v4.4s\n" /* outr03 = w1 * r0[4]*/
- "fmla v19.4s , %[w1].4s, v7.4s\n" /* outr10 = w1 * r1[1]*/
- "fmla v20.4s , %[w1].4s, v8.4s\n" /* outr11 = w1 * r1[2]*/
- "fmla v21.4s , %[w1].4s, v9.4s\n" /* outr12 = w1 * r1[3]*/
- "fmla v22.4s , %[w1].4s, v10.4s\n"/* outr13 = w1 * r1[4]*/
- /* r0, r1, mul w2, get out r0, r1 */
- "fmla v15.4s , %[w2].4s, v2.4s\n" /* outr00 = w2 * r0[2]*/
- "fmla v16.4s , %[w2].4s, v3.4s\n" /* outr01 = w2 * r0[3]*/
- "ldp q2, q3, [%[inr2]], #32\n" /* load input r2*/
- "fmla v17.4s , %[w2].4s, v4.4s\n" /* outr02 = w2 * r0[4]*/
- "fmla v18.4s , %[w2].4s, v5.4s\n" /* outr03 = w2 * r0[5]*/
- "ldp q4, q5, [%[inr2]]\n" /* load input r2*/
- "fmla v19.4s , %[w2].4s, v8.4s\n" /* outr10 = w2 * r1[2]*/
- "fmla v20.4s , %[w2].4s, v9.4s\n" /* outr11 = w2 * r1[3]*/
- "fmla v21.4s , %[w2].4s, v10.4s\n"/* outr12 = w2 * r1[4]*/
- "fmla v22.4s , %[w2].4s, v11.4s\n"/* outr13 = w2 * r1[5]*/
- /* r1, r2, mul w3, get out r0, r1 */
- "fmla v15.4s , %[w3].4s, v6.4s\n" /* outr00 = w3 * r1[0]*/
- "fmla v16.4s , %[w3].4s, v7.4s\n" /* outr01 = w3 * r1[1]*/
- "fmla v17.4s , %[w3].4s, v8.4s\n" /* outr02 = w3 * r1[2]*/
- "fmla v18.4s , %[w3].4s, v9.4s\n" /* outr03 = w3 * r1[3]*/
- "fmla v19.4s , %[w3].4s, v0.4s\n" /* outr10 = w3 * r2[0]*/
- "fmla v20.4s , %[w3].4s, v1.4s\n" /* outr11 = w3 * r2[1]*/
- "fmla v21.4s , %[w3].4s, v2.4s\n" /* outr12 = w3 * r2[2]*/
- "fmla v22.4s , %[w3].4s, v3.4s\n" /* outr13 = w3 * r2[3]*/
- /* r1, r2, mul w4, get out r0, r1 */
- "fmla v15.4s , %[w4].4s, v7.4s\n" /* outr00 = w4 * r1[1]*/
- "ldp q6, q7, [%[inr3]], #32\n" /* load input r3*/
- "fmla v16.4s , %[w4].4s, v8.4s\n" /* outr01 = w4 * r1[2]*/
- "fmla v17.4s , %[w4].4s, v9.4s\n" /* outr02 = w4 * r1[3]*/
- "fmla v18.4s , %[w4].4s, v10.4s\n"/* outr03 = w4 * r1[4]*/
- "ldp x0, x1, [%[outl]] \n"
- "fmla v19.4s , %[w4].4s, v1.4s\n" /* outr10 = w4 * r2[1]*/
- "fmla v20.4s , %[w4].4s, v2.4s\n" /* outr11 = w4 * r2[2]*/
- "fmla v21.4s , %[w4].4s, v3.4s\n" /* outr12 = w4 * r2[3]*/
- "fmla v22.4s , %[w4].4s, v4.4s\n" /* outr13 = w4 * r2[4]*/
- /* r1, r2, mul w5, get out r0, r1 */
- "fmla v15.4s , %[w5].4s, v8.4s\n" /* outr00 = w5 * r1[2]*/
- "fmla v16.4s , %[w5].4s, v9.4s\n" /* outr01 = w5 * r1[3]*/
- "ldp q8, q9, [%[inr3]], #32\n" /* load input r3*/
- "fmla v17.4s , %[w5].4s, v10.4s\n"/* outr02 = w5 * r1[4]*/
- "fmla v18.4s , %[w5].4s, v11.4s\n"/* outr03 = w5 * r1[5]*/
- "ldp q10, q11, [%[inr3]]\n" /* load input r3*/
- "fmla v19.4s , %[w5].4s, v2.4s\n" /* outr10 = w5 * r2[2]*/
- "fmla v20.4s , %[w5].4s, v3.4s\n" /* outr11 = w5 * r2[3]*/
- "fmla v21.4s , %[w5].4s, v4.4s\n" /* outr12 = w5 * r2[4]*/
- "fmla v22.4s , %[w5].4s, v5.4s\n" /* outr13 = w5 * r2[5]*/
- /* r2, r3, mul w6, get out r0, r1 */
- "fmla v15.4s , %[w6].4s, v0.4s\n" /* outr00 = w6 * r2[0]*/
- "fmla v16.4s , %[w6].4s, v1.4s\n" /* outr01 = w6 * r2[1]*/
- "fmla v17.4s , %[w6].4s, v2.4s\n" /* outr02 = w6 * r2[2]*/
- "fmla v18.4s , %[w6].4s, v3.4s\n" /* outr03 = w6 * r2[3]*/
- "ldp x2, x3, [%[outl], #16] \n"
- "fmla v19.4s , %[w6].4s, v6.4s\n" /* outr10 = w6 * r3[0]*/
- "fmla v20.4s , %[w6].4s, v7.4s\n" /* outr11 = w6 * r3[1]*/
- "fmla v21.4s , %[w6].4s, v8.4s\n" /* outr12 = w6 * r3[2]*/
- "fmla v22.4s , %[w6].4s, v9.4s\n" /* outr13 = w6 * r3[3]*/
- /* r2, r3, mul w7, get out r0, r1 */
- "fmla v15.4s , %[w7].4s, v1.4s\n" /* outr00 = w7 * r2[1]*/
- "fmla v16.4s , %[w7].4s, v2.4s\n" /* outr01 = w7 * r2[2]*/
- "fmla v17.4s , %[w7].4s, v3.4s\n" /* outr02 = w7 * r2[3]*/
- "fmla v18.4s , %[w7].4s, v4.4s\n" /* outr03 = w7 * r2[4]*/
- "ldp x4, x5, [%[outl], #32] \n"
- "fmla v19.4s , %[w7].4s, v7.4s\n" /* outr10 = w7 * r3[1]*/
- "fmla v20.4s , %[w7].4s, v8.4s\n" /* outr11 = w7 * r3[2]*/
- "fmla v21.4s , %[w7].4s, v9.4s\n" /* outr12 = w7 * r3[3]*/
- "fmla v22.4s , %[w7].4s, v10.4s\n"/* outr13 = w7 * r3[4]*/
- /* r2, r3, mul w8, get out r0, r1 */
- "fmla v15.4s , %[w8].4s, v2.4s\n" /* outr00 = w8 * r2[2]*/
- "fmla v16.4s , %[w8].4s, v3.4s\n" /* outr01 = w8 * r2[3]*/
- "fmla v17.4s , %[w8].4s, v4.4s\n" /* outr02 = w8 * r2[0]*/
- "fmla v18.4s , %[w8].4s, v5.4s\n" /* outr03 = w8 * r2[1]*/
- "ldp x6, x7, [%[outl], #48] \n"
- "fmla v19.4s , %[w8].4s, v8.4s\n" /* outr10 = w8 * r3[2]*/
- "fmla v20.4s , %[w8].4s, v9.4s\n" /* outr11 = w8 * r3[3]*/
- "fmla v21.4s , %[w8].4s, v10.4s\n"/* outr12 = w8 * r3[0]*/
- "fmla v22.4s , %[w8].4s, v11.4s\n"/* outr13 = w8 * r3[1]*/
-
- "fadd v15.4s, v15.4s, %[vbias].4s\n"/* add bias */
- "fadd v16.4s, v16.4s, %[vbias].4s\n"/* add bias */
- "fadd v17.4s, v17.4s, %[vbias].4s\n"/* add bias */
- "fadd v18.4s, v18.4s, %[vbias].4s\n"/* add bias */
- "fadd v19.4s, v19.4s, %[vbias].4s\n"/* add bias */
- "fadd v20.4s, v20.4s, %[vbias].4s\n"/* add bias */
- "fadd v21.4s, v21.4s, %[vbias].4s\n"/* add bias */
- "fadd v22.4s, v22.4s, %[vbias].4s\n"/* add bias */
-
- /* transpose */
- "trn1 v0.4s, v15.4s, v16.4s\n" /* r0: a0a1c0c1*/
- "trn2 v1.4s, v15.4s, v16.4s\n" /* r0: b0b1d0d1*/
- "trn1 v2.4s, v17.4s, v18.4s\n" /* r0: a2a3c2c3*/
- "trn2 v3.4s, v17.4s, v18.4s\n" /* r0: b2b3d2d3*/
- "trn1 v4.4s, v19.4s, v20.4s\n" /* r1: a0a1c0c1*/
- "trn2 v5.4s, v19.4s, v20.4s\n" /* r1: b0b1d0d1*/
- "trn1 v6.4s, v21.4s, v22.4s\n" /* r1: a2a3c2c3*/
- "trn2 v7.4s, v21.4s, v22.4s\n" /* r1: b2b3d2d3*/
- "trn1 v15.2d, v0.2d, v2.2d\n" /* r0: a0a1a2a3*/
- "trn2 v19.2d, v0.2d, v2.2d\n" /* r0: c0c1c2c3*/
- "trn1 v17.2d, v1.2d, v3.2d\n" /* r0: b0b1b2b3*/
- "trn2 v21.2d, v1.2d, v3.2d\n" /* r0: d0d1d2d3*/
- "trn1 v16.2d, v4.2d, v6.2d\n" /* r1: a0a1a2a3*/
- "trn2 v20.2d, v4.2d, v6.2d\n" /* r1: c0c1c2c3*/
- "trn1 v18.2d, v5.2d, v7.2d\n" /* r1: b0b1b2b3*/
- "trn2 v22.2d, v5.2d, v7.2d\n" /* r1: d0d1d2d3*/
-
- "cbz %w[flag_relu], 0f\n" /* skip relu*/
- "movi v0.4s, #0\n" /* for relu */
- "fmax v15.4s, v15.4s, v0.4s\n"
- "fmax v16.4s, v16.4s, v0.4s\n"
- "fmax v17.4s, v17.4s, v0.4s\n"
- "fmax v18.4s, v18.4s, v0.4s\n"
- "fmax v19.4s, v19.4s, v0.4s\n"
- "fmax v20.4s, v20.4s, v0.4s\n"
- "fmax v21.4s, v21.4s, v0.4s\n"
- "fmax v22.4s, v22.4s, v0.4s\n"
- "0:\n"
- "cbnz %w[flag_mask], 1f\n"
- "str q15, [x0]\n" /* save outc00 */
- "str q16, [x4]\n" /* save outc01 */
- "str q17, [x1]\n" /* save outc10 */
- "str q18, [x5]\n" /* save outc11 */
- "str q19, [x2]\n" /* save outc20 */
- "str q20, [x6]\n" /* save outc21 */
- "str q21, [x3]\n" /* save outc30 */
- "str q22, [x7]\n" /* save outc31 */
- "b 2f\n"
- "1:\n"
- "str q15, [%[out]], #16 \n" /* save remain to pre_out */
- "str q17, [%[out]], #16 \n" /* save remain to pre_out */
- "str q19, [%[out]], #16 \n" /* save remain to pre_out */
- "str q21, [%[out]], #16 \n" /* save remain to pre_out */
- "str q16, [%[out]], #16 \n" /* save remain to pre_out */
- "str q18, [%[out]], #16 \n" /* save remain to pre_out */
- "str q20, [%[out]], #16 \n" /* save remain to pre_out */
- "str q22, [%[out]], #16 \n" /* save remain to pre_out */
- "2:\n"
- :[inr0] "+r"(inr0), [inr1] "+r"(inr1),
- [inr2] "+r"(inr2), [inr3] "+r"(inr3),
- [out]"+r"(out0)
- :[w0] "w"(w0), [w1] "w"(w1), [w2] "w"(w2),
- [w3] "w"(w3), [w4] "w"(w4), [w5] "w"(w5),
- [w6] "w"(w6), [w7] "w"(w7), [w8] "w"(w8),
- [vbias]"w" (vbias), [outl] "r" (outl_ptr),
- [flag_mask] "r" (flag_mask), [flag_relu] "r" (flag_relu)
- : "cc", "memory",
- "v0","v1","v2","v3","v4","v5","v6","v7",
- "v8", "v9", "v10", "v11", "v15",
- "v16","v17","v18","v19","v20","v21","v22",
- "x0", "x1", "x2", "x3", "x4", "x5", "x6", "x7"
- );
-#else
- asm volatile(
- /* load weights */
- "vld1.32 {d10-d13}, [%[wc0]]! @ load w0, w1, to q5, q6\n"
- "vld1.32 {d14-d15}, [%[wc0]]! @ load w2, to q7\n"
- /* load r0, r1 */
- "vld1.32 {d0-d3}, [%[r0]]! @ load r0, q0, q1\n"
- "vld1.32 {d4-d7}, [%[r0]]! @ load r0, q2, q3\n"
- /* main loop */
- "0: @ main loop\n"
- /* mul r0 with w0, w1, w2, get out r0 */
- "vmul.f32 q8, q5, q0 @ w0 * inr00\n"
- "vmul.f32 q9, q5, q1 @ w0 * inr01\n"
- "vmul.f32 q10, q5, q2 @ w0 * inr02\n"
- "vmul.f32 q11, q5, q3 @ w0 * inr03\n"
- "vmla.f32 q8, q6, q1 @ w1 * inr01\n"
- "vld1.32 {d0-d3}, [%[r0]] @ load r0, q0, q1\n"
- "vmla.f32 q9, q6, q2 @ w1 * inr02\n"
- "vmla.f32 q10, q6, q3 @ w1 * inr03\n"
- "vmla.f32 q11, q6, q0 @ w1 * inr04\n"
- "vmla.f32 q8, q7, q2 @ w2 * inr02\n"
- "vmla.f32 q9, q7, q3 @ w2 * inr03\n"
- "vld1.32 {d4-d7}, [%[r1]]! @ load r0, q2, q3\n"
- "vmla.f32 q10, q7, q0 @ w2 * inr04\n"
- "vmla.f32 q11, q7, q1 @ w2 * inr05\n"
- "vld1.32 {d0-d3}, [%[r1]]! @ load r0, q0, q1\n"
- "vld1.32 {d8-d9}, [%[wc0]]! @ load w3 to q4\n"
- /* mul r1 with w0-w5, get out r0, r1 */
- "vmul.f32 q12, q5, q2 @ w0 * inr10\n"
- "vmul.f32 q13, q5, q3 @ w0 * inr11\n"
- "vmul.f32 q14, q5, q0 @ w0 * inr12\n"
- "vmul.f32 q15, q5, q1 @ w0 * inr13\n"
- "vld1.32 {d10-d11}, [%[wc0]]! @ load w4 to q5\n"
- "vmla.f32 q8, q4, q2 @ w3 * inr10\n"
- "vmla.f32 q9, q4, q3 @ w3 * inr11\n"
- "vmla.f32 q10, q4, q0 @ w3 * inr12\n"
- "vmla.f32 q11, q4, q1 @ w3 * inr13\n"
- /* mul r1 with w1, w4, get out r1, r0 */
- "vmla.f32 q8, q5, q3 @ w4 * inr11\n"
- "vmla.f32 q12, q6, q3 @ w1 * inr11\n"
- "vld1.32 {d4-d7}, [%[r1]] @ load r1, q2, q3\n"
- "vmla.f32 q9, q5, q0 @ w4 * inr12\n"
- "vmla.f32 q13, q6, q0 @ w1 * inr12\n"
- "vmla.f32 q10, q5, q1 @ w4 * inr13\n"
- "vmla.f32 q14, q6, q1 @ w1 * inr13\n"
- "vmla.f32 q11, q5, q2 @ w4 * inr14\n"
- "vmla.f32 q15, q6, q2 @ w1 * inr14\n"
- "vld1.32 {d12-d13}, [%[wc0]]! @ load w5 to q6\n"
- /* mul r1 with w2, w5, get out r1, r0 */
- "vmla.f32 q12, q7, q0 @ w2 * inr12\n"
- "vmla.f32 q13, q7, q1 @ w2 * inr13\n"
- "vmla.f32 q8, q6, q0 @ w5 * inr12\n"
- "vmla.f32 q9, q6, q1 @ w5 * inr13\n"
- "vld1.32 {d0-d3}, [%[r2]]! @ load r2, q0, q1\n"
- "vmla.f32 q14, q7, q2 @ w2 * inr14\n"
- "vmla.f32 q15, q7, q3 @ w2 * inr15\n"
- "vmla.f32 q10, q6, q2 @ w5 * inr14\n"
- "vmla.f32 q11, q6, q3 @ w5 * inr15\n"
- "vld1.32 {d4-d7}, [%[r2]]! @ load r2, q0, q1\n"
- "vld1.32 {d14-d15}, [%[wc0]]! @ load w6, to q7\n"
- /* mul r2 with w3-w8, get out r0, r1 */
- "vmla.f32 q12, q4, q0 @ w3 * inr20\n"
- "vmla.f32 q13, q4, q1 @ w3 * inr21\n"
- "vmla.f32 q14, q4, q2 @ w3 * inr22\n"
- "vmla.f32 q15, q4, q3 @ w3 * inr23\n"
- "vld1.32 {d8-d9}, [%[wc0]]! @ load w7, to q4\n"
- "vmla.f32 q8, q7, q0 @ w6 * inr20\n"
- "vmla.f32 q9, q7, q1 @ w6 * inr21\n"
- "vmla.f32 q10, q7, q2 @ w6 * inr22\n"
- "vmla.f32 q11, q7, q3 @ w6 * inr23\n"
- /* mul r2 with w4, w7, get out r1, r0 */
- "vmla.f32 q8, q4, q1 @ w7 * inr21\n"
- "vmla.f32 q12, q5, q1 @ w4 * inr21\n"
- "vld1.32 {d0-d3}, [%[r2]] @ load r2, q0, q1\n"
- "vmla.f32 q9, q4, q2 @ w7 * inr22\n"
- "vmla.f32 q13, q5, q2 @ w4 * inr22\n"
- "vmla.f32 q10, q4, q3 @ w7 * inr23\n"
- "vmla.f32 q14, q5, q3 @ w4 * inr23\n"
- "vmla.f32 q11, q4, q0 @ w7 * inr24\n"
- "vmla.f32 q15, q5, q0 @ w4 * inr24\n"
- "vld1.32 {d10-d11}, [%[wc0]]! @ load w8 to q5\n"
- /* mul r1 with w5, w8, get out r1, r0 */
- "vmla.f32 q12, q6, q2 @ w5 * inr22\n"
- "vmla.f32 q13, q6, q3 @ w5 * inr23\n"
- "vmla.f32 q8, q5, q2 @ w8 * inr22\n"
- "vmla.f32 q9, q5, q3 @ w8 * inr23\n"
- "vld1.32 {d4-d7}, [%[r3]]! @ load r3, q2, q3\n"
- "ldr r4, [%[outl], #32] @ load bias addr to r4\n"
- "vmla.f32 q14, q6, q0 @ w5 * inr24\n"
- "vmla.f32 q15, q6, q1 @ w5 * inr25\n"
- "vmla.f32 q10, q5, q0 @ w8 * inr24\n"
- "vmla.f32 q11, q5, q1 @ w8 * inr25\n"
- "vld1.32 {d0-d3}, [%[r3]]! @ load r3, q0, q1\n"
- "sub %[wc0], %[wc0], #144 @ wc0 - 144 to start address\n"
- /* mul r3 with w6, w7, w8, get out r1 */
- "vmla.f32 q12, q7, q2 @ w6 * inr30\n"
- "vmla.f32 q13, q7, q3 @ w6 * inr31\n"
- "vmla.f32 q14, q7, q0 @ w6 * inr32\n"
- "vmla.f32 q15, q7, q1 @ w6 * inr33\n"
- "vmla.f32 q12, q4, q3 @ w7 * inr31\n"
- "vld1.32 {d4-d7}, [%[r3]] @ load r3, q2, q3\n"
- "vld1.32 {d12-d13}, [r4] @ load bias\n"
- "vmla.f32 q13, q4, q0 @ w7 * inr32\n"
- "vmla.f32 q14, q4, q1 @ w7 * inr33\n"
- "vmla.f32 q15, q4, q2 @ w7 * inr34\n"
- "ldr r0, [%[outl]] @ load outc00 to r0\n"
- "vmla.f32 q12, q5, q0 @ w8 * inr32\n"
- "vmla.f32 q13, q5, q1 @ w8 * inr33\n"
- "ldr r5, [%[outl], #36] @ load flag_relu to r5\n"
- "vmla.f32 q14, q5, q2 @ w8 * inr34\n"
- "vmla.f32 q15, q5, q3 @ w8 * inr35\n"
- "ldr r1, [%[outl], #4] @ load outc10 to r1\n"
- "vadd.f32 q8, q8, q6 @ r00 add bias\n"
- "vadd.f32 q9, q9, q6 @ r01 add bias\n"
- "vadd.f32 q10, q10, q6 @ r02 add bias\n"
- "vadd.f32 q11, q11, q6 @ r03 add bias\n"
- "ldr r2, [%[outl], #8] @ load outc20 to r2\n"
- "vadd.f32 q12, q12, q6 @ r10 add bias\n"
- "vadd.f32 q13, q13, q6 @ r11 add bias\n"
- "vadd.f32 q14, q14, q6 @ r12 add bias\n"
- "vadd.f32 q15, q15, q6 @ r13 add bias\n"
- "ldr r3, [%[outl], #12] @ load outc30 to r3\n"
- "vmov.u32 q7, #0 @ mov zero to q7\n"
- "cmp r5, #0 @ cmp flag relu\n"
- "beq 1f @ skip relu\n"
- "vmax.f32 q8, q8, q7 @ r00 relu\n"
- "vmax.f32 q9, q9, q7 @ r01 relu\n"
- "vmax.f32 q10, q10, q7 @ r02 relu\n"
- "vmax.f32 q11, q11, q7 @ r03 relu\n"
- "vmax.f32 q12, q12, q7 @ r10 relu\n"
- "vmax.f32 q13, q13, q7 @ r11 relu\n"
- "vmax.f32 q14, q14, q7 @ r12 relu\n"
- "vmax.f32 q15, q15, q7 @ r13 relu\n"
- "1:\n"
- "ldr r4, [%[outl], #16] @ load outc01 to r4\n"
- "vtrn.32 q8, q9 @ r0: q8 : a0a1c0c1, q9 : b0b1d0d1\n"
- "vtrn.32 q10, q11 @ r0: q10: a2a3c2c3, q11: b2b3d2d3\n"
- "vtrn.32 q12, q13 @ r1: q12: a0a1c0c1, q13: b0b1d0d1\n"
- "vtrn.32 q14, q15 @ r1: q14: a2a3c2c3, q15: b2b3d2d3\n"
- "ldr r5, [%[outl], #20] @ load outc11 to r5\n"
- "vswp d17, d20 @ r0: q8 : a0a1a2a3, q10: c0c1c2c3 \n"
- "vswp d19, d22 @ r0: q9 : b0b1b2b3, q11: d0d1d2d3 \n"
- "vswp d25, d28 @ r1: q12: a0a1a2a3, q14: c0c1c2c3 \n"
- "vswp d27, d30 @ r1: q13: b0b1b2b3, q15: d0d1d2d3 \n"
- "cmp %[flag_mask], #0 @ cmp flag mask\n"
- "bne 2f\n"
- "vst1.32 {d16-d17}, [r0] @ save outc00\n"
- "vst1.32 {d18-d19}, [r1] @ save outc10\n"
- "vst1.32 {d20-d21}, [r2] @ save outc20\n"
- "vst1.32 {d22-d23}, [r3] @ save outc30\n"
- "vst1.32 {d24-d25}, [r4] @ save outc01\n"
- "vst1.32 {d26-d27}, [r5] @ save outc11\n"
- "ldr r0, [%[outl], #24] @ load outc21 to r0\n"
- "ldr r1, [%[outl], #28] @ load outc31 to r1\n"
- "vst1.32 {d28-d29}, [r0] @ save outc21\n"
- "vst1.32 {d30-d31}, [r1] @ save outc31\n"
- "b 3f @ branch end\n"
- "2: \n"
- "vst1.32 {d16-d17}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d18-d19}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d20-d21}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d22-d23}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d24-d25}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d26-d27}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d28-d29}, [%[out0]]! @ save remain to pre_out\n"
- "vst1.32 {d30-d31}, [%[out0]]! @ save remain to pre_out\n"
- "3: \n"
- : [r0] "+r"(inr0), [r1] "+r"(inr1),
- [r2] "+r"(inr2), [r3] "+r"(inr3),
- [out0] "+r"(out0), [wc0] "+r"(weight_c)
- : [flag_mask] "r" (flag_mask), [outl] "r" (outl_ptr)
- : "cc", "memory",
- "q0", "q1", "q2", "q3", "q4", "q5", "q6", "q7", "q8", "q9",
- "q10", "q11", "q12", "q13","q14", "q15", "r0", "r1", "r2", "r3", "r4", "r5"
- );
-#endif // __arch64__
- // clang-format on
- outl[0] += 4;
- outl[1] += 4;
- outl[2] += 4;
- outl[3] += 4;
- outl[4] += 4;
- outl[5] += 4;
- outl[6] += 4;
- outl[7] += 4;
- if (flag_mask) {
- memcpy(outl[0] - 4, pre_out, remain * sizeof(float));
- memcpy(outl[1] - 4, pre_out + 4, remain * sizeof(float));
- memcpy(outl[2] - 4, pre_out + 8, remain * sizeof(float));
- memcpy(outl[3] - 4, pre_out + 12, remain * sizeof(float));
- memcpy(outl[4] - 4, pre_out + 16, remain * sizeof(float));
- memcpy(outl[5] - 4, pre_out + 20, remain * sizeof(float));
- memcpy(outl[6] - 4, pre_out + 24, remain * sizeof(float));
- memcpy(outl[7] - 4, pre_out + 28, remain * sizeof(float));
- }
- }
- }
- }
- }
-}
-
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/conv3x3s2_depthwise_fp32.cc b/lite/backends/arm/math/conv3x3s2_depthwise_fp32.cc
deleted file mode 100644
index 2d75323a9677f1cfbed726a1a28920dd77131688..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv3x3s2_depthwise_fp32.cc
+++ /dev/null
@@ -1,361 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include "lite/backends/arm/math/conv_block_utils.h"
-#include "lite/backends/arm/math/conv_impl.h"
-#include "lite/core/context.h"
-#include "lite/operators/op_params.h"
-#ifdef ARM_WITH_OMP
-#include
-#endif
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-
-void conv_3x3s2_depthwise_fp32(const float* i_data,
- float* o_data,
- int bs,
- int oc,
- int oh,
- int ow,
- int ic,
- int ih,
- int win,
- const float* weights,
- const float* bias,
- const operators::ConvParam& param,
- ARMContext* ctx) {
- int threads = ctx->threads();
- const int pad_h = param.paddings[0];
- const int pad_w = param.paddings[1];
- const int out_c_block = 4;
- const int out_h_kernel = 1;
- const int out_w_kernel = 4;
- const int win_ext = ow * 2 + 1;
- const int ow_round = ROUNDUP(ow, 4);
- const int win_round = ROUNDUP(win_ext, 4);
- const int hin_round = oh * 2 + 1;
- const int prein_size = win_round * hin_round * out_c_block;
- auto workspace_size =
- threads * prein_size + win_round /*tmp zero*/ + ow_round /*tmp writer*/;
- ctx->ExtendWorkspace(sizeof(float) * workspace_size);
-
- bool flag_relu = param.fuse_relu;
- bool flag_bias = param.bias != nullptr;
-
- /// get workspace
- auto ptr_zero = ctx->workspace_data();
- memset(ptr_zero, 0, sizeof(float) * win_round);
- float* ptr_write = ptr_zero + win_round;
-
- int size_in_channel = win * ih;
- int size_out_channel = ow * oh;
-
- int ws = -pad_w;
- int we = ws + win_round;
- int hs = -pad_h;
- int he = hs + hin_round;
- int w_loop = ow_round / 4;
- auto remain = w_loop * 4 - ow;
- bool flag_remain = remain > 0;
- remain = 4 - remain;
- remain = remain > 0 ? remain : 0;
- int row_len = win_round * out_c_block;
-
- for (int n = 0; n < bs; ++n) {
- const float* din_batch = i_data + n * ic * size_in_channel;
- float* dout_batch = o_data + n * oc * size_out_channel;
-#pragma omp parallel for num_threads(threads)
- for (int c = 0; c < oc; c += out_c_block) {
-#ifdef ARM_WITH_OMP
- float* pre_din = ptr_write + ow_round + omp_get_thread_num() * prein_size;
-#else
- float* pre_din = ptr_write + ow_round;
-#endif
- /// const array size
- prepack_input_nxwc4_dw(
- din_batch, pre_din, c, hs, he, ws, we, ic, win, ih, ptr_zero);
- const float* weight_c = weights + c * 9; // kernel_w * kernel_h
- float* dout_c00 = dout_batch + c * size_out_channel;
- float bias_local[4] = {0, 0, 0, 0};
- if (flag_bias) {
- bias_local[0] = bias[c];
- bias_local[1] = bias[c + 1];
- bias_local[2] = bias[c + 2];
- bias_local[3] = bias[c + 3];
- }
-#ifdef __aarch64__
- float32x4_t w0 = vld1q_f32(weight_c); // w0, v23
- float32x4_t w1 = vld1q_f32(weight_c + 4); // w1, v24
- float32x4_t w2 = vld1q_f32(weight_c + 8); // w2, v25
- float32x4_t w3 = vld1q_f32(weight_c + 12); // w3, v26
- float32x4_t w4 = vld1q_f32(weight_c + 16); // w4, v27
- float32x4_t w5 = vld1q_f32(weight_c + 20); // w5, v28
- float32x4_t w6 = vld1q_f32(weight_c + 24); // w6, v29
- float32x4_t w7 = vld1q_f32(weight_c + 28); // w7, v30
- float32x4_t w8 = vld1q_f32(weight_c + 32); // w8, v31
-#endif
- for (int h = 0; h < oh; h += out_h_kernel) {
- float* outc0 = dout_c00 + h * ow;
- float* outc1 = outc0 + size_out_channel;
- float* outc2 = outc1 + size_out_channel;
- float* outc3 = outc2 + size_out_channel;
- const float* inr0 = pre_din + h * 2 * row_len;
- const float* inr1 = inr0 + row_len;
- const float* inr2 = inr1 + row_len;
- if (c + out_c_block > oc) {
- switch (c + out_c_block - oc) {
- case 3:
- outc1 = ptr_write;
- case 2:
- outc2 = ptr_write;
- case 1:
- outc3 = ptr_write;
- default:
- break;
- }
- }
- auto c0 = outc0;
- auto c1 = outc1;
- auto c2 = outc2;
- auto c3 = outc3;
- float pre_out[16];
- for (int w = 0; w < w_loop; ++w) {
- bool flag_mask = (w == w_loop - 1) && flag_remain;
- if (flag_mask) {
- c0 = outc0;
- c1 = outc1;
- c2 = outc2;
- c3 = outc3;
- outc0 = pre_out;
- outc1 = pre_out + 4;
- outc2 = pre_out + 8;
- outc3 = pre_out + 12;
- }
-// clang-format off
-#ifdef __aarch64__
- asm volatile(
- "ldr q8, [%[bias]]\n" /* load bias */
- "ldp q0, q1, [%[inr0]], #32\n" /* load input r0*/
- "and v19.16b, v8.16b, v8.16b\n"
- "ldp q2, q3, [%[inr0]], #32\n" /* load input r0*/
- "and v20.16b, v8.16b, v8.16b\n"
- "ldp q4, q5, [%[inr0]], #32\n" /* load input r0*/
- "and v21.16b, v8.16b, v8.16b\n"
- "ldp q6, q7, [%[inr0]], #32\n" /* load input r0*/
- "and v22.16b, v8.16b, v8.16b\n"
- "ldr q8, [%[inr0]]\n" /* load input r0*/
- /* r0 mul w0-w2, get out */
- "fmla v19.4s , %[w0].4s, v0.4s\n" /* outr0 = w0 * r0, 0*/
- "fmla v20.4s , %[w0].4s, v2.4s\n" /* outr1 = w0 * r0, 2*/
- "fmla v21.4s , %[w0].4s, v4.4s\n" /* outr2 = w0 * r0, 4*/
- "fmla v22.4s , %[w0].4s, v6.4s\n" /* outr3 = w0 * r0, 6*/
- "fmla v19.4s , %[w1].4s, v1.4s\n" /* outr0 = w1 * r0, 1*/
- "ldp q0, q1, [%[inr1]], #32\n" /* load input r1*/
- "fmla v20.4s , %[w1].4s, v3.4s\n" /* outr1 = w1 * r0, 3*/
- "fmla v21.4s , %[w1].4s, v5.4s\n" /* outr2 = w1 * r0, 5*/
- "fmla v22.4s , %[w1].4s, v7.4s\n" /* outr3 = w1 * r0, 7*/
- "fmla v19.4s , %[w2].4s, v2.4s\n" /* outr0 = w0 * r0, 2*/
- "ldp q2, q3, [%[inr1]], #32\n" /* load input r1*/
- "fmla v20.4s , %[w2].4s, v4.4s\n" /* outr1 = w0 * r0, 4*/
- "ldp q4, q5, [%[inr1]], #32\n" /* load input r1*/
- "fmla v21.4s , %[w2].4s, v6.4s\n" /* outr2 = w0 * r0, 6*/
- "ldp q6, q7, [%[inr1]], #32\n" /* load input r1*/
- "fmla v22.4s , %[w2].4s, v8.4s\n" /* outr3 = w0 * r0, 8*/
- "ldr q8, [%[inr1]]\n" /* load input r1*/
- /* r1, mul w3-w5, get out */
- "fmla v19.4s , %[w3].4s, v0.4s\n" /* outr0 = w3 * r1, 0*/
- "fmla v20.4s , %[w3].4s, v2.4s\n" /* outr1 = w3 * r1, 2*/
- "fmla v21.4s , %[w3].4s, v4.4s\n" /* outr2 = w3 * r1, 4*/
- "fmla v22.4s , %[w3].4s, v6.4s\n" /* outr3 = w3 * r1, 6*/
- "fmla v19.4s , %[w4].4s, v1.4s\n" /* outr0 = w4 * r1, 1*/
- "ldp q0, q1, [%[inr2]], #32\n" /* load input r2*/
- "fmla v20.4s , %[w4].4s, v3.4s\n" /* outr1 = w4 * r1, 3*/
- "fmla v21.4s , %[w4].4s, v5.4s\n" /* outr2 = w4 * r1, 5*/
- "fmla v22.4s , %[w4].4s, v7.4s\n" /* outr3 = w4 * r1, 7*/
- "fmla v19.4s , %[w5].4s, v2.4s\n" /* outr0 = w5 * r1, 2*/
- "ldp q2, q3, [%[inr2]], #32\n" /* load input r2*/
- "fmla v20.4s , %[w5].4s, v4.4s\n" /* outr1 = w5 * r1, 4*/
- "ldp q4, q5, [%[inr2]], #32\n" /* load input r2*/
- "fmla v21.4s , %[w5].4s, v6.4s\n" /* outr2 = w5 * r1, 6*/
- "ldp q6, q7, [%[inr2]], #32\n" /* load input r2*/
- "fmla v22.4s , %[w5].4s, v8.4s\n" /* outr3 = w5 * r1, 8*/
- "ldr q8, [%[inr2]]\n" /* load input r2*/
- /* r2, mul w6-w8, get out r0, r1 */
- "fmla v19.4s , %[w6].4s, v0.4s\n" /* outr0 = w6 * r2, 0*/
- "fmla v20.4s , %[w6].4s, v2.4s\n" /* outr1 = w6 * r2, 2*/
- "fmla v21.4s , %[w6].4s, v4.4s\n" /* outr2 = w6 * r2, 4*/
- "fmla v22.4s , %[w6].4s, v6.4s\n" /* outr3 = w6 * r2, 6*/
- "fmla v19.4s , %[w7].4s, v1.4s\n" /* outr0 = w7 * r2, 1*/
- "fmla v20.4s , %[w7].4s, v3.4s\n" /* outr1 = w7 * r2, 3*/
- "fmla v21.4s , %[w7].4s, v5.4s\n" /* outr2 = w7 * r2, 5*/
- "fmla v22.4s , %[w7].4s, v7.4s\n" /* outr3 = w7 * r2, 7*/
- "fmla v19.4s , %[w8].4s, v2.4s\n" /* outr0 = w8 * r2, 2*/
- "fmla v20.4s , %[w8].4s, v4.4s\n" /* outr1 = w8 * r2, 4*/
- "fmla v21.4s , %[w8].4s, v6.4s\n" /* outr2 = w8 * r2, 6*/
- "fmla v22.4s , %[w8].4s, v8.4s\n" /* outr3 = w8 * r2, 8*/
- /* transpose */
- "trn1 v0.4s, v19.4s, v20.4s\n" /* r0: a0a1c0c1*/
- "trn2 v1.4s, v19.4s, v20.4s\n" /* r0: b0b1d0d1*/
- "trn1 v2.4s, v21.4s, v22.4s\n" /* r0: a2a3c2c3*/
- "trn2 v3.4s, v21.4s, v22.4s\n" /* r0: b2b3d2d3*/
- "trn1 v19.2d, v0.2d, v2.2d\n" /* r0: a0a1a2a3*/
- "trn2 v21.2d, v0.2d, v2.2d\n" /* r0: c0c1c2c3*/
- "trn1 v20.2d, v1.2d, v3.2d\n" /* r0: b0b1b2b3*/
- "trn2 v22.2d, v1.2d, v3.2d\n" /* r0: d0d1d2d3*/
- /* relu */
- "cbz %w[flag_relu], 0f\n" /* skip relu*/
- "movi v0.4s, #0\n" /* for relu */
- "fmax v19.4s, v19.4s, v0.4s\n"
- "fmax v20.4s, v20.4s, v0.4s\n"
- "fmax v21.4s, v21.4s, v0.4s\n"
- "fmax v22.4s, v22.4s, v0.4s\n"
- /* save result */
- "0:\n"
- "str q19, [%[outc0]], #16\n"
- "str q20, [%[outc1]], #16\n"
- "str q21, [%[outc2]], #16\n"
- "str q22, [%[outc3]], #16\n"
- :[inr0] "+r"(inr0), [inr1] "+r"(inr1),
- [inr2] "+r"(inr2),
- [outc0]"+r"(outc0), [outc1]"+r"(outc1),
- [outc2]"+r"(outc2), [outc3]"+r"(outc3)
- :[w0] "w"(w0), [w1] "w"(w1), [w2] "w"(w2),
- [w3] "w"(w3), [w4] "w"(w4), [w5] "w"(w5),
- [w6] "w"(w6), [w7] "w"(w7), [w8] "w"(w8),
- [bias] "r" (bias_local), [flag_relu]"r"(flag_relu)
- : "cc", "memory",
- "v0","v1","v2","v3","v4","v5","v6","v7",
- "v8", "v19","v20","v21","v22"
- );
-#else
- asm volatile(
- /* fill with bias */
- "vld1.32 {d16-d17}, [%[bias]]\n" /* load bias */
- /* load weights */
- "vld1.32 {d18-d21}, [%[wc0]]!\n" /* load w0-2, to q9-11 */
- "vld1.32 {d0-d3}, [%[r0]]!\n" /* load input r0, 0,1*/
- "vand.i32 q12, q8, q8\n"
- "vld1.32 {d4-d7}, [%[r0]]!\n" /* load input r0, 2,3*/
- "vand.i32 q13, q8, q8\n"
- "vld1.32 {d8-d11}, [%[r0]]!\n" /* load input r0, 4,5*/
- "vand.i32 q14, q8, q8\n"
- "vld1.32 {d12-d15}, [%[r0]]!\n" /* load input r0, 6,7*/
- "vand.i32 q15, q8, q8\n"
- "vld1.32 {d16-d17}, [%[r0]]\n" /* load input r0, 8*/
- /* mul r0 with w0, w1, w2 */
- "vmla.f32 q12, q9, q0 @ w0 * inr0\n"
- "vmla.f32 q13, q9, q2 @ w0 * inr2\n"
- "vld1.32 {d22-d23}, [%[wc0]]!\n" /* load w2, to q11 */
- "vmla.f32 q14, q9, q4 @ w0 * inr4\n"
- "vmla.f32 q15, q9, q6 @ w0 * inr6\n"
- "vmla.f32 q12, q10, q1 @ w1 * inr1\n"
- "vld1.32 {d0-d3}, [%[r1]]! @ load r1, 0, 1\n"
- "vmla.f32 q13, q10, q3 @ w1 * inr3\n"
- "vmla.f32 q14, q10, q5 @ w1 * inr5\n"
- "vmla.f32 q15, q10, q7 @ w1 * inr7\n"
- "vld1.32 {d18-d21}, [%[wc0]]!\n" /* load w3-4, to q9-10 */
- "vmla.f32 q12, q11, q2 @ w2 * inr2\n"
- "vld1.32 {d4-d7}, [%[r1]]! @ load r1, 2, 3\n"
- "vmla.f32 q13, q11, q4 @ w2 * inr4\n"
- "vld1.32 {d8-d11}, [%[r1]]! @ load r1, 4, 5\n"
- "vmla.f32 q14, q11, q6 @ w2 * inr6\n"
- "vld1.32 {d12-d15}, [%[r1]]! @ load r1, 6, 7\n"
- "vmla.f32 q15, q11, q8 @ w2 * inr8\n"
- /* mul r1 with w3, w4, w5 */
- "vmla.f32 q12, q9, q0 @ w3 * inr0\n"
- "vmla.f32 q13, q9, q2 @ w3 * inr2\n"
- "vld1.32 {d22-d23}, [%[wc0]]!\n" /* load w5, to q11 */
- "vmla.f32 q14, q9, q4 @ w3 * inr4\n"
- "vmla.f32 q15, q9, q6 @ w3 * inr6\n"
- "vld1.32 {d16-d17}, [%[r1]]\n" /* load input r1, 8*/
- "vmla.f32 q12, q10, q1 @ w4 * inr1\n"
- "vld1.32 {d0-d3}, [%[r2]]! @ load r2, 0, 1\n"
- "vmla.f32 q13, q10, q3 @ w4 * inr3\n"
- "vmla.f32 q14, q10, q5 @ w4 * inr5\n"
- "vmla.f32 q15, q10, q7 @ w4 * inr7\n"
- "vld1.32 {d18-d21}, [%[wc0]]!\n" /* load w6-7, to q9-10 */
- "vmla.f32 q12, q11, q2 @ w5 * inr2\n"
- "vld1.32 {d4-d7}, [%[r2]]! @ load r2, 2, 3\n"
- "vmla.f32 q13, q11, q4 @ w5 * inr4\n"
- "vld1.32 {d8-d11}, [%[r2]]! @ load r2, 4, 5\n"
- "vmla.f32 q14, q11, q6 @ w5 * inr6\n"
- "vld1.32 {d12-d15}, [%[r2]]! @ load r2, 6, 7\n"
- "vmla.f32 q15, q11, q8 @ w5 * inr8\n"
- /* mul r2 with w6, w7, w8 */
- "vmla.f32 q12, q9, q0 @ w6 * inr0\n"
- "vmla.f32 q13, q9, q2 @ w6 * inr2\n"
- "vld1.32 {d22-d23}, [%[wc0]]!\n" /* load w8, to q11 */
- "vmla.f32 q14, q9, q4 @ w6 * inr4\n"
- "vmla.f32 q15, q9, q6 @ w6 * inr6\n"
- "vld1.32 {d16-d17}, [%[r2]]\n" /* load input r2, 8*/
- "vmla.f32 q12, q10, q1 @ w7 * inr1\n"
- "vmla.f32 q13, q10, q3 @ w7 * inr3\n"
- "vmla.f32 q14, q10, q5 @ w7 * inr5\n"
- "vmla.f32 q15, q10, q7 @ w7 * inr7\n"
- "sub %[wc0], %[wc0], #144 @ wc0 - 144 to start address\n"
- "vmla.f32 q12, q11, q2 @ w8 * inr2\n"
- "vmla.f32 q13, q11, q4 @ w8 * inr4\n"
- "vmla.f32 q14, q11, q6 @ w8 * inr6\n"
- "vmla.f32 q15, q11, q8 @ w8 * inr8\n"
- /* transpose */
- "vtrn.32 q12, q13\n" /* a0a1c0c1, b0b1d0d1*/
- "vtrn.32 q14, q15\n" /* a2a3c2c3, b2b3d2d3*/
- "vswp d25, d28\n" /* a0a1a2a3, c0c1c2c3*/
- "vswp d27, d30\n" /* b0b1b2b3, d0d1d2d3*/
- "cmp %[flag_relu], #0\n"
- "beq 0f\n" /* skip relu*/
- "vmov.u32 q0, #0\n"
- "vmax.f32 q12, q12, q0\n"
- "vmax.f32 q13, q13, q0\n"
- "vmax.f32 q14, q14, q0\n"
- "vmax.f32 q15, q15, q0\n"
- "0:\n"
- "vst1.32 {d24-d25}, [%[outc0]]!\n" /* save outc0*/
- "vst1.32 {d26-d27}, [%[outc1]]!\n" /* save outc1*/
- "vst1.32 {d28-d29}, [%[outc2]]!\n" /* save outc2*/
- "vst1.32 {d30-d31}, [%[outc3]]!\n" /* save outc3*/
- :[r0] "+r"(inr0), [r1] "+r"(inr1),
- [r2] "+r"(inr2), [wc0] "+r" (weight_c),
- [outc0]"+r"(outc0), [outc1]"+r"(outc1),
- [outc2]"+r"(outc2), [outc3]"+r"(outc3)
- :[bias] "r" (bias_local),
- [flag_relu]"r"(flag_relu)
- :"cc", "memory",
- "q0","q1","q2","q3","q4","q5","q6","q7",
- "q8", "q9","q10","q11","q12","q13","q14","q15"
- );
-#endif // __arch64__
- // clang-format off
- if (flag_mask) {
- for (int i = 0; i < remain; ++i) {
- c0[i] = pre_out[i];
- c1[i] = pre_out[i + 4];
- c2[i] = pre_out[i + 8];
- c3[i] = pre_out[i + 12];
- }
- }
- }
- }
- }
- }
-}
-
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/conv_depthwise_3x3p0.cc b/lite/backends/arm/math/conv_depthwise_3x3p0.cc
deleted file mode 100644
index 0c050ffe6fb0f064f5c26ea0da6acee17f4403ae..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv_depthwise_3x3p0.cc
+++ /dev/null
@@ -1,4178 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/arm/math/conv_depthwise.h"
-#include
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-
-void conv_depthwise_3x3s1p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s1p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s2p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s1p0_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s1p0_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p0_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s2p0_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3p0_fp32(const float* din,
- float* dout,
- int num,
- int ch_out,
- int h_out,
- int w_out,
- int ch_in,
- int h_in,
- int w_in,
- const float* weights,
- const float* bias,
- int stride,
- bool flag_bias,
- bool flag_relu,
- ARMContext* ctx) {
- if (stride == 1) {
- if (flag_relu) {
- if (w_in > 5) {
- conv_depthwise_3x3s1p0_bias_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p0_bias_s_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- } else {
- if (w_in > 5) {
- conv_depthwise_3x3s1p0_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p0_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- } else { //! stride = 2
- if (flag_relu) {
- if (w_in > 8) {
- conv_depthwise_3x3s2p0_bias_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p0_bias_s_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- } else {
- if (w_in > 8) {
- conv_depthwise_3x3s2p0_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p0_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width > 4
- */
-// 4line
-void conv_depthwise_3x3s1p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = w_out >> 2;
- int remain = w_out % 4;
-
- unsigned int size_pad_right = (unsigned int)(6 + (tile_w << 2) - w_in);
- const int remian_idx[4] = {0, 1, 2, 3};
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_s32(vdupq_n_s32(remain), vld1q_s32(remian_idx));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
-#ifdef __aarch64__
- for (int c = 0; c < ch_in; c++) {
- float* dout_ptr = dout_batch + c * size_out_channel;
-
- const float* din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float* wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
- // wr0 = vsetq_lane_f32(0.f, wr0, 3);
- // wr1 = vsetq_lane_f32(0.f, wr1, 3);
- // wr2 = vsetq_lane_f32(0.f, wr2, 3);
-
- float* doutr0 = dout_ptr;
- float* doutr1 = doutr0 + w_out;
- float* doutr2 = doutr1 + w_out;
- float* doutr3 = doutr2 + w_out;
-
- const float* dr0 = din_ch_ptr;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
- const float* dr5 = dr4 + w_in;
-
- const float* din_ptr0 = dr0;
- const float* din_ptr1 = dr1;
- const float* din_ptr2 = dr2;
- const float* din_ptr3 = dr3;
- const float* din_ptr4 = dr4;
- const float* din_ptr5 = dr5;
-
- for (int i = 0; i < h_out; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
-
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 >= h_in) {
- switch (i + 5 - h_in) {
- case 5:
- din_ptr1 = zero_ptr;
- case 4:
- din_ptr2 = zero_ptr;
- case 3:
- din_ptr3 = zero_ptr;
- case 2:
- din_ptr4 = zero_ptr;
- case 1:
- din_ptr5 = zero_ptr;
- case 0:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = tile_w;
- asm volatile(
- "PRFM PLDL1KEEP, [%[din_ptr0]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr1]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr2]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr3]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr4]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr5]] \n"
- "movi v21.4s, #0x0\n" /* out0 = 0 */
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v17 = 2345 */
-
- // mid
- // "cmp %[cnt], #1 \n"
- // "blt 5f \n"
- "4: \n"
- // r0
- "fmla v12.4s , v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r4
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r5
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "bne 4b \n"
-
- // right
- "5: \n"
- "cmp %[remain], #1 \n"
- "blt 0f \n"
- "ld1 {v18.4s, v19.4s}, [%[vmask]] \n"
- "ld1 {v22.4s}, [%[doutr0]] \n"
- "ld1 {v23.4s}, [%[doutr1]] \n"
- "ld1 {v24.4s}, [%[doutr2]] \n"
- "ld1 {v25.4s}, [%[doutr3]] \n"
-
- "bif v0.16b, %[vzero].16b, v18.16b \n"
- "bif v1.16b, %[vzero].16b, v19.16b \n"
- "bif v2.16b, %[vzero].16b, v18.16b \n"
- "bif v3.16b, %[vzero].16b, v19.16b \n"
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
-
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v4.16b, %[vzero].16b, v18.16b \n"
- "bif v5.16b, %[vzero].16b, v19.16b \n"
- "bif v6.16b, %[vzero].16b, v18.16b \n"
- "bif v7.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s, v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v8.16b, %[vzero].16b, v18.16b \n"
- "bif v9.16b, %[vzero].16b, v19.16b \n"
- "bif v10.16b, %[vzero].16b, v18.16b \n"
- "bif v11.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v18.4s}, [%[rmask]] \n"
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v12.16b, v22.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v13.16b, v23.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v14.16b, v24.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "bif v15.16b, v25.16b, v18.16b \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- // end
- "0: \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- dout_ptr = dout_ptr + 4 * w_out;
- }
- }
-#else
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float bias_val = flag_bias ? bias[i] : 0.f;
-
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- const float* din0_ptr = nullptr;
- const float* din1_ptr = nullptr;
- const float* din2_ptr = nullptr;
- const float* din3_ptr = nullptr;
-
- float* doutr0 = nullptr;
- float* doutr1 = nullptr;
-
- float* ptr_zero = const_cast(zero);
-
- for (int i = 0; i < h_out; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
-
- doutr0 = dout_channel;
- doutr1 = dout_channel + w_out;
-
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- //! process bottom pad
- if (i + 3 >= h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din1_ptr = zero_ptr;
- case 2:
- din2_ptr = zero_ptr;
- case 1:
- din3_ptr = zero_ptr;
- case 0:
- din3_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = tile_w;
- unsigned int* rmask_ptr = rmask;
- unsigned int* vmask_ptr = vmask;
- asm volatile(
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r1\n"
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r2\n"
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r3\n"
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
- // mid
- "1: @ right pad entry\n"
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "subs %[cnt], #1 @ loop count minus 1\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "bne 1b @ jump to main loop start "
- "point\n"
-
- // right
- "3: @ right pad entry\n"
- "cmp %[remain], #1 @ check whether has "
- "mid cols\n"
- "blt 0f @ jump to main loop start "
- "point\n"
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d31}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d19}, [%[rmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[rmask]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[dout_ptr1]] @ load din r0\n"
- "vld1.32 {d20-d21}, [%[dout_ptr2]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d8, d16, d19 @ bit select, deal with right pad\n"
- "vbif d9, d17, d23 @ bit select, deal with right pad\n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vbif d10, d20, d19 @ bit select, deal with right "
- "pad\n"
- "vbif d11, d21, d23 @ bit select, deal with right "
- "pad\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
- "0: \n"
-
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [din3_ptr] "+r"(din3_ptr),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- dout_channel += 2 * w_out;
- } //! end of processing mid rows
- }
-#endif
- }
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2
- */
-// w_in > 7
-void conv_depthwise_3x3s2p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
-
- int tile_w = w_out >> 2;
- int cnt_remain = w_out % 4;
-
- unsigned int size_right_remain = (unsigned int)(w_in - (tile_w << 3));
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- float32x4_t wbias;
- float bias_c = 0.f;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- bias_c = bias[i];
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_out; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- dr0 = dr4;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i + 4 >= h_in) {
- switch (i + 4 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- case 0:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = tile_w;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "prfm pldl1keep, [%[inptr0]] \n"
- "prfm pldl1keep, [%[inptr1]] \n"
- "prfm pldl1keep, [%[inptr2]] \n"
- "prfm pldl1keep, [%[inptr3]] \n"
- "prfm pldl1keep, [%[inptr4]] \n"
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
-
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- // mid
- "2: \n"
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, v18.16b, #4 \n" // v10 = {2,4,6,8}
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, v19.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, v20.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, v21.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 4f \n"
- "3: \n"
- "bif v0.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v1.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v2.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v3.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v4.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v5.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "ext v10.16b, v0.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- "bif v6.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v7.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "bif v8.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v9.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "ld1 {v0.4s}, [%[outptr0]] \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
- "ld1 {v1.4s}, [%[outptr1]] \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "bif v16.16b, v0.16b, %[wmask].16b \n" // pipei
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "bif v17.16b, v1.16b, %[wmask].16b \n" // pipei
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
- for (int i = 0; i < h_out; i++) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- //! process bottom pad
- if (i + 2 > h_in) {
- switch (i + 2 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = tile_w;
- unsigned int* mask_ptr = dmask;
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "vmov.u32 q9, #0 \n"
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r1\n"
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n"
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n"
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
-
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- // mid
- "2: \n"
- "vext.32 q6, q10, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din1_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q7, q12, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din2_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "subs %[cnt], #1 \n"
-
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 3f \n"
-
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.f32 {d20-d21}, [%[outptr]] @ load output\n"
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vld1.f32 {d22-d23}, [%[mask_ptr]] @ load mask\n"
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vbif.f32 q3, q10, q11 @ write mask\n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "3: \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-
-// 4line
-void conv_depthwise_3x3s1p0_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = w_out >> 2;
- int remain = w_out % 4;
-
- unsigned int size_pad_right = (unsigned int)(6 + (tile_w << 2) - w_in);
- const int remian_idx[4] = {0, 1, 2, 3};
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_s32(vdupq_n_s32(remain), vld1q_s32(remian_idx));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
-#ifdef __aarch64__
- for (int c = 0; c < ch_in; c++) {
- float* dout_ptr = dout_batch + c * size_out_channel;
-
- const float* din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float* wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
- // wr0 = vsetq_lane_f32(0.f, wr0, 3);
- // wr1 = vsetq_lane_f32(0.f, wr1, 3);
- // wr2 = vsetq_lane_f32(0.f, wr2, 3);
-
- float* doutr0 = dout_ptr;
- float* doutr1 = doutr0 + w_out;
- float* doutr2 = doutr1 + w_out;
- float* doutr3 = doutr2 + w_out;
-
- const float* dr0 = din_ch_ptr;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
- const float* dr5 = dr4 + w_in;
-
- const float* din_ptr0 = dr0;
- const float* din_ptr1 = dr1;
- const float* din_ptr2 = dr2;
- const float* din_ptr3 = dr3;
- const float* din_ptr4 = dr4;
- const float* din_ptr5 = dr5;
-
- for (int i = 0; i < h_out; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
-
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 >= h_in) {
- switch (i + 5 - h_in) {
- case 5:
- din_ptr1 = zero_ptr;
- case 4:
- din_ptr2 = zero_ptr;
- case 3:
- din_ptr3 = zero_ptr;
- case 2:
- din_ptr4 = zero_ptr;
- case 1:
- din_ptr5 = zero_ptr;
- case 0:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = tile_w;
- asm volatile(
- "PRFM PLDL1KEEP, [%[din_ptr0]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr1]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr2]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr3]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr4]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr5]] \n"
- "movi v21.4s, #0x0\n" /* out0 = 0 */
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v17 = 2345 */
-
- // mid
- "4: \n"
- // r0
- "fmla v12.4s , v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /* relu */
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- // r4
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /* relu */
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- // r5
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /* relu */
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /* relu */
-
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "bne 4b \n"
-
- // right
- "5: \n"
- "cmp %[remain], #1 \n"
- "blt 0f \n"
- "ld1 {v18.4s, v19.4s}, [%[vmask]] \n"
- "ld1 {v22.4s}, [%[doutr0]] \n"
- "ld1 {v23.4s}, [%[doutr1]] \n"
- "ld1 {v24.4s}, [%[doutr2]] \n"
- "ld1 {v25.4s}, [%[doutr3]] \n"
-
- "bif v0.16b, %[vzero].16b, v18.16b \n"
- "bif v1.16b, %[vzero].16b, v19.16b \n"
- "bif v2.16b, %[vzero].16b, v18.16b \n"
- "bif v3.16b, %[vzero].16b, v19.16b \n"
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
-
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v4.16b, %[vzero].16b, v18.16b \n"
- "bif v5.16b, %[vzero].16b, v19.16b \n"
- "bif v6.16b, %[vzero].16b, v18.16b \n"
- "bif v7.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s, v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v8.16b, %[vzero].16b, v18.16b \n"
- "bif v9.16b, %[vzero].16b, v19.16b \n"
- "bif v10.16b, %[vzero].16b, v18.16b \n"
- "bif v11.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
- "ld1 {v18.4s}, [%[rmask]] \n"
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /* relu */
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v12.16b, v22.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /* relu */
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v13.16b, v23.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /* relu */
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v14.16b, v24.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /* relu */
-
- "bif v15.16b, v25.16b, v18.16b \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- // end
- "0: \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- dout_ptr = dout_ptr + 4 * w_out;
- }
- }
-#else
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float bias_val = flag_bias ? bias[i] : 0.f;
-
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- const float* din0_ptr = nullptr;
- const float* din1_ptr = nullptr;
- const float* din2_ptr = nullptr;
- const float* din3_ptr = nullptr;
-
- float* doutr0 = nullptr;
- float* doutr1 = nullptr;
-
- float* ptr_zero = const_cast(zero);
-
- for (int i = 0; i < h_out; i += 2) {
- //! process top pad pad_h = 1
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
-
- doutr0 = dout_channel;
- doutr1 = dout_channel + w_out;
-
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- //! process bottom pad
- if (i + 3 >= h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din1_ptr = zero_ptr;
- case 2:
- din2_ptr = zero_ptr;
- case 1:
- din3_ptr = zero_ptr;
- case 0:
- din3_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = tile_w;
- unsigned int* rmask_ptr = rmask;
- unsigned int* vmask_ptr = vmask;
- asm volatile(
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r1\n"
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r2\n"
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r3\n"
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // mid
- "1: @ right pad entry\n"
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "subs %[cnt], #1 @ loop count minus 1\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "bne 1b @ jump to main loop start "
- "point\n"
-
- // right
- "3: @ right pad entry\n"
- "cmp %[remain], #1 @ check whether has "
- "mid cols\n"
- "blt 0f @ jump to main loop start "
- "point\n"
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d31}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d19}, [%[rmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[rmask]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[dout_ptr1]] @ load din r0\n"
- "vld1.32 {d20-d21}, [%[dout_ptr2]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d8, d16, d19 @ bit select, deal with right pad\n"
- "vbif d9, d17, d23 @ bit select, deal with right pad\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "vbif d10, d20, d19 @ bit select, deal with right "
- "pad\n"
- "vbif d11, d21, d23 @ bit select, deal with right "
- "pad\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
- "0: \n"
-
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [din3_ptr] "+r"(din3_ptr),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- dout_channel += 2 * w_out;
- } //! end of processing mid rows
- }
-#endif
- }
-}
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, with reulu
- */
-// w_in > 7
-void conv_depthwise_3x3s2p0_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
-
- int tile_w = w_out >> 2;
- int cnt_remain = w_out % 4;
-
- unsigned int size_right_remain = (unsigned int)(w_in - (tile_w << 3));
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- float32x4_t wbias;
- float bias_c = 0.f;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- bias_c = bias[i];
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_out; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- dr0 = dr4;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i + 4 >= h_in) {
- switch (i + 4 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- case 0:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = tile_w;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "prfm pldl1keep, [%[inptr0]] \n"
- "prfm pldl1keep, [%[inptr1]] \n"
- "prfm pldl1keep, [%[inptr2]] \n"
- "prfm pldl1keep, [%[inptr3]] \n"
- "prfm pldl1keep, [%[inptr4]] \n"
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
-
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- // mid
- "2: \n"
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, v18.16b, #4 \n" // v10 = {2,4,6,8}
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, v19.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, v20.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, v21.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */
-
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 4f \n"
- "3: \n"
- "bif v0.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v1.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v2.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v3.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v4.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v5.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "ext v10.16b, v0.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- "bif v6.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v7.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "bif v8.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v9.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "ld1 {v0.4s}, [%[outptr0]] \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
- "ld1 {v1.4s}, [%[outptr1]] \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "bif v16.16b, v0.16b, %[wmask].16b \n" // pipei
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */
-
- "bif v17.16b, v1.16b, %[wmask].16b \n" // pipei
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
- for (int i = 0; i < h_out; i++) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- //! process bottom pad
- if (i + 2 > h_in) {
- switch (i + 2 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = tile_w;
- unsigned int* mask_ptr = dmask;
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "vmov.u32 q9, #0 \n"
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r1\n"
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n"
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n"
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
-
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- // mid
- "2: \n"
- "vext.32 q6, q10, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din1_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q7, q12, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din2_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "subs %[cnt], #1 \n"
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 3f \n"
-
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.f32 {d20-d21}, [%[outptr]] @ load output\n"
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vld1.f32 {d22-d23}, [%[mask_ptr]] @ load mask\n"
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "vbif.f32 q3, q10, q11 @ write mask\n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "3: \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
- const float zero_ptr[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp1 =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(6 - w_in));
- uint32x4_t vmask_rp2 =
- vcgeq_s32(vld1q_s32(right_pad_idx + 4), vdupq_n_s32(6 - w_in));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float* dout_channel = dout_batch + i * size_out_channel;
- const float* din_channel = din_batch + i * size_in_channel;
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- float* doutr0 = dout_channel;
- float* doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_out; j += 2) {
- const float* dr0 = din_channel + j * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- doutr0 = dout_channel + j * w_out;
- doutr1 = doutr0 + w_out;
-
- if (j + 3 >= h_in) {
- switch (j + 3 - h_in) {
- case 3:
- dr1 = zero_ptr;
- case 2:
- dr2 = zero_ptr;
- case 1:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- case 0:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- default:
- break;
- }
- }
-#ifdef __aarch64__
- asm volatile(
- "prfm pldl1keep, [%[din0]]\n"
- "prfm pldl1keep, [%[din1]]\n"
- "prfm pldl1keep, [%[din2]]\n"
- "prfm pldl1keep, [%[din3]]\n"
-
- "ld1 {v0.4s, v1.4s}, [%[din0]]\n"
- "ld1 {v2.4s, v3.4s}, [%[din1]]\n"
- "ld1 {v4.4s, v5.4s}, [%[din2]]\n"
- "ld1 {v6.4s, v7.4s}, [%[din3]]\n"
-
- "bif v0.16b, %[zero].16b, %[mask1].16b\n" // d0_1234
- "bif v1.16b, %[zero].16b, %[mask2].16b\n" // d0_1234
-
- "bif v2.16b, %[zero].16b, %[mask1].16b\n" // d1_1234
- "bif v3.16b, %[zero].16b, %[mask2].16b\n" // d1_1234
-
- "bif v4.16b, %[zero].16b, %[mask1].16b\n" // d2_1234
- "bif v5.16b, %[zero].16b, %[mask2].16b\n" // d2_1234
-
- "bif v6.16b, %[zero].16b, %[mask1].16b\n" // d3_1234
- "bif v7.16b, %[zero].16b, %[mask2].16b\n" // d3_1234
-
- "ext v8.16b, v0.16b, v1.16b, #4\n" // d1_2345
- "ext v9.16b, v0.16b, v1.16b, #8\n" // d1_3450
-
- "and v12.16b, %[vbias].16b, %[vbias].16b \n" // v12 = vbias
- "and v13.16b, %[vbias].16b, %[vbias].16b \n" // v13 = vbias
-
- // r0
- "fmul v10.4s, v0.4s, %[wr0].s[0]\n" // d0_1234 * w0[0]
- "fmul v11.4s, v8.4s, %[wr0].s[1]\n" // d1_2345 * w0[1]
- "fmla v12.4s, v9.4s, %[wr0].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v2.16b, v3.16b, #4\n" // d1_2345
- "ext v9.16b, v2.16b, v3.16b, #8\n" // d1_3450
-
- // r1
- "fmul v14.4s, v2.4s, %[wr0].s[0]\n" // d0_1234 * w0[0]
- "fmla v10.4s, v2.4s, %[wr1].s[0]\n" // d0_1234 * w0[0]
-
- "fmul v15.4s, v8.4s, %[wr0].s[1]\n" // d1_2345 * w0[1]
- "fmla v11.4s, v8.4s, %[wr1].s[1]\n" // d1_2345 * w0[1]
-
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n" // d0_3456 * w0[2]
- "fmla v12.4s, v9.4s, %[wr1].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v4.16b, v5.16b, #4\n" // d1_2345
- "ext v9.16b, v4.16b, v5.16b, #8\n" // d1_3450
-
- // r2
- "fmla v14.4s, v4.4s, %[wr1].s[0]\n" // d0_1234 * w0[0]
- "fmla v10.4s, v4.4s, %[wr2].s[0]\n" // d0_1234 * w0[0]
-
- "fmla v15.4s, v8.4s, %[wr1].s[1]\n" // d1_2345 * w0[1]
- "fmla v11.4s, v8.4s, %[wr2].s[1]\n" // d1_2345 * w0[1]
-
- "fmla v13.4s, v9.4s, %[wr1].s[2]\n" // d0_3456 * w0[2]
- "fmla v12.4s, v9.4s, %[wr2].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v6.16b, v7.16b, #4\n" // d1_2345
- "ext v9.16b, v6.16b, v7.16b, #8\n" // d1_3450
-
- // r3
- "fmla v14.4s, v6.4s, %[wr2].s[0]\n" // d0_1234 * w0[0]
-
- "fmla v15.4s, v8.4s, %[wr2].s[1]\n" // d1_2345 * w0[1]
-
- "fadd v12.4s, v12.4s, v10.4s\n"
-
- "fmla v13.4s, v9.4s, %[wr2].s[2]\n" // d0_3456 * w0[2]
-
- "fadd v12.4s, v12.4s, v11.4s\n" // out1
- "fadd v13.4s, v13.4s, v14.4s\n" // out2
- "fadd v13.4s, v13.4s, v15.4s\n" // out2
-
- "prfm pldl1keep, [%[out1]]\n"
- "prfm pldl1keep, [%[out2]]\n"
-
- "st1 {v12.4s}, [%[out1]]\n"
- "st1 {v13.4s}, [%[out2]]\n"
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vbias] "w"(wbias),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [zero] "w"(vzero),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
-#else
- unsigned int* vmask_ptr = vmask;
- float bias_val = flag_bias ? bias[i] : 0.f;
- asm volatile(
- "pld [%[din0]]\n"
- "pld [%[din1]]\n"
- "pld [%[din2]]\n"
- "pld [%[din3]]\n"
-
- "vld1.32 {d16-d18}, [%[din0]] @ load din r0\n"
- "vld1.32 {d20-d22}, [%[din1]] @ load din r1\n"
- "vld1.32 {d24-d26}, [%[din2]] @ load din r2\n"
- "vld1.32 {d28-d30}, [%[din3]] @ load din r3\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
-
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
-
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmul.f32 q8, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmul.f32 q10, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmul.f32 q9, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmul.f32 q11, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q8, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q10, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q9, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q11, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vmla.f32 q8, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
- "vadd.f32 q4, q4, q10 @ q4 += q10 \n"
-
- "pld [%[out1]]\n"
- "pld [%[out2]]\n"
-
- "vmla.f32 q9, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
- "vadd.f32 q4, q4, q11 @ q4 += q10 \n"
-
- "vadd.f32 q5, q5, q8 @ q4 += q10 \n"
- "vadd.f32 q5, q5, q9 @ q4 += q10 \n"
-
- "vst1.32 {d8-d9}, [%[out1]] @ store result, add pointer\n"
- "vst1.32 {d10-d11}, [%[out2]] @ store result, add pointer\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [bias_val] "r"(bias_val),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 4
- */
-
-void conv_depthwise_3x3s2p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- float out_buf[4];
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- for (int j = 0; j < h_out; ++j) {
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
-
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "movi v9.4s, #0 \n"
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]], #32 \n"
-
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" // v10={0,2,4,6}
- // v11={1,3,5,7}
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" // v13={0,2,4,6}
- // v12={1,3,5,7}
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" // v14={0,2,4,6}
- // v15={1,3,5,7}
- "and v4.16b, %[bias].16b, %[bias].16b \n" // v10 = vbias
-
- "bif v10.16b, v9.16b, v6.16b \n"
- "bif v11.16b, v9.16b, v7.16b \n"
- "bif v12.16b, v9.16b, v6.16b \n"
- "bif v13.16b, v9.16b, v7.16b \n"
- "bif v14.16b, v9.16b, v6.16b \n"
- "bif v15.16b, v9.16b, v7.16b \n"
-
- "ext v6.16b, v10.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
- "ext v7.16b, v12.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
- "ext v8.16b, v14.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
-
- "fmla v4.4s, v10.4s, %[wr0].s[0] \n" // 0246 * w00
- "fmul v5.4s, v11.4s, %[wr0].s[1] \n" // 1357 * w01
- "fmul v16.4s, v6.4s, %[wr0].s[2] \n" // 2468 * w02
-
- "fmla v4.4s, v12.4s, %[wr1].s[0] \n" // v12 * w11
- "fmla v5.4s, v13.4s, %[wr1].s[1] \n" // v13 * w12
- "fmla v16.4s, v7.4s, %[wr1].s[2] \n" // v7 * w10
-
- "fmla v4.4s, v14.4s, %[wr2].s[0] \n" // v14 * w20
- "fmla v5.4s, v15.4s, %[wr2].s[1] \n" // v15 * w21
- "fmla v16.4s, v8.4s, %[wr2].s[2] \n" // v8 * w22
-
- "fadd v4.4s, v4.4s, v5.4s \n"
- "fadd v4.4s, v4.4s, v16.4s \n"
-
- // "fadd v4.4s, v4.4s, %[bias].4s \n"
- "st1 {v4.4s}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16");
-
-#else
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "vmov.u32 q9, #0 \n"
- "vld1.f32 {d12-d15}, [%[mask_ptr]] @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q3 =
- // vbias
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // q10={0,2,4,6} q11={1,3,5,7}
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // q13={0,2,4,6} q12={1,3,5,7}
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // q14={0,2,4,6} q15={1,3,5,7}
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,0}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q7 = {2,4,6,0}
- "vext.32 q8, q14, q9, #1 @ shift left 1 \n" // q8 = {2,4,6,0}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // {0,2,4,6}
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // {1,3,5,7}
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // {2,4,6,0}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q12 * w11
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q13 * w12
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q7 * w10
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q14 * w20
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q15 * w21
- "vmla.f32 q3, q8, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q8 * w22
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vst1.32 {d6-d7}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf),
- [mask_ptr] "r"(dmask)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- }
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p0_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
- const float zero_ptr[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp1 =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(6 - w_in));
- uint32x4_t vmask_rp2 =
- vcgeq_s32(vld1q_s32(right_pad_idx + 4), vdupq_n_s32(6 - w_in));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float* dout_channel = dout_batch + i * size_out_channel;
- const float* din_channel = din_batch + i * size_in_channel;
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- float* doutr0 = dout_channel;
- float* doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_out; j += 2) {
- const float* dr0 = din_channel + j * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- doutr0 = dout_channel + j * w_out;
- doutr1 = doutr0 + w_out;
-
- if (j + 3 >= h_in) {
- switch (j + 3 - h_in) {
- case 3:
- dr1 = zero_ptr;
- case 2:
- dr2 = zero_ptr;
- case 1:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- case 0:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- default:
- break;
- }
- }
-#ifdef __aarch64__
- asm volatile(
- "prfm pldl1keep, [%[din0]]\n"
- "prfm pldl1keep, [%[din1]]\n"
- "prfm pldl1keep, [%[din2]]\n"
- "prfm pldl1keep, [%[din3]]\n"
-
- "ld1 {v0.4s, v1.4s}, [%[din0]]\n"
- "ld1 {v2.4s, v3.4s}, [%[din1]]\n"
- "ld1 {v4.4s, v5.4s}, [%[din2]]\n"
- "ld1 {v6.4s, v7.4s}, [%[din3]]\n"
-
- "bif v0.16b, %[zero].16b, %[mask1].16b\n" // d0_1234
- "bif v1.16b, %[zero].16b, %[mask2].16b\n" // d0_1234
-
- "bif v2.16b, %[zero].16b, %[mask1].16b\n" // d1_1234
- "bif v3.16b, %[zero].16b, %[mask2].16b\n" // d1_1234
-
- "bif v4.16b, %[zero].16b, %[mask1].16b\n" // d2_1234
- "bif v5.16b, %[zero].16b, %[mask2].16b\n" // d2_1234
-
- "bif v6.16b, %[zero].16b, %[mask1].16b\n" // d3_1234
- "bif v7.16b, %[zero].16b, %[mask2].16b\n" // d3_1234
-
- "ext v8.16b, v0.16b, v1.16b, #4\n" // d1_2345
- "ext v9.16b, v0.16b, v1.16b, #8\n" // d1_3450
-
- "and v12.16b, %[vbias].16b, %[vbias].16b \n" // v12 = vbias
- "and v13.16b, %[vbias].16b, %[vbias].16b \n" // v13 = vbias
-
- // r0
- "fmul v10.4s, v0.4s, %[wr0].s[0]\n" // d0_1234 * w0[0]
- "fmul v11.4s, v8.4s, %[wr0].s[1]\n" // d1_2345 * w0[1]
- "fmla v12.4s, v9.4s, %[wr0].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v2.16b, v3.16b, #4\n" // d1_2345
- "ext v9.16b, v2.16b, v3.16b, #8\n" // d1_3450
-
- // r1
- "fmul v14.4s, v2.4s, %[wr0].s[0]\n" // d0_1234 * w0[0]
- "fmla v10.4s, v2.4s, %[wr1].s[0]\n" // d0_1234 * w0[0]
-
- "fmul v15.4s, v8.4s, %[wr0].s[1]\n" // d1_2345 * w0[1]
- "fmla v11.4s, v8.4s, %[wr1].s[1]\n" // d1_2345 * w0[1]
-
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n" // d0_3456 * w0[2]
- "fmla v12.4s, v9.4s, %[wr1].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v4.16b, v5.16b, #4\n" // d1_2345
- "ext v9.16b, v4.16b, v5.16b, #8\n" // d1_3450
-
- // r2
- "fmla v14.4s, v4.4s, %[wr1].s[0]\n" // d0_1234 * w0[0]
- "fmla v10.4s, v4.4s, %[wr2].s[0]\n" // d0_1234 * w0[0]
-
- "fmla v15.4s, v8.4s, %[wr1].s[1]\n" // d1_2345 * w0[1]
- "fmla v11.4s, v8.4s, %[wr2].s[1]\n" // d1_2345 * w0[1]
-
- "fmla v13.4s, v9.4s, %[wr1].s[2]\n" // d0_3456 * w0[2]
- "fmla v12.4s, v9.4s, %[wr2].s[2]\n" // d0_3456 * w0[2]
-
- "ext v8.16b, v6.16b, v7.16b, #4\n" // d1_2345
- "ext v9.16b, v6.16b, v7.16b, #8\n" // d1_3450
-
- // r3
- "fmla v14.4s, v6.4s, %[wr2].s[0]\n" // d0_1234 * w0[0]
-
- "fmla v15.4s, v8.4s, %[wr2].s[1]\n" // d1_2345 * w0[1]
-
- "fadd v12.4s, v12.4s, v10.4s\n"
-
- "fmla v13.4s, v9.4s, %[wr2].s[2]\n" // d0_3456 * w0[2]
-
- "fadd v12.4s, v12.4s, v11.4s\n" // out1
- "fadd v13.4s, v13.4s, v14.4s\n" // out2
- "fadd v13.4s, v13.4s, v15.4s\n" // out2
-
- "prfm pldl1keep, [%[out1]]\n"
- "prfm pldl1keep, [%[out2]]\n"
- "fmax v12.4s, v12.4s, %[zero].4s \n"
- "fmax v13.4s, v13.4s, %[zero].4s \n"
-
- "st1 {v12.4s}, [%[out1]]\n"
- "st1 {v13.4s}, [%[out2]]\n"
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vbias] "w"(wbias),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [zero] "w"(vzero),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
-#else
- unsigned int* vmask_ptr = vmask;
- float bias_val = flag_bias ? bias[i] : 0.f;
- asm volatile(
- "pld [%[din0]]\n"
- "pld [%[din1]]\n"
- "pld [%[din2]]\n"
- "pld [%[din3]]\n"
-
- "vld1.32 {d16-d18}, [%[din0]] @ load din r0\n"
- "vld1.32 {d20-d22}, [%[din1]] @ load din r1\n"
- "vld1.32 {d24-d26}, [%[din2]] @ load din r2\n"
- "vld1.32 {d28-d30}, [%[din3]] @ load din r3\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
-
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
-
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmul.f32 q8, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmul.f32 q10, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmul.f32 q9, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmul.f32 q11, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q8, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q10, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q9, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q11, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vmla.f32 q8, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
- "vadd.f32 q4, q4, q10 @ q4 += q10 \n"
-
- "pld [%[out1]]\n"
- "pld [%[out2]]\n"
-
- "vmla.f32 q9, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
- "vadd.f32 q4, q4, q11 @ q4 += q10 \n"
-
- "vadd.f32 q5, q5, q8 @ q4 += q10 \n"
- "vadd.f32 q5, q5, q9 @ q4 += q10 \n"
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "vst1.32 {d8-d9}, [%[out1]] @ store result, add pointer\n"
- "vst1.32 {d10-d11}, [%[out2]] @ store result, add pointer\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [bias_val] "r"(bias_val),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- // doutr0 = doutr1;
- // doutr1 += w_out;
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 7
- */
-void conv_depthwise_3x3s2p0_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- float out_buf[4];
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- for (int j = 0; j < h_out; ++j) {
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
-
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "movi v9.4s, #0 \n"
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]] \n"
-
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" // v10={0,2,4,6}
- // v11={1,3,5,7}
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" // v13={0,2,4,6}
- // v12={1,3,5,7}
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" // v14={0,2,4,6}
- // v15={1,3,5,7}
- "and v4.16b, %[bias].16b, %[bias].16b \n" // v10 = vbias
-
- "bif v10.16b, v9.16b, v6.16b \n"
- "bif v11.16b, v9.16b, v7.16b \n"
- "bif v12.16b, v9.16b, v6.16b \n"
- "bif v13.16b, v9.16b, v7.16b \n"
- "bif v14.16b, v9.16b, v6.16b \n"
- "bif v15.16b, v9.16b, v7.16b \n"
-
- "ext v6.16b, v10.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
- "ext v7.16b, v12.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
- "ext v8.16b, v14.16b, v9.16b, #4 \n" // v6 =
- // {2,4,6,8}
-
- "fmla v4.4s, v10.4s, %[wr0].s[0] \n" // 0246 * w00
- "fmul v5.4s, v11.4s, %[wr0].s[1] \n" // 1357 * w01
- "fmul v16.4s, v6.4s, %[wr0].s[2] \n" // 2468 * w02
-
- "fmla v4.4s, v12.4s, %[wr1].s[0] \n" // v12 * w11
- "fmla v5.4s, v13.4s, %[wr1].s[1] \n" // v13 * w12
- "fmla v16.4s, v7.4s, %[wr1].s[2] \n" // v7 * w10
-
- "fmla v4.4s, v14.4s, %[wr2].s[0] \n" // v14 * w20
- "fmla v5.4s, v15.4s, %[wr2].s[1] \n" // v15 * w21
- "fmla v16.4s, v8.4s, %[wr2].s[2] \n" // v8 * w22
-
- "fadd v4.4s, v4.4s, v5.4s \n"
- "fadd v4.4s, v4.4s, v16.4s \n"
- "fmax v4.4s, v4.4s, v9.4s \n"
-
- // "fadd v4.4s, v4.4s, %[bias].4s \n"
- "st1 {v4.4s}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf),
- [mask_ptr] "r"(mask_ptr)
- : "cc",
- "memory",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16");
-
-#else
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "vmov.u32 q9, #0 \n"
- "vld1.f32 {d12-d15}, [%[mask_ptr]] @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q3 =
- // vbias
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // q10={0,2,4,6} q11={1,3,5,7}
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // q13={0,2,4,6} q12={1,3,5,7}
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // q14={0,2,4,6} q15={1,3,5,7}
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,0}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q7 = {2,4,6,0}
- "vext.32 q8, q14, q9, #1 @ shift left 1 \n" // q8 = {2,4,6,0}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // {0,2,4,6}
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // {1,3,5,7}
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // {2,4,6,0}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q12 * w11
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q13 * w12
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q7 * w10
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q14 * w20
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q15 * w21
- "vmla.f32 q3, q8, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q8 * w22
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "vst1.32 {d6-d7}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf),
- [mask_ptr] "r"(mask_ptr)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- }
- }
- }
-}
-
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/conv_depthwise_3x3p1.cc b/lite/backends/arm/math/conv_depthwise_3x3p1.cc
deleted file mode 100644
index 6f28d48d6d2bdd60e0c33f9b4b753835337fc8a4..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv_depthwise_3x3p1.cc
+++ /dev/null
@@ -1,4850 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/arm/math/conv_depthwise.h"
-#include
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-
-void conv_depthwise_3x3s1p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s1p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s2p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s1p1_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s1p1_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p1_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-//! for input width <= 4
-void conv_depthwise_3x3s2p1_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3p1_fp32(const float* din,
- float* dout,
- int num,
- int ch_out,
- int h_out,
- int w_out,
- int ch_in,
- int h_in,
- int w_in,
- const float* weights,
- const float* bias,
- int stride,
- bool flag_bias,
- bool flag_relu,
- ARMContext* ctx) {
- if (stride == 1) {
- if (flag_relu) {
- if (w_in > 4) {
- conv_depthwise_3x3s1p1_bias_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p1_bias_s_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- } else {
- if (w_in > 4) {
- conv_depthwise_3x3s1p1_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p1_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- } else { //! stride = 2
- if (flag_relu) {
- if (w_in > 7) {
- conv_depthwise_3x3s2p1_bias_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p1_bias_s_relu(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- } else {
- if (w_in > 7) {
- conv_depthwise_3x3s2p1_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p1_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width > 4
- */
-// 4line
-void conv_depthwise_3x3s1p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- // printf("conv3x3_dw start \n");
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = (w_in + 3) >> 2;
- int cnt_col = tile_w - 2;
-
- unsigned int size_pad_right = (unsigned int)(1 + (tile_w << 2) - w_in);
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
-#ifdef __aarch64__
- for (int c = 0; c < ch_in; c++) {
- float* dout_ptr = dout_batch + c * size_out_channel;
-
- const float* din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float* wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
-
- float* doutr0 = dout_ptr;
- float* doutr1 = doutr0 + w_out;
- float* doutr2 = doutr1 + w_out;
- float* doutr3 = doutr2 + w_out;
-
- const float* dr0 = din_ch_ptr;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
- const float* dr5 = dr4 + w_in;
-
- const float* din_ptr0 = dr0;
- const float* din_ptr1 = dr1;
- const float* din_ptr2 = dr2;
- const float* din_ptr3 = dr3;
- const float* din_ptr4 = dr4;
- const float* din_ptr5 = dr5;
-
- for (int i = 0; i < h_in; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
- if (i == 0) {
- din_ptr0 = zero_ptr;
- din_ptr1 = dr0;
- din_ptr2 = dr1;
- din_ptr3 = dr2;
- din_ptr4 = dr3;
- din_ptr5 = dr4;
- dr0 = dr3;
- dr1 = dr4;
- dr2 = dr5;
- } else {
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- }
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 > h_in) {
- switch (i + 5 - h_in) {
- case 5:
- din_ptr1 = zero_ptr;
- case 4:
- din_ptr2 = zero_ptr;
- case 3:
- din_ptr3 = zero_ptr;
- case 2:
- din_ptr4 = zero_ptr;
- case 1:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = cnt_col;
- asm volatile(
- "PRFM PLDL1KEEP, [%[din_ptr0]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr1]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr2]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr3]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr4]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr5]] \n"
- "movi v21.4s, #0x0\n" /* out0 = 0 */
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "ext v16.16b, %[vzero].16b, v0.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
-
- // left
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[1]\n" /* outr00 += din0_0123 *
- w0[1]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "sub %[din_ptr0], %[din_ptr0], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr1], %[din_ptr1], #4 \n" /* din_ptr0-- */
-
- "fmla v12.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din0_0012 *
- w0[0]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "sub %[din_ptr2], %[din_ptr2], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr3], %[din_ptr3], #4 \n" /* din_ptr0-- */
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_1234 *
- w0[2]*/
-
- "ext v16.16b, %[vzero].16b, v2.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[1]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v2.4s, %[w1].s[1]\n" /* outr00 += din1_0123 *
- w1[1]*/
- "sub %[din_ptr4], %[din_ptr4], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr5], %[din_ptr5], #4 \n" /* din_ptr0-- */
-
- "fmla v13.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v4.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[1]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v4.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v12.4s , v4.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v6.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[1]\n" /*outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v6.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v13.4s , v6.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v8.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234 */
-
- // r4
- "fmla v15.4s , v8.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v14.4s , v8.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n" /* vst1q_f32() */
- "st1 {v13.4s}, [%[doutr1]], #16 \n" /* vst1q_f32() */
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v10.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234 */
-
- // r5
- "fmla v15.4s , v10.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n" /* vst1q_f32() */
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
-
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n" /* vst1q_f32() */
- "cmp %[cnt], #1 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "blt 3f \n"
- // mid
- "1: \n"
- // r0
- "fmla v12.4s , v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "bne 1b \n"
-
- // right
- "3: \n"
- "ld1 {v18.4s, v19.4s}, [%[vmask]] \n"
- "ld1 {v22.4s}, [%[doutr0]] \n"
- "ld1 {v23.4s}, [%[doutr1]] \n"
- "ld1 {v24.4s}, [%[doutr2]] \n"
- "ld1 {v25.4s}, [%[doutr3]] \n"
-
- "bif v0.16b, %[vzero].16b, v18.16b \n"
- "bif v1.16b, %[vzero].16b, v19.16b \n"
- "bif v2.16b, %[vzero].16b, v18.16b \n"
- "bif v3.16b, %[vzero].16b, v19.16b \n"
-
- "bif v4.16b, %[vzero].16b, v18.16b \n"
- "bif v5.16b, %[vzero].16b, v19.16b \n"
- "bif v6.16b, %[vzero].16b, v18.16b \n"
- "bif v7.16b, %[vzero].16b, v19.16b \n"
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v8.16b, %[vzero].16b, v18.16b \n"
- "bif v9.16b, %[vzero].16b, v19.16b \n"
- "bif v10.16b, %[vzero].16b, v18.16b \n"
- "bif v11.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s, v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v18.4s}, [%[rmask]] \n"
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v12.16b, v22.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v13.16b, v23.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v14.16b, v24.16b, v18.16b \n"
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "bif v15.16b, v25.16b, v18.16b \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- dout_ptr = dout_ptr + 4 * w_out;
- }
- }
-#else
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float bias_val = flag_bias ? bias[i] : 0.f;
-
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- const float* din0_ptr = nullptr;
- const float* din1_ptr = nullptr;
- const float* din2_ptr = nullptr;
- const float* din3_ptr = nullptr;
-
- float* doutr0 = nullptr;
- float* doutr1 = nullptr;
-
- float* ptr_zero = const_cast(zero);
-
- for (int i = 0; i < h_in; i += 2) {
- //! process top pad pad_h = 1
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
-
- doutr0 = dout_channel;
- doutr1 = dout_channel + w_out;
- // unsigned int* rst_mask = rmask;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- din3_ptr = dr2;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr3;
- dr3 = dr2 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- }
- //! process bottom pad
- if (i + 3 > h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din1_ptr = zero_ptr;
- case 2:
- din2_ptr = zero_ptr;
- case 1:
- din3_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = cnt_col;
- unsigned int* rmask_ptr = rmask;
- unsigned int* vmask_ptr = vmask;
- asm volatile(
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vld1.32 {d16-d18}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d22}, [%[din1_ptr]]! @ load din r1\n"
- "vld1.32 {d24-d26}, [%[din2_ptr]]! @ load din r2\n"
- "vld1.32 {d28-d30}, [%[din3_ptr]]! @ load din r3\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vext.32 q6, %q[vzero], q8, #3 @ 0012\n"
- "vext.32 q7, q8, q9, #1 @ 1234\n"
-
- // left
- // r0
- "vmla.f32 q4, q8, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "sub %[din0_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din1_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din2_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din3_ptr], #12 @ 1pad + 2 float data overlap\n"
-
- "vmla.f32 q4, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q10, #3 @ 0012\n"
- "vext.32 q7, q10, q11, #1 @ 1234\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q10, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q12, #3 @ 0012\n"
- "vext.32 q7, q12, q13, #1 @ 1234\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q12, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q14, #3 @ 0012\n"
- "vext.32 q7, q14, q15, #1 @ 1234\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
- "cmp %[cnt], #1 @ check whether has "
- "mid cols\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
- "blt 3f @ jump to main loop start "
- "point\n"
-
- // mid
- "1: @ right pad entry\n"
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "subs %[cnt], #1 @ loop count minus 1\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "bne 1b @ jump to main loop start "
- "point\n"
-
- // right
- "3: @ right pad entry\n"
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d31}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d19}, [%[rmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[rmask]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[dout_ptr1]] @ load din r0\n"
- "vld1.32 {d20-d21}, [%[dout_ptr2]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d8, d16, d19 @ bit select, deal with right pad\n"
- "vbif d9, d17, d23 @ bit select, deal with right pad\n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vbif d10, d20, d19 @ bit select, deal with right "
- "pad\n"
- "vbif d11, d21, d23 @ bit select, deal with right "
- "pad\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [din3_ptr] "+r"(din3_ptr),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- dout_channel += 2 * w_out;
- } //! end of processing mid rows
- }
-#endif
- }
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2
- */
-// w_in > 7
-void conv_depthwise_3x3s2p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- int size_pad_bottom = h_out * 2 - h_in;
-
- int cnt_col = (w_out >> 2) - 2;
- int size_right_remain = w_in - (7 + cnt_col * 8);
- if (size_right_remain >= 9) {
- cnt_col++;
- size_right_remain -= 8;
- }
- int cnt_remain = (size_right_remain == 8) ? 4 : (w_out % 4); //
-
- int size_right_pad = w_out * 2 - w_in;
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- float32x4_t wbias;
- float bias_c = 0.f;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- bias_c = bias[i];
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_in; i += 4) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- din3_ptr = dr2;
- din4_ptr = dr3;
- dr0 = dr3;
- dr1 = dr4;
- } else {
- dr0 = dr4;
- dr1 = dr0 + w_in;
- }
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i + 4 > h_in) {
- switch (i + 4 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i / 2 + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = cnt_col;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "prfm pldl1keep, [%[inptr0]] \n"
- "prfm pldl1keep, [%[inptr1]] \n"
- "prfm pldl1keep, [%[inptr2]] \n"
- "prfm pldl1keep, [%[inptr3]] \n"
- "prfm pldl1keep, [%[inptr4]] \n"
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
-
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "ext v10.16b, %[vzero].16b, v1.16b, #12 \n" // v10 = {0,1,3,5}
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[1] \n" // {0,2,4,6} * w01
- "fmul v12.4s, v1.4s, %[w0].s[2] \n" // {1,3,5,7} * w02
- "fmla v16.4s, v10.4s, %[w0].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v3.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr0], %[inptr0], #4 \n"
- "sub %[inptr1], %[inptr1], #4 \n"
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[1] \n" // {0,2,4,6} * w01
- "fmla v12.4s, v3.4s, %[w1].s[2] \n" // {1,3,5,7} * w02
- "fmla v16.4s, v10.4s, %[w1].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v5.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr2], %[inptr2], #4 \n"
- "sub %[inptr3], %[inptr3], #4 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[1] \n" // {0,2,4,6} * w01
- "fmla v11.4s, v4.4s, %[w2].s[1] \n" // {0,2,4,6} * w01
-
- "fmul v14.4s, v5.4s, %[w0].s[2] \n" // {1,3,5,7} * w02
- "fmla v12.4s, v5.4s, %[w2].s[2] \n" // {1,3,5,7} * w02
-
- "fmla v17.4s, v10.4s, %[w0].s[0] \n" // {0,1,3,5} * w00
- "fmla v16.4s, v10.4s, %[w2].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v7.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr4], %[inptr4], #4 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[1] \n" // {0,2,4,6} * w01
- "fmla v14.4s, v7.4s, %[w1].s[2] \n" // {1,3,5,7} * w02
- "fmla v17.4s, v10.4s, %[w1].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v9.16b, #12 \n" // v10 = {0,1,3,5}
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[1] \n" // {0,2,4,6} * w01
- "fmla v14.4s, v9.4s, %[w2].s[2] \n" // {1,3,5,7} * w02
- "fmla v17.4s, v10.4s, %[w2].s[0] \n" // {0,1,3,5} * w00
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "cmp %[cnt], #1 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "blt 1f \n"
- // mid
- "2: \n"
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, v18.16b, #4 \n" // v10 = {2,4,6,8}
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, v19.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, v20.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, v21.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "subs %[cnt], %[cnt], #1 \n"
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 4f \n"
- "3: \n"
- "bif v0.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v1.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v2.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v3.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v4.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v5.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "ext v10.16b, v0.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- "bif v6.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v7.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "bif v8.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v9.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "ld1 {v0.4s}, [%[outptr0]] \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
- "ld1 {v1.4s}, [%[outptr1]] \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "bif v16.16b, v0.16b, %[wmask].16b \n" // pipei
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "bif v17.16b, v1.16b, %[wmask].16b \n" // pipei
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
- for (int i = 0; i < h_in; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr1 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- }
-
- //! process bottom pad
- if (i + 2 > h_in) {
- switch (i + 2 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = cnt_col;
- unsigned int* mask_ptr = dmask;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "vmov.u32 q9, #0 \n"
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r1\n" // v11={0,2,4,6} v12={1,3,5,7}, q10, q11
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v11={0,2,4,6} v12={1,3,5,7}, q12, q13
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" // v13={0,2,4,6} v14={1,3,5,7}, q14, q15
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
-
- "vext.32 q6, q9, q11, #3 @ shift right 1 "
- "data\n" // q2 = {0,1,3,5}
- "vext.32 q7, q9, q13, #3 @ shift right 1 "
- "data\n" // q6 = {0,1,3,5}
- "vext.32 q8, q9, q15, #3 @ shift right 1 "
- "data\n" // q6 = {0,1,3,5}
-
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 1, "
- "out0\n" // q11 * w01
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 1, "
- "out0\n" // q12 * w02
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 1, "
- "out0\n" // q6 * w00
-
- "sub %[din0_ptr], #4 @ inpitr0 - 1\n"
- "sub %[din1_ptr], #4 @ inpitr1 - 1\n"
- "sub %[din2_ptr], #4 @ inpitr2 - 1\n"
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q11 * w01
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q12 * w02
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w00
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 1, "
- "out1\n" // q0 * w01
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 1, "
- "out1\n" // q1 * w02
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 1, "
- "out1\n" // q2 * w00
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "cmp %[cnt], #1 \n"
- "blt 1f \n"
- // mid
- "2: \n"
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- "vext.32 q6, q10, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din1_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q7, q12, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din2_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "subs %[cnt], #1 \n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 3f \n"
-
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.f32 {d20-d21}, [%[outptr]] @ load output\n"
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vld1.f32 {d22-d23}, [%[mask_ptr]] @ load mask\n"
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vbif.f32 q3, q10, q11 @ write mask\n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "3: \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-
-// 4line
-void conv_depthwise_3x3s1p1_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- // printf("conv3x3_dw start \n");
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = (w_in + 3) >> 2;
- int tile_h = (h_in + 3) >> 2;
- int cnt_col = tile_w - 2;
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int size_pad_right = (unsigned int)(1 + (tile_w << 2) - w_in);
- int size_pad_bottom = (unsigned int)(1 + (tile_h << 2) - h_in);
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
-#ifdef __aarch64__
- for (int c = 0; c < ch_in; c++) {
- float* dout_ptr = dout_batch + c * size_out_channel;
-
- const float* din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float* wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
-
- float* doutr0 = dout_ptr;
- float* doutr1 = doutr0 + w_out;
- float* doutr2 = doutr1 + w_out;
- float* doutr3 = doutr2 + w_out;
-
- const float* dr0 = din_ch_ptr;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
- const float* dr5 = dr4 + w_in;
-
- const float* din_ptr0 = dr0;
- const float* din_ptr1 = dr1;
- const float* din_ptr2 = dr2;
- const float* din_ptr3 = dr3;
- const float* din_ptr4 = dr4;
- const float* din_ptr5 = dr5;
-
- for (int i = 0; i < h_in; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
- if (i == 0) {
- din_ptr0 = zero_ptr;
- din_ptr1 = dr0;
- din_ptr2 = dr1;
- din_ptr3 = dr2;
- din_ptr4 = dr3;
- din_ptr5 = dr4;
- dr0 = dr3;
- dr1 = dr4;
- dr2 = dr5;
- } else {
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- }
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 > h_in) {
- switch (i + 5 - h_in) {
- case 5:
- din_ptr1 = zero_ptr;
- case 4:
- din_ptr2 = zero_ptr;
- case 3:
- din_ptr3 = zero_ptr;
- case 2:
- din_ptr4 = zero_ptr;
- case 1:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = cnt_col;
- asm volatile(
- "PRFM PLDL1KEEP, [%[din_ptr0]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr1]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr2]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr3]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr4]] \n"
- "PRFM PLDL1KEEP, [%[din_ptr5]] \n"
- "movi v21.4s, #0x0\n" /* out0 = 0 */
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "ext v16.16b, %[vzero].16b, v0.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
-
- // left
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[1]\n" /* outr00 += din0_0123 *
- w0[1]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "sub %[din_ptr0], %[din_ptr0], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr1], %[din_ptr1], #4 \n" /* din_ptr0-- */
-
- "fmla v12.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din0_0012 *
- w0[0]*/
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "sub %[din_ptr2], %[din_ptr2], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr3], %[din_ptr3], #4 \n" /* din_ptr0-- */
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_1234 *
- w0[2]*/
-
- "ext v16.16b, %[vzero].16b, v2.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[1]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v2.4s, %[w1].s[1]\n" /* outr00 += din1_0123 *
- w1[1]*/
- "sub %[din_ptr4], %[din_ptr4], #4 \n" /* din_ptr0-- */
- "sub %[din_ptr5], %[din_ptr5], #4 \n" /* din_ptr0-- */
-
- "fmla v13.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v4.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[1]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v4.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v12.4s , v4.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v6.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[1]\n" /*outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v6.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v13.4s , v6.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v8.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234 */
-
- // r4
- "fmla v15.4s , v8.4s, %[w1].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
- "fmla v14.4s , v8.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w2[1]*/
-
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n" /* vst1q_f32() */
- "st1 {v13.4s}, [%[doutr1]], #16 \n" /* vst1q_f32() */
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w1[1]*/
-
- "ext v16.16b, %[vzero].16b, v10.16b, #12 \n" /* v16 = 00123*/
- "ext v17.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234 */
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- // r5
- "fmla v15.4s , v10.4s, %[w2].s[1]\n" /* outr00 += din2_0123 *
- w1[1]*/
-
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/
-
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 *
- w0[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n" /* vst1q_f32() */
-
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 *
- w0[1]*/
-
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n" /* vst1q_f32() */
- "cmp %[cnt], #1 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "blt 3f \n"
- // mid
- "1: \n"
- // r0
- "fmla v12.4s , v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
-
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- "subs %[cnt], %[cnt], #1 \n"
-
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
- "bne 1b \n"
-
- // right
- "3: \n"
- "ld1 {v18.4s, v19.4s}, [%[vmask]] \n"
- "ld1 {v22.4s}, [%[doutr0]] \n"
- "ld1 {v23.4s}, [%[doutr1]] \n"
- "ld1 {v24.4s}, [%[doutr2]] \n"
- "ld1 {v25.4s}, [%[doutr3]] \n"
-
- "bif v0.16b, %[vzero].16b, v18.16b \n"
- "bif v1.16b, %[vzero].16b, v19.16b \n"
- "bif v2.16b, %[vzero].16b, v18.16b \n"
- "bif v3.16b, %[vzero].16b, v19.16b \n"
-
- "bif v4.16b, %[vzero].16b, v18.16b \n"
- "bif v5.16b, %[vzero].16b, v19.16b \n"
- "bif v6.16b, %[vzero].16b, v18.16b \n"
- "bif v7.16b, %[vzero].16b, v19.16b \n"
-
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */
-
- // r0
- "fmla v12.4s, v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "bif v8.16b, %[vzero].16b, v18.16b \n"
- "bif v9.16b, %[vzero].16b, v19.16b \n"
- "bif v10.16b, %[vzero].16b, v18.16b \n"
- "bif v11.16b, %[vzero].16b, v19.16b \n"
-
- "fmla v12.4s, v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "ld1 {v18.4s}, [%[rmask]] \n"
-
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */
-
- // r1
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */
-
- // r2
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v12.16b, v22.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */
-
- // r3
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "st1 {v12.4s}, [%[doutr0]], #16 \n"
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v13.16b, v23.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */
-
- "st1 {v13.4s}, [%[doutr1]], #16 \n"
-
- // r3
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 *
- w0[0]*/
-
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/
-
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 *
- w0[1]*/
-
- "bif v14.16b, v24.16b, v18.16b \n"
-
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 *
- w0[2]*/
-
- "st1 {v14.4s}, [%[doutr2]], #16 \n"
-
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/
-
- "bif v15.16b, v25.16b, v18.16b \n"
-
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- dout_ptr = dout_ptr + 4 * w_out;
- }
- }
-#else
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float bias_val = flag_bias ? bias[i] : 0.f;
-
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- const float* din0_ptr = nullptr;
- const float* din1_ptr = nullptr;
- const float* din2_ptr = nullptr;
- const float* din3_ptr = nullptr;
-
- float* doutr0 = nullptr;
- float* doutr1 = nullptr;
-
- float* ptr_zero = const_cast(zero);
-
- for (int i = 0; i < h_in; i += 2) {
- //! process top pad pad_h = 1
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
-
- doutr0 = dout_channel;
- doutr1 = dout_channel + w_out;
- // unsigned int* rst_mask = rmask;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- din3_ptr = dr2;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr3;
- dr3 = dr2 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- }
- //! process bottom pad
- if (i + 3 > h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din1_ptr = zero_ptr;
- case 2:
- din2_ptr = zero_ptr;
- case 1:
- din3_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = cnt_col;
- unsigned int* rmask_ptr = rmask;
- unsigned int* vmask_ptr = vmask;
- asm volatile(
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vld1.32 {d16-d18}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d22}, [%[din1_ptr]]! @ load din r1\n"
- "vld1.32 {d24-d26}, [%[din2_ptr]]! @ load din r2\n"
- "vld1.32 {d28-d30}, [%[din3_ptr]]! @ load din r3\n"
-
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
-
- "vext.32 q6, %q[vzero], q8, #3 @ 0012\n"
- "vext.32 q7, q8, q9, #1 @ 1234\n"
-
- // left
- // r0
- "vmla.f32 q4, q8, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "sub %[din0_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din1_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din2_ptr], #12 @ 1pad + 2 float data overlap\n"
- "sub %[din3_ptr], #12 @ 1pad + 2 float data overlap\n"
-
- "vmla.f32 q4, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q10, #3 @ 0012\n"
- "vext.32 q7, q10, q11, #1 @ 1234\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q10, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q12, #3 @ 0012\n"
- "vext.32 q7, q12, q13, #1 @ 1234\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q12, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, %q[vzero], q14, #3 @ 0012\n"
- "vext.32 q7, q14, q15, #1 @ 1234\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
-
- "vmla.f32 q5, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "cmp %[cnt], #1 @ check whether has "
- "mid cols\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q5
- // =
- // vbias
- "blt 3f @ jump to main loop start "
- "point\n"
-
- // mid
- "1: @ right pad entry\n"
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
- "pld [%[din3_ptr]] @ preload data\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n"
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
- "vdup.32 q4, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- "subs %[cnt], #1 @ loop count minus 1\n"
-
- "vdup.32 q5, %[bias_val] @ and \n" // q4
- // =
- // vbias
-
- "bne 1b @ jump to main loop start "
- "point\n"
-
- // right
- "3: @ right pad entry\n"
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n"
-
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n"
- "vld1.32 {d31}, [%[vmask]]! @ load din r0\n"
-
- "vbif d16, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d17, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d18, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vbif d20, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d21, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d22, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vext.32 q6, q8, q9, #1 @ 1234\n"
- "vext.32 q7, q8, q9, #2 @ 2345\n"
-
- // r0
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n"
-
- "vbif d24, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d25, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d26, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d28, %e[vzero], d19 @ bit select, deal with "
- "right pad\n"
- "vbif d29, %e[vzero], d23 @ bit select, deal with "
- "right pad\n"
- "vbif d30, %e[vzero], d27 @ bit select, deal with "
- "right pad\n"
-
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n"
-
- "vext.32 q6, q10, q11, #1 @ 1234\n"
- "vext.32 q7, q10, q11, #2 @ 2345\n"
-
- // r1
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d19}, [%[rmask]]! @ load din r0\n"
- "vld1.32 {d23}, [%[rmask]]! @ load din r0\n"
-
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
-
- "vld1.32 {d16-d17}, [%[dout_ptr1]] @ load din r0\n"
- "vld1.32 {d20-d21}, [%[dout_ptr2]] @ load din r0\n"
-
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q12, q13, #1 @ 1234\n"
- "vext.32 q7, q12, q13, #2 @ 2345\n"
-
- // r2
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n"
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n"
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n"
-
- "vext.32 q6, q14, q15, #1 @ 1234\n"
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
- // r3
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n"
-
- "vmax.f32 q4, q4, %q[vzero] @ relu \n"
-
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n"
-
- "vbif d8, d16, d19 @ bit select, deal with right pad\n"
- "vbif d9, d17, d23 @ bit select, deal with right pad\n"
-
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n"
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n"
-
- "vmax.f32 q5, q5, %q[vzero] @ relu \n"
-
- "vbif d10, d20, d19 @ bit select, deal with right "
- "pad\n"
- "vbif d11, d21, d23 @ bit select, deal with right "
- "pad\n"
-
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add "
- "pointer\n"
-
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [din3_ptr] "+r"(din3_ptr),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- dout_channel += 2 * w_out;
- } //! end of processing mid rows
- }
-#endif
- }
-}
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, with reulu
- */
-// w_in > 7
-void conv_depthwise_3x3s2p1_bias_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- int size_pad_bottom = h_out * 2 - h_in;
-
- int cnt_col = (w_out >> 2) - 2;
- int size_right_remain = w_in - (7 + cnt_col * 8);
- if (size_right_remain >= 9) {
- cnt_col++;
- size_right_remain -= 8;
- }
- int cnt_remain = (size_right_remain == 8) ? 4 : (w_out % 4); //
-
- int size_right_pad = w_out * 2 - w_in;
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- float32x4_t wbias;
- float bias_c = 0.f;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- bias_c = bias[i];
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_in; i += 4) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- din3_ptr = dr2;
- din4_ptr = dr3;
- dr0 = dr3;
- dr1 = dr4;
- } else {
- dr0 = dr4;
- dr1 = dr0 + w_in;
- }
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i + 4 > h_in) {
- switch (i + 4 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i / 2 + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = cnt_col;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "prfm pldl1keep, [%[inptr0]] \n"
- "prfm pldl1keep, [%[inptr1]] \n"
- "prfm pldl1keep, [%[inptr2]] \n"
- "prfm pldl1keep, [%[inptr3]] \n"
- "prfm pldl1keep, [%[inptr4]] \n"
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
-
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "ext v10.16b, %[vzero].16b, v1.16b, #12 \n" // v10 = {0,1,3,5}
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[1] \n" // {0,2,4,6} * w01
- "fmul v12.4s, v1.4s, %[w0].s[2] \n" // {1,3,5,7} * w02
- "fmla v16.4s, v10.4s, %[w0].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v3.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr0], %[inptr0], #4 \n"
- "sub %[inptr1], %[inptr1], #4 \n"
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[1] \n" // {0,2,4,6} * w01
- "fmla v12.4s, v3.4s, %[w1].s[2] \n" // {1,3,5,7} * w02
- "fmla v16.4s, v10.4s, %[w1].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v5.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr2], %[inptr2], #4 \n"
- "sub %[inptr3], %[inptr3], #4 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[1] \n" // {0,2,4,6} * w01
- "fmla v11.4s, v4.4s, %[w2].s[1] \n" // {0,2,4,6} * w01
-
- "fmul v14.4s, v5.4s, %[w0].s[2] \n" // {1,3,5,7} * w02
- "fmla v12.4s, v5.4s, %[w2].s[2] \n" // {1,3,5,7} * w02
-
- "fmla v17.4s, v10.4s, %[w0].s[0] \n" // {0,1,3,5} * w00
- "fmla v16.4s, v10.4s, %[w2].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v7.16b, #12 \n" // v10 = {0,1,3,5}
-
- "sub %[inptr4], %[inptr4], #4 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[1] \n" // {0,2,4,6} * w01
- "fmla v14.4s, v7.4s, %[w1].s[2] \n" // {1,3,5,7} * w02
- "fmla v17.4s, v10.4s, %[w1].s[0] \n" // {0,1,3,5} * w00
-
- "ext v10.16b, %[vzero].16b, v9.16b, #12 \n" // v10 = {0,1,3,5}
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[1] \n" // {0,2,4,6} * w01
- "fmla v14.4s, v9.4s, %[w2].s[2] \n" // {1,3,5,7} * w02
- "fmla v17.4s, v10.4s, %[w2].s[0] \n" // {0,1,3,5} * w00
-
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */
-
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
-
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
-
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */
-
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "cmp %[cnt], #1 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "blt 1f \n"
- // mid
- "2: \n"
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, v18.16b, #4 \n" // v10 = {2,4,6,8}
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" // v0={0,2,4,6}
- // v1={1,3,5,7}
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, v19.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n"
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, v20.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n"
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, v21.16b, #4 \n" // v10 = {2,4,6,8}
-
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n"
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" // v10 = vbias
- "subs %[cnt], %[cnt], #1 \n"
-
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
-
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" // v16 = vbias
-
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 4f \n"
- "3: \n"
- "bif v0.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v1.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v2.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v3.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "bif v4.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v5.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- "ext v10.16b, v0.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- "bif v6.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v7.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r0
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v2.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "bif v8.16b, %[vzero].16b, %[mask1].16b \n" // pipei
- "bif v9.16b, %[vzero].16b, %[mask2].16b \n" // pipei
-
- // r1
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v4.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r2
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" // {0,2,4,6} * w00
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
-
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" // {1,3,5,7} * w01
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
-
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" // {2,4,6,8} * w02
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v6.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
-
- // r3
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" // {2,4,6,8} * w02
-
- "ext v10.16b, v8.16b, %[vzero].16b, #4 \n" // v10 = {2,4,6,8}
- "ld1 {v0.4s}, [%[outptr0]] \n"
-
- "fadd v16.4s, v16.4s, v11.4s \n"
- "fadd v16.4s, v16.4s, v12.4s \n"
- "ld1 {v1.4s}, [%[outptr1]] \n"
-
- // r4
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" // {0,2,4,6} * w00
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" // {1,3,5,7} * w01
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" // {2,4,6,8} * w02
-
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */
-
- "fadd v17.4s, v17.4s, v13.4s \n"
-
- "bif v16.16b, v0.16b, %[wmask].16b \n" // pipei
-
- "fadd v17.4s, v17.4s, v14.4s \n"
-
- "st1 {v16.4s}, [%[outptr0]], #16 \n"
-
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */
-
- "bif v17.16b, v1.16b, %[wmask].16b \n" // pipei
-
- "st1 {v17.4s}, [%[outptr1]], #16 \n"
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
-
- for (int i = 0; i < h_in; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr1 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- }
-
- //! process bottom pad
- if (i + 2 > h_in) {
- switch (i + 2 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = cnt_col;
-
- unsigned int* mask_ptr = dmask;
- asm volatile(
- // top
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "0: \n"
- "vmov.u32 q9, #0 \n"
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r1\n" // v11={0,2,4,6} v12={1,3,5,7}, q10, q11
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v11={0,2,4,6} v12={1,3,5,7}, q12, q13
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" // v13={0,2,4,6} v14={1,3,5,7}, q14, q15
- "pld [%[din0_ptr]] @ preload data\n"
- "pld [%[din1_ptr]] @ preload data\n"
- "pld [%[din2_ptr]] @ preload data\n"
-
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
-
- "vext.32 q6, q9, q11, #3 @ shift right 1 "
- "data\n" // q2 = {0,1,3,5}
- "vext.32 q7, q9, q13, #3 @ shift right 1 "
- "data\n" // q6 = {0,1,3,5}
- "vext.32 q8, q9, q15, #3 @ shift right 1 "
- "data\n" // q6 = {0,1,3,5}
-
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 1, "
- "out0\n" // q11 * w01
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 1, "
- "out0\n" // q12 * w02
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 1, "
- "out0\n" // q6 * w00
-
- "sub %[din0_ptr], #4 @ inpitr0 - 1\n"
- "sub %[din1_ptr], #4 @ inpitr1 - 1\n"
- "sub %[din2_ptr], #4 @ inpitr2 - 1\n"
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q11 * w01
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q12 * w02
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w00
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 1, "
- "out1\n" // q0 * w01
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 1, "
- "out1\n" // q1 * w02
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 1, "
- "out1\n" // q2 * w00
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "cmp %[cnt], #1 \n"
- "blt 1f \n"
- // mid
- "2: \n"
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" // q2={8,10,12,14}
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
- "vext.32 q6, q10, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din1_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q7, q12, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.32 {d16}, [%[din2_ptr]] @ load din r1\n" // q2={8,10,12,14}
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q8, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // v0={0,2,4,6} v1={1,3,5,7}
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // v4={0,2,4,6} v5={1,3,5,7}
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "subs %[cnt], #1 \n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "bne 2b \n"
-
- // right
- "1: \n"
- "cmp %[remain], #1 \n"
- "blt 3f \n"
-
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q10 =
- // vbias
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
-
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q0 * w00
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w02
-
- "vext.32 q6, q14, q9, #1 @ shift left 1 \n" // q6 = {2,4,6,8}
- "vld1.f32 {d20-d21}, [%[outptr]] @ load output\n"
-
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q6 * w02
-
- "vld1.f32 {d22-d23}, [%[mask_ptr]] @ load mask\n"
-
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q0 * w00
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q1 * w01
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q6 * w02
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu \n"
-
- "vbif.f32 q3, q10, q11 @ write mask\n"
-
- "vst1.32 {d6-d7}, [%[outptr]]! \n"
- "3: \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[4] = {3, 2, 1, 0};
- const float zero[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(4 - w_in));
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float* dout_channel = dout_batch + i * size_out_channel;
- const float* din_channel = din_batch + i * size_in_channel;
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- int hs = -1;
- int he = 3;
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- int h_cnt = (h_out + 1) >> 1;
- float* doutr0 = dout_channel;
- float* doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_cnt; ++j) {
- const float* dr0 = din_channel + hs * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- if (hs == -1) {
- dr0 = zero;
- }
-
- switch (he - h_in) {
- case 2:
- dr2 = zero;
- doutr1 = trash_buf;
- case 1:
- dr3 = zero;
- default:
- break;
- }
-#ifdef __aarch64__
- asm volatile(
- "prfm pldl1keep, [%[din0]]\n"
- "prfm pldl1keep, [%[din1]]\n"
- "prfm pldl1keep, [%[din2]]\n"
- "prfm pldl1keep, [%[din3]]\n"
-
- "ld1 {v0.4s}, [%[din0]], #16\n"
- "ld1 {v1.4s}, [%[din1]], #16\n"
- "ld1 {v2.4s}, [%[din2]], #16\n"
- "ld1 {v3.4s}, [%[din3]], #16\n"
-
- "bif v0.16b, %[zero].16b, %[mask].16b\n" // d0_1234
- "bif v1.16b, %[zero].16b, %[mask].16b\n" // d1_1234
- "bif v2.16b, %[zero].16b, %[mask].16b\n" // d2_1234
- "bif v3.16b, %[zero].16b, %[mask].16b\n" // d3_1234
-
- "ext v4.16b, %[zero].16b, v0.16b, #12\n" // d0_0123
- "ext v5.16b, %[zero].16b, v1.16b, #12\n" // d1_0123
- "ext v6.16b, %[zero].16b, v2.16b, #12\n" // d2_0123
- "ext v7.16b, %[zero].16b, v3.16b, #12\n" // d3_0123
-
- "ext v8.16b, v0.16b, %[zero].16b, #4\n" // d0_2340
- "ext v9.16b, v1.16b, %[zero].16b, #4\n" // d1_2340
- "ext v10.16b, v2.16b, %[zero].16b, #4\n" // d2_2340
- "ext v11.16b, v3.16b, %[zero].16b, #4\n" // d3_2340
-
- "fmul v12.4s, v0.4s, %[wr0].s[1]\n"
- "fmul v13.4s, v1.4s, %[wr0].s[1]\n"
-
- "fmul v14.4s, v1.4s, %[wr1].s[1]\n"
- "fmul v15.4s, v2.4s, %[wr1].s[1]\n"
-
- "fmul v16.4s, v2.4s, %[wr2].s[1]\n"
- "fmul v17.4s, v3.4s, %[wr2].s[1]\n"
-
- "fmla v12.4s, v4.4s, %[wr0].s[0]\n"
- "fmla v13.4s, v5.4s, %[wr0].s[0]\n"
-
- "fmla v14.4s, v5.4s, %[wr1].s[0]\n"
- "fmla v15.4s, v6.4s, %[wr1].s[0]\n"
-
- "fmla v16.4s, v6.4s, %[wr2].s[0]\n"
- "fmla v17.4s, v7.4s, %[wr2].s[0]\n"
-
- "fmla v12.4s, v8.4s, %[wr0].s[2]\n"
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n"
-
- "fmla v14.4s, v9.4s, %[wr1].s[2]\n"
- "fmla v15.4s, v10.4s, %[wr1].s[2]\n"
-
- "fmla v16.4s, v10.4s, %[wr2].s[2]\n"
- "fmla v17.4s, v11.4s, %[wr2].s[2]\n"
-
- "fadd v12.4s, v12.4s, v14.4s\n"
- "fadd v12.4s, v12.4s, v16.4s\n"
-
- "fadd v13.4s, v13.4s, v15.4s\n" // out1
- "fadd v13.4s, v13.4s, v17.4s\n" // out2
-
- "fadd v12.4s, v12.4s, %[bias].4s\n" // out1 add bias
- "fadd v13.4s, v13.4s, %[bias].4s\n" // out2 add bias
-
- "prfm pldl1keep, [%[out1]]\n"
- "prfm pldl1keep, [%[out2]]\n"
-
- "st1 {v12.4s}, [%[out1]]\n"
- "st1 {v13.4s}, [%[out2]]\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17");
-#else
- asm volatile(
- "pld [%[din0]]\n"
- "pld [%[din1]]\n"
- "pld [%[din2]]\n"
- "pld [%[din3]]\n"
-
- "vld1.32 {d12-d13}, [%[din0]]!\n"
- "vld1.32 {d14-d15}, [%[din1]]!\n"
- "vld1.32 {d16-d17}, [%[din2]]!\n"
- "vld1.32 {d18-d19}, [%[din3]]!\n"
-
- "vbif q6, %q[zero], %q[mask]\n" // d0_1234
- "vbif q7, %q[zero], %q[mask]\n" // d1_1234
- "vbif q8, %q[zero], %q[mask]\n" // d2_1234
- "vbif q9, %q[zero], %q[mask]\n" // d3_1234
-
- "vmul.f32 q14, q6, %e[wr0][1]\n"
- "vmul.f32 q15, q7, %e[wr0][1]\n"
-
- "vmla.f32 q14, q7, %e[wr1][1]\n"
- "vmla.f32 q15, q8, %e[wr1][1]\n"
-
- "vmla.f32 q14, q8, %e[wr2][1]\n"
- "vmla.f32 q15, q9, %e[wr2][1]\n"
-
- "vext.32 q10, %q[zero], q6, #3\n" // d0_0123
- "vext.32 q11, %q[zero], q7, #3\n" // d1_0123
- "vext.32 q12, %q[zero], q8, #3\n" // d2_0123
- "vext.32 q13, %q[zero], q9, #3\n" // d3_0123
-
- "vmla.f32 q14, q10, %e[wr0][0]\n"
- "vmla.f32 q15, q11, %e[wr0][0]\n"
-
- "vmla.f32 q14, q11, %e[wr1][0]\n"
- "vmla.f32 q15, q12, %e[wr1][0]\n"
-
- "vmla.f32 q14, q12, %e[wr2][0]\n"
- "vmla.f32 q15, q13, %e[wr2][0]\n"
-
- "vext.32 q10, q6, %q[zero], #1\n" // d0_2340
- "vext.32 q11, q7, %q[zero], #1\n" // d1_2340
- "vext.32 q12, q8, %q[zero], #1\n" // d2_2340
- "vext.32 q13, q9, %q[zero], #1\n" // d3_2340
-
- "vmla.f32 q14, q10, %f[wr0][0]\n"
- "vmla.f32 q15, q11, %f[wr0][0]\n"
-
- "vmla.f32 q14, q11, %f[wr1][0]\n"
- "vmla.f32 q15, q12, %f[wr1][0]\n"
-
- "vmla.f32 q14, q12, %f[wr2][0]\n" // out1
- "vmla.f32 q15, q13, %f[wr2][0]\n" // out2
-
- "vadd.f32 q14, q14, %q[bias]\n" // out1 add bias
- "vadd.f32 q15, q15, %q[bias]\n" // out2 add bias
-
- "pld [%[out1]]\n"
- "pld [%[out2]]\n"
-
- "vst1.32 {d28-d29}, [%[out1]]\n"
- "vst1.32 {d30-d31}, [%[out2]]\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- doutr0 = doutr1;
- doutr1 += w_out;
- hs += 2;
- he += 2;
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 4
- */
-
-void conv_depthwise_3x3s2p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- int hs = -1;
- int he = 2;
- float out_buf[4];
- for (int j = 0; j < h_out; ++j) {
- const float* dr0 = din_channel + hs * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- if (hs == -1) {
- dr0 = zeros;
- }
- if (he > h_in) {
- dr2 = zeros;
- }
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "movi v9.4s, #0 \n"
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]], #32 \n"
-
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" // v10={0,2,4,6}
- // v11={1,3,5,7}
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" // v13={0,2,4,6}
- // v12={1,3,5,7}
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" // v14={0,2,4,6}
- // v15={1,3,5,7}
-
- "bif v10.16b, v9.16b, v6.16b \n"
- "bif v11.16b, v9.16b, v7.16b \n"
- "bif v12.16b, v9.16b, v6.16b \n"
- "bif v13.16b, v9.16b, v7.16b \n"
- "bif v14.16b, v9.16b, v6.16b \n"
- "bif v15.16b, v9.16b, v7.16b \n"
-
- "ext v6.16b, v9.16b, v11.16b, #12 \n" // v6 =
- // {0,1,3,5}
- "ext v7.16b, v9.16b, v13.16b, #12 \n" // v7 =
- // {0,1,3,5}
- "ext v8.16b, v9.16b, v15.16b, #12 \n" // v8 =
- // {0,1,3,5}
-
- "fmul v4.4s, v10.4s, %[wr0].s[1] \n" // v10 * w01
- "fmul v5.4s, v11.4s, %[wr0].s[2] \n" // v11 * w02
- "fmul v6.4s, v6.4s, %[wr0].s[0] \n" // v6 * w00
-
- "fmla v4.4s, v12.4s, %[wr1].s[1] \n" // v12 * w11
- "fmla v5.4s, v13.4s, %[wr1].s[2] \n" // v13 * w12
- "fmla v6.4s, v7.4s, %[wr1].s[0] \n" // v7 * w10
-
- "fmla v4.4s, v14.4s, %[wr2].s[1] \n" // v14 * w20
- "fmla v5.4s, v15.4s, %[wr2].s[2] \n" // v15 * w21
- "fmla v6.4s, v8.4s, %[wr2].s[0] \n" // v8 * w22
-
- "fadd v4.4s, v4.4s, v5.4s \n"
- "fadd v4.4s, v4.4s, v6.4s \n"
-
- "fadd v4.4s, v4.4s, %[bias].4s \n"
-
- "st1 {v4.4s}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
-
-#else
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "vmov.u32 q9, #0 \n"
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q3 =
- // vbias
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // q10={0,2,4,6} q11={1,3,5,7}
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // q13={0,2,4,6} q12={1,3,5,7}
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // q14={0,2,4,6} q15={1,3,5,7}
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q9, q11, #3 @ shift left 1 \n" // q6 = {0,1,3,5}
- "vext.32 q7, q9, q13, #3 @ shift left 1 \n" // q7 = {0,1,3,5}
- "vext.32 q8, q9, q15, #3 @ shift left 1 \n" // q8 = {0,1,3,5}
-
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q10 * w01
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q11 * w02
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w00
-
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q12 * w11
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q13 * w12
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q7 * w10
-
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q14 * w20
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q15 * w21
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q8 * w22
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vst1.32 {d6-d7}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- hs += 2;
- he += 2;
- }
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p1_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[4] = {3, 2, 1, 0};
- const float zero[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(4 - w_in));
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float* dout_channel = dout_batch + i * size_out_channel;
- const float* din_channel = din_batch + i * size_in_channel;
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- int hs = -1;
- int he = 3;
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- int h_cnt = (h_out + 1) >> 1;
- float* doutr0 = dout_channel;
- float* doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_cnt; ++j) {
- const float* dr0 = din_channel + hs * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
-
- if (hs == -1) {
- dr0 = zero;
- }
-
- switch (he - h_in) {
- case 2:
- dr2 = zero;
- doutr1 = trash_buf;
- case 1:
- dr3 = zero;
- default:
- break;
- }
-#ifdef __aarch64__
- asm volatile(
- "prfm pldl1keep, [%[din0]]\n"
- "prfm pldl1keep, [%[din1]]\n"
- "prfm pldl1keep, [%[din2]]\n"
- "prfm pldl1keep, [%[din3]]\n"
-
- "ld1 {v0.4s}, [%[din0]], #16\n"
- "ld1 {v1.4s}, [%[din1]], #16\n"
- "ld1 {v2.4s}, [%[din2]], #16\n"
- "ld1 {v3.4s}, [%[din3]], #16\n"
-
- "bif v0.16b, %[zero].16b, %[mask].16b\n" // d0_1234
- "bif v1.16b, %[zero].16b, %[mask].16b\n" // d1_1234
- "bif v2.16b, %[zero].16b, %[mask].16b\n" // d2_1234
- "bif v3.16b, %[zero].16b, %[mask].16b\n" // d3_1234
-
- "ext v4.16b, %[zero].16b, v0.16b, #12\n" // d0_0123
- "ext v5.16b, %[zero].16b, v1.16b, #12\n" // d1_0123
- "ext v6.16b, %[zero].16b, v2.16b, #12\n" // d2_0123
- "ext v7.16b, %[zero].16b, v3.16b, #12\n" // d3_0123
-
- "ext v8.16b, v0.16b, %[zero].16b, #4\n" // d0_2340
- "ext v9.16b, v1.16b, %[zero].16b, #4\n" // d1_2340
- "ext v10.16b, v2.16b, %[zero].16b, #4\n" // d2_2340
- "ext v11.16b, v3.16b, %[zero].16b, #4\n" // d3_2340
-
- "fmul v12.4s, v0.4s, %[wr0].s[1]\n"
- "fmul v13.4s, v1.4s, %[wr0].s[1]\n"
-
- "fmul v14.4s, v1.4s, %[wr1].s[1]\n"
- "fmul v15.4s, v2.4s, %[wr1].s[1]\n"
-
- "fmul v16.4s, v2.4s, %[wr2].s[1]\n"
- "fmul v17.4s, v3.4s, %[wr2].s[1]\n"
-
- "fmla v12.4s, v4.4s, %[wr0].s[0]\n"
- "fmla v13.4s, v5.4s, %[wr0].s[0]\n"
-
- "fmla v14.4s, v5.4s, %[wr1].s[0]\n"
- "fmla v15.4s, v6.4s, %[wr1].s[0]\n"
-
- "fmla v16.4s, v6.4s, %[wr2].s[0]\n"
- "fmla v17.4s, v7.4s, %[wr2].s[0]\n"
-
- "fmla v12.4s, v8.4s, %[wr0].s[2]\n"
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n"
-
- "fmla v14.4s, v9.4s, %[wr1].s[2]\n"
- "fmla v15.4s, v10.4s, %[wr1].s[2]\n"
-
- "fmla v16.4s, v10.4s, %[wr2].s[2]\n"
- "fmla v17.4s, v11.4s, %[wr2].s[2]\n"
-
- "fadd v12.4s, v12.4s, v14.4s\n"
- "fadd v12.4s, v12.4s, v16.4s\n"
-
- "fadd v13.4s, v13.4s, v15.4s\n" // out1
- "fadd v13.4s, v13.4s, v17.4s\n" // out2
-
- "fadd v12.4s, v12.4s, %[bias].4s\n" // out1 add bias
- "fadd v13.4s, v13.4s, %[bias].4s\n" // out2 add bias
-
- "prfm pldl1keep, [%[out1]]\n"
- "prfm pldl1keep, [%[out2]]\n"
-
- "fmax v12.4s, v12.4s, %[zero].4s\n" // out1 -> relu
- "fmax v13.4s, v13.4s, %[zero].4s\n" // out2 -> relu
-
- "st1 {v12.4s}, [%[out1]]\n"
- "st1 {v13.4s}, [%[out2]]\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17");
-#else
- asm volatile(
- "pld [%[din0]]\n"
- "pld [%[din1]]\n"
- "pld [%[din2]]\n"
- "pld [%[din3]]\n"
-
- "vld1.32 {d12-d13}, [%[din0]]!\n"
- "vld1.32 {d14-d15}, [%[din1]]!\n"
- "vld1.32 {d16-d17}, [%[din2]]!\n"
- "vld1.32 {d18-d19}, [%[din3]]!\n"
-
- "vbif q6, %q[zero], %q[mask]\n" // d0_1234
- "vbif q7, %q[zero], %q[mask]\n" // d1_1234
- "vbif q8, %q[zero], %q[mask]\n" // d2_1234
- "vbif q9, %q[zero], %q[mask]\n" // d3_1234
-
- "vmul.f32 q14, q6, %e[wr0][1]\n"
- "vmul.f32 q15, q7, %e[wr0][1]\n"
-
- "vmla.f32 q14, q7, %e[wr1][1]\n"
- "vmla.f32 q15, q8, %e[wr1][1]\n"
-
- "vmla.f32 q14, q8, %e[wr2][1]\n"
- "vmla.f32 q15, q9, %e[wr2][1]\n"
-
- "vext.32 q10, %q[zero], q6, #3\n" // d0_0123
- "vext.32 q11, %q[zero], q7, #3\n" // d1_0123
- "vext.32 q12, %q[zero], q8, #3\n" // d2_0123
- "vext.32 q13, %q[zero], q9, #3\n" // d3_0123
-
- "vmla.f32 q14, q10, %e[wr0][0]\n"
- "vmla.f32 q15, q11, %e[wr0][0]\n"
-
- "vmla.f32 q14, q11, %e[wr1][0]\n"
- "vmla.f32 q15, q12, %e[wr1][0]\n"
-
- "vmla.f32 q14, q12, %e[wr2][0]\n"
- "vmla.f32 q15, q13, %e[wr2][0]\n"
-
- "vext.32 q10, q6, %q[zero], #1\n" // d0_2340
- "vext.32 q11, q7, %q[zero], #1\n" // d1_2340
- "vext.32 q12, q8, %q[zero], #1\n" // d2_2340
- "vext.32 q13, q9, %q[zero], #1\n" // d3_2340
-
- "vmla.f32 q14, q10, %f[wr0][0]\n"
- "vmla.f32 q15, q11, %f[wr0][0]\n"
-
- "vmla.f32 q14, q11, %f[wr1][0]\n"
- "vmla.f32 q15, q12, %f[wr1][0]\n"
-
- "vmla.f32 q14, q12, %f[wr2][0]\n" // out1
- "vmla.f32 q15, q13, %f[wr2][0]\n" // out2
-
- "vadd.f32 q14, q14, %q[bias]\n" // out1 add bias
- "vadd.f32 q15, q15, %q[bias]\n" // out2 add bias
-
- "pld [%[out1]]\n"
- "pld [%[out2]]\n"
-
- "vmax.f32 q14, q14, %q[zero]\n" // out1 -> relu
- "vmax.f32 q15, q15, %q[zero]\n" // out2 -> relu
-
- "vst1.32 {d28-d29}, [%[out1]]\n"
- "vst1.32 {d30-d31}, [%[out2]]\n"
-
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- doutr0 = doutr1;
- doutr1 += w_out;
- hs += 2;
- he += 2;
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 7
- */
-void conv_depthwise_3x3s2p1_bias_s_relu(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- int hs = -1;
- int he = 2;
- float out_buf[4];
- for (int j = 0; j < h_out; ++j) {
- const float* dr0 = din_channel + hs * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- if (hs == -1) {
- dr0 = zeros;
- }
- if (he > h_in) {
- dr2 = zeros;
- }
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "movi v9.4s, #0 \n"
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]], #32 \n"
-
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" // v10={0,2,4,6}
- // v11={1,3,5,7}
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" // v13={0,2,4,6}
- // v12={1,3,5,7}
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" // v14={0,2,4,6}
- // v15={1,3,5,7}
-
- "bif v10.16b, v9.16b, v6.16b \n"
- "bif v11.16b, v9.16b, v7.16b \n"
- "bif v12.16b, v9.16b, v6.16b \n"
- "bif v13.16b, v9.16b, v7.16b \n"
- "bif v14.16b, v9.16b, v6.16b \n"
- "bif v15.16b, v9.16b, v7.16b \n"
-
- "ext v6.16b, v9.16b, v11.16b, #12 \n" // v6 =
- // {0,1,3,5}
- "ext v7.16b, v9.16b, v13.16b, #12 \n" // v7 =
- // {0,1,3,5}
- "ext v8.16b, v9.16b, v15.16b, #12 \n" // v8 =
- // {0,1,3,5}
-
- "fmul v4.4s, v10.4s, %[wr0].s[1] \n" // v10 * w01
- "fmul v5.4s, v11.4s, %[wr0].s[2] \n" // v11 * w02
- "fmul v6.4s, v6.4s, %[wr0].s[0] \n" // v6 * w00
-
- "fmla v4.4s, v12.4s, %[wr1].s[1] \n" // v12 * w11
- "fmla v5.4s, v13.4s, %[wr1].s[2] \n" // v13 * w12
- "fmla v6.4s, v7.4s, %[wr1].s[0] \n" // v7 * w10
-
- "fmla v4.4s, v14.4s, %[wr2].s[1] \n" // v14 * w20
- "fmla v5.4s, v15.4s, %[wr2].s[2] \n" // v15 * w21
- "fmla v6.4s, v8.4s, %[wr2].s[0] \n" // v8 * w22
-
- "fadd v4.4s, v4.4s, v5.4s \n"
- "fadd v4.4s, v4.4s, v6.4s \n"
-
- "fadd v4.4s, v4.4s, %[bias].4s \n" // out add bias
- "fmax v4.4s, v4.4s, v9.4s \n"
-
- "st1 {v4.4s}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
-
-#else
- asm volatile(
- // Load up 12 elements (3 vectors) from each of 8 sources.
- "vmov.u32 q9, #0 \n"
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n"
- "vdup.32 q3, %[bias] @ and \n" // q3 =
- // vbias
-
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" // q10={0,2,4,6} q11={1,3,5,7}
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" // q13={0,2,4,6} q12={1,3,5,7}
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" // q14={0,2,4,6} q15={1,3,5,7}
-
- "vbif q10, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q11, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q12, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q13, q9, q7 @ bit select, deal "
- "with right pad\n"
- "vbif q14, q9, q6 @ bit select, deal "
- "with right pad\n"
- "vbif q15, q9, q7 @ bit select, deal "
- "with right pad\n"
-
- "vext.32 q6, q9, q11, #3 @ shift left 1 \n" // q6 = {0,1,3,5}
- "vext.32 q7, q9, q13, #3 @ shift left 1 \n" // q7 = {0,1,3,5}
- "vext.32 q8, q9, q15, #3 @ shift left 1 \n" // q8 = {0,1,3,5}
-
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 0, "
- "out0\n" // q10 * w01
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 0, "
- "out0\n" // q11 * w02
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 0, "
- "out0\n" // q6 * w00
-
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, "
- "out0\n" // q12 * w11
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, "
- "out0\n" // q13 * w12
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, "
- "out0\n" // q7 * w10
-
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 2, "
- "out0\n" // q14 * w20
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 2, "
- "out0\n" // q15 * w21
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 2, "
- "out0\n" // q8 * w22
-
- "vadd.f32 q3, q3, q4 @ add \n"
- "vadd.f32 q3, q3, q5 @ add \n"
-
- "vmax.f32 q3, q3, q9 @ relu\n"
-
- "vst1.32 {d6-d7}, [%[out]] \n"
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
-#endif // __aarch64__
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- hs += 2;
- he += 2;
- }
- }
- }
-}
-
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/conv_depthwise_3x3s1.cc b/lite/backends/arm/math/conv_depthwise_3x3s1.cc
deleted file mode 100644
index 8d0ebb58ad1b7e325bae3649b13914641021038f..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv_depthwise_3x3s1.cc
+++ /dev/null
@@ -1,2539 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/arm/math/conv_depthwise.h"
-#include
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-
-void conv_depthwise_3x3s1p0_bias(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx);
-
-void conv_depthwise_3x3s1p0_bias_s(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx);
-
-void conv_depthwise_3x3s1p1_bias(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx);
-
-void conv_depthwise_3x3s1p1_bias_s(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx);
-
-void conv_depthwise_3x3s1_fp32(const float *din,
- float *dout,
- int num,
- int ch_out,
- int h_out,
- int w_out,
- int ch_in,
- int h_in,
- int w_in,
- const float *weights,
- const float *bias,
- int pad,
- bool flag_bias,
- bool flag_relu,
- ARMContext *ctx) {
- if (pad == 0) {
- if (w_in > 5) {
- conv_depthwise_3x3s1p0_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p0_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- if (pad == 1) {
- if (w_in > 4) {
- conv_depthwise_3x3s1p1_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s1p1_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
-}
-
-#ifdef __aarch64__
-#define INIT_S1 \
- "PRFM PLDL1KEEP, [%[din_ptr0]] \n" \
- "PRFM PLDL1KEEP, [%[din_ptr1]] \n" \
- "PRFM PLDL1KEEP, [%[din_ptr2]] \n" \
- "PRFM PLDL1KEEP, [%[din_ptr3]] \n" \
- "PRFM PLDL1KEEP, [%[din_ptr4]] \n" \
- "PRFM PLDL1KEEP, [%[din_ptr5]] \n" \
- "movi v21.4s, #0x0\n" /* out0 = 0 */ \
- \
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/
-
-#define LEFT_COMPUTE_S1 \
- "ext v16.16b, %[vzero].16b, v0.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */ /* r0 */ \
- "fmla v12.4s, v0.4s, %[w0].s[1]\n" /* outr00 += din0_0123 * w0[1]*/ \
- \
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "sub %[din_ptr0], %[din_ptr0], #4 \n" /* din_ptr0-- */ \
- "sub %[din_ptr1], %[din_ptr1], #4 \n" /* din_ptr0-- */ \
- \
- "fmla v12.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din0_0012 * w0[0]*/ \
- \
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/ \
- "sub %[din_ptr2], %[din_ptr2], #4 \n" /* din_ptr0-- */ \
- "sub %[din_ptr3], %[din_ptr3], #4 \n" /* din_ptr0-- */ \
- \
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_1234 * w0[2]*/ \
- \
- "ext v16.16b, %[vzero].16b, v2.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234 */ /* r1 */ \
- "fmla v13.4s , v2.4s, %[w0].s[1]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v12.4s , v2.4s, %[w1].s[1]\n" /* outr00 += din1_0123 * w1[1]*/ \
- "sub %[din_ptr4], %[din_ptr4], #4 \n" /* din_ptr0-- */ \
- "sub %[din_ptr5], %[din_ptr5], #4 \n" /* din_ptr0-- */ \
- \
- "fmla v13.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ext v17.16b, v4.16b, v5.16b, #4 \n" /* v16=1234 */ \
- "ext v16.16b, %[vzero].16b, v4.16b, #12 \n" /* v16 = 00123*/ \
- \
- /* r2 */ \
- "fmla v14.4s , v4.4s, %[w0].s[1]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v13.4s , v4.4s, %[w1].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- "fmla v12.4s , v4.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w2[1]*/ \
- \
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v14.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ext v16.16b, %[vzero].16b, v6.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234 */ /* r3 */ \
- "fmla v15.4s , v6.4s, %[w0].s[1]\n" /*outr00 += din2_0123 * w0[1]*/ \
- "fmla v14.4s , v6.4s, %[w1].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- "fmla v13.4s , v6.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w2[1]*/ \
- \
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v16.4s, %[w0].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ext v16.16b, %[vzero].16b, v8.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234 */
-
-#define LEFT_RESULT_S1 \
- /* r4 */ \
- "fmla v15.4s , v8.4s, %[w1].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w2[1]*/ \
- \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" /* vst1q_f32() */ \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" /* vst1q_f32() */ \
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ext v16.16b, %[vzero].16b, v10.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234 */ /* r5 */ \
- "fmla v15.4s , v10.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" /* vst1q_f32() */ \
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- \
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- \
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */ \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n" /* vst1q_f32() */ \
- "cmp %w[cnt], #1 \n" \
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "blt 3f \n"
-
-#define MID_COMPUTE_S1 \
- "1: \n" /* r0 */ \
- "fmla v12.4s , v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v0.4s}, [%[din_ptr0]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v12.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v1.4s}, [%[din_ptr0]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */ /* r1 */ \
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v2.4s}, [%[din_ptr1]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v3.4s}, [%[din_ptr1]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */ /* r2 */ \
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v4.4s}, [%[din_ptr2]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v5.4s}, [%[din_ptr2]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
-#define MID_RESULT_S1 \
- /* r3 */ \
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" \
- \
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" \
- \
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" \
- \
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */ \
- \
- "subs %w[cnt], %w[cnt], #1 \n" \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n" \
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "bne 1b \n"
-
-#define RIGHT_COMPUTE_S1 \
- "3: \n" \
- "ld1 {v18.4s, v19.4s}, [%[vmask]] \n" \
- "ld1 {v22.4s}, [%[doutr0]] \n" \
- "ld1 {v23.4s}, [%[doutr1]] \n" \
- "ld1 {v24.4s}, [%[doutr2]] \n" \
- "ld1 {v25.4s}, [%[doutr3]] \n" \
- \
- "bif v0.16b, %[vzero].16b, v18.16b \n" \
- "bif v1.16b, %[vzero].16b, v19.16b \n" \
- "bif v2.16b, %[vzero].16b, v18.16b \n" \
- "bif v3.16b, %[vzero].16b, v19.16b \n" \
- \
- "bif v4.16b, %[vzero].16b, v18.16b \n" \
- "bif v5.16b, %[vzero].16b, v19.16b \n" \
- "bif v6.16b, %[vzero].16b, v18.16b \n" \
- "bif v7.16b, %[vzero].16b, v19.16b \n" \
- \
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */ /* r0 */ \
- "fmla v12.4s, v0.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "bif v8.16b, %[vzero].16b, v18.16b \n" \
- "bif v9.16b, %[vzero].16b, v19.16b \n" \
- "bif v10.16b, %[vzero].16b, v18.16b \n" \
- "bif v11.16b, %[vzero].16b, v19.16b \n" \
- \
- "fmla v12.4s, v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "ld1 {v18.4s}, [%[rmask]] \n" \
- \
- "fmla v12.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v2.16b, v3.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v2.16b, v3.16b, #8 \n" /* v16 = 2345 */ /* r1 */ \
- "fmla v13.4s , v2.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v12.4s , v2.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "fmla v13.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "fmla v13.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v12.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v4.16b, v5.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v4.16b, v5.16b, #8 \n" /* v16 = 2345 */ /* r2 */ \
- "fmla v14.4s , v4.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v4.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v12.4s , v4.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "fmla v14.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v12.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "fmla v14.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v12.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v6.16b, v7.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v6.16b, v7.16b, #8 \n" /* v16 = 2345 */
-
-#define RIGHT_RESULT_S1 \
- /* r3 */ \
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "bif v12.16b, v22.16b, v18.16b \n" \
- \
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" \
- \
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "bif v13.16b, v23.16b, v18.16b \n" \
- \
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "bif v14.16b, v24.16b, v18.16b \n" \
- \
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "bif v15.16b, v25.16b, v18.16b \n" \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
-
-#define LEFT_RESULT_S1_RELU \
- /* r4 */ \
- "fmla v15.4s , v8.4s, %[w1].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w2[1]*/ \
- \
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/ \
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/ \
- \
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v16.4s, %[w1].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" /* vst1q_f32() */ \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" /* vst1q_f32() */ \
- \
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w1[1]*/ \
- \
- "ext v16.16b, %[vzero].16b, v10.16b, #12 \n" /* v16 = 00123*/ \
- "ext v17.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234 */ \
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ /* r5*/ \
- "fmla v15.4s , v10.4s, %[w2].s[1]\n" /* outr00 += din2_0123 * w1[1]*/ \
- \
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/ \
- \
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v16.4s, %[w2].s[0]\n" /* outr00 += din2_0123 * w0[1]*/ \
- \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" /* vst1q_f32() */ \
- \
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/ \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din1_0123 * w0[1]*/ \
- \
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */ \
- \
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/ \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n" /* vst1q_f32() */ \
- "cmp %w[cnt], #1 \n" \
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- "blt 3f \n"
-
-#define MID_RESULT_S1_RELU \
- /* r3 */ \
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v6.4s}, [%[din_ptr3]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" \
- \
- "ld1 {v7.4s}, [%[din_ptr3]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v12.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" \
- \
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v13.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */ \
- \
- /* r3 */ \
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/ \
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" \
- \
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/ \
- "ld1 {v14.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v16 = 2345 */ \
- \
- "subs %w[cnt], %w[cnt], #1 \n" \
- \
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/ \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n" \
- "ld1 {v15.4s}, [%[bias_val]] \n" /*vdupq_n_f32(bias_val)*/ \
- \
- "bne 1b \n"
-
-#define RIGHT_RESULT_S1_RELU \
- /* r3 */ \
- "fmla v15.4s , v6.4s, %[w0].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v6.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v13.4s , v6.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "fmax v12.4s, v12.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w0].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v13.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "bif v12.16b, v22.16b, v18.16b \n" \
- \
- "fmla v15.4s , v17.4s, %[w0].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v13.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v8.16b, v9.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v8.16b, v9.16b, #8 \n" /* v16 = 2345 */ /* r3 */ \
- "fmla v15.4s , v8.4s, %[w1].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- "fmla v14.4s , v8.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "st1 {v12.4s}, [%[doutr0]], #16 \n" \
- "fmax v13.4s, v13.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w1].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- "fmla v14.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "bif v13.16b, v23.16b, v18.16b \n" \
- \
- "fmla v15.4s , v17.4s, %[w1].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- "fmla v14.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "ext v16.16b, v10.16b, v11.16b, #4 \n" /* v16 = 1234*/ \
- "ext v17.16b, v10.16b, v11.16b, #8 \n" /* v16 = 2345 */ \
- \
- "st1 {v13.4s}, [%[doutr1]], #16 \n" /* r3 */ \
- "fmla v15.4s , v10.4s, %[w2].s[0]\n" /* outr00 += din0_0123 * w0[0]*/ \
- \
- "fmax v14.4s, v14.4s, %[vzero].4s \n" /*relu*/ \
- \
- "fmla v15.4s , v16.4s, %[w2].s[1]\n" /* outr00 += din0_1234 * w0[1]*/ \
- \
- "bif v14.16b, v24.16b, v18.16b \n" \
- \
- "fmla v15.4s , v17.4s, %[w2].s[2]\n" /* outr00 += din0_2345 * w0[2]*/ \
- \
- "st1 {v14.4s}, [%[doutr2]], #16 \n" \
- \
- "fmax v15.4s, v15.4s, %[vzero].4s \n" /*relu*/ \
- \
- "bif v15.16b, v25.16b, v18.16b \n" \
- \
- "st1 {v15.4s}, [%[doutr3]], #16 \n"
-
-#define COMPUTE_S_S1 \
- "prfm pldl1keep, [%[din0]]\n" \
- "prfm pldl1keep, [%[din1]]\n" \
- "prfm pldl1keep, [%[din2]]\n" \
- "prfm pldl1keep, [%[din3]]\n" \
- \
- "ld1 {v0.4s}, [%[din0]], #16\n" \
- "ld1 {v1.4s}, [%[din1]], #16\n" \
- "ld1 {v2.4s}, [%[din2]], #16\n" \
- "ld1 {v3.4s}, [%[din3]], #16\n" \
- \
- "bif v0.16b, %[zero].16b, %[mask].16b\n" \
- "bif v1.16b, %[zero].16b, %[mask].16b\n" \
- "bif v2.16b, %[zero].16b, %[mask].16b\n" \
- "bif v3.16b, %[zero].16b, %[mask].16b\n" \
- \
- "ext v4.16b, %[zero].16b, v0.16b, #12\n" \
- "ext v5.16b, %[zero].16b, v1.16b, #12\n" \
- "ext v6.16b, %[zero].16b, v2.16b, #12\n" \
- "ext v7.16b, %[zero].16b, v3.16b, #12\n" \
- \
- "ext v8.16b, v0.16b, %[zero].16b, #4\n" \
- "ext v9.16b, v1.16b, %[zero].16b, #4\n" \
- "ext v10.16b, v2.16b, %[zero].16b, #4\n" \
- "ext v11.16b, v3.16b, %[zero].16b, #4\n" \
- \
- "fmul v12.4s, v0.4s, %[wr0].s[1]\n" \
- "fmul v13.4s, v1.4s, %[wr0].s[1]\n" \
- \
- "fmul v14.4s, v1.4s, %[wr1].s[1]\n" \
- "fmul v15.4s, v2.4s, %[wr1].s[1]\n" \
- \
- "fmul v16.4s, v2.4s, %[wr2].s[1]\n" \
- "fmul v17.4s, v3.4s, %[wr2].s[1]\n" \
- \
- "fmla v12.4s, v4.4s, %[wr0].s[0]\n" \
- "fmla v13.4s, v5.4s, %[wr0].s[0]\n" \
- \
- "fmla v14.4s, v5.4s, %[wr1].s[0]\n" \
- "fmla v15.4s, v6.4s, %[wr1].s[0]\n" \
- \
- "fmla v16.4s, v6.4s, %[wr2].s[0]\n" \
- "fmla v17.4s, v7.4s, %[wr2].s[0]\n" \
- \
- "fmla v12.4s, v8.4s, %[wr0].s[2]\n" \
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n" \
- \
- "fmla v14.4s, v9.4s, %[wr1].s[2]\n" \
- "fmla v15.4s, v10.4s, %[wr1].s[2]\n" \
- \
- "fmla v16.4s, v10.4s, %[wr2].s[2]\n" \
- "fmla v17.4s, v11.4s, %[wr2].s[2]\n" \
- \
- "fadd v12.4s, v12.4s, v14.4s\n" \
- "fadd v12.4s, v12.4s, v16.4s\n" \
- \
- "fadd v13.4s, v13.4s, v15.4s\n" \
- "fadd v13.4s, v13.4s, v17.4s\n" \
- \
- "fadd v12.4s, v12.4s, %[bias].4s\n" \
- "fadd v13.4s, v13.4s, %[bias].4s\n"
-
-#define RESULT_S_S1 \
- "prfm pldl1keep, [%[out1]]\n" \
- "prfm pldl1keep, [%[out2]]\n" \
- \
- "st1 {v12.4s}, [%[out1]]\n" \
- "st1 {v13.4s}, [%[out2]]\n"
-
-#define RESULT_S_S1_RELU \
- "prfm pldl1keep, [%[out1]]\n" \
- "prfm pldl1keep, [%[out2]]\n" \
- \
- "fmax v12.4s, v12.4s, %[zero].4s\n" \
- "fmax v13.4s, v13.4s, %[zero].4s\n" \
- \
- "st1 {v12.4s}, [%[out1]]\n" \
- "st1 {v13.4s}, [%[out2]]\n"
-
-#define COMPUTE_S_S1_P0 \
- "prfm pldl1keep, [%[din0]]\n" \
- "prfm pldl1keep, [%[din1]]\n" \
- "prfm pldl1keep, [%[din2]]\n" \
- "prfm pldl1keep, [%[din3]]\n" \
- \
- "ld1 {v0.4s, v1.4s}, [%[din0]]\n" \
- "ld1 {v2.4s, v3.4s}, [%[din1]]\n" \
- "ld1 {v4.4s, v5.4s}, [%[din2]]\n" \
- "ld1 {v6.4s, v7.4s}, [%[din3]]\n" \
- \
- "bif v0.16b, %[zero].16b, %[mask1].16b\n" \
- "bif v1.16b, %[zero].16b, %[mask2].16b\n" \
- \
- "bif v2.16b, %[zero].16b, %[mask1].16b\n" \
- "bif v3.16b, %[zero].16b, %[mask2].16b\n" \
- \
- "bif v4.16b, %[zero].16b, %[mask1].16b\n" \
- "bif v5.16b, %[zero].16b, %[mask2].16b\n" \
- \
- "bif v6.16b, %[zero].16b, %[mask1].16b\n" \
- "bif v7.16b, %[zero].16b, %[mask2].16b\n" \
- \
- "ext v8.16b, v0.16b, v1.16b, #4\n" \
- "ext v9.16b, v0.16b, v1.16b, #8\n" \
- \
- "and v12.16b, %[vbias].16b, %[vbias].16b \n" \
- "and v13.16b, %[vbias].16b, %[vbias].16b \n" /* r0 */ \
- "fmul v10.4s, v0.4s, %[wr0].s[0]\n" \
- "fmul v11.4s, v8.4s, %[wr0].s[1]\n" \
- "fmla v12.4s, v9.4s, %[wr0].s[2]\n" \
- \
- "ext v8.16b, v2.16b, v3.16b, #4\n" \
- "ext v9.16b, v2.16b, v3.16b, #8\n" /* r1 */ \
- "fmul v14.4s, v2.4s, %[wr0].s[0]\n" \
- "fmla v10.4s, v2.4s, %[wr1].s[0]\n" \
- \
- "fmul v15.4s, v8.4s, %[wr0].s[1]\n" \
- "fmla v11.4s, v8.4s, %[wr1].s[1]\n" \
- \
- "fmla v13.4s, v9.4s, %[wr0].s[2]\n" \
- "fmla v12.4s, v9.4s, %[wr1].s[2]\n" \
- \
- "ext v8.16b, v4.16b, v5.16b, #4\n" \
- "ext v9.16b, v4.16b, v5.16b, #8\n" /* r2 */ \
- "fmla v14.4s, v4.4s, %[wr1].s[0]\n" \
- "fmla v10.4s, v4.4s, %[wr2].s[0]\n" \
- \
- "fmla v15.4s, v8.4s, %[wr1].s[1]\n" \
- "fmla v11.4s, v8.4s, %[wr2].s[1]\n" \
- \
- "fmla v13.4s, v9.4s, %[wr1].s[2]\n" \
- "fmla v12.4s, v9.4s, %[wr2].s[2]\n" \
- \
- "ext v8.16b, v6.16b, v7.16b, #4\n" \
- "ext v9.16b, v6.16b, v7.16b, #8\n" \
- \
- "fmla v14.4s, v6.4s, %[wr2].s[0]\n" \
- \
- "fmla v15.4s, v8.4s, %[wr2].s[1]\n" \
- \
- "fadd v12.4s, v12.4s, v10.4s\n" \
- \
- "fmla v13.4s, v9.4s, %[wr2].s[2]\n" \
- \
- "fadd v12.4s, v12.4s, v11.4s\n" \
- "fadd v13.4s, v13.4s, v14.4s\n" \
- "fadd v13.4s, v13.4s, v15.4s\n" // \
- // "prfm pldl1keep, [%[out1]]\n" \
- // "prfm pldl1keep, [%[out2]]\n" \
- // \
- // "st1 {v12.4s}, [%[out1]]\n" \
- // "st1 {v13.4s}, [%[out2]]\n" \
-
-
-#else
-#define INIT_S1 \
- "pld [%[din0_ptr]] @ preload data\n" \
- "pld [%[din1_ptr]] @ preload data\n" \
- "pld [%[din2_ptr]] @ preload data\n" \
- "pld [%[din3_ptr]] @ preload data\n" \
- \
- "vld1.32 {d16-d18}, [%[din0_ptr]]! @ load din r0\n" \
- "vld1.32 {d20-d22}, [%[din1_ptr]]! @ load din r1\n" \
- "vld1.32 {d24-d26}, [%[din2_ptr]]! @ load din r2\n" \
- "vld1.32 {d28-d30}, [%[din3_ptr]]! @ load din r3\n" \
- \
- "vdup.32 q4, %[bias_val] @ and \n" \
- "vdup.32 q5, %[bias_val] @ and \n"
-
-#define LEFT_COMPUTE_S1 \
- "vext.32 q6, %q[vzero], q8, #3 @ 0012\n" \
- "vext.32 q7, q8, q9, #1 @ 1234\n" /* r0 */ \
- "vmla.f32 q4, q8, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "sub %[din0_ptr], #12 @ 1pad + 2 float data overlap\n" \
- "sub %[din1_ptr], #12 @ 1pad + 2 float data overlap\n" \
- "sub %[din2_ptr], #12 @ 1pad + 2 float data overlap\n" \
- "sub %[din3_ptr], #12 @ 1pad + 2 float data overlap\n" \
- \
- "vmla.f32 q4, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n" \
- \
- "pld [%[din0_ptr]] @ preload data\n" \
- "pld [%[din1_ptr]] @ preload data\n" \
- "pld [%[din2_ptr]] @ preload data\n" \
- "pld [%[din3_ptr]] @ preload data\n" \
- \
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n" \
- \
- "vext.32 q6, %q[vzero], q10, #3 @ 0012\n" \
- "vext.32 q7, q10, q11, #1 @ 1234\n" \
- \
- /* r1 */ \
- "vmla.f32 q5, q10, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q10, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n" \
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q5, q6, %e[wr0][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n" \
- \
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n" \
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n" \
- \
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[2]\n" \
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n" \
- \
- "vext.32 q6, %q[vzero], q12, #3 @ 0012\n" \
- "vext.32 q7, q12, q13, #1 @ 1234\n" \
- \
- /* r2 */ \
- "vmla.f32 q5, q12, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q12, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q5, q6, %e[wr1][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n" \
- \
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n" \
- \
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[2]\n" \
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n" \
- \
- "vext.32 q6, %q[vzero], q14, #3 @ 0012\n" \
- "vext.32 q7, q14, q15, #1 @ 1234\n"
-
-#define LEFT_RESULT_S1 \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n" \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmla.f32 q5, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n" \
- \
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n" \
- "vdup.32 q4, %[bias_val] @ and \n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" \
- "cmp %[cnt], #1 @ check whether has mid cols\n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n" \
- \
- "vdup.32 q5, %[bias_val] @ and \n" \
- "blt 3f @ jump to main loop start point\n"
-
-#define MID_COMPUTE_S1 \
- "1: @ right pad entry\n" /* r0 */ \
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "pld [%[din0_ptr]] @ preload data\n" \
- "pld [%[din1_ptr]] @ preload data\n" \
- "pld [%[din2_ptr]] @ preload data\n" \
- "pld [%[din3_ptr]] @ preload data\n" \
- \
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d16-d17}, [%[din0_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vld1.32 {d18}, [%[din0_ptr]] @ load din r0\n" \
- \
- "vext.32 q6, q10, q11, #1 @ 1234\n" \
- "vext.32 q7, q10, q11, #2 @ 2345\n" /* r1 */ \
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d20-d21}, [%[din1_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d22}, [%[din1_ptr]] @ load din r0\n" \
- \
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q12, q13, #1 @ 1234\n" \
- "vext.32 q7, q12, q13, #2 @ 2345\n" /* r2 */ \
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d24-d25}, [%[din2_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d26}, [%[din2_ptr]] @ load din r0\n" \
- \
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q14, q15, #1 @ 1234\n" \
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
-#define MID_RESULT_S1 \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n" \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n" \
- "vdup.32 q4, %[bias_val] @ and \n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n" \
- \
- "subs %[cnt], #1 @ loop count minus 1\n" \
- \
- "vdup.32 q5, %[bias_val] @ and \n" \
- \
- "bne 1b @ jump to main loop start point\n"
-
-#define RIGHT_COMPUTE_S1 \
- "3: @ right pad entry\n" \
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n" \
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n" \
- \
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n" \
- "vld1.32 {d31}, [%[vmask]]! @ load din r0\n" \
- \
- "vbif d16, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d17, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d18, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vbif d20, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d21, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d22, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" /* r0 */ \
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vbif d24, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d25, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d26, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vbif d28, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d29, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d30, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vext.32 q6, q10, q11, #1 @ 1234\n" \
- "vext.32 q7, q10, q11, #2 @ 2345\n" /* r1 */ \
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d19}, [%[rmask]]! @ load din r0\n" \
- "vld1.32 {d23}, [%[rmask]]! @ load din r0\n" \
- \
- "vmla.f32 q5, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d16-d17}, [%[dout_ptr1]] @ load din r0\n" \
- "vld1.32 {d20-d21}, [%[dout_ptr2]] @ load din r0\n" \
- \
- "vmla.f32 q5, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q12, q13, #1 @ 1234\n" \
- "vext.32 q7, q12, q13, #2 @ 2345\n" /* r2 */ \
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmla.f32 q5, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmla.f32 q5, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q4, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q14, q15, #1 @ 1234\n" \
- "vext.32 q7, q14, q15, #2 @ 2345\n"
-
-#define RIGHT_RESULT_S1 \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vbif d8, d16, d19 @ bit select, deal with right pad\n" \
- "vbif d9, d17, d23 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vbif d10, d20, d19 @ bit select, deal with right pad\n" \
- "vbif d11, d21, d23 @ bit select, deal with right pad\n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n"
-
-#define LEFT_RESULT_S1_RELU \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n" \
- "vmax.f32 q4, q4, %q[vzero] @ relu \n" \
- \
- "vmla.f32 q5, q6, %e[wr2][0] @ q4 += 1234 * wr0[0]\n" \
- \
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n" \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 1234 * wr0[2]\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" \
- "vdup.32 q4, %[bias_val] @ and \n" \
- \
- "vmax.f32 q5, q5, %q[vzero] @ relu \n" \
- \
- "cmp %[cnt], #1 @ check whether has mid cols\n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n" \
- \
- "vdup.32 q5, %[bias_val] @ and \n" \
- "blt 3f @ jump to main loop start point\n"
-
-#define MID_RESULT_S1_RELU \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vld1.32 {d28-d29}, [%[din3_ptr]]! @ load din r0\n" \
- "vmax.f32 q4, q4, %q[vzero] @ relu \n" \
- \
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vld1.32 {d30}, [%[din3_ptr]] @ load din r0\n" \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" \
- "vdup.32 q4, %[bias_val] @ and \n" \
- \
- "vmax.f32 q5, q5, %q[vzero] @ relu \n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n" \
- \
- "subs %[cnt], #1 @ loop count minus 1\n" \
- \
- "vdup.32 q5, %[bias_val] @ and \n" \
- \
- "bne 1b @ jump to main loop start point\n"
-
-#define RIGHT_RESULT_S1_RELU \
- /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vmax.f32 q4, q4, %q[vzero] @ relu \n" \
- \
- "vmla.f32 q5, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vbif d8, d16, d19 @ bit select, deal with right pad\n" \
- "vbif d9, d17, d23 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q5, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n" \
- "vst1.32 {d8-d9}, [%[dout_ptr1]]! @ store result, add pointer\n" \
- \
- "vmax.f32 q5, q5, %q[vzero] @ relu \n" \
- \
- "vbif d10, d20, d19 @ bit select, deal with right pad\n" \
- "vbif d11, d21, d23 @ bit select, deal with right pad\n" \
- \
- "vst1.32 {d10-d11}, [%[dout_ptr2]]! @ store result, add pointer\n"
-
-#define COMPUTE_S_S1 \
- "pld [%[din0]]\n" \
- "pld [%[din1]]\n" \
- "pld [%[din2]]\n" \
- "pld [%[din3]]\n" \
- \
- "vld1.32 {d12-d13}, [%[din0]]!\n" \
- "vld1.32 {d14-d15}, [%[din1]]!\n" \
- "vld1.32 {d16-d17}, [%[din2]]!\n" \
- "vld1.32 {d18-d19}, [%[din3]]!\n" \
- \
- "vbif q6, %q[vzero], %q[mask]\n" \
- "vbif q7, %q[vzero], %q[mask]\n" \
- "vbif q8, %q[vzero], %q[mask]\n" \
- "vbif q9, %q[vzero], %q[mask]\n" \
- \
- "vmul.f32 q14, q6, %e[wr0][1]\n" \
- "vmul.f32 q15, q7, %e[wr0][1]\n" \
- \
- "vmla.f32 q14, q7, %e[wr1][1]\n" \
- "vmla.f32 q15, q8, %e[wr1][1]\n" \
- \
- "vmla.f32 q14, q8, %e[wr2][1]\n" \
- "vmla.f32 q15, q9, %e[wr2][1]\n" \
- \
- "vext.32 q10, %q[vzero], q6, #3\n" \
- "vext.32 q11, %q[vzero], q7, #3\n" \
- "vext.32 q12, %q[vzero], q8, #3\n" \
- "vext.32 q13, %q[vzero], q9, #3\n" \
- \
- "vmla.f32 q14, q10, %e[wr0][0]\n" \
- "vmla.f32 q15, q11, %e[wr0][0]\n" \
- \
- "vmla.f32 q14, q11, %e[wr1][0]\n" \
- "vmla.f32 q15, q12, %e[wr1][0]\n" \
- \
- "vmla.f32 q14, q12, %e[wr2][0]\n" \
- "vmla.f32 q15, q13, %e[wr2][0]\n" \
- \
- "vext.32 q10, q6, %q[vzero], #1\n" \
- "vext.32 q11, q7, %q[vzero], #1\n" \
- "vext.32 q12, q8, %q[vzero], #1\n" \
- "vext.32 q13, q9, %q[vzero], #1\n" \
- \
- "vmla.f32 q14, q10, %f[wr0][0]\n" \
- "vmla.f32 q15, q11, %f[wr0][0]\n" \
- \
- "vmla.f32 q14, q11, %f[wr1][0]\n" \
- "vmla.f32 q15, q12, %f[wr1][0]\n" \
- \
- "vmla.f32 q14, q12, %f[wr2][0]\n" \
- "vmla.f32 q15, q13, %f[wr2][0]\n" \
- \
- "vadd.f32 q14, q14, %q[bias]\n" \
- "vadd.f32 q15, q15, %q[bias]\n"
-
-#define RESULT_S_S1 \
- "pld [%[out1]]\n" \
- "pld [%[out2]]\n" \
- \
- "vst1.32 {d28-d29}, [%[out1]]\n" \
- "vst1.32 {d30-d31}, [%[out2]]\n"
-
-#define RESULT_S_S1_RELU \
- "pld [%[out1]]\n" \
- "pld [%[out2]]\n" \
- \
- "vmax.f32 q14, q14, %q[vzero]\n" \
- "vmax.f32 q15, q15, %q[vzero]\n" \
- \
- "vst1.32 {d28-d29}, [%[out1]]\n" \
- "vst1.32 {d30-d31}, [%[out2]]\n"
-
-#define COMPUTE_S_S1_P0 \
- "pld [%[din0]]\n" \
- "pld [%[din1]]\n" \
- "pld [%[din2]]\n" \
- "pld [%[din3]]\n" \
- "vld1.32 {d16-d18}, [%[din0]] @ load din r0\n" \
- "vld1.32 {d20-d22}, [%[din1]] @ load din r1\n" \
- "vld1.32 {d24-d26}, [%[din2]] @ load din r2\n" \
- "vld1.32 {d28-d30}, [%[din3]] @ load din r3\n" \
- \
- "vdup.32 q4, %[bias_val] @ and \n" \
- "vdup.32 q5, %[bias_val] @ and \n" \
- \
- "vld1.32 {d19}, [%[vmask]]! @ load din r0\n" \
- "vld1.32 {d23}, [%[vmask]]! @ load din r0\n" \
- \
- "vld1.32 {d27}, [%[vmask]]! @ load din r0\n" \
- \
- "vbif d16, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d20, %e[vzero], d19 @ bit select, deal with right pad\n" \
- \
- "vbif d17, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d21, %e[vzero], d23 @ bit select, deal with right pad\n" \
- \
- "vbif d18, %e[vzero], d27 @ bit select, deal with right pad\n" \
- "vbif d22, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vext.32 q6, q8, q9, #1 @ 1234\n" \
- "vext.32 q7, q8, q9, #2 @ 2345\n" /* r0 */ \
- "vmla.f32 q4, q8, %e[wr0][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vbif d24, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d25, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d26, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q4, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vbif d28, %e[vzero], d19 @ bit select, deal with right pad\n" \
- "vbif d29, %e[vzero], d23 @ bit select, deal with right pad\n" \
- "vbif d30, %e[vzero], d27 @ bit select, deal with right pad\n" \
- \
- "vmla.f32 q4, q7, %f[wr0][0] @ q4 += 2345 * wr0[2]\n" \
- \
- "vext.32 q6, q10, q11, #1 @ 1234\n" \
- "vext.32 q7, q10, q11, #2 @ 2345\n" /* r1 */ \
- "vmla.f32 q5, q10, %e[wr0][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q10, %e[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmul.f32 q8, q6, %e[wr0][1] @ q4 += 1234 * wr0[1]\n" \
- "vmul.f32 q10, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmul.f32 q9, q7, %f[wr0][0] @ q4 += 1234 * wr0[1]\n" \
- "vmul.f32 q11, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q12, q13, #1 @ 1234\n" \
- "vext.32 q7, q12, q13, #2 @ 2345\n" /* r2 */ \
- "vmla.f32 q5, q12, %e[wr1][0] @ q4 += 1234 * wr0[0]\n" \
- "vmla.f32 q4, q12, %e[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmla.f32 q8, q6, %e[wr1][1] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q10, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- \
- "vmla.f32 q9, q7, %f[wr1][0] @ q4 += 1234 * wr0[1]\n" \
- "vmla.f32 q11, q7, %f[wr2][0] @ q4 += 1234 * wr0[1]\n" \
- \
- "vext.32 q6, q14, q15, #1 @ 1234\n" \
- "vext.32 q7, q14, q15, #2 @ 2345\n" /* r3 */ \
- "vmla.f32 q5, q14, %e[wr2][0] @ q4 += 0123 * wr0[0]\n" \
- \
- "vmla.f32 q8, q6, %e[wr2][1] @ q4 += 1234 * wr0[1]\n" \
- "vadd.f32 q4, q4, q10 @ q4 += q10 \n" \
- \
- "pld [%[out1]]\n" \
- "pld [%[out2]]\n" \
- \
- "vmla.f32 q9, q7, %f[wr2][0] @ q4 += 2345 * wr0[2]\n" \
- "vadd.f32 q14, q4, q11 @ q4 += q10 \n" \
- \
- "vadd.f32 q5, q5, q8 @ q4 += q10 \n" \
- "vadd.f32 q15, q5, q9 @ q4 += q10 \n"
-
-#endif
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width > 4
- */
-void conv_depthwise_3x3s1p1_bias(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- float *zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float *write_ptr = zero_ptr + w_in;
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = (w_in + 3) >> 2;
- int cnt_col = tile_w - 2;
-
- unsigned int size_pad_right = (unsigned int)(1 + (tile_w << 2) - w_in);
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float *din_batch = din + n * ch_in * size_in_channel;
- float *dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int c = 0; c < ch_in; c++) {
- float *dout_ptr = dout_batch + c * size_out_channel;
-
- const float *din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float *wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
-
- float *doutr0 = dout_ptr;
- float *doutr1 = doutr0 + w_out;
- float *doutr2 = doutr1 + w_out;
- float *doutr3 = doutr2 + w_out;
-
- const float *dr0 = din_ch_ptr;
- const float *dr1 = dr0 + w_in;
- const float *dr2 = dr1 + w_in;
- const float *dr3 = dr2 + w_in;
- const float *dr4 = dr3 + w_in;
- const float *dr5 = dr4 + w_in;
-
- const float *din_ptr0 = dr0;
- const float *din_ptr1 = dr1;
- const float *din_ptr2 = dr2;
- const float *din_ptr3 = dr3;
- const float *din_ptr4 = dr4;
- const float *din_ptr5 = dr5;
- float *ptr_zero = const_cast(zero);
-#ifdef __aarch64__
- for (int i = 0; i < h_in; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
- if (i == 0) {
- din_ptr0 = zero_ptr;
- din_ptr1 = dr0;
- din_ptr2 = dr1;
- din_ptr3 = dr2;
- din_ptr4 = dr3;
- din_ptr5 = dr4;
- dr0 = dr3;
- dr1 = dr4;
- dr2 = dr5;
- } else {
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- }
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 > h_in) {
- switch (i + 5 - h_in) {
- case 5:
- din_ptr1 = zero_ptr;
- case 4:
- din_ptr2 = zero_ptr;
- case 3:
- din_ptr3 = zero_ptr;
- case 2:
- din_ptr4 = zero_ptr;
- case 1:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = cnt_col;
- if (flag_relu) {
- asm volatile(
- INIT_S1 LEFT_COMPUTE_S1 LEFT_RESULT_S1_RELU MID_COMPUTE_S1
- MID_RESULT_S1_RELU RIGHT_COMPUTE_S1 RIGHT_RESULT_S1_RELU
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- } else {
- asm volatile(INIT_S1 LEFT_COMPUTE_S1 LEFT_RESULT_S1 MID_COMPUTE_S1
- MID_RESULT_S1 RIGHT_COMPUTE_S1 RIGHT_RESULT_S1
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- }
- dout_ptr = dout_ptr + 4 * w_out;
- }
-#else
- for (int i = 0; i < h_in; i += 2) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
-
- doutr0 = dout_ptr;
- doutr1 = dout_ptr + w_out;
- // unsigned int* rst_mask = rmask;
-
- if (i == 0) {
- din_ptr0 = zero_ptr;
- din_ptr1 = dr0;
- din_ptr2 = dr1;
- din_ptr3 = dr2;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr3;
- dr3 = dr2 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- }
- //! process bottom pad
- if (i + 3 > h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din_ptr1 = zero_ptr;
- case 2:
- din_ptr2 = zero_ptr;
- case 1:
- din_ptr3 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = cnt_col;
- unsigned int *rmask_ptr = rmask;
- unsigned int *vmask_ptr = vmask;
- if (flag_relu) {
- asm volatile(
- INIT_S1 LEFT_COMPUTE_S1 LEFT_RESULT_S1_RELU MID_COMPUTE_S1
- MID_RESULT_S1_RELU RIGHT_COMPUTE_S1 RIGHT_RESULT_S1_RELU
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din_ptr0),
- [din1_ptr] "+r"(din_ptr1),
- [din2_ptr] "+r"(din_ptr2),
- [din3_ptr] "+r"(din_ptr3),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(INIT_S1 LEFT_COMPUTE_S1 LEFT_RESULT_S1 MID_COMPUTE_S1
- MID_RESULT_S1 RIGHT_COMPUTE_S1 RIGHT_RESULT_S1
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din_ptr0),
- [din1_ptr] "+r"(din_ptr1),
- [din2_ptr] "+r"(din_ptr2),
- [din3_ptr] "+r"(din_ptr3),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
- dout_ptr += 2 * w_out;
- } //! end of processing mid rows
-#endif
- }
- }
-}
-
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p1_bias_s(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[4] = {3, 2, 1, 0};
- const float zero[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(4 - w_in));
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float *din_batch = din + n * ch_in * size_in_channel;
- float *dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float *dout_channel = dout_batch + i * size_out_channel;
- const float *din_channel = din_batch + i * size_in_channel;
- const float *weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-
- int hs = -1;
- int he = 3;
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- int h_cnt = (h_out + 1) >> 1;
- float *doutr0 = dout_channel;
- float *doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_cnt; ++j) {
- const float *dr0 = din_channel + hs * w_in;
- const float *dr1 = dr0 + w_in;
- const float *dr2 = dr1 + w_in;
- const float *dr3 = dr2 + w_in;
-
- if (hs == -1) {
- dr0 = zero;
- }
-
- switch (he - h_in) {
- case 2:
- dr2 = zero;
- doutr1 = trash_buf;
- case 1:
- dr3 = zero;
- default:
- break;
- }
-#ifdef __aarch64__
- if (flag_relu) {
- asm volatile(COMPUTE_S_S1 RESULT_S_S1_RELU
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17");
- } else {
- asm volatile(COMPUTE_S_S1 RESULT_S_S1
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [zero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17");
- }
-#else
- if (flag_relu) {
- asm volatile(COMPUTE_S_S1 RESULT_S_S1_RELU
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(COMPUTE_S_S1 RESULT_S_S1
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [mask] "w"(vmask_rp),
- [bias] "w"(wbias),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
-#endif
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- doutr0 = doutr1;
- doutr1 += w_out;
- hs += 2;
- he += 2;
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width > 4
- */
-void conv_depthwise_3x3s1p0_bias(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx) {
- //! pad is done implicit
- const float zero[8] = {0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f, 0.f};
- //! for 4x6 convolution window
- const unsigned int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
-
- float *zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float *write_ptr = zero_ptr + w_in;
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- int w_stride = 9;
-
- int tile_w = w_out >> 2;
- int remain = w_out % 4;
-
- unsigned int size_pad_right = (unsigned int)(6 + (tile_w << 2) - w_in);
- const int remian_idx[4] = {0, 1, 2, 3};
-
- uint32x4_t vmask_rp1 =
- vcgeq_u32(vld1q_u32(right_pad_idx), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_rp2 =
- vcgeq_u32(vld1q_u32(right_pad_idx + 4), vdupq_n_u32(size_pad_right));
- uint32x4_t vmask_result =
- vcgtq_s32(vdupq_n_s32(remain), vld1q_s32(remian_idx));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- unsigned int rmask[4];
- vst1q_u32(rmask, vmask_result);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
- for (int n = 0; n < num; ++n) {
- const float *din_batch = din + n * ch_in * size_in_channel;
- float *dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int c = 0; c < ch_in; c++) {
- float *dout_ptr = dout_batch + c * size_out_channel;
-
- const float *din_ch_ptr = din_batch + c * size_in_channel;
-
- float bias_val = flag_bias ? bias[c] : 0.f;
- float vbias[4] = {bias_val, bias_val, bias_val, bias_val};
-
- const float *wei_ptr = weights + c * w_stride;
-
- float32x4_t wr0 = vld1q_f32(wei_ptr);
- float32x4_t wr1 = vld1q_f32(wei_ptr + 3);
- float32x4_t wr2 = vld1q_f32(wei_ptr + 6);
-
- float *doutr0 = dout_ptr;
- float *doutr1 = doutr0 + w_out;
- float *doutr2 = doutr1 + w_out;
- float *doutr3 = doutr2 + w_out;
-
- const float *dr0 = din_ch_ptr;
- const float *dr1 = dr0 + w_in;
- const float *dr2 = dr1 + w_in;
- const float *dr3 = dr2 + w_in;
- const float *dr4 = dr3 + w_in;
- const float *dr5 = dr4 + w_in;
-
- const float *din_ptr0 = dr0;
- const float *din_ptr1 = dr1;
- const float *din_ptr2 = dr2;
- const float *din_ptr3 = dr3;
- const float *din_ptr4 = dr4;
- const float *din_ptr5 = dr5;
-
- float *ptr_zero = const_cast(zero);
-#ifdef __aarch64__
- for (int i = 0; i < h_out; i += 4) {
- //! process top pad pad_h = 1
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
- din_ptr4 = dr4;
- din_ptr5 = dr5;
-
- doutr0 = dout_ptr;
- doutr1 = doutr0 + w_out;
- doutr2 = doutr1 + w_out;
- doutr3 = doutr2 + w_out;
-
- dr0 = dr4;
- dr1 = dr5;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
- dr5 = dr4 + w_in;
-
- //! process bottom pad
- if (i + 5 >= h_in) {
- switch (i + 5 - h_in) {
- case 4:
- din_ptr1 = zero_ptr;
- case 3:
- din_ptr2 = zero_ptr;
- case 2:
- din_ptr3 = zero_ptr;
- case 1:
- din_ptr4 = zero_ptr;
- case 0:
- din_ptr5 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 4 > h_out) {
- switch (i + 4 - h_out) {
- case 3:
- doutr1 = write_ptr;
- case 2:
- doutr2 = write_ptr;
- case 1:
- doutr3 = write_ptr;
- default:
- break;
- }
- }
-
- int cnt = tile_w;
- if (flag_relu) {
- asm volatile(
- INIT_S1
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v17 = 2345 */
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- MID_COMPUTE_S1 MID_RESULT_S1_RELU
- "cmp %w[remain], #1 \n"
- "blt 0f \n" RIGHT_COMPUTE_S1
- RIGHT_RESULT_S1_RELU "0: \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- } else {
- asm volatile(
- INIT_S1
- "ld1 {v8.4s}, [%[din_ptr4]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v10.4s}, [%[din_ptr5]], #16 \n" /*vld1q_f32(din_ptr0)*/
- "ext v16.16b, v0.16b, v1.16b, #4 \n" /* v16 = 1234 */
- "ext v17.16b, v0.16b, v1.16b, #8 \n" /* v17 = 2345 */
- "ld1 {v9.4s}, [%[din_ptr4]] \n" /*vld1q_f32(din_ptr0)*/
- "ld1 {v11.4s}, [%[din_ptr5]] \n" /*vld1q_f32(din_ptr0)*/
- MID_COMPUTE_S1 MID_RESULT_S1
- "cmp %w[remain], #1 \n"
- "blt 0f \n" RIGHT_COMPUTE_S1
- RIGHT_RESULT_S1 "0: \n"
- : [cnt] "+r"(cnt),
- [din_ptr0] "+r"(din_ptr0),
- [din_ptr1] "+r"(din_ptr1),
- [din_ptr2] "+r"(din_ptr2),
- [din_ptr3] "+r"(din_ptr3),
- [din_ptr4] "+r"(din_ptr4),
- [din_ptr5] "+r"(din_ptr5),
- [doutr0] "+r"(doutr0),
- [doutr1] "+r"(doutr1),
- [doutr2] "+r"(doutr2),
- [doutr3] "+r"(doutr3)
- : [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [bias_val] "r"(vbias),
- [vmask] "r"(vmask),
- [rmask] "r"(rmask),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21",
- "v22",
- "v23",
- "v24",
- "v25");
- }
- dout_ptr = dout_ptr + 4 * w_out;
- }
-#else
- for (int i = 0; i < h_out; i += 2) {
- din_ptr0 = dr0;
- din_ptr1 = dr1;
- din_ptr2 = dr2;
- din_ptr3 = dr3;
-
- doutr0 = dout_ptr;
- doutr1 = dout_ptr + w_out;
-
- dr0 = dr2;
- dr1 = dr3;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- //! process bottom pad
- if (i + 3 >= h_in) {
- switch (i + 3 - h_in) {
- case 3:
- din_ptr1 = zero_ptr;
- case 2:
- din_ptr2 = zero_ptr;
- case 1:
- din_ptr3 = zero_ptr;
- case 0:
- din_ptr3 = zero_ptr;
- default:
- break;
- }
- }
- //! process bottom remain
- if (i + 2 > h_out) {
- doutr1 = write_ptr;
- }
- int cnt = tile_w;
- unsigned int *rmask_ptr = rmask;
- unsigned int *vmask_ptr = vmask;
- if (flag_relu) {
- asm volatile(INIT_S1
- "sub %[din0_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din1_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din2_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din3_ptr], #8 @ 0pad + 2 float data overlap\n"
- "vext.32 q6, q8, q9, #1 @ 0012\n"
- "vext.32 q7, q8, q9, #2 @ 1234\n" MID_COMPUTE_S1
- MID_RESULT_S1_RELU
- "cmp %[remain], #1 \n"
- "blt 0f \n" RIGHT_COMPUTE_S1
- RIGHT_RESULT_S1_RELU "0: \n"
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din_ptr0),
- [din1_ptr] "+r"(din_ptr1),
- [din2_ptr] "+r"(din_ptr2),
- [din3_ptr] "+r"(din_ptr3),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(INIT_S1
- "sub %[din0_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din1_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din2_ptr], #8 @ 0pad + 2 float data overlap\n"
- "sub %[din3_ptr], #8 @ 0pad + 2 float data overlap\n"
- "vext.32 q6, q8, q9, #1 @ 0012\n"
- "vext.32 q7, q8, q9, #2 @ 1234\n" MID_COMPUTE_S1
- MID_RESULT_S1
- "cmp %[remain], #1 \n"
- "blt 0f \n" RIGHT_COMPUTE_S1
- RIGHT_RESULT_S1 "0: \n"
- : [dout_ptr1] "+r"(doutr0),
- [dout_ptr2] "+r"(doutr1),
- [din0_ptr] "+r"(din_ptr0),
- [din1_ptr] "+r"(din_ptr1),
- [din2_ptr] "+r"(din_ptr2),
- [din3_ptr] "+r"(din_ptr3),
- [cnt] "+r"(cnt),
- [rmask] "+r"(rmask_ptr),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias_val] "r"(bias_val),
- [vzero] "w"(vzero),
- [remain] "r"(remain)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
- dout_ptr += 2 * w_out;
- } //! end of processing mid rows
-#endif
- }
- }
-}
-/**
- * \brief depthwise convolution, kernel size 3x3, stride 1, pad 1, with bias,
- * width <= 4
- */
-void conv_depthwise_3x3s1p0_bias_s(float *dout,
- const float *din,
- const float *weights,
- const float *bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext *ctx) {
- //! 3x3s1 convolution, implemented by direct algorithm
- //! pad is done implicit
- //! for 4x6 convolution window
- const int right_pad_idx[8] = {5, 4, 3, 2, 1, 0, 0, 0};
- const float zero_ptr[4] = {0.f, 0.f, 0.f, 0.f};
-
- float32x4_t vzero = vdupq_n_f32(0.f);
- uint32x4_t vmask_rp1 =
- vcgeq_s32(vld1q_s32(right_pad_idx), vdupq_n_s32(6 - w_in));
- uint32x4_t vmask_rp2 =
- vcgeq_s32(vld1q_s32(right_pad_idx + 4), vdupq_n_s32(6 - w_in));
-
- unsigned int vmask[8];
- vst1q_u32(vmask, vmask_rp1);
- vst1q_u32(vmask + 4, vmask_rp2);
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
- for (int n = 0; n < num; ++n) {
- const float *din_batch = din + n * ch_in * size_in_channel;
- float *dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- float *dout_channel = dout_batch + i * size_out_channel;
- const float *din_channel = din_batch + i * size_in_channel;
- const float *weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
-#ifdef __aarch64__
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-#endif // __aarch64__
-
- float out_buf1[4];
- float out_buf2[4];
- float trash_buf[4];
-
- float *doutr0 = dout_channel;
- float *doutr1 = dout_channel + w_out;
-
- for (int j = 0; j < h_out; j += 2) {
- const float *dr0 = din_channel + j * w_in;
- const float *dr1 = dr0 + w_in;
- const float *dr2 = dr1 + w_in;
- const float *dr3 = dr2 + w_in;
-
- doutr0 = dout_channel + j * w_out;
- doutr1 = doutr0 + w_out;
-
- if (j + 3 >= h_in) {
- switch (j + 3 - h_in) {
- case 3:
- dr1 = zero_ptr;
- case 2:
- dr2 = zero_ptr;
- case 1:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- case 0:
- dr3 = zero_ptr;
- doutr1 = trash_buf;
- default:
- break;
- }
- }
-#ifdef __aarch64__
- if (flag_relu) {
- asm volatile(COMPUTE_S_S1_P0 RESULT_S_S1_RELU
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vbias] "w"(wbias),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [zero] "w"(vzero),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
- } else {
- asm volatile(COMPUTE_S_S1_P0 RESULT_S_S1
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vbias] "w"(wbias),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [zero] "w"(vzero),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
- }
-#else
- unsigned int *vmask_ptr = vmask;
- float bias_val = flag_bias ? bias[i] : 0.f;
- if (flag_relu) {
- asm volatile(COMPUTE_S_S1_P0 RESULT_S_S1_RELU
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [bias_val] "r"(bias_val),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(COMPUTE_S_S1_P0 RESULT_S_S1
- : [din0] "+r"(dr0),
- [din1] "+r"(dr1),
- [din2] "+r"(dr2),
- [din3] "+r"(dr3),
- [vmask] "+r"(vmask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [vzero] "w"(vzero),
- [bias_val] "r"(bias_val),
- [out1] "r"(out_buf1),
- [out2] "r"(out_buf2)
- : "cc",
- "memory",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
-#endif
- for (int w = 0; w < w_out; ++w) {
- *doutr0++ = out_buf1[w];
- *doutr1++ = out_buf2[w];
- }
- } // end of processing heights
- } // end of processing channels
- } // end of processing batchs
-}
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/conv_depthwise_3x3s2.cc b/lite/backends/arm/math/conv_depthwise_3x3s2.cc
deleted file mode 100644
index ec039af98cb7e4fb037475dd4e5ee29204252165..0000000000000000000000000000000000000000
--- a/lite/backends/arm/math/conv_depthwise_3x3s2.cc
+++ /dev/null
@@ -1,1862 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/arm/math/conv_depthwise.h"
-#include
-
-namespace paddle {
-namespace lite {
-namespace arm {
-namespace math {
-void conv_depthwise_3x3s2p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx);
-
-void conv_depthwise_3x3s2_fp32(const float* din,
- float* dout,
- int num,
- int ch_out,
- int h_out,
- int w_out,
- int ch_in,
- int h_in,
- int w_in,
- const float* weights,
- const float* bias,
- int pad,
- bool flag_bias,
- bool flag_relu,
- ARMContext* ctx) {
- if (pad == 0) {
- if (w_in > 7) {
- conv_depthwise_3x3s2p0_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p0_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
- if (pad == 1) {
- if (w_in > 7) {
- conv_depthwise_3x3s2p1_bias(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- } else {
- conv_depthwise_3x3s2p1_bias_s(dout,
- din,
- weights,
- bias,
- flag_bias,
- flag_relu,
- num,
- ch_in,
- h_in,
- w_in,
- h_out,
- w_out,
- ctx);
- }
- }
-}
-#ifdef __aarch64__
-#define INIT_S2 \
- "prfm pldl1keep, [%[inptr0]] \n" \
- "prfm pldl1keep, [%[inptr1]] \n" \
- "prfm pldl1keep, [%[inptr2]] \n" \
- "prfm pldl1keep, [%[inptr3]] \n" \
- "prfm pldl1keep, [%[inptr4]] \n" \
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" \
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n" \
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n" \
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n" \
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n" \
- \
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" \
- "and v17.16b, %[vbias].16b, %[vbias].16b \n"
-
-#define LEFT_COMPUTE_S2 \
- "ext v10.16b, %[vzero].16b, v1.16b, #12 \n" /* r0 */ \
- "fmul v11.4s, v0.4s, %[w0].s[1] \n" /* {0,2,4,6} * w01 */ \
- "fmul v12.4s, v1.4s, %[w0].s[2] \n" /* {1,3,5,7} * w02 */ \
- "fmla v16.4s, v10.4s, %[w0].s[0] \n" /* {0,1,3,5} * w00*/ \
- \
- "ext v10.16b, %[vzero].16b, v3.16b, #12 \n" /* v10 = {0,1,3,5} */ \
- \
- "sub %[inptr0], %[inptr0], #4 \n" \
- "sub %[inptr1], %[inptr1], #4 \n" /* r1 */ \
- "fmla v11.4s, v2.4s, %[w1].s[1] \n" \
- "fmla v12.4s, v3.4s, %[w1].s[2] \n" \
- "fmla v16.4s, v10.4s, %[w1].s[0] \n" \
- \
- "ext v10.16b, %[vzero].16b, v5.16b, #12 \n" \
- \
- "sub %[inptr2], %[inptr2], #4 \n" \
- "sub %[inptr3], %[inptr3], #4 \n" /* r2 */ \
- "fmul v13.4s, v4.4s, %[w0].s[1] \n" \
- "fmla v11.4s, v4.4s, %[w2].s[1] \n" \
- \
- "fmul v14.4s, v5.4s, %[w0].s[2] \n" \
- "fmla v12.4s, v5.4s, %[w2].s[2] \n" \
- \
- "fmla v17.4s, v10.4s, %[w0].s[0] \n" \
- "fmla v16.4s, v10.4s, %[w2].s[0] \n" \
- \
- "ext v10.16b, %[vzero].16b, v7.16b, #12 \n" \
- \
- "sub %[inptr4], %[inptr4], #4 \n" /* r3 */ \
- "fmla v13.4s, v6.4s, %[w1].s[1] \n" \
- "fmla v14.4s, v7.4s, %[w1].s[2] \n" \
- "fmla v17.4s, v10.4s, %[w1].s[0] \n" \
- \
- "ext v10.16b, %[vzero].16b, v9.16b, #12 \n" \
- "fadd v16.4s, v16.4s, v11.4s \n" \
- "fadd v16.4s, v16.4s, v12.4s \n"
-
-#define LEFT_RESULT_S2 \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[1] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[2] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[0] \n" \
- \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" \
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n" \
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n" \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n" \
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n" \
- "ld1 {v15.4s}, [%[inptr0]] \n" \
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "ld1 {v18.4s}, [%[inptr1]] \n" \
- "ld1 {v19.4s}, [%[inptr2]] \n" \
- \
- "ext v10.16b, v0.16b, v15.16b, #4 \n" \
- \
- "ld1 {v20.4s}, [%[inptr3]] \n" \
- "ld1 {v21.4s}, [%[inptr4]] \n" \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- \
- "cmp %w[cnt], #1 \n" \
- \
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "blt 1f \n"
-
-#define MID_COMPUTE_S2 \
- "2: \n" /* r0 */ \
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" \
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" \
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" \
- \
- "ext v10.16b, v2.16b, v18.16b, #4 \n" \
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" /* r1 */ \
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" \
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" \
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" \
- \
- "ext v10.16b, v4.16b, v19.16b, #4 \n" \
- \
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n" /* r2 */ \
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" \
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" \
- \
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" \
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" \
- \
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" \
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" \
- \
- "ext v10.16b, v6.16b, v20.16b, #4 \n" \
- \
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n" /* r3 */ \
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" \
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" \
- \
- "ext v10.16b, v8.16b, v21.16b, #4 \n" \
- \
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n" \
- \
- "fadd v16.4s, v16.4s, v11.4s \n" \
- "fadd v16.4s, v16.4s, v12.4s \n"
-
-#define MID_RESULT_S2 \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" \
- \
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n" \
- "ld1 {v15.4s}, [%[inptr0]] \n" \
- "ld1 {v18.4s}, [%[inptr1]] \n" \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "ld1 {v19.4s}, [%[inptr2]] \n" \
- "ld1 {v20.4s}, [%[inptr3]] \n" \
- "ld1 {v21.4s}, [%[inptr4]] \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "ext v10.16b, v0.16b, v15.16b, #4 \n" \
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" \
- "subs %w[cnt], %w[cnt], #1 \n" \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- \
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "bne 2b \n"
-
-#define RIGHT_COMPUTE_S2 \
- "1: \n" \
- "cmp %w[remain], #1 \n" \
- "blt 4f \n" \
- "3: \n" \
- "bif v0.16b, %[vzero].16b, %[mask1].16b \n" \
- "bif v1.16b, %[vzero].16b, %[mask2].16b \n" \
- \
- "bif v2.16b, %[vzero].16b, %[mask1].16b \n" \
- "bif v3.16b, %[vzero].16b, %[mask2].16b \n" \
- \
- "bif v4.16b, %[vzero].16b, %[mask1].16b \n" \
- "bif v5.16b, %[vzero].16b, %[mask2].16b \n" \
- \
- "ext v10.16b, v0.16b, %[vzero].16b, #4 \n" \
- \
- "bif v6.16b, %[vzero].16b, %[mask1].16b \n" \
- "bif v7.16b, %[vzero].16b, %[mask2].16b \n" /* r0 */ \
- "fmul v11.4s, v0.4s, %[w0].s[0] \n" \
- "fmul v12.4s, v1.4s, %[w0].s[1] \n" \
- "fmla v16.4s, v10.4s, %[w0].s[2] \n" \
- \
- "ext v10.16b, v2.16b, %[vzero].16b, #4 \n" \
- "bif v8.16b, %[vzero].16b, %[mask1].16b \n" \
- "bif v9.16b, %[vzero].16b, %[mask2].16b \n" /* r1 */ \
- "fmla v11.4s, v2.4s, %[w1].s[0] \n" \
- "fmla v12.4s, v3.4s, %[w1].s[1] \n" \
- "fmla v16.4s, v10.4s, %[w1].s[2] \n" \
- \
- "ext v10.16b, v4.16b, %[vzero].16b, #4 \n" /* r2 */ \
- "fmul v13.4s, v4.4s, %[w0].s[0] \n" \
- "fmla v11.4s, v4.4s, %[w2].s[0] \n" \
- \
- "fmul v14.4s, v5.4s, %[w0].s[1] \n" \
- "fmla v12.4s, v5.4s, %[w2].s[1] \n" \
- \
- "fmla v17.4s, v10.4s, %[w0].s[2] \n" \
- "fmla v16.4s, v10.4s, %[w2].s[2] \n" \
- \
- "ext v10.16b, v6.16b, %[vzero].16b, #4 \n" /* r3 */ \
- "fmla v13.4s, v6.4s, %[w1].s[0] \n" \
- "fmla v14.4s, v7.4s, %[w1].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w1].s[2] \n" \
- \
- "ext v10.16b, v8.16b, %[vzero].16b, #4 \n" \
- "ld1 {v0.4s}, [%[outptr0]] \n" \
- \
- "fadd v16.4s, v16.4s, v11.4s \n" \
- "fadd v16.4s, v16.4s, v12.4s \n" \
- "ld1 {v1.4s}, [%[outptr1]] \n"
-
-#define RIGHT_RESULT_S2 \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" \
- \
- "bif v16.16b, v0.16b, %[wmask].16b \n" \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "bif v17.16b, v1.16b, %[wmask].16b \n" \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- "4: \n"
-
-#define LEFT_RESULT_S2_RELU \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[1] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[2] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[0] \n" \
- \
- "fmax v16.4s, v16.4s, %[vzero].4s \n" \
- \
- "ld2 {v0.4s, v1.4s}, [%[inptr0]], #32 \n" \
- "ld2 {v2.4s, v3.4s}, [%[inptr1]], #32 \n" \
- "ld2 {v4.4s, v5.4s}, [%[inptr2]], #32 \n" \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "ld2 {v6.4s, v7.4s}, [%[inptr3]], #32 \n" \
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n" \
- "ld1 {v15.4s}, [%[inptr0]] \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "ld1 {v18.4s}, [%[inptr1]] \n" \
- "ld1 {v19.4s}, [%[inptr2]] \n" \
- \
- "ext v10.16b, v0.16b, v15.16b, #4 \n" \
- \
- "fmax v17.4s, v17.4s, %[vzero].4s \n" \
- \
- "ld1 {v20.4s}, [%[inptr3]] \n" \
- "ld1 {v21.4s}, [%[inptr4]] \n" \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- \
- "cmp %w[cnt], #1 \n" \
- \
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "blt 1f \n"
-
-#define MID_RESULT_S2_RELU \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" \
- \
- "ld2 {v8.4s, v9.4s}, [%[inptr4]], #32 \n" \
- "ld1 {v15.4s}, [%[inptr0]] \n" \
- "ld1 {v18.4s}, [%[inptr1]] \n" \
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */ \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "ld1 {v19.4s}, [%[inptr2]] \n" \
- "ld1 {v20.4s}, [%[inptr3]] \n" \
- "ld1 {v21.4s}, [%[inptr4]] \n" \
- \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "ext v10.16b, v0.16b, v15.16b, #4 \n" \
- "and v16.16b, %[vbias].16b, %[vbias].16b \n" \
- "subs %w[cnt], %w[cnt], #1 \n" \
- \
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */ \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- \
- "and v17.16b, %[vbias].16b, %[vbias].16b \n" \
- \
- "bne 2b \n"
-
-#define RIGHT_RESULT_S2_RELU \
- /* r4 */ \
- "fmla v13.4s, v8.4s, %[w2].s[0] \n" \
- "fmla v14.4s, v9.4s, %[w2].s[1] \n" \
- "fmla v17.4s, v10.4s, %[w2].s[2] \n" \
- \
- "fmax v16.4s, v16.4s, %[vzero].4s \n" /* relu */ \
- \
- "fadd v17.4s, v17.4s, v13.4s \n" \
- \
- "bif v16.16b, v0.16b, %[wmask].16b \n" \
- \
- "fadd v17.4s, v17.4s, v14.4s \n" \
- \
- "st1 {v16.4s}, [%[outptr0]], #16 \n" \
- \
- "fmax v17.4s, v17.4s, %[vzero].4s \n" /* relu */ \
- \
- "bif v17.16b, v1.16b, %[wmask].16b \n" \
- \
- "st1 {v17.4s}, [%[outptr1]], #16 \n" \
- "4: \n"
-
-#define COMPUTE_S_S2 \
- "movi v9.4s, #0 \n" \
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]], #32 \n" \
- \
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" \
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" \
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" \
- \
- "bif v10.16b, v9.16b, v6.16b \n" \
- "bif v11.16b, v9.16b, v7.16b \n" \
- "bif v12.16b, v9.16b, v6.16b \n" \
- "bif v13.16b, v9.16b, v7.16b \n" \
- "bif v14.16b, v9.16b, v6.16b \n" \
- "bif v15.16b, v9.16b, v7.16b \n" \
- \
- "ext v6.16b, v9.16b, v11.16b, #12 \n" \
- "ext v7.16b, v9.16b, v13.16b, #12 \n" \
- "ext v8.16b, v9.16b, v15.16b, #12 \n" \
- \
- "fmul v4.4s, v10.4s, %[wr0].s[1] \n" \
- "fmul v5.4s, v11.4s, %[wr0].s[2] \n" \
- "fmul v6.4s, v6.4s, %[wr0].s[0] \n" \
- \
- "fmla v4.4s, v12.4s, %[wr1].s[1] \n" \
- "fmla v5.4s, v13.4s, %[wr1].s[2] \n" \
- "fmla v6.4s, v7.4s, %[wr1].s[0] \n" \
- \
- "fmla v4.4s, v14.4s, %[wr2].s[1] \n" \
- "fmla v5.4s, v15.4s, %[wr2].s[2] \n" \
- "fmla v6.4s, v8.4s, %[wr2].s[0] \n" \
- \
- "fadd v4.4s, v4.4s, v5.4s \n" \
- "fadd v4.4s, v4.4s, v6.4s \n"
-
-#define RESULT_S_S2 \
- "fadd v4.4s, v4.4s, %[bias].4s \n" \
- \
- "st1 {v4.4s}, [%[out]] \n"
-
-#define RESULT_S_S2_RELU \
- "fadd v4.4s, v4.4s, %[bias].4s \n" \
- "fmax v4.4s, v4.4s, v9.4s \n" \
- \
- "st1 {v4.4s}, [%[out]] \n"
-
-#define COMPUTE_S_S2_P0 \
- "movi v9.4s, #0 \n" \
- "ld1 {v6.4s, v7.4s}, [%[mask_ptr]], #32 \n" \
- \
- "ld2 {v10.4s, v11.4s}, [%[din0_ptr]], #32 \n" \
- "ld2 {v12.4s, v13.4s}, [%[din1_ptr]], #32 \n" \
- "ld2 {v14.4s, v15.4s}, [%[din2_ptr]], #32 \n" \
- "and v4.16b, %[bias].16b, %[bias].16b \n" \
- \
- "bif v10.16b, v9.16b, v6.16b \n" \
- "bif v11.16b, v9.16b, v7.16b \n" \
- "bif v12.16b, v9.16b, v6.16b \n" \
- "bif v13.16b, v9.16b, v7.16b \n" \
- "bif v14.16b, v9.16b, v6.16b \n" \
- "bif v15.16b, v9.16b, v7.16b \n" \
- \
- "ext v6.16b, v10.16b, v9.16b, #4 \n" \
- "ext v7.16b, v12.16b, v9.16b, #4 \n" \
- "ext v8.16b, v14.16b, v9.16b, #4 \n" \
- \
- "fmla v4.4s, v10.4s, %[wr0].s[0] \n" \
- "fmul v5.4s, v11.4s, %[wr0].s[1] \n" \
- "fmul v16.4s, v6.4s, %[wr0].s[2] \n" \
- \
- "fmla v4.4s, v12.4s, %[wr1].s[0] \n" \
- "fmla v5.4s, v13.4s, %[wr1].s[1] \n" \
- "fmla v16.4s, v7.4s, %[wr1].s[2] \n" \
- \
- "fmla v4.4s, v14.4s, %[wr2].s[0] \n" \
- "fmla v5.4s, v15.4s, %[wr2].s[1] \n" \
- "fmla v16.4s, v8.4s, %[wr2].s[2] \n" \
- \
- "fadd v4.4s, v4.4s, v5.4s \n" \
- "fadd v4.4s, v4.4s, v16.4s \n"
-
-#define RESULT_S_S2_P0 "st1 {v4.4s}, [%[out]] \n"
-
-#define RESULT_S_S2_P0_RELU \
- "fmax v4.4s, v4.4s, v9.4s \n" \
- "st1 {v4.4s}, [%[out]] \n"
-
-#else
-#define INIT_S2 \
- "vmov.u32 q9, #0 \n" \
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r1\n" \
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" \
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" \
- "pld [%[din0_ptr]] @ preload data\n" \
- "pld [%[din1_ptr]] @ preload data\n" \
- "pld [%[din2_ptr]] @ preload data\n" \
- \
- "vdup.32 q3, %[bias] @ and \n"
-
-#define LEFT_COMPUTE_S2 \
- "vext.32 q6, q9, q11, #3 @ shift right 1 data\n" \
- "vext.32 q7, q9, q13, #3 @ shift right 1 data\n" \
- "vext.32 q8, q9, q15, #3 @ shift right 1 data\n" \
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 1, out0\n" \
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 1, out0\n" \
- \
- "sub %[din0_ptr], #4 @ inpitr0 - 1\n" \
- "sub %[din1_ptr], #4 @ inpitr1 - 1\n" \
- "sub %[din2_ptr], #4 @ inpitr2 - 1\n" \
- \
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, out0\n" \
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, out0\n" \
- \
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" \
- \
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 1, out1\n" \
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 1, out1\n" \
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 1, out1\n" \
- \
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r1\n" \
- \
- "vadd.f32 q3, q3, q4 @ add \n" \
- "vadd.f32 q3, q3, q5 @ add \n"
-
-#define LEFT_RESULT_S2 \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "cmp %[cnt], #1 \n" \
- "blt 1f \n"
-
-#define MID_COMPUTE_S2 \
- "2: \n" \
- "vld1.32 {d16}, [%[din0_ptr]] @ load din r0\n" \
- "vdup.32 q3, %[bias] @ and \n" \
- "vext.32 q6, q10, q8, #1 @ shift left 1 \n" \
- "vld1.32 {d16}, [%[din1_ptr]] @ load din r1\n" \
- \
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, out0\n" \
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, out0\n" \
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, out0\n" \
- \
- "vext.32 q7, q12, q8, #1 @ shift left 1 \n" \
- "vld1.32 {d16}, [%[din2_ptr]] @ load din r1\n" \
- \
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" \
- \
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, out0\n" \
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, out0\n" \
- \
- "vext.32 q6, q14, q8, #1 @ shift left 1 \n" \
- \
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" \
- \
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, out0\n" \
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, out0\n" \
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, out0\n" \
- \
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" \
- \
- "vadd.f32 q3, q3, q4 @ add \n" \
- "vadd.f32 q3, q3, q5 @ add \n"
-
-#define MID_RESULT_S2 \
- "subs %[cnt], #1 \n" \
- \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "bne 2b \n"
-
-#define RIGHT_COMPUTE_S2 \
- "1: \n" \
- "cmp %[remain], #1 \n" \
- "blt 3f \n" \
- \
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n" \
- "vdup.32 q3, %[bias] @ and \n" \
- \
- "vbif q10, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q11, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q12, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q13, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q14, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q15, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- \
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" \
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" \
- \
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, out0\n" \
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, out0\n" \
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, out0\n" \
- \
- "vext.32 q6, q14, q9, #1 @ shift left 1 \n" \
- "vld1.f32 {d20-d21}, [%[outptr]] @ load output\n" \
- \
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, out0\n" \
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, out0\n" \
- \
- "vld1.f32 {d22-d23}, [%[mask_ptr]] @ load mask\n" \
- \
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, out0\n" \
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, out0\n" \
- "vmla.f32 q3, q6, %f[wr2][0] @ mul weight 2, out0\n" \
- \
- "vadd.f32 q3, q3, q4 @ add \n" \
- "vadd.f32 q3, q3, q5 @ add \n"
-
-#define RIGHT_RESULT_S2 \
- "vbif.f32 q3, q10, q11 @ write mask\n" \
- \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "3: \n"
-
-#define LEFT_RESULT_S2_RELU \
- "vmax.f32 q3, q3, q9 @ relu \n" \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "cmp %[cnt], #1 \n" \
- "blt 1f \n"
-
-#define MID_RESULT_S2_RELU \
- "vmax.f32 q3, q3, q9 @ relu \n" \
- "subs %[cnt], #1 \n" \
- \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "bne 2b \n"
-
-#define RIGHT_RESULT_S2_RELU \
- "vmax.f32 q3, q3, q9 @ relu \n" \
- "vbif.f32 q3, q10, q11 @ write mask\n" \
- \
- "vst1.32 {d6-d7}, [%[outptr]]! \n" \
- "3: \n"
-
-#define COMPUTE_S_S2 \
- "vmov.u32 q9, #0 \n" \
- "vld1.f32 {d12-d15}, [%[mask_ptr]]! @ load mask\n" \
- "vdup.32 q3, %[bias] @ and \n" \
- \
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" \
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" \
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" \
- \
- "vbif q10, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q11, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q12, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q13, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q14, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q15, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- \
- "vext.32 q6, q9, q11, #3 @ shift left 1 \n" \
- "vext.32 q7, q9, q13, #3 @ shift left 1 \n" \
- "vext.32 q8, q9, q15, #3 @ shift left 1 \n" \
- \
- "vmul.f32 q4, q10, %e[wr0][1] @ mul weight 0, out0\n" \
- "vmul.f32 q5, q11, %f[wr0][0] @ mul weight 0, out0\n" \
- "vmla.f32 q3, q6, %e[wr0][0] @ mul weight 0, out0\n" \
- \
- "vmla.f32 q4, q12, %e[wr1][1] @ mul weight 1, out0\n" \
- "vmla.f32 q5, q13, %f[wr1][0] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q7, %e[wr1][0] @ mul weight 1, out0\n" \
- \
- "vmla.f32 q4, q14, %e[wr2][1] @ mul weight 2, out0\n" \
- "vmla.f32 q5, q15, %f[wr2][0] @ mul weight 2, out0\n" \
- "vmla.f32 q3, q8, %e[wr2][0] @ mul weight 2, out0\n" \
- \
- "vadd.f32 q3, q3, q4 @ add \n" \
- "vadd.f32 q3, q3, q5 @ add \n"
-
-#define RESULT_S_S2 "vst1.32 {d6-d7}, [%[out]] \n"
-
-#define RESULT_S_S2_RELU \
- "vmax.f32 q3, q3, q9 @ relu\n" \
- \
- "vst1.32 {d6-d7}, [%[out]] \n"
-
-#define COMPUTE_S_S2_P0 \
- "vmov.u32 q9, #0 \n" \
- "vld1.f32 {d12-d15}, [%[mask_ptr]] @ load mask\n" \
- "vdup.32 q3, %[bias] @ and \n" \
- \
- "vld2.32 {d20-d23}, [%[din0_ptr]]! @ load din r0\n" \
- "vld2.32 {d24-d27}, [%[din1_ptr]]! @ load din r1\n" \
- "vld2.32 {d28-d31}, [%[din2_ptr]]! @ load din r2\n" \
- \
- "vbif q10, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q11, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q12, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q13, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- "vbif q14, q9, q6 @ bit select, deal with " \
- "right pad\n" \
- "vbif q15, q9, q7 @ bit select, deal with " \
- "right pad\n" \
- \
- "vext.32 q6, q10, q9, #1 @ shift left 1 \n" \
- "vext.32 q7, q12, q9, #1 @ shift left 1 \n" \
- "vext.32 q8, q14, q9, #1 @ shift left 1 \n" \
- \
- "vmul.f32 q4, q10, %e[wr0][0] @ mul weight 0, out0\n" \
- "vmul.f32 q5, q11, %e[wr0][1] @ mul weight 0, out0\n" \
- "vmla.f32 q3, q6, %f[wr0][0] @ mul weight 0, out0\n" \
- \
- "vmla.f32 q4, q12, %e[wr1][0] @ mul weight 1, out0\n" \
- "vmla.f32 q5, q13, %e[wr1][1] @ mul weight 1, out0\n" \
- "vmla.f32 q3, q7, %f[wr1][0] @ mul weight 1, out0\n" \
- \
- "vmla.f32 q4, q14, %e[wr2][0] @ mul weight 2, out0\n" \
- "vmla.f32 q5, q15, %e[wr2][1] @ mul weight 2, out0\n" \
- "vmla.f32 q3, q8, %f[wr2][0] @ mul weight 2, out0\n" \
- \
- "vadd.f32 q3, q3, q4 @ add \n" \
- "vadd.f32 q3, q3, q5 @ add \n"
-
-#define RESULT_S_S2_P0 "vst1.32 {d6-d7}, [%[out]] \n"
-
-#define RESULT_S_S2_P0_RELU \
- "vmax.f32 q3, q3, q9 @ relu \n" \
- "vst1.32 {d6-d7}, [%[out]] \n"
-
-#endif
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2
- * w_in > 7
- */
-void conv_depthwise_3x3s2p1_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- int size_pad_bottom = h_out * 2 - h_in;
-
- int cnt_col = (w_out >> 2) - 2;
- int size_right_remain = w_in - (7 + cnt_col * 8);
- if (size_right_remain >= 9) {
- cnt_col++;
- size_right_remain -= 8;
- }
- int cnt_remain = (size_right_remain == 8) ? 4 : (w_out % 4); //
-
- int size_right_pad = w_out * 2 - w_in;
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-#ifdef __aarch64__
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-#else
- float bias_c = 0.f;
- if (flag_bias) {
- bias_c = bias[i];
- }
-#endif // __aarch64__
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_in; i += 4) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- din3_ptr = dr2;
- din4_ptr = dr3;
- dr0 = dr3;
- dr1 = dr4;
- } else {
- dr0 = dr4;
- dr1 = dr0 + w_in;
- }
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i + 4 > h_in) {
- switch (i + 4 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i / 2 + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = cnt_col;
- if (flag_relu) {
- asm volatile(
- INIT_S2 LEFT_COMPUTE_S2 LEFT_RESULT_S2_RELU MID_COMPUTE_S2
- MID_RESULT_S2_RELU RIGHT_COMPUTE_S2 RIGHT_RESULT_S2_RELU
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- } else {
- asm volatile(INIT_S2 LEFT_COMPUTE_S2 LEFT_RESULT_S2 MID_COMPUTE_S2
- MID_RESULT_S2 RIGHT_COMPUTE_S2 RIGHT_RESULT_S2
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- }
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
- for (int i = 0; i < h_in; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- if (i == 0) {
- din0_ptr = zero_ptr;
- din1_ptr = dr0;
- din2_ptr = dr1;
- dr0 = dr1;
- dr1 = dr2;
- dr2 = dr1 + w_in;
- } else {
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- }
-
- //! process bottom pad
- if (i + 2 > h_in) {
- switch (i + 2 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = cnt_col;
- unsigned int* mask_ptr = dmask;
- if (flag_relu) {
- asm volatile(
- INIT_S2 LEFT_COMPUTE_S2 LEFT_RESULT_S2_RELU MID_COMPUTE_S2
- MID_RESULT_S2_RELU RIGHT_COMPUTE_S2 RIGHT_RESULT_S2_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(INIT_S2 LEFT_COMPUTE_S2 LEFT_RESULT_S2 MID_COMPUTE_S2
- MID_RESULT_S2 RIGHT_COMPUTE_S2 RIGHT_RESULT_S2
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 4
- */
-void conv_depthwise_3x3s2p1_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- int hs = -1;
- int he = 2;
- float out_buf[4];
- for (int j = 0; j < h_out; ++j) {
- const float* dr0 = din_channel + hs * w_in;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- if (hs == -1) {
- dr0 = zeros;
- }
- if (he > h_in) {
- dr2 = zeros;
- }
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- if (flag_relu) {
- asm volatile(COMPUTE_S_S2 RESULT_S_S2_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
- } else {
- asm volatile(COMPUTE_S_S2 RESULT_S_S2
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15");
- }
-#else
- if (flag_relu) {
- asm volatile(COMPUTE_S_S2 RESULT_S_S2_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(COMPUTE_S_S2 RESULT_S_S2
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
-#endif
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- hs += 2;
- he += 2;
- }
- }
- }
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2
- */
-// w_in > 7
-void conv_depthwise_3x3s2p0_bias(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
-
- int tile_w = w_out >> 2;
- int cnt_remain = w_out % 4;
-
- unsigned int size_right_remain = (unsigned int)(w_in - (tile_w << 3));
-
- uint32x4_t vmask_rp1 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 = vcgtq_s32(vdupq_n_s32(size_right_remain),
- vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
- uint32x4_t wmask =
- vcgtq_s32(vdupq_n_s32(cnt_remain), vld1q_s32(out_pad_idx)); // 0 1 2 3
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- float* zero_ptr = ctx->workspace_data();
- memset(zero_ptr, 0, w_in * sizeof(float));
- float* write_ptr = zero_ptr + w_in;
-
- unsigned int dmask[12];
-
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
- vst1q_u32(dmask + 8, wmask);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float32x4_t vzero = vdupq_n_f32(0.f);
-
-#ifdef __aarch64__
- float32x4_t wbias;
- if (flag_bias) {
- wbias = vdupq_n_f32(bias[i]);
- } else {
- wbias = vdupq_n_f32(0.f);
- }
-#else
- float bias_c = 0.f;
- if (flag_bias) {
- bias_c = bias[i];
- }
-#endif // __aarch64__
-
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- const float* dr3 = dr2 + w_in;
- const float* dr4 = dr3 + w_in;
-
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- const float* din3_ptr = dr3;
- const float* din4_ptr = dr4;
-
- float* doutr0 = dout_channel;
- float* doutr0_ptr = nullptr;
- float* doutr1_ptr = nullptr;
-
-#ifdef __aarch64__
- for (int i = 0; i < h_out; i += 2) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
- din3_ptr = dr3;
- din4_ptr = dr4;
-
- doutr0_ptr = doutr0;
- doutr1_ptr = doutr0 + w_out;
-
- dr0 = dr4;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
- dr3 = dr2 + w_in;
- dr4 = dr3 + w_in;
-
- //! process bottom pad
- if (i * 2 + 5 > h_in) {
- switch (i * 2 + 5 - h_in) {
- case 4:
- din1_ptr = zero_ptr;
- case 3:
- din2_ptr = zero_ptr;
- case 2:
- din3_ptr = zero_ptr;
- case 1:
- din4_ptr = zero_ptr;
- case 0:
- din4_ptr = zero_ptr;
- default:
- break;
- }
- }
- //! process output pad
- if (i + 2 > h_out) {
- doutr1_ptr = write_ptr;
- }
- int cnt = tile_w;
- if (flag_relu) {
- asm volatile(
- INIT_S2
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- MID_COMPUTE_S2 MID_RESULT_S2_RELU
- "cmp %w[remain], #1 \n"
- "blt 4f \n" RIGHT_COMPUTE_S2
- RIGHT_RESULT_S2_RELU
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- } else {
- asm volatile(
- INIT_S2
- "ld1 {v15.4s}, [%[inptr0]] \n"
- "ld1 {v18.4s}, [%[inptr1]] \n"
- "ld1 {v19.4s}, [%[inptr2]] \n"
- "ld1 {v20.4s}, [%[inptr3]] \n"
- "ld1 {v21.4s}, [%[inptr4]] \n"
- "ext v10.16b, v0.16b, v15.16b, #4 \n" // v10 = {2,4,6,8}
- MID_COMPUTE_S2 MID_RESULT_S2
- "cmp %w[remain], #1 \n"
- "blt 4f \n" RIGHT_COMPUTE_S2
- RIGHT_RESULT_S2
- "4: \n"
- : [inptr0] "+r"(din0_ptr),
- [inptr1] "+r"(din1_ptr),
- [inptr2] "+r"(din2_ptr),
- [inptr3] "+r"(din3_ptr),
- [inptr4] "+r"(din4_ptr),
- [outptr0] "+r"(doutr0_ptr),
- [outptr1] "+r"(doutr1_ptr),
- [cnt] "+r"(cnt)
- : [vzero] "w"(vzero),
- [w0] "w"(wr0),
- [w1] "w"(wr1),
- [w2] "w"(wr2),
- [remain] "r"(cnt_remain),
- [mask1] "w"(vmask_rp1),
- [mask2] "w"(vmask_rp2),
- [wmask] "w"(wmask),
- [vbias] "w"(wbias)
- : "cc",
- "memory",
- "v0",
- "v1",
- "v2",
- "v3",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16",
- "v17",
- "v18",
- "v19",
- "v20",
- "v21");
- }
- doutr0 = doutr0 + 2 * w_out;
- }
-#else
- for (int i = 0; i < h_out; i++) {
- din0_ptr = dr0;
- din1_ptr = dr1;
- din2_ptr = dr2;
-
- doutr0_ptr = doutr0;
-
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- //! process bottom pad
- if (i * 2 + 3 > h_in) {
- switch (i * 2 + 3 - h_in) {
- case 2:
- din1_ptr = zero_ptr;
- case 1:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- int cnt = tile_w;
- unsigned int* mask_ptr = dmask;
- if (flag_relu) {
- asm volatile(INIT_S2 MID_COMPUTE_S2 MID_RESULT_S2_RELU
- RIGHT_COMPUTE_S2 RIGHT_RESULT_S2_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(INIT_S2 MID_COMPUTE_S2 MID_RESULT_S2 RIGHT_COMPUTE_S2
- RIGHT_RESULT_S2
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [outptr] "+r"(doutr0_ptr),
- [cnt] "+r"(cnt),
- [mask_ptr] "+r"(mask_ptr)
- : [remain] "r"(cnt_remain),
- [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
- doutr0 = doutr0 + w_out;
- }
-#endif
- }
- }
-}
-
-/**
- * \brief depthwise convolution kernel 3x3, stride 2, width <= 4
- */
-void conv_depthwise_3x3s2p0_bias_s(float* dout,
- const float* din,
- const float* weights,
- const float* bias,
- bool flag_bias,
- bool flag_relu,
- const int num,
- const int ch_in,
- const int h_in,
- const int w_in,
- const int h_out,
- const int w_out,
- ARMContext* ctx) {
- int right_pad_idx[8] = {0, 2, 4, 6, 1, 3, 5, 7};
- int out_pad_idx[4] = {0, 1, 2, 3};
- float zeros[8] = {0.0f};
- const float zero_ptr[4] = {0.f, 0.f, 0.f, 0.f};
-
- uint32x4_t vmask_rp1 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx)); // 0 2 4 6
- uint32x4_t vmask_rp2 =
- vcgtq_s32(vdupq_n_s32(w_in), vld1q_s32(right_pad_idx + 4)); // 1 3 5 7
-
- int size_in_channel = w_in * h_in;
- int size_out_channel = w_out * h_out;
-
- unsigned int dmask[8];
- vst1q_u32(dmask, vmask_rp1);
- vst1q_u32(dmask + 4, vmask_rp2);
-
- for (int n = 0; n < num; ++n) {
- const float* din_batch = din + n * ch_in * size_in_channel;
- float* dout_batch = dout + n * ch_in * size_out_channel;
-#pragma omp parallel for
- for (int i = 0; i < ch_in; ++i) {
- const float* din_channel = din_batch + i * size_in_channel;
- float* dout_channel = dout_batch + i * size_out_channel;
-
- const float* weight_ptr = weights + i * 9;
- float32x4_t wr0 = vld1q_f32(weight_ptr);
- float32x4_t wr1 = vld1q_f32(weight_ptr + 3);
- float32x4_t wr2 = vld1q_f32(weight_ptr + 6);
-
- float bias_c = 0.f;
-
- if (flag_bias) {
- bias_c = bias[i];
- }
- float32x4_t vbias = vdupq_n_f32(bias_c);
- float out_buf[4];
- const float* dr0 = din_channel;
- const float* dr1 = dr0 + w_in;
- const float* dr2 = dr1 + w_in;
- for (int j = 0; j < h_out; j++) {
- const float* din0_ptr = dr0;
- const float* din1_ptr = dr1;
- const float* din2_ptr = dr2;
- if (j * 2 + 2 >= h_in) {
- switch (j + 2 - h_in) {
- case 1:
- din1_ptr = zero_ptr;
- case 0:
- din2_ptr = zero_ptr;
- default:
- break;
- }
- }
- dr0 = dr2;
- dr1 = dr0 + w_in;
- dr2 = dr1 + w_in;
-
- unsigned int* mask_ptr = dmask;
-#ifdef __aarch64__
- if (flag_relu) {
- asm volatile(COMPUTE_S_S2_P0 RESULT_S_S2_P0_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16");
- } else {
- asm volatile(COMPUTE_S_S2_P0 RESULT_S_S2_P0
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr),
- [mask_ptr] "+r"(mask_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "w"(vbias),
- [out] "r"(out_buf)
- : "cc",
- "memory",
- "v4",
- "v5",
- "v6",
- "v7",
- "v8",
- "v9",
- "v10",
- "v11",
- "v12",
- "v13",
- "v14",
- "v15",
- "v16");
- }
-#else
- if (flag_relu) {
- asm volatile(COMPUTE_S_S2_P0 RESULT_S_S2_P0_RELU
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf),
- [mask_ptr] "r"(dmask)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- } else {
- asm volatile(COMPUTE_S_S2_P0 RESULT_S_S2_P0
- : [din0_ptr] "+r"(din0_ptr),
- [din1_ptr] "+r"(din1_ptr),
- [din2_ptr] "+r"(din2_ptr)
- : [wr0] "w"(wr0),
- [wr1] "w"(wr1),
- [wr2] "w"(wr2),
- [bias] "r"(bias_c),
- [out] "r"(out_buf),
- [mask_ptr] "r"(dmask)
- : "cc",
- "memory",
- "q3",
- "q4",
- "q5",
- "q6",
- "q7",
- "q8",
- "q9",
- "q10",
- "q11",
- "q12",
- "q13",
- "q14",
- "q15");
- }
-#endif
- for (int w = 0; w < w_out; ++w) {
- *dout_channel++ = out_buf[w];
- }
- }
- }
- }
-}
-} // namespace math
-} // namespace arm
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/arm/math/reduce_prod.cc b/lite/backends/arm/math/reduce_prod.cc
old mode 100755
new mode 100644
diff --git a/lite/backends/arm/math/reduce_prod.h b/lite/backends/arm/math/reduce_prod.h
old mode 100755
new mode 100644
diff --git a/lite/backends/arm/math/split_merge_lod_tenosr.cc b/lite/backends/arm/math/split_merge_lod_tenosr.cc
old mode 100755
new mode 100644
diff --git a/lite/backends/arm/math/split_merge_lod_tenosr.h b/lite/backends/arm/math/split_merge_lod_tenosr.h
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/KD/debugger.hpp b/lite/backends/fpga/KD/debugger.hpp
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/KD/dl_engine.cpp b/lite/backends/fpga/KD/dl_engine.cpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/dl_engine.hpp b/lite/backends/fpga/KD/dl_engine.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/llapi/zynqmp_api.cpp b/lite/backends/fpga/KD/llapi/zynqmp_api.cpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/llapi/zynqmp_api.h b/lite/backends/fpga/KD/llapi/zynqmp_api.h
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/conv_process.hpp b/lite/backends/fpga/KD/pes/conv_process.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/crop_pe.cpp b/lite/backends/fpga/KD/pes/crop_pe.cpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/depthwise_conv_pe.hpp b/lite/backends/fpga/KD/pes/depthwise_conv_pe.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/elementwise_mul_pe.hpp b/lite/backends/fpga/KD/pes/elementwise_mul_pe.hpp
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/KD/pes/fully_connected_pe.hpp b/lite/backends/fpga/KD/pes/fully_connected_pe.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/gru_pe.hpp b/lite/backends/fpga/KD/pes/gru_pe.hpp
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/KD/pes/gru_util.hpp b/lite/backends/fpga/KD/pes/gru_util.hpp
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/KD/pes/output_pe.hpp b/lite/backends/fpga/KD/pes/output_pe.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/pooling_pe.hpp b/lite/backends/fpga/KD/pes/pooling_pe.hpp
old mode 100644
new mode 100755
diff --git a/lite/backends/fpga/KD/pes/scale_pe.hpp b/lite/backends/fpga/KD/pes/scale_pe.hpp
old mode 100755
new mode 100644
diff --git a/lite/backends/fpga/lite_tensor.cc b/lite/backends/fpga/lite_tensor.cc
old mode 100644
new mode 100755
diff --git a/lite/backends/npu/builder.cc b/lite/backends/npu/builder.cc
deleted file mode 100644
index 954fad8c916e152c5de06ce285b4ac17ecf22a01..0000000000000000000000000000000000000000
--- a/lite/backends/npu/builder.cc
+++ /dev/null
@@ -1,192 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/npu/builder.h"
-#include // NOLINT
-#include
-#include "lite/backends/npu/runtime.h"
-
-namespace paddle {
-namespace lite {
-namespace npu {
-
-// Build HIAI IR graph to om model, and store om model data into lite tensor
-bool BuildModel(std::vector& inputs, // NOLINT
- std::vector& outputs, // NOLINT
- lite::Tensor* model_data) {
- LOG(INFO) << "[NPU] Build model.";
- CHECK_GT(inputs.size(), 0);
- CHECK_GT(outputs.size(), 0);
- CHECK_NE(model_data, 0);
- // build IR graph to om model
- ge::Graph ir_graph("graph");
- ir_graph.SetInputs(inputs).SetOutputs(outputs);
- ge::Model om_model("model", "model");
- om_model.SetGraph(ir_graph);
- domi::HiaiIrBuild ir_build;
- domi::ModelBufferData om_model_buf;
- if (!ir_build.CreateModelBuff(om_model, om_model_buf)) {
- LOG(WARNING) << "[NPU] CreateModelBuff failed!";
- return false;
- }
- if (!ir_build.BuildIRModel(om_model, om_model_buf)) {
- LOG(WARNING) << "[NPU] BuildIRModel failed!";
- return false;
- }
- // store om model into tensor
- model_data->Resize({om_model_buf.length});
- memcpy(model_data->mutable_data(),
- om_model_buf.data,
- om_model_buf.length);
- ir_build.ReleaseModelBuff(om_model_buf);
- return true;
-}
-
-std::string UniqueName(const std::string& prefix) {
- static std::mutex counter_mtx;
- static std::unordered_map counter_map;
- std::unique_lock counter_lck(counter_mtx);
- int counter = 1;
- auto it = counter_map.find(prefix);
- if (it == counter_map.end()) {
- counter_map[prefix] = counter;
- } else {
- counter = ++(it->second);
- }
- return prefix + "_" + std::to_string(counter);
-}
-
-ge::DataType CvtPrecisionType(PrecisionType itype) {
- ge::DataType otype = ge::DT_FLOAT;
- switch (itype) {
- case PRECISION(kFloat):
- otype = ge::DT_FLOAT;
- break;
- case PRECISION(kInt8):
- otype = ge::DT_INT8;
- break;
- case PRECISION(kInt32):
- otype = ge::DT_INT32;
- break;
- default:
- LOG(FATAL) << "[NPU] Can not convert precision type("
- << PrecisionToStr(itype) << ") from Lite to NPU";
- break;
- }
- return otype;
-}
-
-ge::Format CvtDataLayoutType(DataLayoutType itype) {
- ge::Format otype = ge::FORMAT_NCHW;
- switch (itype) {
- case DATALAYOUT(kNCHW):
- otype = ge::FORMAT_NCHW;
- break;
- // TODO(hong19860320) support more data layout type
- default:
- LOG(FATAL) << "[NPU] Can not convert data layout type("
- << DataLayoutToStr(itype) << ") from Lite to NPU";
- break;
- }
- return otype;
-}
-
-ge::TensorPtr CvtTensor(lite::Tensor* in_tensor,
- std::vector out_shape,
- PrecisionType in_ptype,
- DataLayoutType in_ltype) {
- uint8_t* in_data = nullptr;
- auto in_size = in_tensor->dims().production();
- auto in_shape = in_tensor->dims().Vectorize();
- if (out_shape.empty()) {
- out_shape = in_shape;
- }
- int in_bytes;
- if (in_ptype == PRECISION(kFloat)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(float);
- } else if (in_ptype == PRECISION(kInt32)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(int32_t);
- } else if (in_ptype == PRECISION(kInt8)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(int8_t);
- } else {
- LOG(FATAL) << "[NPU] Unknow precision type " << PrecisionToStr(in_ptype);
- }
- ge::DataType out_ptype = CvtPrecisionType(in_ptype);
- ge::Format out_ltype = CvtDataLayoutType(in_ltype);
-
- ge::TensorDesc out_desc(ge::Shape(out_shape), out_ltype, out_ptype);
- CHECK_EQ(out_ltype, ge::FORMAT_NCHW);
-
- auto out_size = out_desc.GetShape().GetShapeSize();
- CHECK_EQ(out_size, in_size);
-
- ge::TensorPtr out_tensor = std::make_shared();
- out_tensor->SetTensorDesc(out_desc);
- out_tensor->SetData(in_data, in_bytes);
- return out_tensor;
-}
-
-int CvtActMode(std::string act_type) {
- int act_mode = 1;
- if (act_type == "sigmoid") {
- act_mode = 0;
- } else if (act_type == "relu") {
- act_mode = 1;
- } else if (act_type == "tanh") {
- act_mode = 2;
- } else if (act_type == "relu_clipped") {
- act_mode = 3;
- } else if (act_type == "elu") {
- act_mode = 4;
- } else if (act_type == "leaky_relu") {
- act_mode = 5;
- } else if (act_type == "abs") {
- act_mode = 6;
- } else if (act_type == "softsign") {
- act_mode = 8;
- } else if (act_type == "softplus") {
- act_mode = 9;
- } else if (act_type == "hard_sigmoid") {
- act_mode = 10;
- } else {
- // TODO(hong19860320) support more activation mode
- LOG(FATAL) << "[NPU] Unsupported activation type " << act_type;
- }
- return act_mode;
-}
-
-bool HasInputArg(const OpInfo* op_info,
- const Scope* scope,
- const std::string& argname) {
- auto iarg_names = op_info->input_argnames();
- if (std::find(iarg_names.begin(), iarg_names.end(), argname) !=
- iarg_names.end()) {
- auto inputs = op_info->Input(argname);
- if (inputs.empty()) {
- return false;
- }
- auto var_name = inputs.front();
- auto var = scope->FindVar(var_name);
- return var != nullptr;
- } else {
- return false;
- }
-}
-
-} // namespace npu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/npu/builder.h b/lite/backends/npu/builder.h
deleted file mode 100644
index 70200354fbab15f043a537300e92e2a26a3d739e..0000000000000000000000000000000000000000
--- a/lite/backends/npu/builder.h
+++ /dev/null
@@ -1,145 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-#include "ai_ddk_lib/include/graph/buffer.h"
-#include "ai_ddk_lib/include/graph/graph.h"
-#include "ai_ddk_lib/include/graph/model.h"
-#include "ai_ddk_lib/include/graph/op/all_ops.h"
-#include "ai_ddk_lib/include/graph/operator.h"
-#include "ai_ddk_lib/include/graph/operator_reg.h"
-#include "ai_ddk_lib/include/hiai_ir_build.h"
-#include "lite/core/op_lite.h"
-#include "lite/core/target_wrapper.h"
-#include "lite/core/tensor.h"
-
-// Extended Ops of HIAI DDK
-namespace ge {
-/**
- * Pads a tensor.
- *
- * output : the output tensor
- *
- * t_paddings : Default DT_INT32 , t_paddings must be the same with
- * datatype of the padding
- * mode : 0: CONSTANT, 1: REFLECT, 2: SYMMETRIC
- * T : datatype of constant_values DT_INT32:3 DT_FLOAT:0
- */
-REG_OP(Pad)
- .INPUT(x, TensorType({DT_FLOAT, DT_INT32}))
- .INPUT(padding, TensorType({DT_INT32}))
- .OPTIONAL_INPUT(constant_values, TensorType({DT_INT32, DT_FLOAT}))
- .OUTPUT(output, TensorType({DT_FLOAT, DT_INT32}))
- .ATTR(t_paddings, AttrValue::INT{3})
- .ATTR(mode, AttrValue::INT{0})
- .REQUIRED_ATTR(T, AttrValue::INT)
- .OP_END();
-
-} // namespace ge
-
-namespace paddle {
-namespace lite {
-namespace npu {
-
-class OpList {
- public:
- static OpList& Global() {
- static thread_local OpList x;
- return x;
- }
- void clear() { lists_.clear(); }
- void add(std::shared_ptr p) { lists_.push_back(p); }
-
- private:
- std::vector> lists_;
-};
-
-// Build HIAI IR graph to om model, and store om model data into lite tensor
-bool BuildModel(std::vector& inputs, // NOLINT
- std::vector& outputs, // NOLINT
- lite::Tensor* model_data);
-
-std::string UniqueName(const std::string& prefix);
-
-ge::DataType CvtPrecisionType(PrecisionType itype);
-
-ge::Format CvtDataLayoutType(DataLayoutType itype);
-
-ge::TensorPtr CvtTensor(Tensor* in_tensor,
- std::vector out_shape = {},
- PrecisionType in_ptype = PRECISION(kFloat),
- DataLayoutType in_ltype = DATALAYOUT(kNCHW));
-
-template
-ge::TensorPtr CreateTensorAndFillData(std::vector data,
- std::vector shape = {},
- ge::Format format = ge::FORMAT_NCHW) {
- const std::type_info& info = typeid(T);
- ge::DataType type = ge::DT_FLOAT;
- if (info == typeid(float)) {
- type = ge::DT_FLOAT;
- } else if (info == typeid(int8_t)) {
- type = ge::DT_INT8;
- } else if (info == typeid(int32_t)) {
- type = ge::DT_INT32;
- } else {
- LOG(FATAL) << "[NPU] Unknow value type " << info.name();
- }
- if (shape.empty()) {
- shape = {static_cast(data.size())};
- } else {
- int size = 1;
- for (auto i : shape) {
- size *= i;
- }
- CHECK_EQ(data.size(), size);
- }
- ge::TensorDesc desc(ge::Shape(shape), format, type);
- ge::TensorPtr tensor = std::make_shared();
- tensor->SetTensorDesc(desc);
- tensor->SetData(reinterpret_cast(data.data()),
- data.size() * sizeof(T));
- return tensor;
-}
-
-template
-ge::TensorPtr CreateTensorAndFillData(T value,
- std::vector shape = {1},
- ge::Format format = ge::FORMAT_NCHW) {
- int64_t size = 1;
- for (auto i : shape) {
- size *= i;
- }
- std::vector data(size, value);
- return CreateTensorAndFillData(data, shape, format);
-}
-
-int CvtActMode(std::string act_type);
-
-bool HasInputArg(const OpInfo* op_info,
- const Scope* scope,
- const std::string& argname);
-
-} // namespace npu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/npu/device.cc b/lite/backends/npu/device.cc
old mode 100755
new mode 100644
diff --git a/lite/backends/npu/device.h b/lite/backends/npu/device.h
old mode 100755
new mode 100644
index 3eba0b77e4bdeb26cdff869771645a5ce7637ae4..411600ae0a38e4ee1b4a3ce3d6519b927eeb0a1a
--- a/lite/backends/npu/device.h
+++ b/lite/backends/npu/device.h
@@ -18,8 +18,8 @@
#include
#include
#include
-#include "ai_ddk_lib/include/HiAiModelManagerService.h"
-#include "ai_ddk_lib/include/hiai_ir_build.h"
+#include "HiAiModelManagerService.h" // NOLINT
+#include "hiai_ir_build.h" // NOLINT
namespace paddle {
namespace lite {
diff --git a/lite/backends/npu/runtime.cc b/lite/backends/npu/runtime.cc
deleted file mode 100644
index 3485f63c7c8bb91081fd1969d0d41733417149d9..0000000000000000000000000000000000000000
--- a/lite/backends/npu/runtime.cc
+++ /dev/null
@@ -1,60 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/npu/runtime.h"
-#include
-#include
-#include "lite/utils/cp_logging.h"
-
-namespace paddle {
-namespace lite {
-namespace npu {
-
-// Create hiai model manager to load om model from lite tensor, and return the
-// manager and an unique model name
-bool LoadModel(const lite::Tensor &model_data,
- std::shared_ptr *model_client,
- std::string *model_name) {
- LOG(INFO) << "[NPU] Load model.";
- auto model_data_ptr = model_data.data();
- auto model_data_size = model_data.numel() * sizeof(int8_t);
- if (model_data_ptr == nullptr || model_data_size == 0) {
- return false;
- }
- *model_client = std::make_shared();
- int ret = (*model_client)->Init(nullptr);
- if (ret != hiai::AI_SUCCESS) {
- LOG(WARNING) << "[NPU] AiModelMngerClient init failed(" << ret << ")!";
- return false;
- }
- *model_name = "model.om";
- auto model_desc = std::make_shared(
- *model_name,
- DeviceInfo::Global().freq_level(),
- DeviceInfo::Global().framework_type(),
- DeviceInfo::Global().model_type(),
- DeviceInfo::Global().device_type());
- model_desc->SetModelBuffer(model_data_ptr, model_data_size);
- std::vector> model_descs;
- model_descs.push_back(model_desc);
- if ((*model_client)->Load(model_descs) != hiai::AI_SUCCESS) {
- LOG(WARNING) << "[NPU] AiModelMngerClient load model failed!";
- return false;
- }
- return true;
-}
-
-} // namespace npu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/npu/runtime.h b/lite/backends/npu/runtime.h
deleted file mode 100644
index 8b1ad51518d8626d9a6ecd6203a70b2637bb6004..0000000000000000000000000000000000000000
--- a/lite/backends/npu/runtime.h
+++ /dev/null
@@ -1,50 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-#include
-#include
-#include "ai_ddk_lib/include/HiAiModelManagerService.h"
-#include "lite/core/tensor.h"
-
-namespace paddle {
-namespace lite {
-namespace npu {
-
-class DeviceInfo {
- public:
- static DeviceInfo &Global() {
- static DeviceInfo x;
- return x;
- }
- DeviceInfo() {}
-
- int freq_level() { return freq_level_; }
- int framework_type() { return framework_type_; }
- int model_type() { return model_type_; }
- int device_type() { return device_type_; }
-
- private:
- int freq_level_{3};
- int framework_type_{0};
- int model_type_{0};
- int device_type_{0};
-};
-
-bool LoadModel(const lite::Tensor &model_data,
- std::shared_ptr *model_client,
- std::string *model_name);
-} // namespace npu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/opencl/cl_kernel/image/conv2d_1x1_kernel.cl b/lite/backends/opencl/cl_kernel/image/conv2d_1x1_kernel.cl
old mode 100755
new mode 100644
diff --git a/lite/backends/opencl/cl_kernel/image/reshape_kernel.cl b/lite/backends/opencl/cl_kernel/image/reshape_kernel.cl
old mode 100755
new mode 100644
diff --git a/lite/backends/x86/jit/README.en.md b/lite/backends/x86/jit/README.en.md
index cd2aa5c242dba1a9be669a536cd9b614bf890e48..dc9eb4cf239155ba15a855c98e5515adb717d2d5 100644
--- a/lite/backends/x86/jit/README.en.md
+++ b/lite/backends/x86/jit/README.en.md
@@ -89,7 +89,7 @@ All kernels are inlcuded in `lite/backends/x86/jit/kernels.h`, which is automati
3. Add reference function of `your_key`.
Note:
- this should be run on CPU and do not depend on any third-party.
- - Add `USE_JITKERNEL_REFER(your_key)` in `refer/CmakeLists.txt` to make sure this code can be used.
+ - Add `USE_JITKERNEL_REFER_LITE(your_key)` in `refer/CmakeLists.txt` to make sure this code can be used.
4. Add unit test in `test.cc`, and verfiy at least `float` and `double`.
Test more data type for some special functions if necessary, for example `int8`.
5. Add functions in `benchmark.cc` to test all function of same `KernelType`. Make sure `GetDefaultBestFunc` always get the best one.
diff --git a/lite/backends/x86/jit/README.md b/lite/backends/x86/jit/README.md
index 6998c5d867b079dfef69a71ca56e6f3fc30363d4..bc0e27234d05c82c9b0dcc431343d7db1a0f4067 100644
--- a/lite/backends/x86/jit/README.md
+++ b/lite/backends/x86/jit/README.md
@@ -79,7 +79,7 @@ PaddlePaddle/Paddle/paddle/fluid/
# 如何添加新的算子
1. 在`KernelType` 中添加 `your_key` 。
-2. 实现Reference 的逻辑,这个是必须是在CPU上的实现,并且不能依赖任何第三方库。实现后在`refer/CmakeLists.txt`中添加`USE_JITKERNEL_REFER(your_key)`来使用该kernel。
+2. 实现Reference 的逻辑,这个是必须是在CPU上的实现,并且不能依赖任何第三方库。实现后在`refer/CmakeLists.txt`中添加`USE_JITKERNEL_REFER_LITE(your_key)`来使用该kernel。
3. (optional) 实现更多的算法在`more`目录下,可以依赖mkl,intrinsic或者mkldnn等第三方库。
4. (optional) 实现基于Xbyak的生成code,在`gen`目下。 jitcode需要实现自己的`JitCodeCreator`,并注册在与refer相同的`KernelType`上。
5. 添加新的`KernelTuple`,需要与`KernelType`一一对应,是所有类型的一个打包,包括数据类型,属性的类型,以及返回的函数类型。可以参考`SeqPoolTuple`,新加的Attr类型需要特例化`JitCodeKey`方法。
diff --git a/lite/backends/x86/jit/gen/CMakeLists.txt b/lite/backends/x86/jit/gen/CMakeLists.txt
index 99244ea9bd919a018732b75d1ab811e8bf338516..62500775282d1c3d960f0fa9b00d3d4a2aef9390 100644
--- a/lite/backends/x86/jit/gen/CMakeLists.txt
+++ b/lite/backends/x86/jit/gen/CMakeLists.txt
@@ -4,33 +4,33 @@ file(GLOB jitcode_cc_srcs RELATIVE "${CMAKE_CURRENT_SOURCE_DIR}" "*.cc")
cc_library(jit_kernel_jitcode SRCS ${jitcode_cc_srcs} DEPS jit_kernel_base xbyak)
set(JIT_KERNEL_DEPS ${JIT_KERNEL_DEPS} xbyak jit_kernel_jitcode PARENT_SCOPE)
-function(USE_JITKERNEL_GEN TARGET)
- file(APPEND ${jit_file} "USE_JITKERNEL_GEN(${TARGET});\n")
+function(USE_JITKERNEL_GEN_LITE TARGET)
+ file(APPEND ${jit_file} "USE_JITKERNEL_GEN_LITE(${TARGET});\n")
endfunction()
# use gen jitcode kernel by name
-USE_JITKERNEL_GEN(kMatMul)
-USE_JITKERNEL_GEN(kVMul)
-USE_JITKERNEL_GEN(kVAdd)
-USE_JITKERNEL_GEN(kVSub)
-USE_JITKERNEL_GEN(kVAddRelu)
-USE_JITKERNEL_GEN(kVScal)
-USE_JITKERNEL_GEN(kVAddBias)
-USE_JITKERNEL_GEN(kVRelu)
-USE_JITKERNEL_GEN(kVSquare)
-USE_JITKERNEL_GEN(kVIdentity)
-USE_JITKERNEL_GEN(kVExp)
-USE_JITKERNEL_GEN(kVSigmoid)
-USE_JITKERNEL_GEN(kVTanh)
-USE_JITKERNEL_GEN(kLSTMCtHt)
-USE_JITKERNEL_GEN(kLSTMC1H1)
-USE_JITKERNEL_GEN(kGRUH1)
-USE_JITKERNEL_GEN(kGRUHtPart1)
-USE_JITKERNEL_GEN(kGRUHtPart2)
-USE_JITKERNEL_GEN(kNCHW16CMulNC)
-USE_JITKERNEL_GEN(kSeqPool)
-USE_JITKERNEL_GEN(kHMax)
-USE_JITKERNEL_GEN(kHSum)
-USE_JITKERNEL_GEN(kEmbSeqPool)
-USE_JITKERNEL_GEN(kSgd)
-USE_JITKERNEL_GEN(kVBroadcast)
+USE_JITKERNEL_GEN_LITE(kMatMul)
+USE_JITKERNEL_GEN_LITE(kVMul)
+USE_JITKERNEL_GEN_LITE(kVAdd)
+USE_JITKERNEL_GEN_LITE(kVSub)
+USE_JITKERNEL_GEN_LITE(kVAddRelu)
+USE_JITKERNEL_GEN_LITE(kVScal)
+USE_JITKERNEL_GEN_LITE(kVAddBias)
+USE_JITKERNEL_GEN_LITE(kVRelu)
+USE_JITKERNEL_GEN_LITE(kVSquare)
+USE_JITKERNEL_GEN_LITE(kVIdentity)
+USE_JITKERNEL_GEN_LITE(kVExp)
+USE_JITKERNEL_GEN_LITE(kVSigmoid)
+USE_JITKERNEL_GEN_LITE(kVTanh)
+USE_JITKERNEL_GEN_LITE(kLSTMCtHt)
+USE_JITKERNEL_GEN_LITE(kLSTMC1H1)
+USE_JITKERNEL_GEN_LITE(kGRUH1)
+USE_JITKERNEL_GEN_LITE(kGRUHtPart1)
+USE_JITKERNEL_GEN_LITE(kGRUHtPart2)
+USE_JITKERNEL_GEN_LITE(kNCHW16CMulNC)
+USE_JITKERNEL_GEN_LITE(kSeqPool)
+USE_JITKERNEL_GEN_LITE(kHMax)
+USE_JITKERNEL_GEN_LITE(kHSum)
+USE_JITKERNEL_GEN_LITE(kEmbSeqPool)
+USE_JITKERNEL_GEN_LITE(kSgd)
+USE_JITKERNEL_GEN_LITE(kVBroadcast)
diff --git a/lite/backends/x86/jit/gen/act.cc b/lite/backends/x86/jit/gen/act.cc
index f1f261c199d8d25997b1ce235aa99356834e43a8..45f4f7ddcce8e8864821712698c4496cf40b618c 100644
--- a/lite/backends/x86/jit/gen/act.cc
+++ b/lite/backends/x86/jit/gen/act.cc
@@ -156,9 +156,9 @@ size_t VTanhCreator::CodeSize(const int& d) const {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kVRelu, gen::VReluCreator);
-REGISTER_JITKERNEL_GEN(kVSquare, gen::VSquareCreator);
-REGISTER_JITKERNEL_GEN(kVIdentity, gen::VIdentityCreator);
-REGISTER_JITKERNEL_GEN(kVExp, gen::VExpCreator);
-REGISTER_JITKERNEL_GEN(kVSigmoid, gen::VSigmoidCreator);
-REGISTER_JITKERNEL_GEN(kVTanh, gen::VTanhCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVRelu, gen::VReluCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVSquare, gen::VSquareCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVIdentity, gen::VIdentityCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVExp, gen::VExpCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVSigmoid, gen::VSigmoidCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVTanh, gen::VTanhCreator);
diff --git a/lite/backends/x86/jit/gen/blas.cc b/lite/backends/x86/jit/gen/blas.cc
index 0bddea6ace7fd338d14da918516223bb17bafdbd..37183e66404dfae139a2bcd25c2855df119f939d 100644
--- a/lite/backends/x86/jit/gen/blas.cc
+++ b/lite/backends/x86/jit/gen/blas.cc
@@ -181,10 +181,10 @@ DECLARE_BLAS_CREATOR(VAddBias);
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kVMul, gen::VMulCreator);
-REGISTER_JITKERNEL_GEN(kVAdd, gen::VAddCreator);
-REGISTER_JITKERNEL_GEN(kVSub, gen::VSubCreator);
-REGISTER_JITKERNEL_GEN(kVAddRelu, gen::VAddReluCreator);
-REGISTER_JITKERNEL_GEN(kVScal, gen::VScalCreator);
-REGISTER_JITKERNEL_GEN(kVAddBias, gen::VAddBiasCreator);
-REGISTER_JITKERNEL_GEN(kNCHW16CMulNC, gen::NCHW16CMulNCCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVMul, gen::VMulCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVAdd, gen::VAddCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVSub, gen::VSubCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVAddRelu, gen::VAddReluCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVScal, gen::VScalCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVAddBias, gen::VAddBiasCreator);
+REGISTER_JITKERNEL_GEN_LITE(kNCHW16CMulNC, gen::NCHW16CMulNCCreator);
diff --git a/lite/backends/x86/jit/gen/embseqpool.cc b/lite/backends/x86/jit/gen/embseqpool.cc
index 2ff6894383f95699e4209215b0df3a84507a06b4..7e697014ed241a75693b783127633b255964f80b 100644
--- a/lite/backends/x86/jit/gen/embseqpool.cc
+++ b/lite/backends/x86/jit/gen/embseqpool.cc
@@ -145,4 +145,4 @@ class EmbSeqPoolCreator : public JitCodeCreator {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kEmbSeqPool, gen::EmbSeqPoolCreator);
+REGISTER_JITKERNEL_GEN_LITE(kEmbSeqPool, gen::EmbSeqPoolCreator);
diff --git a/lite/backends/x86/jit/gen/gru.cc b/lite/backends/x86/jit/gen/gru.cc
index c5737faf134287697ef49b88f10c2590da4cc07d..4c2c57413e30589de96385c34e09733458f66b7b 100644
--- a/lite/backends/x86/jit/gen/gru.cc
+++ b/lite/backends/x86/jit/gen/gru.cc
@@ -111,6 +111,6 @@ DECLARE_GRU_CREATOR(GRUHtPart2);
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kGRUH1, gen::GRUH1Creator);
-REGISTER_JITKERNEL_GEN(kGRUHtPart1, gen::GRUHtPart1Creator);
-REGISTER_JITKERNEL_GEN(kGRUHtPart2, gen::GRUHtPart2Creator);
+REGISTER_JITKERNEL_GEN_LITE(kGRUH1, gen::GRUH1Creator);
+REGISTER_JITKERNEL_GEN_LITE(kGRUHtPart1, gen::GRUHtPart1Creator);
+REGISTER_JITKERNEL_GEN_LITE(kGRUHtPart2, gen::GRUHtPart2Creator);
diff --git a/lite/backends/x86/jit/gen/hopv.cc b/lite/backends/x86/jit/gen/hopv.cc
index 4304dc48c5a084a747227bd4d4aedb1cec1775cd..0fdd63a7405647860416d43a86a7a7abe9fad760 100644
--- a/lite/backends/x86/jit/gen/hopv.cc
+++ b/lite/backends/x86/jit/gen/hopv.cc
@@ -99,5 +99,5 @@ DECLARE_HOP_CREATOR(HSum);
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kHMax, gen::HMaxCreator);
-REGISTER_JITKERNEL_GEN(kHSum, gen::HSumCreator);
+REGISTER_JITKERNEL_GEN_LITE(kHMax, gen::HMaxCreator);
+REGISTER_JITKERNEL_GEN_LITE(kHSum, gen::HSumCreator);
diff --git a/lite/backends/x86/jit/gen/lstm.cc b/lite/backends/x86/jit/gen/lstm.cc
index 44e58d0b75612238115d5771082d28c30cad55a2..e4417355202c6370563eadd80e5cb3da6af8cdc6 100644
--- a/lite/backends/x86/jit/gen/lstm.cc
+++ b/lite/backends/x86/jit/gen/lstm.cc
@@ -138,5 +138,5 @@ DECLARE_LSTM_CREATOR(LSTMC1H1);
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kLSTMCtHt, gen::LSTMCtHtCreator);
-REGISTER_JITKERNEL_GEN(kLSTMC1H1, gen::LSTMC1H1Creator);
+REGISTER_JITKERNEL_GEN_LITE(kLSTMCtHt, gen::LSTMCtHtCreator);
+REGISTER_JITKERNEL_GEN_LITE(kLSTMC1H1, gen::LSTMC1H1Creator);
diff --git a/lite/backends/x86/jit/gen/matmul.cc b/lite/backends/x86/jit/gen/matmul.cc
index 2c75f6dd5dc4bbf12513d10ef0a4e02e709135fd..010c80fac4842e74c9b8272db472ddf6cf954771 100644
--- a/lite/backends/x86/jit/gen/matmul.cc
+++ b/lite/backends/x86/jit/gen/matmul.cc
@@ -130,4 +130,4 @@ class MatMulCreator : public JitCodeCreator {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kMatMul, gen::MatMulCreator);
+REGISTER_JITKERNEL_GEN_LITE(kMatMul, gen::MatMulCreator);
diff --git a/lite/backends/x86/jit/gen/seqpool.cc b/lite/backends/x86/jit/gen/seqpool.cc
index e0cf5e5a5a7646f09666f6ccb35b18610c845317..4c80737aac4bc9cd09f4ff222c8fad8c441887ec 100644
--- a/lite/backends/x86/jit/gen/seqpool.cc
+++ b/lite/backends/x86/jit/gen/seqpool.cc
@@ -82,4 +82,4 @@ class SeqPoolCreator : public JitCodeCreator {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kSeqPool, gen::SeqPoolCreator);
+REGISTER_JITKERNEL_GEN_LITE(kSeqPool, gen::SeqPoolCreator);
diff --git a/lite/backends/x86/jit/gen/sgd.cc b/lite/backends/x86/jit/gen/sgd.cc
index 10659f50844d73c14403f9e7a35d800364be1e7b..44e083366132c675b339b2da4bbb3b7c1c6b7569 100644
--- a/lite/backends/x86/jit/gen/sgd.cc
+++ b/lite/backends/x86/jit/gen/sgd.cc
@@ -127,4 +127,4 @@ class SgdCreator : public JitCodeCreator {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kSgd, gen::SgdCreator);
+REGISTER_JITKERNEL_GEN_LITE(kSgd, gen::SgdCreator);
diff --git a/lite/backends/x86/jit/gen/vbroadcast.cc b/lite/backends/x86/jit/gen/vbroadcast.cc
index 9e02dca8c40975fb45feed1d818bbe6d3e65db19..fb1e71f7b0b1e6f68a331d264682e80fbab7c219 100644
--- a/lite/backends/x86/jit/gen/vbroadcast.cc
+++ b/lite/backends/x86/jit/gen/vbroadcast.cc
@@ -88,4 +88,4 @@ class VBroadcastCreator : public JitCodeCreator {
namespace gen = paddle::lite::jit::gen;
-REGISTER_JITKERNEL_GEN(kVBroadcast, gen::VBroadcastCreator);
+REGISTER_JITKERNEL_GEN_LITE(kVBroadcast, gen::VBroadcastCreator);
diff --git a/lite/backends/x86/jit/more/CMakeLists.txt b/lite/backends/x86/jit/more/CMakeLists.txt
index 2ddbbcd16a3ffef560581592e3a009c61844d4d5..5641466d8a86e4be7b88d7eaf977e5a58d18f085 100644
--- a/lite/backends/x86/jit/more/CMakeLists.txt
+++ b/lite/backends/x86/jit/more/CMakeLists.txt
@@ -1,6 +1,6 @@
-function(USE_JITKERNEL_MORE TARGET TYPE)
- file(APPEND ${jit_file} "USE_JITKERNEL_MORE(${TARGET} ${TYPE});\n")
+function(USE_JITKERNEL_MORE_LITE TARGET TYPE)
+ file(APPEND ${jit_file} "USE_JITKERNEL_MORE_LITE(${TARGET} ${TYPE});\n")
endfunction()
# enable it latter
diff --git a/lite/backends/x86/jit/more/intrinsic/CMakeLists.txt b/lite/backends/x86/jit/more/intrinsic/CMakeLists.txt
index 468937a4f6b27ae525bfd0d8e99cc891eedbc353..80dabc72fbe2db46359cd69760eb5a02cea615af 100644
--- a/lite/backends/x86/jit/more/intrinsic/CMakeLists.txt
+++ b/lite/backends/x86/jit/more/intrinsic/CMakeLists.txt
@@ -5,5 +5,5 @@ cc_library(jit_kernel_intrinsic SRCS ${jit_kernel_cc_intrinsic} DEPS jit_kernel_
set(JIT_KERNEL_DEPS ${JIT_KERNEL_DEPS} jit_kernel_intrinsic PARENT_SCOPE)
# use mkl kernels by name and type
-USE_JITKERNEL_MORE(kCRFDecoding, intrinsic)
-USE_JITKERNEL_MORE(kLayerNorm, intrinsic)
+USE_JITKERNEL_MORE_LITE(kCRFDecoding, intrinsic)
+USE_JITKERNEL_MORE_LITE(kLayerNorm, intrinsic)
diff --git a/lite/backends/x86/jit/more/mix/CMakeLists.txt b/lite/backends/x86/jit/more/mix/CMakeLists.txt
index dd039d29152961210958470a48f086a133ab640c..5e0238f26f1ebbd298dba0957bdc93e16671505f 100644
--- a/lite/backends/x86/jit/more/mix/CMakeLists.txt
+++ b/lite/backends/x86/jit/more/mix/CMakeLists.txt
@@ -5,11 +5,11 @@ cc_library(jit_kernel_mix SRCS ${jit_kernel_mix_cc} DEPS jit_kernel_base)
set(JIT_KERNEL_DEPS ${JIT_KERNEL_DEPS} jit_kernel_mix PARENT_SCOPE)
-USE_JITKERNEL_MORE(kVSigmoid, mix)
-USE_JITKERNEL_MORE(kVTanh, mix)
-USE_JITKERNEL_MORE(kLSTMCtHt, mix)
-USE_JITKERNEL_MORE(kLSTMC1H1, mix)
-USE_JITKERNEL_MORE(kGRUH1, mix)
-USE_JITKERNEL_MORE(kGRUHtPart1, mix)
-USE_JITKERNEL_MORE(kGRUHtPart2, mix)
-USE_JITKERNEL_MORE(kSoftmax, mix)
+USE_JITKERNEL_MORE_LITE(kVSigmoid, mix)
+USE_JITKERNEL_MORE_LITE(kVTanh, mix)
+USE_JITKERNEL_MORE_LITE(kLSTMCtHt, mix)
+USE_JITKERNEL_MORE_LITE(kLSTMC1H1, mix)
+USE_JITKERNEL_MORE_LITE(kGRUH1, mix)
+USE_JITKERNEL_MORE_LITE(kGRUHtPart1, mix)
+USE_JITKERNEL_MORE_LITE(kGRUHtPart2, mix)
+USE_JITKERNEL_MORE_LITE(kSoftmax, mix)
diff --git a/lite/backends/x86/jit/more/mkl/CMakeLists.txt b/lite/backends/x86/jit/more/mkl/CMakeLists.txt
index 56f1a62ad4e06807dace2a81156d92f6b02a14df..3557f531a561caace51225ad23e2d547ad48d08c 100644
--- a/lite/backends/x86/jit/more/mkl/CMakeLists.txt
+++ b/lite/backends/x86/jit/more/mkl/CMakeLists.txt
@@ -3,18 +3,18 @@ cc_library(jit_kernel_mkl SRCS mkl.cc DEPS jit_kernel_base dynload_mklml)
set(JIT_KERNEL_DEPS ${JIT_KERNEL_DEPS} dynload_mklml jit_kernel_mkl PARENT_SCOPE)
# use mkl kernels by name and type
-USE_JITKERNEL_MORE(kMatMul, mkl)
-USE_JITKERNEL_MORE(kVMul, mkl)
-USE_JITKERNEL_MORE(kVAdd, mkl)
-USE_JITKERNEL_MORE(kVScal, mkl)
-USE_JITKERNEL_MORE(kStrideScal, mkl)
-USE_JITKERNEL_MORE(kVExp, mkl)
-USE_JITKERNEL_MORE(kVSquare, mkl)
-USE_JITKERNEL_MORE(kVCopy, mkl)
-USE_JITKERNEL_MORE(kVSigmoid, mkl)
-USE_JITKERNEL_MORE(kVTanh, mkl)
-USE_JITKERNEL_MORE(kSeqPool, mkl)
-USE_JITKERNEL_MORE(kSoftmax, mkl)
-USE_JITKERNEL_MORE(kEmbSeqPool, mkl)
-USE_JITKERNEL_MORE(kSgd, mkl)
-USE_JITKERNEL_MORE(kVBroadcast, mkl)
+USE_JITKERNEL_MORE_LITE(kMatMul, mkl)
+USE_JITKERNEL_MORE_LITE(kVMul, mkl)
+USE_JITKERNEL_MORE_LITE(kVAdd, mkl)
+USE_JITKERNEL_MORE_LITE(kVScal, mkl)
+USE_JITKERNEL_MORE_LITE(kStrideScal, mkl)
+USE_JITKERNEL_MORE_LITE(kVExp, mkl)
+USE_JITKERNEL_MORE_LITE(kVSquare, mkl)
+USE_JITKERNEL_MORE_LITE(kVCopy, mkl)
+USE_JITKERNEL_MORE_LITE(kVSigmoid, mkl)
+USE_JITKERNEL_MORE_LITE(kVTanh, mkl)
+USE_JITKERNEL_MORE_LITE(kSeqPool, mkl)
+USE_JITKERNEL_MORE_LITE(kSoftmax, mkl)
+USE_JITKERNEL_MORE_LITE(kEmbSeqPool, mkl)
+USE_JITKERNEL_MORE_LITE(kSgd, mkl)
+USE_JITKERNEL_MORE_LITE(kVBroadcast, mkl)
diff --git a/lite/backends/x86/jit/refer/CMakeLists.txt b/lite/backends/x86/jit/refer/CMakeLists.txt
index 7133f596620410d37ffe52a2ee92b7a9974bf1cc..c52b21ad7dca102d18aee25aa60079bf03ae82b9 100644
--- a/lite/backends/x86/jit/refer/CMakeLists.txt
+++ b/lite/backends/x86/jit/refer/CMakeLists.txt
@@ -2,39 +2,39 @@
cc_library(jit_kernel_refer SRCS refer.cc DEPS jit_kernel_base)
set(JIT_KERNEL_DEPS ${JIT_KERNEL_DEPS} jit_kernel_refer PARENT_SCOPE)
-function(USE_JITKERNEL_REFER TARGET)
- file(APPEND ${jit_file} "USE_JITKERNEL_REFER(${TARGET});\n")
+function(USE_JITKERNEL_REFER_LITE TARGET)
+ file(APPEND ${jit_file} "USE_JITKERNEL_REFER_LITE(${TARGET});\n")
endfunction()
# use refer kernel by name
-USE_JITKERNEL_REFER(kVMul)
-USE_JITKERNEL_REFER(kVAdd)
-USE_JITKERNEL_REFER(kVAddRelu)
-USE_JITKERNEL_REFER(kVSub)
-USE_JITKERNEL_REFER(kVScal)
-USE_JITKERNEL_REFER(kStrideScal)
-USE_JITKERNEL_REFER(kVAddBias)
-USE_JITKERNEL_REFER(kVCopy)
-USE_JITKERNEL_REFER(kVRelu)
-USE_JITKERNEL_REFER(kVIdentity)
-USE_JITKERNEL_REFER(kVExp)
-USE_JITKERNEL_REFER(kVSigmoid)
-USE_JITKERNEL_REFER(kVTanh)
-USE_JITKERNEL_REFER(kLSTMCtHt)
-USE_JITKERNEL_REFER(kLSTMC1H1)
-USE_JITKERNEL_REFER(kGRUH1)
-USE_JITKERNEL_REFER(kGRUHtPart1)
-USE_JITKERNEL_REFER(kGRUHtPart2)
-USE_JITKERNEL_REFER(kCRFDecoding)
-USE_JITKERNEL_REFER(kLayerNorm)
-USE_JITKERNEL_REFER(kNCHW16CMulNC)
-USE_JITKERNEL_REFER(kSeqPool)
-USE_JITKERNEL_REFER(kMatMul)
-USE_JITKERNEL_REFER(kVSquare)
-USE_JITKERNEL_REFER(kHSum)
-USE_JITKERNEL_REFER(kHMax)
-USE_JITKERNEL_REFER(kStrideASum)
-USE_JITKERNEL_REFER(kSoftmax)
-USE_JITKERNEL_REFER(kEmbSeqPool)
-USE_JITKERNEL_REFER(kSgd)
-USE_JITKERNEL_REFER(kVBroadcast)
+USE_JITKERNEL_REFER_LITE(kVMul)
+USE_JITKERNEL_REFER_LITE(kVAdd)
+USE_JITKERNEL_REFER_LITE(kVAddRelu)
+USE_JITKERNEL_REFER_LITE(kVSub)
+USE_JITKERNEL_REFER_LITE(kVScal)
+USE_JITKERNEL_REFER_LITE(kStrideScal)
+USE_JITKERNEL_REFER_LITE(kVAddBias)
+USE_JITKERNEL_REFER_LITE(kVCopy)
+USE_JITKERNEL_REFER_LITE(kVRelu)
+USE_JITKERNEL_REFER_LITE(kVIdentity)
+USE_JITKERNEL_REFER_LITE(kVExp)
+USE_JITKERNEL_REFER_LITE(kVSigmoid)
+USE_JITKERNEL_REFER_LITE(kVTanh)
+USE_JITKERNEL_REFER_LITE(kLSTMCtHt)
+USE_JITKERNEL_REFER_LITE(kLSTMC1H1)
+USE_JITKERNEL_REFER_LITE(kGRUH1)
+USE_JITKERNEL_REFER_LITE(kGRUHtPart1)
+USE_JITKERNEL_REFER_LITE(kGRUHtPart2)
+USE_JITKERNEL_REFER_LITE(kCRFDecoding)
+USE_JITKERNEL_REFER_LITE(kLayerNorm)
+USE_JITKERNEL_REFER_LITE(kNCHW16CMulNC)
+USE_JITKERNEL_REFER_LITE(kSeqPool)
+USE_JITKERNEL_REFER_LITE(kMatMul)
+USE_JITKERNEL_REFER_LITE(kVSquare)
+USE_JITKERNEL_REFER_LITE(kHSum)
+USE_JITKERNEL_REFER_LITE(kHMax)
+USE_JITKERNEL_REFER_LITE(kStrideASum)
+USE_JITKERNEL_REFER_LITE(kSoftmax)
+USE_JITKERNEL_REFER_LITE(kEmbSeqPool)
+USE_JITKERNEL_REFER_LITE(kSgd)
+USE_JITKERNEL_REFER_LITE(kVBroadcast)
diff --git a/lite/backends/x86/jit/refer/refer.cc b/lite/backends/x86/jit/refer/refer.cc
index e1b1240c5d5b0bc382fae8bd1b77f6c412522bdd..c47f8216abd999e66e914b208d96b8f352226f71 100644
--- a/lite/backends/x86/jit/refer/refer.cc
+++ b/lite/backends/x86/jit/refer/refer.cc
@@ -18,7 +18,7 @@
namespace refer = paddle::lite::jit::refer;
#define REGISTER_REFER_KERNEL(func) \
- REGISTER_JITKERNEL_REFER( \
+ REGISTER_JITKERNEL_REFER_LITE( \
k##func, refer::func##Kernel, refer::func##Kernel)
REGISTER_REFER_KERNEL(VMul);
diff --git a/lite/backends/x86/jit/registry.h b/lite/backends/x86/jit/registry.h
index 7613a8dd4376045beb3636954668130e7220521e..65e3152d70fdd6262583cddced78e43513f0e0a1 100644
--- a/lite/backends/x86/jit/registry.h
+++ b/lite/backends/x86/jit/registry.h
@@ -77,16 +77,16 @@ class JitKernelRegistrar {
void Touch() {}
};
-#define STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE(uniq_name, msg) \
+#define STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE(uniq_name, msg) \
struct __test_global_namespace_##uniq_name##__ {}; \
static_assert(std::is_same<::__test_global_namespace_##uniq_name##__, \
__test_global_namespace_##uniq_name##__>::value, \
msg)
// Refer always on CPUPlace
-#define REGISTER_JITKERNEL_REFER(kernel_type, ...) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_##kernel_type##_refer_CPUPlace, \
+#define REGISTER_JITKERNEL_REFER_LITE(kernel_type, ...) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_##kernel_type##_refer_CPUPlace, \
"REGISTER_KERNEL_REFER must be called in global namespace"); \
static ::paddle::lite::jit::JitKernelRegistrar< \
::paddle::lite::jit::ReferKernelPool, \
@@ -94,84 +94,84 @@ class JitKernelRegistrar {
__VA_ARGS__> \
__jit_kernel_registrar_##kernel_type##_refer_CPUPlace_( \
::paddle::lite::jit::KernelType::kernel_type); \
- int TouchJitKernelReg_##kernel_type##_refer_CPUPlace_() { \
+ int LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_() { \
__jit_kernel_registrar_##kernel_type##_refer_CPUPlace_.Touch(); \
return 0; \
}
// kernel_type: should be in paddle::lite::jit::KernelType
// place_type: should be one of CPUPlace and GPUPlace in paddle::platform
-#define REGISTER_KERNEL_MORE(kernel_type, impl_type, place_type, ...) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_##kernel_type##_##impl_type##_##place_type, \
- "REGISTER_KERNEL_MORE must be called in global namespace"); \
- extern int TouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
+#define REGISTER_KERNEL_MORE_LITE(kernel_type, impl_type, place_type, ...) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_##kernel_type##_##impl_type##_##place_type, \
+ "REGISTER_KERNEL_MORE_LITE must be called in global namespace"); \
+ extern int LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
static int __assert_##kernel_type##_##impl_type##_##place_type##_has_refer_ \
- UNUSED = TouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
+ UNUSED = LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
static ::paddle::lite::jit::JitKernelRegistrar< \
::paddle::lite::jit::KernelPool, \
::paddle::lite::fluid::place_type, \
__VA_ARGS__> \
__jit_kernel_registrar_##kernel_type##_##impl_type##_##place_type##_( \
::paddle::lite::jit::KernelType::kernel_type); \
- int TouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_() { \
+ int LiteTouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_() { \
__jit_kernel_registrar_##kernel_type##_##impl_type##_##place_type##_ \
.Touch(); \
return 0; \
}
#define REGISTER_JITKERNEL_MORE(kernel_type, impl_type, ...) \
- REGISTER_KERNEL_MORE(kernel_type, impl_type, CPUPlace, __VA_ARGS__)
-
-#define REGISTER_GPUKERNEL_MORE(kernel_type, impl_type, ...) \
- REGISTER_KERNEL_MORE(kernel_type, impl_type, GPUPlace, __VA_ARGS__)
-
-#define REGISTER_JITKERNEL_GEN(kernel_type, ...) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_gen_##kernel_type##_CPUPlace_, \
- "REGISTER_JITKERNEL_GEN must be called in global namespace"); \
- extern int TouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
- static int __assert_gen_##kernel_type##_has_refer_ UNUSED = \
- TouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
- static ::paddle::lite::jit::JitKernelRegistrar< \
- ::paddle::lite::jit::JitCodeCreatorPool, \
- ::paddle::lite::fluid::CPUPlace, \
- __VA_ARGS__> \
- __jit_kernel_registrar_gen_##kernel_type##_CPUPlace_( \
- ::paddle::lite::jit::KernelType::kernel_type); \
- int TouchJitKernelReg_gen_##kernel_type##_CPUPlace_() { \
- __jit_kernel_registrar_gen_##kernel_type##_CPUPlace_.Touch(); \
- return 0; \
+ REGISTER_KERNEL_MORE_LITE(kernel_type, impl_type, CPUPlace, __VA_ARGS__)
+
+#define REGISTER_GPUKERNEL_MORE_LITE(kernel_type, impl_type, ...) \
+ REGISTER_KERNEL_MORE_LITE(kernel_type, impl_type, GPUPlace, __VA_ARGS__)
+
+#define REGISTER_JITKERNEL_GEN_LITE(kernel_type, ...) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_gen_##kernel_type##_CPUPlace_, \
+ "REGISTER_JITKERNEL_GEN_LITE must be called in global namespace"); \
+ extern int LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
+ static int __assert_gen_##kernel_type##_has_refer_ UNUSED = \
+ LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
+ static ::paddle::lite::jit::JitKernelRegistrar< \
+ ::paddle::lite::jit::JitCodeCreatorPool, \
+ ::paddle::lite::fluid::CPUPlace, \
+ __VA_ARGS__> \
+ __jit_kernel_registrar_gen_##kernel_type##_CPUPlace_( \
+ ::paddle::lite::jit::KernelType::kernel_type); \
+ int LiteTouchJitKernelReg_gen_##kernel_type##_CPUPlace_() { \
+ __jit_kernel_registrar_gen_##kernel_type##_CPUPlace_.Touch(); \
+ return 0; \
}
-#define USE_JITKERNEL_GEN(kernel_type) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_gen_##kernel_type##_CPUPlace_, \
- "USE_JITKERNEL_GEN must be called in global namespace"); \
- extern int TouchJitKernelReg_gen_##kernel_type##_CPUPlace_(); \
- static int use_jitkernel_gen_##kernel_type##_CPUPlace_ UNUSED = \
- TouchJitKernelReg_gen_##kernel_type##_CPUPlace_()
-
-#define USE_JITKERNEL_REFER(kernel_type) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_##kernel_type##_refer_CPUPlace_, \
- "USE_JITKERNEL_REFER must be called in global namespace"); \
- extern int TouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
- static int use_jitkernel_##kernel_type##_refer_CPUPlace_ UNUSED = \
- TouchJitKernelReg_##kernel_type##_refer_CPUPlace_()
-
-#define USE_KERNEL_MORE(kernel_type, impl_type, place_type) \
- STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE( \
- __reg_jitkernel_##kernel_type##_##impl_type##_##place_type##_, \
- "USE_JITKERNEL_MORE must be called in global namespace"); \
- extern int \
- TouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_(); \
- static int use_jitkernel_##kernel_type##_##impl_type##_##place_type##_ \
- UNUSED = \
- TouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_()
-
-#define USE_JITKERNEL_MORE(kernel_type, impl_type) \
- USE_KERNEL_MORE(kernel_type, impl_type, CPUPlace)
+#define USE_JITKERNEL_GEN_LITE(kernel_type) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_gen_##kernel_type##_CPUPlace_, \
+ "USE_JITKERNEL_GEN_LITE must be called in global namespace"); \
+ extern int LiteTouchJitKernelReg_gen_##kernel_type##_CPUPlace_(); \
+ static int use_litejitkernel_gen_##kernel_type##_CPUPlace_ UNUSED = \
+ LiteTouchJitKernelReg_gen_##kernel_type##_CPUPlace_()
+
+#define USE_JITKERNEL_REFER_LITE(kernel_type) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_##kernel_type##_refer_CPUPlace_, \
+ "USE_JITKERNEL_REFER_LITE must be called in global namespace"); \
+ extern int LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_(); \
+ static int use_litejitkernel_##kernel_type##_refer_CPUPlace_ UNUSED = \
+ LiteTouchJitKernelReg_##kernel_type##_refer_CPUPlace_()
+
+#define USE_KERNEL_MORE_LITE(kernel_type, impl_type, place_type) \
+ STATIC_ASSERT_JITKERNEL_GLOBAL_NAMESPACE_LITE( \
+ __reg_litejitkernel_##kernel_type##_##impl_type##_##place_type##_, \
+ "USE_JITKERNEL_MORE_LITE must be called in global namespace"); \
+ extern int \
+ LiteTouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_(); \
+ static int use_litejitkernel_##kernel_type##_##impl_type##_##place_type##_ \
+ UNUSED = \
+ LiteTouchJitKernelReg_##kernel_type##_##impl_type##_##place_type##_()
+
+#define USE_JITKERNEL_MORE_LITE(kernel_type, impl_type) \
+ USE_KERNEL_MORE_LITE(kernel_type, impl_type, CPUPlace)
} // namespace jit
} // namespace lite
diff --git a/lite/backends/x86/parallel.h b/lite/backends/x86/parallel.h
old mode 100755
new mode 100644
diff --git a/lite/backends/xpu/builder.cc b/lite/backends/xpu/builder.cc
deleted file mode 100644
index 796eaf9c46ceb3d29f1ffdc4c86ac45509f07ba1..0000000000000000000000000000000000000000
--- a/lite/backends/xpu/builder.cc
+++ /dev/null
@@ -1,189 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/xpu/builder.h"
-#include // NOLINT
-#include
-#include "lite/backends/xpu/runtime.h"
-
-namespace paddle {
-namespace lite {
-namespace xpu {
-
-bool HasInputArg(const OpInfo* op_info,
- const Scope* scope,
- const std::string& argname) {
- auto iarg_names = op_info->input_argnames();
- if (std::find(iarg_names.begin(), iarg_names.end(), argname) !=
- iarg_names.end()) {
- auto inputs = op_info->Input(argname);
- if (inputs.empty()) {
- return false;
- }
- auto var_name = inputs.front();
- auto var = scope->FindVar(var_name);
- return var != nullptr;
- } else {
- return false;
- }
-}
-
-std::string UniqueName(const std::string& prefix) {
- static std::mutex counter_mtx;
- static std::unordered_map counter_map;
- std::unique_lock counter_lck(counter_mtx);
- int counter = 1;
- auto it = counter_map.find(prefix);
- if (it == counter_map.end()) {
- counter_map[prefix] = counter;
- } else {
- counter = ++(it->second);
- }
- return prefix + "_" + std::to_string(counter);
-}
-
-xtcl::DataType CvtPrecisionType(PrecisionType in_type) {
- xtcl::DataType out_type = ::xtcl::Float(32);
- switch (in_type) {
- case PRECISION(kFloat):
- out_type = ::xtcl::Float(32);
- break;
- case PRECISION(kInt8):
- out_type = ::xtcl::Int(8);
- break;
- case PRECISION(kInt32):
- out_type = ::xtcl::Int(32);
- break;
- default:
- LOG(FATAL) << "Can not convert precision type(" << PrecisionToStr(in_type)
- << ") from Lite to XPU";
- break;
- }
- return out_type;
-}
-
-DLDataType CvtDataType(PrecisionType in_type) {
- DLDataType out_type = {kDLFloat, 32, 1};
- switch (in_type) {
- case PRECISION(kFloat):
- out_type = {kDLFloat, 32, 1};
- break;
- case PRECISION(kInt8):
- out_type = {kDLInt, 8, 1};
- break;
- case PRECISION(kInt32):
- out_type = {kDLInt, 32, 1};
- break;
- default:
- LOG(FATAL) << "Can not convert data type(" << PrecisionToStr(in_type)
- << ") from Lite to XPU";
- break;
- }
- return out_type;
-}
-
-xtcl::Array CvtShape(const std::vector& in_shape) {
- xtcl::Array out_shape;
- for (auto dim : in_shape) {
- out_shape.push_back(dim);
- }
- return out_shape;
-}
-
-xtcl::Array CvtShape(const std::vector& in_shape) {
- return CvtShape(std::vector(in_shape.begin(), in_shape.end()));
-}
-
-xtcl::Array CvtShape(const DDim& in_dims) {
- return CvtShape(in_dims.Vectorize());
-}
-
-std::shared_ptr CvtTensor(lite::Tensor* in_tensor,
- std::vector out_shape,
- PrecisionType in_ptype,
- DataLayoutType in_ltype) {
- uint8_t* in_data = nullptr;
- auto in_size = in_tensor->dims().production();
- auto in_shape = in_tensor->dims().Vectorize();
- if (out_shape.empty()) {
- out_shape = in_shape;
- }
- int in_bytes;
- if (in_ptype == PRECISION(kFloat)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(float);
- } else if (in_ptype == PRECISION(kInt32)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(int32_t);
- } else if (in_ptype == PRECISION(kInt8)) {
- in_data = reinterpret_cast(in_tensor->mutable_data());
- in_bytes = in_size * sizeof(int8_t);
- } else {
- LOG(FATAL) << "Unknow precision type " << PrecisionToStr(in_ptype);
- }
- auto out_tensor = std::make_shared(
- xtcl::xNDArray::Empty(out_shape, CvtDataType(in_ptype), {kDLCPU, 0}));
- auto out_data =
- reinterpret_cast(out_tensor->ToDLPack()->dl_tensor.data);
- std::memcpy(out_data, in_data, in_bytes);
- return out_tensor;
-}
-
-// Build the XPU subgraph to the XPU model, store the model data into the
-// weight tensor of the graph op, and the model data will be loaded again
-// by the graph computing kernel when the graph op is executed for inference.
-// Due to the lack of XPU APIs for building and outputing the model data,
-// the compiled XPU runtime object will be managed by the global variable
-// 'DeviceInfo' and the key name for finding the runtime object will be
-// stored in the weight tensor of graph op.
-// TODO(hong19860320) Compile the XPU subgraph and output the compiled model
-// data to the weight tensor of graph op.
-bool BuildModel(
- std::shared_ptr builder,
- std::shared_ptr params,
- std::vector>* outputs,
- lite::Tensor* model) {
- LOG(INFO) << "[XPU] Build Model.";
- CHECK(builder != nullptr);
- CHECK(outputs != nullptr);
- CHECK_GT(outputs->size(), 0);
- CHECK(model != nullptr);
-
- // build graph and fill all of constant params
- xtcl::xNetwork network = builder->FinalizeNetwork(*((*outputs)[0]));
- auto target = xtcl::Target::Create("llvm");
- auto compiler = xtcl::network::xTensorCompiler(network, target);
- compiler.SetParams(*params); // set the data of constant tensors
- compiler.Build();
-
- // create and register runtime
- auto runtime = std::make_shared(
- compiler.CreateRuntimeInstance());
- if (runtime == nullptr) {
- LOG(WARNING) << "[XPU] Build Model failed!";
- return false;
- }
- std::string name = UniqueName("xpu");
- LOG(INFO) << "[XPU] Model Name: " << name;
- DeviceInfo::Global().Insert(name, runtime);
- model->Resize({static_cast(name.length() + 1)});
- memcpy(model->mutable_data(),
- reinterpret_cast(name.c_str()),
- name.length() + 1);
- return true;
-}
-
-} // namespace xpu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/xpu/builder.h b/lite/backends/xpu/builder.h
deleted file mode 100644
index f0ac2b303aac7fa7f827e6e2f8f0fdf614b604b5..0000000000000000000000000000000000000000
--- a/lite/backends/xpu/builder.h
+++ /dev/null
@@ -1,60 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-#include
-#include "lite/core/op_lite.h"
-#include "lite/core/target_wrapper.h"
-#include "lite/core/tensor.h"
-
-namespace paddle {
-namespace lite {
-namespace xpu {
-
-bool HasInputArg(const OpInfo* op_info,
- const Scope* scope,
- const std::string& argname);
-
-std::string UniqueName(const std::string& prefix);
-
-xtcl::DataType CvtPrecisionType(PrecisionType in_type);
-
-DLDataType CvtDataType(PrecisionType in_type);
-
-xtcl::Array CvtShape(const std::vector& in_shape);
-
-xtcl::Array CvtShape(const std::vector& in_shape);
-
-xtcl::Array CvtShape(const DDim& in_dims);
-
-std::shared_ptr CvtTensor(
- Tensor* in_tensor,
- std::vector out_shape = {},
- PrecisionType in_ptype = PRECISION(kFloat),
- DataLayoutType in_ltype = DATALAYOUT(kNCHW));
-
-bool BuildModel(
- std::shared_ptr builder,
- std::shared_ptr params,
- std::vector>* outputs,
- lite::Tensor* model);
-
-} // namespace xpu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/xpu/device.cc b/lite/backends/xpu/device.cc
old mode 100755
new mode 100644
index dbf88ff83302c38cdc1b266f6e5c829c5a5c1da1..badde878ad870bfc5fcd1984e39923174a11e9e2
--- a/lite/backends/xpu/device.cc
+++ b/lite/backends/xpu/device.cc
@@ -36,8 +36,11 @@ std::unique_ptr Device::Build(
}
xtcl::xNetwork network =
builder->FinalizeNetwork(xtcl::relay::TupleNode::make(all_outs));
- auto target = xtcl::Target::Create(device_name_);
- auto compiler = xtcl::network::xTensorCompiler(network, target);
+ auto target = xtcl::NullValue();
+ if (!target_.empty()) {
+ target = xtcl::Target::Create(target_);
+ }
+ xtcl::network::xTensorCompiler compiler(network, target);
compiler.SetParams(*params); // Set the data of constant tensors
compiler.Build();
VLOG(3) << "[XPU] Build done";
diff --git a/lite/backends/xpu/device.h b/lite/backends/xpu/device.h
old mode 100755
new mode 100644
index bf9a8bf76af168a8a73f8f497b793df88f48f96b..6de18d5466da6e6b791363d2e275ea72376c78b8
--- a/lite/backends/xpu/device.h
+++ b/lite/backends/xpu/device.h
@@ -15,6 +15,7 @@
#pragma once
#include
+#include
#include
#include
#include
@@ -30,7 +31,18 @@ class Device {
static Device x;
return x;
}
- Device() {}
+ Device() {
+ char* name = std::getenv("XPU_DEVICE_NAME");
+ if (name) {
+ name_ = std::string(name);
+ }
+ // XPU_DEVICE_TARGET for XPU model building, which supports 'llvm' and 'xpu
+ // -libs=xdnn'
+ char* target = std::getenv("XPU_DEVICE_TARGET");
+ if (target) {
+ target_ = std::string(target);
+ }
+ }
// Build the XPU graph to the XPU runtime, return the XPU runtime which can be
// used to run inference.
@@ -39,10 +51,12 @@ class Device {
xtcl::network::xTensorCompiler::ParamNDArrayMap* params,
std::vector* outputs);
+ const std::string name() const { return name_; }
+ const std::string target() const { return target_; }
+
private:
- // Keep reserved fields
- int device_id_{0};
- std::string device_name_{"llvm"};
+ std::string name_{""};
+ std::string target_{""};
};
} // namespace xpu
diff --git a/lite/backends/xpu/runtime.cc b/lite/backends/xpu/runtime.cc
deleted file mode 100644
index a2c34b95758e8abf81c8294507d0ca60aad7c021..0000000000000000000000000000000000000000
--- a/lite/backends/xpu/runtime.cc
+++ /dev/null
@@ -1,46 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "lite/backends/xpu/runtime.h"
-#include
-#include "lite/utils/cp_logging.h"
-
-namespace paddle {
-namespace lite {
-namespace xpu {
-
-// Extract the model data and recover the XPU model for inference, the function
-// is called by the graph computing kernel when the graph op is executed.
-// Due to the lack of XPU APIs for loading and recovering the XPU model from
-// memory, the key name is obtained from the weight tensor of graph op, to get
-// the runtime object for inference from the global variable 'DeviceInfo'.
-// TODO(hong19860320) Recover the XPU model from the weight tensor of graph op.
-bool LoadModel(const lite::Tensor &model,
- std::shared_ptr *runtime) {
- LOG(INFO) << "[XPU] Load Model.";
- CHECK_GT(model.dims().production(), 0);
- std::string name(reinterpret_cast(model.data()));
- LOG(INFO) << "[XPU] Model Name: " << name;
- CHECK(runtime != nullptr);
- *runtime = DeviceInfo::Global().Find(name);
- if (*runtime == nullptr) {
- LOG(WARNING) << "[XPU] Load Model failed!";
- return false;
- }
- return true;
-}
-
-} // namespace xpu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/backends/xpu/runtime.h b/lite/backends/xpu/runtime.h
deleted file mode 100644
index 4ff8d75bce6156d51a4988d427058da34460443f..0000000000000000000000000000000000000000
--- a/lite/backends/xpu/runtime.h
+++ /dev/null
@@ -1,69 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#pragma once
-
-#include
-#include
-#include
-#include
-#include
-#include "lite/core/tensor.h"
-
-namespace paddle {
-namespace lite {
-namespace xpu {
-
-class DeviceInfo {
- public:
- static DeviceInfo& Global() {
- static DeviceInfo x;
- return x;
- }
- DeviceInfo() {}
-
- void Insert(const std::string& name,
- std::shared_ptr runtime) {
- if (runtimes_.find(name) != runtimes_.end()) {
- LOG(WARNING) << "[XPU] Model " << name << " already exists.";
- return;
- }
- runtimes_.emplace(std::make_pair(name, runtime));
- }
-
- void Clear() { runtimes_.clear(); }
-
- std::shared_ptr Find(
- const std::string& name) const {
- if (runtimes_.find(name) != runtimes_.end()) {
- return runtimes_.at(name);
- } else {
- return nullptr;
- }
- }
-
- private:
- int device_id_{0};
- std::string device_name_{"default"};
- std::unordered_map>
- runtimes_;
-};
-
-bool LoadModel(const lite::Tensor& model,
- std::shared_ptr* runtime);
-
-} // namespace xpu
-} // namespace lite
-} // namespace paddle
diff --git a/lite/core/CMakeLists.txt b/lite/core/CMakeLists.txt
index 57f353c0ee5432bddec8cddc5a639c2f72ecf172..1d0558451fce67433d966d1f4bff82af26459e33 100644
--- a/lite/core/CMakeLists.txt
+++ b/lite/core/CMakeLists.txt
@@ -96,7 +96,15 @@ add_custom_command(
add_custom_target(op_list_h DEPENDS ops.h)
add_custom_target(kernel_list_h DEPENDS kernels.h)
add_custom_target(all_kernel_faked_cc DEPENDS all_kernel_faked.cc)
-
+# create headfile to restore ops info sorted by suppported platforms
+add_custom_command(
+ COMMAND python ${CMAKE_SOURCE_DIR}/lite/tools/cmake_tools/record_supported_kernel_op.py
+ ${kernels_src_list}
+ ${ops_src_list}
+ ${CMAKE_BINARY_DIR}/supported_kernel_op_info.h
+ OUTPUT supported_kernel_op_info.h # not a real path to the output to force it execute every time.
+ )
+ add_custom_target(supported_kernel_op_info_h DEPENDS supported_kernel_op_info.h)
#----------------------------------------------- NOT CHANGE -----------------------------------------------
lite_cc_library(kernel SRCS kernel.cc
DEPS context type_system target_wrapper any op_params tensor
diff --git a/lite/core/arena/CMakeLists.txt b/lite/core/arena/CMakeLists.txt
index d379b31b84f09f1e99742be52d58c3f0b1ee10f3..1c85353d5386fea1ae7f4a0f1869a95f8a2478af 100644
--- a/lite/core/arena/CMakeLists.txt
+++ b/lite/core/arena/CMakeLists.txt
@@ -6,5 +6,5 @@ endif()
lite_cc_library(arena_framework SRCS framework.cc DEPS program gtest)
if((NOT LITE_WITH_OPENCL) AND (LITE_WITH_X86 OR LITE_WITH_ARM))
- lite_cc_test(test_arena_framework SRCS framework_test.cc DEPS arena_framework ${npu_kernels} ${bm_kernels} ${xpu_kernels} ${x86_kernels} ${fpga_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_arena_framework SRCS framework_test.cc DEPS arena_framework ${npu_kernels} ${xpu_kernels} ${x86_kernels} ${cuda_kernels} ${fpga_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
endif()
diff --git a/lite/core/framework.proto b/lite/core/framework.proto
index 5adf2a18b98c2a2d3e2f6e8f7dd5688150674dc6..84b5502ff7b369452e7c9988d185450934c78b03 100644
--- a/lite/core/framework.proto
+++ b/lite/core/framework.proto
@@ -13,7 +13,6 @@ See the License for the specific language governing permissions and
limitations under the License. */
syntax = "proto2";
-option optimize_for = LITE_RUNTIME;
package paddle.framework.proto;
// Any incompatible changes to ProgramDesc and its dependencies should
diff --git a/lite/core/kernel.h b/lite/core/kernel.h
index 86193235a2984b15a33c2eeaff15865d9f126eeb..18a1243c11652afc181f13f0f5a497858a30885f 100644
--- a/lite/core/kernel.h
+++ b/lite/core/kernel.h
@@ -83,14 +83,11 @@ class KernelBase {
#if defined(LITE_WITH_CUDA)
WorkSpace::Global_CUDA().AllocReset();
#endif
-
#ifdef LITE_WITH_PROFILE
- CHECK(profiler_) << "Profiler pointer of kernel can not be nullptr. "
- "When LITE_WITH_PROFILE is defined, please set a "
- "Profiler for Instruction.";
- profiler_->StartTiming(profile_id_, ctx_.get());
+ profiler_->StopTiming(profile::Type::kCreate, profile_id_, ctx_.get());
+ profiler_->StartTiming(profile::Type::kDispatch, profile_id_, ctx_.get());
Run();
- profiler_->StopTiming(profile_id_, ctx_.get());
+ profiler_->StopTiming(profile::Type::kDispatch, profile_id_, ctx_.get());
#else
Run();
#endif
diff --git a/lite/core/mir/elimination/elementwise_mul_constant_eliminate_pass.cc b/lite/core/mir/elimination/elementwise_mul_constant_eliminate_pass.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/elementwise_add_activation_fuse_pass.cc b/lite/core/mir/fusion/elementwise_add_activation_fuse_pass.cc
index 97f6a2657f0f7ed8963529cdbec5aad00e763807..8447865bdc85f4e007d94d34be724cbe8329903b 100644
--- a/lite/core/mir/fusion/elementwise_add_activation_fuse_pass.cc
+++ b/lite/core/mir/fusion/elementwise_add_activation_fuse_pass.cc
@@ -35,5 +35,7 @@ void ElementwiseAddActivationFusePass::Apply(
REGISTER_MIR_PASS(lite_elementwise_add_activation_fuse_pass,
paddle::lite::mir::ElementwiseAddActivationFusePass)
.BindTargets({TARGET(kAny)})
- .ExcludeTargets({TARGET(kXPU), TARGET(kBM)})
+ .ExcludeTargets({TARGET(kXPU)})
+ .ExcludeTargets({TARGET(kBM)})
+ .ExcludeTargets({TARGET(kX86)})
.BindKernel("fusion_elementwise_add_activation");
diff --git a/lite/core/mir/fusion/fc_fuse_pass.cc b/lite/core/mir/fusion/fc_fuse_pass.cc
index 5b8e8563ba2e44c1c855cd3d4c6a9a08c06c826f..c85d34cbaecc63d3f6bb12a654e2ba0ea2a3232b 100644
--- a/lite/core/mir/fusion/fc_fuse_pass.cc
+++ b/lite/core/mir/fusion/fc_fuse_pass.cc
@@ -23,8 +23,13 @@ namespace lite {
namespace mir {
void FcFusePass::Apply(const std::unique_ptr& graph) {
- fusion::FcFuser fuser;
+#ifdef LITE_WITH_X86
+ fusion::FcFuser fuser(true);
fuser(graph.get());
+#endif
+
+ fusion::FcFuser fuser2(false);
+ fuser2(graph.get());
}
} // namespace mir
@@ -33,5 +38,7 @@ void FcFusePass::Apply(const std::unique_ptr& graph) {
REGISTER_MIR_PASS(lite_fc_fuse_pass, paddle::lite::mir::FcFusePass)
.BindTargets({TARGET(kAny)})
- .ExcludeTargets({TARGET(kXPU), TARGET(kBM)})
+ .ExcludeTargets({TARGET(kXPU)})
+ .ExcludeTargets({TARGET(kBM)})
+ .ExcludeTargets({TARGET(kCUDA)})
.BindKernel("fc");
diff --git a/lite/core/mir/fusion/fc_fuse_pass_test.cc b/lite/core/mir/fusion/fc_fuse_pass_test.cc
index f7aa4bb5adcb848531ecc3a8f63bace1c2e3e0ff..54260732c5efe788f0d3740197253fa2321a7d02 100644
--- a/lite/core/mir/fusion/fc_fuse_pass_test.cc
+++ b/lite/core/mir/fusion/fc_fuse_pass_test.cc
@@ -88,6 +88,7 @@ USE_LITE_OP(mul);
USE_LITE_OP(elementwise_add);
USE_LITE_OP(elementwise_sub);
USE_LITE_OP(fc);
+USE_LITE_OP(relu);
USE_LITE_OP(feed);
USE_LITE_OP(fetch);
USE_LITE_OP(io_copy);
diff --git a/lite/core/mir/fusion/fc_fuser.cc b/lite/core/mir/fusion/fc_fuser.cc
index 460c0fdf7a4309638b9852a315ca0efda02801ab..3c99131083d37ea2c8511ed136bff17c891529af 100644
--- a/lite/core/mir/fusion/fc_fuser.cc
+++ b/lite/core/mir/fusion/fc_fuser.cc
@@ -35,12 +35,23 @@ void FcFuser::BuildPattern() {
std::vector mul_inputs{W, x};
std::vector add_inputs{mul_out, b};
mul_inputs >> *mul >> *mul_out;
- add_inputs >> *add >> *Out;
// Some op specialities.
mul_out->AsIntermediate();
mul->AsIntermediate();
add->AsIntermediate();
+
+ if (with_relu_) {
+ auto* add_out = VarNode("add_out");
+ auto* relu = OpNode("relu", "relu");
+ std::vector relu_inputs{add_out};
+ add_inputs >> *add >> *add_out;
+ relu_inputs >> *relu >> *Out;
+ add_out->AsIntermediate();
+ relu->AsIntermediate();
+ } else {
+ add_inputs >> *add >> *Out;
+ }
}
void FcFuser::InsertNewNode(SSAGraph* graph, const key2nodes_t& matched) {
@@ -71,6 +82,9 @@ cpp::OpDesc FcFuser::GenOpDesc(const key2nodes_t& matched) {
op_desc.SetAttr(
"in_num_col_dims",
matched.at("mul")->stmt()->op_info()->GetAttr("x_num_col_dims"));
+ if (with_relu_) {
+ op_desc.SetAttr("activation_type", std::string{"relu"});
+ }
return op_desc;
}
diff --git a/lite/core/mir/fusion/fc_fuser.h b/lite/core/mir/fusion/fc_fuser.h
index 7ba07527898c7e648c5f7f9151642ab0928fa496..6cb08f41574b67df1c78fa296d2d395771a66ee1 100644
--- a/lite/core/mir/fusion/fc_fuser.h
+++ b/lite/core/mir/fusion/fc_fuser.h
@@ -25,11 +25,13 @@ namespace fusion {
class FcFuser : public FuseBase {
public:
+ explicit FcFuser(bool with_relu) : with_relu_(with_relu) {}
void BuildPattern() override;
void InsertNewNode(SSAGraph* graph, const key2nodes_t& matched) override;
private:
cpp::OpDesc GenOpDesc(const key2nodes_t& matched) override;
+ bool with_relu_;
};
} // namespace fusion
diff --git a/lite/core/mir/fusion/sequence_pool_concat_fuse_pass.cc b/lite/core/mir/fusion/sequence_pool_concat_fuse_pass.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/sequence_pool_concat_fuse_pass.h b/lite/core/mir/fusion/sequence_pool_concat_fuse_pass.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/sequence_pool_concat_fuser.cc b/lite/core/mir/fusion/sequence_pool_concat_fuser.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/sequence_pool_concat_fuser.h b/lite/core/mir/fusion/sequence_pool_concat_fuser.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/var_conv_2d_activation_fuse_pass.cc b/lite/core/mir/fusion/var_conv_2d_activation_fuse_pass.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/var_conv_2d_activation_fuse_pass.h b/lite/core/mir/fusion/var_conv_2d_activation_fuse_pass.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/var_conv_2d_activation_fuser.cc b/lite/core/mir/fusion/var_conv_2d_activation_fuser.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/fusion/var_conv_2d_activation_fuser.h b/lite/core/mir/fusion/var_conv_2d_activation_fuser.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/generate_program_pass.cc b/lite/core/mir/generate_program_pass.cc
index 9ad69b8152273628d70c796228f978e9f990ed9e..76c97d2da6ed9e7c6fc1f1889d80095278b68ec0 100644
--- a/lite/core/mir/generate_program_pass.cc
+++ b/lite/core/mir/generate_program_pass.cc
@@ -29,7 +29,6 @@ void GenerateProgramPass::Apply(const std::unique_ptr& graph) {
if (item->IsStmt()) {
auto& stmt = item->AsStmt();
VLOG(4) << stmt;
- LOG(INFO) << stmt;
insts_.emplace_back(stmt.op(), std::move(stmt.kernels().front()));
}
}
diff --git a/lite/core/mir/subgraph/CMakeLists.txt b/lite/core/mir/subgraph/CMakeLists.txt
index 1ac4ab346f15edf9e039d3143c0a301d49a1c0b4..f8aa09676c2d1e6d4df6fafbaf6a54bc69491acc 100644
--- a/lite/core/mir/subgraph/CMakeLists.txt
+++ b/lite/core/mir/subgraph/CMakeLists.txt
@@ -4,7 +4,7 @@ lite_cc_library(subgraph_detector
lite_cc_library(subgraph_pass
SRCS subgraph_pass.cc
DEPS mir_pass types context ${mir_fusers} subgraph_detector)
-if (WITH_TESTING)
+if (WITH_TESTING AND NOT LITE_WITH_CUDA)
lite_cc_test(test_subgraph_detector
SRCS subgraph_detector_test.cc
DEPS subgraph_detector mir_passes gflags model_parser cxx_api
diff --git a/lite/core/mir/subgraph/subgraph_detector.cc b/lite/core/mir/subgraph/subgraph_detector.cc
old mode 100755
new mode 100644
index bf04d5c2ef2a7c000849b883bb6b09c400d28399..6d48b053a1a4140252d35e85d2351644d3c216e9
--- a/lite/core/mir/subgraph/subgraph_detector.cc
+++ b/lite/core/mir/subgraph/subgraph_detector.cc
@@ -94,7 +94,7 @@ std::string SubgraphVisualizer::operator()() {
}
auto res = dot.Build();
- //std::cout << "subgraphs: " << subgraphs_.size() << "\n" << res << std::endl;
+ std::cout << "subgraphs: " << subgraphs_.size() << "\n" << res << std::endl;
return res;
}
diff --git a/lite/core/mir/subgraph/subgraph_detector.h b/lite/core/mir/subgraph/subgraph_detector.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/subgraph/subgraph_detector_test.cc b/lite/core/mir/subgraph/subgraph_detector_test.cc
old mode 100755
new mode 100644
diff --git a/lite/core/mir/subgraph/subgraph_pass.cc b/lite/core/mir/subgraph/subgraph_pass.cc
old mode 100755
new mode 100644
index af5bcdee08273d84c21b68deffec8ffad765af66..116b3616814641dcd68ca56026cde10e8e1058d1
--- a/lite/core/mir/subgraph/subgraph_pass.cc
+++ b/lite/core/mir/subgraph/subgraph_pass.cc
@@ -27,7 +27,7 @@ namespace mir {
void NPUSubgraphPass::Apply(const std::unique_ptr& graph) {
std::unordered_set supported_lists;
-#define USE_SUBGRAPH_BRIDGE(dev_type, op_type) supported_lists.insert(#op_type);
+#define USE_SUBGRAPH_BRIDGE(op_type, target) supported_lists.insert(#op_type);
#include "lite/kernels/npu/bridges/paddle_use_bridges.h"
#undef USE_SUBGRAPH_BRIDGE
auto teller = [&](Node* node) {
@@ -41,7 +41,7 @@ void NPUSubgraphPass::Apply(const std::unique_ptr& graph) {
void XPUSubgraphPass::Apply(const std::unique_ptr& graph) {
std::unordered_set supported_lists;
-#define USE_SUBGRAPH_BRIDGE(dev_type, op_type) supported_lists.insert(#op_type);
+#define USE_SUBGRAPH_BRIDGE(op_type, target) supported_lists.insert(#op_type);
#include "lite/kernels/xpu/bridges/paddle_use_bridges.h"
#undef USE_SUBGRAPH_BRIDGE
auto teller = [&](Node* node) {
@@ -55,7 +55,7 @@ void XPUSubgraphPass::Apply(const std::unique_ptr& graph) {
void BMSubgraphPass::Apply(const std::unique_ptr& graph) {
std::unordered_set supported_lists;
-#define USE_SUBGRAPH_BRIDGE(dev_type, op_type) supported_lists.insert(#op_type);
+#define USE_SUBGRAPH_BRIDGE(op_type, target) supported_lists.insert(#op_type);
#include "lite/kernels/bm/bridges/paddle_use_bridges.h"
#undef USE_SUBGRAPH_BRIDGE
auto teller = [&](Node* node) {
diff --git a/lite/core/mir/subgraph/subgraph_pass.h b/lite/core/mir/subgraph/subgraph_pass.h
old mode 100755
new mode 100644
diff --git a/lite/core/mir/subgraph/subgraph_pass_test.cc b/lite/core/mir/subgraph/subgraph_pass_test.cc
old mode 100755
new mode 100644
index 0d5fc7bf5e21e1d44cb62a507d17a3c7027573c2..a56c364f975fa6c3f82e1bbbb4489c93eb6ab724
--- a/lite/core/mir/subgraph/subgraph_pass_test.cc
+++ b/lite/core/mir/subgraph/subgraph_pass_test.cc
@@ -92,7 +92,7 @@ void FillInputTensors(
#define FILL_TENSOR_WITH_TYPE(type) \
auto input_tensor_data = input_tensor->mutable_data(); \
for (int j = 0; j < input_tensor_size; j++) { \
- input_tensor_data[i] = static_cast(value); \
+ input_tensor_data[j] = static_cast(value); \
}
for (int i = 0; i < input_tensor_shape.size(); i++) {
auto input_tensor = predictor->GetInput(i);
diff --git a/lite/core/profile/profiler.cc b/lite/core/profile/profiler.cc
index 78317f78ac6bf7024c1984c2127434d55b738ad6..f4d0e3c0afbe1f9df4e381a502e1800a3d58ba68 100644
--- a/lite/core/profile/profiler.cc
+++ b/lite/core/profile/profiler.cc
@@ -28,36 +28,55 @@ auto op_comp = [](const OpCharacter& c1, const OpCharacter& c2) {
};
}
-int Profiler::NewTimer(const OpCharacter& ch) {
- StatisUnit unit;
- unit.character = ch;
+std::map TypeStr{
+ {Type::kUnk, "Unknown"},
+ {Type::kCreate, "Create"},
+ {Type::kDispatch, "Dispatch"},
+};
+
+StatisUnit::StatisUnit(const OpCharacter& ch) : character(ch) {
+ create_t.reset(new DeviceTimer());
if (ch.target == TargetType::kCUDA) {
#ifdef LITE_WITH_CUDA
- unit.timer.reset(new DeviceTimer());
+ dispatch_t.reset(new DeviceTimer());
#else
LOG(ERROR) << "The timer type specified as cuda is uninitialized, so the "
"default x86 timer is used instead.";
#endif
} else {
- unit.timer.reset(new DeviceTimer());
+ dispatch_t.reset(new DeviceTimer());
}
+}
+
+lite::profile::Timer* StatisUnit::Timer(Type type) {
+ if (type == Type::kCreate) {
+ return create_t.get();
+ } else if (type == Type::kDispatch) {
+ return dispatch_t.get();
+ }
+ LOG(FATAL) << "Timer cannot be returned for unknown platforms.";
+ return nullptr;
+}
+
+int Profiler::NewTimer(const OpCharacter& ch) {
+ StatisUnit unit(ch);
units_.push_back(std::move(unit));
return units_.size() - 1;
}
-void Profiler::StartTiming(const int index, KernelContext* ctx) {
+void Profiler::StartTiming(Type type, const int index, KernelContext* ctx) {
CHECK_LT(index, units_.size())
<< "The timer index in the profiler is out of range.";
- units_[index].timer->Start(ctx);
+ units_[index].Timer(type)->Start(ctx);
}
-float Profiler::StopTiming(const int index, KernelContext* ctx) {
+float Profiler::StopTiming(Type type, const int index, KernelContext* ctx) {
CHECK_LT(index, units_.size())
<< "The timer index in the profiler is out of range.";
- return units_[index].timer->Stop(ctx);
+ return units_[index].Timer(type)->Stop(ctx);
}
-std::string Profiler::Summary(bool concise, size_t w) {
+std::string Profiler::Summary(Type type, bool concise, size_t w) {
using std::setw;
using std::left;
using std::fixed;
@@ -65,12 +84,14 @@ std::string Profiler::Summary(bool concise, size_t w) {
std::string title;
// Title.
if (concise) {
- ss << "Timing cycle = " << units_.front().timer->LapTimes().Size()
+ ss << "Timing cycle = " << units_.front().Timer(type)->LapTimes().Size()
<< std::endl;
- ss << "===== Concise Profiler Summary: " << name_ << ", Exclude " << w
+ ss << "===== Concise " << TypeStr.find(type)->second
+ << " Profiler Summary: " << name_ << ", Exclude " << w
<< " warm-ups =====" << std::endl;
} else {
- ss << "===== Detailed Profiler Summary: " << name_ << ", Exclude " << w
+ ss << "===== Detailed " << TypeStr.find(type)->second
+ << " Profiler Summary: " << name_ << ", Exclude " << w
<< " warm-ups =====" << std::endl;
}
ss << setw(25) << left << "Operator Type"
@@ -84,16 +105,16 @@ std::string Profiler::Summary(bool concise, size_t w) {
if (concise) {
std::map summary(op_comp);
for (auto& unit : units_) {
- auto ch = summary.find(unit.character);
+ auto ch = summary.find(unit.Character());
if (ch != summary.end()) {
- ch->second.avg += unit.timer->LapTimes().Avg(w);
- ch->second.min += unit.timer->LapTimes().Min(w);
- ch->second.max += unit.timer->LapTimes().Max(w);
+ ch->second.avg += unit.Timer(type)->LapTimes().Avg(w);
+ ch->second.min += unit.Timer(type)->LapTimes().Min(w);
+ ch->second.max += unit.Timer(type)->LapTimes().Max(w);
} else {
- TimeInfo info({unit.timer->LapTimes().Avg(w),
- unit.timer->LapTimes().Min(w),
- unit.timer->LapTimes().Max(w)});
- summary.insert({unit.character, info});
+ TimeInfo info({unit.Timer(type)->LapTimes().Avg(w),
+ unit.Timer(type)->LapTimes().Min(w),
+ unit.Timer(type)->LapTimes().Max(w)});
+ summary.insert({unit.Character(), info});
}
}
for (const auto& item : summary) {
@@ -109,14 +130,15 @@ std::string Profiler::Summary(bool concise, size_t w) {
}
} else {
for (auto& unit : units_) {
+ const auto& times = unit.Timer(type)->LapTimes();
// clang-format off
- ss << setw(25) << left << fixed << unit.character.op_type \
- << " " << setw(40) << left << fixed << unit.character.kernel_name \
- << " " << setw(12) << left << fixed << unit.character.remark \
- << " " << setw(12) << left << fixed << unit.timer->LapTimes().Avg(w) \
- << " " << setw(12) << left << fixed << unit.timer->LapTimes().Min(w) \
- << " " << setw(12) << left << fixed << unit.timer->LapTimes().Max(w) \
- << " " << setw(12) << left << fixed << unit.timer->LapTimes().Last(w) \
+ ss << setw(25) << left << fixed << unit.Character().op_type \
+ << " " << setw(40) << left << fixed << unit.Character().kernel_name \
+ << " " << setw(12) << left << fixed << unit.Character().remark \
+ << " " << setw(12) << left << fixed << times.Avg(w) \
+ << " " << setw(12) << left << fixed << times.Min(w) \
+ << " " << setw(12) << left << fixed << times.Max(w) \
+ << " " << setw(12) << left << fixed << times.Last(w) \
<< std::endl;
// clang-format on
}
diff --git a/lite/core/profile/profiler.h b/lite/core/profile/profiler.h
index 4e9e9ae31c1a6d7f331eac2e77c4971986bd42a1..3933e5ba01ebcb20420494a955cbc0e202879f76 100644
--- a/lite/core/profile/profiler.h
+++ b/lite/core/profile/profiler.h
@@ -13,6 +13,7 @@
// limitations under the License.
#pragma once
+#include
#include
#include
#include
@@ -22,6 +23,14 @@ namespace paddle {
namespace lite {
namespace profile {
+enum class Type {
+ kUnk = 0,
+ kCreate,
+ kDispatch,
+};
+
+extern std::map TypeStr;
+
struct TimeInfo {
float avg;
float min;
@@ -35,8 +44,15 @@ struct OpCharacter {
std::string remark{std::string("N/A")};
};
-struct StatisUnit {
- std::unique_ptr timer;
+class StatisUnit final {
+ public:
+ explicit StatisUnit(const OpCharacter& ch);
+ lite::profile::Timer* Timer(Type type);
+ const OpCharacter& Character() const { return character; }
+
+ protected:
+ std::unique_ptr create_t;
+ std::unique_ptr dispatch_t;
OpCharacter character;
};
@@ -45,9 +61,9 @@ class Profiler final {
Profiler() = default;
explicit Profiler(const std::string& name) : name_(name) {}
int NewTimer(const OpCharacter& ch);
- void StartTiming(const int index, KernelContext* ctx);
- float StopTiming(const int index, KernelContext* ctx);
- std::string Summary(bool concise = true, size_t warm_up = 10);
+ void StartTiming(Type type, const int index, KernelContext* ctx);
+ float StopTiming(Type type, const int index, KernelContext* ctx);
+ std::string Summary(Type type, bool concise = true, size_t warm_up = 10);
private:
std::string name_{std::string("N/A")};
diff --git a/lite/core/profile/test_timer.cc b/lite/core/profile/test_timer.cc
index 6f49698ef4a8f83e4192a16801566fdcbd7baf9a..3841f0151890d377a87f4f5d4b6d069ee75b560e 100644
--- a/lite/core/profile/test_timer.cc
+++ b/lite/core/profile/test_timer.cc
@@ -69,10 +69,10 @@ TEST(profiler, real_latency) {
ch.op_type = "operator/1";
ch.kernel_name = "kernel/1";
int idx = profiler.NewTimer(ch);
- profiler.StartTiming(idx, &ctx);
+ profiler.StartTiming(Type::kDispatch, idx, &ctx);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
- profiler.StopTiming(idx, &ctx);
- std::cout << profiler.Summary();
+ profiler.StopTiming(Type::kDispatch, idx, &ctx);
+ std::cout << profiler.Summary(Type::kDispatch);
}
#endif
diff --git a/lite/core/program.cc b/lite/core/program.cc
index 8dc8fb0dddc54d7d83b2368b31b5f30725469296..41d178f015d723aff739e608501e4619f8b10f5d 100644
--- a/lite/core/program.cc
+++ b/lite/core/program.cc
@@ -137,8 +137,7 @@ void RuntimeProgram::UpdateVarsOfProgram(cpp::ProgramDesc* desc) {
void RuntimeProgram::Run() {
for (auto& inst : instructions_) {
- std::string op_type = inst.op()->op_info()->Type();
- if (op_type == "feed" || op_type == "fetch") continue;
+ if (inst.is_feed_fetch_op()) continue;
inst.Run();
#ifdef LITE_WITH_PROFILE
#ifdef LITE_WITH_PRECISION_PROFILE
@@ -147,7 +146,7 @@ void RuntimeProgram::Run() {
#endif // LITE_WITH_PROFILE
}
#ifdef LITE_WITH_PROFILE
- LOG(INFO) << "\n" << profiler_.Summary(false, 0);
+ LOG(INFO) << "\n" << profiler_.Summary(profile::Type::kDispatch, false, 0);
#endif // LITE_WITH_PROFILE
}
@@ -252,8 +251,16 @@ void Program::PrepareWorkspace(const cpp::ProgramDesc& prog) {
}
void Instruction::Run() {
+#ifdef LITE_WITH_PROFILE
+ CHECK(profiler_) << "Profiler pointer of kernel can not be nullptr. "
+ "When LITE_WITH_PROFILE is defined, please set a "
+ "Profiler for Instruction.";
+ profiler_->StartTiming(
+ profile::Type::kCreate, profile_id_, kernel_->mutable_context());
+#endif
CHECK(op_) << "op null";
CHECK(kernel_) << "kernel null";
+
if (first_epoch_) {
first_epoch_ = false;
CHECK(op_->CheckShape());
@@ -263,10 +270,7 @@ void Instruction::Run() {
return;
}
- // VLOG(4) << "kernel launch";
op_->InferShape();
- // VLOG(4) << ">> Running kernel: " << op_->op_info()->Repr() << " on Target "
- // << TargetToStr(kernel_->target());
kernel_->Launch();
has_run_ = true;
}
diff --git a/lite/core/program.h b/lite/core/program.h
index 291252619b396f18576b935a0189f4ecdba7867f..c845a17c52c0c565e339a13e093f3e8f59e8d4a7 100644
--- a/lite/core/program.h
+++ b/lite/core/program.h
@@ -90,7 +90,12 @@ struct Program {
struct Instruction {
Instruction(const std::shared_ptr& op,
std::unique_ptr&& kernel)
- : op_(op), kernel_(std::move(kernel)) {}
+ : op_(op), kernel_(std::move(kernel)) {
+ std::string op_type = op->Type();
+ if (op_type == "feed" || op_type == "fetch") {
+ is_feed_fetch_op_ = true;
+ }
+ }
// Run the instruction.
void Run();
@@ -101,6 +106,8 @@ struct Instruction {
const KernelBase* kernel() const { return kernel_.get(); }
KernelBase* mutable_kernel() { return kernel_.get(); }
+ bool is_feed_fetch_op() const { return is_feed_fetch_op_; }
+
#ifdef LITE_WITH_PROFILE
void set_profiler(profile::Profiler* profiler) {
profiler_ = profiler;
@@ -118,6 +125,7 @@ struct Instruction {
private:
std::shared_ptr op_;
std::unique_ptr kernel_;
+ bool is_feed_fetch_op_{false};
bool first_epoch_{true};
bool has_run_{false};
@@ -143,7 +151,8 @@ class LITE_API RuntimeProgram {
}
~RuntimeProgram() {
#ifdef LITE_WITH_PROFILE
- LOG(INFO) << "\n" << profiler_.Summary();
+ LOG(INFO) << "\n" << profiler_.Summary(profile::Type::kCreate);
+ LOG(INFO) << "\n" << profiler_.Summary(profile::Type::kDispatch);
#endif // LITE_WITH_PROFILE
}
diff --git a/lite/core/tensor.h b/lite/core/tensor.h
index de08aa82f327ebfb9c84b121f6d411dbbab24ff6..41a2d16f75f946c9ef8250d3e2af1ac6ee370d60 100644
--- a/lite/core/tensor.h
+++ b/lite/core/tensor.h
@@ -139,6 +139,22 @@ class TensorLite {
// For other devices, T and R may be the same type.
template
R *mutable_data() {
+ auto type_id = typeid(T).hash_code();
+ if (type_id == typeid(bool).hash_code()) { // NOLINT
+ precision_ = PrecisionType::kBool;
+ } else if (type_id == typeid(float).hash_code()) { // NOLINT
+ precision_ = PrecisionType::kFloat;
+ } else if (type_id == typeid(int8_t).hash_code()) {
+ precision_ = PrecisionType::kInt8;
+ } else if (type_id == typeid(int16_t).hash_code()) {
+ precision_ = PrecisionType::kInt16;
+ } else if (type_id == typeid(int32_t).hash_code()) {
+ precision_ = PrecisionType::kInt32;
+ } else if (type_id == typeid(int64_t).hash_code()) {
+ precision_ = PrecisionType::kInt64;
+ } else {
+ precision_ = PrecisionType::kUnk;
+ }
memory_size_ = dims_.production() * sizeof(T);
buffer_->ResetLazy(target_, memory_size_);
return reinterpret_cast(static_cast(buffer_->data()) +
@@ -163,10 +179,7 @@ class TensorLite {
template
R *mutable_data(TargetType target) {
target_ = target;
- memory_size_ = dims_.production() * sizeof(T);
- buffer_->ResetLazy(target, memory_size());
- return reinterpret_cast(static_cast(buffer_->data()) +
- offset_);
+ return mutable_data();
}
void *mutable_data(size_t memory_size);
void *mutable_data(TargetType target, size_t memory_size);
diff --git a/lite/demo/cxx/README.md b/lite/demo/cxx/README.md
index 5e0ec49adda2c6f7372bdbba1fdd04b610b0a0bc..3217a7ed49006325715e22f8aa82d155bc8bf927 100644
--- a/lite/demo/cxx/README.md
+++ b/lite/demo/cxx/README.md
@@ -1,91 +1,111 @@
# C++ Demo
-1. 使用`lite/tools/Dockerfile.mobile`生成docker镜像
-2. 运行并进入docker镜像环境,执行`wget http://paddle-inference-dist.bj.bcebos.com/lite_release/v2.1.0/inference_lite_lib.android.armv8.tar.gz `下载所需demo环境。(armv7 demo可使用命令`wget http://paddle-inference-dist.bj.bcebos.com/lite_release/v2.1.0/inference_lite_lib.android.armv7.tar.gz` 进行下载)。
-3. 解压下载文件`tar zxvf inference_lite_lib.android.armv8.tar.gz `
-4. 执行以下命令准备模拟器环境
-```shell
-# armv8
-adb kill-server
-adb devices | grep emulator | cut -f1 | while read line; do adb -s $line emu kill; done
-echo n | avdmanager create avd -f -n paddle-armv8 -k "system-images;android-24;google_apis;arm64-v8a"
-echo -ne '\n' | ${ANDROID_HOME}/emulator/emulator -avd paddle-armv8 -noaudio -no-window -gpu off -port 5554 &
-sleep 1m
-```
-```shell
-# armv7
-adb kill-server
-adb devices | grep emulator | cut -f1 | while read line; do adb -s $line emu kill; done
-echo n | avdmanager create avd -f -n paddle-armv7 -k "system-images;android-24;google_apis;armeabi-v7a"
-echo -ne '\n' | ${ANDROID_HOME}/emulator/emulator -avd paddle-armv7 -noaudio -no-window -gpu off -port 5554 &
-sleep 1m
-```
-5. 准备模型、编译并运行完整api的demo
+1. 环境准备
+ - 保证Android NDK在/opt目录下
+ - 一台armv7或armv8架构的安卓手机
+2. 编译并运行全量api的demo(注:当编译模式为tiny_pubish时将不存在该demo)
```shell
cd inference_lite_lib.android.armv8/demo/cxx/mobile_full
wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
tar zxvf mobilenet_v1.tar.gz
make
-adb -s emulator-5554 push mobilenet_v1 /data/local/tmp/
-adb -s emulator-5554 push mobilenetv1_full_api /data/local/tmp/
-adb -s emulator-5554 push ../../../cxx/lib/libpaddle_full_api_shared.so /data/local/tmp/
-adb -s emulator-5554 shell chmod +x /data/local/tmp/mobilenetv1_full_api
-adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+adb push mobilenet_v1 /data/local/tmp/
+adb push mobilenetv1_full_api /data/local/tmp/
+adb push ../../../cxx/lib/libpaddle_full_api_shared.so /data/local/tmp/
+adb shell chmod +x /data/local/tmp/mobilenetv1_full_api
+adb shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
/data/local/tmp/mobilenetv1_full_api --model_dir=/data/local/tmp/mobilenet_v1 --optimized_model_dir=/data/local/tmp/mobilenet_v1.opt"
```
运行成功将在控制台输出预测结果的前10个类别的预测概率
-6. 编译并运行轻量级api的demo
+3. 编译并运行轻量级api的demo
```shell
cd ../mobile_light
make
-adb -s emulator-5554 push mobilenetv1_light_api /data/local/tmp/
-adb -s emulator-5554 push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
-adb -s emulator-5554 shell chmod +x /data/local/tmp/mobilenetv1_light_api
-adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+adb push mobilenetv1_light_api /data/local/tmp/
+adb push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
+adb shell chmod +x /data/local/tmp/mobilenetv1_light_api
+adb shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
/data/local/tmp/mobilenetv1_light_api /data/local/tmp/mobilenet_v1.opt"
```
+运行成功将在控制台输出预测结果的前10个类别的预测概率
-7. 编译并运行目标检测的demo
+4. 编译并运行ssd目标检测的demo
```shell
-cd ../mobile_detection
+cd ../ssd_detection
wget https://paddle-inference-dist.bj.bcebos.com/mobilenetv1-ssd.tar.gz
tar zxvf mobilenetv1-ssd.tar.gz
make
-adb -s emulator-5554 push mobile_detection /data/local/tmp/
-adb -s emulator-5554 push test.jpg /data/local/tmp/
-adb -s emulator-5554 push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
-adb -s emulator-5554 shell chmod +x /data/local/tmp/mobile_detection
-adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
-/data/local/tmp/mobile_detection /data/local/tmp/mobilenetv1-ssd /data/local/tmp/test.jpg"
-adb -s emulator-5554 pull /data/local/tmp/test_detection_result.jpg ./
+adb push ssd_detection /data/local/tmp/
+adb push test.jpg /data/local/tmp/
+adb push mobilenetv1-ssd /data/local/tmp
+adb push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
+adb shell chmod +x /data/local/tmp/ssd_detection
+adb shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+/data/local/tmp/ssd_detection /data/local/tmp/mobilenetv1-ssd /data/local/tmp/test.jpg"
+adb pull /data/local/tmp/test_ssd_detection_result.jpg ./
```
-运行成功将在mobile_detection目录下看到生成的目标检测结果图像: test_detection_result.jpg
+运行成功将在ssd_detection目录下看到生成的目标检测结果图像: test_ssd_detection_result.jpg
-8. 编译并运行物体分类的demo
+5. 编译并运行yolov3目标检测的demo
+```shell
+cd ../yolov3_detection
+wget https://paddle-inference-dist.bj.bcebos.com/mobilenetv1-yolov3.tar.gz
+tar zxvf mobilenetv1-yolov3.tar.gz
+make
+adb push yolov3_detection /data/local/tmp/
+adb push test.jpg /data/local/tmp/
+adb push mobilenetv1-yolov3 /data/local/tmp
+adb push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
+adb shell chmod +x /data/local/tmp/yolov3_detection
+adb shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+/data/local/tmp/yolov3_detection /data/local/tmp/mobilenetv1-yolov3 /data/local/tmp/test.jpg"
+adb pull /data/local/tmp/test_yolov3_detection_result.jpg ./
+```
+运行成功将在yolov3_detection目录下看到生成的目标检测结果图像: test_yolov3_detection_result.jpg
+
+6. 编译并运行物体分类的demo
```shell
cd ../mobile_classify
wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
tar zxvf mobilenet_v1.tar.gz
+./model_optimize_tool optimize model
make
+
adb -s emulator-5554 push mobile_classify /data/local/tmp/
adb -s emulator-5554 push test.jpg /data/local/tmp/
adb -s emulator-5554 push labels.txt /data/local/tmp/
adb -s emulator-5554 push ../../../cxx/lib/libpaddle_light_api_shared.so /data/local/tmp/
adb -s emulator-5554 shell chmod +x /data/local/tmp/mobile_classify
adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
-/data/local/tmp/mobile_classify /data/local/tmp/mobilenet_v1 /data/local/tmp/test.jpg /data/local/tmp/labels.txt"
+/data/local/tmp/mobile_classify /data/local/tmp/mobilenetv1opt2 /data/local/tmp/test.jpg /data/local/tmp/labels.txt"
```
运行成功将在控制台输出预测结果的前5个类别的预测概率
- 如若想看前10个类别的预测概率,在运行命令输入topk的值即可
eg:
```shell
adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
- /data/local/tmp/mobile_classify /data/local/tmp/mobilenet_v1 /data/local/tmp/test.jpg /data/local/tmp/labels.txt 10"
+ /data/local/tmp/mobile_classify /data/local/tmp/mobilenetv1opt2/ /data/local/tmp/test.jpg /data/local/tmp/labels.txt 10"
```
- 如若想看其他模型的分类结果, 在运行命令输入model_dir 及其model的输入大小即可
eg:
```shell
adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
- /data/local/tmp/mobile_classify /data/local/tmp/mobilenet_v2 /data/local/tmp/test.jpg /data/local/tmp/labels.txt 10 224 224"
+ /data/local/tmp/mobile_classify /data/local/tmp/mobilenetv2opt2/ /data/local/tmp/test.jpg /data/local/tmp/labels.txt 10 224 224"
```
+9. 编译含CV预处理库模型单测demo
+```shell
+cd ../test_cv
+wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
+tar zxvf mobilenet_v1.tar.gz
+./model_optimize_tool optimize model
+make
+adb -s emulator-5554 push test_model_cv /data/local/tmp/
+adb -s emulator-5554 push test.jpg /data/local/tmp/
+adb -s emulator-5554 push labels.txt /data/local/tmp/
+adb -s emulator-5554 push ../../../cxx/lib/libpaddle_full_api_shared.so /data/local/tmp/
+adb -s emulator-5554 shell chmod +x /data/local/tmp/test_model_cv
+adb -s emulator-5554 shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+/data/local/tmp/test_model_cv /data/local/tmp/mobilenetv1opt2 /data/local/tmp/test.jpg /data/local/tmp/labels.txt"
+```
+运行成功将在控制台输出预测结果的前10个类别的预测概率
diff --git a/lite/demo/cxx/makefiles/mobile_classify/Makefile.android.armv7 b/lite/demo/cxx/makefiles/mobile_classify/Makefile.android.armv7
old mode 100755
new mode 100644
diff --git a/lite/demo/cxx/makefiles/mobile_classify/Makefile.android.armv8 b/lite/demo/cxx/makefiles/mobile_classify/Makefile.android.armv8
old mode 100755
new mode 100644
diff --git a/lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv7 b/lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv7
similarity index 90%
rename from lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv7
rename to lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv7
index 784ad73da4bf1d37ee23c17ac7c4dfc5c08f2627..05f1c2e276b9cc41cfd4e3f9b4c82790d844ba52 100644
--- a/lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv7
+++ b/lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv7
@@ -40,11 +40,11 @@ CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_light_api_shared $(SY
#CXX_LIBS = $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
-mobile_detection: fetch_opencv mobile_detection.o
- $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) mobile_detection.o -o mobile_detection $(CXX_LIBS) $(LDFLAGS)
+ssd_detection: fetch_opencv ssd_detection.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) ssd_detection.o -o ssd_detection $(CXX_LIBS) $(LDFLAGS)
-mobile_detection.o: mobile_detection.cc
- $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o mobile_detection.o -c mobile_detection.cc
+ssd_detection.o: ssd_detection.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o ssd_detection.o -c ssd_detection.cc
fetch_opencv:
@ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
@@ -57,5 +57,5 @@ fetch_opencv:
.PHONY: clean
clean:
- rm -f mobile_detection.o
- rm -f mobile_detection
+ rm -f ssd_detection.o
+ rm -f ssd_detection
diff --git a/lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv8 b/lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv8
similarity index 89%
rename from lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv8
rename to lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv8
index 2304b38efffdd96e7e13073020df4954b5e53034..77ff07df9541c554ac5fabf3cf56ee4a8904ea9c 100644
--- a/lite/demo/cxx/makefiles/mobile_detection/Makefile.android.armv8
+++ b/lite/demo/cxx/makefiles/ssd_detection/Makefile.android.armv8
@@ -40,11 +40,11 @@ CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_light_api_shared $(SY
#CXX_LIBS = $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
-mobile_detection: fetch_opencv mobile_detection.o
- $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) mobile_detection.o -o mobile_detection $(CXX_LIBS) $(LDFLAGS)
+ssd_detection: fetch_opencv ssd_detection.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) ssd_detection.o -o ssd_detection $(CXX_LIBS) $(LDFLAGS)
-mobile_detection.o: mobile_detection.cc
- $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o mobile_detection.o -c mobile_detection.cc
+ssd_detection.o: ssd_detection.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o ssd_detection.o -c ssd_detection.cc
fetch_opencv:
@ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
@@ -57,5 +57,5 @@ fetch_opencv:
.PHONY: clean
clean:
- rm -f mobile_detection.o
- rm -f mobile_detection
+ rm -f ssd_detection.o
+ rm -f ssd_detection
diff --git a/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv7 b/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv7
new file mode 100644
index 0000000000000000000000000000000000000000..d659a316cd856fd550e83b125573409f239b8cf2
--- /dev/null
+++ b/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv7
@@ -0,0 +1,71 @@
+ARM_ABI = arm7
+LITE_WITH_CV = ON
+export ARM_ABI
+export LITE_WITH_CV
+
+include ../Makefile.def
+
+LITE_ROOT=../../../
+
+THIRD_PARTY_DIR=${LITE_ROOT}/third_party
+
+OPENCV_VERSION=opencv4.1.0
+
+OPENCV_LIBS = ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_imgcodecs.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_imgproc.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_core.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libtegra_hal.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibjpeg-turbo.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibwebp.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibpng.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibjasper.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibtiff.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libIlmImf.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libtbb.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libcpufeatures.a
+
+OPENCV_INCLUDE = -I../../../third_party/${OPENCV_VERSION}/armeabi-v7a/include
+
+CXX_INCLUDES = $(INCLUDES) ${OPENCV_INCLUDE} -I$(LITE_ROOT)/cxx/include
+
+CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_full_api_shared $(SYSTEM_LIBS)
+
+###############################################################
+# How to use one of static libaray: #
+# `libpaddle_api_full_bundled.a` #
+# `libpaddle_api_light_bundled.a` #
+###############################################################
+# Note: default use lite's shared library. #
+###############################################################
+# 1. Comment above line using `libpaddle_light_api_shared.so`
+# 2. Undo comment below line using `libpaddle_api_light_bundled.a`
+
+#CXX_LIBS = $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
+
+test_model_cv: fetch_opencv test_model_cv.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_model_cv.o -o test_model_cv $(CXX_LIBS) $(LDFLAGS)
+
+test_model_cv.o: test_model_cv.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_model_cv.o -c test_model_cv.cc
+
+test_img_prepross: fetch_opencv test_img_prepross.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_img_prepross.o -o test_img_prepross $(CXX_LIBS) $(LDFLAGS)
+
+test_img_prepross.o: test_img_prepross.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_img_prepross.o -c test_img_prepross.cc
+
+fetch_opencv:
+ @ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
+ @ test -e ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz || \
+ (echo "fetch opencv libs" && \
+ wget -P ${THIRD_PARTY_DIR} https://paddle-inference-dist.bj.bcebos.com/${OPENCV_VERSION}.tar.gz)
+ @ test -d ${THIRD_PARTY_DIR}/${OPENCV_VERSION} || \
+ tar -zxvf ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz -C ${THIRD_PARTY_DIR}
+
+
+.PHONY: clean
+clean:
+ rm -f test_model_cv.o
+ rm -f test_model_cv
+ rm -f test_img_prepross.o
+ rm -f test_img_prepross
diff --git a/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv8 b/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv8
new file mode 100644
index 0000000000000000000000000000000000000000..c80b07d5c029a3624a514e07375fd08e8770da25
--- /dev/null
+++ b/lite/demo/cxx/makefiles/test_cv/Makefile.android.armv8
@@ -0,0 +1,70 @@
+ARM_ABI = arm8
+LITE_WITH_CV = ON
+export ARM_ABI
+export LITE_WITH_CV
+
+include ../Makefile.def
+
+LITE_ROOT=../../../
+
+THIRD_PARTY_DIR=${LITE_ROOT}/third_party
+
+OPENCV_VERSION=opencv4.1.0
+
+OPENCV_LIBS = ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_imgcodecs.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_imgproc.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_core.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libtegra_hal.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibjpeg-turbo.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibwebp.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibpng.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibjasper.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibtiff.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libIlmImf.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libtbb.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libcpufeatures.a
+
+OPENCV_INCLUDE = -I../../../third_party/${OPENCV_VERSION}/arm64-v8a/include
+
+CXX_INCLUDES = $(INCLUDES) ${OPENCV_INCLUDE} -I$(LITE_ROOT)/cxx/include
+
+CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_full_api_shared $(SYSTEM_LIBS)
+###############################################################
+# How to use one of static libaray: #
+# `libpaddle_api_full_bundled.a` #
+# `libpaddle_api_light_bundled.a` #
+###############################################################
+# Note: default use lite's shared library. #
+###############################################################
+# 1. Comment above line using `libpaddle_light_api_shared.so`
+# 2. Undo comment below line using `libpaddle_api_light_bundled.a`
+
+#CXX_LIBS = ${OPENCV_LIBS} $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
+
+test_model_cv: fetch_opencv test_model_cv.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_model_cv.o -o test_model_cv $(CXX_LIBS) $(LDFLAGS)
+
+test_model_cv.o: test_model_cv.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_model_cv.o -c test_model_cv.cc
+
+test_img_prepross: fetch_opencv test_img_prepross.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_img_prepross.o -o test_img_prepross $(CXX_LIBS) $(LDFLAGS)
+
+test_img_prepross.o: test_img_prepross.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_img_prepross.o -c test_img_prepross.cc
+
+fetch_opencv:
+ @ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
+ @ test -e ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz || \
+ (echo "fetch opencv libs" && \
+ wget -P ${THIRD_PARTY_DIR} https://paddle-inference-dist.bj.bcebos.com/${OPENCV_VERSION}.tar.gz)
+ @ test -d ${THIRD_PARTY_DIR}/${OPENCV_VERSION} || \
+ tar -zxvf ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz -C ${THIRD_PARTY_DIR}
+
+
+.PHONY: clean
+clean:
+ rm -f test_model_cv.o
+ rm -f test_model_cv
+ rm -f test_img_prepross.o
+ rm -f test_img_prepross
diff --git a/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv7 b/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv7
new file mode 100644
index 0000000000000000000000000000000000000000..b584f5623594fd64f10a86766828c62cdfe08aef
--- /dev/null
+++ b/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv7
@@ -0,0 +1,61 @@
+ARM_ABI = arm7
+export ARM_ABI
+
+include ../Makefile.def
+
+LITE_ROOT=../../../
+
+THIRD_PARTY_DIR=${LITE_ROOT}/third_party
+
+OPENCV_VERSION=opencv4.1.0
+
+OPENCV_LIBS = ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_imgcodecs.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_imgproc.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/libs/libopencv_core.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libtegra_hal.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibjpeg-turbo.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibwebp.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibpng.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibjasper.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/liblibtiff.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libIlmImf.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libtbb.a \
+ ../../../third_party/${OPENCV_VERSION}/armeabi-v7a/3rdparty/libs/libcpufeatures.a
+
+OPENCV_INCLUDE = -I../../../third_party/${OPENCV_VERSION}/armeabi-v7a/include
+
+CXX_INCLUDES = $(INCLUDES) ${OPENCV_INCLUDE} -I$(LITE_ROOT)/cxx/include
+
+CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_light_api_shared $(SYSTEM_LIBS)
+
+###############################################################
+# How to use one of static libaray: #
+# `libpaddle_api_full_bundled.a` #
+# `libpaddle_api_light_bundled.a` #
+###############################################################
+# Note: default use lite's shared library. #
+###############################################################
+# 1. Comment above line using `libpaddle_light_api_shared.so`
+# 2. Undo comment below line using `libpaddle_api_light_bundled.a`
+
+#CXX_LIBS = $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
+
+yolov3_detection: fetch_opencv yolov3_detection.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) yolov3_detection.o -o yolov3_detection $(CXX_LIBS) $(LDFLAGS)
+
+yolov3_detection.o: yolov3_detection.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o yolov3_detection.o -c yolov3_detection.cc
+
+fetch_opencv:
+ @ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
+ @ test -e ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz || \
+ (echo "fetch opencv libs" && \
+ wget -P ${THIRD_PARTY_DIR} https://paddle-inference-dist.bj.bcebos.com/${OPENCV_VERSION}.tar.gz)
+ @ test -d ${THIRD_PARTY_DIR}/${OPENCV_VERSION} || \
+ tar -zxvf ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz -C ${THIRD_PARTY_DIR}
+
+
+.PHONY: clean
+clean:
+ rm -f yolov3_detection.o
+ rm -f yolov3_detection
diff --git a/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv8 b/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv8
new file mode 100644
index 0000000000000000000000000000000000000000..27779817012bce527d4506a0dcd377bf4ced3c1a
--- /dev/null
+++ b/lite/demo/cxx/makefiles/yolov3_detection/Makefile.android.armv8
@@ -0,0 +1,61 @@
+ARM_ABI = arm8
+export ARM_ABI
+
+include ../Makefile.def
+
+LITE_ROOT=../../../
+
+THIRD_PARTY_DIR=${LITE_ROOT}/third_party
+
+OPENCV_VERSION=opencv4.1.0
+
+OPENCV_LIBS = ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_imgcodecs.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_imgproc.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/libs/libopencv_core.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libtegra_hal.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibjpeg-turbo.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibwebp.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibpng.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibjasper.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/liblibtiff.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libIlmImf.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libtbb.a \
+ ../../../third_party/${OPENCV_VERSION}/arm64-v8a/3rdparty/libs/libcpufeatures.a
+
+OPENCV_INCLUDE = -I../../../third_party/${OPENCV_VERSION}/arm64-v8a/include
+
+CXX_INCLUDES = $(INCLUDES) ${OPENCV_INCLUDE} -I$(LITE_ROOT)/cxx/include
+
+CXX_LIBS = ${OPENCV_LIBS} -L$(LITE_ROOT)/cxx/lib/ -lpaddle_light_api_shared $(SYSTEM_LIBS)
+
+###############################################################
+# How to use one of static libaray: #
+# `libpaddle_api_full_bundled.a` #
+# `libpaddle_api_light_bundled.a` #
+###############################################################
+# Note: default use lite's shared library. #
+###############################################################
+# 1. Comment above line using `libpaddle_light_api_shared.so`
+# 2. Undo comment below line using `libpaddle_api_light_bundled.a`
+
+#CXX_LIBS = $(LITE_ROOT)/cxx/lib/libpaddle_api_light_bundled.a $(SYSTEM_LIBS)
+
+yolov3_detection: fetch_opencv yolov3_detection.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) yolov3_detection.o -o yolov3_detection $(CXX_LIBS) $(LDFLAGS)
+
+yolov3_detection.o: yolov3_detection.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o yolov3_detection.o -c yolov3_detection.cc
+
+fetch_opencv:
+ @ test -d ${THIRD_PARTY_DIR} || mkdir ${THIRD_PARTY_DIR}
+ @ test -e ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz || \
+ (echo "fetch opencv libs" && \
+ wget -P ${THIRD_PARTY_DIR} https://paddle-inference-dist.bj.bcebos.com/${OPENCV_VERSION}.tar.gz)
+ @ test -d ${THIRD_PARTY_DIR}/${OPENCV_VERSION} || \
+ tar -zxvf ${THIRD_PARTY_DIR}/${OPENCV_VERSION}.tar.gz -C ${THIRD_PARTY_DIR}
+
+
+.PHONY: clean
+clean:
+ rm -f yolov3_detection.o
+ rm -f yolov3_detection
diff --git a/lite/demo/cxx/mobile_classify/mobile_classify.cc b/lite/demo/cxx/mobile_classify/mobile_classify.cc
old mode 100755
new mode 100644
index c651bf9f4cca0db0e126311e5a03b3ade6ccf886..d0cf59e185e1330b7d8487d562afa0af29236007
--- a/lite/demo/cxx/mobile_classify/mobile_classify.cc
+++ b/lite/demo/cxx/mobile_classify/mobile_classify.cc
@@ -117,7 +117,7 @@ void pre_process(const cv::Mat& img,
float* means,
float* scales) {
cv::Mat rgb_img;
- // cv::cvtColor(img, rgb_img, cv::COLOR_BGR2RGB);
+ cv::cvtColor(img, rgb_img, cv::COLOR_BGR2RGB);
cv::resize(rgb_img, rgb_img, cv::Size(width, height), 0.f, 0.f);
cv::Mat imgf;
rgb_img.convertTo(imgf, CV_32FC3, 1 / 255.f);
diff --git a/lite/demo/cxx/mobile_detection/test.jpg b/lite/demo/cxx/mobile_detection/test.jpg
deleted file mode 100644
index 6bb36e136deec6088c7b75215fc35d6231283673..0000000000000000000000000000000000000000
Binary files a/lite/demo/cxx/mobile_detection/test.jpg and /dev/null differ
diff --git a/lite/demo/cxx/mobile_detection/mobile_detection.cc b/lite/demo/cxx/ssd_detection/ssd_detection.cc
similarity index 98%
rename from lite/demo/cxx/mobile_detection/mobile_detection.cc
rename to lite/demo/cxx/ssd_detection/ssd_detection.cc
index 9b8f02aeedef991496541400e7db67c3e3ff0e51..011733eb87f551141c52ab8e23d9625c93c742fc 100644
--- a/lite/demo/cxx/mobile_detection/mobile_detection.cc
+++ b/lite/demo/cxx/ssd_detection/ssd_detection.cc
@@ -194,7 +194,7 @@ void RunModel(std::string model_dir, std::string img_path) {
}
auto rec_out = detect_object(outptr, static_cast(cnt / 6), 0.6f, img);
std::string result_name =
- img_path.substr(0, img_path.find(".")) + "_detection_result.jpg";
+ img_path.substr(0, img_path.find(".")) + "_ssd_detection_result.jpg";
cv::imwrite(result_name, img);
}
diff --git a/lite/demo/cxx/test_cv/README.md b/lite/demo/cxx/test_cv/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..36d2985a4fd4f243027f8caab9b6c5a8beb94cad
--- /dev/null
+++ b/lite/demo/cxx/test_cv/README.md
@@ -0,0 +1,131 @@
+# 图像预测库的使用
+1. 下载源码(https://github.com/PaddlePaddle/Paddle-Lite),打开LITE_WITH_CV=ON,编译full_publish模式
+example:
+```shell
+set BUILD_WITH_CV=ON or LITE_WITH_CV=ON
+./lite/tools/build.sh
+--arm_os=android
+--arm_abi=armv8
+--arm_lang=gcc
+--android_stl=c++_static
+full_publish
+```
+
+2. 准备模型和优化模型
+example:
+```shell
+wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
+tar zxvf mobilenet_v1.tar.gz
+./lite/tools/build.sh build_optimize_tool
+./build.model_optimize_tool/lite/api/model_optimize_tool
+--optimize_out_type=naive_buffer
+--optimize_out=model_dir
+--model_dir=model_dir
+--prefer_int8_kernel=false
+```
+
+3. 编译并运行完整test_model_cv demo
+example:
+```shell
+cd inference_lite_lib.android.armv8/demo/cxx/test_cv
+```
+
+- 修改MakeFile, 注释编译test_img_propress 语句
+ ```shell
+ test_model_cv: fetch_opencv test_model_cv.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_model_cv.o -o test_model_cv $(CXX_LIBS) $(LDFLAGS)
+
+ test_model_cv.o: test_model_cv.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_model_cv.o -c test_model_cv.cc
+
+ #test_img_propress: fetch_opencv test_img_propress.o
+ # $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_img_propress.o -o test_img_propress $(CXX_LIBS) $(LDFLAGS)
+
+ #test_img_propress.o: test_img_propress.cc
+ # $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_img_propress.o -c test_img_propress.cc
+
+ .PHONY: clean
+ clean:
+ rm -f test_model_cv.o
+ rm -f test_model_cv
+ #rm -f test_img_propress.o
+ #rm -f test_img_propress
+ ```
+- 修改../../..//cxx/include/paddle_image_preprocess.h, 修改paddle_api.h头文件的路径
+ ```shell
+ origin:
+ #include "lite/api/paddle_api.h"
+ #include "lite/api/paddle_place.h"
+ now:
+ #include "paddle_api.h"
+ #include "paddle_place.h"
+ ```
+- 测试模型必须是优化后的模型
+
+```shell
+make
+
+adb -s device_id push mobilenet_v1 /data/local/tmp/
+adb -s device_id push test_model_cv /data/local/tmp/
+adb -s device_id push test.jpg /data/local/tmp/
+adb -s device_id push ../../../cxx/lib/libpaddle_full_api_shared.so /data/local/tmp/
+adb -s device_id shell chmod +x /data/local/tmp/test_model_cv
+adb -s device_id shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+/data/local/tmp/test_model_cv /data/local/tmp/mobilenet_v1 /data/local/tmp/test.jpg 1 3 224 224 "
+```
+运行成功将在控制台输出部分预测结果
+
+4. 编译并运行完整test_img_preprocess demo
+example:
+```shell
+cd inference_lite_lib.android.armv8/demo/cxx/test_cv
+```
+
+- 修改MakeFile, 注释编译test_model_cv 语句
+ ```shell
+ #test_model_cv: fetch_opencv test_model_cv.o
+ # $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_model_cv.o -o test_model_cv $(CXX_LIBS) $(LDFLAGS)
+
+ #test_model_cv.o: test_model_cv.cc
+ # $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_model_cv.o -c test_model_cv.cc
+
+ test_img_propress: fetch_opencv test_img_propress.o
+ $(CC) $(SYSROOT_LINK) $(CXXFLAGS_LINK) test_img_propress.o -o test_img_propress $(CXX_LIBS) $(LDFLAGS)
+
+ test_img_propress.o: test_img_propress.cc
+ $(CC) $(SYSROOT_COMPLILE) $(CXX_DEFINES) $(CXX_INCLUDES) $(CXX_FLAGS) -o test_img_propress.o -c test_img_propress.cc
+
+ .PHONY: clean
+ clean:
+ #rm -f test_model_cv.o
+ #rm -f test_model_cv
+ rm -f test_img_propress.o
+ rm -f test_img_propress
+ ```
+- 修改../../..//cxx/include/paddle_image_preprocess.h, 修改paddle_api.h头文件的路径
+ ```shell
+ origin:
+ #include "lite/api/paddle_api.h"
+ #include "lite/api/paddle_place.h"
+ now:
+ #include "paddle_api.h"
+ #include "paddle_place.h"
+ ```
+- 测试模型必须是优化后的模型
+
+```shell
+make
+
+adb -s device_id push mobilenet_v1 /data/local/tmp/
+adb -s device_id push test_img_propress /data/local/tmp/
+adb -s device_id push test.jpg /data/local/tmp/
+adb -s device_id push ../../../cxx/lib/libpaddle_full_api_shared.so /data/local/tmp/
+adb -s device_id shell chmod +x /data/local/tmp/test_model_cv
+adb -s device_id shell "export LD_LIBRARY_PATH=/data/local/tmp/:$LD_LIBRARY_PATH &&
+/data/local/tmp/test_img_propress /data/local/tmp/test.jpg /data/local/tmp/ 3 3 1 3 224 224 /data/local/tmp/mobilenet_v1 "
+adb -s device_id pull /data/local/tmp/resize.jpg ./
+adb -s device_id pull /data/local/tmp/convert.jpg ./
+adb -s device_id pull /data/local/tmp/flip.jpg ./
+adb -s device_id pull /data/local/tmp/rotate.jpg ./
+```
+运行成功将在控制台输出OpenCV 和 Padlle-lite的耗时;同时,将在test_cv目录下看到生成的图像预处理结果图: 如:resize.jpg、convert.jpg等
diff --git a/lite/demo/cxx/test_cv/test_img_prepross.cc b/lite/demo/cxx/test_cv/test_img_prepross.cc
new file mode 100644
index 0000000000000000000000000000000000000000..c2cbd66cc0a15a1032141641d83fbf8db85d20bf
--- /dev/null
+++ b/lite/demo/cxx/test_cv/test_img_prepross.cc
@@ -0,0 +1,389 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "paddle_api.h" // NOLINT
+#include "paddle_image_preprocess.h" // NOLINT
+#include "time.h" // NOLINT
+typedef paddle::lite_api::Tensor Tensor;
+typedef paddle::lite::utils::cv::ImageFormat ImageFormat;
+typedef paddle::lite::utils::cv::FlipParam FlipParam;
+typedef paddle::lite::utils::cv::TransParam TransParam;
+typedef paddle::lite::utils::cv::ImagePreprocess ImagePreprocess;
+typedef paddle::lite_api::DataLayoutType LayoutType;
+using namespace paddle::lite_api; // NOLINT
+
+void fill_with_mat(cv::Mat& mat, uint8_t* src) { // NOLINT
+ for (int i = 0; i < mat.rows; i++) {
+ for (int j = 0; j < mat.cols; j++) {
+ int tmp = (i * mat.cols + j) * 3;
+ cv::Vec3b& rgb = mat.at(i, j);
+ rgb[0] = src[tmp];
+ rgb[1] = src[tmp + 1];
+ rgb[2] = src[tmp + 2];
+ }
+ }
+}
+void test_img(std::vector cluster_id,
+ std::vector thread_num,
+ std::string img_path,
+ std::string dst_path,
+ ImageFormat srcFormat,
+ ImageFormat dstFormat,
+ int width,
+ int height,
+ float rotate,
+ FlipParam flip,
+ LayoutType layout,
+ std::string model_dir,
+ int test_iter = 1) {
+ // init
+ // paddle::lite::DeviceInfo::Init();
+ // read img and pre-process
+ cv::Mat img = imread(img_path, cv::IMREAD_COLOR);
+ float means[3] = {0.485f, 0.456f, 0.406f};
+ float scales[3] = {0.229f, 0.224f, 0.225f};
+ int srch = img.rows;
+ int srcw = img.cols;
+ for (auto& cls : cluster_id) {
+ for (auto& th : thread_num) {
+ std::cout << "cluster: " << cls << ", threads: " << th << std::endl;
+ // 1. Set MobileConfig
+ MobileConfig config;
+ config.set_model_dir(model_dir);
+ config.set_power_mode((PowerMode)cls);
+ config.set_threads(th);
+ std::cout << "model: " << model_dir;
+
+ // 2. Create PaddlePredictor by MobileConfig
+ std::shared_ptr predictor =
+ CreatePaddlePredictor(config);
+
+ // 3. Prepare input data from image
+ std::unique_ptr input_tensor(predictor->GetInput(0));
+
+ /*
+ imread(img_path, param)
+ IMREAD_UNCHANGED(<0) 表示加载原图,不做任何改变
+ IMREAD_GRAYSCALE ( 0)表示把原图作为灰度图像加载进来
+ IMREAD_COLOR (>0) 表示把原图作为RGB图像加载进来
+ */
+ cv::Mat img;
+ if (srcFormat == ImageFormat::BGR || srcFormat == ImageFormat::RGB) {
+ img = imread(img_path, cv::IMREAD_COLOR);
+ } else if (srcFormat == ImageFormat::GRAY) {
+ img = imread(img_path, cv::IMREAD_GRAYSCALE);
+ } else {
+ printf("this format %d does not support \n", srcFormat);
+ return;
+ }
+ if (img.empty()) {
+ std::cout << "opencv read image " << img_path.c_str() << " failed"
+ << std::endl;
+ return;
+ }
+ int srch = img.rows;
+ int srcw = img.cols;
+ int dsth = height;
+ int dstw = width;
+
+ std::cout << " input tensor size, num= " << 1 << ", channel= " << 1
+ << ", height= " << srch << ", width= " << srcw
+ << ", srcFormat= " << (ImageFormat)srcFormat << std::endl;
+ // RGBA = 0, BGRA, RGB, BGR, GRAY, NV21 = 11, NV12,
+ if (srcFormat == ImageFormat::GRAY) {
+ std::cout << "srcFormat: GRAY" << std::endl;
+ }
+ if (srcFormat == ImageFormat::BGR) {
+ std::cout << "srcFormat: BGR" << std::endl;
+ }
+ if (srcFormat == ImageFormat::RGB) {
+ std::cout << "srcFormat: RGB" << std::endl;
+ }
+ std::cout << " output tensor size, num=" << 1 << ", channel=" << 1
+ << ", height=" << dsth << ", width=" << dstw
+ << ", dstFormat= " << (ImageFormat)dstFormat << std::endl;
+
+ if (dstFormat == ImageFormat::GRAY) {
+ std::cout << "dstFormat: GRAY" << std::endl;
+ }
+ if (dstFormat == ImageFormat::BGR) {
+ std::cout << "dstFormat: BGR" << std::endl;
+ }
+ if (dstFormat == ImageFormat::RGB) {
+ std::cout << "dstFormat: RGB" << std::endl;
+ }
+
+ std::cout << "Rotate = " << rotate << ", Flip = " << flip
+ << ", Layout = " << static_cast(layout) << std::endl;
+ if (static_cast(layout) != 1 && static_cast(layout) != 3) {
+ std::cout << "this layout" << static_cast(layout)
+ << " is no support" << std::endl;
+ }
+ int size = 3 * srch * srcw;
+ if (srcFormat == ImageFormat::BGR || srcFormat == ImageFormat::RGB) {
+ size = 3 * srch * srcw;
+ } else if (srcFormat == ImageFormat::GRAY) {
+ size = srch * srcw;
+ }
+ uint8_t* src = img.data;
+
+ int out_size = srch * srcw;
+ int resize = dstw * dsth;
+ if (dstFormat == ImageFormat::BGR || dstFormat == ImageFormat::RGB) {
+ out_size = 3 * srch * srcw;
+ resize = 3 * dsth * dstw;
+ } else if (dstFormat == ImageFormat::GRAY) {
+ out_size = srch * srcw;
+ resize = dsth * dstw;
+ }
+ // out
+ uint8_t* lite_dst = new uint8_t[out_size];
+ uint8_t* resize_tmp = new uint8_t[resize];
+ uint8_t* tv_out_ratote = new uint8_t[out_size];
+ uint8_t* tv_out_flip = new uint8_t[out_size];
+ std::vector shape_out = {1, 3, srch, srcw};
+
+ input_tensor->Resize(shape_out);
+ Tensor dst_tensor = *input_tensor;
+ std::cout << "opencv compute" << std::endl;
+ cv::Mat im_convert;
+ cv::Mat im_resize;
+ cv::Mat im_rotate;
+ cv::Mat im_flip;
+ double to_1 = 0;
+ double to_2 = 0;
+ double to_3 = 0;
+ double to_4 = 0;
+ double to1 = 0;
+ for (int i = 0; i < test_iter; i++) {
+ clock_t start = clock();
+ clock_t begin = clock();
+ // convert bgr-gray
+ if (dstFormat == srcFormat) {
+ im_convert = img;
+ } else if (dstFormat == ImageFormat::BGR &&
+ srcFormat == ImageFormat::GRAY) {
+ cv::cvtColor(img, im_convert, cv::COLOR_GRAY2BGR);
+ } else if (srcFormat == ImageFormat::BGR &&
+ dstFormat == ImageFormat::GRAY) {
+ cv::cvtColor(img, im_convert, cv::COLOR_BGR2GRAY);
+ } else if (dstFormat == srcFormat) {
+ printf("convert format error \n");
+ return;
+ }
+ clock_t end = clock();
+ to_1 += (end - begin);
+
+ begin = clock();
+ // resize default linear
+ cv::resize(im_convert, im_resize, cv::Size(dstw, dsth), 0.f, 0.f);
+ end = clock();
+ to_2 += (end - begin);
+
+ begin = clock();
+ // rotate 90
+ if (rotate == 90) {
+ cv::flip(im_convert.t(), im_rotate, 1);
+ } else if (rotate == 180) {
+ cv::flip(im_convert, im_rotate, -1);
+ } else if (rotate == 270) {
+ cv::flip(im_convert.t(), im_rotate, 0);
+ }
+ end = clock();
+ to_3 += (end - begin);
+
+ begin = clock();
+ // flip
+ cv::flip(im_convert, im_flip, flip);
+ end = clock();
+ to_4 += (end - begin);
+ clock_t ovet = clock();
+ to1 += (ovet - start);
+ }
+
+ std::cout << "Paddle-lite compute" << std::endl;
+ double lite_to = 0;
+ double lite_to_1 = 0;
+ double lite_to_2 = 0;
+ double lite_to_3 = 0;
+ double lite_to_4 = 0;
+ double lite_to_5 = 0;
+ TransParam tparam;
+ tparam.ih = srch;
+ tparam.iw = srcw;
+ tparam.oh = dsth;
+ tparam.ow = dstw;
+ tparam.flip_param = flip;
+ tparam.rotate_param = rotate;
+
+ ImagePreprocess image_preprocess(srcFormat, dstFormat, tparam);
+
+ for (int i = 0; i < test_iter; ++i) {
+ clock_t start = clock();
+ clock_t begin = clock();
+ image_preprocess.imageConvert(src, lite_dst);
+ clock_t end = clock();
+ lite_to_1 += (end - begin);
+
+ begin = clock();
+ image_preprocess.imageResize(lite_dst, resize_tmp);
+ end = clock();
+ lite_to_2 += (end - begin);
+
+ begin = clock();
+ image_preprocess.imageRotate(
+ lite_dst, tv_out_ratote, (ImageFormat)dstFormat, srcw, srch, 90);
+ end = clock();
+ lite_to_3 += (end - begin);
+
+ begin = clock();
+ image_preprocess.imageFlip(
+ lite_dst, tv_out_flip, (ImageFormat)dstFormat, srcw, srch, flip);
+ end = clock();
+ lite_to_4 += (end - begin);
+
+ clock_t over = clock();
+ lite_to += (over - start);
+
+ begin = clock();
+ image_preprocess.image2Tensor(lite_dst,
+ &dst_tensor,
+ (ImageFormat)dstFormat,
+ srcw,
+ srch,
+ layout,
+ means,
+ scales);
+ end = clock();
+ lite_to_5 += (end - begin);
+ }
+ to_1 = 1000 * to_1 / CLOCKS_PER_SEC;
+ to_2 = 1000 * to_2 / CLOCKS_PER_SEC;
+ to_3 = 1000 * to_3 / CLOCKS_PER_SEC;
+ to_4 = 1000 * to_4 / CLOCKS_PER_SEC;
+ to1 = 1000 * to1 / CLOCKS_PER_SEC;
+ std::cout << "opencv convert run time: " << to_1
+ << "ms, avg: " << to_1 / test_iter << std::endl;
+ std::cout << "opencv resize run time: " << to_2
+ << "ms, avg: " << to_2 / test_iter << std::endl;
+ std::cout << "opencv rotate run time: " << to_3
+ << "ms, avg: " << to_3 / test_iter << std::endl;
+ std::cout << "opencv flip time: " << to_4
+ << "ms, avg: " << to_4 / test_iter << std::endl;
+ std::cout << "opencv total run time: " << to1
+ << "ms, avg: " << to1 / test_iter << std::endl;
+ std::cout << "------" << std::endl;
+
+ lite_to_1 = 1000 * lite_to_1 / CLOCKS_PER_SEC;
+ lite_to_2 = 1000 * lite_to_2 / CLOCKS_PER_SEC;
+ lite_to_3 = 1000 * lite_to_3 / CLOCKS_PER_SEC;
+ lite_to_4 = 1000 * lite_to_4 / CLOCKS_PER_SEC;
+ lite_to_5 = 1000 * lite_to_5 / CLOCKS_PER_SEC;
+ lite_to = 1000 * lite_to / CLOCKS_PER_SEC;
+ std::cout << "lite convert run time: " << lite_to_1
+ << "ms, avg: " << lite_to_1 / test_iter << std::endl;
+ std::cout << "lite resize run time: " << lite_to_2
+ << "ms, avg: " << lite_to_2 / test_iter << std::endl;
+ std::cout << "lite rotate run time: " << lite_to_3
+ << "ms, avg: " << lite_to_3 / test_iter << std::endl;
+ std::cout << "lite flip time: " << lite_to_4
+ << "ms, avg: " << lite_to_4 / test_iter << std::endl;
+ std::cout << "lite total run time: " << lite_to
+ << "ms, avg: " << lite_to / test_iter << std::endl;
+ std::cout << "lite img2tensor time: " << lite_to_5
+ << "ms, avg: " << lite_to_5 / test_iter << std::endl;
+ std::cout << "------" << std::endl;
+
+ double max_ratio = 0;
+ double max_diff = 0;
+ const double eps = 1e-6f;
+ // save_img
+ std::cout << "write image: " << std::endl;
+ std::string resize_name = dst_path + "/resize.jpg";
+ std::string convert_name = dst_path + "/convert.jpg";
+ std::string rotate_name = dst_path + "/rotate.jpg";
+ std::string flip_name = dst_path + "/flip.jpg";
+ cv::Mat resize_mat(dsth, dstw, CV_8UC3);
+ cv::Mat convert_mat(srch, srcw, CV_8UC3);
+ cv::Mat rotate_mat;
+ if (rotate == 90 || rotate == 270) {
+ rotate_mat = cv::Mat(srcw, srch, CV_8UC3);
+ } else {
+ rotate_mat = cv::Mat(srch, srcw, CV_8UC3);
+ }
+ cv::Mat flip_mat(srch, srcw, CV_8UC3);
+ fill_with_mat(resize_mat, resize_tmp);
+ fill_with_mat(convert_mat, lite_dst);
+ fill_with_mat(rotate_mat, tv_out_ratote);
+ fill_with_mat(flip_mat, tv_out_flip);
+ cv::imwrite(convert_name, convert_mat);
+ cv::imwrite(resize_name, resize_mat);
+ cv::imwrite(rotate_name, rotate_mat);
+ cv::imwrite(flip_name, flip_mat);
+ delete[] lite_dst;
+ delete[] resize_tmp;
+ delete[] tv_out_ratote;
+ delete[] tv_out_flip;
+ }
+ }
+}
+
+int main(int argc, char** argv) {
+ if (argc < 7) {
+ std::cerr << "[ERROR] usage: " << argv[0]
+ << " image_path dst_apth srcFormat dstFormat width height\n";
+ exit(1);
+ }
+ std::string image_path = argv[1];
+ std::string dst_path = argv[2];
+ int srcFormat = atoi(argv[3]);
+ int dstFormat = atoi(argv[4]);
+ int width = atoi(argv[5]);
+ int height = atoi(argv[6]);
+ int flip = -1;
+ float rotate = 90;
+ int layout = 1;
+ std::string model_dir = "mobilenet_v1";
+ if (argc > 7) {
+ model_dir = argv[7];
+ }
+ if (argc > 8) {
+ flip = atoi(argv[8]);
+ }
+ if (argc > 9) {
+ rotate = atoi(argv[9]);
+ }
+ if (argc > 10) {
+ layout = atoi(argv[10]);
+ }
+ test_img({3},
+ {1, 2, 4},
+ image_path,
+ dst_path,
+ (ImageFormat)srcFormat,
+ (ImageFormat)dstFormat,
+ width,
+ height,
+ rotate,
+ (FlipParam)flip,
+ (LayoutType)layout,
+ model_dir,
+ 20);
+ return 0;
+}
diff --git a/lite/demo/cxx/test_cv/test_model_cv.cc b/lite/demo/cxx/test_cv/test_model_cv.cc
new file mode 100644
index 0000000000000000000000000000000000000000..24f408bf4a55ea2d499e39902201597c0e8c6e4e
--- /dev/null
+++ b/lite/demo/cxx/test_cv/test_model_cv.cc
@@ -0,0 +1,224 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "paddle_api.h" // NOLINT
+#include "paddle_image_preprocess.h" // NOLINT
+#include "time.h" // NOLINT
+
+using namespace paddle::lite_api; // NOLINT
+
+int64_t ShapeProduction(const shape_t& shape) {
+ int64_t res = 1;
+ for (auto i : shape) res *= i;
+ return res;
+}
+// fill tensor with mean and scale and trans layout: nhwc -> nchw, neon speed up
+void neon_mean_scale(
+ const float* din, float* dout, int size, float* mean, float* scale) {
+ float32x4_t vmean0 = vdupq_n_f32(mean[0]);
+ float32x4_t vmean1 = vdupq_n_f32(mean[1]);
+ float32x4_t vmean2 = vdupq_n_f32(mean[2]);
+ float32x4_t vscale0 = vdupq_n_f32(1.f / scale[0]);
+ float32x4_t vscale1 = vdupq_n_f32(1.f / scale[1]);
+ float32x4_t vscale2 = vdupq_n_f32(1.f / scale[2]);
+
+ float* dout_c0 = dout;
+ float* dout_c1 = dout + size;
+ float* dout_c2 = dout + size * 2;
+
+ int i = 0;
+ for (; i < size - 3; i += 4) {
+ float32x4x3_t vin3 = vld3q_f32(din);
+ float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0);
+ float32x4_t vsub1 = vsubq_f32(vin3.val[1], vmean1);
+ float32x4_t vsub2 = vsubq_f32(vin3.val[2], vmean2);
+ float32x4_t vs0 = vmulq_f32(vsub0, vscale0);
+ float32x4_t vs1 = vmulq_f32(vsub1, vscale1);
+ float32x4_t vs2 = vmulq_f32(vsub2, vscale2);
+ vst1q_f32(dout_c0, vs0);
+ vst1q_f32(dout_c1, vs1);
+ vst1q_f32(dout_c2, vs2);
+
+ din += 12;
+ dout_c0 += 4;
+ dout_c1 += 4;
+ dout_c2 += 4;
+ }
+ for (; i < size; i++) {
+ *(dout_c0++) = (*(din++) - mean[0]) * scale[0];
+ *(dout_c0++) = (*(din++) - mean[1]) * scale[1];
+ *(dout_c0++) = (*(din++) - mean[2]) * scale[2];
+ }
+}
+void pre_process(const cv::Mat& img, int width, int height, Tensor dstTensor) {
+#ifdef LITE_WITH_CV
+ typedef paddle::lite::utils::cv::ImageFormat ImageFormat;
+ typedef paddle::lite::utils::cv::FlipParam FlipParam;
+ typedef paddle::lite::utils::cv::TransParam TransParam;
+ typedef paddle::lite::utils::cv::ImagePreprocess ImagePreprocess;
+ typedef paddle::lite_api::DataLayoutType LayoutType;
+ // init TransParam
+ TransParam tp;
+ tp.iw = img.cols;
+ tp.ih = img.rows;
+ tp.ow = width;
+ tp.oh = height;
+ ImageFormat srcFormat = ImageFormat::BGR;
+ ImageFormat dstFormat = ImageFormat::RGB;
+ // init ImagePreprocess
+ ImagePreprocess img_process(srcFormat, dstFormat, tp);
+ // init temp var
+ const uint8_t* img_ptr = reinterpret_cast(img.data);
+ uint8_t* rgb_ptr = new uint8_t[img.cols * img.rows * 3];
+ uint8_t* resize_ptr = new uint8_t[width * height * 3];
+ // do convert bgr--rgb
+ img_process.imageConvert(img_ptr, rgb_ptr);
+ // do resize
+ img_process.imageResize(rgb_ptr, resize_ptr);
+ // data--tensor and normalize
+ float means[3] = {103.94f, 116.78f, 123.68f};
+ float scales[3] = {0.017f, 0.017f, 0.017f};
+ img_process.image2Tensor(
+ resize_ptr, &dstTensor, LayoutType::kNCHW, means, scales);
+ float* data = dstTensor.mutable_data();
+#else
+ cv::Mat rgb_img;
+ cv::cvtColor(img, rgb_img, cv::COLOR_BGR2RGB);
+ cv::resize(rgb_img, rgb_img, cv::Size(width, height), 0.f, 0.f);
+ cv::Mat imgf;
+ rgb_img.convertTo(imgf, CV_32FC3, 1 / 255.f);
+ float means[3] = {0.485f, 0.456f, 0.406f};
+ float scales[3] = {0.229f, 0.224f, 0.225f};
+ const float* dimg = reinterpret_cast(imgf.data);
+ float* data = dstTensor.mutable_data();
+ neon_mean_scale(dimg, data, width * height, means, scales);
+#endif
+}
+
+void RunModel(std::string model_dir,
+ std::string img_path,
+ std::vector input_shape,
+ PowerMode power_mode,
+ int thread_num,
+ int test_iter,
+ int warmup = 0) {
+ // 1. Set MobileConfig
+ MobileConfig config;
+ config.set_model_dir(model_dir);
+ config.set_power_mode(power_mode);
+ config.set_threads(thread_num);
+
+ // 2. Create PaddlePredictor by MobileConfig
+ std::shared_ptr predictor =
+ CreatePaddlePredictor(config);
+ // 3. Prepare input data from image
+ std::unique_ptr input_tensor(std::move(predictor->GetInput(0)));
+ input_tensor->Resize(
+ {input_shape[0], input_shape[1], input_shape[2], input_shape[3]});
+ auto* data = input_tensor->mutable_data();
+ // read img and pre-process
+ cv::Mat img = imread(img_path, cv::IMREAD_COLOR);
+
+ pre_process(img, input_shape[3], input_shape[2], *input_tensor);
+
+ // 4. Run predictor
+ for (int i = 0; i < warmup; ++i) {
+ predictor->Run();
+ }
+ double lps = 0.f;
+ double min_time = 1000000.f;
+ double max_time = 0.f;
+ for (int i = 0; i < test_iter; ++i) {
+ clock_t begin = clock();
+ predictor->Run();
+ clock_t end = clock();
+ double t = (end - begin) * 1000;
+ t = t / CLOCKS_PER_SEC;
+ lps += t;
+ if (t < min_time) {
+ min_time = t;
+ }
+ if (t > max_time) {
+ max_time = t;
+ }
+ std::cout << "iter: " << i << ", time: " << t << " ms" << std::endl;
+ }
+ std::cout << "================== Speed Report ==================="
+ << std::endl;
+ std::cout << "Model: " << model_dir
+ << ", power_mode: " << static_cast(power_mode)
+ << ", threads num " << thread_num << ", warmup: " << warmup
+ << ", repeats: " << test_iter << ", avg time: " << lps / test_iter
+ << " ms"
+ << ", min time: " << min_time << " ms"
+ << ", max time: " << max_time << " ms." << std::endl;
+
+ // 5. Get output and post process
+ std::unique_ptr output_tensor(
+ std::move(predictor->GetOutput(0)));
+ auto* outptr = output_tensor->data();
+ auto shape_out = output_tensor->shape();
+ int output_num = 1;
+ for (int i = 0; i < shape_out.size(); ++i) {
+ output_num *= shape_out[i];
+ }
+ std::cout << "output_num: " << output_num << std::endl;
+ for (int i = 0; i < output_num; i += 100) {
+ std::cout << "i: " << i << ", out: " << outptr[i] << std::endl;
+ }
+}
+
+int main(int argc, char** argv) {
+ if (argc < 7) {
+ std::cerr << "[ERROR] usage: " << argv[0]
+ << " model_dir image_path input_shape\n";
+ exit(1);
+ }
+ std::string model_dir = argv[1];
+ std::string img_path = argv[2];
+ std::vector input_shape;
+ input_shape.push_back(atoi(argv[3]));
+ input_shape.push_back(atoi(argv[4]));
+ input_shape.push_back(atoi(argv[5]));
+ input_shape.push_back(atoi(argv[6]));
+ int power_mode = 3;
+ int threads = 1;
+ int test_iter = 100;
+ int warmup = 10;
+ if (argc > 7) {
+ power_mode = atoi(argv[7]);
+ }
+ if (argc > 8) {
+ threads = atoi(argv[8]);
+ }
+ if (argc > 9) {
+ test_iter = atoi(argv[9]);
+ }
+ if (argc > 10) {
+ warmup = atoi(argv[10]);
+ }
+ RunModel(model_dir,
+ img_path,
+ input_shape,
+ (PowerMode)power_mode,
+ threads,
+ test_iter,
+ warmup);
+ return 0;
+}
diff --git a/lite/demo/cxx/yolov3_detection/yolov3_detection.cc b/lite/demo/cxx/yolov3_detection/yolov3_detection.cc
new file mode 100644
index 0000000000000000000000000000000000000000..a9beb1ed28de1f3c28eb5c03b3b660d518ee10c5
--- /dev/null
+++ b/lite/demo/cxx/yolov3_detection/yolov3_detection.cc
@@ -0,0 +1,238 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include "opencv2/core.hpp"
+#include "opencv2/imgcodecs.hpp"
+#include "opencv2/imgproc.hpp"
+#include "paddle_api.h" // NOLINT
+
+using namespace paddle::lite_api; // NOLINT
+
+struct Object {
+ cv::Rect rec;
+ int class_id;
+ float prob;
+};
+
+int64_t ShapeProduction(const shape_t& shape) {
+ int64_t res = 1;
+ for (auto i : shape) res *= i;
+ return res;
+}
+
+const char* class_names[] = {"person", "bicycle", "car",
+ "motorcycle", "airplane", "bus",
+ "train", "truck", "boat",
+ "traffic light", "fire hydrant", "stop sign",
+ "parking meter", "bench", "bird",
+ "cat", "dog", "horse",
+ "sheep", "cow", "elephant",
+ "bear", "zebra", "giraffe",
+ "backpack", "umbrella", "handbag",
+ "tie", "suitcase", "frisbee",
+ "skis", "snowboard", "sports ball",
+ "kite", "baseball bat", "baseball glove",
+ "skateboard", "surfboard", "tennis racket",
+ "bottle", "wine glass", "cup",
+ "fork", "knife", "spoon",
+ "bowl", "banana", "apple",
+ "sandwich", "orange", "broccoli",
+ "carrot", "hot dog", "pizza",
+ "donut", "cake", "chair",
+ "couch", "potted plant", "bed",
+ "dining table", "toilet", "tv",
+ "laptop", "mouse", "remote",
+ "keyboard", "cell phone", "microwave",
+ "oven", "toaster", "sink",
+ "refrigerator", "book", "clock",
+ "vase", "scissors", "teddy bear",
+ "hair drier", "toothbrush"};
+
+// fill tensor with mean and scale and trans layout: nhwc -> nchw, neon speed up
+void neon_mean_scale(const float* din,
+ float* dout,
+ int size,
+ const std::vector mean,
+ const std::vector scale) {
+ if (mean.size() != 3 || scale.size() != 3) {
+ std::cerr << "[ERROR] mean or scale size must equal to 3\n";
+ exit(1);
+ }
+ float32x4_t vmean0 = vdupq_n_f32(mean[0]);
+ float32x4_t vmean1 = vdupq_n_f32(mean[1]);
+ float32x4_t vmean2 = vdupq_n_f32(mean[2]);
+ float32x4_t vscale0 = vdupq_n_f32(1.f / scale[0]);
+ float32x4_t vscale1 = vdupq_n_f32(1.f / scale[1]);
+ float32x4_t vscale2 = vdupq_n_f32(1.f / scale[2]);
+
+ float* dout_c0 = dout;
+ float* dout_c1 = dout + size;
+ float* dout_c2 = dout + size * 2;
+
+ int i = 0;
+ for (; i < size - 3; i += 4) {
+ float32x4x3_t vin3 = vld3q_f32(din);
+ float32x4_t vsub0 = vsubq_f32(vin3.val[0], vmean0);
+ float32x4_t vsub1 = vsubq_f32(vin3.val[1], vmean1);
+ float32x4_t vsub2 = vsubq_f32(vin3.val[2], vmean2);
+ float32x4_t vs0 = vmulq_f32(vsub0, vscale0);
+ float32x4_t vs1 = vmulq_f32(vsub1, vscale1);
+ float32x4_t vs2 = vmulq_f32(vsub2, vscale2);
+ vst1q_f32(dout_c0, vs0);
+ vst1q_f32(dout_c1, vs1);
+ vst1q_f32(dout_c2, vs2);
+
+ din += 12;
+ dout_c0 += 4;
+ dout_c1 += 4;
+ dout_c2 += 4;
+ }
+ for (; i < size; i++) {
+ *(dout_c0++) = (*(din++) - mean[0]) * scale[0];
+ *(dout_c0++) = (*(din++) - mean[1]) * scale[1];
+ *(dout_c0++) = (*(din++) - mean[2]) * scale[2];
+ }
+}
+
+void pre_process(const cv::Mat& img, int width, int height, float* data) {
+ cv::Mat rgb_img;
+ cv::cvtColor(img, rgb_img, cv::COLOR_BGR2RGB);
+ cv::resize(
+ rgb_img, rgb_img, cv::Size(width, height), 0.f, 0.f, cv::INTER_CUBIC);
+ cv::Mat imgf;
+ rgb_img.convertTo(imgf, CV_32FC3, 1 / 255.f);
+ std::vector mean = {0.485f, 0.456f, 0.406f};
+ std::vector 
