diff --git a/cmake/external/flatbuffers.cmake b/cmake/external/flatbuffers.cmake
index 47b3042234cfa482ca7187baf8e51275ea8d3ac8..d679eb19f7061720aa9b4b3340fca620bf75861f 100644
--- a/cmake/external/flatbuffers.cmake
+++ b/cmake/external/flatbuffers.cmake
@@ -45,7 +45,7 @@ SET(OPTIONAL_ARGS "-DCMAKE_CXX_COMPILER=${HOST_CXX_COMPILER}"
ExternalProject_Add(
extern_flatbuffers
${EXTERNAL_PROJECT_LOG_ARGS}
- GIT_REPOSITORY "https://github.com/google/flatbuffers.git"
+ GIT_REPOSITORY "https://github.com/Shixiaowei02/flatbuffers.git"
GIT_TAG "v1.12.0"
SOURCE_DIR ${FLATBUFFERS_SOURCES_DIR}
PREFIX ${FLATBUFFERS_PREFIX_DIR}
diff --git a/docs/index.rst b/docs/index.rst
index 88170c3f6ee177b55631b008c888cb88eda866d3..adc52db898ce48818db3352cdecc8bc1ae6ed6bb 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -46,6 +46,7 @@ Welcome to Paddle-Lite's documentation!
user_guides/post_quant_with_data
user_guides/post_quant_no_data
user_guides/model_quantization
+ user_guides/model_visualization
user_guides/debug
.. toctree::
diff --git a/docs/user_guides/model_visualization.md b/docs/user_guides/model_visualization.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d7d9fe1c0f509b66f1e8856b59bec987e9898c8
--- /dev/null
+++ b/docs/user_guides/model_visualization.md
@@ -0,0 +1,214 @@
+# 模型可视化方法
+
+Paddle Lite框架中主要使用到的模型结构有2种:(1) 为[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)深度学习框架产出的模型格式; (2) 使用[Lite模型优化工具opt](model_optimize_tool)优化后的模型格式。因此本章节包含内容如下:
+
+1. [Paddle推理模型可视化](model_visualization.html#paddle)
+2. [Lite优化模型可视化](model_visualization.html#lite)
+3. [Lite子图方式下模型可视化](model_visualization.html#id2)
+
+## Paddle推理模式可视化
+
+Paddle用于推理的模型是通过[save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/save_inference_model_cn.html#save-inference-model)这个API保存下来的,存储格式有两种,由save_inference_model接口中的 `model_filename` 和 `params_filename` 变量控制:
+
+- **non-combined形式**:参数保存到独立的文件,如设置 `model_filename` 为 `None` , `params_filename` 为 `None`
+
+ ```bash
+ $ ls -l recognize_digits_model_non-combined/
+ total 192K
+ -rw-r--r-- 1 root root 28K Sep 24 09:39 __model__ # 模型文件
+ -rw-r--r-- 1 root root 104 Sep 24 09:39 conv2d_0.b_0 # 独立权重文件
+ -rw-r--r-- 1 root root 2.0K Sep 24 09:39 conv2d_0.w_0 # 独立权重文件
+ -rw-r--r-- 1 root root 224 Sep 24 09:39 conv2d_1.b_0 # ...
+ -rw-r--r-- 1 root root 98K Sep 24 09:39 conv2d_1.w_0
+ -rw-r--r-- 1 root root 64 Sep 24 09:39 fc_0.b_0
+ -rw-r--r-- 1 root root 32K Sep 24 09:39 fc_0.w_0
+ ```
+
+- **combined形式**:参数保存到同一个文件,如设置 `model_filename` 为 `model` , `params_filename` 为 `params`
+
+ ```bash
+ $ ls -l recognize_digits_model_combined/
+ total 160K
+ -rw-r--r-- 1 root root 28K Sep 24 09:42 model # 模型文件
+ -rw-r--r-- 1 root root 132K Sep 24 09:42 params # 权重文件
+ ```
+
+通过以上方式保存下来的模型文件都可以通过[Netron](https://lutzroeder.github.io/netron/)工具来打开查看模型的网络结构。
+
+**注意:**[Netron](https://github.com/lutzroeder/netron)当前要求PaddlePaddle的保存模型文件名必须为`__model__`,否则无法识别。如果是通过第二种方式保存下来的combined形式的模型文件,需要将文件重命名为`__model__`。
+
+
+
+## Lite优化模型可视化
+
+Paddle Lite在执行模型推理之前需要使用[模型优化工具opt](model_optimize_tool)来对模型进行优化,优化后的模型结构同样可以使用[Netron](https://lutzroeder.github.io/netron/)工具进行查看,但是必须保存为`protobuf`格式,而不是`naive_buffer`格式。
+
+**注意**: 为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型(该模型格式是以`.nb`为后缀的单个文件)。但是Naive Buffer格式的模型为序列化模型,不支持可视化。
+
+这里以[paddle_lite_opt](opt/opt_python)工具为例:
+
+- 当模型输入为`non-combined`格式的Paddle模型时,需要通过`--model_dir`来指定模型文件夹
+
+ ```bash
+ $ paddle_lite_opt \
+ --model_dir=./recognize_digits_model_non-combined/ \
+ --valid_targets=arm \
+ --optimize_out_type=protobuf \ # 注意:这里必须输出为protobuf格式
+ --optimize_out=model_opt_dir_non-combined
+ ```
+
+ 优化后的模型文件会存储在由`--optimize_out`指定的输出文件夹下,格式如下
+
+ ```bash
+ $ ls -l model_opt_dir_non-combined/
+ total 152K
+ -rw-r--r-- 1 root root 17K Sep 24 09:51 model # 优化后的模型文件
+ -rw-r--r-- 1 root root 132K Sep 24 09:51 params # 优化后的权重文件
+ ```
+
+- 当模式输入为`combined`格式的Paddle模型时,需要同时输入`--model_file`和`--param_file`来分别指定Paddle模型的模型文件和权重文件
+
+ ```bash
+ $ paddle_lite_opt \
+ --model_file=./recognize_digits_model_combined/model \
+ --param_file=./recognize_digits_model_combined/params \
+ --valid_targets=arm \
+ --optimize_out_type=protobuf \ # 注意:这里必须输出为protobuf格式
+ --optimize_out=model_opt_dir_combined
+ ```
+ 优化后的模型文件同样存储在由`--optimize_out`指定的输出文件夹下,格式相同
+
+ ```bash
+ ls -l model_opt_dir_combined/
+ total 152K
+ -rw-r--r-- 1 root root 17K Sep 24 09:56 model # 优化后的模型文件
+ -rw-r--r-- 1 root root 132K Sep 24 09:56 params # 优化后的权重文件
+ ```
+
+
+将通过以上步骤输出的优化后的模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开即可查看优化后的模型结构。将优化前后的模型进行对比,即可发现优化后的模型比优化前的模型更轻量级,在推理任务中耗费资源更少且执行速度也更快。
+
+
+
+
+## Lite子图方式下模型可视化
+
+当模型优化的目标硬件平台为 [华为NPU](../demo_guides/huawei_kirin_npu), [百度XPU](../demo_guides/baidu_xpu), [瑞芯微NPU](../demo_guides/rockchip_npu), [联发科APU](../demo_guides/mediatek_apu) 等通过子图方式接入的硬件平台时,得到的优化后的`protobuf`格式模型中运行在这些硬件平台上的算子都由`subgraph`算子包含,无法查看具体的网络结构。
+
+以[华为NPU](../demo_guides/huawei_kirin_npu)为例,运行以下命令进行模型优化,得到输出文件夹下的`model, params`两个文件。
+
+```bash
+$ paddle_lite_opt \
+ --model_dir=./recognize_digits_model_non-combined/ \
+ --valid_targets=npu,arm \ # 注意:这里的目标硬件平台为NPU,ARM
+ --optimize_out_type=protobuf \
+ --optimize_out=model_opt_dir_npu
+```
+
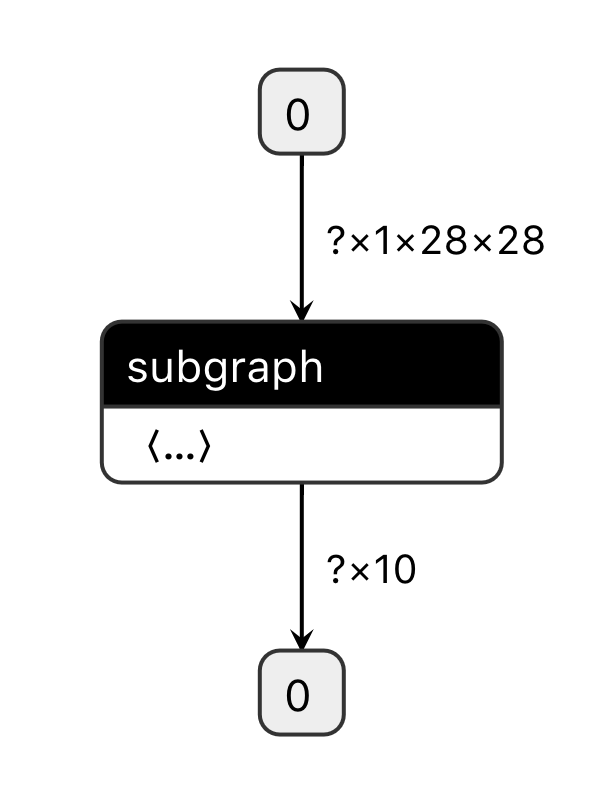
+将优化后的模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开,只看到单个的subgraph算子,如下图所示:
+
+
+
+如果想要查看subgraph中的具体模型结构和算子信息需要打开Lite Debug Log,Lite在优化过程中会以.dot文本形式输出模型的拓扑结构,将.dot的文本内容复制到[webgraphviz](http://www.webgraphviz.com/)即可查看模型结构。
+
+```bash
+$ export GLOG_v=5 # 注意:这里打开Lite中Level为5及以下的的Debug Log信息
+$ paddle_lite_opt \
+ --model_dir=./recognize_digits_model_non-combined/ \
+ --valid_targets=npu,arm \
+ --optimize_out_type=protobuf \
+ --optimize_out=model_opt_dir_npu > debug_log.txt 2>&1
+# 以上命令会将所有的debug log存储在debug_log.txt文件中
+```
+
+打开debug_log.txt文件,将会看到多个由以下格式构成的拓扑图定义,由于recognize_digits模型在优化后仅存在一个subgraph,所以在文本搜索`subgraphs`的关键词,即可得到子图拓扑如下:
+
+```shell
+I0924 10:50:12.715279 122828 optimizer.h:202] == Running pass: npu_subgraph_pass
+I0924 10:50:12.715335 122828 ssa_graph.cc:27] node count 33
+I0924 10:50:12.715412 122828 ssa_graph.cc:27] node count 33
+I0924 10:50:12.715438 122828 ssa_graph.cc:27] node count 33
+subgraphs: 1 # 注意:搜索subgraphs:这个关键词,
+digraph G {
+ node_30[label="fetch"]
+ node_29[label="fetch0" shape="box" style="filled" color="black" fillcolor="white"]
+ node_28[label="save_infer_model/scale_0.tmp_0"]
+ node_26[label="fc_0.tmp_1"]
+ node_24[label="fc_0.w_0"]
+ node_23[label="fc0_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
+ ...
+ node_15[label="batch_norm_0.tmp_1"]
+ node_17[label="conv2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
+ node_19[label="conv2d_1.b_0"]
+ node_1->node_0
+ node_0->node_2
+ node_2->node_3
+ ...
+ node_28->node_29
+ node_29->node_30
+} // end G
+I0924 10:50:12.715745 122828 op_lite.h:62] valid places 0
+I0924 10:50:12.715764 122828 op_registry.cc:32] creating subgraph kernel for host/float/NCHW
+I0924 10:50:12.715770 122828 op_lite.cc:89] pick kernel for subgraph host/float/NCHW get 0 kernels
+```
+
+将以上文本中以`digraph G {`开头和以`} // end G`结尾的这段文本复制粘贴到[webgraphviz](http://www.webgraphviz.com/),即可看到子图中的具体模型结构,如下图。其中高亮的方形节点为算子,椭圆形节点为变量或张量。
+
+
+
+
+
+若模型中存在多个子图,以上方法同样可以得到所有子图的具体模型结构。
+
+同样以[华为NPU](../demo_guides/huawei_kirin_npu)和ARM平台混合调度为例,子图的产生往往是由于模型中存在部分算子无法运行在NPU平台上(比如NPU不支持的算子),这会�导致整个模型被切分为多个子图,子图中包含的算子会运行在NPU平台上,而子图与子图之间的一个或多个算子则只能运行在ARM平台上。这里可以通过[华为NPU](../demo_guides/huawei_kirin_npu)的[自定义子图分割](../demo_guides/huawei_kirin_npu.html#npuarm-cpu)功能,将recognize_digits模型中的`batch_norm`设置为禁用NPU的算子,从而将模型分割为具有两个子图的模型:
+
+```bash
+# 此txt配置文件文件中的内容为 batch_norm
+$ export SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE=./subgraph_custom_partition_config_file.txt
+$ export GLOG_v=5 # 继续打开Lite的Debug Log信息
+$ paddle_lite_opt \
+ --model_dir=./recognize_digits_model_non-combined/ \
+ --valid_targets=npu,arm \
+ --optimize_out_type=protobuf \
+ --optimize_out=model_opt_dir_npu > debug_log.txt 2>&1 #
+```
+
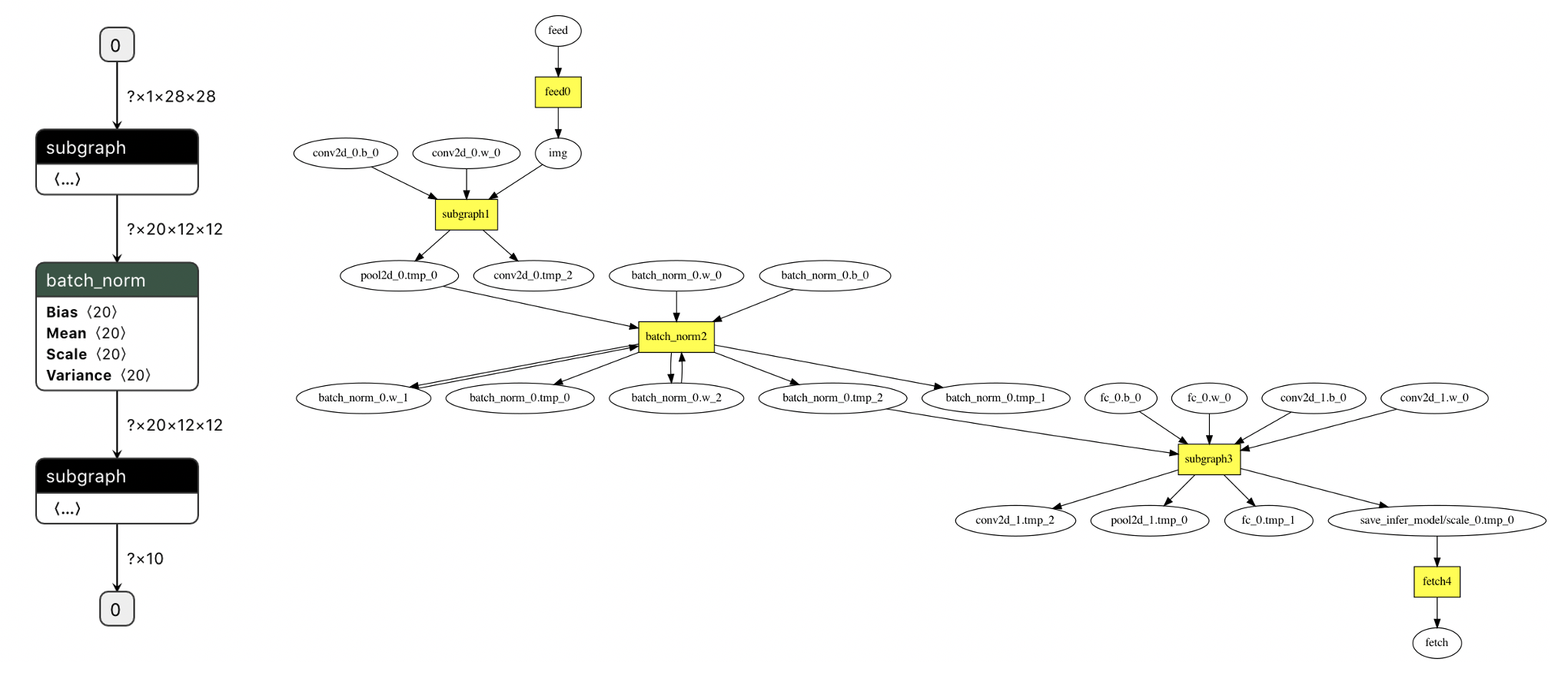
+将执行以上命令之后,得到的优化后模型文件`model`重命名为`__model__`,然后用[Netron](https://lutzroeder.github.io/netron/)工具打开,就可以看到优化后的模型中存在2个subgraph算子,如左图所示,两个子图中间即为通过环境变量和配置文件指定的禁用NPU的`batch_norm`算子。
+
+打开新保存的debug_log.txt文件,搜索`final program`关键字,拷贝在这之后的以`digraph G {`开头和以`} // end G`结尾的文本用[webgraphviz](http://www.webgraphviz.com/)查看,也是同样的模型拓扑结构,存在`subgraph1`和`subgraph3`两个子图,两个子图中间同样是被禁用NPU的`batch_norm`算子,如右图所示。
+
+
+
+之后继续在debug_log.txt文件中,搜索`subgraphs`关键字,可以得到所有子图的.dot格式内容如下:
+
+```bash
+digraph G {
+ node_30[label="fetch"]
+ node_29[label="fetch0" shape="box" style="filled" color="black" fillcolor="white"]
+ node_28[label="save_infer_model/scale_0.tmp_0"]
+ node_26[label="fc_0.tmp_1"]
+ node_24[label="fc_0.w_0"]
+ ...
+ node_17[label="conv2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
+ node_19[label="conv2d_1.b_0"]
+ node_0[label="feed0" shape="box" style="filled" color="black" fillcolor="white"]
+ node_5[label="conv2d_0.b_0"]
+ node_1[label="feed"]
+ node_23[label="fc0_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
+ node_7[label="pool2d0_subgraph_1" shape="box" style="filled" color="black" fillcolor="green"]
+ node_21[label="pool2d1_subgraph_0" shape="box" style="filled" color="black" fillcolor="red"]
+ ...
+ node_18[label="conv2d_1.w_0"]
+ node_1->node_0
+ node_0->node_2
+ ...
+ node_28->node_29
+ node_29->node_30
+} // end G
+```
+
+将以上文本复制到[webgraphviz](http://www.webgraphviz.com/)查看,即可显示两个子图分别在整个模型中的结构,如下图所示。可以看到图中绿色高亮的方形节点的为`subgraph1`中的算子,红色高亮的方形节点为`subgraph2`中的算子,两个子图中间白色不高亮的方形节点即为被禁用NPU的`batch_norm`算子。
+
+
+
+**注意:** 本章节用到的recognize_digits模型代码位于[PaddlePaddle/book](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits)
diff --git a/lite/CMakeLists.txt b/lite/CMakeLists.txt
index d69f6d6d9e77668c5789baff3f2f1051afe5df46..abb769261f1e756d140d7dcf64fb5730fbe7b775 100755
--- a/lite/CMakeLists.txt
+++ b/lite/CMakeLists.txt
@@ -38,34 +38,31 @@ if (LITE_WITH_LIGHT_WEIGHT_FRAMEWORK AND NOT LITE_ON_TINY_PUBLISH)
endif()
if (WITH_TESTING)
+ set(LITE_URL_FOR_UNITTESTS "http://paddle-inference-dist.bj.bcebos.com/PaddleLite/models_and_data_for_unittests")
+ # models
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "lite_naive_model.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v2_relu.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "inception_v4_simple.tar.gz")
if(LITE_WITH_LIGHT_WEIGHT_FRAMEWORK)
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1_int16.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v2_relu.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "resnet50.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "inception_v4_simple.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "MobileNetV1_quant.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "transformer_with_mask_fp32.tar.gz")
- endif()
- if(NOT LITE_WITH_LIGHT_WEIGHT_FRAMEWORK)
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "mobilenet_v1_int8_for_mediatek_apu.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "mobilenet_v1_int8_for_rockchip_npu.tar.gz")
+ else()
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "GoogleNet_inference.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v1.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "mobilenet_v2_relu.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "inception_v4_simple.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL} "step_rnn.tar.gz")
-
- set(LITE_URL_FOR_UNITTESTS "http://paddle-inference-dist.bj.bcebos.com/PaddleLite/models_and_data_for_unittests")
- # models
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "resnet50.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "bert.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "ernie.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "GoogLeNet.tar.gz")
lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "VGG19.tar.gz")
- # data
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "ILSVRC2012_small.tar.gz")
- lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "bert_data.tar.gz")
endif()
+ # data
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "ILSVRC2012_small.tar.gz")
+ lite_download_and_uncompress(${LITE_MODEL_DIR} ${LITE_URL_FOR_UNITTESTS} "bert_data.tar.gz")
endif()
# ----------------------------- PUBLISH -----------------------------
diff --git a/lite/backends/arm/math/conv3x3s1p01_depthwise_fp32_relu.cc b/lite/backends/arm/math/conv3x3s1p01_depthwise_fp32_relu.cc
index 3e02eddfdb2de33b7f75e2448c3a5809ebcb88d7..bca36f5f0baa02fa780aada094700f0a7b5ae378 100644
--- a/lite/backends/arm/math/conv3x3s1p01_depthwise_fp32_relu.cc
+++ b/lite/backends/arm/math/conv3x3s1p01_depthwise_fp32_relu.cc
@@ -2307,12 +2307,10 @@ void conv_depthwise_3x3s1p0_bias_no_relu(float *dout,
//! process bottom pad
if (i + 3 >= h_in) {
switch (i + 3 - h_in) {
- case 3:
- din_ptr1 = zero_ptr;
case 2:
- din_ptr2 = zero_ptr;
+ din_ptr1 = zero_ptr;
case 1:
- din_ptr3 = zero_ptr;
+ din_ptr2 = zero_ptr;
case 0:
din_ptr3 = zero_ptr;
default:
@@ -2591,12 +2589,10 @@ void conv_depthwise_3x3s1p0_bias_relu(float *dout,
//! process bottom pad
if (i + 3 >= h_in) {
switch (i + 3 - h_in) {
- case 3:
- din_ptr1 = zero_ptr;
case 2:
- din_ptr2 = zero_ptr;
+ din_ptr1 = zero_ptr;
case 1:
- din_ptr3 = zero_ptr;
+ din_ptr2 = zero_ptr;
case 0:
din_ptr3 = zero_ptr;
default:
@@ -2730,12 +2726,10 @@ void conv_depthwise_3x3s1p0_bias_s_no_relu(float *dout,
if (j + 3 >= h_in) {
switch (j + 3 - h_in) {
- case 3:
- dr1 = zero_ptr;
case 2:
- dr2 = zero_ptr;
+ dr1 = zero_ptr;
case 1:
- dr3 = zero_ptr;
+ dr2 = zero_ptr;
doutr1 = trash_buf;
case 0:
dr3 = zero_ptr;
@@ -2889,12 +2883,10 @@ void conv_depthwise_3x3s1p0_bias_s_relu(float *dout,
if (j + 3 >= h_in) {
switch (j + 3 - h_in) {
- case 3:
- dr1 = zero_ptr;
case 2:
- dr2 = zero_ptr;
+ dr1 = zero_ptr;
case 1:
- dr3 = zero_ptr;
+ dr2 = zero_ptr;
doutr1 = trash_buf;
case 0:
dr3 = zero_ptr;
diff --git a/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc b/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
index b4539db98c3ffb1a143c38dd3c4dd9e9924bd63e..25ee9f940481a0c92f354e819d6d2b8d45eff169 100644
--- a/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
+++ b/lite/backends/arm/math/conv3x3s1px_depthwise_fp32.cc
@@ -645,7 +645,6 @@ void conv_3x3s1_depthwise_fp32_bias(const float* i_data,
bool flag_bias = param.bias != nullptr;
/// get workspace
- LOG(INFO) << "conv_3x3s1_depthwise_fp32_bias: ";
float* ptr_zero = ctx->workspace_data();
memset(ptr_zero, 0, sizeof(float) * win_round);
float* ptr_write = ptr_zero + win_round;
diff --git a/lite/backends/arm/math/conv3x3s2p01_depthwise_fp32_relu.cc b/lite/backends/arm/math/conv3x3s2p01_depthwise_fp32_relu.cc
index 61f446137144b20b51df31c872fe708ddac68e33..7a3e6e9348da12a0f362cbbe6c652ed70ee94fea 100644
--- a/lite/backends/arm/math/conv3x3s2p01_depthwise_fp32_relu.cc
+++ b/lite/backends/arm/math/conv3x3s2p01_depthwise_fp32_relu.cc
@@ -713,7 +713,7 @@ void conv_depthwise_3x3s2p1_bias_relu(float* dout,
cnt_col++;
size_right_remain -= 8;
}
- int cnt_remain = (size_right_remain == 8) ? 4 : (w_out % 4); //
+ int cnt_remain = (size_right_remain == 8 && w_out % 4 == 0) ? 4 : (w_out % 4);
int size_right_pad = w_out * 2 - w_in;
@@ -966,7 +966,7 @@ void conv_depthwise_3x3s2p1_bias_no_relu(float* dout,
cnt_col++;
size_right_remain -= 8;
}
- int cnt_remain = (size_right_remain == 8) ? 4 : (w_out % 4); //
+ int cnt_remain = (size_right_remain == 8 && w_out % 4 == 0) ? 4 : (w_out % 4);
int size_right_pad = w_out * 2 - w_in;
diff --git a/lite/backends/arm/math/conv_impl.cc b/lite/backends/arm/math/conv_impl.cc
index fa2f85311b3ff4247d52505d750566ec80e47256..af722fd6413c22c2be7474ba38b54d3f30d0011c 100644
--- a/lite/backends/arm/math/conv_impl.cc
+++ b/lite/backends/arm/math/conv_impl.cc
@@ -620,10 +620,8 @@ void conv_depthwise_3x3_fp32(const void* din,
int pad = pad_w;
bool flag_bias = param.bias != nullptr;
bool pads_less = ((paddings[1] < 2) && (paddings[3] < 2));
- bool ch_four = ch_in <= 4 * w_in;
if (stride == 1) {
- if (ch_four && pads_less && (pad_h == pad_w) &&
- (pad < 2)) { // support pad = [0, 1]
+ if (pads_less && (pad_h == pad_w) && (pad < 2)) { // support pad = [0, 1]
conv_depthwise_3x3s1_fp32(reinterpret_cast(din),
reinterpret_cast(dout),
num,
@@ -656,8 +654,7 @@ void conv_depthwise_3x3_fp32(const void* din,
ctx);
}
} else if (stride == 2) {
- if (ch_four && pads_less && pad_h == pad_w &&
- (pad < 2)) { // support pad = [0, 1]
+ if (pads_less && pad_h == pad_w && (pad < 2)) { // support pad = [0, 1]
conv_depthwise_3x3s2_fp32(reinterpret_cast(din),
reinterpret_cast(dout),
num,
diff --git a/lite/backends/arm/math/interpolate.cc b/lite/backends/arm/math/interpolate.cc
index 4345c2e8137dbe0d0d1031cb4b41a2163d49ed57..1c53142fc53bc785efcbf28fa007d403ad99ab70 100644
--- a/lite/backends/arm/math/interpolate.cc
+++ b/lite/backends/arm/math/interpolate.cc
@@ -70,8 +70,7 @@ void bilinear_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool align_corners,
- bool align_mode) {
+ bool with_align) {
int* buf = new int[w_out + h_out + w_out * 2 + h_out * 2];
int* xofs = buf;
@@ -79,13 +78,14 @@ void bilinear_interp(const float* src,
float* alpha = reinterpret_cast(buf + w_out + h_out);
float* beta = reinterpret_cast(buf + w_out + h_out + w_out * 2);
- bool with_align = (align_mode == 0 && !align_corners);
float fx = 0.0f;
float fy = 0.0f;
int sx = 0;
int sy = 0;
- if (!with_align) {
+ if (with_align) {
+ scale_x = static_cast(w_in - 1) / (w_out - 1);
+ scale_y = static_cast(h_in - 1) / (h_out - 1);
// calculate x axis coordinate
for (int dx = 0; dx < w_out; dx++) {
fx = dx * scale_x;
@@ -105,6 +105,8 @@ void bilinear_interp(const float* src,
beta[dy * 2 + 1] = fy;
}
} else {
+ scale_x = static_cast(w_in) / w_out;
+ scale_y = static_cast(h_in) / h_out;
// calculate x axis coordinate
for (int dx = 0; dx < w_out; dx++) {
fx = scale_x * (dx + 0.5f) - 0.5f;
@@ -466,9 +468,15 @@ void nearest_interp(const float* src,
float* dst,
int w_out,
int h_out,
- float scale_w_new,
- float scale_h_new,
+ float scale_x,
+ float scale_y,
bool with_align) {
+ float scale_w_new = (with_align)
+ ? (static_cast(w_in - 1) / (w_out - 1))
+ : (static_cast(w_in) / (w_out));
+ float scale_h_new = (with_align)
+ ? (static_cast(h_in - 1) / (h_out - 1))
+ : (static_cast(h_in) / (h_out));
if (with_align) {
for (int h = 0; h < h_out; ++h) {
float* dst_p = dst + h * w_out;
@@ -498,8 +506,7 @@ void interpolate(lite::Tensor* X,
int out_height,
int out_width,
float scale,
- bool align_corners,
- bool align_mode,
+ bool with_align,
std::string interpolate_type) {
int in_h = X->dims()[2];
int in_w = X->dims()[3];
@@ -524,12 +531,12 @@ void interpolate(lite::Tensor* X,
out_width = out_size_data[1];
}
}
- // float height_scale = scale;
- // float width_scale = scale;
- // if (out_width > 0 && out_height > 0) {
- // height_scale = static_cast(out_height / X->dims()[2]);
- // width_scale = static_cast(out_width / X->dims()[3]);
- // }
+ float height_scale = scale;
+ float width_scale = scale;
+ if (out_width > 0 && out_height > 0) {
+ height_scale = static_cast(out_height / X->dims()[2]);
+ width_scale = static_cast(out_width / X->dims()[3]);
+ }
int num_cout = X->dims()[0];
int c_cout = X->dims()[1];
Out->Resize({num_cout, c_cout, out_height, out_width});
@@ -544,10 +551,6 @@ void interpolate(lite::Tensor* X,
int spatial_in = in_h * in_w;
int spatial_out = out_h * out_w;
- float scale_x = (align_corners) ? (static_cast(in_w - 1) / (out_w - 1))
- : (static_cast(in_w) / (out_w));
- float scale_y = (align_corners) ? (static_cast(in_h - 1) / (out_h - 1))
- : (static_cast(in_h) / (out_h));
if ("Bilinear" == interpolate_type) {
#pragma omp parallel for
for (int i = 0; i < count; ++i) {
@@ -557,10 +560,9 @@ void interpolate(lite::Tensor* X,
dout + spatial_out * i,
out_w,
out_h,
- scale_x,
- scale_y,
- align_corners,
- align_mode);
+ 1.f / width_scale,
+ 1.f / height_scale,
+ with_align);
}
} else if ("Nearest" == interpolate_type) {
#pragma omp parallel for
@@ -571,9 +573,9 @@ void interpolate(lite::Tensor* X,
dout + spatial_out * i,
out_w,
out_h,
- scale_x,
- scale_y,
- align_corners);
+ 1.f / width_scale,
+ 1.f / height_scale,
+ with_align);
}
}
}
diff --git a/lite/backends/arm/math/interpolate.h b/lite/backends/arm/math/interpolate.h
index 82c4c068b69567c01d37cfa901f9b58626574865..e9c41c5bc86c8f00d57e096e3cd2b5f37df3a474 100644
--- a/lite/backends/arm/math/interpolate.h
+++ b/lite/backends/arm/math/interpolate.h
@@ -30,8 +30,7 @@ void bilinear_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool align_corners,
- bool align_mode);
+ bool with_align);
void nearest_interp(const float* src,
int w_in,
@@ -41,7 +40,7 @@ void nearest_interp(const float* src,
int h_out,
float scale_x,
float scale_y,
- bool align_corners);
+ bool with_align);
void interpolate(lite::Tensor* X,
lite::Tensor* OutSize,
@@ -51,8 +50,7 @@ void interpolate(lite::Tensor* X,
int out_height,
int out_width,
float scale,
- bool align_corners,
- bool align_mode,
+ bool with_align,
std::string interpolate_type);
} /* namespace math */
diff --git a/lite/core/arena/CMakeLists.txt b/lite/core/arena/CMakeLists.txt
index 53988f063b89ae3e75f4c27cc1d937d12bb6dae5..d5adf8475364b99fec07af1959a6dd5569a6572b 100644
--- a/lite/core/arena/CMakeLists.txt
+++ b/lite/core/arena/CMakeLists.txt
@@ -6,5 +6,5 @@ endif()
lite_cc_library(arena_framework SRCS framework.cc DEPS program gtest)
if((NOT LITE_WITH_OPENCL) AND (LITE_WITH_X86 OR LITE_WITH_ARM))
- lite_cc_test(test_arena_framework SRCS framework_test.cc DEPS arena_framework ${rknpu_kernels} ${mlu_kernels} ${bm_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${xpu_kernels} ${x86_kernels} ${cuda_kernels} ${fpga_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_arena_framework SRCS framework_test.cc DEPS arena_framework ${rknpu_kernels} ${mlu_kernels} ${bm_kernels} ${npu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${xpu_kernels} ${x86_kernels} ${cuda_kernels} ${fpga_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
endif()
diff --git a/lite/core/mir/fusion/conv_conv_fuse_pass.cc b/lite/core/mir/fusion/conv_conv_fuse_pass.cc
index b2c5d8d15ab95fbcc43adc01c4189ae83b1316ed..e7f816ae4c99b3d27e9473c0937936a2f25a232b 100644
--- a/lite/core/mir/fusion/conv_conv_fuse_pass.cc
+++ b/lite/core/mir/fusion/conv_conv_fuse_pass.cc
@@ -27,7 +27,7 @@ namespace mir {
void ConvConvFusePass::Apply(const std::unique_ptr& graph) {
// initialze fuser params
std::vector conv_has_bias_cases{true, false};
- std::vector conv_type_cases{"conv2d", "depthwise_conv2d"};
+ std::vector conv_type_cases{"conv2d"};
bool has_int8 = false;
bool has_weight_quant = false;
for (auto& place : graph->valid_places()) {
diff --git a/lite/core/mir/fusion/conv_conv_fuser.cc b/lite/core/mir/fusion/conv_conv_fuser.cc
index f2e24d06fa089ea4f575116d26f333060757e789..2393ff533007460f6f3d15dce11ef73ca09e802b 100644
--- a/lite/core/mir/fusion/conv_conv_fuser.cc
+++ b/lite/core/mir/fusion/conv_conv_fuser.cc
@@ -132,8 +132,8 @@ void ConvConvFuser::BuildPattern() {
VLOG(5) << "The kernel size of the second conv must be 1x1";
continue;
}
- if (groups1 != 1) {
- VLOG(5) << "The groups of weight1_dim must be 1";
+ if (groups0 != 1 || groups1 != 1) {
+ VLOG(5) << "The all groups of weight_dim must be 1";
continue;
}
if (ch_out_0 != ch_in_1) {
diff --git a/lite/kernels/arm/conv_depthwise.cc b/lite/kernels/arm/conv_depthwise.cc
index c5b43a31a0f495f3635d389939acf44e979a3dc7..e04e774cce3af5bd6f8b67c6adfeba06fa814768 100644
--- a/lite/kernels/arm/conv_depthwise.cc
+++ b/lite/kernels/arm/conv_depthwise.cc
@@ -32,11 +32,10 @@ void DepthwiseConv::PrepareForRun() {
auto hin = param.x->dims()[2];
auto win = param.x->dims()[3];
auto paddings = *param.paddings;
- bool ch_four = channel <= 4 * win;
// select dw conv kernel
if (kw == 3) {
bool pads_less = ((paddings[1] < 2) && (paddings[3] < 2));
- if (ch_four && pads_less && paddings[0] == paddings[2] &&
+ if (pads_less && paddings[0] == paddings[2] &&
(paddings[0] == 0 || paddings[0] == 1)) {
flag_trans_weights_ = false;
} else {
diff --git a/lite/kernels/arm/interpolate_compute.cc b/lite/kernels/arm/interpolate_compute.cc
index 8593758d5af6ea7d5badc6870ea51e13a443ed99..760b2fcf0630a632d1f1bbaeda7760d2de25a7a4 100644
--- a/lite/kernels/arm/interpolate_compute.cc
+++ b/lite/kernels/arm/interpolate_compute.cc
@@ -35,7 +35,6 @@ void BilinearInterpCompute::Run() {
int out_w = param.out_w;
int out_h = param.out_h;
bool align_corners = param.align_corners;
- bool align_mode = param.align_mode;
std::string interp_method = "Bilinear";
lite::arm::math::interpolate(X,
OutSize,
@@ -46,7 +45,6 @@ void BilinearInterpCompute::Run() {
out_w,
scale,
align_corners,
- align_mode,
interp_method);
}
@@ -61,7 +59,6 @@ void NearestInterpCompute::Run() {
int out_w = param.out_w;
int out_h = param.out_h;
bool align_corners = param.align_corners;
- bool align_mode = param.align_mode;
std::string interp_method = "Nearest";
lite::arm::math::interpolate(X,
OutSize,
@@ -72,7 +69,6 @@ void NearestInterpCompute::Run() {
out_w,
scale,
align_corners,
- align_mode,
interp_method);
}
diff --git a/lite/kernels/x86/activation_compute.cc b/lite/kernels/x86/activation_compute.cc
index 9b4c2fadd9ce427db272a9bb0cfd0e0a10716f11..aee6bd6bd3f41972e759fb2b87fb1b1c549975e2 100644
--- a/lite/kernels/x86/activation_compute.cc
+++ b/lite/kernels/x86/activation_compute.cc
@@ -88,3 +88,14 @@ REGISTER_LITE_KERNEL(sigmoid,
.BindInput("X", {LiteType::GetTensorTy(TARGET(kX86))})
.BindOutput("Out", {LiteType::GetTensorTy(TARGET(kX86))})
.Finalize();
+
+// float
+REGISTER_LITE_KERNEL(relu6,
+ kX86,
+ kFloat,
+ kNCHW,
+ paddle::lite::kernels::x86::Relu6Compute,
+ def)
+ .BindInput("X", {LiteType::GetTensorTy(TARGET(kX86))})
+ .BindOutput("Out", {LiteType::GetTensorTy(TARGET(kX86))})
+ .Finalize();
diff --git a/lite/kernels/x86/activation_compute.h b/lite/kernels/x86/activation_compute.h
index 520adaf44f808748c75960f88cd07799c9f2d4ed..b76e94398e6824759372bc5eb91ed3cea8acaf6e 100644
--- a/lite/kernels/x86/activation_compute.h
+++ b/lite/kernels/x86/activation_compute.h
@@ -248,6 +248,42 @@ class SoftsignCompute : public KernelLite {
virtual ~SoftsignCompute() = default;
};
+// relu6(x) = min(max(0, x), 6)
+template
+struct Relu6Functor {
+ float threshold;
+ explicit Relu6Functor(float threshold_) : threshold(threshold_) {}
+
+ template
+ void operator()(Device d, X x, Out out) const {
+ out.device(d) =
+ x.cwiseMax(static_cast(0)).cwiseMin(static_cast(threshold));
+ }
+};
+
+template
+class Relu6Compute : public KernelLite {
+ public:
+ using param_t = operators::ActivationParam;
+
+ void Run() override {
+ auto& param = *param_.get_mutable();
+
+ param.Out->template mutable_data();
+ auto X = param.X;
+ auto Out = param.Out;
+ auto place = lite::fluid::EigenDeviceType();
+ CHECK(X);
+ CHECK(Out);
+ auto x = lite::fluid::EigenVector::Flatten(*X);
+ auto out = lite::fluid::EigenVector::Flatten(*Out);
+ Relu6Functor functor(param.threshold);
+ functor(place, x, out);
+ }
+
+ virtual ~Relu6Compute() = default;
+};
+
} // namespace x86
} // namespace kernels
} // namespace lite
diff --git a/lite/kernels/x86/reduce_compute.cc b/lite/kernels/x86/reduce_compute.cc
index f95f4cfb881fef329ea940ca8b9fa6b4fd6ff7b6..edeac0a84eb60ca1e34ab6e7437e54ffe8922815 100644
--- a/lite/kernels/x86/reduce_compute.cc
+++ b/lite/kernels/x86/reduce_compute.cc
@@ -23,3 +23,13 @@ REGISTER_LITE_KERNEL(reduce_sum,
.BindInput("X", {LiteType::GetTensorTy(TARGET(kX86))})
.BindOutput("Out", {LiteType::GetTensorTy(TARGET(kX86))})
.Finalize();
+
+REGISTER_LITE_KERNEL(reduce_mean,
+ kX86,
+ kFloat,
+ kNCHW,
+ paddle::lite::kernels::x86::ReduceMeanCompute,
+ def)
+ .BindInput("X", {LiteType::GetTensorTy(TARGET(kX86))})
+ .BindOutput("Out", {LiteType::GetTensorTy(TARGET(kX86))})
+ .Finalize();
diff --git a/lite/kernels/x86/reduce_compute.h b/lite/kernels/x86/reduce_compute.h
index 1b7c99eeef9dd80525eb9ed249bdf6ed1e493443..fb02348759014578a1cf7a17c27903ce84dfe54b 100644
--- a/lite/kernels/x86/reduce_compute.h
+++ b/lite/kernels/x86/reduce_compute.h
@@ -31,11 +31,18 @@ struct SumFunctor {
}
};
-#define HANDLE_DIM(NDIM, RDIM) \
- if (ndim == NDIM && rdim == RDIM) { \
- paddle::lite::kernels::x86:: \
- ReduceFunctor( \
- *input, output, dims, keep_dim); \
+struct MeanFunctor {
+ template
+ void operator()(X* x, Y* y, const Dim& dim) {
+ y->device(lite::fluid::EigenDeviceType()) = x->mean(dim);
+ }
+};
+
+#define HANDLE_DIM(NDIM, RDIM, FUNCTOR) \
+ if (ndim == NDIM && rdim == RDIM) { \
+ paddle::lite::kernels::x86:: \
+ ReduceFunctor( \
+ *input, output, dims, keep_dim); \
}
template
@@ -64,19 +71,58 @@ class ReduceSumCompute : public KernelLite {
} else {
int ndim = input->dims().size();
int rdim = dims.size();
- HANDLE_DIM(4, 3);
- HANDLE_DIM(4, 2);
- HANDLE_DIM(4, 1);
- HANDLE_DIM(3, 2);
- HANDLE_DIM(3, 1);
- HANDLE_DIM(2, 1);
- HANDLE_DIM(1, 1);
+ HANDLE_DIM(4, 3, SumFunctor);
+ HANDLE_DIM(4, 2, SumFunctor);
+ HANDLE_DIM(4, 1, SumFunctor);
+ HANDLE_DIM(3, 2, SumFunctor);
+ HANDLE_DIM(3, 1, SumFunctor);
+ HANDLE_DIM(2, 1, SumFunctor);
+ HANDLE_DIM(1, 1, SumFunctor);
}
}
virtual ~ReduceSumCompute() = default;
};
+template
+class ReduceMeanCompute : public KernelLite {
+ public:
+ using param_t = operators::ReduceParam;
+
+ void Run() override {
+ auto& param = *param_.get_mutable();
+ // auto& context = ctx_->As();
+ auto* input = param.x;
+ auto* output = param.output;
+ param.output->template mutable_data();
+
+ const auto& dims = param.dim;
+ bool keep_dim = param.keep_dim;
+
+ if (dims.size() == 0) {
+ // Flatten and reduce 1-D tensor
+ auto x = lite::fluid::EigenVector::Flatten(*input);
+ auto out = lite::fluid::EigenScalar::From(output);
+ // auto& place = *platform::CPUDeviceContext().eigen_device();
+ auto reduce_dim = Eigen::array({{0}});
+ MeanFunctor functor;
+ functor(&x, &out, reduce_dim);
+ } else {
+ int ndim = input->dims().size();
+ int rdim = dims.size();
+ HANDLE_DIM(4, 3, MeanFunctor);
+ HANDLE_DIM(4, 2, MeanFunctor);
+ HANDLE_DIM(4, 1, MeanFunctor);
+ HANDLE_DIM(3, 2, MeanFunctor);
+ HANDLE_DIM(3, 1, MeanFunctor);
+ HANDLE_DIM(2, 1, MeanFunctor);
+ HANDLE_DIM(1, 1, MeanFunctor);
+ }
+ }
+
+ virtual ~ReduceMeanCompute() = default;
+};
+
} // namespace x86
} // namespace kernels
} // namespace lite
diff --git a/lite/operators/activation_ops.cc b/lite/operators/activation_ops.cc
index 9b20f4348b4090abfb2138547915e44f7c3418c0..a25297f01206dd157484c720d6dd134186d2a7bd 100644
--- a/lite/operators/activation_ops.cc
+++ b/lite/operators/activation_ops.cc
@@ -89,6 +89,9 @@ bool ActivationOp::AttachImpl(const cpp::OpDesc& opdesc, lite::Scope* scope) {
} else if (opdesc.Type() == "elu") {
param_.active_type = lite_api::ActivationType::kElu;
param_.Elu_alpha = opdesc.GetAttr("alpha");
+ } else if (opdesc.Type() == "relu6") {
+ param_.active_type = lite_api::ActivationType::kRelu6;
+ param_.threshold = opdesc.GetAttr("threshold");
}
VLOG(4) << "opdesc.Type():" << opdesc.Type();
diff --git a/lite/operators/op_params.h b/lite/operators/op_params.h
index 2fccbb9593f87ceb3c841790373609c1b47178de..d1533c4cf6638afa2ffa31ce2e780354153b0d6e 100644
--- a/lite/operators/op_params.h
+++ b/lite/operators/op_params.h
@@ -403,6 +403,8 @@ struct ActivationParam : ParamBase {
float relu_threshold{1.0f};
// elu
float Elu_alpha{1.0f};
+ // relu6
+ float threshold{6.0f};
///////////////////////////////////////////////////////////////////////////////////
// get a vector of input tensors
diff --git a/lite/tests/api/CMakeLists.txt b/lite/tests/api/CMakeLists.txt
index 795b195a03e6dac8366f8b05f52984983c10676d..636d9d557400152c871bded938f26f74e282dd1e 100644
--- a/lite/tests/api/CMakeLists.txt
+++ b/lite/tests/api/CMakeLists.txt
@@ -1,52 +1,71 @@
-if(LITE_WITH_ARM)
- lite_cc_test(test_transformer_with_mask_fp32_arm SRCS test_transformer_with_mask_fp32_arm.cc
+function(lite_cc_test_with_model_and_data TARGET)
+ if(NOT WITH_TESTING)
+ return()
+ endif()
+
+ set(options "")
+ set(oneValueArgs MODEL DATA CONFIG ARGS)
+ set(multiValueArgs "")
+ cmake_parse_arguments(args "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN})
+
+ set(ARGS "")
+ if(DEFINED args_MODEL)
+ set(ARGS "${ARGS} --model_dir=${LITE_MODEL_DIR}/${args_MODEL}")
+ endif()
+ if(DEFINED args_DATA)
+ set(ARGS "${ARGS} --data_dir=${LITE_MODEL_DIR}/${args_DATA}")
+ endif()
+ if(DEFINED args_CONFIG)
+ set(ARGS "${ARGS} --config_dir=${LITE_MODEL_DIR}/${args_CONFIG}")
+ endif()
+ if(DEFINED args_ARGS)
+ set(ARGS "${ARGS} ${args_ARGS}")
+ endif()
+ lite_cc_test(${TARGET} SRCS ${TARGET}.cc
DEPS ${lite_model_test_DEPS} paddle_api_full
ARM_DEPS ${arm_kernels}
- ARGS --model_dir=${LITE_MODEL_DIR}/transformer_with_mask_fp32 SERIAL)
- if(WITH_TESTING)
- add_dependencies(test_transformer_with_mask_fp32_arm extern_lite_download_transformer_with_mask_fp32_tar_gz)
+ X86_DEPS ${x86_kernels}
+ NPU_DEPS ${npu_kernels} ${npu_bridges}
+ HUAWEI_ASCEND_NPU_DEPS ${huawei_ascend_npu_kernels} ${huawei_ascend_npu_bridges}
+ XPU_DEPS ${xpu_kernels} ${xpu_bridges}
+ APU_DEPS ${apu_kernels} ${apu_bridges}
+ RKNPU_DEPS ${rknpu_kernels} ${rknpu_bridges}
+ BM_DEPS ${bm_kernels} ${bm_bridges}
+ MLU_DEPS ${mlu_kernels} ${mlu_bridges}
+ ARGS ${ARGS} SERIAL)
+ if(DEFINED args_MODEL)
+ add_dependencies(${TARGET} extern_lite_download_${args_MODEL}_tar_gz)
endif()
-endif()
-
-function(xpu_x86_without_xtcl_test TARGET MODEL DATA)
- if(${DATA} STREQUAL "")
- lite_cc_test(${TARGET} SRCS ${TARGET}.cc
- DEPS mir_passes lite_api_test_helper paddle_api_full paddle_api_light gflags utils
- ${ops} ${host_kernels} ${x86_kernels} ${xpu_kernels}
- ARGS --model_dir=${LITE_MODEL_DIR}/${MODEL})
- else()
- lite_cc_test(${TARGET} SRCS ${TARGET}.cc
- DEPS mir_passes lite_api_test_helper paddle_api_full paddle_api_light gflags utils
- ${ops} ${host_kernels} ${x86_kernels} ${xpu_kernels}
- ARGS --model_dir=${LITE_MODEL_DIR}/${MODEL} --data_dir=${LITE_MODEL_DIR}/${DATA})
+ if(DEFINED args_DATA)
+ add_dependencies(${TARGET} extern_lite_download_${args_DATA}_tar_gz)
endif()
-
- if(WITH_TESTING)
- add_dependencies(${TARGET} extern_lite_download_${MODEL}_tar_gz)
- if(NOT ${DATA} STREQUAL "")
- add_dependencies(${TARGET} extern_lite_download_${DATA}_tar_gz)
- endif()
+ if(DEFINED args_CONFIG)
+ add_dependencies(${TARGET} extern_lite_download_${args_CONFIG}_tar_gz)
endif()
endfunction()
+if(LITE_WITH_ARM)
+ lite_cc_test_with_model_and_data(test_transformer_with_mask_fp32_arm MODEL transformer_with_mask_fp32 ARGS)
+endif()
+
+if(LITE_WITH_NPU)
+ lite_cc_test_with_model_and_data(test_mobilenetv1_fp32_huawei_kirin_npu MODEL mobilenet_v1 DATA ILSVRC2012_small)
+ lite_cc_test_with_model_and_data(test_mobilenetv2_fp32_huawei_kirin_npu MODEL mobilenet_v2_relu DATA ILSVRC2012_small)
+ lite_cc_test_with_model_and_data(test_resnet50_fp32_huawei_kirin_npu MODEL resnet50 DATA ILSVRC2012_small)
+endif()
+
if(LITE_WITH_XPU AND NOT LITE_WITH_XTCL)
- xpu_x86_without_xtcl_test(test_resnet50_fp32_xpu resnet50 ILSVRC2012_small)
- xpu_x86_without_xtcl_test(test_googlenet_fp32_xpu GoogLeNet ILSVRC2012_small)
- xpu_x86_without_xtcl_test(test_vgg19_fp32_xpu VGG19 ILSVRC2012_small)
- xpu_x86_without_xtcl_test(test_ernie_fp32_xpu ernie bert_data)
- xpu_x86_without_xtcl_test(test_bert_fp32_xpu bert bert_data)
+ lite_cc_test_with_model_and_data(test_resnet50_fp32_xpu MODEL resnet50 DATA ILSVRC2012_small)
+ lite_cc_test_with_model_and_data(test_googlenet_fp32_xpu MODEL GoogLeNet DATA ILSVRC2012_small)
+ lite_cc_test_with_model_and_data(test_vgg19_fp32_xpu MODEL VGG19 DATA ILSVRC2012_small)
+ lite_cc_test_with_model_and_data(test_ernie_fp32_xpu MODEL ernie DATA bert_data)
+ lite_cc_test_with_model_and_data(test_bert_fp32_xpu MODEL bert DATA bert_data)
endif()
if(LITE_WITH_RKNPU)
- lite_cc_test(test_mobilenetv1_int8_rknpu SRCS test_mobilenetv1_int8_rknpu.cc
- DEPS ${lite_model_test_DEPS} paddle_api_full
- RKNPU_DEPS ${rknpu_kernels} ${rknpu_bridges}
- ARGS --model_dir=${LITE_MODEL_DIR}/MobilenetV1_full_quant SERIAL)
+ lite_cc_test_with_model_and_data(test_mobilenetv1_int8_rockchip_npu MODEL mobilenet_v1_int8_for_rockchip_npu DATA ILSVRC2012_small)
endif()
if(LITE_WITH_APU)
- lite_cc_test(test_mobilenetv1_int8_apu SRCS test_mobilenetv1_int8_apu.cc
- DEPS ${lite_model_test_DEPS} paddle_api_full
- APU_DEPS ${apu_kernels} ${apu_bridges}
- ARGS --model_dir=${LITE_MODEL_DIR}/MobilenetV1_full_quant SERIAL)
+ lite_cc_test_with_model_and_data(test_mobilenetv1_int8_mediatek_apu MODEL mobilenet_v1_int8_for_mediatek_apu DATA ILSVRC2012_small)
endif()
diff --git a/lite/tests/api/test_mobilenetv1_fp32_huawei_kirin_npu.cc b/lite/tests/api/test_mobilenetv1_fp32_huawei_kirin_npu.cc
new file mode 100644
index 0000000000000000000000000000000000000000..0b890cdd0855bb629a1aa9ea1ebf62d15240f7cd
--- /dev/null
+++ b/lite/tests/api/test_mobilenetv1_fp32_huawei_kirin_npu.cc
@@ -0,0 +1,101 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/lite_api_test_helper.h"
+#include "lite/api/paddle_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/tests/api/ILSVRC2012_utility.h"
+#include "lite/utils/cp_logging.h"
+
+DEFINE_string(data_dir, "", "data dir");
+DEFINE_int32(iteration, 100, "iteration times to run");
+DEFINE_int32(batch, 1, "batch of image");
+DEFINE_int32(channel, 3, "image channel");
+
+namespace paddle {
+namespace lite {
+
+TEST(MobileNetV1, test_mobilenetv1_fp32_huawei_kirin_npu) {
+ lite_api::CxxConfig config;
+ config.set_model_dir(FLAGS_model_dir);
+ config.set_valid_places({lite_api::Place{TARGET(kARM), PRECISION(kFloat)},
+ lite_api::Place{TARGET(kNPU), PRECISION(kFloat)}});
+ auto predictor = lite_api::CreatePaddlePredictor(config);
+
+ std::string raw_data_dir = FLAGS_data_dir + std::string("/raw_data");
+ std::vector input_shape{
+ FLAGS_batch, FLAGS_channel, FLAGS_im_width, FLAGS_im_height};
+ auto raw_data = ReadRawData(raw_data_dir, input_shape, FLAGS_iteration);
+
+ int input_size = 1;
+ for (auto i : input_shape) {
+ input_size *= i;
+ }
+
+ for (int i = 0; i < FLAGS_warmup; ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ for (int j = 0; j < input_size; j++) {
+ data[j] = 0.f;
+ }
+ predictor->Run();
+ }
+
+ std::vector> out_rets;
+ out_rets.resize(FLAGS_iteration);
+ double cost_time = 0;
+ for (size_t i = 0; i < raw_data.size(); ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ memcpy(data, raw_data[i].data(), sizeof(float) * input_size);
+
+ double start = GetCurrentUS();
+ predictor->Run();
+ cost_time += GetCurrentUS() - start;
+
+ auto output_tensor = predictor->GetOutput(0);
+ auto output_shape = output_tensor->shape();
+ auto output_data = output_tensor->data();
+ ASSERT_EQ(output_shape.size(), 2UL);
+ ASSERT_EQ(output_shape[0], 1);
+ ASSERT_EQ(output_shape[1], 1000);
+
+ int output_size = output_shape[0] * output_shape[1];
+ out_rets[i].resize(output_size);
+ memcpy(&(out_rets[i].at(0)), output_data, sizeof(float) * output_size);
+ }
+
+ LOG(INFO) << "================== Speed Report ===================";
+ LOG(INFO) << "Model: " << FLAGS_model_dir << ", threads num " << FLAGS_threads
+ << ", warmup: " << FLAGS_warmup << ", batch: " << FLAGS_batch
+ << ", iteration: " << FLAGS_iteration << ", spend "
+ << cost_time / FLAGS_iteration / 1000.0 << " ms in average.";
+
+ std::string labels_dir = FLAGS_data_dir + std::string("/labels.txt");
+ float out_accuracy = CalOutAccuracy(out_rets, labels_dir);
+ ASSERT_GE(out_accuracy, 0.57f);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/tests/api/test_mobilenetv1_int8_apu.cc b/lite/tests/api/test_mobilenetv1_int8_apu.cc
deleted file mode 100644
index 730ed3e82341d04e79c96a5cacefdf4c48715e61..0000000000000000000000000000000000000000
--- a/lite/tests/api/test_mobilenetv1_int8_apu.cc
+++ /dev/null
@@ -1,160 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-#include
-#include
-#include
-
-#include "lite/api/paddle_api.h"
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
-#include "lite/api/paddle_use_passes.h"
-using namespace paddle::lite_api; // NOLINT
-
-inline double GetCurrentUS() {
- struct timeval time;
- gettimeofday(&time, NULL);
- return 1e+6 * time.tv_sec + time.tv_usec;
-}
-
-inline int64_t ShapeProduction(std::vector shape) {
- int64_t s = 1;
- for (int64_t dim : shape) {
- s *= dim;
- }
- return s;
-}
-
-int main(int argc, char** argv) {
- if (argc < 2) {
- std::cerr << "[ERROR] usage: ./" << argv[0]
- << " model_dir [thread_num] [warmup_times] [repeat_times] "
- "[input_data_path] [output_data_path]"
- << std::endl;
- return -1;
- }
- std::string model_dir = argv[1];
- int thread_num = 1;
- if (argc > 2) {
- thread_num = atoi(argv[2]);
- }
- int warmup_times = 5;
- if (argc > 3) {
- warmup_times = atoi(argv[3]);
- }
- int repeat_times = 10;
- if (argc > 4) {
- repeat_times = atoi(argv[4]);
- }
- std::string input_data_path;
- if (argc > 5) {
- input_data_path = argv[5];
- }
- std::string output_data_path;
- if (argc > 6) {
- output_data_path = argv[6];
- }
- paddle::lite_api::CxxConfig config;
- config.set_model_dir(model_dir);
- config.set_threads(thread_num);
- config.set_power_mode(paddle::lite_api::LITE_POWER_HIGH);
- config.set_valid_places(
- {paddle::lite_api::Place{
- TARGET(kARM), PRECISION(kFloat), DATALAYOUT(kNCHW)},
- paddle::lite_api::Place{
- TARGET(kARM), PRECISION(kInt8), DATALAYOUT(kNCHW)},
- paddle::lite_api::Place{
- TARGET(kAPU), PRECISION(kInt8), DATALAYOUT(kNCHW)}});
- auto predictor = paddle::lite_api::CreatePaddlePredictor(config);
-
- std::unique_ptr input_tensor(
- std::move(predictor->GetInput(0)));
- input_tensor->Resize({1, 3, 224, 224});
- auto input_data = input_tensor->mutable_data();
- auto input_size = ShapeProduction(input_tensor->shape());
-
- // test loop
- int total_imgs = 500;
- float test_num = 0;
- float top1_num = 0;
- float top5_num = 0;
- int output_len = 1000;
- std::vector index(1000);
- bool debug = true; // false;
- int show_step = 500;
- for (int i = 0; i < total_imgs; i++) {
- // set input
- std::string filename = input_data_path + "/" + std::to_string(i);
- std::ifstream fs(filename, std::ifstream::binary);
- if (!fs.is_open()) {
- std::cout << "open input file fail.";
- }
- auto input_data_tmp = input_data;
- for (int i = 0; i < input_size; ++i) {
- fs.read(reinterpret_cast(input_data_tmp), sizeof(*input_data_tmp));
- input_data_tmp++;
- }
- int label = 0;
- fs.read(reinterpret_cast(&label), sizeof(label));
- fs.close();
-
- if (debug && i % show_step == 0) {
- std::cout << "input data:" << std::endl;
- std::cout << input_data[0] << " " << input_data[10] << " "
- << input_data[input_size - 1] << std::endl;
- std::cout << "label:" << label << std::endl;
- }
-
- // run
- predictor->Run();
- auto output0 = predictor->GetOutput(0);
- auto output0_data = output0->data();
-
- // get output
- std::iota(index.begin(), index.end(), 0);
- std::stable_sort(
- index.begin(), index.end(), [output0_data](size_t i1, size_t i2) {
- return output0_data[i1] > output0_data[i2];
- });
- test_num++;
- if (label == index[0]) {
- top1_num++;
- }
- for (int i = 0; i < 5; i++) {
- if (label == index[i]) {
- top5_num++;
- }
- }
-
- if (debug && i % show_step == 0) {
- std::cout << index[0] << " " << index[1] << " " << index[2] << " "
- << index[3] << " " << index[4] << std::endl;
- std::cout << output0_data[index[0]] << " " << output0_data[index[1]]
- << " " << output0_data[index[2]] << " "
- << output0_data[index[3]] << " " << output0_data[index[4]]
- << std::endl;
- std::cout << output0_data[630] << std::endl;
- }
- if (i % show_step == 0) {
- std::cout << "step " << i << "; top1 acc:" << top1_num / test_num
- << "; top5 acc:" << top5_num / test_num << std::endl;
- }
- }
- std::cout << "final result:" << std::endl;
- std::cout << "top1 acc:" << top1_num / test_num << std::endl;
- std::cout << "top5 acc:" << top5_num / test_num << std::endl;
- return 0;
-}
diff --git a/lite/tests/api/test_mobilenetv1_int8_mediatek_apu.cc b/lite/tests/api/test_mobilenetv1_int8_mediatek_apu.cc
new file mode 100644
index 0000000000000000000000000000000000000000..76b3722d2d6d4d15fb57a00b055d714ad8d2e1c5
--- /dev/null
+++ b/lite/tests/api/test_mobilenetv1_int8_mediatek_apu.cc
@@ -0,0 +1,102 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/lite_api_test_helper.h"
+#include "lite/api/paddle_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/tests/api/ILSVRC2012_utility.h"
+#include "lite/utils/cp_logging.h"
+
+DEFINE_string(data_dir, "", "data dir");
+DEFINE_int32(iteration, 100, "iteration times to run");
+DEFINE_int32(batch, 1, "batch of image");
+DEFINE_int32(channel, 3, "image channel");
+
+namespace paddle {
+namespace lite {
+
+TEST(MobileNetV1, test_mobilenetv1_int8_mediatek_apu) {
+ lite_api::CxxConfig config;
+ config.set_model_dir(FLAGS_model_dir);
+ config.set_valid_places({lite_api::Place{TARGET(kARM), PRECISION(kFloat)},
+ lite_api::Place{TARGET(kARM), PRECISION(kInt8)},
+ lite_api::Place{TARGET(kAPU), PRECISION(kInt8)}});
+ auto predictor = lite_api::CreatePaddlePredictor(config);
+
+ std::string raw_data_dir = FLAGS_data_dir + std::string("/raw_data");
+ std::vector input_shape{
+ FLAGS_batch, FLAGS_channel, FLAGS_im_width, FLAGS_im_height};
+ auto raw_data = ReadRawData(raw_data_dir, input_shape, FLAGS_iteration);
+
+ int input_size = 1;
+ for (auto i : input_shape) {
+ input_size *= i;
+ }
+
+ for (int i = 0; i < FLAGS_warmup; ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ for (int j = 0; j < input_size; j++) {
+ data[j] = 0.f;
+ }
+ predictor->Run();
+ }
+
+ std::vector> out_rets;
+ out_rets.resize(FLAGS_iteration);
+ double cost_time = 0;
+ for (size_t i = 0; i < raw_data.size(); ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ memcpy(data, raw_data[i].data(), sizeof(float) * input_size);
+
+ double start = GetCurrentUS();
+ predictor->Run();
+ cost_time += GetCurrentUS() - start;
+
+ auto output_tensor = predictor->GetOutput(0);
+ auto output_shape = output_tensor->shape();
+ auto output_data = output_tensor->data();
+ ASSERT_EQ(output_shape.size(), 2UL);
+ ASSERT_EQ(output_shape[0], 1);
+ ASSERT_EQ(output_shape[1], 1000);
+
+ int output_size = output_shape[0] * output_shape[1];
+ out_rets[i].resize(output_size);
+ memcpy(&(out_rets[i].at(0)), output_data, sizeof(float) * output_size);
+ }
+
+ LOG(INFO) << "================== Speed Report ===================";
+ LOG(INFO) << "Model: " << FLAGS_model_dir << ", threads num " << FLAGS_threads
+ << ", warmup: " << FLAGS_warmup << ", batch: " << FLAGS_batch
+ << ", iteration: " << FLAGS_iteration << ", spend "
+ << cost_time / FLAGS_iteration / 1000.0 << " ms in average.";
+
+ std::string labels_dir = FLAGS_data_dir + std::string("/labels.txt");
+ float out_accuracy = CalOutAccuracy(out_rets, labels_dir);
+ ASSERT_GE(out_accuracy, 0.55f);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/tests/api/test_mobilenetv1_int8_rknpu.cc b/lite/tests/api/test_mobilenetv1_int8_rknpu.cc
deleted file mode 100644
index 8c123088b3f69560abf3555dd2e459af926426ef..0000000000000000000000000000000000000000
--- a/lite/tests/api/test_mobilenetv1_int8_rknpu.cc
+++ /dev/null
@@ -1,127 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-#include
-#include
-#include
-#include
-#include "lite/api/paddle_api.h"
-#include "lite/api/paddle_use_kernels.h"
-#include "lite/api/paddle_use_ops.h"
-#include "lite/api/paddle_use_passes.h"
-
-inline double GetCurrentUS() {
- struct timeval time;
- gettimeofday(&time, NULL);
- return 1e+6 * time.tv_sec + time.tv_usec;
-}
-
-inline int64_t ShapeProduction(std::vector shape) {
- int64_t s = 1;
- for (int64_t dim : shape) {
- s *= dim;
- }
- return s;
-}
-
-int main(int argc, char** argv) {
- if (argc < 2) {
- std::cerr << "[ERROR] usage: ./" << argv[0]
- << " model_dir [thread_num] [warmup_times] [repeat_times] "
- "[input_data_path] [output_data_path]"
- << std::endl;
- return -1;
- }
- std::string model_dir = argv[1];
- int thread_num = 1;
- if (argc > 2) {
- thread_num = atoi(argv[2]);
- }
- int warmup_times = 5;
- if (argc > 3) {
- warmup_times = atoi(argv[3]);
- }
- int repeat_times = 10;
- if (argc > 4) {
- repeat_times = atoi(argv[4]);
- }
- std::string input_data_path;
- if (argc > 5) {
- input_data_path = argv[5];
- }
- std::string output_data_path;
- if (argc > 6) {
- output_data_path = argv[6];
- }
- paddle::lite_api::CxxConfig config;
- config.set_model_dir(model_dir);
- config.set_threads(thread_num);
- config.set_power_mode(paddle::lite_api::LITE_POWER_HIGH);
- config.set_valid_places(
- {paddle::lite_api::Place{
- TARGET(kARM), PRECISION(kFloat), DATALAYOUT(kNCHW)},
- paddle::lite_api::Place{
- TARGET(kARM), PRECISION(kInt8), DATALAYOUT(kNCHW)},
- paddle::lite_api::Place{
- TARGET(kARM), PRECISION(kInt8), DATALAYOUT(kNCHW)},
- paddle::lite_api::Place{
- TARGET(kRKNPU), PRECISION(kInt8), DATALAYOUT(kNCHW)}});
- auto predictor = paddle::lite_api::CreatePaddlePredictor(config);
-
- std::unique_ptr input_tensor(
- std::move(predictor->GetInput(0)));
- input_tensor->Resize({1, 3, 224, 224});
- auto input_data = input_tensor->mutable_data();
- auto input_size = ShapeProduction(input_tensor->shape());
- if (input_data_path.empty()) {
- for (int i = 0; i < input_size; i++) {
- input_data[i] = 1;
- }
- } else {
- std::fstream fs(input_data_path, std::ios::in);
- if (!fs.is_open()) {
- std::cerr << "open input data file failed." << std::endl;
- return -1;
- }
- for (int i = 0; i < input_size; i++) {
- fs >> input_data[i];
- }
- }
-
- for (int i = 0; i < warmup_times; ++i) {
- predictor->Run();
- }
-
- auto start = GetCurrentUS();
- for (int i = 0; i < repeat_times; ++i) {
- predictor->Run();
- }
-
- std::cout << "Model: " << model_dir << ", threads num " << thread_num
- << ", warmup times: " << warmup_times
- << ", repeat times: " << repeat_times << ", spend "
- << (GetCurrentUS() - start) / repeat_times / 1000.0
- << " ms in average." << std::endl;
-
- std::unique_ptr output_tensor(
- std::move(predictor->GetOutput(0)));
- auto output_data = output_tensor->data();
- auto output_size = ShapeProduction(output_tensor->shape());
- std::cout << "output data:";
- for (int i = 0; i < output_size; i += 100) {
- std::cout << "[" << i << "] " << output_data[i] << std::endl;
- }
- return 0;
-}
diff --git a/lite/tests/api/test_mobilenetv1_int8_rockchip_npu.cc b/lite/tests/api/test_mobilenetv1_int8_rockchip_npu.cc
new file mode 100644
index 0000000000000000000000000000000000000000..7b52e4398a5db2e11499a2a96a07ffe4971f6100
--- /dev/null
+++ b/lite/tests/api/test_mobilenetv1_int8_rockchip_npu.cc
@@ -0,0 +1,102 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/lite_api_test_helper.h"
+#include "lite/api/paddle_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/tests/api/ILSVRC2012_utility.h"
+#include "lite/utils/cp_logging.h"
+
+DEFINE_string(data_dir, "", "data dir");
+DEFINE_int32(iteration, 100, "iteration times to run");
+DEFINE_int32(batch, 1, "batch of image");
+DEFINE_int32(channel, 3, "image channel");
+
+namespace paddle {
+namespace lite {
+
+TEST(MobileNetV1, test_mobilenetv1_int8_rockchip_apu) {
+ lite_api::CxxConfig config;
+ config.set_model_dir(FLAGS_model_dir);
+ config.set_valid_places({lite_api::Place{TARGET(kARM), PRECISION(kFloat)},
+ lite_api::Place{TARGET(kARM), PRECISION(kInt8)},
+ lite_api::Place{TARGET(kRKNPU), PRECISION(kInt8)}});
+ auto predictor = lite_api::CreatePaddlePredictor(config);
+
+ std::string raw_data_dir = FLAGS_data_dir + std::string("/raw_data");
+ std::vector input_shape{
+ FLAGS_batch, FLAGS_channel, FLAGS_im_width, FLAGS_im_height};
+ auto raw_data = ReadRawData(raw_data_dir, input_shape, FLAGS_iteration);
+
+ int input_size = 1;
+ for (auto i : input_shape) {
+ input_size *= i;
+ }
+
+ for (int i = 0; i < FLAGS_warmup; ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ for (int j = 0; j < input_size; j++) {
+ data[j] = 0.f;
+ }
+ predictor->Run();
+ }
+
+ std::vector> out_rets;
+ out_rets.resize(FLAGS_iteration);
+ double cost_time = 0;
+ for (size_t i = 0; i < raw_data.size(); ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ memcpy(data, raw_data[i].data(), sizeof(float) * input_size);
+
+ double start = GetCurrentUS();
+ predictor->Run();
+ cost_time += GetCurrentUS() - start;
+
+ auto output_tensor = predictor->GetOutput(0);
+ auto output_shape = output_tensor->shape();
+ auto output_data = output_tensor->data();
+ ASSERT_EQ(output_shape.size(), 2UL);
+ ASSERT_EQ(output_shape[0], 1);
+ ASSERT_EQ(output_shape[1], 1000);
+
+ int output_size = output_shape[0] * output_shape[1];
+ out_rets[i].resize(output_size);
+ memcpy(&(out_rets[i].at(0)), output_data, sizeof(float) * output_size);
+ }
+
+ LOG(INFO) << "================== Speed Report ===================";
+ LOG(INFO) << "Model: " << FLAGS_model_dir << ", threads num " << FLAGS_threads
+ << ", warmup: " << FLAGS_warmup << ", batch: " << FLAGS_batch
+ << ", iteration: " << FLAGS_iteration << ", spend "
+ << cost_time / FLAGS_iteration / 1000.0 << " ms in average.";
+
+ std::string labels_dir = FLAGS_data_dir + std::string("/labels.txt");
+ float out_accuracy = CalOutAccuracy(out_rets, labels_dir);
+ ASSERT_GE(out_accuracy, 0.52f);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/tests/api/test_mobilenetv2_fp32_huawei_kirin_npu.cc b/lite/tests/api/test_mobilenetv2_fp32_huawei_kirin_npu.cc
new file mode 100644
index 0000000000000000000000000000000000000000..11fa9df4206b65d0c82c4ab09dc35d302c13282b
--- /dev/null
+++ b/lite/tests/api/test_mobilenetv2_fp32_huawei_kirin_npu.cc
@@ -0,0 +1,101 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/lite_api_test_helper.h"
+#include "lite/api/paddle_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/tests/api/ILSVRC2012_utility.h"
+#include "lite/utils/cp_logging.h"
+
+DEFINE_string(data_dir, "", "data dir");
+DEFINE_int32(iteration, 100, "iteration times to run");
+DEFINE_int32(batch, 1, "batch of image");
+DEFINE_int32(channel, 3, "image channel");
+
+namespace paddle {
+namespace lite {
+
+TEST(MobileNetV2, test_mobilenetv2_fp32_huawei_kirin_npu) {
+ lite_api::CxxConfig config;
+ config.set_model_dir(FLAGS_model_dir);
+ config.set_valid_places({lite_api::Place{TARGET(kARM), PRECISION(kFloat)},
+ lite_api::Place{TARGET(kNPU), PRECISION(kFloat)}});
+ auto predictor = lite_api::CreatePaddlePredictor(config);
+
+ std::string raw_data_dir = FLAGS_data_dir + std::string("/raw_data");
+ std::vector input_shape{
+ FLAGS_batch, FLAGS_channel, FLAGS_im_width, FLAGS_im_height};
+ auto raw_data = ReadRawData(raw_data_dir, input_shape, FLAGS_iteration);
+
+ int input_size = 1;
+ for (auto i : input_shape) {
+ input_size *= i;
+ }
+
+ for (int i = 0; i < FLAGS_warmup; ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ for (int j = 0; j < input_size; j++) {
+ data[j] = 0.f;
+ }
+ predictor->Run();
+ }
+
+ std::vector> out_rets;
+ out_rets.resize(FLAGS_iteration);
+ double cost_time = 0;
+ for (size_t i = 0; i < raw_data.size(); ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ memcpy(data, raw_data[i].data(), sizeof(float) * input_size);
+
+ double start = GetCurrentUS();
+ predictor->Run();
+ cost_time += GetCurrentUS() - start;
+
+ auto output_tensor = predictor->GetOutput(0);
+ auto output_shape = output_tensor->shape();
+ auto output_data = output_tensor->data();
+ ASSERT_EQ(output_shape.size(), 2UL);
+ ASSERT_EQ(output_shape[0], 1);
+ ASSERT_EQ(output_shape[1], 1000);
+
+ int output_size = output_shape[0] * output_shape[1];
+ out_rets[i].resize(output_size);
+ memcpy(&(out_rets[i].at(0)), output_data, sizeof(float) * output_size);
+ }
+
+ LOG(INFO) << "================== Speed Report ===================";
+ LOG(INFO) << "Model: " << FLAGS_model_dir << ", threads num " << FLAGS_threads
+ << ", warmup: " << FLAGS_warmup << ", batch: " << FLAGS_batch
+ << ", iteration: " << FLAGS_iteration << ", spend "
+ << cost_time / FLAGS_iteration / 1000.0 << " ms in average.";
+
+ std::string labels_dir = FLAGS_data_dir + std::string("/labels.txt");
+ float out_accuracy = CalOutAccuracy(out_rets, labels_dir);
+ ASSERT_GE(out_accuracy, 0.57f);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/tests/api/test_resnet50_fp32_huawei_kirin_npu.cc b/lite/tests/api/test_resnet50_fp32_huawei_kirin_npu.cc
new file mode 100644
index 0000000000000000000000000000000000000000..af48c5c5dbad3ba3e5958fefddaf2b88c660e301
--- /dev/null
+++ b/lite/tests/api/test_resnet50_fp32_huawei_kirin_npu.cc
@@ -0,0 +1,101 @@
+// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include
+#include
+#include
+#include "lite/api/lite_api_test_helper.h"
+#include "lite/api/paddle_api.h"
+#include "lite/api/paddle_use_kernels.h"
+#include "lite/api/paddle_use_ops.h"
+#include "lite/api/paddle_use_passes.h"
+#include "lite/api/test_helper.h"
+#include "lite/tests/api/ILSVRC2012_utility.h"
+#include "lite/utils/cp_logging.h"
+
+DEFINE_string(data_dir, "", "data dir");
+DEFINE_int32(iteration, 100, "iteration times to run");
+DEFINE_int32(batch, 1, "batch of image");
+DEFINE_int32(channel, 3, "image channel");
+
+namespace paddle {
+namespace lite {
+
+TEST(ResNet50, test_resnet50_fp32_huawei_kirin_npu) {
+ lite_api::CxxConfig config;
+ config.set_model_dir(FLAGS_model_dir);
+ config.set_valid_places({lite_api::Place{TARGET(kARM), PRECISION(kFloat)},
+ lite_api::Place{TARGET(kNPU), PRECISION(kFloat)}});
+ auto predictor = lite_api::CreatePaddlePredictor(config);
+
+ std::string raw_data_dir = FLAGS_data_dir + std::string("/raw_data");
+ std::vector input_shape{
+ FLAGS_batch, FLAGS_channel, FLAGS_im_width, FLAGS_im_height};
+ auto raw_data = ReadRawData(raw_data_dir, input_shape, FLAGS_iteration);
+
+ int input_size = 1;
+ for (auto i : input_shape) {
+ input_size *= i;
+ }
+
+ for (int i = 0; i < FLAGS_warmup; ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ for (int j = 0; j < input_size; j++) {
+ data[j] = 0.f;
+ }
+ predictor->Run();
+ }
+
+ std::vector> out_rets;
+ out_rets.resize(FLAGS_iteration);
+ double cost_time = 0;
+ for (size_t i = 0; i < raw_data.size(); ++i) {
+ auto input_tensor = predictor->GetInput(0);
+ input_tensor->Resize(
+ std::vector(input_shape.begin(), input_shape.end()));
+ auto* data = input_tensor->mutable_data();
+ memcpy(data, raw_data[i].data(), sizeof(float) * input_size);
+
+ double start = GetCurrentUS();
+ predictor->Run();
+ cost_time += GetCurrentUS() - start;
+
+ auto output_tensor = predictor->GetOutput(0);
+ auto output_shape = output_tensor->shape();
+ auto output_data = output_tensor->data();
+ ASSERT_EQ(output_shape.size(), 2UL);
+ ASSERT_EQ(output_shape[0], 1);
+ ASSERT_EQ(output_shape[1], 1000);
+
+ int output_size = output_shape[0] * output_shape[1];
+ out_rets[i].resize(output_size);
+ memcpy(&(out_rets[i].at(0)), output_data, sizeof(float) * output_size);
+ }
+
+ LOG(INFO) << "================== Speed Report ===================";
+ LOG(INFO) << "Model: " << FLAGS_model_dir << ", threads num " << FLAGS_threads
+ << ", warmup: " << FLAGS_warmup << ", batch: " << FLAGS_batch
+ << ", iteration: " << FLAGS_iteration << ", spend "
+ << cost_time / FLAGS_iteration / 1000.0 << " ms in average.";
+
+ std::string labels_dir = FLAGS_data_dir + std::string("/labels.txt");
+ float out_accuracy = CalOutAccuracy(out_rets, labels_dir);
+ ASSERT_GE(out_accuracy, 0.64f);
+}
+
+} // namespace lite
+} // namespace paddle
diff --git a/lite/tests/kernels/CMakeLists.txt b/lite/tests/kernels/CMakeLists.txt
index ad909bef694bfa5a36370abc6869d6a482e4c52b..bff045522f6a057bcfd0801eb87289ebb4e62b7d 100644
--- a/lite/tests/kernels/CMakeLists.txt
+++ b/lite/tests/kernels/CMakeLists.txt
@@ -1,100 +1,100 @@
-if((NOT LITE_WITH_OPENCL AND NOT LITE_WITH_FPGA AND NOT LITE_WITH_BM AND NOT LITE_WITH_MLU AND NOT LITE_WITH_RKNPU) AND (LITE_WITH_X86 OR LITE_WITH_ARM))
- lite_cc_test(test_kernel_conv_compute SRCS conv_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_conv_transpose_compute SRCS conv_transpose_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_scale_compute SRCS scale_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_power_compute SRCS power_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_shuffle_channel_compute SRCS shuffle_channel_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_yolo_box_compute SRCS yolo_box_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_fc_compute SRCS fc_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_elementwise_compute SRCS elementwise_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_lrn_compute SRCS lrn_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_decode_bboxes_compute SRCS decode_bboxes_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_box_coder_compute SRCS box_coder_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_activation_compute SRCS activation_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_argmax_compute SRCS argmax_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_axpy_compute SRCS axpy_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_norm_compute SRCS norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_cast_compute SRCS cast_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_instance_norm_compute SRCS instance_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_grid_sampler_compute SRCS grid_sampler_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_group_norm_compute SRCS group_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+if((NOT LITE_WITH_OPENCL AND NOT LITE_WITH_FPGA AND NOT LITE_WITH_BM AND NOT LITE_WITH_MLU) AND (LITE_WITH_X86 OR LITE_WITH_ARM))
+ lite_cc_test(test_kernel_conv_compute SRCS conv_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_conv_transpose_compute SRCS conv_transpose_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_scale_compute SRCS scale_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_power_compute SRCS power_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_shuffle_channel_compute SRCS shuffle_channel_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_yolo_box_compute SRCS yolo_box_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_fc_compute SRCS fc_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_elementwise_compute SRCS elementwise_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_lrn_compute SRCS lrn_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_decode_bboxes_compute SRCS decode_bboxes_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_box_coder_compute SRCS box_coder_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_activation_compute SRCS activation_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_argmax_compute SRCS argmax_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_axpy_compute SRCS axpy_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_norm_compute SRCS norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_cast_compute SRCS cast_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_instance_norm_compute SRCS instance_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_grid_sampler_compute SRCS grid_sampler_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_group_norm_compute SRCS group_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
#lite_cc_test(test_kernel_sequence_softmax_compute SRCS sequence_softmax_compute_test.cc DEPS arena_framework ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
#lite_cc_test(test_kernel_im2sequence_compute SRCS im2sequence_compute_test.cc DEPS arena_framework ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_compare_compute SRCS compare_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_logical_compute SRCS logical_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_topk_compute SRCS topk_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_increment_compute SRCS increment_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_write_to_array_compute SRCS write_to_array_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_read_from_array_compute SRCS read_from_array_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_concat_compute SRCS concat_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_transpose_compute SRCS transpose_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_reshape_compute SRCS reshape_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_layer_norm_compute SRCS layer_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_dropout_compute SRCS dropout_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_softmax_compute SRCS softmax_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_mul_compute SRCS mul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_multiclass_nms_compute SRCS multiclass_nms_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_matrix_nms_compute SRCS matrix_nms_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_batch_norm_compute SRCS batch_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_pool_compute SRCS pool_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_fill_constant_compute SRCS fill_constant_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_fill_constant_batch_size_like_compute SRCS fill_constant_batch_size_like_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_compare_compute SRCS compare_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_logical_compute SRCS logical_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_topk_compute SRCS topk_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_increment_compute SRCS increment_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_write_to_array_compute SRCS write_to_array_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_read_from_array_compute SRCS read_from_array_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_concat_compute SRCS concat_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_transpose_compute SRCS transpose_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_reshape_compute SRCS reshape_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_layer_norm_compute SRCS layer_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_dropout_compute SRCS dropout_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_softmax_compute SRCS softmax_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_mul_compute SRCS mul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_multiclass_nms_compute SRCS multiclass_nms_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_batch_norm_compute SRCS batch_norm_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_pool_compute SRCS pool_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_fill_constant_compute SRCS fill_constant_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_fill_constant_batch_size_like_compute SRCS fill_constant_batch_size_like_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
if(LITE_BUILD_EXTRA)
- lite_cc_test(test_gru_unit SRCS gru_unit_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- #lite_cc_test(test_kernel_sequence_pool_compute SRCS sequence_pool_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_sequence_conv_compute SRCS sequence_conv_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_reduce_max_compute SRCS reduce_max_compute_test.cc DEPS arena_framework ${bm_kernels} ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_unsqueeze_compute SRCS unsqueeze_compute_test.cc DEPS arena_framework ${bm_kernels} ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_assign_compute SRCS assign_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_assign_value_compute SRCS assign_value_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_box_clip_compute SRCS box_clip_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_reduce_mean_compute SRCS reduce_mean_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_reduce_sum_compute SRCS reduce_sum_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_reduce_prod_compute SRCS reduce_prod_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_stack_compute SRCS stack_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_range_compute SRCS range_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_affine_channel_compute SRCS affine_channel_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_anchor_generator_compute SRCS anchor_generator_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_gru_unit SRCS gru_unit_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ #lite_cc_test(test_kernel_sequence_pool_compute SRCS sequence_pool_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_sequence_conv_compute SRCS sequence_conv_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_reduce_max_compute SRCS reduce_max_compute_test.cc DEPS arena_framework ${bm_kernels} ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_unsqueeze_compute SRCS unsqueeze_compute_test.cc DEPS arena_framework ${bm_kernels} ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_assign_compute SRCS assign_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_assign_value_compute SRCS assign_value_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_box_clip_compute SRCS box_clip_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_reduce_mean_compute SRCS reduce_mean_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_reduce_sum_compute SRCS reduce_sum_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_reduce_prod_compute SRCS reduce_prod_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_stack_compute SRCS stack_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_range_compute SRCS range_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_affine_channel_compute SRCS affine_channel_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_anchor_generator_compute SRCS anchor_generator_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_matrix_nms_compute SRCS matrix_nms_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
#lite_cc_test(test_kernel_generate_proposals_compute SRCS generate_proposals_compute_test.cc DEPS arena_framework ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
#lite_cc_test(test_kernel_roi_align_compute SRCS roi_align_compute_test.cc DEPS arena_framework ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_search_aligned_mat_mul_compute SRCS search_aligned_mat_mul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_search_seq_fc_compute SRCS search_seq_fc_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_lookup_table_compute SRCS lookup_table_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_lookup_table_dequant_compute SRCS lookup_table_dequant_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_gather_compute SRCS gather_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_ctc_align_compute SRCS ctc_align_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_clip_compute SRCS clip_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_pixel_shuffle_compute SRCS pixel_shuffle_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_scatter_compute SRCS scatter_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_sequence_expand_as_compute SRCS sequence_expand_as_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_search_aligned_mat_mul_compute SRCS search_aligned_mat_mul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_search_seq_fc_compute SRCS search_seq_fc_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${bm_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_lookup_table_compute SRCS lookup_table_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_lookup_table_dequant_compute SRCS lookup_table_dequant_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_gather_compute SRCS gather_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_ctc_align_compute SRCS ctc_align_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_clip_compute SRCS clip_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_pixel_shuffle_compute SRCS pixel_shuffle_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_scatter_compute SRCS scatter_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_sequence_expand_as_compute SRCS sequence_expand_as_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
# for training kernel
if (LITE_WITH_TRAIN)
- lite_cc_test(test_kernel_mean_compute SRCS mean_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_activation_grad_compute SRCS activation_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_elementwise_grad_compute SRCS elementwise_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_mul_grad_compute SRCS mul_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_sgd_compute SRCS sgd_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_sequence_pool_grad_compute SRCS sequence_pool_grad_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_mean_compute SRCS mean_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_activation_grad_compute SRCS activation_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_elementwise_grad_compute SRCS elementwise_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_mul_grad_compute SRCS mul_grad_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_sgd_compute SRCS sgd_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_sequence_pool_grad_compute SRCS sequence_pool_grad_compute_test.cc DEPS ${bm_kernels} arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
endif()
endif()
- lite_cc_test(test_kernel_pad2d_compute SRCS pad2d_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_prior_box_compute SRCS prior_box_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_negative_compute SRCS negative_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_interp_compute SRCS interp_compute_test.cc DEPS arena_framework ${xpu_kernels} ${bm_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_shape_compute SRCS shape_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_is_empty_compute SRCS is_empty_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_crop_compute SRCS crop_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_sequence_expand_compute SRCS sequence_expand_compute_test.cc DEPS arena_framework ${xpu_kernels} ${bm_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_squeeze_compute SRCS squeeze_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_slice_compute SRCS slice_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_expand_compute SRCS expand_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_expand_as_compute SRCS expand_as_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_matmul_compute SRCS matmul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- lite_cc_test(test_kernel_flatten_compute SRCS flatten_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
- #lite_cc_test(test_kernel_crf_decoding_compute SRCS crf_decoding_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_pad2d_compute SRCS pad2d_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_prior_box_compute SRCS prior_box_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_negative_compute SRCS negative_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_interp_compute SRCS interp_compute_test.cc DEPS arena_framework ${xpu_kernels} ${bm_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_shape_compute SRCS shape_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_is_empty_compute SRCS is_empty_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_crop_compute SRCS crop_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${bm_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_sequence_expand_compute SRCS sequence_expand_compute_test.cc DEPS arena_framework ${xpu_kernels} ${bm_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_squeeze_compute SRCS squeeze_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_slice_compute SRCS slice_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_expand_compute SRCS expand_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_expand_as_compute SRCS expand_as_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_matmul_compute SRCS matmul_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ lite_cc_test(test_kernel_flatten_compute SRCS flatten_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
+ #lite_cc_test(test_kernel_crf_decoding_compute SRCS crf_decoding_compute_test.cc DEPS arena_framework ${xpu_kernels} ${npu_kernels} ${rknpu_kernels} ${apu_kernels} ${huawei_ascend_npu_kernels} ${bm_kernels} ${x86_kernels} ${cuda_kernels} ${arm_kernels} ${lite_ops} ${host_kernels})
lite_cc_test(test_uniform_random_compute SRCS uniform_random_compute_test.cc DEPS arena_framework ${lite_ops} ${host_kernels})
endif()
diff --git a/lite/tests/kernels/activation_compute_test.cc b/lite/tests/kernels/activation_compute_test.cc
index fb88f6b553f6eac88845a045531cfe57c174bedf..6799da30da3135b49fd4c423ee094b3c22a73bcb 100644
--- a/lite/tests/kernels/activation_compute_test.cc
+++ b/lite/tests/kernels/activation_compute_test.cc
@@ -58,6 +58,7 @@ class ActivationComputeTester : public arena::TestCase {
float hard_swish_offset = 3.0;
float relu_threshold_ = 1.0;
float elu_alpha_ = 1.0;
+ float threshold_ = 6.0;
DDim dims_{{1}};
std::string type_ = "";
activation_type_test act_type_ = RELU;
@@ -170,7 +171,8 @@ class ActivationComputeTester : public arena::TestCase {
case RELU6: {
for (int i = 0; i < dims_.production(); i++) {
output_data[i] = x_data[i] > 0.f ? x_data[i] : 0.f;
- output_data[i] = output_data[i] < 6.0 ? output_data[i] : 6.0;
+ output_data[i] =
+ output_data[i] < threshold_ ? output_data[i] : threshold_;
}
break;
}
@@ -273,6 +275,9 @@ class ActivationComputeTester : public arena::TestCase {
if (act_type_ == ELU) {
op_desc->SetAttr("alpha", elu_alpha_);
}
+ if (act_type_ == RELU6) {
+ op_desc->SetAttr("threshold", threshold_);
+ }
}
void PrepareData() override {
@@ -510,6 +515,8 @@ TEST(Activation_relu6, precision) {
#elif defined(LITE_WITH_HUAWEI_ASCEND_NPU)
place = TARGET(kHuaweiAscendNPU);
abs_error = 1e-2; // precision_mode default is force_fp16
+#elif defined(LITE_WITH_X86)
+ place = TARGET(kX86);
#else
return;
#endif
diff --git a/lite/tests/kernels/interp_compute_test.cc b/lite/tests/kernels/interp_compute_test.cc
index 8d10040bca61f42ffc93d745baf42a23eb11c08d..f512808632f3d99153c1ca93c94e3edc679b9c96 100644
--- a/lite/tests/kernels/interp_compute_test.cc
+++ b/lite/tests/kernels/interp_compute_test.cc
@@ -416,6 +416,10 @@ void TestInterpAlignMode(Place place, float abs_error = 2e-5) {
for (auto x_dims : std::vector>{{3, 4, 8, 9}}) {
for (bool align_corners : {true, false}) {
for (int align_mode : {0, 1}) {
+ // may exist bug in arm kernel
+ if (place == TARGET(kARM) && align_mode == 1 && !align_corners) {
+ continue;
+ }
// Ascend NPU DDK
if (place == TARGET(kHuaweiAscendNPU) && align_mode == 0 &&
!align_corners) {
diff --git a/lite/tests/kernels/reduce_mean_compute_test.cc b/lite/tests/kernels/reduce_mean_compute_test.cc
index 0d41d251799d3506c77686b4ab9b48e6b1a105d7..d679d027a68735b49255f2c08dfa566a0f50e088 100644
--- a/lite/tests/kernels/reduce_mean_compute_test.cc
+++ b/lite/tests/kernels/reduce_mean_compute_test.cc
@@ -333,9 +333,10 @@ void test_reduce_mean(Place place) {
}
TEST(ReduceMean, precision) {
-// #ifdef LITE_WITH_X86
-// Place place(TARGET(kX86));
-// #endif
+#ifdef LITE_WITH_X86
+ Place place(TARGET(kX86));
+ test_reduce_mean(place);
+#endif
#ifdef LITE_WITH_ARM
Place place(TARGET(kARM));
test_reduce_mean(place);
diff --git a/lite/tests/math/conv_compute_test.cc b/lite/tests/math/conv_compute_test.cc
index 9ad98ce6f4566898b3821e6bf540b331a84b97bb..54d9448b86489a777045ac8c63495a153a426c3a 100644
--- a/lite/tests/math/conv_compute_test.cc
+++ b/lite/tests/math/conv_compute_test.cc
@@ -306,8 +306,7 @@ void test_conv_fp32(const std::vector& input_dims,
const float leakey_relu_scale) {}
#endif // LITE_WITH_ARM
-// TODO(chenjiaoAngel): fix multi-threds, diff: 3x3 depthwise conv
-#if 0 // 3x3dw
+#if 0 // 3x3dw if only run one case. its ok
TEST(TestConv3x3DW, test_conv3x3_depthwise) {
if (FLAGS_basic_test) {
for (auto& stride : {1, 2}) {
@@ -325,13 +324,6 @@ TEST(TestConv3x3DW, test_conv3x3_depthwise) {
dims.push_back(DDim({batch, c, h, h}));
}
}
-#ifdef __aarch64__
-#else
- if (stride == 1 && (pad_bottom == 2 || pad_right == 2 ||
- pad_top == 2 || pad_left == 2)) {
- continue;
- }
-#endif
const float leakey_relu_scale = 8.88;
test_conv_fp32(dims,
weights_dim,
diff --git a/lite/tools/ci_build.sh b/lite/tools/ci_build.sh
index 166137bf02b034219f2d6afc6c486ed553cdfe7a..d5d8fd6c461b70f9ba1d6901c519f96e5022f008 100755
--- a/lite/tools/ci_build.sh
+++ b/lite/tools/ci_build.sh
@@ -18,6 +18,10 @@ NUM_CORES_FOR_COMPILE=${LITE_BUILD_THREADS:-8}
# global variables
#whether to use emulator as adb devices,when USE_ADB_EMULATOR=ON we use emulator, else we will use connected mobile phone as adb devices.
USE_ADB_EMULATOR=ON
+# Use real android devices, set the device names for adb connection, ignored if USE_ADB_EMULATOR=ON
+ADB_DEVICE_LIST=""
+# The list of tests which are ignored, use commas to separate them, such as "test_cxx_api,test_mobilenetv1_int8"
+TEST_SKIP_LIST=""
LITE_WITH_COVERAGE=OFF
# if operating in mac env, we should expand the maximum file num
@@ -392,6 +396,380 @@ function build_test_xpu {
test_xpu
}
+function is_available_adb_device {
+ local adb_device_name=$1
+ if [[ -n "$adb_device_name" ]]; then
+ for line in `adb devices | grep -v "List" | awk '{print $1}'`
+ do
+ online_device_name=`echo $line | awk '{print $1}'`
+ if [[ "$adb_device_name" == "$online_device_name" ]];then
+ return 0
+ fi
+ done
+ fi
+ return 1
+}
+
+function pick_an_available_adb_device {
+ local adb_device_list=$1
+ local adb_device_names=(${adb_device_list//,/ })
+ for adb_device_name in ${adb_device_names[@]}; do
+ is_available_adb_device $adb_device_name
+ if [[ $? -eq 0 ]]; then
+ echo $adb_device_name
+ return 0
+ fi
+ done
+ echo ""
+ return 1
+}
+
+function run_test_case_on_adb_device {
+ local adb_device_name=""
+ local adb_work_dir=""
+ local target_name=""
+ local model_dir=""
+ local data_dir=""
+ local config_dir=""
+ # Extract arguments from command line
+ for i in "$@"; do
+ case $i in
+ --adb_device_name=*)
+ adb_device_name="${i#*=}"
+ shift
+ ;;
+ --adb_work_dir=*)
+ adb_work_dir="${i#*=}"
+ shift
+ ;;
+ --target_name=*)
+ target_name="${i#*=}"
+ shift
+ ;;
+ --model_dir=*)
+ model_dir="${i#*=}"
+ shift
+ ;;
+ --data_dir=*)
+ data_dir="${i#*=}"
+ shift
+ ;;
+ --config_dir=*)
+ config_dir="${i#*=}"
+ shift
+ ;;
+ *)
+ shift
+ ;;
+ esac
+ done
+
+ # Check device is available
+ is_available_adb_device $adb_device_name
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name not found!"
+ exit 1
+ fi
+
+ # Be careful!!! Don't delete the root or system directories if the device is rooted.
+ if [[ -z "$adb_work_dir" ]]; then
+ echo "$adb_work_dir can't be empty!"
+ exit 1
+ fi
+ if [[ "$adb_work_dir" == "/" ]]; then
+ echo "$adb_work_dir can't be root dir!"
+ exit 1
+ fi
+
+ # Copy the executable unit test to the remote device
+ local target_path=$(find ./lite -name $target_name)
+ if [[ -z "$target_path" ]]; then
+ echo "$target_name not found!"
+ exit 1
+ fi
+ adb -s $adb_device_name shell "rm -f $adb_work_dir/$target_name"
+ adb -s $adb_device_name push $target_path $adb_work_dir
+
+ local command_line="./$target_name"
+ # Copy the model files to the remote device
+ if [[ -n "$model_dir" ]]; then
+ local model_name=$(basename $model_dir)
+ adb -s $adb_device_name shell "rm -rf $adb_work_dir/$model_name"
+ adb -s $adb_device_name push $model_dir $adb_work_dir
+ command_line="$command_line --model_dir ./$model_name"
+ fi
+
+ # Copy the test data files to the remote device
+ if [[ -n "$data_dir" ]]; then
+ local data_name=$(basename $data_dir)
+ adb -s $adb_device_name shell "rm -rf $adb_work_dir/$data_name"
+ adb -s $adb_device_name push $data_dir $adb_work_dir
+ command_line="$command_line --data_dir ./$data_name"
+ fi
+
+ # Copy the config files to the remote device
+ if [[ -n "$config_dir" ]]; then
+ local config_name=$(basename $config_dir)
+ adb -s $adb_device_name shell "rm -rf $adb_work_dir/$config_name"
+ adb -s $adb_device_name push $config_dir $adb_work_dir
+ command_line="$command_line --config_dir ./$config_name"
+ fi
+
+ # Run the model on the remote device
+ adb -s $adb_device_name shell "cd $adb_work_dir; export GLOG_v=5; LD_LIBRARY_PATH=$LD_LIBRARY_PATH:. $command_line"
+}
+
+function run_all_tests_on_adb_device {
+ local adb_device_list=$1
+ local test_skip_list=$2
+ local adb_work_dir=$3
+ local sdk_root_dir=$4
+ local test_arch_list=$5
+ local test_toolchain_list=$6
+ local build_targets_func=$7
+ local prepare_devices_func=$8
+
+ # Pick the first available adb device from list
+ local adb_device_name=$(pick_an_available_adb_device $adb_device_list)
+ if [[ -z $adb_device_name ]]; then
+ echo "No adb device available!"
+ exit 1
+ else
+ echo "Found a device $adb_device_name."
+ fi
+
+ # Run all of unittests and model tests
+ local test_archs=(${test_arch_list//,/ })
+ local test_toolchains=(${test_toolchain_list//,/ })
+ local test_skip_names=(${test_skip_list//,/ })
+ local test_model_params=(${test_model_list//:/ })
+ for arch in $test_archs; do
+ for toolchain in $test_toolchains; do
+ # Build all tests and prepare device environment for running tests
+ echo "Build tests for MediaTek APU with $arch+$toolchain"
+ ${build_targets_func} $arch $toolchain $sdk_root_dir
+ ${prepare_devices_func} $adb_device_name $adb_work_dir $arch $toolchain $sdk_root_dir
+ # Run all of unit tests and model tests
+ for test_name in $(cat $TESTS_FILE); do
+ local is_skip=0
+ for test_skip_name in ${test_skip_names[@]}; do
+ if [[ "$test_skip_name" == "$test_name" ]]; then
+ echo "skip " $test_name
+ is_skip=1
+ break
+ fi
+ done
+ if [[ $is_skip -ne 0 ]]; then
+ continue
+ fi
+ # Extract the arguments from ctest command line
+ test_args=$(echo $(ctest -V -N -R ${test_name}) | sed "/.*${test_name} \"\(.*\)\".*/ s//\1/g")
+ run_test_case_on_adb_device --adb_device_name=$adb_device_name --adb_work_dir=$adb_work_dir --target_name=$test_name $test_args
+ done
+ cd - > /dev/null
+ done
+ done
+}
+
+# Huawei Kirin NPU
+function huawei_kirin_npu_prepare_device {
+ local adb_device_name=$1
+ local adb_work_dir=$2
+ local arch=$3
+ local toolchain=$4
+ local sdk_root_dir=$5
+
+ # Check device is available
+ is_available_adb_device $adb_device_name
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name not found!"
+ exit 1
+ fi
+
+ # Only root user can use HiAI runtime libraries in the android shell executables
+ adb -s $adb_device_name root
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name hasn't the root permission!"
+ exit 1
+ fi
+
+ # Copy the runtime libraries of HiAI DDK to the target device
+ local sdk_lib_dir=""
+ if [[ $arch == "armv8" ]]; then
+ sdk_lib_dir="$sdk_root_dir/lib64"
+ elif [[ $arch == "armv7" ]]; then
+ sdk_lib_dir="$sdk_root_dir/lib"
+ else
+ echo "$arch isn't supported by HiAI DDK!"
+ exit 1
+ fi
+ adb -s $adb_device_name push $sdk_lib_dir/. $adb_work_dir
+}
+
+function huawei_kirin_npu_build_targets {
+ local arch=$1
+ local toolchain=$2
+ local sdk_root_dir=$3
+
+ # Build all of tests
+ rm -rf ./build
+ mkdir -p ./build
+ cd ./build
+ prepare_workspace
+ cmake .. \
+ -DWITH_GPU=OFF \
+ -DWITH_MKL=OFF \
+ -DWITH_LITE=ON \
+ -DLITE_WITH_CUDA=OFF \
+ -DLITE_WITH_X86=OFF \
+ -DLITE_WITH_ARM=ON \
+ -DWITH_ARM_DOTPROD=ON \
+ -DLITE_WITH_LIGHT_WEIGHT_FRAMEWORK=ON \
+ -DWITH_TESTING=ON \
+ -DLITE_BUILD_EXTRA=ON \
+ -DLITE_WITH_TRAIN=ON \
+ -DANDROID_STL_TYPE="c++_shared" \
+ -DLITE_WITH_NPU=ON \
+ -DNPU_DDK_ROOT="$sdk_root_dir" \
+ -DARM_TARGET_OS="android" -DARM_TARGET_ARCH_ABI=$arch -DARM_TARGET_LANG=$toolchain
+ make lite_compile_deps -j$NUM_CORES_FOR_COMPILE
+}
+
+function huawei_kirin_npu_build_and_test {
+ run_all_tests_on_adb_device $1 $2 "/data/local/tmp" "$(readlink -f ./hiai_ddk_lib_330)" "armv7" "gcc,clang" huawei_kirin_npu_build_targets huawei_kirin_npu_prepare_device
+}
+
+# Rockchip NPU
+function rockchip_npu_prepare_device {
+ local adb_device_name=$1
+ local adb_work_dir=$2
+ local arch=$3
+ local toolchain=$4
+ local sdk_root_dir=$5
+
+ # Check device is available
+ is_available_adb_device $adb_device_name
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name not found!"
+ exit 1
+ fi
+
+ # Use high performance mode
+ adb -s $adb_device_name shell "echo userspace > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "echo 1608000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_setspeed"
+ adb -s $adb_device_name shell "echo userspace > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "echo 1608000 > /sys/devices/system/cpu/cpu1/cpufreq/scaling_setspeed"
+
+ # Copy the runtime libraries of Rockchip NPU to the target device
+ local sdk_lib_dir=""
+ if [[ $arch == "armv8" ]]; then
+ sdk_lib_dir="$sdk_root_dir/lib64"
+ elif [[ $arch == "armv7" ]]; then
+ sdk_lib_dir="$sdk_root_dir/lib"
+ else
+ echo "$arch isn't supported by Rockchip NPU SDK!"
+ exit 1
+ fi
+ adb -s $adb_device_name push $sdk_lib_dir/. $adb_work_dir
+}
+
+function rockchip_npu_build_targets {
+ local arch=$1
+ local toolchain=$2
+ local sdk_root_dir=$3
+
+ # Build all of tests
+ rm -rf ./build
+ mkdir -p ./build
+ cd ./build
+ prepare_workspace
+ cmake .. \
+ -DWITH_GPU=OFF \
+ -DWITH_MKL=OFF \
+ -DWITH_LITE=ON \
+ -DLITE_WITH_CUDA=OFF \
+ -DLITE_WITH_X86=OFF \
+ -DLITE_WITH_ARM=ON \
+ -DWITH_ARM_DOTPROD=ON \
+ -DLITE_WITH_LIGHT_WEIGHT_FRAMEWORK=ON \
+ -DWITH_TESTING=ON \
+ -DLITE_BUILD_EXTRA=ON \
+ -DLITE_WITH_TRAIN=ON \
+ -DLITE_WITH_RKNPU=ON \
+ -DRKNPU_DDK_ROOT="$sdk_root_dir" \
+ -DARM_TARGET_OS="armlinux" -DARM_TARGET_ARCH_ABI=$arch -DARM_TARGET_LANG=$toolchain
+ make lite_compile_deps -j$NUM_CORES_FOR_COMPILE
+}
+
+function rockchip_npu_build_and_test {
+ run_all_tests_on_adb_device $1 $2 "/userdata/bin" "$(readlink -f ./rknpu_ddk)" "armv8" "gcc" rockchip_npu_build_targets rockchip_npu_prepare_device
+}
+
+# MediaTek APU
+function mediatek_apu_prepare_device {
+ local adb_device_name=$1
+ local adb_work_dir=$2
+ local arch=$3
+ local toolchain=$4
+ local sdk_root_dir=$5
+
+ # Check device is available
+ is_available_adb_device $adb_device_name
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name not found!"
+ exit 1
+ fi
+
+ # Use high performance mode
+ adb -s $adb_device_name root
+ if [[ $? -ne 0 ]]; then
+ echo "$adb_device_name hasn't the root permission!"
+ exit 1
+ fi
+ adb -s $adb_device_name shell "echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "echo performance > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "echo performance > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "echo performance > /sys/devices/system/cpu/cpu3/cpufreq/scaling_governor"
+ adb -s $adb_device_name shell "cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq"
+ adb -s $adb_device_name shell "echo 800000 > /proc/gpufreq/gpufreq_opp_freq"
+ adb -s $adb_device_name shell "echo dvfs_debug 0 > /sys/kernel/debug/vpu/power"
+ adb -s $adb_device_name shell "echo 0 > /sys/devices/platform/soc/10012000.dvfsrc/helio-dvfsrc/dvfsrc_force_vcore_dvfs_opp"
+ adb -s $adb_device_name shell "echo 0 > /sys/module/mmdvfs_pmqos/parameters/force_step"
+ adb -s $adb_device_name shell "echo 0 > /proc/sys/kernel/printk"
+}
+
+function mediatek_apu_build_targets {
+ local arch=$1
+ local toolchain=$2
+ local sdk_root_dir=$3
+
+ # Build all of tests
+ rm -rf ./build
+ mkdir -p ./build
+ cd ./build
+ prepare_workspace
+ cmake .. \
+ -DWITH_GPU=OFF \
+ -DWITH_MKL=OFF \
+ -DWITH_LITE=ON \
+ -DLITE_WITH_CUDA=OFF \
+ -DLITE_WITH_X86=OFF \
+ -DLITE_WITH_ARM=ON \
+ -DWITH_ARM_DOTPROD=ON \
+ -DLITE_WITH_LIGHT_WEIGHT_FRAMEWORK=ON \
+ -DWITH_TESTING=ON \
+ -DLITE_BUILD_EXTRA=ON \
+ -DLITE_WITH_TRAIN=ON \
+ -DLITE_WITH_APU=ON \
+ -DAPU_DDK_ROOT="$sdk_root_dir" \
+ -DARM_TARGET_OS="android" -DARM_TARGET_ARCH_ABI=$arch -DARM_TARGET_LANG=$toolchain
+ make lite_compile_deps -j$NUM_CORES_FOR_COMPILE
+}
+
+function mediatek_apu_build_and_test {
+ run_all_tests_on_adb_device $1 $2 "/data/local/tmp" "$(readlink -f ./apu_ddk)" "armv7" "gcc" mediatek_apu_build_targets mediatek_apu_prepare_device
+}
+
function cmake_huawei_ascend_npu {
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:$PWD/third_party/install/mklml/lib"
prepare_workspace
@@ -478,77 +856,6 @@ function test_arm_android {
adb -s ${device} shell "rm -f ${adb_work_dir}/${test_name}"
}
-# test_npu
-function test_npu {
- local test_name=$1
- local device=$2
- if [[ "${test_name}x" == "x" ]]; then
- echo "test_name can not be empty"
- exit 1
- fi
- if [[ "${device}x" == "x" ]]; then
- echo "Port can not be empty"
- exit 1
- fi
-
- echo "test name: ${test_name}"
- adb_work_dir="/data/local/tmp"
-
- skip_list=("test_model_parser" "test_mobilenetv1" "test_mobilenetv2" "test_resnet50" "test_inceptionv4" "test_light_api" "test_apis" "test_paddle_api" "test_cxx_api" "test_gen_code")
- for skip_name in ${skip_list[@]} ; do
- [[ $skip_name =~ (^|[[:space:]])$test_name($|[[:space:]]) ]] && echo "skip $test_name" && return
- done
-
- local testpath=$(find ./lite -name ${test_name})
-
- # note the ai_ddk_lib is under paddle-lite root directory
- adb -s ${device} push ../ai_ddk_lib/lib64/* ${adb_work_dir}
- adb -s ${device} push ${testpath} ${adb_work_dir}
-
- if [[ ${test_name} == "test_npu_pass" ]]; then
- local model_name=mobilenet_v1
- adb -s ${device} push "./third_party/install/${model_name}" ${adb_work_dir}
- adb -s ${device} shell "rm -rf ${adb_work_dir}/${model_name}_opt "
- adb -s ${device} shell "cd ${adb_work_dir}; export LD_LIBRARY_PATH=./ ; export GLOG_v=0; ./${test_name} --model_dir=./${model_name} --optimized_model=./${model_name}_opt"
- elif [[ ${test_name} == "test_subgraph_pass" ]]; then
- local model_name=mobilenet_v1
- adb -s ${device} push "./third_party/install/${model_name}" ${adb_work_dir}
- adb -s ${device} shell "cd ${adb_work_dir}; export LD_LIBRARY_PATH=./ ; export GLOG_v=0; ./${test_name} --model_dir=./${model_name}"
- else
- adb -s ${device} shell "cd ${adb_work_dir}; export LD_LIBRARY_PATH=./ ; ./${test_name}"
- fi
-}
-
-function test_npu_model {
- local test_name=$1
- local device=$2
- local model_dir=$3
-
- if [[ "${test_name}x" == "x" ]]; then
- echo "test_name can not be empty"
- exit 1
- fi
- if [[ "${device}x" == "x" ]]; then
- echo "Port can not be empty"
- exit 1
- fi
- if [[ "${model_dir}x" == "x" ]]; then
- echo "Model dir can not be empty"
- exit 1
- fi
-
- echo "test name: ${test_name}"
- adb_work_dir="/data/local/tmp"
-
- testpath=$(find ./lite -name ${test_name})
- adb -s ${device} push ../ai_ddk_lib/lib64/* ${adb_work_dir}
- adb -s ${device} push ${model_dir} ${adb_work_dir}
- adb -s ${device} push ${testpath} ${adb_work_dir}
- adb -s ${device} shell chmod +x "${adb_work_dir}/${test_name}"
- local adb_model_path="${adb_work_dir}/`basename ${model_dir}`"
- adb -s ${device} shell "export LD_LIBRARY_PATH=${adb_work_dir}; ${adb_work_dir}/${test_name} --model_dir=$adb_model_path"
-}
-
# test the inference high level api
function test_arm_api {
local device=$1
@@ -643,32 +950,6 @@ function _test_paddle_code_generator {
$adb shell $remote_test --optimized_model $remote_model --generated_code_file $ADB_WORK_DIR/gen_code.cc
}
-function cmake_npu {
- prepare_workspace
- # $1: ARM_TARGET_OS in "android" , "armlinux"
- # $2: ARM_TARGET_ARCH_ABI in "armv8", "armv7" ,"armv7hf"
- # $3: ARM_TARGET_LANG in "gcc" "clang"
-
- # NPU libs need API LEVEL 24 above
- build_dir=`pwd`
-
- cmake .. \
- -DWITH_GPU=OFF \
- -DWITH_MKL=OFF \
- -DWITH_LITE=ON \
- -DLITE_WITH_CUDA=OFF \
- -DLITE_WITH_X86=OFF \
- -DLITE_WITH_ARM=ON \
- -DWITH_ARM_DOTPROD=ON \
- -DLITE_WITH_LIGHT_WEIGHT_FRAMEWORK=ON \
- -DWITH_TESTING=ON \
- -DLITE_WITH_NPU=ON \
- -DANDROID_API_LEVEL=24 \
- -DLITE_BUILD_EXTRA=ON \
- -DNPU_DDK_ROOT="${build_dir}/../ai_ddk_lib/" \
- -DARM_TARGET_OS=$1 -DARM_TARGET_ARCH_ABI=$2 -DARM_TARGET_LANG=$3
-}
-
function cmake_arm {
prepare_workspace
# $1: ARM_TARGET_OS in "android" , "armlinux"
@@ -756,31 +1037,6 @@ function build_ios {
cd -
}
-# $1: ARM_TARGET_OS in "android"
-# $2: ARM_TARGET_ARCH_ABI in "armv8", "armv7"
-# $3: ARM_TARGET_LANG in "gcc" "clang"
-# $4: test_name
-function build_npu {
- os=$1
- abi=$2
- lang=$3
- local test_name=$4
-
- cur_dir=$(pwd)
-
- build_dir=$cur_dir/build.lite.npu.${os}.${abi}.${lang}
- mkdir -p $build_dir
- cd $build_dir
-
- cmake_npu ${os} ${abi} ${lang}
-
- if [[ "${test_name}x" != "x" ]]; then
- build_single $test_name
- else
- build $TESTS_FILE
- fi
-}
-
# $1: ARM_TARGET_OS in "android" , "armlinux"
# $2: ARM_TARGET_ARCH_ABI in "armv8", "armv7" ,"armv7hf"
# $3: ARM_TARGET_LANG in "gcc" "clang"
@@ -1029,42 +1285,6 @@ function build_test_arm {
build_test_arm_subtask_armlinux
}
-function build_test_npu {
- local test_name=$1
- local port_armv8=5554
- local port_armv7=5556
- local os=android
- local abi=armv8
- local lang=gcc
-
- local test_model_name=test_mobilenetv1
- local model_name=mobilenet_v1
- cur_dir=$(pwd)
-
- build_npu "android" "armv8" "gcc" $test_name
-
- # just test the model on armv8
- # prepare_emulator $port_armv8
-
- prepare_emulator $port_armv8 $port_armv7
- local device_armv8=emulator-$port_armv8
-
- if [[ "${test_name}x" != "x" ]]; then
- test_npu ${test_name} ${device_armv8}
- else
- # run_gen_code_test ${port_armv8}
- for _test in $(cat $TESTS_FILE | grep npu); do
- test_npu $_test $device_armv8
- done
- fi
-
- test_npu_model $test_model_name $device_armv8 "./third_party/install/$model_name"
- cd -
- # just test the model on armv8
- # adb devices | grep emulator | cut -f1 | while read line; do adb -s $line emu kill; done
- echo "Done"
-}
-
function mobile_publish {
# only check os=android abi=armv8 lang=gcc now
local os=android
@@ -1147,6 +1367,21 @@ function main {
USE_ADB_EMULATOR="${i#*=}"
shift
;;
+ --adb_device_list=*)
+ ADB_DEVICE_LIST="${i#*=}"
+ if [[ -n $ADB_DEVICE_LIST && $USE_ADB_EMULATOR != "OFF" ]]; then
+ set +x
+ echo
+ echo -e "Need to set USE_ADB_EMULATOR=OFF if '--adb_device_list' is specified."
+ echo
+ exit 1
+ fi
+ shift
+ ;;
+ --test_skip_list=*)
+ TEST_SKIP_LIST="${i#*=}"
+ shift
+ ;;
--lite_with_coverage=*)
LITE_WITH_COVERAGE="${i#*=}"
shift
@@ -1192,10 +1427,6 @@ function main {
test_arm $ARM_OS $ARM_ABI $ARM_LANG $ARM_PORT
shift
;;
- test_npu)
- test_npu $TEST_NAME $ARM_PORT
- shift
- ;;
test_arm_android)
test_arm_android $TEST_NAME $ARM_PORT
shift
@@ -1225,6 +1456,18 @@ function main {
build_test_xpu ON
shift
;;
+ huawei_kirin_npu_build_and_test)
+ huawei_kirin_npu_build_and_test $ADB_DEVICE_LIST $TEST_SKIP_LIST
+ shift
+ ;;
+ rockchip_npu_build_and_test)
+ rockchip_npu_build_and_test $ADB_DEVICE_LIST $TEST_SKIP_LIST
+ shift
+ ;;
+ mediatek_apu_build_and_test)
+ mediatek_apu_build_and_test $ADB_DEVICE_LIST $TEST_SKIP_LIST
+ shift
+ ;;
build_test_huawei_ascend_npu)
build_test_huawei_ascend_npu
shift